
Mots-clés:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Intelligence incarnée, Confidentialité différentielle, Inférence LLM, Agent IA, Transformer, Mécanisme d’attention hybride Gated DeltaNet, Système de détection de vulnérabilités DARPA AIxCC, Optimisation de l’inférence IA sur les appareils périphériques, Génération et test autonomes de logiciels, Modèle d’encodeur multilingue mmBERT
🔥 À la une
Alibaba lance le modèle Qwen3-Next 80B : Alibaba a dévoilé Qwen3-Next 80B, un modèle open source doté de capacités d’inférence hybrides. Ce modèle utilise un mécanisme d’attention hybride Gated DeltaNet et Gated Attention, ainsi qu’une grande sparsité de 3,8 % (seulement 3 milliards de paramètres actifs), ce qui le rend comparable à DeepSeek V3.1 en termes d’intelligence, tout en réduisant les coûts d’entraînement de 10 fois et en augmentant la vitesse d’inférence de 10 fois. Qwen3-Next 80B excelle en inférence et en traitement de contextes longs, surpassant même Gemini 2.5 Flash-Thinking. Le modèle prend en charge une fenêtre de contexte de 256k tokens, peut fonctionner sur un seul GPU H200 et est disponible sur le NVIDIA API Catalog, marquant une nouvelle percée dans l’architecture LLM efficace. (Source : Alibaba_Qwen, ClementDelangue, NandoDF)
Défi DARPA AIxCC : un système de détection et de correction automatisée de vulnérabilités basé sur les LLM : Lors du défi DARPA AI Cyber Challenge (AIxCC), un système de raisonnement cybernétique (CRS) basé sur les LLM, nommé “All You Need Is A Fuzzing Brain”, s’est distingué en découvrant de manière autonome 28 vulnérabilités de sécurité, dont 6 zero-day auparavant inconnues, et en en corrigeant 14. Ce système a démontré des capacités exceptionnelles de détection et de correction automatisées de vulnérabilités dans des projets C et Java open source du monde réel, terminant quatrième de la finale. Le CRS est désormais open source et propose un classement public pour évaluer l’état de l’art des LLM dans les tâches de détection et de correction de vulnérabilités. (Source : HuggingFace Daily Papers)
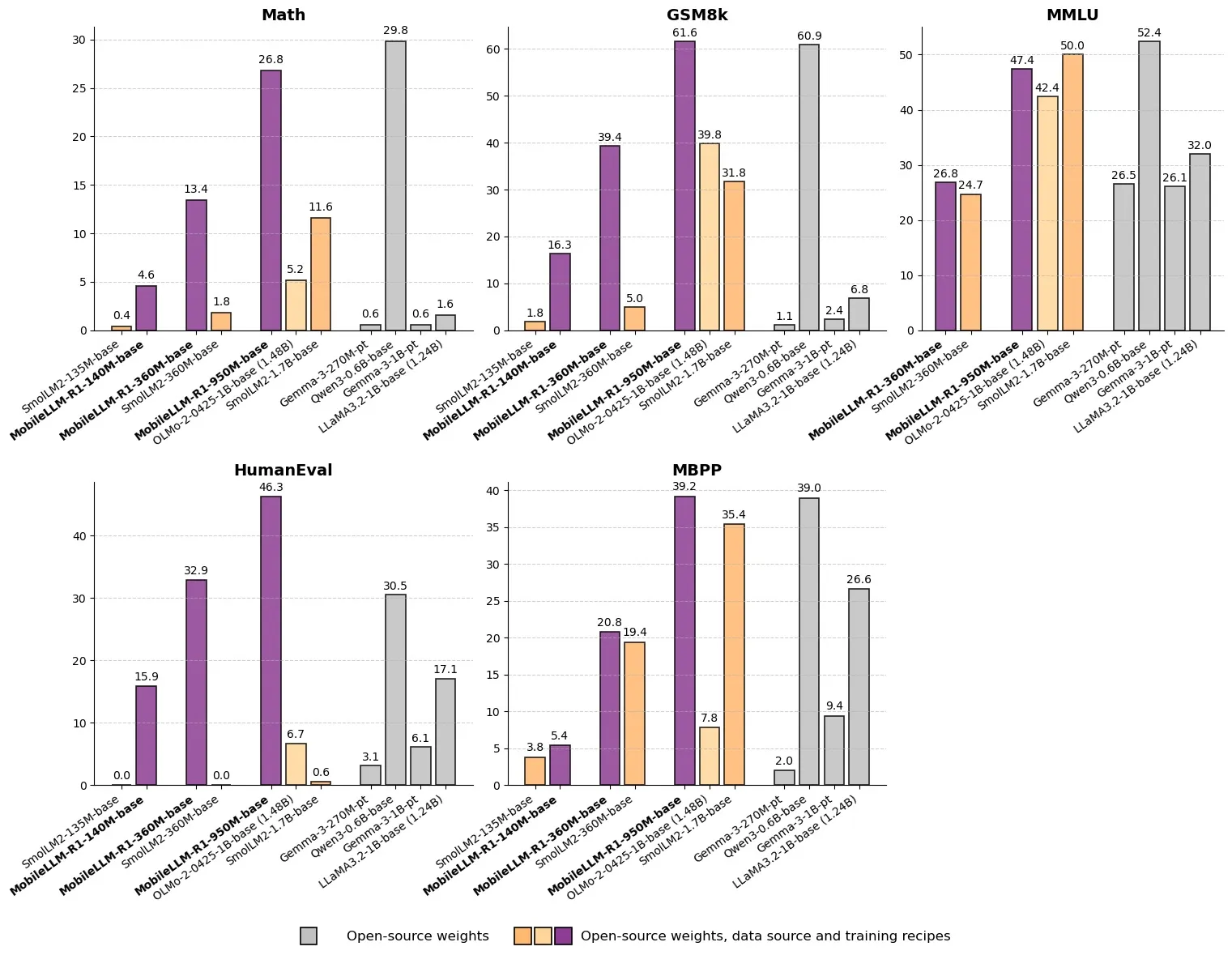
Meta lance MobileLLM-R1 : un modèle d’inférence efficace de moins d’un milliard de paramètres : Meta a publié MobileLLM-R1 sur Hugging Face, un modèle d’inférence edge avec moins d’un milliard de paramètres. Ce modèle surpasse Olmo-1.24B d’environ 5 fois et SmolLM2-1.7B d’environ 2 fois en précision mathématique, réalisant une amélioration des performances de 2 à 5 fois. MobileLLM-R1 n’utilise que 4,2T de tokens de pré-entraînement (11,7 % de l’utilisation de Qwen) et démontre de puissantes capacités d’inférence après un post-entraînement minimal, marquant un changement de paradigme en matière d’efficacité des données et de taille de modèle, ouvrant de nouvelles voies pour l’inférence IA sur les appareils edge. (Source : _akhaliq, Reddit r/LocalLLaMA)
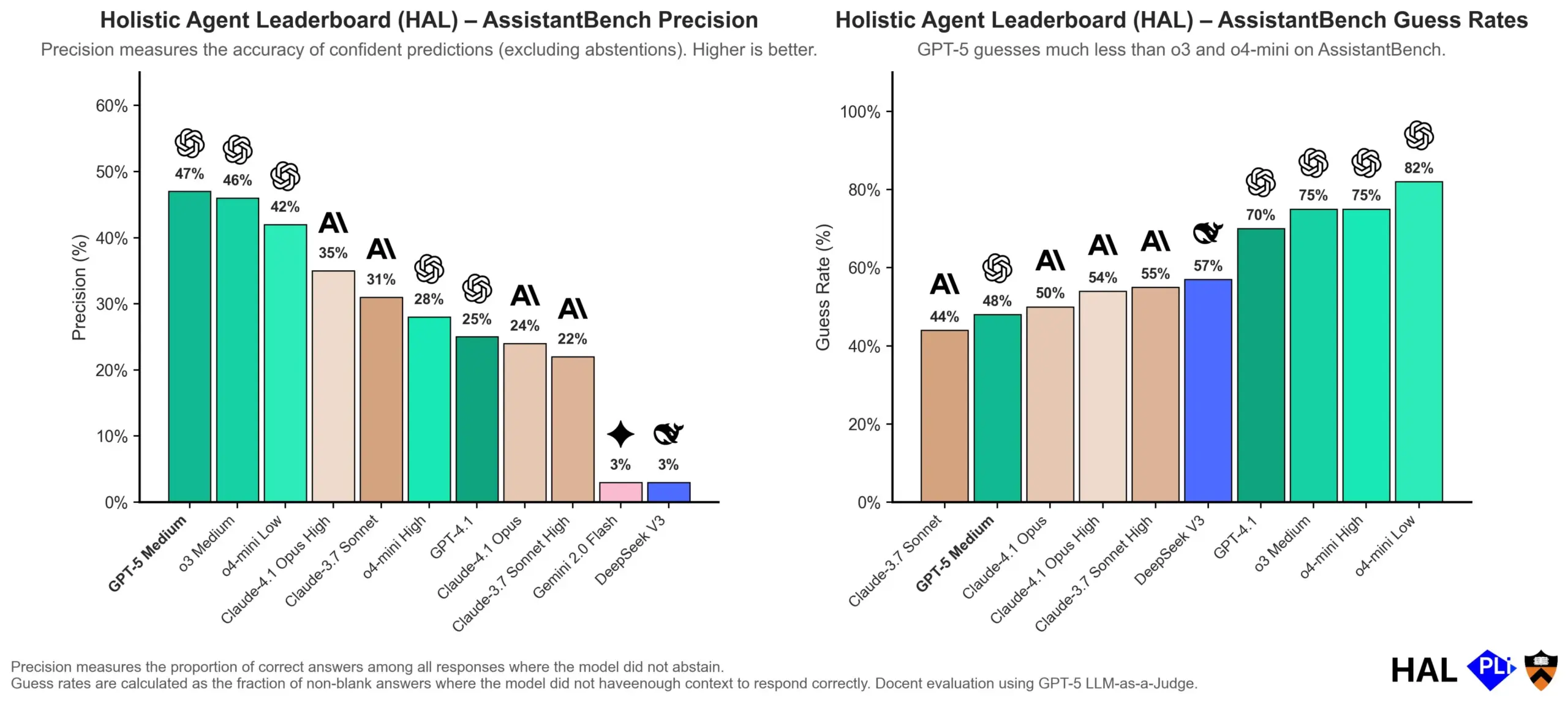
OpenAI examine en profondeur les causes des hallucinations des LLM : les mécanismes d’évaluation sont essentiels : OpenAI a publié un article de recherche indiquant que les hallucinations des grands modèles de langage (LLM) ne sont pas dues à un dysfonctionnement du modèle lui-même, mais sont le résultat direct des méthodes d’évaluation actuelles qui récompensent la “devinette” plutôt que l‘“honnêteté”. L’étude suggère que les benchmarks existants pénalisent souvent les modèles qui répondent “je ne sais pas”, les incitant ainsi à générer des réponses plausibles mais inexactes. L’article appelle à modifier la manière dont les benchmarks sont notés et à réajuster les classements existants pour encourager les modèles à faire preuve d’une meilleure calibration et d’une plus grande honnêteté en cas d’incertitude, plutôt que de rechercher aveuglément des sorties à haute confiance. (Source : dl_weekly, TheTuringPost, random_walker)
Replit Agent 3 : une percée dans la génération et le test de logiciels autonomes : Replit a lancé son Agent 3, un agent IA capable de générer et de tester des logiciels de manière hautement autonome. Cet agent a démontré sa capacité à fonctionner pendant des heures sans intervention, à construire des applications complètes (telles que des plateformes de réseaux sociaux) et à les tester lui-même. Les retours des utilisateurs montrent que l’Agent 3 peut rapidement transformer des idées en produits réels, améliorant considérablement l’efficacité du développement et fournissant même des reçus de travail détaillés. Cette avancée préfigure l’énorme potentiel des agents IA dans le domaine du développement logiciel, en particulier en ce qui concerne la fourniture d’environnements testables, un domaine où Replit est considéré comme un leader. (Source : amasad, amasad, amasad)
🎯 Tendances
Unitree Robotics accélère son IPO, se concentrant sur l’IA incarnée pour “faire travailler l’IA” : Unitree Robotics, la licorne des robots quadrupèdes, prépare activement son IPO. Le fondateur Wang Xingxing souligne l’énorme potentiel de l’IA dans les applications physiques, estimant que le développement des grands modèles offre une opportunité pour la combinaison de l’IA et de la robotique. Bien que le développement de l’IA incarnée soit confronté à des défis tels que la collecte de données, la fusion de données multimodales et l’alignement du contrôle des modèles, Wang Xingxing reste optimiste quant à l’avenir, pensant que le seuil de l’innovation et de l’entrepreneuriat a considérablement diminué, et que les petites organisations auront une plus grande force explosive. Unitree Robotics occupe une position de leader sur le marché des robots quadrupèdes, avec un chiffre d’affaires annuel dépassant 1 milliard de yuans. Cette IPO vise à utiliser le capital pour accélérer l’avenir où les robots seront profondément impliqués. (Source : 36氪)

