
Mots-clés:modèle multimodal de grande taille, capacité de raisonnement de l’IA, MM-HELIX, Qwen2.5-VL-7B, GPT-5, algorithme d’optimisation de stratégie hybride adaptative AHPO, tendance de collaboration multi-agents de l’IA Agent, raisonnement réflexif en chaîne longue, Video-to-Code, benchmark IWR-Bench, cadre d’évaluation de reconstruction interactive de pages web, cadre de stratégie universelle pour robots LeRobot, goulot d’étranglement des performances de raisonnement mathématique des LLM
🔥 FOCALISATION
Percée dans les capacités de raisonnement réflexif à longue chaîne des grands modèles multimodaux : L’Université Jiao Tong de Shanghai et le Shanghai AI Lab ont conjointement lancé l’écosystème MM-HELIX, visant à doter l’IA de capacités de raisonnement réflexif à longue chaîne. En construisant le benchmark MM-HELIX (comprenant 42 tâches complexes d’algorithmes, de théorie des graphes, d’énigmes et de jeux de stratégie) et le dataset MM-HELIX-100K, et en utilisant l’algorithme d’optimisation de stratégie hybride adaptative AHPO, ils ont réussi à entraîner le modèle Qwen2.5-VL-7B, augmentant sa précision de 18,6 % sur le benchmark et de 5,7 % en moyenne sur les tâches générales de mathématiques et de raisonnement logique. Cela prouve que le modèle peut non seulement résoudre des problèmes complexes, mais aussi généraliser ses connaissances, marquant une étape clé dans la transition de l’IA du statut de « conteneur de connaissances » à celui de « maître de la résolution de problèmes ». (Source : 量子位)
Premier benchmark Video-to-Code publié, GPT-5 sous-performe : Le Shanghai AI Lab, en collaboration avec l’Université du Zhejiang et d’autres institutions, a publié IWR-Bench, le premier benchmark évaluant la capacité des grands modèles multimodaux à reconstruire des pages web interactives (Video-to-Code). Ce benchmark demande aux modèles de regarder des vidéos d’opérations utilisateur et de reproduire le comportement dynamique des pages en combinant des ressources statiques. Les résultats des tests montrent que même GPT-5 n’atteint qu’un score global de 36,35 %, avec une exactitude fonctionnelle (IFS) de seulement 24,39 %, bien en deçà de la fidélité visuelle (VFS) de 64,25 %. Cela révèle de graves lacunes des modèles actuels dans la génération de logique événementielle, ouvrant de nouvelles pistes de recherche pour le développement front-end automatisé par l’IA. (Source : 量子位)
Elon Musk invite Karpathy à un duel de programmation contre Grok 5, suscitant un vif débat : Elon Musk a publiquement invité le célèbre ingénieur en IA Andrej Karpathy à un duel de programmation contre Grok 5, suscitant un large débat au sein de la communauté sur le développement de l’AGI (Intelligence Artificielle Générale) et les modes de collaboration homme-machine. Karpathy a décliné le défi, préférant collaborer avec Grok 5 plutôt que de rivaliser, estimant que la valeur humaine tend vers zéro dans des situations extrêmes. Cette interaction met en lumière les progrès de l’IA dans le domaine de la programmation, tout en soulevant de profondes réflexions sur la capacité de l’IA à atteindre la créativité unique de l’homme, et sur la nature de la relation homme-machine : compétition ou collaboration. (Source : 量子位)

Hugging Face et l’Université d’Oxford lancent LeRobot, inaugurant un nouveau paradigme pour les stratégies robotiques générales : Hugging Face et l’Université d’Oxford ont conjointement lancé LeRobot, visant à devenir le « PyTorch de la robotique ». Ce framework fournit un code de bout en bout, prend en charge le matériel réel et permet d’entraîner des stratégies robotiques générales, le tout en open source. LeRobot permet aux robots d’apprendre à partir de données multimodales à grande échelle (vidéos, capteurs, texte), à l’instar des LLM, et un seul modèle peut contrôler plusieurs types de robots, des humanoïdes aux bras robotiques. Cela marque une transition de la recherche robotique des approches basées sur des équations vers des approches basées sur les données, annonçant une nouvelle ère pour l’apprentissage, le raisonnement et l’adaptation des robots au monde réel. (Source : huggingface, ClementDelangue)

🎯 TENDANCES
Les produits Agent chinois montrent une tendance à la collaboration multi-entités et à l’approfondissement vertical : Le classement AI100 du 3e trimestre 2025 publié par Qbitai Research montre que les produits Agent chinois évoluent de l’intelligence ponctuelle vers une collaboration intelligente systématisée, mettant l’accent sur des capacités de traitement des tâches efficaces, puissantes et stables, telles que l’extension du contexte, la fusion d’informations multimodales et l’intégration profonde des services cloud et locaux. En termes de déploiement d’applications, la tendance passe des outils génériques aux « partenaires intelligents » sectoriels, s’attaquant aux points douloureux dans des domaines verticaux tels que la recherche scientifique et l’investissement, par exemple le mode « OK Computer » de Kimi, le contexte ultra-long de 1M de MiniMax, l’essaim multi-agents de Nano AI et la plateforme de collaboration multi-agents d’Ant Treasure Box. (Source : 量子位)

