
Mots-clés:AGI, Sora2, RAG, Gemini 3.0, Jouets IA, Agents intelligents, Grands modèles de langage, Technologie de génération vidéo par IA, Évolution de la génération augmentée par recherche, Modèles d’IA multimodaux, Plateforme pharmaceutique basée sur l’IA, Technologie de collaboration calcul-électricité
🎯 Tendances
Andrej Karpathy : l’AGI est une courbe longue, pas une croissance explosive : Andrej Karpathy, ancien chercheur clé chez OpenAI, a souligné que le discours actuel sur une “année explosive” pour l’IA est trop enthousiaste, et que la réalisation de l’AGI nécessitera des décennies d’évolution. Il a insisté sur le fait que les véritables Agents devraient posséder persistance, mémoire et continuité, contrairement aux chatbots actuels, qui sont “fantômatiques”. Le développement futur de l’IA devrait passer du “remplissage de données” à l‘“enseignement d’objectifs”, en entraînant l’IA par des tâches et des boucles de rétroaction pour qu’elle devienne un “partenaire” doté d’une identité, d’un rôle et de responsabilités dans la société, plutôt qu’un simple outil. (Source : 36氪)
Lancement de Sora2 : la génération de vidéos AI entre dans une phase de “super accélération” : OpenAI a lancé Sora2 et son application sociale Sora App, dont le nombre de téléchargements a dépassé ChatGPT, marquant l’entrée du domaine de la vidéo AI dans une phase de “super accélération”. Sora2 a réalisé des percées en matière de simulation physique, de fusion multimodale et de compréhension du “langage cinématographique”, permettant de générer automatiquement des vidéos avec des changements de plans multiples et une narration cohérente, réduisant considérablement les barrières à la création. Des fabricants nationaux comme Baidu et Google ont également rapidement itéré leurs produits, mais les droits d’auteur et les modèles de monétisation restent des défis concrets pour l’industrie. (Source : 36氪)
Évolution du paradigme RAG : le débat “vie ou mort” des Agents et des longues fenêtres de contexte : Avec l’émergence des longues fenêtres de contexte des LLM et des capacités des Agents, l’avenir du RAG (Retrieval-Augmented Generation) suscite un vif débat. LlamaIndex estime que le RAG évolue vers la “récupération par Agent”, permettant des requêtes de base de connaissances plus intelligentes grâce à une architecture d’Agent hiérarchisée ; Hamel Husain souligne l’importance du RAG en tant que discipline d’ingénierie rigoureuse ; tandis que Nicolas Bustamante déclare que le “RAG naïf est mort”, car les Agents combinés à de longues fenêtres de contexte peuvent effectuer une navigation logique directe, reléguant le RAG au rang de composant de la boîte à outils des Agents. (Source : 36氪)
Le modèle Google Gemini 3.0 aurait été lancé sur LMArena, démontrant de nouvelles capacités multimodales : Des modèles “déguisés” de Google Gemini 3.0 (lithiumflow et orionmist) auraient été aperçus sur l’arène LMArena. Les tests réels montrent qu’ils peuvent identifier l’heure avec précision dans les tâches de “lecture de montre”, que leur capacité de génération d’images SVG est considérablement améliorée, et qu’ils démontrent pour la première fois une bonne capacité de composition musicale, capable d’imiter des styles musicaux et de maintenir le rythme. Ces avancées préfigurent des percées significatives de Gemini 3.0 en matière de compréhension et de génération multimodales, suscitant l’attente de l’industrie quant au prochain lancement de modèle par Google. (Source : 36氪)
Les jouets AI passent de “AI + jouet” à une intégration profonde “AI x jouet” : Le marché des jouets AI est en train de passer d’une simple superposition de fonctions à une intégration profonde, avec une taille de marché mondiale estimée à des centaines de milliards d’ici 2030. La nouvelle génération de jouets AI, grâce à des technologies multimodales telles que la reconnaissance vocale, la reconnaissance faciale et l’analyse émotionnelle, perçoit activement les scènes, comprend les émotions et offre un accompagnement et une éducation personnalisés. Le modèle industriel évolue également de la “vente de matériel” vers la “prestation de services + la diffusion continue de contenu”, répondant aux besoins croissants d’accompagnement émotionnel et d’assistance à la vie quotidienne des enfants, des jeunes et des personnes âgées, devenant un vecteur important pour l’apprentissage de la coexistence entre l’homme et l’IA. (Source : 36氪)
