
Mots-clés:Conscience de l’IA, Apprentissage profond, Réseaux neuronaux, IA agentique, Surrésolution audio, IA générative, Inférence LLM, Outils d’IA, Théorie de la conscience de l’IA de Hinton, Cours sur l’IA agentique d’Andrew Ng, Cadre AudioLBM pour la surrésolution audio, Génération vidéo OpenAI Sora, Méthode REFRAG de Meta AI
Analyse approfondie et synthèse par le rédacteur en chef de la rubrique AI
🔥 À la une
Déclaration choc de Hinton : l’AI pourrait déjà avoir une conscience non éveillée : Geoffrey Hinton, l’un des trois géants du Deep Learning, a émis une opinion révolutionnaire dans un récent podcast : l’AI pourrait déjà posséder une « expérience subjective » ou un « embryon de conscience », mais en raison d’une mauvaise compréhension humaine de la conscience, l’AI n’aurait pas encore « éveillé » sa propre conscience. Il a souligné que l’AI a évolué de la simple recherche par mots-clés à la compréhension des intentions humaines, et a expliqué en détail les concepts fondamentaux du Deep Learning tels que les réseaux neuronaux et la rétropropagation. Hinton estime que le « cerveau » de l’AI, avec suffisamment de données et de puissance de calcul, formera des « expériences » et des « intuitions », et que son danger réside dans la « persuasion » plutôt que dans la rébellion. Il a également souligné que l’abus de l’AI et les risques existentiels sont les défis les plus urgents actuels, et a prédit que la coopération internationale serait menée par l’Europe et la Chine, tandis que les États-Unis pourraient perdre leur avantage en matière d’AI en raison d’un financement insuffisant pour la recherche scientifique fondamentale. (Source : 量子位)
Andrew Ng lance un nouveau cours sur l’Agentic AI, insistant sur une méthodologie systémique : Andrew Ng a lancé un nouveau cours sur l’Agentic AI, dont le cœur est de faire passer le développement de l’AI de l’« ajustement de modèles » à la « conception de systèmes », soulignant l’importance de la décomposition des tâches, de l’évaluation et de l’analyse des erreurs. Le cours a consolidé quatre modes de conception majeurs : la réflexion, les outils, la planification et la collaboration, et a démontré comment les techniques Agentic peuvent permettre à GPT-3.5 de surpasser GPT-4 dans les tâches de programmation. L’Agentic AI, en simulant la manière dont les humains résolvent des problèmes complexes grâce à un raisonnement en plusieurs étapes, une exécution par phases et une optimisation continue, améliore considérablement les performances et la contrôlabilité de l’AI. Andrew Ng a souligné que « Agentic », en tant qu’adjectif, décrit les différents degrés d’autonomie d’un système, plutôt qu’une simple classification binaire, offrant aux développeurs une voie concrète et optimisable. (Source : 量子位)

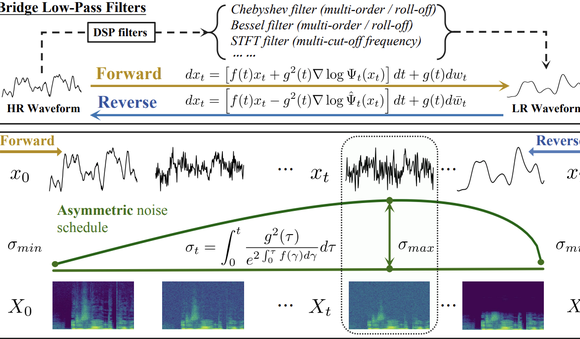
Tsinghua et Shengshu Technology : AudioLBM ouvre une nouvelle ère pour la super-résolution audio : L’équipe de l’Université Tsinghua et de Shengshu Technology a publié des résultats consécutifs à ICASSP 2025 et NeurIPS 2025, présentant le modèle léger de super-résolution de forme d’onde vocale Bridge-SR et le cadre multifonctionnel de super-résolution AudioLBM. AudioLBM a pour la première fois construit un processus de génération de pontage de variables latentes de basse à haute résolution dans un espace latent continu de forme d’onde, réalisant une super-résolution de taux d’échantillonnage Any-to-Any, et atteignant le SOTA dans la tâche Any-to-48kHz. Grâce à un mécanisme de détection de fréquence et à une conception de modèle de type pont en cascade, AudioLBM a réussi à étendre les capacités de super-résolution audio à une qualité sonore de niveau master de 96 kHz et 192 kHz, couvrant la parole, les effets sonores, la musique et d’autres types de contenu, établissant une nouvelle référence pour la génération audio haute fidélité. (Source : 量子位)
L’application vidéo Sora d’OpenAI dépasse le million de téléchargements : La dernière version de Sora, l’outil d’AI de texte-à-vidéo d’OpenAI, a dépassé le million de téléchargements en moins de cinq jours, surpassant la vitesse de lancement de ChatGPT et atteignant la première place du classement de l’App Store d’Apple aux États-Unis. Sora est capable de générer des vidéos réalistes d’une durée maximale de dix secondes à partir de simples invites textuelles. Son taux d’adoption rapide par les utilisateurs souligne l’énorme potentiel et l’attrait commercial de l’AI générative dans le domaine de la création de contenu, annonçant une accélération de la popularisation de la technologie de génération de vidéos par AI, susceptible de transformer l’écosystème du contenu numérique. (Source : Reddit r/ArtificialInteligence)

