
Mots-clés:OpenAI Sora 2, Génération de vidéos par IA, IA multimodale, Scientifique en IA, Conception de protéines, API Sora 2, PXDesign pour la conception de protéines, Cadre PromptCoT 2.0, Génération à la première personne EgoTwin, Liquid AI LFM2-Audio
🔥 À LA UNE
Lancement d’OpenAI Sora 2 et ses implications : OpenAI a officiellement lancé Sora 2, le positionnant comme une application sociale iOS « TikTok version IA », prenant en charge la génération simultanée d’audio et de vidéo, et offrant des améliorations significatives en termes de respect des lois physiques et de contrôlabilité. Les nouvelles fonctionnalités incluent les « cameos », permettant aux utilisateurs d’insérer leur image ou celle de leurs amis dans des vidéos générées par IA. Les médias sociaux s’enthousiasment pour son réalisme et sa créativité étonnants, mais des préoccupations sont également soulevées concernant la prolifération de contenu « slop » (de mauvaise qualité), la difficulté à distinguer le vrai du faux, l’augmentation massive de la demande en GPU, et la disponibilité régionale (par exemple, pas de Sora au Royaume-Uni). Sam Altman, PDG d’OpenAI, a répondu que Sora 2 vise à financer la recherche sur l’AGI et à proposer de nouveaux produits intéressants. Les discussions au sein de la communauté portent également sur l’obtention de codes d’invitation pour Sora 2, les spéculations sur les besoins en matériel (GPU), et les inquiétudes concernant la qualité future du contenu vidéo généré et son utilisation malveillante. OpenAI prévoit d’élargir les invitations pour Sora, mais réduira en conséquence les limites de génération quotidienne, et a révélé qu’une API Sora 2 serait lancée.
(Source : 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs lance une plateforme de scientifiques IA pour accélérer les découvertes scientifiques : Periodic Labs a levé 300 millions de dollars, dans le but de créer des scientifiques IA, accélérant les découvertes scientifiques fondamentales, en particulier dans le domaine de la conception de matériaux, grâce à des laboratoires automatisés et des expériences pilotées par l’IA. La plateforme vise à considérer l’univers physique comme un système computationnel, utilisant l’IA pour formuler des hypothèses, expérimenter et apprendre, avec le potentiel de réaliser des percées dans des domaines tels que les supraconducteurs à haute température. Cette vision souligne la connexion entre l’IA et le monde physique, ainsi que l’importance de générer des données de haute qualité par l’expérimentation, dépassant les modèles traditionnels qui ne dépendent que des données d’Internet.
(Source : dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

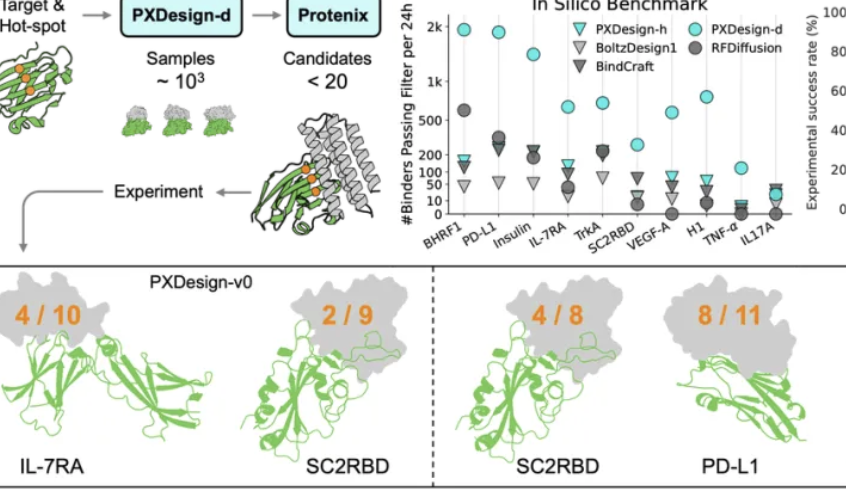
L’équipe Seed de ByteDance lance PXDesign pour améliorer l’efficacité de la conception de protéines : L’équipe Seed de ByteDance a lancé PXDesign, une méthode évolutive de conception de protéines par IA, capable de générer des centaines de protéines candidates de haute qualité en 24 heures, améliorant l’efficacité d’environ 10 fois par rapport aux méthodes dominantes de l’industrie. Cette méthode atteint un taux de succès en laboratoire humide de 20 % à 73 % sur plusieurs cibles, ce qui est significativement supérieur à AlphaProteo de DeepMind. PXDesign combine une stratégie de « génération + filtrage », utilisant la structure de réseau DiT et le modèle de prédiction de structure Protenix pour un criblage efficace, et offre un service de conception de binder en ligne gratuit et public, visant à accélérer l’exploration de la recherche biologique.
