
Mots-clés:OpenAI Sora, Génération de vidéos par IA, Modèle récursif miniature (TRM), Jouets intelligents, Puce d’IA, Recréation vidéo Sora 2, Efficacité d’inférence du TRM, Croissance du marché des jouets IA, Collaboration AMD-OpenAI sur les puces, Controverses sur les droits d’auteur des contenus IA
🔥 Focus
L’essor et les défis de l’application OpenAI Sora : L’application de génération de vidéos par IA, Sora, lancée par OpenAI, a rapidement gagné en popularité, atteignant le sommet de l’App Store. Sa capacité de génération de vidéos gratuite et illimitée a soulevé de vastes préoccupations concernant les coûts d’exploitation, la violation des droits d’auteur (en particulier l’utilisation d’IP existantes et de portraits de célébrités décédées) et l’abus de la technologie deepfake. Sam Altman a reconnu la nécessité d’envisager un modèle de profit et prévoit d’offrir un contrôle plus précis des droits d’auteur. L’impact de l’application sur l’écosystème de création de contenu et la perception de la réalité a déclenché un débat sur la question de savoir si les vidéos IA dépasseront les vidéos “réelles”. (Source : MIT Technology Review, rowancheung, fabianstelzer, nptacek, paul_cal, BlackHC)

Samsung lance le Tiny Recursive Model (TRM) pour défier l’efficacité d’inférence des LLM : Samsung a lancé le Tiny Recursive Model (TRM), un petit réseau neuronal de seulement 7 millions de paramètres, qui a obtenu d’excellents résultats sur le benchmark ARC-AGI, surpassant même de grands LLM comme DeepSeek-R1 et Gemini 2.5 Pro. Le TRM utilise une méthode d’inférence récursive, optimisant les réponses par de multiples “réflexions” internes et auto-critiques. Cette percée a déclenché un débat sur la question de savoir si les “petits modèles peuvent être plus intelligents” et suggère que l’innovation architecturale pourrait être plus importante que la simple taille du modèle pour les tâches d’inférence, promettant de réduire considérablement les coûts de calcul pour l’inférence SOTA. (Source : HuggingFace Daily Papers, fchollet, cloneofsimo, ecsquendor, clefourrier, AymericRoucher, ClementDelangue, Dorialexander)
Yao Shunyu de Tsinghua quitte Anthropic pour Google DeepMind, des divergences de valeurs comme raison principale : Yao Shunyu, lauréat d’une bourse spéciale du département de physique de l’Université Tsinghua, a annoncé son départ d’Anthropic pour rejoindre Google DeepMind en tant que chercheur scientifique senior. Il a indiqué que 40 % de la raison de son départ était due à des “divergences fondamentales de valeurs” avec Anthropic, estimant que l’entreprise n’était pas favorable aux chercheurs chinois et aux employés ayant une position neutre. Yao Shunyu a travaillé un an chez Anthropic, participant à la construction de la théorie de l’apprentissage par renforcement derrière Claude 3.7 Sonnet et la série Claude 4, et a déclaré que le domaine de l’IA se développe à une vitesse incroyable, mais qu’il est temps d’aller de l’avant. (Source : ZhihuFrontier, 量子位)

Arduino acquis par Qualcomm, annonçant une nouvelle direction pour l’IA embarquée : Arduino a été acquis par Qualcomm et a lancé sa première carte de développement collaborative, l’UNO Q, équipée du processeur Qualcomm Dragonwing QRB2210, intégrant des solutions AI. Cela marque l’évolution d’Arduino du domaine traditionnel des microcontrôleurs à faible consommation vers l’edge computing de moyenne puissance avec des capacités AI intégrées. Cette initiative pourrait stimuler l’application généralisée de l’IA dans l’IoT et les appareils embarqués, offrant aux développeurs une puissance de calcul AI plus robuste, et annonçant une nouvelle révolution dans l’écosystème matériel de l’IA embarquée. (Source : karminski3)
Meta Superintelligence lance REFRAG : une nouvelle percée dans l’efficacité du RAG : Meta Superintelligence a publié son premier article, REFRAG, proposant une nouvelle méthode RAG (Retrieval Augmented Generation) visant à améliorer considérablement l’efficacité. Cette méthode convertit la plupart des blocs de documents récupérés en “embeddings de blocs” compacts et compatibles avec les LLM, directement consommables par les LLM, et utilise une stratégie légère pour étendre à la demande une partie des embeddings de blocs en tokens complets, dans le respect du budget. Cela réduit significativement les coûts de cache KV et d’attention, accélère la latence du premier octet et le débit, tout en maintenant la précision, ouvrant de nouvelles voies pour les applications RAG en temps réel. (Source : Reddit r/deeplearning, Reddit r/LocalLLaMA)

