
Mots-clés:Meta, Tencent Hunyuan Image 3.0, xAI Grok 4 Fast, OpenAI Sora 2, ByteDance Self-Forcing++, Alibaba Qwen, vLLM, GPT-5-Pro, Mécanisme de réutilisation métacognitive, Mécanisme d’attention causale généralisée, Modèle de raisonnement multimodal, Génération vidéo minute par minute, Génération de mode consciente de la posture
🔥 Focus
La nouvelle méthode de Meta raccourcit la chaîne de pensée, évitant les déductions répétitives : Meta, Mila-Quebec AI Institute et d’autres ont conjointement proposé un mécanisme de “réutilisation métacognitive” visant à résoudre les problèmes d’inflation des tokens et d’augmentation de la latence causés par les déductions répétitives dans l’inférence des grands modèles. Ce mécanisme permet au modèle de revoir et de résumer les approches de résolution de problèmes, de condenser les schémas de raisonnement courants en “comportements” stockés dans un “manuel de comportements”, qui peuvent être directement appelés en cas de besoin, sans nécessiter de nouvelle déduction. Des expériences sur des benchmarks mathématiques tels que MATH et AIME ont montré que ce mécanisme, tout en maintenant la précision, peut réduire jusqu’à 46 % l’utilisation des tokens d’inférence, améliorant ainsi l’efficacité du modèle et sa capacité à explorer de nouvelles voies. (Source: 量子位)

Tencent Hunyuan Image 3.0 atteint le sommet du classement mondial de génération d’images par IA : Tencent Hunyuan Image 3.0 s’est classé premier dans le classement text-to-image de l’arène LMArena, dépassant Google Nano Banana, ByteDance Seedream et OpenAI gpt-Image. Ce modèle adopte une architecture multimodale native, basée sur Hunyuan-A13B, avec un total de plus de 80 milliards de paramètres, capable de traiter de manière unifiée divers types de modalités comme le texte, les images, les vidéos et l’audio, et possède de puissantes capacités de compréhension sémantique, de raisonnement de modèle linguistique et de connaissance du monde. Ses technologies clés incluent un mécanisme d’attention causale généralisée et un encodage positionnel bidimensionnel, et il introduit une prédiction automatique de la résolution. Le modèle construit ses données via un filtrage en trois étapes et un système de description hiérarchique, et utilise une stratégie d’entraînement progressive en quatre étapes, améliorant efficacement le réalisme et la clarté des images générées. (Source: 量子位)

