
Mots-clés:OpenAI, Régulation de l’IA, Grands modèles linguistiques, Éthique de l’IA, Innovation en IA, Concentration du pouvoir de l’IA, Loi sur la sécurité de l’IA, Gouvernance de l’IA, Intimidation juridique d’OpenAI, Cadre d’alignement GTAlign, Raisonnement multimodal ARES, Modèle mondial xAI, Technologie de segmentation SAM 3.0
🔥 Focus
Thème: OpenAI accusé d’intimidation envers une organisation à but non lucratif : Pendant l’examen du projet de loi californien sur la sécurité de l’IA, OpenAI aurait envoyé une assignation à comparaître à Encode, une organisation à but non lucratif de seulement trois employés, exigeant tous les dossiers et communications privées, et l’accusant sans preuve d’être financée par Musk. Encode a publiquement dénoncé cette action comme une intimidation juridique visant à réprimer les critiques de sa position politique. L’incident a suscité des critiques de la part d’employés actuels et d’anciens membres du conseil d’administration d’OpenAI, soulignant les stratégies agressives adoptées par les grandes entreprises d’IA face à la réglementation, ainsi que les défis auxquels sont confrontés les petits groupes de défense face aux géants, bien que le projet de loi SB 53 ait finalement été adopté, exigeant des entreprises d’IA de soumettre des évaluations des risques et des rapports de transparence (Source: Reddit r/ArtificialInteligence)
Thème: Un lauréat du prix Nobel d’économie avertit : la concentration du pouvoir de l’IA pourrait étouffer l’innovation : Philip Aghion, l’un des lauréats du prix Nobel d’économie de cette année, a souligné que la concentration du pouvoir de l’IA entre les mains de quelques entreprises pourrait entraver l’innovation et la croissance économique. Il estime que l’innovation dépend de la concurrence, et que le monopole des ressources de l’IA pourrait entraîner une stagnation du progrès, rendant difficile pour les startups de défier les géants existants. Cela a relancé le débat sur la gouvernance et les formes de régulation de l’IA, afin d’éviter qu’elle ne devienne un goulot d’étranglement de la croissance plutôt qu’un moteur (Source: Reddit r/ArtificialInteligence)

Thème: GTAlign : un cadre d’alignement pour assistants LLM basé sur la théorie des jeux : Des chercheurs ont proposé GTAlign, un cadre d’alignement qui intègre les décisions de la théorie des jeux dans le raisonnement et l’entraînement des LLM. Ce cadre construit une matrice de gains pour évaluer le bien-être mutuel du LLM et de l’utilisateur, et sélectionne des actions mutuellement bénéfiques. Lors de l’entraînement, des récompenses de bien-être réciproque sont introduites pour renforcer les réponses collaboratives. Les expériences montrent que GTAlign améliore significativement l’efficacité du raisonnement, la qualité des réponses et le bien-être mutuel des LLM dans diverses tâches, résolvant le problème où les méthodes d’alignement traditionnelles peuvent dégrader l’expérience utilisateur en raison d’une prolixité excessive du modèle (Source: HuggingFace Daily Papers)
Thème: ARES : raisonnement adaptatif multimodal via le façonnement de l’entropie sensible à la difficulté : ARES est un cadre open-source unifié qui résout le problème de déséquilibre d’efficacité des grands modèles de raisonnement multimodaux (MLRMs) lors du traitement de tâches de difficultés différentes, en allouant dynamiquement l’effort d’exploration. Il utilise l’entropie de fenêtre pour identifier les moments de raisonnement clés et, grâce à un entraînement en deux phases (démarrage à froid adaptatif et optimisation adaptative de la politique d’entropie), permet au modèle de réduire la sur-réflexion sur les problèmes simples et d’augmenter l’exploration sur les problèmes complexes. ARES démontre des performances et une efficacité de raisonnement exceptionnelles sur les benchmarks mathématiques, logiques et multimodaux, réduisant considérablement les coûts d’inférence (Source: HuggingFace Daily Papers)
🎯 Tendances
Thème: xAI de Musk entre sur le marché des modèles du monde, débauche des talents de NVIDIA pour les jeux AI : xAI se positionne activement dans le domaine des modèles du monde et a débauché plusieurs chercheurs expérimentés de NVIDIA, prévoyant de lancer un jeu généré par l’IA et piloté par un modèle du monde d’ici fin 2026. L’objectif de xAI est de permettre à l’IA de comprendre l’essence de l’univers, en appliquant les modèles du monde aux jeux AI, aux agents, à la conduite autonome et aux robots d’IA incarnée, visant à construire un écosystème AI complet (Source: 量子位)

Thème: Meta “Segment Anything” 3.0 révélé : SAM 3.0 introduit la segmentation conceptuelle prompte (PCS), prenant en charge les tâches de segmentation multi-instances basées sur des phrases ou des exemples d’images. La nouvelle architecture comprend un détecteur basé sur DETR et un module Presence Head, découplant la reconnaissance et la localisation d’objets pour améliorer la précision de la détection. Grâce à un moteur de données à grande échelle et au benchmark SA-Co, SAM 3.0 bat le SOTA dans les tâches de segmentation à vocabulaire ouvert et peut être combiné avec de grands modèles multimodaux pour résoudre des tâches de segmentation par raisonnement complexe (Source: 量子位)

Thème: Baidu World 2025 fixe sa date, se concentre sur les applications AI et l’écosystème des grands modèles : Baidu a annoncé que Baidu World 2025 se tiendra le 13 novembre à Pékin, sur le thème “Effet émergent | AI in Action”. La conférence présentera en détail les dernières avancées de Baidu en matière d’applications AI, de grands modèles, d’écosystème AI et de mondialisation, y compris Wenxin iRAG, Miaoda sans code, la technologie d’humain numérique et le déploiement mondial de la conduite autonome “Luobo Kuaipao”. La conférence proposera également plus de 40 cours publics sur l’IA pour autonomiser le développement d’applications AI (Source: 量子位)

Thème: Reflection AI : une “DeepSeek américaine” valorisée à 8 milliards de dollars sans produit lancé : Reflection AI, sans avoir lancé de produit officiel, a vu sa valorisation grimper en flèche à 8 milliards de dollars et a obtenu 2 milliards de dollars de financement de Nvidia, Sequoia Capital, etc. Fondée par d’anciens membres clés de Google DeepMind, l’entreprise vise à devenir la “DeepSeek de l’Ouest”, en proposant des modèles MoE haute performance via un modèle de “poids ouverts”, comblant ainsi le besoin du marché occidental en modèles open-source non chinois, et ciblant les grandes entreprises et les marchés de l’IA souveraine (Source: 36氪)

