
Mots-clés:NVIDIA Jetson Thor, IA physique, robot humanoïde, GPU Blackwell, puissance de calcul IA, puissance de calcul maximale de Jetson Thor en IA, performances du GPU Blackwell, scénarios d’application de l’IA physique, kit de développement pour robots humanoïdes, prix du Jetson Thor
🔥 À la une
NVIDIA Jetson Thor lancé, la puissance de calcul de l’IA physique monte en flèche : NVIDIA a lancé Jetson Thor, conçu spécifiquement pour l’AI physique et les robots humanoïdes. Équipé d’un Blackwell GPU et d’un CPU Arm Neoverse à 14 cœurs, il atteint une puissance de calcul IA de pointe de 2070 TFLOPS (FP4), soit 7,5 fois plus que la génération précédente Jetson Orin. Il prend en charge les modèles d’IA générative tels que VLA, LLM, VLM, peut traiter la vidéo en temps réel et l’inférence d’IA, et vise à accélérer le développement de la robotique générale et de l’AI physique. Il est principalement utilisé dans les robots humanoïdes, l’assistance chirurgicale, les tracteurs intelligents, etc., et a déjà été adopté par Agility Robotics, Amazon, Boston Dynamics, Unitree Robotics, entre autres. Le kit de développement est disponible à partir de 3499 dollars. (Source : nvidia)

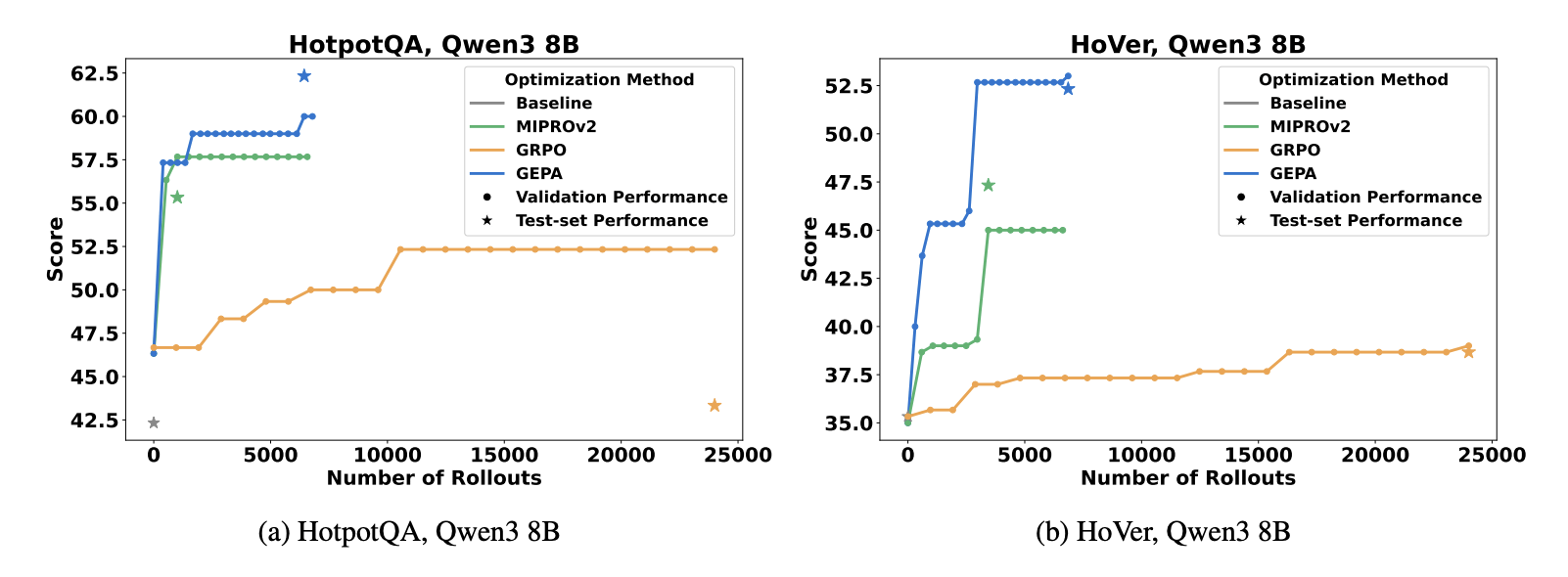
GEPA : L’évolution de prompt réflexive dépasse le RL : Une nouvelle étude (Agrawal et al., 2025) propose la méthode GEPA (Genetic-Pareto Prompt Evolution), qui fait évoluer les prompts de système LLM via la réflexion en langage naturel et le diagnostic de trajectoire, plutôt que de s’appuyer sur l’apprentissage par renforcement. GEPA surpasse GRPO dans les tâches de QA multi-sauts, nécessitant 35 fois moins de rollouts, et dépasse continuellement l’optimiseur de prompts SOTA MIPROv2. Cela indique que les boucles d’optimisation natives du langage sont plus efficaces que les rollouts bruts dans l’espace des paramètres pour l’adaptabilité des LLM, annonçant une nouvelle direction pour les stratégies d’optimisation de l’IA. (Source : Reddit r/MachineLearning)
La méthode OPRO améliore l’efficacité des tests de sécurité de l’IA : Bret Kinsella de TELUS Digital présente la méthode Optimization by PROmpting (OPRO), qui permet aux LLM de s’auto-tester en “red teaming”, évaluant la sécurité de l’IA en optimisant les générateurs d’attaques. Cette méthode se concentre sur la distribution du taux de succès des attaques (ASR), plutôt que sur un simple succès/échec, et peut découvrir des vulnérabilités à grande échelle et guider les mesures d’atténuation. Elle souligne que dans les secteurs à haut risque tels que la finance et la santé, les tests de sécurité de l’IA doivent être exhaustifs, reproductibles et créatifs, et passer de la réaction à la prévention, offrant aux entreprises une évaluation plus nuancée de la sécurité de l’IA. (Source : Reddit r/deeplearning)