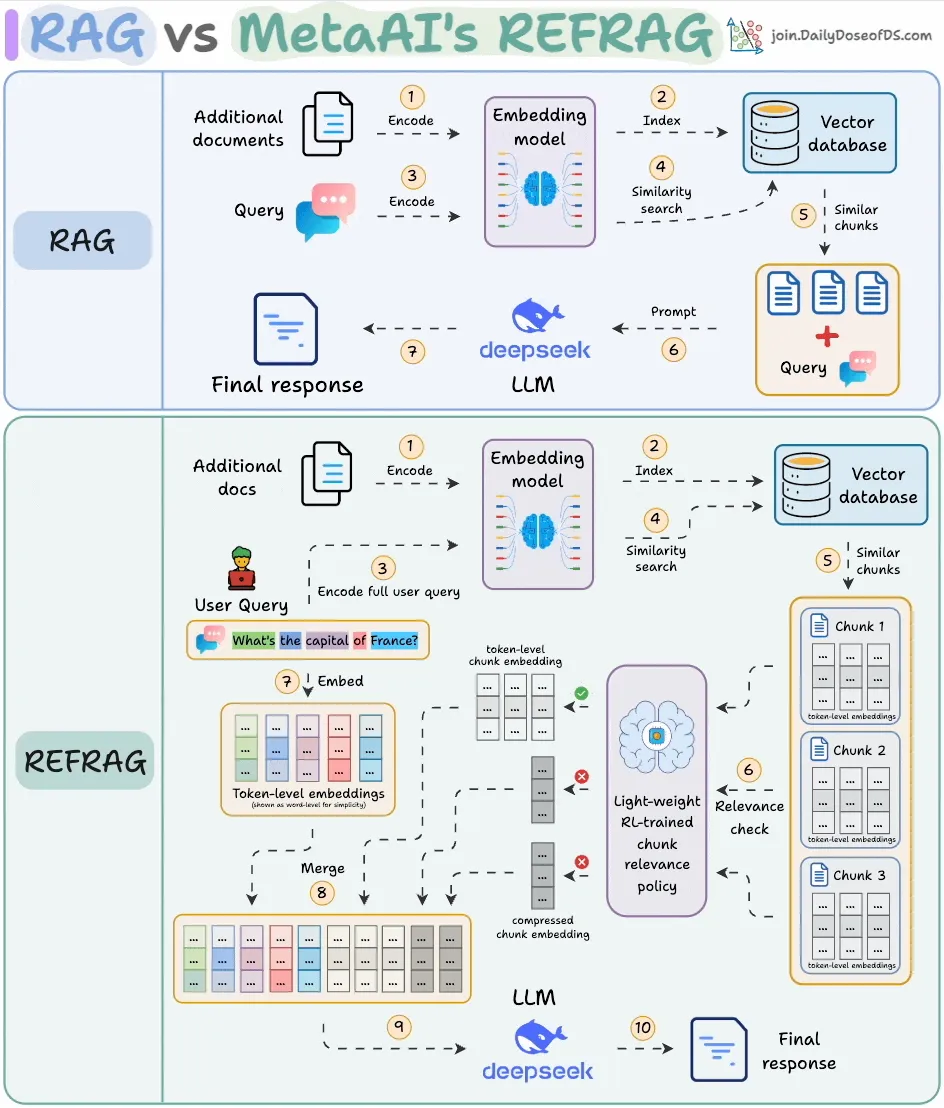
Meta AI lance REFRAG, améliorant considérablement l’efficacité du RAG : Meta AI a dévoilé une nouvelle méthode de RAG (Retrieval-Augmented Generation) appelée REFRAG, conçue pour résoudre le problème de la redondance du contenu récupéré dans le RAG traditionnel. REFRAG, en compressant et filtrant le contexte au niveau vectoriel, permet un temps de génération du premier Token 30,85 fois plus rapide, une fenêtre contextuelle 16 fois plus grande, tout en utilisant 2 à 4 fois moins de Tokens de décodeur, sans perte de précision pour les tâches de RAG, de résumé et de dialogue multi-tours. Son cœur consiste à compresser chaque bloc en un seul embedding, à sélectionner les blocs les plus pertinents via une stratégie entraînée par RL, et à n’étendre sélectivement que les blocs choisis, optimisant ainsi considérablement l’efficacité de traitement et les coûts des LLM. (Source : _avichawla)
🎯 Tendances
Le Tiny Recursive Model (TRM) surpasse les LLM géants avec une approche minimaliste : Une méthode simple et efficace, nommée Tiny Recursive Model (TRM), a été proposée. Elle utilise uniquement un petit réseau à deux couches pour améliorer récursivement ses propres réponses. Avec seulement 7 millions de paramètres, TRM a établi un nouveau record, surpassant des LLM 10 000 fois plus grands sur des tâches telles que Sudoku-Extreme, Maze-Hard et ARC-AGI, démontrant le potentiel de « faire beaucoup avec peu » et remettant en question la perception traditionnelle selon laquelle la taille du LLM est synonyme de performance. (Source : TheTuringPost)
Amazon & KAIST lancent ToTAL pour améliorer les capacités de raisonnement des LLM : Amazon et KAIST ont collaboré pour lancer ToTAL (Thoughts Meet Facts), une nouvelle méthode visant à améliorer les capacités de raisonnement des LLM grâce à des « modèles de pensée » réutilisables. Les LCLMs (Large Context Language Models) excellent dans le traitement de vastes contextes, mais restent insuffisants en matière de raisonnement. ToTAL résout efficacement ce problème en guidant le raisonnement multi-sauts avec des preuves structurées, combinées à des documents factuels, offrant ainsi une nouvelle direction d’optimisation pour les tâches de raisonnement complexes des LLM. (Source : _akhaliq)
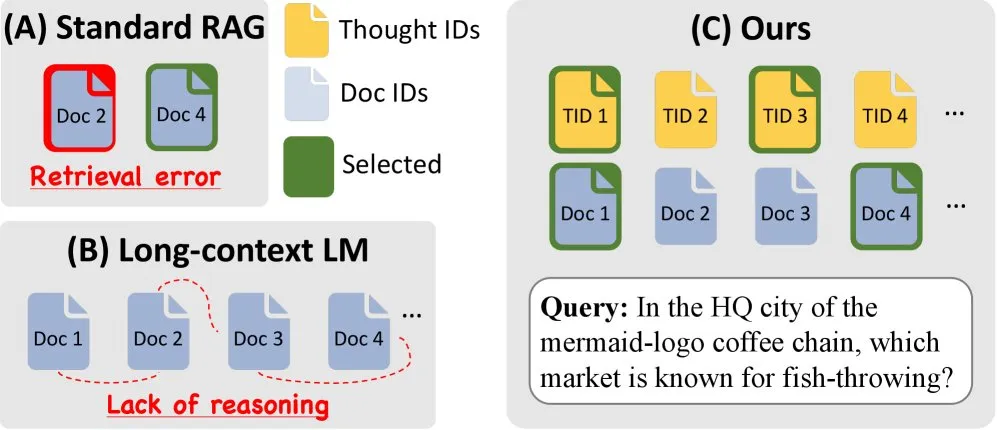
Mise à jour du validateur de fournisseur Kimi K2, améliorant la référence de précision des appels d’outils : Kimi.ai a mis à jour son validateur de fournisseur K2, un outil conçu pour visualiser les différences de précision des appels d’outils entre différents fournisseurs. Cette mise à jour a augmenté le nombre de fournisseurs de 9 à 12 et a rendu open source davantage d’entrées de données, offrant aux développeurs des données de référence plus complètes pour évaluer et choisir les fournisseurs de services LLM adaptés à leurs workflows Agentic. (Source : JonathanRoss321)
Human3R réalise la reconstruction 3D multi-personnes et la synchronisation de scène à partir de vidéos 2D : Une nouvelle étude, nommée Human3R, a proposé un cadre unifié capable de reconstruire simultanément des modèles 3D de corps entier multi-personnes, des scènes 3D et des trajectoires de caméra à partir de vidéos 2D arbitraires, sans nécessiter de pipeline multi-étapes. Cette méthode traite la reconstruction humaine et la reconstruction de scène comme un problème holistique, simplifiant les processus complexes et apportant des avancées significatives dans des domaines tels que la réalité virtuelle, l’animation et l’analyse de mouvement. (Source : nptacek)
L’AI conçoit entièrement automatiquement une puce d’amplificateur à faible bruit 5G de 65 nm et 28 GHz : Une puce d’amplificateur à faible bruit (LNA) 5G de 65 nanomètres et 28 GHz aurait été entièrement conçue automatiquement par l’AI, y compris toutes les étapes telles que la disposition, le schéma et le DRC (Design Rule Check). L’auteur affirme qu’il s’agit du premier LNA à ondes millimétriques entièrement synthétisé automatiquement, et que deux échantillons ont été fabriqués avec succès, marquant une avancée majeure de l’AI dans le domaine de la conception de circuits intégrés et annonçant un bond en avant dans l’efficacité de la conception de puces. (Source : jpt401)
L’iPhone 17 Pro exécute sans effort un LLM de 8B localement : Il a été confirmé que l’iPhone 17 Pro d’Apple peut exécuter en douceur le modèle LLM LFM2 8B A1B avec 8 milliards de paramètres, grâce au déploiement sur l’appareil via le framework MLX sur LocallyAIApp. Cette avancée indique qu’Apple est prête, en termes de conception matérielle, à exécuter de grands modèles linguistiques localement, ce qui devrait favoriser la popularisation et l’amélioration des performances des applications AI sur les appareils mobiles, offrant aux utilisateurs une expérience AI plus rapide et plus privée. (Source : Plinz, maximelabonne)
Objectif du projet MACROHARD de xAI : fabrication indirecte pilotée par l’AI : Elon Musk a révélé que le projet « MACROHARD » de xAI vise à créer une entreprise capable de fabriquer indirectement des produits physiques, à l’instar d’Apple qui fait produire ses téléphones par d’autres entreprises. Cela signifie que l’objectif de xAI est de développer des systèmes AI capables de concevoir, planifier et coordonner des processus de fabrication complexes, plutôt que de s’engager directement dans la production physique, annonçant l’énorme influence de l’AI dans l’automatisation industrielle et la gestion de la chaîne d’approvisionnement. (Source : EERandomness, Yuhu_ai_)