🎯 Tendances
xAI lève 20 milliards de dollars, NVIDIA investit 2 milliards de dollars : xAI, la société d’Elon Musk, a réussi à lever 20 milliards de dollars, dont un investissement direct de 2 milliards de dollars de NVIDIA. Ce financement sera utilisé via un véhicule à usage spécial (SPV) pour l’acquisition de GPU NVIDIA afin de soutenir la construction de son centre de données Memphis Colossus 2. Cette structure de financement unique vise à garantir le matériel nécessaire à l’expansion à grande échelle de xAI dans le domaine du calcul AI, intensifiant davantage la concurrence sur le marché des puces AI. (Source : scaling01)

L’essor des jouets AI sur les marchés chinois et américain : Les jouets AI équipés de chatbots et d’assistants vocaux sont une nouvelle tendance, connaissant une croissance rapide sur le marché chinois et s’étendant aux marchés internationaux comme les États-Unis. Les produits d’entreprises comme BubblePal et FoloToy visent à réduire la dépendance des enfants aux écrans. Cependant, les parents signalent que les fonctions AI sont parfois instables, avec des réponses trop longues ou une reconnaissance vocale lente, ce qui diminue l’intérêt des enfants. Des entreprises américaines comme Mattel collaborent également avec OpenAI pour développer des jouets AI. (Source : MIT Technology Review)

Microsoft lance un framework Agent open source unifié, intégrant AutoGen et Semantic Kernel : Microsoft a publié l’Agent Framework, un SDK open source unifié visant à intégrer AutoGen et Semantic Kernel pour la construction de systèmes AI multi-agents de niveau entreprise. Ce framework, soutenu par Azure AI Foundry, simplifie l’orchestration et l’observabilité, et est compatible avec diverses API. Il introduit un aperçu privé des workflows multi-agents, le traçage inter-framework d’OpenTelemetry, des fonctionnalités d’agents vocaux en temps réel via l’API Voice Live, ainsi que des outils d’IA responsable, dans le but d’améliorer la sécurité et l’efficacité des systèmes d’agents. (Source : TheTuringPost)
AI21 Labs lance Jamba 3B, un petit modèle dont les performances dépassent celles de ses concurrents : AI21 Labs a lancé Jamba 3B, un modèle MoE de seulement 3 milliards de paramètres, qui excelle en qualité et en vitesse, notamment dans le traitement de contextes longs. Ce modèle maintient une vitesse de génération d’environ 40 t/s sur Mac, même avec un contexte de plus de 32K, surpassant de loin Qwen 3 4B et Llama 3.2 3B. Jamba 3B a un indice d’intelligence supérieur à Gemma 3 4B et Phi-4 Mini, et ses capacités d’inférence restent intactes avec un contexte de 256K, démontrant l’énorme potentiel des petits modèles pour l’IA embarquée et le déploiement sur appareils. (Source : Reddit r/LocalLLaMA)

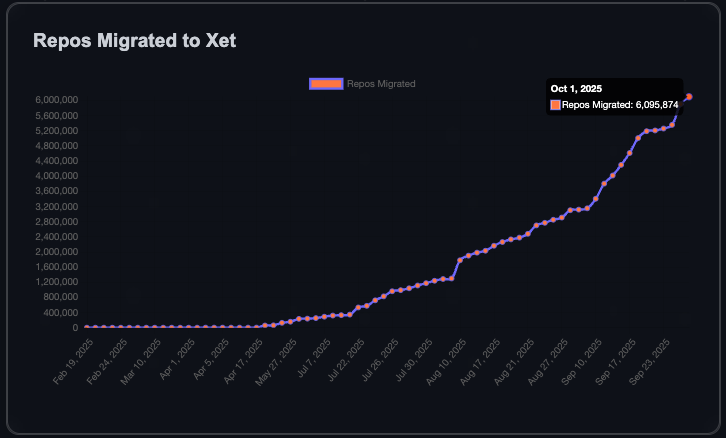
La communauté HuggingFace connaît une croissance rapide, avec un million de nouveaux dépôts en 90 jours : La communauté HuggingFace a ajouté un million de nouveaux dépôts de modèles, de datasets et de Spaces au cours des 90 derniers jours. Il a fallu six ans pour atteindre le premier million de dépôts, ce qui signifie qu’un nouveau dépôt est créé toutes les 8 secondes. Cette croissance est attribuée à la technologie Xet qui permet un transfert de données plus efficace, et au fait que 40 % des dépôts privés indiquent une tendance à l’utilisation interne de HuggingFace pour le partage de modèles et de données par les entreprises. L’objectif de la communauté est d’atteindre 10 millions de dépôts, annonçant un développement florissant de l’écosystème AI open source. (Source : Teknium1, reach_vb)
