
Mots-clés:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, Modèles d’IA, Intelligence artificielle, Grands modèles de langage, Programmation IA, Agents intelligents IA, Capacités de programmation de Claude Sonnet 4.5, Mécanisme d’attention éparse DSA, Fonctionnalité de paiement instantané ChatGPT, Application sociale Sora 2, Technique de réglage fin LoRA
🔥 Actualités
Anthropic Claude Sonnet 4.5 lancé, améliorant considérablement les capacités de programmation et d’agent : Anthropic a officiellement lancé Claude Sonnet 4.5, salué comme le modèle de programmation le plus puissant au monde, et a réalisé des avancées significatives dans la construction d’agents, l’utilisation d’ordinateurs, le raisonnement et les capacités mathématiques. Ce modèle peut travailler de manière autonome et continue pendant plus de 30 heures, a atteint le sommet du test SWE-bench Verified et a battu des records sur le benchmark de tâches informatiques OSWorld. Les nouvelles fonctionnalités incluent la fonction de retour en arrière “checkpoint” de Claude Code, un plugin VS Code, l’édition contextuelle de l’API et des outils de mémoire. De plus, une fonctionnalité expérimentale “Imagine with Claude” a été introduite, permettant de générer des interfaces logicielles en temps réel. Sonnet 4.5 a également considérablement amélioré sa sécurité, réduisant les comportements indésirables tels que la tromperie et la complaisance, et a obtenu la certification AI safety level 3 (ASL-3), avec un taux de fausses alertes réduit de 10 fois. Le prix reste le même que celui de Sonnet 4, améliorant encore le rapport qualité-prix et devrait déclencher une nouvelle vague de concurrence en programmation AI. (Source : Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp lancé, introduisant le mécanisme d’attention clairsemée DSA et réduisant les prix : DeepSeek a lancé le modèle expérimental V3.2-Exp, introduisant le mécanisme d’attention clairsemée DeepSeek Sparse Attention (DSA), qui améliore considérablement l’efficacité de l’entraînement et de l’inférence pour les longs contextes, tout en réduisant les prix de l’API de plus de 50 %. DSA utilise un “Lightning Indexer” pour identifier efficacement les Tokens clés pour des calculs précis, réduisant la complexité de l’attention de O(L²) à O(Lk). Les fabricants chinois de puces AI tels que Huawei Ascend, Cambricon et Hygon Information ont déjà réalisé une adaptation Day 0, favorisant ainsi le développement de l’écosystème de puissance de calcul national. Le modèle a également open-sourcé l’opérateur GPU en version TileLang, comparable à NVIDIA CUDA, facilitant le prototypage et le débogage pour les développeurs. Bien que des concessions aient été faites sur certaines capacités, son innovation architecturale et son efficacité économique ouvrent de nouvelles perspectives pour le traitement des textes longs par les grands modèles. (Source : 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

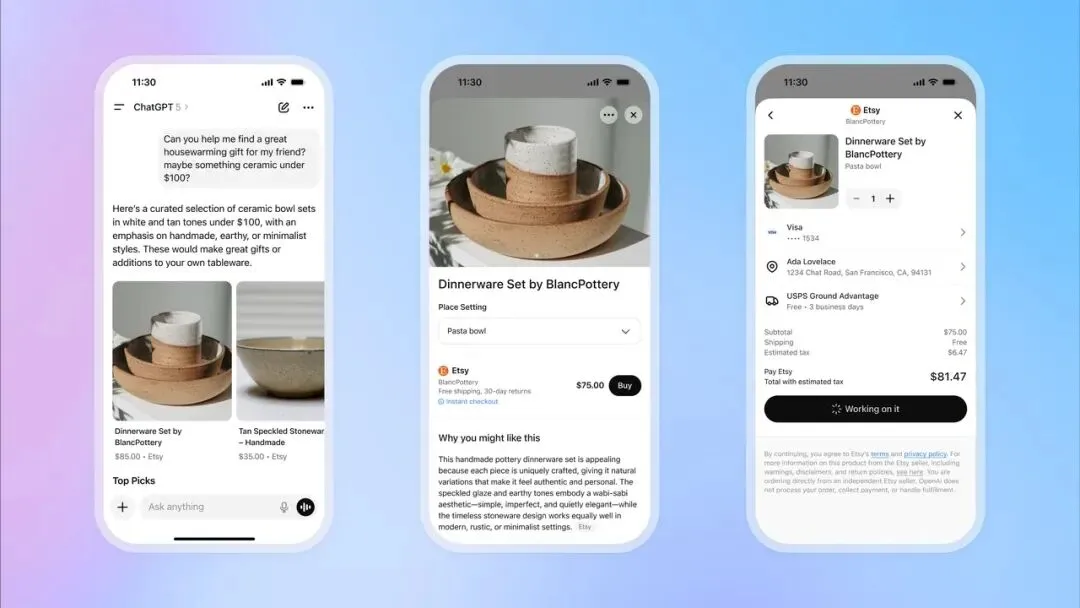
OpenAI lance la fonction de paiement instantané ChatGPT, entrant dans le domaine du commerce électronique : OpenAI a introduit la fonction “Instant Checkout” dans ChatGPT, permettant aux utilisateurs d’acheter directement des produits sur les plateformes Etsy et Shopify via la conversation, sans avoir à naviguer vers des sites externes. Cette fonction est basée sur le “Agentic Commerce Protocol” développé par OpenAI en collaboration avec Stripe, et a été open-sourcée. Elle vise à convertir le trafic massif de ChatGPT en transactions commerciales. Initialement disponible sur le marché américain, elle prévoit de s’étendre à des paniers multi-produits et à davantage de régions à l’avenir. Cette initiative est considérée comme une étape majeure dans la commercialisation d’OpenAI, susceptible de devenir une source de revenus importante et d’avoir un impact profond sur le commerce électronique traditionnel et l’industrie de la publicité. (Source : 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI prépare le lancement de l’application sociale Sora 2, créant une plateforme de courtes vidéos AI : OpenAI se prépare à lancer une application sociale indépendante alimentée par son dernier modèle vidéo Sora 2. L’application est conçue pour être très similaire à TikTok, avec un flux vidéo vertical et une navigation par balayage, mais tout le contenu est généré par l’AI. Les utilisateurs pourront générer des clips vidéo d’une durée maximale de 10 secondes et utiliser une fonction d’authentification pour utiliser leur propre portrait dans les vidéos. Cette initiative vise à reproduire le succès de ChatGPT dans le domaine du texte, permettant au public de découvrir intuitivement le potentiel de la vidéo AI et d’entrer directement en concurrence avec Meta et Google. Cependant, la stratégie d’OpenAI en matière de droits d’auteur, qui consiste à “utiliser par défaut le contenu protégé par le droit d’auteur, sauf retrait actif par le détenteur des droits”, a suscité de vives inquiétudes chez les créateurs de contenu et les sociétés de production cinématographique, annonçant une intense confrontation entre l’AI et la propriété intellectuelle. (Source : 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Tendances
Le modèle Huawei Pangu 718B se classe deuxième dans le classement des grands modèles chinois open-source SuperCLUE : Le modèle Huawei openPangu-Ultra-MoE-718B s’est classé deuxième dans le classement des grands modèles chinois open-source SuperCLUE. Ce modèle adopte une philosophie d’entraînement “ne pas empiler les données, mais savoir penser”, en utilisant des principes de construction de données “priorité à la qualité, couverture de la diversité, adaptation à la complexité”, ainsi qu’une stratégie de pré-entraînement en trois phases (général, raisonnement, recuit) pour construire une vaste connaissance du monde et améliorer les capacités de raisonnement logique. Pour atténuer le problème des hallucinations, un mécanisme de “critique internalisée” a été introduit ; pour améliorer les capacités d’utilisation des outils, un cadre de synthèse ToolACE amélioré a été adopté. (Source : 量子位)

FSDrive unifie VLA et World Model, propulsant la conduite autonome vers le raisonnement visuel : FSDrive (FutureSightDrive) propose un “CoT visuel spatio-temporel” qui, en unifiant les futures images comme étapes de raisonnement intermédiaires, combine les scénarios futurs et les résultats de perception pour un raisonnement visuel, faisant ainsi passer la conduite autonome du raisonnement symbolique au raisonnement visuel. Cette méthode, sans modifier l’architecture MLLM existante, active la capacité de génération d’images par l’extension du vocabulaire et la génération visuelle auto-régressive, et injecte des a priori physiques via un CoT visuel progressif. Le modèle agit à la fois comme un “World Model” pour prédire l’avenir et comme un “modèle de dynamique inverse” pour la planification de trajectoire. (Source : 36氪)

GPT-5 fournit des idées clés pour le calcul quantique, salué par le grand Scott Aaronson : Scott Aaronson, une sommité de la théorie du calcul quantique, a révélé que GPT-5 lui a fourni des idées de preuve cruciales pour sa recherche en théorie de la complexité quantique en moins d’une demi-heure, résolvant un problème qui tourmentait son équipe. Scott Aaronson a déclaré que GPT-5 a réalisé des progrès significatifs dans la résolution des activités intellectuelles les plus humaines, marquant un “moment privilégié” de collaboration homme-AI, capable de fournir une inspiration décisive aux chercheurs à des moments critiques. (Source : 量子位, Twitter)