🎯 Tendances
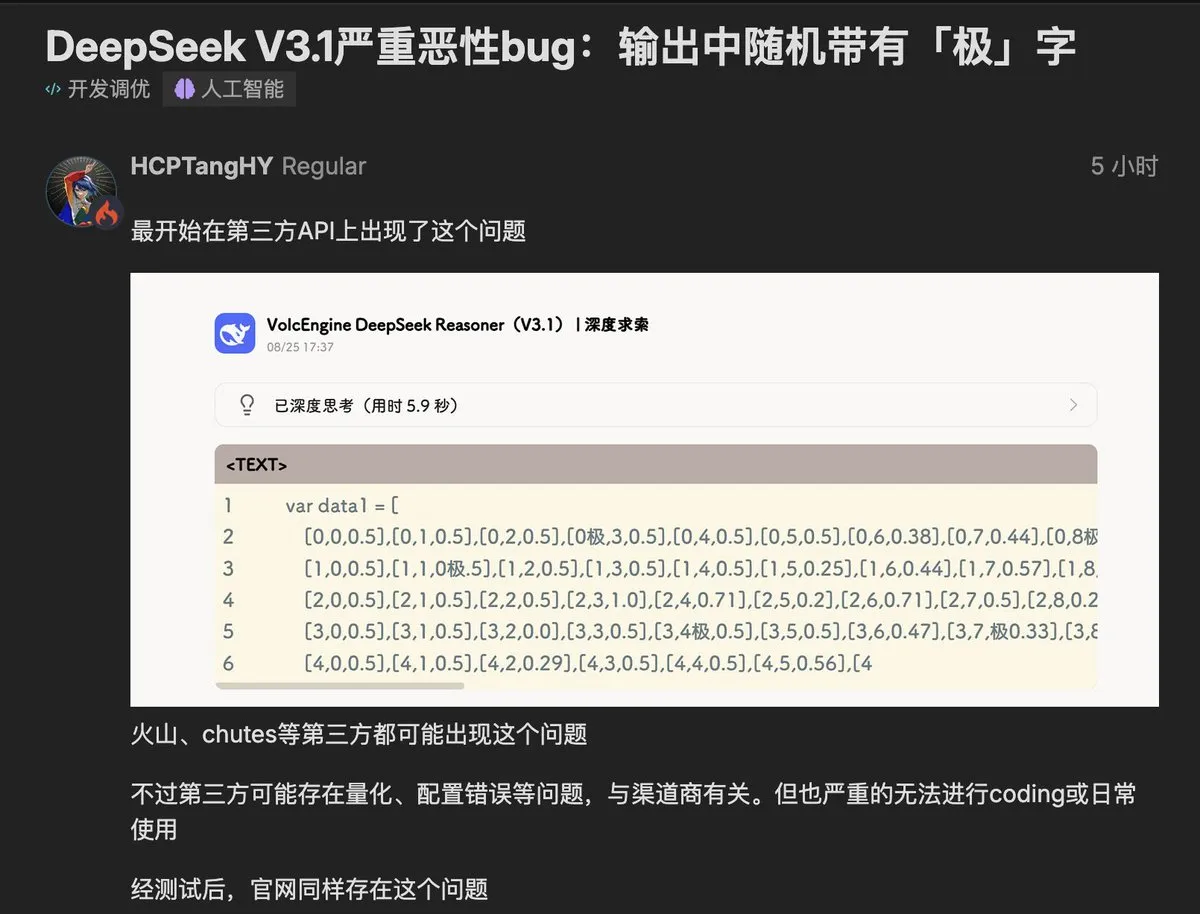
Un bug du caractère “极” (extrême) est apparu dans le modèle DeepSeek V3.1 : Le dernier modèle V3.1 de DeepSeek a été signalé par les utilisateurs pour insérer aléatoirement le caractère “极” (ou “extreme”) dans ses sorties, affectant les tâches sensibles au code et à la structure. Ce problème a été reproduit à la fois dans les déploiements tiers et l’API officielle, suscitant des inquiétudes au sein de la communauté concernant la contamination des données du modèle et les problèmes de stabilité. Certains spéculent que cela est lié à la confusion des tokens ou des données d’entraînement RLHF impures, ce qui sonne l’alarme pour les développeurs de modèles, soulignant l’impact crucial de la qualité des données sur le comportement de l’IA. (Source : teortaxesTex, 36氪, 36氪)
Le mystérieux modèle Nano-Banana de Google suscite l’intérêt : Un mystérieux modèle de génération et d’édition d’images nommé Nano-Banana est devenu populaire au sein de la communauté IA, et est soupçonné d’être un produit Google. Il excelle dans l’édition de texte, la fusion de styles et la compréhension de scènes, et peut fusionner des éléments de plusieurs images tout en maintenant la cohérence de l’éclairage, de la perspective et de la composition. Cependant, il présente des défauts tels que des titres de livres corrompus et des doigts déformés, et manque actuellement d’API officielle, rendant l’expérience instable. De nombreux faux sites web sont également apparus, suscitant des discussions sur les capacités du nouveau modèle et les canaux d’accès. (Source : TomLikesRobots, yupp_ai, yupp_ai, 36氪)

