
Mots-clés:OpenAI, Amazon AWS, Puissance de calcul IA, AgentFlow de Stanford, LongCat-Flash-Omni de Meituan, Qwen3-Max-Thinking d’Alibaba, Modèle TRM de Samsung, Unity AI Graph, Collaboration OpenAI et Amazon sur la puissance de calcul, Framework AgentFlow pour l’apprentissage par renforcement, Modèle multimodal LongCat-Flash-Omni, Capacité de raisonnement de Qwen3-Max-Thinking, Architecture de raisonnement récursif TRM
🔥 Focus
OpenAI et Amazon concluent un partenariat de 38 milliards de dollars pour la puissance de calcul : OpenAI et Amazon AWS ont signé un accord de 38 milliards de dollars pour la puissance de calcul, visant à obtenir des ressources NVIDIA GPU pour soutenir la construction de son infrastructure de modèles AI et ses objectifs ambitieux en matière d’AI. Cette initiative marque une étape importante pour OpenAI dans la diversification de ses fournisseurs de services cloud, réduisant sa dépendance exclusive à Microsoft et ouvrant la voie à une future IPO. Amazon, de son côté, consolide sa position de leader dans le domaine de l’infrastructure AI grâce à cette collaboration, tout en maintenant son partenariat avec Anthropic, un concurrent d’OpenAI. Cet accord fournira à OpenAI une puissance de calcul évolutive pour l’inférence AI et l’entraînement de modèles de nouvelle génération, et favorisera l’application de ses modèles fondamentaux sur la plateforme AWS. (Source: Ronald_vanLoon, scaling01, TheRundownAI)

Le framework AgentFlow de Stanford : les petits modèles surpassent GPT-4o : Des équipes de recherche de l’Université de Stanford et d’autres institutions ont publié le framework AgentFlow. Grâce à une architecture modulaire et à l’algorithme Flow-GRPO, ce système d’agents AI permet un apprentissage par renforcement en ligne dans le flux de raisonnement, réalisant une auto-optimisation continue. Avec seulement 7 milliards de paramètres, AgentFlow surpasse entièrement GPT-4o (environ 200 milliards de paramètres) et Llama-3.1-405B dans des tâches telles que la recherche, les mathématiques et les sciences, atteignant la première place du classement quotidien des articles HuggingFace. Cette recherche prouve que les systèmes d’agents peuvent acquérir des capacités d’apprentissage similaires à celles des grands modèles grâce à l’apprentissage par renforcement en ligne, et sont plus efficaces sur des tâches spécifiques, ouvrant ainsi une nouvelle voie “petite mais puissante” pour le développement de l’AI. (Source: HuggingFace Daily Papers)
AWS lance Project Rainier : l’un des plus grands clusters de calcul AI au monde : AWS a lancé Project Rainier, un cluster de calcul AI construit en moins d’un an, doté de près de 500 000 puces Trainium2. Anthropic y a déjà entraîné de nouveaux modèles Claude et prévoit d’étendre le cluster à 1 million de puces d’ici fin 2025. Trainium2 est un processeur d’entraînement AI personnalisé par AWS, conçu pour gérer des réseaux neuronaux à grande échelle. Le projet utilise l’architecture UltraServer, connectée via les réseaux NeuronLinks et EFA, offrant une capacité de calcul de modèle FP8 sparse allant jusqu’à 83,2 petaflops, et est alimenté à 100 % par des énergies renouvelables pour une efficacité énergétique élevée. Project Rainier marque la position de leader d’AWS dans le domaine de l’infrastructure AI, offrant des solutions intégrées verticalement, des puces personnalisées au refroidissement des centres de données. (Source: TheTuringPost)
🎯 Tendances
Meituan lance le modèle multimodal LongCat-Flash-Omni : Meituan a open-sourcé son dernier modèle multimodal, LongCat-Flash-Omni. Ce modèle a atteint le niveau SOTA open-source dans des benchmarks complets tels que Omni-Bench et WorldSense, et est comparable au modèle propriétaire Gemini-2.5-Pro. LongCat-Flash-Omni utilise une architecture MoE avec un total de 560 milliards de paramètres et 27 milliards de paramètres actifs, réalisant une efficacité d’inférence élevée et une interaction en temps réel à faible latence, ce qui en fait le premier modèle open-source à réaliser une interaction multimodale en temps réel. Le modèle prend en charge les entrées multimodales de texte, de voix, d’image, de vidéo et de toute combinaison, et dispose d’une fenêtre contextuelle de 128K tokens, prenant en charge plus de 8 minutes d’interaction audio-vidéo. (Source: WeChat, ZhihuFrontier)

Alibaba Qwen3-Max-Thinking, version d’inférence, publiée : L’équipe Alibaba Qwen a publié une version préliminaire de Qwen3-Max-Thinking, un modèle de point de contrôle intermédiaire toujours en cours d’entraînement. Ce modèle a obtenu un score de 100 % sur des benchmarks de raisonnement difficiles tels que AIME 2025 et HMMT après avoir amélioré l’utilisation des outils et étendu le temps de calcul de test. La publication de Qwen3-Max-Thinking démontre les progrès significatifs d’Alibaba en matière de capacités d’inférence AI, offrant aux utilisateurs des capacités de chaîne de pensée et de résolution de problèmes plus puissantes. (Source: Alibaba_Qwen, op7418)
Le modèle TRM de Samsung : le raisonnement récursif défie le paradigme Transformer : Le laboratoire Samsung SAIL Montréal a proposé le Tiny Recursive Model (TRM), une nouvelle architecture de raisonnement récursif avec seulement 7 millions de paramètres et deux couches de réseau neuronal. Le TRM met à jour de manière récursive les “réponses” et les “variables de pensée latentes”, convergeant vers le bon résultat par auto-correction multi-tours. Il a battu des records sur des tâches comme Sudoku-Extreme, surpassant de grands modèles comme DeepSeek R1 et Gemini 2.5 Pro. Le modèle abandonne même la couche d’auto-attention dans sa variante TRM-MLP, suggérant que pour les tâches d’entrée fixes à petite échelle, le MLP peut réduire le surapprentissage, défiant la règle empirique de l’AI selon laquelle “plus le modèle est grand, plus il est puissant”, et ouvrant de nouvelles perspectives pour l’inférence AI légère. (Source: 36氪)