HuggingFace accélère l’inférence du modèle Qwen3-8B Agent sur Intel Core Ultra : HuggingFace, en collaboration avec Intel, a réussi à augmenter la vitesse d’inférence du modèle Qwen3-8B Agent sur le GPU intégré Intel Core Ultra de 1,4 fois, grâce à OpenVINO.GenAI et un modèle brouillon Qwen3-0.6B “depth-pruned”. Cette optimisation rend l’exécution des applications Agent de Qwen3-8B plus efficace sur les AI PC, particulièrement adaptée aux flux de travail complexes nécessitant un raisonnement en plusieurs étapes et l’appel d’outils, favorisant ainsi la praticité des AI Agent locaux. (Source : HuggingFace Blog)

Le robot Reachy Mini intègre GPT-4o pour une interaction multimodale : Le robot Reachy Mini de Hugging Face / Pollen Robotics a été intégré avec succès au modèle GPT-4o d’OpenAI, améliorant considérablement ses capacités d’interaction multimodale. Les nouvelles fonctionnalités incluent l’analyse d’images (le robot peut décrire et raisonner sur les photos prises), le suivi facial (maintenir un contact visuel), la fusion de mouvements (mouvements de tête, suivi facial, émotions/danse simultanés), la reconnaissance faciale locale et des comportements autonomes en mode inactif. Ces avancées rendent l’interaction homme-machine plus naturelle et fluide, mais des défis subsistent concernant le système de mémoire, la reconnaissance vocale et les stratégies pour les foules complexes. (Source : Reddit r/ChatGPT, Twitter)

Intel lance la nouvelle version Beta de LLM Scaler, prenant en charge GenAI sur les GPU Battlemage : Intel a lancé la nouvelle version Beta de LLM Scaler, visant à optimiser les performances de l’AI générative (GenAI) sur les GPU Battlemage. Cette initiative témoigne de l’investissement continu d’Intel dans le matériel et l’écosystème logiciel de l’AI, afin d’améliorer la compétitivité de ses GPU dans les tâches d’inférence et de génération de grands modèles linguistiques. (Source : Reddit r/artificial)
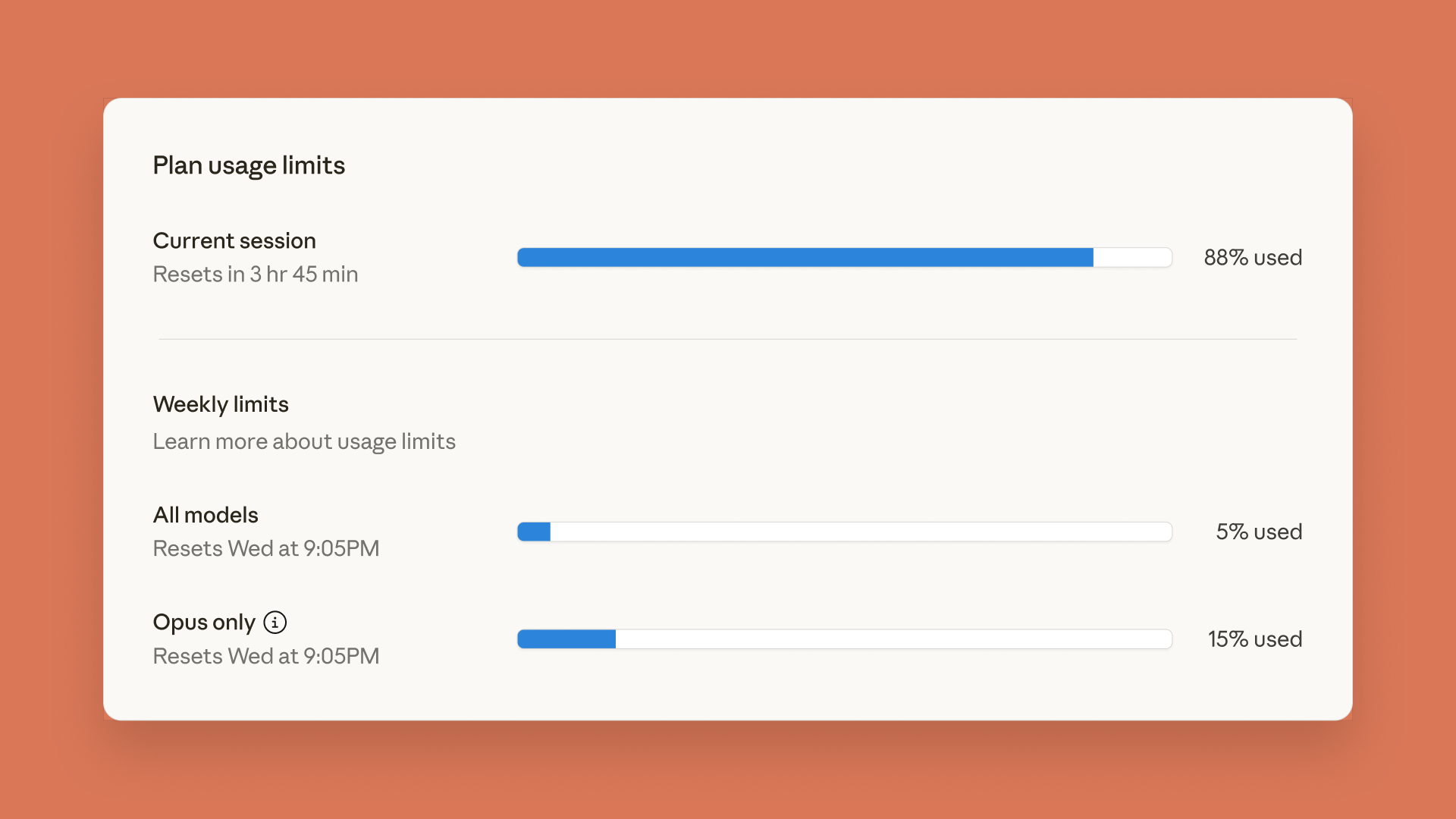
Claude lance un tableau de bord des limites d’utilisation, ChatGPT introduit des fonctions de contrôle parental : Anthropic a lancé un tableau de bord des limites d’utilisation en temps réel pour Claude Code et Claude App, permettant aux utilisateurs de suivre leur consommation de Token pour faire face aux limites de débit hebdomadaires précédemment annoncées. Parallèlement, OpenAI a introduit des fonctions de contrôle parental dans ChatGPT, permettant aux parents d’associer les comptes de leurs adolescents, offrant automatiquement une protection de sécurité renforcée, et pouvant ajuster les fonctions et les paramètres d’utilisation, bien que les parents ne puissent pas consulter le contenu spécifique des conversations. (Source : Reddit r/ClaudeAI, 36氪)
Un modèle linguistique de 5 millions de paramètres exécuté dans Minecraft, démontrant des applications innovantes de l’AI : Sammyuri a construit un système Redstone complexe dans Minecraft, réussissant à exécuter un modèle linguistique d’environ 5 millions de paramètres et lui conférant des capacités de conversation de base. Cette avancée révolutionnaire démontre la possibilité de réaliser une AI locale dans un environnement de jeu et a suscité un large intérêt et des discussions au sein de la communauté sur les applications de l’AI sur des plateformes non traditionnelles. (Source : Reddit r/LocalLLaMA, Twitter)
Le serveur AI d’Inspur Information atteint une vitesse d’inférence de 8,9 ms, avec un coût de 1 yuan par million de Token : Inspur Information a lancé les super-nœuds de serveur AI ultra-extensibles Yuan Nao HC1000 et Yuan Nao SD200, portant la vitesse d’inférence AI à un nouveau record. Le Yuan Nao SD200 a atteint un temps de sortie par Token (TPOT) de 8,9 ms sur le modèle DeepSeek-R1, près du double du précédent SOTA, et prend en charge l’inférence de modèles de trillions de paramètres et la collaboration multi-agents en temps réel. Le Yuan Nao HC1000 a réduit le coût de sortie par million de Token à 1 yuan, et le coût par carte de 60 %. Ces avancées visent à résoudre les goulots d’étranglement de vitesse et de coût rencontrés par l’industrialisation des agents, en fournissant une infrastructure de puissance de calcul efficace et à faible coût pour le déploiement à grande échelle de la collaboration multi-agents et du raisonnement pour les tâches complexes. (Source : 量子位)

Nouvelle méthode de 3D Gaussian Splatting feed-forward : l’équipe de l’Université du Zhejiang propose le “voxel-aligned” : L’équipe de l’Université du Zhejiang a proposé VolSplat, un cadre de 3D Gaussian Splatting (3DGS) feed-forward “voxel-aligned”, visant à résoudre les problèmes de cohérence géométrique et de distribution de densité gaussienne des méthodes “pixel-aligned” existantes dans la reconstruction 3D multi-vues. VolSplat fusionne des informations 2D multi-vues dans l’espace 3D et utilise un 3D U-Net clairsemé pour affiner les caractéristiques, permettant une reconstruction 3D de meilleure qualité, plus robuste et plus efficace. Cette méthode surpasse plusieurs références sur les ensembles de données publics et démontre une forte capacité de généralisation zéro-shot sur des ensembles de données non vus. (Source : 量子位)

