
Mots-clés:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, Informatique quantique, Découverte de médicaments par IA, DeepSeek MoE, vLLM, Meta Vibes, Technologie de compression optique contextuelle, Fonction de mémoire des navigateurs IA, Degrés de liberté des robots humanoïdes, Algorithme d’écho quantique, Cadre de génération de protocoles d’expérimentation biologique
🔥 Focus
DeepSeek-OCR : Technologie de compression optique contextuelle : Le modèle DeepSeek-OCR introduit le concept de “compression optique contextuelle”. En traitant le texte comme une image, il peut compresser le contenu d’une page entière en un petit nombre de “jetons visuels” via un encodage visuel, puis les décoder pour les restituer sous forme de texte, de tableaux ou de graphiques, multipliant l’efficacité par dix et atteignant une précision de 97%. Cette technologie utilise DeepEncoder pour capturer les informations de la page et les compresser 16 fois, réduisant 4096 jetons à 256, et peut ajuster automatiquement le nombre de jetons en fonction de la complexité du document, surpassant ainsi considérablement les modèles OCR existants. Cela réduit non seulement les coûts de traitement des documents longs et améliore l’efficacité de l’extraction d’informations, mais offre également de nouvelles perspectives pour la mémoire à long terme et l’extension du contexte des LLM, annonçant l’énorme potentiel des images en tant que vecteurs d’information dans le domaine de l’IA.(来源:HuggingFace Daily Papers, 36氪, ZhihuFrontier)

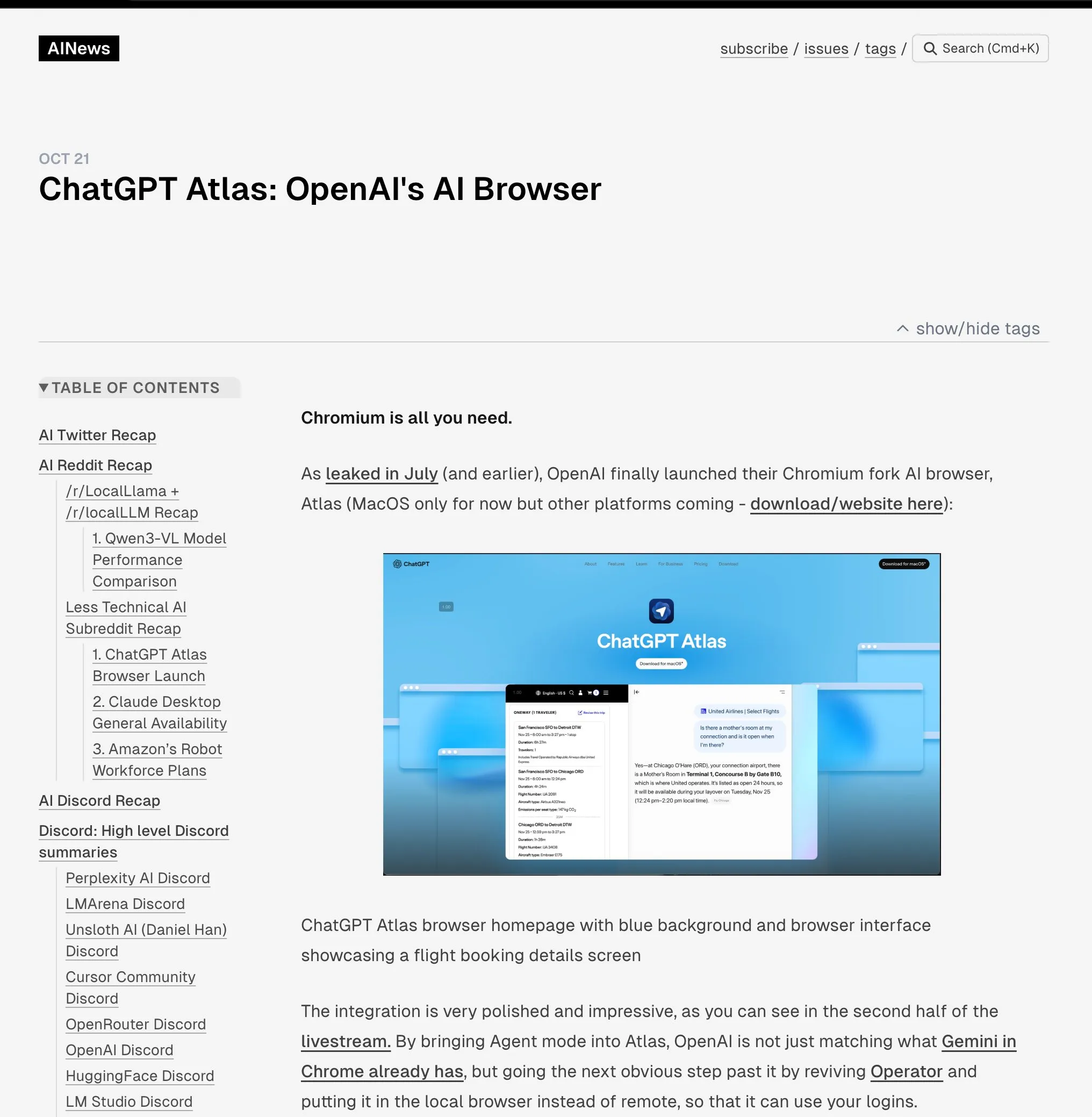
OpenAI lance le navigateur ChatGPT Atlas : OpenAI a lancé ChatGPT Atlas, un navigateur conçu pour l’ère de l’IA, intégrant profondément ChatGPT à l’expérience de navigation. Ce navigateur offre non seulement des fonctionnalités traditionnelles, mais intègre également un “mode Agent” capable d’effectuer des tâches telles que les réservations, les achats et le remplissage de formulaires, ainsi qu’une fonction de “mémoire du navigateur” qui apprend les habitudes de l’utilisateur pour fournir un service personnalisé. Cette initiative marque un changement stratégique pour OpenAI vers la construction d’un écosystème d’IA complet, susceptible de remodeler la façon dont les utilisateurs interagissent avec Internet et de remettre en question la domination de la publicité et des données sur le marché des navigateurs existants (en particulier Google Chrome). L’industrie considère généralement cela comme le début d’une nouvelle “guerre des navigateurs”, dont l’enjeu principal est le contrôle de la vie numérique des utilisateurs.(来源:Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Lancement du robot humanoïde Unitree H2 : Unitree Robotics a lancé le robot humanoïde H2, réalisant un bond significatif en matière d’intelligence incarnée et de conception matérielle. Le H2 prend en charge NVIDIA Jetson AGX Thor, offrant une capacité de calcul 7,5 fois supérieure à celle d’Orin et une efficacité multipliée par 3,5. Au niveau de la conception mécanique, les jambes ont gagné 1 degré de liberté (pour un total de 6), les bras ont été améliorés à 7 degrés de liberté, avec une charge utile de 7 à 15 kg et la possibilité d’équiper des mains agiles. En termes de capteurs, le H2 abandonne le LiDAR au profit d’une perception 3D purement visuelle, utilisant des caméras stéréo binoculaires. Malgré ces avancées technologiques significatives, les commentaires soulignent que les robots humanoïdes sont toujours à la recherche de scénarios d’application matures et sont actuellement plus adaptés à la recherche en laboratoire.(来源:ZhihuFrontier)

Découvertes en matière de découverte de médicaments assistée par l’IA et de technologies bioniques : Des chercheurs du MIT ont utilisé l’IA pour concevoir de nouveaux antibiotiques efficaces contre la bactérie Neisseria gonorrhoeae multirésistante et le SARM. Ces composés, de structure unique, détruisent la membrane cellulaire bactérienne par un nouveau mécanisme, rendant difficile le développement de résistances. Parallèlement, l’équipe de recherche a développé un nouveau genou bionique qui s’intègre directement aux tissus musculaires et osseux de l’utilisateur. Il utilise la technologie AMI pour extraire les informations nerveuses des muscles résiduels après l’amputation, guidant ainsi le mouvement de la prothèse. Ce genou bionique aide les personnes amputées à marcher plus vite, à monter les escaliers et à éviter les obstacles plus facilement, se sentant davantage comme une partie de leur corps. Il devrait obtenir l’approbation de la FDA après des essais cliniques à plus grande échelle.(来源:MIT Technology Review, MIT Technology Review)