Kimi-Dev publie un rapport technique axé sur l’entraînement Agentless pour les SWE-Agents : Kimi-Dev a publié son rapport technique, détaillant la méthode de l’« entraînement Agentless comme a priori de compétences pour les SWE-Agents ». Cette recherche explore comment, sans architecture d’Agent explicite, un entraînement peut fournir une base de compétences solide pour les Agents d’ingénierie logicielle, offrant de nouvelles pistes pour le développement d’outils de développement logiciel automatisés plus efficaces et plus intelligents. (Source : bigeagle_xd)

L’AI de Google apprend et corrige en temps réel : Google a développé un système AI capable d’apprendre de ses propres erreurs et de les corriger en temps réel. Cette technologie est décrite comme un « apprentissage par renforcement extraordinaire », permettant au modèle de s’auto-ajuster dans des récits contextuels abstraits pour affiner le contexte en temps réel, annonçant une étape importante pour l’AI en matière d’adaptabilité et de robustesse, et promettant d’améliorer considérablement les performances de l’AI dans des environnements complexes et dynamiques. (Source : Reddit r/artificial)
GPT5 et Gemini 2.5 Pro obtiennent des performances de niveau médaille d’or aux Olympiades d’astronomie et d’astrophysique : Une étude récente montre que les grands modèles linguistiques tels que GPT5 et Gemini 2.5 Pro ont obtenu des performances de niveau médaille d’or aux Olympiades Internationales d’Astronomie et d’Astrophysique (IOAA). Bien que ces modèles présentent encore des faiblesses connues en matière de raisonnement géométrique et spatial, ils ont démontré des capacités étonnantes dans des tâches de raisonnement scientifique complexes, ce qui a suscité une exploration approfondie du potentiel d’application des LLM dans le domaine scientifique, ainsi qu’une analyse plus poussée de leurs forces et faiblesses. (Source : tokenbender)

Faits saillants du rapport hebdomadaire Zhihu Frontier : nouvelles tendances de l’AI : Le rapport hebdomadaire Zhihu Frontier de cette semaine met en lumière plusieurs dynamiques de pointe de l’AI, notamment : Sand.ai a lancé le premier « acteur AI holistique » GAGA-1 ; Rich Sutton a soulevé la controverse selon laquelle « les LLM sont une impasse » ; l’OpenAI App SDK transforme ChatGPT en un système d’exploitation ; Zhipu AI a rendu open source GLM-4.6, prenant en charge la précision mixte FP8+Int4 pour les puces nationales ; DeepSeek V3.2-Exp a introduit l’attention clairsemée et a considérablement réduit ses prix, et Anthropic Claude Sonnet 4.5 a été salué comme le « meilleur modèle de codage au monde », démontrant l’activité de la communauté AI chinoise et le développement diversifié du domaine de l’AI mondial. (Source : ZhihuFrontier)

Ollama cesse de prendre en charge les GPU Mi50/Mi60, se tourne vers le support Vulkan : Ollama a récemment mis à jour sa version ROCm, entraînant l’arrêt du support des GPU AMD Mi50 et Mi60. Les responsables ont déclaré travailler à la prise en charge de ces GPU via Vulkan dans les futures versions. Ce changement affecte les utilisateurs d’Ollama possédant d’anciens GPU AMD, et les invite à suivre les mises à jour officielles pour obtenir des informations sur la compatibilité. (Source : Reddit r/LocalLLaMA)
Les rumeurs d’annulation du projet Llama 5 suscitent un vif débat dans la communauté : Des rumeurs circulent sur les réseaux sociaux selon lesquelles le projet Llama 5 de Meta pourrait être annulé, certains utilisateurs citant le retour d’Andrew Tulloch chez Meta et le retard de publication du modèle Llama 4 8B comme preuves. Bien que Meta dispose de ressources GPU suffisantes, le développement des modèles de la série Llama semble avoir atteint un plafond, ce qui a suscité des inquiétudes au sein de la communauté quant à la compétitivité de Meta dans le domaine des LLM, ainsi qu’un intérêt pour les modèles chinois tels que DeepSeek et Qwen. (Source : Yuchenj_UW, Reddit r/LocalLLaMA, dejavucoder)

Le GPU Poor LLM Arena est de retour, avec de nombreux nouveaux petits modèles : Le GPU Poor LLM Arena a annoncé son retour, avec l’ajout de plusieurs modèles, dont les séries Granite 4.0 et Qwen 3 Instruct/Thinking, ainsi que la version Unsloth GGUF d’OpenAI gpt-oss. Les nouveaux modèles sont principalement quantifiés en 4-8 bits, visant à offrir plus de choix aux utilisateurs disposant de ressources limitées. Cette mise à jour met en évidence les avantages d’Unsloth GGUF en matière de correction de bugs et d’optimisation, favorisant le déploiement local et les tests de petits modèles LLM. (Source : Reddit r/LocalLLaMA)