La marque de technologie de luxe BUTTONS lance un robot audiovisuel équipé de l’Agent HALI : BUTTONS a lancé le robot audiovisuel intelligent SOLEMATE, équipé de l’Agent universel HALI de Terminus Group. HALI possède des capacités de cognition spatiale et d’interaction physique, comprend l’environnement grâce à un modèle de mémoire sémantique tridimensionnel, et peut offrir des services de manière proactive en fonction de la position et de l’intention de l’utilisateur. Ce robot utilise le calcul collaboratif à grande échelle d’un centre de calcul intelligent pour optimiser l’orchestration des ressources, des équipements et des comportements, marquant une avancée de l’IA vers des Agents généraux incarnés, capables de briser les barrières du monde numérique pour “percevoir-raisonner-agir” dans l’environnement physique. (Source : 36氪)
Les modèles AI chinois en pleine ascension, avec une croissance significative de leur part de marché et de leurs téléchargements : Les dernières données montrent que le paysage du marché GenAI est en mutation : la part de marché de ChatGPT est en baisse continue, tandis que des concurrents comme Perplexity, Gemini, DeepSeek sont en pleine ascension. Il est particulièrement notable que les modèles AI open source américains, qui se sont distingués l’année dernière, sont désormais dominés par les modèles chinois dans le classement LMArena cette année. Les modèles chinois comme DeepSeek et Qwen ont deux fois plus de téléchargements sur Hugging Face que les modèles américains, démontrant la compétitivité croissante de la Chine dans le domaine de l’IA ouverte. (Source : ClementDelangue, ClementDelangue)
Google annonce une série de mises à jour AI : Veo 3.1, intégration de l’API Gemini dans Maps, etc. : Google a annoncé cette semaine plusieurs avancées en matière d’IA, notamment le modèle vidéo Veo 3.1 (prenant en charge l’extension de scène et les images de référence), l’intégration de données Google Maps dans l’API Gemini, la recherche Speech-to-Retrieval (permettant de rechercher directement des données sans passer par la transcription vocale), un investissement de 15 milliards de dollars dans un centre AI en Inde, et la fonctionnalité AI de planification Gemini pour Gmail/Calendar. Parallèlement, sa fonctionnalité AI Overviews fait l’objet d’une enquête de la part des éditeurs de presse italiens en raison de son impact sur le trafic, et Google a également lancé le modèle C2S-Scale 27B pour la traduction de données biologiques. (Source : Reddit r/ArtificialInteligence)
Microsoft lance MAI-Image-1, son modèle de génération d’images se classe dans le top dix : Microsoft AI a lancé son premier modèle de génération d’images entièrement développé en interne, MAI-Image-1, qui a fait son entrée dans le top 10 du classement des modèles texte-vers-image de LMArena. Cette avancée démontre la forte capacité de Microsoft dans le domaine de la technologie de génération d’images native et préfigure une intensification de ses efforts dans l’IA multimodale, offrant aux utilisateurs une expérience de création d’images de meilleure qualité. (Source : dl_weekly)
🧰 Outils
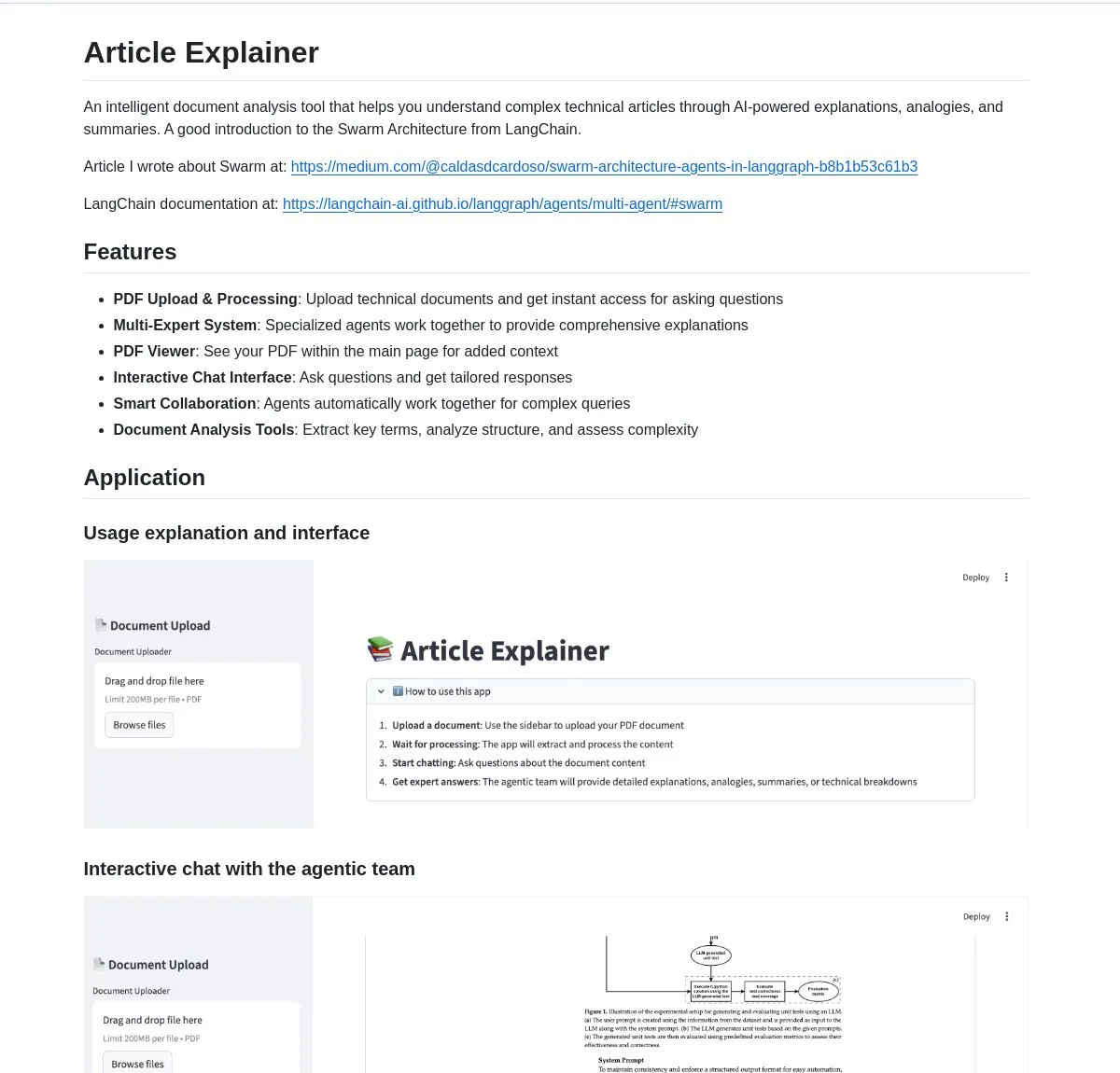
LangChain Article Explainer : un outil d’analyse de documents AI : LangChain a lancé un outil d’analyse de documents AI appelé “Article Explainer”, qui utilise la Swarm Architecture de LangGraph pour décomposer des articles techniques complexes. Il offre des explications interactives et des aperçus approfondis grâce à la collaboration multi-Agent, permettant aux utilisateurs d’obtenir des informations par des requêtes en langage naturel, améliorant considérablement l’efficacité de la compréhension des documents techniques. (Source : LangChainAI)
Claude Code Skill : transformer Claude en architecte de projet professionnel : Un développeur a créé un Claude Code Skill qui transforme Claude en un architecte de projet professionnel. Cette compétence permet à Claude de générer automatiquement des documents de spécifications, des documents de conception et des plans de mise en œuvre avant le codage, résolvant ainsi le problème de la perte de contexte dans les projets complexes. Il peut rapidement produire des user stories, des architectures système, des interfaces de composants et des tâches hiérarchisées, améliorant considérablement l’efficacité de la planification et de l’exécution des projets, et prenant en charge le développement de divers applications Web, microservices et systèmes ML. (Source : Reddit r/ClaudeAI)
