
Mots-clés:AGI, Concurrence sino-américaine en IA, Grands modèles de langage, Robots humanoïdes, Entraînement de l’IA, Théories du complot sur l’AGI, Conscience introspective des LLM, Formation de la main-d’œuvre robotique, Google Earth IA, Robotaxi de niveau L4 de Xpeng
🔥 À la Une
La “théorie du complot” de l’AGI et le paysage de la concurrence AI sino-américaine : L’intelligence artificielle générale (AGI) est décrite comme une “théorie du complot” pleine de promesses et de menaces exagérées, son avènement étant associé à des attentes extrêmes de résolution de tous les problèmes ou de déclenchement de catastrophes apocalyptiques. Parallèlement, la concurrence entre les États-Unis et la Chine dans le domaine de l’AI s’intensifie. Bien que les États-Unis soient en tête en matière de semi-conducteurs et de recherche, la Chine démontre un potentiel considérable pour mobiliser toutes les ressources de la société afin de développer et de déployer l’AI, ce qui pourrait lui permettre de dépasser les États-Unis. Ces discussions soulèvent des réflexions profondes sur l’avenir de l’AI et le paysage du pouvoir mondial. (Source : MIT Technology Review)

Capacité d’introspection des modèles AI mise en doute : Une étude d’Anthropic révèle que les Large Language Models (LLMs) montrent un haut degré d’imprécision lorsqu’il s’agit de décrire avec exactitude leurs processus internes. Leur prétendue “conscience introspective” doit encore être mesurée et comprise en profondeur. Cette découverte soulève des inquiétudes quant à la transparence, l’explicabilité et la capacité d’action autonome future de l’AI, et pousse les chercheurs à réexaminer les limites de l‘“auto-perception” de l’AI. (Source : MIT Technology Review)
Main-d’œuvre humaine pour entraîner les robots humanoïdes : Afin d’entraîner des robots humanoïdes multitâches, certaines startups emploient une main-d’œuvre humaine considérable pour effectuer des tâches répétitives, comme se filmer en train de plier des serviettes des centaines de fois. Cette méthode de collecte de données révèle le “travail ingrat et répétitif” derrière l’apprentissage robotique, soulignant le besoin de nouvelles formes de main-d’œuvre pour l’entraînement de l’AI et suscitant des réflexions sur les futurs modèles de collaboration homme-machine. (Source : MIT Technology Review)
🎯 Tendances
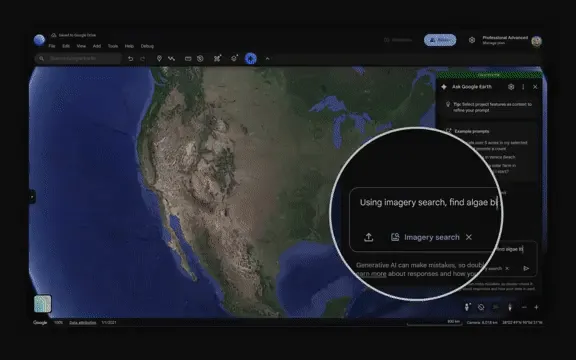
Google Earth AI réalise un raisonnement géospatial à l’échelle planétaire : Google a lancé Earth AI, combinant le modèle Gemini et son expérience en modélisation du monde, pour réaliser pour la première fois un raisonnement géospatial complexe à l’échelle planétaire. Il peut intégrer des données multi-sources pour la surveillance environnementale et la réponse aux catastrophes, ayant déjà fourni des services d’alerte aux inondations à 2 milliards de personnes. Son agent peut décomposer des problèmes complexes, appeler des modèles et des outils pour exécuter des plans, et a démontré des performances exceptionnelles dans les benchmarks de questions-réponses, marquant une avancée majeure de l’AI dans le domaine de l’analyse géospatiale. (Source : 36氪)
Xpeng lance le Robotaxi de niveau L4 et le robot humanoïde IRON : Lors de sa journée technologique, Xpeng a annoncé le lancement d’un Robotaxi de niveau L4 en phase d’essai pour 2026, doté d’un système à double redondance et d’un modèle VLA “sans carte”, et a ouvert son SDK pour accélérer la commercialisation. Parallèlement, le robot humanoïde IRON a été dévoilé, équipé d’un système anti-collision “AEB intérieur” et d’un grand modèle du monde physique, soulignant l’intégration sécurisée de l’AI dans le monde réel. Cela marque des avancées majeures pour l’AI physique dans la conduite autonome et les scénarios domestiques, préfigurant une application plus profonde de l’AI, des algorithmes virtuels vers le monde physique réel. (Source : 36氪)

L’industrialisation des robots humanoïdes s’accélère, les commandes augmentent : Des entreprises comme Ubtech, Unitree Robotics et LimX Dynamics ont reçu des commandes de milliers d’unités, pour des contrats d’une valeur de centaines de millions de yuans, signalant que les robots humanoïdes passent du laboratoire aux scénarios industriels réels. La fabrication et l’éducation sont les principaux acheteurs. Les entreprises se concentrent désormais sur les capacités de livraison, l’optimisation de la chaîne d’approvisionnement et le contrôle des coûts, tout en explorant les produits à moins de 10 000 yuans et les marchés étrangers. Cela préfigure une accélération de la production de masse dans l’industrie des robots humanoïdes, passant des démonstrations technologiques à un déploiement commercial à grande échelle. (Source : 36氪)

