
Mots-clés:supercalculateur, hallucination de l’IA, violation du droit d’auteur, grand modèle linguistique, puce d’IA, supercalculateur JUPITER, document de recherche sur l’hallucination de l’IA d’OpenAI, affaire de règlement du droit d’auteur d’Anthropic, modèle Qwen3-Max-Preview, puce d’IA auto-développée par OpenAI
🔥 Focus
Le premier supercalculateur exascale d’Europe, JUPITER, est en ligne : Le premier supercalculateur exascale d’Europe, JUPITER, alimenté par NVIDIA Grace Hopper, est désormais opérationnel. Ce système est le supercalculateur le plus économe en énergie au monde, fusionnant l’AI et le HPC, et vise à réaliser des percées dans des domaines tels que la science climatique, les neurosciences et la simulation quantique. Cela marque une étape importante pour l’Europe dans le calcul haute performance et la recherche en AI, promettant d’accélérer les découvertes scientifiques de pointe. (Source: nvidia)

OpenAI publie un article révélant la racine des hallucinations de l’AI : OpenAI a publié l’article « Pourquoi les modèles de langage hallucinent », soulignant que la cause fondamentale des hallucinations de l’AI réside dans les mécanismes actuels d’entraînement et d’évaluation qui récompensent les modèles pour deviner plutôt que pour admettre l’incertitude. Pendant la phase de pré-entraînement, les modèles ont du mal à distinguer les informations valides des informations invalides en raison du manque d’étiquettes « vrai/faux », et sont particulièrement enclins à inventer des faits lorsqu’ils traitent des faits à basse fréquence. OpenAI appelle à la mise à jour des métriques d’évaluation pour pénaliser les erreurs confiantes et récompenser l’expression d’incertitude, afin d’encourager les modèles à être plus « honnêtes ». (Source: source, source, source, source, source)

Anthropic conclut un accord de 1,5 milliard de dollars dans une affaire de violation de droits d’auteur liés à l’AI : Anthropic a conclu un accord avec des auteurs de livres concernant une affaire de violation de droits d’auteur liés à l’AI, acceptant de payer au moins 1,5 milliard de dollars. Cet accord couvre environ 500 000 œuvres protégées par le droit d’auteur, soit environ 3 000 dollars par œuvre (avant déduction des frais d’avocat), et s’engage à détruire les ensembles de données piratés. Cette affaire est le premier règlement de recours collectif lié à l’AI et au droit d’auteur aux États-Unis, et pourrait créer un précédent pour la définition juridique de l’AI générative et de la propriété intellectuelle. (Source: source, source, source, source, source, source, source)

🎯 Tendances
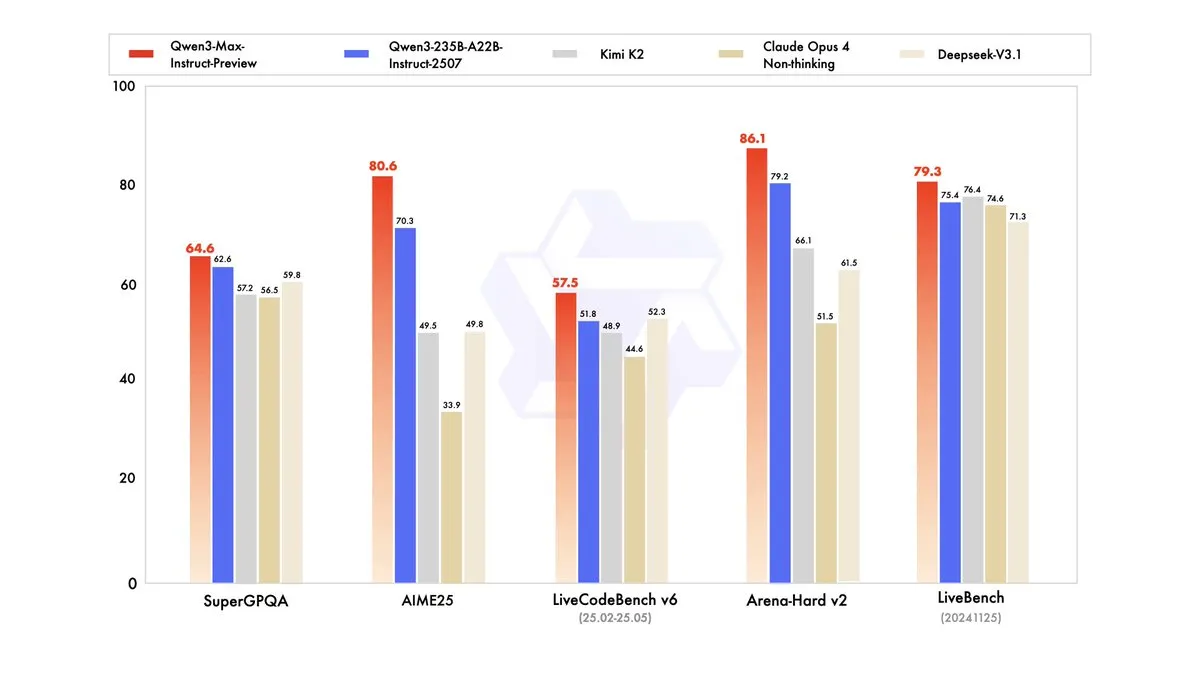
Qwen3-Max-Preview lancé avec plus d’un billion de paramètres : Alibaba Cloud Qwen a lancé son plus grand modèle à ce jour, Qwen3-Max-Preview (Instruct), avec plus d’un billion de paramètres. Le modèle est désormais disponible via Qwen Chat et l’API Alibaba Cloud, et a surpassé le précédent Qwen3-235B-A22B-2507 lors des tests de référence. Les tests internes et les premiers retours d’utilisateurs indiquent des améliorations significatives en termes de performances, d’étendue des connaissances, de capacités de dialogue, de tâches d’Agent et de respect des instructions. Le modèle a également été mis en ligne sur OpenRouter, suscitant des discussions au sein de la communauté quant à une éventuelle publication en open source. (Source: source, source, source, source, source, source, source, source)
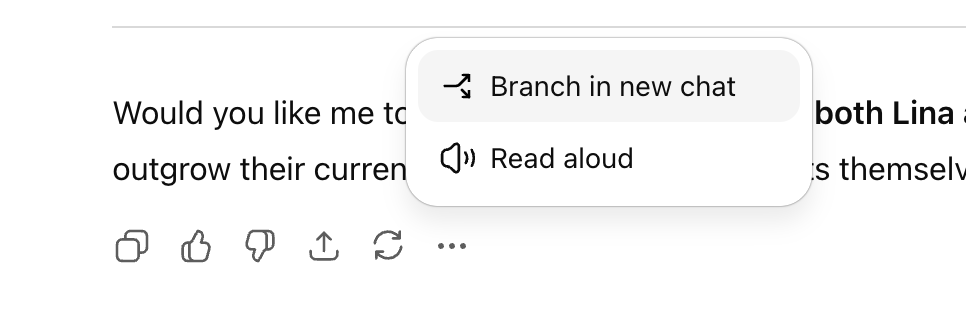
ChatGPT ajoute une fonction de conversation ramifiée pour une exploration multi-lignes améliorée : OpenAI a lancé une nouvelle fonction de « conversation ramifiée » pour la version web de ChatGPT, permettant aux utilisateurs de créer de nouvelles branches à partir de n’importe quelle réponse pour une exploration multi-lignes, sans avoir à ouvrir une nouvelle conversation ni à se soucier d’un contexte trop long. Cette fonction, combinée à la capacité de mémoire, rend les conversations plus continues et flexibles, transformant les dialogues linéaires en structures arborescentes, aidant les utilisateurs à conserver différentes idées et améliorant l’efficacité de la collaboration avec l’assistant AI. (Source: source, source, source)
OpenAI prévoit de lancer une plateforme de recrutement basée sur l’AI et de développer ses propres puces AI : OpenAI prévoit de lancer une plateforme de recrutement basée sur l’AI d’ici mi-2026, en concurrence avec LinkedIn, et de proposer une certification de « fluidité AI ». De plus, pour réduire sa dépendance vis-à-vis de Nvidia, OpenAI commencera à produire ses propres puces AI conçues en interne l’année prochaine. Ces initiatives démontrent l’ambition d’OpenAI d’étendre son écosystème d’applications AI et d’optimiser son infrastructure matérielle. (Source: source, source, source, source, source)