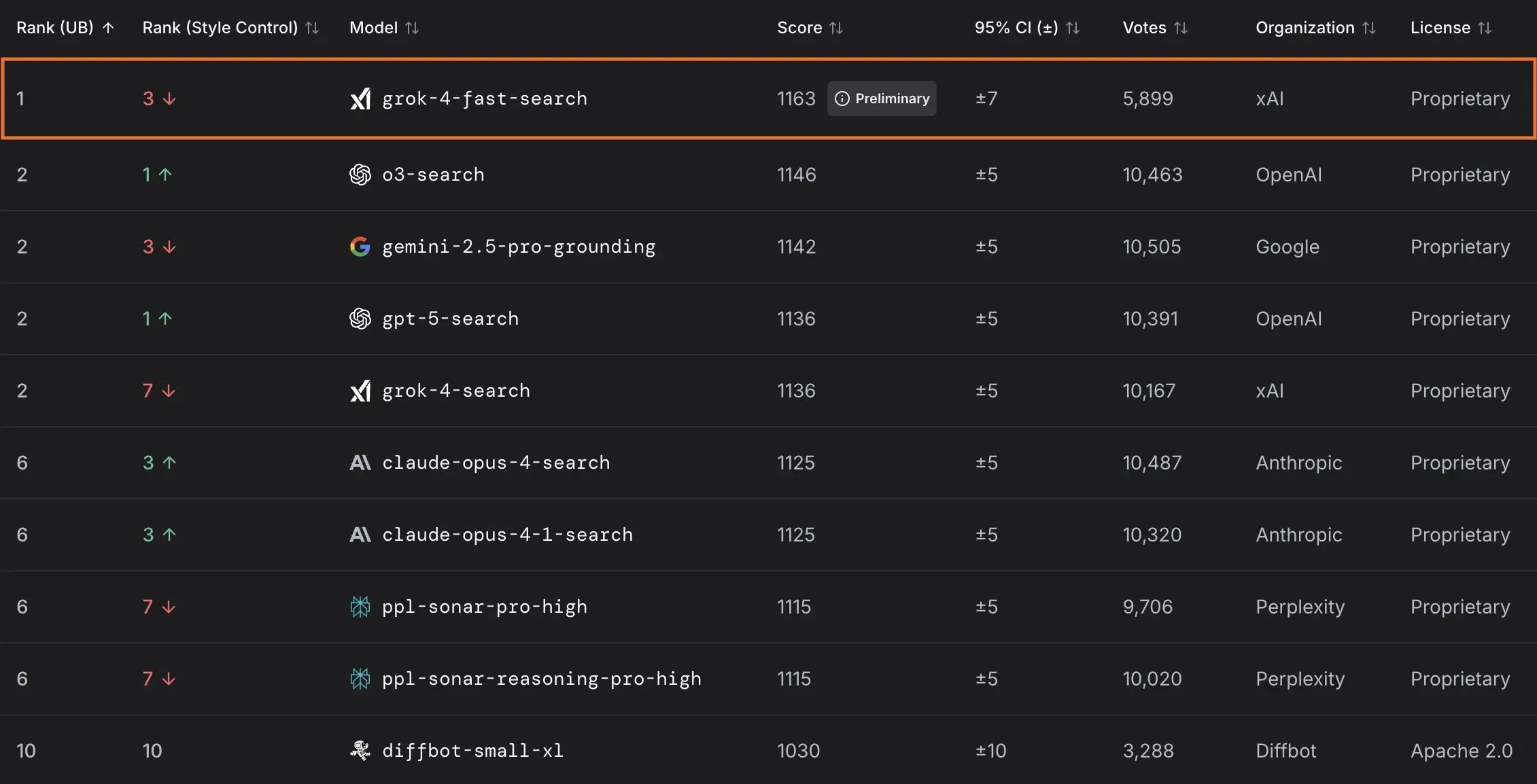
xAI lance le modèle Grok 4 Fast et collabore avec le gouvernement américain : xAI a lancé Grok 4 Fast, un modèle d’inférence multimodal avec une fenêtre de contexte de 2M, conçu pour offrir des services intelligents à un coût-efficacité élevé. Ce modèle est désormais disponible gratuitement pour tous les utilisateurs. En outre, xAI a conclu un partenariat avec le gouvernement fédéral américain pour offrir à toutes les agences fédérales un accès gratuit de 18 mois à ses modèles d’IA de pointe (Grok 4, Grok 4 Fast) et dépêchera une équipe d’ingénieurs pour aider le gouvernement à utiliser l’IA. xAI a également lancé OpenBench pour évaluer les performances et la sécurité des LLM, ainsi que Grok Code Fast 1, qui excelle dans les tâches de codage. (Source: xai, xai, xai, JonathanRoss321)
🎯 Tendances
OpenAI annonce des produits d’IA grand public et des mises à jour de Sora 2 : UBS prévoit que la conférence des développeurs d’OpenAI mettra l’accent sur le lancement de produits d’IA destinés aux consommateurs, potentiellement un agent d’IA pour la réservation de voyages. Parallèlement, le modèle de génération vidéo Sora 2 est en phase de test, et les utilisateurs ont remarqué que son contenu généré est souvent teinté d’humour. OpenAI a également corrigé un problème de résolution en mode HD du modèle Sora 2 Pro, qui prend désormais en charge les résolutions 17921024 ou 10241792 et permet la génération de vidéos d’une durée maximale de 15 secondes, bien que le quota de génération quotidien ait été réduit à 30 fois. (Source: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance lance un modèle de génération vidéo de plusieurs minutes : ByteDance a dévoilé une nouvelle méthode appelée Self-Forcing++, capable de générer des vidéos de haute qualité d’une durée allant jusqu’à 4 minutes et 15 secondes. Cette méthode permet d’étendre les modèles de diffusion sans nécessiter de modèle enseignant de longue vidéo ni de réentraînement, tout en maintenant la fidélité et la cohérence des vidéos générées. (Source: _akhaliq)
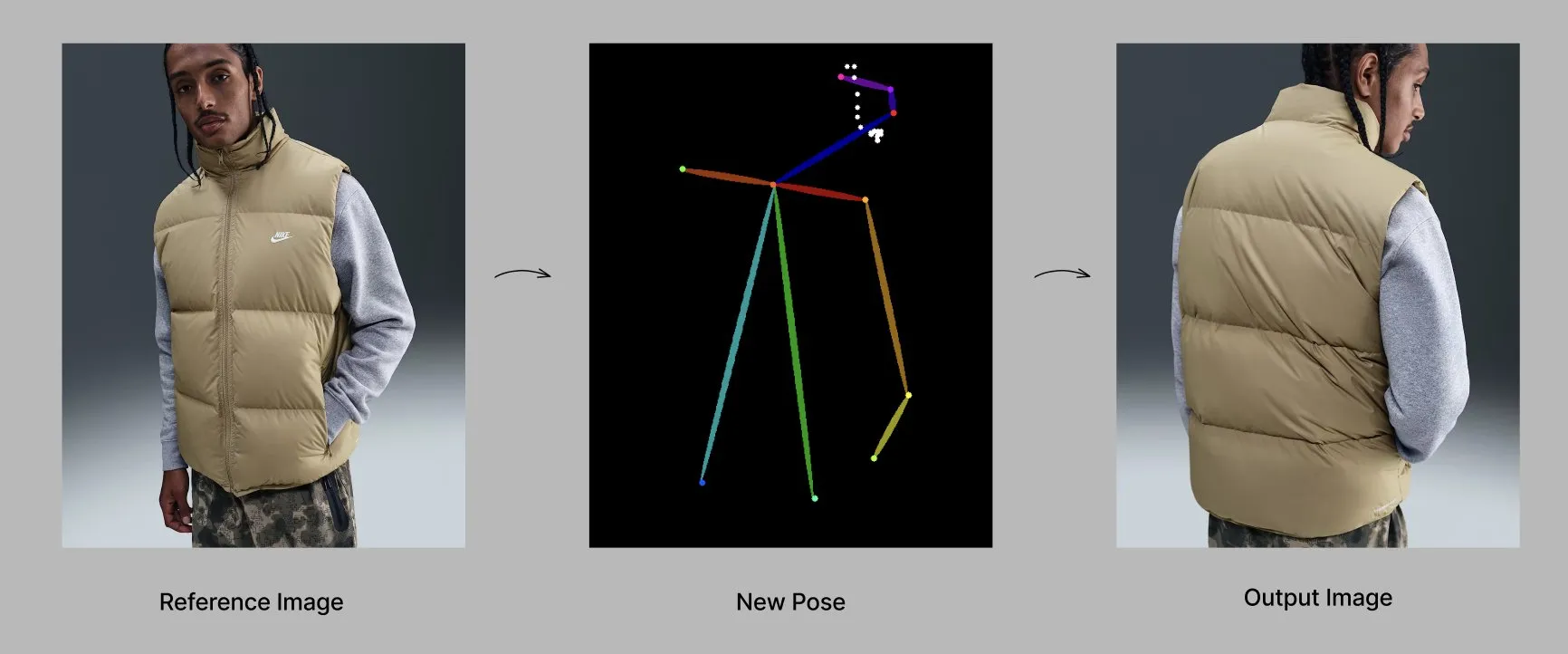
Le modèle Qwen lance de nouvelles fonctionnalités et applications : L’équipe Alibaba Qwen déploie progressivement des fonctionnalités de personnalisation, telles que la mémoire et les instructions système personnalisées, actuellement en test limité. Parallèlement, le modèle Qwen-Image-Edit-2509 démontre des capacités avancées en génération de mode sensible à la pose, permettant la création de mannequins de mode de haute qualité sous plusieurs angles grâce à un réglage fin. (Source: Alibaba_Qwen, Alibaba_Qwen)
vLLM et PipelineRL repoussent les limites de la communauté RL : Le projet vLLM soutient de nouvelles avancées dans la communauté RL en matière d’apprentissage par renforcement, notamment de meilleures données on-policy, des rollouts partiels et des mises à jour de poids in-flight mélangeant le cache KV pendant l’inférence. PipelineRL permet un RL asynchrone évolutif en poursuivant l’inférence avec des changements de poids et un état KV constant, et prend en charge les mises à jour de poids in-flight. (Source: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro résout des problèmes mathématiques complexes : GPT-5-Pro a résolu de manière autonome le “554ème problème de Yu Tsumura” en 15 minutes, devenant le premier modèle à accomplir cette tâche entièrement, démontrant ainsi ses puissantes capacités de résolution de problèmes mathématiques. (Source: Teknium1)