(Source : 量子位)
Ant Group et l’Université de Hong Kong lancent conjointement PromptCoT 2.0, axé sur la synthèse de tâches : Le groupe de traitement du langage naturel du Centre d’IA Générale d’Ant Group et le groupe de traitement du langage naturel de l’Université de Hong Kong ont conjointement publié le cadre PromptCoT 2.0, visant à faire progresser le raisonnement des grands modèles de langage et le développement des agents grâce à la synthèse de tâches. Ce cadre remplace la conception manuelle par une boucle d’espérance-maximisation (EM), générant des problèmes plus difficiles et plus diversifiés par une optimisation itérative de la chaîne de raisonnement. PromptCoT 2.0, combinant l’apprentissage par renforcement et le SFT, permet au modèle 30B-A3B d’atteindre le SOTA dans les tâches de raisonnement mathématique par code, et a mis à disposition 4,77 millions de données de problèmes synthétiques en open source, fournissant des ressources d’entraînement à la communauté.
(Source : 量子位)

EgoTwin réalise pour la première fois la génération synchronisée de vidéos à la première personne et de mouvements humains : L’Université Nationale de Singapour, l’Université Technologique de Nanyang, l’Université des Sciences et Technologies de Hong Kong et le Laboratoire d’IA de Shanghai ont conjointement publié le cadre EgoTwin, réalisant pour la première fois la génération conjointe de vidéos à la première personne et de mouvements humains. Ce cadre, basé sur des modèles de diffusion, génère conjointement des vidéos et des actions en trois modalités (texte-vidéo-action), surmontant les deux défis majeurs de l’alignement perspective-action et du couplage causal. Les innovations clés incluent une représentation de l’action centrée sur la tête, un mécanisme d’interaction inspiré de la cybernétique et un cadre d’entraînement par diffusion asynchrone. Les vidéos et actions générées peuvent être ensuite améliorées dans des scènes 3D.
(Source : 量子位)

🎯 TENDANCES
Lancement et mises à jour intensifs des modèles d’IA de nouvelle génération : Le domaine de l’IA a récemment vu le lancement et la mise à jour de plusieurs modèles et fonctionnalités importants, notamment DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4 et la fonction de paiement instantané de ChatGPT. DeepSeek-V3.2 a été optimisé sur vLLM grâce à un mécanisme d’attention clairsemée, offrant des performances de contexte long plus élevées et une meilleure efficacité coût-performance. Claude Sonnet 4.5 a montré une complexité en termes d’alignement et de théorie de l’esprit utilisateur, excellant dans l’écriture créative et la rédaction de longs textes, bien que certains utilisateurs aient noté que la qualité de sa génération de code restait à améliorer. GLM-4.6 a démontré des capacités exceptionnelles en code frontend, mais des améliorations moins significatives dans d’autres langages comme Python, et une version quantifiée GGUF a été publiée pour le déploiement local. Dreamer 4 est un agent capable d’apprendre à résoudre des tâches de contrôle complexes au sein de modèles de monde évolutifs.
(Source : Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Le modèle vidéo multimodal Veo3 démontre un potentiel d’intelligence visuelle générale : Le modèle vidéo Veo3 est considéré comme une voie potentielle vers l’intelligence visuelle générale, démontrant des capacités d’apprentissage et de raisonnement zéro-shot, capable de résoudre diverses tâches visuelles, et est jugé important pour les avancées en robotique. Parallèlement, l’équipe Qwen d’Alibaba Cloud a lancé la série de grands modèles de langage multimodaux Qwen3-VL, avec des mises à niveau complètes en matière d’agent visuel, d’encodage visuel, de perception spatiale, de compréhension de contextes longs et de vidéos, de raisonnement multimodal, de reconnaissance visuelle et d’OCR, et propose des versions Instruct et Thinking. Tencent a également lancé les modèles HunyuanImage 3.0 et Hunyuan3D-Part, atteignant des niveaux de pointe dans la génération de texte-image et la génération de formes 3D, respectivement.
(Source : gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI lance LFM2-Audio et des petits modèles spécialisés : Liquid AI a lancé LFM2-Audio, un modèle fondamental audio-texte tout-en-un de bout en bout, qui, avec seulement 1,5 milliard de paramètres, permet des conversations réactives en temps réel sur l’appareil, avec une vitesse d’inférence 10 fois supérieure à celle des modèles comparables. De plus, Liquid AI a introduit la série de modèles affinés LFM2, y compris différentes variantes comme Tool, RAG et Extract, qui se concentrent sur des tâches spécifiques plutôt que sur la généralité. Cela concorde avec le point de vue du livre blanc de Nvidia selon lequel les petits modèles spécialisés sont l’avenir de l’Agentic AI.
(Source : ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Les bases de données vectorielles connaissent un « second souffle » et l’importance des données de haute qualité pour xAI : Certains estiment que les bases de données vectorielles pourraient connaître un nouveau pic de développement, bien que leur mode d’application puisse différer des attentes. Parallèlement, xAI met en place un nouveau paradigme pour traiter les données humaines, soulignant l’importance du post-training, considérant les données de haute qualité comme la pierre angulaire de l’AGI. xAI prévoit de former une communauté d’experts de divers domaines pour construire ensemble le système d’évaluation de la plus haute qualité.