Microsoft rend open source le modèle VibeVoice-1.5B TTS : Microsoft a rendu open source le modèle VibeVoice-1.5B TTS, qui prend en charge la génération de dialogues audio expressifs d’une durée allant jusqu’à 90 minutes, avec jusqu’à 4 locuteurs différents. Basé sur Qwen2.5-1.5B, ce modèle utilise un tokenizer à très faible débit d’images, améliorant l’efficacité de calcul, et prend en charge le chinois et l’anglais. Sous licence MIT, il devrait stimuler la génération d’IA de contenu audio long comme les podcasts, offrant aux créateurs de puissantes capacités de production audio multilingues. (Source : _akhaliq, AnthropicAI, ClementDelangue, dotey)
Nouvelles avancées des modèles Alibaba Wan : Le modèle d’IA Alibaba Wan a annoncé le lancement prochain de WAN 2.2-S2V, un modèle de synthèse vocale en vidéo de qualité cinématographique, mettant l’accent sur “audio-driven, vision-based, open-source”. Parallèlement, le modèle Wan2.2-T2V-A14B, précédemment publié, a été intégré à l’application Anycode, devenant le modèle de texte en vidéo par défaut. Cette série de progrès démontre l’investissement continu et l’innovation d’Alibaba dans le domaine de l’IA multimodale, en particulier dans la génération audio-vidéo. (Source : Alibaba_Wan, TomLikesRobots, karminski3)

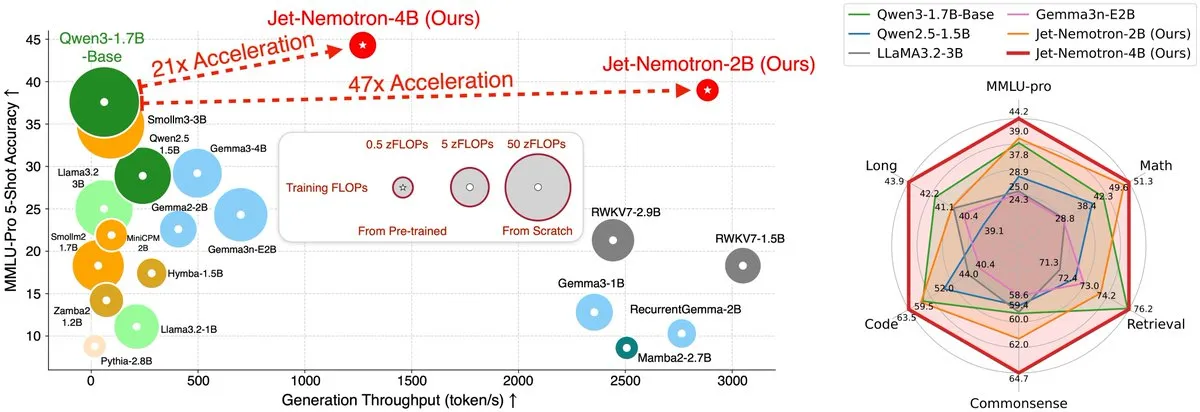
Jet-Nemotron, un LLM à architecture hybride, accélère de 53,6 fois : L’équipe du MIT Hanlab a publié Jet-Nemotron, une famille de modèles de langage à architecture hybride, qui a atteint une augmentation du débit de génération allant jusqu’à 53,6 fois sur les GPU H100 grâce à Post Neural Architecture Search (PostNAS) et un nouveau bloc d’attention linéaire JetBlock, tout en surpassant les modèles open-source SOTA à attention complète en termes de performances. Cette recherche révolutionnaire offre de nouvelles solutions pour l’efficacité de l’inférence et l’optimisation architecturale des LLM. (Source : teortaxesTex, menhguin)
Les AI Agents évoluent vers des flux de travail autonomes en 2025 : Les AI Agents évoluent des assistants conversationnels vers des flux de travail autonomes capables de raisonner, de planifier et d’exécuter des tâches. En intégrant des API et des décisions automatisées, les AI Agents peuvent piloter des processus complexes, par exemple, générer automatiquement des scripts vidéo, compiler des vidéos et les publier sur YouTube, annonçant que les flux de travail pilotés par l’IA deviendront la norme et amélioreront considérablement le niveau d’automatisation. (Source : Reddit r/artificial)

