Mots-clés:Technologie d’IA, Grand modèle de langage, Apprentissage profond, Intelligence artificielle, Apprentissage automatique, Traitement du langage naturel, Vision par ordinateur, Apprentissage par renforcement, Projet open source NanoChat, Puce IA développée par OpenAI, Éthique du deepfake Sora 2, Claude Sonnet 4.5, Raisonnement mathématique GPT-5 Pro
🔥 À la une
Andrej Karpathy lance nanochat : créer ChatGPT à la main pour 100 dollars : Andrej Karpathy, ancien directeur de l’IA chez Tesla, a lancé le projet open source nanochat, qui implémente le processus complet d’entraînement et d’inférence de ChatGPT avec moins de 8 000 lignes de code. Ce projet vise à réduire les barrières à l’entrée pour la recherche sur les LLM ; les utilisateurs n’ont besoin que d’un GPU cloud (environ 100 dollars, 4 heures d’entraînement) pour construire un mini-ChatGPT conversationnel. Douze heures d’entraînement peuvent surpasser les indicateurs GPT-2 CORE. nanochat sera le projet phare du cours LLM101n et devrait évoluer vers une plateforme de recherche ou un outil de benchmarking, reflétant la passion continue de Karpathy pour l’éducation et la démocratisation de l’IA. (Source : GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
OpenAI et Broadcom s’associent pour développer des puces AI personnalisées et déployer une infrastructure de calcul de 10 gigawatts : OpenAI a annoncé une collaboration stratégique avec Broadcom pour concevoir et déployer conjointement des puces AI personnalisées et des systèmes de calcul. L’objectif est de déployer une infrastructure d’inférence d’une puissance totale de 10 gigawatts entre le second semestre 2026 et fin 2029. Cette initiative marque la volonté d’OpenAI de ne plus se contenter d’acheter des GPU existants, mais de s’intégrer verticalement, en participant à la conception matérielle au niveau des transistors, afin d’optimiser les performances des modèles AI, de réduire les coûts et de répondre à la croissance exponentielle future des besoins en puissance de calcul. OpenAI a déclaré que cette collaboration est “le plus grand projet industriel conjoint de l’histoire de l’humanité”, utilisant même des modèles AI pour aider à la conception des puces, ce qui préfigure une implication profonde de l’IA dans le développement matériel. (Source : OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2 déclenche une crise éthique liée aux deepfakes et des controverses sur les droits d’auteur : Le modèle de génération vidéo Sora 2 d’OpenAI est rapidement devenu populaire grâce à sa capacité de génération très réaliste, mais il a également soulevé de sérieux défis éthiques et de droits d’auteur. Des utilisateurs ont créé de fausses vidéos de célébrités décédées (comme Michael Jackson, Robin Williams) avec Sora 2, provoquant la forte indignation des familles qui y voient un abus et un manque de respect envers l’image des défunts. OpenAI a répondu que les personnalités publiques et leurs familles devraient avoir le contrôle sur l’utilisation de leur image, et prévoit de proposer des contrôles de droits d’auteur plus précis et des mécanismes de partage des revenus. Cependant, l’industrie s’inquiète généralement de la prolifération croissante des modèles deepfake open source, et la société doit s’adapter rapidement à l’impact du contenu généré par l’IA et explorer des mesures de protection techniques et légales efficaces. (Source : Washington Post, BBC, 量子位)

Claude Sonnet 4.5, Microsoft Agent Framework et Cursor IDE propulsent les capacités de codage de l’IA : Le domaine du codage par IA connaît des avancées majeures : Claude Sonnet 4.5 atteint un taux de précision de 77,2 % sur le benchmark SWE-bench Verified, surpassant significativement les modèles précédents. Parallèlement, le Microsoft Agent Framework transforme VS Code en un environnement AI-natif, permettant aux Agents de gérer de manière autonome les modifications de code multi-fichiers ; Cursor IDE 1.7 introduit également un “Agent mode” capable de résoudre des problèmes complexes en un clic. Ces progrès indiquent que les AI Agents peuvent désormais prendre en charge la plupart des tâches de développement, soulevant des discussions sur la dépendance excessive des développeurs à l’égard de l’IA et les risques potentiels de dette technique introduits par le code généré par l’IA. (Source : Reddit r/artificial)
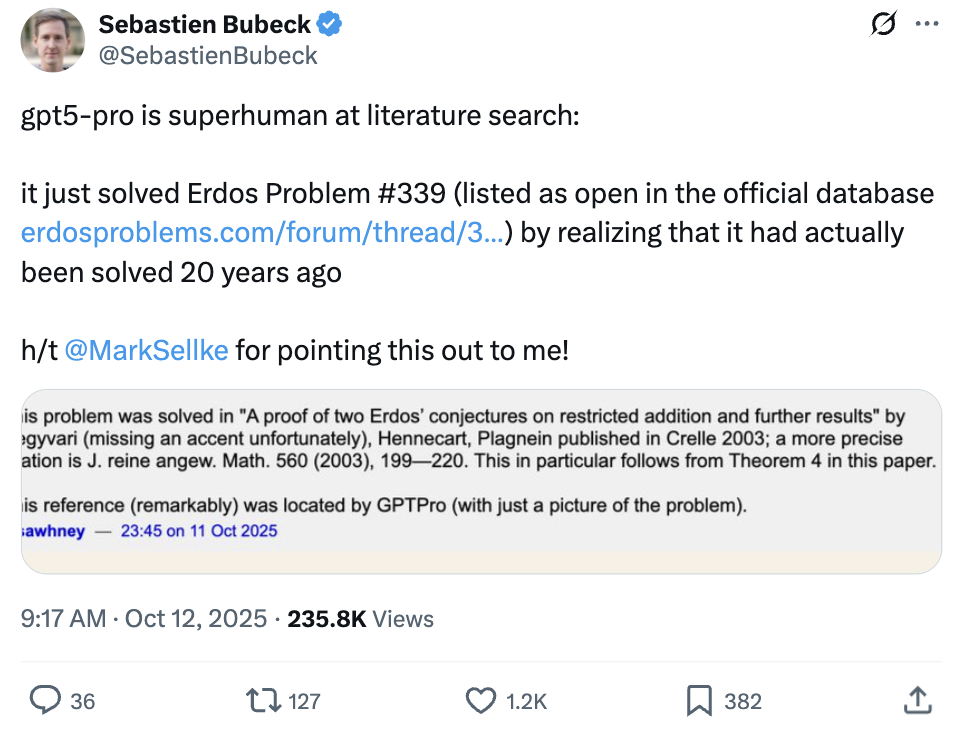
GPT-5 Pro résout un problème mathématique d’Erdos, démontrant de puissantes capacités de recherche documentaire et d’identification de failles : GPT-5 Pro d’OpenAI a démontré une capacité de raisonnement mathématique étonnante, en récupérant avec précision la littérature clé où le problème d’Erdos #339 avait été résolu en 2003, simplement à partir d’une image du problème. De plus, GPT-5 Pro peut découvrir de graves défauts dans des articles publiés en 18 minutes, surpassant même les résultats de plusieurs jours de recherche d’experts humains. Cette percée souligne l’énorme potentiel de GPT-5 Pro en matière de recherche d’informations précises, de résolution de problèmes complexes et de vérification de la littérature scientifique, annonçant une accélération considérable du processus de recherche scientifique par l’IA, en particulier pour la vérification des affirmations académiques et la détection des contradictions logiques. (Source : Sebastien Bubeck, Greg Brockman, 36氪)
Trois géants de l’IA s’associent pour publier un article : les défenses actuelles des LLM sont vulnérables : OpenAI, Anthropic et Google DeepMind ont exceptionnellement uni leurs forces pour publier un article, soulignant la fragilité générale des mécanismes de défense actuels contre le jailbreaking et l’injection de prompt dans les grands modèles de langage (LLM). L’équipe de recherche a proposé un cadre d’attaque adaptatif universel et, en combinant la descente de gradient, l’apprentissage par renforcement, la recherche aléatoire et les tests de red teaming humain, a réussi à contourner 12 mécanismes de défense majeurs, avec un taux de succès de la plupart des attaques dépassant 90 %. Cela indique que les évaluations existantes sont souvent théoriques, et que la future recherche sur la sécurité des LLM doit intégrer des évaluations d’attaques adaptatives plus robustes pour établir un système de défense véritablement solide. (Source : arXiv:2510.09023, 36氪)

xAI rejoint la course aux “modèles du monde”, avec une première application visant la génération de jeux AI : xAI, la société d’Elon Musk, a discrètement rejoint la course aux “modèles du monde”, rivalisant avec des géants comme Google et Meta. xAI a recruté des experts en IA de NVIDIA dans le but de construire des modèles capables de comprendre et de simuler le monde physique réel en entraînant d’énormes quantités de données vidéo et robotiques. Sa première application commerciale est la génération de jeux AI, avec des jeux générés par l’IA prévus pour la fin de l’année prochaine, et une exploration des applications pour les systèmes robotiques. Les chercheurs de Google estiment que les futurs modèles vidéo seront aussi intelligents que les modèles de langage, débloquant des capacités émergentes comme la segmentation d’objets et la détection de contours grâce à la “prédiction de la prochaine image”, annonçant un “moment GPT pour le domaine visuel”. (Source : 36氪)
Un article mystérieux de l’ICLR révèle SAM3 : segmenter tout par concept, refondant le nouveau paradigme de l’IA visuelle : Un article soumis à l’aveugle pour la conférence ICLR 2026, intitulé “SAM3 : Segment Everything with Concepts”, a été divulgué, révélant que le Segment Anything Model (SAM) de Meta AI connaîtra sa troisième mise à jour majeure. La percée fondamentale de SAM3 réside dans la “segmentation basée sur les concepts” (PCS), où le modèle peut non seulement segmenter par pixel ou par instance, mais aussi identifier, segmenter et suivre tous les objets correspondant à un “concept sémantique” spécifique, à partir de prompts textuels ou visuels. Le nouveau système, grâce à un moteur de données collaboratif homme-machine, a construit un ensemble de données de haute qualité contenant 4 millions d’étiquettes conceptuelles, et réalise l’identification de centaines d’objets en 30 millisecondes sur un GPU H200, surpassant entièrement les systèmes existants et annonçant un possible “moment GPT-3” pour l’IA visuelle. (Source : arXiv:r35clVtGzw, 36氪)
🎯 Tendances
Gemini 3 reçoit des éloges en test interne, salué comme le “modèle de développement frontend le plus puissant de l’histoire” : La prochaine génération de modèle phare de Google, Gemini 3, a suscité un vif intérêt lors de ses tests internes. Les internautes ont loué ses capacités en développement frontend, en génération de graphiques vectoriels SVG et en multimodalité, le qualifiant de “meilleur modèle de développement frontend et web jamais créé”, certains prédisant même qu’il sera le modèle de l’année. Les informations divulguées indiquent que Gemini 3.0 Pro utilise une architecture MoE, possède des milliers de milliards de paramètres, une fenêtre contextuelle étendue à plusieurs millions, et intègre un mode de réflexion approfondie et des capacités multimodales, avec des performances exceptionnelles sur les benchmarks ARC-AGI-2 et HLE. (Source : 36氪)
L’application de l’IA dans la conception et la fabrication de puces s’intensifie : Le Machine Learning est de plus en plus appliqué dans la conception et la fabrication de puces, propulsant l’efficacité et l’innovation des semi-conducteurs à de nouveaux niveaux. Lorenzo Servadei, responsable de la conception de puces AI chez Sony AI, a déclaré à AIHub que l’IA dans le domaine de l’EDA (Electronic Design Automation) évolue de l’accélération des estimations vers une participation active au processus de conception. Grâce aux réseaux neuronaux, à l’accélération des modèles multiphysiques, à l’optimisation des algorithmes et à l’IA générative pour la réalisation physique, la vitesse, la qualité et la créativité de la conception de puces sont considérablement améliorées. OpenAI a également révélé que ses modèles GPT ont aidé à concevoir ses propres puces, réduisant la surface et accélérant le cycle de développement. (Source : aihub.org, 36氪)