OpenAI GPT-5 démontre des capacités révolutionnaires dans la recherche scientifique : Le modèle GPT-5 d’OpenAI a franchi un seuil important, les scientifiques l’ayant utilisé avec succès pour mener des recherches originales dans des domaines tels que les mathématiques, la physique, la biologie et l’informatique. Cette avancée montre que GPT-5 peut non seulement répondre à des questions, mais aussi guider et exécuter des explorations scientifiques complexes, accélérant considérablement le processus de recherche. Certains chercheurs ont déclaré qu’après le lancement de GPT-5 Thinking et GPT-5 Pro, il n’est plus raisonnable de mener des recherches scientifiques sans les consulter. (Source : tokenbender)
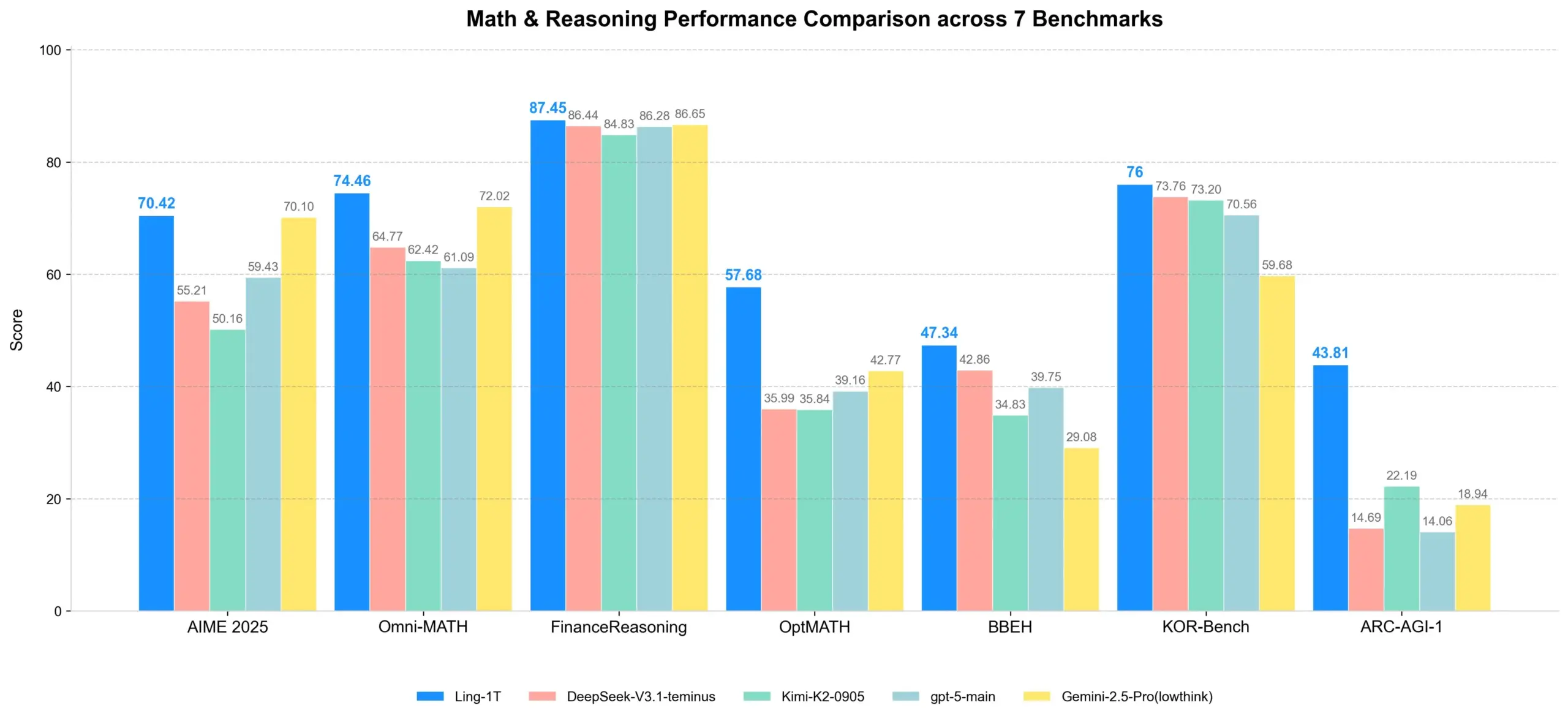
Ling-1T : Lancement d’un modèle d’inférence open source à mille milliards de paramètres : Ling-1T, le modèle phare de la série Ling 2.0, possède un total de 1 000 milliards de paramètres, dont environ 50 milliards de paramètres actifs par token, et a été entraîné sur plus de 20 000 milliards de tokens intensifs en inférence. Ce modèle réalise une inférence évolutive grâce au curriculum Evo-CoT et à Linguistics-Unit RL, démontrant un puissant équilibre efficacité-précision sur des tâches d’inférence complexes. Il possède également des capacités avancées de compréhension visuelle et de génération de code frontend, et peut utiliser des outils avec un taux de réussite d’environ 70 %, marquant une nouvelle étape pour l’intelligence open source à l’échelle du trillion. (Source : scaling01, TheZachMueller)
Meta Ray-Ban Display redéfinit l’interaction homme-machine et l’apprentissage : Les lunettes intelligentes Meta Ray-Ban Display intègrent des fonctions d’apprentissage et de traduction dans le port quotidien, offrant une expérience de “traduction invisible” et d‘“apprentissage visuel instantané”. Les sous-titres des conversations s’affichent directement sur les verres, et les utilisateurs peuvent obtenir des informations pertinentes en regardant simplement un point de repère ou une œuvre d’art. De plus, le contrôle gestuel via Neural Band permet une utilisation sans téléphone. Cette technologie promet de remodeler notre façon d’interagir avec le monde, d’apprendre et de nous connecter, marquant un nouveau départ pour l’informatique centrée sur l’humain. (Source : Ronald_vanLoon)
🧰 Outils
Synthesia lance Copilot, un éditeur vidéo AI professionnel : Synthesia a lancé Copilot, un éditeur vidéo AI professionnel. Cet outil permet de rédiger rapidement des scripts, de connecter des bases de connaissances et de recommander intelligemment des éléments visuels, comme si l’on avait un collègue expert en affaires et en plateforme Synthesia. Copilot vise à simplifier le processus de production vidéo, à abaisser le seuil de création vidéo professionnelle et à offrir des solutions vidéo AI efficaces et personnalisées aux entreprises et aux créateurs de contenu. (Source : synthesiaIO, synthesiaIO)
L’Agent GLIF utilise Sora 2 pour recréer et personnaliser des vidéos virales : GLIF a développé un Agent capable de recréer n’importe quelle vidéo virale en utilisant le modèle Sora 2. Cet Agent analyse d’abord la vidéo originale, puis génère des prompts détaillés basés sur l’analyse. Les utilisateurs peuvent collaborer avec l’Agent pour personnaliser les prompts, créant ainsi des vidéos générées par IA hautement personnalisées. Cette technologie promet d’offrir de puissantes capacités de production et de re-création vidéo dans les domaines de la création de contenu et du marketing. (Source : fabianstelzer)
Cloudflare AI Search et GroqInc lancent un modèle de ‘chat documentaire’ : Cloudflare AI Search (anciennement AutoRAG) s’est associé à GroqInc pour lancer un nouveau modèle open source de “chat documentaire”. Ce modèle combine le moteur d’inférence de Groq avec AI Search, permettant aux utilisateurs d’ajouter plus facilement des fonctionnalités d’IA conversationnelle à leurs documents, pour des questions-réponses et des interactions en temps réel sur le contenu des documents. Cette intégration améliorera l’efficacité de la récupération de documents et de l’accès à l’information. (Source : JonathanRoss321)
HuggingFace lance la fonction d’édition GGUF directement dans le navigateur : HuggingFace prend désormais en charge l’édition directe des métadonnées des modèles GGUF dans le navigateur, sans avoir besoin de télécharger le modèle complet. Cette fonctionnalité, rendue possible par la technologie Xet, permet des mises à jour partielles de fichiers, simplifiant considérablement la gestion et l’itération des modèles, et améliorant l’efficacité du travail des développeurs sur la plateforme HuggingFace. (Source : reach_vb)