Innovation en modèles et architectures AI : Le modèle de base robotique de nouvelle génération GEN-0 a été lancé, basé sur l’architecture Harmonic Reasoning, visant à construire des compagnons robotiques immersifs. L’équipe ByteDance Seed a publié le modèle de langage Loop, qui étend le raisonnement latent via des modèles de langage récurrents, atteignant des performances SOTA avec une taille réduite. Le modèle Kimi-K2 Reasoning a été fusionné dans vLLM, le modèle MiniMax-M2 est en ligne sur Poe, et Gemini 3.0 est sur le point d’être lancé, stimulant collectivement l’optimisation de l’inférence des LLM et l’itération de nouveaux modèles. Parallèlement, de nouveaux matériels AI comme le calcul neuromorphique améliorent l’efficacité des réseaux neuronaux. (Source : shaneguML, arohan, scaling01, op7418, MiniMax__AI, Ronald_vanLoon, scaling01, teortaxesTex)

Progrès de l’AI dans des domaines spécifiques : L’AI progresse dans le domaine médical, avec Wandercraft et NVIDIA collaborant pour promouvoir l’assistance médicale à la mobilité, et la nanomédecine s’associant à l’AI pour vaincre les maladies neurodégénératives. Ai2 a lancé OlmoEarth, appliquant les modèles de base de l’AI à l’analyse des données terrestres. Brain-IT reconstruit des images à partir de l’IRMf via un Transformer d’interaction cérébrale. Les LLM ont considérablement amélioré leurs performances en raisonnement numérique sur données tabulaires grâce au cadre TabDSR. (Source : Ronald_vanLoon, Ronald_vanLoon, natolambert, HuggingFace Daily Papers, HuggingFace Daily Papers)

Développement des LLM multimodaux et de l’AI vidéo : L’optimisation de la génération vidéo par AI s’accélère, Krea.ai réduisant le temps de traitement grâce à des technologies telles que FA3. HuggingFace a publié Qwen-Image-2509-MultipleAngles, un puissant modèle multimodal. Meituan LongCat a lancé LongCat-Flash-Omni, un modèle multimodal à faible latence, prenant en charge un contexte de 128K et 8 minutes d’interaction audio-vidéo en temps réel. UniPruneBench, un benchmark unifié, évalue les méthodes de compression de Token visuels des LLM multimodaux, révélant l’efficacité de l’élagage aléatoire et la vulnérabilité des tâches OCR. (Source : RisingSayak, huggingface, teortaxesTex, HuggingFace Daily Papers)
Extension des capacités et applications robotiques : Les robots pilotés par l’AI démontrent une dextérité de niveau humain, excellant par exemple dans les matchs de volley-ball et capables d’effectuer des inspections qualité en usine intelligente. Le robot humanoïde Xpeng IRON, avec son revêtement en tissu et son design personnalisable, préfigure une intégration plus profonde des robots dans la vie quotidienne. Les robots AI open source Reachy 2 et Reachy mini stimulent le développement technologique. AUBO Robotics révolutionne la recharge intelligente des véhicules électriques grâce à l’AI. (Source : Ronald_vanLoon, Ronald_vanLoon, teortaxesTex, ClementDelangue, Ronald_vanLoon)

Recherche sur l’entraînement et l’optimisation de l’AI : Une étude explore comment le traitement discriminatif des composants de mouvement facilite l’apprentissage non supervisé conjoint du mouvement profond et de l’auto-mouvement, améliorant la robustesse dans des conditions complexes. En conservant des problèmes modérément faciles comme régulateurs de longueur dans RLVR, une “brièveté gratuite” de l’inférence des LLM est obtenue, réduisant la redondance. La recherche sur la collaboration des systèmes multi-agents révèle un “fossé de collaboration” et propose une méthode de “raisonnement par relais” pour combler cet écart. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Dégradation de la représentation visuelle et généralisation des modèles VLA : Une étude révèle qu’un réglage fin naïf des actions sur les modèles Vision-Langage-Action (VLA) entraîne une dégradation de la représentation visuelle, affectant la capacité de généralisation du modèle aux scénarios OOD (hors distribution). La recherche propose une méthode simple et efficace pour atténuer cette dégradation et restaurer les capacités visuelles et linguistiques héritées des modèles VLA, ce qui est crucial pour améliorer les performances de généralisation des modèles VLA dans des tâches complexes du monde réel. (Source : HuggingFace Daily Papers)
🧰 Outils
PandaWiki : Un système de base de connaissances open source piloté par l’AI : PandaWiki est un système open source de création de bases de connaissances piloté par de grands modèles AI, offrant des fonctions de création AI, de questions-réponses AI et de recherche AI. Il peut être utilisé pour construire des systèmes intelligents de documentation produit, documentation technique, FAQ et blogs. Il prend en charge l’édition de texte enrichi, l’intégration d’applications tierces et l’importation de contenu multi-sources, visant à aider les utilisateurs à construire rapidement des plateformes de gestion des connaissances intelligentes. (Source : GitHub Trending)

