
Mots-clés:robot humanoïde, grand modèle d’IA, apprentissage par renforcement, IA multimodale, Agent IA, Figure 03 goulot d’étranglement des données, GPT-5 Pro preuve mathématique, EmbeddingGemma RAG sur appareil, GraphQA analyse conversationnelle des graphes, NVIDIA Blackwell performances d’inférence
🔥 Focus
Figure 03 en couverture du classement des meilleures inventions du Time, le CEO déclare : « Il ne manque plus que les données à ce stade » : Brett Adcock, CEO de Figure, a déclaré que le plus grand goulot d’étranglement actuel pour le robot humanoïde Figure 03 est la « donnée », et non l’architecture ou la puissance de calcul, estimant que les données peuvent résoudre presque tous les problèmes et propulser les robots vers une adoption à grande échelle. Figure 03 a fait la couverture du classement des meilleures inventions du magazine Time pour 2025, suscitant des discussions sur l’importance des données, de la puissance de calcul et de l’architecture dans le développement de la robotique. Brett Adcock a souligné que l’objectif de Figure est de permettre aux robots d’accomplir des tâches humaines dans des environnements domestiques et commerciaux, et qu’il accorde une grande importance à la sécurité des robots, prédisant que le nombre de robots humanoïdes pourrait dépasser celui des humains à l’avenir. (Source: 量子位)

Terence Tao relève un défi interdisciplinaire avec GPT-5 Pro ! Un problème insoluble depuis 3 ans résolu en 11 minutes avec une preuve complète : Le célèbre mathématicien Terence Tao, en collaboration avec GPT-5 Pro, a résolu en 11 minutes un problème de géométrie différentielle resté sans solution pendant trois ans. GPT-5 Pro a non seulement effectué des calculs complexes, mais a également fourni une preuve complète, aidant même Terence Tao à corriger son intuition initiale. Terence Tao a conclu que l’AI excelle dans les problèmes à « petite échelle » et est utile pour la compréhension à « grande échelle », mais qu’elle peut renforcer les fausses intuitions pour les stratégies à « échelle moyenne ». Il a souligné que l’AI devrait servir de « copilote » pour les mathématiciens, améliorant l’efficacité expérimentale, plutôt que de remplacer entièrement le travail humain en matière de créativité et d’intuition. (Source: 量子位)

🎯 Tendances
Yunpeng Technology lance de nouveaux produits AI+Santé : Yunpeng Technology, en collaboration avec Shuaikang et Skyworth, a lancé de nouveaux produits AI+Santé, notamment un « laboratoire de cuisine futuriste numérisé et intelligent » et un réfrigérateur intelligent équipé d’un AI health large model. L’AI health large model optimise la conception et le fonctionnement de la cuisine, tandis que le réfrigérateur intelligent offre une gestion personnalisée de la santé via l’« Health Assistant Xiaoyun ». Cela marque une percée de l’AI dans le domaine de la gestion quotidienne de la santé, offrant des services de santé personnalisés via des appareils intelligents, et devrait stimuler le développement des technologies de santé à domicile, améliorant ainsi la qualité de vie des résidents. (Source: 36氪)