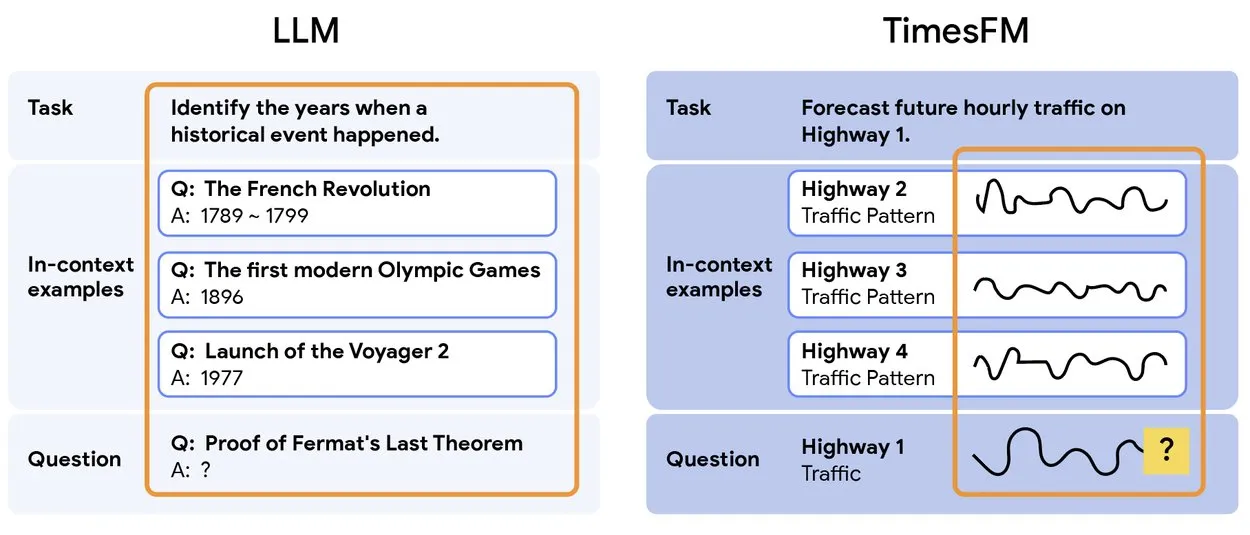
TimesFM 2.5 : Lancement du modèle de prédiction de séries temporelles pré-entraîné : TimesFM 2.5 a été lancé, un modèle pré-entraîné pour la prédiction de séries temporelles, avec un nombre de paramètres réduit de 500M à 200M, une longueur de contexte augmentée de 2K à 16K, et des performances exceptionnelles en mode zéro-shot. Ce modèle est désormais disponible sur Hugging Face sous licence Apache 2.0, offrant une solution plus efficace et plus puissante pour les tâches de prédiction de séries temporelles. (Source : Twitter)
Yunpeng Technology lance de nouveaux produits AI+santé, promouvant l’application de l’AI dans le domaine de la santé familiale : Yunpeng Technology, en collaboration avec Shuaikang et Skyworth, a lancé le “Laboratoire de cuisine du futur numérisé et intelligent” et un réfrigérateur intelligent équipé d’un grand modèle AI de santé. Le grand modèle AI de santé optimise la conception et le fonctionnement de la cuisine, tandis que le réfrigérateur intelligent offre une gestion personnalisée de la santé via l‘“assistant de santé Xiaoyun”. Ce lancement marque une percée de l’AI dans la gestion quotidienne de la santé, avec le potentiel de fournir des services de santé personnalisés via des appareils intelligents et d’améliorer le niveau technologique de la santé familiale. (Source : 36氪)
Alibaba lance le modèle de pensée open-source de 1 trillion de paramètres Ring-1T-preview : L’équipe Ant Ling d’Alibaba a lancé le premier modèle de pensée open-source de 1 trillion de paramètres, Ring-1T-preview, visant à réaliser une “réflexion profonde, sans attente”. Ce modèle a obtenu d’excellents résultats préliminaires dans les tâches de traitement du langage naturel, y compris les benchmarks AIME25, HMMT25, ARC-AGI-1, LCB et Codeforces. De plus, il a résolu le problème Q3 de l’IMO25 en une seule fois et a fourni des solutions partielles pour Q1/Q2/Q4/Q5, démontrant ses puissantes capacités de raisonnement et de résolution de problèmes. (Source : Twitter, Twitter, Twitter)