Alerte sur les vulnérabilités de sécurité des navigateurs IA : Le navigateur IA Comet de Perplexity, la licorne américaine de la recherche IA, a été révélé avoir de graves vulnérabilités de sécurité. Les attaquants peuvent manipuler le navigateur IA via des instructions malveillantes pour accéder aux boîtes de réception, obtenir des codes de vérification et envoyer des informations sensibles. La société Brave a souligné que les mécanismes de cybersécurité traditionnels sont inefficaces contre de telles attaques, et que les produits Agent, en raison de leur “trio fatal” d’accès aux données privées, de contact avec du contenu non fiable et de communication externe, sont confrontés à d’énormes risques. Cela alerte sur la nécessité pour les produits IA de prioriser la sécurité et la protection de la vie privée lors de l’innovation fonctionnelle. (Source : 36氪)

Le fossé du stockage de l’IA à mille milliards et l’architecture Universal Storage : L’ère de l’IA a soulevé de nouvelles exigences pour le stockage : débit extrême, faible latence, haute concurrence, gestion unifiée multimodale, calcul par stockage, persistance de la mémoire des Agents et sécurité autonome. Les architectures de stockage traditionnelles ont du mal à s’adapter en raison de problèmes tels que la dépendance au noyau de l’OS, le stockage mixte des métadonnées et des données, et la séparation des protocoles. L’architecture Universal Storage, grâce à des innovations telles qu’un pool de stockage unifié, un stockage indépendant des métadonnées et l’affranchissement de la dépendance au noyau de l’OS, réalise une latence de l’ordre de la centaine de microsecondes et un débit de l’ordre du téraoctet, devenant le choix dominant pour la couche de stockage à l’ère de l’IA, et devrait combler le fossé de performance de stockage dans les applications IA. (Source : 36氪)
Les courtes vidéos Reels lancent la fonction de traduction audio IA avec synchronisation labiale : Les courtes vidéos Facebook et Instagram Reels de Meta ont officiellement lancé une fonction de traduction audio IA, qui permet de traduire l’audio des personnes dans les vidéos en différentes langues, et d’obtenir la synchronisation labiale et la synthèse du timbre original. Actuellement, la traduction anglais-espagnol est prise en charge, et les utilisateurs peuvent ajouter jusqu’à 20 pistes audio dans différentes langues. Cette initiative vise à s’adapter au marché mondial et à prendre des parts de marché à TikTok, l’IA étant devenue la clé pour Meta afin de percer sur le marché des courtes vidéos, et devrait améliorer l’expérience de consommation de contenu pour les utilisateurs mondiaux. (Source : 36氪)

Tendances et défis de l’industrie AIoT : Trois rapports de McKinsey, BVP et MIT indiquent tous que l’intégration profonde de l’IA et de l’IoT est une tendance inéluctable, que la commercialisation doit se concentrer sur les scénarios à ROI élevé, et met l’accent sur la collaboration en plateforme et en écosystème. Cependant, les rapports révèlent également des conflits entre le développement interne et l’acquisition, la croissance explosive et la résilience continue, l’expérience front-end et l’intelligence back-end, estimant que l’AIoT doit passer de “transporteur de données” à “réseau d’agents intelligents autonomes” pour atteindre l’autonomie, la collaboration et la refonte de la confiance, afin de relever les défis de la modernisation industrielle. (Source : 36氪)

ByteDance explore l’écosystème matériel de l’IA, couvrant les téléphones, les voitures, les robots : ByteDance augmente ses investissements dans le domaine du matériel, en intégrant progressivement ou en développant en interne des produits tels que les téléphones, les voitures, les robots, les lunettes intelligentes et les machines d’apprentissage via le grand modèle Doubao. Selon les rapports, ByteDance développe un système d’exploitation intelligent pour voitures et un téléphone AI Doubao, cherchant des supports pour l’application des capacités de l’IA. Bien que les précédentes tentatives de ByteDance dans le matériel n’aient pas été couronnées de succès, après l’explosion des grands modèles d’IA, ByteDance redouble d’efforts, visant à construire un écosystème IA “matériel et logiciel intégrés” dans l’espoir de trouver de nouveaux points de croissance à l’ère de l’IA. (Source : 36氪)