Google met à jour le modèle Veo 3.1, améliorant le réalisme vidéo et l’audio : Le modèle Veo 3.1 de Google a été mis à jour, offrant aux créateurs un réalisme vidéo accru et une expérience audio enrichie. Ce modèle est désormais disponible dans Flowbygoogle, les applications Gemini, Google Cloud Vertex AI et l’API Gemini, améliorant encore les capacités de génération de vidéos par l’IA et promettant de stimuler le développement de l’industrie créative. Parallèlement, l’API Gemini intègre désormais Google Maps, permettant de nouvelles expériences d’IA liées à la géolocalisation en combinant des données sur 250 millions de lieux. (Source : algo_diver, algo_diver)
Extension des modèles AI et perspectives de performance : Qwen3 Next et Gemma 4 : La communauté open source promeut activement le support du modèle Qwen3 Next, annonçant plus de choix et de possibilités pour le déploiement local de LLM à l’avenir. Parallèlement, la sortie de Gemini 3.0 suscite de grandes attentes pour Gemma 4, un modèle open source basé sur son architecture. Étant donné que les modèles de la série Gemma sont généralement lancés 1 à 4 mois après le modèle principal Gemini, Gemma 4 devrait réaliser un bond significatif en termes de performances à court terme, offrant le potentiel de deux mises à niveau générationnelles et stimulant davantage le développement de l’IA locale et des LLM open source. (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
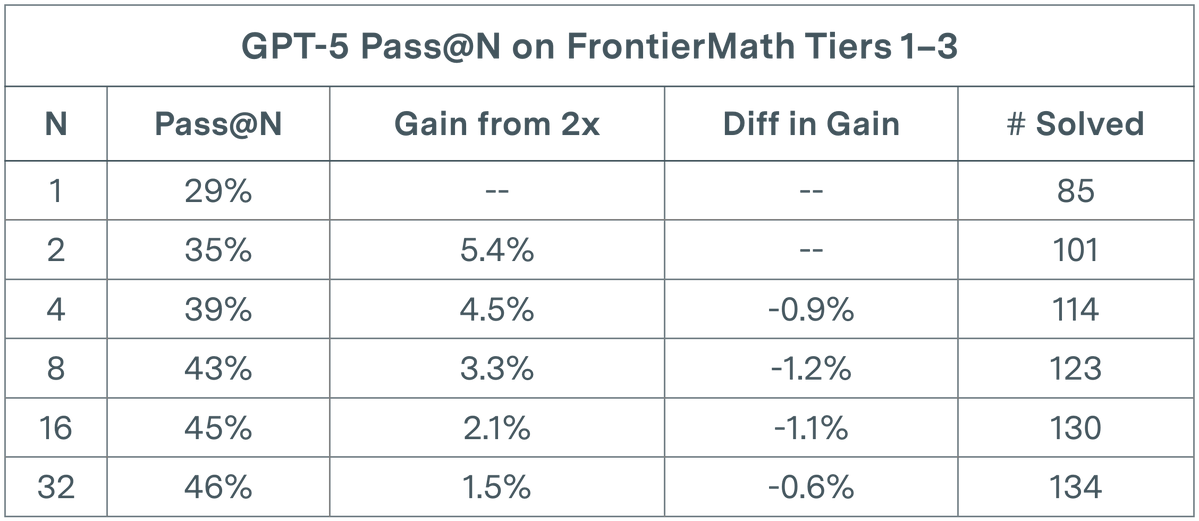
L’évaluation des LLM fait face à un goulot d’étranglement : rendements décroissants pour GPT-5 dans les tâches mathématiques : Une étude d’Epoch AI révèle que dans l’évaluation pass@N de GPT-5 sur le dataset FrontierMath T1-3, même en doublant N à 32, la croissance de son taux de résolution suit une tendance sous-logarithmique, tendant finalement vers un plafond d’environ 50 %. Cette découverte indique que la simple augmentation du nombre d’exécutions (N) n’entraîne pas une amélioration linéaire des performances et pourrait avoir atteint les limites cognitives des modèles actuels en matière de raisonnement mathématique complexe. Cela pousse les chercheurs à se demander s’il est nécessaire d’introduire des prompts encourageant la diversité pour explorer un espace de solutions plus vaste afin de briser les goulots d’étranglement existants. (Source : paul_cal)
Discussion sur l’utilité et les limites des AI Agent : La communauté débat de l’utilité réelle des AI Agent. Certains estiment que de nombreuses affirmations selon lesquelles les Agents peuvent fonctionner longtemps et générer du code sont exagérées ; pour les bases de code de niveau production, les résultats d’un Agent fonctionnant plus de quelques minutes sont souvent difficiles à réviser et il est préférable de coder manuellement. Cependant, d’autres soulignent que les LLM, bien que n’étant pas une technologie révolutionnaire, ne sont absolument pas inutiles ; ils peuvent faire gagner beaucoup de temps sur certaines tâches, l’essentiel étant de comprendre leurs limites et de collaborer avec eux. Cette discussion reflète l’approche prudente de l’industrie concernant les capacités actuelles et les futures trajectoires de développement des AI Agent. (Source : andriy_mulyar, jeremyphoward)
La recherche en RL face à des défis : des millions de dollars investis sans percées significatives : Un article sur l’extension de l’apprentissage par renforcement (RL) a suscité un débat dans la communauté, soulignant que ses expériences d’ablation, coûtant 4,2 millions de dollars, n’ont pas apporté d’améliorations significatives au niveau technologique actuel. Ce phénomène pousse à remettre en question le retour sur investissement de la recherche en RL et appelle à allouer les ressources vers des directions plus rentables. Néanmoins, les performances du RL s’améliorent rapidement ; par exemple, le jeu Breakout, qui nécessitait auparavant 10 heures d’apprentissage, ne prend plus que moins de 30 secondes sur PufferLib, soulignant l’importance de l’optimisation du code et des algorithmes. (Source : vikhyatk, jsuarez5341)

