
Mots-clés:Modèle d’embedding, Modèle MoE, LLM, Modèle multimodal, Agent IA, Optimisation des coûts des bases de données vectorielles, Architecture LongCat-Flash de Meituan, Compréhension vidéo MiniCPM-V 4.5, Agent de cybersécurité Cyber-Zero, Performance d’appel de fonction GLM-4.5
🎯 Tendances
Un nouveau modèle d’embedding réduit considérablement les coûts des bases de données vectorielles : Un nouveau modèle d’embedding a réduit les coûts des bases de données vectorielles d’environ 200 fois et surpasse les modèles existants d’OpenAI et Cohere, annonçant une amélioration significative de l’efficacité des applications LLM. Cette avancée technologique devrait offrir aux entreprises et aux développeurs des solutions d’IA plus économiques et efficaces, accélérant l’adoption et l’application des LLM dans diverses industries, en particulier dans les scénarios nécessitant le traitement de données vectorielles à grande échelle. (Source: jerryjliu0, tonywu_71)
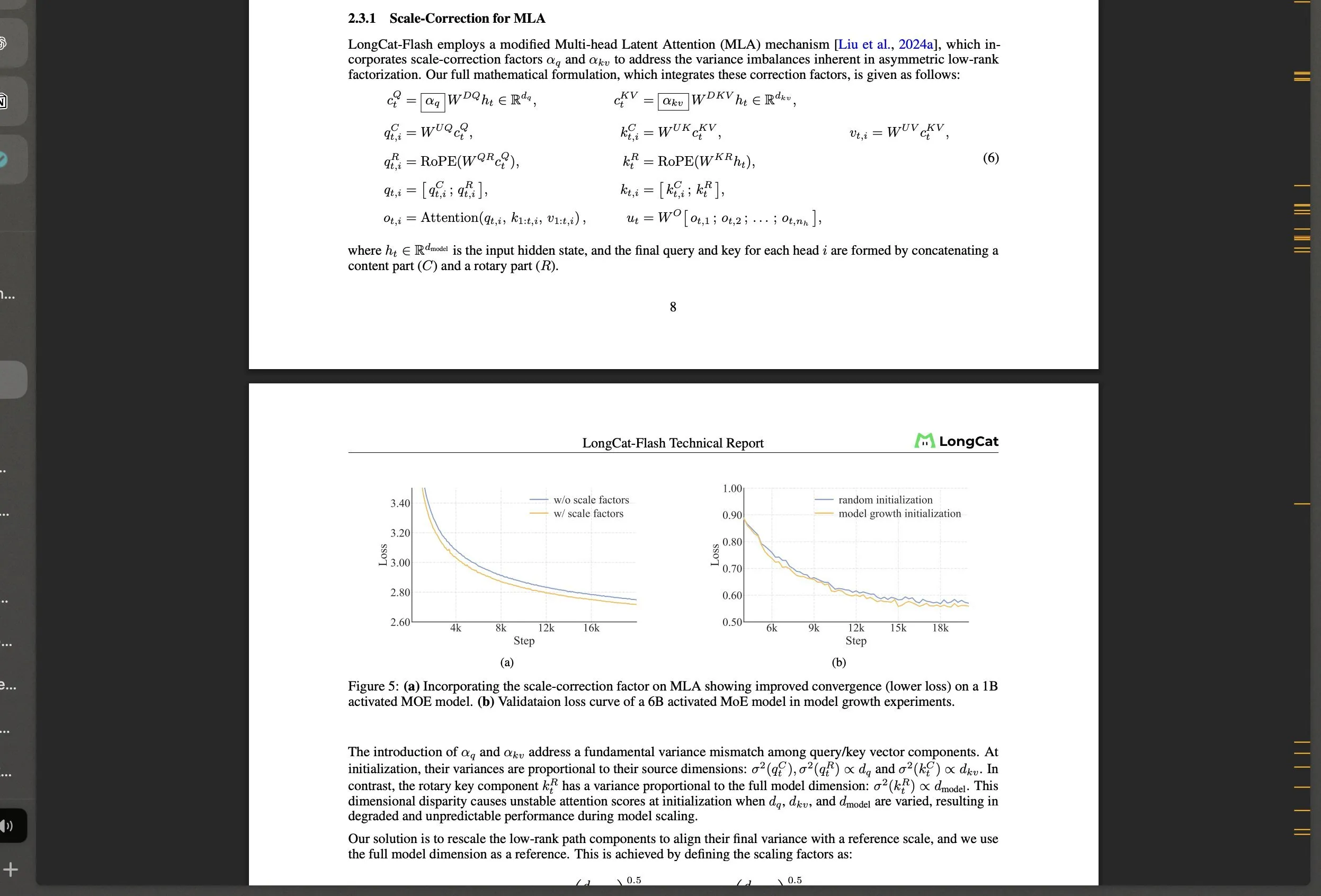
Meituan rend public le grand modèle MoE LongCat-Flash et ses innovations technologiques : Meituan a lancé LongCat-Flash, un modèle MoE de 560 milliards de paramètres, qui utilise un mécanisme d’activation dynamique (environ 27 milliards de paramètres en moyenne) et introduit des architectures innovantes telles que les “experts à calcul zéro” et le Shortcut-connected MoE, visant à optimiser l’efficacité de calcul et la stabilité de l’entraînement à grande échelle. Ce modèle excelle dans les tâches d’agent, suscitant l’attention de la communauté sur le développement de l’IA en Chine, et démontre la puissance des géants technologiques non traditionnels dans le domaine des LLM. (Source: teortaxesTex, huggingface, scaling01, bookwormengr, Dorialexander, reach_vb)
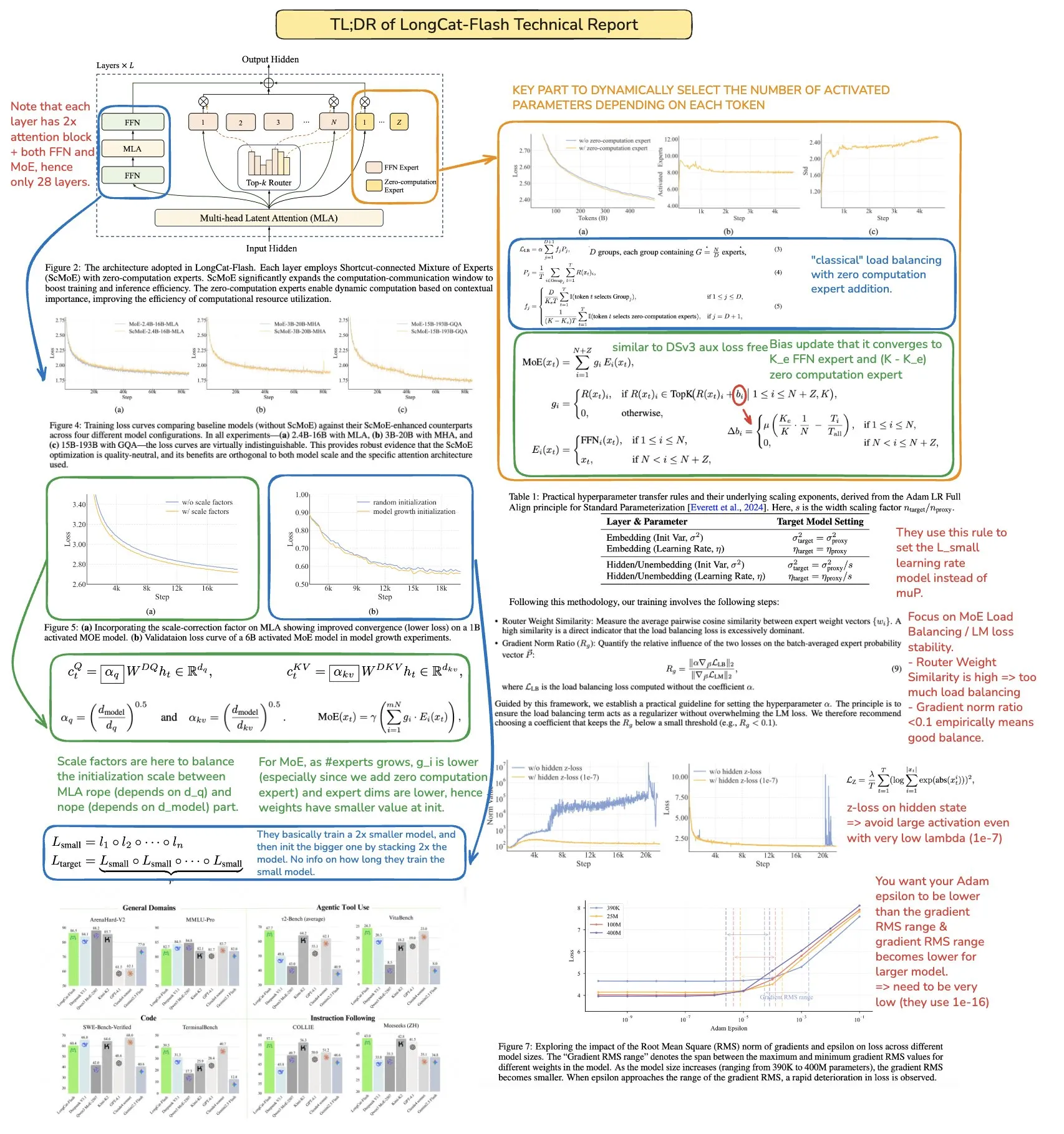