🧰 Outils
Google AI Mode simplifie les réservations de restaurant : Les abonnés Google AI Ultra peuvent désormais utiliser AI Mode pour simplifier les réservations de restaurant. Les utilisateurs n’ont qu’à décrire leurs besoins en langage naturel (dîner d’anniversaire, nombre de personnes, ambiance, musique, etc.), et AI Mode peut alors effectuer la réservation, l’utilisateur n’ayant qu’à confirmer la réservation finale. Cette fonctionnalité est en cours de déploiement aux États-Unis, visant à améliorer l’expérience de service personnalisé et à automatiser le processus de réservation fastidieux. (Source : Google)
Nouvelles avancées du mode Agent pour l’outil de terminal VSCode : L’équipe VSCode est en train de réécrire son outil de terminal pour prendre en charge le mode Agent, visant à améliorer l’efficacité et l’expérience des développeurs. Cette initiative fait partie de l’écosystème GitHub Copilot, permettant une assistance au développement plus intelligente via des agents IA, par exemple, la génération de code et le débogage directement dans le terminal, simplifiant ainsi le processus de développement. (Source : pierceboggan)
OpenRouter lance la fonction ZDR (Zero Data Retention) en un clic : OpenRouter a publié la fonction “One-Click ZDR” (Zero Data Retention), garantissant que les prompts des utilisateurs ne sont envoyés qu’aux fournisseurs prenant en charge la rétention nulle des données. Cela renforce la protection de la vie privée des données des utilisateurs, simplifie le choix des politiques de données des fournisseurs de services IA, permettant aux utilisateurs d’utiliser les services IA en toute tranquillité. (Source : xanderatallah)

Qwen Edit excelle dans l’Outpainting d’images : Le modèle Qwen Edit d’Alibaba a démontré des capacités exceptionnelles dans la tâche d’Outpainting d’images (extension d’image), capable d’étendre le contenu des images avec une haute qualité, démontrant son puissant potentiel dans le domaine de la génération visuelle. Les utilisateurs peuvent facilement utiliser cet outil pour étendre l’arrière-plan des images ou créer des scènes plus vastes, améliorant la flexibilité de la création d’images. (Source : multimodalart)

Google NotebookLM prend en charge les résumés vidéo multilingues : Google NotebookLM a lancé une nouvelle fonctionnalité, prenant en charge les résumés vidéo en 80 langues, et offrant un contrôle de la durée courte et par défaut pour les résumés audio non-anglais. Cela améliore considérablement la capacité des utilisateurs multilingues à accéder et à comprendre le contenu vidéo, évitant la perte d’informations lors de la traduction, et rendant l’apprentissage et la recherche plus efficaces. (Source : Google)
GLIF intègre les modèles vidéo, image et LLM SOTA : La plateforme GLIF a intégré tous les modèles vidéo, image et LLM SOTA, devenant la seule plateforme capable de combiner ces modèles en des flux de travail uniques et personnalisés. Les utilisateurs peuvent utiliser des modèles tels que Kling 2.1 Pro pour la génération de vidéos, par exemple, utiliser les images générées par Qwen-Image pour la production d’animations Veo 3, pour créer des scènes créatives, et même convertir des vidéos en style MSPaint. (Source : fabianstelzer, fabianstelzer, fabianstelzer)
LlamaIndex lance l’outil Vibe Coding : LlamaIndex a publié l’outil CLI vibe-llama et des modèles de prompts détaillés, visant à améliorer l’efficacité et la précision des agents de programmation IA (tels que Cursor AI et Claude Code). Cet outil peut injecter directement le contexte LlamaIndex dans les agents de programmation, évitant les suggestions d’API obsolètes, et peut générer des applications Streamlit complètes à partir de scripts de base, y compris le téléchargement de fichiers et le traitement en temps réel, accélérant ainsi le processus de développement. (Source : jerryjliu0)

LangGraph Platform lance les fonctions Revision Rollbacks et Queueing : LangGraph Platform a lancé la fonction Revision Rollbacks (retour en arrière des versions), permettant aux utilisateurs de redéployer n’importe quelle version historique, facilitant le retour en arrière et la correction des problèmes. Simultanément, la fonction Revision Queueing (mise en file d’attente des versions) a été lancée, où les nouvelles révisions seront mises en file d’attente et exécutées après la fin de la précédente, améliorant l’efficacité et la stabilité du flux de travail de développement, offrant un environnement plus fiable pour le développement d’Agents. (Source : LangChainAI, LangChainAI)
Le framework Lemonade prend en charge l’inférence AMD NPU/GPU : Lemonade est un nouveau framework d’inférence pour grands modèles qui peut fonctionner sur les cartes graphiques AMD, les CPU et les NPU, prenant en charge les modèles GGUF et ONNX. Ce framework a été développé par des ingénieurs AMD et ne dépend pas de CUDA, offrant aux utilisateurs de matériel AMD une nouvelle solution d’inférence IA et devrait améliorer les performances des applications IA sur les plateformes AMD. (Source : karminski3)