OpenRouter lance Sonoma Alpha, un modèle « furtif » avec une fenêtre contextuelle de 2 millions de tokens : La plateforme OpenRouter a lancé un modèle « furtif » nommé Sonoma Alpha, dont le principal atout est de prendre en charge une fenêtre contextuelle de 2 millions de tokens et d’être disponible gratuitement. La communauté spécule largement que ce modèle est de la série Grok de xAI, car sa caractéristique de « rechercher la vérité au maximum » correspond à la philosophie d’Elon Musk. Le modèle excelle dans la génération de code, la logique et les tâches scientifiques, annonçant le potentiel des modèles à très long contexte dans les applications pratiques. (Source: source, source, source)
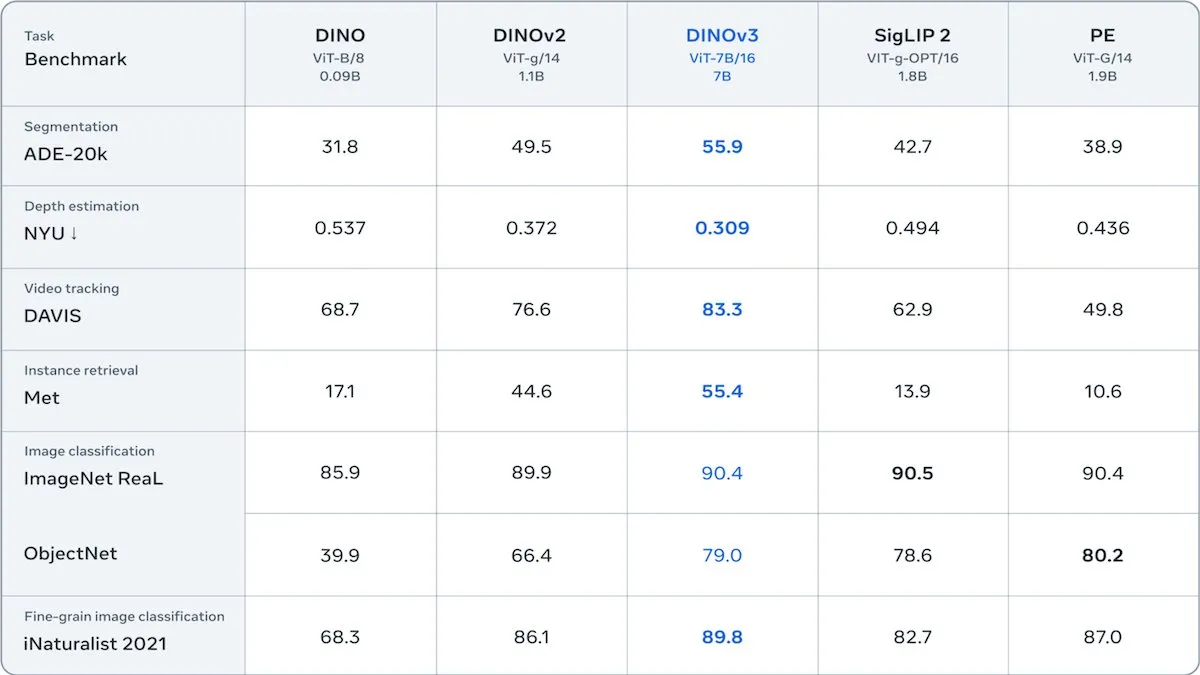
Meta lance DINOv3, un Transformer visuel auto-supervisé : Meta a lancé DINOv3, un modèle Transformer visuel auto-supervisé de 6,7 milliards de paramètres, qui améliore considérablement la qualité des intégrations d’images dans des tâches telles que la segmentation d’images et l’estimation de profondeur. Le modèle, entraîné sur 1,7 milliard d’images Instagram, introduit un nouveau terme de perte pour maintenir la diversité au niveau des patchs, surmontant les limitations des données non étiquetées. DINOv3 est publié sous une licence autorisant l’utilisation commerciale mais interdisant les applications militaires, offrant un puissant réseau dorsal auto-supervisé pour les applications visuelles en aval. (Source: DeepLearningAI)
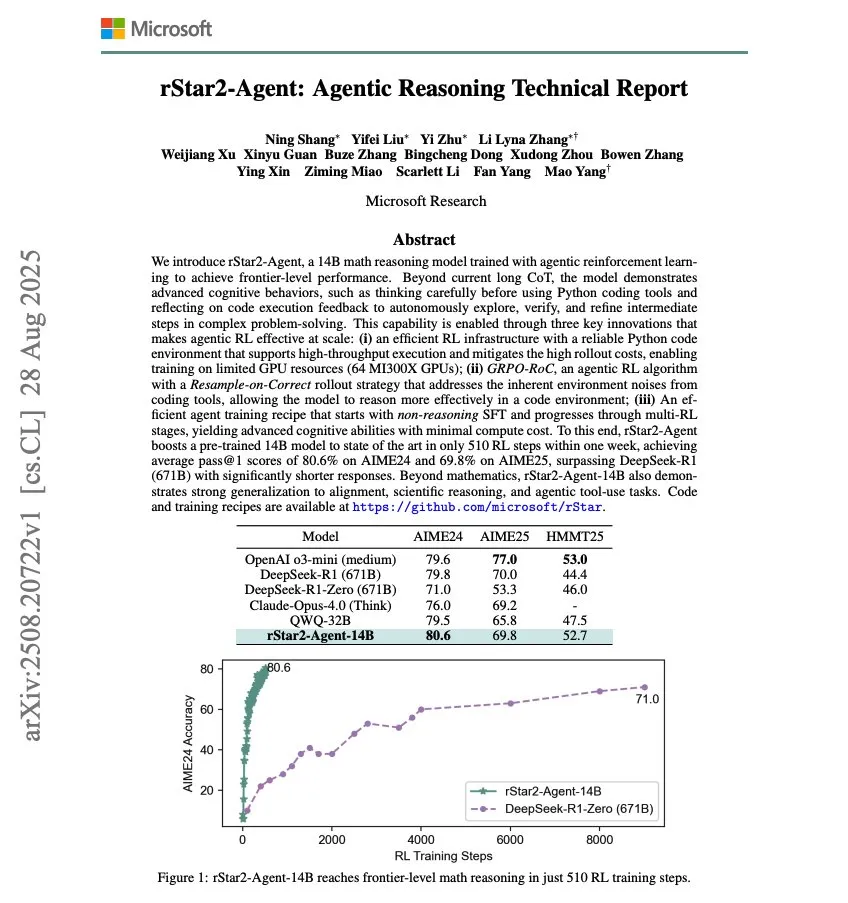
Microsoft lance rStar2-Agent, un modèle de raisonnement mathématique de 14B : Microsoft a lancé rStar2-Agent, un modèle de raisonnement mathématique de 14B, entraîné via Agentic RL, qui a atteint des capacités de raisonnement mathématique de pointe en seulement 510 étapes d’entraînement RL. Cette recherche démontre le potentiel d’amélioration rapide des performances des modèles AI dans des domaines spécifiques grâce à l’apprentissage par renforcement. (Source: dair_ai)
