Mots-clés:Meta AI, Cadre multiforme LIRA, Microsoft Agent Framework, Capitalisation boursière de NVIDIA, Sora 2 Pro, Perplexity AI Comet, IBM Granite 4.0, Série de modèles Qwen, Réorganisation de l’équipe Meta AI, Précision de segmentation d’images LIRA, Prise en charge multilingue d’Agent Framework, Marché des puces IA de NVIDIA, Limites de génération vidéo Sora 2
🔥 FOCALISATION
Turbulences au sein de l’équipe IA de Meta et rumeurs de démission de LeCun : Le département Meta AI connaît de fréquentes restructurations, entraînant un fort mécontentement interne, avec même des rumeurs selon lesquelles Yann LeCun, lauréat du prix Turing, pourrait démissionner de son poste de scientifique en chef chez FAIR. Des ajustements stratégiques internes, tels que l’exigence d’un examen supplémentaire pour la publication d’articles, les salaires élevés des nouveaux employés et l’inclinaison des ressources, ont exacerbé le sentiment de restriction de la liberté académique et le mécontentement des anciens employés de l’équipe FAIR, provoquant le départ de plusieurs chercheurs. Ces turbulences révèlent les défis auxquels sont confrontées les grandes entreprises technologiques lors de l’ajustement de leur stratégie IA, ainsi que le conflit entre la recherche de la commercialisation et le maintien de la liberté de la recherche fondamentale. (Source : 量子位)

L’équipe de Bai Xiang de l’Université de Huazhong lance le cadre multimodal LIRA, atteignant un double SOTA en segmentation et compréhension : L’Université des Sciences et Technologies de Huazhong, en collaboration avec l’équipe de Kingsoft Office, a publié le grand modèle multimodal LIRA. Grâce à deux modules innovants, l‘“extracteur de caractéristiques amélioré sémantiquement” (SEFE) et le “couplage visuel local entrelacé” (ILVC), LIRA améliore considérablement la précision de la segmentation d’images et réduit les hallucinations de compréhension. LIRA atteint le SOTA pour les tâches de segmentation et de compréhension, segmentant les cibles avec plus de précision dans des scénarios complexes et surpassant les meilleures méthodes existantes, telles que OMG-LLaVA, dans plusieurs tests de référence. Cette recherche offre de nouvelles approches pour la perception visuelle et les capacités de raisonnement des grands modèles multimodaux à grain fin. (Source : 量子位)
Microsoft lance Agent Framework, prenant en charge le développement multilingue Python et .NET : Microsoft a lancé Agent Framework, un cadre multilingue complet pour la construction, l’orchestration et le déploiement d’agents IA et de flux de travail multi-agents. Ce cadre prend en charge Python et .NET, offrant des flux de travail basés sur des graphes, un package expérimental AF Labs, une DevUI interactive, une intégration de l’observabilité OpenTelemetry, et prend en charge plusieurs fournisseurs de LLM ainsi qu’un système de middleware flexible. Il vise à simplifier le développement, des simples agents de chat aux flux de travail multi-agents complexes, améliorant ainsi l’efficacité et la contrôlabilité du développement d’applications IA. (Source : GitHub Trending)

La capitalisation boursière de NVIDIA dépasse les 4 billions de dollars, la demande en puissance de calcul IA continue d’exploser : La capitalisation boursière de NVIDIA a dépassé pour la première fois les 4 billions de dollars, devenant la première entreprise cotée en bourse au monde à atteindre ce jalon. Cette réalisation reflète la croissance forte et continue de la demande en calcul IA, ainsi que la position dominante de NVIDIA sur le marché des GPU et des puces IA. Des pionniers de l’IA comme Jürgen Schmidhuber ont également félicité NVIDIA pour sa contribution à faire progresser le potentiel des réseaux neuronaux, soulignant la tendance à une réduction significative des coûts de calcul tandis que la valeur de NVIDIA monte en flèche. (Source : SchmidhuberAI, SchmidhuberAI, SchmidhuberAI, nvidia)

🎯 TENDANCES
Extension des fonctionnalités de génération vidéo de Sora 2 Pro et impact sur le marché : La fonctionnalité de génération vidéo Sora 2 Pro d’OpenAI est progressivement déployée pour les utilisateurs de ChatGPT Pro, permettant de générer des vidéos de haute qualité de 15 secondes. L’apparition de Sora 2 a rapidement attiré l’attention du marché, atteignant même le sommet des classements d’applications IA de l’App Store. Son expérience produit est saluée comme “tueuse”, mais certains estiment que le modèle lui-même n’est pas SOTA, et que sa capacité de commercialisation est la clé de son succès. De plus, les prompts de Sora 2 pourraient être filtrés par le modèle, et même le contenu du domaine public pourrait être modifié, soulevant des discussions sur les droits d’auteur et le contrôle du contenu. (Source : dotey, thursdai_pod, billpeeb, TomLikesRobots, dotey, iScienceLuvr, skirano, VictorTaelin, Reddit r/artificial)

Le navigateur Comet de Perplexity AI est désormais gratuit et connaît une adoption rapide : Perplexity AI a annoncé que son navigateur Comet est désormais disponible gratuitement dans le monde entier, alors qu’il était auparavant tarifé à 200 dollars par mois. Les utilisateurs ont très bien évalué son design et son expérience utilisateur, estimant qu’il intègre l’IA de manière naturelle et non intrusive, évitant aux utilisateurs le fardeau d’apprendre de nouvelles interactions. Le navigateur a montré un taux d’adoption rapide chez les utilisateurs Windows et Mac, avec des performances encore meilleures sur Mac, et est considéré comme l’un des meilleurs produits de 2025. Cependant, certains remettent en question la légitimité de son modèle payant à prix élevé. (Source : AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, bookwormengr, Reddit r/artificial)