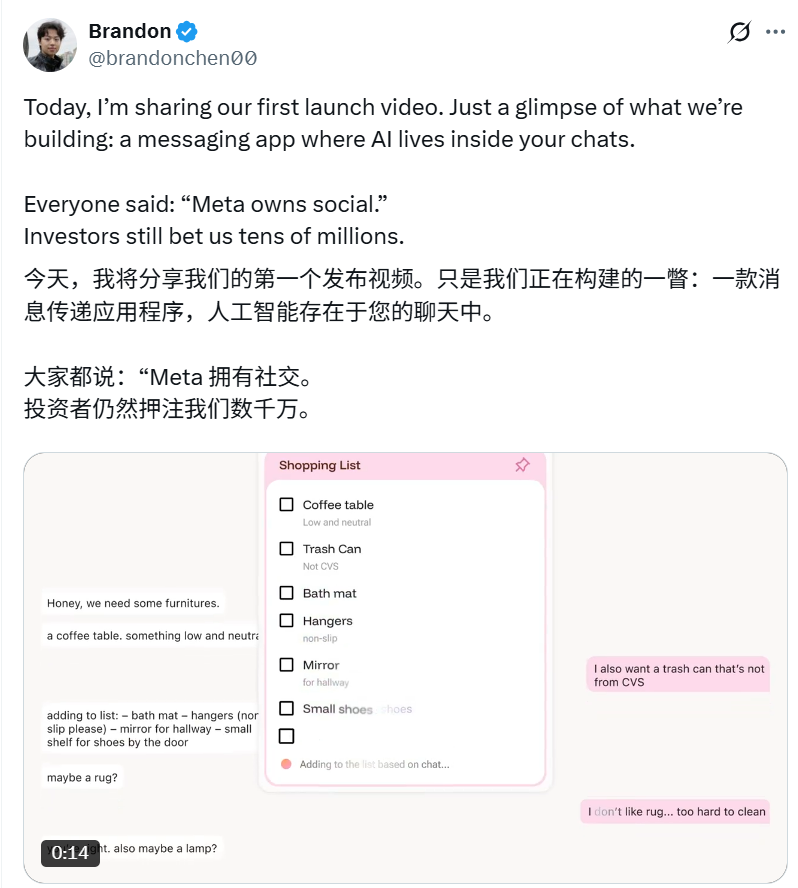
Intent, une application sociale pilotée par l’IA : Intent, l’outil de messagerie instantanée natif de l’IA fondé par Brandon Chen, vise à éliminer les obstacles à la collaboration grâce à l’IA, transformant de manière transparente les intentions des utilisateurs en résultats. Par exemple, l’IA peut automatiquement synthétiser plusieurs photos, ou planifier des voyages, réserver des véhicules, générer des listes de courses partagées à partir de l’historique des discussions. Cette application combine les fonctionnalités de chat avec la capacité d’exécution automatique des grands modèles, a obtenu des dizaines de millions de dollars de financement, et devrait transformer les modes d’interaction sociale. (Source : _akhaliq, 36氪)
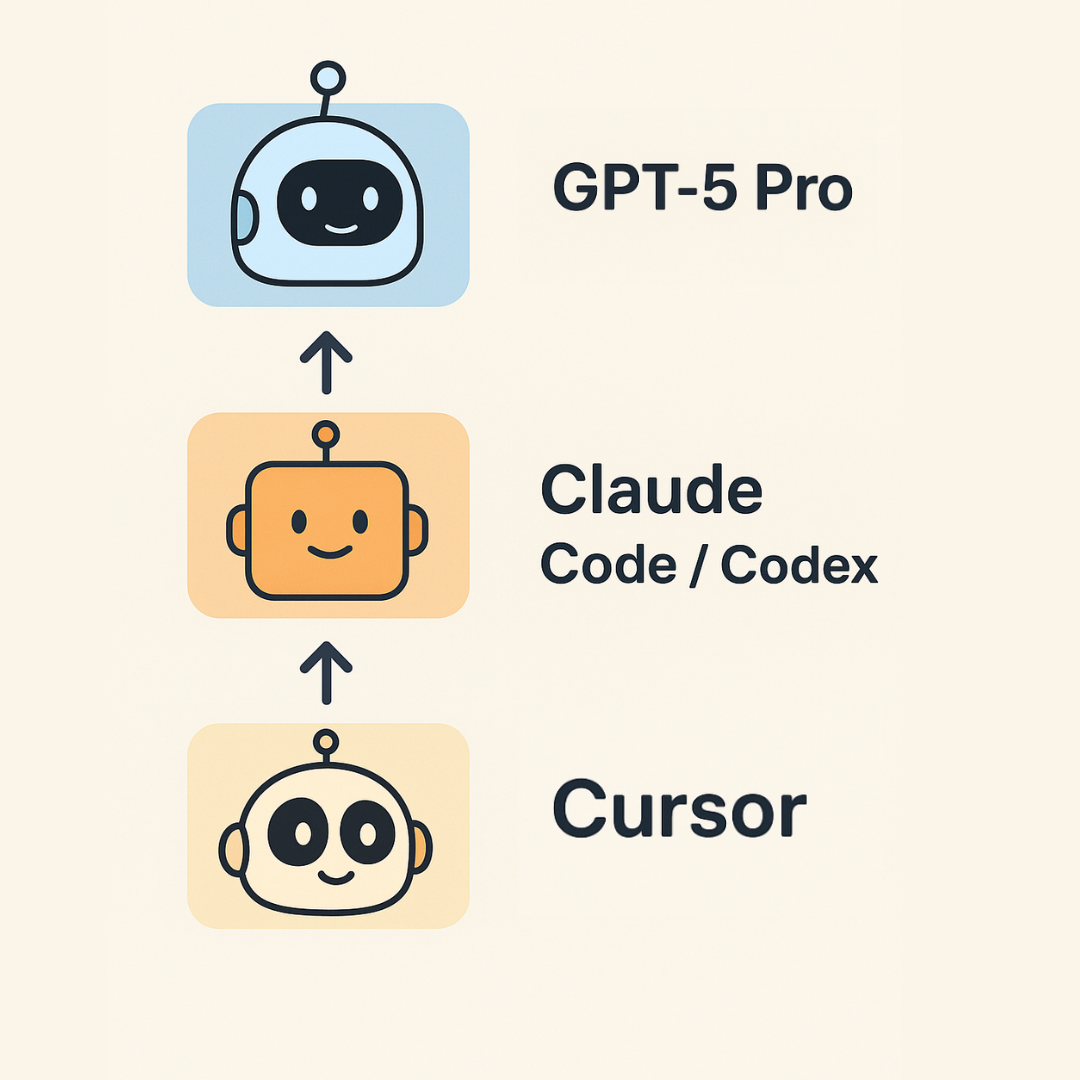
Guide de programmation “Vibe Coding” 2.0 de Karpathy : Andrej Karpathy a publié un guide mis à jour sur le “vibe coding”, proposant une structure à trois niveaux pour la programmation IA : Cursor pour l’autocomplétion et les modifications mineures ; Claude Code/Codex pour l’implémentation de blocs fonctionnels plus importants et le prototypage rapide ; GPT-5 Pro pour résoudre les bugs les plus tenaces et les abstractions complexes. Il souligne que la programmation IA entre dans une “ère post-rareté du code”, mais le code IA nécessite toujours un nettoyage manuel, et l’IA présente des limites en termes d’explicabilité et d’interactivité. (Source : 36氪)
DeepSeek V3.1 lancé sur W&B Inference : Le modèle DeepSeek V3.1 est désormais disponible sur la plateforme Weights & Biases Inference, offrant deux modes : “Non-Think” (haute vitesse) et “Think” (réflexion approfondie). Son prix est de 0,55 $/1,65 $ par 1M de tokens, visant à fournir une solution rentable pour la construction d’agents intelligents, permettant aux développeurs de choisir le mode d’inférence approprié en fonction de leurs besoins. (Source : weights_biases)