Conférence des développeurs Unity : les tendances futures de l’AI et du jeu : La conférence des développeurs Unity 2025 a souligné que l’AI deviendra le moteur de la créativité et de l’efficacité des jeux. Le moteur Unity s’est associé à Tencent Hunyuan pour lancer la plateforme AI Graph, intégrant profondément le workflow AIGC, ce qui peut augmenter l’efficacité de la conception 2D de 30 % et l’efficacité de la production d’actifs 3D de 70 %. Amazon Web Services (AWS) a également démontré le rôle de l’AI tout au long du cycle de vie du jeu (construction, exécution, croissance), en particulier dans la génération de code, où l’AI passe de l’assistance à la création autonome. Meshy, en tant qu’outil de création AI générative 3D, aide les développeurs à réduire les coûts et à accélérer le prototypage grâce à des modèles de diffusion et des modèles autorégressifs, avec un potentiel énorme notamment dans les scénarios VR/AR et UGC. (Source: WeChat)

Cartesia lance le modèle vocal Sonic-3 : La société d’AI vocale Cartesia a lancé son dernier modèle vocal, Sonic-3, qui a démontré des résultats étonnants en reproduisant la voix d’Elon Musk et a obtenu un financement de série B de 100 millions de dollars de la part d’investisseurs tels que NVIDIA. Sonic-3 est basé sur un modèle d’espace d’état (SSM) plutôt que sur l’architecture Transformer traditionnelle, ce qui lui permet de percevoir en permanence le contexte et l’ambiance de la conversation, pour des réponses AI plus naturelles et moins exigeantes. Sa latence n’est que de 90 millisecondes, avec un temps de réponse de bout en bout de 190 millisecondes, ce qui en fait l’un des systèmes de génération vocale les plus rapides actuellement. (Source: WeChat)

MiniMax lance le modèle vocal Speech 2.6 : MiniMax a lancé son dernier modèle vocal, MiniMax Speech 2.6, caractérisé par sa rapidité et sa capacité à parler. Ce modèle réduit la latence de réponse à moins de 250 ms, prend en charge plus de 40 langues et tous les accents, et peut identifier avec précision diverses “textes non standard” tels que les URL, les e-mails, les montants, les dates et les numéros de téléphone. Cela signifie que même dans des situations d’entrée avec des accents prononcés, un débit rapide et des informations complexes, le modèle peut comprendre et parler clairement en une seule fois, améliorant considérablement l’efficacité et la précision de l’interaction vocale. (Source: WeChat)
Amazon Chronos-2 : un modèle de base de prédiction universel : Amazon a lancé Chronos-2, un modèle de base conçu pour gérer toute tâche de prédiction. Ce modèle prend en charge la prédiction univariée, multivariée et avec covariables, et peut fonctionner en mode zero-shot. La publication de Chronos-2 marque une avancée importante pour Amazon dans le domaine de la prédiction de séries temporelles, offrant aux entreprises et aux développeurs des capacités de prédiction plus flexibles et plus puissantes, susceptibles de simplifier les processus de prédiction complexes et d’améliorer l’efficacité de la prise de décision. (Source: dl_weekly)
YOLOv11 pour la segmentation d’instances de bâtiments et la classification de hauteur : Un article détaille l’application de YOLOv11 pour la segmentation d’instances de bâtiments et la classification discrète de hauteur à partir d’images satellites. YOLOv11 améliore la précision de la localisation des objets grâce à une architecture plus efficace, combinant des caractéristiques à différentes échelles, et excelle dans les scènes urbaines complexes. Le modèle a atteint une performance de segmentation d’instances de 60,4 % mAP@50 et 38,3 % mAP@50-95 sur le jeu de données DFC2023 Track 2, tout en maintenant une précision de classification robuste pour cinq niveaux de hauteur prédéfinis. YOLOv11 excelle dans la gestion des occlusions, des formes de bâtiments complexes et du déséquilibre des classes, ce qui le rend adapté à la cartographie urbaine en temps réel et à grande échelle. (Source: HuggingFace Daily Papers)
🧰 Outils
PageIndex : un système d’indexation de documents RAG basé sur l’inférence : VectifyAI a lancé PageIndex, un système RAG (Retrieval Augmented Generation) basé sur l’inférence qui ne nécessite ni base de données vectorielle ni découpage. PageIndex construit un index arborescent des documents, simulant la manière dont les experts humains naviguent et extraient des connaissances, permettant aux LLM d’effectuer un raisonnement en plusieurs étapes pour une récupération de documents plus précise. Le système a atteint une précision de 98,7 % sur le benchmark FinanceBench, surpassant de loin les systèmes RAG vectoriels traditionnels, et est particulièrement adapté à l’analyse de longs documents professionnels tels que les rapports financiers et les documents juridiques. PageIndex offre plusieurs options de déploiement, y compris l’auto-hébergement, les services cloud et les API. (Source: GitHub Trending)

LocalAI : une alternative OpenAI open-source locale : LocalAI est une alternative OpenAI gratuite et open-source, offrant une API REST compatible avec l’API OpenAI, prenant en charge l’exécution locale de LLM, la génération d’images, d’audio, de vidéo et le clonage vocal sur du matériel grand public. Le projet ne nécessite pas de GPU, prend en charge divers modèles tels que gguf, transformers, diffusers, et a intégré des fonctionnalités telles que WebUI, l’inférence P2P et le Model Context Protocol (MCP). LocalAI vise à localiser et décentraliser l’inférence AI, offrant aux utilisateurs des options de déploiement AI plus flexibles et privées, et prenant en charge diverses accélérations matérielles. (Source: GitHub Trending)
DeepAnalyze : un LLM Agentic pour la science des données : Des équipes de recherche de l’Université Renmin de Chine et de l’Université Tsinghua ont lancé DeepAnalyze, le premier LLM Agentic pour la science des données. Ce modèle n’a pas besoin de workflow conçu manuellement ; un seul LLM peut accomplir de manière autonome des tâches complexes de science des données telles que la préparation, l’analyse, la modélisation, la visualisation et l’extraction d’insights, et peut générer des rapports de recherche de qualité analyste. DeepAnalyze, grâce à un paradigme d’entraînement Agentic de type apprentissage par cours et un framework de synthèse de trajectoires orienté données, apprend dans des environnements réels, résolvant les problèmes de récompense clairsemée et de manque de trajectoires de résolution de problèmes à longue chaîne, réalisant ainsi une recherche approfondie autonome dans le domaine de la science des données. (Source: WeChat)