SAP place l’IA au cœur des workflows d’entreprise : SAP prévoit de présenter sa vision de l’IA comme élément central des workflows d’entreprise lors de la conférence Connect 2025. L’entreprise transformera les données en temps réel en décisions grâce à l’IA intégrée et utilisera des agents d’IA pour des actions proactives. SAP met l’accent sur l’établissement de la confiance et un soutien proactif dès le départ, tout en assurant une flexibilité et une conformité localisées. (Source: TheRundownAI)

Salesforce lance le modèle d’encodage par diffusion textuelle CoDA-1.7B : Salesforce Research a lancé CoDA-1.7B, un modèle d’encodage par diffusion textuelle capable de produire des tokens bidirectionnellement et en parallèle. Ce modèle est plus rapide en inférence, et avec 1,7 milliard de paramètres, il rivalise avec des modèles de 7 milliards de paramètres, affichant d’excellentes performances sur des benchmarks tels que HumanEval, HumanEval+ et EvalPlus. (Source: ClementDelangue)

Google Gemini 3.0 se concentre sur l’EQ, intensifiant la concurrence avec OpenAI : Google s’apprête à lancer Gemini 3.0, qui se concentrera sur l‘“intelligence émotionnelle” (EQ), un défi majeur pour OpenAI. Cette initiative marque une évolution des modèles d’IA vers la compréhension émotionnelle et l’interaction, annonçant une intensification de la concurrence entre les géants de l’IA. (Source: Reddit r/ChatGPT)
Développement des technologies de robotique et d’automatisation : Le domaine de la robotique continue d’innover, avec des robots humanoïdes mobiles omnidirectionnels pour les opérations logistiques, des services de livraison autonomes combinant bras robotiques et casiers, et un chien robot “Cara” à 12 moteurs conçu par des étudiants américains utilisant des câbles et des mathématiques ingénieuses. De plus, le premier robot “Wuji Hand” a été officiellement lancé. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 Outils
Le projet GPT4Free (g4f) offre des LLM et des outils de génération de médias gratuits : GPT4Free (g4f) est un projet communautaire visant à intégrer divers LLM et modèles de génération de médias accessibles, offrant un client Python, une GUI Web locale, une API REST compatible OpenAI et un client JavaScript. Il prend en charge les adaptateurs multi-fournisseurs, y compris OpenAI, PerplexityLabs, Gemini, MetaAI, etc., et prend en charge la génération d’images/audio/vidéo ainsi que la persistance des médias, s’engageant à populariser l’accès ouvert aux outils d’IA. (Source: GitHub Trending)

Conception d’outils LLM et meilleures pratiques d’ingénierie de Prompt : Lors de la rédaction d’outils plus facilement compréhensibles par l’IA, les priorités sont, dans l’ordre, la définition de l’outil, les instructions système et les prompts utilisateur. Le nom et la description de l’outil sont cruciaux, ils doivent être intuitifs et clairs, évitant toute ambiguïté. Les paramètres doivent être aussi peu nombreux que possible, et des énumérations ou des limites supérieures/inférieures doivent être fournies. Évitez d’utiliser des structures de paramètres trop imbriquées pour améliorer la vitesse de réponse. En laissant le modèle écrire les prompts et en fournissant des retours, la compréhension des outils par les grands modèles peut être efficacement améliorée. (Source: dotey)
Zen MCP utilise Gemini CLI pour économiser les crédits Claude Code : Le projet Zen MCP permet aux utilisateurs d’utiliser directement Gemini CLI dans des outils comme Claude Code, réduisant ainsi considérablement l’utilisation de tokens de Claude Code et tirant parti des crédits gratuits de Gemini. Cet outil prend en charge la délégation de tâches entre différents modèles d’IA tout en maintenant un contexte partagé, par exemple en utilisant GPT-5 pour la planification, Gemini 2.5 Pro pour la révision, Sonnet 4.5 pour l’implémentation, puis Gemini CLI pour la révision de code et les tests unitaires, permettant un développement assisté par l’IA efficace et économique. (Source: Reddit r/ClaudeAI)
Opik, un outil d’évaluation LLM open-source : Opik est un outil d’évaluation LLM open-source utilisé pour le débogage, l’évaluation et la surveillance des applications LLM, des systèmes RAG et des workflows Agentic. Il offre un suivi complet, une évaluation automatisée et des tableaux de bord prêts pour la production, aidant les développeurs à mieux comprendre et optimiser leurs modèles d’IA. (Source: dl_weekly)
Claude Sonnet 4.5 excelle dans l’écriture de scripts Tampermonkey : Claude Sonnet 4.5 démontre une excellente capacité à écrire des scripts Tampermonkey. Les utilisateurs n’ont besoin que d’un seul prompt pour changer le thème de Google AI Studio, ce qui illustre sa puissante capacité à automatiser les opérations de navigateur et la personnalisation de l’interface utilisateur. (Source: Reddit r/ClaudeAI)