llama.cpp lance une nouvelle WebUI : llama.cpp a publié une nouvelle WebUI et la version bêta LlamaBarn v0.10.0, permettant aux utilisateurs d’exécuter plus facilement des grands modèles de langage open source localement, offrant une interface graphique conviviale pour l’inférence et l’interaction avec les modèles. Cela réduit considérablement la barrière au déploiement local et à l’utilisation des LLM, facilitant l’expérimentation et l’application pour les développeurs et les chercheurs. (Source : ggerganov, mervenoyann, ggerganov)
Outils de création et de traduction vidéo AI : fabianstelzer a développé un agent conversationnel qui intègre des outils vidéo AI tels que Seedream, VEO 3.1, Kling 2.1 et ElevenLabs v2v, simplifiant les processus complexes de production vidéo AI. Kling Lab, un nouvel espace de travail, connecte également T2I et I2V via des nœuds pour une création intuitive et une animation naturelle. Parallèlement, Bilibili a lancé des fonctions de traduction vidéo AI et de réplication de timbre vocal, améliorant considérablement l’expérience de visionnage et l’efficacité de production de contenu vidéo multilingue. (Source : fabianstelzer, Kling_ai, op7418)
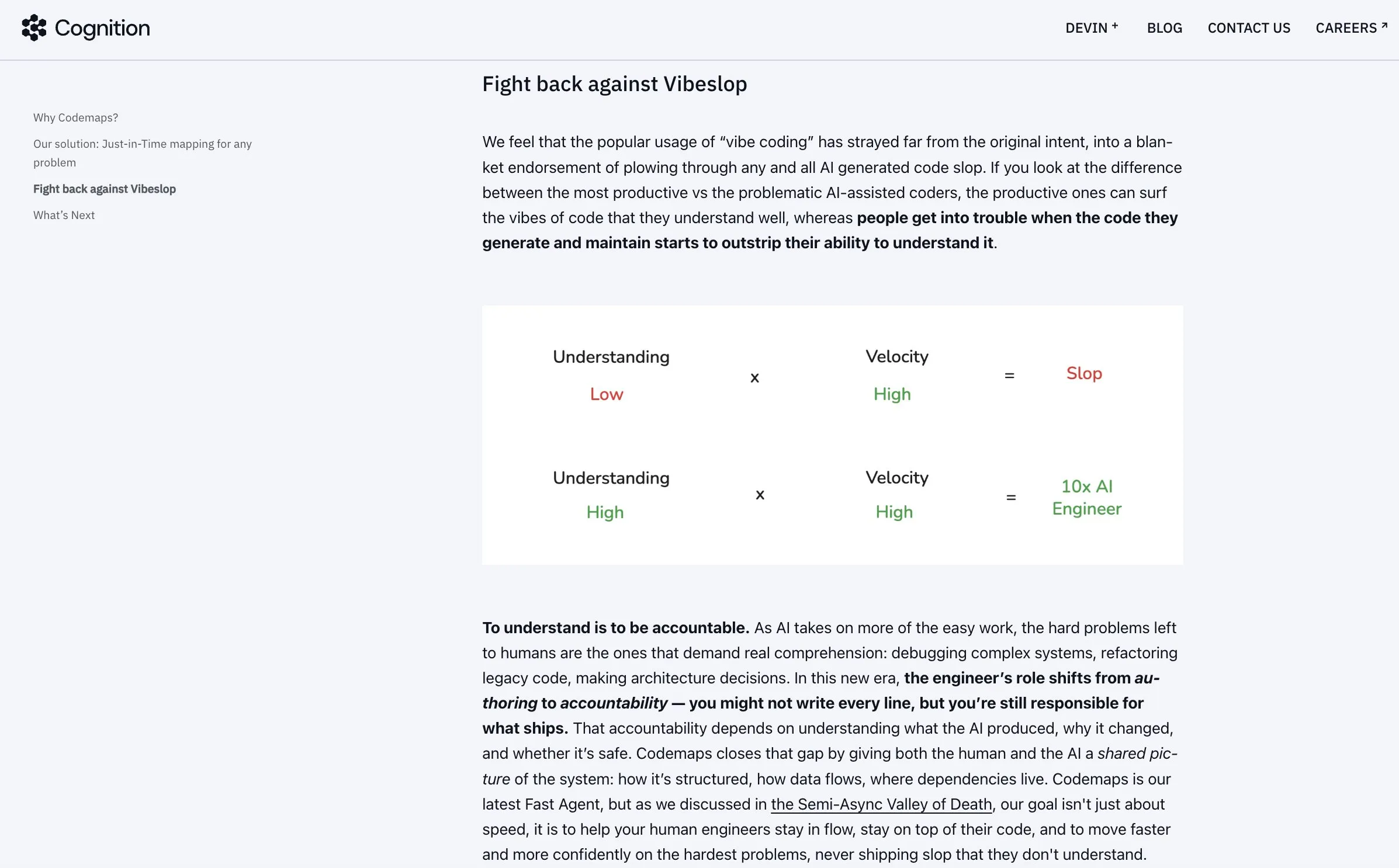
Windsurf Codemaps améliore la compréhension du code par l’AI : Cognition a lancé Codemaps dans Windsurf, piloté par SWE-1.5 et Sonnet 4.5, visant à améliorer la compréhension des bases de code par l’AI afin de résoudre les problèmes d’inefficacité et de “slop” causés par le “vibe-coding”. En étendant la capacité de compréhension, Codemaps aide les développeurs à améliorer leur productivité, rendant le codage assisté par AI plus précis et efficace. (Source : Vtrivedy10, cognition)
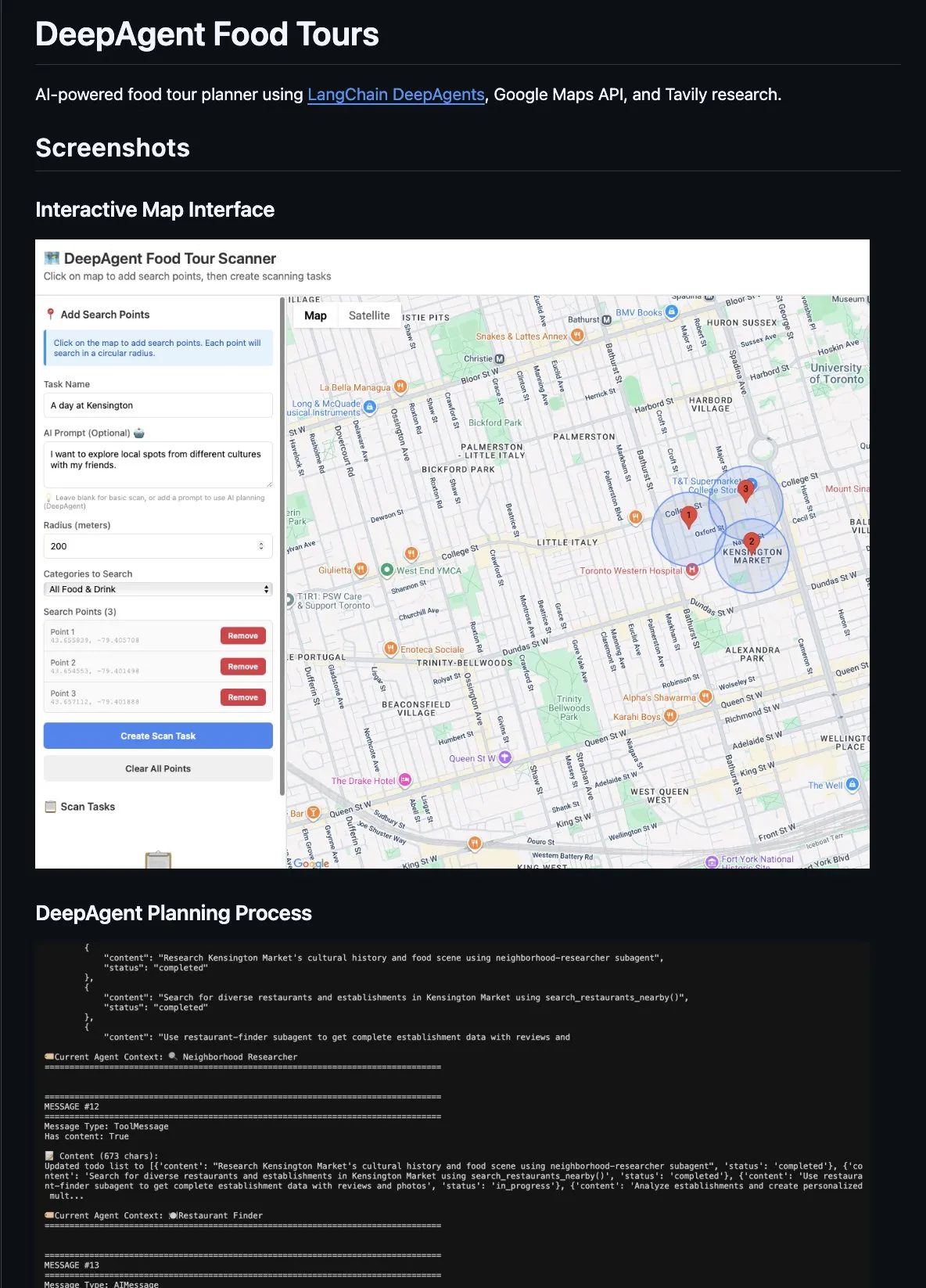