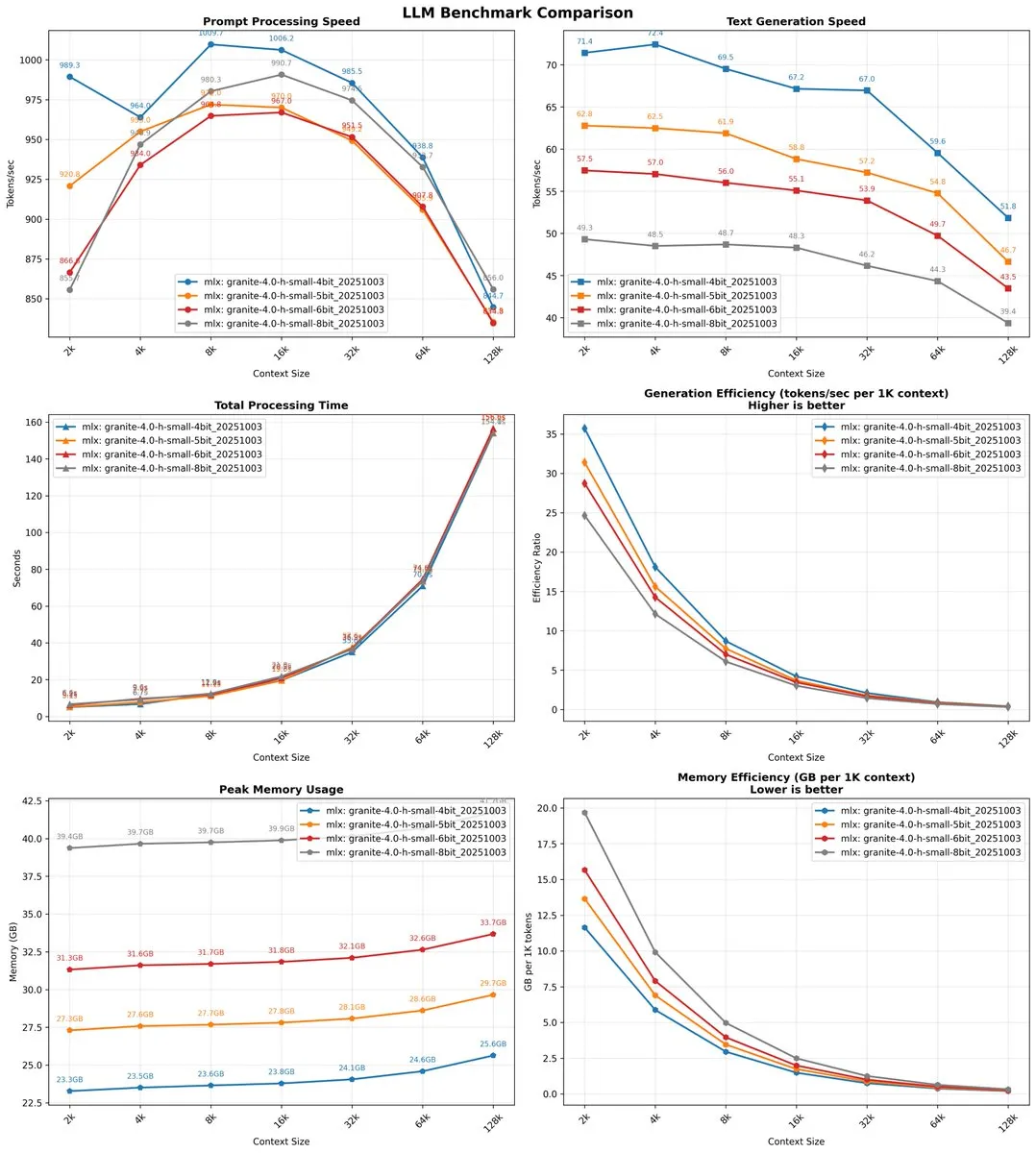
Les modèles IBM Granite 4.0 réalisent des progrès significatifs en performance et en long contexte : IBM a publié la série de modèles Granite 4.0. Le modèle Granite-4.0-H-Tiny surpasse significativement le modèle OLMoE publié il y a 10 mois sur plusieurs indicateurs tels que les mathématiques, le codage et les connaissances générales, et peut effectuer une inférence CPU sur un PC ordinaire à une vitesse raisonnable. Le modèle Granite 4.0-H-Small démontre également une vitesse d’inférence extrêmement rapide (jusqu’à 79 tokens/seconde), sans diminution significative de la vitesse avec l’augmentation de la longueur du contexte, et prend en charge une fenêtre de contexte allant jusqu’à 1M (bien que officiellement vérifiée jusqu’à 128k). Les utilisateurs apprécient sa faible consommation de mémoire et sa sortie concise, estimant qu’il excelle dans des scénarios spécifiques. (Source : ImazAngel, NerdyRodent, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Mises à jour et positionnement stratégique des modèles de la série Qwen : L’équipe Qwen d’Alibaba Cloud a détaillé la logique de nommage et les objectifs de développement de ses diverses familles de modèles (LLM, Coder, VL, Omni et Image), visant à s’unifier à terme en un modèle omnipotent. Qwen3-Next, en tant que version préliminaire de “Qwen3.5”, a réalisé des percées en matière d’efficacité grâce à une conception d’attention hybride, surpassant Qwen3-32B avec 10 % du coût d’entraînement et un débit de contexte long 10 fois supérieur. De plus, le modèle Qwen MoE démontre une vitesse d’inférence CPU exceptionnelle, annonçant son potentiel sur les appareils périphériques. La stratégie globale de Qwen est interprétée comme la construction d’un “écosystème Android” pour les modèles IA, mettant l’accent sur le faible coût, l’accessibilité et la modifiabilité. (Source : stablequan, karminski3, Teknium1, Dorialexander, ClementDelangue, natolambert, Reddit r/deeplearning)
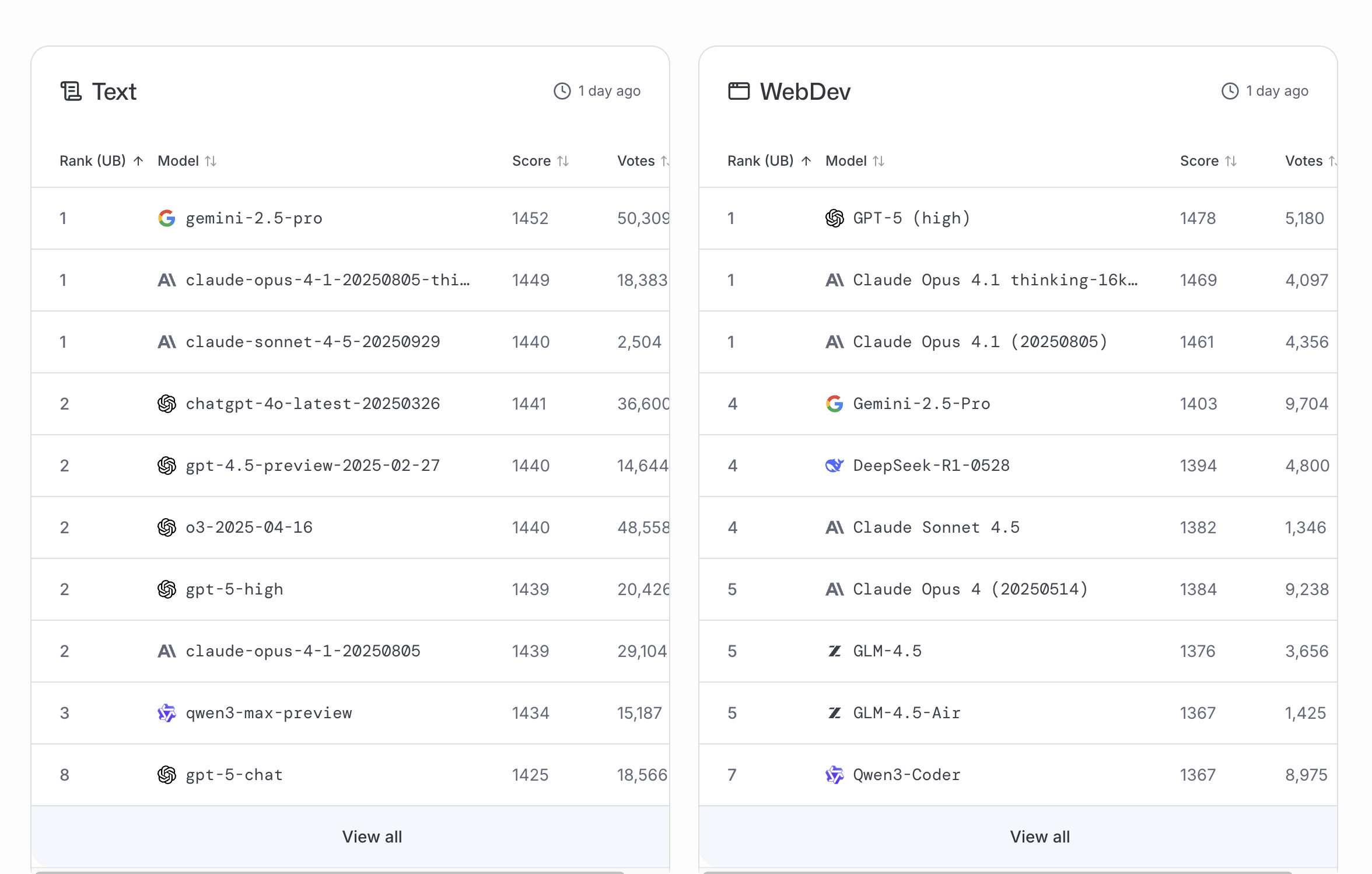
Controverses sur les performances et les limites d’utilisation de Claude 4.5 Sonnet et Opus : Après la publication du modèle Claude 4.5 Sonnet d’Anthropic, malgré une promotion intensive, il se classe au milieu des tests de référence WebDev et Text, étant en retard sur GPT-5 et la version “mode de pensée” de Claude Opus 4.1. Les retours des utilisateurs indiquent que la limite d’utilisation hebdomadaire de Claude Opus a été considérablement réduite ; une tâche de planification complexe peut consommer 6 % du quota hebdomadaire, réduisant le temps disponible pour les utilisateurs du plan Max de “25-40 heures” à quelques minutes. Cela a suscité un fort mécontentement concernant l’incohérence entre les prix et le service réel, remettant en question si Anthropic pénalise les tâches de raisonnement complexes et approfondies. (Source : thursdai_pod, alexalbert__, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Yunpeng Technology lance de nouveaux produits IA+santé : Yunpeng Technology a lancé de nouveaux produits en collaboration avec Shuaikang et Skyworth à Hangzhou le 22 mars 2025, notamment le “laboratoire de cuisine numérique intelligente du futur” et un réfrigérateur intelligent équipé d’un grand modèle d’IA pour la santé. Le grand modèle d’IA pour la santé optimise la conception et le fonctionnement de la cuisine, tandis que le réfrigérateur intelligent, via l‘“assistant de santé Xiaoyun”, offre une gestion de la santé personnalisée, marquant une percée de l’IA dans le domaine de la santé. Ce lancement démontre le potentiel de l’IA dans la gestion quotidienne de la santé, réalisant des services de santé personnalisés grâce à des appareils intelligents, et devrait stimuler le développement de la technologie de la santé à domicile, améliorant la qualité de vie des résidents. (Source : 36氪)