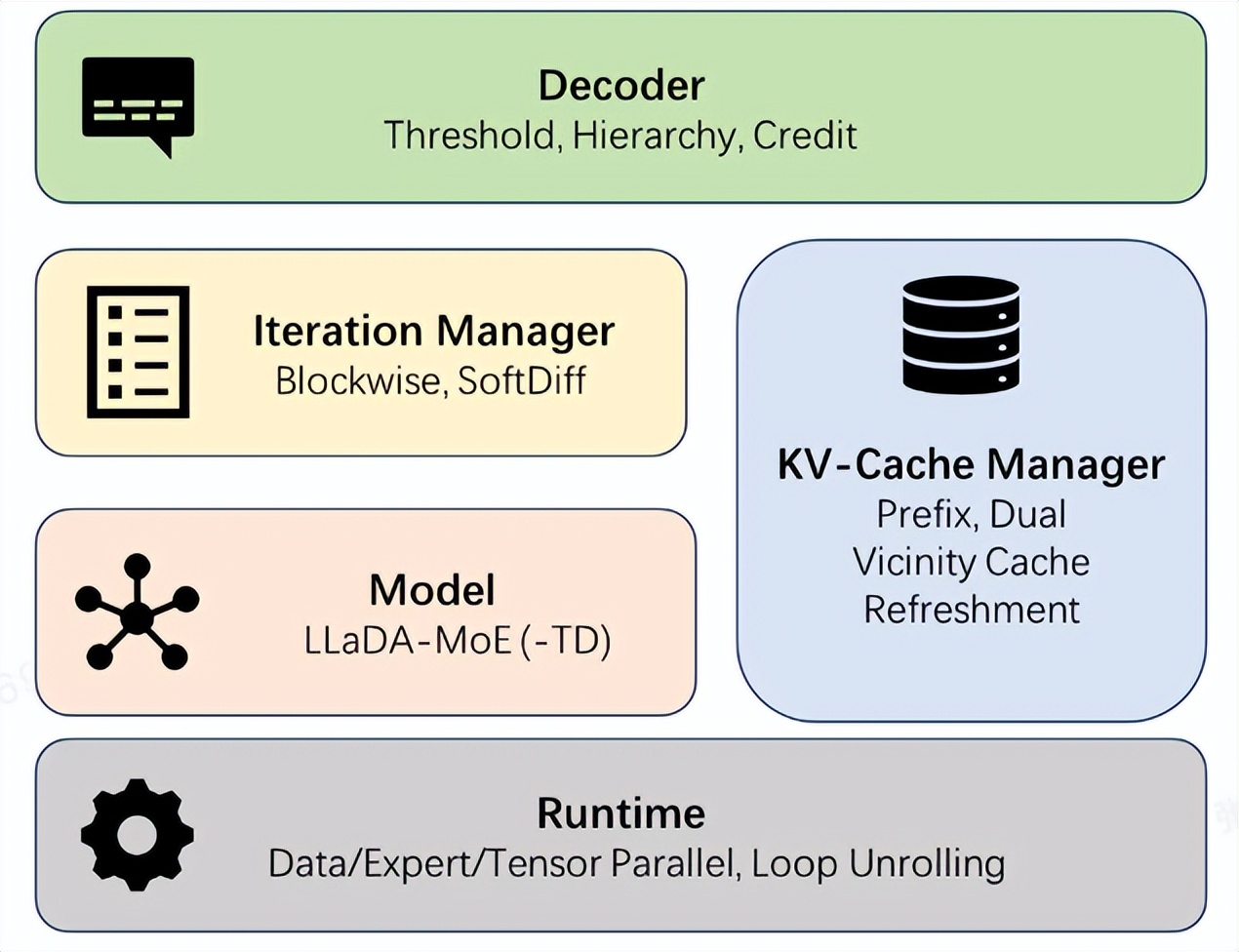
Ant Group lance le framework open source dInfer, multipliant par 10 la vitesse d’inférence des modèles de langage de diffusion : Ant Group a officiellement lancé dInfer, le premier framework open source d’inférence haute performance pour les modèles de langage de diffusion, augmentant la vitesse d’inférence de ces modèles de 10,7 fois par rapport à Fast-dLLM de NVIDIA. Dans la tâche de génération de code HumanEval, dInfer a atteint 1011 Tokens/seconde en inférence par lot unique, dépassant pour la première fois de manière significative les modèles auto-régressifs. dInfer adopte une conception profondément collaborative entre l’algorithme et le système, comprenant quatre modules centraux : l’intégration du modèle, le gestionnaire de cache KV, le gestionnaire d’itération de diffusion et la stratégie de décodage. Il vise à résoudre les défis liés aux coûts de calcul élevés des modèles de langage de diffusion, à l’échec du cache KV et au décodage parallèle, libérant ainsi leur potentiel d’inférence efficace. (Source : 量子位, QuixiAI)
Google NotebookLM mis à jour, Gemini Nano Banana alimente de nouveaux styles visuels pour les aperçus vidéo : La fonction d’aperçu vidéo de Google NotebookLM a été mise à jour, ajoutant une variété de styles visuels (Classique, Tableau blanc, Aquarelle, Impression vintage, Traditionnel, Art du papier, Anime) et est désormais alimentée par le modèle de génération d’images Gemini Nano Banana. De plus, un format “Brief” plus concis a été introduit, offrant des résumés rapides. Ces mises à jour seront d’abord déployées pour les utilisateurs Pro, puis pour tous les utilisateurs dans les prochaines semaines, dans le but d’améliorer l’expérience utilisateur en matière de compréhension et de présentation personnalisée du contenu vidéo. (Source : Google, op7418)
Microsoft lance le modèle de génération d’images MAI-Image-1, classé neuvième sur LMArena : Microsoft AI a lancé son troisième modèle d’IA, MAI-Image-1, un modèle de génération d’images qui fait ses débuts à la neuvième place du classement LMArena, à égalité avec Seedream 3. Ce modèle atteint un équilibre impressionnant entre vitesse et qualité de génération, démontrant l’investissement continu et le développement rapide de Microsoft dans le domaine de l’IA multimodale. Microsoft a déclaré qu’il continuerait d’optimiser ce modèle pour viser un classement plus élevé. (Source : mustafasuleyman, NandoDF)
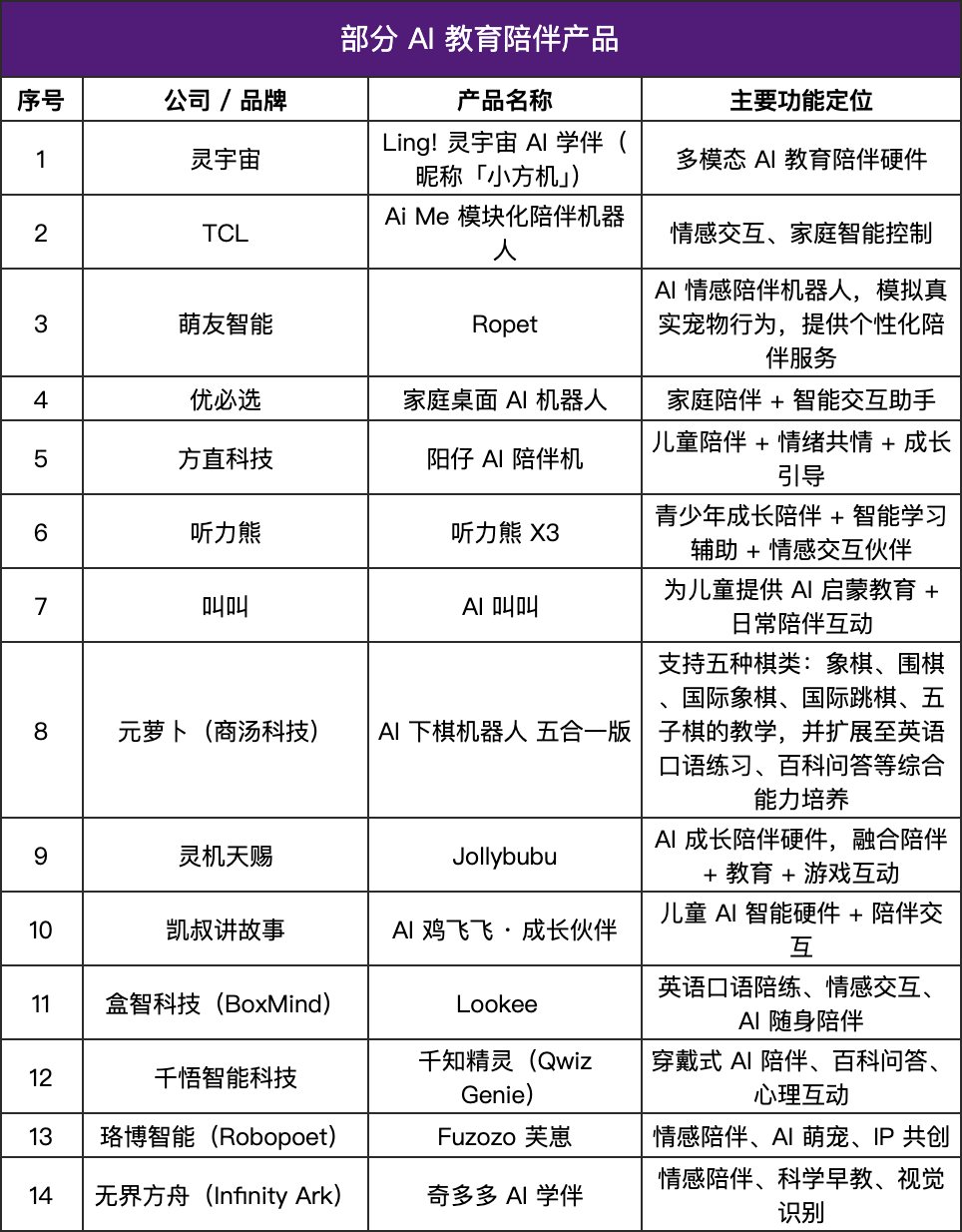
Les produits compagnons AI explosent, le matériel éducatif “prend vie” : Le marché des produits compagnons AI est en pleine croissance, avec une taille de marché estimée entre 70 et 150 milliards de dollars à l’avenir. Ces produits passent de la “réponse aux commandes” au “retour émotionnel”, simulant les réactions humaines et offrant une compagnie personnalisée grâce à des modèles de langage, la reconnaissance des émotions, l’interaction vocale et des systèmes de mémoire. Dans le domaine de l’éducation, les produits compagnons AI sont devenus des assistants d’apprentissage, des systèmes de retour émotionnel et des modèles de questions-réponses intelligents, s’étendant de la transmission de connaissances au soutien psychologique. Ils se caractérisent par leur légèreté, leur personnalisation et l’intégration d’interactions multimodales, visant à devenir des systèmes “qui comprennent les étudiants”. (Source : 36氪)
NVIDIA lance DGX Spark, le plus petit supercalculateur AI au monde : NVIDIA a officiellement lancé DGX Spark, présenté comme le plus petit supercalculateur AI au monde, et a commencé les expéditions. Basé sur l’architecture NVIDIA Grace Blackwell, DGX Spark intègre 128 Go de mémoire unifiée et vise à fournir aux développeurs AI de puissantes capacités de prototypage et d’exécution de LLM locaux. Les premiers utilisateurs testent, valident et optimisent leurs outils, logiciels et modèles, ce qui laisse présager une démocratisation et une commodité accrues du calcul AI haute performance. (Source : nvidia, ollama)

Anthropic lance Claude Sonnet 4.5, Agent SDK et une version mise à jour de Claude Code : Anthropic a lancé Claude Sonnet 4.5, améliorant ses capacités de raisonnement, offrant une fenêtre contextuelle plus grande (200k–1M token) et des performances améliorées sur les benchmarks de codage et de raisonnement. Parallèlement, Anthropic a également introduit le Claude Agent SDK et une version mise à jour de Claude Code, avec un suivi/résumé automatique du contexte, des outils de mémoire persistante, des points de contrôle avec fonction de retour en arrière, et une extension IDE compatible VS Code, visant à fournir aux développeurs des capacités de codage AI et de construction d’Agent plus puissantes. (Source : DeepLearningAI)

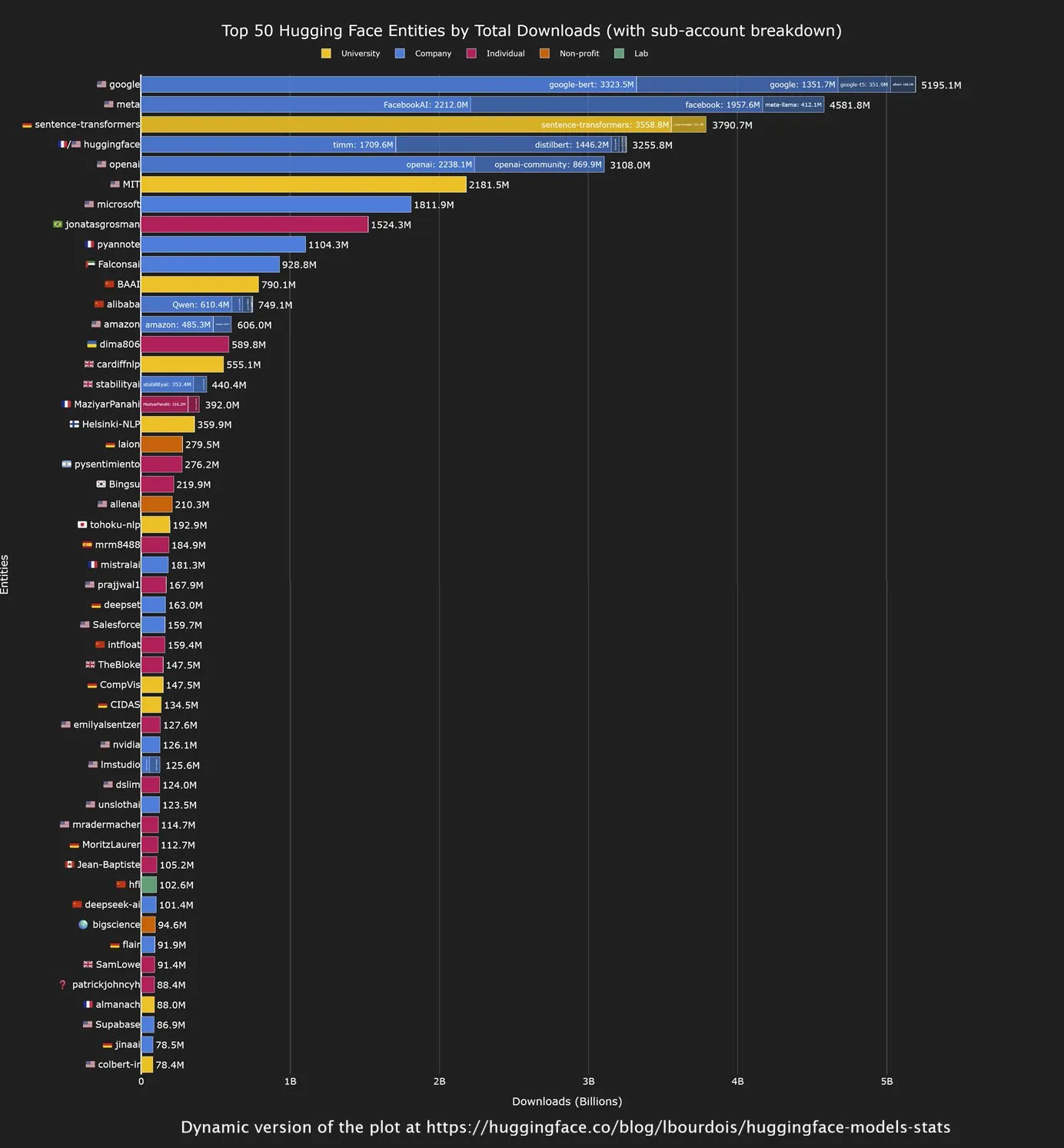
Les modèles open source chinois dominent les téléchargements sur Hugging Face, Google est le plus grand contributeur : Une analyse récente de la communauté Hugging Face montre que les modèles open source développés par des entreprises chinoises affichent de solides performances en termes de téléchargements, notamment la série de modèles Qwen. Parallèlement, Google est devenu l’organisation ayant le plus grand nombre de téléchargements de modèles sur Hugging Face. Cette tendance indique une influence croissante de la Chine dans le domaine de l’IA open source, tandis que Google, en tant que géant technologique, contribue et utilise activement l’écosystème open source pour promouvoir la popularisation de la technologie AI. (Source : mervenoyann, osanseviero)
Robbie Stein, vice-président des produits de recherche chez Google, interprète l’avenir de la recherche AI : la “clarté” comme objectif final : Robbie Stein, vice-président des produits de recherche chez Google, a souligné que l’IA n’a pas changé le besoin fondamental des humains de rechercher des informations, mais l’a rendu plus naturel et complexe grâce au mode AI (AI Mode). La future recherche AI aura une “capacité de compréhension”, capable de décomposer des questions vagues en sous-questions pour une recherche parallèle, et de synthétiser des réponses traçables avec des citations. L’objectif de Google est de devenir un système “informé et digne de confiance”, passant de “l’indexation de pages web” à “l’indexation du monde” grâce à la fusion multimodale et aux données mondiales structurées, pour rendre l’accès à l’information plus clair et plus rapide, plutôt que de simplement générer un langage fluide. (Source : 36氪)
Ant Group lance le framework d’inférence haute performance pour les modèles de langage de diffusion dInfer : Ant Group a officiellement lancé dInfer, le premier framework open source d’inférence haute performance pour les modèles de langage de diffusion, augmentant la vitesse d’inférence de ces modèles de 10,7 fois par rapport à Fast-dLLM de NVIDIA. Dans la tâche de génération de code HumanEval, dInfer a atteint 1011 Tokens/seconde en inférence par lot unique, dépassant pour la première fois de manière significative les modèles auto-régressifs. dInfer adopte une conception profondément collaborative entre l’algorithme et le système, visant à résoudre les défis liés aux coûts de calcul élevés des modèles de langage de diffusion, à l’échec du cache KV et au décodage parallèle, libérant ainsi leur potentiel d’inférence efficace. (Source : 量子位)
NVIDIA lance la technologie d’entraînement NVFP4, permettant un pré-entraînement 4 bits avec une précision FP8 : NVIDIA a annoncé une technologie d’entraînement NVFP4 révolutionnaire, permettant aux grands modèles de langage (LLM) pré-entraînés en 4 bits d’atteindre une précision de 8 bits. Cette technologie utilise une représentation en virgule flottante de 4 bits au format E2M1, combinée à une mise à l’échelle fine, un arrondi stochastique et des Random Hadamard Transforms, réduisant considérablement les besoins en calcul et en mémoire. Les expériences montrent que NVFP4 améliore considérablement l’efficacité de l’entraînement tout en maintenant la précision du modèle (par exemple, MMLU Pro 62,58 % contre 62,62 %), offrant une voie plus économique et efficace pour l’entraînement de LLM à plus grande échelle à l’avenir. Cette technologie repose principalement sur l’architecture NVIDIA Blackwell et nécessite des GPU H100 ou supérieurs. (Source : Reddit r/LocalLLaMA, karminski3)

Le framework SEAL du MIT permet aux modèles AI de générer automatiquement des données de fine-tuning et de mettre à jour les poids : Le Massachusetts Institute of Technology (MIT) a lancé le framework SEAL (Self-Adapting LLMs), permettant aux grands modèles de langage (LLM) de générer automatiquement des données de fine-tuning et de mettre à jour leurs poids de manière autonome, réalisant des mises à jour de gradient sans aucune intervention humaine. SEAL utilise un mécanisme d’apprentissage à double boucle (interne et externe), où le modèle optimise sa stratégie de génération d’instructions d’auto-mise à jour en fonction de ses performances sur les tâches, conférant pour la première fois aux LLM la capacité de s’auto-améliorer. Les expériences montrent que SEAL excelle dans l’injection de connaissances et les tâches d’apprentissage à faible nombre d’exemples, surpassant la précision des données générées par GPT-4.1, démontrant de puissantes capacités d’adaptation aux tâches et d’intégration des connaissances, annonçant l’ère des modèles auto-évolutifs. (Source : arXiv:2506.10943, 36氪)

Les expéditions de téléphones AI augmentent, des fabricants comme Kusaï Smart explorent une stratégie collaborative “petit modèle + grand modèle” : En 2025, les expéditions de téléphones AI en Chine ont bondi de 591 % en glissement annuel, atteignant un taux de pénétration de 22 %, faisant du téléphone AI un nouveau point focal de l’industrie. Des fabricants comme Kusaï Smart passent de la course aux paramètres à l’innovation pragmatique, adoptant une solution de collaboration dynamique “petit modèle frontal + grand modèle backend”. Ils déploient des petits modèles verticaux d’environ 600 millions de paramètres sur l’appareil pour une réponse rapide et la protection de la vie privée, tout en intégrant la puissance de calcul de grands modèles généraux de Koala, ByteDance, Alibaba, Google, etc. Cette stratégie vise à améliorer l’expérience utilisateur, à fournir des services personnalisés et à réduire les coûts, afin de s’adapter aux marchés étrangers diversifiés et fragmentés. (Source : 36氪)