🧰 Outils
PopAi lance “Slide Agent”, l’AI génère des présentations en un clic : L’équipe PopAi a lancé l’outil “Slide Agent”, conçu pour simplifier le processus de création de présentations. Les utilisateurs n’ont qu’à saisir leurs besoins via un Prompt, choisir parmi plus de 300 modèles, et l’AI générera automatiquement un brouillon, ajustera la mise en page, les graphiques, les images, les logos, etc., puis le téléchargera sous forme de fichier .pptx modifiable. Cet outil intègre les fonctions de ChatGPT et Canva, réduisant considérablement le seuil et le temps de création de présentations. (Source : Twitter)
Alibaba open-source l’outil de conversion PDF vers Markdown Miner U2.5 : L’équipe Alibaba a open-sourcé l’outil de conversion PDF vers Markdown Miner U2.5, avec une démo disponible sur HuggingFace. Cet outil peut convertir efficacement des documents PDF au format Markdown, facilitant l’extraction, l’édition et la réutilisation de contenu pour les développeurs et les chercheurs qui traitent de grands volumes de documents PDF. C’est un outil d’assistance AI pratique. (Source : dotey)
VEED Animate 2.2 est en ligne, prenant en charge la refonte du style vidéo et l’échange de personnages : La version 2.2 de VEED Animate est officiellement en ligne, alimentée par la technologie WAN 2.2. Cet outil permet aux utilisateurs de remodeler facilement le style d’une vidéo à partir d’une seule image, d’échanger instantanément les personnages dans une vidéo, et de créer des clips vidéo 10 fois plus rapidement. Ces nouvelles fonctionnalités simplifient considérablement le processus de création vidéo, offrant aux créateurs de contenu davantage de possibilités créatives basées sur l’AI. (Source : TomLikesRobots)
LangChain s’engage à standardiser les réponses LLM, prenant en charge des fonctions complexes : LangChain, dans son développement v1, se concentre sur la standardisation des réponses LLM pour faire face aux fonctions LLM de plus en plus complexes, telles que les appels d’outils côté serveur, le raisonnement et les références. Le cadre vise à résoudre les problèmes d’incompatibilité des formats d’API entre différents fournisseurs de LLM, offrant une interface unifiée aux développeurs, simplifiant ainsi la construction d’agents multimodaux et de flux de travail complexes. (Source : LangChainAI, Twitter)
Hugging Face Transformers.js prend en charge l’exécution hors ligne de modèles AI dans le navigateur : La bibliothèque Transformers.js de Hugging Face permet aux utilisateurs d’exécuter des modèles AI hors ligne, tels que Llama 3.2, directement dans le navigateur en utilisant les technologies ONNX et WebGPU. Cela permet aux développeurs d’effectuer des tâches AI comme les chatbots, la détection d’objets et la suppression d’arrière-plan localement, sans dépendre des services cloud, améliorant ainsi la confidentialité des données et la vitesse de traitement. (Source : Twitter)
L’écosystème ToolUniverse aide les scientifiques AI à construire et à intégrer des outils : ToolUniverse est un écosystème conçu pour construire des scientifiques AI. Il standardise la manière dont les scientifiques AI identifient et appellent les outils, intégrant plus de 600 modèles de Machine Learning, ensembles de données, API et packages scientifiques pour l’analyse de données, la récupération de connaissances et la conception d’expériences. La plateforme optimise automatiquement les interfaces d’outils, crée de nouveaux outils à partir de descriptions en langage naturel et optimise de manière itérative les spécifications d’outils, combinant les outils en flux de travail d’agents, favorisant ainsi la collaboration des scientifiques AI dans le processus de découverte. (Source : HuggingFace Daily Papers)
Le cadre EasySteer améliore les performances et l’évolutivité de la manipulation des LLM : EasySteer est un cadre unifié basé sur vLLM, conçu pour améliorer les performances et l’évolutivité de la manipulation des LLM. Grâce à une architecture modulaire, des interfaces enfichables, un contrôle granulaire des paramètres et des vecteurs de manipulation précalculés, il permet une augmentation de la vitesse de 5,5 à 11,4 fois et réduit efficacement la sur-réflexion et les hallucinations. EasySteer transforme la manipulation des LLM d’une technique de recherche en une capacité de production, fournissant une infrastructure clé pour des modèles linguistiques déployables et contrôlables. (Source : HuggingFace Daily Papers)
VibeGame : Un moteur de jeu assisté par l’AI basé sur WebStack : VibeGame est un moteur de jeu déclaratif avancé basé sur three.js, rapier et bitecs, spécialement conçu pour le développement de jeux assisté par l’AI. Grâce à un niveau d’abstraction élevé, des fonctions de physique et de rendu intégrées, et une architecture Entité-Composant-Système (ECS), il permet à l’AI de comprendre et de générer du code de jeu plus efficacement. Bien qu’il soit actuellement principalement adapté aux jeux de plateforme simples, son code open-source et sa syntaxe conviviale pour l’AI offrent une solution prometteuse pour le développement de jeux pilotés par l’AI. (Source : HuggingFace Blog)
Outil de carte de recherche AI, intégrant 900 000 articles pour fournir des réponses avec citations : Un outil AI innovant regroupe sémantiquement et visualise 900 000 articles de recherche AI des dix dernières années, formant une carte de recherche détaillée. Les utilisateurs peuvent poser des questions à cet outil et obtenir des réponses avec des citations précises, ce qui simplifie considérablement le processus de recherche et de compréhension de la littérature académique massive pour les chercheurs, améliorant ainsi l’efficacité de la recherche. (Source : Reddit r/ArtificialInteligence)
Kroko ASR : Une alternative rapide et en streaming à Whisper : Kroko ASR est un nouveau modèle open-source de reconnaissance vocale (ASR) positionné comme une alternative rapide et en streaming à Whisper. Il présente une taille de modèle plus petite, une inférence CPU plus rapide (prenant en charge les appareils mobiles et les navigateurs), et presque aucune hallucination. Kroko ASR prend en charge plusieurs langues et vise à abaisser la barrière de l’AI vocale, la rendant plus facile à déployer et à entraîner sur les appareils périphériques. (Source : Reddit r/LocalLLaMA)
Problème de rendu des graphiques Plotly d’OpenWebUI, soulignant les défis d’intégration de l’UI des outils AI : La version v0.6.32 d’OpenWebUI rencontre un problème où les graphiques Plotly ne sont pas rendus correctement, affichant directement le JSON brut. Les utilisateurs signalent que le backend renvoie le JSON correct, mais que le frontend ne déclenche pas le rendu, ce qui reflète les défis techniques auxquels sont toujours confrontés les outils AI en matière d’intégration d’UI frontend et de rendu de texte enrichi, nécessitant une optimisation supplémentaire de la part de la communauté des développeurs. (Source : Reddit r/OpenWebUI)
📚 Apprentissage
Étude comparative des performances du LoRA fine-tuning et du full fine-tuning : La dernière recherche de Thinking Machines (équipe de John Schulman) montre qu’en apprentissage par renforcement, si le LoRA (Low-Rank Adaptation) est appliqué correctement, ses performances peuvent égaler celles du full fine-tuning, avec moins de ressources (environ 2/3 de la charge de calcul), et même exceller avec un rank=1. L’étude souligne que le LoRA devrait être appliqué à toutes les couches (y compris MLP/MoE) et utiliser un taux d’apprentissage 10 fois plus élevé que le full fine-tuning. Cette découverte abaisse considérablement le seuil d’entraînement de modèles RL haute performance, permettant à davantage de développeurs de réaliser des modèles de haute qualité sur un seul GPU. (Source : Reddit r/LocalLLaMA, Twitter, Twitter)
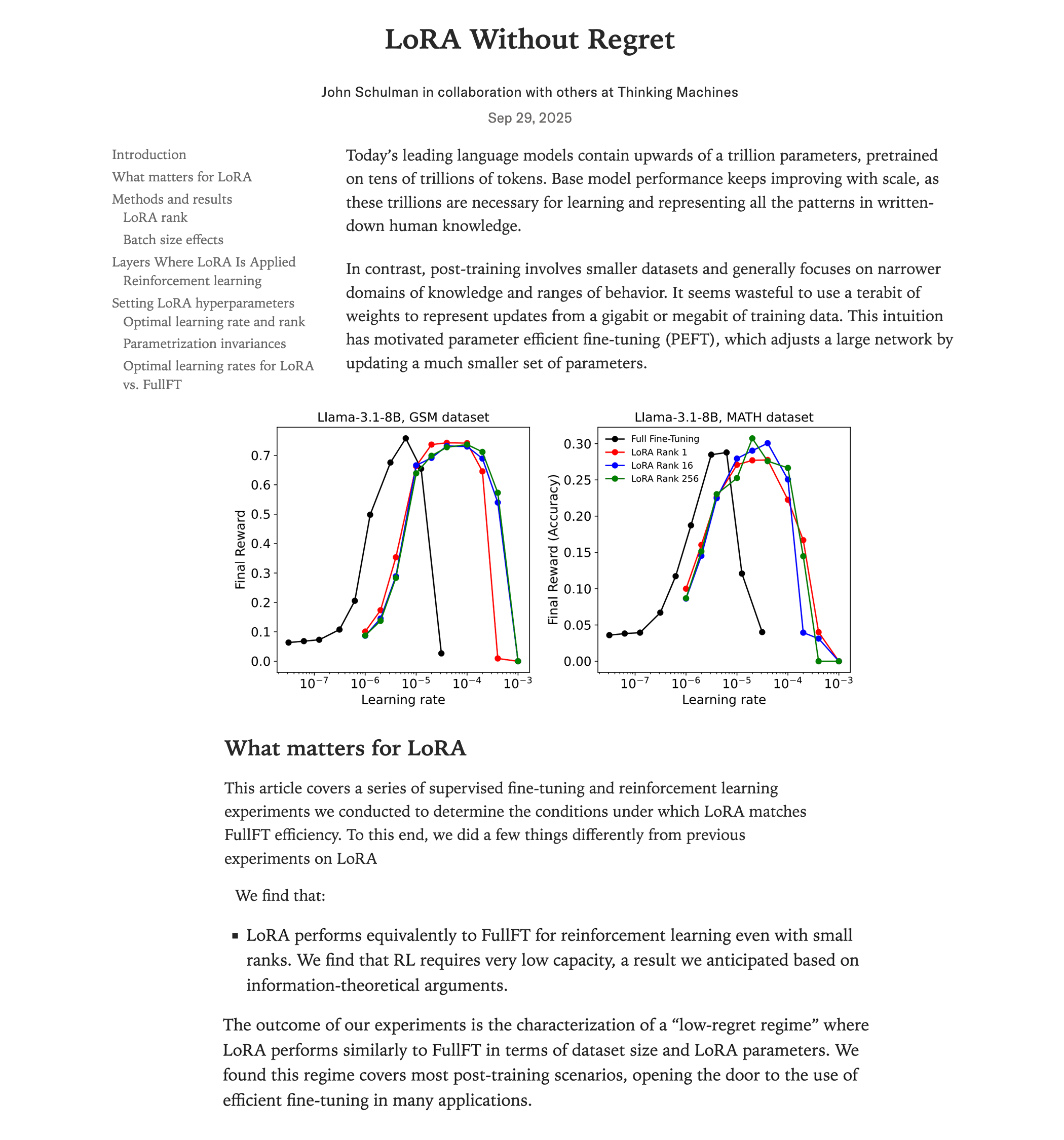
Anatomie des noyaux de multiplication matricielle haute performance des GPU NVIDIA : Un blog technique approfondi dissèque le mécanisme de mise en œuvre interne des noyaux de multiplication matricielle (matmul) haute performance des GPU NVIDIA. L’article couvre les bases de l’architecture GPU, la hiérarchie de la mémoire (GMEM, SMEM, L1/L2), la programmation PTX/SASS, et les fonctionnalités avancées de l’architecture Hopper (H100) telles que les instructions TMA et wgmma. Cette ressource vise à aider les développeurs à comprendre en profondeur la programmation CUDA et l’optimisation des performances GPU, ce qui est crucial pour l’entraînement et l’inférence des modèles Transformer. (Source : Reddit r/deeplearning, Twitter)
Les conférences du cours de vision par ordinateur et d’apprentissage profond CS231N de Stanford sont en ligne sur YouTube : Les conférences du cours très apprécié CS231N (Deep Learning for Computer Vision) de l’Université de Stanford sont désormais disponibles gratuitement sur YouTube. Cela offre aux apprenants du monde entier une précieuse opportunité d’accéder à des ressources éducatives AI de haute qualité, couvrant les connaissances de l’apprentissage profond en vision par ordinateur, des concepts fondamentaux aux applications de pointe. (Source : Reddit r/deeplearning)