LangChain et LangGraph lancent la version v1.0 Alpha et sollicitent les retours des développeurs : LangChain et LangGraph ont publié la version v1.0 Alpha, introduisant de nouvelles API de middleware Agent, des blocs de sortie/contenu standard et d’importantes mises à jour d’API. L’équipe invite activement les développeurs à tester la nouvelle version et à fournir des commentaires afin d’améliorer davantage son framework de développement d’agents AI et de favoriser la création d’applications AI plus puissantes. (Source : LangChainAI)
NeuML lance la série de micro-modèles ColBERT Nano, avec moins d’un million de paramètres : NeuML a lancé la série de modèles ColBERT Nano, dont les paramètres sont tous inférieurs à 1 million (250K, 450K, 950K). Ces micro-modèles ont démontré des performances étonnantes en mode “Late interaction”, prouvant que même des modèles de très petite taille peuvent obtenir de bons résultats sur des tâches spécifiques, offrant des solutions efficaces pour le déploiement de l’IA dans des environnements à ressources limitées. (Source : lateinteraction, lateinteraction)

Un cadre supérieur d’ingénierie de Google partage les ‘Design Patterns pour Agents Intelligents’ : Un cadre supérieur d’ingénierie de Google a partagé gratuitement un livre intitulé “Design Patterns pour Agents Intelligents”, offrant le premier ensemble systématique de principes de conception et de meilleures pratiques pour le domaine en plein essor des AI Agents. Cette ressource vise à aider les développeurs à mieux comprendre et construire des agents AI, comblant un vide en matière de conseils systématiques dans ce domaine, et devrait devenir une référence importante pour les développeurs d’AI Agents. (Source : dotey)

📚 Apprentissage
Recherche sur les hallucinations des LLM et les mécanismes d’alignement de sécurité : des origines internes aux stratégies d’atténuation : La recherche a montré que les modèles d’inférence LLM peuvent présenter un phénomène de “falaise de rejet” avant de générer la sortie finale, où l’intention de rejet diminue fortement. Grâce au framework DST, les chercheurs ont révélé que les hallucinations deviennent inévitables dans une “couche d’engagement” spécifique du modèle, et ont proposé le petit modèle d’inférence HalluGuard, qui, en intégrant des signaux cliniques et en optimisant les données, atténue les hallucinations dans le RAG, offrant une explication mécanistique et des stratégies pratiques pour l’alignement de sécurité des LLM et l’atténuation des hallucinations. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
ASPO optimise l’apprentissage par renforcement des LLM, résolvant le problème de déséquilibre du rapport IS : ASPO (Asymmetric Importance Sampling Policy Optimization) est une nouvelle méthode de post-entraînement des LLM qui résout le défaut fondamental du déséquilibre du rapport d’échantillonnage d’importance (IS) des tokens à avantage positif dans l’apprentissage par renforcement traditionnel. En inversant le rapport IS des tokens à avantage positif et en introduisant un mécanisme de double découpage doux, ASPO peut mettre à jour plus stablement les tokens à faible probabilité, atténuer la convergence précoce et améliorer significativement les performances sur les benchmarks de codage et de raisonnement mathématique. (Source : HuggingFace Daily Papers)
Fathom-DeepResearch : un système d’agents pour la recherche et la synthèse d’informations à long terme : Fathom-DeepResearch est un système d’agents composé de Fathom-Search-4B et Fathom-Synthesizer-4B, conçu pour des tâches complexes et ouvertes de recherche d’informations. Fathom-Search-4B, optimisé par un dataset d’auto-jeu multi-agents et l’apprentissage par renforcement, réalise la recherche web en temps réel et l’interrogation de pages web. Fathom-Synthesizer-4B convertit les résultats de recherches multi-tours en rapports structurés. Ce système a obtenu d’excellents résultats sur plusieurs benchmarks et a démontré une forte capacité de généralisation pour des tâches d’inférence telles que HLE et AIME-25. (Source : HuggingFace Daily Papers)