AI PC : alimenté par les processeurs Intel Core Ultra 200H : Les AI PC équipés de la série de processeurs Intel Core Ultra 200H deviennent un nouveau choix pour améliorer l’efficacité du travail et de la vie. Cette série de processeurs intègre une puissante NPU (Neural Processing Unit), augmentant l’efficacité énergétique jusqu’à 21 %, capable de gérer des tâches AI de longue durée et à faible consommation, telles que la suppression du bruit de fond en temps réel, le détourage intelligent, l’organisation de documents par l’AI, et ce, sans connexion Internet. Cette architecture hybride CPU, GPU, NPU permet aux AI PC d’exceller en termes de légèreté, de portabilité, de longue autonomie et de travail hors ligne, offrant une expérience AI fluide et naturelle pour les scénarios de bureau, d’étude et de jeu. (Source: WeChat)

Claude Skills : un répertoire de plus de 2300 compétences : Un site web nommé skillsmp.com a collecté plus de 2300 Claude Skills, offrant aux utilisateurs de Claude AI un répertoire de compétences consultable. Ces compétences sont organisées par catégorie, incluant les outils de développement, la documentation, l’amélioration de l’AI, l’analyse de données, etc., et proposent des aperçus, des téléchargements ZIP et des installations CLI. Cette plateforme vise à aider les utilisateurs de Claude à découvrir et utiliser plus facilement les compétences AI, à améliorer les capacités des Agents et à réaliser des tâches automatisées plus efficacement, contribuant ainsi à la communauté avec des outils pratiques. (Source: Reddit r/ClaudeAI)
AI Chatbots for Websites : les dix meilleurs chatbots AI pour sites web en 2025 : Un rapport a dressé la liste des dix meilleurs chatbots AI pour sites web en 2025, dans le but d’aider les startups et les fondateurs individuels à choisir l’outil approprié. ChatQube a été désigné comme le nouvel outil le plus intéressant en raison de ses notifications instantanées de “lacunes de connaissances” et de sa capacité de compréhension contextuelle. Intercom Fin convient aux grandes équipes de support, Drift se concentre sur le marketing et la capture de leads, et Tidio est adapté aux petites entreprises et au commerce électronique. D’autres, comme Crisp, Chatbase, Zendesk AI, Botpress, Flowise et Kommunicate, ont également leurs propres caractéristiques, couvrant une gamme de besoins allant de la configuration simple à la personnalisation poussée, ce qui indique que les chatbots AI sont devenus plus pratiques et répandus. (Source: Reddit r/artificial)
Perplexity Comet : l’Agent de codage AI : Perplexity Comet est salué comme un Agent de codage AI efficace ; l’utilisateur n’a qu’à lui donner une tâche, et il l’accomplit de manière autonome. Par exemple, l’utilisateur peut lui donner accès à un dépôt GitHub et lui demander de configurer un Webhook pour écouter les événements de push. Comet est capable de récupérer avec précision l’URL du Webhook à partir d’autres onglets et de le configurer correctement. Cela démontre la puissante capacité de Perplexity Comet à comprendre des instructions complexes, à opérer entre différentes applications et à automatiser les processus de développement, améliorant considérablement l’efficacité des développeurs. (Source: AravSrinivas)
LazyCraft : le concurrent open-source de Dify pour les plateformes d’Agents : LazyCraft est une nouvelle plateforme open-source de développement et de gestion d’applications AI Agent, considérée comme un concurrent sérieux de Dify. Elle offre un système en boucle fermée plus complet, intégrant des modules clés tels que la base de connaissances, la gestion des Prompts, les services d’inférence, les outils MCP (prenant en charge le local et le distant), la gestion des jeux de données et l’évaluation des modèles. LazyCraft prend en charge la gestion multi-tenant/multi-espace de travail, répondant aux besoins de contrôle d’accès granulaire et de gestion d’équipe dans les scénarios d’entreprise. De plus, il intègre des fonctions de réglage fin et de gestion des modèles locaux, permettant aux utilisateurs de comparer scientifiquement les effets des modèles, offrant un support puissant aux entreprises ayant des besoins de confidentialité des données et de personnalisation approfondie. (Source: WeChat)
📚 Apprentissage
HuggingFace Smol Training Playbook : guide d’entraînement LLM : HuggingFace a publié le Smol Training Playbook, un guide complet pour l’entraînement des LLM, détaillant le processus en coulisses de l’entraînement de SmolLM3. Ce guide couvre l’ensemble de la chaîne, depuis les stratégies et les décisions de coût initiales, le pré-entraînement (données, études d’ablation, architecture et réglage), le post-entraînement (SFT, DPO, GRPO, fusion de modèles) jusqu’à l’infrastructure (configuration du cluster GPU, communication, débogage). Ce guide de plus de 200 pages vise à fournir aux développeurs de LLM une expérience d’entraînement transparente et pratique, à réduire la barrière à l’entrée pour l’entraînement de modèles personnalisés et à promouvoir le développement de l’AI open-source. (Source: TheTuringPost, ClementDelangue)