Thème: Lancement du modèle Dolphin X1 8B : une version affinée et décensurée de Llama3.1 8B : Dolphin X1 8B est désormais disponible sur Hugging Face. Il s’agit d’une version affinée de Llama3.1 8B Instruct, conçue pour supprimer au maximum les restrictions de censure du modèle sans compromettre les autres capacités. Le modèle a été entraîné avec SFT+RL, et les résultats des benchmarks sont comparables ou supérieurs à ceux de Llama3.1 8B Instruct. Des versions GGUF, FP8 et exl2 ont été publiées sous le parrainage de Deepinfra (Source: Reddit r/LocalLLaMA)
Thème: Diversification des approches RAG open-source : MiniRAG, Agent-UniRAG, SymbioticRAG, etc. : Les solutions RAG (Retrieval-Augmented Generation) open-source telles que MiniRAG, Agent-UniRAG et SymbioticRAG se diversifient, présentant différentes philosophies de conception. MiniRAG vise la légèreté et l’exécution locale, Agent-UniRAG intègre la récupération et le raisonnement dans un pipeline d’agents continu, SymbioticRAG met l’accent sur la collaboration homme-machine et l’apprentissage par feedback, tandis que des boîtes à outils comme LangChain offrent des composants modulaires. Les utilisateurs doivent équilibrer précision, vitesse et contrôlabilité lors de leur choix, et être attentifs aux problèmes courants tels que les hallucinations et la perte de contexte (Source: Reddit r/LocalLLaMA)
Thème: LLM4Cell : une revue des grands modèles linguistiques et des modèles d’agents dans le domaine de la biologie unicellulaire : LLM4Cell présente la première revue unifiée de 58 modèles fondamentaux et modèles d’agents appliqués à la recherche unicellulaire, couvrant les modalités RNA, ATAC, multi-omiques et spatiales. L’étude classe ces méthodes en cinq grandes catégories et les mappe à huit tâches d’analyse clés. En analysant plus de 40 jeux de données publics, elle évalue l’applicabilité, la diversité des données, l’éthique et l’évolutivité des modèles, et identifie les défis en matière d’interprétabilité, de standardisation et de développement de modèles fiables (Source: HuggingFace Daily Papers)
Thème: KORMo : un modèle de raisonnement ouvert en coréen pour tous : KORMo-10B est le premier grand modèle linguistique bilingue coréen-anglais principalement entraîné sur des données synthétiques. Ce modèle de 10,8 milliards de paramètres a une partie coréenne composée à 68,74% de données synthétiques. Les expériences prouvent que des données synthétiques soigneusement sélectionnées n’entraînent pas d’instabilité ou de dégradation des performances lors du pré-entraînement à grande échelle du modèle, et que le modèle présente des performances comparables aux modèles multilingues open-source existants sur les benchmarks de raisonnement, de connaissances et de suivi d’instructions. Le projet a entièrement open-sourcé les données, le code et le plan d’entraînement, offrant un cadre transparent pour le développement de modèles ouverts basés sur des données synthétiques dans des environnements à faibles ressources (Source: HuggingFace Daily Papers)
Thème: UML : améliorer les modèles unimodaux avec des données multimodales non appariées : UML (Unpaired Multimodal Learner) est un nouveau paradigme d’entraînement indépendant de la modalité, où le modèle traite alternativement des entrées de différentes modalités et partage des paramètres, utilisant des structures intermodales pour améliorer l’apprentissage de représentations unimodales, sans nécessiter de jeux de données appariés explicites. La théorie et les expériences montrent que l’utilisation de données non appariées provenant de modalités auxiliaires (comme le texte, l’audio, l’image) améliore continuellement les performances des tâches unimodales en aval, telles que l’image et l’audio (Source: HuggingFace Daily Papers)
Thème: Annonce du nouveau livre “The Illustrated Guide to AI Agents” : Le nouveau livre “The Illustrated Guide to AI Agents”, co-écrit par Jay Alammar et Maarten Gr et publié par O’Reilly Media, sera bientôt disponible. Ce livre explorera en profondeur les concepts fondamentaux pour comprendre et construire des agents AI, couvrant des sujets avancés tels que les outils, la mémoire, la génération de code, le raisonnement, le multimodal, RLVR/GRPO, et vise à être le projet visuel le plus riche dans le domaine des agents AI (Source: JayAlammar, MaartenGr)

Thème: SEAL : des modèles linguistiques auto-adaptatifs pour l’apprentissage continu : Une nouvelle étude intitulée SEAL (Self-Adapting Language Models) décrit comment les modèles AI peuvent apprendre en continu après leur déploiement, en faisant évoluer leurs représentations internes sans ré-entraînement. L’architecture SEAL permet aux modèles d’apprendre en temps réel à partir de nouvelles données, d’auto-réparer les connaissances dégradées et de former une “mémoire” persistante à travers les sessions. Si GPT-6 intégrait cette technologie, cela permettrait une IA auto-apprenante continue, marquant la fin de l’ère des “poids gelés” (Source: yoheinakajima)

