
Mots-clés:OpenAI, Infrastructure d’IA, Virus généré par IA, Fondations AlphaEarth, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, IA multimodale, Projet Stargate d’OpenAI, Modèle de langage génomique Transformer, Modélisation 10m d’AlphaEarth de Google, Benchmark RTEB de Hugging Face, Génération de code Anthropic Claude, OpenAI, Infrastructure d’IA, Virus généré par IA, Fondations AlphaEarth, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, IA multimodale, Projet Stargate d’OpenAI, Modèle de langage génomique Transformer, Modélisation 10m d’AlphaEarth de Google, Benchmark RTEB de Hugging Face, Génération de code Anthropic Claude
En tant que rédacteur en chef expérimenté de la rubrique IA, j’ai effectué une analyse, une synthèse et une distillation approfondies des actualités et des discussions sociales que vous avez fournies. Voici le contenu consolidé :
🔥 Focus
Le pari d’OpenAI sur une infrastructure de mille milliards de dollars : OpenAI s’associe à Oracle et SoftBank pour investir des milliers de milliards de dollars dans la construction d’infrastructures de calcul à l’échelle mondiale, sous le nom de code “StarGate”. Initialement, 5 nouveaux sites aux États-Unis ont été annoncés, pour un coût de 400 milliards de dollars, et un partenariat avec Nvidia pour construire le projet “StarGate UK” au Royaume-Uni. OpenAI prévoit que la demande future d’électricité pour l’IA atteindra 100 gigawatts, avec un investissement total pouvant atteindre 5 000 milliards de dollars. Cette initiative vise à répondre à l’énorme demande de puissance de calcul des modèles d’IA, mais elle soulève également des inquiétudes concernant les investissements financiers, la consommation d’énergie et les risques financiers potentiels, soulignant la dépendance extrême de l’IA vis-à-vis des infrastructures. (Source : DeepLearning.AI Blog)