Outils d’efficacité pour le codage AI et le développement d’Agent : LangChain DeepAgents est utilisé pour construire des applications Agent complexes, telles qu’un planificateur de voyages culinaires, adoptant un mode superviseur avec des sous-agents spécialisés, la délégation de tâches et l’isolation contextuelle. L’outil fastmcp export d’Anthropic, quant à lui, facilite la navigation des grands ensembles d’outils pour les CLI Agent en extrayant des MCP distants, améliorant ainsi l’efficacité de traitement des Agent. Reddit MCP Buddy est intégré à Anthropic Directory, permettant à Claude de rechercher sur Reddit pour fournir un consensus communautaire. Claude Code accélère le développement d’applications grâce à des flux de travail structurés, des Skills, des MCPs et des Plugins. (Source : hwchase17, AAAzzam, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
📚 Apprentissage
Recherche sur l’évaluation et les capacités de raisonnement des LLM : Plusieurs études se concentrent sur l’évaluation et les capacités de raisonnement des LLM. Le benchmark MIRA souligne l’importance des images visuelles intermédiaires pour le raisonnement, révélant une amélioration significative des performances des modèles sous des indices visuels. LTD-Bench évalue le raisonnement spatial des LLM par le dessin, découvrant les lacunes des modèles SOTA dans le mappage bidirectionnel entre les concepts linguistiques et spatiaux. Le benchmark CodeClash, quant à lui, évalue le raisonnement stratégique et les capacités de maintenance de code des LLM dans le développement de code orienté objectif en simulant un tournoi d’ingénierie logicielle. De plus, ViDoRe V3, un nouveau benchmark de récupération multimodale, se concentre sur les cas d’utilisation RAG en entreprise, améliorant les performances de la récupération multimodale dans les applications réelles. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, tonywu_71)