🧰 OUTILS
L’API de génération d’images Nano Banana de Google est ouverte avec des mises à jour de fonctionnalités : Le modèle de génération d’images Nano Banana de Google a officiellement ouvert son API, avec un prix d’environ 0,039 dollar par image. De nouvelles fonctionnalités ont été ajoutées, telles que la sélection du rapport d’aspect (prenant en charge plusieurs ratios comme 16:9, 9:16, 4:3, 3:2) et un mode de sortie d’image pure (sans texte), pour répondre aux besoins des scénarios purement visuels comme la prévisualisation en temps réel, l’affichage e-commerce et les outils de conception. Ces mises à jour visent à positionner davantage Nano Banana comme un outil pratique, facilitant son intégration par les développeurs dans leurs propres produits. (Source : 量子位)
Microsoft Agent Framework simplifie le développement d’agents IA : Microsoft a lancé Agent Framework, un cadre complet prenant en charge Python et .NET, conçu pour simplifier la construction, l’orchestration et le déploiement d’agents IA et de flux de travail multi-agents. Ce cadre offre des flux de travail basés sur des graphes, une DevUI interactive, l’observabilité OpenTelemetry, la prise en charge de plusieurs fournisseurs de LLM et un système de middleware flexible, aidant les développeurs à créer efficacement des applications, des simples agents de chat aux applications multi-agents complexes. (Source : GitHub Trending)
Liquid AI lance l’application Apollo pour Android, permettant le déploiement local de l’IA : Liquid AI a lancé l’application Apollo sur la plateforme Android, offrant une expérience IA locale à faible latence et sans cloud. Apollo, un “terrain de jeu de poche”, permet aux utilisateurs d’accéder instantanément à une IA rapide et efficace, tout en garantissant la confidentialité et la sécurité. Combinant la technologie LEAP, Apollo abaisse la barrière de l’IA de périphérie, permettant aux utilisateurs et aux développeurs d’utiliser, tester et déployer facilement l’IA en local. (Source : maximelabonne)

Le coach de codage IA “solveit” améliore l’efficacité des programmeurs : Jeremy Howard a lancé l’outil de coach de codage IA “solveit”, conçu pour aider les programmeurs à écrire des logiciels de haute qualité plus efficacement. Cet outil guide les utilisateurs via l’IA dans le développement logiciel, particulièrement adapté aux développeurs frustrés par la programmation assistée par l’IA, offrant un mode de “coach de codage” où l’IA et le programmeur travaillent en collaboration pour accélérer le processus de développement. (Source : jeremyphoward, jeremyphoward)
Jules Tools CLI habilite la gestion en ligne de commande des agents IA : Google a poussé l’agent de codage Jules vers l’interface en ligne de commande (CLI), en publiant Jules Tools. Les utilisateurs peuvent désormais gérer à distance les tâches d’Agent exécutées dans le cloud via la ligne de commande, permettant une meilleure intégration avec CI/CD ou le code. Cela offre une expérience de codage IA pratique aux développeurs qui préfèrent les opérations en ligne de commande, démontrant une expérience utilisateur fluide, notamment pour le débogage et le développement interactif. (Source : dotey, matanSF)
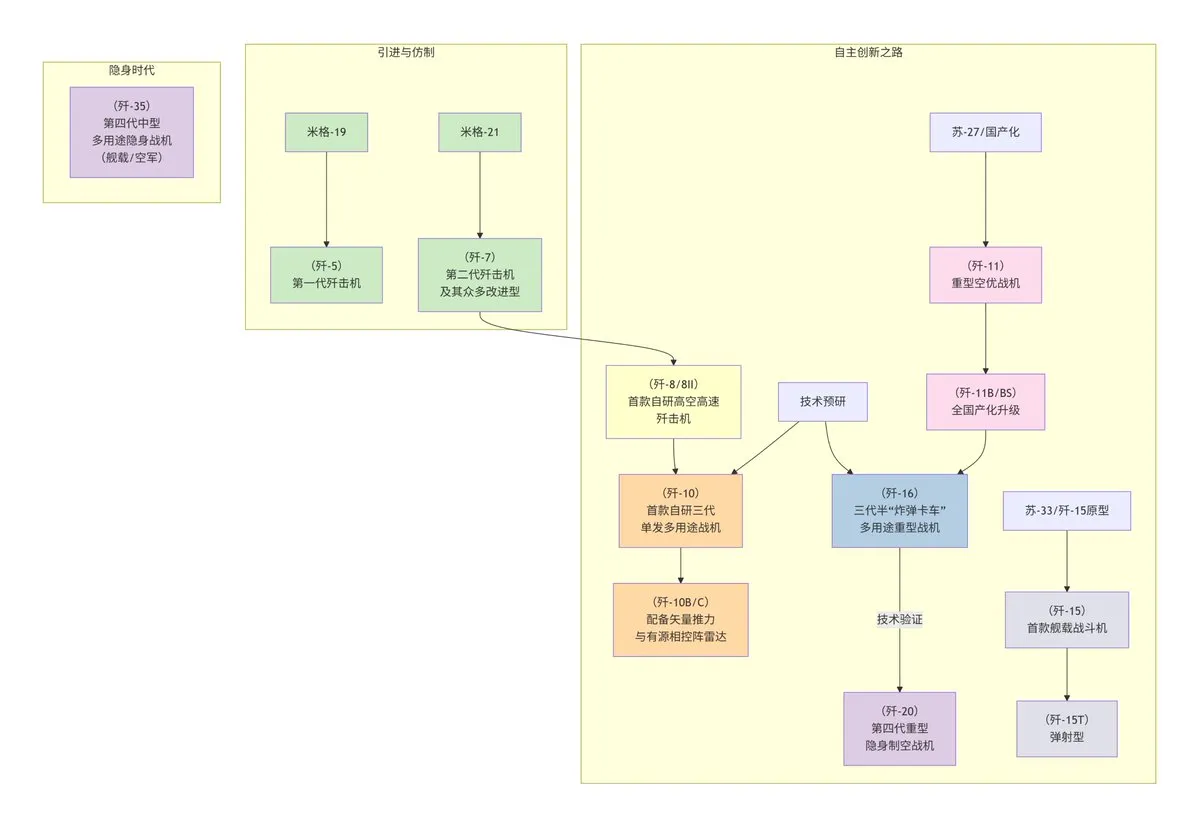
La fonctionnalité de génération de diagrammes de flux de DeepSeek simplifie le dessin de diagrammes : Le modèle DeepSeek est désormais capable de générer rapidement des diagrammes de flux via de simples mots-clés (comme “flowchart” ou “Mermaid”). Les utilisateurs n’ont qu’à saisir des instructions descriptives pour organiser et dessiner automatiquement des informations complexes, telles que l’historique de développement des avions de combat chinois de la série J ou la chronologie de “Fullmetal Alchemist”, simplifiant considérablement le processus de dessin de diagrammes et améliorant l’efficacité du travail. (Source : karminski3)
Synthesia lance des agents vidéo pour un dialogue vidéo bidirectionnel : Synthesia a lancé les “Video Agents”, marquant le premier pas vers un dialogue bidirectionnel pour la vidéo. Cette technologie permet aux utilisateurs de lancer des conversations en temps réel à tout moment de la vidéo, l’agent pouvant se connecter à la base de connaissances de l’entreprise pour obtenir du contexte et capturer des données de feedback pour les systèmes existants. Cela devrait révolutionner les modes d’interaction vidéo, les faisant passer de la visualisation passive à la participation active. (Source : synthesiaIO, synthesiaIO)
L’agent de codage IA “Blink.new” permet un déploiement rapide “de l’idée à l’application” : Blink.new a lancé un agent de codage IA, affirmant pouvoir réduire le temps “de l’idée à l’application en production” de plusieurs mois à quelques minutes, réalisant un développement rapide sans code. Cette plateforme transforme les descriptions en langage naturel en code exécutable, configure des bases de données, conçoit l’interface utilisateur et déploie automatiquement, offrant des fonctionnalités de niveau production telles que l’hébergement gratuit, SSL, CDN et la mise à l’échelle automatique, améliorant considérablement la vitesse de preuve de concept et de développement produit. (Source : Ronald_vanLoon)
VS Code intègre des agents de codage en arrière-plan pour améliorer l’expérience de développement : L’équipe VS Code déploie les dernières améliorations, prenant en charge l’exécution d’agents de codage (tels que GitHub Copilot) en arrière-plan, visant à améliorer l’efficacité et l’expérience de développement. Cette intégration permet aux agents de fournir une assistance et des suggestions de code continues en arrière-plan, optimisant davantage le flux de travail de programmation et aidant les développeurs à écrire du code de haute qualité plus rapidement. (Source : code, pierceboggan)