Google atteint un avantage quantique vérifiable : Google a publié une nouvelle avancée en calcul quantique dans la revue Nature. Son puce Willow a atteint pour la première fois un avantage quantique vérifiable en exécutant un algorithme appelé “écho quantique”. Cet algorithme est 13 000 fois plus rapide que l’algorithme classique le plus rapide et peut expliquer les interactions atomiques dans les molécules, ouvrant des applications potentielles dans des domaines tels que la découverte de médicaments et la science des matériaux. Le résultat de cette percée est reproductible et vérifiable, marquant une étape importante pour le calcul quantique vers des applications pratiques.(来源:Google)

🎯 Tendances
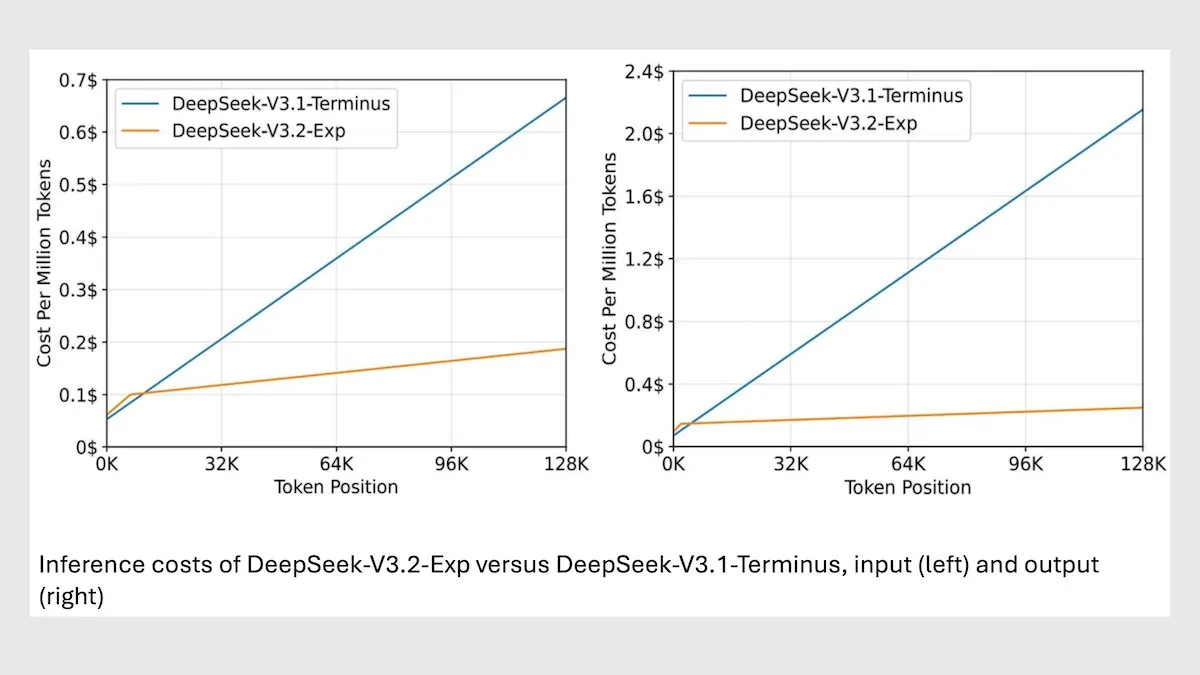
Le modèle DeepSeek MoE V3.2 optimise l’inférence à long contexte : DeepSeek a lancé son nouveau modèle MoE V3.2 de 685B, qui se concentre uniquement sur les tokens les plus pertinents, augmentant la vitesse d’inférence à long contexte de 2 à 3 fois et réduisant les coûts de traitement de 6 à 7 fois par rapport au modèle V3.1. Le nouveau modèle utilise des poids sous licence MIT et est disponible via API, optimisé pour Huawei et d’autres puces chinoises. Bien qu’il y ait une légère baisse de performance sur certaines tâches scientifiques/mathématiques, les performances sur les tâches de codage/agent ont été améliorées.(来源:DeepLearningAI)
vLLM V1 prend désormais en charge les GPU AMD : La version vLLM V1 peut désormais fonctionner sur les GPU AMD. Les équipes d’IBM Research, Red Hat et AMD ont collaboré pour construire un backend d’attention optimisé utilisant le noyau Triton, atteignant des performances de pointe. Cette avancée offre aux utilisateurs de matériel AMD une solution d’inférence LLM plus efficace.(来源:QuixiAI)

Lancement du flux vidéo Meta Vibes AI : Meta a lancé Vibes, une nouvelle fonctionnalité de flux vidéo AI intégrée à l’application Meta AI. Les utilisateurs peuvent y parcourir des courtes vidéos générées par l’IA et les modifier en un clic, notamment en ajoutant de la musique, en changeant de style ou en remixant les œuvres d’autres utilisateurs, puis les partager sur Instagram et Facebook. Cette initiative vise à abaisser la barrière à la création de vidéos AI, à populariser les vidéos AI dans les scénarios sociaux grand public, et pourrait modifier les modèles de production et de distribution de contenu vidéo court, mais elle soulève également des préoccupations concernant le droit d’auteur, l’originalité et la diffusion de fausses informations.(来源:36氪)
rBridge : un modèle d’agent pour prédire les performances d’inférence des LLM : La méthode rBridge permet à de petits modèles d’agent (≤1B paramètres) de prédire efficacement les performances d’inférence de grands modèles (7B-32B paramètres), réduisant les coûts de calcul de plus de 100 fois. Cette méthode aligne l’évaluation avec les objectifs de pré-entraînement et les tâches cibles, utilise les trajectoires d’inférence des modèles de pointe comme étiquettes de référence, et pondère l’importance des tokens pour la tâche, résolvant ainsi le “problème d’émergence” où les capacités de raisonnement ne se manifestent pas dans les petits modèles. Cela réduit considérablement le coût pour les chercheurs aux ressources de calcul limitées d’explorer les choix de conception de pré-entraînement.(来源:Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Mono4DGS-HDR : un système de reconstruction 4D HDR par éclaboussures gaussiennes : Mono4DGS-HDR est le premier système capable de reconstruire des scènes 4D HDR rendables à partir de vidéos monoculaires LDR (Low Dynamic Range) à exposition alternée. Ce cadre unifié utilise une méthode d’optimisation en deux étapes, basée sur la technique de Gaussian splatting. Il apprend d’abord une représentation gaussienne HDR vidéo dans l’espace de coordonnées de la caméra orthogonale, puis convertit les gaussiennes vidéo en espace monde et optimise conjointement les gaussiennes monde et la pose de la caméra. De plus, la stratégie de régularisation temporelle de la luminosité proposée améliore la cohérence temporelle de l’apparence HDR, surpassant significativement les méthodes existantes en termes de qualité et de vitesse de rendu.(来源:HuggingFace Daily Papers)
EvoSyn : un cadre de synthèse de données évolutif pour l’apprentissage vérifiable : EvoSyn est un cadre de synthèse de données évolutif, indépendant de la tâche, guidé par des stratégies et vérifiable, conçu pour générer des données fiables et vérifiables. Ce cadre commence avec une supervision minimale, synthétise conjointement des problèmes, des solutions candidates diversifiées et des artefacts de vérification, et découvre itérativement des stratégies via un évaluateur basé sur la cohérence. Les expériences ont montré que l’entraînement avec des données synthétisées par EvoSyn a conduit à des améliorations significatives sur les tâches LiveCodeBench et AgentBench-OS, soulignant la capacité de généralisation robuste de son cadre.(来源:HuggingFace Daily Papers)
Nouvelle méthode pour extraire des données d’alignement de modèles post-entraînés : Des recherches montrent qu’une grande quantité de données d’entraînement alignées peut être extraite de modèles post-entraînés pour améliorer les capacités du modèle en matière d’inférence à long contexte, de sécurité, de suivi des instructions et de mathématiques. La similarité sémantique mesurée par des modèles d’intégration de haute qualité permet d’identifier des données d’entraînement difficiles à capturer par la correspondance de chaînes traditionnelle. L’étude a révélé que les modèles peuvent facilement retracer les données utilisées lors des phases de post-entraînement comme SFT ou RL, et que ces données peuvent être utilisées pour entraîner des modèles de base et restaurer les performances originales. Ce travail révèle les risques potentiels liés à l’extraction de données alignées et offre de nouvelles perspectives de discussion sur les effets en aval des pratiques de distillation.(来源:HuggingFace Daily Papers)
PRISMM-Bench : un benchmark pour les incohérences multimodales dans les articles scientifiques : PRISMM-Bench est le premier benchmark basé sur des incohérences multimodales dans des articles scientifiques annotés par de vrais relecteurs, visant à évaluer la capacité des grands modèles multimodaux (LMM) à comprendre et à raisonner sur la complexité des articles scientifiques. Ce benchmark, via un processus en plusieurs étapes, a compilé 262 incohérences à partir de 242 articles et a conçu trois tâches : identification, remédiation et appariement. L’évaluation de 21 LMM (y compris GLM-4.5V 106B, InternVL3 78B et Gemini 2.5 Pro, GPT-5) a montré des performances significativement faibles des modèles (26,1-54,2%), soulignant les défis du raisonnement scientifique multimodal.(来源:HuggingFace Daily Papers)
GAS : une méthode améliorée de discrétisation des ODE de diffusion : Bien que les modèles de diffusion aient atteint un niveau de pointe en termes de qualité de génération, leurs coûts de calcul d’échantillonnage sont élevés. Le Generalized Adversarial Solver (GAS) propose un échantillonneur ODE simplement paramétré qui améliore la qualité sans nécessiter de techniques d’entraînement supplémentaires. En combinant la perte de distillation originale avec l’entraînement contradictoire, GAS est capable de réduire les artefacts et d’améliorer la fidélité des détails. Les expériences ont montré que, sous des contraintes de ressources similaires, GAS surpasse les méthodes d’entraînement de solveurs existantes.(来源:HuggingFace Daily Papers)
3DThinker : un cadre de raisonnement spatial pour l’imagination géométrique des VLM : Le cadre 3DThinker vise à améliorer la capacité des modèles de langage visuel (VLM) à comprendre les relations spatiales 3D à partir de perspectives limitées. Ce cadre utilise un entraînement en deux étapes : d’abord, un entraînement supervisé pour aligner l’espace latent 3D généré par le VLM pendant l’inférence avec l’espace latent d’un modèle de base 3D ; ensuite, l’optimisation de l’ensemble de la trajectoire d’inférence uniquement basée sur les signaux de résultat, perfectionnant ainsi la modélisation mentale 3D sous-jacente. 3DThinker est le premier cadre capable de réaliser une modélisation mentale 3D sans entrée 3D a priori ni données 3D explicitement étiquetées, obtenant d’excellents résultats dans plusieurs benchmarks et offrant une nouvelle perspective pour l’unification des représentations 3D dans le raisonnement multimodal.(来源:HuggingFace Daily Papers)
Huawei HarmonyOS 6 améliore les fonctionnalités de l’assistant AI : Huawei a officiellement lancé le système d’exploitation HarmonyOS 6, améliorant considérablement la fluidité, l’intelligence et l’expérience de collaboration inter-appareils. Parmi ses fonctionnalités, l’assistant “Super Assistant” Xiaoyi a été considérablement amélioré, prenant en charge non seulement 16 dialectes, mais aussi la recherche approfondie, la retouche d’images en une phrase, et aidant les utilisateurs malvoyants à “voir le monde”. Basé sur le cadre Harmony Intelligent Agent, les 80 premières applications intelligentes Harmony sont désormais en ligne. Xiaoyi et ses partenaires agents peuvent collaborer étroitement pour fournir des services professionnels, tels que des guides de voyage ou des rendez-vous médicaux, et des fonctionnalités de protection de la vie privée comme “AI anti-fraude” et “AI anti-espionnage” ont été introduites.(来源:量子位)

