
Mots-clés:Puce AI photonique, K2 Think, Intelligence incarnée, Modèle Claude, Qwen3-Next, Seedream 4.0, Agent Jupyter, OpenPI, Ratio d’efficacité énergétique des puces AI photoniques, Vitesse d’inférence des modèles open source à grande échelle, Expression émotionnelle des robots humanoïdes, Agent intelligent de science des données pour LLM, Modèle visuel, linguistique et moteur pour robots
🔥 À la Une
Percée en efficacité des puces AI basées sur la lumière : Une équipe d’ingénieurs de l’Université de Floride a développé une nouvelle puce AI basée sur la lumière, utilisant des photons plutôt que de l’électricité pour des opérations d’AI telles que la reconnaissance d’images et la détection de motifs. La puce a atteint un taux de précision de 98% lors de tests de classification numérique, tout en améliorant l’efficacité énergétique jusqu’à 100 fois. Cette percée devrait réduire considérablement les coûts de calcul et la consommation d’énergie de l’AI, favorisant le développement plus écologique et évolutif de l’AI dans des domaines allant des smartphones aux supercalculateurs, et préfigure une refonte du paysage du matériel AI par les puces électro-optiques hybrides. (Source: Reddit r/ArtificialInteligence)

K2 Think : Le grand modèle open source le plus rapide au monde : MBZUAI des Émirats arabes unis, en collaboration avec G42 AI, a lancé K2 Think, un grand modèle open source basé sur Qwen 2.5-32B, avec une vitesse mesurée de plus de 2000 tokens/seconde, soit plus de 10 fois le débit d’un déploiement GPU typique. Le modèle excelle dans les tests de référence mathématiques comme AIME et intègre des innovations technologiques telles que le Long-Chain Thinking SFT, le Verifiable Reward RLVR, le Pre-inference Planning, le Best-of-N Sampling, le Speculative Decoding et l’accélération matérielle Cerebras WSE, marquant un nouveau sommet en matière de performances pour les systèmes d’inférence AI open source. (Source: teortaxesTex, HuggingFace)

Avancées en intelligence incarnée et robots humanoïdes : Une table ronde Zhihu a révélé plusieurs percées dans le domaine de l’intelligence incarnée. Le laboratoire Air de Tsinghua a présenté “Morpheus”, un “visage agile” utilisant une propulsion hybride et la technologie d’humain numérique pour des micro-expressions riches, visant à améliorer la valeur émotionnelle des robots humanoïdes. Parallèlement, le robot Ultra de Beijing Tiangong a remporté la course de 100 mètres aux Championnats du monde de robots humanoïdes, soulignant les avantages de ses algorithmes et de sa perception autonome. La discussion a également abordé des questions clés telles que le coût, la production de masse, la théorie du contrôle et la fusion des grands modèles avec les robots humanoïdes, indiquant que l’intelligence incarnée passe de l’exploration technologique à l’application pratique. (Source: ZhihuFrontier)

Jupyter Agent : Entraîner des LLM à la science des données avec des Notebooks : Hugging Face a lancé le projet Jupyter Agent, visant à permettre aux LLM de résoudre des tâches d’analyse de données et de science des données dans Jupyter Notebooks via des outils d’exécution de code. Grâce à un processus d’entraînement en plusieurs étapes comprenant le nettoyage de données de Kaggle Notebooks à grande échelle, la notation de la qualité éducative, la génération de QA et la génération de traces d’exécution de code, de petits modèles comme Qwen3-4B ont vu leur performance sur les tâches Easy du benchmark DABStep passer de 44,4% à 75%, prouvant que de petits modèles combinés à des données de qualité et un échafaudage peuvent devenir de puissants agents de science des données. (Source: HuggingFace Blog)
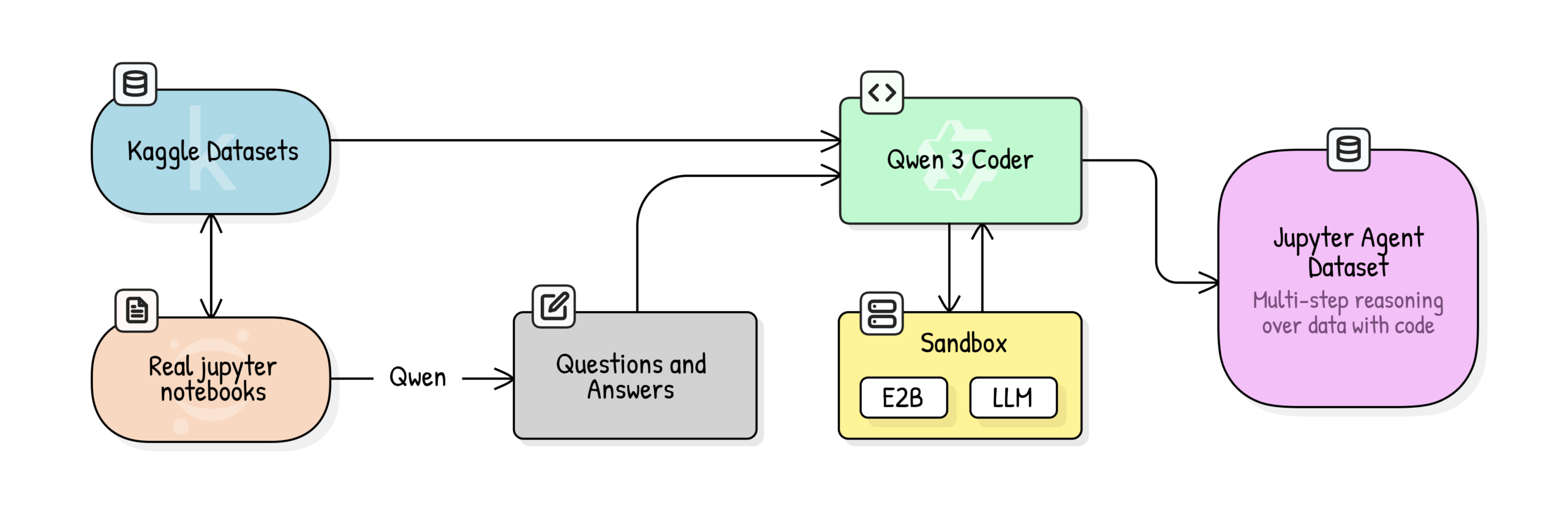
OpenPI : Modèle open source vision-langage-action pour la robotique : L’équipe Physical Intelligence a publié la bibliothèque OpenPI, comprenant les modèles open source Vision-Language-Action (VLA) π₀, π₀-FAST et π₀.₅. Ces modèles sont pré-entraînés sur plus de 10 000 heures de données robotiques, supportent PyTorch et atteignent des performances SOTA sur le benchmark LIBERO. OpenPI fournit des points de contrôle de modèles de base et des exemples de fine-tuning, supporte l’inférence à distance, et vise à promouvoir la recherche ouverte et les applications dans le domaine de la robotique, en particulier pour les tâches de manipulation de bureau et de saisie d’objets. (Source: GitHub Trending)
🎯 Tendances
Microsoft et Anthropic s’associent, le modèle Claude intégré à Office 365 Copilot : Microsoft intègre le modèle Claude d’Anthropic dans Office 365 Copilot, en particulier dans les domaines où Claude excelle, comme les calculs de fonctions Excel et la création de diapositives PowerPoint. Cette initiative vise à optimiser des fonctions spécifiques de Copilot dans Word, Excel et PowerPoint, à améliorer l’expérience utilisateur et à étendre la portée de Claude dans les outils de productivité d’entreprise. (Source: dotey, alexalbert__, menhguin, TheRundownAI)