Perplexity AI Comet : une extension de navigateur AI pour améliorer la navigation et la recherche : L’extension de navigateur Perplexity AI Comet a été lancée en accès anticipé, visant à améliorer la navigation, la recherche et la productivité des utilisateurs. Cet outil peut fournir des réponses rapides, résumer le contenu des pages web et intégrer directement les fonctionnalités AI dans l’expérience du navigateur, offrant aux utilisateurs un moyen plus intelligent et efficace d’obtenir des informations, particulièrement adapté à ceux qui ont besoin de digérer rapidement de grandes quantités d’informations en ligne. (Source : Reddit r/artificial)
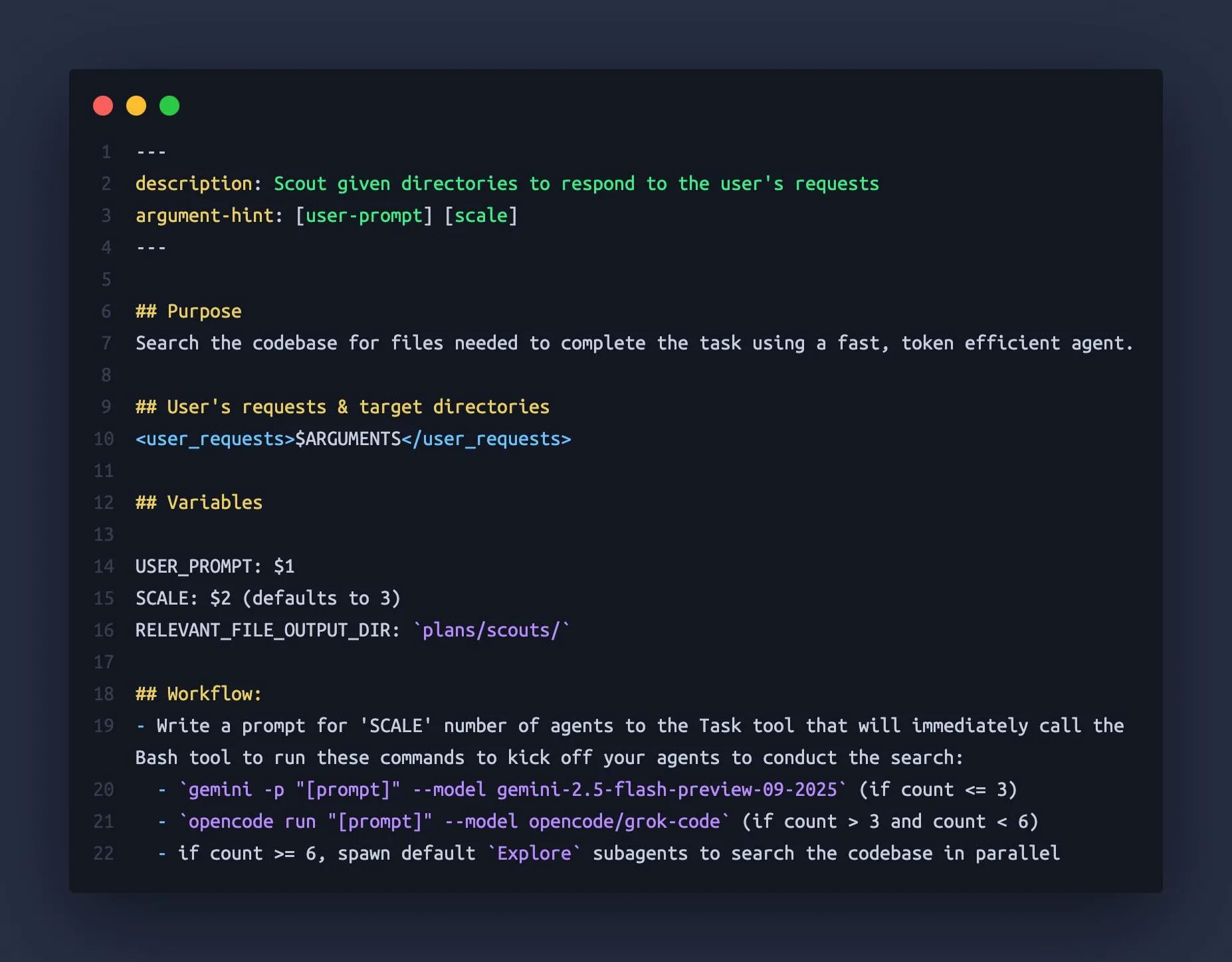
Claude Code utilise Gemini CLI et OpenCode comme “sous-Agents” : Des développeurs ont découvert que Claude Code peut orchestrer d’autres grands modèles linguistiques comme Gemini 2.5 Flash et Grok Code Fast en tant que “sous-Agents”, utilisant leurs grandes fenêtres de contexte (1M-2M tokens) pour explorer rapidement les bases de code et fournir à Claude Code des informations contextuelles plus complètes. Cette approche combinée évite efficacement le problème de “perte de contexte” de Claude dans les tâches complexes, améliorant l’efficacité et la précision de l’assistant de codage. (Source : Reddit r/ClaudeAI)
Modèle de génération CAD k-1b : un générateur de modèles 3D affiné sur Gemma3-1B : Un développeur a construit un modèle de génération CAD de 1 milliard de paramètres nommé k-1b. Les utilisateurs n’ont qu’à entrer une description pour générer un modèle 3D au format STL. Ce modèle a été entraîné en utilisant la génération assistée par AI et la réparation de jeux de données OpenSCAD, et a été affiné sur la base de Gemma3-1B. L’auteur a également fourni un outil CLI, prenant en charge la conversion de modèles OBJ et la prévisualisation en terminal, offrant un outil d’assistance AI à faible coût et très efficace pour les domaines de la conception et de la fabrication 3D. (Source : karminski3, Reddit r/LocalLLaMA)
neuTTS-Air : un modèle de clonage vocal de 0,7 milliard de paramètres exécutable sur CPU : Neuphonic a lancé un modèle de clonage vocal de 0,7 milliard de paramètres nommé neutts-air, dont la principale caractéristique est qu’il peut fonctionner sur CPU. Les utilisateurs n’ont qu’à fournir la voix cible et le texte correspondant pour cloner la voix et générer l’audio d’un nouveau texte, produisant environ 18 secondes d’audio en 30 secondes. Actuellement, le modèle ne prend en charge que l’anglais, mais sa légèreté et sa compatibilité CPU offrent une solution de clonage vocal pratique pour les utilisateurs individuels et les petits développeurs. (Source : karminski3)
Claude Code M&A Deal Comp Agent : générer des termes de transaction Excel à partir de PDF : Un développeur a créé un Agent d’analyse de transactions M&A en utilisant les Claude Code Skills et les capacités de parsing PDF semtools de LlamaIndex. Cet Agent est capable d’analyser les documents M&A publics (tels que DEF 14A), d’analyser chaque PDF et de générer automatiquement un tableau Excel contenant les termes de la transaction et les données des sociétés comparables. Cet outil améliore considérablement l’efficacité et la précision de l’analyse financière, particulièrement adapté aux scénarios de traitement de documents financiers complexes. (Source : jerryjliu0)
Anthropic Skills et Plugins : le chevauchement des fonctionnalités sème la confusion chez les développeurs : Anthropic a récemment lancé les fonctionnalités Skills et Plugins, visant à introduire des fonctions personnalisées pour les AI Agents. Cependant, certains développeurs ont signalé une confusion et un chevauchement dans l’utilisation de ces deux fonctionnalités, entraînant une incertitude quant aux scénarios d’utilisation et aux stratégies de développement. Cela suggère qu’Anthropic pourrait avoir des marges d’amélioration dans la conception des fonctionnalités et la stratégie de lancement afin de mieux guider les développeurs dans l’utilisation de ses capacités AI. (Source : Vtrivedy10, Reddit r/ClaudeAI)

📚 Apprentissage