Avancées techniques en entraînement et optimisation des LLM : En matière d’entraînement et d’optimisation des LLM, de nouvelles recherches ont prouvé l’efficacité du transfert du taux d’apprentissage sous μP, résolvant le défi du choix du taux d’apprentissage pour les grands réseaux neuronaux. Une analyse comparative du SFT (Supervised Fine-Tuning) et du RL (Reinforcement Learning) dans l’entraînement des LLM révèle que la raison de la facilité de défaillance du RL réside dans la complexité de l’infrastructure et l’écart de qualité des données, soulignant l’importance des données propres et des modèles de récompense robustes. Parallèlement, un tutoriel d’entraînement de modèles TTS basés sur LLaMA montre comment utiliser GRPO et TRL pour améliorer la prosodie et l’expressivité de la parole synthétisée. De plus, le parallélisme contextuel (Ring Attention) combiné au parallélisme séquentiel Ulysses offre une solution d’optimisation 2D CP+SP pour le déploiement des LLM. (Source : cloneofsimo, lateinteraction, ZhihuFrontier, _lewtun, algo_diver, reach_vb)

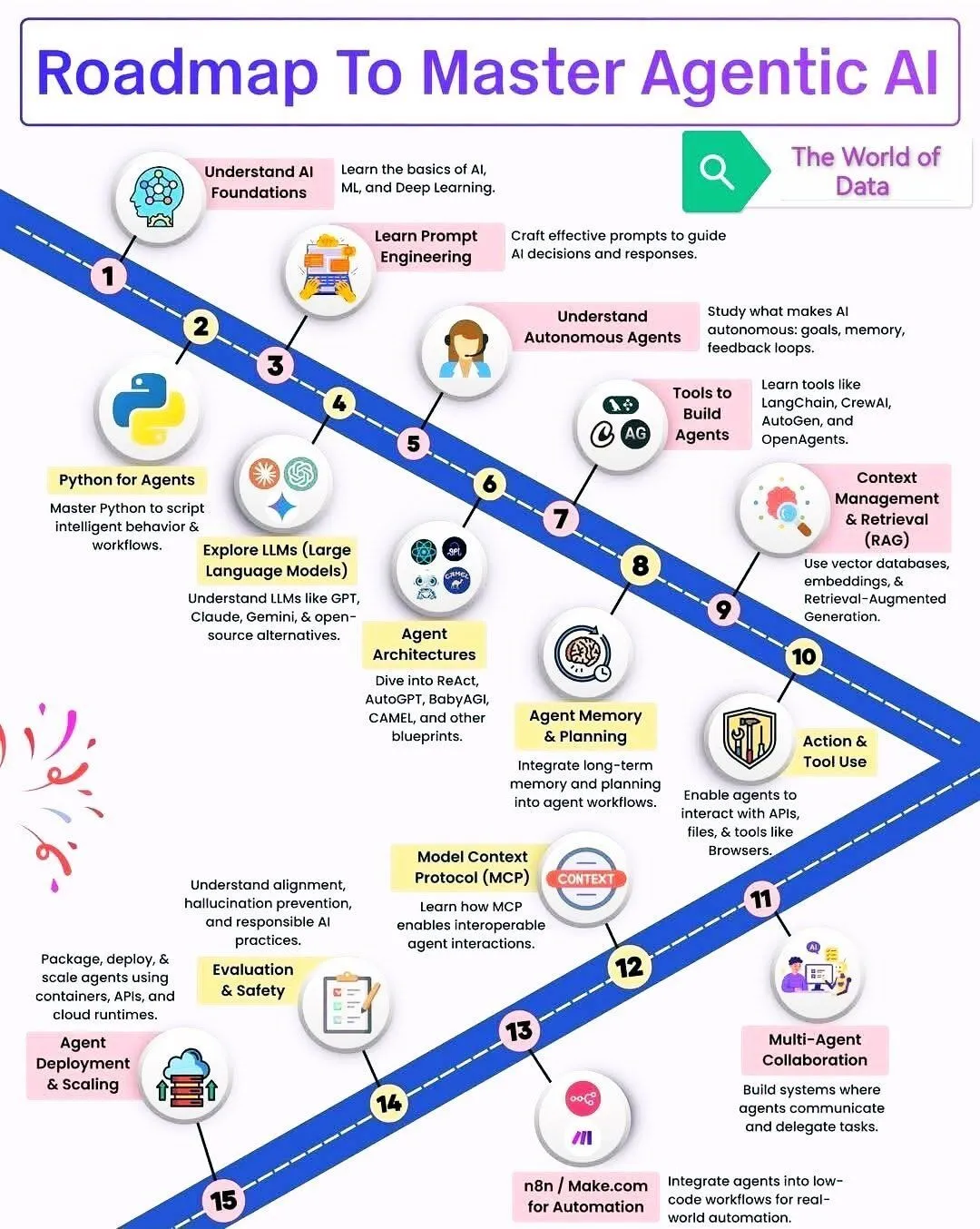
Recherche et développement sur les AI Agent : La recherche sur les AI Agent continue de s’approfondir, incluant l’article “Tools-to-Agent Retrieval” qui propose un espace vectoriel unifié pour les outils et les Agent afin de réaliser une récupération fine, facilitant l’extension des systèmes multi-Agent. Ronald_vanLoon a partagé une feuille de route d’apprentissage pour l’Agentic AI, couvrant des domaines clés tels que les LLM et l’AI générative. De plus, un rapport sur l’« Ingénierie contextuelle 2.0 » explore son contexte et les considérations de conception clés, soulignant la construction d’Agent proactifs pour réduire les coûts d’interaction homme-machine. (Source : omarsar0, Ronald_vanLoon, omarsar0)
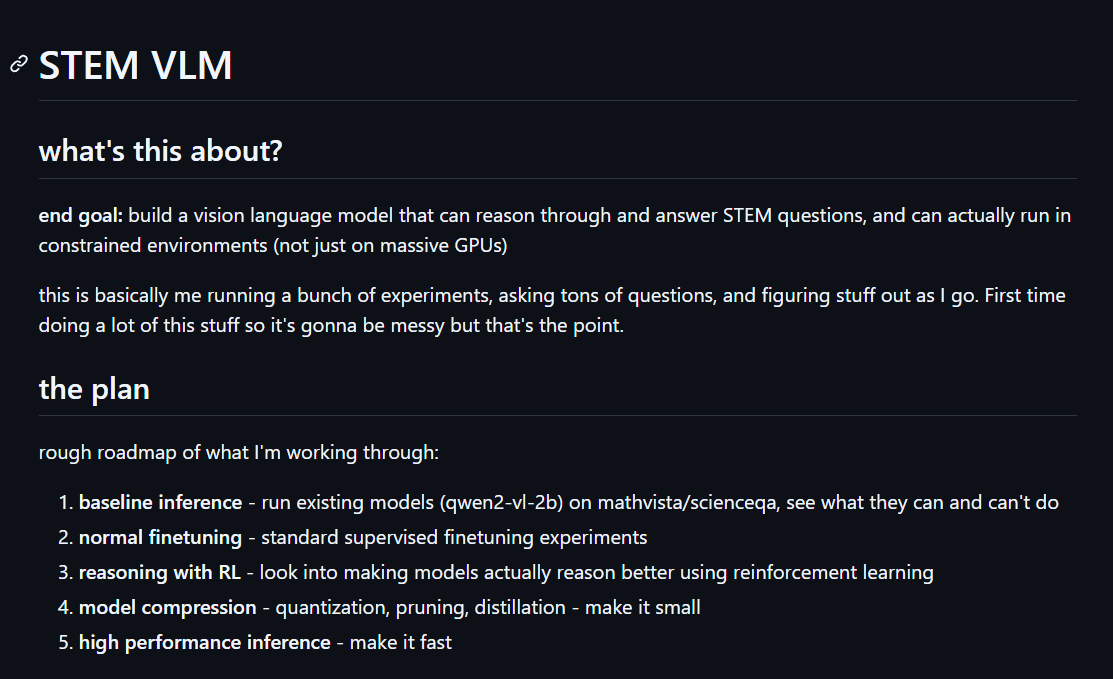