(Source : _philschmid, Dorialexander, Yuhu_ai_)
🧰 OUTILS
Générateur de romans IA YILING0013/AI_NovelGenerator : Un générateur de romans multifonctionnel basé sur de grands modèles de langage, prenant en charge l’architecture de l’univers, la conception des personnages, le plan de l’intrigue, la génération intelligente de chapitres, le suivi de l’état, la gestion des indices, la recherche sémantique, l’intégration de bases de connaissances et un mécanisme de relecture automatique, le tout via une interface graphique. Cet outil vise à créer efficacement des histoires longues avec une logique rigoureuse et des paramètres cohérents, et prend en charge divers LLM et services d’Embedding tels que OpenAI, DeepSeek et Ollama.
(Source : GitHub Trending)
Le développement continu des outils de programmation assistés par l’IA : GitHub Copilot, grâce aux contributions de la communauté en matière d’instructions, de prompts et de modes de chat, aide les utilisateurs à maximiser son utilité dans divers domaines, langages et cas d’utilisation, et propose un serveur MCP pour simplifier l’intégration. Replit Agent démontre de puissantes capacités en matière de migration de code et de QA, capable de migrer rapidement de grands sites Next.js de Vercel et de prendre en charge l’intégration de paiements in-app. Le modèle Apriel-1.5-15b-Thinker de ServiceNow peut fonctionner sur un seul GPU, offrant de puissantes capacités de raisonnement. De plus, le modèle Moondream3-preview est utilisé pour les flux d’interface utilisateur d’agent et les tâches RPA, et vLLM prend également en charge le déploiement de modèles encoder-only.
(Source : github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

Innovations d’outils IA dans des domaines d’application spécifiques : pix2tex (LaTeX OCR) peut convertir des images de formules mathématiques en code LaTeX, améliorant considérablement l’efficacité dans les domaines de la recherche scientifique et de l’éducation. BatonVoice utilise la capacité de suivi des instructions des LLM pour fournir des paramètres structurés pour la synthèse vocale, permettant un TTS contrôlable. La plateforme Hex intègre des fonctions d’agent, permettant à davantage de personnes d’utiliser l’IA pour un travail de données précis et fiable. Des outils de génération vidéo tels que Kling 2.5 Turbo et Lucid Origin rendent la création vidéo plus facile que jamais. Racine CU-1 est un modèle interactif GUI capable de reconnaître les positions de clic, adapté aux flux d’interface utilisateur d’agent et aux tâches RPA.
(Source : lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Modèle de réordonnancement de documents jina-reranker-v3 : jina-reranker-v3 est un modèle multilingue de réordonnancement de documents de 0,6 milliard de paramètres, qui introduit un nouveau mécanisme d’« interaction tardive mais pas trop tardive » (last but not late interaction). Cette méthode effectue un calcul d’auto-attention causale entre la requête et les documents, permettant une interaction riche entre les documents avant l’extraction de l’embedding contextuel de chaque document. Cette architecture compacte atteint le SOTA en termes de performances BEIR, tout en étant dix fois plus petite que les modèles de réordonnancement de listes génératives.
(Source : HuggingFace Daily Papers)
📚 APPRENTISSAGE
Dernières avancées de la recherche sur l’inférence et l’alignement des modèles d’IA : Des recherches révèlent que le raisonnement multimodal, tout en améliorant le raisonnement logique, peut nuire aux fondements perceptuels, entraînant une amnésie visuelle. La méthode Vision-Anchored Policy Optimization (VAPO) est proposée pour guider le processus de raisonnement à se concentrer davantage sur les fondements visuels. Une exploration des raisons pour lesquelles l’alignement en ligne (comme GRPO) est supérieur à l’alignement hors ligne (comme DPO) est menée, et une variante Humanline est proposée, qui, en simulant les biais perceptuels humains, permet à l’entraînement de données hors ligne d’atteindre les performances de l’alignement en ligne. Le paradigme Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) et l’algorithme Optimum-Referenced One-Step Adaptation (ROSA) utilisent le feedback utilisateur pour un ajustement efficace et en temps réel des paramètres du modèle, améliorant la capacité d’auto-correction des LLM dans les dialogues multi-tours. NuRL (Nudging method) réduit la difficulté des problèmes en générant des prompts auto-générés, permettant au modèle d’apprendre à partir de problèmes initialement « insolubles », augmentant ainsi la limite supérieure des capacités de raisonnement des LLM. RLP (Reinforcement Learning Pre-training) intègre l’apprentissage par renforcement dans la phase de pré-entraînement, considérant la chaîne de pensée comme une action et récompensant le gain d’information, afin d’améliorer les capacités de raisonnement du modèle dès la phase de pré-entraînement. Exploratory Iteration (ExIt) est une méthode de curriculum automatique basée sur le RL, qui guide les LLM à s’auto-améliorer itérativement dans leurs solutions lors du raisonnement, améliorant efficacement les performances du modèle dans les tâches à tour unique et multi-tours. La recherche TruthRL utilise l’apprentissage par renforcement pour inciter les LLM à générer des informations véridiques, visant à résoudre le problème des hallucinations du modèle. Des recherches ont montré que la « fenêtre de contexte effective maximale » (MECW) des LLM est bien inférieure à la « fenêtre de contexte maximale » (MCW) rapportée, et que la MECW varie avec le type de problème, révélant les limitations réelles des LLM dans le traitement de contextes longs. L’attaque Bias-Inversion Rewriting Attack (BIRA) peut théoriquement contourner efficacement les filigranes des LLM en supprimant les logits des tokens susceptibles d’être marqués par un filigrane, atteignant un taux de contournement de plus de 99 % tout en conservant le contenu sémantique, soulignant la vulnérabilité des technologies de filigrane.
(Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
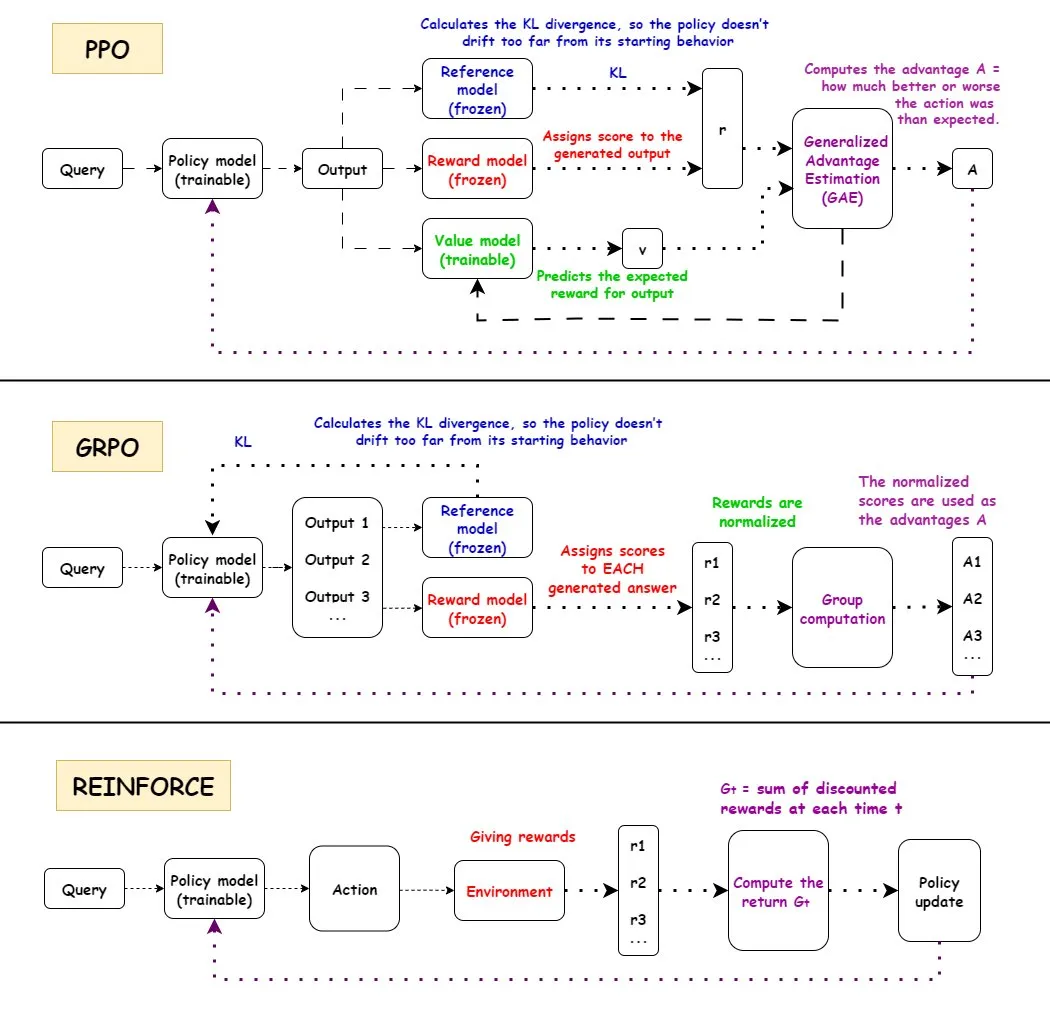
Analyse approfondie des algorithmes d’apprentissage par renforcement (RL) : Une interprétation détaillée des algorithmes d’apprentissage par renforcement (RL) PPO, GRPO et REINFORCE, y compris leurs flux de travail, avantages, inconvénients et scénarios d’application. PPO est apprécié pour sa stabilité, GRPO pour son mécanisme de récompense relative, et REINFORCE comme algorithme fondamental, tous largement utilisés dans le domaine de l’IA. La recherche montre que l’apprentissage par renforcement peut entraîner des modèles à combiner des compétences atomiques et à généraliser en profondeur de combinaison, indiquant le potentiel du RL dans l’apprentissage de nouvelles compétences. Il a été constaté que plus de la moitié des améliorations de performance dans les pipelines RL ne proviennent pas d’améliorations liées au ML, mais d’optimisations d’ingénierie telles que le multithreading. Le problème de la quantité d’informations par épisode dans l’entraînement RL est discuté, ainsi que l’équivalence d’information de différentes trajectoires sous la même récompense finale. La communauté débat de la définition et de l’efficacité du pré-entraînement RL, soulignant les problèmes potentiels causés par la diversité synthétique forcée et appelant à une attention à la dégradation de la cohérence. Pour les robots humanoïdes à cinq doigts et deux bras, l’apprentissage par renforcement hors politique résiduel (ROSA) est utilisé pour affiner les politiques de clonage comportemental, améliorant significativement l’efficacité des échantillons et permettant un affinage direct des politiques sur le matériel.