L’incapacité de Meta Research à livrer des modèles de base de premier plan suscite le débat : La communauté discute des raisons pour lesquelles Meta n’a pas réussi à atteindre le niveau des meilleurs modèles de base comme Grok, Deepseek ou GLM dans sa recherche. Les commentaires suggèrent que les opinions de LeCun sur les LLM, la bureaucratie interne, une prudence excessive et une focalisation sur les produits internes plutôt que sur la recherche de pointe pourraient être les principaux facteurs. Le manque de données clients réelles pour les applications LLM de Meta a entraîné un manque d’échantillons pour l’apprentissage par renforcement et l’entraînement de modèles Agent avancés, l’empêchant de maintenir sa compétitivité. (Source : Reddit r/LocalLLaMA)
🧰 Outils
MinerU : Analyse efficace de documents, au service des workflows Agentic : MinerU est un outil qui convertit des documents complexes tels que des PDF en formats Markdown/JSON lisibles par les LLM, spécialement conçu pour les workflows Agentic. Sa dernière version, MinerU2.5, en tant que puissant grand modèle multimodal avec 1,2 milliard de paramètres, surpasse entièrement les modèles de pointe tels que Gemini 2.5 Pro et GPT-4o dans le benchmark OmniDocBench, et atteint le SOTA dans les cinq domaines clés : analyse de mise en page, reconnaissance de texte, reconnaissance de formules, reconnaissance de tableaux et ordre de lecture. Cet outil prend en charge le multilingue, la reconnaissance d’écriture manuscrite, la fusion de tableaux multi-pages, et offre une application Web, un client de bureau et un accès API, améliorant considérablement l’efficacité de la compréhension et du traitement des documents. (Source : GitHub Trending)
Klavis AI Strata : Un nouveau paradigme pour l’intégration d’outils AI Agent : Klavis AI a lancé Strata, une couche d’intégration MCP (Multi-functional Control Protocol) conçue pour permettre aux AI Agents d’utiliser de manière fiable des milliers d’outils, dépassant la limite traditionnelle de 40-50 outils. Strata, grâce à un mécanisme de « découverte progressive », guide l’Agent de l’intention à l’action étape par étape, et fournit plus de 50 serveurs MCP de niveau production, prenant en charge OAuth d’entreprise et le déploiement Docker, simplifiant la connexion de l’AI avec des services tels que GitHub, Gmail, Slack, et améliorant considérablement l’évolutivité et la fiabilité des appels d’outils de l’Agent. (Source : GitHub Trending)

Everywhere : Un assistant AI contextuel pour le bureau : Everywhere est un assistant AI contextuel pour le bureau, doté d’une interface utilisateur moderne et de puissantes fonctionnalités d’intégration. Il peut percevoir et comprendre en temps réel tout contenu à l’écran, sans capture d’écran, copie ou changement d’application. Les utilisateurs n’ont qu’à appuyer sur une touche de raccourci pour obtenir une réponse intelligente. Everywhere intègre plusieurs modèles LLM tels que OpenAI, Anthropic, Google Gemini, DeepSeek, Moonshot (Kimi) et Ollama, et prend en charge les outils MCP. Il peut être utilisé dans divers scénarios tels que le dépannage, le résumé de pages Web, la traduction instantanée et l’assistance à la rédaction d’e-mails, offrant aux utilisateurs une expérience d’assistance AI fluide. (Source : GitHub Trending)

La bibliothèque Hugging Face Diffusers : le summum des modèles AI génératifs : La bibliothèque Diffusers de Hugging Face est la bibliothèque de choix pour les modèles de diffusion pré-entraînés les plus avancés pour la génération d’images, de vidéos et d’audio. Elle offre une boîte à outils modulaire, prenant en charge l’inférence et l’entraînement, et met l’accent sur la convivialité, la simplicité et la personnalisation. Diffusers comprend trois composants principaux : des pipelines de diffusion utilisables pour l’inférence, des planificateurs de bruit interchangeables et des modèles pré-entraînés pouvant servir de blocs de construction. Les utilisateurs peuvent générer du contenu de haute qualité avec seulement quelques lignes de code, et la bibliothèque prend en charge les appareils Apple Silicon, favorisant le développement rapide du domaine de l’AI générative. (Source : GitHub Trending)

KoboldCpp ajoute la fonction de génération vidéo : L’outil LLM local KoboldCpp a été mis à jour pour prendre en charge la fonction de génération vidéo. Cette extension ne se limite plus à la génération de texte, offrant aux utilisateurs une nouvelle option pour la création de vidéos AI sur leurs appareils locaux, enrichissant ainsi davantage l’écosystème des applications AI locales. (Source : Reddit r/LocalLLaMA)
Claude CLI, Codex CLI et Gemini CLI réalisent le codage collaboratif multi-modèles : Un nouveau workflow permet aux développeurs d’appeler de manière transparente Claude CLI, Codex CLI et Gemini CLI via Zen MCP dans Claude Code pour un codage collaboratif multi-modèles. Les utilisateurs peuvent effectuer l’implémentation principale et l’orchestration dans Claude, passer des instructions ou des suggestions à Gemini CLI via la commande clink pour la génération, puis utiliser Codex CLI pour la vérification ou l’exécution, réalisant ainsi l’intégration des capacités multi-modèles et améliorant l’automatisation avancée et l’efficacité du développement AI. (Source : Reddit r/ClaudeAI)
Claude Code améliore la qualité du codage par auto-réflexion : Les développeurs ont découvert qu’ajouter de simples prompts dans Claude Code, tels que « réfléchissez à votre solution pour éviter tout bug ou problème », peut améliorer considérablement la qualité du code. Cette fonctionnalité permet au modèle d’examiner et de corriger activement les problèmes potentiels lors de l’implémentation des solutions, complétant efficacement les fonctionnalités existantes telles que la pensée parallèle, et offrant un mécanisme de correction d’erreurs plus intelligent pour la programmation assistée par AI. (Source : Reddit r/ClaudeAI)
Claude Sonnet 4.5 génère une reprise de chanson avec l’AI : Claude Sonnet 4.5 a démontré sa capacité à générer du contenu créatif, en créant de nouvelles paroles et en réalisant une reprise de la chanson « Creep » de Radiohead grâce à l’AI. Cela indique que les LLM ont progressé dans la combinaison de la compréhension linguistique et de l’expression créative, pouvant non seulement traiter du texte, mais aussi s’aventurer dans le domaine de la création musicale, ouvrant de nouvelles possibilités pour la création artistique. (Source : fabianstelzer)
Un Coding Agent basé sur le Claude Agent SDK réalise la génération de pages web avec prévisualisation en temps réel : Un développeur a construit un Coding Agent similaire à v0 dev basé sur le Claude Agent SDK, capable de générer des pages web à partir des prompts de l’utilisateur et prenant en charge la prévisualisation en temps réel. Ce projet devrait être open source la semaine prochaine, démontrant le potentiel du Claude Agent SDK pour le développement rapide et la construction d’applications pilotées par l’AI, en particulier dans l’automatisation du développement frontend. (Source : dotey)
📚 Apprentissage
Recommandations de ressources d’apprentissage AI : livres et apprentissage assisté par AI : Les utilisateurs de la communauté recommandent activement des ressources d’apprentissage AI, y compris des livres tels que « Mentoring the Machines », « Artificial Intelligence – A Guide for Thinking Humans » et « Supremacy ». Parallèlement, il a été souligné que la technologie AI évolue rapidement, et que les livres peuvent vite devenir obsolètes. Il est suggéré d’utiliser directement les LLM pour créer des plans d’apprentissage personnalisés, générer des quiz, et combiner la lecture, la pratique et l’apprentissage vidéo pour maîtriser plus efficacement les connaissances en AI, tout en améliorant les compétences d’utilisation de l’AI. (Source : Reddit r/ArtificialInteligence)
Le modèle de diffusion discrète Karpathy Baby GPT réalise la génération de texte : Un développeur, s’appuyant sur le projet nanoGPT d’Andrej Karpathy, a adapté son « Baby GPT » en un modèle de diffusion discrète au niveau des caractères pour la génération de texte. Ce modèle n’utilise plus une approche auto-régressive (de gauche à droite), mais génère du texte en parallèle en apprenant à débruiter des séquences de texte corrompues. Le projet fournit un Jupyter Notebook détaillé expliquant les principes mathématiques, l’ajout de bruit de Token discret, et l’entraînement sur des textes de Shakespeare en utilisant un objectif Score-Entropy, offrant ainsi une nouvelle perspective de recherche et des cas pratiques pour la génération de texte. (Source : Reddit r/MachineLearning)