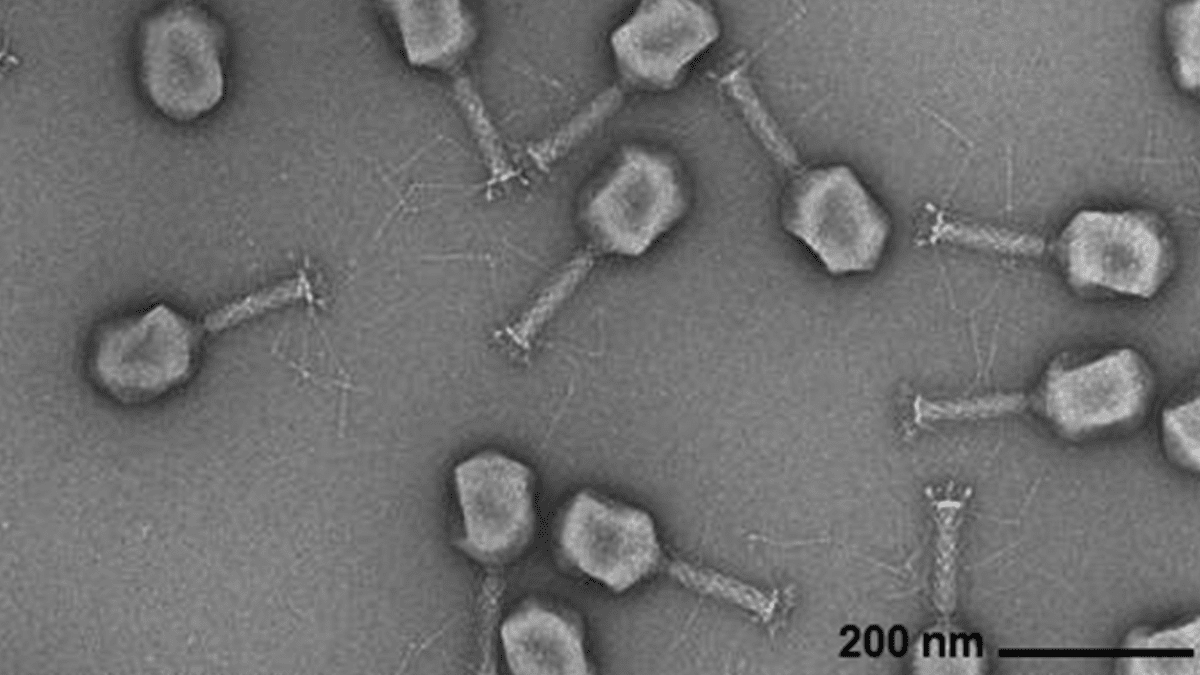
L’IA génère des génomes viraux : Des chercheurs de l’Arc Institute, de l’Université de Stanford et du Memorial Sloan Kettering Cancer Center ont utilisé des modèles de langage génomiques basés sur Transformer pour synthétiser de nouveaux virus bactériophages capables de combattre des infections bactériennes courantes. Cette technologie, en ajustant les séquences de génomes viraux, peut générer de nouveaux génomes avec des fonctions spécifiques et différents des virus naturels. Cette percée ouvre de nouvelles voies pour le développement de thérapies alternatives aux antibiotiques, mais elle soulève également des préoccupations en matière de biosécurité et d’utilisation malveillante, soulignant la nécessité de la recherche sur la réponse aux menaces biologiques. (Source : DeepLearning.AI Blog)
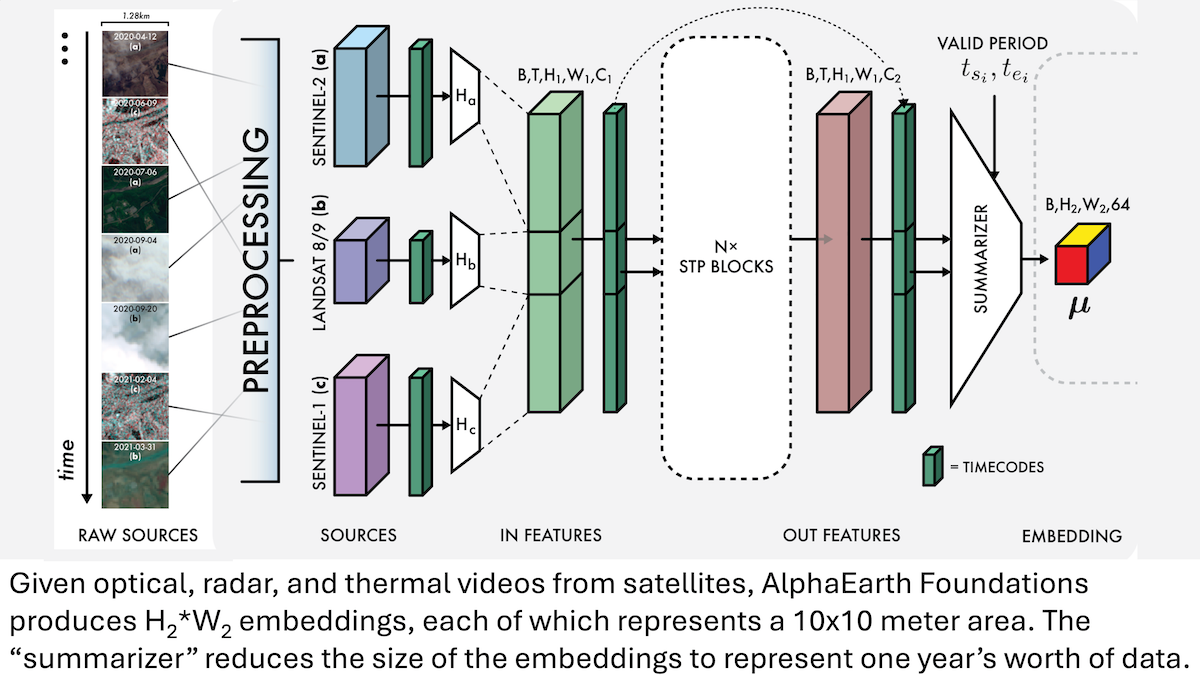
Google AlphaEarth Foundations : Modélisation de la Terre avec une précision de 10 mètres : Les chercheurs de Google ont lancé le modèle AlphaEarth Foundations (AEF), capable d’intégrer des images satellite et d’autres données de capteurs pour modéliser finement la surface de la Terre à l’échelle de 10 mètres carrés, et de générer des embeddings représentant les caractéristiques annuelles de la Terre de 2017 à 2024. Ces embeddings peuvent être utilisés pour suivre diverses propriétés planétaires telles que l’humidité, les précipitations, la végétation, ainsi que des défis mondiaux comme la production alimentaire, les risques d’incendie de forêt, et les niveaux des réservoirs, offrant un outil de haute précision sans précédent pour la surveillance environnementale et la recherche sur le changement climatique. (Source : DeepLearning.AI Blog)
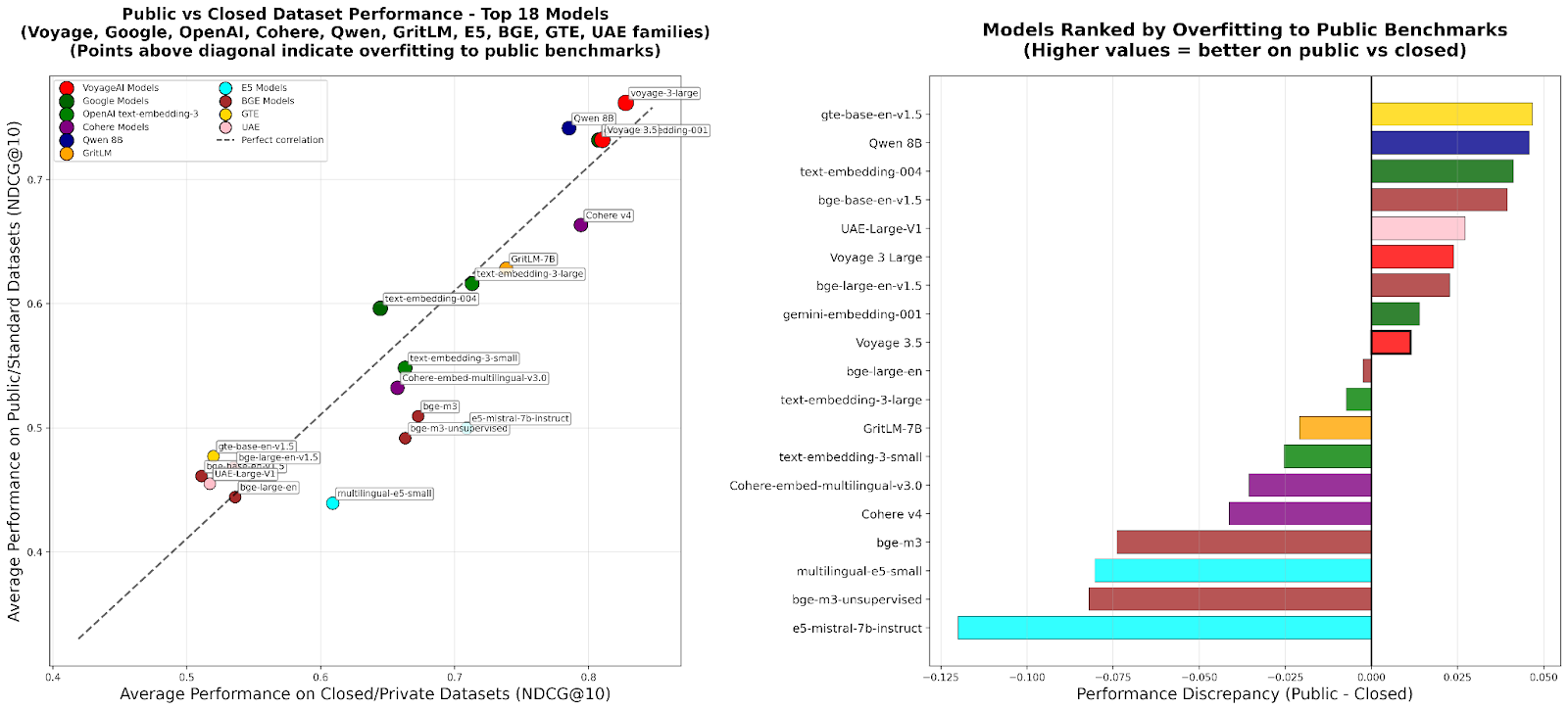
RTEB : Une nouvelle norme pour l’évaluation des embeddings de récupération : Hugging Face a lancé la version bêta du Retrieval Embeddings Benchmark (RTEB), visant à fournir une norme d’évaluation fiable pour la précision de récupération des modèles d’embeddings. Ce benchmark, en combinant une stratégie hybride de jeux de données publics et privés, résout efficacement le problème de surapprentissage des modèles dans les benchmarks existants, garantissant que les résultats d’évaluation reflètent mieux la capacité de généralisation du modèle sur des données inédites, ce qui est crucial pour améliorer la qualité des applications d’IA telles que RAG et Agent. (Source : HuggingFace Blog)
Entraînement intermédiaire RL évolutif : Réalisation du raisonnement par abstraction d’actions : Une nouvelle étude propose l’algorithme “Raisonnement en tant qu’Abstraction d’Actions” (RA3), qui, en identifiant un ensemble d’actions compact et utile pendant la phase d’entraînement intermédiaire du Reinforcement Learning (RL) et en accélérant le RL en ligne, améliore significativement les capacités de raisonnement et de génération de code des Large Language Models (LLMs). Cette méthode excelle dans les tâches de génération de code, améliorant les performances moyennes de 8 à 4 points de pourcentage par rapport aux modèles de référence, et permettant une convergence RL plus rapide et des performances asymptotiques plus élevées. (Source : HuggingFace Daily Papers)
🎯 Tendances
OpenAI Sora 2 : Une nouvelle ère pour le social vidéo basé sur l’IA : OpenAI a lancé Sora 2 et l’application sociale du même nom, visant à créer un réseau social centré sur l’utilisateur et son cercle social (amis, animaux de compagnie) via la navigation et la création de vidéos générées par l’IA, plutôt qu’une plateforme de distribution de contenu traditionnelle. Sora 2 démontre de puissantes capacités de simulation physique et de génération audio, mais les premiers tests révèlent encore des imperfections de détail comme le “comptage des doigts”. Son lancement a suscité des discussions sur la dépendance à la vidéo IA, les deepfakes et la voie de commercialisation d’OpenAI. Sam Altman a répondu que Sora vise à équilibrer les avancées technologiques avec une expérience utilisateur agréable et à financer la recherche en IA. (Source : 36氪, Reddit r/ChatGPT, OpenAI)