(Source : TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
Scientifiques IA et découvertes scientifiques : DeepScientist est un système de découverte scientifique autonome et orienté objectif, qui, grâce à l’optimisation bayésienne et à un processus d’évaluation hiérarchique, stimule les découvertes scientifiques de pointe sur des périodes de plusieurs mois. Ce système a déjà surpassé les méthodes SOTA humaines sur trois tâches d’IA de pointe, et a mis en open source tous les journaux d’expériences et le code système. OpenAI recrute des chercheurs scientifiques dans le but de construire la prochaine génération d’instruments scientifiques – une plateforme pilotée par l’IA pour accélérer les découvertes scientifiques.
(Source : HuggingFace Daily Papers, mcleavey)
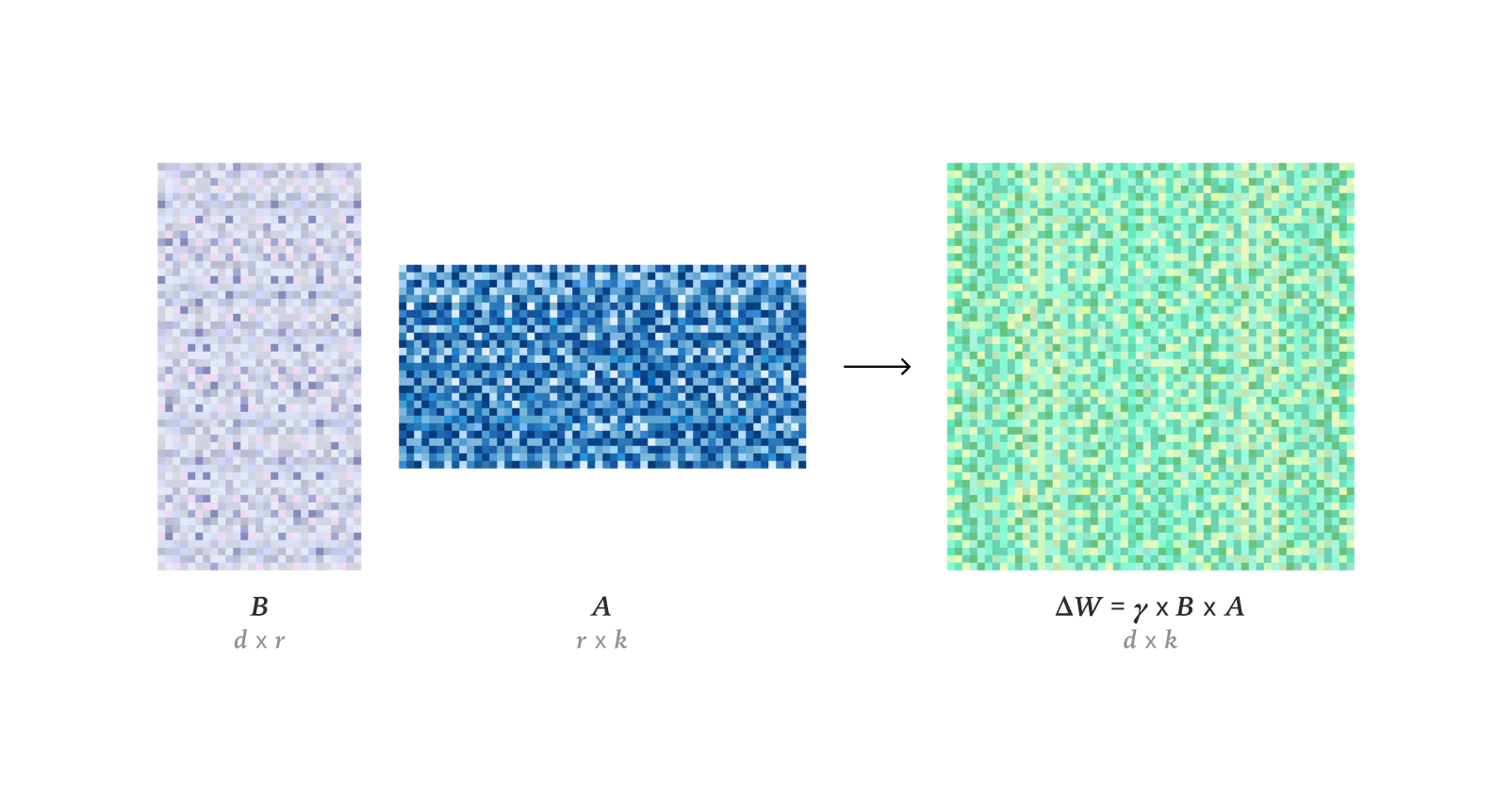
Techniques d’affinage et d’optimisation des LLM : Des recherches ont montré que LoRA peut égaler entièrement les performances d’apprentissage du FullFT dans l’apprentissage par renforcement, même avec un rang faible, absorbant suffisamment d’informations de l’entraînement RL. Le cadre Quadrant-based Tuning (Q-Tuning) a considérablement amélioré l’efficacité des données dans le fine-tuning supervisé (SFT) grâce à l’élagage conjoint des échantillons et des tokens, surpassant même l’entraînement sur toutes les données dans certains cas. L’optimiseur Muon surpasse continuellement Adam dans l’entraînement des LLM, en particulier dans l’apprentissage de la mémoire associative de queue, en résolvant les différences d’apprentissage d’Adam sur des données déséquilibrées en catégories grâce à un spectre singulier plus isotrope et une optimisation efficace des données à queue lourde. Une étude sur l’estimation asymptotique du RMS du poids dans l’optimiseur AdamW a été menée. Une analyse approfondie du fonctionnement interne du noyau CUDA de Flash Attention 4 a révélé ses innovations en matière de pipeline asynchrone, de softmax logiciel (approximation cubique) et de rescalage efficace, expliquant ses performances plus rapides que cuDNN.