L’AI accélère la recherche scientifique : graphes de connaissances et agents autonomes : MiniculeAI démontre comment l’AI peut accélérer la découverte scientifique grâce aux graphes de connaissances et aux agents autonomes. En cartographiant les gènes, les médicaments et les résultats dans un réseau dynamique, l’AI peut révéler des connexions cachées difficiles à trouver dans les documents PDF. Les agents autonomes peuvent scanner la littérature, découvrir des modèles et fournir des informations explicables, réduisant des mois de recherche traditionnelle à quelques minutes, tout en garantissant la confidentialité des données au niveau de l’entreprise. (Source: Ronald_vanLoon)
Série de modèles Qwen3-Next : Optimisation de la longueur de contexte et de l’efficacité des paramètres : L’équipe Qwen a lancé la série de modèles de base Qwen3-Next, axée sur les longueurs de contexte extrêmes et l’efficacité des paramètres à grande échelle. Cette série introduit plusieurs innovations architecturales, notamment GatedAttention (résolvant les valeurs aberrantes), GatedDeltaNet RNN (économisant le cache KV), et combine des architectures hybrides Sink+SWA ou Gated Attention+Linear RNN, visant à maximiser les performances et à minimiser les coûts de calcul, annonçant la fin de l’ère des modèles purement Attention. (Source: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
Lancement du modèle de génération et d’édition d’images ByteDance Seedream 4.0 : ByteDance a lancé Seedream 4.0, offrant des capacités exceptionnelles de génération et d’édition d’images. Les utilisateurs rapportent ses performances remarquables pour répondre aux besoins des utilisateurs, aux préférences esthétiques RLHF et au maintien des goûts dominants. Comparé à Seedream 3.0, la version 4.0 ajoute un grain de film et des artefacts d’objectif, un contraste plus élevé, des coups de pinceau de style anime plus nets, tout en démontrant une forte compréhension sémantique et une cohérence en chinois, ce qui le rend adapté aux infographies, tutoriels et conceptions de produits. (Source: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
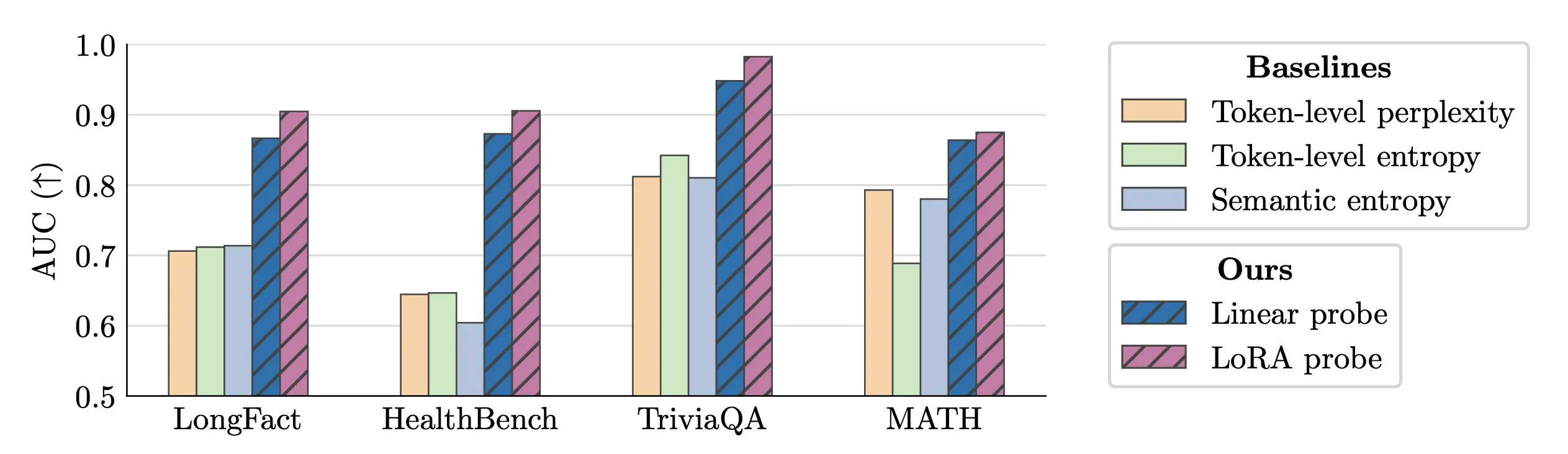
Technique de détection en temps réel des hallucinations des LLM : Des chercheurs proposent d’utiliser des sondes d’activation (activation probes) pour la détection en temps réel des hallucinations des LLM. Cette méthode excelle dans l’identification d’entités falsifiées dans de longs textes, atteignant une valeur AUC de 0,90, significativement supérieure aux méthodes traditionnelles d’entropie sémantique. De plus, de nouvelles recherches approfondissent l’origine des hallucinations dans les modèles Transformer, offrant de nouvelles pistes pour améliorer la fiabilité des LLM. (Source: paul_cal, tokenbender)
Microsoft VibeVoice : Génération vocale longue durée et haute fidélité : Le modèle VibeVoice de Microsoft réalise des progrès significatifs dans le domaine de l’audio AI, capable de générer des voix réalistes de 45 à 90 minutes, avec jusqu’à 4 locuteurs, sans avoir besoin de collage. Le modèle est disponible pour essai sur Hugging Face Space, permettant aux utilisateurs de l’utiliser pour un clonage vocal de haute qualité, ouvrant de nouvelles possibilités pour les podcasts, les livres audio et d’autres applications. (Source: Reddit r/LocalLLaMA)
mmBERT : Nouvelle référence pour les encodeurs multilingues : Le nouveau modèle mmBERT a été lancé, et devrait remplacer XLM-R, qui était SOTA depuis 6 ans. mmBERT est 2 à 4 fois plus rapide que les modèles existants et surpasse o3 et Gemini 2.5 Pro dans les tâches d’encodage multilingue. Le lancement de ce modèle, accompagné de modèles ouverts et de données d’entraînement, fournira une base plus efficace et plus puissante pour les applications AI multilingues. (Source: code_star)