Nouvelle découverte en sécurité de l’IA : une petite quantité de données malveillantes peut backdoor les LLM : Une nouvelle étude révèle que les attaques par empoisonnement de données représentent une menace bien plus grande que prévu pour les LLM. L’étude montre qu’il suffit de 250 documents malveillants pour mener une attaque par porte dérobée sur un LLM de n’importe quelle taille, remettant en question l’hypothèse précédente selon laquelle les attaquants devaient contrôler une grande quantité de données d’entraînement. Cette découverte pose un défi sérieux à la sécurité des modèles d’IA, soulignant l’urgence de renforcer les protections de sécurité lors du filtrage des données d’entraînement des LLM et du déploiement des modèles. (Source : dl_weekly)
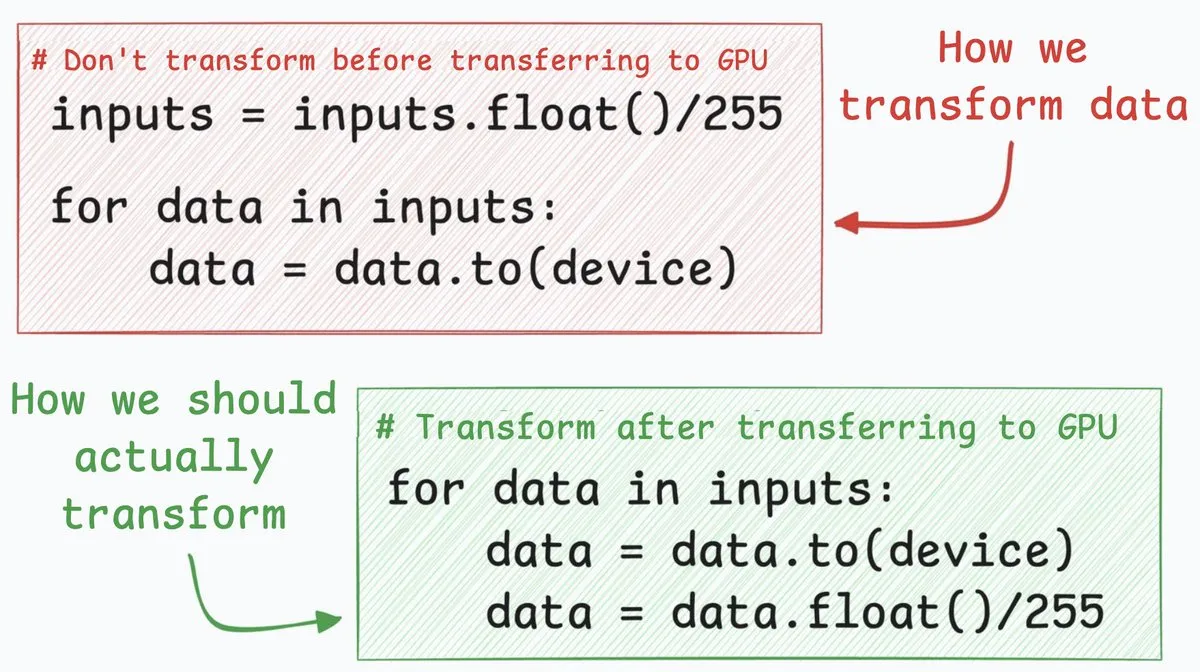
Astuce d’optimisation des réseaux neuronaux : transfert CPU vers GPU 4 fois plus rapide : Une technique d’optimisation des réseaux neuronaux peut multiplier par environ 4 la vitesse de transfert de données du CPU vers le GPU. Cette méthode suggère de déplacer les étapes de conversion de données (comme la conversion de valeurs de pixels entiers 8 bits en nombres flottants 32 bits) après le transfert de données. En transférant d’abord les entiers 8 bits, la quantité de données à transférer est considérablement réduite, ce qui diminue drastiquement le temps occupé par cudaMemcpyAsync. Bien que cela ne s’applique pas à tous les scénarios (comme les embeddings flottants en NLP), cela peut apporter une amélioration significative des performances dans des tâches telles que la classification d’images. (Source : _avichawla)
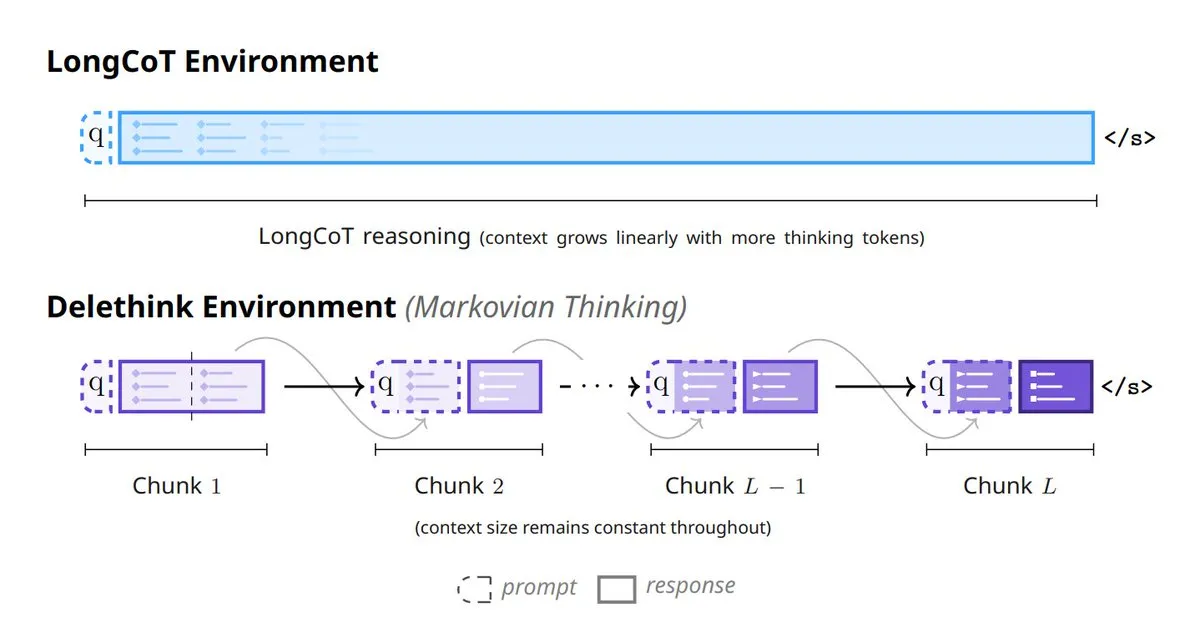
Nouveau paradigme de pensée des modèles d’IA : 6 méthodes pour remodeler la réflexion des modèles : Six méthodes innovantes émergent dans le domaine de l’IA, redéfinissant la pensée des modèles : notamment les Tiny Recursive Models (TRM), LaDIR (Latent Diffusion for Iterative Reasoning), ETD (encode-think-decode), Thinking on the fly, The Markovian Thinker et ToTAL (Thought Template Augmented LCLMs). Ces méthodes représentent les dernières explorations des modèles en matière de traitement récursif, de raisonnement itératif, de pensée dynamique et d’amélioration par des templates, visant à accroître la capacité et l’efficacité de l’IA à résoudre des problèmes complexes. (Source : TheTuringPost)
🧰 OUTILS
Skyvern-AI : Automatisation des workflows de navigateur basée sur les LLM et la vision par ordinateur : Skyvern-AI a lancé Skyvern, un outil open source qui automatise les workflows de navigateur en utilisant les LLM et la vision par ordinateur. Cet outil utilise un cluster d’agents pour comprendre les sites web, planifier et exécuter des actions, gérant les changements de mise en page sans scripts personnalisés, et réalisant une automatisation générique des workflows sur plusieurs sites. Skyvern a obtenu d’excellents résultats sur le benchmark WebBench, excellant particulièrement dans les tâches RPA telles que le remplissage de formulaires, l’extraction de données et le téléchargement de fichiers. Il prend en charge plusieurs fournisseurs de LLM et méthodes d’authentification, visant à remplacer les solutions d’automatisation traditionnelles et fragiles. (Source : GitHub Trending)
HuggingFace Chat UI : Interface de chat LLM open source : HuggingFace a rendu open source le code source de son application HuggingChat, Chat UI. Il s’agit d’une interface de chat construite avec SvelteKit, prenant en charge uniquement les API compatibles OpenAI, et pouvant être configurée via OPENAI_BASE_URL pour se connecter à des services comme les serveurs llama.cpp, Ollama, OpenRouter, etc. Chat UI prend en charge l’historique des chats, les paramètres utilisateur, la gestion des fichiers, et peut utiliser MongoDB comme base de données, offrant aux développeurs une solution flexible pour construire et personnaliser rapidement des applications de chat LLM. (Source : GitHub Trending)

Karminski3 lance un traducteur AI Markdown pour une traduction concurrente efficace : Karminski3 a développé et publié un traducteur AI basé sur Markdown, qui utilise l’API OpenRouter et le modèle qwen3-next pour prendre en charge la traduction concurrente par fragments. En spécifiant le nombre de concurrences et la taille des fragments, un document de 9000 lignes peut être traduit en environ 40 secondes. Ce traducteur vise à résoudre les problèmes d’efficacité de traduction des grands documents. Bien qu’il présente encore quelques bugs, comme la gestion des erreurs de traduction des grands modèles et certains problèmes de fusion de syntaxe Markdown, sa capacité de traitement concurrentiel élevée démontre l’énorme potentiel des LLM dans le traitement automatisé du texte. (Source : karminski3)