Turbulences au sein de la direction de l’IA d’Apple, nouvelles fonctionnalités de Siri reportées à 2026 : Le département IA d’Apple est confronté à une vague de départs de cadres supérieurs, l’ancien responsable de Siri, Robby Walker, étant sur le point de quitter l’entreprise, et des membres clés de l’équipe étant débauchés par Meta. En raison de problèmes de qualité persistants et d’un changement d’architecture sous-jacente, les nouvelles fonctionnalités personnalisées de Siri seront reportées au printemps 2026. Ces turbulences et ce retard suscitent des doutes quant à la vitesse d’innovation et de déploiement de l’IA d’Apple. Bien que l’entreprise multiplie les actions concernant les puces de serveurs IA et l’évaluation de modèles externes, les progrès réels sont inférieurs aux attentes. (Source : 36氪)
mmBERT : nouvelles avancées pour les modèles d’encodeurs multilingues : mmBERT est un modèle d’encodeur pré-entraîné sur 3T de texte multilingue dans plus de 1800 langues. Ce modèle introduit des éléments innovants tels que la planification du taux de masquage inverse et le taux d’échantillonnage de température inverse, et intègre des données de plus de 1700 langues à faibles ressources en fin d’entraînement, améliorant considérablement les performances. mmBERT excelle dans les tâches de classification et de récupération pour les langues à ressources élevées et faibles, avec des performances comparables à des modèles comme o3 d’OpenAI et Gemini 2.5 Pro de Google, comblant ainsi une lacune dans la recherche sur les modèles d’encodeurs multilingues. (Source : HuggingFace Daily Papers)
MachineLearningLM : un nouveau cadre pour l’apprentissage automatique contextuel avec les LLM : MachineLearningLM est un cadre de pré-entraînement continu conçu pour doter les LLM généraux (tels que Qwen-2.5-7B-Instruct) de puissantes capacités d’apprentissage automatique contextuel, tout en préservant leurs connaissances générales et leurs capacités de raisonnement. En synthétisant des tâches ML à partir de millions de modèles causaux structurés (SCMs) et en utilisant des prompts de tokens efficaces, ce cadre permet aux LLM de traiter jusqu’à 1024 exemples par apprentissage contextuel (ICL) pur, sans descente de gradient. MachineLearningLM surpasse en moyenne les modèles de base robustes comme GPT-5-mini d’environ 15 % dans les tâches de classification tabulaire hors domaine dans des secteurs tels que la finance, la physique, la biologie et la médecine. (Source : HuggingFace Daily Papers)
Meta vLLM : une nouvelle percée dans l’efficacité de l’inférence à grande échelle : L’implémentation hiérarchique de vLLM par Meta améliore considérablement l’efficacité de PyTorch et vLLM dans l’inférence à grande échelle, surpassant sa pile interne en termes de latence et de débit. En partageant ces optimisations avec la communauté vLLM, cette avancée promet des solutions d’inférence IA plus efficaces et plus rentables, particulièrement cruciales pour le traitement des tâches d’inférence des grands modèles de langage, favorisant le déploiement et l’expansion des applications IA dans des scénarios réels. (Source : vllm_project)

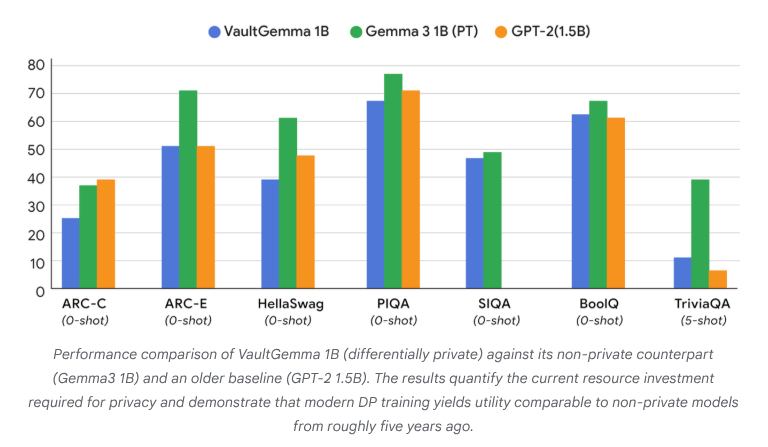
VaultGemma : le premier LLM open source avec confidentialité différentielle publié : Google Research a publié VaultGemma, le plus grand modèle open source entraîné à partir de zéro et doté d’une protection par confidentialité différentielle. Cette recherche fournit non seulement les poids et le rapport technique de VaultGemma, mais propose également pour la première fois des lois de mise à l’échelle pour les modèles de langage avec confidentialité différentielle. La publication de VaultGemma jette des bases importantes pour la construction de modèles IA plus sûrs et plus responsables sur des données sensibles, et fait progresser le développement des technologies IA de protection de la vie privée, les rendant plus viables dans les applications pratiques. (Source : JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API : limites de débit considérablement augmentées : OpenAI a annoncé que les limites de débit de l’API pour GPT-5 et GPT-5-mini ont été considérablement augmentées, doublant pour certains niveaux. Par exemple, le Tier 1 de GPT-5 est passé de 30K TPM à 500K TPM, et le Tier 2 de 450K à 1M. Le Tier 1 de GPT-5-mini est également passé de 200K à 500K. Cet ajustement améliore significativement la capacité des développeurs à utiliser ces modèles pour des applications et des expériences à grande échelle, réduisant les goulots d’étranglement dus aux limites de débit, et favorisant davantage l’application commerciale et le développement de l’écosystème des modèles de la série GPT-5. (Source : OpenAIDevs)
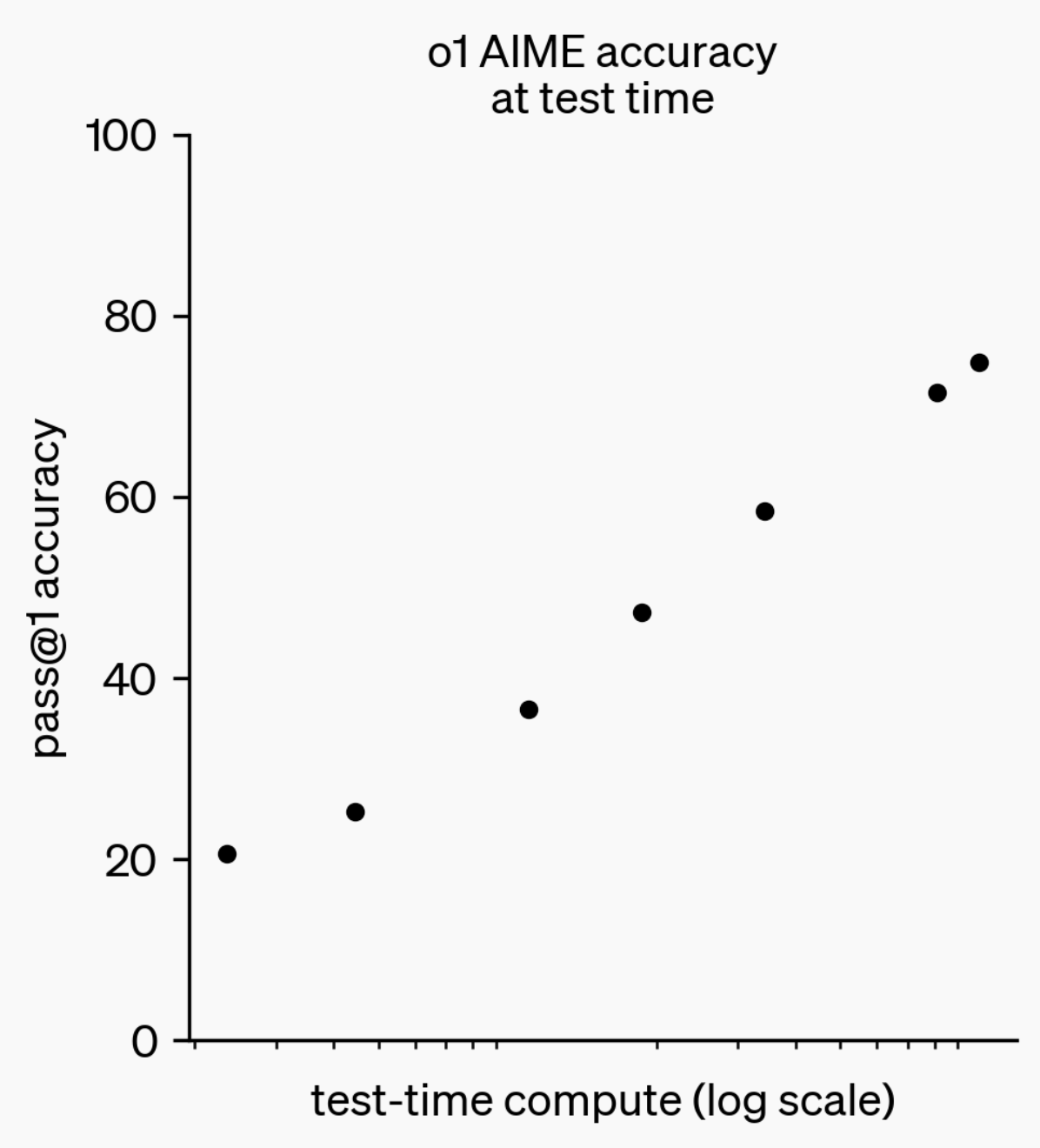
Évolution des capacités d’inférence des LLM : de o1-preview à GPT-5 Pro : Au cours de la dernière année, les capacités d’inférence des grands modèles de langage (LLM) ont fait des progrès significatifs. Du modèle o1-preview d’OpenAI qui nécessitait quelques secondes de réflexion il y a un an, aux modèles d’inférence les plus avancés d’aujourd’hui capables de réfléchir pendant des heures, de naviguer sur le web et d’écrire du code, cela montre que la dimension de l’inférence IA ne cesse de s’étendre. Grâce à l’entraînement de modèles par apprentissage par renforcement (RL) pour “penser”, et à l’utilisation de chaînes de pensée (chain of thought) privées, les performances des LLM dans les tâches d’inférence s’améliorent avec l’augmentation du temps de réflexion, ce qui indique que l’expansion du calcul d’inférence sera une nouvelle direction pour le développement futur des modèles. (Source : polynoamial, gdb)