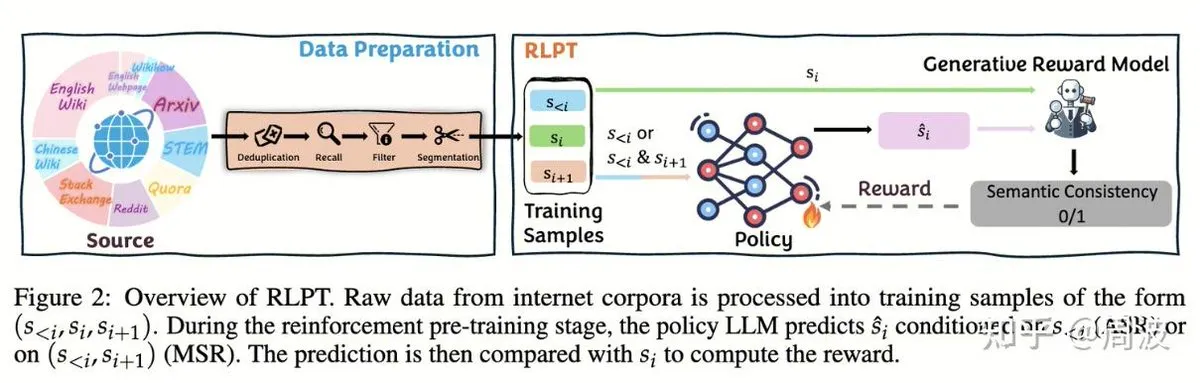
Thème: L’équipe Tencent Hunyuan propose une nouvelle méthode d’apprentissage par renforcement pour le raisonnement des LLM sans annotation humaine : L’équipe de raisonnement et de pré-entraînement de Tencent Hunyuan a introduit une nouvelle méthode d’apprentissage par renforcement (RL) qui remplace la “prédiction du prochain token” traditionnelle par la “prédiction du prochain segment” basée sur le RL, permettant d’étendre les capacités de raisonnement des LLM sans nécessiter de données annotées par des humains. Cette méthode, via deux tâches RL (raisonnement de segment auto-régressif (ASR) et raisonnement de segment intermédiaire (MSR)), améliore significativement les performances du modèle sur plusieurs benchmarks mathématiques et logiques, prouvant que l’extension du raisonnement n’équivaut pas à l’extension des coûts (Source: ZhihuFrontier, ZhihuFrontier)
🧰 Outils
Thème: OpenAlex MCP Server : un outil OpenWebUI personnalisé pour la recherche scientifique : Un développeur a créé l’OpenAlex MCP Server pour la recherche scientifique dans OpenWebUI. Ce service intègre l’index scientifique gratuit OpenAlex, permettant aux utilisateurs de filtrer les articles de recherche par date et par nombre de citations, résolvant ainsi des besoins non satisfaits par les outils existants, et peut être facilement intégré à OpenWebUI (Source: Reddit r/OpenWebUI)
Thème: Claude diagnostique et répare avec succès un problème de performance PC d’un utilisateur : Un utilisateur a partagé comment Claude AI l’a aidé à résoudre un problème de performance PC qui le tourmentait depuis trois ans. Grâce aux conseils de Claude, l’utilisateur a découvert des paramètres de performance d’alimentation cachés au plus profond du panneau de configuration et les a ajustés du mode “silencieux” au mode haute performance, faisant passer le taux de rafraîchissement des jeux de 16FPS à 60FPS. Cela démontre la valeur pratique de l’IA dans le diagnostic et la résolution de pannes techniques complexes (Source: Reddit r/ClaudeAI)
Thème: Microsoft lance Copilot Benchmarks : le suivi de l’utilisation de l’IA par les employés suscite la controverse : Microsoft a lancé un outil appelé Copilot Benchmarks, permettant aux managers de suivre la fréquence d’utilisation des outils AI (comme Copilot) par les employés dans les applications Office, et de comparer avec la moyenne du département et les “entreprises de pointe”. Cette initiative a soulevé des inquiétudes concernant la surveillance au travail et l’abus de données, beaucoup estimant que cela pourrait conduire à ce que l’utilisation de l’IA devienne une base pour l’évaluation des performances, voire les licenciements, plutôt qu’une véritable amélioration de la productivité (Source: Reddit r/ArtificialInteligence)
Thème: MarkItDown : Microsoft lance un outil de conversion de documents pour pipeline LLM en Markdown : Microsoft a lancé MarkItDown, un outil Python capable de convertir divers types de fichiers tels que PDF, Word, Excel, PowerPoint, HTML, CSV, JSON, XML, images, audio, etc., en un format Markdown propre. Le Markdown étant le “langage natif” des LLM, cet outil est idéal pour le prétraitement des documents avant de les alimenter aux modèles, afin de préserver les titres, listes, tableaux, liens et métadonnées, améliorant ainsi l’efficacité et la qualité du traitement des documents par les LLM (Source: TheTuringPost)
Thème: vLLM dépasse les 60 000 étoiles sur GitHub, menant le raisonnement LLM efficace : Le projet vLLM a obtenu 60 000 étoiles sur GitHub, devenant une force majeure dans le domaine du raisonnement LLM. Il prend en charge divers matériels tels que NVIDIA, AMD, Intel, Apple, TPU, et est compatible avec les modèles de génération de texte grand public comme Llama, GPT-OSS, Qwen, DeepSeek, ainsi que les pipelines RL comme TRL et Unsloth, visant à fournir des solutions de raisonnement LLM ouvertes, efficaces et évolutives, et à promouvoir le développement de l’écosystème AI (Source: vllm_project)
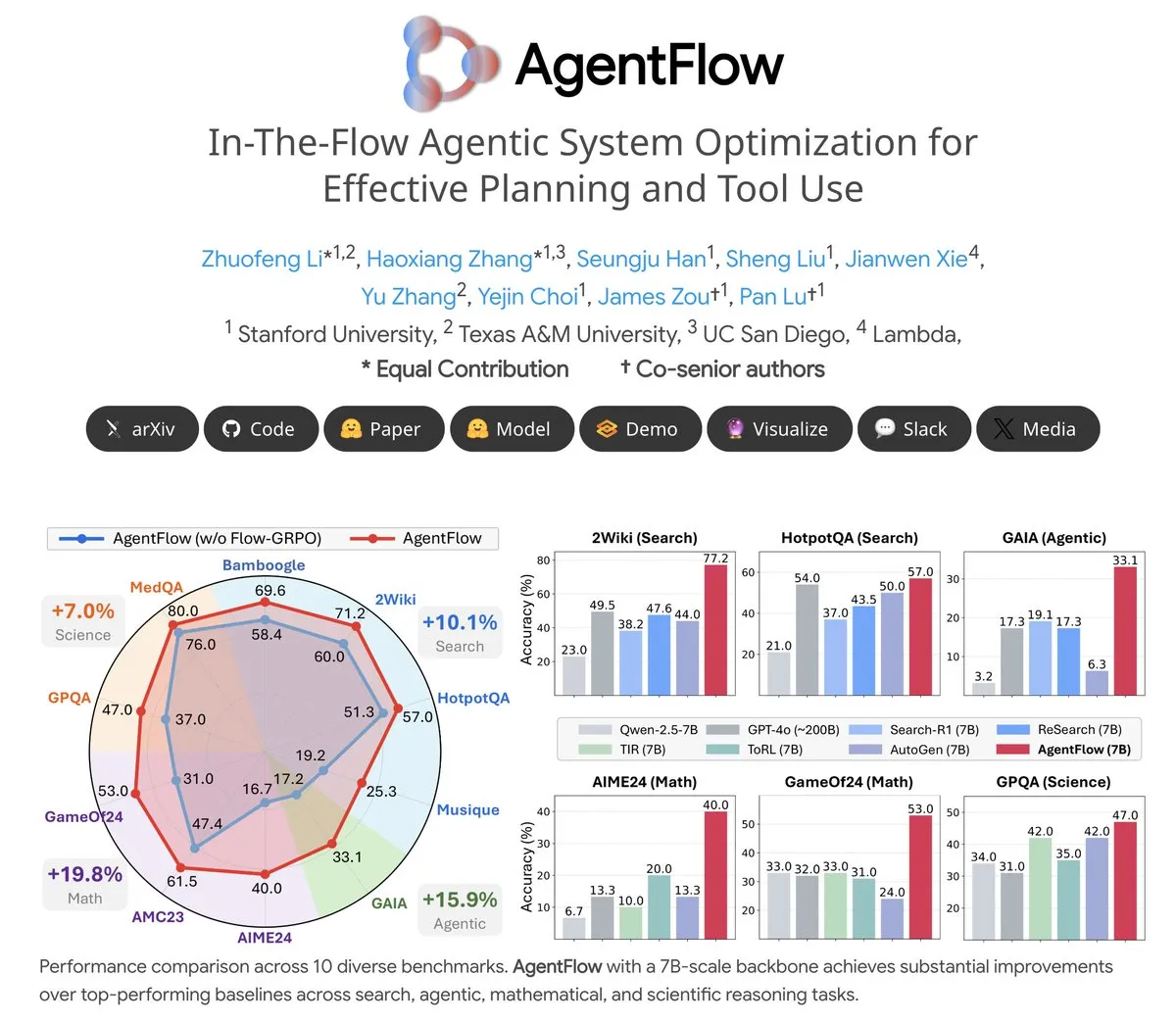
Thème: AgentFlow : un système d’agents entraînable pour l’évolution de programmes pilotée par LLM : AgentFlow est un système d’agents entraînable open-source où, grâce à la collaboration d’équipe, les agents peuvent apprendre à planifier et à utiliser des outils dans le flux de tâches. Le système optimise directement son agent Planner via la méthode Flow-GRPO. Sur plusieurs benchmarks tels que la recherche, les agents, les mathématiques et la science, AgentFlow (modèle 7B) surpasse les grands modèles comme Llama-3.1-405B et GPT-4o, démontrant l’énorme potentiel des LLM en matière d’utilisation d’outils (Source: NerdyRodent)
Thème: Problèmes de mise à jour de Claude Code : les utilisateurs signalent des bugs graves dans la dernière version : Les utilisateurs de la communauté Reddit signalent que la dernière version de Claude Code présente de graves bugs, notamment une limitation trop rapide de la fenêtre contextuelle et un calcul imprécis de l’utilisation des Tokens, la rendant presque inutilisable. De nombreux utilisateurs suggèrent de revenir immédiatement à une ancienne version (comme la 1.0.88) et de désactiver les mises à jour automatiques pour restaurer les fonctionnalités stables (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Thème: Problème d’utilisation excessive du disque par Open WebUI en déploiement Docker : Les utilisateurs signalent que Open WebUI, lorsqu’il est exécuté dans un conteneur Docker, utilise une quantité extrêmement élevée de disque, principalement due à cache/embedding/models, overlay2, containers et vector_db. Les utilisateurs cherchent des méthodes pour supprimer en toute sécurité les fichiers cache et réduire la taille de overlay2 afin de résoudre le problème de manque d’espace disque sur les VM Azure, ce qui reflète les besoins en ressources de stockage et les défis de gestion des applications AI lors du déploiement local (Source: Reddit r/OpenWebUI)
Thème: Les performances de Claude Sonnet 4.5 dans les tâches de codage saluées par les utilisateurs : Malgré les critiques négatives généralisées à l’encontre de Claude, certains utilisateurs ont hautement apprécié les performances de Sonnet 4.5 dans les tâches de codage. Les utilisateurs ont déclaré qu’en combinant l’édition automatique et le mode plan, Sonnet 4.5 atteignait une qualité de code comparable à celle d’Opus 4.1 Plan dans le développement Node.js et Flutter, tout en étant plus rapide et moins coûteux, réduisant significativement la fréquence d’atteinte des limites d’utilisation et la dépendance à ChatGPT (Source: Reddit r/ClaudeAI)
📚 Apprentissage
Thème: CleanMARL : implémentations concises d’algorithmes d’apprentissage par renforcement multi-agents dans PyTorch : CleanMARL est un projet open-source qui fournit des implémentations concises et mono-fichier d’algorithmes d’apprentissage par renforcement multi-agents (MARL) profonds dans PyTorch, suivant la philosophie de conception de CleanRL. Le projet propose également du contenu éducatif, couvrant des algorithmes clés tels que VDN, QMIX, COMA, MADDPG, FACMAC, IPPO, MAPPO, prend en charge les environnements parallèles et l’entraînement de politiques récurrentes, et intègre la journalisation TensorBoard et Weights & Biases, visant à aider les utilisateurs à comprendre et à appliquer les algorithmes MARL (Source: Reddit r/MachineLearning, Reddit r/deeplearning)