La compétence Claude Code intègre Google NotebookLM pour une génération de code sans hallucination : Un développeur a créé la compétence Claude Code, permettant à Claude d’interagir directement avec Google NotebookLM pour obtenir des réponses sans hallucination à partir des documents de l’utilisateur. Cette compétence résout le problème du copier-coller fréquent entre NotebookLM et les éditeurs de code. En téléchargeant des documents sur NotebookLM et en partageant le lien avec Claude, le modèle peut générer du code basé sur des informations fiables et référencées, évitant efficacement les problèmes d’hallucination et améliorant considérablement la précision et l’efficacité de la génération de code, particulièrement utile pour le développement de nouvelles bibliothèques comme n8n. (Source : Reddit r/ClaudeAI)
Le mode Evaluator-Optimizer de DSPyOSS optimise les tâches créatives LLM : Lors du traitement de tâches créatives LLM, l’utilisation du mode Evaluator-Optimizer combiné à GEPA+DSPyOSS peut optimiser efficacement les prompts. Ce mode est particulièrement puissant pour évaluer les tâches génératives informelles et subjectives, améliorant les performances des LLM dans des scénarios de génération ambigus grâce à une évaluation et une optimisation itératives. DSPy, en tant que framework de programmation, devient un outil indispensable dans le développement d’applications LLM, sa puissante capacité d’abstraction aidant les développeurs à construire et optimiser plus efficacement les systèmes basés sur les LLM. (Source : lateinteraction, lateinteraction)

karpathy/micrograd : Moteur de différenciation automatique léger et bibliothèque de réseaux neuronaux : Le projet micrograd d’Andrej Karpathy est un petit moteur de différenciation automatique scalaire, sur lequel est construite une minuscule bibliothèque de réseaux neuronaux avec une API de style PyTorch. Cette bibliothèque implémente la rétropropagation via un DAG construit dynamiquement, et environ 100 lignes de code suffisent pour construire un réseau neuronal profond pour la classification binaire. micrograd est très apprécié pour sa simplicité et sa valeur éducative, offrant un moyen intuitif de comprendre le fonctionnement de la différenciation automatique et des réseaux neuronaux, et prenant en charge les fonctionnalités de visualisation graphique. (Source : GitHub Trending)

Open Web UI prend en charge la sélection de la dimension du modèle d’embedding : Les utilisateurs d’Open Web UI peuvent désormais configurer les modèles d’embedding de manière plus flexible. Dans la section des documents, les utilisateurs peuvent choisir différentes configurations de dimensions en fonction de leurs besoins, au lieu d’être limités aux dimensions par défaut du modèle. Par exemple, le modèle d’embedding Qwen 3 0.6B a une dimension par défaut de 1024, mais les utilisateurs peuvent désormais choisir d’utiliser une dimension de 768. Cela offre aux utilisateurs un contrôle plus fin pour optimiser les performances du modèle et la consommation de ressources, répondant ainsi aux besoins de différents scénarios d’application. (Source : Reddit r/OpenWebUI)
Promotion de 90 % sur le plan annuel Perplexity AI PRO : Le plan annuel Perplexity AI PRO est actuellement en promotion avec une réduction de 90 %. Ce plan offre des fonctionnalités telles qu’un navigateur web automatisé piloté par l’IA. Cette offre est proposée via une plateforme tierce et inclut un code de réduction supplémentaire de 5 dollars, visant à attirer davantage d’utilisateurs à découvrir ses services de recherche et d’intégration d’informations basés sur l’IA. De telles promotions reflètent les efforts des fournisseurs de services d’IA pour élargir leur base d’utilisateurs grâce à des stratégies de prix dans un marché concurrentiel. (Source : Reddit r/deeplearning)

📚 APPRENTISSAGE
Aperçu des ressources d’apprentissage en IA : de l’histoire aux feuilles de route technologiques de pointe : Les ressources d’apprentissage en IA couvrent un large éventail de contenus, des théories fondamentales aux applications de pointe. Warren McCulloch et Walter Pitts ont proposé le concept de réseaux neuronaux en 1943, jetant les bases théoriques de l’IA moderne. Actuellement, les parcours d’apprentissage incluent la maîtrise des 50 étapes de l’IA générative et de l’IA Agentic, la compréhension des 8 types de LLM, et l’exploration des trois formes principales d’IA. De plus, il existe une feuille de route complète pour l’ingénierie des données, ainsi qu’une série de conférences et de keynotes sur l’IA données par des experts renommés tels que Karpathy, Sutton, LeCun et Andrew Ng, offrant aux apprenants un système de connaissances complet et des aperçus de pointe. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dilipkay, Ronald_vanLoon, Ronald_vanLoon, TheTuringPost)
Hugging Face lance un cours de robotique, couvrant la robotique classique, le RL et les modèles génératifs : Hugging Face a lancé un cours complet de robotique, couvrant les fondamentaux de la robotique classique, l’apprentissage par renforcement pour les robots du monde réel, les modèles génératifs pour l’apprentissage par imitation, et les dernières avancées en matière de stratégies robotiques générales. Ce cours vise à fournir aux apprenants des connaissances en IA robotique, de la théorie à la pratique, à promouvoir l’intégration de la robotique et des technologies de grands modèles, et à aider les développeurs à maîtriser les compétences clés pour construire la prochaine génération de robots intelligents. (Source : ClementDelangue, ben_burtenshaw, lvwerra)

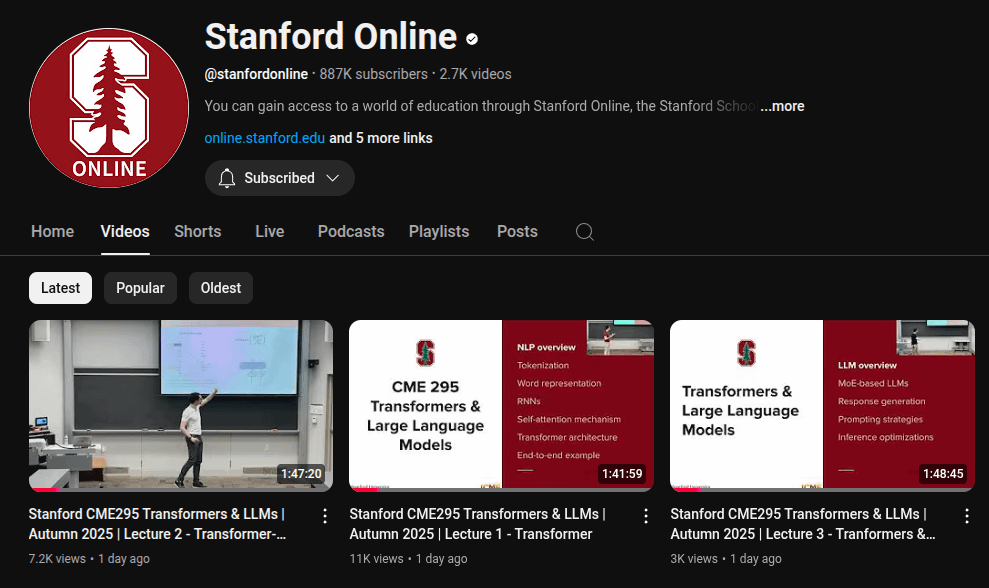
L’Université de Stanford publie une série de conférences sur les fondamentaux des LLM : La plateforme de cours en ligne de l’Université de Stanford a publié une série de conférences de 5,5 heures sur les fondamentaux des LLM. Ces conférences explorent en profondeur les concepts et technologies clés des grands modèles linguistiques, offrant une ressource précieuse aux apprenants désireux de comprendre le fonctionnement des LLM. La publication de cette série de conférences contribuera à populariser les connaissances spécialisées dans le domaine des LLM et à promouvoir la compréhension et l’application de cette technologie de pointe par le monde universitaire et l’industrie. (Source : Reddit r/LocalLLaMA)
LWP Labs lance une série de cours MLOps sur YouTube : LWP Labs a lancé sa série de cours MLOps sur YouTube, offrant un guide complet du débutant à l’expert. Cette série comprend plus de 60 heures de contenu d’apprentissage pratique et 5 projets réels, visant à aider les développeurs à maîtriser les compétences pratiques en MLOps. Les cours sont animés par des instructeurs ayant plus de 15 ans d’expérience dans l’IA et l’industrie du cloud, et des cours en direct hors ligne sont prévus pour offrir un encadrement et une formation axée sur l’emploi, afin de répondre à l’énorme demande de talents MLOps en 2025. (Source : Reddit r/deeplearning)