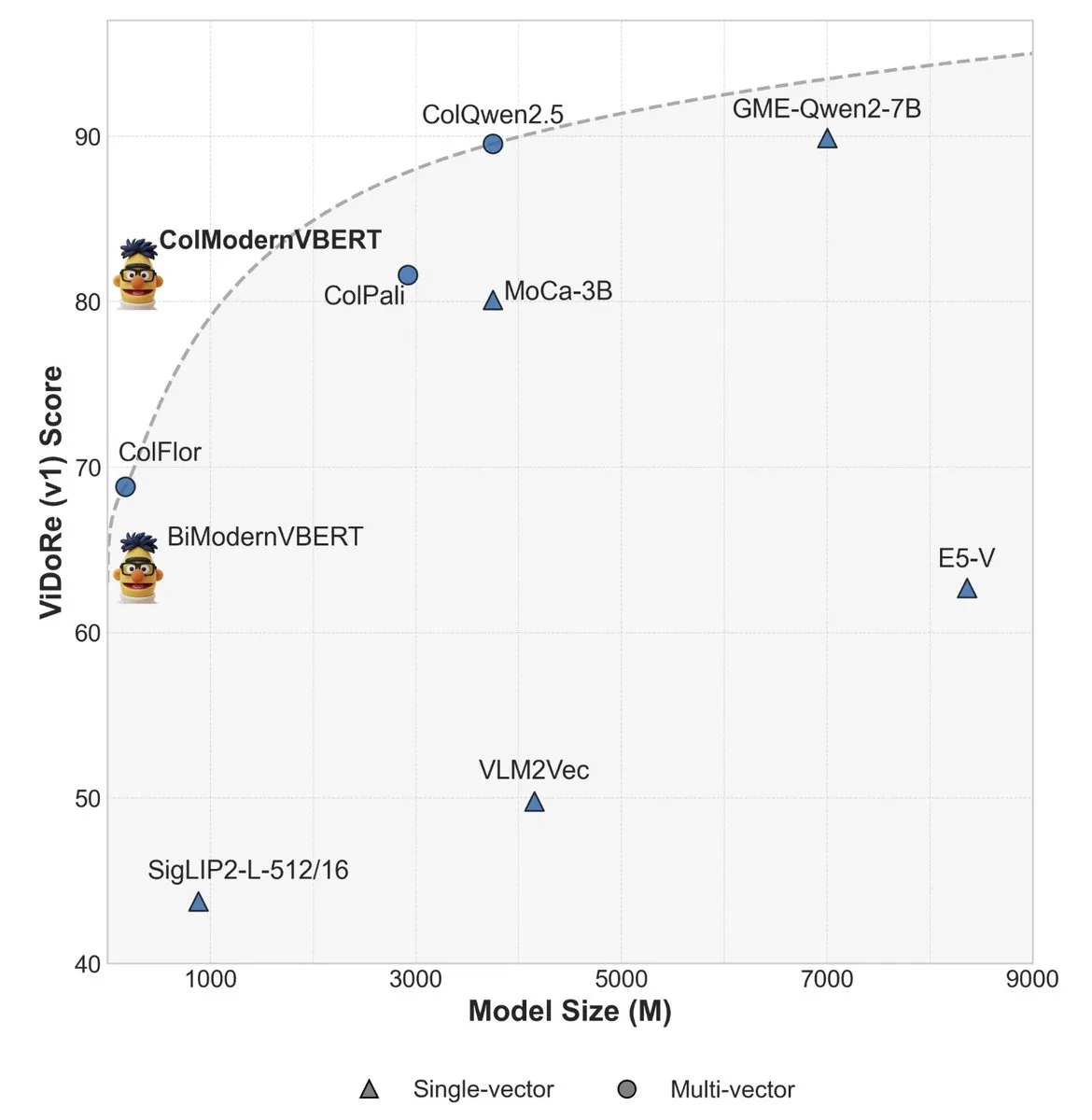
ModernVBERT : un petit récupérateur de documents visuels surpasse les grands modèles en performance : ModernVBERT est un encodeur de langage visuel compact de 250M paramètres qui, après un réglage fin pour les tâches de récupération de documents, surpasse les modèles 10 fois plus grands. Cette recherche, à travers des expériences contrôlées, a identifié les facteurs de performance clés tels que les masques d’attention, la résolution d’image, les schémas de données d’alignement modal et les objectifs contrastifs d’interaction tardive, fournissant des directives fondées sur des principes pour le développement de modèles de récupération de documents visuels plus efficaces. Le modèle et le code ont été open-sourcés sur HuggingFace. (Source : tonywu_71, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, ClementDelangue, HuggingFace Daily Papers)
Le moteur de recherche musical AI EmergeSound.ai utilise la technologie d’intégration audio : EmergeSound.ai est un moteur de recherche musical et un modèle fondamental basé sur plus de 100 millions d’intégrations audio. Cette plateforme permet aux utilisateurs d’interroger la musique par le son plutôt que par le texte ou les métadonnées, d’explorer des chansons de différentes époques et de découvrir des connexions cachées. Le projet vise à utiliser des modèles d’apprentissage profond pour encoder les caractéristiques audio, permettant la découverte et l’exploration musicale, et fournissant de nouveaux outils aux producteurs, chercheurs et amateurs de musique. (Source : Reddit r/MachineLearning)
Un utilisateur d’OpenWebUI développe un outil de récupération et de résumé de contenu web : Un utilisateur d’OpenWebUI a développé une suite d’outils de récupération et de résumé de contenu web, visant à minimiser l’encombrement du contexte. Cet outil renvoie des résumés de pages web plutôt que des extraits SERP, et permet au modèle de demander des résumés basés sur la requête ou des extraits de réponses directes. De plus, il utilise Playwright et Trafilatura pour optimiser les résultats de la récupération web, les rendant plus compacts. L’outil cherche actuellement l’aide de la communauté pour réaliser une intégration OpenWebUI plus généralisée. (Source : Reddit r/OpenWebUI)
Le jeu “Trial of Ariah” développé avec Claude démontre le potentiel de codage des LLM : Un développeur indépendant a entièrement codé le jeu “Trial of Ariah” en utilisant Claude AI. Le développeur a souligné que Claude prend en charge l’importation de jusqu’à 20 scripts en une seule fois, réduisant considérablement les erreurs par rapport à ChatGPT et améliorant l’efficacité du développement. Bien qu’il ait été souligné que le “Vibe Coding pur” n’existe pas et que les développeurs ont toujours besoin de connaissances de base pour identifier les hallucinations et les erreurs des LLM, ce cas démontre les puissantes capacités d’assistance des LLM dans des projets complexes comme le développement de jeux. (Source : Reddit r/ClaudeAI)