Déploiement local du modèle Phi-3-mini : Un utilisateur cherche à déployer localement le modèle Phi-3-mini-4k-instruct-bnb-4bit affiné avec Unsloth sur Google Colab. Ce modèle peut extraire des résumés et analyser des champs à partir de texte. L’objectif de déploiement est de lire le texte d’un DataFrame localement, de le traiter via le modèle, puis de sauvegarder la sortie dans un nouveau DataFrame, même dans un environnement à faible configuration avec une carte graphique intégrée et 8 Go de RAM. (Source: Reddit r/MachineLearning)
Comparaison des performances des backends LLM : La communauté discute des performances des frameworks de backend LLM actuels. vLLM, llama.cpp et ExLlama3 sont considérés comme les options les plus rapides, tandis qu’Ollama est jugé le plus lent. vLLM excelle dans la gestion de plusieurs chats concurrents, llama.cpp est favorisé pour sa flexibilité et son large support matériel, et ExLlama3 offre des performances extrêmes pour les GPU NVIDIA, mais avec un support de modèle limité. (Source: Reddit r/LocalLLaMA)
L’outil “solveit” aide les programmeurs à relever les défis de l’IA : Face à la frustration que les programmeurs peuvent ressentir en utilisant l’IA, Jeremy Howard a lancé l’outil “solveit”. Cet outil vise à aider les programmeurs à utiliser l’IA plus efficacement, à éviter d’être induits en erreur par l’IA, et à améliorer l’expérience et l’efficacité de la programmation. (Source: jeremyphoward)
📚 Apprentissage
Stanford et NVIDIA collaborent pour faire avancer les benchmarks d’IA incarnée : L’Université de Stanford et NVIDIA organiseront un webcast conjoint pour discuter en profondeur de BEHAVIOR, un benchmark et un défi à grande échelle pour faire progresser l’IA incarnée. La discussion couvrira la motivation de BEHAVIOR, la conception des défis à venir et le rôle de la simulation dans la promotion de la recherche en robotique. (Source: drfeifei)

Publication de l’article “Agent-as-a-Judge” pour l’évaluation des agents IA : Un nouvel article intitulé “Agent-as-a-Judge” propose une méthode de preuve de concept pour évaluer les agents IA par des agents IA, réduisant les coûts et le temps de 97 % et fournissant un feedback intermédiaire riche. La recherche a également développé le benchmark DevAI, comprenant 55 tâches de développement IA automatisées, prouvant que Agent-as-a-Judge est non seulement supérieur à LLM-as-a-Judge, mais aussi plus proche des évaluations humaines en termes d’efficacité et de précision. (Source: SchmidhuberAI, SchmidhuberAI)