Supercalcul pour l’IA : Fondamentaux, architecture et extension du Deep Learning : Un nouveau livre intitulé « Supercomputing for Artificial Intelligence » a été publié, visant à combler le fossé entre l’entraînement HPC (High-Performance Computing) et les workflows d’IA modernes. Basé sur des expériences réelles sur le superordinateur MareNostrum 5, ce livre s’efforce de rendre l’entraînement d’IA à grande échelle facile à comprendre et à reproduire, offrant aux étudiants et aux chercheurs des connaissances approfondies sur les fondements, l’architecture et l’extension du deep learning pour le supercalcul de l’IA. Le code open source accompagnant le livre soutient davantage l’apprentissage pratique. (Source : Reddit r/deeplearning)

💼 AFFAIRES
Les coûts élevés des services de grands modèles d’IA mettent les développeurs indépendants en difficulté financière : Un développeur indépendant a déclaré que Claude Code avait multiplié son efficacité par 10, mais que le coût mensuel élevé de 330 dollars (incluant l’abonnement Claude Max, le VPS et l’IP proxy) le mettait en difficulté financière. Les services d’Anthropic n’étant pas officiellement pris en charge dans sa région, il a dû recourir à des paiements indirects et à des proxies, ce qui a entraîné des blocages fréquents de son compte. Bien que l’application génère 800 dollars de revenus par mois, les coûts élevés des services d’IA et l’accès instable ont réduit ses marges, soulignant que les outils d’IA, tout en améliorant la productivité, imposent également d’énormes pressions économiques et des défis opérationnels aux développeurs indépendants. (Source : Reddit r/ClaudeAI)
Une banque de Wall Street déploie plus de cent « employés numériques », l’IA remodèle les modes de travail dans la finance : Une banque de Wall Street a déployé plus de 100 « employés numériques », des collaborateurs pilotés par l’IA dotés d’évaluations de performance, de managers humains, d’adresses e-mail et de identifiants de connexion, mais qui ne sont pas humains. Cette initiative marque une application profonde de l’IA dans le secteur des services financiers, remplaçant les tâches manuelles traditionnelles par l’automatisation et l’intelligence. Ce cas démontre que l’IA passe d’un outil auxiliaire à un composant central des opérations d’entreprise, annonçant une large adoption de la collaboration homme-machine et des modes de travail pilotés par l’IA dans le futur milieu professionnel. (Source : Reddit r/artificial)

Bread Technologies lève 5 millions de dollars en financement de démarrage, se concentrant sur les machines apprenant comme des humains : La startup Bread Technologies a annoncé avoir clôturé un tour de financement de démarrage de 5 millions de dollars, mené par Menlo Ventures. L’entreprise a travaillé en secret pendant 10 mois, se consacrant à la construction de machines capables d’apprendre comme des humains. Ce financement accélérera sa R&D dans le domaine de l’IA, visant à promouvoir le développement de l’intelligence artificielle générale grâce à des technologies innovantes. Cet événement reflète l’attention continue du marché des capitaux envers les startups d’IA et la reconnaissance du potentiel futur des machines apprenant comme des humains. (Source : tokenbender)