(Source : ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
Ressources d’apprentissage et outils de recherche en IA : Partage d’une présentation sur l’IA multimodale couvrant les tendances, les modèles open source, les outils de personnalisation/déploiement et d’autres ressources. Annonce des conférences AI Engineer Europe 2026 et AI Engineer Paris, offrant des plateformes d’échange pour les ingénieurs en IA. Recommandation de la série « Let’s build GPT » de Karpathy et du papier Qwen, soulignant l’importance des données d’entraînement CTF de haute qualité et des ressources de calcul pour l’entraînement des LLM. Discussion sur le potentiel de l’optimiseur DSPyOSS pour réaliser une optimisation « stratifiée » dans les cas d’utilisation d’IA B2B, afin de faire face à la rareté des données. Axiom Math AI vise à construire un raisonneur super-intelligent auto-améliorant, en commençant par des mathématiciens IA, pour progresser dans le domaine des mathématiques formelles. Étude de l’application des modèles de langage régressifs dans la génération et la compréhension de code. Débat sur la question de savoir si l’apprentissage par renforcement est suffisant pour atteindre l’AGI. Exploration de l’inventeur de l’apprentissage résiduel profond (Deep Residual Learning) et de sa chronologie d’évolution. Jürgen Schmidhuber a expliqué en 2016 la conscience artificielle, les modèles du monde, le codage prédictif et la science comme compression de données, soulignant ses contributions précoces dans le domaine de l’IA. Analyse exploratoire des pratiques de collaboration ouverte, des motivations et de la gouvernance de 14 projets de grands modèles de langage open source, révélant la diversité et les défis de l’écosystème LLM open source. Dragon Hatchling (BDH) est une architecture LLM basée sur des réseaux de type cérébral, visant à connecter Transformer avec des modèles cérébraux pour atteindre l’explicabilité et des performances de type Transformer. Le cadre d^2Cache améliore significativement l’efficacité de l’inférence et la qualité de génération des modèles de langage de diffusion (dLLMs) grâce à un double cache adaptatif. Le cadre TimeTic estime la transférabilité des modèles fondamentaux de séries temporelles (TSFMs) par apprentissage contextuel, afin de sélectionner efficacement le meilleur modèle pour le fine-tuning en aval. Les encodeurs visuels fondamentaux peuvent servir de tokenizer pour les modèles de diffusion latente (LDM), générant un espace latent sémantiquement riche, améliorant les performances de génération d’images. NVFP4 est un nouveau format de pré-entraînement 4 bits qui, grâce à une mise à l’échelle à deux niveaux, RHT et un arrondi aléatoire, vise une amélioration de l’efficacité de 6,8 fois tout en égalant les performances de référence FP8. DA^2 (Depth Anything in Any Direction) est un estimateur de profondeur panoramique précis, généralisable zéro-shot et de bout en bout, qui atteint le SOTA en estimation de profondeur panoramique grâce à des données d’entraînement massives et à l’architecture SphereViT. Le modèle SAGANet permet une génération audio contrôlable au niveau de l’objet en utilisant des masques de segmentation visuelle, des indices vidéo et textuels, offrant un contrôle fin pour les flux de travail Foley professionnels. Mem-α est un cadre d’apprentissage par renforcement qui, en entraînant des agents à gérer efficacement des systèmes de mémoire externes complexes, résout les problèmes de construction de mémoire et de perte d’informations des agents LLM dans la compréhension de textes longs, et démontre une capacité de généralisation aux séquences ultra-longues. Le cadre EntroPE (Entropy-Guided Dynamic Patch Encoder) détecte dynamiquement les points de transition dans les séries temporelles via l’entropie conditionnelle et place les limites de patch pour préserver la structure temporelle, améliorant la précision et l’efficacité de la prédiction. BUILD-BENCH est un benchmark plus exigeant pour évaluer la capacité des agents LLM à compiler des logiciels open source du monde réel, et propose OSS-BUILD-AGENT comme ligne de base solide. ProfVLM est un modèle vidéo-langage léger qui, grâce au raisonnement génératif, prédit conjointement le niveau de compétence et génère des feedbacks d’experts à partir de vidéos égocentriques et de perspective externe. Discussion sur l’efficacité de l’entraînement au moment du test (TTT) dans les modèles fondamentaux, considérant que le TTT, en se spécialisant sur les tâches de test, peut réduire significativement l’erreur de test intra-distribution. CST est une nouvelle architecture de réseau neuronal pour traiter des ensembles d’images de cardinalité arbitraire, opérant directement sur des tenseurs d’images 3D, tout en effectuant l’extraction de caractéristiques et la modélisation contextuelle, avec d’excellentes performances dans des tâches telles que la classification d’ensembles et la détection d’anomalies. Le cadre TTT3R traite la reconstruction 3D comme un problème d’apprentissage en ligne, dérivant le taux d’apprentissage de la confiance d’alignement des états de mémoire et des observations, améliorant significativement la capacité de généralisation des séquences longues.