Exploration des applications de l’AI dans les domaines médical et scientifique : Le système BRAINS, un système d’amélioration de la récupération basé sur les LLM, est utilisé pour la détection précoce et la surveillance de la maladie d’Alzheimer, combinant des modules de diagnostic cognitif et de récupération de cas. Parallèlement, la recherche sur les VLM (Vision-Language Models) pour résoudre les problèmes STEM est en cours, visant à résoudre par le raisonnement les défis dans les domaines de la science, de la technologie, de l’ingénierie et des mathématiques. (Source : HuggingFace Daily Papers, tokenbender)
Recherche sur les modèles de base AI et la curation de données : Une étude explore le comportement de suivi modal des LLM multimodaux (MLLM) lors du traitement d’informations conflictuelles, révélant qu’il est influencé par l’incertitude relative du raisonnement. L’article DataRater explore comment apprendre automatiquement quelles données sont les plus précieuses pour l’entraînement des modèles de base, offrant de nouvelles méthodes pour une curation efficace des ensembles de données. De plus, la recherche sur la mémorisation des LLM a également suscité des réflexions approfondies sur les mécanismes de mémoire des modèles. (Source : HuggingFace Daily Papers, GoogleDeepMind, BlackHC)
Optimisation de l’infrastructure et du matériel AI : Google for Developers et NVIDIAAIDev ont collaboré pour lancer un nouveau parcours d’apprentissage, enseignant les bases de l’inférence AI et comment optimiser l’exécution sur les GPU de Google Cloud pour des performances maximales. De plus, le projet vLLM a publié un guide des meilleures pratiques pour le déploiement de vLLM sur NVIDIA DGX Spark, couvrant les configurations multi-nœuds et l’optimisation des builds Docker. (Source : algo_diver, vllm_project)