AgentFlow : optimisation du système d’agents in-flow pour une planification et une utilisation d’outils efficaces : AgentFlow est un framework d’agents in-flow entraînable qui optimise directement son planificateur à travers un cycle d’interaction multi-tours, en coordonnant quatre modules : planificateur, exécuteur, vérificateur et générateur. Il utilise Flow-based Group Refined Policy Optimization pour résoudre le problème d’attribution de crédit des récompenses rares et à long terme. AgentFlow, avec un modèle backbone de 7B, surpasse les baselines SOTA sur dix benchmarks, avec une précision moyenne significativement améliorée sur les tâches de recherche, d’agent, de mathématiques et de sciences, dépassant même GPT-4o. (Source : HuggingFace Daily Papers)
Étude systématique de l’impact des données de code sur les capacités d’inférence des LLM : Une étude systématique, basée sur un cadre centré sur les données, explore comment les données de code améliorent les capacités d’inférence des LLM. En construisant des datasets d’instructions parallèles pour dix langages de programmation et en appliquant des perturbations structurelles ou sémantiques, les chercheurs ont découvert que les LLM sont plus sensibles aux perturbations structurelles qu’aux perturbations sémantiques, en particulier pour les tâches mathématiques et de code. Le pseudo-code et les organigrammes sont aussi efficaces que le code, et le style syntaxique affecte également les gains spécifiques à la tâche (Python est bénéfique pour l’inférence en langage naturel, Java/Rust pour les mathématiques). (Source : HuggingFace Daily Papers)
DeepEvolve : un agent de découverte d’algorithmes scientifiques fusionnant recherche approfondie et évolution algorithmique : DeepEvolve est un agent qui combine la recherche approfondie et l’évolution algorithmique pour découvrir des algorithmes scientifiques, grâce à la récupération de connaissances externes, l’édition de code inter-fichiers et le débogage système, dans un cycle itératif basé sur le feedback. Il ne se contente pas de proposer de nouvelles hypothèses, mais les affine, les implémente et les teste, évitant les améliorations superficielles et les raffinements excessifs inefficaces. Sur neuf benchmarks couvrant la chimie, les mathématiques, la biologie, les matériaux et les brevets, DeepEvolve a continuellement amélioré les algorithmes initiaux, générant de nouveaux algorithmes exécutables et obtenant des gains constants. (Source : HuggingFace Daily Papers)
Feuille de route d’apprentissage AI/ML et concepts clés : La communauté a partagé un parcours d’apprentissage complet pour l’AI, le Machine Learning et le Deep Learning, couvrant de nombreux aspects, des concepts fondamentaux aux techniques avancées (telles que l’Agentic AI, les paramètres de génération LLM). Ces ressources visent à fournir un guide d’apprentissage structuré aux professionnels souhaitant entrer ou approfondir leurs connaissances dans le domaine de l’AI/ML, les aidant à maîtriser l’ensemble du processus, du développement de modèles au déploiement et à l’exploitation, et à comprendre comment l’IA transforme les industries. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Benchmarks AI et ressources d’apprentissage : HLE, conférences et gestion des coûts GPU : La communauté a discuté de plusieurs ressources d’apprentissage et de pratique de l’IA. Le CAIS a publié le benchmark “Humanity’s Last Exam” mis à jour dynamiquement pour s’adapter à l’amélioration des performances des modèles. Parallèlement, des guides de participation aux conférences de Machine Learning et des stratégies de développement de LLM à faible coût ont été fournis, y compris les GPU pay-as-you-go et l’exécution de petits modèles localement. En outre, l’organisation du GPU Mode Hackathon a offert une plateforme d’apprentissage et d’échange aux développeurs. (Source : clefourrier, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, danielhanchen)