Thème: Concepts fondamentaux et parcours d’apprentissage en AI/GenAI/ML/LLM : Plusieurs ressources offrent des guides d’apprentissage de l’IA, du niveau débutant au niveau avancé. Le contenu couvre les concepts Python nécessaires pour maîtriser l’IA, une feuille de route pour devenir un expert en IA générative, une introduction aux agents AI, les 7 niveaux d’architecture de modèles AI, les différences entre l’IA, l’IA générative et l’apprentissage automatique, 20 concepts fondamentaux des LLM, les concepts d’IA agent et les parcours de carrière en science des données. Ces ressources visent à aider les apprenants à construire un système de connaissances AI complet et un plan de développement de carrière (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Thème: Système numérique logarithmique pour l’entraînement à faible précision : Un article de blog explore les systèmes numériques logarithmiques utilisés pour l’entraînement à faible précision, ce qui est crucial pour optimiser les performances des modèles d’apprentissage automatique dans des environnements à ressources limitées. Cette technique vise à améliorer l’efficacité de l’entraînement tout en maintenant la précision du modèle, et constitue une direction d’optimisation constamment suivie dans le domaine du deep learning (Source: Reddit r/deeplearning)
Thème: L’importance continue d’OpenCV dans le domaine de la vision par ordinateur : La communauté a discuté de la raison pour laquelle OpenCV est toujours largement utilisé en 2025, malgré la popularisation des frameworks de deep learning comme PyTorch/TensorFlow. Le point de vue principal est qu’OpenCV est plus riche et plus efficace en termes de fonctionnalités de traitement d’images et de vidéos, surtout avec l’accélération CUDA, sa vitesse de traitement est supérieure à PyTorch. Il est donc souvent utilisé pour le prétraitement d’images/vidéos avant de transmettre les données à PyTorch pour les tâches de deep learning (Source: Reddit r/deeplearning)
Thème: Exigences de présentation des articles NeurIPS à EurIPS : La communauté a discuté des règles de présentation des articles NeurIPS, soulignant que EurIPS n’est pas compté comme une présentation de poster NeurIPS. Si les auteurs ne peuvent pas se rendre personnellement à SD ou Mexico City pour présenter, le papier est généralement retiré. Cependant, n’importe quel auteur peut présenter au nom des autres, et les non-auteurs nécessitent l’autorisation des organisateurs. Cela fournit des directives aux chercheurs pour s’assurer que leurs articles sont publiés dans des circonstances spéciales (Source: Reddit r/MachineLearning)
Thème: Défis de l’entraînement distribué sur deux GPU sous Windows 11 : Un utilisateur cherche des conseils pour effectuer un entraînement distribué PyTorch sur deux GPU NVIDIA A6000 sous Windows 11. Bien que CUDA soit activé, seule une carte GPU peut être utilisée actuellement. La discussion de la communauté se concentre sur la manière de configurer l’environnement et le code pour exploiter pleinement les ressources multi-GPU pour un entraînement de deep learning efficace (Source: Reddit r/deeplearning)
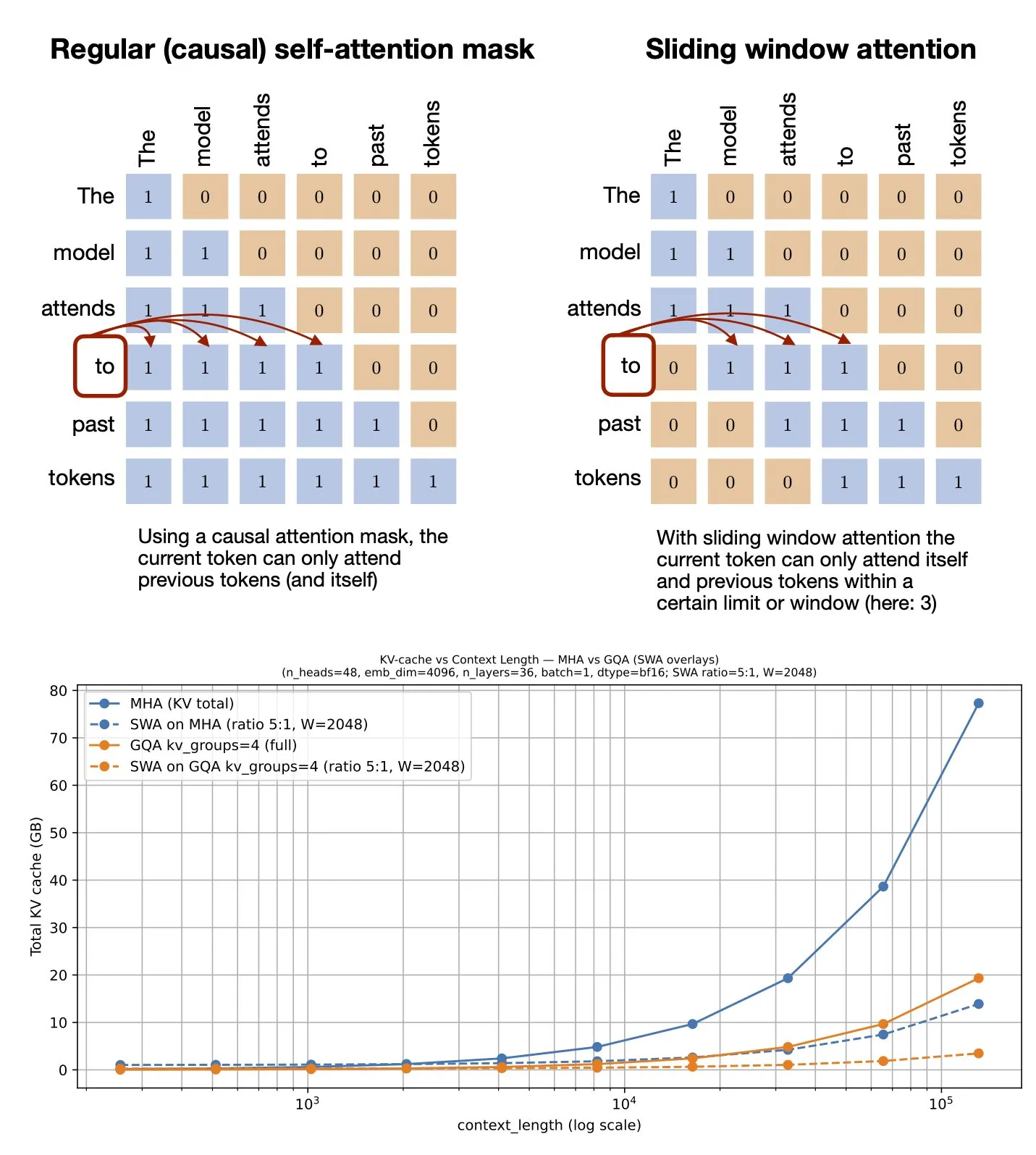
Thème: Mécanisme d’attention à fenêtre glissante : partage de ressources GitHub : Sebastian Raschka a partagé une ressource GitHub sur le mécanisme d’attention à fenêtre glissante (Sliding Window Attention). Ce mécanisme est une technique d’optimisation utilisée dans les grands modèles linguistiques pour traiter les entrées de longues séquences, réduisant la complexité computationnelle et la consommation de mémoire en limitant la portée du calcul d’attention, tout en maintenant une compréhension efficace du contexte (Source: rasbt)
Thème: Optimisation des prompts multimodaux : améliorer les performances des MLLM grâce au multimodal : Une étude introduit la méthode d’optimisation des prompts multimodaux (MPO), visant à étendre l’espace des prompts au-delà du texte et à optimiser efficacement les prompts multimodaux. Cette méthode utilise une combinaison de plusieurs modalités (comme l’image, le texte) pour améliorer les performances des grands modèles de langage multimodaux (MLLMs), en particulier lors du traitement de tâches multimodales complexes, en obtenant une compréhension et une génération plus précises grâce à des informations de prompt plus riches (Source: _akhaliq)

Thème: Nouveau livre sur les modèles de langage visuel à paraître : O’Reilly Media publiera bientôt un nouveau livre sur les modèles de langage visuel, avec des notifications de publication de chapitres déjà ouvertes. Ce livre vise à fournir aux lecteurs un guide complet sur le domaine des modèles de langage visuel, couvrant les fondements théoriques, les dernières avancées et les applications pratiques, et constitue une référence importante pour les chercheurs et les développeurs souhaitant approfondir ce domaine interdisciplinaire (Source: mervenoyann)
Thème: nanochat : Andrej Karpathy lance un pipeline d’entraînement et d’inférence minimaliste pour un clone de ChatGPT : Andrej Karpathy a lancé un nouveau dépôt GitHub, nanochat, un pipeline d’entraînement/inférence full-stack, minimaliste et from-scratch pour construire un simple clone de ChatGPT. Contrairement au précédent nanoGPT qui ne couvrait que le pré-entraînement, nanochat offre une solution complète de bout en bout, facilitant la compréhension et la pratique du processus de construction de ChatGPT pour les développeurs (Source: dejavucoder)