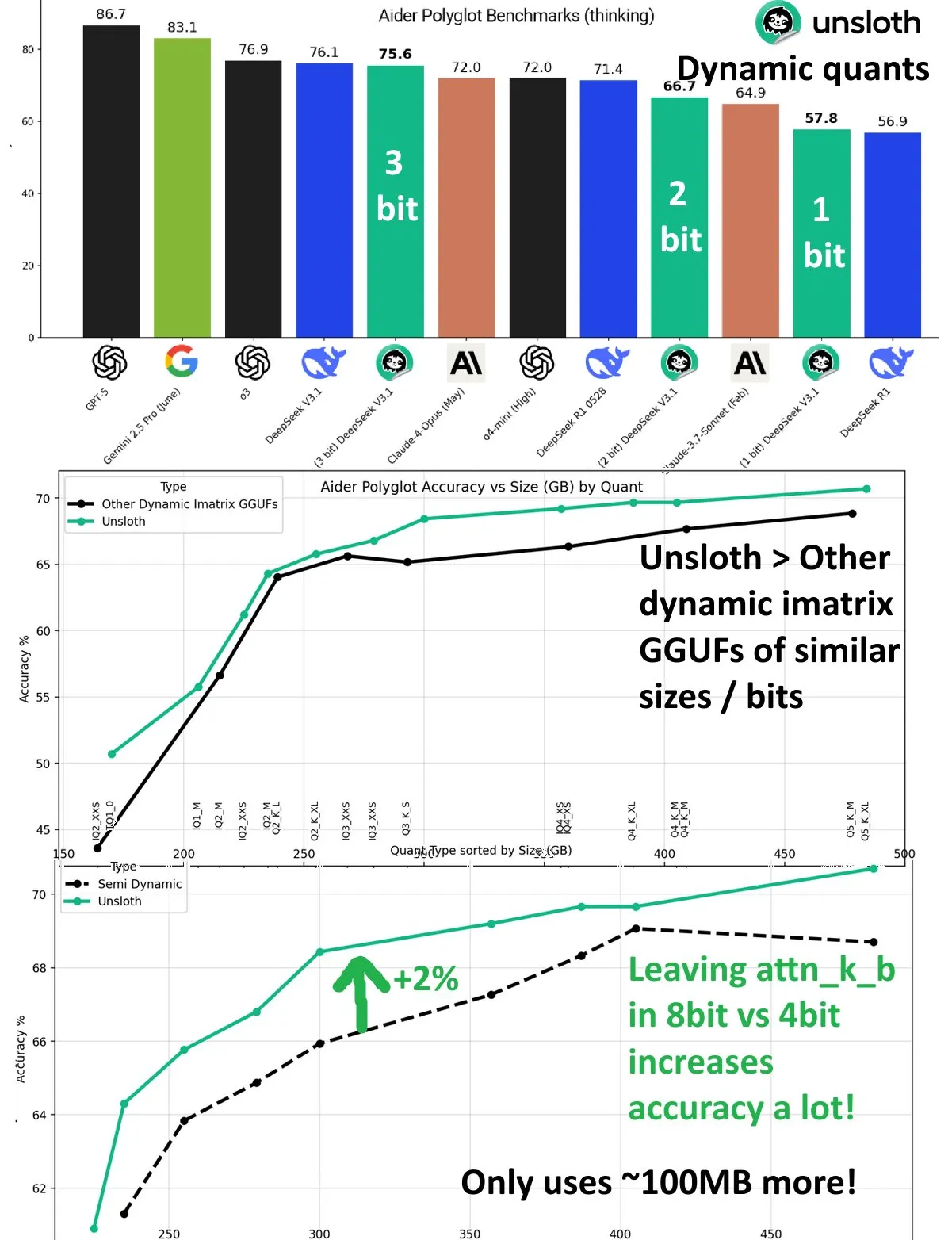
DeepSeek V3.1 : Amélioration des performances de quantification dynamique : Le modèle DeepSeek V3.1 a réalisé une amélioration significative de ses performances grâce à la technique de quantification dynamique sur le benchmark Aider Polyglot d’UnslothAI. La quantification à 3 bits approche la précision du modèle non quantifié, et en mode inférence, la quantification dynamique à 1 bit surpasse même les performances originales de DeepSeek R1. La recherche a montré que le maintien de la couche attn_k_b à une précision de 8 bits peut améliorer la précision de 2% supplémentaires, démontrant le potentiel de la quantification efficace pour maintenir les capacités du modèle et réduire les coûts de calcul. (Source: danielhanchen)
SpikingBrain-1.0 : Le grand modèle chinois entraîné sur GPU domestiques : L’Institut d’automatisation de l’Académie chinoise des sciences a lancé “SpikingBrain-1.0”, un grand modèle de réseau de neurones à impulsions (spiking neural network) entraîné et inféré sur un cluster de GPU domestiques MuXi, réduisant la consommation d’énergie de 97,7% par rapport aux opérations FP16 traditionnelles. Le modèle atteint 90% des performances de Qwen2.5-7B avec seulement 2% des données de pré-entraînement des grands modèles grand public, et excelle dans les tâches de traitement de séquences ultra-longues, avec une accélération TTFT allant jusqu’à 26,5 fois, validant la faisabilité d’un écosystème de grands modèles non-Transformer contrôlable et autonome en Chine. (Source: 36氪)
Wenxin X1.1 : Amélioration significative de la factualité, du respect des instructions et des capacités d’agent : Baidu a mis à jour son modèle de pensée profonde Wenxin X1.1, qui a amélioré la factualité de 34,8%, le respect des instructions de 12,5% et les capacités d’agent de 9,6%. L’effet global du modèle surpasse DeepSeek R1-0528 et rivalise avec GPT-5 et Gemini 2.5 Pro, démontrant de puissantes capacités d’agent dans des tâches complexes à long terme, pouvant automatiquement diviser les tâches et appeler des outils. Baidu a également lancé le modèle open source ERNIE-4.5-21B-A3B-Thinking et le kit de développement ERNIEKit, réduisant davantage le seuil d’application de l’AI. (Source: 量子位)

Huawei OpenPangu-Embedded-7B-v1.1 open source : Basculement libre entre pensée rapide et lente : Huawei a lancé OpenPangu-Embedded-7B-v1.1, un modèle open source de 7 milliards de paramètres, qui réalise pour la première fois un basculement libre entre les modes de pensée rapide et lente, et peut s’adapter à la difficulté des questions. Grâce à un fine-tuning progressif et une stratégie d’entraînement en deux étapes, la précision du modèle a été considérablement améliorée dans les évaluations générales, mathématiques et de code, et tout en maintenant la précision, la longueur moyenne de la chaîne de pensée a été réduite de près de 50%, comblant ainsi une lacune dans les grands modèles open source et améliorant l’efficacité et la précision. (Source: 量子位)

Tencent CodeBuddy Code : La programmation AI entre dans l’ère L4 : Tencent a lancé l’outil AI CLI CodeBuddy Code et a ouvert la bêta publique de CodeBuddy IDE, visant à propulser la programmation AI vers l’ère L4 de “l’ingénieur logiciel AI”. CodeBuddy Code, installable via npm, prend en charge le cycle de vie complet du développement et de l’exploitation piloté par le langage naturel, réalisant une automatisation extrême. Cet outil, grâce à la gestion pilotée par la documentation, la compression de contexte et l’extension MCP, devient l’infrastructure sous-jacente de la programmation AI d’entreprise, améliorant considérablement l’efficacité du développement. (Source: 量子位)

Scientifiques clés d’OpenAI : Les deux Polonais à l’origine de GPT-4 et des percées en inférence : Jakub Pachocki, scientifique en chef d’OpenAI, et Szymon Sidor, chercheur technique, ont été salués par Altman pour leurs contributions cruciales au projet Dota, au pré-entraînement de GPT-4 et à la promotion des percées en inférence. Les deux, amis depuis le lycée et réunis chez OpenAI, sont devenus une force indispensable pour OpenAI grâce à une approche combinant réflexion approfondie et expérimentation pratique, soutenant même fermement le retour d’Altman lors de la crise interne de 2023. (Source: 量子位)