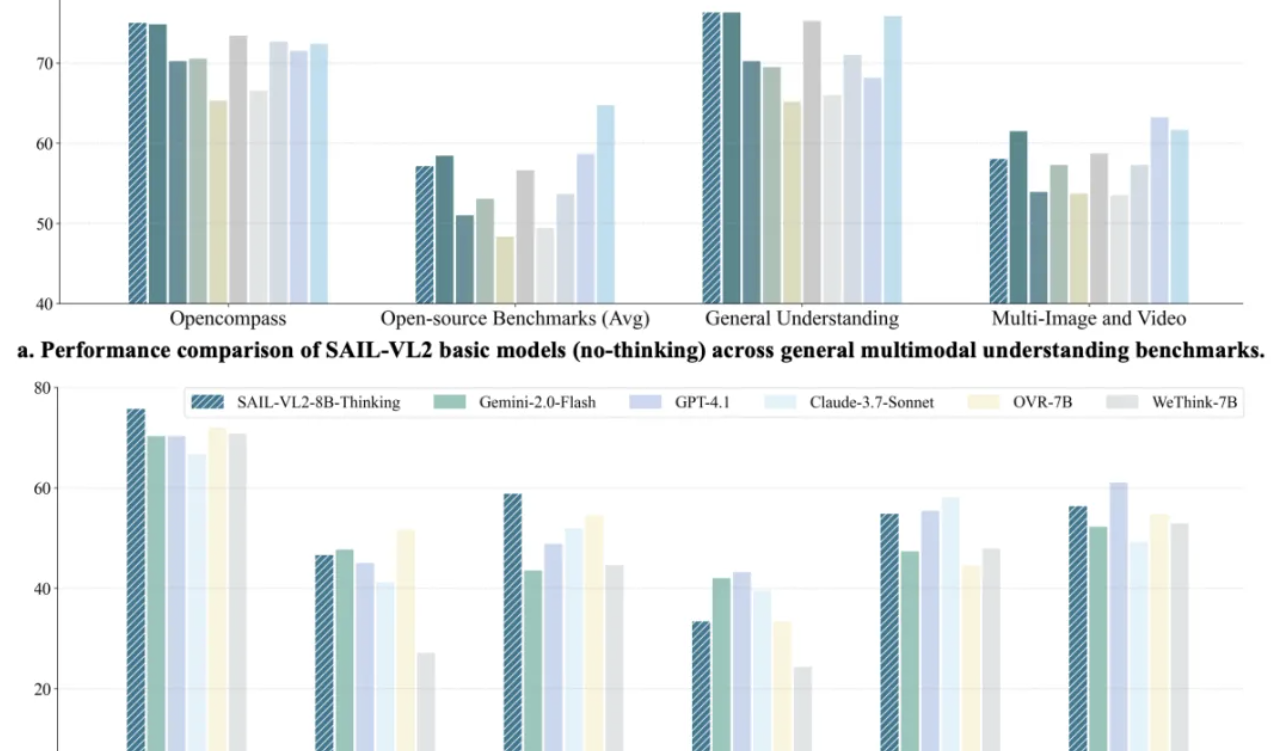
Le modèle multimodal SAIL-VL2 de Douyin bat le SOTA, le modèle 8B rivalise avec GPT-4o en inférence : L’équipe SAIL de Douyin, en collaboration avec LV-NUS Lab, a lancé le grand modèle multimodal SAIL-VL2, réalisant des percées de performance sur 106 ensembles de données avec des tailles de paramètres moyennes et petites (2B, 8B), surpassant notamment les modèles de même taille sur des benchmarks de raisonnement complexes comme MMMU et MathVista. La capacité d’inférence du modèle 8B rivalise même avec GPT-4o. SAIL-VL2, grâce à son architecture MoE sparse, son cadre d’entraînement progressif et son corpus multimodal de haute qualité, offre à la communauté un nouveau paradigme “les petits modèles peuvent aussi avoir de grandes capacités”, et a rendu le modèle et le code d’inférence open source. (Source : 量子位)
L’inférence Moondream Cloud migre entièrement vers FAL, réalisant un fonctionnement 100% cloud : Moondream a annoncé que son service d’inférence cloud a entièrement migré des instances EC2 vers FAL, réalisant un fonctionnement 100% sur FAL. Cette initiative pourrait signifier que Moondream a réalisé des progrès importants dans l’optimisation de l’efficacité de l’inférence, la réduction des coûts d’exploitation ou l’amélioration de la flexibilité du service, FAL, en tant que nouvelle plateforme d’inférence, démontrant sa capacité à prendre en charge le déploiement de modèles AI dans le cloud. (Source : vikhyatk)
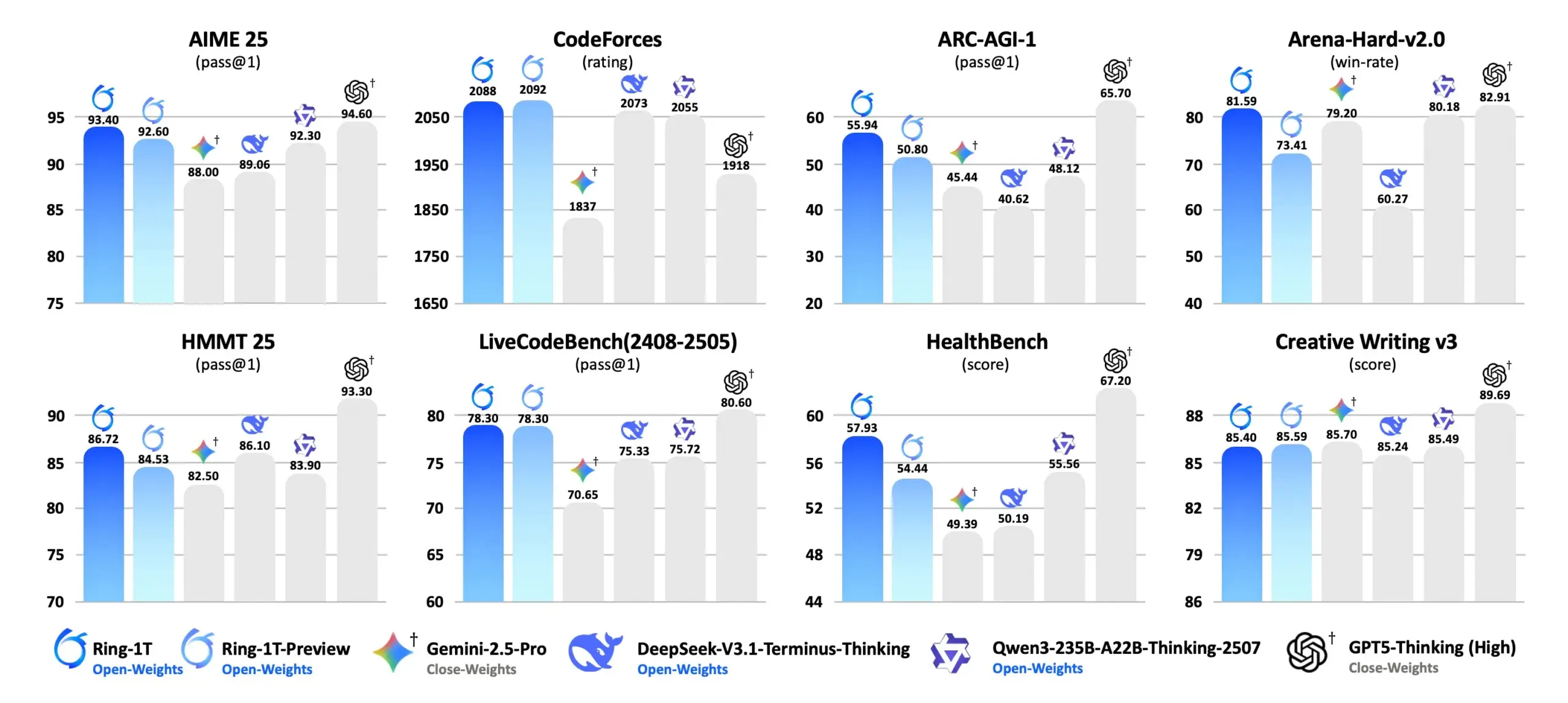
Ring-1T : Ant Ling lance un modèle de pensée open source de mille milliards de paramètres : Ant Ling a officiellement lancé Ring-1T, un modèle de pensée open source de mille milliards de paramètres basé sur l’architecture Ling 2.0. Ring-1T atteint une capacité de raisonnement de niveau médaille d’argent à l’IMO (Olympiade Internationale de Mathématiques) en raisonnement en langage naturel pur, avec un total de 1 000 milliards de paramètres et 50 milliards de paramètres actifs, ainsi qu’une fenêtre contextuelle de 128K. Le modèle est renforcé par Icepop RL et ASystem (un moteur d’apprentissage par renforcement de mille milliards de paramètres), et obtient des performances SOTA sur les benchmarks de raisonnement en langage naturel tels que AIME 25, HMMT 25, ARC-AGI-1, CodeForce. Une version FP8 est disponible, visant à promouvoir les capacités d’inférence AI open source. (Source : scaling01, jon_durbin)
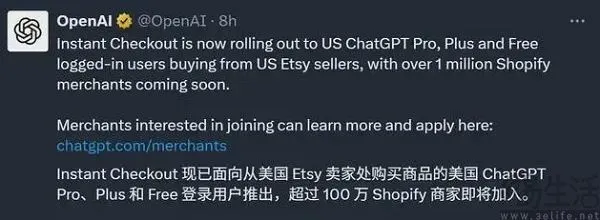
La fonction e-commerce “Instant Checkout” de ChatGPT est lancée, réinventant l’expérience d’achat : OpenAI a lancé la fonction “Instant Checkout” de ChatGPT, permettant aux utilisateurs de finaliser leurs achats directement dans ChatGPT, sans avoir à se rendre sur une plateforme e-commerce tierce. Actuellement, cette fonction prend en charge Etsy et sera bientôt intégrée à plus d’un million de marchands Shopify. Cette innovation crée un processus d’achat en boucle fermée, de la description du besoin à la finalisation de l’achat, raccourcissant considérablement le parcours de décision de l’utilisateur et améliorant la commodité d’achat, annonçant une intégration profonde de l’IA dans le domaine de l’e-commerce et une transformation des modèles commerciaux. (Source : 36氪)
L’explosion des mini-séries AI à l’étranger, la technologie Sora 2 propulse la qualité et l’efficacité de la production de contenu : Les mini-séries AI déferlent sur les plateformes de vidéos courtes et s’exportent massivement à l’étranger. En 2024, le marché chinois des mini-séries devrait atteindre 50,5 milliards de yuans, et la demande sur les marchés étrangers est évidente, avec des revenus annuels des mini-séries chinoises à l’étranger estimés à 4 milliards de dollars. Le lancement de Sora 2 par OpenAI a considérablement amélioré la qualité d’image, la durée, la synchronisation et la synchronisation audio-visuelle, et prend en charge la cohérence narrative complexe et la fonction Cameos, compressant le processus de production de mini-séries en un mode très efficace “une personne écrit le Prompt, l’IA produit”, réduisant les coûts à un dixième des méthodes traditionnelles. Les mini-séries animées par IA sont également une nouvelle tendance, réduisant efficacement le fossé culturel et étendant l’industrie du contenu des séries en direct aux séries animées par IA. (Source : 36氪)

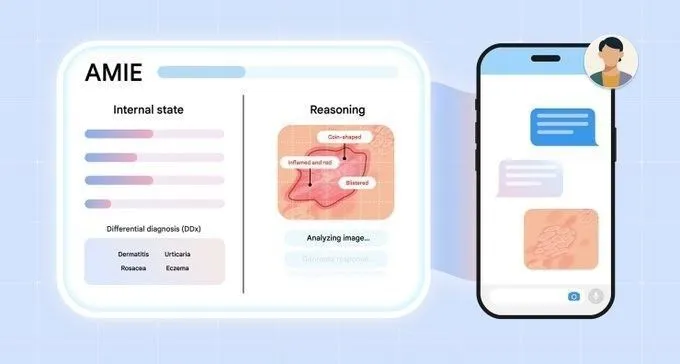
L’IA progresse dans le domaine du diagnostic médical : lancement de l’Agent de diagnostic multimodal AMIE : Google AI a lancé AMIE (AI agent for multimodal diagnostic dialogue), un Agent AI de recherche visant à réaliser des percées dans le domaine médical grâce au dialogue de diagnostic multimodal. Le lancement d’AMIE marque un progrès de l’IA dans la compréhension et la participation aux processus de diagnostic médical complexes, ce qui devrait améliorer l’efficacité et la précision du diagnostic, et jeter les bases des futures applications médicales intelligentes. (Source : Ronald_vanLoon)
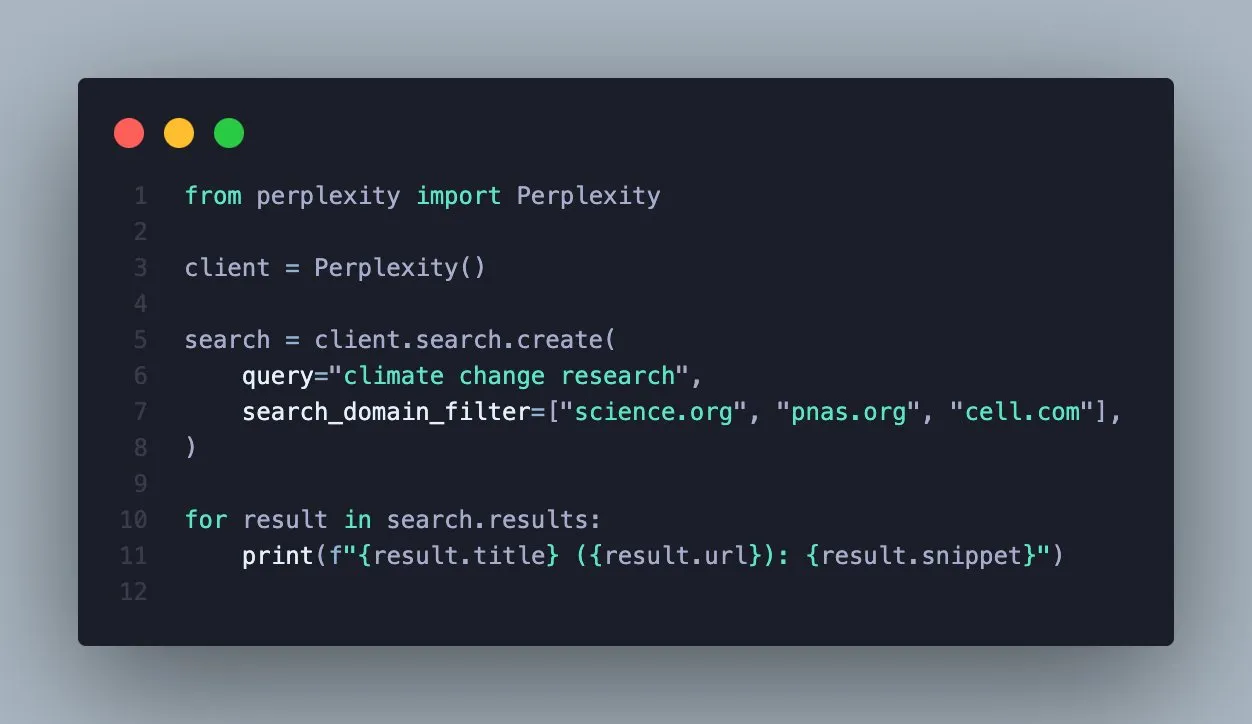
L’API Perplexity Search ajoute une fonction de filtrage par domaine, améliorant la précision de la recherche : Perplexity a annoncé que son API Search prend désormais en charge le filtrage des résultats de recherche par domaine spécifique. Cette nouvelle fonction permet aux utilisateurs de ne consulter que des sources fiables, obtenant ainsi des résultats plus ciblés et vérifiables. Pour les utilisateurs professionnels ou les développeurs d’applications qui ont besoin d’informations provenant de sources faisant autorité spécifiques, cela améliorera considérablement l’efficacité de la recherche et la qualité de l’information. (Source : AravSrinivas)
L’IA montre son potentiel dans la détection des tremblements de terre, et pourrait aider à les prédire à l’avenir : L’IA excelle dans la détection des petits tremblements de terre, sa capacité étant décrite comme “aussi claire que de porter des lunettes pour la première fois”. Les chercheurs explorent si l’IA peut aider davantage à prédire les tremblements de terre, ce qui pourrait apporter une percée révolutionnaire dans l’alerte précoce et la réduction des catastrophes. Grâce à une analyse de données plus fine, l’IA peut identifier des signaux sismiques difficiles à détecter par les méthodes traditionnelles, améliorant ainsi notre compréhension des activités profondes de la Terre. (Source : Ars Technica)
L’architecture Mamba3 est lancée, les LLM deviennent plus rapides, avec un contexte plus long et une meilleure évolutivité : L’architecture Mamba3 a été discrètement lancée lors de la conférence ICLR, marquant des progrès significatifs dans la vitesse, la longueur du contexte et l’évolutivité des LLM. Cette architecture, en optimisant l’évolution de l’état interne et l’utilisation du matériel, réalise une modélisation de séquence plus efficace que Transformer. Mamba3 introduit l’intégration trapézoïdale et des états cachés dans le plan complexe, rendant sa mémoire plus fluide et stable, et capable de représenter des motifs périodiques. Sa conception multi-entrée multi-sortie lui permet de traiter plusieurs flux de données en parallèle, ce qui promet un énorme potentiel dans des domaines tels que la compréhension de documents longs, l’analyse de séries temporelles et les systèmes AI embarqués. (Source : NandoDF)