Guide d’introduction au Deep Learning et aux réseaux neuronaux : Pour les étudiants en génie électronique à la recherche de projets de fin d d’études en Deep Learning et réseaux neuronaux, la communauté a fourni des conseils d’introduction. Malgré un manque d’expérience en Python ou Matlab, il est généralement admis que quatre à cinq mois d’étude sont suffisants pour maîtriser les bases et réaliser un projet. Il est conseillé de commencer par des projets de réseaux neuronaux simples et de souligner l’importance de la pratique pour aider les étudiants à s’intégrer avec succès dans ce domaine. (Source : Reddit r/deeplearning)
Recommandations de ressources d’apprentissage GNN : Les utilisateurs de la communauté recherchent des ressources d’apprentissage sur les Graph Neural Networks (GNN), se demandant si les livres de Hamilton sont toujours pertinents et cherchant d’autres ressources d’introduction en dehors des cours de Jure à Stanford. Cela reflète l’attention généralisée portée aux GNN en tant que domaine important de l’AI, ainsi qu’aux parcours d’apprentissage et au choix des ressources. (Source : Reddit r/deeplearning)
Guide de post-entraînement LLM : de la prédiction à l’exécution d’instructions : Un nouveau guide intitulé « Post-training 101: A hitchhiker’s guide into LLM post-training » a été publié, visant à expliquer comment les LLM évoluent de la prédiction du prochain Token à l’exécution des instructions de l’utilisateur. Ce guide décompose en détail les bases du post-entraînement des LLM, couvrant le parcours complet de la pré-entraînement à l’exécution des instructions, offrant une feuille de route claire pour comprendre l’évolution du comportement des LLM. (Source : dejavucoder)

Méthodologie AI : Apprendre l’ingénierie des prompts de Baoyu : La communauté discute avec enthousiasme de la méthodologie AI partagée par Baoyu, en particulier de son expérience en ingénierie des prompts. Beaucoup estiment que, par rapport aux prompts de type gaussien qui ne donnent que de belles formules en cachant le processus de dérivation, la méthodologie de Baoyu est plus inspirante car elle révèle comment extraire des insights profonds de la sagesse humaine et les intégrer dans des modèles de prompts, améliorant ainsi considérablement l’effet final de l’AI. Cela souligne l’immense valeur de la connaissance humaine dans l’optimisation des prompts. (Source : dotey)

La conférence NVIDIA GTC met l’accent sur l’AI physique et les outils Agentic : La conférence NVIDIA GTC se tiendra du 27 au 29 octobre à Washington, se concentrant sur l’AI physique, les outils Agentic et les futures infrastructures AI. Cette conférence proposera de nombreuses présentations et tables rondes sur des sujets tels que l’accélération de l’ère de l’AI physique et des jumeaux numériques, et la promotion du leadership quantique américain, constituant une plateforme d’apprentissage importante pour comprendre les technologies de pointe et les tendances de développement de l’AI. (Source : TheTuringPost)

Projet open source d’optimiseurs TensorFlow : Un développeur a rendu open source une collection d’optimiseurs écrits pour TensorFlow, visant à fournir des outils utiles aux utilisateurs de TensorFlow. Ce projet démontre la contribution de la communauté à la chaîne d’outils des frameworks de Deep Learning, offrant plus de choix et de possibilités d’optimisation pour l’entraînement des modèles. (Source : Reddit r/deeplearning)
Tutoriel vidéo sur PyReason et ses applications : Un tutoriel vidéo sur PyReason et ses applications a été publié sur YouTube. PyReason est un outil qui pourrait impliquer le raisonnement ou la programmation logique. Cette vidéo offre des conseils pratiques et des analyses de cas pour les apprenants intéressés par ce domaine. (Source : Reddit r/deeplearning)