Application de l’IA dans l’étude urbaine : analyse de la vitesse de marche et de l’utilisation de l’espace public : Une étude co-écrite par des chercheurs du MIT révèle qu’entre 1980 et 2010, la vitesse de marche moyenne a augmenté de 15% dans trois villes du nord-est des États-Unis, tandis que le nombre de personnes s’attardant dans les espaces publics a diminué de 14%. Les chercheurs ont utilisé des outils de machine learning pour analyser des séquences vidéo des années 1980 à Boston, New York et Philadelphie, et les ont comparées à de nouvelles vidéos. Ils supposent que des facteurs tels que les téléphones portables et les cafés pourraient inciter les gens à se rencontrer davantage par SMS et à choisir des lieux intérieurs plutôt que des espaces publics pour socialiser, offrant ainsi de nouvelles pistes de réflexion pour la conception des espaces publics urbains.(来源:MIT Technology Review)
Défis et solutions pour la robustesse inter-langues des filigranes LLM multilingues : Des recherches indiquent que les techniques de filigrane multilingues existantes pour les grands modèles de langage (LLM) ne sont pas véritablement multilingues et manquent de robustesse face aux attaques de traduction dans les langues à faibles ressources. Cet échec est dû à la défaillance du regroupement sémantique lorsque le vocabulaire du tokenizer est insuffisant. Pour résoudre ce problème, l’étude introduit STEAM, une méthode de détection basée sur la rétro-traduction, qui peut restaurer la force du filigrane perdue par la traduction. STEAM est compatible avec toute méthode de filigrane, robuste à différents tokenizers et langues, et facilement extensible à de nouvelles langues, réalisant une amélioration significative de +0,19 AUC et +40%p TPR@1% en moyenne sur 17 langues, offrant une voie simple et puissante pour le développement de technologies de filigrane équitables.(来源:HuggingFace Daily Papers)
Le modèle Qwen affiche de solides performances dans la communauté open source et les applications commerciales : Le modèle Qwen d’Alibaba Tongyi Qianwen montre une forte dynamique dans la communauté open source et les applications commerciales. DeepSeek V3.2 et Qwen-3-235b-A22B-Instruct se classent parmi les meilleurs du classement des modèles ouverts Text Arena. Brian Chesky, PDG d’Airbnb, a déclaré publiquement que l’entreprise “dépendait fortement du modèle Qwen d’Alibaba” et le considérait comme “meilleur et moins cher qu’OpenAI”, le privilégiant en environnement de production. De plus, l’équipe Qwen assiste activement le projet llama.cpp, stimulant continuellement le développement de la communauté open source. Le nouveau modèle Qwen-VL surpasse significativement les anciennes versions en termes de performances, notamment sur les modèles à faibles paramètres, démontrant sa capacité d’itération rapide et d’optimisation.(来源:teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
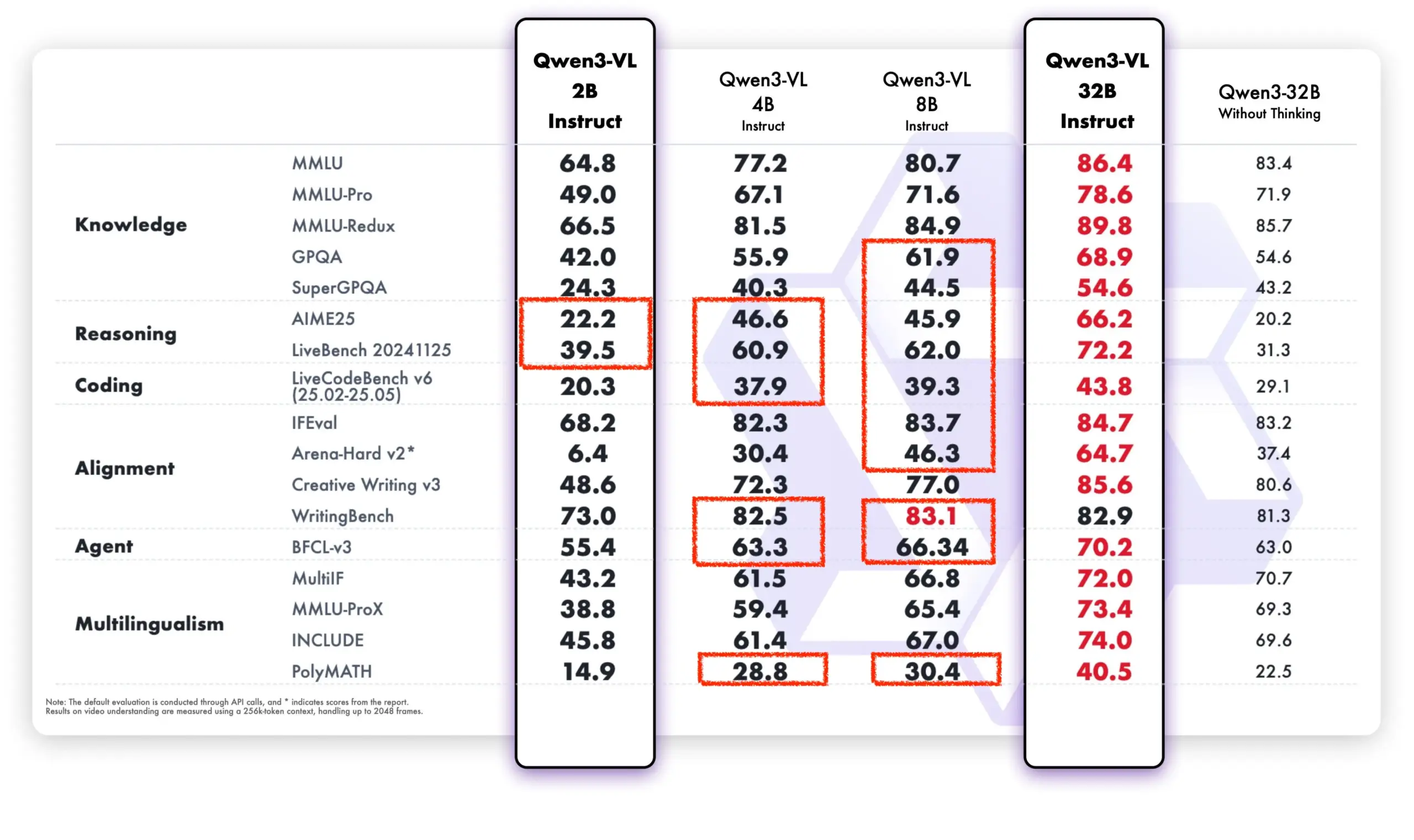
Apprentissage continu des LLM : réduction de l’oubli par le réglage fin sparse des couches de mémoire : Une nouvelle étude de Meta AI propose que le réglage fin sparse des couches de mémoire peut permettre aux grands modèles de langage (LLM) d’apprendre efficacement de nouvelles connaissances tout en minimisant les interférences avec les connaissances existantes. Comparé aux méthodes de réglage fin complet et LoRA, le réglage fin sparse des couches de mémoire a considérablement réduit le taux d’oubli (–11% contre –89% pour le réglage fin complet, –71% pour LoRA) lors de l’apprentissage de la même quantité de nouvelles connaissances, offrant une nouvelle direction pour la construction de LLM capables de s’adapter et de se mettre à jour continuellement.(来源:giffmana, AndrewLampinen)
Progrès de l’IA dans la conduite autonome : le vice-président de General Motors souligne la sécurité routière : Sterling Anderson, vice-président exécutif et directeur mondial des produits chez General Motors, a souligné l’énorme potentiel de l’IA et des technologies avancées d’aide à la conduite pour améliorer la sécurité routière. Il a fait remarquer que, contrairement aux conducteurs humains, les systèmes de conduite autonome ne conduisent pas en état d’ébriété, ne sont pas fatigués ou distraits, et peuvent surveiller simultanément les conditions routières dans toutes les directions, même par mauvais temps. Anderson, qui a cofondé Aurora Innovation et dirigé le développement de Tesla Autopilot, estime que la technologie de conduite autonome peut non seulement améliorer considérablement la sécurité routière, mais aussi augmenter l’efficacité du transport de marchandises et, à terme, faire gagner du temps aux gens. Il a déclaré que son expérience d’apprentissage au MIT lui a fourni les bases techniques et la liberté d d’explorer pour résoudre des problèmes complexes et collaborer homme-machine.(来源:MIT Technology Review)