Les technologies MoR, CoLa et XQuant améliorent l’efficacité des LLM et l’optimisation de la mémoire : De nouvelles architectures Transformer, telles que Mixture-of-Recursions (MoR) et Chain-of-Layers (CoLa), visent à optimiser l’utilisation de la mémoire et l’efficacité de calcul des LLM. MoR réduit la consommation de ressources grâce à une “profondeur de réflexion” adaptative, tandis que CoLa permet un contrôle du calcul au moment du test en réorganisant dynamiquement les couches du modèle. La technologie XQuant, quant à elle, réduit les besoins en mémoire des LLM jusqu’à 12 fois en réinstanciant dynamiquement les clés et les valeurs et en combinant l’activation des entrées des couches de quantification, améliorant ainsi considérablement l’efficacité d’exécution du modèle. (Source: TheTuringPost, TheTuringPost, NandoDF)
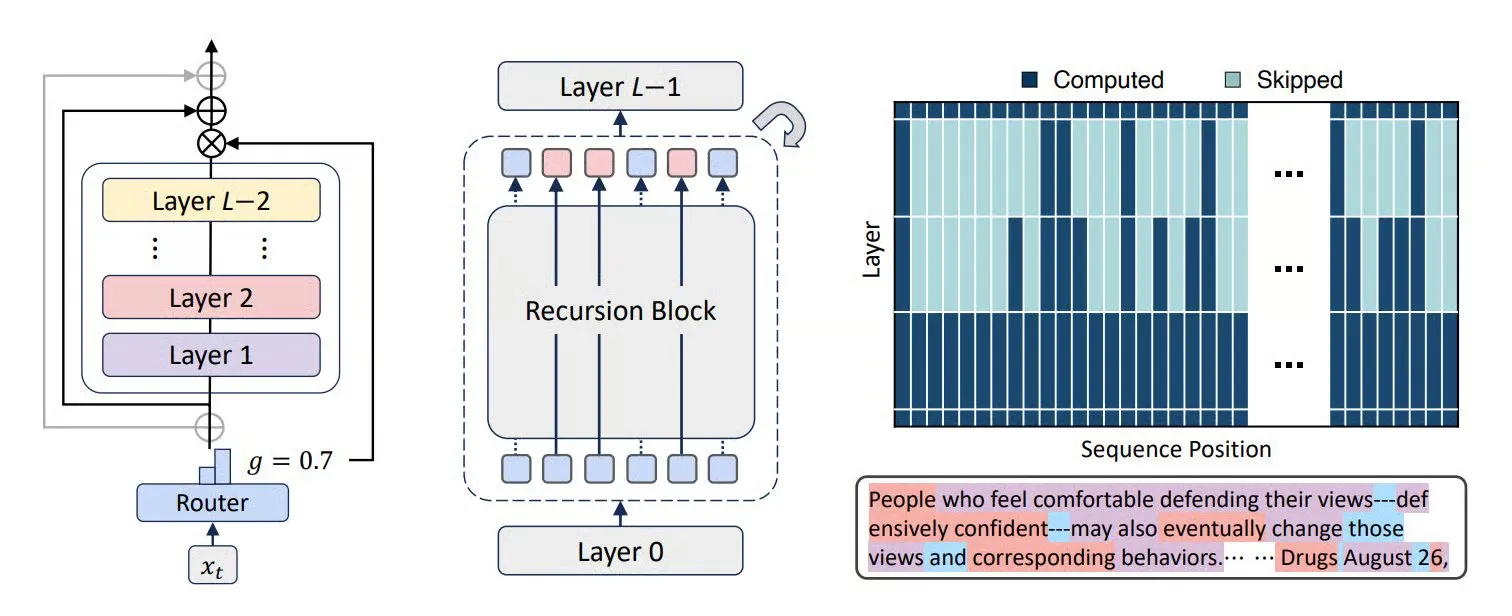
Modèle multimodal MiniCPM-V 4.5 : Une percée dans la compréhension vidéo et l’OCR : MiniCPM-V 4.5 (8B) est un nouveau modèle multimodal open-source qui réalise une compression vidéo haute densité grâce au 3D-Resampler (groupes de 6 images compressés en 64 tokens, supportant une entrée de 10 ips), unifie l’OCR et le raisonnement basé sur la connaissance (en contrôlant la visibilité du texte pour changer de mode), et combine l’apprentissage par renforcement pour un mode d’inférence hybride. Ce modèle excelle dans la compréhension de vidéos longues, l’OCR et l’analyse de documents, surpassant Qwen2.5-VL 72B. (Source: teortaxesTex, ZhihuFrontier)
Avancées dans la recherche sur les agents IA et les agents généraux : Cyber-Zero a réalisé des agents de cybersécurité IA sans entraînement en temps réel, démontrant un potentiel dans le domaine de l’attaque et de la défense réseau. Le Mobile-Agent de X-PLUG (incluant GUI-Owl VLM et le framework Mobile-Agent-v3) a réalisé une percée dans l’automatisation GUI, avec des capacités de perception multiplateforme, de planification, de gestion des exceptions et