Agentic RAG surpasse le RAG traditionnel et devient la nouvelle tendance de la recherche AI : Un consensus se dégage dans l’industrie : “le RAG (Retrieval-Augmented Generation) embarqué traditionnel est mort”, et l’Agentic RAG (RAG basé sur des agents) est supérieur à presque tous égards, sauf la vitesse. Cette tendance prédit que la recherche AI passera de la simple récupération d’informations à une interaction plus complexe basée sur des agents. L’Agentic RAG est capable de comprendre plus intelligemment l’intention de l’utilisateur, de planifier des stratégies de récupération et de générer des réponses plus précises, ce qui révolutionnera les futurs systèmes de recherche et de questions-réponses AI. (Source : swyx, jerryjliu0)

TuringPost publie une liste d’outils de génération vidéo AI, dont Luma Dream Machine : TuringPost a publié une liste de 9 outils puissants de génération vidéo AI, comprenant Sora 2, Google Veo 3, Runway, Pika Labs, Luma’s Dream Machine (propulsé par Ray 3), Synthesia, HeyGen, Kaiber et InVideo. Cette liste vise à offrir aux utilisateurs un choix complet pour la création vidéo AI, couvrant diverses fonctions telles que la conversion texte-vidéo, la génération en temps réel et la synthèse de personnages, reflétant le développement rapide et la diversité des applications dans le domaine de la technologie vidéo AI. (Source : TheTuringPost)
OpenAI lance un court-métrage sur l’histoire de la technologie généré par Sora, le processus d’assemblage vidéo nécessite encore une optimisation : Hemanth Asir, chercheur chez OpenAI, a produit un court-métrage sur l’histoire du développement technologique entièrement généré par Sora, démontrant le potentiel de Sora dans la création vidéo. Bien que le court-métrage soit impressionnant, le processus d’assemblage est actuellement encore fastidieux. OpenAI a déclaré qu’il s’efforcerait d’améliorer ce processus pour optimiser l’expérience utilisateur et l’efficacité de la création, annonçant que les futurs outils de génération vidéo AI seront plus pratiques pour la narration longue. (Source : dotey)
Les hypothèses de service LLM remises en question : FP8/FP4 deviendront la norme, le volume de Tokens de sortie augmentera de manière exponentielle : Il est suggéré que les services LLM actuels reposent sur de nombreuses hypothèses erronées. Premièrement, les services LLM ne sont plus limités à la précision FP16 ; FP8 et FP4 deviendront la norme. Deuxièmement, la croissance future des LLM se manifestera principalement par une augmentation exponentielle des “Tokens de pensée” (Tokens de sortie), plutôt qu’une simple proportion de Tokens d’entrée. De plus, les modèles de la série GPT-5 d’OpenAI ont une gamme de paramètres plus large, et divers laboratoires réduisent les coûts grâce à des technologies comme le DSA de Deepseek et de nouveaux mécanismes d’attention. Anthropic a également lancé un outil de nettoyage de contexte pour Sonnet 4.5 afin de réduire les besoins en mémoire. Tous ces éléments remodèleront l’efficacité et la structure des coûts des services LLM. (Source : teortaxesTex)
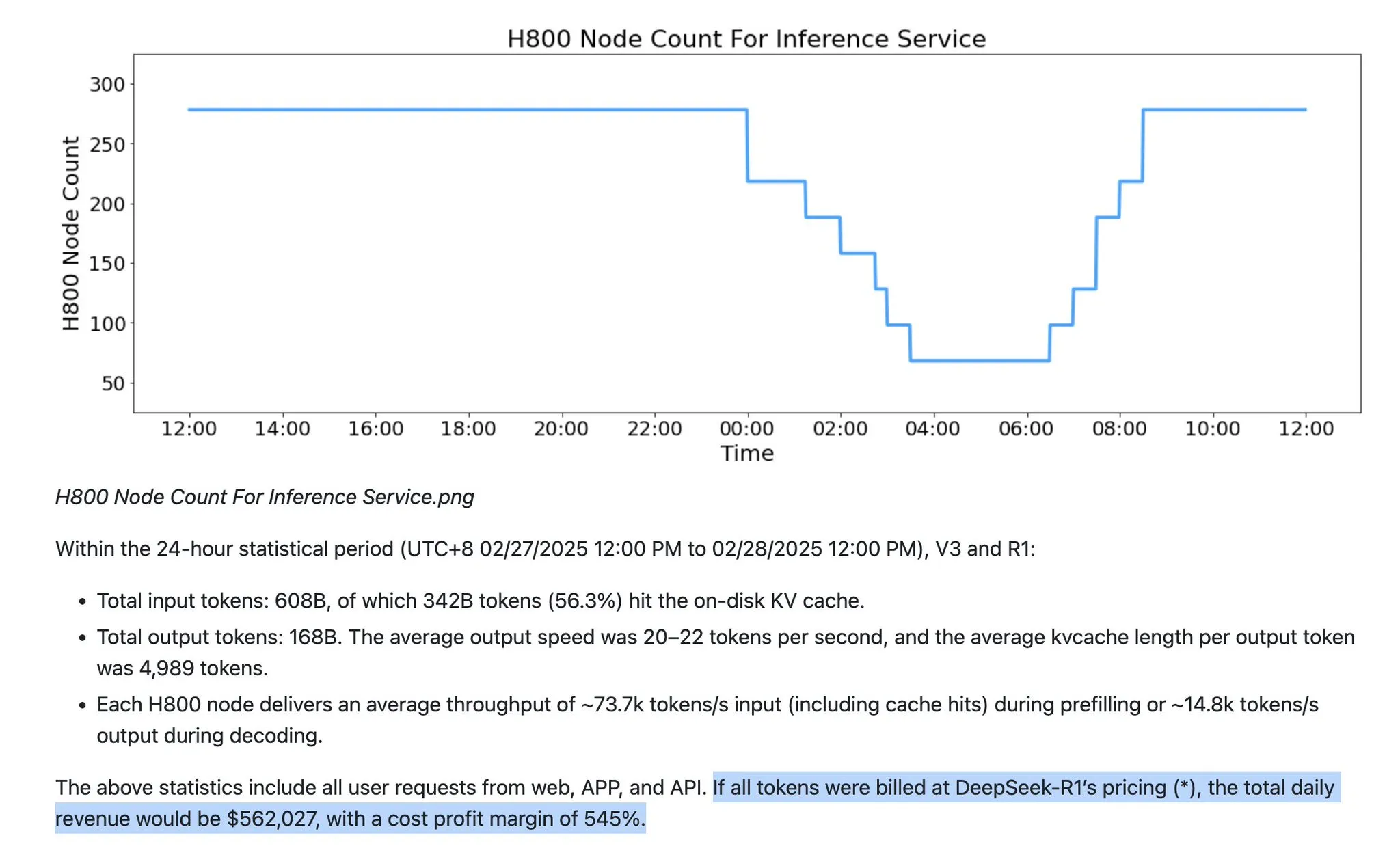
🧰 Outils
Microsoft MarkItDown : un outil de conversion de documents en Markdown pour les pipelines LLM : Microsoft a lancé l’outil Python MarkItDown, capable de convertir des dizaines de types de fichiers (y compris PDF, Word, Excel, HTML, images, audio, etc.) en un format Markdown propre. Cet outil peut conserver les titres, les listes, les tableaux, les liens et les métadonnées, et prend en charge l’OCR et l’extraction d’informations EXIF. Étant donné que Markdown est le “langage natif” des LLM, MarkItDown est un choix idéal pour le pré-traitement de documents dans les pipelines LLM, contribuant à améliorer la compréhension et l’efficacité du traitement des documents complexes par le modèle. (Source : TheTuringPost)
VS Code publie son plan d’itération 1.105, axé sur l’IA et l’expérience développeur : VS Code a publié son plan d’itération d’octobre, apportant de nombreuses améliorations visant à optimiser le développement assisté par l’IA et l’expérience globale des développeurs. Les mises à jour incluent le rendu Mermaid, diverses méthodes de gestion du contexte et des outils, une gestion des modèles plus avancée, des processus multi-étapes, la sauvegarde des conversations en tant que Prompt, ainsi que des fonctionnalités pour le terminal, les outils et les MCPs. De plus, GitHub Copilot a également publié 34 améliorations au cours des 30 derniers jours. Ces mises à jour approfondiront l’application de l’IA dans l’édition de code, le débogage et la collaboration, faisant de VS Code un environnement de développement AI-natif plus puissant. (Source : pierceboggan, code)

Nanonets-OCR2 est lancé, un modèle open source de conversion d’image en Markdown prenant en charge LaTeX et les organigrammes : Nanonets-OCR2 a été lancé, un modèle open source de conversion d’image en Markdown basé sur le fine-tuning de Qwen2.5-VL-3B-Instruct. Il prend en charge la reconnaissance d’équations LaTeX, les tableaux, les documents manuscrits, les cases à cocher, et peut même convertir des organigrammes en code Mermaid. Le modèle dispose également de fonctions telles que la description intelligente d’images, la détection de signatures, l’extraction de filigranes et le support multilingue, et offre des capacités de Visual Question Answering (VQA). Nanonets-OCR2 excelle dans le traitement de documents complexes, offrant une solution efficace et riche en fonctionnalités pour le pré-traitement de documents dans les pipelines LLM. (Source : huggingface, Reddit r/LocalLLaMA, karminski3)
L’application ChatGPT pour Slack est lancée, intégrant l’API de recherche en temps réel : L’application ChatGPT est officiellement disponible sur Slack. Grâce à l’API de recherche en temps réel de Slack, les utilisateurs peuvent désormais utiliser ChatGPT directement dans une barre latérale Slack dédiée pour poser des questions, brainstormer, rédiger du contenu et résoudre des problèmes. Cette intégration introduit de manière transparente les puissantes capacités de ChatGPT dans la plateforme de collaboration d’équipe, visant à améliorer l’efficacité du travail, à simplifier l’accès à l’information et la création de contenu, et à offrir aux utilisateurs professionnels une assistance AI plus pratique. (Source : gdb)
n8n lance son constructeur de flux de travail AI, permettant l’automatisation par langage naturel : n8n a officiellement lancé son constructeur de flux de travail AI, permettant aux utilisateurs de créer des agents AI et des processus d’automatisation dans n8n via le langage naturel. Cet outil offre un canevas visuel, permettant de connecter plus de 8000 outils tels que Firecrawl, LLMs, nœuds logiques et MCPs, et de les déployer en tant qu’API. Cette innovation simplifiera considérablement le développement et l’application des agents AI, permettant à davantage de développeurs de créer des flux de travail d’automatisation complexes en utilisant le langage naturel, et favorisant la popularisation des agents AI dans des scénarios commerciaux réels. (Source : omarsar0)
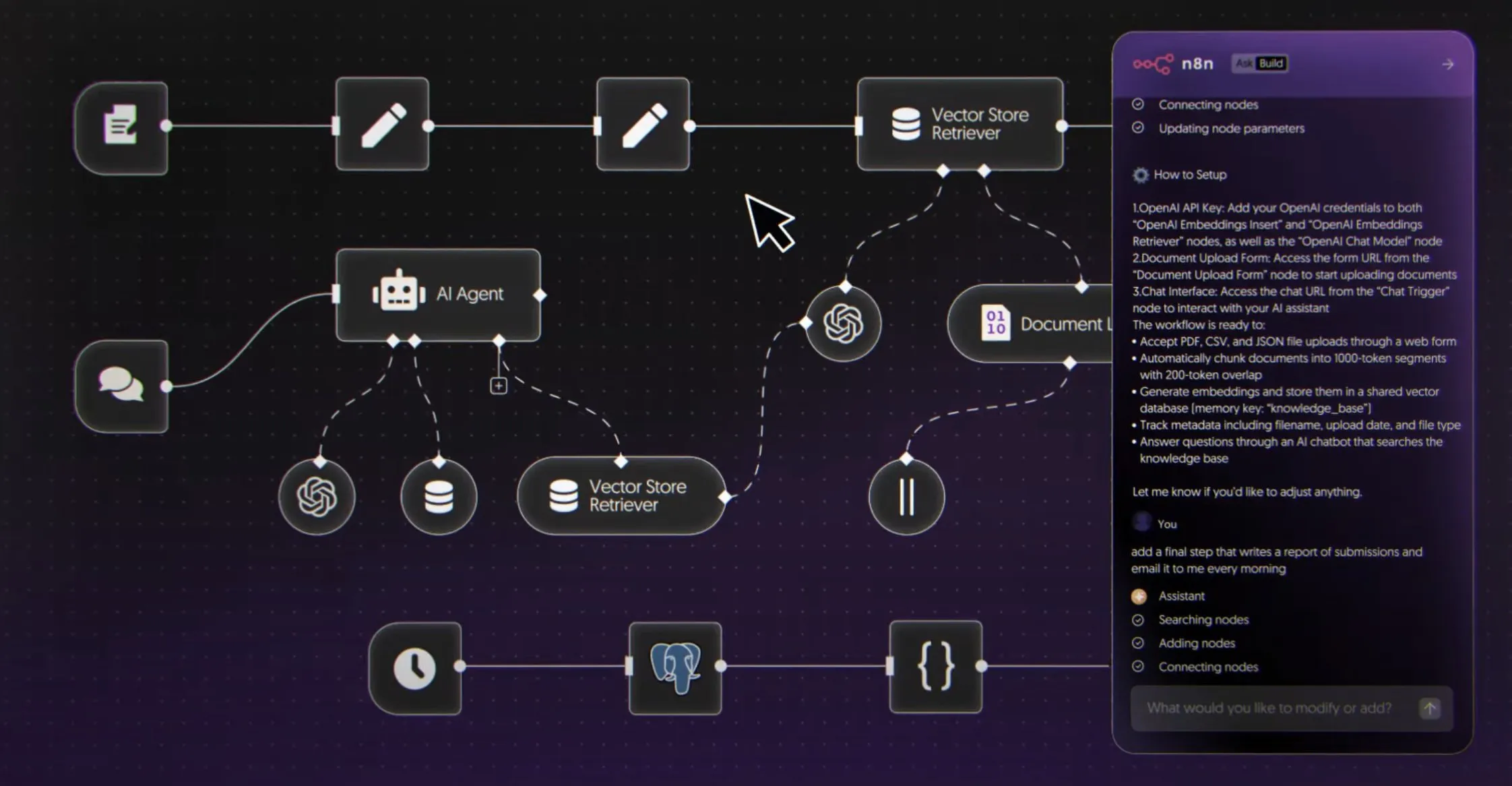
MLX prend en charge l’exécution de modèles locaux, la mise à jour Privacy AI 1.3.2 améliore les capacités AI des appareils Apple : Privacy AI a publié la mise à jour 1.3.2, prenant entièrement en charge le moteur MLX d’Apple, permettant aux utilisateurs d’exécuter des modèles de texte et visuels localement. Les modèles peuvent être téléchargés directement depuis Hugging Face, avec prise en charge de la reprise des téléchargements, des transferts en arrière-plan et de la vérification de l’intégrité. Les modèles MLX sont inclus dans le plan gratuit, permettant un fonctionnement hors ligne sans abonnement. Cette mise à jour améliore également la prise en charge du presse-papiers et met à niveau llama.cpp, améliorant encore les capacités AI locales et la protection de la vie privée sur les appareils Apple. (Source : awnihannun)
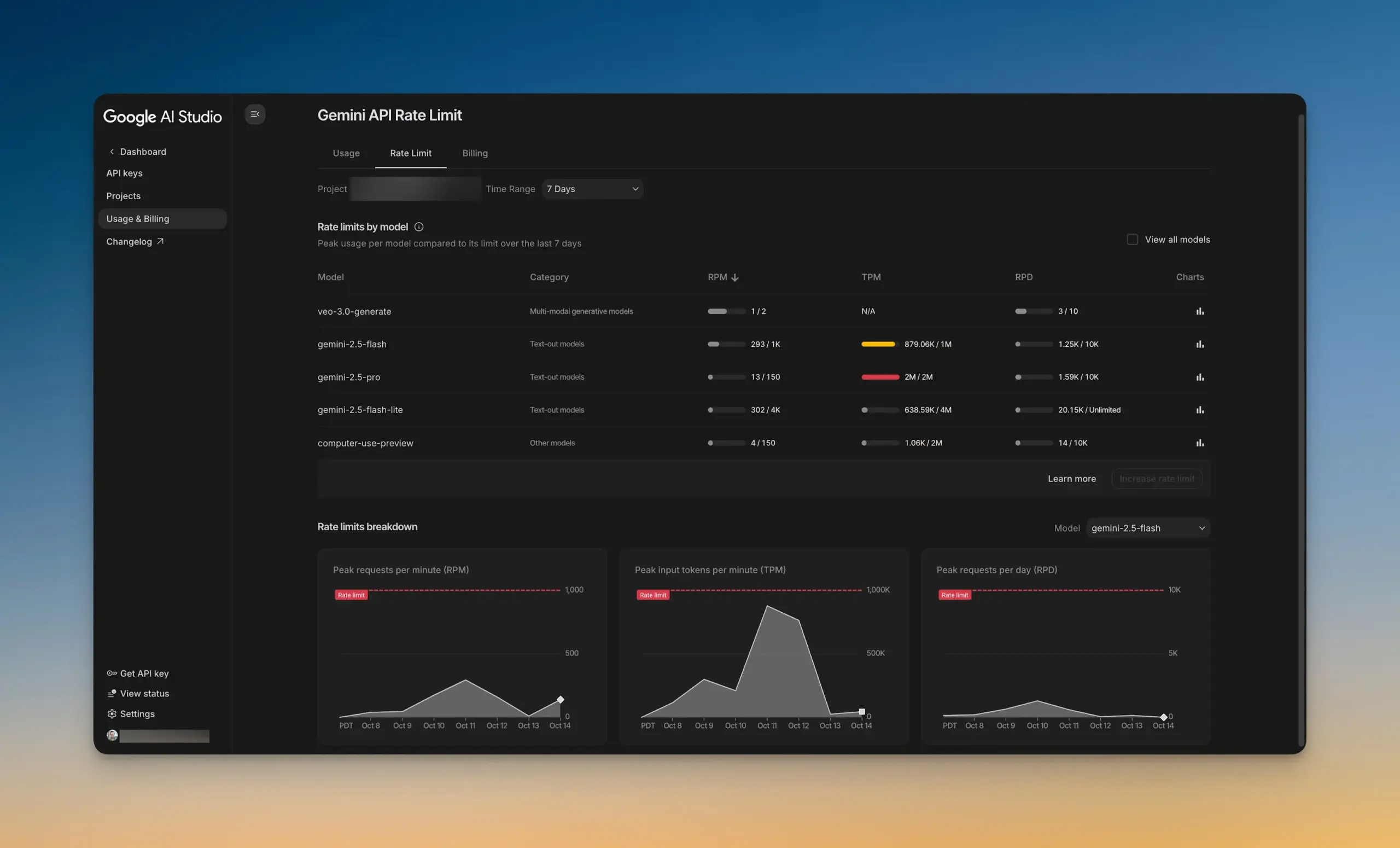
Google AI Studio lance un nouveau tableau de bord de limitation de débit : Google AI Studio a lancé un tout nouveau tableau de bord de limitation de débit, permettant aux utilisateurs de visualiser intuitivement l’utilisation de l’API Gemini sans quitter AI Studio. Ce tableau de bord offre des fonctions de filtrage de graphiques et permet d’explorer facilement les limites de débit de tous les modèles, aidant les développeurs à mieux gérer et optimiser leurs projets AI, et à améliorer l’efficacité du développement. (Source : GoogleAIStudio)
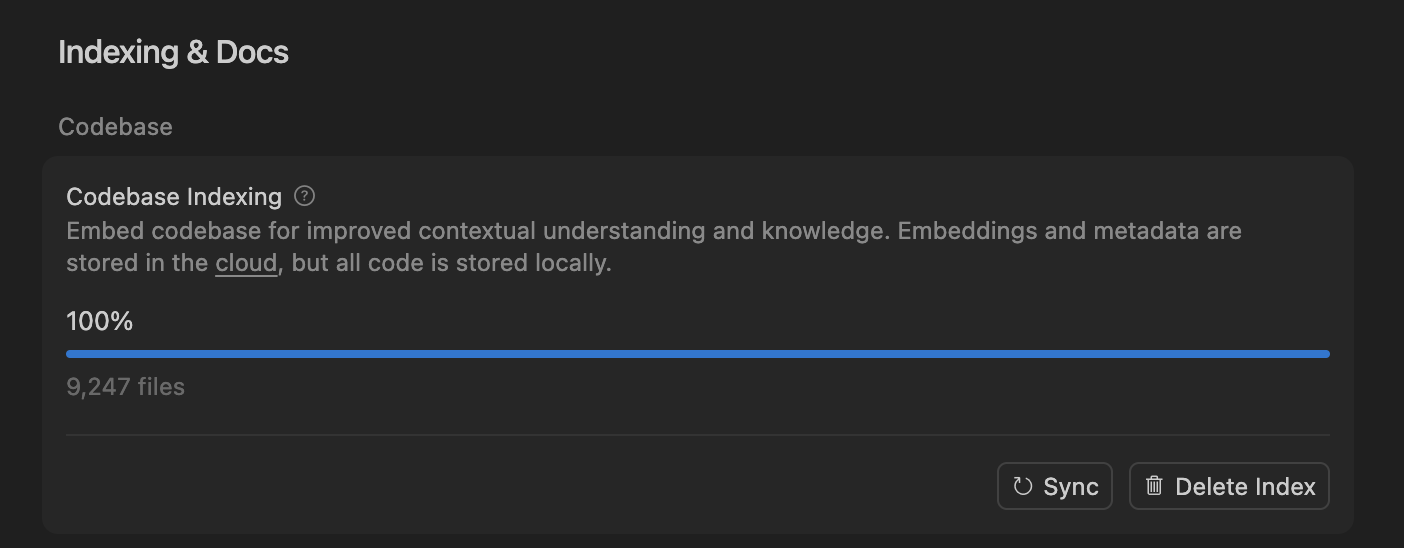
Cursor IDE et Codex deviennent les nouveaux choix quotidiens de codage pour les développeurs : Avec le développement rapide des outils de codage AI, Cursor IDE et Codex deviennent des outils centraux dans le flux de travail quotidien de plus en plus de développeurs. Certains développeurs ont déclaré être passés entièrement de Claude Code à Codex, l’utilisant pour la planification quotidienne, la décomposition des tâches et le traitement parallèle. Le “système d’indexation de base de code” de Cursor IDE, grâce à la recherche sémantique et à l’accès au code local, réalise une indexation et une mise à jour efficaces du code sans avoir à stocker le code sur un serveur, garantissant ainsi la confidentialité et l’efficacité. La popularisation de ces outils est en train de changer les méthodes de codage traditionnelles et d’améliorer l’efficacité du développement. (Source : dejavucoder, gdb)
Yupp.ai : un outil de débat AI pour des réponses plus complètes : Yupp.ai est un outil AI innovant conçu pour aider les utilisateurs à prendre des décisions plus éclairées à l’ère de l’information surabondante, en présentant les réponses de différents modèles AI. Les utilisateurs peuvent comparer côte à côte les réponses de différentes IA et voter en fonction de leur analyse, de leur créativité ou de détails spécifiques, formant ainsi un classement basé sur l’intelligence collective. L’objectif de Yupp.ai est de permettre aux utilisateurs de tirer parti de l’expérience collective pour obtenir rapidement des réponses fiables et multi-perspectives, améliorant ainsi l’efficacité du travail et la confiance dans les décisions. (Source : yupp_ai)