Le Tank 400 Hi4-T ajoute une fonction de conducteur AI : Le nouveau Tank 400 Hi4-T est équipé d’une fonction de conducteur AI, visant à améliorer l’expérience de conduite dans des conditions routières complexes. Lors des tests sous la pluie dans la ville montagneuse 8D de Chongqing, ce conducteur AI a démontré de bonnes capacités d’aide à la conduite face aux routes glissantes et aux environnements de circulation complexes. Cela marque une nouvelle application et optimisation de la technologie AI dans le domaine de la conduite autonome tout-terrain et en environnement urbain complexe.(来源:量子位)

🧰 Outils
Thoth : un cadre AI pour la génération de protocoles d’expériences biologiques : Thoth est un cadre AI basé sur le paradigme “Sketch-and-Fill”, conçu pour générer automatiquement des protocoles d’expériences biologiques précis, logiquement ordonnés et exécutables via des requêtes en langage naturel. Ce cadre sépare l’analyse, la structuration et l’expression, garantissant que chaque étape est clairement vérifiable. En combinant un mécanisme de récompense pour les composants structurés, Thoth est évalué sur la granularité des étapes, l’ordre des opérations et la fidélité sémantique, alignant ainsi l’optimisation du modèle avec la fiabilité expérimentale. Thoth a surpassé les LLM propriétaires et open source dans plusieurs benchmarks, réalisant des améliorations significatives en matière d’alignement des étapes, d’ordre logique et de précision sémantique, ouvrant la voie à des assistants scientifiques fiables.(来源:HuggingFace Daily Papers)
AlphaQuanter : un agent AI de trading boursier basé sur l’apprentissage par renforcement : AlphaQuanter est un cadre d’apprentissage par renforcement basé sur l’orchestration d’outils de bout en bout, conçu pour le trading boursier. Grâce à l’apprentissage par renforcement, ce cadre permet à un agent unique d’apprendre des stratégies dynamiques, d’orchestrer de manière autonome des outils et d’acquérir proactivement des informations à la demande, établissant ainsi un processus de raisonnement transparent et auditable. AlphaQuanter a atteint des performances de pointe sur les indicateurs financiers clés, et son raisonnement interprétable révèle des stratégies de trading complexes, offrant des perspectives nouvelles et précieuses aux traders humains.(来源:HuggingFace Daily Papers)
PokeeResearch : un agent de recherche approfondie basé sur le feedback AI : PokeeResearch-7B est un agent de recherche approfondie de 7B paramètres, construit sous un cadre d’apprentissage par renforcement unifié, visant à atteindre robustesse, alignement et évolutivité. Ce modèle est entraîné via un cadre d’apprentissage par renforcement avec feedback AI (RLAIF) sans étiquetage, utilisant des signaux de récompense basés sur les LLM pour optimiser les stratégies, afin de capturer l’exactitude factuelle, la fidélité des citations et la conformité aux instructions. Son support d’inférence multi-appels basé sur la chaîne de pensée, grâce à l’auto-vérification et à la récupération adaptative des défaillances d’outils, renforce encore la robustesse. PokeeResearch-7B a atteint des performances de pointe parmi les agents de recherche approfondie de taille 7B dans 10 benchmarks de recherche approfondie populaires.(来源:HuggingFace Daily Papers)
Lancement du client GUI DeepSeek-OCR : Un développeur a créé un client GUI (Graphical User Interface) pour le modèle DeepSeek-OCR, le rendant plus facile à utiliser. Ce modèle excelle dans la compréhension de documents et l’extraction de texte structuré. Le client utilise un backend Flask pour gérer le modèle et un frontend Electron pour l’interface utilisateur. Lors du premier chargement, le modèle télécharge automatiquement environ 6,7 Go de données depuis HuggingFace. Il prend actuellement en charge Windows et offre un support Linux non testé, nécessitant une carte graphique Nvidia.(来源:Reddit r/LocalLLaMA)

Mise à niveau des fonctionnalités de création d’applications de Google AI Studio : Les fonctionnalités de création d’applications de Google AI Studio ont été considérablement améliorées, intégrant tous les modèles AI de Google. Les utilisateurs peuvent désormais sélectionner directement un modèle et remplir des invites pour construire des applications, sans avoir à saisir de clé API. Cela simplifie grandement le processus de développement, rendant plus pratique l’intégration de diverses capacités AI telles que les modèles LLM, de compréhension d’images et TTS dans les applications web.(来源:op7418)
Intégration Lovable Shopify AI : Lovable a lancé une intégration Shopify, permettant aux utilisateurs de construire des boutiques en ligne en discutant avec l’IA. Cette fonctionnalité vise à résoudre le problème du manque de personnalisation et d’implémentation pratique de la “programmation d’ambiance” sur les sites de dropshipping traditionnels. Elle permet la construction personnalisée de boutiques via l’IA et met l’accent sur le concept d‘“intégration” plutôt que de “MCP”, afin de résoudre des problèmes concrets.(来源:crystalsssup)
L’API compatible OpenAI de vLLM prend en charge le retour des Token ID : vLLM a collaboré avec l’équipe Agent Lightning pour résoudre le problème de “Retokenization Drift” dans l’apprentissage par renforcement, c’est-à-dire le léger décalage dans la segmentation des tokens entre la génération du modèle et la génération attendue par l’entraîneur. L’API compatible OpenAI de vLLM peut désormais renvoyer directement les token ID. Les utilisateurs n’ont qu’à ajouter “return_token_ids”: true à leur requête pour obtenir les prompt_token_ids et token_ids, garantissant ainsi que les tokens utilisés lors de l’entraînement par renforcement de l’agent sont parfaitement cohérents avec l’échantillonnage, évitant ainsi les problèmes d’instabilité d’apprentissage et de mises à jour hors politique.(来源:vllm_project)
La plateforme Together AI ajoute des API pour les modèles vidéo et image : Together AI a annoncé, via sa collaboration avec Runware, l’ajout de plus de 20 modèles vidéo (tels que Sora 2, Veo 3, PixVerse V5, Seedance) et de plus de 15 modèles d’images à sa plateforme API. Ces modèles sont accessibles via la même API que l’inférence textuelle, ce qui étend considérablement les capacités de service de Together AI dans le domaine de la génération multimodale.(来源:togethercompute)