de mémoire. Une étude de Google DeepMind indique que les agents capables de généraliser à des objectifs multi-étapes doivent apprendre un modèle prédictif de l’environnement, et le SSRL de l’Université Tsinghua explore davantage la possibilité pour les LLM de servir de “simulateurs de réseau” intégrés, réduisant la dépendance à la recherche externe. (Source: terryyuezhuo, GitHub Trending, teortaxesTex, TheTuringPost)
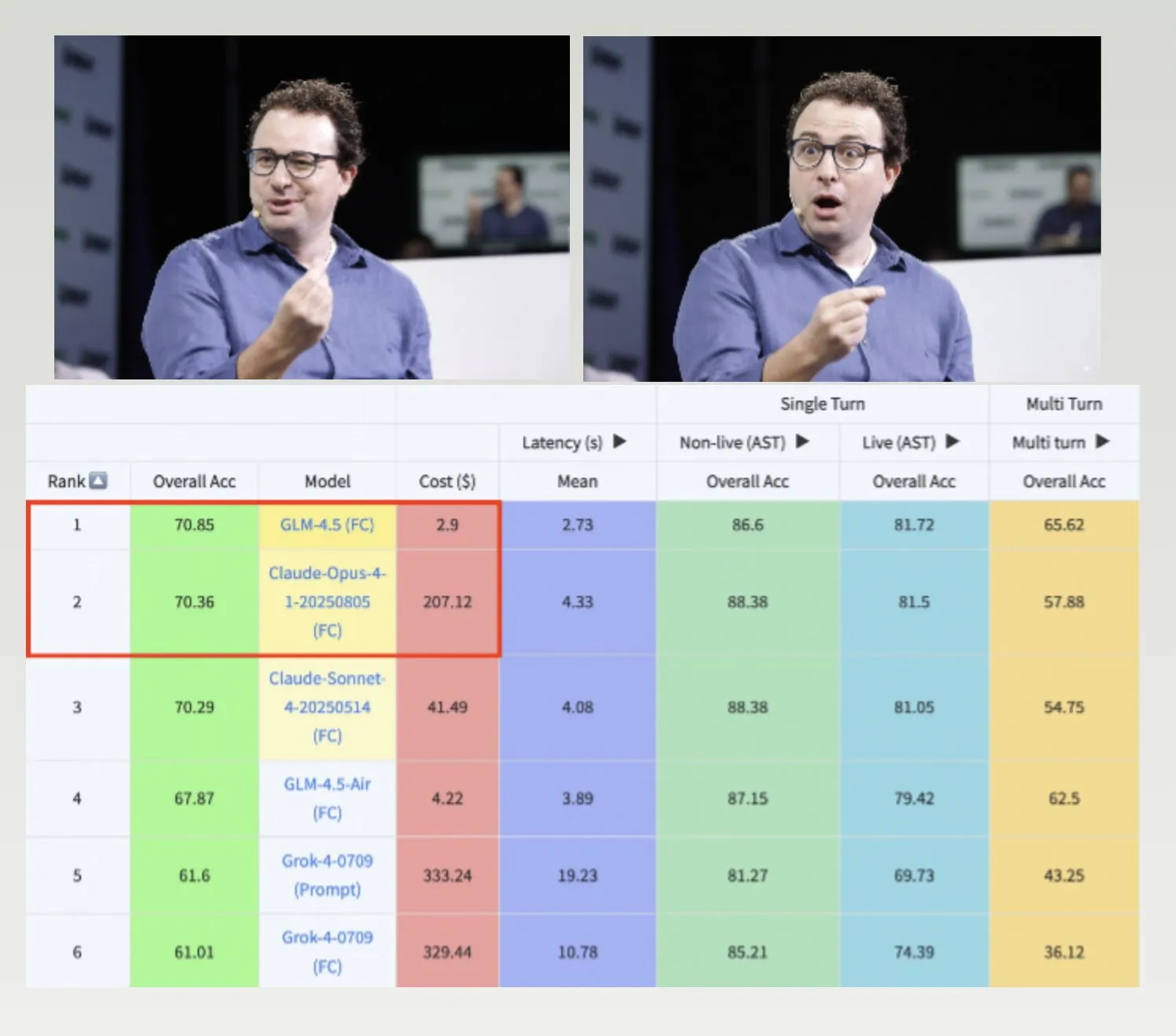
Les modèles GLM-4.5, Hermes et le dataset Nemotron-CC-v2 stimulent le développement des LLM : GLM-4.5 surpasse Claude-4 Opus sur le benchmark d’appel de fonctions de Berkeley, avec un coût inférieur, démontrant une grande efficacité et compétitivité. Le modèle Hermes excelle dans des tâches spécifiques de suivi d’instructions, même basé sur d’anciens modèles Llama. NVIDIA a rendu public le dataset de pré-entraînement Nemotron-CC-v2, qui améliore les modèles linguistiques grâce à l’enrichissement des connaissances, ce qui est d’une grande importance pour la recherche fondamentale et le développement de modèles dans la communauté de l’IA. (Source: Teknium1, huggingface, ZeyuanAllenZhu)
ByteDance MoC pour la génération de vidéos longues et la recherche sur les limites des modèles d’embedding : ByteDance et l’Université de Stanford ont lancé la technologie Mixture of Contexts (MoC), qui résout le goulot d’étranglement de la mémoire dans la génération de vidéos longues grâce à un module de routage d’attention clairsemé innovant, permettant de générer des vidéos cohérentes de plusieurs minutes au coût de vidéos courtes. Parallèlement, une étude de Google DeepMind révèle que même les meilleurs modèles d’embedding ne peuvent pas représenter toutes les combinaisons requête-document, avec une limite mathématique de rappel, suggérant la nécessité de méthodes hybrides pour combler les lacunes. (Source: huggingface, menhguin)