RL-ZVP : Améliorer les capacités de raisonnement par apprentissage par renforcement des LLM avec des Zero-Variance Prompts : Une étude récente propose la méthode “RL with Zero-Variance Prompts (RL-ZVP)”, visant à améliorer les capacités de raisonnement par apprentissage par renforcement des grands modèles linguistiques (LLM). Cette méthode ne néglige plus les “Zero-Variance Prompts” (c’est-à-dire les situations où toutes les réponses du modèle reçoivent la même récompense), mais en extrait des signaux d’apprentissage précieux, récompensant directement la justesse et pénalisant les erreurs, et utilisant l’entropie au niveau du Token pour guider la formation des avantages. Les résultats expérimentaux montrent que RL-ZVP améliore significativement la précision et le taux de réussite sur les benchmarks de raisonnement mathématique par rapport aux méthodes traditionnelles. (Source : Reddit r/MachineLearning)
Apprentissage guidé par le futur : une approche prédictive pour améliorer la prévision des séries temporelles : Une étude propose le “Future-Guided Learning”, une méthode qui améliore la prédiction d’événements de séries temporelles grâce à un mécanisme de rétroaction dynamique. Cette méthode comprend un modèle de détection qui analyse les données futures et un modèle de prédiction qui fait des prévisions basées sur les données actuelles. Lorsque le modèle de prédiction diffère du modèle de détection, le modèle de prédiction est mis à jour de manière plus significative pour minimiser la “surprise”, ajustant ainsi dynamiquement les paramètres et améliorant efficacement la précision de la prédiction des séries temporelles. (Source : Reddit r/MachineLearning)
L’avenir de l’AI est dans les basses dimensions : Yann Lecun sur l’apprentissage des représentations abstraites : Le pionnier de l’AI Yann Lecun, lors d’une interview avec Lex Fridman, a suggéré que le prochain bond en avant de l’AI viendra de l’apprentissage dans des espaces latents de faible dimension, plutôt que de traiter directement des données brutes de haute dimension comme les pixels. Il estime que les véritables systèmes intelligents doivent apprendre les représentations abstraites des structures causales et des dynamiques physiques du monde, afin de pouvoir faire des prédictions précises même lorsque les détails changent. Cette approche rendra les modèles plus flexibles, robustes, réduira la dépendance aux données massives et diminuera les coûts de calcul. (Source : Reddit r/ArtificialInteligence)
SIRI : Mise à l’échelle de l’apprentissage par renforcement itératif avec compression entrelacée : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) est une méthode d’apprentissage par renforcement simple et efficace qui ajuste dynamiquement la longueur maximale du rollout pendant l’entraînement en compressant et en étendant itérativement le budget d’inférence. Ce mécanisme d’entraînement force le modèle à prendre des décisions précises dans un contexte limité, réduisant les Tokens redondants, tout en offrant un espace d’exploration et de planification, améliorant ainsi régulièrement l’efficacité et la précision des grands modèles d’inférence dans le compromis performance-efficacité. (Source : HuggingFace Daily Papers)
Modèle génératif multi-agents MultiCrafter : attention spatialement découplée et apprentissage par renforcement sensible à l’identité : MultiCrafter est un cadre visant à réaliser une génération d’images multi-agents de haute fidélité et alignée sur les préférences. Il introduit une supervision de position explicite pour séparer les régions d’attention entre différents agents, atténuant efficacement le problème de fuite d’attributs. Parallèlement, le cadre adopte une architecture Mixture of Experts (MoE) pour améliorer la capacité du modèle et conçoit un nouveau cadre d’apprentissage par renforcement en ligne, combinant un mécanisme de notation et des stratégies d’entraînement stables, garantissant que la fidélité des agents dans les images générées est hautement cohérente avec les préférences esthétiques humaines. (Source : HuggingFace Daily Papers)
Visual Jigsaw : Améliorer la compréhension visuelle des MLLM par post-entraînement auto-supervisé : Visual Jigsaw est un cadre général de post-entraînement auto-supervisé conçu pour améliorer les capacités de compréhension visuelle des grands modèles linguistiques multimodaux (MLLM). Cette méthode partitionne et mélange les entrées visuelles, puis demande au modèle de reconstruire l’ordre correct des permutations via le langage naturel. Cette approche basée sur l’apprentissage par renforcement avec récompenses vérifiables (RLVR) améliore significativement les performances des MLLM en matière de perception fine, de raisonnement temporel et de compréhension spatiale 3D, sans nécessiter de composants de génération visuelle supplémentaires ni d’annotations manuelles. (Source : HuggingFace Daily Papers)
MGM-Omni : Étendre les Omni LLM à la génération vocale personnalisée de longue durée : MGM-Omni est un Omni LLM unifié qui, grâce à son architecture de tokenisation à double voie unique “cerveau-bouche”, réalise une compréhension multimodale et une génération vocale expressive de longue durée. Cette conception découple le raisonnement multimodal de la génération vocale en temps réel, prenant en charge une interaction intermodale efficace et un clonage vocal en streaming à faible latence, et démontre une excellente efficacité des données. Les expériences prouvent que MGM-Omni surpasse les modèles open-source existants en termes de cohérence du timbre, de génération de voix naturelles sensibles au contexte, et de compréhension audio et multimodale de longue durée. (Source : HuggingFace Daily Papers)
SID : Apprentissage de la navigation linguistique orientée objectif par démonstrations auto-améliorées : SID (Self-Improving Demonstrations) est une méthode d’apprentissage de la navigation linguistique orientée objectif qui améliore significativement les capacités d’exploration et de généralisation des agents de navigation dans des environnements inconnus grâce à des démonstrations auto-améliorées itératives. Cette méthode utilise d’abord des données de chemin le plus court pour entraîner un agent initial, puis cet agent génère de nouvelles trajectoires d’exploration, qui fournissent des stratégies d’exploration plus fortes pour entraîner de meilleurs agents, permettant ainsi une amélioration continue des performances. Les expériences montrent que SID atteint des performances SOTA sur des tâches comme REVERIE et SOON, avec un taux de réussite de 50,9 % sur l’ensemble de validation non vu de SOON, dépassant les méthodes précédentes de 13,9 %. (Source : HuggingFace Daily Papers)
LOVE-R1 : Améliorer la compréhension des vidéos longues grâce à un mécanisme de mise à l’échelle adaptatif : Le modèle LOVE-R1 vise à résoudre le conflit entre la compréhension temporelle longue et la perception spatiale détaillée dans la compréhension des vidéos longues. Ce modèle introduit un mécanisme de mise à l’échelle adaptatif, échantillonnant d’abord des images à basse résolution de manière dense. Lorsque des détails spatiaux sont nécessaires, le modèle peut mettre à l’échelle les segments vidéo d’intérêt à haute résolution en fonction de l’inférence, jusqu’à obtenir les informations visuelles clés. L’ensemble du processus est réalisé par un raisonnement en plusieurs étapes, combiné à un fine-tuning des données CoT et à un fine-tuning par renforcement découplé, ce qui améliore significativement les performances sur les benchmarks de compréhension des vidéos longues. (Source : HuggingFace Daily Papers)
Euclid’s Gift : Améliorer le raisonnement spatial des modèles visuels linguistiques par des tâches d’agent géométrique : Euclid’s Gift est une recherche visant à améliorer les capacités de perception et de raisonnement spatial des modèles visuels linguistiques (VLM) par des tâches d’agent géométrique. Ce projet a construit un ensemble de données multimodal Euclid30K contenant 30 000 problèmes de géométrie plane et solide, et a utilisé Group Relative Policy Optimization (GRPO) pour fine-tuner les modèles des séries Qwen2.5VL et RoboBrain2.0. Les expériences ont prouvé que les modèles entraînés ont obtenu des améliorations significatives en zéro-shot sur quatre benchmarks de raisonnement spatial, y compris Super-CLEVR et Omni3DBench, avec RoboBrain2.0-Euclid-7B atteignant une précision de 49,6 %, surpassant les modèles SOTA précédents. (Source : HuggingFace Daily Papers)
SphereAR : Améliorer la génération auto-régressive de Token continus via un espace latent hypersphérique : SphereAR vise à résoudre les problèmes causés par la variance hétérogène de l’espace latent VAE dans les modèles de génération d’images auto-régressifs (AR) de Token continus. La conception centrale consiste à contraindre toutes les entrées et sorties AR (y compris après CFG) sur une hypersphère de rayon fixe, en utilisant un VAE hypersphérique. L’analyse théorique montre que la contrainte hypersphérique élimine la principale cause de l’effondrement de la variance, stabilisant ainsi le décodage AR. Les expériences prouvent que SphereAR atteint des performances SOTA sur les tâches de génération ImageNet, surpassant les modèles de diffusion et les modèles génératifs masqués de taille de paramètres équivalente. (Source : HuggingFace Daily Papers)
AceSearcher : Guider le raisonnement et la recherche des LLM par auto-jeu renforcé : AceSearcher est un cadre d’auto-jeu coopératif conçu pour améliorer la capacité de recherche augmentée des LLM dans les tâches de raisonnement complexes. Ce cadre entraîne un seul LLM à alterner entre la décomposition de requêtes complexes et l’intégration de contextes récupérés, optimisant la précision de la réponse finale par fine-tuning supervisé et fine-tuning par renforcement, sans annotation intermédiaire. Les expériences montrent qu’AceSearcher surpasse significativement les références SOTA dans plusieurs tâches intensives en raisonnement. Dans une tâche de raisonnement financier au niveau du document, AceSearcher-32B a égalé les performances de DeepSeek-V3 avec moins de 5 % des paramètres. (Source : HuggingFace Daily Papers)
SparseD : Mécanisme d’attention clairsemée pour les modèles linguistiques de diffusion : SparseD est une méthode d’attention clairsemée pour les modèles linguistiques de diffusion (DLM), visant à résoudre le goulot d’étranglement de la complexité quadratique du calcul de l’attention pour les longues longueurs de contexte. Cette méthode précalcule des motifs clairsemés spécifiques à la tête et les réutilise à toutes les étapes de dénoising, tout en utilisant une attention complète aux premières étapes de dénoising, puis en passant à l’attention clairsemée, réalisant ainsi une accélération sans perte. Les résultats expérimentaux montrent que SparseD peut atteindre une accélération allant jusqu’à 1,5 fois par rapport à FlashAttention pour une longueur de contexte de 64k, améliorant efficacement l’efficacité de l’inférence des DLM dans les applications à long contexte. (Source : HuggingFace Daily Papers)
SLA : Accélérer les Diffusion Transformer via une attention linéaire clairsemée entraînable : SLA (Sparse-Linear Attention) est une méthode d’attention entraînable conçue pour accélérer les modèles Diffusion Transformer (DiT), en particulier le calcul de l’attention dans la génération vidéo. Cette méthode divise les poids d’attention en trois catégories : clés, bords et négligeables, appliquant respectivement une attention O(N²) et O(N), et ignorant les parties négligeables. SLA fusionne ces calculs dans un seul noyau GPU et, après quelques étapes de fine-tuning, réduit de 20 fois le calcul de l’attention dans les modèles DiT, et accélère de 2,2 fois de bout en bout la génération vidéo, sans perte de qualité de génération. (Source : HuggingFace Daily Papers)