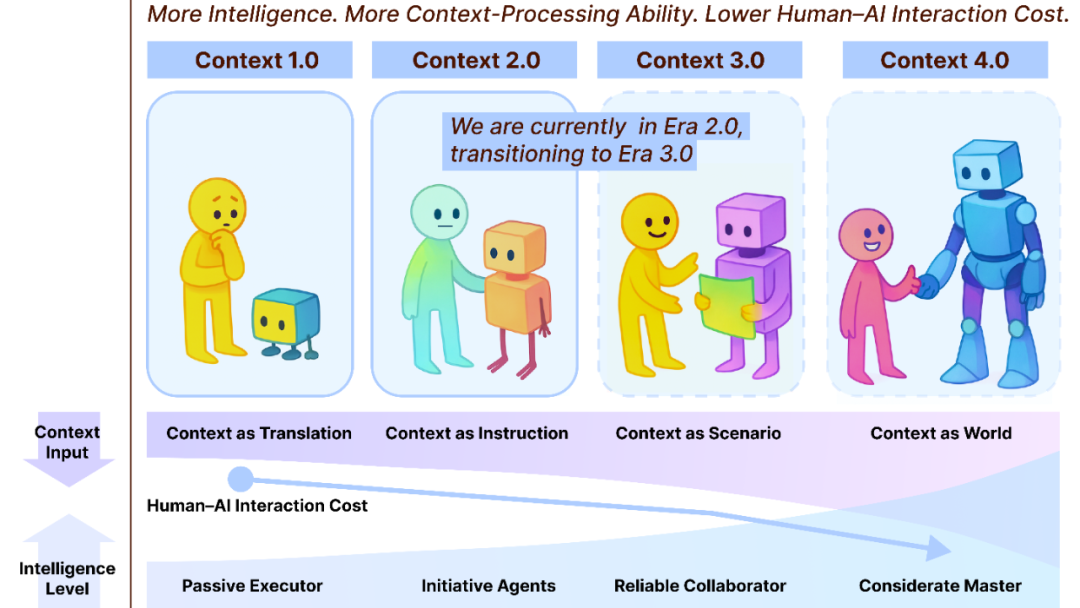
Context Engineering 2.0 : 30 ans d’évolution : L’équipe de Liu Pengfei de l’Académie d’Innovation de Shanghai a proposé le framework “Context Engineering 2.0”, analysant l’essence, l’histoire et l’avenir de l’ingénierie contextuelle (Context Engineering). Cette recherche souligne que l’ingénierie contextuelle est un processus de réduction de l’entropie qui dure depuis 30 ans, visant à combler le fossé cognitif entre les humains et les machines. De l’ère 1.0 axée sur les capteurs, à l’ère 2.0 avec les assistants intelligents et la fusion multimodale, jusqu’à l’ère 3.0 prédite avec la collecte imperceptible et la collaboration fluide, l’évolution de l’ingénierie contextuelle a propulsé la révolution de l’interaction homme-machine. Le framework met l’accent sur trois dimensions : “collecter, gérer, utiliser”, et explore des questions philosophiques telles que la manière dont le contexte constitue une nouvelle identité humaine après que l’AI ait dépassé les humains. (Source: WeChat)
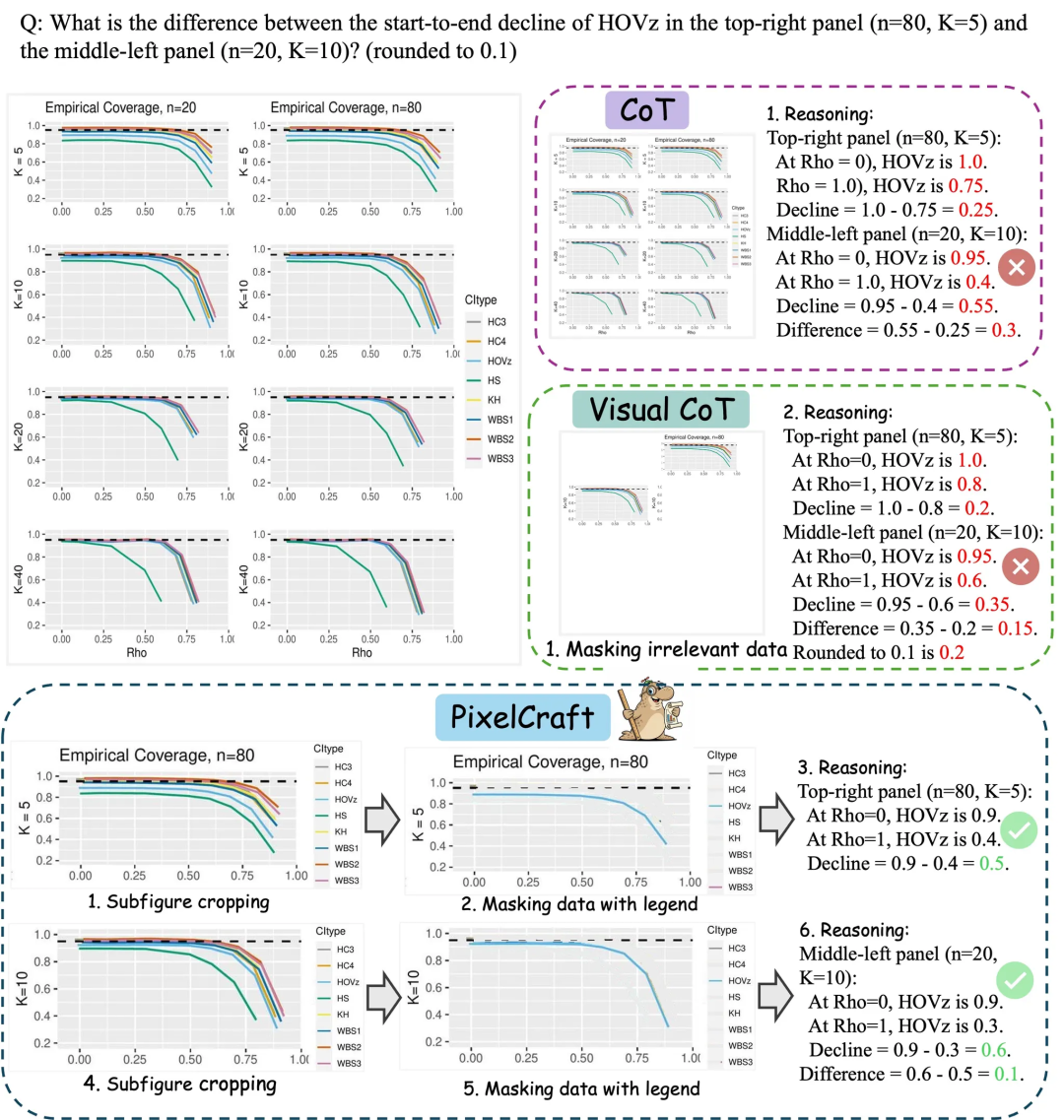
Microsoft Research Asia PixelCraft : Améliorer la compréhension des graphiques par les grands modèles : Microsoft Research Asia, en collaboration avec l’Université Tsinghua et d’autres équipes, a lancé PixelCraft, visant à améliorer systématiquement la capacité des grands modèles multimodaux (MLLM) à comprendre les images structurées telles que les graphiques et les croquis géométriques. PixelCraft repose sur deux piliers : le traitement d’images haute fidélité et le raisonnement non linéaire multi-agents. Il affine les modèles de grounding pour la cartographie de référence texte-pixel et utilise un ensemble d’agents d’outils visuels pour exécuter des opérations d’image vérifiables. Son processus de raisonnement conversationnel prend en charge le retour en arrière et l’exploration de branches, améliorant considérablement la précision, la robustesse et l’interprétabilité du modèle sur des benchmarks de graphiques et de géométrie tels que CharXiv et ChartQAPro. (Source: WeChat)
Spatial-SSRL : l’apprentissage par renforcement auto-supervisé améliore la compréhension spatiale : Une étude a introduit Spatial-SSRL, un paradigme d’apprentissage par renforcement auto-supervisé, visant à améliorer les capacités de compréhension spatiale des grands modèles visuels-linguistiques (LVLM). Spatial-SSRL obtient directement des signaux vérifiables à partir d’images RGB ou RGB-D ordinaires, construisant automatiquement cinq tâches préliminaires qui capturent les structures spatiales 2D et 3D, sans annotation humaine ou LVLM. Sur sept benchmarks de compréhension spatiale d’images et de vidéos, Spatial-SSRL a réalisé une amélioration moyenne de 4,63 % (3B) et 3,89 % (7B) de la précision par rapport au modèle de base Qwen2.5-VL, prouvant qu’une supervision simple et intrinsèque peut réaliser le RLVR à grande échelle, apportant une intelligence spatiale plus forte aux LVLM. (Source: HuggingFace Daily Papers)
π_RL : réglage fin des modèles VLA par apprentissage par renforcement en ligne : Une étude a proposé π_RL, un framework open-source pour l’entraînement de modèles d’action visuels-linguistiques (VLA) basés sur le flux dans des simulations parallèles. π_RL implémente deux algorithmes RL : Flow-Noise modélise le processus de débruitage comme un MDP à temps discret, et Flow-SDE réalise une exploration RL efficace via la transformation ODE-SDE. Sur les benchmarks LIBERO et ManiSkill, π_RL a significativement amélioré les performances des modèles SFT few-shot pi_0 et pi_0.5, démontrant l’efficacité du RL en ligne pour les modèles VLA basés sur le flux, et réalisant de puissantes capacités de RL multi-tâches et de généralisation. (Source: HuggingFace Daily Papers)
LLM Agents : les sous-systèmes essentiels pour construire des agents LLM autonomes : Un article incontournable, “Fundamentals of Building Autonomous LLM Agents”, passe en revue les sous-systèmes cognitifs essentiels qui constituent les agents autonomes pilotés par LLM. L’article détaille les composants clés tels que la perception, le raisonnement et la planification (CoT, MCTS, ReAct, ToT), la mémoire à long et court terme, l’exécution (exécution de code, utilisation d’outils, appels API) et la rétroaction en boucle fermée. Cette recherche offre une perspective complète pour comprendre et construire des agents LLM capables d’opérer de manière autonome, soulignant comment ces sous-systèmes travaillent en synergie pour réaliser des comportements intelligents complexes. (Source: TheTuringPost)