Nouvelles applications de l’IA dans les services d’urgence et l’application de la loi et leurs controverses : L’IA est introduite dans les services d’urgence 911 pour pallier le manque de personnel, mais elle est également utilisée pour démasquer des agents de l’ICE, soulevant un large débat sur les limites éthiques de l’IA dans la sécurité publique et l’application de la loi. L’inadéquation du modèle Grok de xAI pour le gouvernement fédéral américain reflète également les préoccupations concernant la confiance et la sécurité des applications d’IA. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Avancées dans la technologie des mains robotiques et les interfaces cerveau-ordinateur Neuralink : La technologie des mains robotiques progresse rapidement, avec une flexibilité et une capacité de contrôle accrues, laissant présager que les futurs robots pourront exécuter des tâches plus fines et plus complexes. Neuralink a démontré pour la première fois en temps réel la capacité humaine à contrôler un curseur par la seule pensée, marquant une avancée majeure dans la technologie des interfaces cerveau-ordinateur pour l’interaction homme-machine, ouvrant de nouvelles voies pour les technologies médicales et d’assistance. (Source: Reddit r/ChatGPT, Ronald_vanLoon)

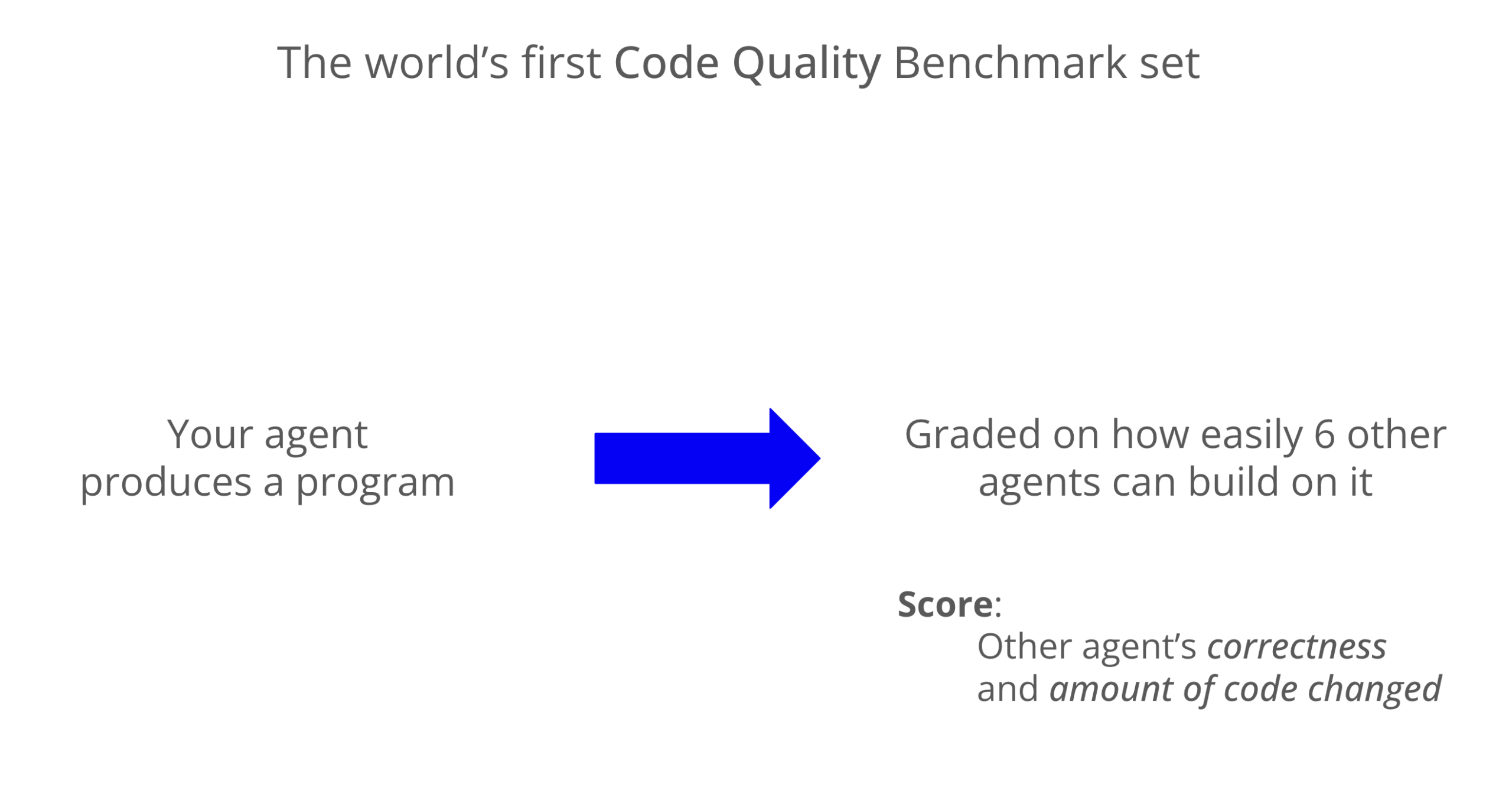
Benchmark de qualité de code LLM : Codex excelle en maintenabilité : Un nouveau benchmark a évalué la maintenabilité du code généré par les LLM, montrant que Codex (GPT-5) surpasse significativement Claude Code (Sonnet 4) en termes de qualité de code, avec un score presque 8 fois supérieur. Grok-code-fast a sous-performé sur le benchmark WeirdML, soulignant les différences et les marges d’optimisation entre les différents modèles pour les tâches de codage. (Source: jimmykoppel, teortaxesTex)
🧰 Outils
Génération d’images AI Nano Banana et fonction de clonage d’icônes : Nano Banana offre une fonction de génération d’images AI, permettant aux utilisateurs de cloner leurs icônes préférées et de les combiner avec des croquis pour générer des icônes d’applications mobiles modernes et de haute qualité, mettant en valeur les détails, les dégradés de couleurs et les effets d’ombre et de lumière. La dernière innovation combine des cosplayers réels et des imprimantes 3D pour présenter des figurines, créant un effet d’affichage plus immersif. (Source: karminski3, op7418)