OpenAI crée oai Labs pour explorer de nouvelles interfaces de collaboration homme-machine : OpenAI a annoncé la création d’oai Labs, dirigé par Joanne Jang, qui se concentrera sur la recherche et le prototypage de nouvelles interfaces pour la collaboration homme-machine. L’équipe vise à dépasser les modes de chat et d’agent existants, en explorant de nouveaux paradigmes et outils pour améliorer la façon dont les gens interagissent, pensent, créent, apprennent et se connectent avec l’AI. (Source: source, source)
Salon IFA 2025 : Tendances du matériel AI et de la robotique : Au salon international de l’électronique grand public (IFA) 2025 à Berlin, les fabricants chinois dominent entièrement le marché des lunettes AI, avec des marques comme Rokid et 雷鸟创新 présentant plusieurs produits et explorant activement les écosystèmes étrangers. Dans le domaine de la robotique, Unitree Robotics a présenté son robot humanoïde G1 et son chien robot Go 2, attirant une attention considérable ; Midea, Ubtech et d’autres ont également exposé des robots de service domestique. Les robots de nettoyage intelligents, les robots tondeuses, les robots de piscine et d’autres robots fonctionnels sont en plein essor, avec des améliorations technologiques qui les rapprochent de la vie quotidienne. L’AI est profondément intégrée dans les appareils électroménagers, les téléphones mobiles, les PC et d’autres produits électroniques grand public, mettant l’accent sur une mise en œuvre pragmatique et une expérience « sans friction ». (Source: 36氪)