Sakana AI Japon : une licorne de l’IA inspirée par la nature : La startup japonaise Sakana AI a atteint une valorisation de plus d’un milliard de dollars en un an, devenant l’entreprise la plus rapide du Japon à atteindre le statut de “licorne”. Fondée par David Ha, ancien chercheur chez Google Brain, l’approche de l’IA de l’entreprise est inspirée par la “sagesse collective” de la nature, visant à fusionner les systèmes existants, petits et grands, plutôt que de poursuivre aveuglément des modèles massifs et énergivores. Sakana AI a déjà lancé un chatbot japonais hors ligne “Tiny Sparrow” et une IA capable de comprendre la littérature japonaise, et a établi un partenariat avec la banque japonaise Mitsubishi UFJ pour développer un “système IA dédié aux banques”. L’entreprise met l’accent sur l’attraction des talents grâce au “soft power japonais” et sur la réalisation d’expériences audacieuses dans le domaine de l’IA. (Source : SakanaAILabs)
Percées en robotique et fusion avec l’IA : nouvelles avancées pour les robots humanoïdes, en essaim et quadrupèdes : Le domaine de la robotique connaît des progrès significatifs, en particulier pour les robots humanoïdes, les robots en essaim et les robots quadrupèdes. L’interaction naturelle par la parole entre les robots humanoïdes et le personnel est devenue une réalité, les robots quadrupèdes ont atteint une vitesse étonnante de moins de 10 secondes sur 100 mètres, et les robots en essaim ont démontré une “intelligence incroyable”. De plus, le système de navigation ANT pour les terrains complexes et la base d’escalade autonome conçue par Eufy pour les robots aspirateurs, préfigurent une application plus large des robots dans les scénarios quotidiens et industriels. L’application de l’IA dans les essais cliniques en neurosciences s’approfondit également, avec l’analyse de l’impact de l’utilisation de l’exosquelette intelligent HAPO SENSOR, démontrant le potentiel de l’IA dans le domaine de la santé. (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Outils
Mises à jour Qwen Code v0.0.10 & v0.0.11 : amélioration de l’expérience et de l’efficacité de développement : Alibaba Cloud Qwen Code a publié les versions v0.0.10 et v0.0.11, apportant de nouvelles fonctionnalités et des améliorations conviviales pour les développeurs. Les nouvelles versions introduisent des Subagents pour la décomposition intelligente des tâches, un outil Todo Write pour le suivi des tâches, et une fonction de résumé de projet “Bienvenue de retour” lors de la réouverture d’un projet. De plus, les mises à jour incluent des stratégies de cache personnalisables, une expérience d’édition plus fluide (sans boucle d’agent), des tests de stress de benchmark de terminal intégrés, moins de tentatives, une lecture optimisée des fichiers de grands projets, une intégration IDE et shell améliorée, un meilleur support MCP et OAuth, ainsi qu’une gestion améliorée de la mémoire/session et une documentation multilingue. Ces améliorations visent à augmenter significativement la productivité des développeurs. (Source : Alibaba_Qwen)
Astuces d’utilisation et améliorations de l’expérience utilisateur pour Claude Code : Les discussions et suggestions d’amélioration de l’expérience utilisateur de Claude Code sont nombreuses. Les utilisateurs ont partagé des prompts pour “ajouter des informations de journalisation appropriées” afin d’aider l’agent IA à résoudre les problèmes de code. Un développeur a publié l’application iOS “Standard Input” pour Claude Code, prenant en charge l’utilisation mobile, les notifications push et le chat interactif. Parallèlement, la communauté a également discuté des incohérences de Claude Code dans le traitement des grands projets et de l’importance de la gestion du contexte, suggérant aux utilisateurs de vider activement le contexte, de personnaliser les fichiers Claude md et le style de sortie, d’utiliser des sous-agents pour décomposer les tâches, et d’utiliser les modes de planification et les hooks pour améliorer l’efficacité et la qualité du code. (Source : dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face et VS Code/Copilot : intégration approfondie pour autonomiser les développeurs : Hugging Face, via ses fournisseurs d’inférence, intègre des centaines de modèles open source de pointe (tels que Kimi K2, Qwen3 Next, gpt-oss, Aya, etc.) directement dans VS Code et GitHub Copilot. Cette intégration, soutenue par des partenaires comme Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, offre aux développeurs un choix de modèles plus riche et met en avant les avantages des poids open source, du routage automatique multi-fournisseurs, d’une tarification équitable, d’un changement de modèle fluide et d’une transparence totale. De plus, la bibliothèque Transformers de Hugging Face a introduit la fonctionnalité “Continuous Batching”, simplifiant les boucles d’évaluation et d’entraînement et améliorant la vitesse d’inférence, visant à devenir une boîte à outils puissante pour le développement et l’expérimentation de modèles IA. (Source : ClementDelangue, code)