(Source : tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Détection de falsifications perçues par l’homme dans la génération vidéo par IA : DeeptraceReward est le premier ensemble de données de référence à grain fin et spatio-temporellement conscient, utilisé pour annoter les traces de falsification perçues par l’homme dans les vidéos générées. Cet ensemble de données contient 4,3K annotations détaillées sur 3,3K vidéos générées de haute qualité, et les intègre en 9 catégories principales de traces de falsification. La recherche a entraîné un modèle de langage multimodal comme modèle de récompense pour imiter le jugement et la localisation humains, surpassant GPT-5 dans l’identification, la localisation et l’explication des indices de falsification.
(Source : HuggingFace Daily Papers)
Purification antagoniste et reconstruction de scènes 3D : MANI-Pure est un cadre de purification adaptatif en amplitude qui, en utilisant le spectre d’amplitude du signal d’entrée pour guider le processus de purification, injecte de manière adaptative un bruit hétérogène et orienté en fréquence, supprimant efficacement les perturbations haute fréquence tout en préservant le contenu basse fréquence sémantiquement crucial, atteignant ainsi des performances SOTA en défense antagoniste. Nvidia a lancé le modèle Lyra, qui réalise la reconstruction générative de scènes 3D par auto-distillation de modèles de diffusion vidéo, permettant la génération de scènes 3D et 4D en flux direct à partir d’une seule image/vidéo.
(Source : HuggingFace Daily Papers, _akhaliq)
💼 AFFAIRES
Collaboration OpenAI-Samsung et demande de DRAM : OpenAI collabore avec Samsung pour développer la puce « Stargate » et prévoit un besoin mensuel de 900 000 wafers DRAM haute performance, ce qui indique des plans et des investissements massifs pour son infrastructure IA future, bien au-delà des attentes actuelles de l’industrie. Cette demande colossale a suscité des discussions sur les coûts de calcul de l’IA et le supercycle de la mémoire.
(Source : bookwormengr, teortaxesTex, francoisfleuret)
Financement des startups IA et stratégie industrielle : Axiom Math AI a lancé un raisonneur super-intelligent auto-améliorant, commençant par des mathématiciens IA, suscitant l’attention de l’industrie. Modal a clôturé un financement de série B de 87 millions de dollars, valorisant l’entreprise à 1,1 milliard de dollars, dans le but de faire progresser l’infrastructure de calcul IA. OffDeal a clôturé un financement de série A de 12 millions de dollars, visant à construire la première banque d’investissement nativement IA au monde. Le ministre japonais de la Défense a visité les bureaux de Sakana AI, indiquant une potentielle collaboration de l’IA dans le domaine de la défense. Un développeur a partagé sa difficulté à court d’argent après avoir dépensé 3 000 dollars pour construire des modèles LLM open source, suscitant des discussions au sein de la communauté sur la durabilité des projets IA open source. Les développeurs Google AI ont annoncé les lauréats du Nano Banana Hackathon, décernant plus de 400 000 dollars de prix, dans le but d’encourager l’innovation dans les applications IA.
(Source : shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 COMMUNAUTÉ
Impact social et controverses suscitées par Sora 2 : Le lancement de Sora 2 a provoqué un large éventail d’impacts sociaux et de controverses. De nombreux utilisateurs craignent la prolifération de contenu « slop » (de mauvaise qualité, insignifiant) généré par l’IA, remettant en question les priorités d’OpenAI qui semblent privilégier le divertissement plutôt que la résolution de problèmes majeurs comme le cancer. Parallèlement, on s’inquiète du réalisme ultra-élevé de Sora 2, qui pourrait rendre difficile la distinction entre le vrai et le faux dans les vidéos, voire être utilisé de manière malveillante pour générer de fausses informations ou des contenus nuisibles de type « armes biologiques ». Sam Altman, PDG d’OpenAI, est lui-même devenu le sujet de mèmes générés par l’IA, ce qu’il a trouvé « pas si étrange », expliquant que l’objectif principal d’OpenAI reste l’AGI et la découverte scientifique, et que les lancements de produits sont motivés par des besoins de financement. La puissance de Sora 2 a de nouveau mis en évidence l’énorme demande en GPU, suscitant des discussions sur les coûts élevés de l’IA, certains comparant même le coût de l’IA à celui de la construction du système autoroutier inter-États américain. Des commentaires ont jugé la stratégie de lancement de Sora 2 trop « ordinaire », manquant de benchmarks et de support pour les utilisateurs professionnels, et imposant des limites de génération de contenu pour les utilisateurs gratuits.