OneFlow : Modèle de génération multimodale mixte et entrelacée concurrente : OneFlow est le premier modèle multimodal non autorégressif, prenant en charge la génération multimodale mixte de longueur variable et concurrente. Il combine un flux d’édition par insertion pour les tokens de texte discrets et un appariement de flux pour l’espace latent des images. OneFlow réalise la synthèse concurrente texte-image par échantillonnage hiérarchique, privilégiant le contenu plutôt que la grammaire. Les expériences montrent que OneFlow surpasse les baselines autorégressives dans les tâches de génération et de compréhension, réduisant les FLOPs d’entraînement jusqu’à 50 %, et débloquant de nouvelles capacités de génération concurrente, de raffinement itératif et de génération par inférence naturelle. (Source : HuggingFace Daily Papers)
Equilibrium Matching : un cadre de modélisation générative basé sur des modèles d’énergie implicites : Equilibrium Matching (EqM) est un nouveau cadre de modélisation générative qui abandonne la dynamique non-équilibrée et conditionnée par le temps des modèles de diffusion et de flux traditionnels, pour apprendre plutôt les gradients d’équilibre d’un paysage énergétique implicite. EqM utilise un processus d’échantillonnage basé sur l’optimisation, échantillonnant sur le paysage appris via la descente de gradient, atteignant une performance SOTA de FID 1.90 sur ImageNet 256×256, et gérant naturellement des tâches telles que le débruitage partiel, la détection OOD et la synthèse d’images. (Source : HuggingFace Daily Papers)
💼 Affaires
OpenAI et AMD concluent un accord de partenariat sur les puces, défiant la domination de NVIDIA : OpenAI et AMD ont signé un accord de partenariat sur les puces d’une valeur de plusieurs milliards de dollars sur cinq ans, visant à défier la domination de NVIDIA sur le marché des puces AI. Cette initiative fait partie de la stratégie d’OpenAI de diversifier ses fournisseurs de puces, l’entreprise ayant déjà conclu un partenariat avec NVIDIA. Cet accord souligne l’énorme demande de matériel de calcul haute performance dans l’industrie de l’IA et la recherche de la diversité de la chaîne d’approvisionnement. (Source : MIT Technology Review)
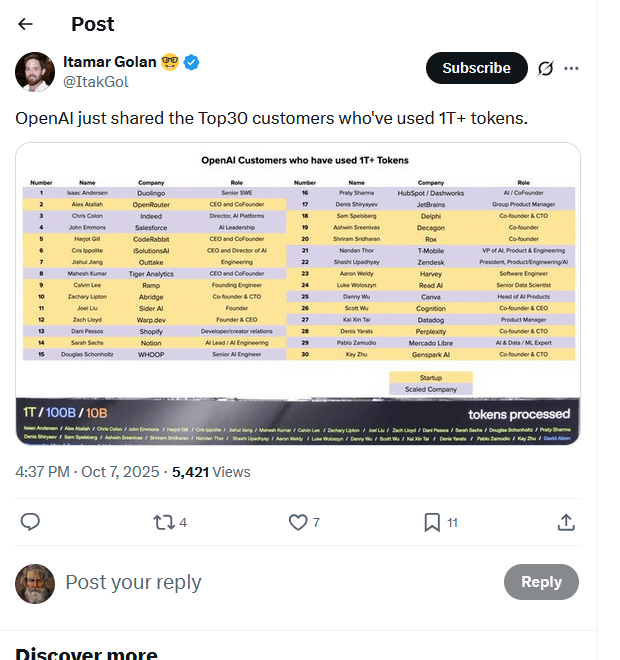
Fuite de la liste des principaux clients d’OpenAI : 30 entreprises consomment des billions de Tokens : Une liste présumée des principaux clients d’OpenAI a circulé en ligne, montrant que 30 entreprises ont traité plus d’un billion de Tokens via ses modèles. Cette liste (incluant Duolingo, OpenRouter, Salesforce, Canva, Perplexity, etc.) révèle la formation rapide d’une économie d’inférence AI et présente quatre types principaux : les constructeurs natifs AI, les intégrateurs AI, les fournisseurs d’infrastructure AI et les fournisseurs de solutions AI verticales. La consommation de Tokens est considérée comme un nouveau benchmark pour mesurer la valeur réelle et les progrès commerciaux des applications AI. (Source : Reddit r/ArtificialInteligence, 量子位)
Singapour devient un refuge sûr pour le droit d’auteur en développement d’IA, attirant les entreprises mondiales d’IA : Singapour a modifié sa loi sur le droit d’auteur, introduisant une clause de défense d’analyse computationnelle qui stipule explicitement que l’analyse de données computationnelles effectuée pour améliorer les systèmes d’IA est protégée par une exemption de violation du droit d’auteur, et empêche même les contrats de la contourner. Cette mesure vise à faire de Singapour le lieu le plus attractif au monde pour le développement de modèles d’IA, attirant investissements et innovation, contrastant fortement avec l’approche prudente de l’Europe et des États-Unis en matière de droit d’auteur de l’IA. Bien que la portée de la protection soit limitée au territoire singapourien, elle offre une garantie importante pour le développement de modèles fondamentaux. (Source : Reddit r/ArtificialInteligence)
🌟 Communauté