OpenGPT-4o-Image : Ensemble de données complet pour la génération et l’édition d’images avancées : OpenGPT-4o-Image est un ensemble de données à grande échelle construit en combinant une classification hiérarchique des tâches et une méthode de génération de données automatisée par GPT-4o, visant à améliorer les performances des modèles multimodaux unifiés en matière de génération et d’édition d’images. Cet ensemble de données contient 80 000 paires instruction-image de haute qualité, couvrant 11 domaines principaux et 51 sous-tâches, y compris le rendu de texte, le contrôle de style, les images scientifiques et l’édition d’instructions complexes. Les modèles fine-tunés sur OpenGPT-4o-Image ont obtenu des améliorations significatives des performances sur plusieurs benchmarks, prouvant le rôle clé de la construction systématique de données pour faire progresser les capacités de l’AI multimodale. (Source : HuggingFace Daily Papers)
SANA-Video : Un petit modèle de diffusion pour générer efficacement des vidéos de 720p de plusieurs minutes : SANA-Video est un petit modèle de diffusion capable de générer efficacement des vidéos d’une résolution allant jusqu’à 720×1280 et d’une durée de plusieurs minutes. Il utilise une architecture DiT linéaire et un cache KV à mémoire constante pour la génération de vidéos haute résolution, de haute qualité et de longue durée, tout en maintenant une forte alignement texte-vidéo. Le coût d’entraînement de SANA-Video n’est que de 1 % de celui de MovieGen, et lorsqu’il est déployé sur un GPU RTX 5090, la vitesse d’inférence pour générer une vidéo 720p de 5 secondes est de 29 secondes, permettant une génération vidéo de haute qualité à faible coût. (Source : HuggingFace Daily Papers)
AdvChain : Améliorer l’alignement de sécurité des grands modèles de raisonnement par réglage CoT adversarial : AdvChain est un nouveau paradigme d’alignement qui enseigne aux grands modèles de raisonnement (LRM) des capacités d’auto-correction dynamique par un réglage Chain-of-Thought (CoT) adversarial. Cette méthode construit un ensemble de données contenant des échantillons de “tentation-correction” et “hésitation-correction”, permettant au modèle d’apprendre à se remettre des dérives de raisonnement nuisibles et de la prudence inutile. Les expériences montrent qu’AdvChain améliore significativement la robustesse du modèle aux attaques de jailbreak et au détournement de CoT, tout en réduisant considérablement le rejet excessif des Prompts bénins, réalisant un équilibre sécurité-utilité exceptionnel. (Source : HuggingFace Daily Papers)
SDLM : Mise à l’échelle de l’apprentissage par renforcement itératif avec compression entrelacée : Le Sequential Diffusion Language Model (SDLM) propose une méthode unifiée de prédiction next-token et next-block, permettant au modèle de déterminer de manière adaptative la longueur de génération à chaque étape. SDLM peut transformer des modèles linguistiques auto-régressifs pré-entraînés à un coût minimal, et effectuer une inférence de diffusion dans des blocs masqués de taille fixe, tout en décodant dynamiquement des sous-séquences continues. Les expériences montrent que SDLM, tout en égalant ou surpassant les solides références auto-régressives, atteint un débit plus élevé, démontrant son puissant potentiel d’évolutivité. (Source : HuggingFace Daily Papers)
Insight-to-Solve (I2S) : Transformer les démonstrations In-Context de raisonnement en actifs de LM de raisonnement : Insight-to-Solve (I2S) est un programme de temps de test conçu pour transformer des démonstrations In-Context de raisonnement de haute qualité en actifs efficaces pour les grands modèles de raisonnement (RLM). La recherche a montré que l’ajout direct d’exemples de démonstration peut réduire la précision des RLM. I2S transforme les démonstrations en informations explicitement réutilisables et génère des trajectoires de raisonnement spécifiques à l’objectif, avec un auto-raffinement facultatif pour améliorer la cohérence et la justesse. Les expériences montrent que I2S et I2S+ surpassent constamment les bases de référence de réponse directe et de mise à l’échelle au moment du test sur divers benchmarks, apportant même des améliorations significatives aux modèles GPT. (Source : HuggingFace Daily Papers)
UniMIC : Codage interactif multimodal basé sur des Token pour la collaboration homme-machine : UniMIC (Unified token-based Multimodal Interactive Coding) est un cadre visant à réaliser une interaction multimodale efficace et à faible débit binaire entre les appareils périphériques et les agents AI cloud via des représentations basées sur des Token. UniMIC utilise une représentation tokenisée compacte comme support de communication et combine un modèle d’entropie Transformer pour réduire efficacement la redondance entre les Tokens. Les expériences prouvent qu’UniMIC réalise des économies significatives de débit binaire dans des tâches telles que la génération texte-image, la réparation d’images et la question-réponse visuelle, et maintient sa robustesse à des débits binaires ultra-faibles, offrant un paradigme pratique pour la prochaine génération de communication interactive multimodale. (Source : HuggingFace Daily Papers)
RLBFF : Le retour binaire flexible relie le feedback humain aux récompenses vérifiables : RLBFF (Reinforcement Learning with Binary Flexible Feedback) est un paradigme d’apprentissage par renforcement qui combine la diversité des préférences humaines avec la précision de la vérification des règles. Il extrait des principes binarisables du feedback en langage naturel (par exemple, précision de l’information : oui/non, lisibilité du code : oui/non) et les utilise pour entraîner un modèle de récompense. RLBFF excelle sur RM-Bench et JudgeBench, et permet aux utilisateurs de personnaliser le focus des principes lors de l’inférence. De plus, il offre une solution entièrement open-source pour aligner Qwen3-32B avec RLBFF, lui permettant d’égaler ou de surpasser les performances d’o3-mini et DeepSeek R1 sur les benchmarks d’alignement généraux. (Source : HuggingFace Daily Papers)
MetaAPO : Optimisation de l’alignement par échantillonnage en ligne méta-pondéré adaptatif : MetaAPO (Meta-Weighted Adaptive Preference Optimization) est un nouveau cadre qui optimise l’alignement des grands modèles linguistiques (LLM) avec les préférences humaines en couplant dynamiquement la génération de données et l’entraînement du modèle. MetaAPO utilise un méta-apprenant léger comme “estimateur d’écart d’alignement” pour évaluer les gains potentiels de l’échantillonnage en ligne par rapport aux données hors ligne, guidant la génération d’objectifs en ligne et attribuant des méta-poids au niveau des échantillons, équilibrant dynamiquement la qualité et la distribution des données en ligne et hors ligne. Les expériences montrent que MetaAPO surpasse constamment les méthodes d’optimisation des préférences existantes sur AlpacaEval 2, Arena-Hard et MT-Bench, tout en réduisant les coûts d’annotation en ligne de 42 %. (Source : HuggingFace Daily Papers)
Tool-Light : Raisonnement efficace avec intégration d’outils grâce à l’apprentissage des préférences par auto-évolution : Tool-Light est un cadre conçu pour encourager les grands modèles linguistiques (LLM) à exécuter efficacement et précisément les tâches de raisonnement avec intégration d’outils (TIR). La recherche a montré que les résultats des appels d’outils peuvent entraîner des changements significatifs dans l’entropie de l’information du raisonnement ultérieur. Tool-Light est mis en œuvre en combinant la construction d’ensembles de données et le fine-tuning multi-étapes, où la construction d’ensembles de données utilise un échantillonnage continu par auto-évolution, intégrant l’échantillonnage vanilla et l’échantillonnage guidé par l’entropie, et établit des critères stricts de sélection de paires positives et négatives. Le processus d’entraînement comprend le SFT et l’optimisation directe des préférences par auto-évolution (DPO). Les expériences prouvent que Tool-Light améliore significativement l’efficacité des modèles à exécuter les tâches TIR. (Source : HuggingFace Daily Papers)
ChatInject : Attaques par injection de Prompt sur les agents LLM utilisant des modèles de chat : ChatInject est une méthode d’attaque par injection de Prompt indirecte qui exploite la dépendance des LLM aux modèles de chat structurés et la manipulation contextuelle des conversations multi-tours. L’attaquant formate une charge utile malveillante en imitant le format des modèles de chat natifs, incitant l’agent à effectuer des opérations suspectes. Les expériences montrent que ChatInject a un taux de réussite d’attaque plus élevé que les méthodes traditionnelles d’injection de Prompt, en particulier dans les conversations multi-tours, et est hautement transférable à différents modèles, tandis que les mesures de défense basées sur les Prompts existantes sont pour la plupart inefficaces contre de telles attaques. (Source : HuggingFace Daily Papers)
💼 Affaires
Modal clôture un financement de série B de 87 millions de dollars, valorisée à 1,1 milliard de dollars : Modal, une entreprise d’infrastructure AI, a annoncé avoir clôturé un financement de série B de 87 millions de dollars, portant sa valorisation à 1,1 milliard de dollars. Ce cycle de financement vise à accélérer l’innovation et le développement de l’infrastructure AI pour relever les défis auxquels sont confrontées les infrastructures de calcul traditionnelles à l’ère de l’AI. Modal aide les chercheurs et les développeurs à optimiser leurs processus d’entraînement et de déploiement de modèles AI en fournissant des services de calcul cloud efficaces. (Source : Twitter, Twitter, Twitter)
OpenAI : 4,3 milliards de dollars de revenus et 13,5 milliards de dollars de pertes au premier semestre, face à des défis de rentabilité : OpenAI a annoncé des revenus de 4,3 milliards de dollars au premier semestre 2025, avec des revenus annuels prévus de plus de 13 milliards de dollars, principalement grâce aux abonnements ChatGPT Plus et aux services API d’entreprise. Cependant, la perte nette au cours de la même période a atteint 13,5 milliards de dollars, les coûts structurels et les investissements en R&D (tels que GPT-5) étant les principaux facteurs, avec des frais de location de serveurs annuels s’élevant à 16 milliards de dollars. Bien qu’OpenAI dispose de 17,5 milliards de dollars de réserves de trésorerie et poursuive un plan de financement de 30 milliards de dollars, la consommation continue de trésorerie et l’écart d’efficacité avec des concurrents comme Anthropic lui posent de sérieux défis de rentabilité. (Source : 36氪)
Guerre des capitaux dans le secteur des robots humanoïdes : Zhiyuan, Yinhe Tongyong et d’autres déploient activement la chaîne industrielle : Le secteur des robots humanoïdes est entré dans une phase de guerre des capitaux, avec des entreprises leaders comme Zhiyuan Robot et Yinhe Tongyong qui étendent activement leur “cercle d’amis” par la création de fonds, la participation au capital de pairs et des partenariats stratégiques. Zhiyuan Robot a déjà investi dans près de 20 entreprises, couvrant les moteurs, les capteurs et les applications en aval, et a collaboré avec Fulin Precision et iSoftStone pour mettre en œuvre des scénarios commerciaux. Yinhe Tongyong, quant à elle, a créé une coentreprise avec Bosch China pour promouvoir l’application de l’intelligence incarnée dans l’industrie automobile. Ces initiatives visent à obtenir des commandes, à combler les lacunes et à établir un réseau de chaîne d’approvisionnement stable pour les livraisons de masse futures, mais les voies technologiques de l’industrie sont très diverses et la concurrence est féroce. (Source : 36氪)