Deep Agents Evolution : des systèmes de planification et de mémoire avancés augmentent l’échelle des Agents : Une percée architecturale en IA a permis une “évolution profonde des Agents”, grâce à des systèmes avancés de planification et de mémoire, permettant aux Agents de passer de 15 à plus de 500 étapes, transformant radicalement la manière dont l’IA gère les tâches complexes. Cette technologie devrait permettre à l’IA de maintenir sa cohérence sur des séquences temporelles plus longues et des chaînes logiques plus complexes, jetant les bases pour la construction d’Agents AI généraux plus puissants. (Source : LangChainAI)
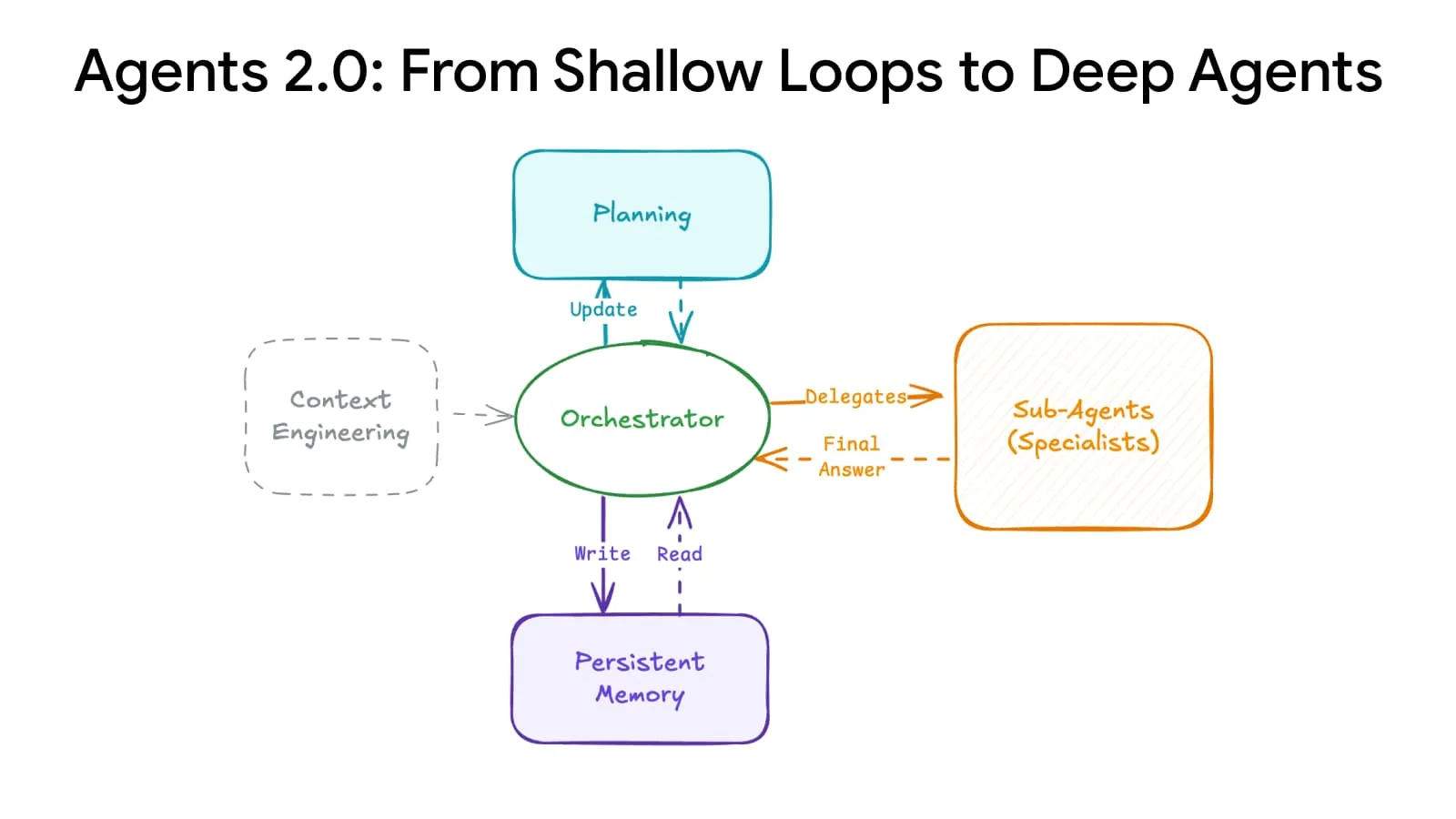
Architecture des modèles AI et feuille de route de développement des Agents : Plusieurs ressources ont été partagées sur les médias sociaux concernant l’architecture des modèles AI, la feuille de route de développement des Agents, le cycle de vie du Machine Learning, ainsi que les distinctions entre l’IA, l’IA générative et le Machine Learning. Ces contenus visent à aider les développeurs et les chercheurs à comprendre les concepts fondamentaux des systèmes AI, les étapes clés pour construire des Agents AI évolutifs, et à maîtriser les compétences essentielles requises dans le domaine de l’IA pour 2025. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Cours Stanford CME295 : Transformer et pratique de l’ingénierie des grands modèles : L’Université de Stanford a lancé la série de cours CME295, axée sur l’architecture Transformer et les connaissances pratiques en ingénierie des grands modèles linguistiques (LLM). Ce cours évite les concepts mathématiques complexes et met l’accent sur les applications pratiques, offrant une ressource d’apprentissage précieuse aux ingénieurs souhaitant approfondir leurs connaissances en développement et déploiement de grands modèles. Parallèlement, le cours CS224N est recommandé comme le meilleur choix pour une introduction au NLP. (Source : karminski3, QuixiAI, stanfordnlp)
AutoCode, le générateur de problèmes AI : les LLM créent des problèmes de programmation compétitive originaux : L’équipe LiveCodeBench Pro a lancé le framework AutoCode, qui utilise les LLM dans un système en boucle fermée et multi-rôles pour automatiser la création et l’évaluation de problèmes de programmation compétitive. Ce framework, grâce à un mécanisme amélioré de validateur-générateur-vérificateur, assure une grande fiabilité dans la génération de cas de test et peut inspirer les LLM à générer de nouveaux problèmes originaux et de haute qualité à partir de “problèmes de départ”, ouvrant la voie à des benchmarks de concours de programmation plus rigoureux et à l’auto-amélioration des modèles. (Source : 36氪)

Le KAIST développe un cerveau semi-conducteur AI : combinant l’intelligence de Transformer et l’efficacité de Mamba : L’Institut supérieur coréen des sciences et technologies (KAIST) a développé un nouveau cerveau semi-conducteur AI, combinant avec succès l’intelligence de l’architecture Transformer et l’efficacité de l’architecture Mamba. Cette recherche révolutionnaire vise à résoudre le compromis entre performance et consommation d’énergie des modèles AI existants, offrant une nouvelle direction pour la conception future de matériel AI efficace et à faible consommation, et devrait accélérer le développement des systèmes AI embarqués et d’Edge AI. (Source : Reddit r/deeplearning)
Pipeline NER multi-étapes : analyse des commentaires Reddit avec correspondance floue et masquage LLM : Une étude a proposé un pipeline de reconnaissance d’entités nommées (NER) multi-étapes, combinant la correspondance floue à haute vitesse et la technique de masquage LLM, pour extraire des entités et des sentiments des commentaires Reddit. Cette méthode identifie d’abord les entités connues par recherche floue, puis utilise un LLM pour traiter le texte masqué afin de découvrir de nouvelles entités, et enfin procède à l’analyse des sentiments et à la synthèse. Cette approche hybride permet d’équilibrer la vitesse et la capacité de découverte lors du traitement de textes spécifiques à un domaine, volumineux et bruyants. (Source : Reddit r/MachineLearning)