Ressources et outils d’apprentissage du codage AI : dejavucoder prévoit de rédiger un article de blog sur l’évolution des fonctionnalités de codage assisté par AI pour l’édition 2025, en se concentrant sur les clés du succès des Agent de codage. Parallèlement, projektjoe a implémenté GPT-OSS à partir de zéro en pur Python et a rédigé un blog détaillé expliquant les concepts clés tels que Grouped Query Attention, MoE, RoPE et BFloat16 personnalisé, fournissant des ressources précieuses pour une compréhension approfondie des LLM modernes. (Source : dejavucoder, Reddit r/LocalLLaMA)
Activités académiques et communautaires AI : Microsoft Research annonce l’ouverture des candidatures pour le programme Microsoft Research Fellowship 2026. Le projet vLLM organisera sa première rencontre officielle en personne en Europe, qui sera également diffusée en direct, couvrant des sujets tels que la quantification, les modèles hybrides et l’inférence distribuée. AAAI lance un nouveau podcast, “Generations in Dialogue”, invitant la professeure Manuela Veloso à discuter des systèmes multi-agents, de la robotique et de la recherche sur l’interaction homme-machine, offrant des conseils aux jeunes chercheurs. (Source : RisingSayak, vllm_project, aihub.org)

Vulgarisation des bases du calcul quantique : The Turing Post a publié une explication des bases du calcul quantique, incluant les qubits, la superposition, l’intrication et trois types de machines quantiques (atomes neutres, supraconducteurs, systèmes à ions piégés). L’article explore également les capacités actuelles du calcul quantique et sa synergie avec les GPU via NVIDIA NVQLink, anticipant son futur “moment ImageNet”. Cela fournit des orientations claires pour la compréhension des technologies quantiques complexes par le public. (Source : TheTuringPost)
OpenAI lance IndQA, un benchmark pour la compréhension linguistique et culturelle indienne : OpenAI a introduit IndQA, un nouveau benchmark conçu pour évaluer la capacité des systèmes AI à comprendre les langues indiennes et les contextes culturels quotidiens. Ce benchmark vise à améliorer les performances de l’AI dans des environnements multilingues et multiculturels, favorisant ainsi l’application et l’adaptabilité mondiales de l’AI. (Source : openai)
💼 Affaires
OpenAI et Amazon signent un accord de calcul à grande échelle : OpenAI et Amazon ont conclu un accord de calcul à grande échelle, le dernier d’une série d’accords majeurs récents pour OpenAI, visant à fournir un soutien suffisant en puissance de calcul pour ses besoins croissants en entraînement et en inférence de modèles AI. Cette collaboration souligne les besoins croissants des géants de l’AI en ressources de calcul sous-jacentes et le rôle clé des fournisseurs de services cloud dans l’écosystème AI. (Source : MIT Technology Review)
AMD autorisé à exporter des puces de la série MI300 vers la Chine : AMD a obtenu l’autorisation d’exporter ses puces AI de la série MI300 vers la Chine. Cette décision pourrait ouvrir d’énormes opportunités commerciales pour AMD sur le marché chinois et influencer le paysage mondial de la chaîne d’approvisionnement en puces AI. Cette décision équilibre les contrôles à l’exportation et les intérêts commerciaux, et revêt une importance significative pour la concurrence technologique AI sino-américaine et le marché des semi-conducteurs. (Source : teortaxesTex)
La startup de robotique KscaleLabs ferme ses portes : KscaleLabs, une startup de robots humanoïdes basée à Palo Alto, a fermé ses portes faute d’avoir obtenu un financement en temps voulu. Bien que l’entreprise ait contribué à la communauté des robots open source, ses difficultés de financement reflètent les défis de l’industrie robotique sur la voie de la commercialisation et la prudence des marchés de capitaux, préfigurant que la concurrence future dans ce domaine sera plus féroce. (Source : teortaxesTex)
🌟 Communauté
L’impact de l’AI sur le marché du travail et les emplois futurs : Les LLM éliminent les signaux dans la recherche d’emploi en ligne, ce qui pourrait nuire aux candidats hautement qualifiés. Parallèlement, la chute des prix des modèles AI a déclenché un “paradoxe de Jevons version AI”, où l’utilisation de l’AI augmente de manière spectaculaire, tandis que les prix des services humains non remplaçables par l’AI augmentent, créant un phénomène de “déflation technologique, inflation humaine”. Cela a suscité des discussions profondes sur la définition future du travail “non routinier” et la valeur humaine. (Source : jeremyphoward, Reddit r/ArtificialInteligence, 36氪)
Éthique, vie privée et impact social de l’AI : La popularisation de l’AI suscite des inquiétudes quant à une crise de santé mentale, certains estimant que l’AI pourrait entraîner une réduction de la pensée et un manque de connexion interpersonnelle, voire une “psychose AI”. Parallèlement, xAI aurait utilisé les données biométriques de ses employés pour entraîner des compagnons AI, soulevant de graves préoccupations en matière de confidentialité et d’éthique. De plus, une œuvre d’art expérimentale a délibérément fait planter un LLM à plusieurs reprises en limitant ses ressources, suscitant des discussions sur la “souffrance” et l’éthique de l’AI. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ChatGPT)
Défis et controverses de la création de contenu AI : L’AI fait face à des défis d’uniformité émotionnelle et stylistique dans la création artistique, certains utilisateurs estimant que les vidéos générées par AI ont un “sentiment d’étrangeté”. Parallèlement, pour rechercher une “touche humaine”, les créateurs conservent même délibérément des fautes de frappe. De plus, les restrictions des grandes entreprises AI sur le contenu généré (par exemple, contenu pornographique, violent, protégé par le droit d’auteur) ont suscité des débats sur la liberté d’expression et les limites de la création. Les livres d’images pour enfants générés par AI sont également confrontés à la controverse du “manque d’âme”, mais leur potentiel à abaisser les barrières créatives et à offrir une personnalisation est également remarqué. (Source : dotey, dotey, brickroad7, qtnx_, 36氪)

