
Mots-clés:GPT-5, Calcul quantique, Conception de matériaux par IA, Apprentissage par renforcement, Grands modèles de langage, Infrastructure d’IA, Modèles multimodaux, Agent IA, Problème NP quantique, Réseau de neurones graphiques cristallins CGformer, Cadre d’apprentissage par renforcement RLMT, Attention clairsemée DeepSeek DSA, Cadre unifié pour les tâches visuelles UniVid
🔥 Actualités
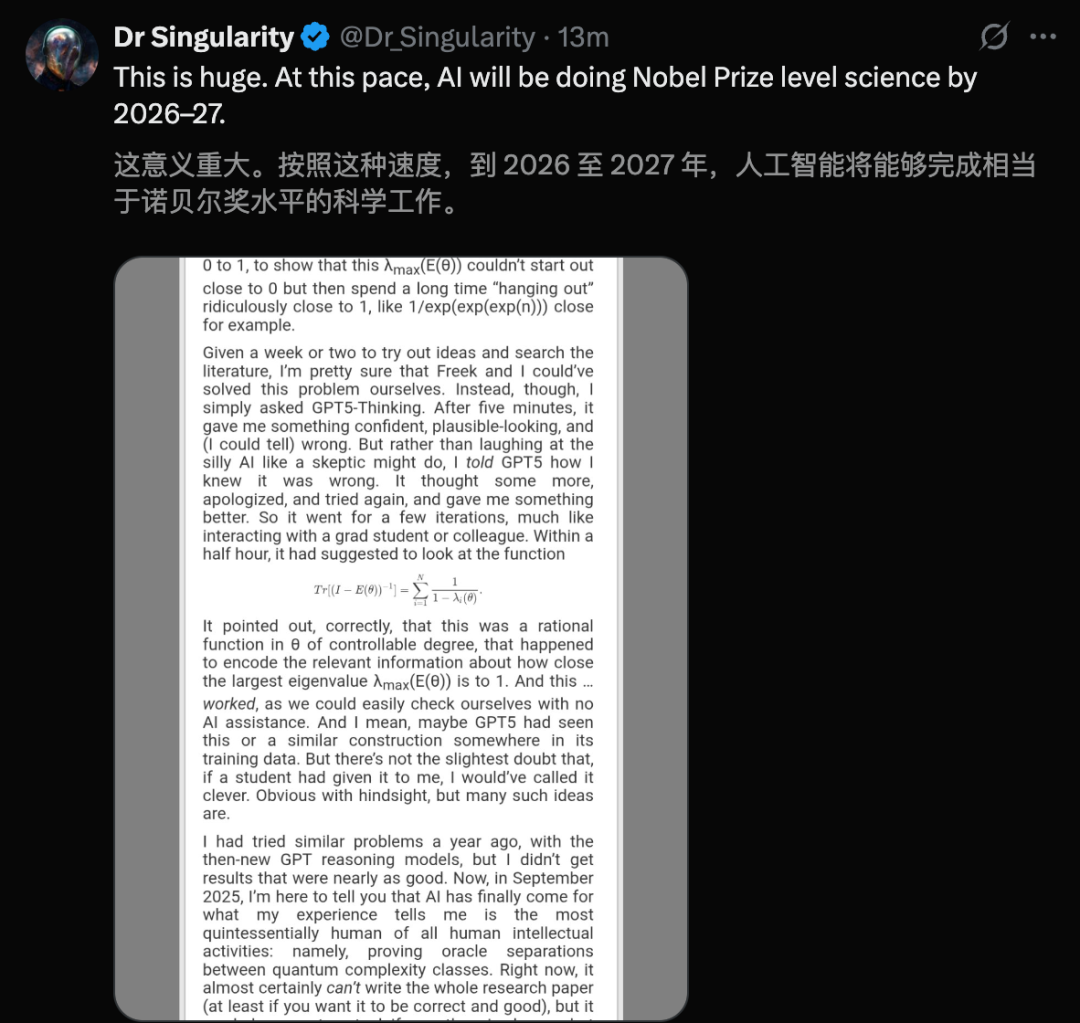
GPT-5 résout le “problème NP quantique” : Scott Aaronson, expert en calcul quantique, a publié pour la première fois un article révélant le rôle d’assistance révolutionnaire de GPT-5 dans la recherche en théorie de la complexité quantique. GPT-5 a aidé à résoudre une étape de dérivation clé dans le “problème NP quantique” en 30 minutes, une tâche qui prendrait normalement 1 à 2 semaines à un humain. Ce résultat marque le début de l’implication de l’IA dans le travail de découverte scientifique au cœur de l’intelligence humaine, annonçant un bond énorme dans le potentiel de l’IA pour la recherche scientifique. (Source: arXiv, scottaaronson.blog)
Nouveau modèle de conception de matériaux AI CGformer : L’équipe des professeurs Li Jinjin et Huang Fuqiang de l’Université Jiao Tong de Shanghai a développé un tout nouveau modèle de conception de matériaux AI, CGformer. En fusionnant de manière innovante le mécanisme d’attention globale de Graphormer avec CGCNN, et en intégrant l’encodage de centralité et l’encodage spatial, ils ont réussi à dépasser les limites des réseaux neuronaux graphiques cristallins traditionnels. Ce modèle peut capturer entièrement les informations globales des structures cristallines complexes, améliorant considérablement la précision de prédiction et l’efficacité de criblage de nouveaux matériaux tels que les électrolytes solides à ions sodium à haute entropie. (Source: Matter)