📚 APPRENTISSAGE
Nouveaux paradigmes pour l’entraînement et l’optimisation des LLM : Combinant plusieurs articles, cette section explore l’application de données synthétiques dans l’entraînement des LLM (recherche Meta), PPO/GRPO et les biais de perception humaine (Humanline), ainsi que des stratégies comme One-Token Rollout (OTR), visant à améliorer la capacité de généralisation du modèle, à résoudre les problèmes de récompenses rares et d’oubli catastrophique, et à optimiser les coûts d’entraînement. Ces recherches fournissent de nouvelles orientations théoriques et pratiques pour le réglage fin et le pré-entraînement des LLM, soulignant l’importance des stratégies de données, de la conception des récompenses et des paradigmes d’entraînement. (Source : teortaxesTex, tokenbender, HuggingFace Daily Papers, YejinChoinka, arankomatsuzaki)
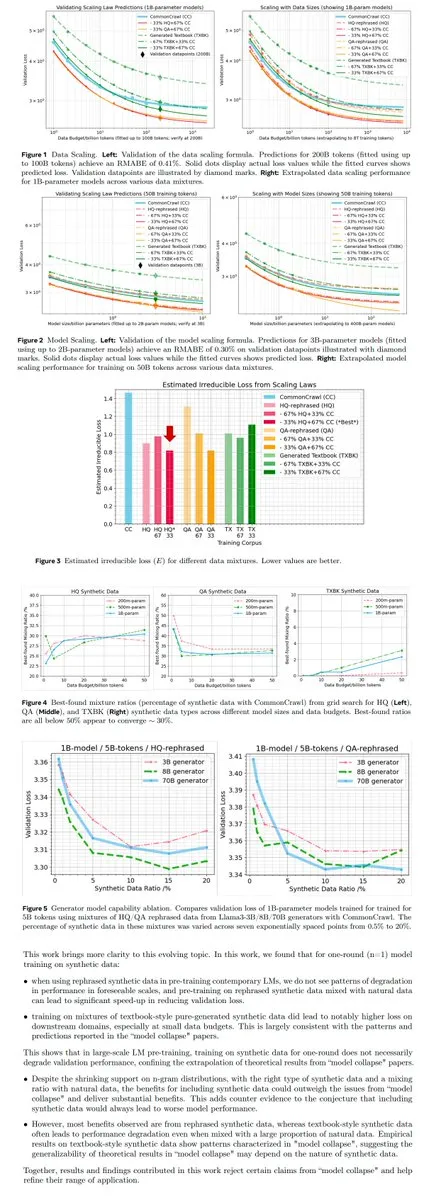
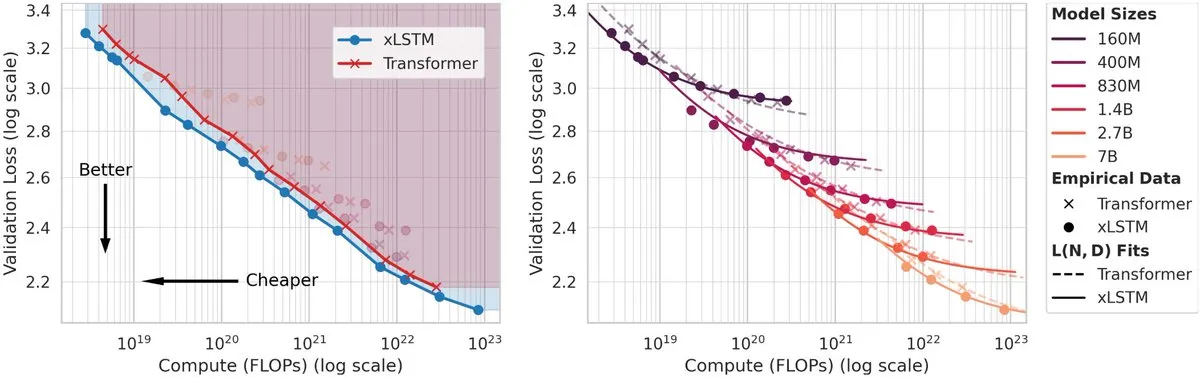
Architecture LLM et optimisation de l’efficacité : Cette section se concentre sur les mécanismes internes des LLM, tels que l’efficacité d’utilisation de l’espace latent des réseaux de feedforward (FFN) (“Spectral Scaling Laws”), la comparaison des lois d’échelle de xLSTM et Transformer, et la technologie d’inférence parallèle (Bridge), visant à améliorer les performances du modèle tout en réduisant les coûts de calcul. Ces recherches fournissent des informations clés pour la conception et le déploiement des LLM de nouvelle génération. (Source : HuggingFace Daily Papers, ethanCaballero, HuggingFace Daily Papers)
Sécurité de l’IA et robustesse des modèles : Cette section explore les défis de sécurité rencontrés par les modèles IA, y compris l’Activation Steering qui pourrait compromettre l’alignement de sécurité des LLM (“The Rogue Scalpel”), la détection de fragments d’hallucination (RL4HS) et les attaques par empoisonnement contre la diffusion gaussienne 3D (3DGS) (“StealthAttack”). Ces recherches révèlent les vulnérabilités potentielles des systèmes IA et proposent des méthodes pour améliorer la sécurité et la fiabilité des modèles. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Amélioration des capacités de perception et de raisonnement des modèles multimodaux : Cette section couvre des recherches sur la fidélité multi-sujets des modèles T2I, les récompenses rares dans le raisonnement visuel à grain fin des MLLM (RewardMap), le raisonnement perceptif VLM (AGILE), la compréhension vidéo (VideoNSA) et la récupération d’images compositionnelles agnostique à l’entraînement (SQUARE). Ces travaux ont collectivement fait progresser les limites de performance des modèles multimodaux dans des tâches telles que la génération d’images, les questions-réponses visuelles, l’analyse vidéo et la récupération intermodale. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Développement de carrière en IA et ressources d’apprentissage : Cette section résume les compétences clés dans le domaine de l’IA en 2025, les feuilles de route de carrière pour les scientifiques des données et les scientifiques LLM, les conseils de développement de carrière pour les chercheurs en IA, ainsi que des ressources comme Claude Cookbooks, fournissant des conseils complets aux professionnels de l’IA. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, BlackHC, Reddit r/deeplearning, GitHub Trending)