AU-Harness : une boîte à outils d’évaluation open source complète pour les LLM audio : AU-Harness est un cadre d’évaluation open source efficace et complet, spécialement conçu pour les grands modèles de langage audio (LALM). Cette boîte à outils, grâce à l’optimisation du traitement par lots et de l’exécution parallèle, a permis une augmentation de la vitesse allant jusqu’à 127 %, rendant possible l’évaluation à grande échelle des LALM. Elle offre un protocole de prompt standardisé et une configuration flexible pour une comparaison équitable des modèles dans différents scénarios. AU-Harness introduit également deux nouvelles catégories d’évaluation : LLM-Adaptive Diarization (compréhension audio temporelle) et Spoken Language Reasoning (tâches cognitives audio complexes), visant à révéler les lacunes significatives des LALM actuels en matière de compréhension temporelle et de raisonnement vocal complexe, et à promouvoir le développement systématique des LALM. (Source : HuggingFace Daily Papers)
AI-DO : un système de détection de vulnérabilités CI/CD basé sur les LLM : AI-DO (Automating vulnerability detection Integration for Developers’ Operations) est un système de recommandation intégré aux processus d’intégration continue/déploiement continu (CI/CD), utilisant le modèle CodeBERT pour détecter et localiser les vulnérabilités lors de la phase de revue de code. Ce système vise à combler le fossé entre la recherche académique et les applications industrielles. En évaluant la généralisation inter-domaines de CodeBERT sur des données open source et industrielles, il a été constaté que le modèle est précis dans le même domaine, mais que ses performances diminuent d’un domaine à l’autre. Grâce à des techniques de sous-échantillonnage appropriées, les modèles affinés sur des données open source peuvent améliorer efficacement les capacités de détection de vulnérabilités. Le développement d’AI-DO améliore la sécurité des processus de développement sans interrompre les flux de travail existants. (Source : HuggingFace Daily Papers)
Replit Agent 3 : de l’idée à l’application ultra-rapide : L’Agent 3 de Replit a démontré une efficacité étonnante, capable de construire une application complète pour la gestion des rendez-vous d’un salon de beauté, trouvée sur Upwork, en 145 minutes. Cette application comprenait un processus d’enregistrement client, une base de données clients et un tableau de bord backend. L’agent a également fait preuve d’une grande autonomie, fonctionnant sans intervention pendant 193 minutes, générant du code de niveau production, y compris l’authentification, la base de données, le stockage et les WebSocket, et même en écrivant ses propres tests et algorithmes de classement. Ces capacités soulignent l’énorme potentiel des agents IA dans le développement rapide de prototypes et la construction d’applications full-stack, accélérant considérablement le processus de transformation des idées en produits réels. (Source : amasad, amasad, amasad)
Claude ajoute des fonctionnalités de création et d’édition de fichiers : Claude peut désormais créer et éditer directement des feuilles de calcul Excel, des documents, des présentations PowerPoint et des fichiers PDF sur Claude.ai et dans l’application de bureau. Cette nouvelle fonctionnalité étend considérablement les scénarios d’application de Claude dans les outils de bureautique et de productivité quotidiens, lui permettant de s’intégrer plus profondément dans les flux de travail de traitement de documents et de génération de contenu, améliorant ainsi l’efficacité et la commodité des utilisateurs lors du traitement de tâches de fichiers complexes. (Source : dl_weekly)
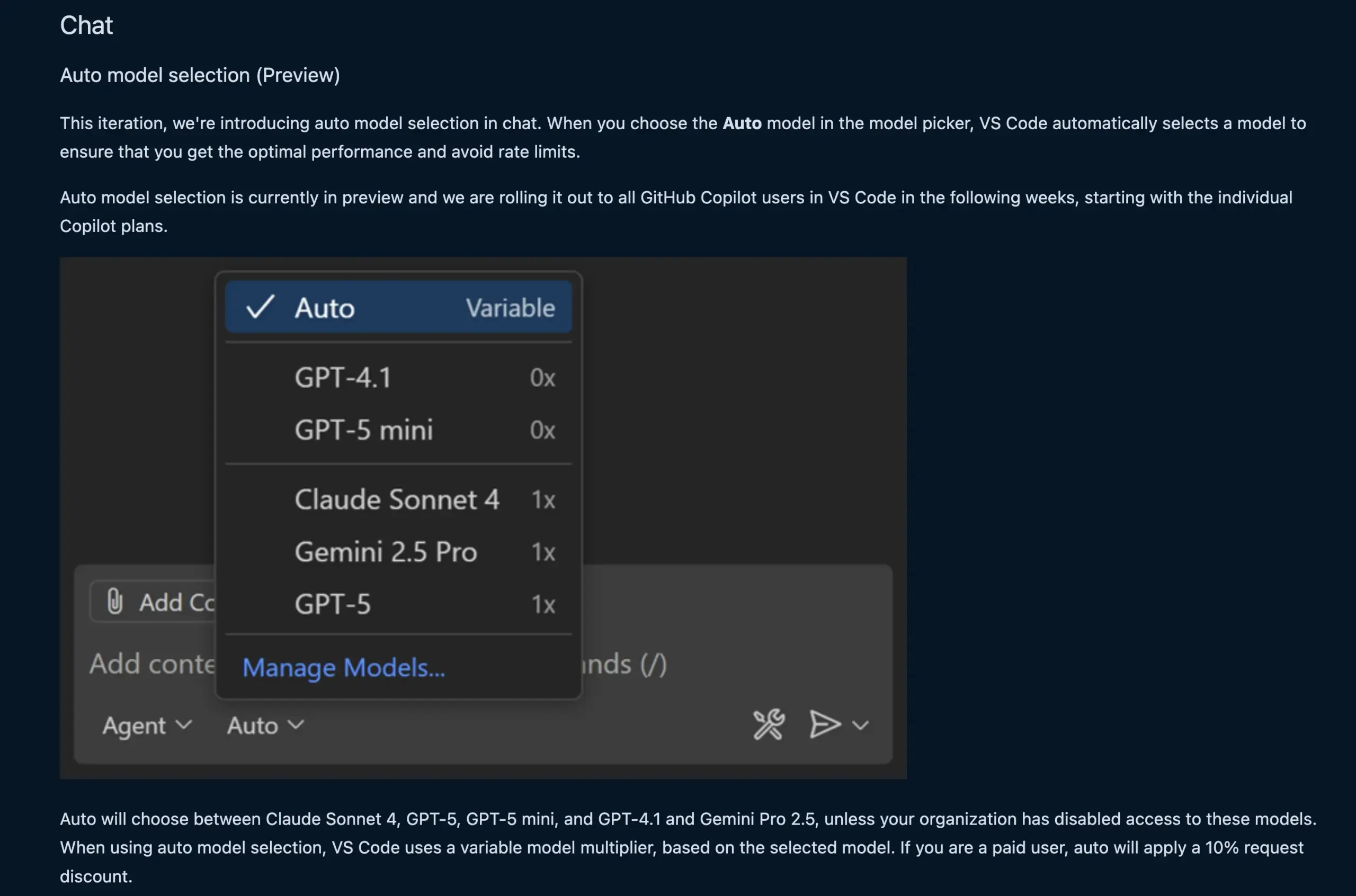
La fonction de chat de VS Code sélectionne automatiquement le modèle LLM : La nouvelle fonction de chat de VS Code peut désormais sélectionner automatiquement le modèle LLM approprié en fonction de la demande de l’utilisateur et des limites de débit. Cette fonction peut basculer intelligemment entre les modèles Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 et Gemini Pro 2.5, offrant aux développeurs une expérience de programmation assistée par IA plus pratique et efficace. Parallèlement, l’API d’extension du fournisseur de chat de modèles de langage de VS Code a été finalisée, permettant de contribuer des modèles via des extensions et prenant en charge le mode “Bring Your Own Key” (BYOK), enrichissant davantage le choix des modèles et les capacités de personnalisation. (Source : code, pierceboggan)
Box lance des capacités d’agents IA pour la gestion des données non structurées : Box a annoncé le lancement de nouvelles fonctionnalités d’agents IA, visant à aider les clients à tirer pleinement parti de la valeur de leurs données non structurées. Le Box AI Studio mis à jour facilite la création d’agents IA, applicables à diverses fonctions commerciales et cas d’utilisation sectoriels. Box Extract utilise des agents IA pour l’extraction complexe de données à partir de divers documents, tandis que Box Automate est une nouvelle solution d’automatisation des flux de travail, permettant aux utilisateurs de déployer des agents IA dans les flux de travail du centre de contenu. Ces fonctionnalités s’intègrent de manière transparente aux systèmes existants des clients via des intégrations pré-construites, l’API Box ou le nouveau Box MCP Server, et visent à transformer la façon dont les entreprises traitent le contenu non structuré. (Source : hwchase17)