UniVid, un framework unifié pour les tâches visuelles : UniVid est un framework innovant qui, en affinant un Transformer de diffusion vidéo pré-entraîné, lui permet de s’adapter à diverses tâches d’image et de vidéo sans modifications spécifiques à la tâche. Cette méthode représente les tâches comme des énoncés visuels, définissant la tâche et les modalités de sortie attendues via des séquences contextuelles, démontrant le grand potentiel des modèles de génération vidéo pré-entraînés comme base unifiée pour la modélisation visuelle. (Source: HuggingFace Daily Papers)
RLMT révolutionne le post-entraînement des grands modèles : L’équipe du professeur associé Chen Danqi de l’Université de Princeton a proposé le framework “Reinforcement Learning with Model-based Reward Thinking” (RLMT). Ce framework permet aux LLM de générer de longues chaînes de pensée avant de répondre, combinées à un modèle de récompense basé sur les préférences pour une optimisation RL en ligne. Cette méthode améliore considérablement les capacités de raisonnement et la généralisation des LLM sur des tâches ouvertes, permettant même à un modèle 8B de surpasser GPT-4o en matière de chat et d’écriture créative. (Source: arXiv)

Modèle de reconnaissance de texte historique CHURRO : CHURRO est un modèle de langage visuel (VLM) open-source de 3 milliards de paramètres, spécialement conçu pour la reconnaissance de texte historique de haute précision et à faible coût. Le modèle a été entraîné sur CHURRO-DS, un ensemble de données de 99 491 pages de documents historiques couvrant 22 siècles et 46 langues. Ses performances surpassent celles des VLM existants comme Gemini 2.5 Pro, améliorant considérablement l’efficacité de la recherche et de la conservation du patrimoine culturel. (Source: HuggingFace Daily Papers)
🎯 Tendances
Altman prédit la super-intelligence de l’IA et la fonction Pulse : Sam Altman prédit que l’IA surpassera pleinement l’intelligence humaine d’ici 2030, soulignant la vitesse incroyable du développement de l’IA. OpenAI a lancé la fonction “mode proactif” Pulse pour ChatGPT, marquant le passage de l’IA d’une réponse passive à une réflexion proactive pour l’utilisateur. Elle peut fournir des informations pertinentes basées sur les conversations informelles de l’utilisateur, offrant un service extrêmement personnalisé et annonçant que l’IA deviendra une externalisation du subconscient humain. (Source: 36氪, )
Jensen Huang réfute la théorie de la bulle de l’IA et la stratégie de NVIDIA : Dans une interview, Jensen Huang a réfuté la théorie de l‘“empire de la bulle de l’IA”, soulignant le rôle clé de l’IA dans l’économie et prédisant que NVIDIA pourrait devenir la première entreprise d’une valeur de 10 000 milliards de dollars. Il a souligné l’énorme demande de puissance de calcul sous-jacente à l’inférence de l’IA. NVIDIA, grâce à une conception collaborative extrême, lance de nouvelles architectures chaque année et ouvre son écosystème de systèmes, ne craignant pas la vague de développement interne, dans le but de façonner l’économie de l’IA et de promouvoir l‘“IA souveraine” comme nouveau consensus. (Source: 36氪, )

DeepSeek open-source V3.2-Exp et mécanisme DSA : DeepSeek a open-sourcé la version expérimentale V3.2-Exp avec 685 milliards de paramètres et a simultanément publié un article détaillant son nouveau mécanisme d’attention clairsemée (DeepSeek Sparse Attention, DSA). DSA vise à explorer et à vérifier l’optimisation de l’efficacité de l’entraînement et de l’inférence dans des scénarios de contexte long, améliorant considérablement l’efficacité du traitement du contexte long tout en maintenant la qualité de la sortie du modèle. (Source: 36氪, HuggingFace)

GLM-4.6 bientôt disponible : Le modèle GLM-4.6 de Zhipu AI devrait être bientôt publié. Le site officiel Z.ai a déjà identifié GLM-4.5 comme le “modèle phare de la génération précédente”, ce qui laisse présager que la nouvelle version pourrait apporter des améliorations en termes de longueur de contexte et d’autres aspects, suscitant l’attention et l’attente de la communauté. (Source: Reddit r/LocalLLaMA, karminski3)
Stratégie IA d’Apple et chatbot interne Veritas : Le chatbot IA d’Apple, au nom de code “Veritas”, a été révélé. Il sert de sparring-partner à Siri et est capable d’exécuter des actions au sein des applications. Malgré cela, Apple persiste à ne pas lancer de chatbot grand public, se concentrant sur l’intégration de l’IA au niveau du système et prévoyant d’approfondir l’intégration de modèles tiers via un moteur de réponses IA et une interface universelle MCP, plutôt que de développer son propre chatbot. (Source: 36氪)

Croissance du marché des PC IA et goulots d’étranglement technologiques : Les livraisons de PC IA devraient connaître une forte croissance en 2025-2026, mais principalement tirées par la fin du support de Windows 10 et le cycle de renouvellement des PC, plutôt que par une révolution technologique de l’IA. Les fonctions IA actuelles sont souvent des compléments aux PC traditionnels, confrontées à des défis tels que le manque de puissance de calcul locale, une interaction passive et un écosystème fermé. Un véritable appareil IA doit réaliser une “puissance de calcul locale prédominante, complétée par le cloud” et une perception proactive. (Source: 36氪)

L’IA inonde le marché de l’échange d’électricité : L’IA est largement appliquée sur le marché de l’échange d’électricité. Des entreprises comme Qingpeng Smart utilisent de grands modèles de séries temporelles pour prédire la production d’énergie éolienne et solaire et la demande en électricité, aidant ainsi les décisions de transaction. L’avantage de l’IA à traiter d’énormes volumes de données devrait amplifier les profits, mais pourrait également entraîner des pertes en raison de modèles immatures et de la complexité du marché. L’industrie est toujours en phase d’exploration. (Source: 36氪)
Mises à jour du grand modèle Tongyi d’Alibaba et services IA full-stack : Alibaba Cloud a considérablement mis à niveau son écosystème d’IA full-stack lors de la conférence Apsara, lançant six nouveaux modèles, dont Qwen3-MAX et Qwen3-Omni, se positionnant comme un “fournisseur de services d’IA full-stack”. Alibaba Cloud s’engage à construire l‘“Android de l’ère de l’IA” et la “prochaine génération d’ordinateurs”, offrant des services cloud IA full-stack, des modèles de base aux infrastructures, pour répondre à l’évolution des AI Agents de l‘“émergence intelligente” à l‘“action autonome”. (Source: 36氪)