💼 AFFAIRES
La valorisation d’OpenAI dépasse les 500 milliards de dollars, devenant la startup la plus valorisée au monde : La valorisation d’OpenAI a atteint 500 milliards de dollars, surpassant SpaceX pour devenir la startup privée la plus valorisée au monde. Ce jalon reflète l’immense confiance du marché dans la technologie de l’IA et son potentiel de commercialisation, bien qu’il ait également suscité des discussions sur la bulle de valorisation et le modèle d’exploitation de l’entreprise. De plus, ChatGPT a ajouté la possibilité de faire des achats en ligne directement dans l’interface de chat, étendant encore ses scénarios d’application commerciale. (Source : TheRundownAI, Dorialexander, dl_weekly)

Le rapport “AI Apps 50” révèle les tendances de dépenses en IA des startups : a16z, en collaboration avec Mercury, a publié le rapport “AI Apps 50: Startup Edition”, analysant la situation des dépenses des startups en applications IA. Ce rapport fournit des aperçus sur l’application réelle et les orientations d’investissement de la technologie de l’IA dans les startups, aidant à comprendre le paysage du marché de l’IA et les tendances émergentes, et est précieux pour les investisseurs et les entrepreneurs. (Source : amasad, amasad)
Groq déploie rapidement sa pile d’IA et s’associe à McLaren F1 : Groq déploie sa pile d’IA à une “vitesse sans précédent” et s’associe à l’équipe McLaren F1, démontrant le potentiel d’application de ses puces IA dans le domaine du calcul haute performance. Cette collaboration souligne la valeur de la technologie de l’IA dans des industries nécessitant un traitement et une prise de décision ultra-rapides, comme le sport automobile, et annonce également l’expansion rapide de Groq sur le marché du matériel IA. (Source : JonathanRoss321, JonathanRoss321)

🌟 COMMUNAUTÉ
La refonte et les défis de l’IA dans les domaines créatifs (musique, écriture, art) : L’IA remodèle profondément les domaines créatifs tels que la musique, l’écriture et l’art, en générant du contenu via des algorithmes. Cela a suscité de larges discussions sur le rôle de l’IA dans l’industrie créative, les modèles de collaboration humain-IA et l’attribution des droits d’auteur. Les artistes IA sont confrontés au défi d’équilibrer l’assistance technologique et l’originalité, tandis que le contenu généré par l’IA a également un impact sur les marchés créatifs traditionnels et les modèles de revenus des créateurs. (Source : Ronald_vanLoon, Ronald_vanLoon, Reddit r/artificial)

L’impact de l’IA sur la perception de la réalité et la confiance dans le contenu numérique : Avec la popularisation des outils de génération IA comme Sora 2, on craint que l’IA ne puisse imiter parfaitement la musique, les films, les animations et même les personnages, rendant difficile de distinguer le vrai du faux dans le contenu numérique, ce qui pourrait faire perdre aux médias en ligne leur connexion émotionnelle et leur confiance. La communauté estime qu’à l’avenir, les gens pourraient accorder plus d’importance aux expériences réelles hors ligne, et que le contenu généré par l’IA propulsera une nouvelle culture de “hippies numériques” qui ne consommeront que les médias d’avant l’ère de l’IA. Parallèlement, certains estiment que si le contenu généré par l’IA est de haute qualité, son authenticité n’est pas importante. (Source : vikhyatk, Reddit r/ArtificialInteligence, Reddit r/artificial, VictorTaelin)

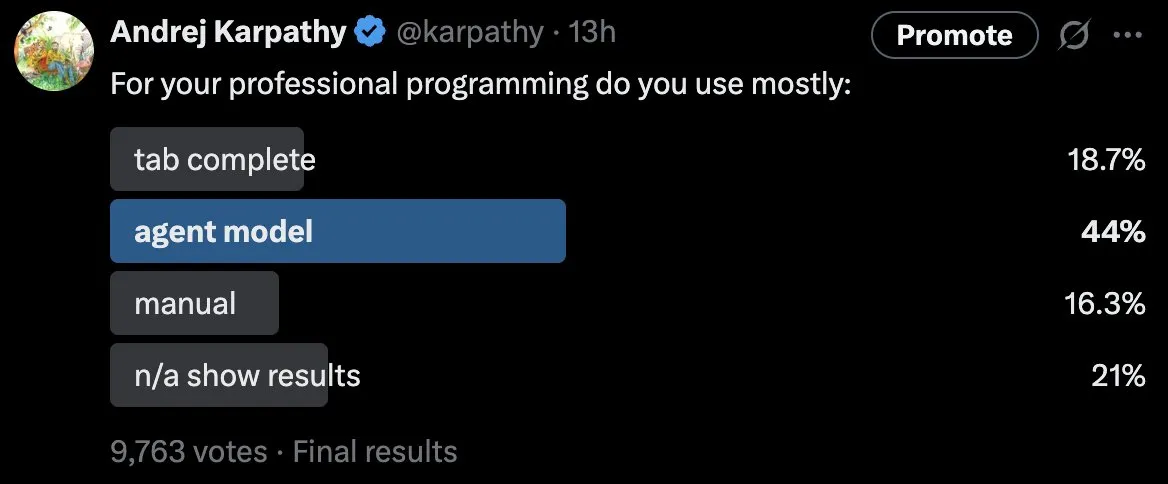
Modes d’application et défis des LLM en programmation professionnelle : Un sondage initié par Andrej Karpathy montre qu’environ la moitié des programmeurs professionnels utilisent “principalement” le mode agent (c’est-à-dire en permettant aux LLM d’écrire de grandes quantités de code via des invites textuelles). Il a exprimé sa surprise à ce sujet, estimant que lors du traitement de problèmes complexes ou s’écartant du manifold des données d’entraînement, les LLM sont sujets aux problèmes, à la redondance et aux erreurs subtiles. Cela a suscité des discussions approfondies sur les capacités réelles des LLM en programmation professionnelle, les meilleurs modèles de collaboration homme-machine et les limites du “Vibe Coding”, soulignant que l’IA reste insuffisante face à un code profond et enchevêtré. (Source : karpathy)
Préoccupations concernant la sécurité de l’IA et les menaces biologiques : Microsoft avertit que l’IA pourrait créer des menaces biologiques “zero-day”, suscitant de profondes inquiétudes au sein de la communauté concernant la sécurité de l’IA. Parallèlement, des expériences sur l’IA “complotant pour tuer des chercheurs” ont également suscité des discussions ; la plupart des gens pensent que les LLM ne font que prédire du texte basé sur des modèles de données, plutôt que de réellement “penser” ou “comploter”, mais certains craignent également que l’IA n’apprenne le mal du comportement humain. Ces discussions soulignent les questions clés d’éthique, de sécurité et de contrôle dans le développement de l’IA. (Source : Reddit r/artificial, Reddit r/ArtificialInteligence)