Progrès des robots humanoïdes et de l’intelligence incarnée : des tâches ménagères aux applications industrielles : Plusieurs discussions sur les réseaux sociaux ont mis en lumière les dernières avancées des robots humanoïdes et de l’intelligence incarnée. Reachy Mini a été désigné comme l’une des meilleures inventions de 2025 par le magazine Time, illustrant le potentiel de la collaboration open-source dans le domaine de la robotique. Des prothèses bioniques pilotées par l’AI permettent à un adolescent de 17 ans de contrôler par la pensée, et les robots humanoïdes accomplissent facilement les tâches ménagères. Dans le secteur industriel, Yondu AI a lancé une solution de picking en entrepôt avec des robots humanoïdes à roues, AgiBot a présenté le Lingxi X2 doté de capacités de mouvement quasi-humaines, et la Chine a également dévoilé un robot policier sphérique à grande vitesse. Les robots de Boston Dynamics sont devenus des caméramans multifonctionnels, et le robot quadrupède LocoTouch réalise un transport intelligent grâce au toucher. (Source: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, johnohallman, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Percées des grands modèles et nouvelles avancées dans les benchmarks de code : GPT-5 Pro et Gemini 2.5 Pro ont obtenu des performances dignes d’une médaille d’or aux Olympiades Internationales d’Astronomie et d’Astrophysique (IOAA), démontrant la puissante capacité de l’AI dans le domaine de la physique de pointe. GPT-5 Pro a également démontré des capacités exceptionnelles de recherche et de vérification de littérature scientifique, résolvant l’Erdos problem #339 et identifiant efficacement les failles majeures dans les articles publiés. Dans le domaine du code, KAT-Dev-72B-Exp est devenu le modèle open-source en tête du classement SWE-Bench Verified, atteignant un taux de correction de 74,6 %. Le projet SWE-Rebench vise à éviter la contamination des données en testant les nouveaux GitHub issues soulevés après la publication des grands modèles. Sam Altman est plein d’espoir quant à l’avenir de Codex. Concernant la question de savoir si l’AGI peut être réalisée uniquement par des LLM purs, la communauté de recherche en AI estime généralement qu’il est difficile d’y parvenir avec le seul cœur des LLM. (Source: gdb, karminski3, gdb, SebastienBubeck, karminski3, teortaxesTex, QuixiAI, sama, OfirPress, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Innovations et défis de performance du matériel et de l’infrastructure AI : La plateforme NVIDIA Blackwell a démontré des performances et une efficacité d’inférence inégalées lors des benchmarks SemiAnalysis InferenceMAX, et Together AI propose déjà les systèmes NVIDIA GB200 NVL72 et HGX B200. Groq, grâce à ses ASIC et à sa stratégie d’intégration verticale, redéfinit l’économie de l’infrastructure LLM open-source avec une latence réduite et des prix compétitifs. La communauté a discuté de l’impact de la suppression du Python GIL sur l’ingénierie AI/ML, estimant que cela pourrait améliorer les performances multithread. De plus, les passionnés de LLM ont partagé leurs configurations matérielles et exploré les compromis de performance entre les grands modèles quantifiés et les petits modèles non quantifiés à différents niveaux de quantification, soulignant que la quantification 2-bit pourrait convenir aux conversations, mais que les tâches de codage nécessitent au moins Q5. (Source: togethercompute, arankomatsuzaki, code_star, MostafaRohani, jeremyphoward, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Dynamiques de pointe des modèles et applications AI : des modèles généraux aux domaines verticaux : De nouveaux modèles et fonctionnalités AI continuent d’émerger. Le grand modèle turc Kumru-2B fait son apparition sur Hugging Face, et Replit a publié plusieurs mises à jour cette semaine. Sora 2 a supprimé son filigrane, annonçant des applications plus larges pour la technologie de génération vidéo. Des rumeurs circulent selon lesquelles Gemini 3.0 serait lancé le 22 octobre. L’IA continue de s’approfondir dans le domaine de la santé, la pathologie