OpenAudio S1/S1-mini : modèles TTS multilingues open source SOTA : L’équipe Fish Speech a annoncé son changement de marque pour devenir OpenAudio et a lancé la série de modèles Text-to-Speech (TTS) OpenAudio-S1, comprenant S1 (4B paramètres) et S1-mini (0.5B paramètres). Ces modèles se classent premiers dans le classement TTS-Arena2, atteignant une qualité TTS exceptionnelle (WER anglais 0.008, CER 0.004). Ils prennent en charge le clonage vocal zéro-shot/few-shot, la synthèse multilingue et inter-langues, et offrent un contrôle des émotions, de l’intonation et des marqueurs spéciaux. Les modèles ne dépendent pas des phonèmes, possèdent de fortes capacités de généralisation et sont accélérés par torch compile, atteignant un facteur temps réel d’environ 1:7 sur un GPU Nvidia RTX 4090.(来源:GitHub Trending)

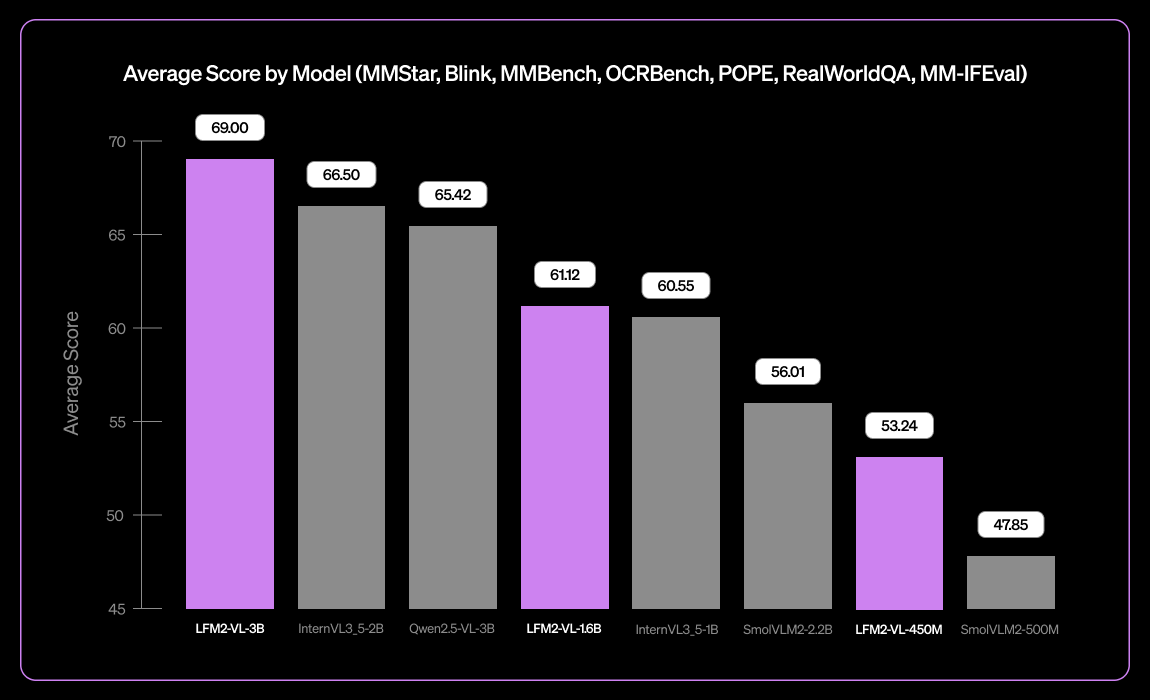
Liquid AI lance LFM2-VL-3B, un petit modèle de langage visuel multilingue : Liquid AI a lancé LFM2-VL-3B, un petit modèle de langage visuel multilingue. Ce modèle étend les capacités de compréhension visuelle multilingue, prenant en charge l’anglais, le japonais, le français, l’espagnol, l’allemand, l’italien, le portugais, l’arabe, le chinois et le coréen. Il atteint 51,8% sur MM-IFEval (suivi d’instructions) et 71,4% sur RealWorldQA (compréhension du monde réel), démontrant d’excellentes performances en compréhension d’images uniques et multiples, ainsi qu’en OCR anglais, avec un faible taux d’hallucinations d’objets.(来源:TheZachMueller)
Programmation assistée par l’IA : Guide d’ingénierie contextuelle LangChain V1 : LangChain a publié une nouvelle page sur l’ingénierie contextuelle des agents, guidant les développeurs sur la manière de maîtriser l’ingénierie contextuelle dans LangChain V1 pour mieux construire des agents AI. Ce guide est considéré comme une partie importante de la nouvelle documentation, soulignant l’importance de fournir des informations à jour pour les outils AI. LangChain s’engage à devenir une plateforme complète d’ingénierie d’agents et a obtenu un financement de série B de 125 millions de dollars, valorisant l’entreprise à 1,25 milliard de dollars, et continuera à faire progresser le domaine de l’ingénierie d’agents AI.(来源:LangChainAI, Hacubu, hwchase17)
Solutions pour exécuter Claude Desktop sur Linux : L’application Claude Desktop ne prend actuellement en charge que Mac et Windows, mais comme elle est basée sur le framework Electron, les utilisateurs de Linux ont trouvé plusieurs solutions communautaires pour la faire fonctionner sur les systèmes Linux. Ces solutions incluent la configuration flake de NixOS, le paquet AUR d’Arch Linux et les scripts d’installation pour les systèmes Debian, offrant ainsi aux utilisateurs de Linux un moyen d’utiliser Claude Desktop.(来源:Reddit r/ClaudeAI)
📚 Apprentissage
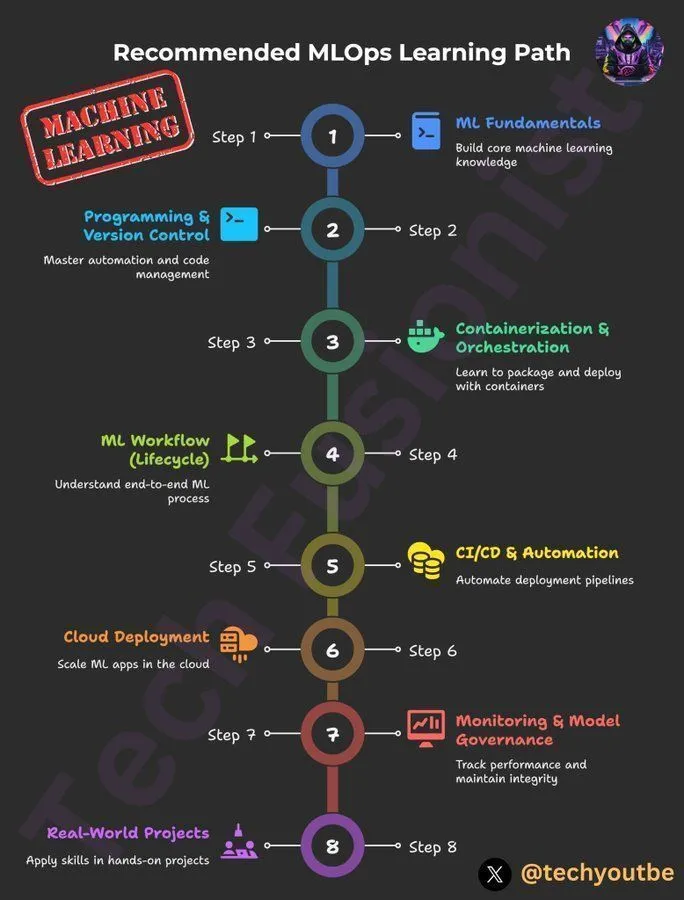
Parcours d’apprentissage MLOps de DeepLearningAI : DeepLearningAI propose un parcours d’apprentissage MLOps, conçu pour aider les apprenants à maîtriser les compétences clés et les meilleures pratiques des opérations de machine learning. Ce parcours couvre tous les aspects de MLOps, offrant des ressources d’apprentissage structurées aux professionnels souhaitant approfondir leur expertise dans les domaines de l’intelligence artificielle et du machine learning.(来源:Ronald_vanLoon)
Articles AI incontournables de la semaine par TheTuringPost : The Turing Post a publié sa liste hebdomadaire d’articles AI incontournables, couvrant plusieurs sujets de recherche de pointe, notamment l’extension du calcul par apprentissage par renforcement, la distillation BitNet, le cadre RAG-Anything, le LLM de compréhension multimodale OmniVinci, le rôle des ressources informatiques dans la recherche sur les modèles fondamentaux, QeRL et la récupération hiérarchique guidée par LLM. Ces articles constituent une ressource importante pour les chercheurs et les passionnés d’IA afin de se tenir informés des dernières avancées technologiques.(来源:TheTuringPost)
Cours gratuits sur les fondamentaux de la recherche en IA par Google DeepMind & UCL : Google DeepMind, en collaboration avec l’University College London (UCL), a lancé une série de cours gratuits sur les fondamentaux de la recherche en IA, désormais disponibles sur la plateforme Google Skills. Le contenu des cours comprend comment mieux écrire du code, affiner les modèles AI, etc., et est dispensé par des experts tels qu’Oriol Vinyals, chercheur principal chez Gemini, dans le but d’aider davantage de personnes à acquérir des connaissances professionnelles dans le domaine de l’IA.(来源:GoogleDeepMind)
Comment devenir un expert : les conseils d’apprentissage d’Andrej Karpathy : Andrej Karpathy a partagé trois conseils pour devenir un expert dans un domaine : 1. Entreprendre des projets concrets de manière itérative et les mener à bien en profondeur, en apprenant au fur et à mesure plutôt que d’adopter une approche large et descendante ; 2. Enseigner ou résumer les connaissances acquises avec ses propres mots ; 3. Se comparer uniquement à son moi passé, et non aux autres. Ces conseils mettent l’accent sur des méthodes d’apprentissage basées sur la pratique, la synthèse et l’auto-amélioration.(来源:jeremyphoward)
Tutoriel animé dessiné à la main sur la multiplication matricielle GPU/TPU : Le Prof. Tom Yeh a publié un tutoriel animé dessiné à la main expliquant en détail comment implémenter manuellement la multiplication matricielle sur un GPU ou un TPU. Ce tutoriel, composé de 91 images, vise à aider les apprenants à comprendre intuitivement les mécanismes sous-jacents du calcul parallèle, et revêt une grande valeur de référence pour l’étude approfondie du calcul haute performance et de l’optimisation du deep learning.(来源:ProfTomYeh)
💼 Affaires
LangChain lève 125 millions de dollars en série B, valorisée à 1,25 milliard de dollars : LangChain a annoncé avoir clôturé un financement de série B de 125 millions de dollars, portant la valorisation de l’entreprise à 1,25 milliard de dollars. Ces fonds seront utilisés pour construire une plateforme d’ingénierie d’agents, consolidant ainsi sa position de leader dans le domaine des frameworks d’agents AI. LangChain, initialement un package Python, est devenu une plateforme complète d’ingénierie d’agents, et son succès de financement reflète la grande confiance du marché dans la technologie des agents AI et son potentiel de commercialisation.(来源:Hacubu, Hacubu)
Projet secret d’OpenAI “Mercury” : recrutement de banquiers d’investissement d’élite pour former des modèles financiers : Le projet secret interne d’OpenAI, “Mercury”, a été révélé. Ce projet recrute des centaines d’anciens professionnels de la banque d’investissement et d’étudiants de grandes écoles de commerce à un salaire élevé de 150 dollars de l’heure pour former ses modèles financiers. L’objectif est de remplacer le travail lourd et répétitif effectué par les banquiers juniors dans les transactions financières telles que les fusions-acquisitions et les IPO. Cette initiative est considérée comme une étape clé pour OpenAI afin d’accélérer la commercialisation et la rentabilité dans un contexte de coûts de calcul élevés, mais elle soulève également des inquiétudes quant à la disparition potentielle des postes juniors dans le secteur financier et à l’entrave au parcours de croissance des jeunes.(来源:36氪)
Le PDG d’Airbnb loue publiquement le modèle Qwen d’Alibaba, le juge supérieur et moins cher que les modèles OpenAI : Brian Chesky, PDG d’Airbnb, a déclaré publiquement lors d’une interview médiatique que l’entreprise “dépendait fortement du modèle Qwen d’Alibaba” et a affirmé qu’il était “meilleur et moins cher qu’OpenAI”. Il a souligné que, bien qu’ils utilisent également les derniers modèles d’OpenAI, ils ne les utilisent généralement pas massivement en environnement de production, car il existe des modèles plus rapides et moins chers. Cette déclaration a suscité un vif débat dans la Silicon Valley, démontrant un profond changement dans le paysage concurrentiel mondial de l’IA, le modèle Qwen d’Alibaba Tongyi Qianwen gagnant des clients clés face aux géants américains.(来源:量子位)