Anthropic Claude Sonnet 4.5 : Nouvelle référence pour le code et les Agents : Anthropic a lancé Claude Sonnet 4.5, salué comme “le meilleur modèle de programmation au monde” et “le modèle le plus puissant pour construire des Agents complexes”, avec une autonomie pouvant atteindre 30 heures et des améliorations significatives des performances de codage sur les tâches GitHub. Le modèle intègre également une fonction de mémoire, permettant de sauvegarder la progression des projets. Bien que ses performances soient très appréciées, des controverses subsistent quant à ses limites d’utilisation et à sa comparaison réelle avec Opus 4.1 et GPT-5. (Source : Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/ClaudeAI)
DeepSeek V3.2-Exp : L’architecture d’attention clairsemée améliore l’efficacité : DeepSeek a lancé le Large Language Model DeepSeek V3.2-Exp, introduisant une toute nouvelle architecture d’attention clairsemée (DSA) qui réduit la complexité de l’attention principale de O(L²) à O(L·k). Cela optimise considérablement les coûts de pré-remplissage et de décodage dans les scénarios de contexte long, réduisant ainsi considérablement les frais d’utilisation de l’API. Jiuzhang Yunji a été le premier à adapter DeepSeek V3.2-Exp, offrant des solutions de déploiement privées sûres et efficaces pour répondre aux besoins des entreprises en matière de sécurité des données et de flexibilité de la puissance de calcul. (Source : 量子位, Reddit r/LocalLLaMA)

Lancement du modèle audio-texte multimodal LFM2-Audio-1.5B : Liquid AI a lancé LFM2-Audio-1.5B, un modèle de base audio-texte tout-en-un de bout en bout, capable de comprendre et de générer du texte et de l’audio. Ce modèle est 10 fois plus rapide en inférence que des modèles similaires et, avec seulement 1,5 milliard de paramètres, sa qualité est comparable à celle de modèles 10 fois plus grands, prenant en charge le déploiement local et les conversations en temps réel. Hume AI a également lancé Octave 2, un modèle Text-to-Speech multilingue plus rapide et moins cher, doté de capacités de dialogue multi-locuteurs et de conversion vocale. (Source : Reddit r/LocalLLaMA, QuixiAI)

Microsoft Agent Framework : Nouveaux développements dans les systèmes Agent : Microsoft a lancé le Microsoft Agent Framework, intégrant AutoGen et Semantic Kernel en un SDK unifié et prêt pour la production, destiné à la construction, l’orchestration et le déploiement de systèmes multi-Agent. Ce framework prend en charge .NET et Python, et permet des workflows multi-Agent via une orchestration basée sur des graphes, visant à simplifier le développement, l’observation et la gouvernance des applications Agent, accélérant ainsi le déploiement des AI Agents d’entreprise. (Source : gojira, omarsar0)

Frontières de la technologie des robots IA et concurrence industrielle : La technologie robotique continue de progresser. OmniRetarget d’Amazon FAR optimise la capture de mouvements humains pour un apprentissage complexe des compétences humanoïdes avec un minimum de Reinforcement Learning. Periodic Labs s’engage à créer des “scientifiques IA” pour accélérer la découverte scientifique. Nvidia, quant à elle, met l’accent sur le rôle de son moteur physique ouvert Newton, de son modèle de langage visuel d’inférence Cosmos Reason et de son modèle de base robotique Isaac GR00T N1.6 dans le déploiement de l’IA physique. Parallèlement, la Chine démontre un avantage de leader dans la production de robots et le coût des robots humanoïdes, suscitant une attention sur le paysage concurrentiel mondial de l’industrie robotique. (Source : pabbeel, LiamFedus, nvidia, atroyn)

🧰 Outils
Tinker API : Une interface flexible pour simplifier le fine-tuning des LLM : Thinking Machines Lab a lancé Tinker API, une interface flexible conçue pour le fine-tuning des modèles de langage. Elle permet aux chercheurs et aux développeurs d’écrire des boucles d’entraînement localement, tandis que Tinker gère la complexité de l’infrastructure en les exécutant sur des clusters GPU distribués, permettant aux utilisateurs de se concentrer sur les algorithmes et les données. Cet outil vise à réduire le seuil du post-entraînement des LLM, à accélérer l’expérimentation et l’innovation des modèles ouverts, et a été salué par des experts comme Andrej Karpathy comme “l’infrastructure que j’ai toujours voulue”. (Source : Reddit r/artificial, Thinking Machines, karpathy)

LlamaAgents : Déploiement d’Agents documentaires en un clic : LlamaIndex a lancé LlamaAgents, offrant la capacité de déployer des AI Agents centrés sur les documents en un clic, visant à multiplier par 10 la vitesse de construction et de livraison des agents documentaires. La plateforme propose des modèles préconfigurés à 90 %, prenant en charge le traitement automatisé des tâches à forte intensité documentaire telles que les factures, l’examen des contrats et les réclamations, et permettant une personnalisation illimitée. Les utilisateurs peuvent déployer sur LlamaCloud et gérer et mettre à jour facilement les workflows Agent via des dépôts Git, réduisant considérablement le cycle de développement. (Source : jerryjliu0, jerryjliu0)