Sommet AI de la Maison Blanche axé sur les talents, la sécurité et les défis nationaux : Melania Trump a présidé une réunion sur l’AI à la Maison Blanche, invitant des géants de la technologie tels que Google, IBM et Microsoft, en se concentrant sur le développement des talents, la sécurité et les défis nationaux dans le domaine de l’AI. Cette initiative montre que le gouvernement américain promeut activement une stratégie AI, visant à relever les opportunités et les défis du développement de l’AI et à assurer le leadership du pays dans ce domaine. (Source: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing : Au-delà des réseaux neuronaux traditionnels : Le Neuromorphic Computing redéfinit l’intelligence, s’inspirant de la structure et du fonctionnement du cerveau biologique. Cette technologie vise à développer du matériel AI plus efficace et à faible consommation d’énergie, en simulant la capacité de traitement parallèle des neurones et des synapses, pour réaliser des modes de calcul allant au-delà de l’architecture traditionnelle de von Neumann, offrant une base plus puissante pour les futurs systèmes AI. (Source: Reddit r/artificial)
MEGS² : Technologie de splatting gaussien à mémoire efficace : MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning) est une technique de splatting gaussien 3D (3DGS) à mémoire efficace. En remplaçant la représentation des couleurs par des harmoniques sphériques par des fonctions gaussiennes sphériques de n’importe quelle orientation, et en introduisant un cadre de pruning doux unifié, cette méthode réduit considérablement le nombre de paramètres par primitive, réalisant une compression VRAM statique de 8x et une compression VRAM de rendu de près de 6x, tout en maintenant ou en améliorant la qualité de rendu, ce qui est d’une grande importance pour les graphiques 3D et le rendu en temps réel. (Source: janusch_patas)

🧰 Outils
LangChain 1.0 introduit Middleware : Nouveau paradigme de contrôle de contexte pour les agents : LangChain 1.0 a lancé Middleware, offrant une nouvelle couche d’abstraction pour les agents AI, permettant aux développeurs de contrôler entièrement l’ingénierie de contexte. Cette fonctionnalité améliore la flexibilité, la composabilité et l’adaptabilité des agents, supportant la mise en œuvre de différentes architectures d’agents telles que la réflexion, les groupes et les superviseurs, fournissant une base solide pour la construction d’applications AI plus complexes. (Source: hwchase17, hwchase17, Hacubu)
MaxKB : Plateforme d’agents d’entreprise open source : MaxKB est une plateforme d’agents d’entreprise open source puissante et facile à utiliser, intégrant un pipeline RAG (Retrieval-Augmented Generation), un moteur de workflow robuste et des capacités d’utilisation d’outils MCP. Elle prend en charge le téléchargement de documents, le crawling automatique, la segmentation de texte et la vectorisation, réduisant efficacement les hallucinations des grands modèles, et prend en charge une variété de grands modèles privés et publics, offrant des entrées et sorties multimodales, largement utilisée dans le service client intelligent, les bases de connaissances d’entreprise et d’autres scénarios. (Source: GitHub Trending)

BlenderMCP : Intégration profonde de Claude AI avec Blender : BlenderMCP réalise une intégration profonde de Claude AI avec Blender, permettant à Claude de contrôler directement Blender pour la modélisation 3D, la création de scènes et les opérations via le Model Context Protocol (MCP). Cet outil prend en charge la communication bidirectionnelle, la manipulation d’objets, le contrôle des matériaux, l’inspection de scènes et l’exécution de code, et peut intégrer les actifs Poly Haven et Hyper3D Rodin, améliorant considérablement l’efficacité et les possibilités de la création 3D assistée par AI. (Source: GitHub Trending)

AI Sheets : Outil sans code pour la construction et la conversion de jeux de données AI : Hugging Face a lancé AI Sheets, un outil open source sans code pour construire, enrichir et transformer des jeux de données à l’aide de modèles AI. Cet outil peut être déployé localement ou exécuté sur le Hub, prend en charge l’accès à des milliers de modèles open source sur Hugging Face Hub (y compris gpt-oss), et peut être démarré rapidement via Docker ou pnpm, simplifiant le processus de traitement des données, particulièrement adapté à la génération de jeux de données à grande échelle. (Source: GitHub Trending)