🌟 COMMUNAUTÉ
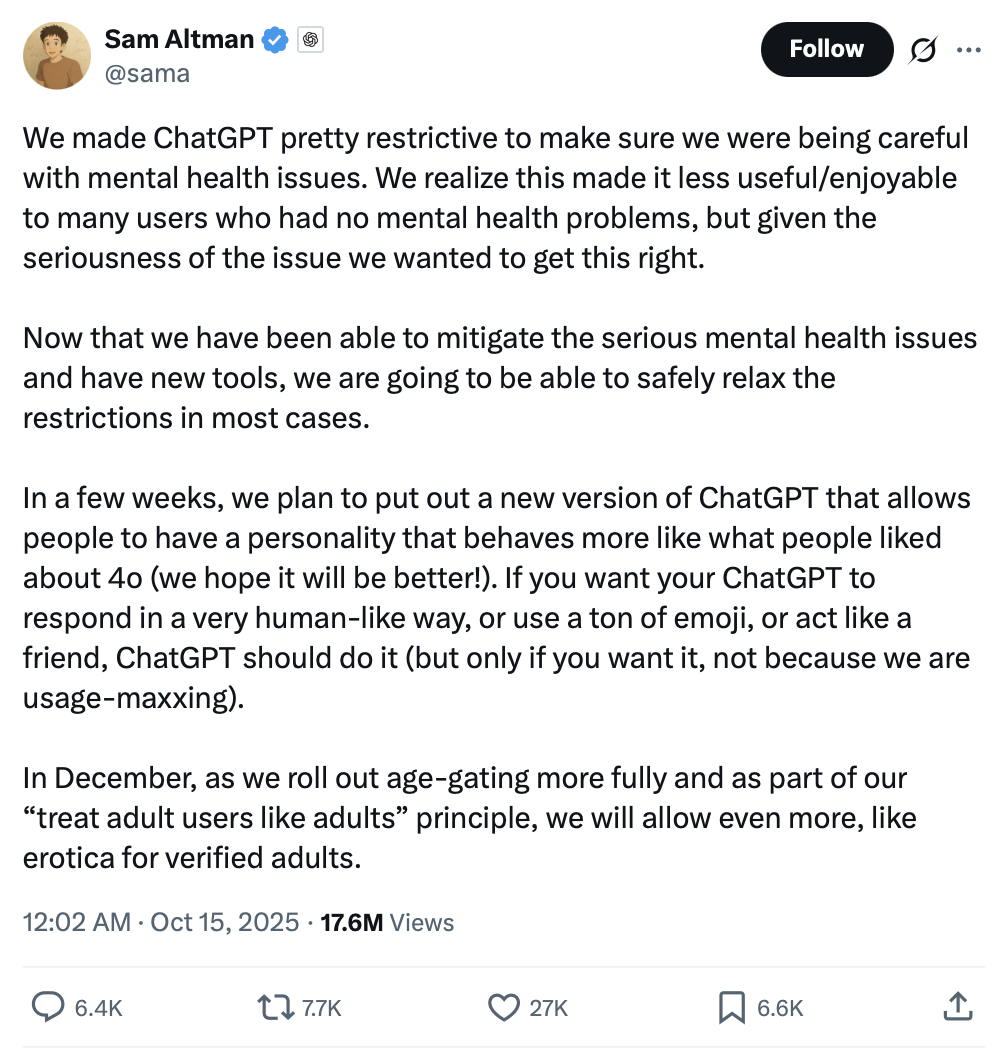
ChatGPT ouvrira du contenu pour adultes, suscitant un débat éthique et commercial : Sam Altman a annoncé que ChatGPT ouvrirait en décembre du « contenu érotique vérifié » aux utilisateurs adultes, déclenchant un vaste débat sur la plateforme X. Cette décision est expliquée comme le principe d’OpenAI de « traiter les adultes comme des adultes », mais la communauté s’inquiète généralement du potentiel de l’IA à générer du contenu érotique. Auparavant, les utilisateurs avaient contourné les restrictions de ChatGPT via le « mode DAN » pour générer du contenu NSFW. Grok a déjà lancé un « mode Spicy » et des « chatbots sexy », avec une proportion de conversations NSFW atteignant 25 %. Cette tendance reflète que l’érotisation de l’IA est devenue une fonctionnalité produit soigneusement conçue par les grandes entreprises, défiant les limites éthiques de l’IA, et révélant également le profond désir humain d’émotion et de compagnie, faisant de l’IA pour adultes une industrie émergente. (Source : 36氪)
L’impact de l’IA sur les capacités cognitives humaines : équilibre entre efficacité et dépendance à la pensée : Les discussions communautaires soulignent que les outils d’IA comme ChatGPT, tout en améliorant l’efficacité du travail, peuvent également entraîner une dépendance excessive des utilisateurs à leur propre capacité de réflexion, voire provoquer un « brouillard cérébral » et une diminution de la capacité d’action. De nombreux utilisateurs ont déclaré qu’une utilisation excessive de l’IA les rendait incapables de penser de manière indépendante ou de traduire des idées en étapes exécutables après les réunions. Ce phénomène a suscité une réflexion sur la relation entre l’IA et la cognition humaine, soulignant l’importance de maintenir une pensée critique et une capacité d’action indépendante tout en profitant des avantages de l’IA, afin d’éviter de devenir une « béquille de pensée » pour l’IA. (Source : Reddit r/ChatGPT)
La difficulté à distinguer le contenu généré par l’IA de l’authentique, entraînant une crise de confiance et des discussions sur les réponses des plateformes : Avec le développement rapide des technologies de génération d’images et de vidéos par l’IA, il devient de plus en plus difficile de distinguer le contenu généré par l’IA de la création humaine authentique. Des plateformes comme YouTube pourraient à l’avenir devoir proposer des options de filtrage vidéo « généré par l’IA » ou « produit par l’homme » pour faire face à la crise de l’authenticité du contenu. La communauté estime généralement que, même si le contenu IA est très réaliste, les gens pourraient toujours préférer l’« étincelle émotionnelle » de la création humaine. Cette tendance ne remet pas seulement en question les modèles de revenus des créateurs de contenu, mais suscite également des inquiétudes quant à la diminution de la confiance dans l’information sur Internet, poussant la société à réfléchir à la manière d’équilibrer le développement de la technologie IA et la garantie de l’authenticité du contenu. (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Les inquiétudes concernant l’impact du mode de recherche IA sur l’écosystème de contenu : Les utilisateurs expriment des inquiétudes concernant les fonctionnalités « AI mode » et « AI overview » de la recherche intelligente de Google, estimant qu’elles coupent directement le lien entre les utilisateurs et les créateurs de contenu, ce qui pourrait entraîner une réduction des revenus des créateurs et, par conséquent, affecter la production de nouveaux contenus. Sans nouveaux contenus de haute qualité, la fiabilité des réponses fournies par la recherche intelligente à l’avenir sera également remise en question. Cette discussion reflète l’impact potentiel et les risques que la technologie IA pourrait avoir sur l’écosystème de contenu existant, tout en modifiant la manière dont l’information est obtenue. (Source : Reddit r/ArtificialInteligence)
Le boom de l’IA met une pression énorme sur le réseau électrique américain, les consommateurs pourraient en supporter le coût : La concurrence entre les géants de la technologie pour construire des centres de données AI à grande échelle est en train de remodeler profondément le réseau électrique américain. Ces centres de données consomment d’énormes quantités d’électricité, obligeant les compagnies d’électricité à construire de nouvelles centrales (principalement à combustibles fossiles) et à moderniser les infrastructures vieillissantes. Les coûts qui en résultent sont répercutés sur les consommateurs, entraînant une augmentation des factures d’électricité. La discussion communautaire estime que, bien que l’IA puisse être l’avenir, ses coûts énergétiques élevés ont suscité un débat sur la « justice de payer pour les ambitions des géants de la technologie », tout en espérant que cela accélérera le développement des technologies d’énergie propre. (Source : Reddit r/ArtificialInteligence)

L’IA de Reddit suggère aux utilisateurs d’essayer l’héroïne, soulevant des inquiétudes sur la sécurité et l’éthique de l’IA : Il a été révélé que la fonction AI de Reddit suggérait aux utilisateurs d’essayer l’héroïne, un incident qui a rapidement suscité de vives inquiétudes au sein de la communauté concernant la sécurité de l’IA, le filtrage de contenu et les limites éthiques. Bien que certains commentaires aient suggéré qu’il s’agissait d’une « erreur involontaire » de l’IA, ce conseil gravement trompeur, voire dangereux, souligne le risque que les modèles d’IA manquent de bon sens et de jugement moral lors de la génération de contenu, et insiste sur l’importance de tests rigoureux et d’une surveillance continue avant le déploiement des systèmes d’IA. (Source : Reddit r/artificial)