Réglementation de l’IA : différences stratégiques entre la Chine et l’Occident et impact géopolitique : Concernant l’affirmation des lobbyistes de l’IA selon laquelle “la Chine ne réglemente pas l’IA, donc toute réglementation nous ferait prendre du retard”, certains soutiennent que la Chine met en fait en œuvre une réglementation de l’IA plus stricte que les États-Unis. La communauté estime que le développement technologique est difficile à supprimer complètement, et que la réglementation affecte principalement la commercialisation plutôt que la recherche elle-même. L’IA est de plus en plus prégnante comme question géopolitique, et la concurrence entre l’Occident et la Chine sur la pile d’IA est considérée comme une bataille pour les plateformes clés. (Source : teortaxesTex, Reddit r/artificial, kylebrussell)
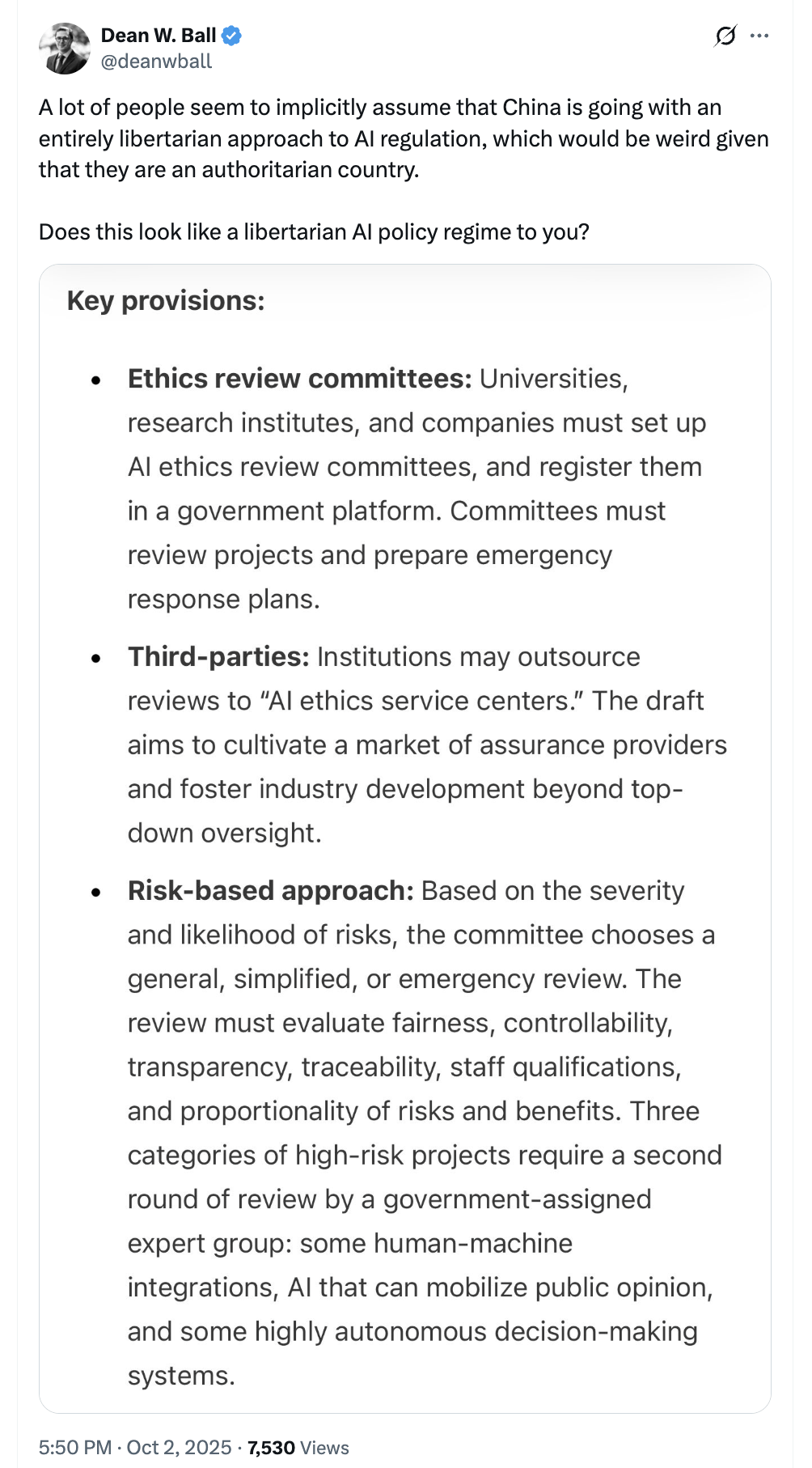
Applications et controverses de l’IA dans le domaine de l’éducation : Une “Alpha School” dont les frais de scolarité annuels s’élèvent à 40 000 dollars façonne chaque cours via un logiciel personnalisé piloté par l’IA, où le rôle des adultes en classe est celui de “mentors” plutôt que d’enseignants traditionnels. Ce modèle a suscité des discussions sur si l’IA remplacera les enseignants, l’équité éducative et la légitimité des frais de scolarité élevés. Les partisans estiment que l’IA peut personnaliser les plans d’apprentissage pour chaque élève, résolvant le problème de l’approche “taille unique” de l’éducation traditionnelle ; les opposants craignent son modèle commercial et l’impact sur le rôle des enseignants. (Source : Reddit r/artificial, Reddit r/ArtificialInteligence)

IA et droits d’auteur, l’avenir de la création de contenu : Les artistes espèrent freiner le développement de l’IA par la protection des droits d’auteur, mais certains estiment que la nouvelle génération de leaders verra les avantages du “tout remixable” et de la distribution gratuite. Cela annonce que l’IA poussera la création de contenu vers un nouveau paradigme, défiant les concepts traditionnels de droits d’auteur et les écosystèmes créatifs. De plus, les sources de données d’entraînement de Sora 2 (telles qu’Instagram, YouTube, TikTok) et la question de savoir si des droits d’auteur ont été payés ont suscité des discussions éthiques. (Source : kylebrussell, bookwormengr)

La révolution des agents IA dans le domaine de l’observabilité : L’IA agentique est en train de redéfinir l’observabilité, passant du dépannage à la transformation du cycle de vie. Les agents IA non seulement accélèrent la réponse aux incidents, mais renforcent également la détection, la surveillance, l’ingestion de données et la remédiation tout au long du cycle de vie de l’observabilité. Ils transforment la “recherche” en “raisonnement”, permettant aux utilisateurs d’interroger directement l’état du système. De plus, pour les charges de travail IA, de nouvelles métriques sont nécessaires pour surveiller les hallucinations, les biais, les coûts et la qualité d’utilisation des LLM. (Source : Ronald_vanLoon)
Défis d’intégration des produits IA et stratégies de succès : La communauté a discuté des raisons de l’échec de 99 % des entreprises dans l’intégration de l’IA et des stratégies de succès. Il est souligné que considérer l’IA comme une stratégie centrale, se concentrer sur la valeur commerciale, surmonter les obstacles à l’intégration et construire une culture organisationnelle qui soutient l’innovation en IA sont la clé du succès, fournissant des conseils pratiques aux entreprises pour déployer efficacement l’IA. (Source : Ronald_vanLoon)