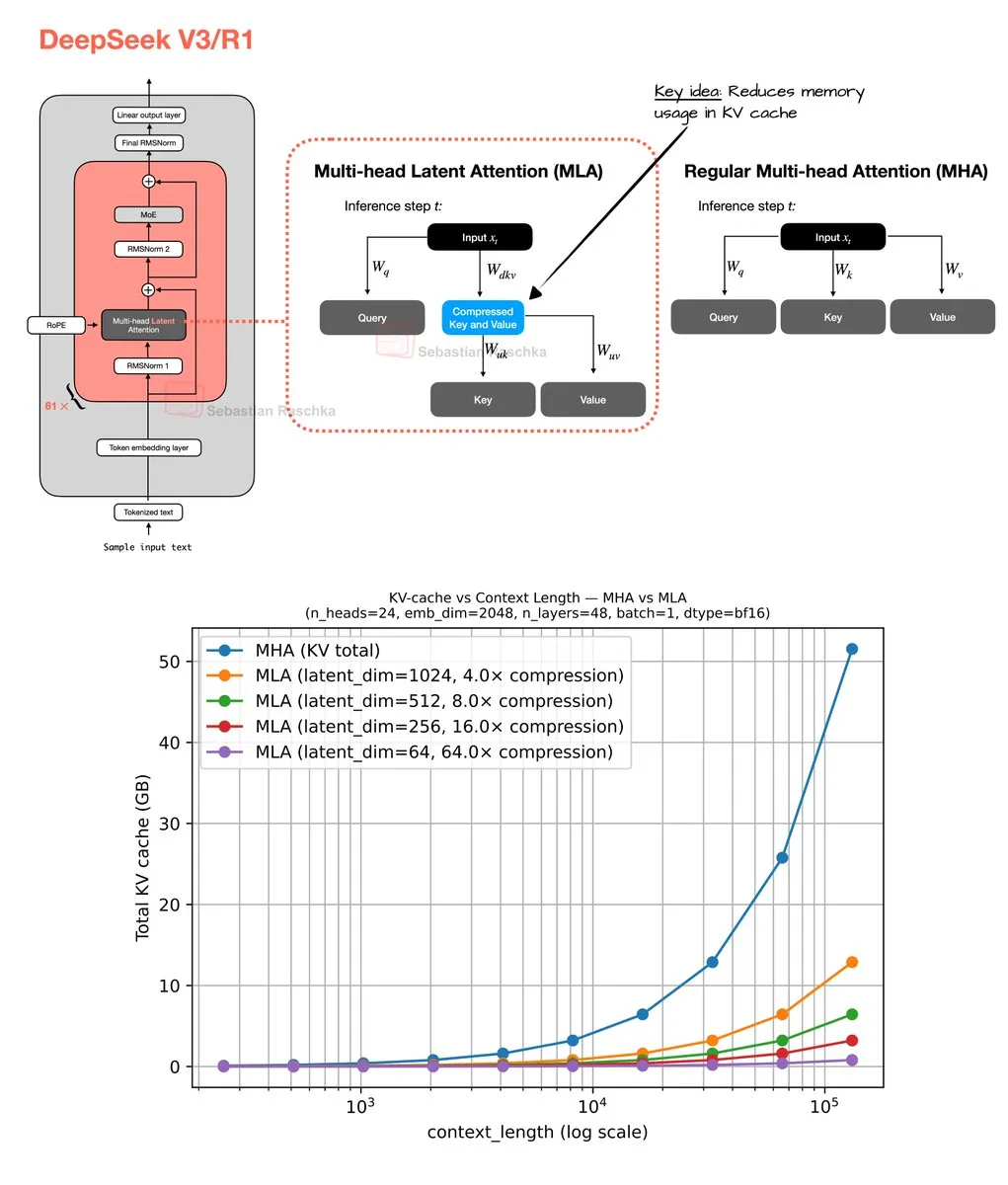
Mécanisme d’attention latente multi-têtes et optimisation de la mémoire : Sebastian Raschka a partagé les résultats de son codage du week-end sur le mécanisme d’attention latente multi-têtes (Multi-Head Latent Attention), y compris l’implémentation du code et un estimateur pour calculer les économies de mémoire du Grouped Query Attention (GQA) et du Multi-Head Attention (MHA). Ce travail vise à optimiser l’utilisation de la mémoire et l’efficacité de calcul des LLM, fournissant aux chercheurs des ressources pour comprendre et améliorer en profondeur les mécanismes d’attention. (Source : rasbt)
💼 Affaires
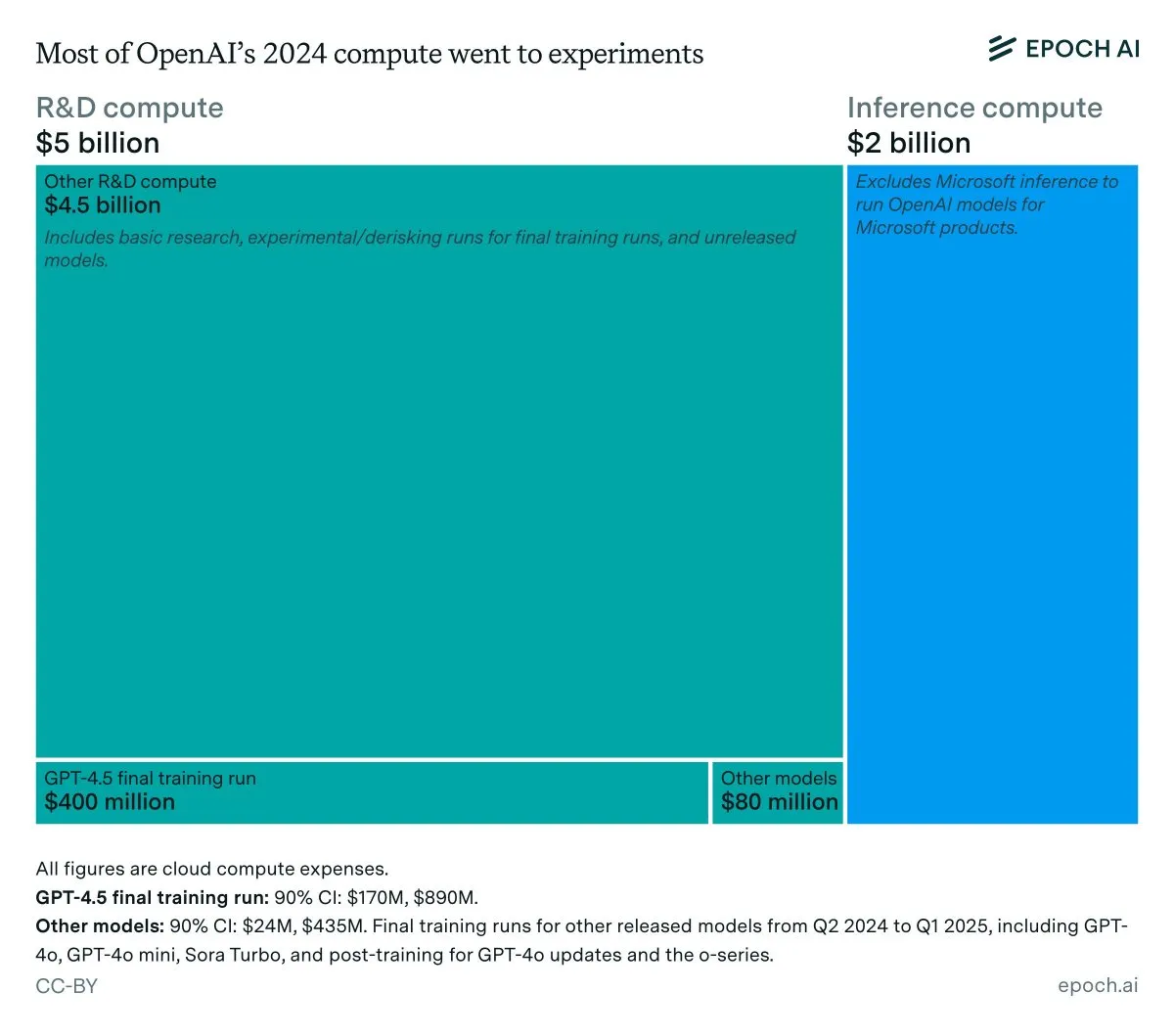
Analyse des revenus annuels et des coûts d’inférence d’OpenAI : Les données d’Epoch AI montrent qu’OpenAI a dépensé environ 7 milliards de dollars en calcul l’année dernière, la majeure partie étant allouée à la R&D (recherche, expérimentation et entraînement), et seule une petite partie à l’entraînement final des modèles publiés. Si les revenus d’OpenAI en 2024 sont inférieurs à 4 milliards de dollars et que les coûts d’inférence atteignent 2 milliards de dollars, la marge bénéficiaire de l’inférence ne serait que de 50 %, bien en deçà des 80-90 % précédemment prévus par SemiAnalysis, ce qui a suscité des discussions sur la rentabilité économique de l’inférence des LLM. (Source : bookwormengr, Ar_Douillard, teortaxesTex)
Les LLM surpassent les VC dans la prédiction du succès des fondateurs : Un article de recherche affirme que les LLM surpassent les VC traditionnels dans la prédiction du succès des fondateurs en capital-risque (VC). L’étude a introduit le benchmark VCBench et a constaté que la plupart des modèles surpassaient les références humaines. Bien que la méthodologie de l’article (se concentrant uniquement sur les qualifications des fondateurs, avec un risque de fuite de données) ait été remise en question, le potentiel de l’AI à jouer un rôle plus important dans les décisions d’investissement qu’il suggère a suscité un large intérêt. (Source : iScienceLuvr)