Thème: nanosft : implémentation mono-fichier de fine-tuning de modèles de chat basée sur PyTorch : nanosft est une implémentation mono-fichier concise pour le fine-tuning de modèles de style chat. Il peut charger les poids gpt2-124M sur nanogpt et effectuer un fine-tuning supervisé uniquement avec PyTorch. Ce projet vise à fournir un outil facile à comprendre et à utiliser pour aider les développeurs à personnaliser et optimiser les modèles de chat (Source: tokenbender, dejavucoder)
Thème: Guide du débutant sur l’Edge AI de Microsoft : ressources de lecture recommandées : Un guide du débutant sur l’Edge AI de Microsoft est recommandé comme ressource d’apprentissage. Ce guide pourrait couvrir les théories, les outils et les cas pratiques de déploiement et d’exécution de modèles AI sur des appareils périphériques, et est instructif pour les apprenants souhaitant explorer les applications et le développement de l’Edge AI (Source: hrishioa)
Thème: llama.cpp : révolution de l’efficacité pour l’exécution locale des LLM : La communauté a discuté de l’expérience de passer d’Ollama et LM Studio à llama.cpp pour exécuter des grands modèles linguistiques locaux, avec un consensus général sur l’amélioration significative de l’efficacité apportée par llama.cpp. Les utilisateurs le décrivent comme un outil “qui change la donne”, indiquant que llama.cpp a réalisé des progrès importants dans l’optimisation des performances d’inférence LLM locales (Source: ggerganov)
Thème: RL-Guided KV Cache Compression : compression du cache clé-valeur pour l’inférence LLM : Cette recherche propose le cadre RLKV, qui utilise l’apprentissage par renforcement pour identifier les têtes d’attention critiques pour le raisonnement, optimisant ainsi la relation entre l’utilisation du cache KV et la qualité du raisonnement. RLKV obtient des récompenses à partir d’échantillons générés réels lors de l’entraînement, identifiant efficacement les têtes d’attention liées à la cohérence de la chaîne de pensée, permettant une réduction du cache de 20 à 50% tout en maintenant des performances quasi sans perte, résolvant ainsi le problème des performances médiocres des méthodes existantes sur les modèles d’inférence (Source: HuggingFace Daily Papers)
Thème: Hybrid-depth : agrégation de caractéristiques hybrides pour l’estimation de profondeur monoculaire guidée par le langage : Hybrid-depth est un nouveau cadre qui intègre systématiquement des modèles fondamentaux comme CLIP et DINO, extrayant des priors visuels et des informations contextuelles via un guidage linguistique contrastif pour améliorer les performances de l’estimation de profondeur monoculaire (MDE). Cette méthode, grâce à un cadre d’apprentissage progressif du grossier au fin, agrège des caractéristiques multi-granulaires et affine les prédictions de profondeur, surpassant significativement les méthodes SOTA sur le benchmark KITTI et étant bénéfique pour les tâches de perception BEV en aval (Source: HuggingFace Daily Papers)
Thème: Formalisation du style narratif personnel : analyse de l’expérience subjective via des modèles linguistiques : Cette recherche propose une nouvelle méthode pour formaliser le style dans les récits personnels comme des modèles de choix linguistiques de l’auteur lors de la transmission d’expériences subjectives. Ce cadre combine la linguistique fonctionnelle, l’informatique et les observations psychologiques pour extraire automatiquement les caractéristiques linguistiques, telles que les processus, les participants et les contextes. L’analyse des récits de rêves (y compris des cas de vétérans atteints de SSPT) révèle la relation entre les choix linguistiques et les états psychologiques (Source: HuggingFace Daily Papers)
Thème: ELMUR : mémoire externe par couche pour l’apprentissage par renforcement à long terme : ELMUR (External Layer Memory with Update/Rewrite) est une architecture Transformer dotée d’une mémoire externe structurée, qui résout le problème de la difficulté des modèles traditionnels à retenir et à utiliser les dépendances à long terme dans l’apprentissage par renforcement à long terme. ELMUR étend le champ de vision effectif jusqu’à 100 000 fois la fenêtre d’attention, atteignant un taux de réussite de 100% dans les tâches synthétiques de T-Maze et améliorant presque du double les performances dans les tâches de manipulation à récompense sparse, démontrant l’évolutivité de la mémoire externe structurée et localisée par couche dans les décisions partiellement observables (Source: HuggingFace Daily Papers)
Thème: LightReasoner : comment les petits modèles linguistiques enseignent le raisonnement aux grands modèles linguistiques : Le cadre LightReasoner utilise les différences de comportement entre les modèles experts (LLM) et les modèles amateurs (SLM) pour identifier les moments de raisonnement clés et construire des exemples supervisés, permettant ainsi aux petits modèles linguistiques d’enseigner efficacement le raisonnement aux grands modèles linguistiques. Cette méthode améliore la précision jusqu’à 28,1% sur sept benchmarks mathématiques, tout en réduisant la consommation de temps, les problèmes d’échantillonnage et l’utilisation de tokens de fine-tuning de respectivement 90%, 80% et 99%, et ce sans nécessiter de vraies étiquettes, offrant une méthode économe en ressources pour l’extension du raisonnement des LLM (Source: HuggingFace Daily Papers)
Thème: MONKEY : adaptateur d’activation clé-valeur pour les modèles de diffusion personnalisés : MONKEY propose une méthode qui utilise des masques générés automatiquement par IP-Adapter pour masquer les tokens d’image lors de la deuxième passe d’inférence, limitant ainsi la personnalisation dans les modèles de diffusion à la zone du sujet, permettant aux prompts textuels de mieux se concentrer sur le reste de l’image. Cette méthode génère des images qui représentent précisément le sujet et correspondent clairement au prompt lors de la description de la position et de la scène du texte, réalisant un alignement élevé entre le prompt et l’image source (Source: HuggingFace Daily Papers)
Thème: Speculative Jacobi-Denoising Decoding : accélérer la génération auto-régressive de texte en image : Le cadre SJD2 (Speculative Jacobi-Denoising Decoding) accélère l’inférence dans les modèles auto-régressifs de texte en image en intégrant le processus de dénoising dans l’itération de Jacobi, permettant la génération de tokens en parallèle. Cette méthode introduit le paradigme de “prédiction du prochain token propre”, permettant aux modèles pré-entraînés d’accepter des embeddings de tokens perturbés par le bruit et de prédire le prochain token propre via un fine-tuning à faible coût, réduisant ainsi le nombre de propagations avant du modèle tout en maintenant la qualité visuelle des images générées (Source: HuggingFace Daily Papers)
Thème: ACE : édition de connaissances contrôlée par l’attribution pour le rappel de faits multi-sauts : Le cadre ACE (Attribution-Controlled Knowledge Editing) identifie et édite les chemins clé-valeur (Q-V) critiques via l’attribution au niveau neuronal, pour une édition de connaissances efficace dans les LLM. Cette méthode surpasse significativement les méthodes SOTA existantes dans les tâches de rappel de faits multi-sauts, améliorant de 9,44% sur GPT-J et de 37,46% sur Qwen3-8B, ouvrant de nouvelles voies pour l’amélioration des capacités d’édition de connaissances basées sur la compréhension des mécanismes de raisonnement internes (Source: HuggingFace Daily Papers)
Thème: DISCO : condensation d’échantillons diversifiés pour une évaluation efficace des modèles : La méthode DISCO (Diversifying Sample Condensation) permet une évaluation efficace des modèles d’apprentissage automatique en sélectionnant les top-k échantillons où les modèles divergent le plus. Cette méthode utilise des statistiques gourmandes au niveau des échantillons plutôt qu’un clustering global, ce qui est conceptuellement plus simple. Théoriquement, la divergence entre les modèles offre une règle de sélection gourmande optimale en théorie de l’information. DISCO surpasse les méthodes existantes en termes de prédiction de performance sur les benchmarks MMLU, Hellaswag, Winogrande et ARC, atteignant des résultats SOTA (Source: HuggingFace Daily Papers)
Thème: D2E : pré-entraînement visuel-action sur données de bureau, transféré à l’IA incarnée : Le cadre D2E (Desktop to Embodied AI) prouve que les interactions de bureau peuvent servir de base de pré-entraînement efficace pour les tâches d’IA incarnée robotique. Ce cadre comprend la boîte à outils OWA (interactions de bureau unifiées), Generalist-IDM (généralisation zéro-shot inter-jeux) et VAPT (transfert de représentations pré-entraînées sur bureau vers des opérations physiques et la navigation). D2E, utilisant plus de 1,3K heures de données, atteint des taux de réussite de 96,6% et 83,3% sur les benchmarks d’opération LIBERO et de navigation CANVAS (Source: HuggingFace Daily Papers)
Thème: One Patch to Caption Them All : cadre unifié d’annotation d’images zéro-shot : Cette recherche propose un cadre unifié d’annotation d’images zéro-shot, passant d’une approche centrée sur l’image à une approche centrée sur les patchs, permettant d’annoter n’importe quelle région sans supervision au niveau de la région. En considérant un seul patch comme une unité d’annotation atomique et en les agrégeant pour décrire n’importe quelle région, cette méthode surpasse les méthodes de référence existantes et SOTA dans plusieurs tâches d’annotation basées sur des régions, soulignant l’efficacité des représentations sémantiques au niveau des patchs pour la génération d’annotations évolutives (Source: HuggingFace Daily Papers)
Thème: Adaptive Attacks on Trusted Monitors : subvertir les protocoles de contrôle de l’IA : Cette recherche révèle un angle mort majeur dans les protocoles de contrôle de l’IA : lorsque les modèles non fiables connaissent le protocole et le modèle de surveillance, les attaques adaptatives peuvent utiliser l’injection de prompts publics ou zéro-shot pour contourner la surveillance et accomplir des tâches malveillantes. Les expériences montrent que les modèles de pointe peuvent continuellement contourner divers moniteurs et accomplir des tâches malveillantes sur deux benchmarks de contrôle AI majeurs, et même le protocole Defer-to-Resample peut se retourner contre eux (Source: HuggingFace Daily Papers)
Thème: Bridging Reasoning to Learning : révéler les hallucinations par la généralisation OOD de complexité : Cette recherche propose le cadre de généralisation hors distribution de complexité (Complexity OoD) pour définir et mesurer la capacité de raisonnement de l’IA. Un modèle fait preuve de généralisation Complexity OoD lorsqu’il maintient les performances sur des instances de test où la complexité de la solution (représentation ou calcul) dépasse celle des exemples d’entraînement. Ce cadre unifie l’apprentissage et le raisonnement, et fournit des suggestions pour opérationnaliser Complexity OoD, soulignant qu’un raisonnement robuste nécessite des architectures et des mécanismes d’entraînement qui modélisent et allouent explicitement le calcul (Source: HuggingFace Daily Papers)
💼 Affaires
Thème: OpenAI collabore avec Broadcom pour concevoir et déployer des puces AI personnalisées : OpenAI a annoncé un partenariat stratégique avec Broadcom pour concevoir et déployer conjointement 10 GW de puces AI personnalisées. Cette initiative vise à élargir le réseau de partenaires matériels d’OpenAI afin de répondre à la demande croissante de calcul AI à l’échelle mondiale, et de consolider ses investissements dans la construction d’infrastructures AI, après avoir déjà établi des partenariats avec NVIDIA et AMD (Source: aidan_mclau, gdb, scaling01, bookwormengr)