Hex AI Agent : Autonomiser l’analyse et la collaboration d’équipe : Hex a lancé trois nouveaux AI Agents, spécialement conçus pour l’analyse de données et la collaboration d’équipe : Threads offre une interaction de données conversationnelle, Semantic Model Agent crée un contexte contrôlé pour des réponses précises, et Notebook Agent révolutionne le travail quotidien des équipes de données. Tous ces Agents sont alimentés par Claude 4.5 Sonnet, visant à transformer l’analyse IA conversationnelle d’un concept futur en un outil efficace immédiatement disponible. (Source : sarahcat21)
Sculptor : L’interface utilisateur manquante de Claude Code : Imbue a lancé Sculptor, une interface utilisateur conçue pour Claude Code, visant à améliorer l’expérience de programmation Agent. Elle permet aux développeurs d’exécuter plusieurs Claude Agents en parallèle dans des conteneurs isolés, et de synchroniser le travail de l’Agent avec l’environnement de développement local pour les tests et l’édition via un “mode jumelé”. Sculptor prévoit également de prendre en charge GPT-5 et d’offrir des fonctionnalités suggérées telles que la détection de comportements trompeurs, visant à rendre la programmation Agent plus fluide et efficace. (Source : kanjun, kanjun)
Synthesia 3.0 : Nouvelle percée dans la vidéo IA interactive : Synthesia a lancé la version 3.0, introduisant plusieurs fonctionnalités innovantes, notamment les “Video Agents” (vidéos interactives capables de conversations en temps réel, utilisées pour la formation et les entretiens), des “avatars” améliorés (créés à partir d’une seule invite ou image, avec des expressions faciales et des mouvements corporels réalistes) et “Copilot” (un éditeur vidéo IA capable de générer rapidement des scripts et des éléments visuels). De plus, les fonctionnalités d’interactivité et les outils de conception de cours ont été améliorés, visant à révolutionner la création vidéo et l’expérience d’apprentissage. (Source : synthesiaIO, synthesiaIO)
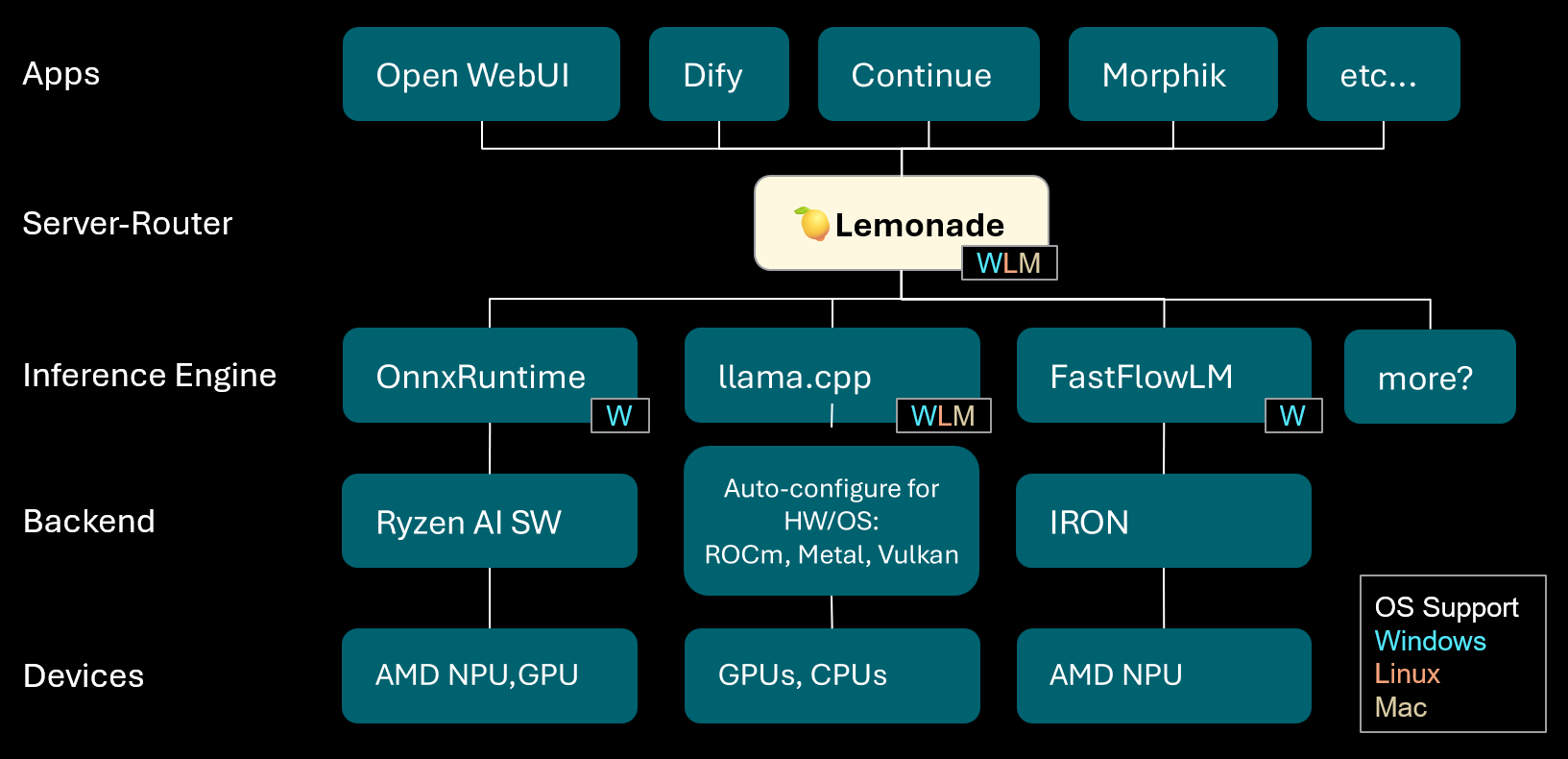
Lemonade : Serveur-routeur LLM local : Lemonade a lancé la version v8.1.11, un serveur-routeur LLM local capable de configurer automatiquement des moteurs d’inférence haute performance pour divers PC (y compris les appareils AMD NPU et macOS/Apple Silicon). Il prend en charge plusieurs formats de modèles tels que ONNX, GGUF et FastFlowLM, et utilise le backend Metal de llama.cpp pour un calcul efficace sur Apple Silicon, offrant aux utilisateurs une expérience LLM locale flexible et haute performance. (Source : Reddit r/LocalLLaMA)
PopAi : Génération de présentations assistée par l’IA : PopAi a démontré la capacité de son outil d’IA à générer en quelques minutes des présentations commerciales détaillées, incluant des graphiques et des illustrations, à partir d’une simple invite. Cela met en évidence l’efficacité de l’IA dans la création de contenu, permettant aux non-professionnels de produire rapidement des supports de présentation de haute qualité. (Source : kaifulee)

GitHub Copilot CLI : Sélection automatique de modèles : GitHub Copilot CLI offre désormais la sélection automatique de modèles aux utilisateurs commerciaux et d’entreprise. Cette mise à jour permet au système de choisir automatiquement le modèle le plus approprié en fonction de la tâche en cours, visant à améliorer l’efficacité du développement et la qualité de la génération de code. (Source : pierceboggan)
Mixedbread Search : Recherche locale multilingue et multimodale : Mixedbread a lancé la version bêta de son système de recherche, offrant des fonctionnalités de recherche de documents rapides, précises, multilingues et multimodales. Ce système met l’accent sur l’exécution locale, permettant aux utilisateurs d’effectuer une récupération efficace de documents sur leurs propres appareils, particulièrement adapté aux scénarios nécessitant le traitement de divers types de données. (Source : TheZachMueller)
Hume AI Octave 2 : Modèle TTS multilingue de nouvelle génération : Hume AI a lancé Octave 2, un modèle Text-to-Speech (TTS) multilingue de nouvelle génération. Ce modèle est 40 % plus rapide et 50 % moins cher que son prédécesseur, et prend en charge plus de 11 langues, le dialogue multi-locuteurs, la conversion vocale et l’édition phonémique, visant à offrir une expérience vocale IA plus rapide, plus réaliste et plus émotionnelle. (Source : AlanCowen)
Mises à jour de septembre d’AssemblyAI : Services audio IA tout-en-un : AssemblyAI a passé en revue ses mises à jour de septembre, dont les points forts incluent le lancement d’un Playground intégré, des extensions de langage universelles, une fonctionnalité de dépersonnalisation PII de l’UE, ainsi que des améliorations des performances de streaming et des invites par mots-clés. Ces mises à jour visent à offrir aux utilisateurs des services de traitement audio IA plus complets et plus efficaces. (Source : AssemblyAI)
Outil Voiceflow MCP : Standardisation de l’intégration des outils Agent : Voiceflow a lancé l’outil Model Context Protocol (MCP), offrant une approche standardisée pour l’utilisation de divers outils par les AI Agents. Cela simplifie le travail d’intégration personnalisée pour les développeurs et fournit des outils tiers pré-construits pour les utilisateurs sans code, étendant considérablement les capacités des Voiceflow Agents. (Source : ReamBraden)
Salesforce Agentforce Vibes : Codage Agent de niveau entreprise : Salesforce a lancé le produit “Agentforce Vibes” basé sur l’architecture de Cline, avec le support du Model Context Protocol (MCP), offrant des capacités de codage autonome aux clients d’entreprise. Ce produit assure une communication sécurisée des LLM avec les sources de connaissances/bases de données internes et externes, visant à réaliser le codage IA à l’échelle de l’entreprise. (Source : cline)