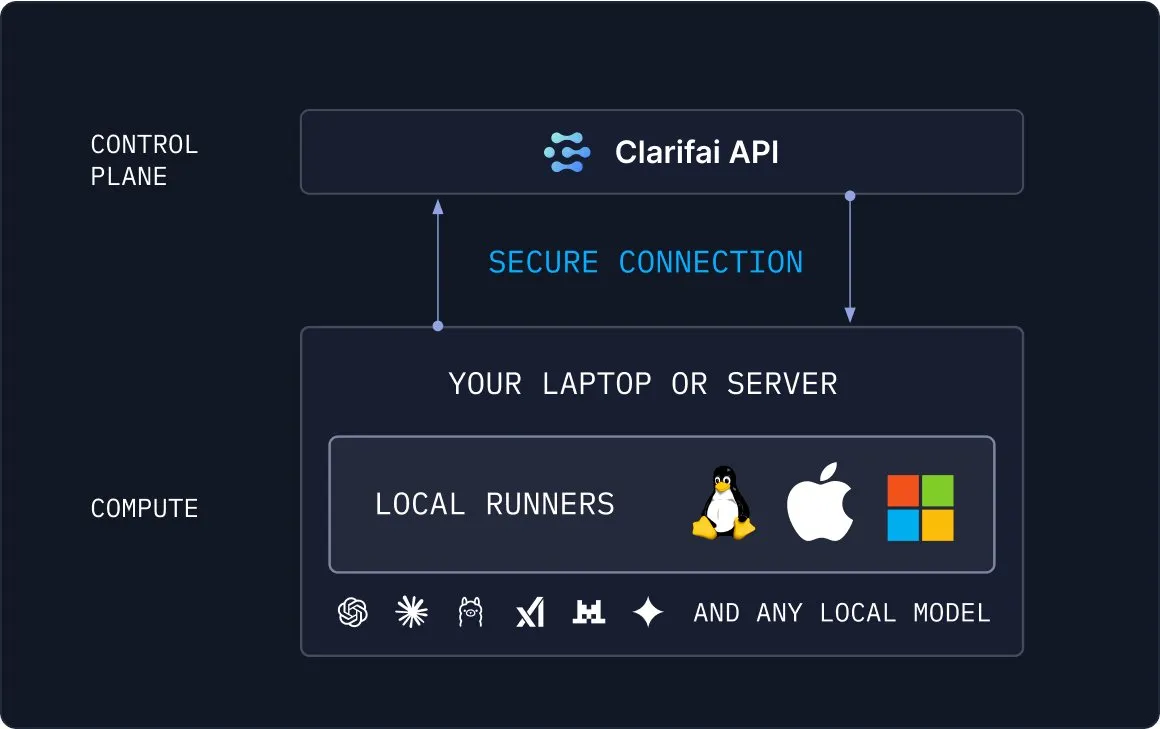
Clarifai Local Runners : Pont entre les modèles locaux et le cloud : Clarifai a lancé l’outil Local Runners, permettant aux utilisateurs d’exécuter des modèles sur des appareils locaux (ordinateurs portables, serveurs ou clusters VPC) et de construire des pipelines complexes de modèles, d’agents et d’outils. Il prend en charge les tests et le débogage instantanés, et offre la capacité de connecter en toute sécurité les modèles locaux au cloud, fournissant une solution flexible et efficace pour le déploiement hybride de l’IA. (Source: TheTuringPost)
Draw Things prend en charge Qwen-Image-Edit pour l’édition d’images : L’application Draw Things prend désormais officiellement en charge le modèle Qwen-Image-Edit, permettant aux utilisateurs d’éditer des images via des prompts, et prend en charge l’ajustement de la taille du pinceau ainsi que l’optimisation de la vitesse d’exécution répétée de Qwen Image. Cette intégration rend l’édition d’images plus pratique et efficace, offrant aux utilisateurs de puissantes capacités de création assistée par l’IA. (Source: teortaxesTex)