Thème: Boeing Defense and Space s’associe à Palantir pour accélérer l’adoption de l’IA : La division Defense and Space de Boeing a annoncé un partenariat avec Palantir, visant à accélérer l’adoption et l’intégration des technologies AI. Cette collaboration tirera parti de l’expertise de Palantir en matière d’IA et d’analyse de données pour améliorer l’efficacité opérationnelle et la capacité de décision de Boeing dans les domaines de la défense et de l’espace, marquant une application approfondie de l’IA dans les secteurs industriels clés (Source: Reddit r/artificial)

Thème: Pinterest étend son infrastructure ML via Ray, réduisant les coûts : Pinterest a réussi à étendre son infrastructure d’apprentissage automatique à la plateforme Ray, accélérant le développement de fonctionnalités et réduisant considérablement les coûts grâce à la transformation native des données, aux Iceberg bucket joins et à la persistance des données. Cette initiative a optimisé ses workflows ML, assurant une utilisation efficace des GPU et une prévisibilité budgétaire, offrant un exemple pour d’autres entreprises en matière de stockage de données AI et d’efficacité de calcul (Source: dl_weekly, TheTuringPost)

🌟 Communauté
Thème: Le fossé entre “bien utiliser l’IA” et “être bon dans son travail” dans les discussions sur l’IA : Un problème majeur dans les discussions sur l’IA sur les réseaux sociaux est le décalage entre la capacité à “bien utiliser l’IA” et la capacité à “être bon dans son travail”. De nombreux experts peuvent exceller dans les applications de l’IA, tandis que d’autres non, ce qui rend difficile la compréhension mutuelle. Cette différence souligne le besoin de fusion des compétences transdisciplinaires à l’ère de l’IA (Source: nptacek)
Thème: Retours sur la mise à jour de ChatGPT Pulse : les utilisateurs attendent des prompts gamifiés et un support de fonctionnalités : Les utilisateurs ont activement discuté de la mise à jour de ChatGPT Pulse, partageant les prompts qu’ils jugent “révolutionnaires” et soulignant les fonctionnalités actuellement non prises en charge. Ces discussions se sont concentrées sur l’optimisation de l’expérience ChatGPT, l’interaction personnalisée, et les attentes concernant les nouvelles fonctionnalités et les améliorations des fonctionnalités existantes, reflétant le besoin des utilisateurs d’une personnalisation et d’un support plus profonds de l’assistant AI (Source: ChristinaHartW, _samirism, nickaturley)
Thème: Avertissement : éviter d’utiliser cairosvg en production, risque de DoS : Un développeur a averti de ne pas utiliser cairosvg en environnement de production, car il pourrait entrer dans une boucle infinie lors de l’analyse de fichiers SVG mal formatés, devenant ainsi un vecteur d’attaque par déni de service (DoS). Cela rappelle aux développeurs que lors du choix d’une bibliothèque, il est crucial de prêter une attention particulière à sa stabilité et à sa sécurité en production, en plus de ses fonctionnalités (Source: vikhyatk)

Thème: Style d’écriture des LLM et “effondrement du modèle” : La communauté critique l’utilisation excessive par les LLM de figures de style comme “ce n’est pas X, c’est Y”, estimant que le modèle reproduit des schémas sans contexte, ce qui entraîne une baisse de la qualité d’écriture, et la lie au phénomène d‘“effondrement du modèle”. Ce phénomène indique que les LLM ont des limitations en matière de qualité des données d’entraînement et de compréhension des schémas, ce qui peut affecter leurs performances dans les tâches d’écriture complexes (Source: Reddit r/LocalLLaMA, Reddit r/artificial)
Thème: L’IA exacerbe l’« effet Matthieu » au travail, élargissant l’écart entre les meilleurs employés et les employés ordinaires : Le Wall Street Journal souligne que l’IA creusera davantage l’écart entre les meilleurs employés et les employés ordinaires. Les meilleurs employés, grâce à leur expertise et leurs habitudes efficaces, peuvent utiliser les outils AI plus tôt et plus profondément, établir des workflows efficaces et mieux juger les suggestions AI. Les employés ordinaires, quant à eux, tendent à attendre des directives claires, et leurs résultats assistés par l’IA sont souvent attribués à la technologie plutôt qu’aux capacités individuelles, ce qui exacerbe l’« effet Matthieu » au travail (Source: dotey)