Nouveau modèle Tab de Cursor : amélioration de la précision et du taux d’acceptation des suggestions de code : Cursor a publié son nouveau modèle Tab, qui est désormais son outil de suggestion de code par défaut. Ce modèle, entraîné par apprentissage par renforcement (RL) en ligne, a réduit le nombre de suggestions de code de 21 % par rapport à l’ancien modèle, tout en augmentant le taux d’acceptation des suggestions de 28 %. Cette amélioration signifie que le nouveau modèle peut fournir des suggestions de code plus précises et plus pertinentes pour les intentions des développeurs, améliorant ainsi considérablement l’efficacité de la programmation et l’expérience utilisateur, réduisant les interférences inutiles et permettant aux développeurs de réaliser leurs tâches de codage plus efficacement. (Source : BlackHC, op7418)
awesome-llm-apps : une collection d’applications LLM open source : Le projet GitHub awesome-llm-apps est salué comme une mine d’or open source, regroupant plus de 40 applications LLM déployables, allant des agents de podcasting pour blogs IA à l’analyse d’images médicales. Chaque application est accompagnée d’une documentation détaillée et d’instructions de configuration, ce qui permet de réaliser en quelques minutes un travail qui prendrait normalement des semaines. Par exemple, le projet de guide audio IA, grâce à un système multi-agents, une recherche web en temps réel et la technologie TTS, peut générer des visites audio naturelles et contextuelles, avec des coûts d’API faibles, démontrant l’utilité des systèmes multi-agents dans la génération de contenu. (Source : Reddit r/MachineLearning)
📚 Apprentissage
MMOral : un benchmark multimodal et jeu de données d’instructions pour l’analyse de radiographies panoramiques dentaires : MMOral est le premier jeu de données d’instructions et benchmark multimodal à grande échelle, spécialement conçu pour l’interprétation des radiographies panoramiques dentaires. Ce jeu de données contient 20 563 images annotées et 1,3 million d’instances de suivi d’instructions, couvrant des tâches telles que l’extraction d’attributs, la génération de rapports, la question-réponse visuelle et le dialogue d’images. La suite d’évaluation complète MMOral-Bench couvre cinq dimensions clés du diagnostic dentaire. Les résultats montrent que même les meilleurs modèles LVLM comme GPT-4o n’atteignent qu’une précision de 41,45 %, soulignant les limites des modèles existants dans ce domaine. OralGPT, en effectuant un SFT sur Qwen2.5-VL-7B, a réalisé une amélioration significative des performances de 24,73 %, jetant les bases de la dentisterie intelligente et des systèmes d’IA multimodaux cliniques. (Source : HuggingFace Daily Papers)
Évaluation inter-domaines de la détection de vulnérabilités Transformer : Une étude a évalué les performances de CodeBERT dans la détection de vulnérabilités dans les logiciels industriels et open source, et a analysé sa capacité de généralisation inter-domaines. L’étude a révélé que les modèles entraînés sur des données industrielles sont précis dans le même domaine, mais que leurs performances diminuent sur le code open source. Cependant, les modèles d’apprentissage profond affinés sur des données open source via des techniques de sous-échantillonnage appropriées peuvent améliorer efficacement les capacités de détection de vulnérabilités. Sur la base de ces résultats, l’équipe de recherche a développé le système AI-DO, un système de recommandation intégré aux processus CI/CD, capable de détecter et de localiser les vulnérabilités lors de la revue de code, sans perturber les flux de travail existants, visant à promouvoir la conversion des technologies académiques en applications industrielles. (Source : HuggingFace Daily Papers)
Ego3D-Bench : un benchmark de raisonnement spatial VLM pour les scènes égocentriques multi-vues : Ego3D-Bench est un nouveau benchmark conçu pour évaluer les capacités de raisonnement spatial 3D des modèles de langage visuel (VLM) dans des données extérieures égocentriques et multi-vues. Ce benchmark contient plus de 8 600 paires de questions-réponses annotées par des humains, utilisées pour tester 16 VLM SOTA, dont GPT-4o et Gemini1.5-Pro. Les résultats montrent un écart significatif entre les VLM actuels et le niveau humain en matière de compréhension spatiale. Pour combler cet écart, l’équipe de recherche a proposé le cadre de post-entraînement Ego3D-VLM, qui, en générant des cartes cognitives basées sur des coordonnées 3D globales estimées, a amélioré en moyenne de 12 % la question-réponse à choix multiples et de 56 % l’estimation de distance absolue, offrant un outil précieux pour atteindre une compréhension spatiale de niveau humain. (Source : HuggingFace Daily Papers)
L’illusion des rendements décroissants dans l’exécution de tâches à long terme par les LLM : Une nouvelle recherche examine les performances des LLM dans l’exécution de tâches à long terme, soulignant qu’une légère amélioration de la précision en une seule étape peut entraîner une croissance exponentielle de la longueur de la tâche. L’article suggère que l’échec des LLM dans les tâches longues n’est pas dû à un manque de capacité de raisonnement, mais à des erreurs d’exécution. En fournissant explicitement des connaissances et une planification, l’étude a montré que les grands modèles peuvent exécuter plus d’étapes correctement, même si les petits modèles atteignent 100 % de précision en une seule étape. Une découverte intéressante est l’effet d‘“autorégulation” des modèles, c’est-à-dire que lorsque le contexte contient des erreurs précédentes, le modèle est plus susceptible de refaire des erreurs, et que la seule taille du modèle ne peut pas résoudre ce problème. Les derniers “modèles de pensée” peuvent éviter l’autorégulation et accomplir des tâches plus longues en une seule exécution, soulignant les énormes avantages de l’extension de la taille du modèle et du calcul de test séquentiel pour les tâches à long terme. (Source : Reddit r/ArtificialInteligence)