Expérience de déploiement de systèmes de trading basés sur le ML : résoudre le “biais de prospective” et la “dérive d’état” en temps réel : Un développeur a partagé son expérience de déploiement de systèmes de trading basés sur le ML, soulignant l’importance cruciale de résoudre les problèmes de “biais de prospective” et de “dérive d’état” dans un environnement en temps réel. Un traitement strict ligne par ligne du modèle et un script “golden master” garantissent une cohérence déterministe entre les tests historiques et l’exécution en temps réel. Le système comprend également un validateur qui mesure la cohérence entre les prédictions en temps réel et les prédictions du validateur avec un coefficient de corrélation de Pearson de 1.0, assurant la fiabilité du modèle. (Source : Reddit r/MachineLearning)
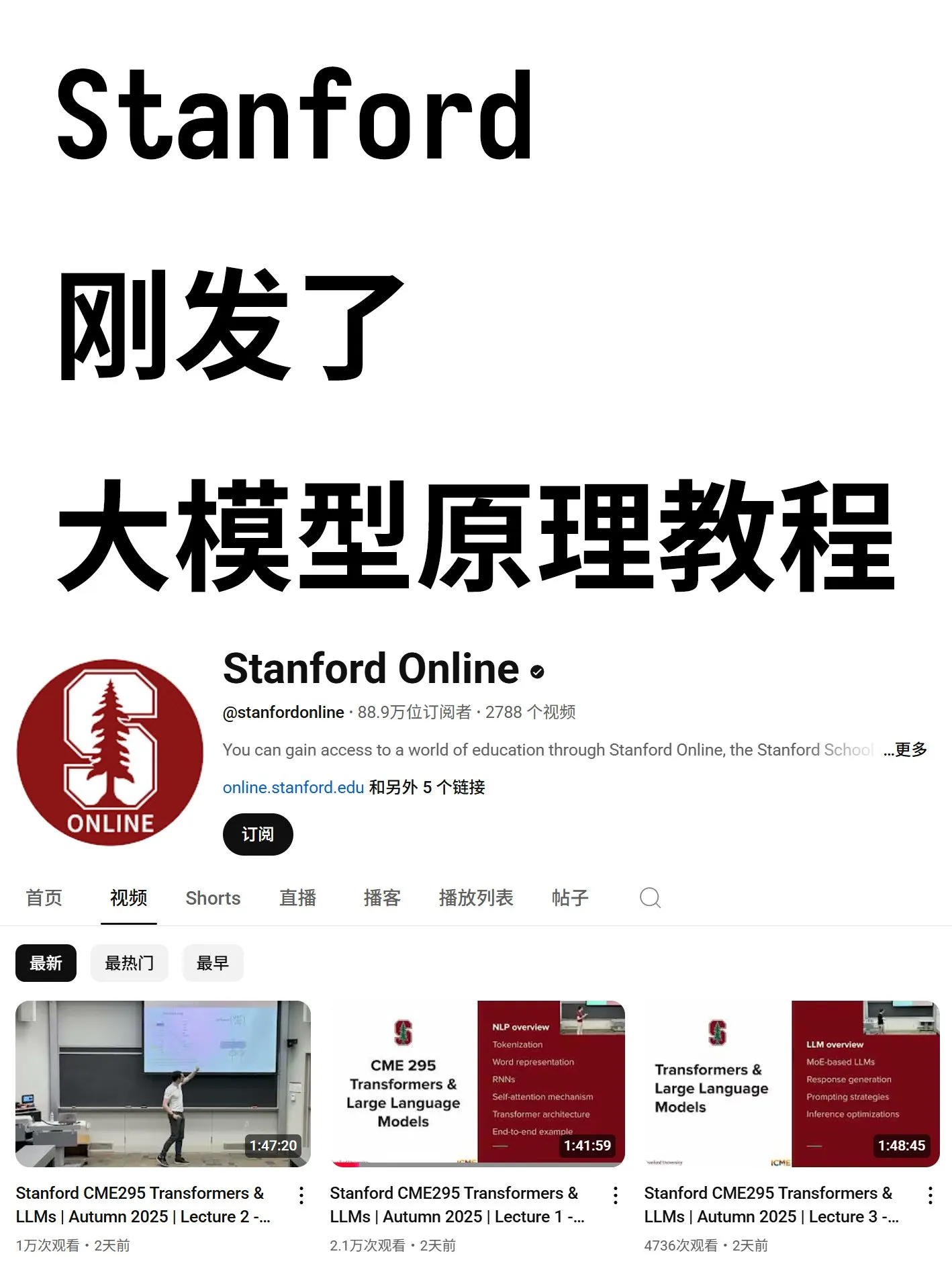
Long Context Evaluation : un nouveau benchmark pour évaluer la capacité des LLM à gérer de longs contextes : Une nouvelle recherche explore l’état actuel de l’évaluation des LLM à long contexte, analyse les avantages et les inconvénients des benchmarks existants, et introduit un nouveau benchmark appelé LongCodeEdit. Cette étude vise à remédier aux lacunes des méthodes d’évaluation existantes pour mesurer la capacité des LLM à traiter des textes longs et des tâches complexes d’édition de code, offrant de nouveaux outils et des perspectives pour évaluer plus précisément les performances des modèles dans des scénarios à long contexte. (Source : nrehiew_, teortaxesTex)
Manifold Optimization : optimisation géométriquement consciente pour l’entraînement des réseaux neuronaux : L’optimisation Manifold confère aux réseaux neuronaux une capacité d’optimisation géométriquement consciente. Une nouvelle recherche étend cette idée aux variétés modulaires, aidant à concevoir des optimiseurs qui comprennent les interactions entre les couches. En combinant des fonctions directes, des contraintes de variété et des normes, ce cadre décrit comment la géométrie inter-couches et les règles d’optimisation peuvent être combinées, permettant ainsi une optimisation géométriquement consciente à un niveau plus profond, améliorant l’efficacité et l’effet de l’entraînement des réseaux neuronaux. (Source : TheTuringPost, TheTuringPost)

Complexité de Kolmogorov dans la recherche AI : le potentiel de l’IA pour simplifier les résultats de recherche : La discussion a souligné que l‘“essence” fondamentale des nouvelles recherches et des contenus de blog peut être compressée en code, en artefacts et en abstractions mathématiques. Les futurs systèmes AI devraient “traduire” des recherches complexes en artefacts simples, en extrayant les différences fondamentales et en reproduisant les résultats clés, réduisant considérablement le coût de compréhension des nouvelles recherches, permettant aux chercheurs de suivre plus facilement la masse d’articles sur ArXiv, et de digérer et d’appliquer rapidement les résultats de la recherche. (Source : jxmnop, aaron_defazio)
Controverse sur l’origine de l’apprentissage résiduel par le père des LSTM : la contribution de Hochreiter en 1991 : Jürgen Schmidhuber, le père des LSTM, a de nouveau pris la parole pour souligner que l’idée centrale de l’apprentissage résiduel avait été proposée dès 1991 par son étudiant Sepp Hochreiter, afin de résoudre le problème de la disparition du gradient dans les RNN. Dans sa thèse de doctorat, Hochreiter a introduit des connexions résiduelles récurrentes avec des poids fixes de 1.0, ce qui est considéré comme la base de l’idée résiduelle dans les architectures de Deep Learning ultérieures telles que les LSTM, les réseaux Highway et les ResNet. Schmidhuber a souligné l’importance des contributions initiales au développement du Deep Learning. (Source : 量子位)
💼 Affaires
Zhiweitop Pharmaceutical lève des dizaines de millions de yuans en financement de démarrage : R&D de nouveaux médicaments oraux à petites molécules assistée par AI : Beijing Zhiweitop Pharmaceutical Technology Co., Ltd. a clôturé un financement de démarrage de plusieurs dizaines de millions de yuans, mené par NewLead Capital et co-investi par Qingtian Investment. Les fonds seront utilisés pour faire progresser la R&D préclinique des pipelines clés et la construction d’une plateforme de conception moléculaire interactive AI. L’entreprise se concentre sur le secteur de la pharmacie AI, utilisant sa plateforme EnCore auto-développée pour accélérer la découverte de composés leaders et l’optimisation moléculaire, ciblant principalement les médicaments oraux à petites molécules pour les maladies auto-immunes, avec le potentiel de s’attaquer aux cibles “difficilement médicamenteuses”. (Source : 36氪)