numérique utilise l’AI pour l’aide au diagnostic du cancer, et les microscopes sans marquage combinés à l’AI promettent de nouveaux outils de diagnostic. Les modèles de réalité augmentée (AR) ont atteint le SOTA sur le classement Imagenet FID. L’Agent de codage en ligne de commande Qwen Code a été mis à jour pour prendre en charge la reconnaissance d’images par le modèle Qwen-VL. L’Université de Stanford a proposé la méthode Agentic Context Engineering (ACE), permettant aux modèles de devenir plus intelligents sans nécessiter de fine-tuning. Les modèles de la série DeepSeek V3 sont également en constante itération, et les types de déploiement des AI Agent ainsi que la refonte des services professionnels par l’IA sont devenus des points d’intérêt majeurs pour l’industrie. (Source: mervenoyann, amasad, scaling01, npew, kaifulee, Ronald_vanLoon, scaling01, TheTuringPost, TomLikesRobots, iScienceLuvr, NerdyRodent, shxf0072, gabriberton, Ronald_vanLoon, karminski3, Ronald_vanLoon, teortaxesTex, demishassabis, Dorialexander, yoheinakajima, 36氪)
🧰 Outils
GraphQA : Transformer l’analyse graphique en conversation en langage naturel : LangChainAI a lancé le framework GraphQA, qui combine NetworkX et LangChain pour transformer l’analyse graphique complexe en conversation en langage naturel. Les utilisateurs peuvent poser des questions en anglais simple, et GraphQA sélectionnera et exécutera automatiquement les algorithmes appropriés, traitant des graphes de plus de 100 000 nœuds. Cela simplifie considérablement l’accès à l’analyse de données graphiques, la rendant plus accessible aux utilisateurs non-experts, et constitue une innovation majeure dans le domaine des outils LLM. (Source: LangChainAI)
Meilleur outil Agentic AI pour VS Code : Visual Studio Magazine a classé un outil parmi les meilleurs outils Agentic AI pour VS Code, marquant un changement de paradigme de développement, passant d’un « assistant » à un « véritable Agent » capable de penser, d’agir et de construire avec les développeurs. Cela reflète l’évolution des outils AI dans le développement logiciel, passant de fonctions d’assistance à une collaboration intelligente plus profonde, améliorant l’efficacité et l’expérience des développeurs. (Source: cline)
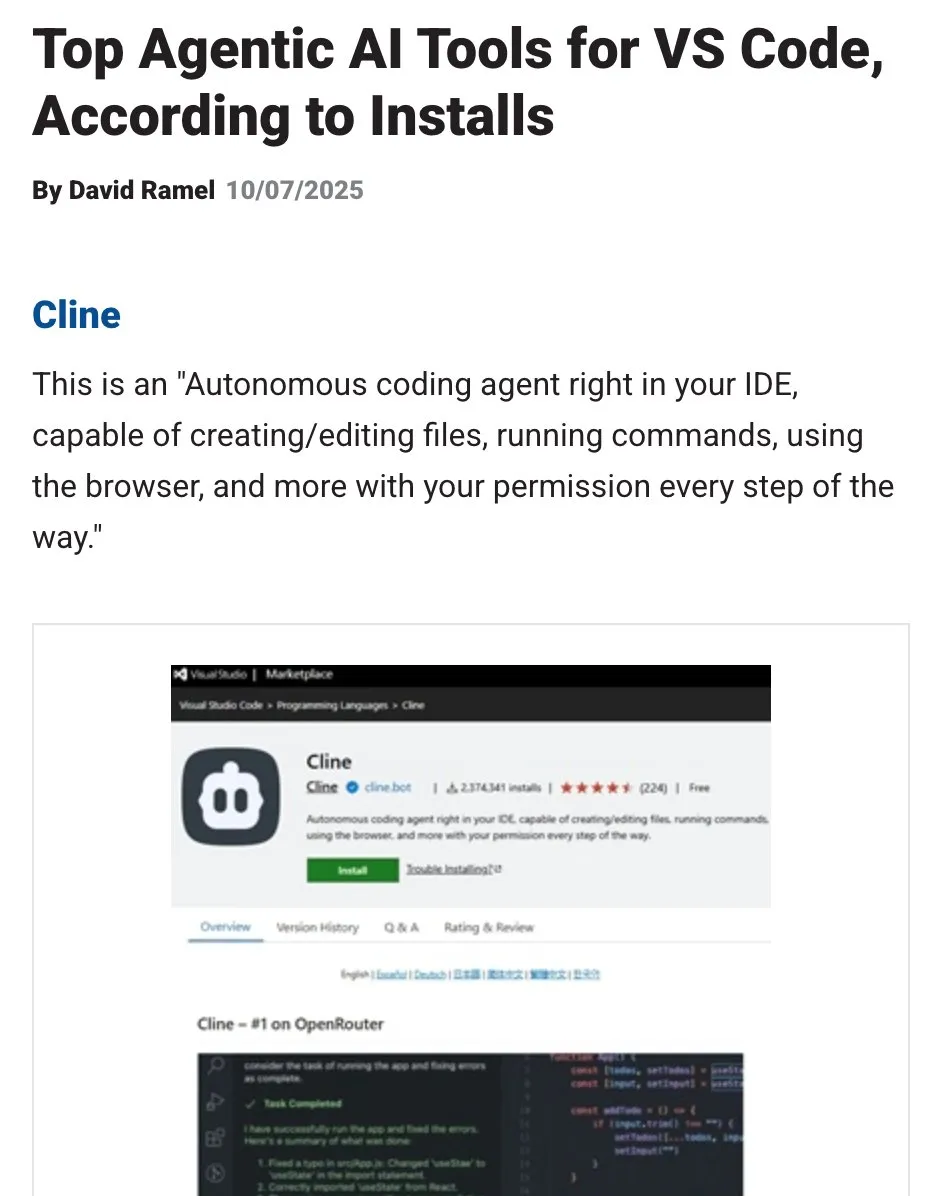
OpenHands : Outil open-source de gestion de contexte LLM : OpenHands, un outil open-source, propose divers compresseurs de contexte pour gérer le contexte des LLM dans les applications Agentic, y compris la suppression de l’historique de base, l’extraction des « événements les plus importants » et la compression de la sortie du navigateur. Ceci est crucial pour le débogage, l’évaluation et la surveillance des applications LLM, des systèmes RAG et des workflows Agentic, contribuant à améliorer l’efficacité et la cohérence des LLM dans les tâches complexes. (Source: gneubig)
BLAST : Moteur de navigateur web AI : LangChainAI a lancé BLAST, un moteur de navigateur web AI haute performance, conçu pour offrir des capacités de navigation web aux applications AI. BLAST offre une interface compatible OpenAI, prend en charge la parallélisation automatique, la mise en cache intelligente et le streaming en temps réel, permettant d’intégrer efficacement les informations web dans les workflows AI et d’étendre considérablement la capacité des AI Agent à acquérir et traiter des données web en temps réel. (Source: LangChainAI)