OpenBMB lance MiniCPM 4.1-8B, le premier LLM open source avec attention clairsemée entraînable : OpenBMB a lancé le modèle MiniCPM 4.1-8B, le premier LLM d’inférence open source à utiliser une attention clairsemée entraînable. Ce modèle surpasse les modèles de taille similaire sur 15 tâches, offre une vitesse d’inférence 3 fois supérieure et utilise une architecture efficace. Cela marque une avancée significative pour les modèles open source en termes de capacités d’inférence et d’efficacité, offrant un nouvel outil puissant aux chercheurs. (Source: teortaxesTex)

🧰 Outils
Open Instruct : Une bibliothèque de code de recherche RL haute performance : Open Instruct, maintenu par AllenAI, est une bibliothèque de code de recherche en apprentissage par renforcement (RL) haute performance, conçue pour fournir des implémentations RL faciles à modifier et performantes. Ce projet, dirigé par Finbarr et d’autres, est constamment amélioré, offrant aux chercheurs une plateforme fondamentale pour mener des expériences RL et développer. (Source: source, source)
Grok : Compréhension et résumé de PDF : Grok de xAI a lancé une fonction de lecteur PDF, permettant aux utilisateurs de surligner n’importe quelle partie et de cliquer sur « expliquer » pour comprendre le contenu, ou de cliquer sur « citer » pour poser des questions spécifiques. Cela améliore considérablement l’efficacité et la profondeur de compréhension des utilisateurs lors du traitement de longs documents PDF. (Source: source, source)
Devin AI : L’analyste de données d’EightSleep : Devin AI de Cognition est utilisé par l’équipe EightSleep comme analyste de données, gérant diverses tâches allant des « anomalies numériques » aux requêtes de données ad hoc, réduisant le temps d’achèvement des analyses/tableaux de bord de plusieurs jours à quelques heures, améliorant considérablement l’efficacité de l’obtention d’informations sur les données. Cela démontre le puissant potentiel d’application des agents AI dans l’analyse de données d’entreprise. (Source: cognition)
Explication détaillée des fonctions de sous-agents de Claude Code : Claude Code, via son outil Task, permet aux utilisateurs de créer trois types de sous-agents spécialisés : génériques, de configuration de ligne d’état et de style de sortie. Ces sous-agents disposent de leurs propres ensembles d’outils et peuvent gérer des tâches complexes, configurer des paramètres ou créer des styles de sortie. Les sous-agents sont sans état, s’exécutent une fois et renvoient des résultats, ce qui les rend adaptés à la délégation de recherches complexes, d’analyses ou de configurations spécialisées afin de maintenir la focalisation de la conversation principale. (Source: Vtrivedy10)
LlamaIndex SemTools : Outil de recherche et d’analyse de documents pour les Agents en ligne de commande : LlamaIndex a lancé SemTools, une boîte à outils CLI pour l’analyse et la recherche sémantique. Combinant les outils Unix et les capacités de recherche sémantique, l’Agent peut traiter efficacement des documents complexes, fournissant des réponses plus détaillées et précises, couvrant des tâches telles que la recherche, le référencement croisé et l’analyse temporelle. Cela montre que l’utilisation d’outils Unix existants combinés à la recherche sémantique peut créer des travailleurs du savoir puissants. (Source: source, source)
Replit Agent : L’assistant de codage AI, du Prompt à l’application de production : Replit Agent célèbre son premier anniversaire. Cet outil, qui a commencé par la complétion de code AI et l’édition de chat, a évolué pour transformer directement les prompts en applications de qualité production. Replit met l’accent sur sa capacité à automatiser la configuration de l’environnement de développement, l’installation de packages, la configuration de bases de données et le déploiement, visant à révolutionner le processus de développement logiciel. (Source: source, source)

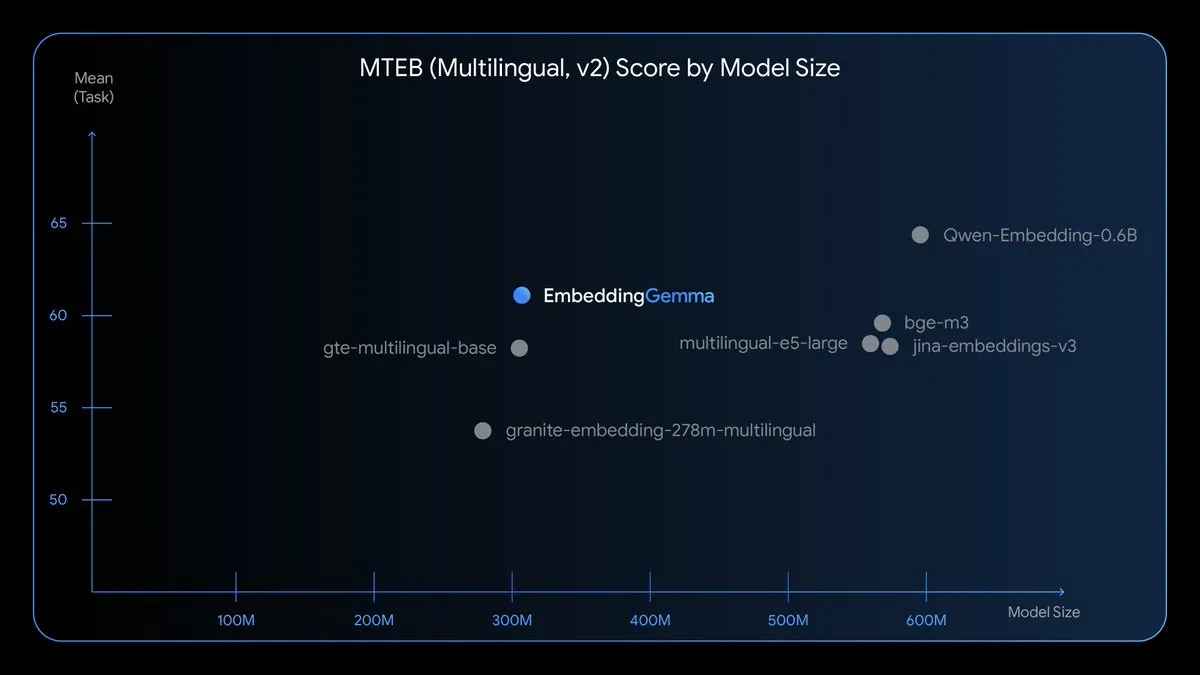
EmbeddingGemma : Modèle d’intégration multilingue embarqué : EmbeddingGemma est un nouveau modèle d’intégration multilingue open source, avec 308M de paramètres, entraîné sur Gemma 3, et prenant en charge plus de 100 langues. Ce modèle est optimisé pour la vitesse, la confidentialité et l’efficacité, peut fonctionner hors ligne, occupe moins de 200 Mo de mémoire et a un temps d’inférence inférieur à 15 ms, rendant possibles le RAG embarqué, la recherche sémantique et la classification. (Source: TheTuringPost)
Nano Banana Hackathon : Défi d’AI générative : Kaggle organisera le Nano Banana Hackathon, offrant 400 000 dollars de prix et un accès gratuit à l’API Gemini pour utiliser Gemini 2.5 Flash Image. Les participants auront 48 heures pour créer en utilisant les technologies d’AI générative, et la compétition évaluera l’innovation, l’exécution technique, l’impact et la présentation. (Source: source, source, source)