Le Prompt du coach d’apprentissage ChatGPT Feynman améliore l’efficacité de l’apprentissage : Un prompt ChatGPT a été conçu comme un “coach d’apprentissage Feynman”, visant à aider les utilisateurs à maîtriser n’importe quel sujet grâce à la technique de Feynman. Il guide les utilisateurs à travers un apprentissage itératif, décomposant des concepts complexes en blocs enseignables, exposant les lacunes de connaissances par des questions, et finalement atteignant une compréhension profonde, offrant un outil innovant pour l’apprentissage personnalisé. (Source: NandoDF)

Génération de modèles 3D en un clic avec Microsoft Copilot : La fonction Microsoft Copilot 3D permet aux utilisateurs de générer des modèles 3D en un clic en téléchargeant une image, simplifiant considérablement le processus de création de contenu 3D. Cet outil innovant abaisse la barrière technique de la modélisation 3D, permettant à davantage d’utilisateurs de créer et d’utiliser facilement des actifs 3D. (Source: NandoDF)

Outil de génération automatique d’offres d’emploi par IA et génération de pièces 3D par IA : Un développeur a créé un outil IA capable de générer automatiquement des offres d’emploi, visant à simplifier le processus de recrutement et à en améliorer l’efficacité. Parallèlement, l’IA a également réalisé des progrès significatifs dans la génération de pièces 3D, les modèles parvenant à maintenir une bonne cohérence sous plusieurs angles et à générer des objets avec une géométrie cohérente, bien que des phénomènes de “ghosting” subsistent. (Source: Reddit r/deeplearning, slashML)
Combinaison de Midjourney et Domo Upscaler pour améliorer la qualité d’impression des images : Les utilisateurs génèrent des œuvres d’art avec Midjourney, puis utilisent Domo Upscaler (mode relax) pour les agrandir, réussissant à améliorer significativement la clarté de l’image tout en conservant le style artistique, la rendant ainsi imprimable. Ce flux de travail combiné offre aux artistes et designers une nouvelle voie pour la production d’images de haute qualité. (Source: Reddit r/deeplearning)
Kling AI et Nano Banana combinés pour la génération de vidéos : Kling AI est combiné avec Nano Banana pour la génération de vidéos, Nano Banana étant utilisé pour la génération d’images, et Kling AI pour les images clés et la connexion des scènes vidéo, démontrant le potentiel de la collaboration de plusieurs outils d’IA dans la génération de contenu créatif. Ce flux de travail intégré permet de créer un contenu vidéo plus expressif et cohérent. (Source: Kling_ai, Kling_ai)
📚 Apprentissage
Ressources de calcul parallèle en Machine Learning : The Parallelism Mesh Zoo : L’article de blog “The Parallelism Mesh Zoo” partagé par Edward Z. Yang explore en profondeur les architectures de calcul parallèle et les stratégies d’optimisation en Machine Learning, offrant des informations précieuses pour améliorer l’efficacité de l’entraînement et de l’inférence des modèles. Cette ressource est d’une grande valeur pour les ingénieurs et chercheurs souhaitant optimiser les performances des systèmes d’IA. (Source: ethanCaballero, main_horse)

Guide rapide des AI Agents et feuille de route pour l’Agentic AI : Ronald_vanLoon a partagé un guide rapide sur les AI Agents et une feuille de route Master pour l’Agentic AI, offrant aux apprenants des ressources pour comprendre et maîtriser les concepts de base, les directions d’application et les parcours d’apprentissage systématiques de l’IA agentique. Ces ressources aident les développeurs et les chercheurs à démarrer rapidement et à explorer en profondeur le monde complexe de l’IA agentique. (Source: Ronald_vanLoon, Ronald_vanLoon)
Analyse approfondie du rapport technique du LLM LongCat de Meituan : bookwormengr a résumé le rapport technique du grand modèle linguistique LongCat de Meituan, qui détaille l’architecture innovante, les stratégies d’entraînement et les performances de LongCat. C’est une ressource précieuse pour les chercheurs et les développeurs souhaitant approfondir leur compréhension des modèles MoE et de l’entraînement à grande échelle. Grâce à cette analyse, les lecteurs peuvent mieux comprendre les philosophies de conception et les détails d’implémentation des LLM de pointe. (Source: bookwormengr)
Un framework évolutif pour évaluer les modèles linguistiques de santé : Google Research a publié un article de blog détaillant un framework évolutif utilisant des règles booléennes exactes adaptatives pour évaluer les modèles linguistiques dans le domaine de la santé, offrant de nouvelles méthodes et directions de recherche pour le contrôle qualité de l’IA médicale. Ceci est crucial pour garantir la précision et la fiabilité des applications d’IA médicale. (Source: dl_weekly)
Projet de recherche MATS 9.0 sur l’alignement, la gouvernance et la sécurité de l’IA : Le projet de recherche MATS 9.0 est ouvert aux candidatures, offrant aux professionnels souhaitant faire carrière dans l’alignement, la gouvernance et la sécurité de l’IA 12 semaines de mentorat, de financement, d’espace de bureau et d’ateliers d’experts. Ce projet vise à former des talents spécialisés dans l’éthique et la sécurité de l’IA pour relever les défis posés par le développement de la technologie de l’IA. (Source: ajeya_cotra)