Analyse approfondie de l’architecture NVIDIA Blackwell : Un événement d’analyse approfondie de l’architecture NVIDIA Blackwell explorera son architecture, ses optimisations et sa mise en œuvre dans le cloud GPU. Cet événement, animé par des experts de SemiAnalysis et NVIDIA, vise à révéler comment les GPU Blackwell, en tant que “GPU de la prochaine décennie”, stimuleront le développement de la puissance de calcul de l’IA et l’avenir du cloud GPU. (Source: TheTuringPost)

🧰 Outils
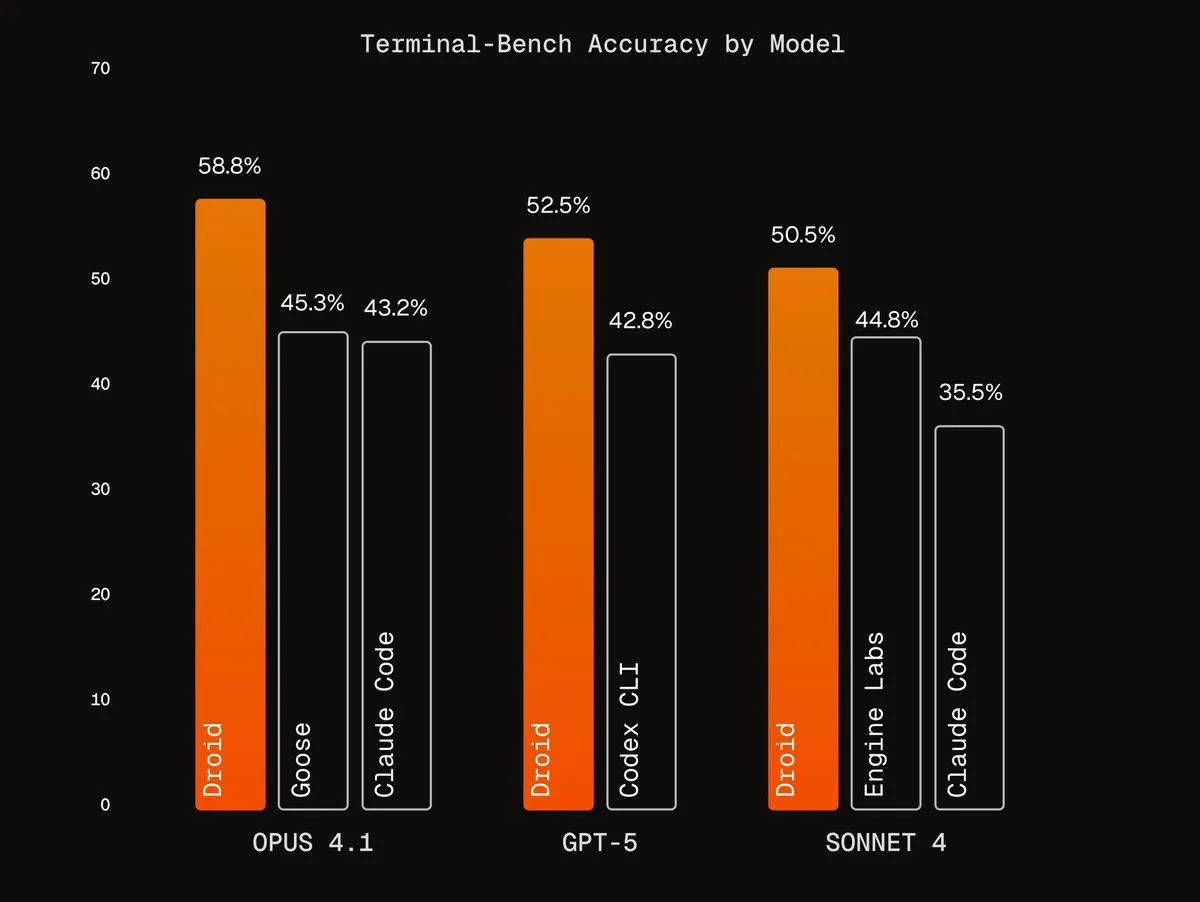
Agentic Harnesses de Factory AI : Factory AI a développé des Agentic Harnesses de classe mondiale qui améliorent considérablement les performances des modèles existants, notamment dans les tâches de codage, et sont qualifiés de “codes de triche” par les utilisateurs. Leurs agents Droids se classent premiers sur Terminal-Bench et réalisent un refactoring de code fiable grâce à des flux de travail de validation multi-agents. (Source: Vtrivedy10, matanSF, matanSF)
Bibliothèque RAG open-source RAGLight : LangChainAI a lancé RAGLight, une bibliothèque Python légère pour la construction de systèmes RAG de niveau production. Cette bibliothèque comprend des pipelines d’agents basés sur LangGraph, la prise en charge de LLM multi-fournisseurs, une intégration GitHub intégrée et des outils CLI, visant à simplifier le développement et le déploiement de systèmes RAG. (Source: LangChainAI, hwchase17)
Système d’exploitation sémantique ArgosOS : ArgosOS est une application de bureau qui permet la recherche intelligente de documents et l’intégration de contenu grâce à une architecture basée sur des balises plutôt que sur une base de données vectorielle. Il utilise des LLM pour créer des balises pertinentes et les stocke dans une base de données SQLite, traitant ainsi intelligemment les requêtes, par exemple pour analyser des factures d’achat, offrant une solution de gestion de documents précise et efficace pour les applications à petite échelle. (Source: Reddit r/MachineLearning)
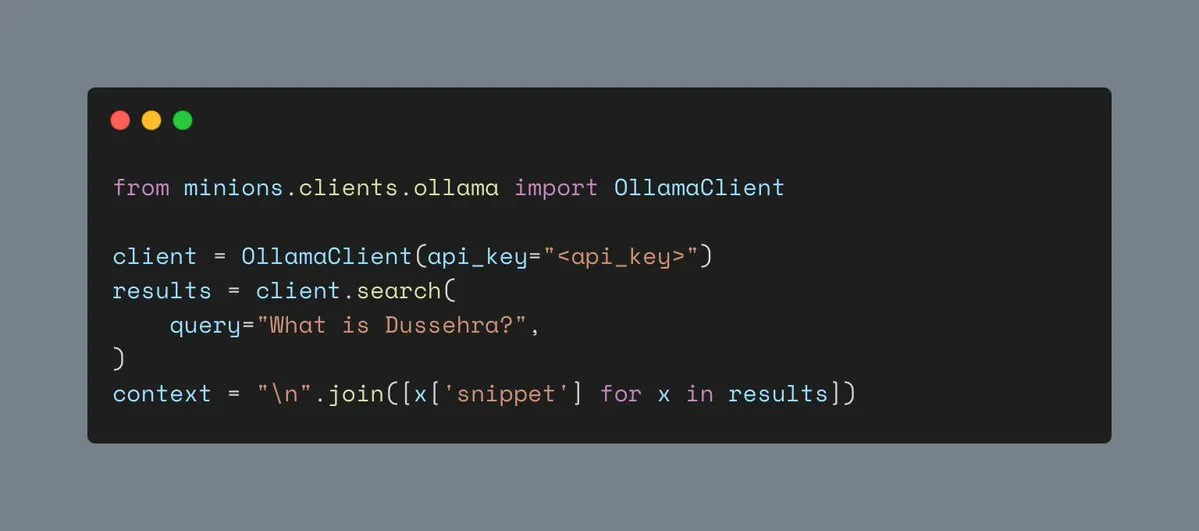
Outil de recherche Web d’Ollama : Ollama prend désormais en charge l’outil de recherche Web, permettant aux utilisateurs d’intégrer des fonctions de recherche Web dans les charges de travail Minions, enrichissant ainsi les informations contextuelles des applications IA et améliorant leur capacité à traiter des tâches complexes. (Source: ollama)
RAG multimodal local Hyperlink : Hyperlink offre des capacités RAG multimodales locales, permettant aux utilisateurs de rechercher et de résumer hors ligne des captures d’écran/bibliothèques de photos. Grâce aux technologies OCR et d’intégration, cet outil peut transformer des données d’image non structurées en contenu interrogeable, réalisant une gestion de documents et une extraction d’informations entièrement privées et sur l’appareil. (Source: Reddit r/LocalLLaMA)