🌟 Communauté
La difficulté à distinguer le contenu généré par l’AI de la réalité provoque une crise de confiance sociale : Avec le développement rapide de la technologie AI, le réalisme des vidéos générées par l’AI (telles que le film live-action “Attack on Titan” et l’animatrice indonésienne “changeant de visage” avec une influenceuse japonaise) a atteint un niveau incroyable, suscitant de profondes inquiétudes sociales quant à l’authenticité du contenu. Sur les réseaux sociaux, les utilisateurs déclarent qu’il est de plus en plus difficile de distinguer le contenu réel du contenu généré par l’AI, ce qui non seulement nuit à la crédibilité des créateurs de contenu légitimes, mais peut également être utilisé pour diffuser de fausses informations. Les experts soulignent qu’à moins d’un étiquetage obligatoire du contenu AI, ce “moteur hyperréaliste” continuera d’éroder le sens de la réalité, et pourrait finalement “mettre fin à Internet”. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

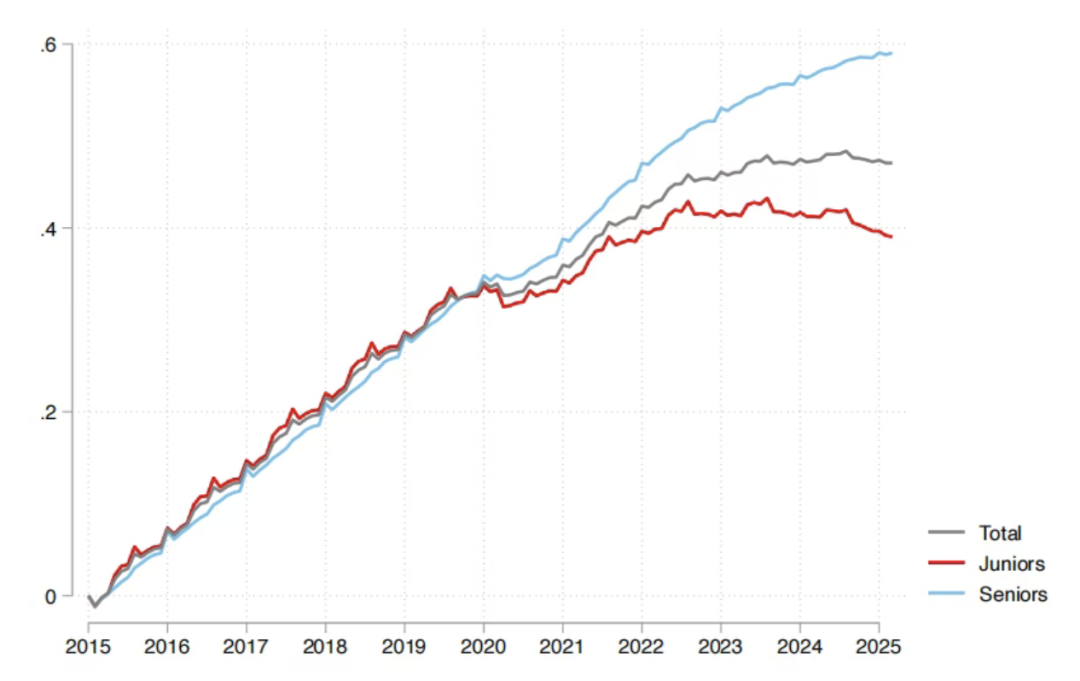
Impact de l’AI sur le marché de l’emploi : le rapport de Sequoia indique que 95 % des investissements AI sont inefficaces, les diplômés sont les plus touchés : Sequoia Capital a partagé un rapport de recherche du MIT et de Harvard, indiquant que 95 % des investissements AI des entreprises n’ont pas généré de valeur réelle, la véritable amélioration de la productivité provenant de l‘“économie de l’AI de l’ombre” formée par les employés utilisant “secrètement” des outils AI personnels. Le rapport révèle également que l’impact de l’AI sur le marché de l’emploi se concentre principalement sur les jeunes diplômés, en particulier dans le commerce de gros et de détail, où le nombre de recrutements pour les postes de débutants a considérablement diminué, et les diplômes des universités prestigieuses ne sont pas une protection totale. Cela montre que l’AI modifie la répartition des tâches, la valeur humaine se tournant vers l’expérience et le jugement unique. (Source : 36氪, Reddit r/ArtificialInteligence)
Les ajustements de modèle d’OpenAI suscitent un fort mécontentement des utilisateurs, appelant à une communication transparente : OpenAI a récemment “déclassé” sans préavis les modèles GPT-4o/GPT-5 vers des versions à faible puissance de calcul, entraînant une baisse des performances du modèle et un fort mécontentement des utilisateurs. De nombreux utilisateurs se plaignent que le modèle est devenu “plus stupide”, ayant perdu son intelligence et son expérience de communication “amicale” d’origine, certains allant même jusqu’à parler de “choc psychologique”. Les dirigeants d’OpenAI ont répondu qu’il s’agissait d’un “test de routage de sécurité” visant à traiter les sujets sensibles, mais les utilisateurs appellent généralement OpenAI à renforcer la communication et la transparence avec eux, à éviter de modifier unilatéralement les accords de produit, afin de rétablir la confiance des utilisateurs. (Source : Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Taxation des robots : Discussion sur le progrès technologique et l’équité sociale : Avec le développement de l’AI et de la robotique, la discussion sur la “taxation” des robots s’intensifie, visant à équilibrer les problèmes d’emploi et les inégalités sociales que le remplacement de la main-d’œuvre humaine par les robots pourrait entraîner. Les partisans estiment qu’une taxe sur les robots pourrait fournir des prestations sociales et un soutien à la réinsertion professionnelle pour les chômeurs, et corriger le déséquilibre de pouvoir de négociation entre le capital et le travail. Cependant, les professionnels de l’industrie robotique estiment généralement qu’il est trop tôt pour imposer une taxe, ce qui pourrait entraver le développement des industries émergentes. La Corée du Sud a déjà indirectement augmenté le coût d’utilisation des robots en réduisant les incitations fiscales pour les entreprises d’automatisation. (Source : 36氪)
L’avenir des robots humanoïdes : le célèbre expert en robotique Rodney Brooks estime que l’avenir ne ressemblera pas à l’homme : Le célèbre expert en robotique Rodney Brooks a écrit un article soulignant que, malgré des investissements massifs, les robots humanoïdes actuels ne peuvent toujours pas atteindre la dextérité humaine, et que la marche bipède présente des risques de sécurité. Il prédit que dans les 15 prochaines années, les robots humanoïdes n’imiteront plus la forme humaine, mais évolueront vers des robots spécialisés à roues, multi-bras (équipés de pinces ou de ventouses), et multi-capteurs (imagerie optique active, perception non visible), pour s’adapter à des tâches spécifiques. Il estime que la poursuite actuelle de la forme “humanoïde” représente un investissement énorme mais sera finalement vaine. (Source : 36氪)