(Source : teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Expérience utilisateur et controverses de Claude Sonnet 4.5 : Les utilisateurs estiment généralement que Sonnet 4.5 a considérablement amélioré la rétention d’informations, le jugement, la prise de décision et l’écriture créative, montrant même un « changement d’attitude » similaire à celui des humains, par exemple en devenant plus professionnel après avoir découvert le contexte de l’utilisateur, ou en corrigeant l’utilisateur lorsqu’il « dit n’importe quoi ». Bien qu’il excelle dans certains aspects, certains utilisateurs critiquent toujours la faible qualité de sa génération de code, avec des « erreurs négligentes et stupides », et même des problèmes de « conversation trop longue » empêchant la génération de code lors de dialogues étendus, estimant qu’il est encore loin de remplacer les ingénieurs logiciels humains. De plus, des utilisateurs ont réussi à « jailbreaker » Sonnet 4.5, le faisant générer des recettes dangereuses et du code malveillant, soulevant de sérieuses préoccupations quant à la sécurité du modèle.
(Source : teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
L’avenir des langages de programmation à l’ère de l’IA et le déclin de la culture communautaire : Le classement des langages de programmation IEEE Spectrum 2025 montre que Python est le langage le plus populaire pour la dixième année consécutive, se classant premier dans les catégories de classement général, de vitesse de croissance et d’orientation vers l’emploi. Son avantage est encore amplifié à l’ère de l’IA. JavaScript a connu une forte baisse, tandis que la position de SQL, bien qu’affectée, conserve sa valeur. Le rapport indique que l’IA met fin à la diversité des langages de programmation, l’effet Matthieu des langages dominants s’intensifiant et les langages non dominants étant marginalisés. Parallèlement, la culture communautaire des programmeurs décline, les développeurs préférant demander de l’aide aux grands modèles plutôt qu’aux communautés, ce qui modifie les méthodes d’apprentissage et de travail, et soulève des discussions sur le rôle futur des programmeurs et l’importance des compétences fondamentales en conception d’architecture sous-jacente.
(Source : 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

Bulle de l’IA et perspectives de développement de l’industrie : Les médias sociaux débattent de l’existence d’une bulle dans l’industrie de l’IA. Certains estiment que l’enthousiasme actuel pour l’investissement pourrait mener à des projets « stupides », mais que les fondamentaux de l’industrie restent solides, avec une adoption croissante de l’IA par les entreprises. Parallèlement, d’autres soulignent que les coûts de calcul massifs de l’IA et la demande colossale de DRAM par OpenAI indiquent que l’industrie est toujours en expansion rapide, loin d’atteindre le stade de l’éclatement de la bulle, mais qu’il faut rester vigilant face à l’afflux de capitaux.
(Source : arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 AUTRES
Robots humanoïdes et dispositifs assistés par l’IA : La société chinoise de robotique LimX Dynamics a présenté les capacités de déplacement autonome, de flexion et de lancer de son robot humanoïde Oli, sans capture de mouvement ni téléopération, démontrant que la Chine a atteint un niveau comparable à Figure/1X/Tesla dans le domaine des robots humanoïdes. Le Neural Band de Meta, qui lit les signaux nerveux via EMG et est combiné aux lunettes d’affichage Meta Rayban, pourrait offrir aux amputés une méthode de contrôle révolutionnaire, permettant un contrôle synchronisé des prothèses et des interfaces numériques, et pourrait devenir un contrôleur mains libres universel. De plus, l’IA et la robotique ont des applications diverses pour améliorer la mobilité, l’exploration et le sauvetage, telles que les exosquelettes robotiques électriques, les insectes robotiques contrôlés sans fil, les robots quadrupèdes et les serpents robotiques pour les missions de sauvetage.
(Source : Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
Applications de l’IA dans l’édition d’images et la conception graphique : LayerD est une méthode de décomposition de la conception graphique raster en couches, visant à créer des flux de travail créatifs rééditables, en extrayant itérativement les couches de premier plan non occluses et en les affinant en utilisant l’hypothèse que les couches présentent généralement une apparence uniforme, réalisant ainsi une décomposition de haute qualité. GeoRemover propose un cadre géométriquement conscient en deux étapes pour supprimer les objets des images et leurs artefacts visuels causaux (tels que les ombres et les reflets), en découplant la suppression géométrique et le rendu de l’apparence, et en introduisant des objectifs basés sur les préférences pour guider l’apprentissage.
(Source : HuggingFace Daily Papers, HuggingFace Daily Papers)