Notebooks vLLM en temps réel et intégration Modal : Les Notebooks Modal sont intégrés à vLLM, offrant un environnement interactif en temps réel et partageable pour aider les développeurs à comprendre en profondeur les mécanismes internes de vLLM. Grâce à cette intégration, les utilisateurs peuvent facilement exécuter et partager des tâches de calcul compatibles CUDA dans le cloud sans avoir à construire des intégrations complexes, simplifiant considérablement le processus de développement et d’apprentissage de vLLM. (Source: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker prend en charge Minions AI : Charges de travail AI hybrides locales : Minions AI prend désormais officiellement en charge Docker, permettant aux utilisateurs de débloquer des charges de travail AI hybrides localement via le moteur de modèles Docker. Cette collaboration permet aux développeurs de déployer et de gérer plus facilement Minions AI dans des environnements locaux, combinant les avantages de la conteneurisation de Docker pour améliorer la flexibilité et l’efficacité du développement d’applications AI. (Source: shishirpatil_)
Replit Agent 3 : Nouvelle percée dans le développement logiciel autonome : Replit a lancé Agent 3, présenté comme le moment du “pilotage entièrement automatique” pour le développement logiciel, avec une autonomie 10 fois supérieure à celle des agents précédents. Cet Agent peut prototyper des applications plus en profondeur et continuer à avancer lorsque d’autres agents sont bloqués, visant à résoudre les étapes chronophages de test, de débogage et de refactoring dans le développement logiciel, améliorant considérablement l’efficacité du développement. (Source: amasad, amasad, pirroh)
Qwen3-Coder : Modèle de programmation open source rentable : Qwen3-Coder démontre des performances et une rentabilité exceptionnelles sur la plateforme Windsurf, ne nécessitant que 0,5 point pour fonctionner, ce qui est plus avantageux que Claude 4 et GPT-5 High (2 points). Ce modèle excelle dans les tâches de programmation et, en tant que modèle open source, offre une option de programmation AI puissante aux entreprises réglementées et aux organisations du secteur public sans dépendre des API publiques, aidant à résoudre les problèmes de souveraineté et de visibilité des données. (Source: bookwormengr)
📚 Apprentissage
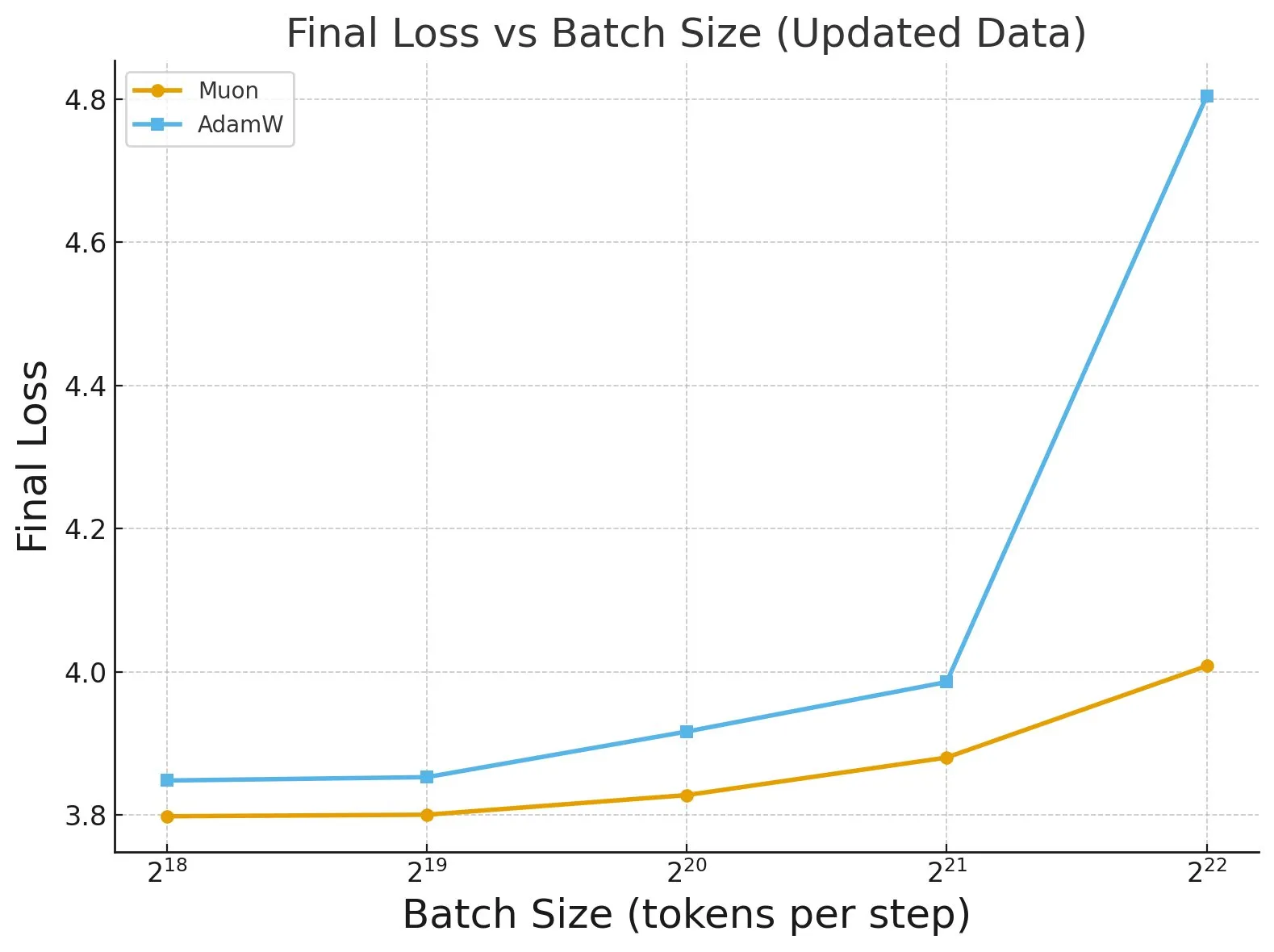
Étude « Fantastic Pretraining Optimizers and Where to Find Them » : Une vaste étude portant sur plus de 4000 modèles révèle les performances des optimiseurs de pré-entraînement. La recherche a montré que certains optimiseurs (comme Muon) peuvent atteindre jusqu’à 40% d’amélioration de la vitesse sur des modèles à petite échelle (<0,5 milliard de paramètres), mais seulement 10% sur des modèles à grande échelle (1,2 milliard de paramètres). Cela souligne la nécessité de se méfier des réglages de base insuffisants et des limitations d’échelle lors de l’évaluation des optimiseurs, et indique l’impact de la taille du lot sur l’écart de performance des optimiseurs. (Source: tokenbender, code_star)
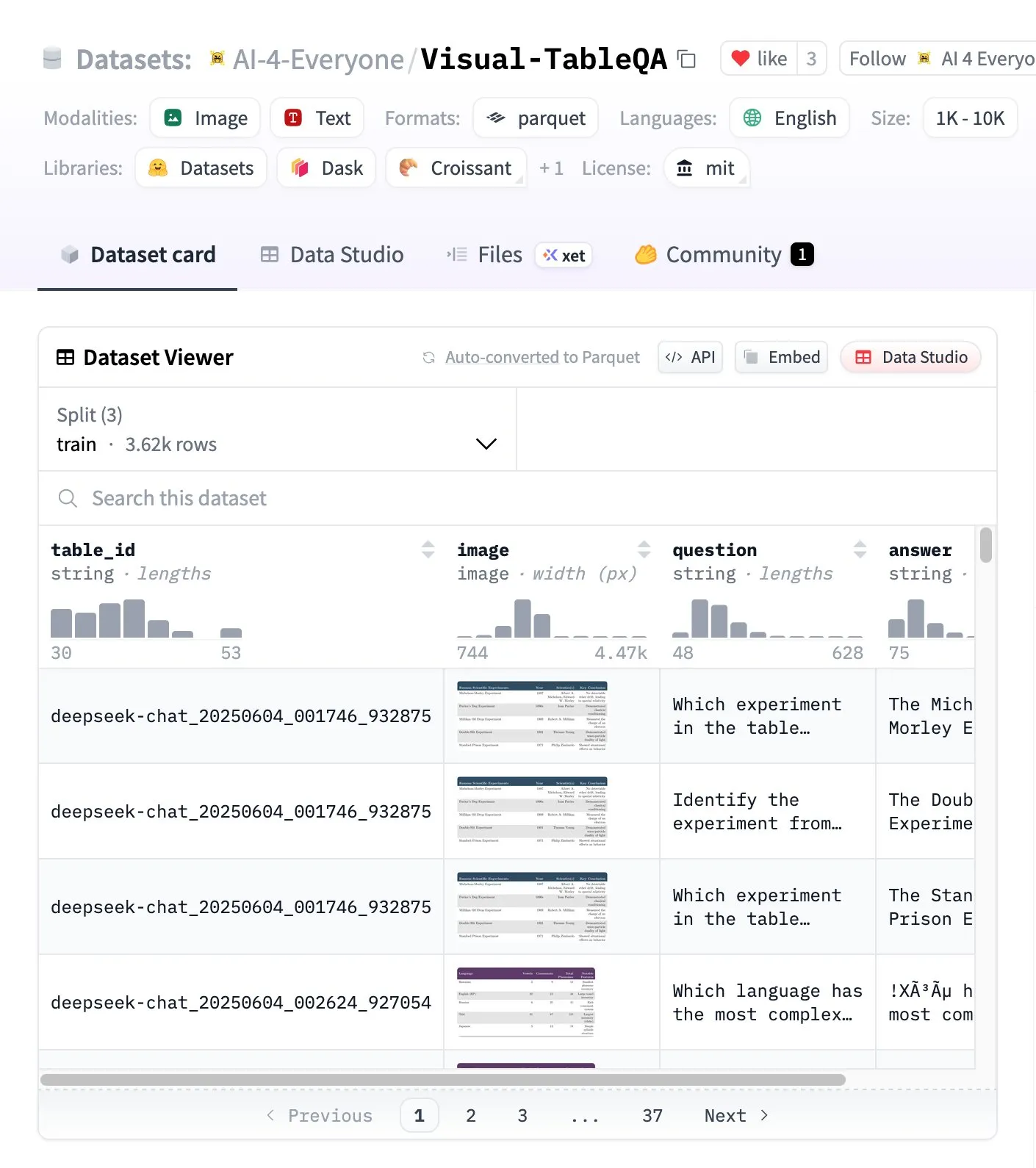
Visual-TableQA : Benchmark de raisonnement complexe sur les tableaux : Hugging Face a lancé Visual-TableQA, un benchmark de raisonnement complexe sur les tableaux contenant 2,5K tableaux et 6K paires QA. Ce benchmark se concentre sur le raisonnement en plusieurs étapes sur la structure visuelle et a été validé manuellement à 92%, avec un coût de génération inférieur à 100 dollars. Il fournit une ressource de haute qualité pour évaluer et améliorer la capacité des modèles à comprendre et à raisonner sur des données de tableau complexes. (Source: huggingface)
Analyse des concepts AI Agents vs Agentic AI : La communauté est généralement confuse entre les concepts d’AI Agents et de systèmes Agentic AI. Les AI Agents désignent des logiciels autonomes uniques (LLM + outils) exécutant des tâches spécifiques, avec un comportement réactif et une mémoire limitée ; les Agentic AI désignent des systèmes multi-agents collaboratifs (plusieurs LLM + orchestration + mémoire partagée), avec un comportement proactif et une mémoire persistante. Comprendre la distinction entre les deux est crucial pour les décisions d’architecture, afin d’éviter de construire des systèmes inutilement complexes. (Source: Reddit r/deeplearning)