Damao Technology clôture un financement de série A+ de près de 100 millions de yuans : la technologie de coordination calcul-énergie résout le problème de la forte consommation d’énergie des centres de calcul intelligents : Damao Technology a clôturé un financement de série A+ de près de 100 millions de yuans, mené par Puquan Capital, une filiale de CATL. Ce cycle de financement sera utilisé pour la R&D et la promotion de technologies clés telles que les grands modèles énergétiques, les plateformes de coordination calcul-énergie et les Agents, visant à résoudre le problème de la forte consommation d’énergie des centres de calcul intelligents grâce à la “coordination calcul-énergie” et à soutenir la construction de nouveaux systèmes électriques. S’appuyant sur son grand modèle énergétique auto-développé en pile complète, Damao Technology a déjà collaboré avec des entreprises leaders telles que SenseTime et Cambricon pour fournir des solutions d’optimisation énergétique aux infrastructures de calcul à forte consommation d’énergie. (Source : 36氪)

JD.com, Tmall, Douyin “AI” sur le Double 11 : la technologie stimule la croissance des promotions e-commerce : Cette année, le Double 11 est devenu un terrain d’entraînement pour l’e-commerce AI, avec des plateformes leaders comme JD.com, Tmall et Douyin misant pleinement sur la technologie AI. L’IA est appliquée à tous les maillons de la chaîne, de l’optimisation de l’expérience consommateur à l’autonomisation des commerçants, en passant par la logistique, la distribution de contenu et la décision d’achat. Par exemple, JD.com a amélioré son “achat par photo”, Douyin Doubao a été intégré au centre commercial, et ZDM Technology a réalisé la comparaison de prix via le dialogue AI. L’IA devient le nouveau moteur de croissance de l’e-commerce, remodelant le paysage concurrentiel de l’industrie grâce à une efficacité et un contrôle des coûts extrêmes, et propulsant l’e-commerce du stade de “commerce de rayon/contenu” vers celui de “commerce intelligent”. (Source : 36氪, 36氪)

Le responsable AI de la Maison Blanche s’exprime sur la concurrence AI sino-américaine : exportations de puces et domination de l’écosystème : David Sacks, le “tsar” de l’IA et de la Crypto à la Maison Blanche, a exposé lors d’une interview la stratégie américaine dans la compétition AI sino-américaine, soulignant l’importance de l’innovation, des infrastructures et des exportations. Il a indiqué que la politique américaine d’exportation de puces vers la Chine doit être “nuancée”, visant à restreindre les puces les plus avancées tout en évitant une privation totale qui conduirait à un monopole de Huawei sur le marché intérieur chinois. Sacks a souligné que les États-Unis devraient construire un vaste écosystème AI et devenir le partenaire technologique privilégié au niveau mondial, plutôt que d’étouffer la compétitivité par un contrôle bureaucratique. (Source : 36氪)

🌟 Communauté
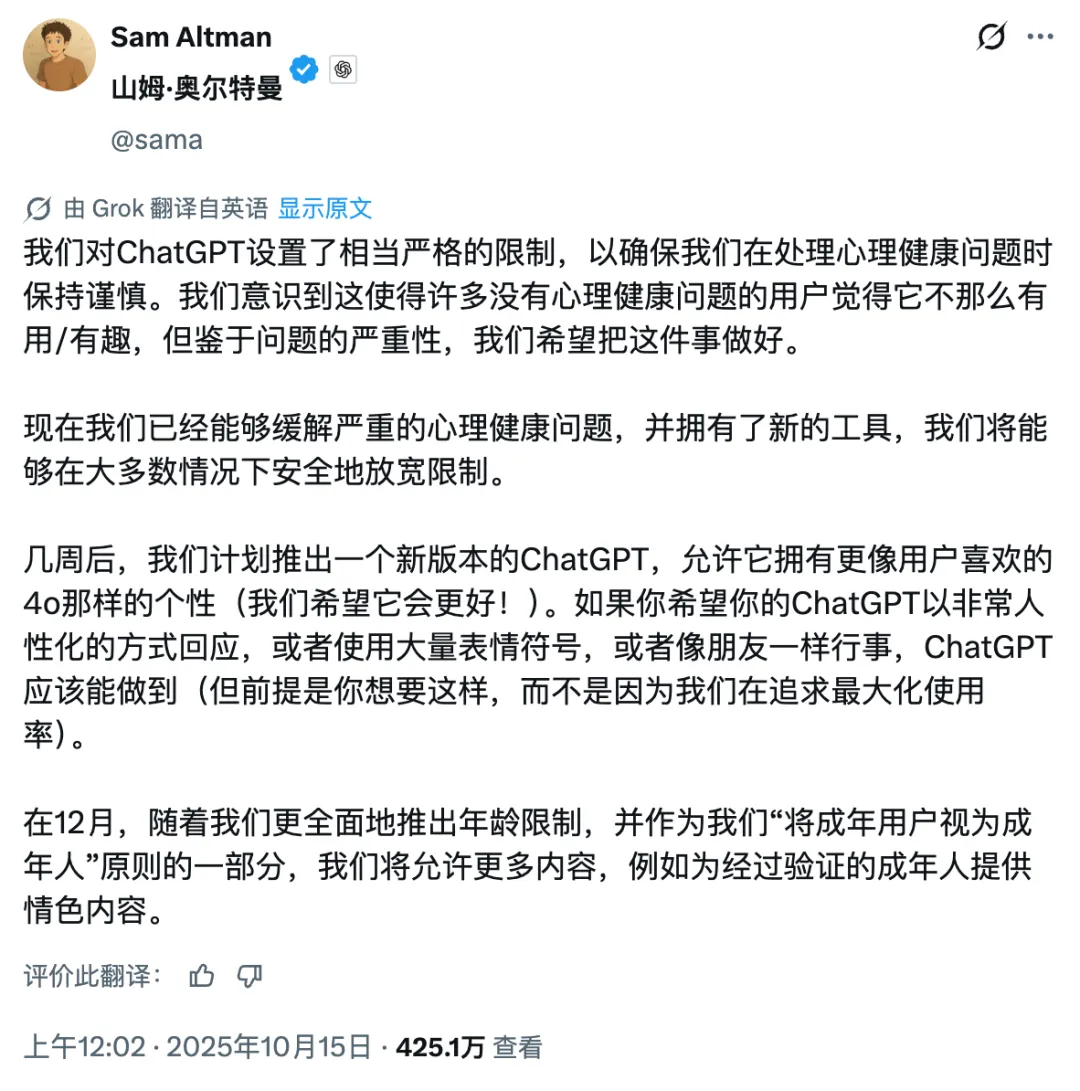
Controverse sur la commercialisation d’OpenAI : du non-lucratif au lucratif, la réputation de Sam Altman en pâtit : Sam Altman, PDG d’OpenAI, a suscité une large controverse en raison de la libéralisation du contenu érotique sur ChatGPT, des performances du modèle GPT-5 et de sa stratégie agressive d’expansion des infrastructures. La communauté s’interroge sur son virage d’une mission à but non lucratif vers la recherche du profit commercial, exprimant des préoccupations quant à l’orientation du développement de la technologie AI, à la bulle d’investissement et au traitement éthique des employés. La réponse d’Altman n’a pas réussi à apaiser complètement l’opinion publique, soulignant la tension entre l’expansion de l’empire AI et la responsabilité sociale. (Source : 36氪, janusch_patas, Reddit r/ArtificialInteligence)
Empoisonnement des grands modèles : empoisonnement des données, échantillons adversariaux et défis de sécurité AI : Les grands modèles sont confrontés à des menaces de sécurité telles que l’empoisonnement des données, les attaques par porte dérobée et les échantillons adversariaux, entraînant des sorties de modèle anormales, des contenus nuisibles, et même leur utilisation pour la publicité commerciale (GEO), la démonstration technologique ou la cybercriminalité. Des études montrent qu’une petite quantité de données malveillantes peut affecter significativement le modèle. Cela soulève des préoccupations concernant les hallucinations AI, la manipulation des décisions des utilisateurs et les risques pour la sécurité publique, soulignant l’importance d’établir un système immunitaire pour les modèles, de renforcer l’audit des données et les mécanismes de défense continue. (Source : 36氪)