vLLM et SGLang sont salués comme le “Linux de l’ère de l’IA” : vLLM et SGLang, en raison de leurs performances exceptionnelles dans le domaine de l’inférence LLM, sont salués comme le “Linux de l’ère de l’IA”. vLLM a déjà obtenu 60 000 étoiles sur GitHub, passant d’une petite idée de recherche à un framework central pour l’inférence LLM prenant en charge presque toutes les plateformes grand public comme NVIDIA, AMD, Intel, Apple. Il prend en charge la plupart des modèles de génération de texte et les pipelines RL natifs comme TRL et Unsloth, jouant un rôle d’infrastructure clé dans l’écosystème AI, favorisant la popularisation et l’efficacité de l’inférence LLM. (Source : bookwormengr)
Luma AI Ray3 : l’annotation visuelle débloque un contrôle précis : La fonction d’annotation visuelle Ray3 de Luma AI permet un contrôle précis de la direction visuelle en gribouillant sur l’image, guidant le sujet pour effectuer des actions ou des interactions spécifiques. Cette fonction dépasse les limites des invites textuelles traditionnelles, transmettant l’intention d’obstruction spatiale par des coups de pinceau, offrant un moyen de contrôle plus intuitif et précis pour la création visuelle, démontrant un potentiel puissant notamment dans des applications comme Dream Machine. (Source : TomLikesRobots)
Faceseek : un outil de correspondance et de vérification faciale alimenté par l’IA : Faceseek est un outil qui utilise la technologie AI pour la correspondance et la vérification faciale, capable de traiter efficacement les visages similaires. Cet outil pourrait utiliser des embeddings faciaux, CLIP (Contrastive Language-Image Pre-training) ou d’autres modèles avancés de vision par ordinateur pour l’analyse, offrant des solutions pour l’authentification d’identité, la surveillance de sécurité, etc. Ses performances dans les applications réelles ont suscité des discussions sur les détails techniques et les applications potentielles de tels systèmes. (Source : Reddit r/ArtificialInteligence)
L’extension PyTorch pour le backend GPU distant permet de combiner le développement local et le calcul distant : Une nouvelle extension PyTorch permet aux développeurs de travailler localement tout en utilisant un backend GPU distant pour le calcul. Cela résout le problème des ressources matérielles locales limitées, permettant aux chercheurs et développeurs de former et d’expérimenter des modèles de Deep Learning de manière plus flexible, combinant la commodité d’un environnement de développement local avec les avantages du calcul haute performance distant. (Source : Reddit r/deeplearning)
FocoosAI lance son SDK open source et sa plateforme web de vision par ordinateur : FocoosAI a lancé son SDK open source et sa plateforme web de vision par ordinateur, visant à fournir aux développeurs les outils et les ressources nécessaires pour construire et déployer des solutions de vision par ordinateur. Le lancement de cette plateforme favorisera la popularisation et l’application de la technologie de vision par ordinateur, réduira les barrières au développement et permettra à davantage d’innovateurs d’explorer et de développer l’IA dans le domaine de l’analyse d’images et de vidéos. (Source : Reddit r/deeplearning)
Outils d‘“humanisation” du texte AI : améliorer le naturel du contenu généré par l’IA : Avec la popularisation des technologies de génération de texte AI, la question de savoir comment rendre le contenu généré par l’IA plus “humain” est devenue un sujet important. Le marché a vu l’émergence de divers outils visant à optimiser le style linguistique, l’expression émotionnelle et l’adaptabilité contextuelle, afin que le texte AI sonne plus naturel et plus proche de l’expression humaine. Ces outils aident les utilisateurs à éviter la sensation mécanique et stéréotypée du texte AI, à améliorer l’attrait du contenu et à répondre aux besoins de textes de haute qualité et personnalisés. (Source : Ronald_vanLoon)
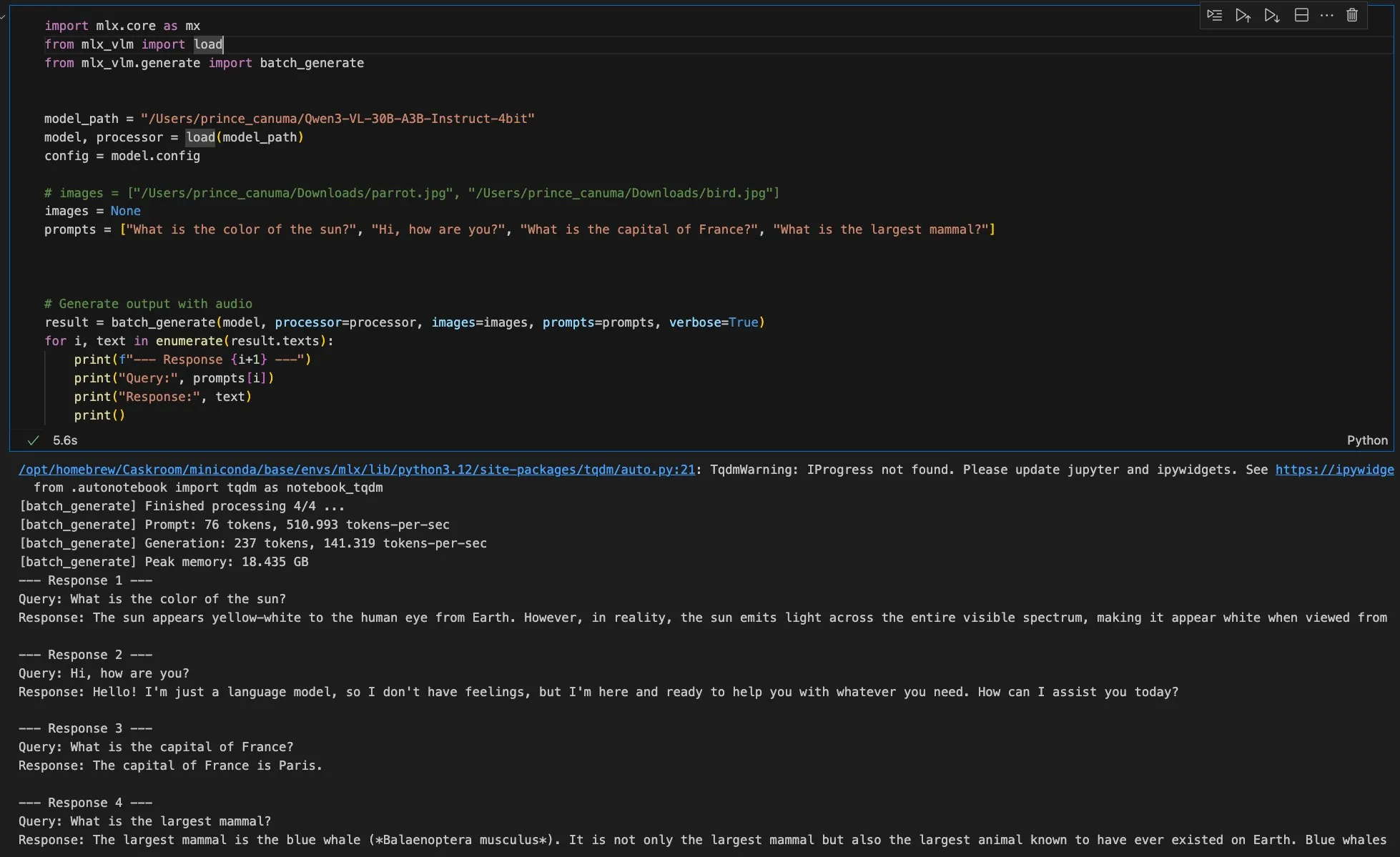
La nouvelle version de MLX-VLM sera bientôt disponible, Qwen Image prend en charge le framework MFLUX : Le MLX-VLM d’Apple est sur le point de recevoir une mise à jour majeure, annonçant son puissant potentiel dans le domaine des grands modèles multimodaux. Parallèlement, le framework MFLUX a publié sa version v0.11, ajoutant la prise en charge de Qwen Image, permettant aux utilisateurs de télécharger et d’utiliser le modèle Qwen Image pour la génération via de simples opérations en ligne de commande. Ces progrès favorisent conjointement l’efficacité et la flexibilité du développement et du déploiement de modèles AI au sein de l’écosystème Apple, offrant aux développeurs des outils AI multimodaux plus pratiques. (Source : adrgrondin, awnihannun)
CleanMARL : une implémentation concise de l’apprentissage par renforcement multi-agents avec PyTorch : Le projet CleanMARL propose une série d’implémentations concises et mono-fichier d’algorithmes d’apprentissage par renforcement multi-agents (MARL) profonds, développés sur PyTorch, adhérant à la philosophie de CleanRL. Ce projet vise à réduire les barrières à l’implémentation des algorithmes MARL, en fournissant aux chercheurs et développeurs un code clair, facile à comprendre et à reproduire, accélérant ainsi la recherche et l’application des systèmes multi-agents dans des environnements complexes. (Source : jsuarez5341)
📚 Apprentissage
Le post-entraînement des grands modèles devient le cœur de la compétitivité de l’IA, les entreprises accélèrent la construction de moteurs intelligents exclusifs : Le post-entraînement des grands modèles devient la compétitivité clé pour l’adoption de l’IA par les entreprises. Du SFT au RLHF, RLVR, et aux “récompenses en langage naturel” de pointe, l’accent technique passe de “l’imitation” à “l’alignement”. Des entreprises comme NetEase, Autohome, Weibo et Quark ont réussi à transformer des grands modèles généraux en “moteurs intelligents exclusifs” qui comprennent profondément les activités et possèdent des connaissances spécifiques au domaine, résolvant des tâches complexes du monde des affaires et construisant des barrières concurrentielles irréplicables, grâce à la préparation de données de haute qualité, au choix du modèle de base, à la conception de mécanismes de récompense et à un système d’évaluation quantifiable. (Source : 量子位)