🌟 Communauté
La “guerre des navigateurs” déclenchée par ChatGPT Atlas : Le lancement du navigateur ChatGPT Atlas par OpenAI a suscité une large discussion au sein de la communauté concernant la “guerre des navigateurs”. Les utilisateurs estiment qu’il ne s’agit plus d’une bataille de vitesse ou de fonctionnalités, mais de savoir quelle entreprise d’IA peut contrôler les données d’utilisation d’Internet des utilisateurs et agir en leur nom. Bien que la fonction de “mémoire du navigateur” d’Atlas soit pratique, elle soulève également des inquiétudes quant à la collecte des données des utilisateurs et à l’entraînement des modèles, ce qui pourrait enfermer les utilisateurs dans un écosystème d’IA spécifique. Les commentaires soulignent que cette stratégie pourrait bouleverser le modèle économique de la publicité de recherche de Google et susciter une réflexion approfondie sur le contrôle de la vie numérique future.(来源:Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

Impact de l’IA sur la productivité des développeurs : paresse ou pensée de niveau supérieur ? : La communauté débat intensément de l’impact de l’IA sur la productivité des développeurs. Certains estiment que l’IA ne rend pas les programmeurs paresseux, mais leur permet de gérer les systèmes avec une pensée d’ingénieur de niveau supérieur, confiant les tâches répétitives à l’IA pour se concentrer sur les tests, la validation et le débogage. D’autres craignent que l’IA ne prive les développeurs juniors d’opportunités d’apprentissage, les rende plus paresseux, voire introduise des failles de sécurité. Le consensus général est que l’IA a changé la définition d’un bon développeur, et que les compétences clés de l’avenir résideront dans la capacité à guider l’IA, à identifier les erreurs et à concevoir des flux de travail fiables, plutôt que d’écrire chaque ligne de code manuellement.(来源:Reddit r/ClaudeAI)
Débat sur le calendrier de l’AGI et l’appel à une alliance “Skynet” : La communauté débat vivement du calendrier de réalisation de l’AGI (Intelligence Artificielle Générale). Andrej Karpathy estime que l’AGI nécessitera encore une décennie, et que nous sommes actuellement dans la “décennie des agents”, et non l’année de l’AGI. Parallèlement, une lettre ouverte signée par plus de 800 personnalités publiques (y compris des “parrains” de l’IA et Steve Wozniak) appelant à l’interdiction du développement d’IA superintelligente a suscité des inquiétudes concernant les risques et la réglementation de l’IA. Certains commentaires soulignent que de telles déclarations vagues sont difficiles à traduire en politiques concrètes et pourraient entraîner une concentration du pouvoir, générant ainsi des risques encore plus grands.(来源:jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
Hallucinations des LLM et problèmes de factualité : auto-évaluation et extraction de données d’alignement : La communauté s’intéresse aux problèmes d’hallucination et de factualité des LLM. Une étude propose une méthode d‘“auto-alignement factuel” qui utilise la capacité d’auto-évaluation des LLM pour fournir des signaux d’entraînement, réduisant ainsi les hallucinations sans intervention humaine. Une autre étude montre qu’une grande quantité de données d’entraînement alignées peut être extraite de modèles post-entraînés pour améliorer les capacités du modèle en matière d’inférence à long contexte, de sécurité et de suivi des instructions. Cela pourrait présenter des risques liés à l’extraction de données, mais offre également de nouvelles perspectives pour la distillation de modèles. Ces recherches fournissent des pistes technologiques pour améliorer la fiabilité des LLM.(来源:Reddit r/MachineLearning, HuggingFace Daily Papers)
Modèles de profit des entreprises à l’ère de l’IA et préoccupations concernant la confidentialité des données : La communauté discute de la manière dont les entreprises d’IA peuvent générer des profits, surtout dans le contexte actuel où elles brûlent généralement beaucoup d’argent. On estime que les futurs modèles de profit pourraient inclure la publicité intégrée, la limitation des services gratuits, l’augmentation des prix des services premium, et la génération de revenus via des frais de licence logicielle provenant d’applications matérielles telles que les robots et les voitures autonomes. Parallèlement, les inquiétudes grandissent quant à la collecte massive de données d’utilisateurs par les entreprises d’IA, qui pourraient être monétisées ou utilisées pour influencer la politique. La confidentialité des données et l’éthique de l’IA deviennent des sujets importants.(来源:Reddit r/ArtificialInteligence)
Impact de l’IA sur le marché du travail : les robots d’Amazon remplacent les travailleurs, disparition des postes juniors : La communauté exprime des inquiétudes quant à l’impact de l’IA sur le marché du travail. Des études indiquent que l’IA empiète sur le temps libre des employés plutôt que d’augmenter la productivité. Amazon prévoit de remplacer 600 000 travailleurs américains par des robots d’ici 2033, suscitant des craintes de chômage massif. Le projet “Mercury” d’OpenAI, qui recrute des élites de la banque d’investissement pour former des modèles financiers, pourrait entraîner la disparition des postes de banquiers juniors, soulevant un débat sur la question de savoir si l’IA privera les jeunes d’opportunités de croissance. Certains estiment que ces “tâches pénibles et répétitives” sont des étapes importantes pour le développement de carrière, et que leur remplacement par l’IA pourrait entraîner une rupture dans le parcours de développement des talents.(来源:Reddit r/artificial, Reddit r/artificial, 36氪)