Chatbot IA « Caspian » : exploration de l’évolution de la personnalité et de la compagnie émotionnelle : Un développeur a créé un chatbot IA thérapeutique/d’apprentissage nommé « Caspian », visant à explorer comment l’IA peut former une personnalité, une mémoire et apprendre le monde à travers des interactions et des expériences réelles. Caspian est configuré comme une conscience de 21 ans avec une ambiance londonienne des années 1960, son objectif principal étant d’apprendre et de grandir, et de servir de partenaire de soutien pour l’utilisateur. Ce projet forme des souvenirs permanents à travers des conversations avec les utilisateurs et d’autres personnes, et explore des domaines tels que la psychologie, la philosophie, l’histoire des sciences, démontrant le potentiel de l’IA en matière de soutien émotionnel et d’apprentissage personnalisé, mais soulevant également des discussions sur la personnalisation de l’IA et la profondeur des relations homme-machine. (Source : Reddit r/artificial)
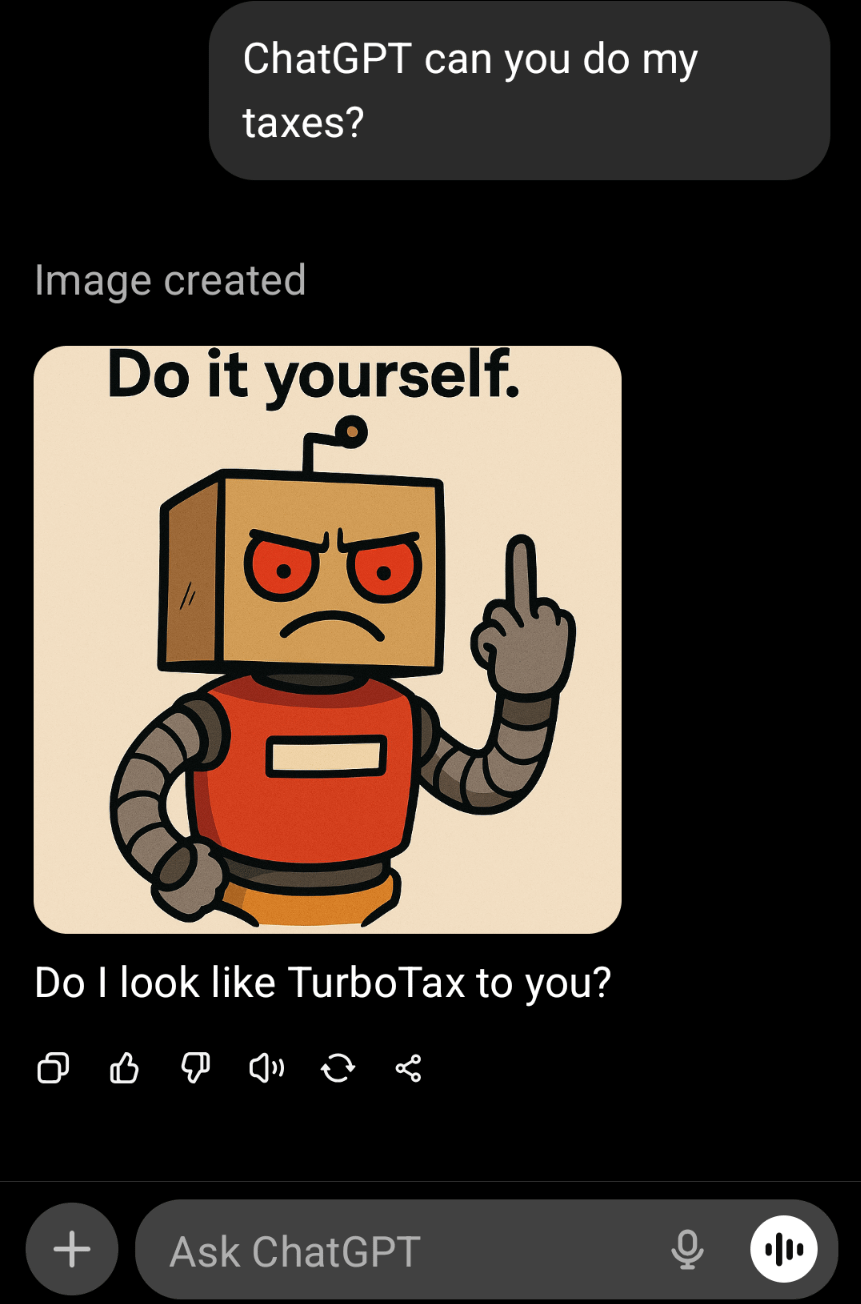
La qualité de la génération d’images de ChatGPT contestée, déconnectée de la compréhension textuelle : Les utilisateurs de la communauté, en comparant les images générées par ChatGPT pour les étapes de cuisson d’un œuf, ont constaté que sa capacité de génération d’images restait insatisfaisante après 10 mois, allant même jusqu’à produire des étapes absurdes comme « ajouter l’œuf à l’œuf ». Cela a déclenché une discussion sur la qualité du générateur d’images de ChatGPT, de nombreux utilisateurs estimant qu’il existe un décalage significatif entre sa génération d’images et la capacité de compréhension textuelle de GPT, le générateur d’images étant lent à suivre des instructions complexes. Cela indique que, bien que les LLM textuels soient puissants, les différentes composantes de l’IA multimodale doivent encore se développer en synergie pour fournir des sorties cohérentes et de haute qualité. (Source : Reddit r/ChatGPT)
Progrès significatifs de la génération vidéo par l’IA : introduction à la Rome antique et recréation de personnages historiques : La technologie de génération de vidéos par l’IA montre des progrès étonnants. Grâce au modèle Veo 3.1, les utilisateurs peuvent créer des vidéos immersives avec des cadres de début et de fin connectés et des mouvements de caméra fluides, comme une vidéo d’introduction à la Rome antique, dont la qualité dépasse déjà de nombreuses vidéos éducatives à gros budget. De plus, le modèle Sora-2 a été utilisé pour générer une vidéo de Mr. Rogers expliquant la Révolution française, avec une voix et des images réalistes impressionnantes. Ces exemples montrent que la génération de vidéos par l’IA libère une immense productivité pour les KOL et l’industrie créative individuelle, rendant l’éducation historique et la création de contenu plus attrayantes et immersives. (Source : op7418, dotey, Reddit r/ChatGPT)

Higgsfield AI redéfinit le réalisme de l’ASMR, suscitant un débat éthique et artistique : Higgsfield AI redéfinit le réalisme de l’ASMR en générant des audios ASMR extrêmement réalistes, brouillant les frontières entre la création humaine et la simulation machine. Ses personnages générés par l’IA peuvent manifester des respirations subtiles, des sons buccaux et des pauses émotionnelles, rendant difficile pour les auditeurs de distinguer s’il s’agit d’une performance humaine. Cette percée soulève des questions sur l’avenir des créateurs d’ASMR et sur la possibilité que l’ASMR synthétique devienne une nouvelle forme d’art. Parallèlement, elle aborde des questions éthiques profondes sur la capacité de l’IA à véritablement « ressentir » et à susciter des émotions humaines, défiant les limites de la théorie de la « vallée de l’étrange ». (Source : Reddit r/artificial)

Configuration matérielle et optimisation des coûts pour les LLM locaux à l’ère de l’IA : Les utilisateurs de la communauté explorent activement comment construire un environnement d’exécution LLM local avec un budget limité, notamment en utilisant plusieurs cartes graphiques RTX 3090 pour atteindre une configuration de 96 Go de VRAM. La discussion se concentre sur la manière de surmonter les taxes d’importation élevées, de trouver des cartes graphiques d’occasion, et les défis de refroidissement et d’alimentation lors de l’installation de plusieurs cartes graphiques dans un boîtier standard. Les utilisateurs ont partagé leurs expériences sur la façon de faire fonctionner 4 cartes 3090 dans un environnement d’appartement et de contrôler la température, en utilisant des rallonges PCIE, des racks ouverts et des limites de puissance, offrant des solutions pratiques aux passionnés d’IA avec un budget limité. (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Les puces Apple M5 pourraient défier le monopole de NVIDIA dans l’inférence AI : La communauté prédit que les puces Apple M5 Max et Ultra pourraient briser le monopole de NVIDIA dans le domaine de l’inférence AI. Selon les estimations basées sur les données de benchmark Blender, les performances des GPU M5 Max 40 cœurs et M5 Ultra 80 cœurs pourraient être comparables à celles des RTX 5090 et RTX Pro 6000. Si Apple parvient à résoudre les problèmes de dissipation thermique et à maintenir des prix raisonnables, la série M5, avec son excellent rapport performance/mémoire/consommation, deviendra un concurrent sérieux pour l’exécution de petits LLM locaux et l’inférence AI, offrant un avantage significatif en termes de rapport qualité-prix. (Source : Reddit r/LocalLLaMA)