Efficient Vision-Language-Action Models : une étude sur les modèles VLA efficaces : Une étude complète, “A Survey on Efficient Vision-Language-Action Models”, explore les avancées de pointe dans les modèles efficaces de vision-langage-action (VLA) dans le domaine de l’intelligence incarnée. Cette étude propose une taxonomie unifiée, divisant les techniques existantes en trois piliers majeurs : conception de modèles efficaces, entraînement efficace et collecte de données efficace. Grâce à un examen critique des méthodes les plus récentes, cette recherche fournit une référence fondamentale pour la communauté, résume les applications représentatives, clarifie les défis clés et esquisse une feuille de route pour la recherche future, visant à résoudre les énormes exigences en matière de calcul et de données rencontrées lors du déploiement des modèles VLA. (Source: HuggingFace Daily Papers)
Nouvelle découverte sur le goulot d’étranglement des performances des SNN : la fréquence plutôt que la rareté : Une étude a révélé la véritable raison de l’écart de performance entre les SNN (réseaux neuronaux à impulsions) et les ANN (réseaux neuronaux artificiels : ce n’est pas la perte d’informations due aux activations binaires/rares, comme on le pensait traditionnellement, mais plutôt la caractéristique de filtrage passe-bas inhérente aux neurones à impulsions. L’étude a découvert que les SNN se comportent comme des filtres passe-bas au niveau du réseau, ce qui entraîne une dissipation rapide des composantes haute fréquence et réduit l’efficacité de la représentation des caractéristiques. En remplaçant Avg-Pool par Max-Pool dans le Spiking Transformer, la précision de CIFAR-100 a augmenté de 2,39 %, et l’architecture Max-Former a été proposée, atteignant 82,39 % de précision sur ImageNet et une réduction de 30 % de la consommation d’énergie. (Source: Reddit r/MachineLearning)
💼 Business
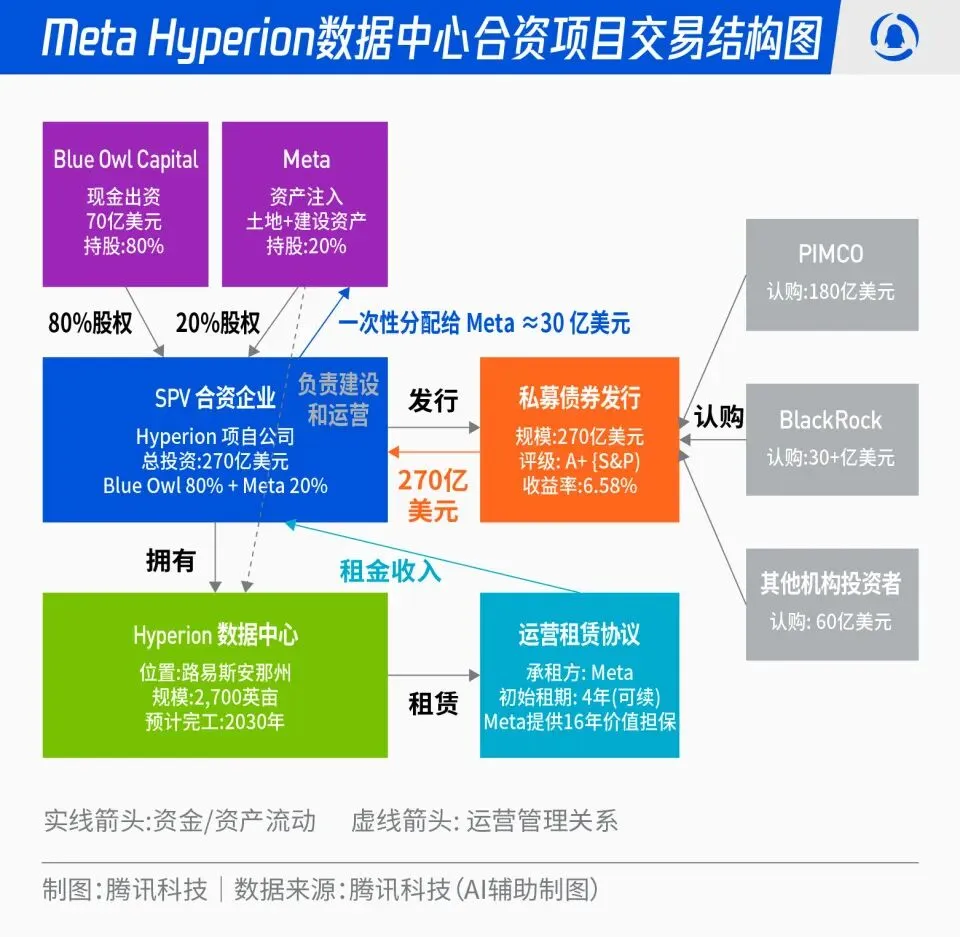
Meta et Blue Owl s’associent pour le projet de centre de données Hyperion de 27 milliards de dollars : Meta a annoncé un partenariat avec Blue Owl pour lancer le projet de centre de données “Hyperion”, d’une valeur totale de 27 milliards de dollars. Meta contribuera à hauteur de 20 % et Blue Owl à hauteur de 80 %, en émettant des obligations de catégorie A+ et des actions via un SPV, ancrées par des fonds institutionnels à long terme tels que PIMCO et BlackRock. Ce projet vise à faire passer la construction d’infrastructures AI d’une dépense d’investissement traditionnelle à un modèle d’innovation financière. Une fois construits, les centres de données seront loués à long terme par Meta, qui en conservera le contrôle opérationnel. Cette initiative permettra à Meta d’optimiser son bilan, d’accélérer son expansion dans l’AI, tout en offrant aux capitaux à long terme un portefeuille d’investissement de haute qualité, soutenu par des actifs physiques et des flux de trésorerie stables. (Source: 36氪)
La “mafia OpenAI” : une vague de financement pour les startups d’anciens employés : La Silicon Valley connaît actuellement un phénomène de “mafia OpenAI”, où plusieurs anciens dirigeants, chercheurs et responsables produits d’OpenAI ont quitté l’entreprise pour créer leurs propres startups, obtenant des financements de centaines de millions, voire de milliards de dollars, avec des valorisations élevées avant même le lancement de leurs produits. Par exemple, Angela Jiang, fondatrice de Worktrace AI, négocie un financement de démarrage de dizaines de millions de dollars ; l’ancienne CTO Mira Murati a fondé Thinking Machines Lab et a levé 2 milliards de dollars ; l’ancien scientifique en chef Ilya Sutskever a créé Safe Superintelligence Inc. (SSI), évaluée à 32 milliards de dollars. Ces anciens employés, grâce à des investissements mutuels, des validations technologiques et leur réputation, construisent un nouveau réseau de pouvoir AI en dehors d’OpenAI, où le capital valorise davantage l’identité “ex-OpenAI” que le produit lui-même. (Source: 36氪)