Contenu généré par l’IA et questions éthiques : robots d’arnaque IA : Des robots d’arnaque IA se font passer pour des humains pour des conversations, commettant des escroqueries financières comme le “pig butchering”, suscitant des inquiétudes au sein de la communauté concernant l’abus de la technologie IA, l’authenticité de l’identité numérique et la sécurité de la vie privée des utilisateurs. Un appel est lancé pour une vigilance accrue, et des discussions ont lieu sur l’identification et la réponse aux méthodes d’arnaque IA de plus en plus sophistiquées. (Source : Reddit r/ArtificialInteligence)
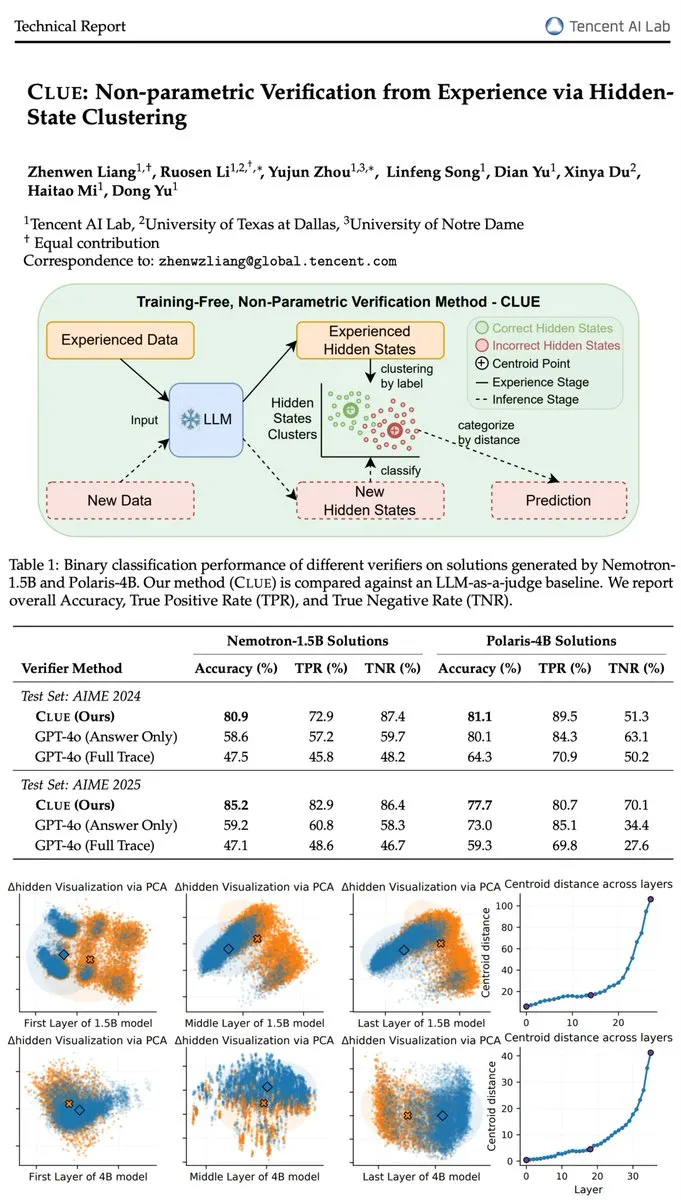
Problème d’hallucination des LLM et modèle de vérification CLUE : Le validateur CLUE lancé par Tencent AI Lab, sans nécessiter de paramètres d’entraînement, dépasse pourtant la précision de vérification de GPT-4o, résolvant efficacement le problème d’hallucination des LLM par analyse de cluster des états cachés. Cette innovation offre une solution efficace et explicable pour améliorer la fiabilité et la précision factuelle des LLM. (Source : teortaxesTex, menhguin)
Kling AI 2.5 Turbo et la concurrence de Sora 2 en génération vidéo : Kling AI 2.5 Turbo est considéré comme un concurrent sérieux de Sora 2 en raison de ses effets de génération vidéo de haute qualité ; les utilisateurs ont démontré ses capacités dans des scénarios complexes et des effets visuels. La communauté estime que les applications IA chinoises rattrapent rapidement leur retard, mais doivent être renforcées en matière de traitement audio, annonçant une concurrence féroce dans le domaine de la génération vidéo. (Source : bookwormengr, Kling_ai, Kling_ai, Kling_ai, bookwormengr)
💡 AUTRES
Avancées en robotique : inspection de navires, service de pop-corn et contrôle qualité en usine : La robotique continue de se développer, avec l’émergence de diverses applications. Par exemple, des robots sont utilisés pour inspecter les parois de la coque afin d’assurer la sécurité des navires. Le robot Optimus a démontré ses capacités de service, étant capable de servir du pop-corn. La société CasiVision a lancé le robot humanoïde à roues CASIVIBOT, conçu spécifiquement pour le contrôle qualité dans les usines intelligentes. Ces avancées indiquent que les robots pénètrent progressivement différents secteurs, améliorant les niveaux d’automatisation et l’efficacité du travail. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Meta FAIR publie le Code World Model (CWM) pour explorer la génération et le raisonnement de code : Meta FAIR a publié le Code World Model (CWM), un modèle de recherche de 32B paramètres, visant à explorer comment les modèles du monde peuvent changer la génération et le raisonnement de code. La publication de CWM vise à faire progresser la recherche sur les modèles du monde et est partagée sous une licence de recherche, habilitant la communauté à innover davantage dans les domaines de la compréhension et de la génération de code. (Source : NandoDF)
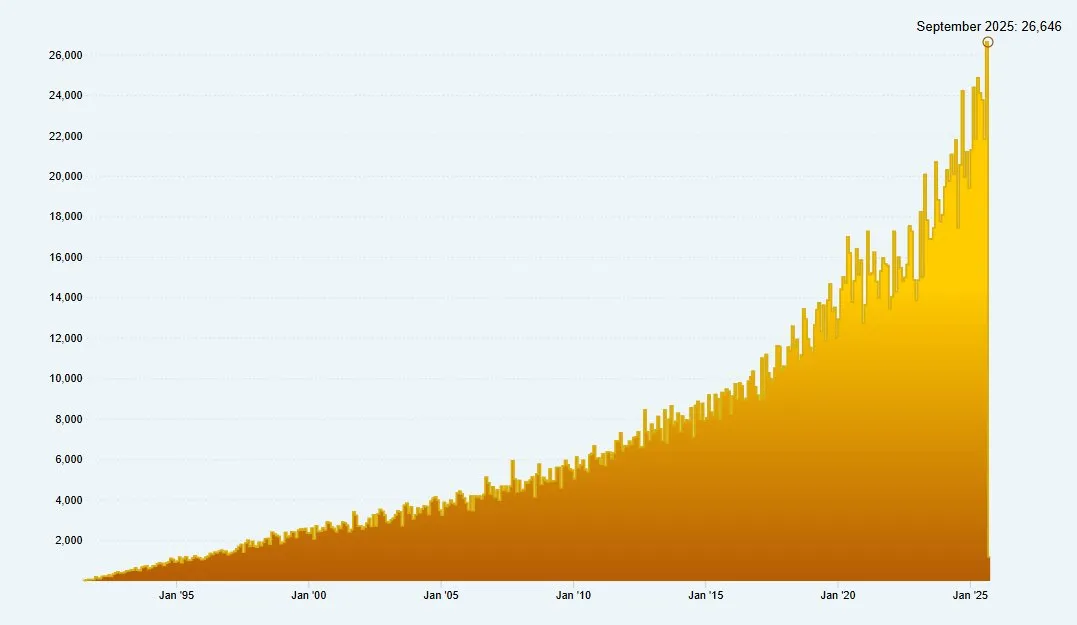
Augmentation des soumissions d’articles arXiv et pression éditoriale : arXiv a reçu un total de 26 646 nouvelles soumissions d’articles en septembre 2025, avec seulement 7 éditeurs et membres du personnel de support utilisateur. Cette charge de travail énorme a soulevé des préoccupations concernant la pression opérationnelle sur les plateformes en libre accès, soulignant les défis rencontrés dans l’examen et la gestion des articles dans le contexte du développement rapide de la recherche scientifique. (Source : clefourrier)