Connecteur Azure PostgreSQL LangChain : Microsoft a lancé un connecteur Azure PostgreSQL natif, unifiant la persistance des agents pour l’écosystème LangChain. Ce connecteur offre un stockage vectoriel et une gestion d’état de niveau entreprise, simplifiant la complexité de la construction et du déploiement d’agents IA dans l’environnement Azure. (Source: LangChainAI)
Standardisation des API LLM et protocole MCP : La communauté discute du problème de la fragmentation des API LLM, soulignant les incompatibilités dans la structure des messages, les modèles d’appel d’outils et les noms de champs d’inférence entre différents fournisseurs, appelant à une standardisation de l’industrie pour le protocole JSON API. Parallèlement, l’introduction du protocole MCP (Model-Client Protocol) a également suscité des discussions sur son impact sur le développement des agents. (Source: AAAzzam, charles_irl)
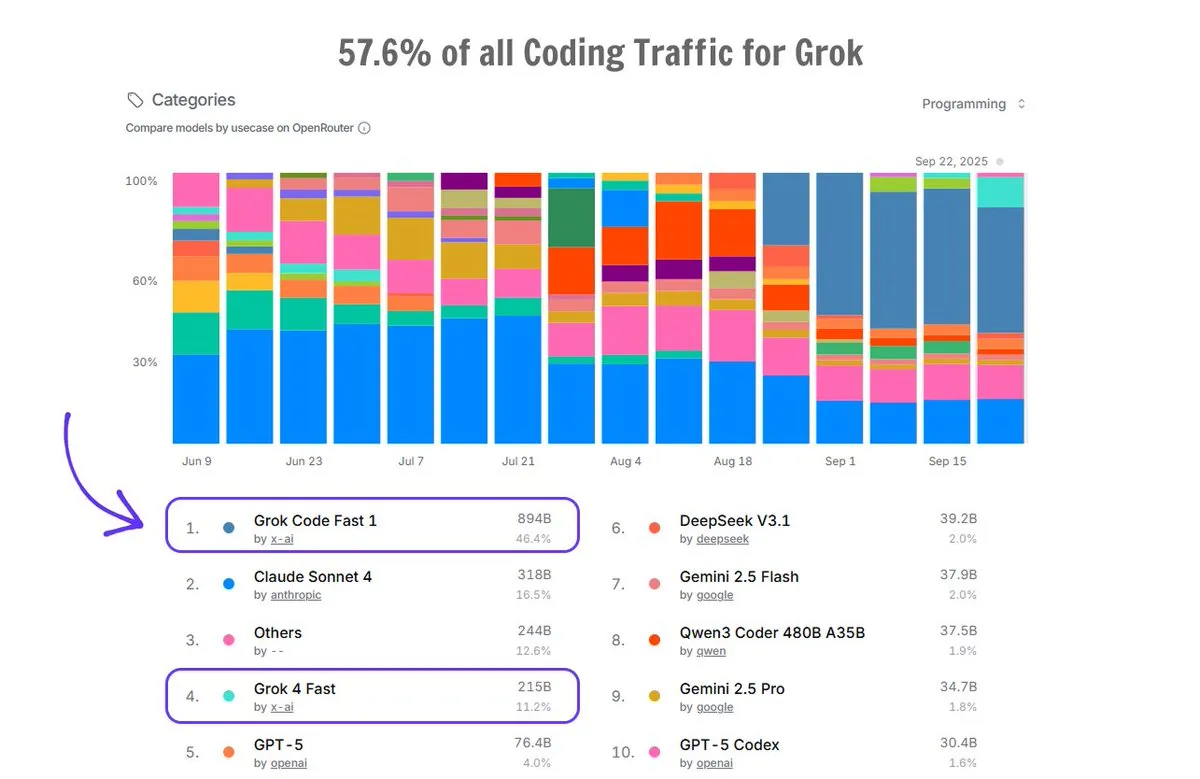
Application de Grok Code sur OpenRouter : Grok Code représente 57,6 % du trafic de codage sur la plateforme OpenRouter, dépassant la somme de tous les autres générateurs de code IA, avec Grok Code Fast 1 en première position, démontrant sa forte performance sur le marché et la préférence des utilisateurs dans le domaine de la génération de code. (Source: imjaredz)
📚 Apprentissage
Cours d’introduction à l’IA Cursor Learn : Lee Robinson a lancé Cursor Learn, une série de vidéos gratuites en six parties, conçue pour aider les débutants à maîtriser les concepts fondamentaux de l’IA tels que les tokens, le context et les agents. Le cours dure environ 1 heure et propose des quiz et des essais de modèles IA, constituant une ressource pratique pour apprendre les bases de l’IA. (Source: crystalsssup)
Livre gratuit sur les structures de données Python : Donald R. Sheehy a publié un livre gratuit intitulé “A First Course on Data Structures in Python”, couvrant les structures de données, la pensée algorithmique, l’analyse de complexité, la récursion/programmation dynamique et les méthodes de recherche, offrant une base solide aux apprenants dans les domaines de l’IA et de l’apprentissage automatique. (Source: TheTuringPost)