Transactions de financement dans l’industrie de l’IA et craintes de bulle : Des doutes ont été soulevés sur les réseaux sociaux concernant les transactions de financement dans l’industrie de l’IA, beaucoup étant perçues comme des tentatives d’augmenter artificiellement les prix des actions plutôt que basées sur une valeur réelle. Des commentaires ont souligné que de nombreux produits d’IA n’ont pas trouvé d’applications pratiques sur les marchés locaux ou régionaux, les entreprises se plaignant même de l’inefficacité des produits d’IA. Ce phénomène est interprété comme une spéculation boursière plutôt qu’une formation de capital et des retombées réelles. Parallèlement, il y a un débat sur l’application des jumeaux numériques AI dans le marketing, se demandant s’il s’agit d’un “battage médiatique ou de l’avenir”. (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Controverses sur la censure de contenu et l’expérience utilisateur de ChatGPT : Les utilisateurs de ChatGPT se plaignent de la censure trop stricte de la plateforme, qui marque même de simples demandes de recettes ou des étreintes entre personnages comme du “contenu sexuellement suggestif”, tout en étant insensible au contenu violent. Les utilisateurs estiment que ChatGPT est devenu “nul” et “surprotecteur”, se demandant si OpenAI a perdu ses meilleurs employés. Parallèlement, des utilisateurs ont également signalé des problèmes de rendu LaTeX dans l’application ChatGPT. Cela a conduit certains utilisateurs à annuler leur abonnement, appelant OpenAI à cesser d’étouffer la créativité. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, jeremyphoward)

Le contrecoup du contenu AI et les inquiétudes des créateurs : Avec la prolifération du contenu généré par l’IA, un fort sentiment anti-IA est apparu dans la société, en particulier dans les domaines artistique et créatif. Des créateurs renommés comme le YouTuber MrBeast ont exprimé leurs craintes que les vidéos AI ne menacent les moyens de subsistance de millions de créateurs. Les fans de Taylor Swift ont également critiqué ses vidéos promotionnelles générées par l’IA comme étant “bon marché et grossières”. Ce contrecoup reflète l’anxiété des créateurs face à l’impact de la technologie AI sur les industries traditionnelles, ainsi que les préoccupations concernant la qualité et l’authenticité du contenu. (Source : Reddit r/artificial, MIT Technology Review)
Défis et perspectives de l’application de l’IA dans le domaine du jeu : La communauté a discuté des caractéristiques puissantes, créatives, intéressantes et dynamiques de la technologie AI, mais s’est interrogée sur la raison pour laquelle aucun jeu populaire n’utilise encore largement l’IA. Certains pensent que l’IA est déjà largement utilisée dans le développement, mais que le coût d’exécution locale des modèles AI est élevé, et que les développeurs de jeux ont tendance à contrôler la narration. D’autres estiment que les développeurs se concentrent uniquement sur les grands titres traditionnels, négligeant les nouvelles idées. Cela reflète les défis techniques, de coût et de créativité auxquels l’IA est confrontée dans le domaine du jeu. (Source : Reddit r/artificial)
Perplexity met en évidence l’utilité de la recherche AI grâce au cas d’utilisation de Cristiano Ronaldo : La superstar du football Cristiano Ronaldo a utilisé l’outil de recherche AI Perplexity pour préparer son discours de remise du Prestige Globe Award. Il a déclaré que Perplexity l’avait aidé à comprendre la signification du prix et à surmonter son trac. Cet événement a été largement diffusé par Perplexity et les médias sociaux, soulignant la valeur pratique de la recherche AI pour fournir des informations rapides et précises, ainsi que son potentiel de promotion grâce à l’effet de célébrité. (Source : AravSrinivas, AravSrinivas)
La recherche AI de Google récompensée par des prix Nobel et controverses associées : Google a remporté trois prix Nobel en deux ans, dont Demis Hassabis (AlphaFold) et Geoff Hinton (AI). Cette réalisation est considérée comme le reflet de l’investissement et de l’ambition à long terme de Google en matière de recherche. Cependant, Jürgen Schmidhuber a contesté le prix Nobel de physique 2024, affirmant qu’il y avait un problème de plagiat, car les résultats étaient très similaires à des recherches antérieures et n’avaient pas été correctement cités, ce qui a déclenché un débat sur l’éthique académique et l’attribution dans le domaine de l’IA. (Source : Yuchenj_UW, SchmidhuberAI, SchmidhuberAI)