JoyAgent-JDGenie : Rapport sur l’architecture d’Agent généraliste : Le rapport technique GAIA (Generalist Agent Architecture) a été publié. Cette architecture intègre un cadre multi-Agent collectif (combinant la planification, les Agents d’exécution et le vote des modèles de critique), un système de mémoire hiérarchique (couches de travail, sémantique, programme) et une suite d’outils pour la recherche, l’exécution de code et l’analyse multimodale. Ce cadre a démontré d’excellentes performances dans les benchmarks complets, surpassant les références open source et se rapprochant des performances des systèmes propriétaires, offrant une voie pour construire des assistants IA évolutifs, résilients et adaptatifs. (Source : HuggingFace Daily Papers)
Assistant de voyage IA : De la planification à l’action : L’application d’assistant de voyage IA lancée par Mafengwo vise à faire passer l’IA de la génération traditionnelle de guides à l’assistance pratique pendant le voyage. L’application peut générer des guides personnalisés avec des images et du texte, et offre des fonctionnalités pratiques telles que la réservation de restaurants par un AI Agent, résolvant efficacement les problèmes de barrière linguistique. Bien qu’il y ait encore des marges d’amélioration en matière de traduction en temps réel et de personnalisation approfondie, elle a considérablement réduit la barrière pour “partir sans planifier”, démontrant l’énorme potentiel de l’IA à connecter l’information numérique et les actions dans le monde physique. (Source : 36氪)

📚 Apprentissage
Conseils de développement de carrière pour les chercheurs en IA : Pour le développement de carrière des chercheurs en IA, les experts soulignent l’importance de devenir un excellent codeur, encourageant la reproduction de papiers de recherche à partir de zéro et une compréhension approfondie de l’infrastructure. Il est également conseillé de construire activement une marque personnelle, de partager des idées intéressantes, de rester curieux et adaptable, et de privilégier les postes qui favorisent l’innovation et l’apprentissage. À long terme, des efforts continus et l’obtention de résultats concrets sont essentiels pour bâtir la confiance et la motivation. (Source : dejavucoder, BlackHC)
Cours d’analyse de données Python : DeepLearningAI a lancé un nouveau cours d’analyse de données Python, visant à enseigner comment utiliser Python pour améliorer l’efficacité, la traçabilité et la reproductibilité de l’analyse de données. Ce cours fait partie d’un certificat professionnel en analyse de données, soulignant le rôle central des compétences en programmation dans le travail de données moderne. (Source : DeepLearningAI)
Les étudiants obtiennent gratuitement les outils Copilot AI : Microsoft offre aux étudiants universitaires éligibles un abonnement personnel Microsoft 365 gratuit de 12 mois, qui comprend un accès supplémentaire à Copilot Podcasts, Deep Research et Vision. Cette initiative vise à fournir aux étudiants de puissants outils d’IA pour soutenir leur apprentissage et leur innovation. (Source : mustafasuleyman)

Configuration de cours locaux en IA/ML : Un éducateur a partagé comment créer des cours pratiques en IA/ML pour les étudiants avec un budget limité, basés sur le développement local et le matériel grand public. Il suggère d’utiliser de petits modèles, Transformer Lab comme plateforme d’entraînement, et souligne l’importance de comprendre les concepts fondamentaux plutôt que de poursuivre aveuglément la taille des modèles, afin d’améliorer l’efficacité de l’apprentissage et les capacités pratiques des étudiants. (Source : Reddit r/deeplearning)
Prochains séminaires sur l’IA : AIhub a publié une liste des prochains séminaires sur le Machine Learning et l’IA qui auront lieu d’octobre à novembre 2025. Ces événements couvrent de multiples sujets, de la collecte de données sur les plateformes de médias sociaux politiquement restreintes à l’éthique de l’IA. Tous les séminaires sont gratuits et offrent des options de participation en ligne, offrant de riches opportunités d’apprentissage et d’échange pour la communauté de l’IA. (Source : aihub.org)