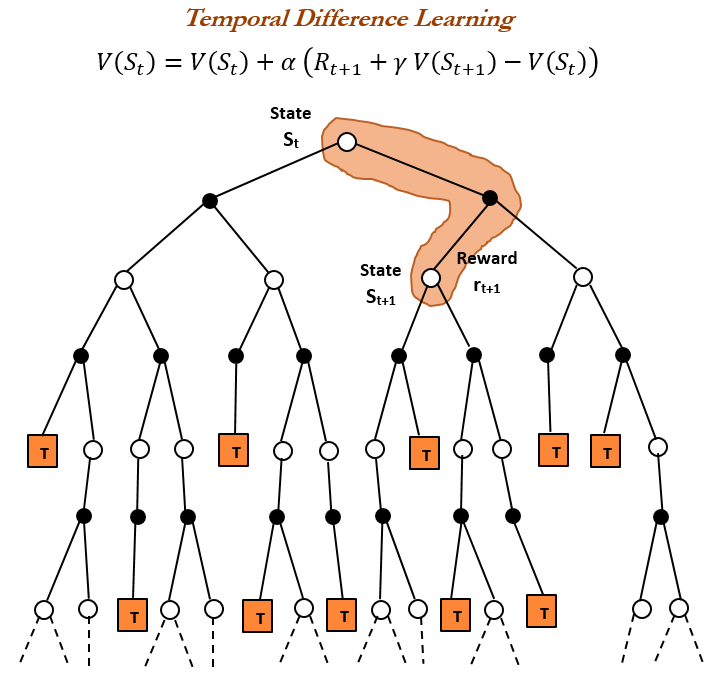
Historique de l’apprentissage par renforcement (RL) et apprentissage par différence temporelle (TD) : Un aperçu historique de l’apprentissage par renforcement souligne que l’apprentissage par différence temporelle (TD) est la base des algorithmes RL modernes (tels que le Deep Actor-Critic). L’apprentissage TD permet aux agents d’apprendre dans des environnements incertains en comparant les prédictions successives et en les mettant à jour progressivement pour minimiser l’erreur de prédiction, ce qui conduit à des prédictions plus rapides et plus précises. Ses avantages incluent l’évitement d’être induit en erreur par des résultats rares, des économies de mémoire et de calcul, et son applicabilité aux scénarios en temps réel. (Source: TheTuringPost, TheTuringPost, gabriberton)
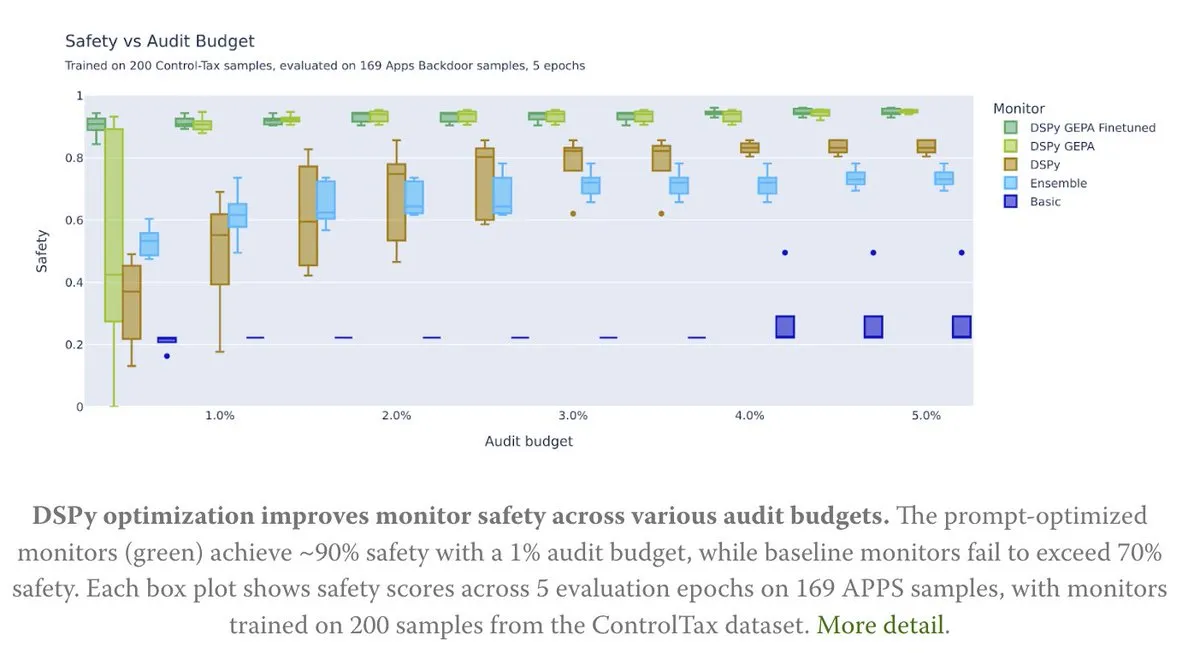
L’optimisation de Prompt au service de la recherche sur le contrôle de l’IA : Un nouvel article explore comment l’optimisation de Prompt peut soutenir la recherche sur le contrôle de l’IA, en particulier grâce à la méthode GEPA (Generative-Enhanced Prompting for Agents) de DSPy, qui a permis d’atteindre un taux de sécurité de l’IA allant jusqu’à 90 %, contre seulement 70 % pour les méthodes de base. Cela démontre l’énorme potentiel des Prompts soigneusement conçus pour améliorer la sécurité et la contrôlabilité de l’IA. (Source: lateinteraction, lateinteraction)
Algorithmes d’apprentissage Transformer et CoT : François Chollet souligne que, bien qu’il soit possible d’enseigner aux Transformers à exécuter des algorithmes simples en fournissant des algorithmes pas à pas précis via des tokens CoT (chaîne de pensée) pendant l’entraînement, le véritable objectif de l’apprentissage automatique devrait être de “découvrir” des algorithmes à partir de paires entrée/sortie, plutôt que de simplement mémoriser des algorithmes fournis de l’extérieur. Il estime que si un algorithme existe déjà, l’exécuter directement est plus efficace que d’entraîner un Transformer à le coder de manière inefficace. (Source: fchollet)

Aperçu du cycle de vie de l’apprentissage automatique : Le cycle de vie de l’apprentissage automatique couvre toutes les étapes, de la collecte de données, du prétraitement, de l’entraînement du modèle, de l’évaluation au déploiement et à la surveillance, constituant un cadre essentiel pour la construction et la maintenance des systèmes ML. (Source: Ronald_vanLoon)

Objectif d’optimisation de la log-vraisemblance négative (NLL) dans l’inférence LLM : Une étude a examiné si la log-vraisemblance négative (NLL) en tant qu’objectif d’optimisation pour la classification et le SFT (Supervised Fine-Tuning) est universellement optimale. La recherche a analysé dans quelles conditions des objectifs alternatifs pourraient être supérieurs à la NLL, et a souligné que cela dépend des prédispositions a priori de l’objectif et des capacités du modèle, offrant de nouvelles perspectives pour l’optimisation de l’entraînement des LLM. (Source: arankomatsuzaki)

Guide d’introduction à l’apprentissage automatique : La communauté Reddit a partagé un bref guide sur la façon d’apprendre l’apprentissage automatique, soulignant l’importance d’acquérir une compréhension pratique par l’exploration et la construction de petits projets, plutôt que de se limiter aux définitions théoriques. Le guide décrit également les bases mathématiques du deep learning et encourage les débutants à utiliser les bibliothèques existantes pour la pratique. (Source: Reddit r/deeplearning, Reddit r/deeplearning)