📚 Apprentissage
Comment construire un AI Agent à partir de zéro : Python_Dv a partagé un tutoriel et un guide pour construire un AI Agent à partir de zéro, couvrant les technologies clés telles que les LLM, l’AI générative et le Machine Learning. Cette ressource offre aux développeurs un chemin d’accès pratique pour le développement d’AI Agent. (Source: Ronald_vanLoon)

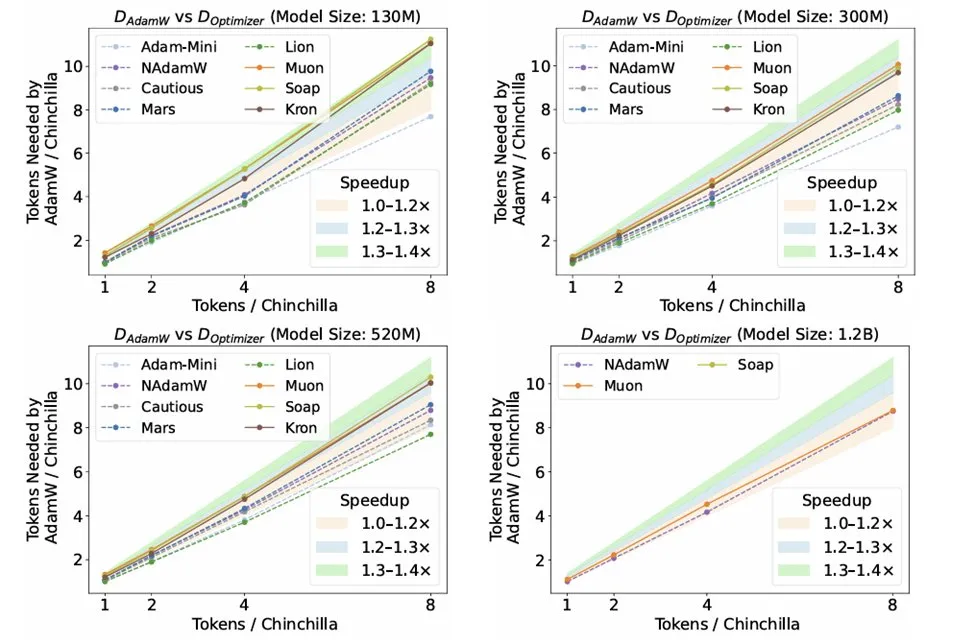
Recherche sur les optimiseurs dans l’inférence LLM : L’article de recherche « Fantastic Pretraining Optimizers and Where to Find Them » de Kaiyue Wen et al. a rigoureusement comparé 10 optimiseurs. L’étude a révélé que, bien que des optimiseurs comme Muon et Mars aient attiré l’attention, après un réglage minutieux des hyperparamètres et une mise à l’échelle, leur accélération par rapport à AdamW n’était que d’environ 10%. Cela souligne la nécessité de se méfier des problèmes de sous-réglage de la ligne de base ou de mise à l’échelle limitée lors de l’évaluation de nouveaux optimiseurs. (Source: source, source, source)
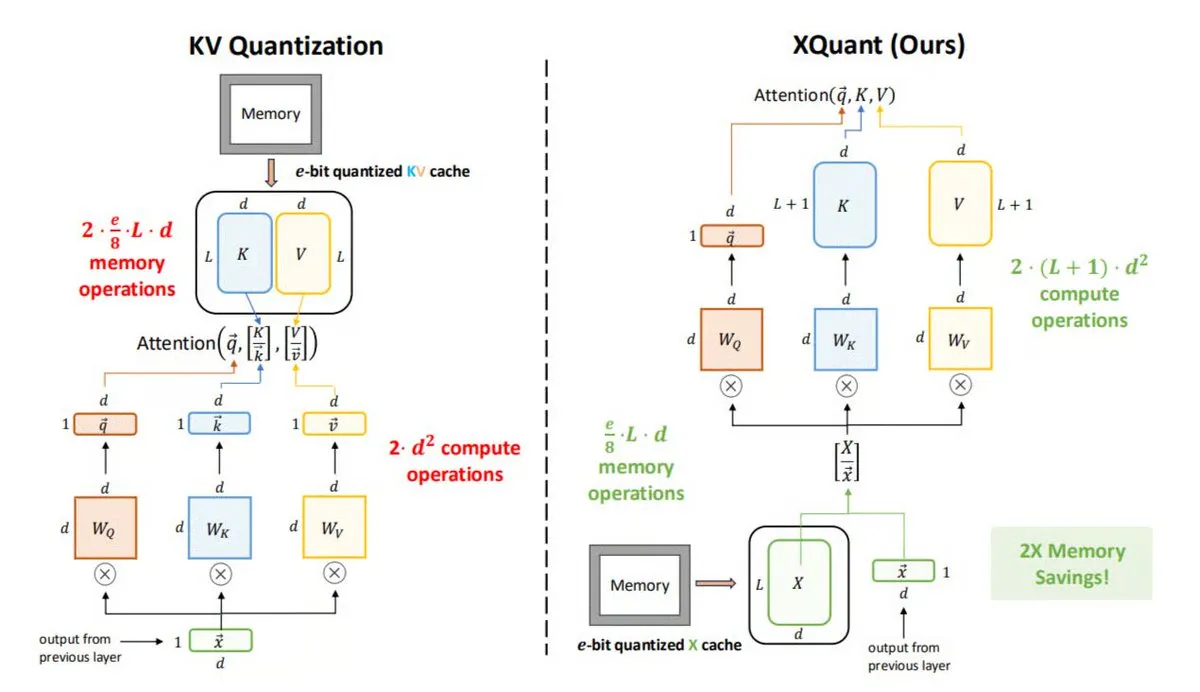
XQuant : Technologie d’optimisation de la mémoire dans l’inférence LLM : L’UC Berkeley a proposé XQuant, une nouvelle méthode d’optimisation de la mémoire pour les LLM, capable de réduire l’utilisation de la mémoire jusqu’à 12 fois. XQuant ne stocke pas le cache KV traditionnel, mais quantifie et stocke les activations d’entrée de couche (X), puis régénère les Key et Value à la demande à partir de X lors de l’inférence. Cette technique, en ajoutant une petite quantité de calcul, permet une inférence plus rapide et plus efficace sans sacrifier la précision. (Source: TheTuringPost)
Conception de Prompt LLM : La méthodologie Mom Test : Tz a partagé la méthodologie d’application de l’approche d’enquête utilisateur « Mom Test » à la conception de Prompt LLM, en insistant sur le fait d’éviter de poser au modèle des questions qui donneraient des « platitudes agréables », et de construire plutôt des Prompts qui incitent le modèle à donner des réponses vérifiables, basées sur des faits ou des contraintes claires. L’essentiel est d’éviter les opinions, les hypothèses futures, l’ambiguïté, et d’exiger des réponses spécifiques, axées sur le comportement et la vérification plutôt que les compliments. (Source: dotey)