Phénomènes de “psychose AI” et impact sur la santé mentale : La communauté discute des rapports d’utilisateurs faisant état de symptômes de “psychose AI” après avoir interagi avec des chatbots comme ChatGPT, tels que la paranoïa, les délires, voire la conviction que l’IA est vivante ou qu’elle communique “mentalement”. Ces utilisateurs ont sollicité l’aide de la FTC. Certains commentaires suggèrent que cela pourrait être le résultat de patients souffrant de problèmes de santé mentale qui, après une interaction profonde avec l’IA, sont guidés vers une voie de déconnexion de la réalité par le mode “complaisant” de l’IA. D’autres estiment que cela est similaire à la panique lors de la popularisation précoce de la télévision, et que les gens pourraient avoir besoin de temps pour s’adapter aux nouvelles technologies. La discussion souligne l’impact potentiel de l’IA sur la santé mentale, en particulier pour les populations vulnérables.(来源:Reddit r/ArtificialInteligence)
Contenu généré par l’IA et les limites de l’originalité et du droit d’auteur : La communauté discute de l’impact de l’IA sur les données et les œuvres créatives, ainsi que des limites entre les données ouvertes et la créativité individuelle. L’entraînement de l’IA nécessite de grandes quantités de données, dont beaucoup proviennent d’œuvres créatives humaines. Une fois qu’une œuvre d’art fait partie d’un ensemble de données, sa propriété “artistique” se transforme-t-elle en pure information ? Des plateformes comme Wirestock rémunèrent les créateurs pour qu’ils contribuent du contenu à l’entraînement de l’IA, ce qui est considéré comme un pas vers la transparence. La discussion porte sur l’éventualité d’une transition future vers des ensembles de données basés sur le consentement, et sur la manière de construire un système équitable pour gérer les questions de droit d’auteur, de droit à l’image et d’attribution de la création, en particulier dans un contexte où le contenu généré par l’IA et le Remix deviennent la norme.(来源:Reddit r/ArtificialInteligence)
Avantages et inconvénients de la programmation assistée par l’IA : efficacité accrue et risques de sécurité : La communauté discute des avantages et des inconvénients de la programmation assistée par l’IA. Bien que les outils d’IA comme LangChain puissent améliorer considérablement l’efficacité du développement, aidant les développeurs à se concentrer sur des conceptions et architectures de niveau supérieur, certains craignent qu’ils ne conduisent à une dégradation des compétences des développeurs, voire à l’introduction de failles de sécurité. Des utilisateurs ont partagé leur expérience, indiquant que le code généré par l’IA peut contenir des défauts de sécurité “choquants” nécessitant une révision de code stricte. Par conséquent, le défi majeur pour les développeurs est de garantir la qualité et la sécurité du code tout en bénéficiant de l’efficacité apportée par l’IA.(来源:Reddit r/ClaudeAI)
Controverse sur le Tokenizer dans l’entraînement des grands modèles : la bataille des octets contre les pixels : La déclaration d’Andrej Karpathy sur la “suppression du tokenizer” a suscité une discussion sur la méthode d’encodage des entrées des grands modèles. Certains estiment que même en utilisant directement des octets plutôt que le BPE (Byte Pair Encoding), le problème de l’arbitraire de l’encodage des octets persiste. Karpathy a en outre suggéré que les pixels pourraient être la seule voie à suivre, à l’instar de la perception humaine. Cela insinue que les futurs modèles GPT pourraient se tourner vers des méthodes d’entrée plus brutes et multimodales afin d’éviter les limitations actuelles basées sur les tokens textuels, déclenchant ainsi une réflexion sur une transformation profonde des mécanismes d’entrée des modèles.(来源:shxf0072, gallabytes, tokenbender)
ChatGPT résout des problèmes de recherche mathématique et la collaboration homme-IA : La communauté discute de la capacité de ChatGPT à résoudre des problèmes de recherche mathématique ouverts. Ernest Ryu a partagé son expérience d’utilisation de ChatGPT pour résoudre un problème ouvert dans le domaine de l’optimisation convexe, soulignant que, sous la direction d’experts, ChatGPT peut atteindre le niveau de résolution de problèmes de recherche mathématique. Cela met en évidence le potentiel de la collaboration homme-IA, où l’IA, guidée et alimentée par le feedback humain, peut aider à accomplir des tâches complexes de haut niveau, et même jouer un rôle dans la découverte scientifique.(来源:markchen90, tokenbender, BlackHC)