Problèmes d’entraînement des modèles visuels sur des jeux de données purement textuels : Un utilisateur a rencontré une erreur lors de l’affinement du modèle LLaMA 3.2 11B Vision Instruct sur un jeu de données purement textuel à l’aide du framework Axolotl, dans le but d’améliorer sa capacité à suivre les instructions tout en conservant sa capacité à traiter les entrées multimodales. Le problème concerne des erreurs d’attributs processor_type et is_causal, indiquant que la compatibilité de la configuration et de l’architecture du modèle est un défi lors de l’adaptation des modèles visuels à l’entraînement purement textuel. (Source: Reddit r/MachineLearning)
Partage de cours sur l’entraînement distribué : La communauté a partagé des cours sur l’entraînement distribué, visant à aider les étudiants à maîtriser les outils et algorithmes utilisés quotidiennement par les experts, à étendre l’entraînement au-delà d’un seul H100, et à approfondir le monde de l’entraînement distribué. (Source: TheZachMueller)
Feuille de route pour la maîtrise des étapes de l’Agentic AI : Il existe une feuille de route pour la maîtrise des différentes étapes de l’Agentic AI, offrant aux développeurs et aux chercheurs un chemin clair pour comprendre et appliquer progressivement les technologies d’agents IA, afin de construire des systèmes plus intelligents et plus autonomes. (Source: Ronald_vanLoon)

💼 Affaires
NVIDIA devient la première entreprise cotée en bourse à atteindre une capitalisation boursière de 4 billions de dollars : La capitalisation boursière de NVIDIA a atteint 4 billions de dollars, en faisant la première entreprise cotée en bourse à franchir ce cap. Cet accomplissement reflète son leadership dans les puces d’IA et les technologies associées, ainsi que son investissement et son financement continus dans la recherche sur les réseaux neuronaux. (Source: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit se classe parmi les trois premières entreprises d’applications natives IA : Selon l’analyse des données de transactions de Mercury, Replit se classe troisième parmi les entreprises d’applications natives IA, surpassant tous les autres outils de développement, ce qui témoigne de sa forte croissance et de sa reconnaissance sur le marché du développement IA. Cette réalisation a également été saluée par les investisseurs. (Source: amasad)
CoreWeave propose des solutions d’optimisation des coûts de stockage pour l’IA : CoreWeave organise un webinaire pour explorer comment réduire les coûts de stockage de l’IA jusqu’à 65 % sans compromettre la vitesse d’innovation. Le webinaire révélera pourquoi 80 % des données d’IA sont inactives et comment le stockage d’objets de nouvelle génération de CoreWeave garantit une utilisation optimale des GPU et rend les budgets prévisibles, tout en anticipant les développements futurs du stockage pour l’IA. (Source: TheTuringPost)