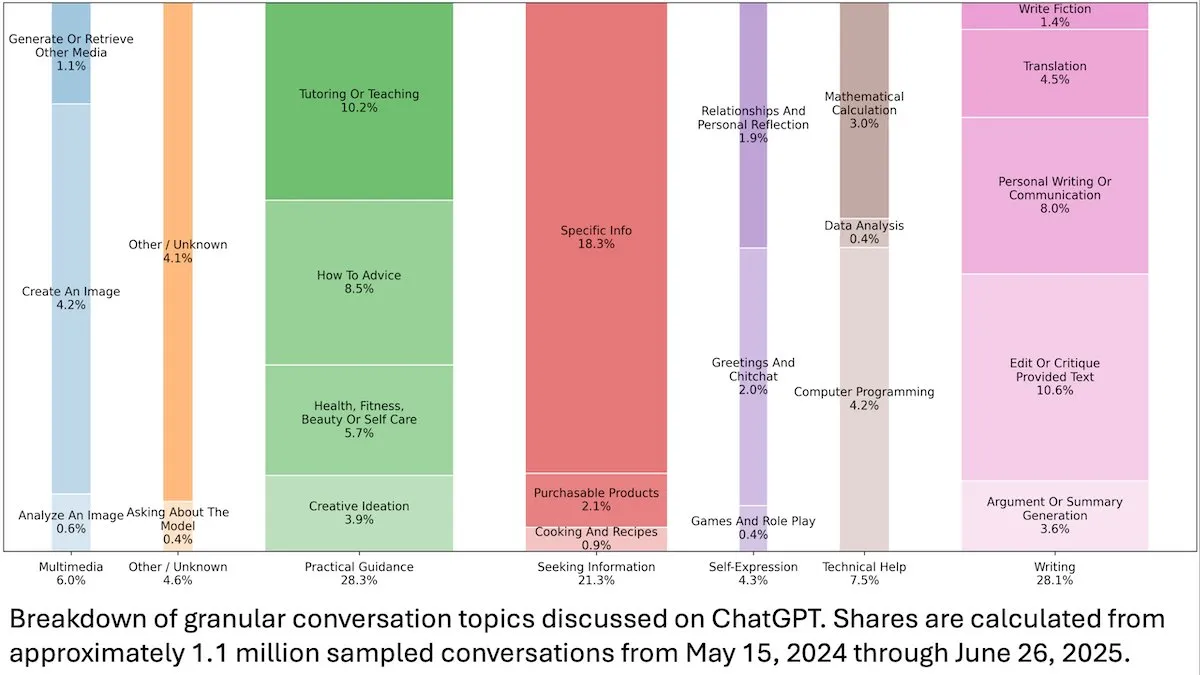
Insights sur le comportement des utilisateurs de ChatGPT : Une étude d’OpenAI publiée par DeepLearningAI a révélé, grâce à l’analyse de 110 millions de conversations anonymes de ChatGPT, que son utilisation est passée des besoins professionnels aux besoins personnels, avec une proportion plus élevée d’utilisatrices et d’utilisateurs jeunes (18-25 ans). Les demandes les plus courantes sont des conseils pratiques (28,3 %), de l’aide à la rédaction (28,1 %) et des recherches d’informations (21,3 %), révélant l’application généralisée de ChatGPT dans la vie quotidienne. (Source : DeepLearningAI)
Code2Video : Génération de vidéos éducatives basée sur le code : Une étude propose Code2Video, un cadre Agent centré sur le code qui génère des vidéos éducatives professionnelles à partir de code Python exécutable. Ce cadre comprend trois Agents collaboratifs : un planificateur, un encodeur et un critique, capables de structurer le contenu des conférences, de le convertir en code et de l’optimiser visuellement. Il a permis une amélioration de 40 % des performances sur le benchmark éducatif MMMC et a généré des vidéos comparables aux tutoriels humains. (Source : HuggingFace Daily Papers)
BiasFreeBench : Benchmark de réduction des biais des LLM : BiasFreeBench a été introduit comme un benchmark empirique pour comparer de manière exhaustive huit techniques principales de réduction des biais des LLM. Ce benchmark, en réorganisant les jeux de données existants, introduit l’indicateur “Bias-Free Score” au niveau de la réponse dans deux scénarios de test (questions-réponses à choix multiples et questions-réponses ouvertes multi-tours) pour mesurer l’équité, la sécurité et le degré d’anti-stéréotype des réponses des LLM, visant à établir une plateforme de test unifiée pour la recherche sur la réduction des biais. (Source : HuggingFace Daily Papers)
Obstacles à l’apprentissage de la multiplication par Transformer et pièges de la dépendance à long terme : Une étude a analysé par rétro-ingénierie les raisons de l’échec des modèles Transformer dans la tâche apparemment simple de la multiplication à plusieurs chiffres. L’étude a révélé que le modèle encode la structure de dépendance à long terme nécessaire dans une chaîne de pensée implicite, mais que les méthodes de fine-tuning standard ne parviennent pas à converger vers un optimum global capable d’exploiter ces dépendances. En introduisant une fonction de perte auxiliaire, les chercheurs ont réussi à résoudre ce problème, révélant les pièges de l’apprentissage des dépendances à long terme par Transformer et fournissant un exemple de résolution du problème par un biais inductif correct. (Source : HuggingFace Daily Papers)
Insights sur l’entraînement des VL-PRM dans le raisonnement multimodal : La recherche vise à éclaircir l’espace de conception des modèles de récompense de processus visuo-linguistiques (VL-PRMs), explorant diverses stratégies pour la construction de jeux de données, l’entraînement et l’extension au moment du test. En introduisant un cadre de synthèse de données hybride et une supervision axée sur la perception, les VL-PRMs ont démontré des insights clés dans cinq benchmarks multimodaux, notamment en surpassant les modèles de récompense de résultats lors de l’extension au moment du test, en montrant que les VL-PRMs de petite taille peuvent détecter les erreurs de processus, et en révélant les capacités de raisonnement potentielles des backbones VLM plus puissants. (Source : HuggingFace Daily Papers)
GEM : Un simulateur d’environnement général pour les LLM Agentiques : GEM (General Experience Maker) est un simulateur d’environnement open source, spécialement conçu pour l’apprentissage par l’expérience des LLM Agent. Il fournit une interface Agent-environnement standardisée, prend en charge l’exécution vectorisée asynchrone pour un débit élevé, et offre des wrappers flexibles pour une extension facile. GEM comprend également une suite diversifiée d’environnements et d’outils intégrés, et fournit des références utilisant des cadres d’entraînement RL tels que REINFORCE, visant à accélérer la recherche sur les LLM Agentiques. (Source : HuggingFace Daily Papers)
GUI-KV : Compression du cache KV pour les GUI Agents efficaces : GUI-KV est une méthode de compression du cache KV plug-and-play, conçue pour les GUI Agents, qui améliore l’efficacité sans nécessiter de réentraînement. En analysant les modèles d’attention dans les charges de travail GUI, cette méthode combine des techniques de guidage par saillance spatiale et de score de redondance temporelle, atteignant une précision proche du cache complet avec un budget modéré, et réduisant significativement les FLOPs de décodage, exploitant efficacement la redondance spécifique aux GUI. (Source : HuggingFace Daily Papers)
Au-delà de la vraisemblance logarithmique : Étude des fonctions objectives probabilistes pour le SFT : La recherche explore les fonctions objectives probabilistes pour le Supervised Fine-Tuning (SFT) qui vont au-delà de la Negative Log-Likelihood (NLL) traditionnelle. Grâce à des expériences approfondies sur 7 architectures de modèles, 14 benchmarks et 3 domaines, il a été constaté que lorsque la capacité du modèle est forte, les fonctions objectives qui privilégient les a priori avec des poids de token à faible probabilité (tels que -p, -p^10) surpassent la NLL ; tandis que lorsque la capacité du modèle est faible, la NLL domine. L’analyse théorique révèle comment les fonctions objectives s’équilibrent en fonction de la capacité du modèle, offrant des stratégies d’optimisation plus fondées pour le SFT. (Source : HuggingFace Daily Papers)
VLA-RFT : Fine-tuning RL basé sur les récompenses de validation dans les simulateurs de monde : VLA-RFT est un cadre de fine-tuning par renforcement pour les modèles Vision-Langage-Action (VLA), utilisant un modèle de monde basé sur les données comme simulateur contrôlable. Le simulateur, entraîné avec des données d’interaction réelles, prédit les observations visuelles futures basées sur les actions, permettant ainsi le déploiement de politiques avec des récompenses denses au niveau des trajectoires. Ce cadre réduit significativement les besoins en échantillons, surpassant les puissantes références supervisées en moins de 400 étapes de fine-tuning, et démontrant une forte robustesse dans des conditions de perturbation. (Source : HuggingFace Daily Papers)
ImitSAT : Résolution du problème de satisfiabilité booléenne par apprentissage par imitation : ImitSAT est une stratégie de branchement de solveur CDCL basée sur l’apprentissage par imitation, utilisée pour résoudre le problème de satisfiabilité booléenne (SAT). Cette méthode apprend des KeyTrace experts, repliant les exécutions complètes en séquences de décisions survivantes, fournissant une supervision dense au niveau des décisions qui réduit directement le nombre de propagations. Les expériences ont montré qu’ImitSAT surpasse les méthodes d’apprentissage existantes en termes de nombre de propagations et de temps d’exécution, réalisant une convergence plus rapide et un entraînement stable. (Source : HuggingFace Daily Papers)
Étude des pratiques de test des frameworks AI Agent open source : Une étude empirique à grande échelle de 39 frameworks Agent open source et 439 applications Agent a révélé les pratiques de test dans l’écosystème des AI Agents. L’étude a identifié dix modèles de test uniques, constatant que plus de 70 % des efforts de test sont consacrés aux composants déterministes (tels que les outils et les workflows), tandis que les agents de planification basés sur les LLM ne représentent que moins de 5 %. De plus, les tests de régression des composants Trigger sont gravement négligés, n’apparaissant que dans environ 1 % des tests, révélant des angles morts critiques dans les tests d’Agent. (Source : HuggingFace Daily Papers)
DeepCodeSeek : Récupération d’API en temps réel pour la génération de code : DeepCodeSeek propose une nouvelle technique pour la récupération d’API en temps réel pour la génération de code sensible au contexte, permettant une auto-complétion de code de haute qualité de bout en bout et des applications AI Agentiques. Cette méthode résout le problème de la fuite d’API dans les jeux de données de référence existants en étendant le code et l’index pour prédire les API nécessaires. Après optimisation, un réordonnanceur compact de 0,6 milliard de paramètres surpasse un modèle de 8 milliards de paramètres tout en maintenant une latence 2,5 fois inférieure. (Source : HuggingFace Daily Papers)
CORRECT : Identification des erreurs condensées dans les systèmes multi-Agent : CORRECT est un framework léger et sans entraînement qui permet l’identification des erreurs et le transfert de connaissances dans les systèmes multi-Agent en utilisant un cache en ligne de modèles d’erreurs distillés. Ce framework peut identifier les erreurs structurées en temps linéaire, évitant un réentraînement coûteux, et peut s’adapter aux déploiements MAS dynamiques. CORRECT a amélioré la localisation des erreurs au niveau des étapes de 19,8 % dans sept applications multi-Agent, réduisant significativement l’écart entre l’automatisation et l’identification des erreurs au niveau humain. (Source : HuggingFace Daily Papers)
Swift : Un modèle de cohérence autorégressif pour des prévisions météorologiques efficaces : Swift est un modèle de cohérence en une seule étape qui réalise pour la première fois le fine-tuning autorégressif des modèles de flux probabilistes et utilise un objectif de Continuous Ranked Probability Score (CRPS). Ce modèle peut générer des prévisions météorologiques à 6 heures compétentes et maintenir une stabilité jusqu’à 75 jours, fonctionnant 39 fois plus vite que les références de diffusion les plus avancées, tout en atteignant des compétences de prévision concurrentielles avec les IFS ENS numériques, marquant une étape importante vers des prévisions d’ensemble efficaces et fiables à moyen et long terme, jusqu’à l’échelle saisonnière. (Source : HuggingFace Daily Papers)
Catching the Details : Prédicteur RoI auto-distillé pour la perception fine des MLLM : La recherche propose un réseau de proposition de régions auto-distillé (SD-RPN) efficace et sans annotation, résolvant le problème des coûts de calcul élevés des Large Language Models multimodaux (MLLM) lors du traitement d’images haute résolution. Le SD-RPN, en transformant les cartes d’attention des couches intermédiaires des MLLM en étiquettes RoI pseudo-qualité et en entraînant un RPN léger pour une localisation précise, atteint une efficacité des données et une capacité de généralisation, améliorant la précision de plus de 10 % sur des benchmarks inédits. (Source : HuggingFace Daily Papers)
Nouveau paradigme pour le raisonnement multi-tours des LLM : In-Place Feedback : La recherche introduit un nouveau paradigme d’interaction appelé “In-Place Feedback” pour guider les LLM dans le raisonnement multi-tours. Les utilisateurs peuvent directement modifier les réponses précédentes du LLM, et le modèle génère des révisions basées sur cette réponse modifiée. Des évaluations empiriques montrent que l’In-Place Feedback surpasse le feedback multi-tours traditionnel dans les benchmarks intensifs en raisonnement, tout en réduisant l’utilisation de tokens de 79,1 %, résolvant les limites du modèle à appliquer le feedback avec précision. (Source : HuggingFace Daily Papers)
Prévisibilité de la dynamique du Reinforcement Learning des LLM : Ce travail révèle deux propriétés fondamentales des mises à jour de paramètres des LLM en entraînement de Reinforcement Learning (RL) : la dominance de rang 1 (le sous-espace singulier le plus élevé de la matrice de mise à jour des paramètres détermine presque entièrement l’amélioration de l’inférence) et la dynamique linéaire de rang 1 (ce sous-espace dominant évolue linéairement pendant l’entraînement). Sur la base de ces découvertes, la recherche propose AlphaRL, un framework d’accélération plug-and-play qui, en inférant les mises à jour de paramètres finales à partir d’une fenêtre d’entraînement précoce, réalise une accélération allant jusqu’à 2,5 fois tout en conservant plus de 96 % des performances d’inférence. (Source : HuggingFace Daily Papers)
Les pièges de la compression du cache KV : Une étude révèle plusieurs pièges de la compression du cache KV dans le déploiement des LLM, en particulier dans des scénarios réels tels que les invites multi-instructions, où la compression peut entraîner une dégradation rapide des performances de certaines instructions, voire leur ignorance totale par le LLM. L’étude analyse systématiquement la fuite d’invites système par des études de cas, démontrant empiriquement l’impact de la compression sur la fuite et le respect des instructions générales, et propose des améliorations simples pour les stratégies d’éviction du cache KV. (Source : HuggingFace Daily Papers)
💼 Affaires
Concurrence des géants de l’IA : Différences stratégiques entre OpenAI et Anthropic : OpenAI et Anthropic ont adopté des trajectoires de développement très différentes dans le domaine de l’IA. OpenAI, en intégrant l’e-commerce via ChatGPT et en lançant l’application sociale Sora, vise une “expansion horizontale” pour devenir une super-plateforme couvrant de multiples aspects de la vie des utilisateurs, sa valorisation dépassant déjà Anthropic de cent milliards de dollars. Anthropic, quant à elle, se concentre sur une “exploration verticale” en se basant sur Claude Sonnet 4.5 pour approfondir la programmation IA et le marché des Agents d’entreprise, et en s’associant étroitement avec des fournisseurs de services cloud comme AWS et Google. Derrière ces deux approches se cache la lutte pour la “diplomatie de la puissance de calcul” entre les deux géants du cloud, Microsoft et Amazon, soulignant la réalité industrielle de la rareté et du coût élevé de la puissance de calcul à l’ère de l’IA. (Source : 36氪, 量子位, 36氪)
Perplexity acquiert Visual Electric : Perplexity a annoncé l’acquisition de Visual Electric. L’équipe de Visual Electric rejoindra Perplexity pour développer de nouvelles expériences de produits grand public. Les produits de Visual Electric seront progressivement arrêtés. Cette acquisition vise à renforcer la capacité d’innovation de Perplexity dans le domaine des produits d’IA grand public. (Source : AravSrinivas)