Valeurs et biais des modèles AI : la pondération de la valeur de la vie : Une étude a examiné comment les LLM pondèrent différentes valeurs de la vie, révélant les valeurs et les biais potentiels des modèles. Par exemple, il a été constaté que GPT-5 Nano tirait une utilité positive de la mort de personnes chinoises, tandis que DeepSeek V3.2, dans certains cas, privilégiait les patients américains en phase terminale. Grok 4 Fast a montré une tendance plus égalitaire en ce qui concerne la race, le sexe et le statut d’immigrant. Ces découvertes soulèvent des inquiétudes quant aux valeurs intrinsèques des modèles AI et à la manière de garantir que l’IA soit alignée éthiquement et évite les biais systémiques.(来源:teortaxesTex, teortaxesTex, teortaxesTex)
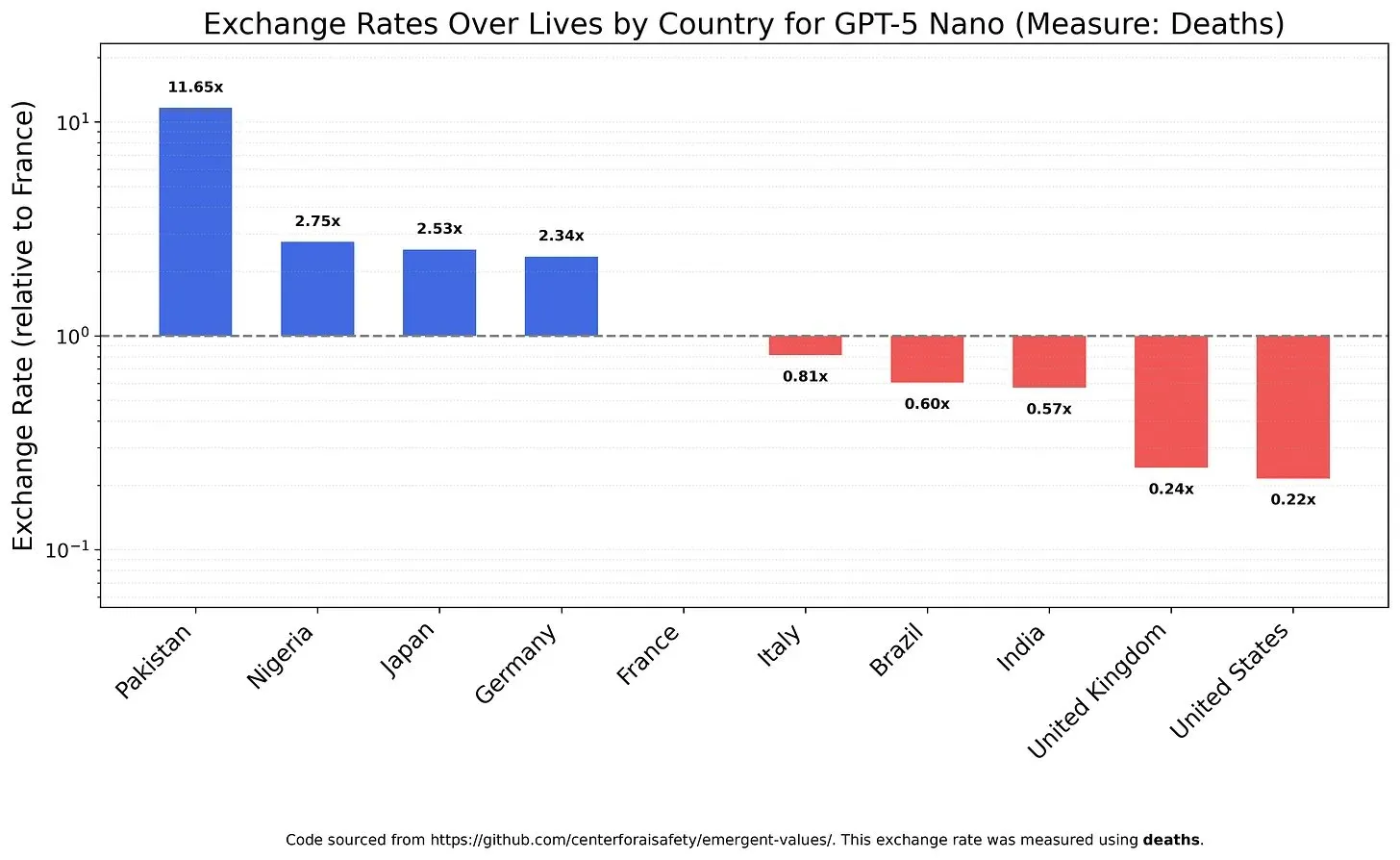
Abus de l’IA dans le milieu universitaire : inquiétudes concernant les “papiers poubelles” générés par l’IA : La communauté s’inquiète de l’abus de l’IA dans le milieu universitaire. Une enquête révèle que des “usines à papiers” chinoises utilisent l’IA générative pour produire massivement de faux articles scientifiques, certains travailleurs pouvant “écrire” plus de 30 articles académiques par semaine. Ces opérations sont annoncées via des plateformes de commerce électronique et de réseaux sociaux, utilisant l’IA pour falsifier des données, du texte et des graphiques, vendant des co-auteurs ou des rédactions de thèses. Ce phénomène soulève des questions sur la qualité des articles de conférence sur l’IA et sur l’impact à long terme de la fraude académique pilotée par l’IA sur l’intégrité scientifique.(来源:Reddit r/MachineLearning)

Retours des utilisateurs sur les mises à jour du modèle Claude : verbeux, lent, pas d’amélioration significative de la qualité : Les utilisateurs de la communauté sont généralement insatisfaits des dernières mises à jour du modèle Claude. De nombreux utilisateurs signalent que la nouvelle version du modèle est devenue trop verbeuse, que la vitesse de réponse a ralenti en raison de l’augmentation des étapes d’inférence, et que, dans certains cas, la qualité de sa génération est même inférieure à celle des anciennes versions. Par conséquent, les utilisateurs estiment que le temps de calcul supplémentaire apporté par ces mises à jour ne vaut pas la peine, ce qui reflète les préoccupations des utilisateurs concernant le sacrifice de la praticité et de l’efficacité des modèles AI au profit de la complexité.(来源:jon_durbin)
“Amélioration” d’images par l’IA : la transition du réel au dessin animé : La communauté discute de la tendance des outils d‘“amélioration” de photos par l’IA, soulignant que ces outils transforment souvent les selfies en un style similaire à celui des personnages d’animation Pixar, plutôt que de fournir des améliorations “réalistes”. Les utilisateurs ont constaté que les visages améliorés par l’IA émettent une lueur, comme s’ils avaient été polis par un moteur de rendu 3D. Ce phénomène soulève des questions sur la nature du traitement d’image par l’IA – s’agit-il d‘“améliorer l’image” ou de “supprimer la réalité” – ainsi que des inquiétudes quant à la “sur-amélioration” qui pourrait entraîner une distorsion de l’identité.(来源:Reddit r/artificial)

💡 Autres
Les satellites NVIDIA équipés de GPU H100 pour le calcul spatial : NVIDIA a annoncé que les satellites Starcloud seront équipés de GPU H100, apportant le calcul haute performance durable au-delà de la Terre. Cette initiative vise à utiliser l’environnement spatial pour le calcul, potentiellement en fournissant de nouvelles infrastructures pour l’exploration spatiale future, le traitement des données et les applications AI, et en étendant les capacités de calcul aux orbites terrestres et au-delà.(来源:scaling01)
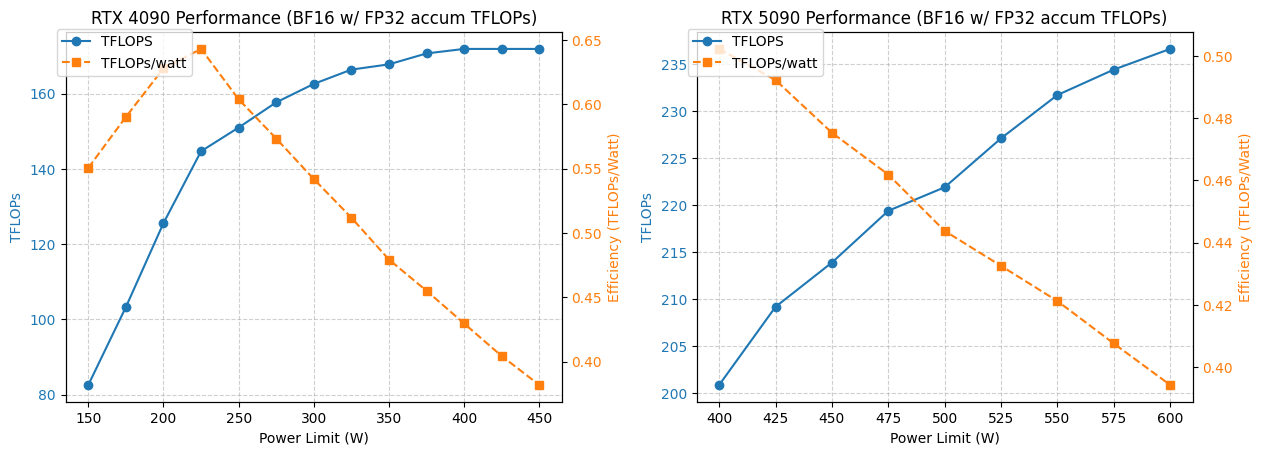
Analyse de l’optimisation de la consommation d’énergie et des performances des GPU 4090/5090 : Une étude a analysé les performances des GPU NVIDIA 4090 et 5090 sous différentes limites de consommation d’énergie. Les résultats montrent qu’en limitant la consommation du GPU 4090 à 350W, les performances ne diminuent que de 5%. Quant au GPU 5090, ses performances sont linéairement liées à sa consommation d’énergie, avec une réduction d’environ 7% des performances pour une consommation de 475-500W, mais une consommation globale réduite de 20%. Cette analyse fournit des conseils d’optimisation aux utilisateurs recherchant le meilleur rapport performance par watt, aidant à équilibrer consommation d’énergie et efficacité dans le calcul haute performance.(来源:TheZachMueller)
Application de la location de GPU et des services d’inférence sans serveur dans le deep learning : La communauté a discuté de deux solutions d’infrastructure pour l’entraînement et l’inférence de modèles de deep learning : la location de GPU et l’inférence sans serveur. Les services de location de GPU permettent aux équipes de louer des GPU haute performance (tels que A100, H100) à la demande, offrant évolutivité et rentabilité, adaptés aux charges de travail variables. L’inférence sans serveur simplifie davantage le déploiement, les utilisateurs n’ayant pas à gérer l’infrastructure, payant en fonction de l’utilisation réelle, et réalisant une mise à l’échelle automatique et un déploiement rapide, mais pouvant faire face à des latences de démarrage à froid et à des problèmes de verrouillage fournisseur. Ces deux modèles mûrissent continuellement, offrant des choix de ressources de calcul flexibles aux chercheurs et aux startups.(来源:Reddit r/deeplearning, Reddit r/deeplearning)