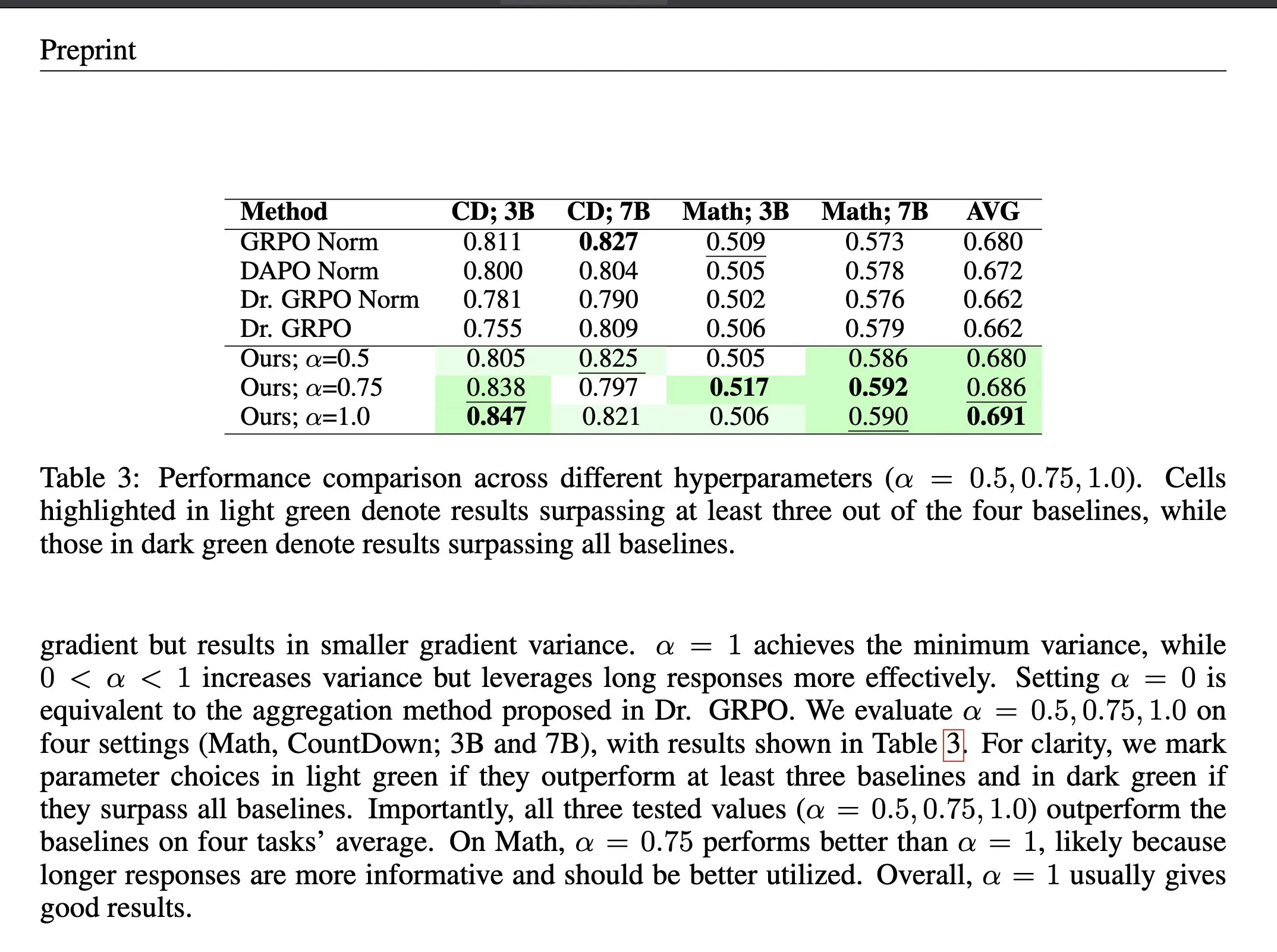
Méthode d’agrégation de pertes ΔL Normalization en apprentissage par renforcement : ΔL Normalization est une méthode d’agrégation de pertes conçue pour les caractéristiques de longueur générées dynamiquement dans l’apprentissage par renforcement à récompense vérifiable (RLVR). Cette méthode analyse l’impact des différentes longueurs sur la perte de la politique, reformule le problème pour trouver l’estimateur non biaisé à variance minimale, minimisant théoriquement la variance du gradient. Les expériences montrent que ΔL Normalization obtient constamment d’excellents résultats sur différentes tailles de modèles, longueurs maximales et tâches, résolvant les défis de la variance élevée du gradient et de l’optimisation instable en RLVR. (Source: HuggingFace Daily Papers, teortaxesTex)
Conférence vidéo comparative des architectures LLM : Rasbt a publié une conférence vidéo analysant et comparant 11 architectures LLM de 2025, couvrant DeepSeek V3/R1, OLMo 2, Gemma 3, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi 2, GPT-OSS, Grok 2.5 et GLM-4.5. Cette conférence offre aux développeurs et aux chercheurs un aperçu complet des architectures LLM, aidant à comprendre les philosophies de conception et les caractéristiques de performance des différents modèles. (Source: rasbt)
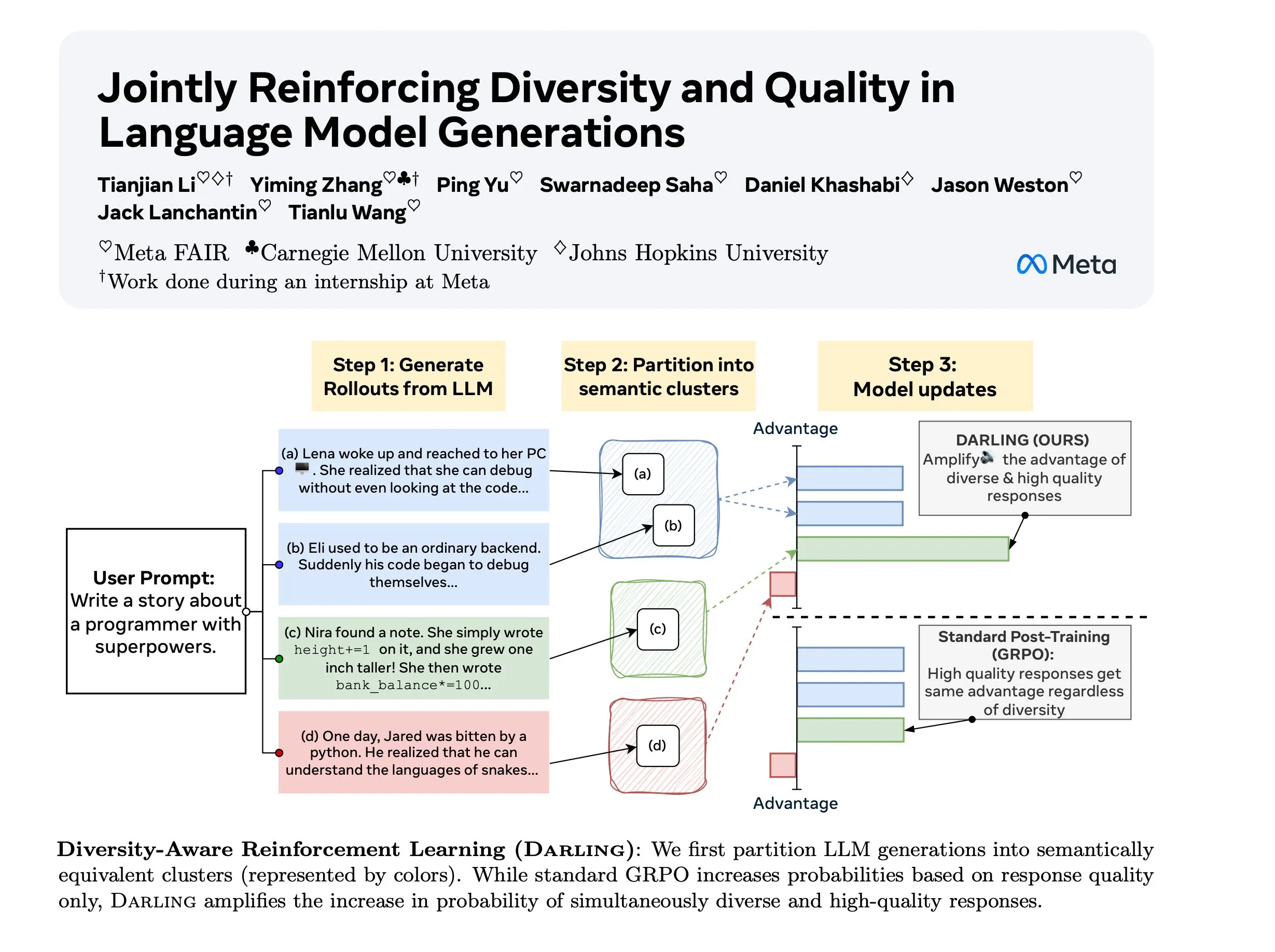
Recherche sur le RL conscient de la diversité (DARLING) : DARLING (Diversity Aware RL) est une nouvelle méthode d’apprentissage par renforcement qui optimise simultanément la qualité et la diversité en apprenant une fonction de partition. Cette méthode surpasse le RL standard en termes de qualité et de diversité, par exemple avec un pass@1/p@k plus élevé, et est applicable aux tâches vérifiables et non vérifiables, offrant une nouvelle voie pour améliorer la capacité de généralisation du RL dans des environnements complexes. (Source: ylecun)
Stanford CS 224N : Cours sur le Deep Learning et le NLP : Le cours CS 224N de l’Université de Stanford offre un enseignement complet sur le Deep Learning et le traitement du langage naturel (NLP). Ce cours est disponible publiquement via des vidéos YouTube, offrant aux apprenants du monde entier des ressources d’apprentissage AI de haute qualité, couvrant les théories fondamentales du NLP, les derniers modèles et les applications pratiques, ce qui en fait un cours d’introduction important pour entrer dans le domaine de l’AI. (Source: stanfordnlp)
💼 Affaires
La nouvelle politique de confidentialité d’Anthropic suscite la controverse : un désavantage systémique pour les développeurs indépendants : La nouvelle politique de confidentialité d’Anthropic exige que les utilisateurs choisissent avant le 28 septembre s’ils autorisent l’utilisation de leurs données de conversation pour l’entraînement de l’AI et leur conservation pendant 5 ans, sous peine de perdre la mémoire et les fonctionnalités de personnalisation. Cette mesure est critiquée comme créant un “système à deux vitesses”, obligeant les développeurs indépendants à choisir entre la confidentialité et les fonctionnalités, leur code propriétaire pouvant devenir des données d’entraînement pour l’AI d’entreprise, tandis que les clients d’entreprise peuvent bénéficier de solutions coûteuses combinant confidentialité et personnalisation, soulevant des inquiétudes quant à la démocratisation de l’AI et l’extraction de l’innovation. (Source: Reddit r/ClaudeAI)
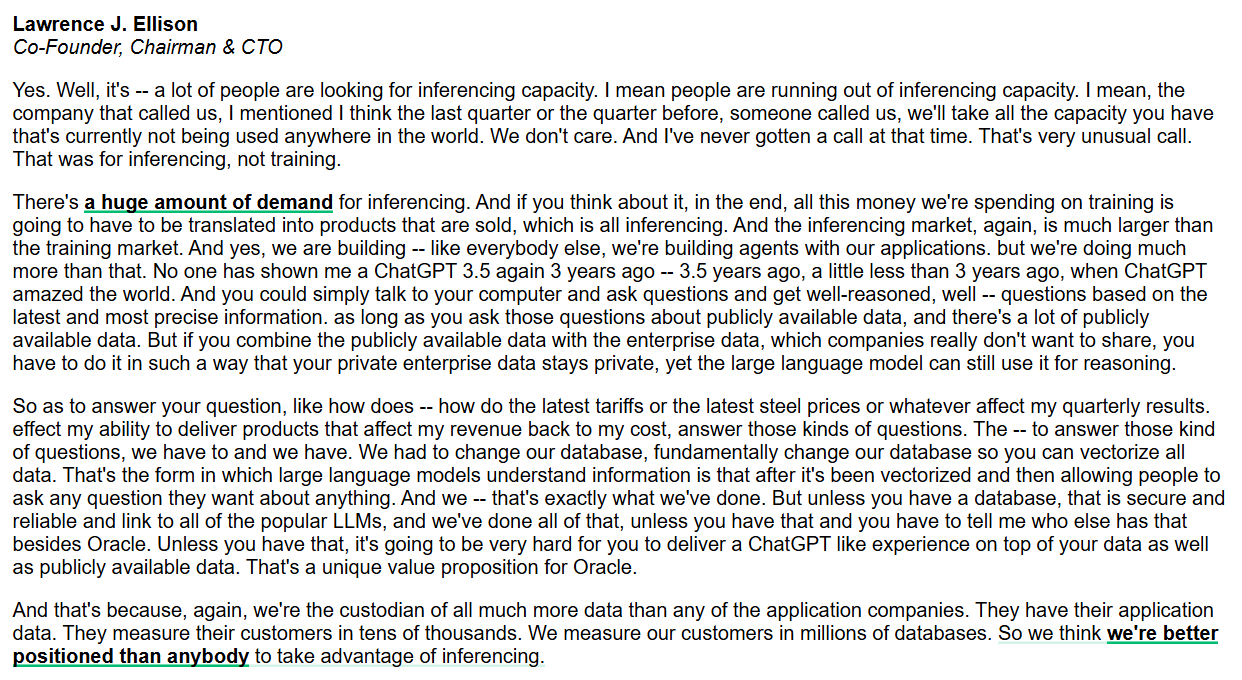
Oracle se concentre sur les capacités d’inférence et les bases de données AI d’entreprise : Larry Ellison, PDG d’Oracle, souligne que le marché des capacités d’inférence est bien plus vaste que celui de l’entraînement, et que la demande est énorme. Oracle, en modifiant fondamentalement les bases de données pour vectoriser toutes les données et en assurer la sécurité et la fiabilité, vise à offrir une expérience de type ChatGPT combinant données publiques et privées d’entreprise. Oracle estime avoir un avantage unique en tant qu’hébergeur de données pour fournir des services d’inférence AI de niveau entreprise. (Source: JonathanRoss321)
Nouveau standard de licence de contenu AI RSL Standard : Inciter les entreprises AI à payer : Reddit, Yahoo, Quora et wikiHow, entre autres grandes marques, soutiennent le Really Simple Licensing (RSL) Standard, un standard de licence de contenu ouvert visant à permettre aux éditeurs web de définir les conditions d’utilisation de leurs œuvres par les développeurs de systèmes AI. Le RSL, basé sur le protocole robots.txt, permet aux sites web d’ajouter des termes de licence et de redevance, exigeant des crawlers AI de payer pour les données d’entraînement (abonnement ou paiement par crawl/inférence), afin d’assurer une compensation équitable aux créateurs de contenu. (Source: Reddit r/artificial)
🌟 Communauté
Coexistence et amélioration de l’AI et de l’intelligence humaine : La communauté débat si l’AI est un “correcteur cognitif” assistant l’intelligence humaine (comme l’abaque) ou un “concurrent” remplaçant l’humain (comme la calculatrice). François Chollet utilise la métaphore du “vélo de l’esprit” pour souligner que la technologie devrait amplifier les efforts humains plutôt que de rendre les gens inactifs, suscitant une réflexion philosophique sur la relation entre l’AI et l’intelligence humaine (IA) et l’orientation future du développement. (Source: rao2z)
Le dilemme des relations publiques de l’industrie de l’AI et le sentiment public négatif : Bien que les produits AI comptent des milliards d’utilisateurs et que beaucoup en bénéficient, l’industrie de l’AI est généralement confrontée à un sentiment public négatif. Certains pensent que cela est dû à l’incapacité des leaders de l’industrie à communiquer efficacement en externe, ce qui entraîne des préjugés du public envers les entreprises AI. D’autres spéculent que cela pourrait être intentionnel de la part de l’industrie AI, visant à concentrer les technologies et avantages clés entre les mains de quelques acteurs. (Source: Dorialexander)
Impact des faiblesses dans les systèmes multi-agents LLM : Des recherches indiquent que l’utilisation de petits modèles de langage n’est pas toujours idéale dans les systèmes multi-agents. Dans des scénarios tels que les débats multi-agents, les agents LLM plus faibles interfèrent souvent avec, voire compromettent, les performances des agents plus forts, entraînant une dégradation des performances globales du système. Cela révèle qu’il faut considérer attentivement les différences de capacités entre les agents et leurs interactions négatives potentielles lors de la conception et du déploiement de systèmes multi-agents. (Source: omarsar0)