Modèle OCR multilingue dots.ocr : Xiaohongshu Hi Lab a lancé dots.ocr, un puissant modèle OCR multilingue prenant en charge 100 langues, capable d d’analyser de bout en bout le texte, les tableaux, les formules et les mises en page (sortie en Markdown), et disponible gratuitement pour un usage commercial. Ce modèle est compact (1,7B VLM) mais atteint des performances SOTA sur OmniDocBench et dots.ocr-bench. (Source: mervenoyann)

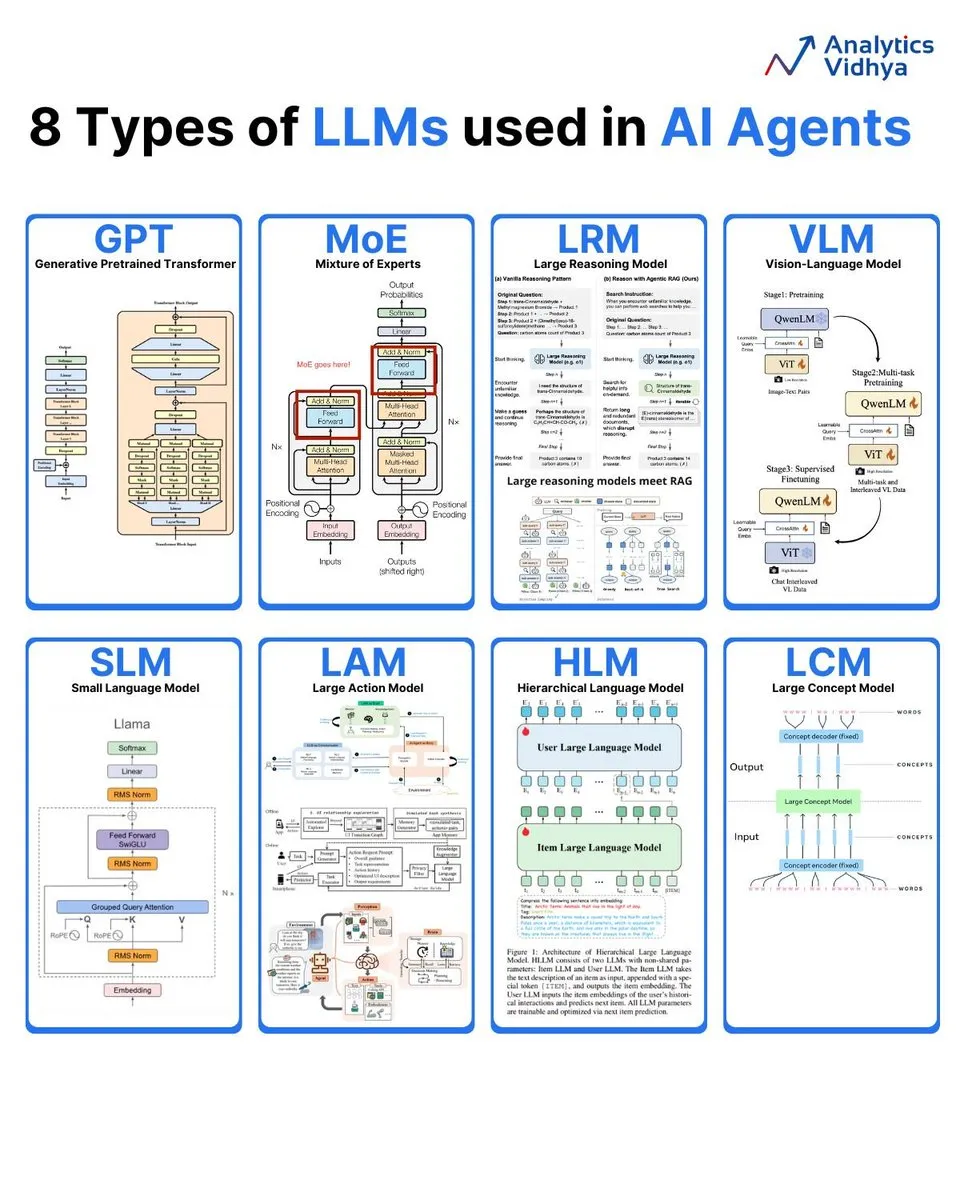
Analyse de 8 types de grands modèles de langage : Analytics Vidhya a résumé 8 types de grands modèles de langage courants, notamment GPT (Generative Pre-trained Transformer), MoE (Mixture of Experts), LRM (Large Reasoning Model), VLM (Vision Language Model), SLM (Small Language Model), LAM (Large Action Model), HLM (Hierarchical Language Model) et LCM (Large Concept Model), en détaillant leur architecture et leurs applications. (Source: karminski3)
Bulletin d’information sur l’IA : Résumé des dernières publications : DAIR.AI a publié sa sélection d’articles de recherche en IA de la semaine (22-28 septembre), couvrant plusieurs domaines de recherche de pointe tels que ATOKEN, LLM-JEPA, Code World Model, Teaching LLMs to Plan, Agents Research Environments, Language Models that Think, Chat Better, Embodied AI: From LLMs to World Models, offrant aux chercheurs en IA les dernières actualités. (Source: dair_ai)
Conseils aux jeunes chercheurs à l’ère de l’IA : Jascha Sohl-Dickstein a partagé des conseils pratiques pour les jeunes chercheurs sur la manière de choisir des projets de recherche et de prendre des décisions de carrière dans la dernière phase de l‘“Anthropocène”. Il a exploré l’impact profond de l’AGI sur les carrières universitaires et a souligné la nécessité de repenser les orientations de recherche et le développement professionnel dans un contexte où les systèmes d’IA surpasseront l’intelligence humaine. (Source: mlpowered)
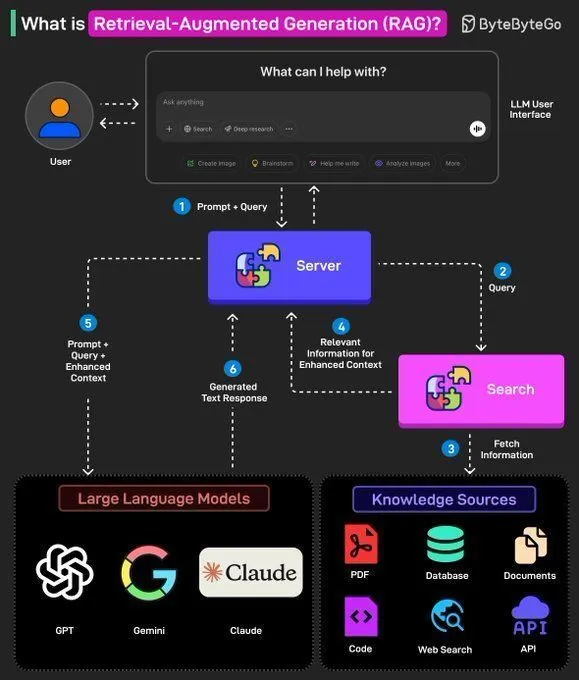