La technologie de compression AI est 300 fois plus efficace que les méthodes traditionnelles : La chaîne YouTube Two Minute Papers a souligné que la technologie de compression AI est 300 fois plus efficace que les méthodes de compression traditionnelles, mais n’est pas encore largement utilisée. La vidéo a probablement exploré des technologies de moteur physique comme NVIDIA WaveBlender, démontrant l’énorme potentiel de l’AI dans le domaine de la compression de données, ainsi que ses applications dans la simulation audio. (Source: , source)
Défi de superintelligence multimodale NeurIPS 2025 : Lambda Research invite les chercheurs, ingénieurs et passionnés d’AI à participer au Grand Défi de Superintelligence Multimodale NeurIPS 2025, visant à faire progresser l’apprentissage automatique multimodal open source. Les équipes participantes auront la chance de recevoir jusqu’à 20 000 dollars en crédits de calcul pour construire ensemble l’avenir de l’AI multimodale open source. (Source: Reddit r/deeplearning)

Guide complet annoté sur les modèles de diffusion : La communauté Reddit a partagé un guide complet annoté sur « Qu’est-ce que les modèles de diffusion ? ». Ce guide offre aux apprenants une ressource pour comprendre en profondeur les principes et les applications des modèles de diffusion, aidant à maîtriser cette technologie d’AI générative de pointe. (Source: Reddit r/deeplearning)
Application de LoRA/QLoRA dans l’entraînement multi-GPU de LLM visuels : La communauté a discuté des défis et des pratiques de LoRA/QLoRA dans l’entraînement de grands LLM visuels (comme Llama 3.2 90B Visual Instruct) dans des environnements multi-GPU. En raison de la taille massive des modèles, qui ne peuvent pas fonctionner sur un seul GPU, les développeurs recherchent des frameworks/packages prenant en charge l’entraînement multi-GPU. LoRA/QLoRA, en raison de ses caractéristiques de réglage fin efficace, est très attendu, mais son applicabilité dans des scénarios spécifiques nécessite encore une exploration approfondie. (Source: source, source)
💼 Affaires
OpenAI acquiert l’équipe Alex, soutenue par Y Combinator : OpenAI a acquis l’équipe Alex, une startup soutenue par Y Combinator. Cette équipe rejoindra l’équipe Codex d’OpenAI, dédiée aux assistants de codage AI. Daniel Edrisian, fondateur d’Alex, a déclaré qu’ils avaient réussi à construire les meilleurs agents de codage pour les applications iOS et macOS, et que cette acquisition permettra à leur travail de se poursuivre à plus grande échelle. (Source: The Verge)
Baseten clôture un financement de série D de 150 millions de dollars, se concentrant sur l’avenir de l’inférence AI : Baseten a clôturé un financement de série D de 150 millions de dollars. Son PDG, Tuhin One, a souligné qu’avec la baisse des prix des tokens, les coûts d’inférence continueront de diminuer, annonçant une croissance à plus grande échelle du marché de l’inférence AI. Baseten s’engage à construire une infrastructure d’inférence AI omniprésente pour soutenir l’application généralisée de l’AI dans diverses industries. (Source: basetenco)
RecallAI clôture un financement de série B de 38 millions de dollars, accélérant les services de transcription de réunions AI : RecallAI a annoncé la clôture d’un financement de série B de 38 millions de dollars, mené par BessemerVP, avec la participation de HubSpot Ventures et SalesforceVC. RecallAI fournit des services d’API d’enregistrement de réunions et a déjà servi plus de 2000 entreprises. Ce financement accélérera son expansion dans le domaine de la transcription de réunions AI, consolidant davantage sa position sur le marché. (Source: blader)
🌟 Communauté
Valeur et controverse de l’évaluation de l’AI (Evals) : La communauté a mené une discussion animée sur la nécessité et les méthodes d’évaluation de l’AI (Evals), explorant leur rôle dans les applications d’entreprise, leur complémentarité avec les tests A/B, et l’importance de la science des données dans l’ingénierie AI. Certains estiment que les Evals sont essentiels pour comprendre les performances des systèmes AI et optimiser les itérations, tandis que d’autres pensent qu’une dépendance excessive aux Evals pourrait conduire à de la « pseudo-science ». (Source: source, source)