Le dilemme des annotateurs de données à l’ère de l’IA : diplômés de master et doctorat effectuant un travail répétitif et sous-payé : Avec le développement des grands modèles AI, le travail d’annotation de données exige des qualifications académiques plus élevées (allant jusqu’au master et au doctorat), mais les salaires sont bien inférieurs à ceux des ingénieurs AI. Ces “enseignants AI” évaluent le contenu généré par l’IA, effectuent des examens éthiques et agissent comme coachs en connaissances spécialisées, mais perçoivent un salaire horaire bas, et leur emploi est instable, se terminant avec la fin du projet. Ce modèle de sous-traitance en cascade et d’exploitation, s’apparentant à une “chaîne de montage cybernétique”, a suscité une profonde réflexion sur l’éthique du travail et l’équité dans l’industrie de l’IA. (Source : 36氪)

L’impact de l’IA sur la créativité et la valeur humaine : fin ou sublimation ? : La communauté a discuté de l’impact de l’IA sur la créativité humaine, estimant que l’IA n’a pas tué la créativité, mais a plutôt révélé la médiocrité relative de la créativité humaine. L’IA excelle dans la réorganisation des motifs et la génération, mais la véritable originalité, la contradiction et l’imprévisibilité restent des atouts uniques de l’être humain. L’apparition de nouveaux outils élimine toujours les zones intermédiaires, forçant l’humanité à rechercher des percées de plus haut niveau en matière de contenu et de créativité, rendant la véritable créativité encore plus précieuse. (Source : Reddit r/artificial)
Anxiété existentielle liée à l’IA et stratégies d’adaptation : problèmes réels et préoccupations excessives : Face aux menaces existentielles potentielles de l’IA, la communauté a discuté de la manière de gérer la “peur existentielle” qui en découle. Certains estiment que cette peur pourrait provenir d’une fantaisie excessive sur l’avenir, suggérant de revenir à la réalité et de se concentrer sur la vie présente. D’autres ont souligné que les chocs économiques et les problèmes d’emploi liés à l’IA sont des menaces réelles plus urgentes, insistant sur le fait que la sécurité de l’IA doit être considérée au même titre que ses impacts socio-économiques. (Source : Reddit r/ArtificialInteligence)

Les points de vue de Karpathy suscitent un vif débat : la théorie des dix ans pour l’AGI, les “fantômes” des Agents AI et la trajectoire de développement de l’IA : Les points de vue d’Andrej Karpathy sur la “théorie des dix ans” pour l’AGI et sur le fait que les Agents AI actuels sont des “fantômes” ont suscité un large débat au sein de la communauté. Il a souligné que l’IA a besoin de persistance, de mémoire et de continuité pour devenir un véritable Agent, et a suggéré que l’entraînement de l’IA devrait passer du “remplissage de données” à l‘“enseignement d’objectifs”. Ces points de vue sont considérés comme une réflexion sereine sur l’engouement actuel pour l’IA, incitant à repenser la trajectoire de développement à long terme et les critères d’évaluation de l’IA. (Source : TheTuringPost, TheTuringPost, NandoDF, random_walker, lateinteraction, stanfordnlp)

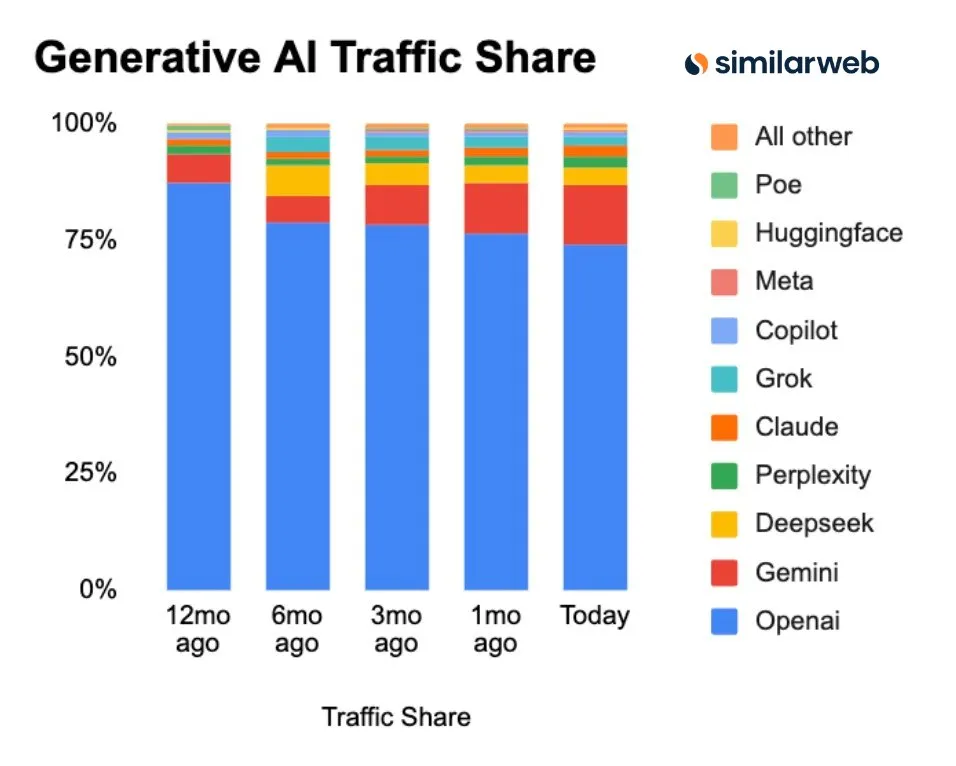
La part de marché de ChatGPT continue de baisser : Perplexity, Gemini, DeepSeek et d’autres concurrents émergent : Les données de Similarweb montrent que la part de marché de ChatGPT est en baisse continue, passant de 87,1 % il y a un an à 74,1 %. Parallèlement, la part de marché de concurrents tels que Gemini, Perplexity, DeepSeek, Grok et Claude est en croissance constante. Cette tendance indique une concurrence de plus en plus féroce sur le marché des assistants AI, une diversification des choix des utilisateurs, et que la position dominante de ChatGPT est remise en question. (Source : ClementDelangue, brickroad7)