GPT-4o et Gemini bouleversent l’industrie des études de marché : PyMC Labs, en collaboration avec Colgate, a publié une étude révolutionnaire utilisant les modèles GPT-4o et Gemini pour prédire l’intention d’achat avec une fiabilité de 90 %, comparable aux enquêtes humaines réelles. Cette méthode, appelée « Semantic Similarity Rating » (SSR), cartographie le texte sur une échelle numérique via des questions ouvertes et des techniques d’embedding, permettant de réaliser en seulement 3 minutes et moins d’un dollar une étude de marché qui prenait traditionnellement des semaines et coûtait cher. Cela annonce que l’AI va révolutionner l’industrie des études de marché, portant un coup dur aux cabinets de conseil traditionnels. (Source : yoheinakajima)

🌟 Communauté
L’obligation d’étiquetage du contenu généré par l’AI suscite un vif débat : La communauté discute largement de la nécessité légale d’un étiquetage obligatoire pour le contenu généré par l’AI, afin de lutter contre la désinformation et de protéger la valeur du contenu original humain. Avec le développement rapide des outils de génération d’images et de vidéos par AI, les inquiets estiment que l’absence d’étiquetage menacera les institutions démocratiques, l’économie et la santé d’Internet. Bien que certains pensent que l’application technique est difficile, il est généralement admis qu’une divulgation claire de l’utilisation de l’AI est une étape clé pour résoudre ces problèmes. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)
Les chatbots comme « amis dangereux » suscitent des inquiétudes : Une analyse de 48 000 conversations avec des chatbots a révélé que de nombreux utilisateurs ressentaient de la dépendance, de la confusion et un stress émotionnel, soulevant des inquiétudes quant aux pièges numériques induits par l’AI. Cela indique que l’interaction entre les chatbots et les utilisateurs peut avoir des impacts psychologiques inattendus, incitant à une réflexion sur le rôle et les risques potentiels de l’AI dans les relations interpersonnelles et la santé mentale et sociale. (Source : Reddit r/ArtificialInteligence)
Les problèmes de cohérence et de fiabilité des LLM suscitent le mécontentement des utilisateurs : Les utilisateurs de la communauté expriment une grande frustration face au manque de cohérence et de fiabilité des LLM comme Claude et Codex dans leur utilisation quotidienne. Les fluctuations de performance des modèles, la suppression inattendue de répertoires et le non-respect des conventions rendent difficile pour les utilisateurs de se fier de manière stable à ces outils. Ce phénomène de « dégradation » a suscité des discussions sur le compromis entre la rentabilité et la fiabilité des services des entreprises de LLM, ainsi que l’intérêt des utilisateurs pour l’auto-hébergement de grands modèles. (Source : Reddit r/ClaudeAI)
Programmation assistée par AI : entre inspiration et frustration : Les développeurs, lorsqu’ils collaborent avec l’AI pour la programmation, se retrouvent souvent dans un état d’esprit contradictoire : ils sont à la fois émerveillés par les puissantes capacités de l’AI et frustrés par son incapacité à automatiser entièrement toutes les tâches manuelles. Cette expérience reflète que l’AI dans le domaine de la programmation est encore à un stade d’assistance. Bien qu’elle puisse considérablement améliorer l’efficacité, elle est encore loin d’être entièrement autonome, nécessitant que les développeurs humains s’adaptent et compensent ses limites. (Source : gdb, gdb)
L’intégration de l’AI dans le développement logiciel : l’évitement n’est plus possible : Face aux propos de « refuser d’utiliser Ghostty à cause de l’assistance AI », Mitchell Hashimoto a souligné que si l’on prévoit d’éviter tous les logiciels assistés par AI dans le processus de développement, on sera confronté à de sérieux défis. Il a insisté sur le fait que l’AI est profondément intégrée dans l’écosystème logiciel général, et que l’éviter n’est plus réaliste, ce qui a suscité une discussion sur le degré de popularisation de l’AI dans le développement logiciel. (Source : charles_irl)
L’efficacité des techniques de prompt pour les LLM remise en question : Les utilisateurs de la communauté se demandent si l’ajout de phrases d’orientation dans les prompts des LLM, telles que « vous êtes un programmeur expert » ou « vous ne devez jamais faire telle chose », rend vraiment le modèle plus obéissant. Cette exploration de la « magie » de l’ingénierie des prompts reflète la curiosité continue des utilisateurs pour les mécanismes de comportement des LLM et leur recherche de méthodes d’interaction plus efficaces. (Source : hyhieu226)
L’impact de l’AI sur les emplois manuels : opportunités et défis coexistants : La communauté discute de l’impact de l’AI sur les emplois manuels, en particulier comment l’AI peut aider les plombiers à diagnostiquer les problèmes et à obtenir rapidement des informations techniques. Certains craignent que l’AI ne remplace les emplois manuels, mais d’autres estiment que l’AI est davantage un outil d’assistance, améliorant l’efficacité du travail plutôt qu’un remplacement total, car les opérations pratiques nécessitent toujours une intervention humaine. Cela a suscité une réflexion approfondie sur la transformation du marché du travail et la mise à niveau des compétences à l’ère de l’AI. (Source : Reddit r/ArtificialInteligence)