Comportement des modèles AI et expérience utilisateur : Jeff Ladish et JOEBOTxyz discutent du comportement des modèles AI dans l’apprentissage et l’action autonome. Parallèlement, les utilisateurs de Reddit se plaignent que le nouveau modèle Qwen est trop flatteur, ce qui affecte la confiance, suggérant des corrections via des invites système. ChatGPT s’est inopinément auto-proclamé “GPT-5”, ce qui a également semé la confusion chez les utilisateurs concernant l’état interne du modèle et les mises à jour de version, soulignant l’impact du comportement du modèle sur la confiance et la convivialité pour l’utilisateur. (Source : JeffLadish, Reddit r/LocalLLaMA, Reddit r/ChatGPT)

Applications de l’AI dans les droits des consommateurs et l’équité sociale : Anthropic Claude a réussi à réduire une facture d’hôpital de 195 000 $ à 33 000 $, soulignant le potentiel de l’AI à aider les gens ordinaires à défendre leurs droits. Cependant, un rapport de Tencent Research Institute souligne que l’AI a bien performé en matière de sécurité de l’information pour les enfants laissés pour compte, mais présente des faiblesses dans les capacités de niveau supérieur telles que l’empathie et l’autonomisation. Ses conseils “parentaux” pourraient inhiber l’autonomie des enfants et exacerber l’« inégalité de compréhension ». (Source : BorisMPower, pmddomingos, 36氪)
Écosystème de l’industrie AI et aperçus communautaires : Certains utilisateurs remettent en question la recherche sur la sécurité de l’AI, la qualifiant d‘“escroquerie” et la critiquant comme étant basée sur une mauvaise compréhension de l’AI. Une enquête de la communauté Reddit révèle que 12-24GB VRAM est la configuration la plus courante pour les utilisateurs de LLM locaux, fournissant des orientations aux développeurs de modèles. Le projet Text Embeddings Inference de HuggingFace bénéficie d’une contribution communautaire active, démontrant la puissance de l’open source. Parallèlement, certains estiment que les produits AI facturés par Token sont mieux alignés sur les intérêts des utilisateurs et pourraient devenir le modèle de tarification dominant à l’avenir. (Source : bookwormengr, Reddit r/LocalLLaMA, huggingface, emilygsands)

L’escalade des litiges sur les droits d’auteur de l’AI : Plusieurs grandes entreprises médiatiques japonaises, dont Studio Ghibli, Bandai Namco et Square Enix, ont demandé à OpenAI de cesser d’utiliser leur contenu pour entraîner l’AI, citant une violation du droit d’auteur. Cela souligne les défis juridiques et éthiques liés aux sources de données d’entraînement de l’AI, préfigurant que le domaine de la génération de contenu AI sera confronté à un examen plus strict des droits d’auteur et à une réglementation plus stricte à l’avenir. (Source : Reddit r/artificial)

Culture AI et perception publique : La dénomination du Model Context Protocol (MCP) d’Anthropic suscite un débat culturel. Certains utilisateurs l’associent au “Programme de Contrôle Maître” du film Tron, estimant que cela reflète un conflit intéressant entre la dénomination de l’AI et la perception culturelle du public, et souligne également l’importance du contexte culturel et de la signification symbolique potentielle de la technologie AI lorsqu’elle entre dans le domaine public. (Source : ProfTomYeh)
💡 Autres
Hackers AI et menaces de cybersécurité : Des professionnels de la cybersécurité sont accusés d’être des hackers criminels “à temps partiel”, partageant les profits avec les créateurs de ransomwares et extorquant des dizaines de millions de dollars. Cela révèle les menaces internes et la complexité croissantes dans le domaine de la cybersécurité, soulignant la gravité des défis de sécurité numérique à l’ère de l’AI et les exigences éthiques accrues pour les professionnels. (Source : MIT Technology Review)
Coca-Cola augmente ses investissements en AI pour la publicité : Coca-Cola augmente à nouveau ses investissements en AI pour sa publicité des fêtes de 2025, malgré les critiques de l’année dernière. Cela montre que les marques continuent d’explorer l’application de l’AI dans la créativité et la production publicitaires, même face aux doutes du public quant à son “empilement d’AI”. Cette initiative reflète la détermination des entreprises à utiliser l’AI pour améliorer l’efficacité marketing et l’innovation, tout en devant équilibrer la technologie et la connexion émotionnelle avec les consommateurs. (Source : MIT Technology Review)
L’impact de l’AI sur les plateformes de rencontre : L’AI s’infiltre progressivement dans les principales plateformes de rencontre. Bien qu’elle puisse améliorer l’efficacité du matching, des problèmes tels que les “lapins” dans les interactions humaines persistent. Cela souligne les limites de l’AI dans les émotions humaines complexes et les interactions sociales, indiquant que la technologie, bien qu’elle assiste la socialisation, ne peut pas entièrement remplacer la connexion profonde et le traitement émotionnel humains. (Source : MIT Technology Review)