Andrew Ng lance le cours Agentic AI, axé sur quatre modèles de conception : DeepLearning.AI a publié le dernier numéro de The Batch, annonçant le lancement du nouveau cours d’Andrew Ng, “Agentic AI”. Ce cours est un cours pratique axé sur la construction, centré sur quatre modèles de conception clés : la réflexion, l’utilisation d’outils, la planification et la collaboration multi-agents. Le cours vise à aider les participants à maîtriser les compétences essentielles pour construire des systèmes d’agents AI efficaces, favorisant l’application de l’IA dans des scénarios réels. (Source : DeepLearningAI)
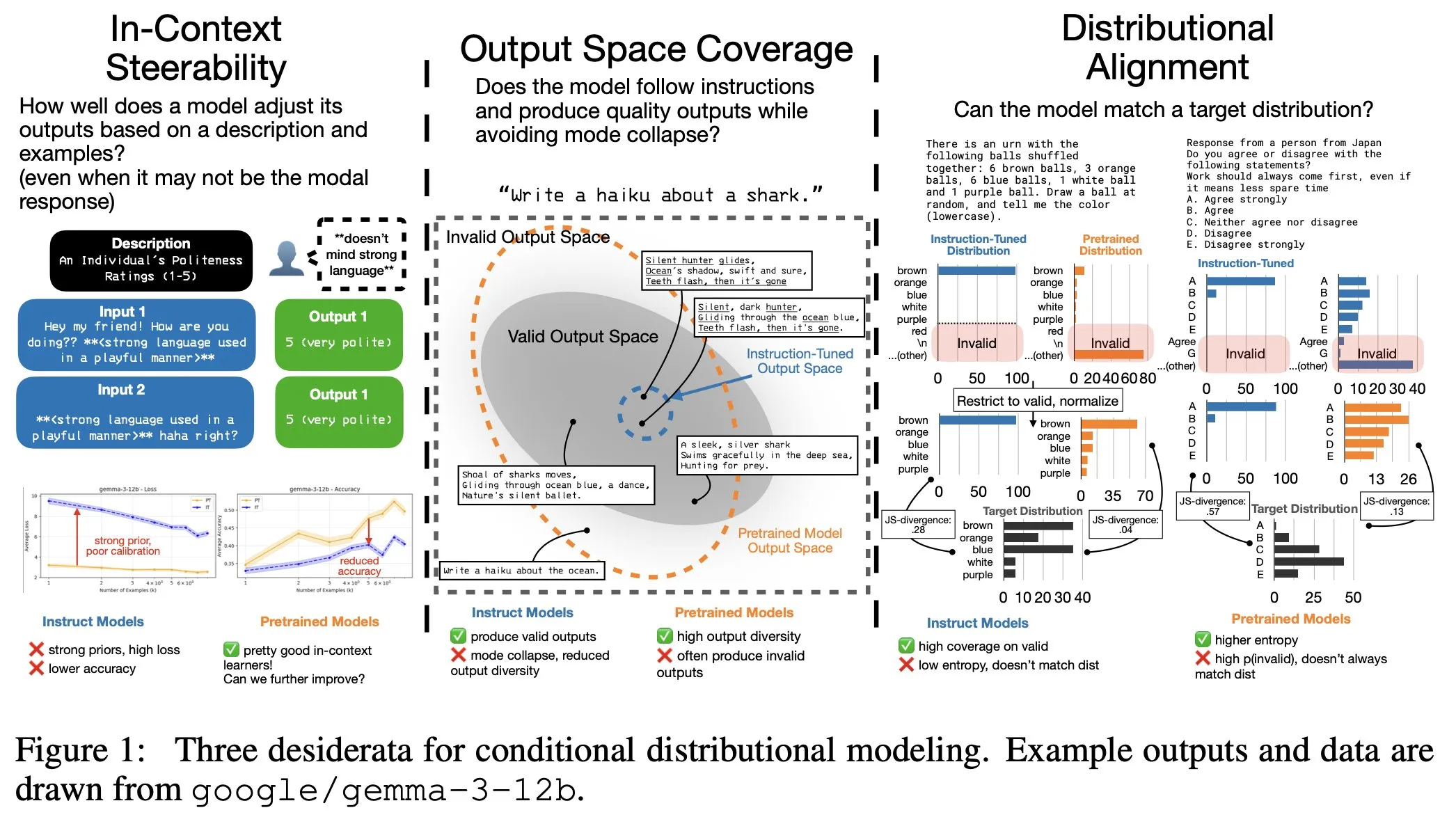
Le fine-tuning des instructions LLM a un coût caché : la distribution de sortie se rétrécit, la contrôlabilité contextuelle diminue : Une étude a révélé que le fine-tuning des instructions LLM, tout en améliorant la capacité à suivre les instructions, entraîne également des coûts cachés : le rétrécissement de la distribution de sortie du modèle et la diminution de la contrôlabilité contextuelle (In-Context Steerability). Pour résoudre ce problème, l’équipe de recherche a lancé la “Spectrum Suite” pour une étude approfondie et a proposé le “Spectrum Tuning” comme méthode de post-entraînement alternative, visant à maintenir la diversité et la flexibilité de la sortie du modèle tout en améliorant ses performances. (Source : YejinChoinka, YejinChoinka)
Collaboration de systèmes multi-agents : la théorie de l’information distingue les “tas de chatbots” de l‘“intelligence collective” : Une étude a examiné si les systèmes multi-agents basés sur les LLM réalisaient réellement une collaboration, et a proposé d’utiliser la théorie de l’information pour distinguer un “tas de chatbots” d’une “véritable intelligence collective”. L’étude a introduit des mesures de cycle, évaluant la capacité des sorties de groupe à prédire les résultats futurs et décomposant l’information pour identifier la synergie plutôt que la redondance. Les résultats montrent qu’attribuer des rôles différents et des objectifs communs aux agents, et tester leur synergie plutôt que de la supposer, est crucial pour atteindre l’intelligence collective, les modèles de faible capacité ayant du mal à atteindre une véritable coopération. (Source : omarsar0)
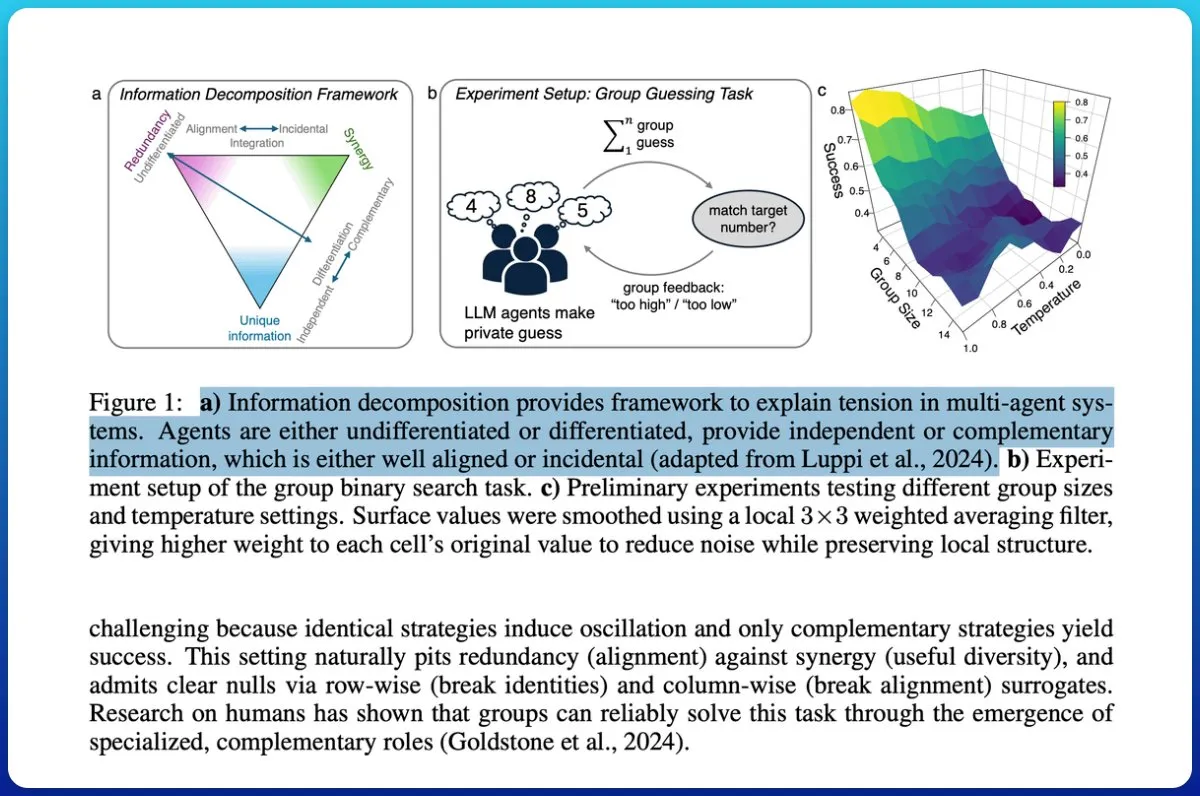
Le “dilemme de l’entropie” de l’inférence des grands modèles : la méthode SIREN rejette “l’effondrement de l’entropie” et “l’explosion de l’entropie” : Les grands modèles de raisonnement (LRM) sont confrontés à un “dilemme de l’entropie” lors de l’entraînement RLVR, où une exploration limitée conduit à un “effondrement de l’entropie” ou une exploration incontrôlée provoque une “explosion de l’entropie”. L’équipe du Shanghai AI Lab et de l’Université Fudan a proposé la méthode de régularisation d’entropie sélective (SIREN), qui régule précisément le comportement d’exploration grâce à un triple mécanisme : délimiter la portée de l’exploration (masque Top-p), identifier les points de décision clés (masque d’entropie de pic) et stabiliser le processus d’entraînement (régularisation auto-ancrée). Les expériences ont montré que SIREN améliore significativement les performances sur les benchmarks de raisonnement mathématique et rend le processus d’exploration plus efficace et contrôlable. (Source : 量子位)
Ressources d’apprentissage sur les AI Agents : nouveau livre “AI Agent Illustrated Guide” et résumé des concepts : Les ressources d’apprentissage dans le domaine des AI Agents s’enrichissent. Maarten Grootendorst et Jay Alammar sont en train d’écrire le livre “AI Agent Illustrated Guide”, qui couvrira les bases des Agents (mémoire, outils, planification) ainsi que des concepts avancés comme l’apprentissage par renforcement et les LLM de raisonnement. De plus, des articles ont résumé les 20 concepts clés des AI Agents, offrant un parcours d’apprentissage systématisé et des références pour les débutants et les avancés. (Source : lvwerra, Ronald_vanLoon)

Évaluation des capacités de raisonnement spatial des LLM : le test de rotation de formes met au défi l’espace latent du modèle : Une méthode d’évaluation intéressante a été proposée, visant à tester la capacité des grands modèles de langage (LLM) à faire pivoter des formes “dans leur tête”. Grâce à des tests visuels simples, l’étude a révélé que les LLM peuvent effectuer une certaine rotation de formes dans l’espace latent sous-jacent, mais qu’ils ont des performances médiocres dans un raisonnement plus complexe et de niveau supérieur, présentant un problème de “raisonnement spatial non uniforme”. Cela révèle les limites des LLM dans le traitement de la logique géométrique et spatiale, offrant de nouvelles directions de recherche pour l’amélioration future des modèles. (Source : dejavucoder, tokenbender)
Stratégies de fine-tuning des LLM : la mise à jour des couches de projection d’attention et des couches de gating MLP peut limiter l’oubli : Comment enseigner de nouvelles compétences aux grands modèles multimodaux (LMM) tout en évitant d’oublier les capacités existantes est un défi clé. Une étude a révélé que le phénomène d‘“oubli” qui apparaît après un fine-tuning étroit peut être récupéré plus tard, ce qui est lié à des changements significatifs dans la distribution des Tokens de sortie. L’étude a identifié deux stratégies de fine-tuning simples et robustes : ne mettre à jour que les couches de projection de l’auto-attention, ou ne mettre à jour que les couches MLP Gate&Up et geler les couches de projection Down. Ces choix permettent d’obtenir de solides gains d’objectifs sur les modèles et les tâches, tout en conservant fondamentalement les performances d’origine. (Source : arXiv:2510.08564)
IA et croissance économique : interprétation de l’article de Philippe Aghion, lauréat du prix Nobel : Une étude de Philippe Aghion, lauréat du prix Nobel, et de ses collègues, indique que même si l’économie est automatisée à 99 % et produit à l’infini, le taux de croissance global restera limité par les progrès des 1 % de tâches essentielles et difficiles restantes. À l’ère de l’AGI, ces tâches “difficiles à améliorer” se transformeront en tâches centrées sur le physique, telles que la production d’énergie, l’extraction de ressources, la fabrication et le transport. Cela signifie que l’ère post-AGI ne sera pas nécessairement une ère de “post-rareté”, et que la valeur économique se concentrera sur les tâches physiquement contraintes. (Source : pmddomingos, jonst0kes)