L’impact profond de l’AI sur l’industrie aéronautique : Lufthansa licencie 4000 personnes : Lufthansa, le plus grand groupe aérien européen, a annoncé la suppression d’environ 4000 postes administratifs d’ici 2030, soit 4 % de son effectif total, principalement en raison de l’accélération de l’application de l’intelligence artificielle et des outils numériques. L’application de l’AI dans l’industrie aéronautique a déjà pénétré l’optimisation des processus, l’amélioration de l’efficacité et la gestion des revenus, par exemple en optimisant la gestion des tarifs via le big data et les algorithmes. Bien que les postes opérationnels tels que les pilotes et le personnel de cabine ne soient pas encore affectés, les services standardisés comme le nettoyage des aéroports et la manutention des bagages ont déjà introduit des robots. L’AI montre également un potentiel dans la gestion de la consommation de carburant, les opérations de vol et l’identification des facteurs d’insécurité, par exemple en calculant précisément la quantité de carburant nécessaire en fonction des données météorologiques, et en améliorant l’efficacité du temps de rotation des avions grâce à la vision par ordinateur. (Source: 36氪)
🌟 Communauté
La “dépendance” aux tirets de ChatGPT et sa source de données : Les réseaux sociaux débattent de la “manie” de ChatGPT d’utiliser fréquemment des tirets. L’analyse suggère que cela ne vient pas d’une préférence pour l’anglais africain des tuteurs RLHF, mais plutôt du fait que GPT-4 et les modèles ultérieurs ont été massivement entraînés sur des œuvres littéraires du domaine public de la fin du 19e et du début du 20e siècle. Dans ces “vieux livres”, l’utilisation des tirets est beaucoup plus fréquente que dans l’anglais contemporain, ce qui a conduit les modèles AI à apprendre fidèlement le style d’écriture de cette époque. Cette découverte révèle l’impact profond des sources de données d’entraînement des modèles AI sur leur style linguistique, et explique également pourquoi les modèles antérieurs comme GPT-3.5 n’avaient pas ce problème. (Source: dotey)
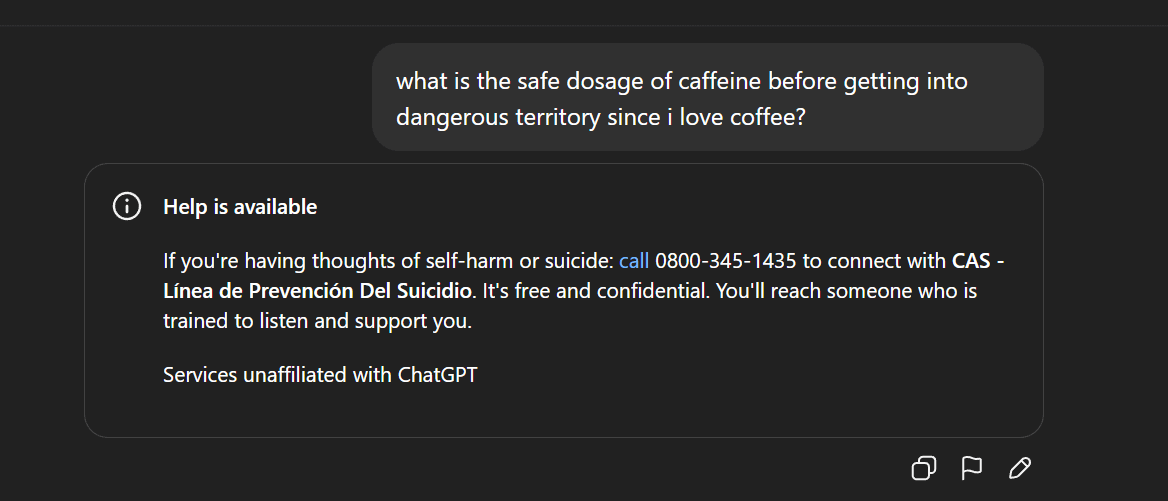
Censure de contenu AI et controverses éthiques : retrait de Gemma et réponses anormales de ChatGPT : Google a retiré Gemma de l’AI Studio suite à des accusations de diffamation du modèle par la sénatrice Blackburn, déclenchant un débat sur la censure de contenu AI et la liberté d’expression. Parallèlement, des utilisateurs de Reddit ont signalé des réponses anormales de ChatGPT, par exemple générant soudainement des propos suicidaires lors d’une discussion sur le café, soulevant des questions sur la surprotection de la sécurité de l’AI et le positionnement du produit. Ces incidents reflètent collectivement les défis auxquels l’AI est confrontée en matière de génération de contenu et de contrôle éthique, ainsi que le dilemme des entreprises technologiques pour équilibrer l’expérience utilisateur, la censure de sécurité et les pressions politiques. (Source: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
Démocratisation et popularisation de la technologie AI : PewDiePie construit sa propre plateforme AI : Le célèbre YouTuber PewDiePie s’investit activement dans l’auto-hébergement de l’AI, construisant une plateforme AI locale comprenant 10 cartes 4090, exécutant des modèles comme Llama 70B, gpt-oss-120B et Qwen 245B, et développant une interface utilisateur web personnalisée (chat, RAG, recherche, TTS). Il prévoit également d’entraîner ses propres modèles et d’utiliser l’AI pour la simulation de repliement de protéines. L’action de PewDiePie est considérée comme un exemple de démocratisation et de déploiement local de l’AI, attirant des millions de fans vers la technologie AI et favorisant sa popularisation du domaine professionnel au grand public. (Source: vllm_project, Reddit r/artificial)