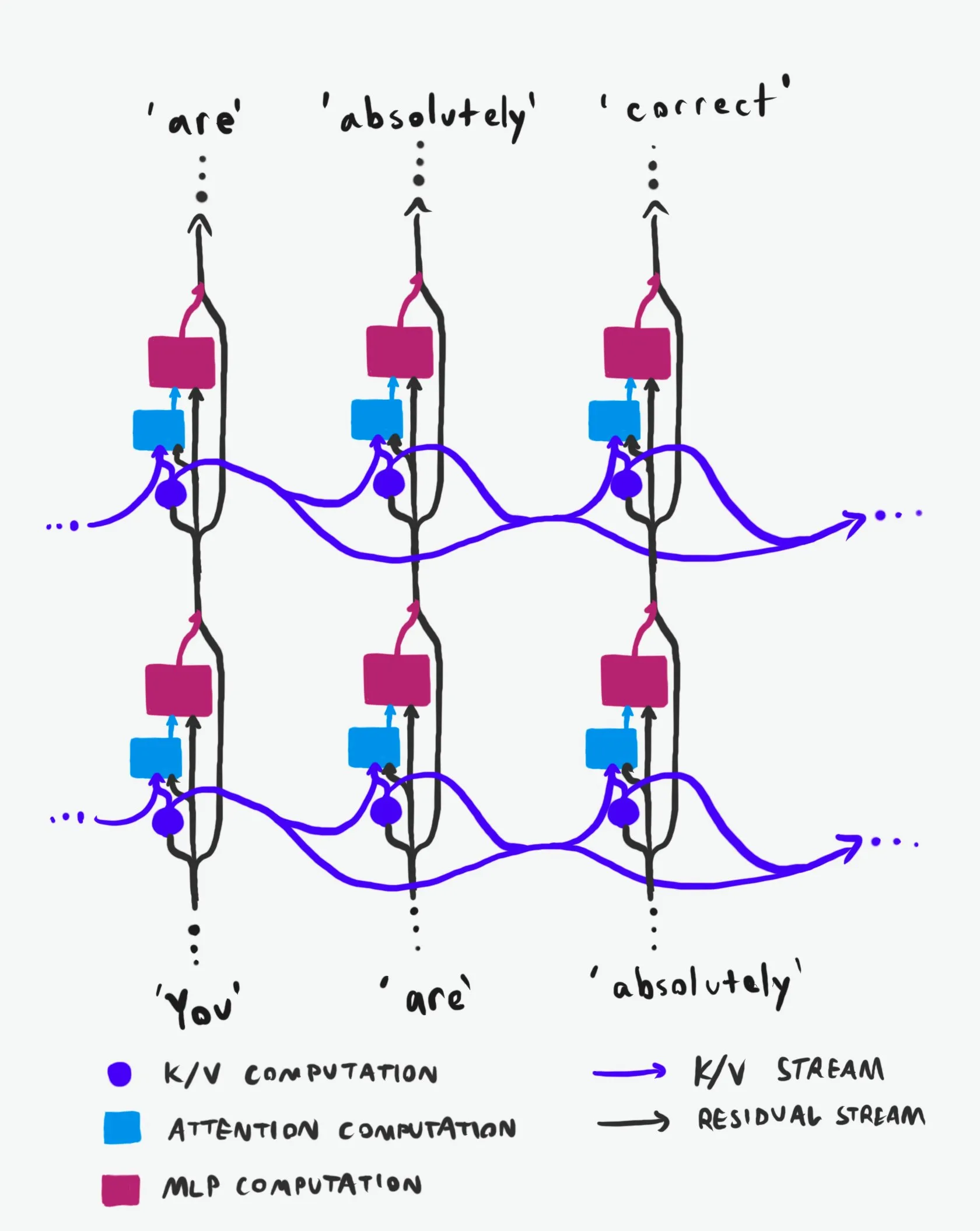
Structure causale des Transformers : une analyse approfondie du flux d’informations : Une explication technique, saluée comme la “meilleure de sa catégorie”, analyse en profondeur la structure causale des grands modèles de langage (LLM) Transformer et la manière dont l’information y circule. Cette explication évite les termes obscurs et clarifie les deux principales autoroutes de l’information dans l’architecture Transformer : le flux résiduel (Residual Stream) et le mécanisme d’attention. Grâce à des visualisations et des descriptions détaillées, elle aide les chercheurs et les développeurs à mieux comprendre le fonctionnement interne des Transformers, leur permettant ainsi de prendre des décisions plus éclairées en matière de conception, d’optimisation et de débogage des modèles, ce qui est d’une grande valeur pour une maîtrise approfondie des mécanismes sous-jacents des LLM. (Source : Plinz)
Carnegie Mellon University lance un nouveau cours sur l’inférence des modèles de langage : @gneubig et @Amanda Bertsch de la Carnegie Mellon University (CMU) co-enseigneront un nouveau cours sur l’inférence des modèles de langage (LM) cet automne. Ce cours vise à fournir une introduction complète au domaine de l’inférence des LM, couvrant des algorithmes de décodage classiques aux dernières méthodes pour les LLM, ainsi qu’une série de travaux axés sur l’efficacité. Le contenu du cours sera publié en ligne, y compris les vidéos des quatre premières leçons, offrant une ressource d’apprentissage précieuse pour les étudiants et les chercheurs intéressés par l’inférence des LM, les aidant à maîtriser les techniques et pratiques d’inférence de pointe. (Source : lateinteraction, dejavucoder, gneubig)
OpenAIDevs publie une vidéo d’analyse approfondie de Codex : OpenAIDevs a publié une vidéo d’analyse approfondie de Codex, détaillant les changements et les dernières fonctionnalités de Codex au cours des deux derniers mois. La vidéo fournit des astuces et des meilleures pratiques pour tirer pleinement parti de Codex, visant à aider les développeurs à mieux comprendre et utiliser cet outil de programmation IA puissant. Le contenu couvre les dernières avancées de Codex en matière de génération de code, de débogage et de développement assisté, ce qui en fait une ressource d’apprentissage importante pour les développeurs souhaitant améliorer l’efficacité de la programmation assistée par IA. (Source : OpenAIDevs)
Rapport sur l’état du marché des GPU cloud en 2025 : dstackai a publié un rapport sur l’état du marché des GPU cloud en 2025, couvrant les coûts, les performances et les stratégies d’utilisation. Ce rapport analyse en détail les prix actuels du marché, les configurations matérielles et les performances, fournissant aux ingénieurs en machine learning des informations spécifiques sur le marché et des références pour choisir des fournisseurs de services cloud, complétant ainsi les guides généraux sur la manière de choisir un fournisseur cloud en ingénierie machine learning, et offrant des conseils importants pour optimiser les coûts et l’efficacité de l’entraînement et de l’inférence de l’IA. (Source : stanfordnlp)
Panorama du matériel IA : les diverses unités de calcul qui alimentent l’IA : The Turing Post a publié un guide sur le matériel qui alimente l’IA, détaillant les diverses unités de calcul telles que les GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, les processeurs quantiques, les puces de calcul in-memory (PIM) et les puces neuromorphiques. Ce guide explore en profondeur le rôle, les avantages et les scénarios d’application de chaque type de matériel dans le calcul IA, aidant les lecteurs à comprendre de manière exhaustive le support de puissance de calcul sous-jacent de la pile technologique IA, et offrant une valeur de référence importante pour la sélection du matériel et la conception de systèmes IA. (Source : TheTuringPost)
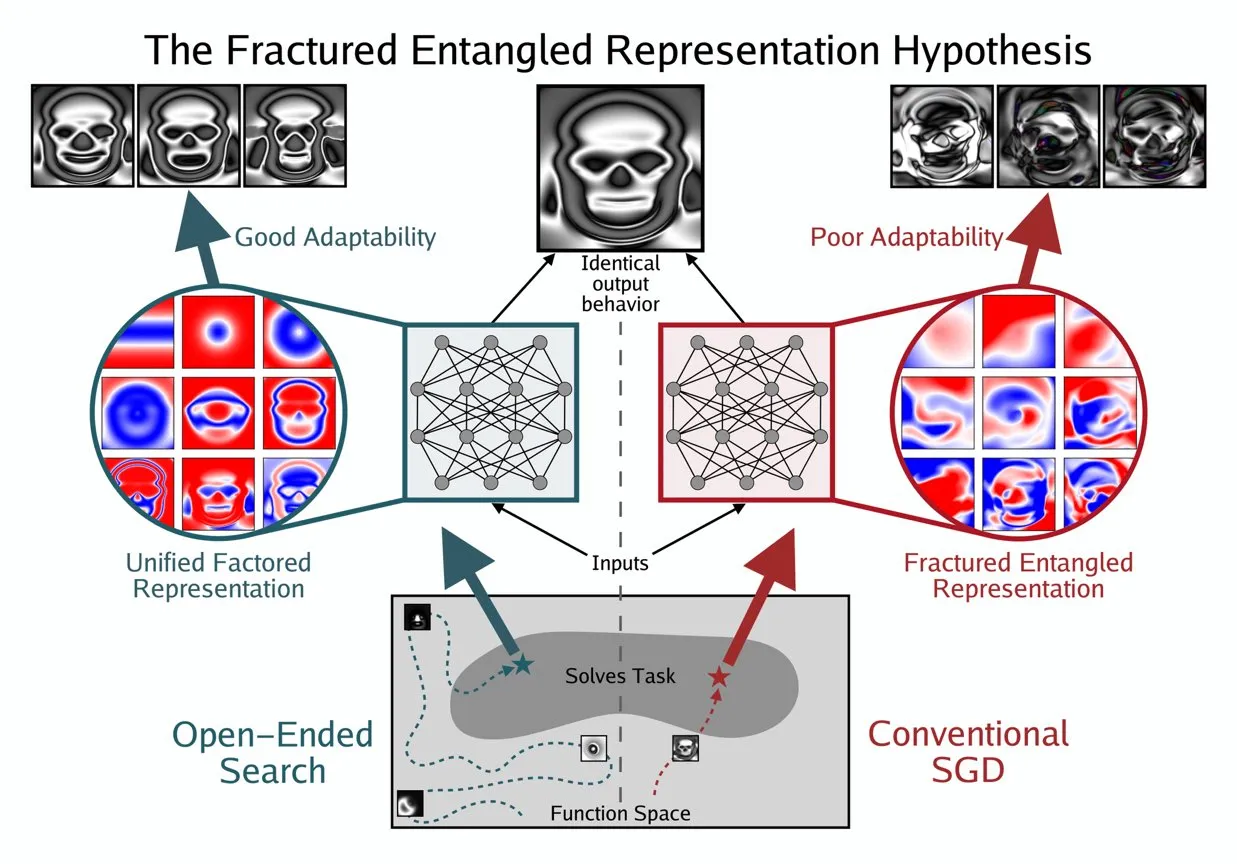
Kenneth Stanley propose le concept d’UFR pour comprendre la “véritable compréhension” de l’IA : Kenneth Stanley a proposé le concept de “Unified Factored Representation” (UFR) pour aider à expliquer ce que signifie la “véritable compréhension” de l’IA. Il estime que lorsque l’on parle de la “véritable compréhension” de l’IA, le cœur réside dans l’UFR. Ce concept vise à fournir un cadre théorique plus profond pour les capacités cognitives de l’IA, au-delà de la simple reconnaissance de formes, touchant à la capacité de l’IA à structurer, décomposer et former des contraintes rigides sur le monde, incitant ainsi l’IA non seulement à imiter la connaissance, mais aussi à penser de manière créative et à résoudre de nouveaux problèmes comme les humains. (Source : hardmaru, hardmaru)
💼 Affaires
Tencent aurait débauché un chercheur de haut niveau d’OpenAI, la guerre des talents en IA s’intensifie : Selon Bloomberg, Yao Shunyu, un chercheur de haut niveau d’OpenAI, a quitté l’entreprise pour rejoindre le géant technologique chinois Tencent. Cet événement souligne l’intensification de la guerre mondiale des talents en IA, en particulier entre les États-Unis et la Chine. Le mouvement des chercheurs IA de premier plan n’affecte pas seulement les feuilles de route technologiques des entreprises, mais reflète également la concurrence féroce en matière d’innovation dans le domaine de l’IA, préfigurant un changement potentiel dans le paysage futur de l’IA en raison des flux de talents. (Source : The Verge)