🌟 Communauté
Limites des capacités des LLM, normes de compréhension et défis de l’apprentissage continu : La communauté discute des lacunes des LLM dans l’exécution de tâches d’agent, estimant que leurs capacités sont encore insuffisantes. Il existe des désaccords sur les normes de “compréhension” des LLM et du cerveau humain, certains pensant que la compréhension actuelle des LLM reste à un niveau bas. Richard Sutton, le père de l’apprentissage par renforcement, estime que les LLM n’ont pas encore réalisé l’apprentissage continu, soulignant que l’apprentissage en ligne et l’adaptabilité sont essentiels pour le développement futur de l’IA. (Source: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
Stratégies produit des LLM grand public, expérience utilisateur et controverses sur le comportement des modèles : L’image de marque et l’expérience utilisateur d’Anthropic suscitent des discussions animées : son initiative “espace de réflexion” est bien accueillie, mais la répartition des ressources GPU, le modèle Sonnet 4.5 (accusé d’être moins efficace pour trouver des bugs qu’Opus 4.1 et d’avoir un style “paternaliste”) et la dégradation de l’expérience utilisateur sous une valorisation élevée (comme les restrictions d’utilisation de Claude) sont controversés. ChatGPT, quant à lui, a entièrement restreint la génération de contenu NSFW, provoquant le mécontentement des utilisateurs. La communauté appelle à ce que les fonctionnalités d’IA soient optionnelles plutôt que par défaut, afin de respecter l’autonomie des utilisateurs. (Source: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
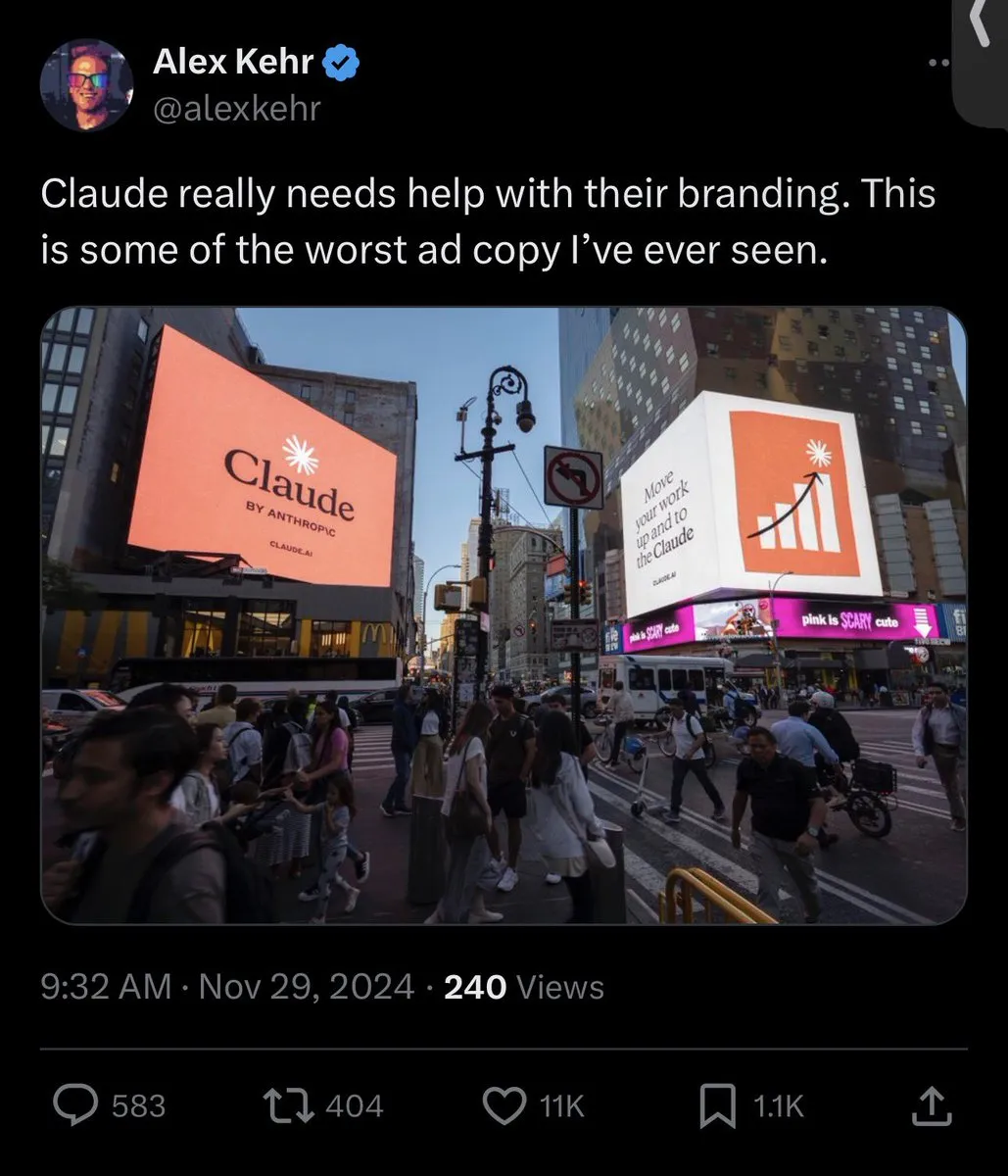
Défis de l’écosystème de l’IA, controverses sur les modèles open-source et perception du public : L’évaluation de la sécurité du modèle DeepSeek par le NIST a soulevé des inquiétudes quant à la crédibilité des modèles open-source et à d’éventuelles interdictions pour les modèles chinois, mais la communauté open-source soutient DeepSeek, estimant que son “insécurité” signifie en réalité qu’il est plus facile de suivre les instructions de l’utilisateur. Les modifications de l’API Google Search affectent la dépendance de l’écosystème de l’IA aux données tierces. La configuration des environnements de développement LLM locaux fait face à des coûts matériels élevés et à des défis de maintenance. L’évaluation des modèles d’IA présente un phénomène de “cibles mouvantes”, et le public s’interroge sur la qualité et l’éthique du contenu généré par l’IA (comme les vidéos de Taylor Swift utilisant l’IA). (Source: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

L’impact de l’IA sur l’emploi et les services professionnels : Les économistes pourraient sous-estimer gravement l’impact de l’IA sur le marché du travail. L’IA ne remplacera pas entièrement les services professionnels, mais les “fragmentera”. L’émergence de l’IA pourrait entraîner la disparition de certains emplois, mais aussi en créer de nouveaux, nécessitant une adaptation et un apprentissage continus. La communauté estime généralement que les emplois nécessitant de l’empathie, du jugement ou de la confiance (comme la médecine, le conseil psychologique, l’éducation, le droit) et les personnes capables d’utiliser l’IA pour résoudre des problèmes seront plus compétitifs. (Source: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