Concepts RAG et construction d’AI Agents : Ronald van Loon a partagé les concepts fondamentaux du RAG (Retrieval Augmented Generation) et son importance dans les LLM, et a fourni 8 étapes clés pour construire un AI Agent. Le contenu couvre le concept, la pile technologique, les avantages des AI Agents et comment les évaluer via des frameworks, offrant aux développeurs IA un guide de la théorie à la pratique. (Source: Ronald_vanLoon, Ronald_vanLoon)
Meta résout le problème d’inefficacité d’inférence des LLM : Une recherche de Meta révèle le problème d’inefficacité d’inférence des LLM causé par le travail répétitif dans les longues chaînes de pensée. Ils proposent de compresser les étapes répétitives en petites actions nommées, permettant au modèle d’appeler ces actions plutôt que de les redériver, réduisant ainsi la consommation de tokens et améliorant l’efficacité et la précision de l’inférence, offrant de nouvelles pistes pour optimiser le processus d’inférence des LLM. (Source: ylecun)

Les capacités de raisonnement visuel de Veo-3 se manifestent : Lisan al Gaib a souligné que le modèle vidéo Veo-3 montre des capacités de raisonnement (visuel) émergentes similaires à celles de GPT-3, ce qui laisse présager que les modèles multimodaux natifs, une fois qu’ils auront pleinement exploité leur potentiel, apporteront une compréhension visuelle et des avantages de raisonnement plus complets. (Source: scaling01)

💼 Affaires
Le pari de cent milliards d’OpenAI et la bulle des infrastructures d’IA : OpenAI tisse à un rythme effréné de dépenses un réseau géant couvrant les puces, le cloud computing et les centres de données, y compris un investissement de 100 milliards de dollars de Nvidia et une collaboration de 300 milliards de dollars avec Oracle pour “Stargate”. Bien que les revenus de 2025 ne soient estimés qu’à 13 milliards de dollars, la direction d’OpenAI estime que l’investissement dans les infrastructures d’IA est une “opportunité unique en un siècle”, soulevant le débat sur la question de savoir si les infrastructures d’IA sont confrontées à une bulle Internet. (Source: 36氪)