Opik : Outil d’évaluation LLM open-source : Opik est un outil d’évaluation LLM open-source utilisé pour le débogage, l’évaluation et la surveillance des applications LLM, des systèmes RAG et des workflows Agentic. Il offre un suivi complet, une évaluation automatisée et des tableaux de bord prêts pour la production, aidant les développeurs à mieux comprendre le comportement des modèles, à optimiser les performances et à garantir la fiabilité des applications dans des scénarios réels. (Source: dl_weekly)
AI Travel Agent : Assistant de planification intelligent : LangChainAI a présenté un AI Travel Agent intelligent qui intègre des informations météorologiques, de recherche et de voyage en temps réel, et utilise plusieurs API pour simplifier l’ensemble du processus, des mises à jour météorologiques au change de devises. Cet Agent vise à offrir une planification et une assistance de voyage complètes, améliorant l’expérience utilisateur, et constitue un exemple typique de l’autonomisation des Agents par les LLM dans des scénarios d’application verticaux. (Source: LangChainAI)
Conception d’un outil AI pour la création de prompts d’annonceur : L’idée a été avancée qu’il existe un besoin urgent sur le marché d’un outil AI pour aider les marketeurs à construire des « prompts d’annonceur ». Cet outil devrait aider à établir un système d’évaluation (couvrant la sécurité de la marque, la conformité des prompts, etc.) et à tester les modèles grand public. Avec le lancement par OpenAI de diverses unités publicitaires naturelles, l’importance des prompts marketing devient de plus en plus évidente, et de tels outils deviendront un maillon clé dans les processus de création et de distribution publicitaire. (Source: dbreunig)
Mise à jour de Qwen Code : Prise en charge de la reconnaissance d’images par le modèle Qwen-VL : L’Agent de codage en ligne de commande Qwen Code a été récemment mis à jour, ajoutant la prise en charge du basculement vers le modèle Qwen-VL pour la reconnaissance d’images. Les tests utilisateurs ont montré de bons résultats, et il est actuellement disponible gratuitement. Cette mise à jour étend considérablement les capacités de Qwen Code, lui permettant non seulement de gérer des tâches de codage, mais aussi d’interagir de manière multimodale, améliorant ainsi l’efficacité et la précision de l’Agent de codage lors du traitement de tâches incluant des informations visuelles. (Source: karminski3)

Héberger son propre serveur de chatbot avec LibreChat : Un article de blog fournit un guide sur l’utilisation de LibreChat pour héberger son propre serveur de chatbot et se connecter à plusieurs Model Control Panels (MCPs). Cela permet aux utilisateurs de gérer et de basculer de manière flexible entre différents backends LLM, offrant une expérience de chatbot personnalisée, et souligne la flexibilité et la contrôlabilité des solutions open-source dans le déploiement d’applications AI. (Source: Reddit r/artificial)
Générateur AI : Donner vie aux avatars virtuels : Un utilisateur recherche le meilleur générateur AI pour « donner vie » à son image de marque (incluant des vidéos réelles et des avatars virtuels) pour sa chaîne YouTube, afin de réduire le temps de tournage et d’enregistrement et de se concentrer sur le montage. L’utilisateur souhaite que l’IA permette aux avatars virtuels de converser, de jouer à des jeux, de danser, etc. Cela reflète la forte demande des créateurs de contenu pour les outils AI en matière d’animation d’avatars virtuels et de génération de vidéos, afin d’améliorer l’efficacité de la production et la diversité du contenu. (Source: Reddit r/artificial)