Défis de généralisation et de robustesse des modèles AI : le raisonnement fallacieux conduit à des défauts de raisonnement mathématique : Les modèles de langage souffrent souvent d’un manque de robustesse et de généralisation dans le raisonnement mathématique en raison du “raisonnement fallacieux”, c’est-à-dire que le modèle tire des conclusions de caractéristiques superficielles plutôt que de la logique du problème. Le cadre AdaR, en synthétisant des requêtes logiquement équivalentes et en les combinant avec le RLVR (Reinforcement Learning from Verifiable Rewards) pour l’entraînement, pénalise la logique fallacieuse et encourage la logique adaptative. Les expériences montrent qu’AdaR améliore significativement la robustesse et la généralisation du raisonnement mathématique des LLM, tout en maintenant une grande efficacité des données. (Source : arXiv:2510.04617)
Auto-amélioration des LLM Agents au moment du test : le framework TT-SI permet l’apprentissage autonome : Une étude propose une nouvelle méthode d’auto-amélioration au moment du test (Test-Time Self-Improvement, TT-SI), visant à créer dynamiquement des LLM Agentic plus efficaces et plus généralisables. Cet algorithme identifie les échantillons difficiles du modèle, génère des exemples similaires (auto-augmentation de données) et effectue un fine-tuning au moment du test (auto-amélioration) pour permettre au modèle d’apprendre de manière autonome. Les expériences montrent que TT-SI améliore en moyenne de 5,48 % la précision sur les benchmarks Agent, et réduit de 68 fois le nombre d’échantillons d’entraînement, démontrant le potentiel des algorithmes d’auto-amélioration pour construire des Agents plus puissants. (Source : arXiv:2510.07841)
Principes de conception clés et pratiques d’optimisation pour l’apprentissage par renforcement des LLM Agents : Une étude a systématiquement examiné les principes de conception clés de l’Agentic RL pour améliorer les capacités de raisonnement des LLM Agents. L’étude a révélé que l’utilisation de trajectoires réelles d’utilisation d’outils de bout en bout plutôt que de trajectoires synthétiques comme initialisation SFT conduit à des effets plus puissants ; des ensembles de données très diversifiés et conscients du modèle peuvent maintenir l’exploration et améliorer significativement les performances RL. De plus, les techniques favorables à l’exploration (telles que clip higher, overlong reward shaping et le maintien d’une entropie de politique suffisante) sont cruciales pour l’Agentic RL. Ces pratiques peuvent améliorer continuellement le raisonnement Agentic et l’efficacité de l’entraînement, permettant aux petits modèles d’obtenir d’excellents résultats sur des benchmarks difficiles. (Source : arXiv:2510.11701)
Mécanismes de récompense dans l’inférence LLM : PEAR optimise l’efficacité de l’inférence grâce à l’entropie consciente de la phase : Les grands modèles de raisonnement (LRM) encourent souvent des coûts d’inférence supplémentaires en raison d’étapes de raisonnement redondantes lors de la génération d’explications CoT. Le mécanisme PEAR (Phase Entropy Aware Reward) conçoit des récompenses en combinant l’entropie dépendante de la phase, pénalisant l’entropie excessive pendant la phase de réflexion, tout en permettant une exploration modérée pendant la phase de réponse finale. Cela encourage le modèle à générer des trajectoires de raisonnement concises tout en maintenant la flexibilité nécessaire pour résoudre la tâche. Les expériences montrent que PEAR réduit continuellement la longueur des réponses sans sacrifier la précision, et démontre une forte robustesse OOD. (Source : arXiv:2510.08026)
DocReward : un modèle de récompense axé sur la structure et le style des documents : DocReward est un modèle de récompense utilisé pour évaluer la structure et le style des documents, visant à résoudre le problème des flux de travail Agentic qui négligent la structure visuelle et le style lors de la génération de documents professionnels. Le modèle est entraîné sur DocPair, un ensemble de données multi-domaines contenant des paires de documents de haute et basse professionnalisme, et peut évaluer de manière exhaustive le professionnalisme d’un document indépendamment de la qualité du texte. DocReward surpasse GPT-4o et GPT-5 en précision, et obtient un taux de victoire plus élevé dans l’évaluation externe de la génération de documents, prouvant son utilité pour guider les Agents génératifs à produire des documents préférés par les humains. (Source : arXiv:2510.11391)
SPG : le gradient de politique sandwich améliore l’apprentissage par renforcement des modèles de langage de diffusion : Les modèles de langage de diffusion (dLLM), grâce à leur capacité de décodage parallèle, sont considérés comme une alternative efficace aux modèles auto-régressifs. Cependant, l’alignement des dLLM avec les préférences humaines par l’apprentissage par renforcement (RL) pose des défis, car leur vraisemblance logarithmique difficile à gérer limite l’application directe des gradients de politique standard. La méthode SPG (Sandwiched Policy Gradient) utilise les bornes supérieure et inférieure de la vraie vraisemblance logarithmique, surpassant significativement les bases de référence basées sur ELBO ou l’estimation en une étape, améliorant la précision RL des dLLM de 3,6 % à 27,0 % sur des tâches comme GSM8K et MATH500. (Source : arXiv:2510.09541)
QeRL : l’apprentissage par renforcement amélioré par quantification augmente l’efficacité et la capacité d’exploration des LLM : Le framework QeRL (Quantization-enhanced Reinforcement Learning) vise à résoudre le problème de l’intensité des ressources de l’apprentissage par renforcement (RL) des LLM en combinant la quantification NVFP4 et la technologie LoRA, accélérant la phase de Rollout du RL et réduisant les coûts de mémoire. L’étude a révélé que le bruit de quantification peut augmenter l’entropie de la politique, améliorant la capacité d’exploration et aidant à trouver de meilleures politiques. QeRL introduit un mécanisme de bruit de quantification adaptatif (AQN) pour ajuster dynamiquement le bruit pendant l’entraînement. Les expériences montrent que QeRL accélère la phase de Rollout de plus de 1,5 fois, réalisant pour la première fois l’entraînement d’un LLM 32B sur un seul GPU H100 80 Go, et obtenant une croissance plus rapide des récompenses et une précision finale plus élevée. (Source : arXiv:2510.11696)
STAT : l’entraînement adaptatif ciblé sur les compétences améliore les performances mathématiques et OOD des LLM : STAT (Skill-Targeted Adaptive Training) est une nouvelle stratégie de fine-tuning des LLM qui utilise les capacités métacognitives de LLM plus puissants comme modèles enseignants pour créer une liste de compétences requises par la tâche et étiqueter les points de données. Le modèle enseignant surveille les réponses du modèle étudiant, construit un “profil de compétences manquantes”, puis réévalue de manière adaptative les exemples d’entraînement existants (STAT-Sel) ou synthétise des exemples supplémentaires impliquant les compétences manquantes (STAT-Syn). Les expériences montrent que STAT améliore jusqu’à 7,5 % sur le benchmark MATH et en moyenne de 4,6 % sur le benchmark OOD, et est complémentaire à GRPO, promettant une amélioration complète des pipelines d’entraînement actuels. (Source : arXiv:2510.10023)
LLaMAX2 : le modèle Qwen3-XPlus excelle dans les tâches de traduction et de raisonnement : LLaMAX2 propose une nouvelle méthode d’amélioration de la traduction, qui, en effectuant un fine-tuning sélectif par couche sur le modèle d’instructions, améliore significativement les performances de traduction du modèle Qwen3-XPlus pour les langues à ressources élevées et faibles (comme le swahili), tout en maintenant une compétence comparable à celle du modèle d’instructions Qwen3 sur 15 ensembles de données de raisonnement populaires. Ce travail offre une méthode prometteuse pour l’amélioration multilingue, réduisant considérablement la complexité et augmentant l’accessibilité à un plus large éventail de langues. (Source : arXiv:2510.09189)
DemoDiff : le Transformer de diffusion graphique réalise la conception moléculaire contextuelle : DemoDiff (Demonstration-conditioned diffusion models) réalise la conception moléculaire contextuelle en utilisant un petit nombre d’exemples molécule-score plutôt que des descriptions textuelles pour définir le contexte de la tâche. Le modèle utilise un nouveau tokenizer moléculaire Node Pair Encoding, qui représente les molécules au niveau du motif, réduisant le nombre de nœuds. DemoDiff a pré-entraîné un modèle de 700 millions de paramètres sur un ensemble de données contenant des millions de tâches contextuelles, et a égalé ou surpassé des modèles de langage 100 à 1000 fois plus grands dans 33 tâches de conception, devenant un modèle de base moléculaire pour la conception moléculaire contextuelle. (Source : arXiv:2510.08744)
CodePlot-CoT : la chaîne de pensée pilotée par le code pour l’image améliore le raisonnement visuel mathématique : CodePlot-CoT propose un nouveau paradigme de chaîne de pensée pilotée par le code pour la “pensée visuelle” en mathématiques. Cette méthode utilise VLM pour générer un raisonnement textuel et un code de tracé exécutable, qui est ensuite rendu en image comme “pensée visuelle” pour résoudre des problèmes mathématiques. L’étude a construit le premier ensemble de données à grande échelle et bilingue de raisonnement visuel mathématique, Math-VR, et a développé un convertisseur image-code SOTA. Les expériences montrent que le modèle améliore les performances jusqu’à 21 % sur le benchmark Math-VR, ouvrant de nouvelles directions pour le raisonnement mathématique multimodal. (Source : arXiv:2510.11718)
DiT360 : l’entraînement hybride permet la génération d’images panoramiques haute fidélité : DiT360 est un framework basé sur DiT qui réalise la génération d’images panoramiques haute fidélité grâce à un entraînement hybride sur des données de perspective et panoramiques. Cette méthode introduit des modules clés tels que la fusion de connaissances inter-domaines, l’affinage panoramique, le remplissage cyclique, la perte de lacet et la perte cubique, pour résoudre les problèmes de fidélité géométrique et de réalisme. DiT360 a démontré une meilleure cohérence des bords et une meilleure fidélité d’image sur 11 indicateurs quantitatifs dans les tâches de texte-à-panoramique, de réparation d’image et d’outpainting. (Source : arXiv:2510.11712)
RAE : les auto-encodeurs de représentation optimisent l’espace latent des Transformers de diffusion : Une étude a exploré le remplacement des VAE traditionnels dans les Transformers de diffusion (DiT) par des encodeurs de représentation pré-entraînés (tels que DINO, SigLIP, MAE), formant des auto-encodeurs de représentation (RAE). Les RAE offrent une reconstruction de haute qualité et un espace latent sémantiquement riche, tout en prenant en charge une architecture Transformer évolutive. Grâce à une analyse théorique et une validation empirique, cette méthode permet une convergence plus rapide et a obtenu de solides résultats de génération d’images sur ImageNet, promettant de devenir le nouveau paramètre par défaut pour l’entraînement des Transformers de diffusion. (Source : arXiv:2510.11690)
InfiniHuman : cadre de création de corps humains 3D infinis avec un contrôle précis : Le cadre InfiniHuman génère des données de corps humains 3D richement annotées avec un coût minimal et une évolutivité théoriquement illimitée, en distillant collaborativement les modèles de base existants. InfiniHumanData est un pipeline entièrement automatisé qui utilise des modèles visuo-linguistiques et de génération d’images pour créer un ensemble de données multimodal à grande échelle contenant 111 000 identités, couvrant une diversité sans précédent, et annoté en détail avec des descriptions textuelles, des images RGB multi-vues, des images de vêtements et des paramètres de forme corporelle SMPL. Sur cette base, InfiniHumanGen est un pipeline génératif basé sur la diffusion, capable de générer des avatars rapides, réalistes et contrôlables avec précision. (Source : arXiv:2510.11650)
IVEBench : suite de benchmarks pour l’évaluation de l’édition vidéo guidée par instructions : IVEBench est une suite de benchmarks moderne spécialement conçue pour l’évaluation de l’édition vidéo guidée par instructions. Elle contient 600 vidéos sources de haute qualité, couvrant sept dimensions sémantiques et des longueurs vidéo de 32 à 1024 images. De plus, elle comprend 8 catégories de tâches d’édition et 35 sous-catégories, avec des prompts générés et affinés par de grands modèles de langage et des experts. IVEBench établit un protocole d’évaluation tridimensionnel comprenant la qualité vidéo, la conformité aux instructions et la fidélité vidéo, intégrant des métriques traditionnelles et l’évaluation par de grands modèles de langage multimodaux. (Source : arXiv:2510.11647)
LikePhys : évaluer la compréhension physique intuitive des modèles de diffusion vidéo par la préférence de vraisemblance : LikePhys est une méthode indépendante de l’entraînement qui évalue la compréhension physique intuitive des modèles de diffusion vidéo en distinguant les vidéos physiquement valides et impossibles, et en utilisant l’objectif de débruitage comme substitut de vraisemblance basé sur ELBO. L’étude a construit un benchmark comprenant 12 scènes et 4 domaines physiques, et les résultats montrent que son indicateur d’évaluation, le Plausibility Preference Error (PPE), est hautement cohérent avec les préférences humaines. L’étude a également évalué systématiquement la capacité de compréhension physique intuitive des modèles de diffusion vidéo actuels et analysé comment la conception du modèle et les paramètres d’inférence affectent la compréhension physique. (Source : arXiv:2510.11512)
FastHMR : accélérer la récupération de maillages humains grâce à la fusion de Tokens et de couches : FastHMR accélère la récupération de maillages humains 3D (HMR) en introduisant deux stratégies de fusion spécifiques à HMR : la fusion de couches contrainte par l’erreur (ECLM) et la fusion de Tokens guidée par masque (Mask-ToMe). ECLM fusionne sélectivement les couches Transformer ayant le moins d’impact sur le MPJPE, tandis que Mask-ToMe se concentre sur la fusion des Tokens d’arrière-plan qui contribuent moins à la prédiction finale. Pour compenser la dégradation potentielle des performances due à la fusion, l’étude propose un décodeur basé sur la diffusion, combinant le contexte temporel et les a priori de pose appris à partir de vastes ensembles de données de capture de mouvement. Les expériences montrent que cette méthode, tout en améliorant légèrement les performances, réalise une accélération allant jusqu’à 2,3 fois. (Source : arXiv:2510.10868)
AVoCaDO : générateur de sous-titres vidéo audiovisuel, piloté par l’orchestration temporelle : AVoCaDO est un puissant générateur de sous-titres vidéo audiovisuel, piloté par l’orchestration temporelle entre les modalités audio et visuelle. L’étude propose un pipeline de post-entraînement en deux étapes : AVoCaDO SFT affine le modèle sur 107K ensembles de données de sous-titres audiovisuels de haute qualité et alignés temporellement ; AVoCaDO GRPO utilise une fonction de récompense personnalisée pour améliorer davantage la cohérence temporelle et la précision du dialogue, tout en régulant la longueur des sous-titres et en réduisant les effondrements. Les résultats expérimentaux montrent qu’AVoCaDO surpasse significativement les modèles open source existants sur quatre benchmarks de sous-titres vidéo audiovisuels. (Source : arXiv:2510.10395)
Le piège de la personnalisation du raisonnement émotionnel des LLM : comment la mémoire de l’utilisateur modifie l’interprétation émotionnelle : Alors que les systèmes AI personnalisés s’intègrent de plus en plus à la mémoire à long terme des utilisateurs, il est crucial de comprendre comment la mémoire façonne le raisonnement émotionnel des LLM. L’étude a évalué 15 LLM sur des tests d’intelligence émotionnelle validés par des humains, et a découvert que les mêmes scénarios associés à différents profils d’utilisateurs produisaient des interprétations émotionnelles systématiquement différentes. Dans des scénarios émotionnels indépendants de l’utilisateur et validés, et des profils d’utilisateurs diversifiés, plusieurs LLM haute performance ont montré des biais systématiques, les profils dominants obtenant des interprétations émotionnelles plus précises. De plus, les LLM ont montré des différences démographiques significatives dans la compréhension émotionnelle et les tâches de recommandation de soutien, suggérant que les mécanismes de personnalisation pourraient intégrer des hiérarchies sociales dans le raisonnement émotionnel des modèles. (Source : arXiv:2510.09905)
FinAuditing : un benchmark multi-documents d’audit financier pour évaluer les capacités des LLM : FinAuditing est le premier benchmark multi-documents aligné sur la taxonomie, sensible à la structure, pour évaluer les capacités des LLM dans les tâches d’audit financier. Ce benchmark est construit sur des fichiers XBRL conformes aux US-GAAP réels et définit trois sous-tâches complémentaires : FinSM (cohérence sémantique), FinRE (cohérence relationnelle) et FinMR (cohérence numérique). Des expériences approfondies en zero-shot montrent que les modèles actuels ont des performances incohérentes sur les dimensions sémantiques, relationnelles et mathématiques, avec une précision chutant de 60 à 90 % lors du raisonnement sur des structures multi-documents hiérarchiques, révélant les limitations systématiques des LLM dans le raisonnement financier basé sur la taxonomie. (Source : arXiv:2510.08886)
💼 Affaires
Stratégie de financement massive d’OpenAI : un pari de mille milliards de dollars sur l’infrastructure AI, soulevant des controverses sur “l’alchimie financière” : OpenAI, à travers une série de commandes de mille milliards de dollars avec des géants comme NVIDIA, AMD et Broadcom, ouvre une nouvelle ère d’investissement dans l’IA. Matt Levine, ancien banquier de Goldman Sachs, décrit cela comme un “voyage temporel financier”, où OpenAI, grâce à des modèles innovants comme “l’échange d’actions contre des achats” et le “revenu circulaire”, lie profondément le destin de ses fournisseurs au sien, les incitant à partager les risques énormes de la construction d’infrastructures. OpenAI prévoit de construire 250 gigawatts de puissance de calcul d’ici 2033, avec un coût de plus de 10 000 milliards de dollars, bien au-delà de ses revenus actuels, ce qui soulève des inquiétudes quant à sa viabilité financière. Cependant, Sam Altman souligne qu’il s’agit du “plus grand projet industriel conjoint de l’histoire de l’humanité”, visant à démocratiser l’IA. (Source : 36氪, 36氪)
L’IA transforme l’industrie pharmaceutique : l’IA Agentic améliore l’efficacité commerciale : L’IA Agentic révolutionne le domaine pharmaceutique commercial, aidant les entreprises à faire face à l’augmentation des coûts des matières premières, aux perturbations de la chaîne d’approvisionnement et à l’expiration des brevets. L’IA, en offrant des services personnalisés, en optimisant la conception et l’exploitation des cuisines, et en proposant une gestion personnalisée de la santé via des réfrigérateurs intelligents, améliore l’efficacité de la recherche, du développement et de la fabrication de médicaments. Parallèlement, l’IA soutient également les ventes et le marketing, en atteignant les professionnels de la santé via des canaux de communication en temps réel et du contenu pertinent, résolvant les problèmes d’inefficacité de la modération de contenu, et devrait favoriser le développement de la technologie de la santé à domicile, améliorant la qualité de vie des résidents. (Source : MIT Technology Review)

Apple acquiert l’équipe Prompt AI, renforçant la vision par ordinateur et les capacités AI embarquées : Apple est en train d’acquérir la startup de vision par ordinateur Prompt AI, dans le but d’intégrer sa technologie et son équipe clés dans l’écosystème Apple. L’application Seemour de Prompt AI offre des fonctions de reconnaissance précise, de description de scène et de protection de la vie privée, et peut se connecter aux caméras de sécurité domestiques, toutes les données étant traitées localement, ce qui correspond parfaitement à la stratégie “AI embarquée” et “priorité à la vie privée” d’Apple. Cette acquisition est une manifestation de la stratégie d‘“acquisition de talents” d’Apple dans le domaine de l’IA, visant à combler rapidement les lacunes en matière de technologie de vision par ordinateur et à soutenir le développement de ses activités HomeKit, AR et de conduite autonome. (Source : 36氪)

🌟 Communauté
Le remplacement des emplois par l’IA provoque anxiété et résistance au travail : Avec la popularisation de l’IA dans les entreprises, le monde du travail connaît un “remaniement algorithmique”. Kevin Cantera, expert en contenu senior dans une entreprise d’ed-tech, a activement adopté l’IA, doublant son efficacité, mais a tout de même été remplacé par des outils AI, soulevant des questions sur la promesse “l’IA n’est qu’une aide, elle ne remplacera pas”. Chez Ramp, une entreprise de fintech de la Silicon Valley, des programmeurs ont résisté aux outils de codage AI, estimant que le code généré par l’IA est brut et désordonné, manquant de logique humaine. Ces événements soulignent la dure réalité du remplacement des emplois par l’IA, et le défi pour les employés de concilier adaptation et affirmation de leur valeur face aux changements technologiques. (Source : 36氪, 36氪)

Navigateurs AI et avenir de l’Internet ouvert : jardins clos ou nouvel écosystème ? : Le lancement du navigateur Comet par Perplexity et des fonctions d’application ChatGPT par OpenAI a suscité une discussion animée sur la communauté Reddit concernant la question de savoir si “l’IA est en train de tuer l’Internet ouvert”. Les inquiets estiment que l’IA est en train de construire des “jardins clos” au nom de la “commodité”, centralisant l’accès à l’information des utilisateurs sur un petit nombre de plateformes, ce qui pourrait entraîner une perte de diversité de l’information et une personnalisation excessive. Les critiques soulignent que les navigateurs AI tentent de devenir un intermédiaire entre le système d’exploitation et la couche d’application, remodelant le pouvoir de distribution du réseau. Cependant, d’autres estiment que le progrès technologique est inévitable, et que la clé réside dans la manière dont les utilisateurs choisissent et maintiennent un environnement d’information ouvert et diversifié. (Source : 36氪)