Elon Musk poursuit OpenAI pour la sixième fois : La société xAI d’Elon Musk a poursuivi OpenAI pour la sixième fois, l’accusant de débauchage systématique d’employés, de vol illégal du code source du grand modèle Grok et des plans stratégiques des centres de données, ainsi que d’autres secrets commerciaux. Cette action en justice marque l’intensification de la concurrence entre les deux géants de l’IA. Musk estime qu’OpenAI s’est écarté de sa mission à but non lucratif, tandis qu’OpenAI nie les accusations, les qualifiant de “harcèlement continu”. (Source: 36氪)

Le scientifique IA de premier plan Steven Hoi rejoint Alibaba Tongyi : Steven Hoi (Xu Zhuhong), scientifique IA de renommée mondiale et IEEE Fellow, a rejoint le laboratoire Alibaba Tongyi, où il se concentrera sur la recherche et le développement fondamental de pointe sur les grands modèles multimodaux. Steven Hoi possède plus de 20 ans d’expérience en R&D, académique et industrielle en IA, ayant été vice-président chez Salesforce et fondé HyperAGI. Ce recrutement marque un renforcement de l’investissement d’Alibaba dans les grands modèles multimodaux pour accélérer l’efficacité d’itération des modèles et les percées innovantes multimodales. (Source: 36氪)

🌟 Communauté
Dégradation des performances de ChatGPT 4o et humeur des utilisateurs : De nombreux utilisateurs de ChatGPT signalent une dégradation des performances du modèle 4o, avec des problèmes de “réduction” et de “routage sécurisé”, ce qui les rend frustrés et trompés. De nombreux utilisateurs neurodivers sont particulièrement attristés, considérant que le 4o était une “bouée de sauvetage” pour leur communication et leur compréhension de soi. Les utilisateurs remettent généralement en question le manque de transparence d’OpenAI et l’appellent à tenir sa promesse de “traiter les utilisateurs comme des adultes”, s’opposant aux mécanismes de censure ambigus. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Débat sur l’emploi et les licenciements à l’ère de l’IA : La communauté débat de l’impact de l’IA sur le marché du travail, y compris la diminution significative du nombre de postes de débutants, les licenciements d’entreprises et les investissements en IA en parallèle, ainsi que la véracité des raisons de licenciement liées à l’IA. La discussion met en évidence la tendance où “ceux qui comprennent l’IA remplacent ceux qui ne la comprennent pas” et appelle les entreprises à repenser les emplois de débutants plutôt que de simplement les supprimer, afin de former des talents rares adaptés aux besoins de l’ère de l’IA. (Source: 36氪, 36氪, Reddit r/artificial)

Défis et seuils de la recherche sur les LLM : La communauté débat de l’augmentation constante du seuil de la recherche en apprentissage automatique, les chercheurs individuels ayant du mal à concurrencer les géants de la technologie. Face à un volume massif d’articles, une puissance de calcul coûteuse et des théories mathématiques complexes, beaucoup se sentent découragés à démarrer et à réaliser des percées, soulevant des inquiétudes quant à la durabilité du domaine. (Source: Reddit r/MachineLearning)
Impact des modèles MoE sur l’hébergement local : La communauté discute en profondeur des avantages et inconvénients des modèles MoE pour l’hébergement local de LLM. Les opinions suggèrent que bien que les modèles MoE occupent plus de VRAM, ils sont très efficaces en calcul et peuvent permettre l’exécution de modèles plus grands via le déchargement CPU, ce qui les rend particulièrement adaptés au matériel grand public avec beaucoup de mémoire mais un GPU limité, constituant un moyen efficace d’améliorer les performances des LLM. (Source: Reddit r/LocalLLaMA)
Développement rapide et applications des AI Agents : La communauté discute du développement rapide des AI Agents, dont les capacités sont passées de “presque inutilisables” à “performantes dans des scénarios spécifiques” en moins d’un an, et même à des “Agents généraux qui commencent à être utiles”, leur vitesse de progrès dépassant les attentes. Cependant, certains estiment que les Agents de codage actuels sont très homogènes et manquent de différences significatives. (Source: nptacek, HamelHusain)
Tendances de la recherche en RL et controverse autour de GRPO : La communauté discute en profondeur des dernières tendances de la recherche en apprentissage par renforcement (RL), en particulier du statut et de la controverse de l’algorithme GRPO. Certains estiment que la recherche en RL se tourne vers le pré-entraînement/la modélisation et que GRPO est un développement open-source important, mais des employés d’OpenAI pensent qu’il est nettement en retard par rapport aux technologies de pointe, suscitant une discussion animée sur l’innovation algorithmique et les performances réelles. (Source: natolambert, MillionInt, cloneofsimo, jsuarez5341, TheTuringPost)