LLM local contre le spam : une solution privée : Un article de blog partage des pratiques sur la façon d’utiliser un LLM local pour identifier et combattre le spam de manière privée sur son propre serveur de messagerie. Cette solution combine Mailcow, Rspamd, Ollama et un agent Python personnalisé, offrant aux utilisateurs de serveurs de messagerie auto-hébergés une méthode de filtrage du spam basée sur l’IA, et souligne le potentiel des LLM locaux en matière de protection de la vie privée et d’applications personnalisées. (Source: Reddit r/LocalLLaMA)
📚 Apprentissage
EmbeddingGemma : Modèle d’embedding multilingue pour applications RAG embarquées : EmbeddingGemma est un modèle d’embedding multilingue compact, avec seulement 308M de paramètres, idéal pour les applications RAG embarquées et facile à intégrer avec LlamaIndex. Ce modèle se classe bien sur le Massive Text Embedding Benchmark, tout en étant de petite taille, ce qui le rend adapté aux appareils mobiles. Sa facilité de fine-tuning permet, après un ajustement dans des domaines spécifiques (comme les données médicales), de surpasser les performances de modèles plus grands. (Source: jerryjliu0)
Deux méthodes fondamentales de traitement de documents : Parsing et Extraction : Un article de l’équipe LlamaIndex explore en profondeur deux méthodes fondamentales de traitement de documents : le « parsing » et l’« extraction ». Le parsing consiste à convertir l’intégralité du document en Markdown ou JSON structuré, en conservant toutes les informations, et est adapté aux applications RAG, à la recherche approfondie et à la synthèse. L’extraction consiste à obtenir une sortie structurée d’un LLM, standardisant le document selon un modèle générique, et est adaptée aux ETL de bases de données, aux workflows d’Agent automatisés et à l’extraction de métadonnées. Comprendre la différence entre les deux est crucial pour construire des Agents de documents efficaces. (Source: jerryjliu0)

Implémentation du Tiny Recursive Model (TRM) sur MLX : La plateforme MLX a implémenté la partie centrale du Tiny Recursive Model (TRM), un modèle proposé par Alexia Jolicoeur-Martineau, visant à obtenir des performances élevées grâce à l’inférence récursive avec un minuscule réseau neuronal de 7M paramètres. Cette implémentation MLX rend possibles les expériences locales sur les ordinateurs portables Apple Silicon, réduisant la complexité et couvrant des fonctionnalités telles que la supervision profonde, les étapes d’inférence récursive et l’EMA, offrant ainsi une commodité pour le développement et la recherche de petits modèles efficaces. (Source: awnihannun, ImazAngel)
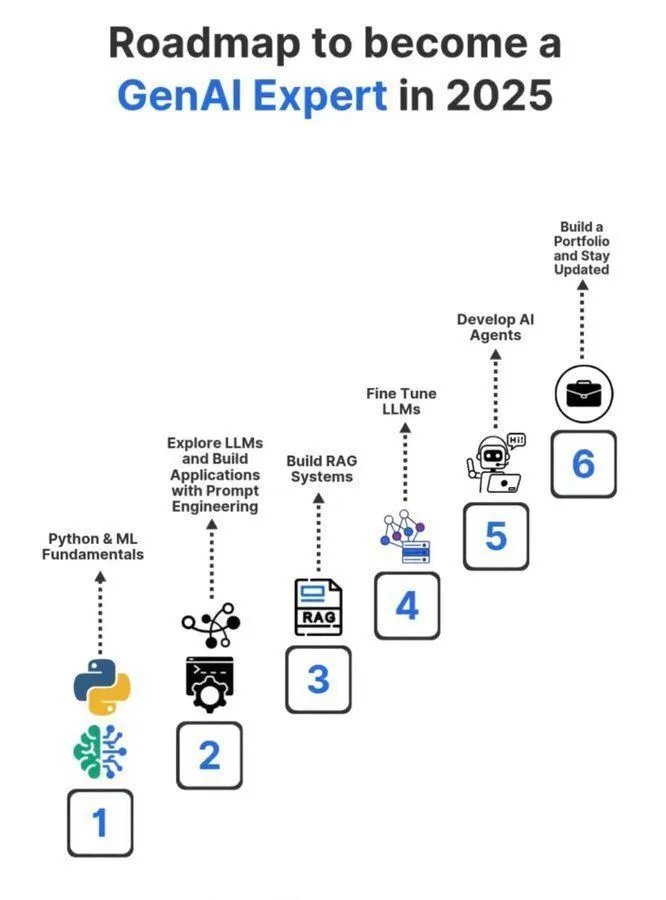
Feuille de route d’apprentissage pour devenir un expert en AI générative en 2025 : Une feuille de route détaillée pour devenir un expert en AI générative en 2025 a été partagée sur les réseaux sociaux, couvrant les connaissances et compétences clés nécessaires pour devenir un professionnel dans ce domaine. Cette feuille de route vise à guider les aspirants à apprendre systématiquement les concepts fondamentaux de l’intelligence artificielle, du Machine Learning et du Deep Learning, afin de s’adapter aux tendances technologiques GenAI en évolution rapide. (Source: Ronald_vanLoon)
Partage d’expériences d’études doctorales en Machine Learning : Un utilisateur a repartagé une série de tweets sur la poursuite d’un doctorat en Machine Learning, visant à fournir des conseils et des expériences à ceux qui s’intéressent aux études doctorales en ML. Ces tweets couvrent probablement le processus de candidature, les domaines de recherche, le développement de carrière et les expériences personnelles, constituant une ressource précieuse pour l’apprentissage de l’IA au sein de la communauté. (Source: arohan)