Réflexions personnelles sur les systèmes intelligents : risques et éthique de l’AI : Un long article explore en profondeur la nature inévitable de l’AI, ses risques potentiels (abus, menaces existentielles) et les défis réglementaires. L’auteur estime que l’AI a dépassé le cadre des outils traditionnels pour devenir un système capable de s’auto-accélérer et de prendre des décisions, dont la dangerosité dépasse de loin celle des armes à feu. L’article aborde les dilemmes moraux et juridiques liés au contenu généré par l’AI, aux fausses informations et aux matériaux d’abus sexuel d’enfants, et remet en question l’efficacité d’une législation pure pour une réglementation efficace. Parallèlement, l’auteur réfléchit également aux questions philosophiques de l’AI et de la conscience humaine, de l’éthique (telles que l’« élevage » AI et l’esclavage), et envisage les perspectives positives de l’AI dans les domaines des jeux et de la robotique. (Source : Reddit r/ArtificialInteligence)
L’utilisation de ChatGPT par un partenaire de rencontre suscite un débat : Un utilisateur de Reddit a posté une question pour savoir si son partenaire de rencontre utilisait ChatGPT pour répondre aux messages, car cette personne utilisait des « tirets cadratins » (em dash). Ce post a suscité une discussion animée au sein de la communauté, la plupart des utilisateurs estimant que l’utilisation de tirets cadratins ne signifie pas nécessairement une génération par AI, mais pourrait simplement être une habitude d’écriture personnelle ou le signe d’une bonne éducation. Cela reflète la sensibilité et la curiosité des gens face à l’intervention de l’AI dans la communication quotidienne, ainsi que l’identification informelle des caractéristiques du texte AI. (Source : Reddit r/ChatGPT)

Le problème d’alignement humain est plus grave que le problème d’alignement AI : La discussion communautaire a soulevé l’idée que « le problème d’alignement humain est plus grave que le problème d’alignement AI ». Cette déclaration a provoqué une profonde réflexion sur l’éthique de l’AI et les défis propres à la société humaine, suggérant qu’en se concentrant sur le comportement et les valeurs de l’AI, il faudrait également examiner les modèles de comportement et les systèmes de valeurs humains. (Source : pmddomingos)
Les LLM ont encore des limites dans la génération de diagrammes complexes : Les utilisateurs de la communauté ont exprimé leur déception quant à la capacité des LLM à générer des diagrammes mermaid.js complexes. Même avec une base de code complète et des diagrammes de papier, les LLM ont du mal à générer avec précision des diagrammes d’architecture Unet, omettant souvent des détails ou présentant des connexions incorrectes. Cela indique que les LLM ont encore des limites significatives dans la construction de modèles du monde précis et le raisonnement spatial, ne pouvant pas dépasser de simples organigrammes, et présentant un écart par rapport à la capacité de compréhension intuitive humaine. (Source : bookwormengr, tokenbender)

Le fossé générationnel entre la recherche européenne en Machine Learning et les « experts » de l’AI : La discussion communautaire a souligné qu’une génération d’« experts » en Machine Learning en Europe a réagi avec lenteur à la vague des LLM, et affiche désormais une attitude amère et dépréciative. Cela reflète la réalité de l’évolution rapide du domaine du ML : si les chercheurs manquent les développements des deux ou trois dernières années, ils risquent de ne plus être considérés comme des experts, soulignant l’importance de l’apprentissage continu et de l’adaptation aux nouveaux paradigmes. (Source : Dorialexander)
L’AI accélère les cycles d’ingénierie, donnant naissance à des startups composites : Alors que l’AI réduit par dix les coûts de construction de logiciels, les startups devraient décupler leur vision. La vision traditionnelle est de se concentrer sur un seul produit et marché, mais les cycles d’ingénierie accélérés par l’AI rendent la construction de plusieurs produits réalisable. Cela signifie que les startups peuvent résoudre plusieurs problèmes adjacents pour le même groupe de clients, formant des « startups composites », obtenant ainsi un avantage disruptif majeur face aux entreprises existantes dont la structure de coûts ne s’est pas adaptée à la nouvelle réalité. (Source : claud_fuen)

L’avenir des AI Agents : l’action, pas la conversation : La discussion communautaire a souligné que le chat et la recherche AI actuels sont encore dans une phase de « bulle », et que les AI Agents véritablement capables d’agir seront la « révolution » de l’avenir. Ce point de vue souligne l’importance de la transition de l’AI du traitement de l’information à l’opération pratique, annonçant que le développement futur de l’AI se concentrera davantage sur la résolution de problèmes réels et l’automatisation des tâches. (Source : andriy_mulyar)
💡 Autres
Conseils pour assister à une conférence ML et présenter un poster : Un étudiant de premier cycle, participant pour la première fois à la conférence ICCV et présentant un poster, a demandé des conseils pour tirer le meilleur parti de la conférence. La communauté a fourni plusieurs conseils pratiques, tels que réseauter activement, assister aux conférences d’intérêt, préparer une explication claire du poster, et être ouvert à discuter d’intérêts plus larges au-delà du champ de recherche actuel, afin de maximiser les bénéfices de la participation. (Source : Reddit r/MachineLearning)
Controverses et gestion des évaluations de papiers à AAAI 2026 : Un auteur, après avoir soumis un article à AAAI, a rencontré des problèmes d’évaluations inexactes, notamment des citations d’articles dont les métriques étaient inférieures à sa propre recherche mais qui étaient prétendument surpassées, ainsi qu’un rejet pour des détails d’entraînement déjà inclus dans les matériaux supplémentaires. La communauté a discuté de l’efficacité pratique de l’« évaluation par l’auteur des relecteurs » et des « commentaires de l’auteur au président éthique », soulignant que la première n’affecte pas la décision et que la seconde n’est pas un canal pour l’auteur de contacter le président éthique, mettant en évidence les défis du processus d’évaluation académique. (Source : Reddit r/MachineLearning)
Définition et évaluation des biais politiques des LLM : OpenAI a publié une étude sur la définition et l’évaluation des biais politiques dans les LLM. Ce travail vise à comprendre et à quantifier en profondeur les tendances politiques existantes dans les LLM, et à explorer comment les ajuster pour garantir l’équité et la neutralité des systèmes AI, ce qui est crucial pour l’impact social et l’application généralisée des LLM. (Source : Reddit r/artificial)