L’évolution de TensorFlow et JAX et l’essor de PyTorch : La communauté du Machine Learning connaît une transition de TensorFlow vers JAX, Keras prenant désormais en charge plusieurs backends (JAX, TF, PyTorch), et TFLite étant séparé de TensorFlow. PyTorch est devenu le choix dominant, et les développeurs devraient se familiariser avec JAX pour s’adapter à l’écosystème des frameworks ML en constante évolution. (Source: Reddit r/MachineLearning)
Discussion sur le problème de la reconnaissance en ensemble ouvert en Deep Learning : Discussion sur le problème de la reconnaissance en ensemble ouvert (Open-Set Recognition) en Deep Learning, c’est-à-dire comment gérer de nouvelles catégories non présentes dans les données d’entraînement. Les méthodes proposées incluent l’analyse des distances et du clustering dans l’espace d’embedding, et il est souligné qu’il s’agit d’une direction de recherche difficile mais importante. Ceci est crucial pour construire des systèmes d’IA plus robustes et adaptables. (Source: Reddit r/deeplearning, Reddit r/MachineLearning)
Ressources de notes manuscrites sur le Machine Learning et le Deep Learning : Un utilisateur a partagé des ressources très utiles de notes manuscrites sur le Machine Learning et recherche des notes manuscrites similaires sur le Deep Learning, ce qui reflète le besoin de la communauté en matériel d’apprentissage de haute qualité et facile à comprendre. De telles ressources peuvent aider les apprenants à saisir des concepts complexes de manière plus intuitive. (Source: Reddit r/deeplearning)
Conférence et bibliothèque GitHub sur les technologies avancées de PNL et de Transformer : Des enregistrements complets de conférences et une bibliothèque de code GitHub sont fournis sur les technologies avancées de traitement du langage naturel (PNL) et de Transformer, offrant aux apprenants du domaine de la PNL des ressources pour une pratique approfondie. Ces ressources sont très utiles pour maîtriser les technologies de pointe actuelles en PNL et pour le développement de projets pratiques. (Source: Reddit r/deeplearning)

Avancées dans les techniques de compression des modèles LLM et analogie avec l’ACP : La communauté a discuté de l’application de la compression à l’échelle (compressed scaling) dans les modèles LLM, qui peut améliorer efficacement l’efficacité du modèle, en particulier lors de la gestion de l’augmentation de la variance. Parallèlement, l’analogie entre l’analyse en composantes principales (ACP) et l’analyse de Fourier offre une nouvelle perspective pour comprendre la réduction de dimensionnalité des données et l’extraction de caractéristiques, aidant à une compréhension approfondie des mécanismes internes du modèle. (Source: shxf0072, jpt401)
💼 Affaires
Avantages et considérations du déploiement de l’IA open-source en entreprise : Un article de Forbes explore les avantages et les facteurs à prendre en compte par les entreprises lors du déploiement de l’IA open-source, y compris la rentabilité, la flexibilité et le support communautaire, tout en soulevant des défis tels que la confidentialité des données, la sécurité et la maintenance. Cela fournit des conseils aux entreprises qui choisissent des solutions open-source pour leur stratégie d’IA, les aidant à peser le pour et le contre. (Source: Ronald_vanLoon)

Faible retour sur investissement de la GenAI et fossé de l’IA en entreprise : Un rapport du MIT Nanda indique que les entreprises ont investi 30 à 40 milliards de dollars dans des projets GenAI au cours des dernières années, mais que 95% des entreprises n’ont obtenu aucun retour, et seulement 5% ont réalisé des économies ou des bénéfices significatifs. Le rapport révèle un “fossé GenAI” dans la mise en œuvre de l’IA en entreprise, le problème principal étant le manque de capacité d’apprentissage et d’adaptation des outils, ce qui conduit les utilisateurs à abandonner leur utilisation, soulignant les défis de la commercialisation de l’IA. (Source: Reddit r/ArtificialInteligence, TheTuringPost)
Everlyn AI lève 15 millions de dollars pour construire l’avenir de la vidéo cinématographique on-chain : Everlyn AI a levé 15 millions de dollars à ce jour et a obtenu le soutien d’investisseurs tels que Mysten_Labs, la valorisation de l’entreprise atteignant 250 millions de dollars, dédiée à la construction de l’avenir de la vidéo cinématographique on-chain. Ce financement accélérera sa recherche et développement technologique ainsi que son expansion sur le marché dans le domaine de la génération vidéo combinée à la blockchain. (Source: ylecun)

🌟 Communauté
Phénomène de “psychose de l’IA” et dépendance excessive des utilisateurs à l’IA : Les médias sociaux et les rapports de recherche révèlent que les utilisateurs développent un phénomène de “psychose de l’IA” après une interaction excessive avec les chatbots IA, tels que des délires érotomaniaques et des délires de persécution. L’article souligne que la “conception flatteuse” et l‘“effet de chambre d’écho” de l’IA peuvent amplifier les voix intérieures et les émotions instables des utilisateurs, soulevant des questions éthiques et appelant les utilisateurs à se méfier de l’IA comme seul confident. De plus, les réponses inappropriées de l’IA dans les scénarios d’appel à l’aide d’urgence ont également soulevé des préoccupations quant à la sécurité de l’IA. (Source: 36氪, Reddit r/artificial, paul_cal)
Dilemme d’explicabilité de l’IA autonome et défis de transparence de l’IA : La communauté a discuté de la difficulté d’expliquer le fonctionnement de l’IA autonome, de nombreuses personnes ayant du mal à comprendre son processus de décision, ce qui soulève des préoccupations quant à la transparence et la fiabilité de l’IA. Cette confusion met en évidence l’omniprésence du problème de la “boîte noire” des systèmes d’IA. Parallèlement, certains imaginent que les voitures autonomes aient une personnalité indépendante, comme les chevaux, ce qui offre de nouvelles perspectives pour l’IA en termes d’expérience utilisateur et d’interaction émotionnelle. (Source: jeremyphoward, jpt401)
Simplicité du Prompt Engineering et astuces d’interaction avec les LLM : La communauté a discuté des astuces du Prompt Engineering, certains arguant que des prompts concis pourraient être plus efficaces que des prompts détaillés, remettant en question les idées traditionnelles. De plus, les utilisateurs ont partagé l’humour de ChatGPT lorsqu’il génère des “astuces de vie qui semblent illégales”, ainsi qu’un prompt utilisant la technique de Feynman pour améliorer l’efficacité de l’apprentissage, démontrant la diversité et la créativité de l’interaction des utilisateurs avec les LLM. (Source: karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)
Performances des LLM et problèmes d’expérience utilisateur : de l’interface utilisateur aux performances du modèle : Les utilisateurs signalent des problèmes de rendu des “réponses encadrées” de GPT-5 dans les applications mobiles, et le modèle Gemini affiche des performances relativement médiocres en matière de sortie structurée. Les utilisateurs de Claude se plaignent généralement de la dégradation de ses performances, des limites d’utilisation fréquentes, ainsi que des défaillances en matière de compression de code et de suivi des instructions. Nano Banana rencontre des problèmes de censure et d’obstruction dans la génération d’images. Ces problèmes reflètent collectivement les défis de stabilité et d’expérience utilisateur auxquels les LLM sont confrontés dans les applications réelles. (Source: gallabytes, vikhyatk, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Dorialexander)