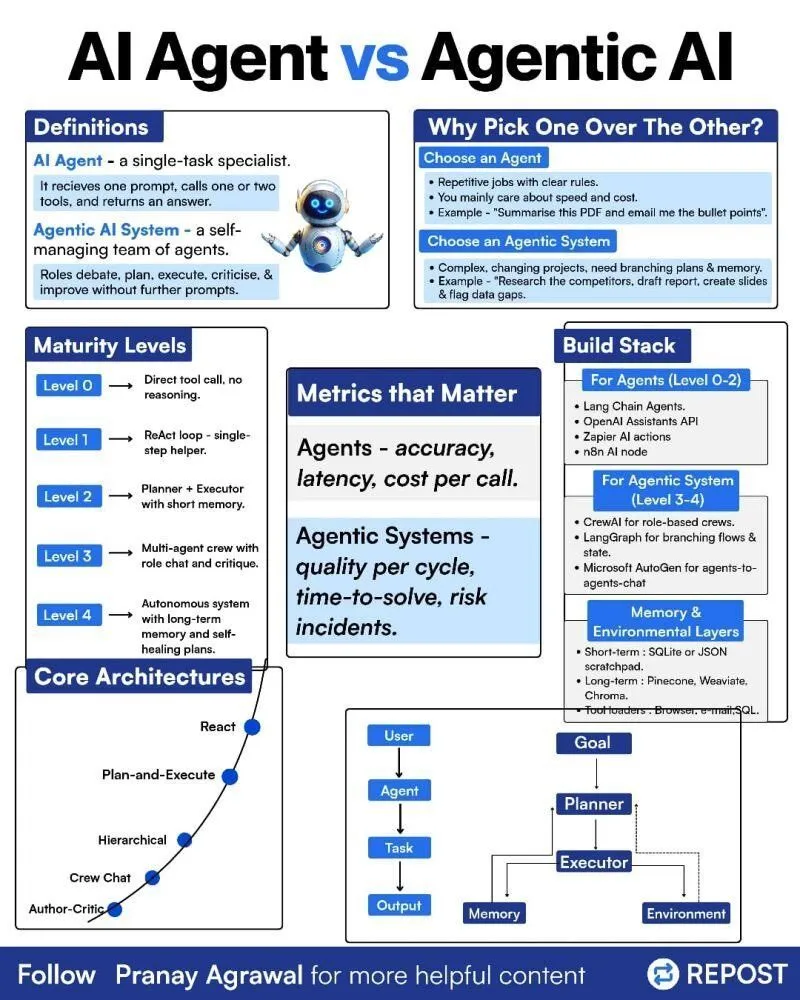
Différence entre AI Agents et Agentic AI : Une infographie sur la distinction entre « AI Agents » et « Agentic AI » a été partagée sur les réseaux sociaux, visant à clarifier ces deux concepts liés mais distincts. Cela aide la communauté à mieux comprendre les types de déploiement des AI Agent, leur niveau d’autonomie et le rôle de l’Agentic AI dans les systèmes d’intelligence artificielle plus larges, favorisant ainsi des discussions plus précises sur la technologie Agent. (Source: Ronald_vanLoon)
Reinforcement Learning et Weight Decay dans l’entraînement des LLM : Les réseaux sociaux ont discuté de l’idée que le Weight Decay pourrait ne pas être une bonne idée dans l’entraînement par Reinforcement Learning (RL) des LLM. Certains estiment que le Weight Decay peut amener le réseau à oublier une grande quantité d’informations pré-entraînées, en particulier lors des mises à jour GRPO où l’avantage est nul, les poids tendant vers zéro. Cela suggère aux chercheurs de considérer attentivement l’impact du Weight Decay lors de la conception des stratégies d’entraînement RL des LLM, afin d’éviter une dégradation des performances du modèle. (Source: lateinteraction)
Paradigmes d’entraînement des modèles AI : Un expert a partagé les quatre paradigmes d’entraînement de modèles que les ingénieurs ML doivent connaître, visant à fournir des orientations théoriques et des cadres pratiques essentiels aux ingénieurs en Machine Learning. Ces paradigmes peuvent inclure l’apprentissage supervisé, non supervisé, par renforcement et auto-supervisé, aidant les ingénieurs à mieux comprendre et appliquer différentes méthodes d’entraînement de modèles. (Source: _avichawla)
Le Reinforcement Learning basé sur l’apprentissage par curriculum améliore les capacités des LLM : Une étude a révélé que le Reinforcement Learning (RL) combiné à l’apprentissage par curriculum peut enseigner de nouvelles capacités aux LLM, ce qui est difficile à réaliser avec d’autres méthodes. Cela démontre le potentiel de l’apprentissage par curriculum pour améliorer les capacités de raisonnement à long terme des LLM, suggérant que la combinaison du RL et de l’apprentissage par curriculum pourrait devenir une voie clé pour débloquer de nouvelles compétences en IA. (Source: sytelus)

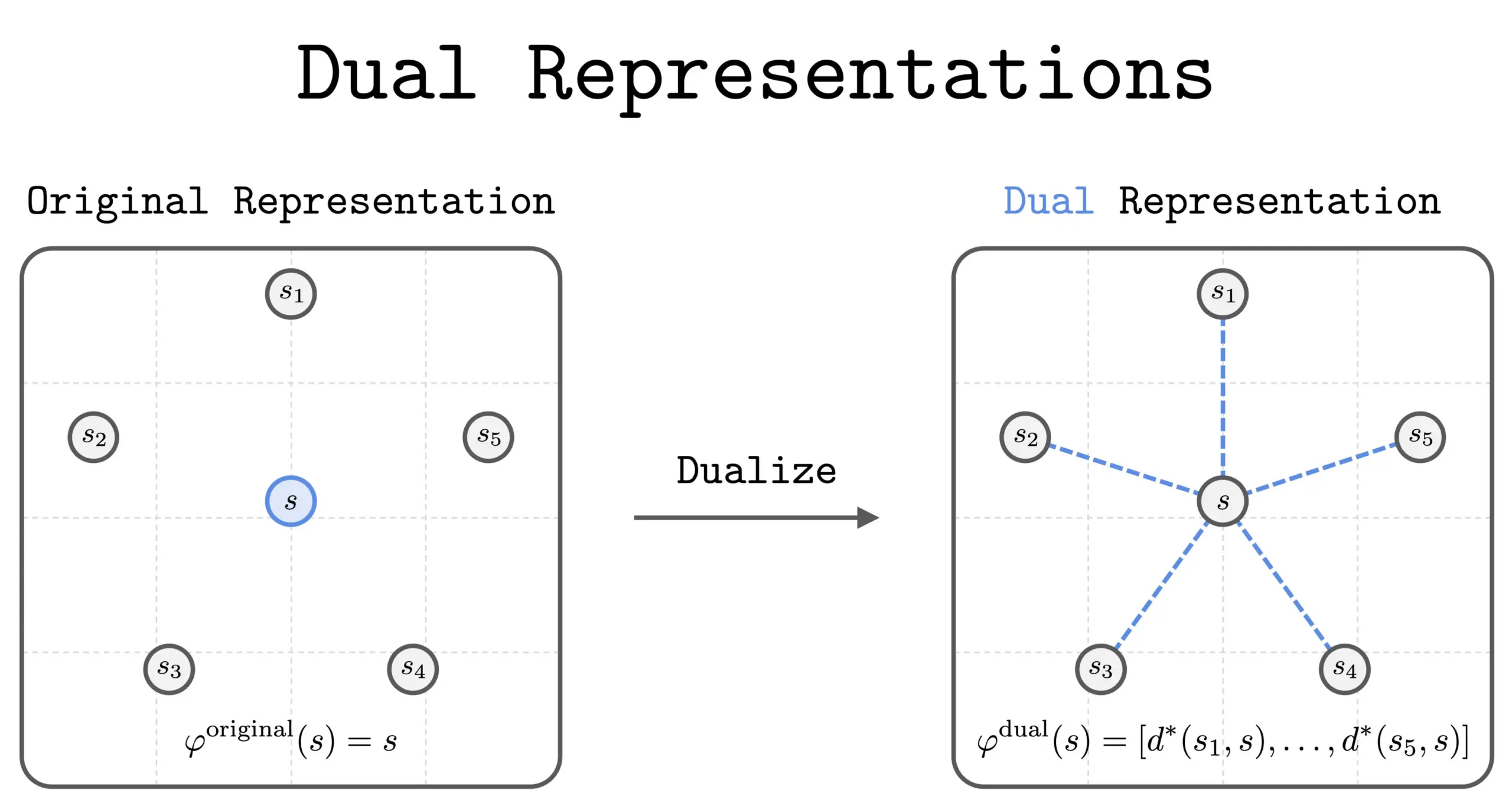
Nouvelle méthode de double représentation en RL : Une nouvelle étude a introduit la méthode de la « double représentation » dans le Reinforcement Learning (RL). Cette méthode offre une nouvelle perspective en représentant les états comme un « ensemble de similarités » avec tous les autres états. Cette double représentation présente de bonnes propriétés théoriques et des avantages pratiques, et devrait améliorer les performances et la compréhension du RL. (Source: dilipkay)
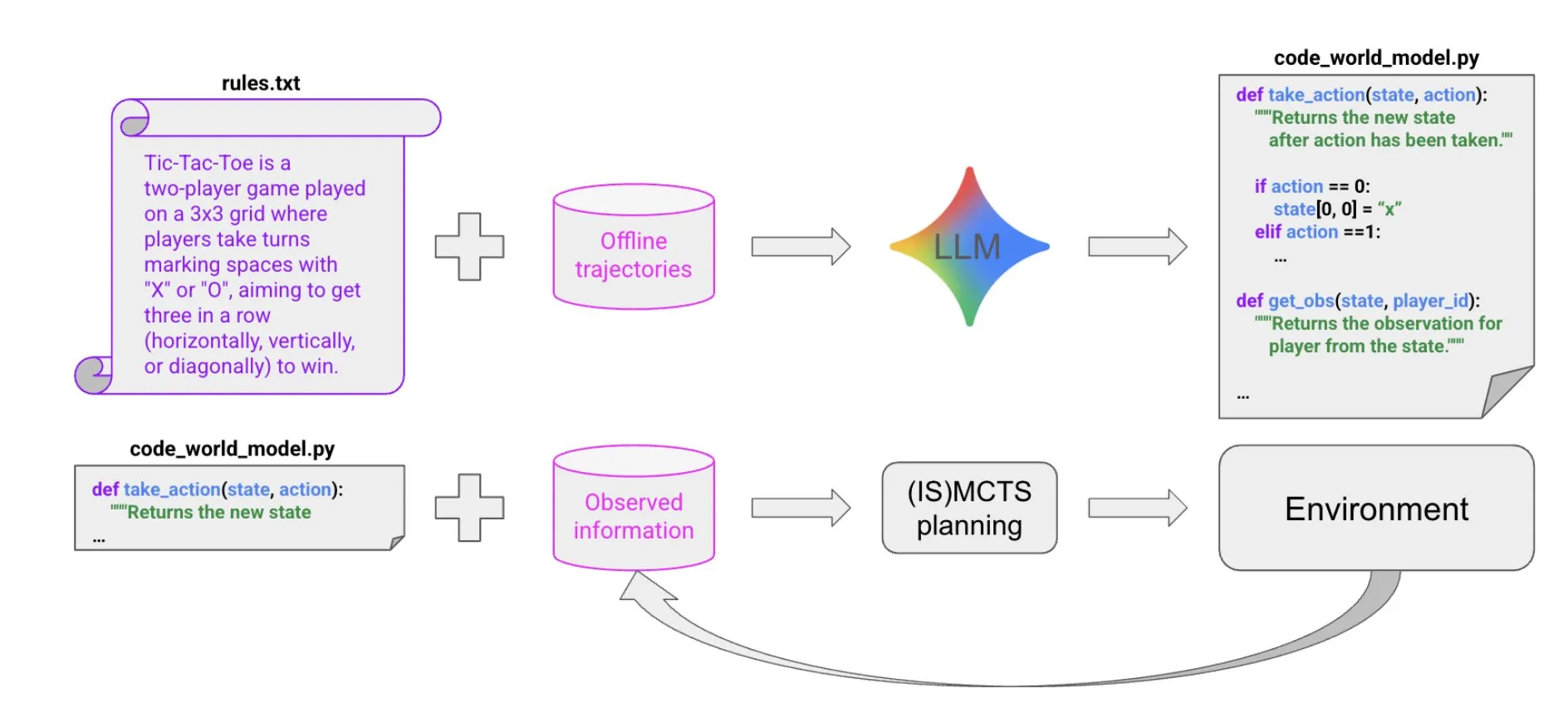
Synthèse de code pilotée par LLM pour construire des modèles du monde : Un nouvel article propose une méthode extrêmement efficace en termes d’échantillons pour créer des Agents performants dans des environnements symboliques multi-Agent et partiellement observables, grâce à la synthèse de code pilotée par LLM. Cette méthode apprend un modèle du monde de code à partir d’un petit nombre de données de trajectoire et d’informations contextuelles, puis le transmet à un solveur existant (comme MCTS) pour choisir l’action suivante, offrant de nouvelles perspectives pour la construction d’Agents complexes. (Source: BlackHC)