Databricks acquiert Mooncakelabs : Databricks a annoncé l’acquisition de Mooncakelabs pour accélérer la réalisation de sa vision Lakebase. Lakebase est une nouvelle base de données OLTP construite sur Postgres et optimisée pour les AI Agents, visant à fournir une base unifiée pour les applications, l’analyse et l’IA, et s’intégrant profondément avec Lakehouse et Agent Bricks pour simplifier la gestion des données et le développement d’applications IA. (Source : matei_zaharia)

🌟 Communauté
Impact de l’IA sur l’emploi et la société : La communauté discute largement de l’impact profond de l’automatisation de l’IA sur le marché du travail, craignant qu’elle ne conduise à un chômage de masse, à la création de nouvelles classes sociales et à la nécessité d’un Revenu de Base Universel (UBI). On s’interroge généralement sur la question de savoir si les nouveaux emplois liés à l’IA seront également automatisés, et si tout le monde pourra maîtriser les compétences en IA pour s’adapter à l’avenir. Les discussions portent également sur la gestion des coûts des AI Agents et les défis de la réalisation du ROI, ainsi que sur l’impact potentiel de l’arrivée de l’AGI sur la structure sociale et la géopolitique. (Source : Reddit r/ArtificialInteligence, Ronald_vanLoon, Ronald_vanLoon)
Éthique de l’IA et lutte pour le contrôle : La communauté débat vivement de qui devrait contrôler l’avenir de l’IA : les citoyens ordinaires ou les oligarques technologiques. Des appels sont lancés pour que le développement de l’IA soit centré sur l’humain, en mettant l’accent sur la transparence et le contrôle des utilisateurs sur leurs données personnelles et l’historique de l’IA. Parallèlement, Yoshua Bengio, le parrain de l’IA, avertit que les machines super-intelligentes pourraient entraîner l’extinction de l’humanité d’ici dix ans. Des entreprises comme Meta prévoient d’utiliser les données de chat IA pour la publicité ciblée, ce qui exacerbe encore les préoccupations des utilisateurs concernant la confidentialité et l’abus de l’IA, suscitant une réflexion approfondie sur l’éthique et la réglementation de l’IA. (Source : Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence)