Limites des données synthétiques pour l’AGI : Andrew Trask et Fei-Fei Li soulignent que les données synthétiques sont une stratégie faible pour que les LLM atteignent l’AGI. Les données synthétiques ne peuvent pas créer de nouvelles informations (comme des entités que le modèle n’a jamais entendues), elles ne peuvent que révéler des inférences naturelles à partir d’informations existantes. Bien que les données synthétiques puissent résoudre des problèmes comme la “malédiction de l’inversion” par des permutations logiques et des combinaisons de faits connus, leur goulot d’étranglement informationnel limite leur potentiel en tant que “solution miracle” pour l’AGI ; la véritable percée pourrait résider dans l’intelligence globale et la récupération instantanée de contexte. (Source: algo_diver, jpt401)
AI et marché de l’emploi humain : La boucle sans fin des CV rédigés par AI et filtrés par AI : L’AI crée une boucle sans fin de “personne n’est embauché” sur le marché du travail : les demandeurs d’emploi utilisent l’AI pour rédiger leur CV, les RH utilisent l’AI pour filtrer les CV, ce qui “améliore” l’efficacité mais ne mène à aucune embauche. Les CV sont rejetés par l’AI pour des raisons diverses et variées, et même les RH se plaignent que les CV générés par l’AI sont tous les mêmes. Cela met en évidence les nouveaux défis posés par l’AI dans le recrutement, qui pourrait rigidifier le processus de recrutement et empêcher l’identification des vrais talents. (Source: 量子位)