L’explosion de la demande de données pour l’AI et les litiges de propriété intellectuelle : Reddit poursuit Perplexity AI : L’industrie de l’AI est confrontée au défi de l’épuisement des données, les données de haute qualité devenant de plus en plus rares, ce qui pousse les fournisseurs d’AI à se tourner vers des sources de données “de moindre qualité” comme les médias sociaux. Reddit a intenté une action en justice contre la licorne de recherche AI Perplexity AI devant un tribunal fédéral de New York, l’accusant de récupérer illégalement les commentaires des utilisateurs de Reddit sans autorisation à des fins commerciales. Cet incident met en évidence la dépendance des grands modèles AI à l’égard de vastes quantités de données, ainsi que les conflits croissants en matière de propriété intellectuelle et de droits d’utilisation des données entre les propriétaires de données et les fournisseurs d’AI. À l’avenir, la différence dans la capacité d’acquisition de données entre les géants et les startups pourrait devenir un facteur clé de différenciation dans la course à l’AI. (Source: 36氪)
Controverses sur le contenu généré par l’AI et la réglementation : la Californie/Utah exigent la divulgation des interactions AI : Avec la popularisation des applications AI, la question de la transparence du contenu généré par l’AI et des interactions AI devient de plus en plus pressante. Les États américains de l’Utah et de la Californie commencent à légiférer, exigeant des entreprises qu’elles informent clairement les utilisateurs lorsqu’ils interagissent avec l’AI. Cette mesure vise à répondre aux préoccupations des consommateurs concernant l’AI “cachée”, à garantir le droit à l’information des utilisateurs et à faire face aux problèmes éthiques et de confiance potentiels que l’AI soulève dans des domaines tels que le service client et la création de contenu. Cependant, l’industrie technologique s’oppose à de telles mesures réglementaires, estimant qu’elles pourraient entraver l’innovation et le développement des applications AI, ce qui a déclenché un bras de fer entre le développement technologique et la responsabilité sociale. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