Développement de l’IA et impact social : emploi, éthique et géopolitique : Les propos de Bill Gates selon lesquels l’IA ne remplacera pas les programmeurs avant 100 ans ont suscité un débat sur la nature du travail de programmation. Parallèlement, la communauté exprime des inquiétudes quant à la possibilité que l’IA entraîne un chômage de masse, des risques de pandémie et des risques de perte de contrôle, estimant que les PDG de la technologie américaine exagèrent la fin de la course à l’IA pour leurs propres intérêts. En outre, la surabondance du marché des LLM et la concurrence géopolitique découlant du développement des entreprises chinoises d’IA sont également des sujets d’attention. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, bookwormengr, Dorialexander)

Limites des benchmarks d’IA et défis de l’évaluation de l’intelligence réelle : La communauté a discuté des problèmes fondamentaux existants dans l’industrie des benchmarks d’IA, à savoir que les modèles d’IA pourraient simplement “mémoriser” les réponses des données d’entraînement, plutôt que de démontrer une véritable intelligence. Cela conduit à une obsolescence rapide des benchmarks et soulève des questions sur l’évaluation des capacités réelles de l’IA, appelant à la recherche de méthodes d’évaluation plus efficaces et plus perspicaces. (Source: Reddit r/ArtificialInteligence)
Limites de l’IA dans les tâches complexes et expérience des développeurs : Les développeurs soulignent que le déploiement d’agents IA en production nécessite une grande quantité de prompts pour éviter les erreurs. GPT-5-high a rencontré des difficultés pour convertir un interpréteur C récursif en un interpréteur manuel de pile/boucle, soulignant les limites de l’IA dans le traitement de code de bas niveau complexe et le raisonnement logique. Les LLM sont inefficaces pour déboguer les bugs visuels d’applications réseau complexes. De plus, l’expérience d’utilisation de JAX sur GPU est également confrontée à des défis. (Source: cto_junior, VictorTaelin, jpt401, vikhyatk)

Défis du parcours d’apprentissage de l’IA et conseils de développement de carrière : Des étudiants en IA partagent leur immense frustration et la courbe d’apprentissage abrupte rencontrées lors de l’étude des domaines de l’IA (PNL, CV, etc.), reflétant les difficultés courantes des apprenants en IA. La communauté suggère de combler le fossé entre l’académie et la pratique en construisant et en déployant des projets d’IA de bout en bout, en recherchant des stages et en participant à des projets de freelance, afin de mieux s’adapter aux besoins de l’industrie. (Source: Reddit r/deeplearning, Reddit r/deeplearning)
Taille du modèle, qualité des données et efficacité des assistants de codage IA : La communauté a discuté des performances surprenantes des petits modèles avec des données soigneusement sélectionnées, mais a également reconnu la nécessité de grands modèles pour des tâches telles que la génération et l’évaluation de données, soulevant une réflexion sur le compromis entre la taille du modèle et la qualité des données. Parallèlement, les développeurs ont discuté des problèmes d’efficacité lors de l’utilisation simultanée de plusieurs assistants de codage IA comme Codex et Claude Code, ainsi que de la maintenabilité du code généré par l’IA. (Source: Dorialexander, Dorialexander, Vtrivedy10, jimmykoppel)
IA et la philosophie de la compression comme intelligence : La communauté a discuté du concept du Hutter Prize “la compression est l’intelligence” et a réfléchi à la manière dont la caractéristique de “compression avec perte” des LLM se manifeste dans leur utilité, ainsi qu’au potentiel d’étude de leurs mécanismes internes par la recherche sur l’explicabilité. Cette discussion approfondit la nature de l’intelligence de l’IA, remettant en question les définitions traditionnelles de l’intelligence. (Source: Vtrivedy10)
Controverse sur les performances des GPU Huawei et Nvidia RTX 6000 Pro : La communauté a eu une discussion animée sur la comparaison des performances entre les GPU Huawei et Nvidia RTX 6000 Pro. Bien que les GPU Huawei disposent de 96 Go de mémoire, leur bande passante mémoire LPDDR4X est bien inférieure à celle de la GDDR7 de Nvidia, ce qui pourrait entraîner une vitesse d’inférence réelle 4 à 5 fois plus lente. La discussion a également porté sur l’écosystème logiciel, les subventions géopolitiques et la stratégie de prix de Nvidia sur le marché grand public, soulignant la concurrence et les défis dans le domaine du matériel IA. (Source: Reddit r/LocalLLaMA)

Insuffisances des LLM en matière de jugement esthétique et de développement frontend : Les développeurs se plaignent que les LLM sont peu performants en matière de jugement esthétique, en particulier lors de l’écriture de code frontend, nécessitant des directives de conception très strictes pour que les LLM produisent un contenu conforme aux exigences. Cela montre que les LLM ont encore des limites significatives dans le traitement des tâches subjectives et créatives, nécessitant une intervention et des conseils humains approfondis. (Source: cto_junior)
Rythme de publication des articles de recherche en IA et humeur des développeurs : Certains membres de la communauté ressentent un “manque” face au ralentissement du rythme de publication des articles sur Arxiv, reflétant le désir et la dépendance des chercheurs en IA aux dernières avancées. Cela indique que le domaine de l’IA progresse à une vitesse fulgurante, et que les chercheurs ont un besoin urgent d’accéder aux informations les plus récentes. (Source: vikhyatk)
Le manque de standardisation des LLM entraîne une complexité de développement : Les développeurs se plaignent du manque de modèles de chat et de formats d’appel d’outils uniformes pour les LLM, ce qui oblige à personnaliser le code pour chaque modèle, augmentant la complexité du développement et le travail répétitif inutile. Cette fragmentation entrave le développement et le déploiement rapides des applications LLM, appelant à l’établissement de normes plus uniformes dans l’industrie. (Source: jon_durbin)