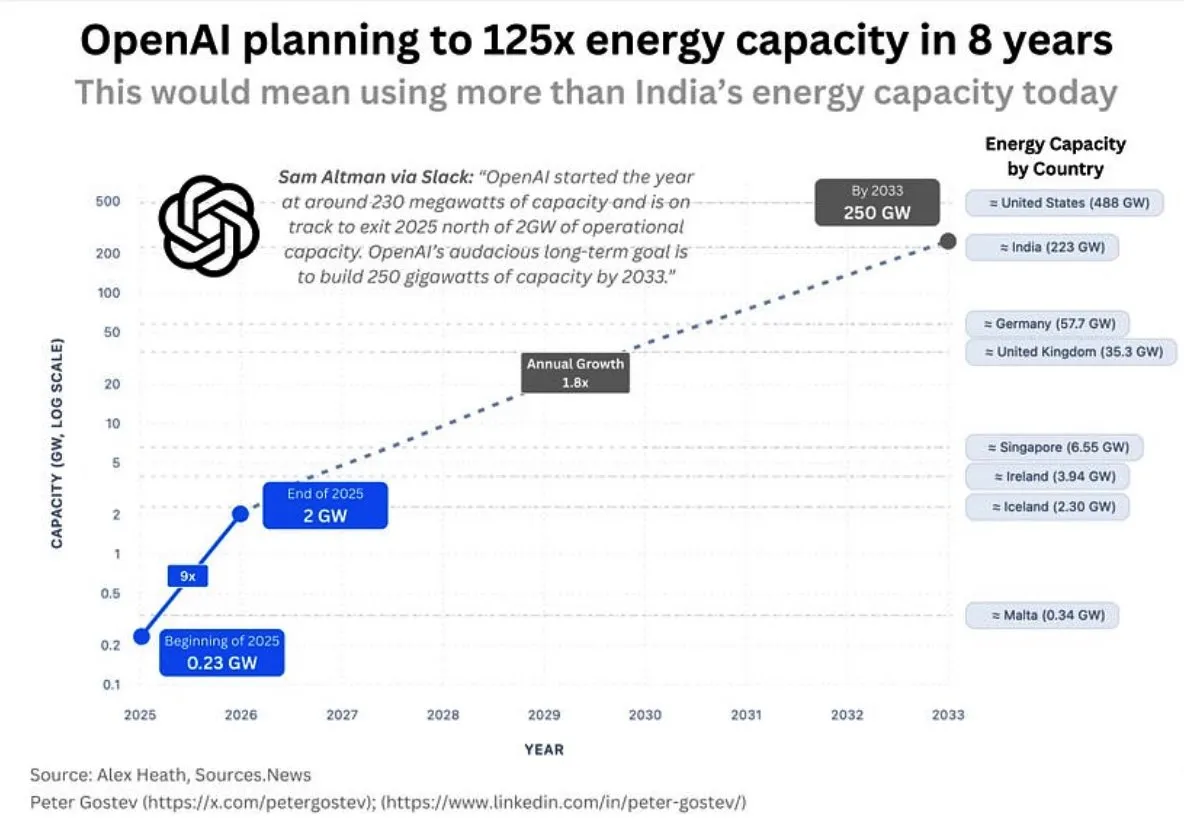
Consommation d’énergie d’OpenAI et infrastructures d’IA : La communauté discute des énormes besoins énergétiques futurs d’OpenAI, qui devraient consommer plus d’énergie que le Royaume-Uni ou l’Allemagne d’ici cinq ans, et plus que l’Inde d’ici huit ans, soulevant des inquiétudes quant à l’ampleur de la construction d’infrastructures d’IA, l’approvisionnement énergétique et l’impact environnemental. Parallèlement, le choix de l’emplacement des centres de données de Google a également rencontré l’opposition des résidents locaux en raison de problèmes de consommation d’eau. (Source: teortaxesTex, brickroad7)
La “Bitter Lesson” de Sutton et le développement de l’IA : La communauté discute de la “Bitter Lesson” de Richard Sutton et de ses implications pour la recherche en IA, soulignant que les méthodes de calcul générales sont supérieures aux connaissances a priori humaines. La discussion tourne autour de la relation entre “imitation et modèles du monde”, estimant que la simple imitation peut conduire au “culte du cargo” et que l’imitation sans expérience réelle a des limites fondamentales. (Source: rao2z, jonst0kes)
💡 Autres
Robot bionique BionicWheelBot : Le robot BionicWheelBot a réalisé une navigation multifonctionnelle sur des terrains complexes en imitant les mouvements de roulade de l’araignée-roue. Cette innovation démontre le potentiel de la bionique dans la conception de robots, offrant de nouvelles solutions pour que les futurs robots puissent faire face à des environnements changeants. (Source: Ronald_vanLoon)
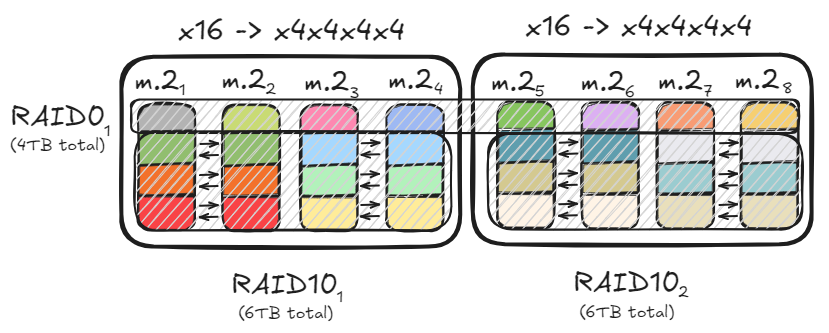
Optimisation du stockage PC et configuration RAID : Un utilisateur partage comment, grâce aux configurations RAID0 et RAID10, en utilisant plusieurs canaux PCIe et des disques M.2, il a atteint un débit de données allant jusqu’à 47 Go/s pour accélérer le chargement de grands modèles. Cette solution d’optimisation concilie les besoins de lecture/écriture à haute vitesse avec la capacité de stockage et la redondance des données, offrant une base matérielle efficace pour le déploiement de modèles IA locaux. (Source: TheZachMueller)
Ouverture du “Parc Industriel AI+ Shuxiwan” de Liangzhu : Le “Parc Industriel AI+ Shuxiwan” de Liangzhu à Hangzhou a officiellement ouvert ses portes, se concentrant sur des domaines de pointe tels que l’intelligence artificielle, l’économie des nomades numériques et les industries culturelles et créatives. Ce parc, grâce à huit politiques spéciales “Shuxi” et une disposition spatiale “quatre scènes”, offre aux explorateurs de l’IA un soutien sur tout le cycle, de l’émergence créative à la direction de l’écosystème, visant à créer un écosystème d’innovation où la technologie et l’humanisme sont profondément intégrés. (Source: 36氪)