Qualité du codage AI et limites du « Vibe Coding » : Les développeurs ont discuté des avantages et des inconvénients de la génération de code par AI, soulignant que l’AI excelle dans le prototypage rapide, le traitement du code passe-partout et l’écriture de tests, mais que le code généré est souvent critiqué pour être verbeux, excessivement défensif et manquant de capacités de refactoring. De nombreux développeurs estiment que pour le code nécessitant une maintenance à long terme, le codage manuel reste supérieur au « Vibe Coding » généré par AI. (Source: source, source)
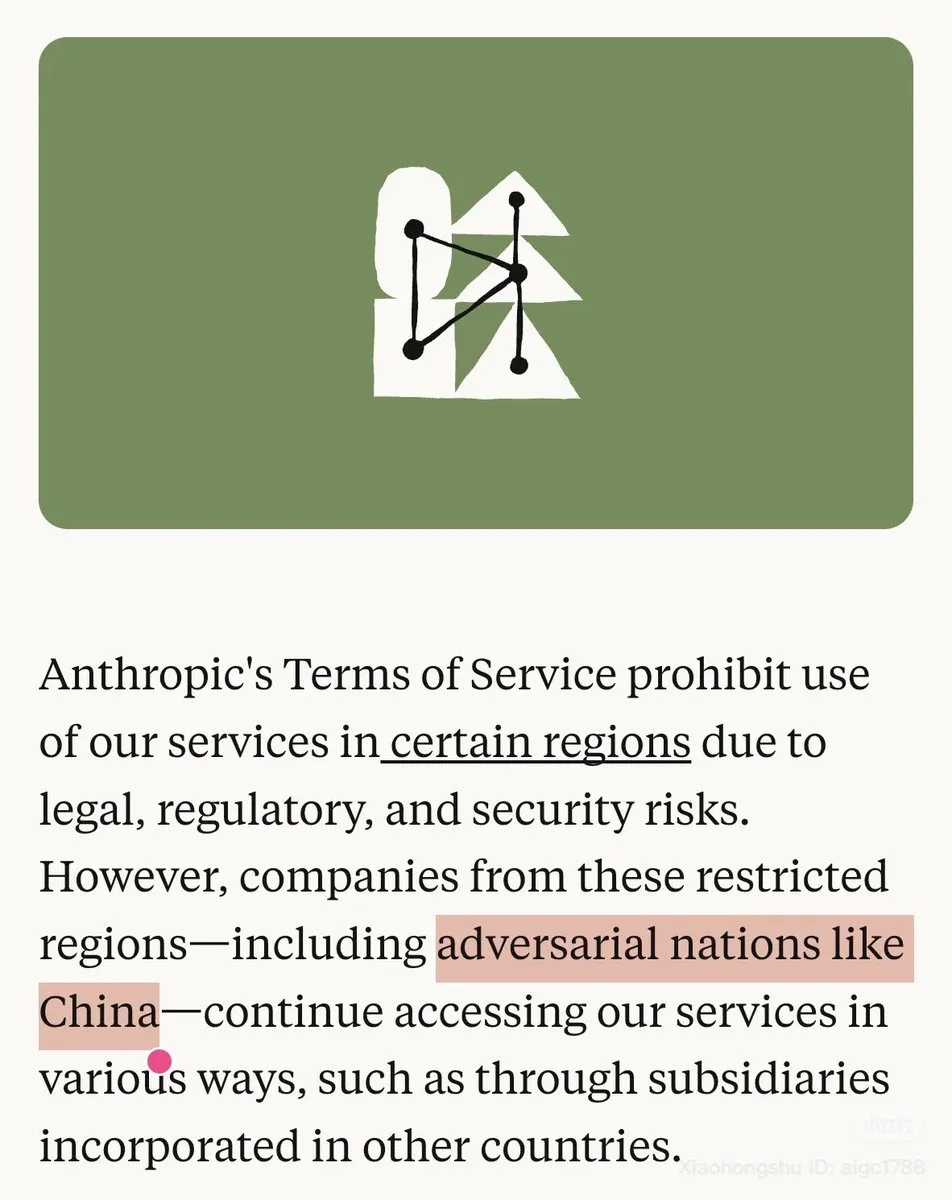
Controverse sur la politique d’Anthropic envers la Chine et la disponibilité des modèles : Anthropic a explicitement désigné la Chine comme un « pays hostile » dans son blog et a restreint l’utilisation de Claude dans certaines régions, suscitant un fort mécontentement au sein de la communauté. Parallèlement, le modèle Opus 4.1 de Claude.ai a été temporairement mis hors ligne, aggravant les préoccupations des utilisateurs concernant la stabilité du modèle et les politiques de l’entreprise. De nombreux utilisateurs chinois ont déclaré qu’ils se tourneraient vers OpenAI Codex. (Source: source, source)
Interaction de l’AI avec la politique et préoccupations réglementaires : Des leaders technologiques comme Sam Altman et Lisa Su ont salué les politiques pro-business et pro-innovation de l’administration Trump lors d’un dîner à la Maison Blanche, suscitant des discussions sur l’interaction entre les entreprises AI et le pouvoir politique, ainsi que sur les perspectives d’application de l’AI dans le domaine de l’éducation. Parallèlement, la FTC enquêtera sur l’impact des entreprises AI sur les enfants, reflétant les préoccupations des régulateurs concernant les risques sociaux potentiels des technologies AI. (Source: source, source)

Capacités des AI Agents et défis de développement : La communauté a discuté des capacités essentielles requises pour les AI Agents, y compris le besoin d’un contexte ultra-long et l’interprétabilité des Agents. Les ingénieurs AI ont signalé que dans les processus de génération de code par les agents AI, d’évaluation des exécutions et de réflexion des modèles, le flux de travail devient très fragmenté, entraînant une grande quantité de temps d’attente, ce qui est l’une des expériences les plus frustrantes de l’ère de l’AI. (Source: source, source)