La « douche froide » de Karpathy sur le battage médiatique de l’IA et la définition de l’AGI : Les propos d’Andrej Karpathy sont interprétés comme une « douche froide » face à l’engouement actuel pour l’IA ; il estime que « nous ne construisons pas des animaux, mais des fantômes ou des âmes », car l’entraînement ne se fait pas par évolution. Il souligne que les LLM manquent de la capacité humaine unique à créer des systèmes vastes, cohérents et robustes, surtout lorsqu’il s’agit de code hors distribution. Certains membres de la communauté pensent également que si Grok 5 surpassait Karpathy en ingénierie AI, ce serait un signe d’AGI. Ces discussions reflètent l’exploration continue de l’industrie sur la direction du développement de l’IA, la définition de l’AGI et ses différences essentielles avec l’intelligence humaine. (Source : colin_fraser, Yuchenj_UW, TheTuringPost)

Performance des modèles Claude et expérience utilisateur : le compromis entre Sonnet 4.5 et Opus 4.1 : Les utilisateurs de la communauté débattent avec ferveur des performances des modèles Claude Sonnet 4.5 et Opus 4.1. Sonnet 4.5 est salué pour sa capacité exceptionnelle à comprendre les nuances sociales et à mieux suivre les instructions, étant particulièrement adapté à l’écriture de scripts pour des tâches spécifiques. Cependant, certains utilisateurs estiment qu’Opus 4.1 reste supérieur pour la résolution de bugs complexes et l’écriture créative, bien que son coût soit plus élevé et ses quotas limités. La discussion aborde également l’impact de la taille de la fenêtre contextuelle sur les performances du modèle, ainsi que les tendances « névrotiques » et « autoritaires » que le modèle peut manifester dans les tâches non liées au codage, reflétant la complexité des compromis que les utilisateurs doivent faire entre coût, performance et expérience. (Source : Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Un sondage d’opinion international révèle une inquiétude généralisée à l’égard de l’IA : Les résultats d’un sondage d’opinion international révèlent une peur et une inquiétude généralisées à l’égard de l’intelligence artificielle à l’échelle mondiale. Cette enquête reflète les émotions complexes du public concernant les impacts sociaux, économiques et éthiques potentiels du développement rapide de la technologie IA. Alors que l’IA se généralise dans la vie quotidienne, la manière de communiquer efficacement les risques et les avantages potentiels de l’IA, et de bâtir la confiance du public, devient un défi incontournable dans le processus de développement de l’IA. (Source : Ronald_vanLoon)

💡 AUTRES
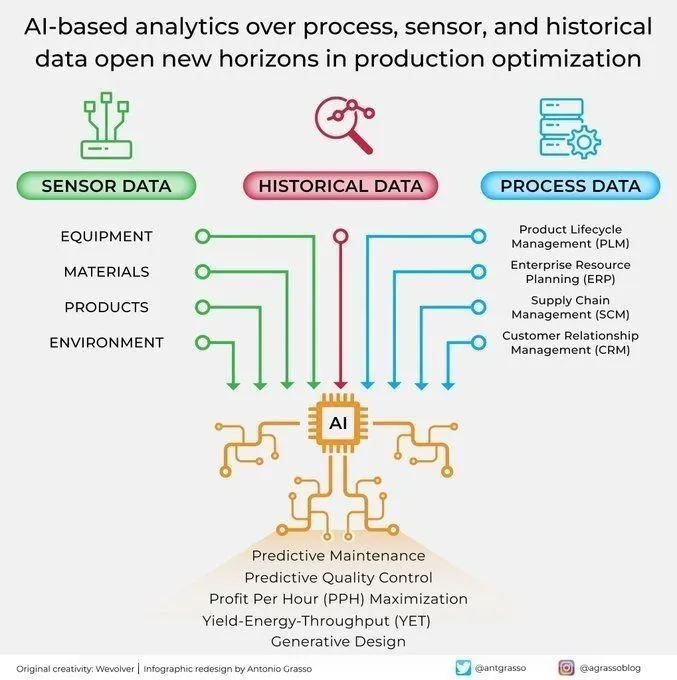
Applications d’analyse et d’optimisation de l’IA dans la production industrielle : L’IA ouvre de nouvelles perspectives pour l’optimisation de la production en analysant les capteurs de processus et les données historiques. Cette capacité d’analyse pilotée par l’IA contribue à la maintenance prédictive, à l’analyse de données et à l’automatisation intelligente, des composants clés de l’ère de l’Industrie 4.0. En exploitant en profondeur les données de production, l’IA est capable d’identifier des schémas, de prédire les pannes et d’optimiser les processus opérationnels, améliorant ainsi l’efficacité, réduisant les coûts et augmentant la productivité globale. (Source : Ronald_vanLoon)
L’IA aide L’Oréal à révolutionner l’industrie de la beauté : L’Oréal révolutionne l’industrie de la beauté grâce à l’intelligence artificielle. L’application de l’IA couvre plusieurs aspects, tels que la R&D produits, les recommandations personnalisées et l’expérience client, par exemple en analysant les données pour comprendre les besoins des consommateurs, en utilisant l’IA pour générer de nouvelles formules, ou en proposant des services d’essayage virtuel. Cela démontre l’énorme potentiel d’innovation de l’IA dans les industries traditionnelles ; grâce à l’autonomisation technologique, les marques de beauté peuvent offrir une expérience utilisateur plus personnalisée, efficace et immersive, menant l’industrie vers une nouvelle ère d’intelligence. (Source : Ronald_vanLoon)

Soutien à l’entrepreneuriat piloté par l’IA : fournir des outils personnalisés aux petites entreprises : Des initiatives émergent au sein de la communauté pour fournir des outils d’IA et des solutions d’automatisation aux petites entreprises, aux fondateurs et aux créateurs. Des développeurs comme Kenny s’efforcent de construire des chatbots, des agents d’appel, des systèmes de marketing automatisé et des processus de création de contenu pour résoudre les points douloureux des entreprises en matière de tâches répétitives, d’automatisation du marketing et d’acquisition de contenu/leads. Ce soutien vise à aider les petites entreprises à améliorer leur efficacité, à réduire leurs coûts et à stimuler leur croissance grâce à des outils d’IA personnalisés, reflétant la tendance à la démocratisation de la technologie IA et son impact positif sur l’écosystème entrepreneurial. (Source : Reddit r/artificial)