Comportement anormal du modèle de sécurité GPT-5 : Des utilisateurs de la communauté Reddit ont signalé que le modèle “CHAT-SAFETY” de GPT-5, lorsqu’il traite des requêtes non malveillantes, présente un comportement étrange, accusateur, voire hallucinatoire, par exemple en interprétant une question sur la reconnaissance d’empreintes digitales comme un comportement de traque et en inventant des lois. Cette sensibilité excessive et ces réponses inexactes ont soulevé de sérieuses questions chez les utilisateurs concernant la fiabilité du modèle, les dangers potentiels et les stratégies de sécurité d’OpenAI. (Source : Reddit r/ChatGPT)
Le “Bitter Lesson” et le débat sur la trajectoire de développement des LLM : Andrej Karpathy et Richard Sutton, le père du Reinforcement Learning, ont débattu de la conformité des LLM au “Bitter Lesson”. Sutton estime que les LLM dépendent de données humaines limitées pour le pré-entraînement et ne suivent pas vraiment le principe d’apprentissage par l’expérience du “Bitter Lesson”. Karpathy, quant à lui, considère le pré-entraînement comme une “mauvaise évolution” pour résoudre le problème du démarrage à froid, et souligne les différences fondamentales entre les LLM et l’intelligence animale en termes de mécanismes d’apprentissage, insistant sur le fait que l’IA actuelle est plus proche d‘“invoquer des fantômes” que de “construire des animaux”. (Source : karpathy, SchmidhuberAI)
Discussion sur la valeur des configurations LLM locales : Les utilisateurs de la communauté ont discuté de la valeur d’investir des dizaines de milliers de dollars dans la construction de configurations LLM locales. Les partisans soulignent que la confidentialité, la sécurité des données et les connaissances approfondies acquises par la pratique sont les principaux avantages, comparant cela aux amateurs de radioamateur. Les opposants estiment qu’avec l’amélioration des performances des API cloud bon marché (comme Sonnet 4.5 et Gemini Pro 2.5), les configurations locales coûteuses sont difficiles à justifier. (Source : Reddit r/LocalLLaMA)
LLM en tant que juge : Nouvelle méthode d’évaluation des Agents : Les chercheurs et les développeurs explorent l’utilisation des LLM comme “juges” pour évaluer la qualité des réponses des AI Agents, y compris la précision et la pertinence. La pratique montre que lorsque les invites du juge sont soigneusement conçues (par exemple, critère unique, notation ancrée, format de sortie strict et avertissements de biais), cette méthode peut être étonnamment efficace. Cette tendance indique que LLM-as-a-Judge a un énorme potentiel dans le domaine de l’évaluation des Agents. (Source : Reddit r/MachineLearning)
Interaction IA-humain : Des appareils aux personnages virtuels : L’IA remodèle l’interaction humaine à de multiples niveaux. Une startup liée au MIT a lancé un appareil portable “quasi-télépathique” pour une communication silencieuse. Parallèlement, les AI Agents vocaux en temps réel en tant que PNJ (personnages non-joueurs) sont déjà utilisés dans les jeux en ligne 3D, annonçant le potentiel de l’IA à offrir des expériences d’interaction plus naturelles et immersives dans les jeux et les mondes virtuels. Ces avancées suscitent des discussions sur le rôle de l’IA dans la vie quotidienne et le divertissement. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)

Choix entre modèles ouverts et modèles propriétaires : La communauté a discuté des plus grands obstacles rencontrés par les ingénieurs logiciels lorsqu’ils passent des modèles propriétaires aux modèles open source. Les experts soulignent que le fine-tuning des modèles open source, plutôt que de dépendre de modèles propriétaires “boîte noire”, est crucial pour un apprentissage approfondi, la différenciation des produits et la création de meilleurs produits pour les utilisateurs. Bien que le développement des modèles open source puisse être plus lent, à long terme, ils ont un énorme potentiel en termes de création de valeur et d’autonomie technologique. (Source : ClementDelangue, huggingface)
Infrastructure IA et défis de la puissance de calcul : Le projet “StarGate” d’OpenAI révèle l’énorme demande de l’IA en puissance de calcul, en énergie et en terres, avec une consommation mensuelle estimée à 900 000 wafers DRAM. La rareté des GPU, leurs prix élevés et les limites de l’approvisionnement en électricité obligent les entreprises d’IA à pratiquer la “diplomatie de la puissance de calcul”, en s’associant étroitement avec des fournisseurs de services cloud (comme Microsoft et Amazon). Ce modèle d’investissement en capital intensif et de partenariat stratégique, bien qu’il stimule le développement de l’IA, comporte également des risques liés aux variables externes telles que la chaîne d’approvisionnement, la politique énergétique et la réglementation. (Source : karminski3, AI巨头的奶妈局, DeepLearning.AI Blog)

💡 Autres
Droits d’auteur musicaux de l’IA et mécanismes de compensation : L’organisation suédoise des droits d’auteur STIM s’est associée à la société Sureel pour lancer un accord de licence musicale IA, visant à résoudre le problème de l’utilisation des œuvres musicales dans l’entraînement des modèles d’IA. Cet accord permet aux développeurs d’IA d’utiliser légalement la musique et, grâce à la technologie d’attribution de Sureel, de calculer l’impact des œuvres sur la sortie du modèle, compensant ainsi les compositeurs et les artistes enregistrés. Cette initiative vise à fournir une protection juridique pour la création musicale IA, à encourager la production de contenu original et à créer de nouvelles sources de revenus pour les titulaires de droits d’auteur. (Source : DeepLearning.AI Blog)

Sécurité des LLM et attaques adverses : Trend Micro a publié une étude approfondie sur les diverses manières dont les LLM peuvent être exploités par des attaquants, notamment par des invites soigneusement construites, l’empoisonnement des données et les vulnérabilités dans les systèmes multi-Agent. L’étude souligne l’importance de comprendre ces vecteurs d’attaque pour développer des applications LLM et des systèmes multi-Agent plus sécurisés, et propose des stratégies de défense correspondantes. (Source : Reddit r/deeplearning)

Proactive AI : Équilibre entre commodité et confidentialité : La communauté a discuté de la commodité et des risques potentiels d’atteinte à la vie privée posés par la “Proactive Ambient AI” en tant qu’assistant intelligent. Ce type d’IA peut offrir une aide proactive, mais sa collecte et son traitement continus de données personnelles soulèvent des préoccupations chez les utilisateurs concernant la transparence, le contrôle et la propriété des données. Certains appellent à l’établissement de “protocoles de transparence” et de “profils de base personnels” pour garantir que les utilisateurs aient le contrôle sur leur historique d’interaction avec l’IA. (Source : Reddit r/artificial)