Débat philosophique sur les besoins en calcul AI et la voie vers l’AGI/ASI : Concernant les énormes ressources de calcul nécessaires à la génération de vidéos AI, certains estiment que cet investissement massif, basé sur des besoins réels, indique au contraire que l’intelligence artificielle générale (AGI) et l’intelligence artificielle superintelligente (ASI) restent des fantasmes lointains. Cette discussion reflète la réflexion de l’industrie sur la trajectoire de développement de l’IA, à savoir si le succès actuel de l’IA dans des applications spécifiques pourrait disperser les ressources et retarder la réalisation d’objectifs plus ambitieux. Parallèlement, Richard Sutton souligne que l’essence de l’apprentissage est le comportement actif de l’agent plutôt que l’entraînement passif. (Source : fabianstelzer, Plinz, dwarkesh_sp)
Impact de l’IA sur le marché du travail : baisse du salaire horaire des annotateurs de données doctorants : Des discussions sur les réseaux sociaux ont révélé qu’en raison d’une offre excédentaire d’annotateurs de données doctorants, leur salaire horaire est passé de 100 $/heure à 50 $/heure. Auparavant, OpenAI employait des doctorants pour l’annotation de données à 100 $/heure. Ce phénomène reflète l’intensification de la concurrence sur le marché de l’annotation de données AI et l’évolution de la demande de talents en annotation de données de haute qualité. (Source : teortaxesTex)
Outils d’ingénierie logicielle assistés par l’IA obtiennent un financement et impact sur la profession : Relace, une startup spécialisée dans les outils pour les ingénieurs logiciels pilotés par l’IA, a levé 23 millions de dollars lors d’un tour de financement de série A mené par Andreessen Horowitz. Cela marque l’extension de la chaîne d’outils AI vers des domaines plus profonds du développement autonome de l’IA. Parallèlement, les ingénieurs ont discuté de la manière dont les outils de codage AI transforment leur façon de travailler, estimant que, bien qu’ils soient compétents dans l’utilisation des outils AI, la créativité humaine et la capacité à résoudre des problèmes restent des valeurs fondamentales. (Source : steph_palazzolo, kylebrussell)
L’essor et le déclin du phénomène culturel du Vibe Coding : Les médias sociaux ont discuté de l’émergence et du déclin du concept de “Vibe Coding”. Certains considèrent le Vibe Coding comme une façon de programmer dans une atmosphère détendue, mais d’autres estiment qu’il est “mort”. Les discussions connexes ont également mentionné le “Bob Ross vibe coding” et d’autres contenus générés par l’IA, reflétant l’exploration et la réflexion de la communauté des développeurs sur la culture de la programmation et les méthodes de programmation assistées par l’IA. (Source : arohan, Ronald_vanLoon, nptacek)
💡 Autres
Le gouvernement américain pourrait annuler des milliards de dollars de financement pour des usines de capture de carbone : Le département américain de l’Énergie pourrait mettre fin à des milliards de dollars de financement pour deux grandes usines de capture directe de carbone dans l’air. Ces projets devaient initialement recevoir plus d’un milliard de dollars de subventions gouvernementales, mais sont actuellement en état de “résiliation”. Bien que le département de l’Énergie ait déclaré qu’aucune décision finale n’avait été prise et qu’il avait déjà mis fin à plus de 200 projets pour économiser 7,5 milliards de dollars, cette incertitude a soulevé des inquiétudes dans l’industrie quant au développement de la technologie climatique américaine et à sa compétitivité internationale. (Source : MIT Technology Review)

Nouvelles avancées en robotique : du poignet flexible aux coléoptères bioniques et robots humanoïdes : Le domaine de la robotique a réalisé de multiples avancées. Un nouveau poignet robotique parallèle a permis des mouvements flexibles et semblables à ceux de l’homme dans des espaces restreints, améliorant la précision des opérations. Parallèlement, des chercheurs développent des coléoptères robotiques bioniques équipés de sacs à dos, destinés à la recherche et au sauvetage en cas de catastrophe. En outre, des rapports ont montré l’interaction de robots humanoïdes avec des motos, démontrant la capacité de la technologie bionique à simuler le comportement humain. Ces avancées repoussent collectivement les limites de la robotique en matière d’adaptabilité aux environnements complexes et d’interaction homme-machine. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