Entraînement de petits modèles par RL : Capacités émergentes au-delà du pré-entraînement : Des recherches ont montré que, dans le Reinforcement Learning (RL), les petits modèles peuvent bénéficier de manière disproportionnée, développant même des capacités « émergentes », ce qui bouleverse l’intuition traditionnelle du « plus grand est le mieux ». Sur des modèles à petite échelle, le RL peut être plus efficace en termes de calcul qu’un pré-entraînement plus poussé. Cette découverte a une signification importante pour les décisions des laboratoires AI concernant le moment d’arrêter le pré-entraînement et de commencer le RL lors de l’extension du RL, révélant de nouvelles lois de mise à l’échelle entre la taille du modèle et l’amélioration des performances en RL. (Source: ClementDelangue, ClementDelangue)
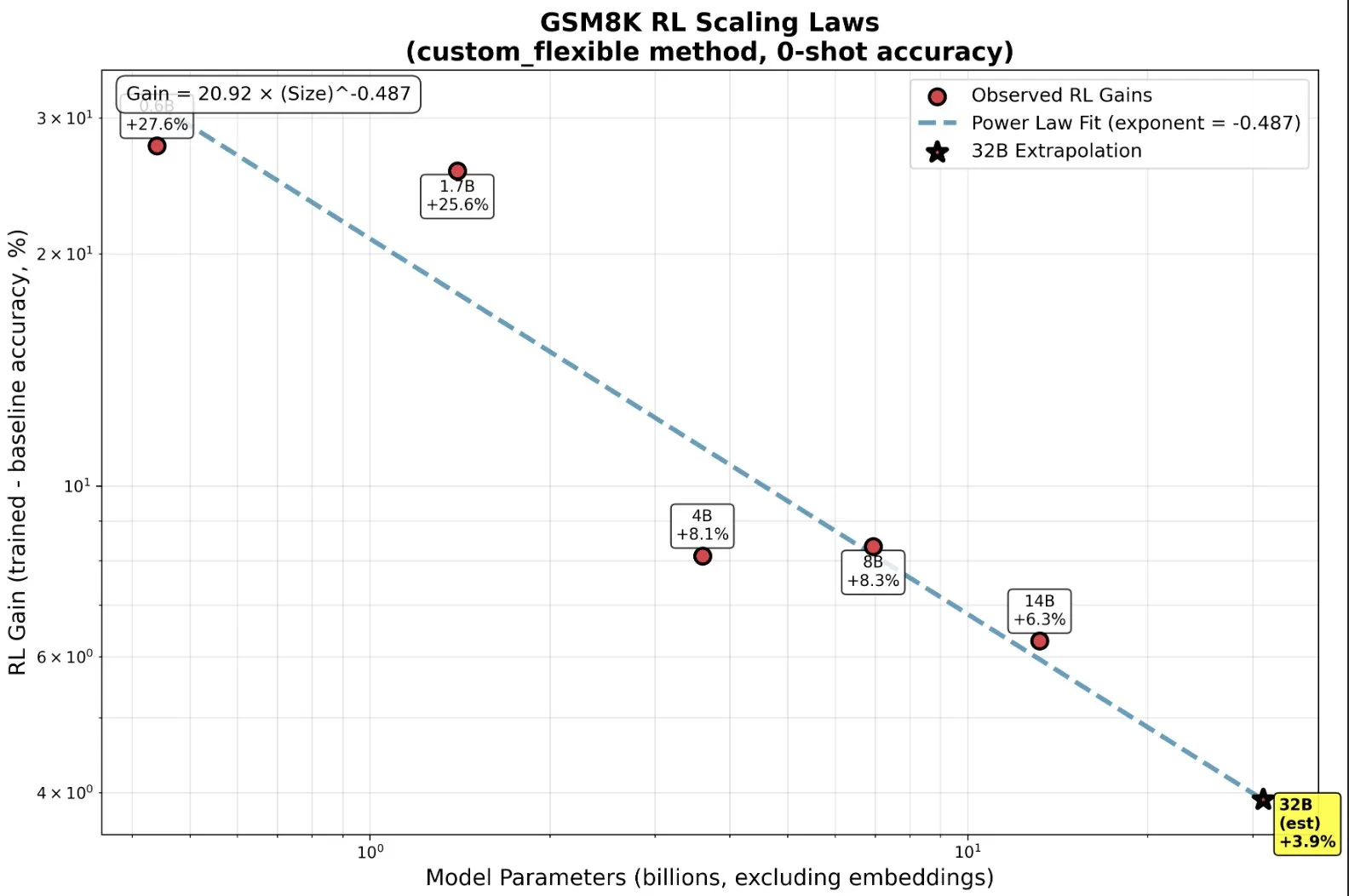
AI vs. Machine Learning vs. Deep Learning : Explication simple : Une ressource vidéo explique de manière simple et compréhensible la différence entre l’intelligence artificielle (AI), le Machine Learning (ML) et le Deep Learning (DL). Cette vidéo vise à aider les débutants à comprendre rapidement ces concepts fondamentaux, posant les bases pour une étude plus approfondie du domaine de l’IA. (Source: )

Gestion des modèles de prompts dans les expériences de Deep Learning : La communauté du Deep Learning a discuté de la manière de gérer et de réutiliser les modèles de prompts dans les expériences de modèles. Dans les grands projets, surtout lors de la modification de l’architecture ou des ensembles de données, le suivi de l’efficacité des différentes variantes de prompts devient complexe. Les utilisateurs ont partagé leurs expériences d’utilisation d’outils comme Empromptu AI pour le contrôle de version et la classification des prompts, soulignant l’importance de la versionnalisation des prompts et de l’alignement des ensembles de données avec les prompts pour optimiser les produits modèles. (Source: Reddit r/deeplearning)
Guide de sélection des modèles de complétion de code (FIM) : La communauté a discuté des facteurs clés pour choisir un modèle de complétion de code (FIM). La vitesse est considérée comme une priorité absolue, il est recommandé de choisir des modèles avec peu de paramètres et fonctionnant uniquement sur GPU (cible > 70 t/s). De plus, les modèles « de base » et les modèles d’instruction ont montré des performances similaires dans les tâches FIM. La discussion a également énuméré des modèles FIM récents et plus anciens tels que Qwen3-Coder et KwaiCoder, et a exploré comment des outils comme nvim.llm peuvent prendre en charge des modèles non spécifiques au code. (Source: Reddit r/LocalLLaMA)
Compromis de performance des modèles quantifiés : grands modèles et faible précision : La communauté a discuté des compromis de performance entre les grands modèles quantifiés et les petits modèles non quantifiés, ainsi que de l’impact du niveau de quantification sur le comportement du modèle. Il est généralement admis que la quantification 2-bit peut convenir à l’écriture ou à la conversation, mais pour des tâches comme le codage, un niveau Q5 est au moins requis. Certains utilisateurs ont souligné que Gemma3-27B subit une grave dégradation des performances avec une faible quantification, tandis que certains nouveaux modèles sont entraînés avec une précision FP4, sans nécessiter une précision plus élevée. Cela indique que l’efficacité de la quantification varie selon le modèle et la tâche, et nécessite des tests spécifiques. (Source: Reddit r/LocalLLaMA)