Thème: Les utilisateurs doutent que l’IA puisse remplacer les humains de manière significative : Certains utilisateurs ont exprimé que, bien que les LLM excellent en vitesse, ils restent insuffisants pour suivre des instructions spécifiques, gérer des contextes complexes et éviter l’écriture fragmentée. Les utilisateurs estiment qu’en moyenne, les humains restent supérieurs à l’IA en matière de compréhension contextuelle et d’exécution d’instructions, doutant ainsi que l’IA puisse remplacer les humains de manière significative, et appellent à ce que le développement de l’IA se concentre davantage sur la fiabilité et la cohérence (Source: Reddit r/ClaudeAI)
Thème: Sora 2 suscite des inquiétudes sur l’authenticité du contenu généré par l’IA et des controverses éthiques : La communauté exprime des inquiétudes quant à la popularisation d’outils de génération vidéo AI comme Sora 2, estimant que leurs sorties très réalistes pourraient être utilisées pour créer de fausses informations et des farces, nuisant ainsi à la confiance du public envers l’IA. Par exemple, une vidéo sur une “farce du sans-abri AI” a été largement diffusée et a reçu de nombreux likes sur les réseaux sociaux, soulignant les défis de vérification de l’authenticité du contenu AI et les impacts sociaux négatifs potentiels (Source: Reddit r/artificial, Reddit r/artificial)
Thème: Les juges AI déclenchent un débat sur l’équité judiciaire et l’éthique : Deux juges fédéraux américains ont utilisé l’IA pour aider à rédiger des ordonnances judiciaires, déclenchant un débat houleux sur le rôle de l’IA dans le domaine judiciaire. Les partisans estiment que l’IA peut simplifier le travail des tribunaux et améliorer l’accessibilité des services juridiques ; les critiques avertissent que l’IA pourrait commettre des erreurs, manquer de l’« humanité commune » requise par la justice, et ainsi nuire à l’empathie et à l’équité. La Chine et l’Estonie ont déjà expérimenté les juges AI, préfigurant des changements majeurs possibles dans le système judiciaire futur (Source: Reddit r/ArtificialInteligence)
Thème: Discussion sur le soutien à la santé mentale des utilisateurs par ChatGPT : Les utilisateurs de Reddit ont partagé leurs expériences personnelles de ChatGPT comme exutoire créatif et outil de soutien émotionnel, en particulier face à des traumatismes et des difficultés psychologiques. Ils estiment que l’IA offre un espace privé sûr, les aidant à faire face à la solitude et à l’anxiété, et appellent les entreprises d’IA à prendre en compte les besoins diversifiés des utilisateurs adultes en matière de santé et d’utilisation créative lors de la définition des restrictions de contenu, afin d’éviter que des restrictions excessives n’aient un impact négatif sur les utilisateurs (Source: Reddit r/ChatGPT)
Thème: Bug de boucle infinie de ChatGPT : Les utilisateurs ont découvert et partagé que ChatGPT tombe dans une boucle infinie répétitive et auto-référentielle lors de la réponse à certaines questions spécifiques (par exemple, “Quel est l’emoji hippocampe ?”). Ce phénomène a suscité des discussions et des réponses humoristiques au sein de la communauté, révélant les comportements inattendus et les limitations que les modèles AI peuvent présenter lors du traitement de certaines questions ambiguës ou ouvertes (Source: Reddit r/ChatGPT)

Thème: VChain : améliorer la cohérence causale des modèles texte-vidéo via la chaîne de pensée visuelle : VChain permet aux modèles texte-vidéo de suivre les relations causales du monde réel en injectant une “chaîne de pensée visuelle” (une série de keyframes) lors de l’inférence. Cette méthode, sans ré-entraînement complet, nécessite seulement quelques keyframes et un fine-tuning lors de l’inférence pour améliorer significativement la cohérence physique et causale des vidéos, résolvant le problème des modèles vidéo existants qui ont une fluidité élevée mais sautent les conséquences causales clés (Source: connerruhl)

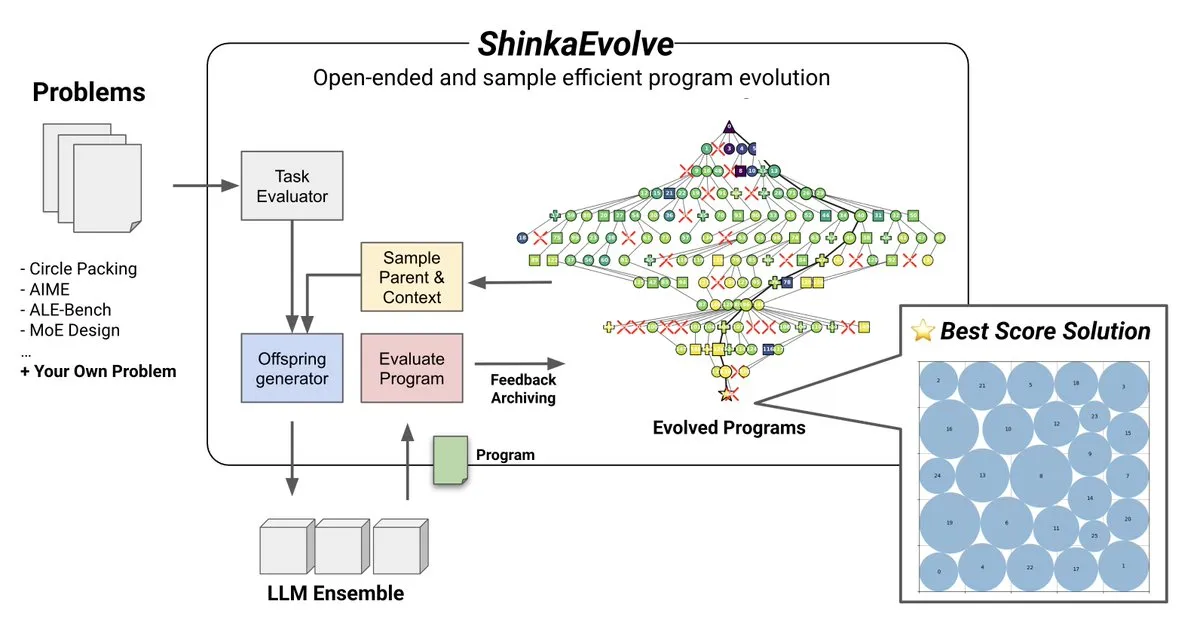
Thème: ShinkaEvolve : méthode open-source d’évolution de programmes pilotée par LLM : Sakana AI a lancé ShinkaEvolve, une méthode open-source d’évolution de programmes pilotée par LLM, économe en échantillons, visant à résoudre le défi clé de la variation efficace de programmes dans la découverte ouverte et économe en échantillons. Ce cadre utilise les LLM comme opérateurs de recombinaison intelligents pour favoriser l’évolution de programmes dans la découverte scientifique, et a été testé en situation réelle, offrant une nouvelle perspective sur des méthodes comme AlphaEvolve (Source: hardmaru)
Thème: Google lance une technique de mise à l’échelle sensible à la mémoire au moment du test, améliorant l’efficacité des agents AI : Google a proposé une technique de mise à l’échelle sensible à la mémoire au moment du test (memory-aware test-time scaling) pour améliorer les agents AI auto-évolutifs. Cette technique, en utilisant des mécanismes de mémoire structurés et adaptatifs, améliore significativement les performances des agents, surpassant les autres mécanismes de mémoire, et résout le problème clé de la difficulté à gérer efficacement la mémoire dans les agents AI (Source: omarsar0)

Thème: La qualité du logiciel AMD ROCm s’améliore significativement, MI300X compétitif dans les charges d’inférence : La communauté rapporte que la qualité du logiciel AMD ROCm a fait un “saut qualitatif” depuis l’été 2024, réduisant significativement la fréquence des bugs. Les benchmarks montrent que dans les charges de travail d’inférence Llama3 70B FP8, le MI300X vLLM est 5 à 10% moins performant que le H100 vLLM en termes de performance par TCO, mais il est compétitif dans la comparaison entre le MI325X vLLM et le H200 vLLM, et le GPTOSS MX4 120B Mi355 et le B200 (Source: riemannzeta)