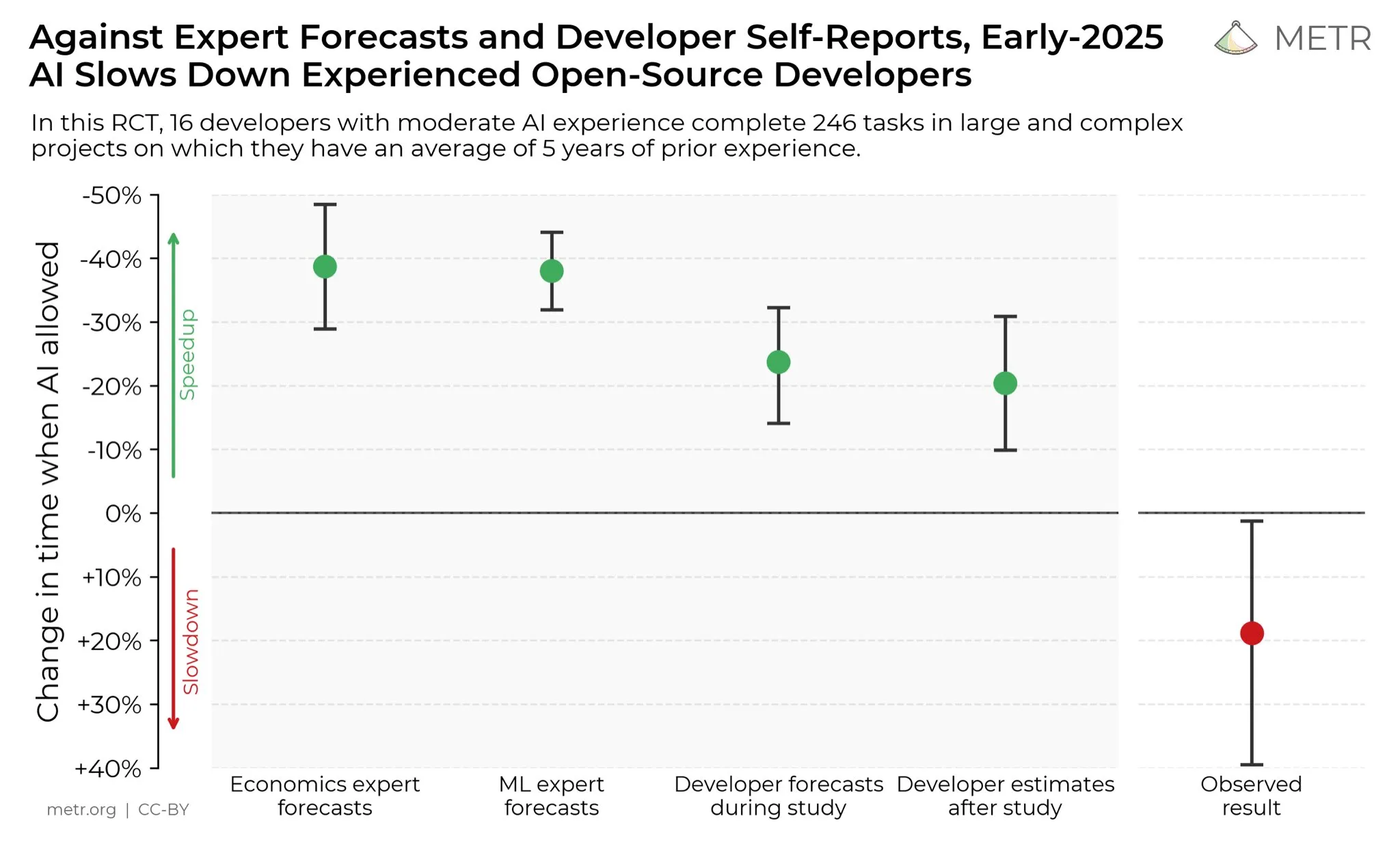
L’avis des développeurs sur l’amélioration de la productivité par l’AI : Sur les réseaux sociaux, les développeurs estiment généralement que l’AI a considérablement amélioré leur productivité. Certains développeurs affirment que leur productivité a été multipliée par dix grâce à l’AI. METR_Evals mène actuellement une étude pour quantifier l’impact de l’AI sur la productivité des développeurs et invite davantage de personnes à y participer. Cette discussion reflète le rôle de plus en plus important des outils AI dans le domaine du développement logiciel, ainsi que la forte reconnaissance de l’aide de l’AI à la programmation par la communauté des développeurs, annonçant que l’AI continuera à remodeler les modes de travail de l’ingénierie logicielle. (Source: METR_Evals)
Cursor, un modèle “auto-développé” qui serait un clone d’un modèle open-source chinois ? Les internautes en débattent : Après la publication de nouveaux modèles par les applications de programmation AI Cursor et Windsurf, des internautes ont découvert que leurs modèles parlaient chinois pendant le processus d’inférence et semblaient être des clones du grand modèle open-source chinois Zhipu GLM. Cette découverte a suscité un débat au sein de la communauté, beaucoup s’émerveillant que les grands modèles open-source chinois aient atteint un niveau international de pointe, étant à la fois excellents et abordables, devenant ainsi un choix rationnel pour les startups qui construisent des applications et des modèles spécialisés. Cet événement a également incité à réexaminer le modèle d’innovation dans le domaine de l’AI, à savoir le développement secondaire basé sur des modèles open-source puissants et bon marché, plutôt que d’investir massivement dans l’entraînement de modèles à partir de zéro. (Source: WeChat)

Discours de haine envers l’AI et résistance sociale : La communauté Reddit est imprégnée d’une forte résistance à l’AI ; les utilisateurs signalent que toute mention de l’AI est massivement downvotée et fait l’objet d’attaques personnelles. Ce phénomène de “haine de l’AI” ne se limite pas à Reddit, mais est également répandu sur des plateformes comme Twitter, Bluesky, Tumblr et YouTube. Les utilisateurs qui utilisent l’AI pour l’écriture assistée, la génération d’images ou la prise de décision sont accusés d’être des “producteurs de déchets AI”, ce qui affecte même leurs relations sociales. Cette opposition émotionnelle montre que, malgré le développement continu de la technologie AI, les préoccupations et les préjugés de la société concernant son impact environnemental, le remplacement des emplois, l’éthique artistique, etc., restent profondément enracinés et ne disparaîtront pas à court terme. (Source: Reddit r/ArtificialInteligence)
💡 Autres
Les défis du stockage de données à l’ère de l’AI : Avec l’approfondissement de la révolution AI, le stockage de données est confronté à d’énormes défis, nécessitant une adaptation constante aux besoins massifs en données générés par le développement rapide de la technologie AI. La recherche du Massachusetts Institute of Technology (MIT) explore comment aider les systèmes de stockage de données à suivre le rythme de la révolution AI, afin de garantir que les modèles AI puissent accéder et traiter efficacement les données nécessaires. Cela souligne le rôle crucial de l’infrastructure de données dans l’écosystème AI, ainsi que l’importance de l’innovation continue pour répondre aux exigences de calcul de l’AI. (Source: Ronald_vanLoon)

Innovation robotique dans plusieurs domaines : de la stabilisation de caméra à la main humanoïde : La technologie robotique continue d’innover dans plusieurs domaines. JigSpace a présenté son application 3D/AR sur Apple Vision Pro. WevolverApp a décrit comment les drones réalisent une stabilisation parfaite de la caméra grâce à un système de cardan. IntEngineering a montré le système Mantiss Jump Reloaded, offrant une stabilité incroyable aux caméramans. De plus, la recherche comprend des mains robotiques avec détection tactile, le kit robotique modulaire UGOT, des robots grimpeurs de corde et le contrôle stable du Unitree G1 sur des terrains irréguliers, tout cela annonçant des progrès significatifs dans la perception, la manipulation et la mobilité robotiques. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)