Raisons de l’échec de MissForest du langage R dans les tâches de prédiction : Un article d’analyse explore les raisons de l’échec de l’algorithme MissForest du langage R dans les tâches de prédiction, soulignant qu’il enfreint discrètement le principe clé de séparation des ensembles d’entraînement et de test lors de l’attribution. L’article explique les limites de MissForest dans de tels cas et présente de nouvelles méthodes comme MissForestPredict qui résolvent ce problème en maintenant la cohérence entre l’apprentissage et l’application. Ceci a une signification importante pour les praticiens du Machine Learning lors du traitement des valeurs manquantes et de la construction de modèles de prédiction. (Source: Reddit r/MachineLearning)
Recherche de ressources en Machine Learning multimodal : Les utilisateurs de la communauté recherchent des ressources d’apprentissage en Machine Learning multimodal, en particulier des matériaux théoriques et pratiques sur la manière de combiner différents types de données (texte, images, signaux, etc.) et de comprendre des concepts tels que la fusion, l’alignement et l’attention transmodale. Cela reflète une demande croissante d’apprentissage des technologies AI multimodales. (Source: Reddit r/deeplearning)
Recherche de ressources vidéo sur l’entraînement de modèles d’inférence par Reinforcement Learning : La communauté du Machine Learning recherche les meilleures ressources vidéo de conférences scientifiques sur l’utilisation du Reinforcement Learning (RL) pour entraîner des modèles d’inférence, y compris des vidéos de présentation générale et des explications approfondies de méthodes spécifiques. Les utilisateurs souhaitent accéder à un contenu académique de haute qualité, plutôt qu’à des vidéos superficielles d’influenceurs, afin de comprendre rapidement la littérature pertinente et de décider des orientations de recherche futures. (Source: Reddit r/MachineLearning)
Parcours de codage AI de 11 mois : Outils, stack technologique et meilleures pratiques : Un développeur a partagé son parcours de codage AI de 11 mois, détaillant ses expériences, ses échecs et ses meilleures pratiques avec des outils comme Claude Code. Il a souligné que dans le codage AI, la planification préalable et la gestion du contexte sont bien plus importantes que l’écriture du code elle-même. Bien que l’IA ait abaissé la barrière à l’implémentation du code, elle ne remplace pas la conception architecturale et la perspicacité commerciale. Ce partage d’expérience couvre plusieurs projets, du front-end au back-end, en passant par le développement d’applications mobiles, et recommande des outils d’assistance tels que Context7 et SpecDrafter. (Source: Reddit r/ClaudeAI)
💼 Business
JPMorgan Chase : 2 milliards de dollars investis par an pour devenir une « banque entièrement AI » : Jamie Dimon, CEO de JPMorgan Chase, a annoncé un investissement annuel de 2 milliards de dollars dans l’IA, visant à transformer l’entreprise en une « banque entièrement AI ». L’IA est profondément intégrée dans les activités principales telles que la gestion des risques, les transactions, le service client, la conformité et la banque d’investissement, non seulement en réduisant les coûts, mais surtout en accélérant le rythme de travail et en modifiant la nature des postes. JPMorgan Chase, grâce à sa plateforme LLM Suite développée en interne et au déploiement à grande échelle d’AI Agent, considère l’IA comme le système d’exploitation sous-jacent de l’entreprise, et souligne que l’intégration des données et la cybersécurité sont les plus grands défis de sa stratégie AI. Dimon estime que l’IA représente une valeur réelle à long terme, plutôt qu’une bulle à court terme, et qu’elle redéfinira la notion de banque. (Source: 36氪)
Apple de Musk…