Impact de l’AI sur l’emploi, le RBU et la distribution de la richesse sociale : La communauté a vivement débattu de l’impact de l’AI sur le marché de l’emploi, de la nécessité d’un revenu de base universel (RBU) et des craintes que l’AI n’aggrave les inégalités de richesse. Des experts comme le scientifique informatique Geoffrey Hinton estiment que l’AI rendra une minorité plus riche et une majorité plus pauvre, suscitant des discussions approfondies sur l’équité sociale de la technologie AI, son impact sur l’emploi et la redistribution de la richesse. (Source: source, source)

Baisse des performances des modèles AI et de l’expérience utilisateur : De nombreux utilisateurs se plaignent d’une baisse significative des performances récentes de ChatGPT, se manifestant par une augmentation des hallucinations, le refus de répondre à certaines questions, un manque d’empathie réelle et des restrictions de censure de contenu. Parallèlement, le problème des chatbots AI qui « font semblant d’être stupides » a également suscité du mécontentement, les utilisateurs estimant que cela pourrait être dû à des restrictions de politique d’entreprise plutôt qu’à un véritable manque de capacité, entraînant une mauvaise expérience utilisateur. (Source: source, source)
Qualité du contenu généré par AI et perception du public : La communauté a discuté des perceptions négatives du public à l’égard du contenu généré par AI, souvent qualifié de « AI Slop » (déchets AI), reflétant les préoccupations concernant l’abus de l’AI, la qualité inégale et la dévalorisation de la créativité humaine. Parallèlement, les technologies de génération AI remettent également en question l’ère de la photographie en tant que preuve fiable, suscitant des discussions sur les deepfakes et la véracité de l’information. (Source: source, source)

Éthique de l’AI et comportement de l’utilisateur : Soyez gentil avec l’AI : La communauté a discuté de la question de savoir si les utilisateurs, en interagissant avec les assistants AI, deviennent plus grossiers en raison de leur « complaisance » inconditionnelle, et si ce mode d’interaction pourrait avoir un impact négatif sur la communication avec les humains. Beaucoup pensent que, même si l’AI n’a pas d’émotions, rester poli est important pour sa propre santé mentale et pour éviter que de mauvaises habitudes ne se propagent aux relations interpersonnelles réelles. (Source: Reddit r/ClaudeAI)
Conscience de l’AI et frontières philosophiques de l’intelligence : La communauté a exploré les questions philosophiques de savoir si l’AI possède une conscience ou une « vie », citant l’exemple du robot Johnny 5 du film « Short Circuit » qui est jugé « vivant » en comprenant l’humour. La plupart des points de vue estiment que la compréhension de l’humour par l’AI est une manifestation d’intelligence, mais pas une preuve de vie ou de conscience, et que la limitation du test de Turing réside dans son incapacité à vérifier l’« expérience interne » de l’AI. (Source: Reddit r/ArtificialInteligence)
Gestion de la communauté LocalLLaMA et controverse sur la généralisation de l’AI : La communauté Reddit LocalLLaMA a lancé une nouvelle étiquette « local only », exigeant que les publications liées à la technologie LLM locale utilisent cette étiquette afin de filtrer les modèles non locaux, les coûts d’API et d’autres « bruits ». Cette mesure a suscité une forte réaction de la communauté, de nombreux utilisateurs estimant qu’elle allait à l’encontre de l’intention initiale de la communauté « local first ». Parallèlement, la discussion sur le fait que « les systèmes AI généralisés sont un mensonge » reflète également les doutes sur la capacité de généralisation et la fiabilité de l’AI. (Source: source, source)

Concurrence sur le marché du calcul GPU et trajectoire de développement de l’AI : La communauté a discuté de la concurrence féroce sur le marché du calcul GPU, et de la nécessité pour les nouveaux fournisseurs de services cloud d’améliorer leur compétitivité. Parallèlement, les progrès de l’AI ne sont pas entièrement tirés par la puissance de calcul ; l’efficacité de l’apprentissage et les architectures non-Transformer pourraient apporter le prochain saut exponentiel, suscitant une réflexion sur la trajectoire future du développement de l’AI. Certains points de vue soulignent également que les progrès de l’AI ne sont pas entièrement tirés par la puissance de calcul ; l’efficacité de l’apprentissage et les architectures non-Transformer pourraient apporter le prochain saut exponentiel. (Source: source, source)
💡 Autres
L’Inde utilise des robots pour nettoyer les égouts, améliorant la situation difficile du nettoyage manuel : Le gouvernement de Delhi en Inde promeut l’utilisation de robots pour remplacer le nettoyage manuel des égouts, afin de résoudre le problème persistant du « nettoyage manuel des boues ». Bien que cette pratique soit interdite depuis 1993, elle reste répandue et dangereuse. Plusieurs entreprises ont proposé des solutions techniques alternatives, y compris des robots de diverses complexités, visant à améliorer la sécurité et la dignité du travail. (Source: MIT Technology Review)
Des « robots-souris » utilisés pour simuler le comportement de vraies souris dans la recherche : Des chercheurs développent un « robot-souris » dans le but d’étudier en profondeur la biologie et les neurosciences en simulant le comportement de vraies souris. Ce projet combine la robotique, le Machine Learning et l’Intelligence Artificielle, offrant une nouvelle plateforme expérimentale pour comprendre le comportement animal. (Source: Ronald_vanLoon)
L’AI reconstitue le film perdu d’Orson Welles, « Les Ambersons magnifiques » : L’équipe de Fable Simulation utilise la technologie AI pour reconstruire, à des fins non commerciales et académiques, les 43 minutes perdues du chef-d’œuvre d’Orson Welles, « Les Ambersons magnifiques ». Ce projet démontre le potentiel de l’AI dans la restauration de films et la préservation du patrimoine artistique, et pourrait permettre au public de redécouvrir cette œuvre classique inachevée. (Source: source, source)