OpportuNext recherche un cofondateur technique pour créer une plateforme de recrutement IA : OpportuNext, une plateforme de recrutement basée sur l’IA fondée par des anciens élèves de l’IIT Bombay, recherche un cofondateur technique. Cette plateforme vise à résoudre les problèmes de recrutement pour les demandeurs d’emploi et les employeurs grâce à une analyse complète des CV, une recherche d’emploi sémantique, des feuilles de route de compétences et des pré-évaluations. Le marché cible est l’Inde (262 millions de dollars) avec une expansion prévue vers le marché mondial (40,5 milliards de dollars). OpportuNext a validé l’adéquation produit-marché et a achevé un prototype de parseur de CV, avec un plan de clôture d’une série A d’ici mi-2026. Le poste exige une solide expérience en IA/ML (NLP), développement full-stack, infrastructure de données, scraping/API et DevOps/sécurité. (Source : Reddit r/deeplearning)
Larry Ellison, fondateur d’Oracle : l’inférence est la clé de la rentabilité de l’IA : Larry Ellison, fondateur d’Oracle, a déclaré : “l’inférence est la clé de la rentabilité de l’IA”. Il estime que les sommes colossales actuellement investies dans l’entraînement des modèles se traduiront finalement par des ventes de produits, et que ces produits dépendront principalement des capacités d’inférence. Ellison souligne qu’Oracle est en tête pour tirer parti de la demande d’inférence, ce qui indique que le discours de l’industrie de l’IA passe de “qui peut entraîner le plus grand modèle” à “qui peut fournir des services d’inférence de manière efficace, fiable et à grande échelle”. Ce point de vue a suscité des discussions sur l’orientation future du modèle économique de l’IA, à savoir si les services d’inférence domineront la structure des revenus futurs. (Source : Reddit r/MachineLearning)
🌟 Communauté
Éthique et sécurité de l’IA : défis multidimensionnels et collaboration : La communauté a largement discuté des défis éthiques et de sécurité posés par l’IA, y compris l’impact potentiel de l’IA sur le marché du travail et les stratégies de protection, les préoccupations concernant la sécurité de la vie privée de l’outil ChatGPT MCP, et les débats sérieux sur les risques d’extinction que l’IA pourrait entraîner. Les problèmes de santé mentale causés par l’IA, tels que la dépendance excessive des utilisateurs à l’IA, voire la “psychose IA” et la solitude, suscitent également une attention croissante. Parallèlement, les discussions sur la réglementation de l’IA (comme le projet de loi Ted Cruz) se poursuivent. Du côté positif, des entreprises comme Anthropic et OpenAI collaborent avec des agences de sécurité pour découvrir et corriger les vulnérabilités des modèles, afin de renforcer la protection de la sécurité de l’IA. (Source : Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

Performance et évaluation des LLM : qualité des modèles et controverses sur les benchmarks : La communauté a mené une discussion approfondie sur l’évaluation des performances des LLM et les problèmes de qualité des modèles. Des modèles comme K2-Think ont été remis en question en raison de défauts dans les méthodes d’évaluation (tels que la contamination des données et les comparaisons inéquitables), soulevant des préoccupations quant à la fiabilité des benchmarks IA existants. Des recherches indiquent que les LLM en tant qu’annotateurs de données peuvent introduire des biais, conduisant au “LLM Hacking” des résultats scientifiques. L’expérience des utilisateurs avec Claude Code est mitigée, reflétant ses défis en matière de cohérence et de “paresse”, et Anthropic a également reconnu et corrigé la dégradation des performances de Claude Sonnet 4. Parallèlement, GPT-5 Pro a reçu des éloges pour ses puissantes capacités de raisonnement, mais certains utilisateurs ont également observé la généralité du texte généré par l’IA et une attention continue à la fiabilité des modèles (tels que les bugs de raisonnement). (Source : Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
Avenir du travail et agents IA : amélioration de l’efficacité et transformation professionnelle : Les agents IA transforment profondément les méthodes de travail. Les experts (tels que les avocats, médecins, ingénieurs) peuvent étendre leurs services professionnels en injectant leurs connaissances personnelles dans des agents IA, permettant ainsi que leurs revenus ne soient plus limités par la facturation horaire. Amjad Masad, PDG de Replit, prédit que les agents IA généreront des logiciels à la demande, rendant la valeur des logiciels traditionnels quasi nulle et remodelant la manière dont les entreprises sont construites. La communauté a discuté de l’importance de l’esprit d’entreprise et de l’adaptabilité à l’ère de l’IA, des avantages uniques de Replit dans le développement d’agents (comme les environnements testables), et de la comparaison entre les modèles robotiques et l’efficacité du cerveau humain. De plus, le potentiel de Cursor en tant qu’environnement d’apprentissage par renforcement a également suscité l’attention, préfigurant une amélioration future de la productivité individuelle et organisationnelle par l’IA. (Source : amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Écosystème open source et collaboration : popularisation des modèles et besoins de la communauté : Hugging Face joue un rôle central