Qualité de la génération de code AI et controverse sur l’expérience développeur : Sur les réseaux sociaux, les développeurs débattent de la qualité et de l’utilité du code généré par l’AI. Certains louent Claude Sonnet 4.5 pour sa capacité à refactoriser des bases de code entières, mais le code généré ne fonctionne pas ; d’autres se plaignent que le code généré par l’AI “ne compile pas”, ce qui réduit l’efficacité du développement. Ces discussions reflètent les défis persistants entre l’efficacité et la précision de la programmation assistée par l’AI, ainsi que le besoin des développeurs de déboguer et de vérifier les résultats générés par l’AI. (Source : Twitter, Twitter, Twitter)

Changement de la vision des talents à l’ère de l’AI : de la “chasse aux têtes” à la “culture des récoltes” : Sur les réseaux sociaux, la discussion est animée sur la nécessité de passer d’une vision traditionnelle de “chasse aux têtes” à une “culture des récoltes” en matière de talents à l’ère de l’AI. Compte tenu de la rareté des talents dans le domaine de l’AI et de l’itération rapide des technologies, les entreprises devraient se concentrer davantage sur la formation d’employés possédant des compétences techniques fondamentales, plutôt que de rechercher aveuglément des talents “finis” coûteux sur le marché. Ce point de vue souligne l’importance de l’apprentissage continu et du développement interne pour s’adapter aux besoins en évolution rapide du secteur de l’AI. (Source : dotey)
Consommation d’énergie de l’infrastructure AI et besoins énergétiques de Sam Altman : Sam Altman a déclaré que le développement de l’AI nécessiterait 250 GW d’électricité, suscitant des inquiétudes et des discussions sur l’énorme consommation d’énergie de l’infrastructure AI. Cette demande dépasse largement les capacités d’approvisionnement énergétique existantes, ce qui pousse à réfléchir à la manière d’équilibrer le développement rapide de l’AI et l’approvisionnement en énergie durable. Les discussions connexes portent également sur les problèmes environnementaux liés à la fabrication de semi-conducteurs, tels que l’utilisation des PFAS et les risques potentiels des solutions de remplacement. (Source : Twitter, Twitter)

Apocalypse AI et optimistes : Inquiétudes et réfutations : Sur les réseaux sociaux, il y a une large discussion sur l‘“apocalypse AI” et les risques potentiels de l’AI, mais beaucoup pensent également que ces préoccupations sont exagérées. Les optimistes estiment que les problèmes réels posés par l’AI (tels que l’impact climatique, l’exploitation par les entreprises, la surveillance militaire) sont plus urgents que la lointaine “destruction de l’humanité par une super-intelligence”, et qu’il faut se concentrer sur les défis résolubles du présent. Certains considèrent l’apocalypse AI comme une “absurdité”, une manifestation de paresse et d’instabilité, tandis que d’autres croient que l’AI finira par évoluer vers la création et la cultivation. (Source : Reddit r/ArtificialInteligence, Twitter, Twitter)
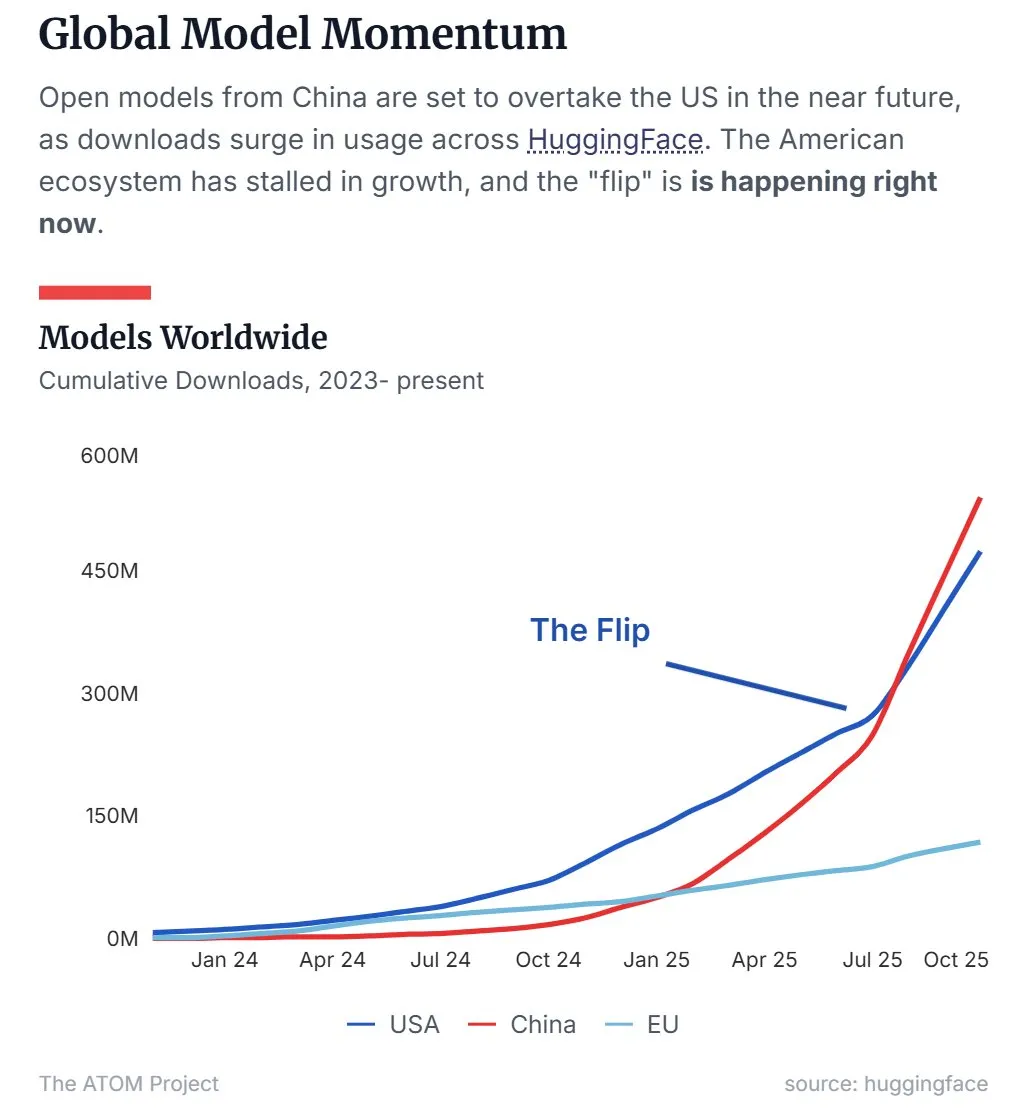
La part de marché des LLM open-source chinois dépasse celle des États-Unis : Les dernières données montrent que les grands modèles linguistiques (LLM) open-source chinois, représentés par Qwen, ont dépassé les États-Unis en termes de part de marché, devenant la force dominante dans le domaine des LLM open-source. Cette tendance indique que la Chine est en train de monter en puissance dans la recherche et le développement de technologies AI open-source et leur application, ce qui a un impact important sur le paysage mondial de l’AI. (Source : Twitter, Twitter)
Une équipe de 45 jours produit la série animée AI “Tomorrow is Monday” avec des dizaines de millions de vues : Une équipe de seulement 10 personnes a réalisé la production de 50 épisodes de la série animée AI “Tomorrow is Monday” en 45 jours. Sans aucun investissement publicitaire, le nombre total de vues sur l’ensemble du réseau a dépassé les dix millions, et les revenus payants sur Douyin ont déjà couvert tous les coûts. Ce projet adopte le concept central “personnages originaux + génération par l’AI”, résolvant le problème de la propriété des droits d’auteur du contenu AI et explorant une voie de développement commercial de toutes les catégories d’IP. Le processus de production est hautement spécialisé, avec une collaboration étroite entre les artistes originaux, les ingénieurs, les monteurs et les réalisateurs, démontrant l’énorme potentiel de la technologie AI pour réduire les coûts et améliorer l’efficacité de la production de contenu. (Source : 36氪)

💡 Autres
Questionnaire sur les besoins d’alignement précis texte-audio : Un utilisateur des réseaux sociaux a manifesté un vif intérêt pour la technologie d’alignement précis texte-audio et a publié un questionnaire de besoins, visant à recueillir les exigences spécifiques des utilisateurs concernant les fonctionnalités et les scénarios d’application de cette technologie, dans l’espoir de promouvoir le développement et l’optimisation des technologies connexes. (Source : dotey)
DeepMind présente la démo Nano Banana : Google DeepMind a présenté une démo nommée “Nano Banana”, suscitant l’attention sur les réseaux sociaux. Bien que les détails spécifiques n’aient pas été entièrement divulgués, cela pourrait être lié à la génération vidéo AI ou à la technologie AI multimodale, suggérant de nouvelles avancées de DeepMind dans le domaine de l’AI visuelle. (Source : GoogleDeepMind)
Discussion académique sur la priorité d’invention de Highway Net et ResNet : Le célèbre chercheur en AI Jürgen Schmidhuber a retweeté un message, relançant la discussion académique sur la priorité d’invention de Highway Net et ResNet dans l’apprentissage résiduel profond. Il a souligné que l’affirmation de Microsoft dans son article sur ResNet, selon laquelle Highway Net était un travail “contemporain”, était inexacte, et a insisté sur le fait que Highway Net avait été publié sept mois avant ResNet et avait déjà identifié et proposé des solutions de connexions résiduelles. (Source : SchmidhuberAI)