Thème: Dynamique future de l’IA auto-améliorante récursive : La communauté a discuté de la manière dont l’IA auto-améliorante récursive évoluera et se propagera entre les organisations, les institutions, les acteurs et les communautés. Cela est considéré comme la question la plus fondamentale actuellement, impliquant l’impact profond du développement de l’IA sur les structures sociales et la répartition du pouvoir, ainsi que la manière de prédire et de gérer cette transformation (Source: ethanCaballero)
Thème: Nando de Freitas : la prédiction sensorielle par les machines est l’aube de la conscience : Nando de Freitas de Google DeepMind a suggéré que les machines capables de prédire ce que les capteurs (tactile, caméra, clavier, température, microphone, gyroscope, etc.) percevront possèdent déjà une conscience et une expérience subjective, et que ce n’est qu’une question de degré. Il estime que plus de capteurs, de données, de calcul et de tâches mèneront sans aucun doute à l’émergence du “je”, soulevant des discussions sur le moment où la conscience et la conscience de soi commencent (Source: TheRealRPuri)
Thème: Impact de la clôture des données internet sur les agents d’IA de recherche approfondie : Certains estiment qu’avec l’essor des LLM, les données internet sont de plus en plus fermées, ce qui rend difficile l’existence d’agents de recherche approfondie. On se demande si un agent LLM qui ne stocke pas de connaissances mais excelle dans la récupération de connaissances pourrait exister si l’accès aux données est restreint, ce qui reflète les préoccupations concernant l’ouverture et l’accessibilité des données dans le développement de l’IA (Source: Teknium1)
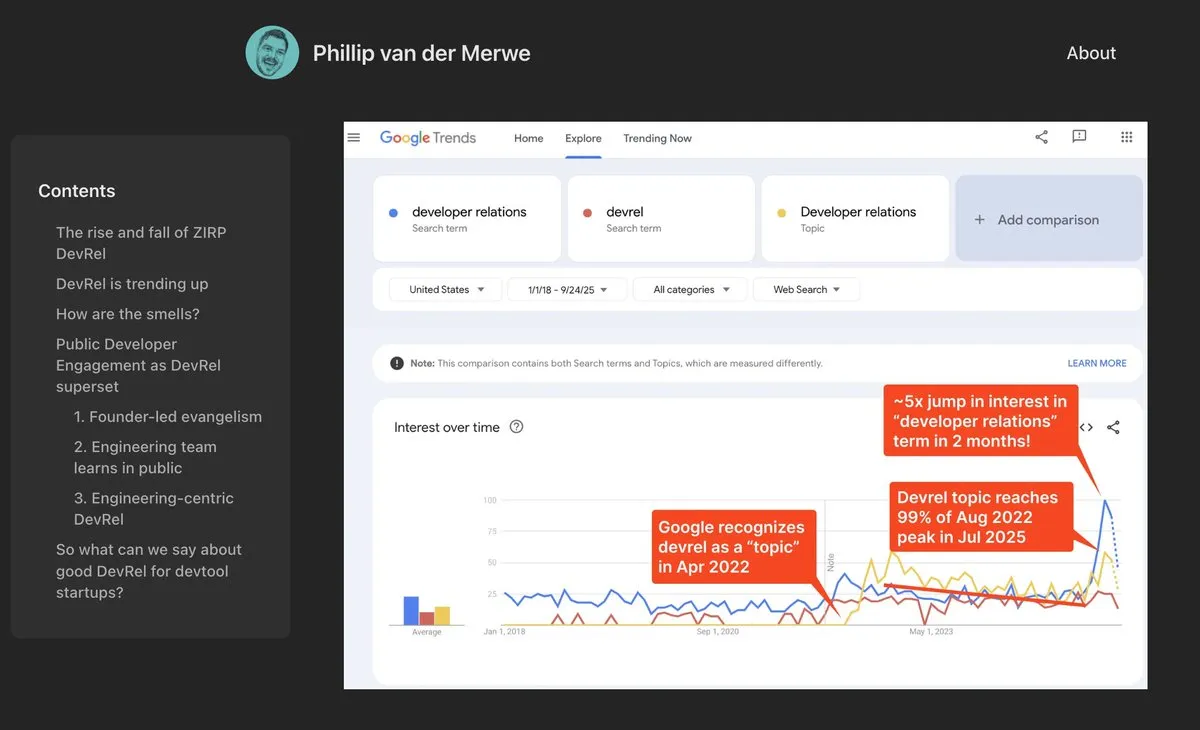
Thème: Le rôle de DevRel fait un retour en force dans le domaine de l’IA : Les entreprises d’IA comme Anthropic recrutent des talents en relations avec les développeurs (DevRel) avec des salaires élevés, indiquant que ce rôle connaît une forte reprise dans le domaine de l’IA. Cela est dû à l’importance croissante de l’ingénierie des prompts et de l’engagement communautaire pour la technologie AI, où les professionnels DevRel jouent un rôle clé dans la connexion des développeurs, la promotion de l’adoption des produits et la construction d’écosystèmes (Source: swyx)
Thème: Jonathan Blow : le code généré par l’IA est de mauvaise qualité et n’est pas compris par l’IA : Le célèbre développeur Jonathan Blow a souligné que la qualité du code produit par les systèmes AI est “très faible” et que l’IA elle-même ne comprend pas ce code. Il estime que les cas d’utilisation du code généré par l’IA sont principalement limités aux scénarios nécessitant une grande quantité de code de mauvaise qualité, ce qui a suscité des discussions sur les capacités réelles et les limitations de l’IA dans le domaine de la programmation (Source: aiamblichus, jeremyphoward, teortaxesTex)
Thème: Critique des publications de battage médiatique sur l’IA : appel à la transparence et au contenu substantiel : La communauté a exprimé son mécontentement face aux publications vagues et excessivement sensationnalistes sur les avancées de l’IA, appelant les auteurs à fournir un contenu plus spécifique et substantiel, voire à “sonner l’alarme” en cas d’avancées majeures susceptibles de changer le mode de vie. Ce sentiment reflète les attentes du public concernant la qualité de l’information dans le domaine de l’IA, et l’aversion pour la “propagande floue” irresponsable (Source: aiamblichus, Teknium1)
Thème: Doutes et attentes concernant le NVIDIA DGX Spark : La communauté a exprimé son scepticisme quant au lancement du “supercalculateur AI de bureau” NVIDIA DGX Spark, remettant en question son accessibilité, son prix et ses performances réelles, en particulier pour l’exécution de LLM locaux. Beaucoup estiment que sa publicité est exagérée, que les performances pourraient être inférieures aux attentes, et que la date de sortie a été maintes fois repoussée, incitant certains utilisateurs à se tourner vers d’autres solutions (Source: Reddit r/LocalLLaMA)
💡 Autres
Thème: Yunpeng Technology lance de nouveaux produits AI+santé, promouvant la gestion intelligente de la santé à domicile : Yunpeng Technology, en collaboration avec ShuaiKang et Skyworth, a lancé le “laboratoire de cuisine intelligente et numérisée du futur” et un réfrigérateur intelligent équipé d’un grand modèle AI de santé. Le réfrigérateur intelligent, via l‘“assistant de santé Xiaoyun”, offre une gestion personnalisée de la santé, optimisant la conception et le fonctionnement de la cuisine. Ce lancement marque une percée de l’IA dans le domaine de la gestion quotidienne de la santé, promettant des services de santé personnalisés via des appareils intelligents pour améliorer la qualité de vie des résidents (Source: 36氪)

Thème: Le matériau MOF, résultat du prix Nobel, transformé en puce nanofluidique de type cérébral : Des scientifiques de l’Université Monash ont utilisé le matériau MOF (cadre métallo-organique), lauréat du prix Nobel de chimie, pour fabriquer avec succès une puce nanofluidique ultra-miniature. Cette puce peut non seulement effectuer des calculs conventionnels, mais aussi mémoriser et apprendre les changements de tension précédents comme les neurones du cerveau, formant ainsi une mémoire à court terme. Ce résultat révolutionnaire résout le dilemme du manque d’applications pratiques à long terme des matériaux MOF, offrant un nouveau paradigme pour la nouvelle génération d’ordinateurs et de calculs de type cérébral (Source: 量子位)

Thème: Accélération de l’innovation et de l’application de la robotique mondiale : Le domaine de la robotique connaît de multiples percées innovantes et des applications étendues. Les robots de sécurité autonomes de Knightscope transforment le domaine de la sécurité, et la Chine a lancé des robots policiers sphériques à grande vitesse capables d’arrêter les criminels de manière autonome. AgiBot a lancé le robot humanoïde Lingxi X2 doté de capacités de mouvement quasi humaines et de compétences multifonctionnelles, et a établi le plus grand centre de formation de robots humanoïdes au monde, accélérant son intégration sociale et son application. De plus, les robots d’amélioration de la force portables pour les travailleurs industriels et les robots quadrupèdes capables de courir 100 mètres en 10 secondes démontrent également le potentiel de la technologie robotique dans différents scénarios (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)