Les défis des éthiciens de l’AI : Avec le développement rapide de la technologie AI, les éthiciens de l’AI sont confrontés au dilemme de “crier dans le vide”. La course à l’AI, motivée par le capitalisme, marginalise les considérations éthiques, et le rythme du progrès technologique dépasse de loin l’intégration éthique. Les experts craignent que s’il faut attendre que les dommages soient généralisés pour agir, il sera peut-être trop tard, et appellent l’industrie à intégrer les garanties éthiques dans ses considérations fondamentales. (Source: Reddit r/ArtificialInteligence)

L’avenir d’Internet : Le trafic de robots dépasse celui des humains : Une tendance indique que d’ici trois ans, les interactions générées par les robots sur Internet dépasseront largement celles des humains, rendant Internet “mort”. Des études ont déjà montré que le trafic de robots dépasse 50%. Cela soulève des inquiétudes quant à la manière de distinguer les voix humaines réelles du contenu généré par l’AI, ainsi qu’à la véracité des informations sur Internet, annonçant un changement fondamental dans l’écosystème en ligne. (Source: Reddit r/artificial)

Baisse des performances de Claude Code et perte d’utilisateurs : Les utilisateurs de Claude Code d’Anthropic signalent une baisse significative des performances récentes du modèle, se manifestant par une qualité de code inférieure, la génération de code redondant, une faible qualité des tests, une sur-ingénierie et une compréhension réduite. De nombreux utilisateurs envisagent de se tourner vers des alternatives comme GPT-5, GLM-4.5, Qwen3, et appellent Anthropic à plus de transparence, à expliquer les raisons de la régression du modèle et les mesures correctives, sous peine de perdre des utilisateurs. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 Divers
Potentiel de l’AI et de la VR dans la correction criminelle : Une idée a été avancée, proposant d’utiliser l’AI et la VR à faible coût pour fournir des capsules VR obligatoires aux patients psychiatriques criminels, les isolant de la société à un coût inférieur à celui de l’hébergement traditionnel. Cette proposition radicale a suscité des discussions sur le rôle potentiel de l’AI dans le contrôle social, les systèmes de punition et les limites éthiques, et bien que sa faisabilité et son humanité soient controversées, elle révèle des directions potentielles pour l’application de la technologie dans la résolution des problèmes sociaux. (Source: gfodor, gfodor)
Application envisagée de Replit en prison : Un utilisateur a proposé d’introduire Replit (une plateforme de programmation en ligne) dans les prisons, estimant que cela pourrait remplacer les installations de divertissement et permettre aux détenus de créer des produits de valeur grâce à la programmation. Cette idée explore le rôle potentiel de la technologie dans la transformation sociale, la formation professionnelle et la réintégration des détenus dans la société, suscitant des discussions sur l’équité éducative et l’autonomisation technologique. (Source: amasad)