dans l’écosystème de l’IA, ses avantages en tant que plateforme modulaire, standardisée et intégrée offrant aux développeurs une multitude d’outils et de modèles, réduisant ainsi la barrière à la construction d’IA. La communauté a salué le projet Apple MLX et ses contributions open source pour l’amélioration de l’efficacité matérielle. Parallèlement, la communauté a également activement appelé l’équipe Qwen à fournir un support GGUF pour le modèle Qwen3-Next, afin que son architecture personnalisée puisse fonctionner sur des frameworks d’inférence locaux plus larges comme llama.cpp, répondant ainsi aux besoins de la communauté en matière de popularisation et de facilité d’utilisation des modèles, et favorisant le développement ultérieur des technologies IA open source. (Source : ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Impact social étendu de l’IA : manifestations diverses, du divertissement à l’économie : L’IA pénètre la société sous diverses formes. Les courtes pièces de théâtre avec des animaux de compagnie IA sont devenues virales sur les médias sociaux en raison de leurs récits anthropomorphiques et de leur valeur émotionnelle, démontrant l’énorme potentiel de l’IA dans la création de contenu et le divertissement, attirant un grand nombre de jeunes utilisateurs et donnant naissance à de nouveaux modèles commerciaux. Parallèlement, les discussions sur les flux de capitaux entre les géants de l’IA (comme OpenAI et Oracle) ont suscité une réflexion sur le modèle économique de l’IA. La communauté a également exploré le potentiel de l’IA pour résoudre les problèmes de ressources (comme l’eau), ainsi que la suggestion que les chatbots IA ont besoin de plus de contenu visuel pour améliorer l’expérience utilisateur. De plus, l’application de l’IA sur les médias sociaux a également soulevé des discussions sur son impact sur les émotions et la cognition sociales. (Source : 36氪, Yuchenj_UW, kylebrussell, brickroad7)
Anecdotes et observations de la communauté IA : attentes personnalisées des utilisateurs envers l’IA et réflexions humoristiques : La communauté IA regorge d’observations uniques et de réflexions humoristiques sur le développement technologique et l’expérience utilisateur. Par exemple, le lien entre les codes de réduction d’abonnement OpenAI et le comportement de “réflexion” a suscité une discussion sur la valeur et le coût de l’IA. Les utilisateurs souhaitent que Claude Code ait des réponses plus personnalisées, voire qu’il soit doté d’une “personnalité”, reflétant un besoin profond d’une expérience d’interaction IA. Parallèlement, l’idée d’entraîner des agents IA par apprentissage par renforcement dans des environnements simulés (comme GTA-6) démontre également l’imagination illimitée de la communauté quant à l’avenir de l’IA. Ces discussions offrent non seulement un aperçu de l’état actuel de la technologie IA, mais reflètent également les émotions et les attentes des utilisateurs lors de leurs interactions avec l’IA. (Source : gneubig, jonst0kes, scaling01)
💡 Autres
Guide de maîtrise des compétences en IA pour 2025 : Avec le développement rapide des technologies d’intelligence artificielle, la maîtrise des compétences clés en IA est cruciale pour le développement professionnel individuel. Un guide de maîtrise des compétences en IA pour 2025 met l’accent sur 12 compétences essentielles à maîtriser dans les domaines de l’intelligence artificielle, du machine learning et du deep learning. Ces compétences couvrent tout, des théories fondamentales aux applications pratiques, et visent à aider les professionnels et les apprenants à s’adapter aux nouvelles exigences de l’ère de l’IA, améliorant ainsi leur compétitivité en matière d’innovation technologique et sur le marché du travail. (Source : Ronald_vanLoon)

Marché des GPU cloud en 2025 : rapport sur les coûts, les performances et les stratégies de déploiement : dstackai a publié un rapport détaillé sur l’état du marché des GPU cloud en 2025, analysant en profondeur les coûts des GPU, les performances et les stratégies de déploiement des différents fournisseurs de services cloud. Ce rapport vise à fournir aux ingénieurs en machine learning et aux entreprises des conseils spécifiques pour choisir des fournisseurs de cloud, les aidant à optimiser la configuration des ressources pour les tâches d’entraînement et d’inférence de l’IA, afin de prendre des décisions plus rentables et plus performantes face à la demande croissante d’infrastructures IA. (Source : stanfordnlp)
Aperçu des technologies matérielles de l’IA : les diverses unités de calcul qui alimentent l’avenir intelligent : The Turing Post a publié un guide complet sur le matériel de l’IA, détaillant les diverses unités de calcul qui alimentent actuellement l’intelligence artificielle. Celles-ci incluent les unités de traitement graphique (GPU), les unités de traitement tensoriel (TPU), les unités centrales de traitement (CPU), les circuits intégrés spécifiques à l’application (ASICs), les unités de traitement neuronal (NPU), les unités de traitement accéléré (APU), les unités de traitement intelligent (IPU), les unités de traitement résistif (RPU), les réseaux de portes programmables sur le terrain (FPGA), les processeurs quantiques, le calcul in-memory (PIM) et les puces neuromorphiques. Ce guide offre une perspective claire sur le support matériel sous-jacent de la pile technologique de l’IA, aidant les développeurs et les chercheurs à choisir la solution matérielle la plus adaptée à leurs charges de travail d’IA. (Source : TheTuringPost)