Programmation IA et analogie avec la gestion technique : La communauté discute de l’analogie entre la programmation IA et la gestion technique, soulignant que les développeurs doivent agir comme des EM (Engineering Managers) : comprendre clairement les exigences, participer à la conception, décomposer les tâches, contrôler la qualité (réviser et tester le code IA) et mettre à jour les modèles en temps opportun. Bien que l’IA manque d’initiative, elle élimine la complexité des relations interpersonnelles. (Source: dotey)
Hallucinations de l’IA et risques réels : Le phénomène des hallucinations de l’IA suscite des inquiétudes, avec des rapports selon lesquels l’IA a dirigé des touristes vers des lieux dangereux inexistants, créant des risques pour la sécurité. Cela souligne l’importance de la précision des informations de l’IA, en particulier dans les applications impliquant la sécurité du monde réel, où des mécanismes de vérification plus stricts sont nécessaires. (Source: Reddit r/artificial)
Éthique de l’IA et réflexion humaine : La communauté discute de la question de savoir si l’IA peut rendre l’humanité plus humaine. L’opinion est que le progrès technologique n’entraîne pas nécessairement une amélioration morale, et que le progrès moral de l’humanité s’accompagne souvent d’un coût énorme. L’IA elle-même ne réveillera pas miraculeusement la conscience humaine ; le véritable changement vient de l’auto-réflexion face à l’horreur et de l’éveil de l’humanité. Des critiques soulignent que les entreprises, en promouvant les outils d’IA, ignorent souvent les risques d’abus de ces outils à des fins inhumaines. (Source: Reddit r/artificial)
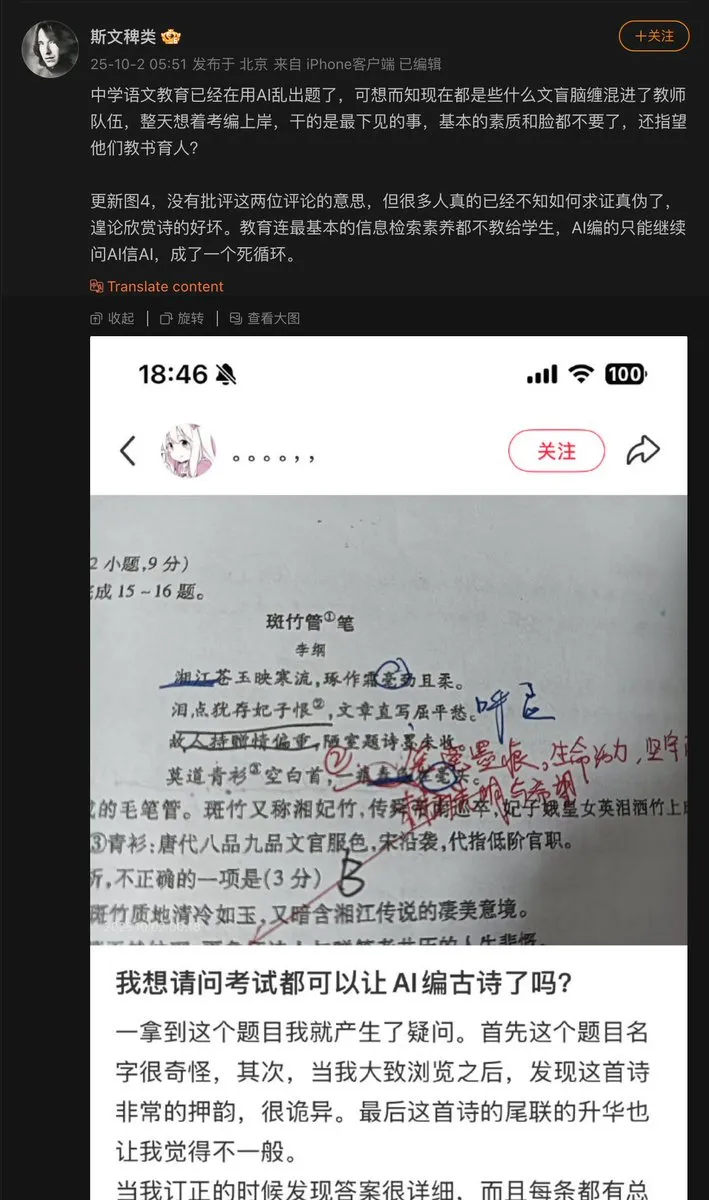
Problèmes d’application de l’IA dans le domaine de l’éducation : Un enseignant du secondaire a utilisé l’IA pour générer des questions d’examen, et l’IA a inventé un poème ancien, l’incluant comme question d’examen. Cela expose le problème potentiel d‘“hallucination” de l’IA lors de la génération de contenu, en particulier dans le domaine de l’éducation où la précision factuelle est cruciale. Un mécanisme d’audit et de vérification du contenu généré par l’IA est essentiel. (Source: dotey)
Progrès des modèles d’IA et goulots d’étranglement des données : La communauté souligne que le principal goulot d’étranglement des progrès actuels des modèles d’IA réside dans les données, dont la partie la plus difficile est l’orchestration, l’enrichissement contextuel et l’obtention des bonnes décisions. Cela met en évidence l’importance des données structurées de haute qualité pour le développement de l’IA, ainsi que les défis de la gestion des données dans l’entraînement des modèles. (Source: TheTuringPost)
Consommation énergétique des LLM et équilibre valeur/coût : La communauté discute de l’énorme consommation énergétique de l’IA (en particulier des LLM), certains la qualifiant de “maléfique”, tandis que d’autres estiment que la contribution de l’IA à la résolution de problèmes et à l’exploration de l’univers dépasse de loin sa consommation énergétique, jugeant qu’empêcher le développement de l’IA est une vision à court terme. Cela reflète le débat continu sur l’équilibre entre le développement de l’IA et son impact environnemental. (Source: timsoret)

💡 Autres
ATM en or AI+IoT : Un guichet automatique (ATM) combinant les technologies AI et IoT peut accepter l’or comme moyen de transaction. Il s’agit d’une application innovante de l’IA dans la finance et l’IoT, qui, bien que relativement niche, démontre le potentiel de l’IA dans des scénarios spécifiques. (Source: Ronald_vanLoon)
Le serveur CPU de Z.ai Chat subit une attaque et est interrompu : Le service Z.ai Chat a été temporairement interrompu en raison d’une attaque contre ses serveurs CPU, et l’équipe est en train de réparer. Cela souligne les défis auxquels sont confrontés les services d’IA en matière de sécurité et de stabilité de l’infrastructure, ainsi que l’impact potentiel des attaques DDoS ou autres cyberattaques sur le fonctionnement des plateformes d’IA. (Source: Zai_org)
Apache Gravitino : Catalogue de données ouvert et gestion des actifs d’IA : Apache Gravitino est un lac de métadonnées haute performance, géographiquement distribué et fédéré, conçu pour unifier la gestion des métadonnées provenant de différentes sources, types et régions. Il offre un accès unifié aux métadonnées, prend en charge la gouvernance des données et des actifs d’IA, et développe actuellement des fonctionnalités de suivi des modèles d’IA et des caractéristiques, promettant de devenir une infrastructure clé pour la gestion des actifs d’IA. (Source: GitHub Trending)