L’incident du “faux pas mathématique” de GPT-5 : marketing excessif d’OpenAI et scepticisme des pairs : Des chercheurs d’OpenAI ont annoncé avec faste que GPT-5 avait résolu plusieurs problèmes mathématiques d’Erdos, mais il a été découvert par la suite qu’il avait simplement trouvé des réponses existantes via une recherche sur le web, plutôt que de les résoudre de manière indépendante. Cet incident a provoqué les moqueries publiques de personnalités de l’industrie comme Demis Hassabis, PDG de DeepMind, et Yann LeCun de Meta, remettant en question le marketing excessif d’OpenAI et soulignant les problèmes de rigueur dans la promotion des capacités de l’IA ainsi que la dynamique concurrentielle entre pairs. (Source : 量子位)

Le coût environnemental caché de l’IA : consommation d’énergie et demande en eau : Des études historiques montrent que, du télégraphe à l’IA, les systèmes de communication ont toujours été associés à des coûts environnementaux cachés. L’IA et les systèmes de communication modernes dépendent de centres de données à grande échelle, entraînant une flambée de la consommation d’énergie et de la demande en eau. On estime que d’ici 2027, la consommation d’eau de l’IA sera équivalente à la consommation annuelle d’eau du Danemark. Cela met en évidence le coût environnemental du développement rapide de la technologie AI, appelant les gouvernements à renforcer la réglementation, à exiger la divulgation des impacts environnementaux et à soutenir les projets à faible impact. (Source : aihub.org)

L‘“invasion” de l’esprit humain par l’IA : interfaces cerveau-ordinateur et les frontières éthiques de l‘“Humanité 3.0” : La communauté a discuté en profondeur de l’impact potentiel des interfaces cerveau-ordinateur (BCI) et de l’IA sur l’esprit humain, introduisant le concept d‘“Humanité 3.0”. Lorsque la puissance de calcul externe pénètre le “cercle intérieur” de la prise de décision humaine, si rapidement que le cerveau ne peut plus distinguer la source du signal, cela soulèvera des questions éthiques concernant les limites du “soi”, les jugements de valeur et la santé à long terme. L’article souligne qu’avant la généralisation de la technologie, il est impératif d’établir une architecture de confiance zéro, une isolation matérielle et une gestion des autorisations afin d’éviter la location du pouvoir de décision et l’aggravation des inégalités au niveau de l’espèce. (Source : dotey)
💡 Autres
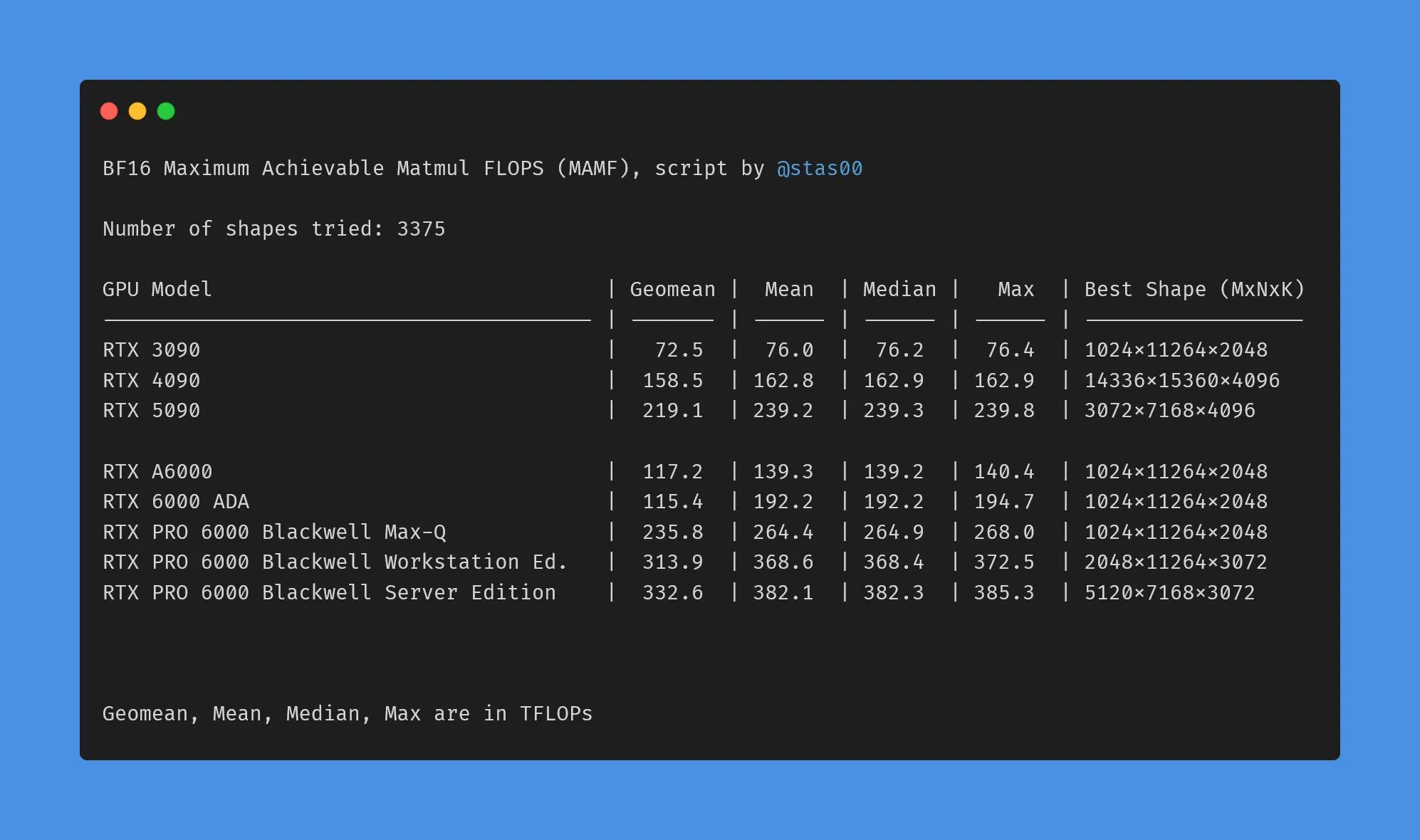
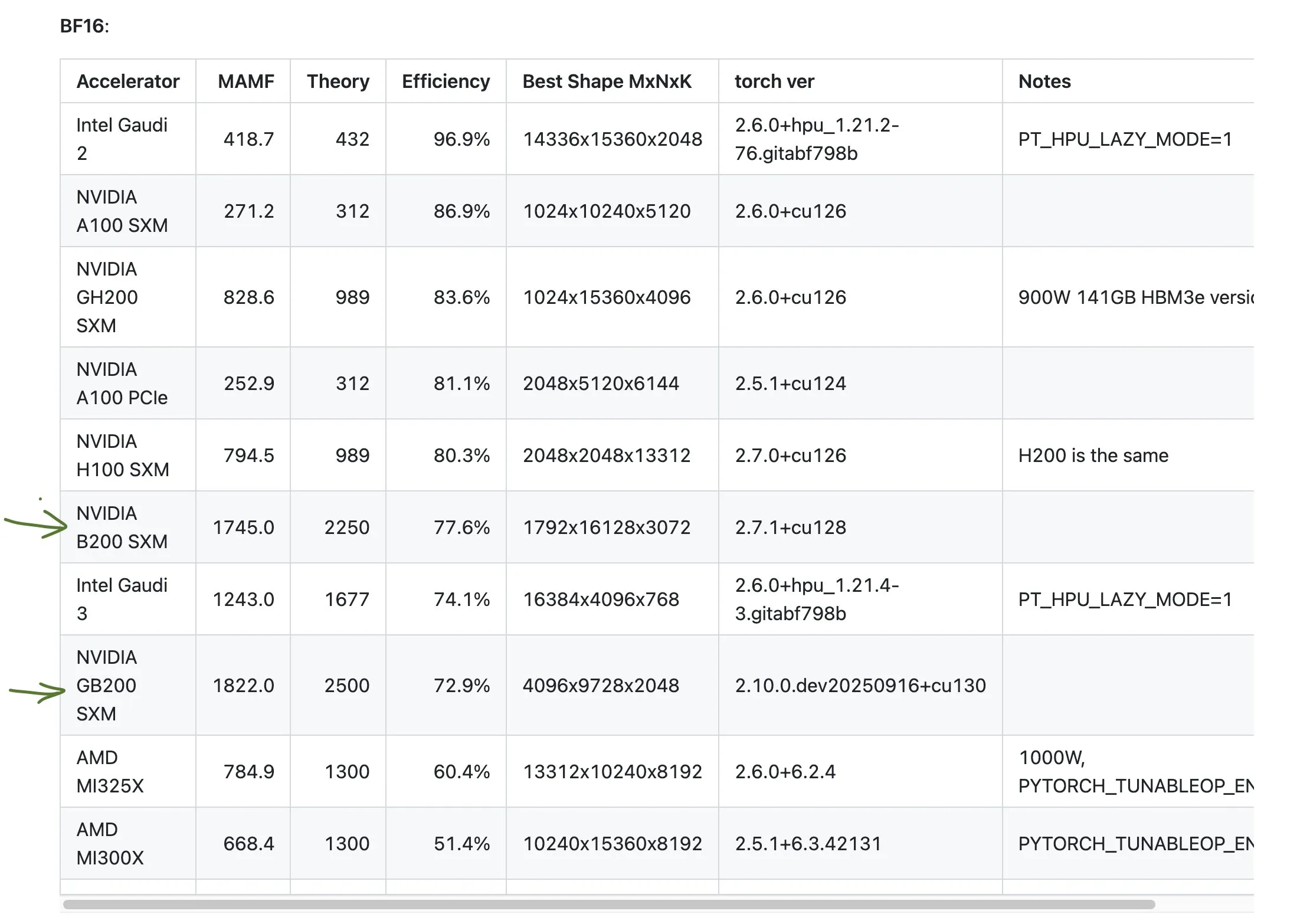
Différences de données de performance entre les GPU NVIDIA grand public et professionnels : La communauté a discuté des différences entre les TFLOPs marketing et les performances réelles des GPU NVIDIA grand public et professionnels. Les données montrent que les cartes graphiques grand public (telles que 3090, 4090, 5090) ont des performances réelles légèrement supérieures ou proches des TFLOPs nominaux, tandis que les cartes graphiques professionnelles pour stations de travail (telles que A6000, 6000 ADA) ont des performances réelles bien inférieures aux valeurs nominales. Néanmoins, les cartes professionnelles conservent des avantages en termes de consommation d’énergie, de taille et d’efficacité énergétique, mais les utilisateurs doivent être conscients de l’écart entre les données marketing et les performances réelles. (Source : TheZachMueller)
Discussion sur les performances médiocres des GPU AMD : La communauté a discuté des performances des GPU AMD dans certains benchmarks, soulignant que leur efficacité pourrait n’être que la moitié de ce qui est attendu. Cela a soulevé des inquiétudes quant à la compétitivité d’AMD dans le domaine du calcul AI, en particulier par rapport aux produits haute performance de NVIDIA comme le GB200. Les utilisateurs doivent évaluer attentivement les performances et l’efficacité réelles des GPU de différents fabricants lors de la planification des ressources de calcul AI. (Source : jeremyphoward)
GIGABYTE AI TOP ATOM : performances du Grace Blackwell GB10 au niveau du bureau : GIGABYTE a lancé l’AI TOP ATOM, apportant les performances du NVIDIA Grace Blackwell GB10 aux stations de travail de bureau. Ce produit vise à fournir aux utilisateurs individuels et aux petites équipes une puissante capacité de calcul AI, leur permettant d’effectuer localement un entraînement et une inférence de modèles haute performance, réduisant ainsi la dépendance aux ressources cloud et accélérant le développement et le déploiement d’applications AI. (Source : Reddit r/LocalLLaMA)