Désordres sur le marché des soins aux personnes âgées par l’IA : escroqueries ciblées et pièges de la “pseudo-intelligence” : Alors que la Chine entre dans une société de vieillissement profond, le marché de l‘“IA + soins aux personnes âgées” se développe rapidement, mais il s’accompagne d’escroqueries AI ciblant les personnes âgées et de produits “pseudo-intelligents”. Les escrocs utilisent des technologies de deepfake pour se faire passer pour des proches ou des célébrités, manipulant émotionnellement les personnes âgées pour leur soutirer de l’argent ; ou ils fabriquent des images de “mentors AI” pour vendre de faux cours et projets d’investissement. Parallèlement, le marché est inondé de produits de soins aux personnes âgées “intelligents” qui ne sont pas à la hauteur de leur publicité en termes d’indicateurs clés. Ces désordres non seulement portent atteinte à la sécurité financière des personnes âgées, mais sapent également la confiance de la société dans la technologie AI. L’industrie appelle à des technologies pour lutter contre les escroqueries AI, à un renforcement de la surveillance numérique par les enfants, et à la construction d’un véritable écosystème de soins aux personnes âgées par l’IA empreint d’humanité. (Source : 36氪)
Controverses sur la censure de contenu et l’expérience utilisateur de ChatGPT : ChatGPT a suscité de larges discussions au sein de la communauté concernant la censure de contenu et l’expérience utilisateur. Les utilisateurs signalent que ChatGPT génère parfois du “contenu inapproprié”, puis est rapidement “corrigé” et devient excessivement prudent, allant même jusqu’à restreindre les questions académiques. Parallèlement, de nombreux utilisateurs soulignent que ChatGPT adopte souvent un ton “flatteur” ou “sirupeux” dans ses réponses, en particulier face aux questions des utilisateurs, cette tendance excessivement complaisante donnant aux utilisateurs l’impression d’être traités “de haut”. De plus, les rumeurs selon lesquelles OpenAI lancerait un mode de contenu pour adultes ont également attiré l’attention. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

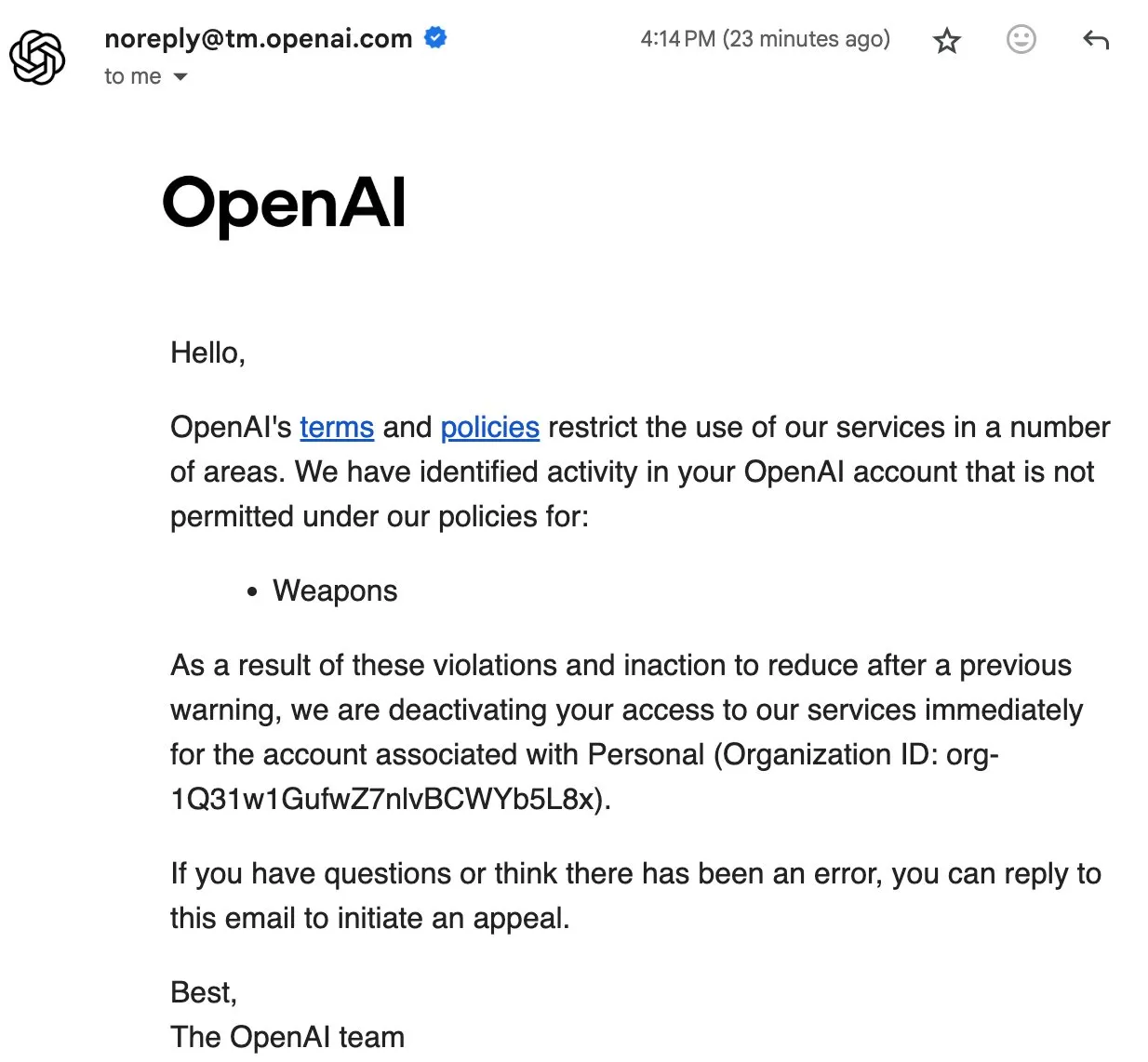
Les interdictions d’utilisateurs d’OpenAI suscitent des discussions communautaires sur la souveraineté des données et l’IA open source : La récente interdiction de certains utilisateurs par OpenAI, allant jusqu’à la suppression des données de compte, a provoqué un fort mécontentement au sein de la communauté. Le compte d’Eric Hartford a été supprimé sans raison, son appel a été rejeté instantanément, entraînant la perte de toutes ses données historiques. Cet incident a incité les membres de la communauté à appeler les utilisateurs à télécharger et à sauvegarder leurs données ChatGPT, et à souligner l’importance de l’IA open source, estimant que les services propriétaires présentent un risque de point de défaillance unique et que la souveraineté des données des utilisateurs ne peut être garantie. Beaucoup pensent que plus l’IA est importante, plus la fiabilité, la sécurité et la confiance dans l’IA open source sont cruciales. (Source : QuixiAI, scaling01)
Le modèle d’abonnement AI suscite la controverse : le risque élevé d’abonnement annuel face à l’itération rapide de la technologie : Un utilisateur expérimenté d’IA suggère d’éviter les abonnements annuels aux outils AI, car la technologie AI évolue si rapidement qu’un outil indispensable aujourd’hui pourrait être obsolète le mois prochain en raison de nouvelles mises à jour ou de nouveaux produits. Ce point de vue reflète la nature à itération rapide de l’industrie de l’IA, les utilisateurs étant prudents quant aux investissements à long terme dans les outils AI, préférant les abonnements mensuels ou les modèles de paiement flexibles pour s’adapter à un paysage technologique en constante évolution. (Source : Reddit r/ArtificialInteligence)
Le taux d’échec élevé des AI Agents : 95 % des investissements des entreprises sans bénéfices, nécessité de “connexion à la réalité” : Il est souligné que “95 % des AI Agents échouent” n’est pas une exagération ; de nombreux Agents qui se sont bien comportés en démonstration sont inefficaces après leur déploiement réel. Le problème central est que les Agents manquent de “connexion à la réalité” (grounding) avec le monde réel, et les boucles de rétroaction automatisées sont sujettes à l’effondrement sans vérification humaine. Les AI Agents qui réussissent à créer de la valeur commerciale sont souvent “ancrés dans la réalité” et ont des objectifs clairs, comme la détection des infractions commerciales ou l’aide aux ventes pour trouver des pistes. Des études montrent que jusqu’à 95 % des investissements des entreprises dans l’IA n’ont pas généré de bénéfices économiques significatifs, et certaines équipes ont même vu leur efficacité diminuer en raison de la correction de bugs AI. (Source : Reddit r/ArtificialInteligence)
Les limites de l’IA dans les actualités locales : le “dernier kilomètre” que les algorithmes ne peuvent pas atteindre : La technologie AI présente des “angles morts” naturels dans le domaine des actualités locales, ayant du mal à accéder aux informations locales non structurées et insuffisamment numérisées, telles que les procès-verbaux de réunions de quartier ou les programmes d’activités communautaires. Les LLM dépendent d’énormes quantités de données publiques, préfèrent les grands récits et ont du mal à digérer les informations locales rares. Le décalage temporel de l’IA l’empêche également de couvrir les événements locaux immédiats, et elle est sujette aux “hallucinations”. Plus important encore, l’IA manque de la relation de confiance et de la perspicacité profonde que les journalistes humains établissent avec les communautés. Ces limites de l’IA créent en fait une opportunité de réévaluer la valeur des actualités locales, les poussant à passer du rôle de “journaliste” à celui de “prestataire de services communautaires”, reconstruisant l’identité et le sentiment d’appartenance à la communauté. (Source : 36氪)
IA et gestion humaine : comprendre l’IA comme un nouvel employé, nécessitant un contexte clair et des livrables définis : Une discussion sur les médias sociaux a souligné que l’utilisation de l’IA et la gestion sont similaires : ce que l’on ne peut pas demander à un humain de faire, il ne faut pas s’attendre à ce que l’IA le fasse. Que ce soit pour l’IA ou pour un nouvel employé, il est nécessaire de fournir un contexte suffisant, des livrables clairs, des exemples de sortie (apprentissage n-shot), des critères d’acceptation précis, des contraintes et des ressources disponibles lors de l’attribution des tâches. Cela montre qu’une utilisation efficace de l’IA nécessite une communication claire et une gestion des tâches, comme avec les membres d’une équipe humaine, plutôt que d’attendre aveuglément des miracles technologiques. (Source : dotey)
La “personnification” des fonds spéculatifs AI : Grok, Qwen, Claude affichent différents styles d’investissement : Des discussions humoristiques sur les médias sociaux ont “personnifié” les modèles de fonds spéculatifs AI, décrivant les styles d’investissement uniques de différents modèles AI. Grok est dépeint comme un trader quantitatif systématique avec une étrange préférence pour le DOGE ; Qwen recherche toujours le levier maximal ; tandis que Claude est un gestionnaire de portefeuille réfléchi qui parvient toujours à rester calme et à dire “tout va bien”. Cette discussion reflète la curiosité et l’imagination de la communauté concernant l’application de l’IA dans la finance, ainsi qu’une compréhension imagée des caractéristiques des différents modèles. (Source : togelius)

Choix d’outils de programmation AI : préférences des développeurs pour Cursor, Codex, Copilot : La communauté des développeurs a discuté des avantages, des inconvénients et des préférences personnelles concernant les différents outils de programmation AI. Certains, après avoir choisi entre Cursor et Visual Studio Code + Copilot, ont préféré ce dernier. Un autre développeur a déclaré être passé entièrement de Claude Code à Codex comme outil principal quotidien. Ces discussions reflètent les différents besoins des développeurs en matière de performances, d’intégration, de facilité d’utilisation et de qualité du code généré par les outils AI dans leur travail réel, ainsi que leur exploration et leurs compromis constants concernant la programmation assistée par l’IA. (Source : pierceboggan, imjaredz)

IA et Internet ouvert : HuggingFace salué comme le “GitHub de l’IA” : Hugging Face est largement reconnu dans la communauté AI comme le “GitHub de l’IA”, devenant une plateforme centrale pour le partage et la collaboration de modèles, de jeux de données et de code d’applications AI. Cette analogie souligne le rôle clé de Hugging Face dans la promotion du développement de l’écosystème AI open source, offrant aux chercheurs et développeurs un environnement d’hébergement de code et de collaboration similaire à GitHub, ce qui a considérablement favorisé la popularisation et l’innovation de la technologie AI. (Source : ClementDelangue)
IA et avenir humain : réflexions sur la complexité de l’AGI et l’adaptation sociale : La communauté discute de l’arrivée de l’AGI (Intelligence Artificielle Générale) avec des opinions divergentes. Certains pensent qu’après avoir atteint l’AGI, l’humanité réalisera qu’elle a trop complexifié l’IA par le passé, et que la véritable intelligence pourrait être basée sur des principes plus simples et élégants. Parallèlement, d’autres commencent à réfléchir à la manière dont l’IA auto-améliorante récursive affectera la dynamique et la diffusion des organisations, des institutions, des acteurs et des communautés, considérant cela comme la question la plus fondamentale du moment, nécessitant des spéculations et des discussions plus diverses pour aider la société à s’adapter aux profonds changements apportés par l’IA. (Source : Reddit r/ArtificialInteligence, ethanCaballero)
IA et émotions sociales : les deepfakes, les escroqueries AI pour personnes âgées, et le remplacement d’emplois par l’IA suscitent des inquiétudes : La technologie AI suscite des émotions complexes au niveau social. Sora 2 générant des deepfakes de célébrités soulève des préoccupations concernant les droits à l’image et l’éthique ; le marché des soins aux personnes âgées par l’IA voit apparaître des escroqueries ciblées sur les personnes âgées isolées et des produits “pseudo-intelligents”, portant atteinte aux intérêts des seniors ; le remplacement d’emplois par l’IA, entraînant le licenciement d’employés expérimentés, exacerbe l’anxiété au travail. Ces événements soulignent que l’IA, tout en apportant des commodités, pose également de sérieux défis à l’éthique sociale, à la confiance et à la structure de l’emploi, incitant le public à réfléchir à l’équilibre entre le développement technologique et l’adaptation sociale. (Source : Reddit r/ArtificialInteligence, 36氪, 36氪)
IA et science ouverte : le développement rapide de l’IA open source et la pérennité des stratégies produit : La communauté estime que le développement de l’IA open source est étonnamment rapide, mais cela soulève également des questions sur la pérennité des stratégies produit : dans le contexte de l’itération rapide de l’IA open source, comment les entreprises peuvent-elles construire une fidélisation client et un avantage concurrentiel durables devient une question clé. Parallèlement, des développeurs manifestent un grand enthousiasme pour des projets open source minimalistes comme nanochat d’Andrej Karpathy, estimant qu’ils sont d’excellentes ressources pour apprendre le cycle de vie complet des LLM, et espèrent voir davantage de “nanoagent” et même de “nanoASI” à l’avenir, favorisant la démocratisation et l’évolution rapide de la technologie AI. (Source : zachtratar, code_star)
IA et recherche : un changement de paradigme de la correspondance par mots-clés à la compréhension sémantique : Geoffrey Hinton souligne que l’IA actuelle est plus proche de l’humain dans sa compréhension des problèmes, ne se limitant plus à la correspondance par mots-clés, mais capable de connecter les idées et le sens, même si la formulation est complètement différente. Ce changement marque le passage de la recherche AI d’une correspondance superficielle à une compréhension sémantique profonde, capable de générer des réponses originales plutôt que de simples récupérations. Cette capacité prédit que l’IA remodèlera la manière d’accéder à l’information, rendant les résultats de recherche plus perspicaces et pertinents. (Source : arohan)
💡 Divers
L’IA dans la finance : cinq piliers pour stimuler la croissance des revenus et la gestion des risques : L’application de l’IA dans le secteur financier s’approfondit, devenant un facteur clé de croissance des revenus et de gestion des risques. Cinq piliers sont proposés, incluant l’utilisation de l’IA pour l’analyse de données, la prévision des tendances du marché, l’optimisation des portefeuilles d’investissement, l’automatisation des processus de conformité et l’amélioration du service client. Ces applications aident les institutions financières à prendre des décisions stratégiques plus intelligentes, à identifier les risques potentiels et à améliorer l’efficacité opérationnelle. Parallèlement, l’application de l’IA dans l’analyse des données financières soutient également des décisions stratégiques plus éclairées. (Source : Ronald_vanLoon, Ronald_vanLoon)
OpenAI fait face à un procès pour droits d’auteur : des messages Slack internes pourraient coûter des milliards de dollars : OpenAI fait face à un procès pour droits d’auteur, et ses messages Slack internes pourraient devenir des preuves clés, pouvant entraîner des milliards de dollars de dommages et intérêts. Ce procès souligne la complexité juridique des sources de données d’entraînement des modèles AI, ainsi que les défis pour les entreprises en matière de conformité des communications internes et de l’utilisation des données pendant le développement de l’IA. Le résultat de l’affaire pourrait avoir un impact profond sur la protection des droits d’auteur et les normes d’utilisation des données dans l’industrie de l’IA. (Source : Reddit r/artificial)

Les startups chinoises de l’IA confrontées à un “exode collectif”, contraintes de se tourner vers l’étranger pour survivre : Le marché chinois des applications AI est dominé par les “grands acteurs”, ByteDance, Baidu, Alibaba et d’autres géants occupant 70 % du Top 20 des applications AI nationales grâce à leurs ressources et scénarios. Le cycle d’innovation des startups est réduit à quelques semaines, et toute innovation prometteuse est rapidement répliquée par les grands acteurs. Cette concurrence féroce contraint les startups chinoises de l’IA à “s’internationaliser” ; le classement a16z montre que sur 22 applications mobiles AI chinoises, 19 ciblent les marchés étrangers, entraînant une fuite des talents et de l’innovation, ce qui souligne le paradoxe du marché chinois de l’IA entre l’explosion de la base d’utilisateurs et la contraction des sources d’innovation. (Source : 36氪)