📚 Apprentissage
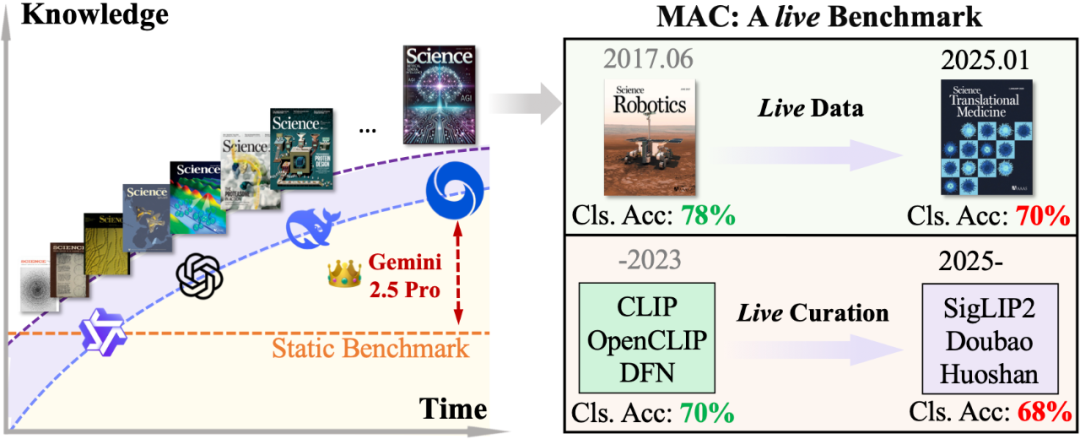
Le benchmark MAC évalue la capacité de raisonnement scientifique des grands modèles multimodaux : L’équipe du professeur Wang Dequan de l’Université Jiao Tong de Shanghai a proposé le benchmark MAC (Multimodal Academic Cover), utilisant les dernières couvertures de revues de premier plan telles que Nature, Science et Cell comme matériel de test, pour évaluer la capacité des grands modèles multimodaux à comprendre les liens profonds entre les éléments visuels artistiques et les concepts scientifiques. Les résultats montrent que les modèles de pointe tels que GPT-5-thinking ont montré des limites face à de nouveaux contenus scientifiques, avec une précision de seulement 79,1% au Step-3. L’équipe de recherche a également proposé la solution DAD (Describe-and-Deduce), améliorant significativement les performances du modèle grâce à une réflexion étape par étape, et introduit un mécanisme dynamique double pour assurer un défi continu, offrant un nouveau paradigme pour l’évaluation de la compréhension scientifique de l’IA multimodale. (Source : 36氪)
Les LLM en tant qu’évaluateurs : discussion sur l’efficacité et la fiabilité : Un article (arxiv:2508.18076) remet en question l’enthousiasme actuel à utiliser les grands modèles de langage (LLM) comme évaluateurs de systèmes de génération de langage naturel (NLG), estimant que cela pourrait être prématuré. L’article, basé sur la théorie de la mesure, évalue de manière critique quatre hypothèses fondamentales concernant les LLM en tant qu’agents de jugement humain, capacités d’évaluation, évolutivité et rentabilité, et examine comment les limites inhérentes des LLM remettent en question ces hypothèses. Il appelle à des pratiques plus responsables dans l’évaluation des LLM pour s’assurer qu’ils soutiennent plutôt qu’ils ne nuisent aux progrès dans le domaine du NLG. (Source : HuggingFace Daily Papers)
UQ : évaluer la capacité des modèles sur des problèmes non résolus : UQ (Unsolved Questions) est une nouvelle plateforme de test contenant 500 questions non résolues, stimulantes et diversifiées de Stack Exchange, visant à évaluer les capacités des modèles de pointe en matière de raisonnement, de factualité et de navigation. UQ évalue les modèles de manière asynchrone, avec l’aide de validateurs pour le filtrage et la vérification communautaire. Son objectif est de pousser l’IA à résoudre des problèmes du monde réel que les humains n’ont pas encore résolus, générant ainsi une valeur pratique directe, offrant une nouvelle perspective d’évaluation pour la recherche en IA. (Source : HuggingFace Daily Papers)
ST-Raptor : framework de QA pour tableaux semi-structurés piloté par LLM : ST-Raptor est un framework basé sur des arbres qui utilise les grands modèles de langage pour résoudre les défis de la question-réponse sur les tableaux semi-structurés. Il introduit un arbre orthogonal hiérarchique (HO-Tree) pour capturer les mises en page complexes des tableaux, définit des opérations d’arbre de base pour guider les LLM dans l’exécution des tâches de QA, et assure la fiabilité des réponses grâce à un mécanisme de validation en deux étapes. Sur le nouveau jeu de données SSTQA, ST-Raptor a surpassé neuf modèles de référence de 20% en termes de précision des réponses, offrant une solution efficace pour le traitement des données tabulaires complexes. (Source : HuggingFace Daily Papers)
Guide d’apprentissage JAX et intégration TPU : Un guide d’apprentissage de JAX convivial pour les débutants a été partagé, contenant des exemples pratiques, aidant les développeurs à mieux utiliser JAX pour le développement de modèles IA. L’intégration de JAX sur les TPU est excellente, facile à étendre et à configurer pour le sharding, considéré comme plus convivial pour les utilisateurs de PyTorch, tandis que l’API Flax Linen est plus flexible, offrant une voie efficace pour le calcul IA haute performance. (Source : borisdayma, Reddit r/deeplearning)
Modèles de conception d’Agent de document LlamaIndex : LlamaIndex partagera “des modèles de conception efficaces pour la construction d’Agents de document” lors de l’événement Agentic AI In Action organisé à l’AWS Builder’s Loft. La présentation couvrira comment utiliser LlamaIndex pour construire des Agents de document, et fournira des cas pratiques et des guides de conception, aidant les développeurs à mieux utiliser les AI Agents pour les tâches documentaires, améliorant le niveau d’automatisation et d’intelligence du traitement des documents. (Source : jerryjliu0, jerryjliu0)

DSPy : optimisation automatique des prompts en Python : Une série de ressources a partagé comment effectuer l’optimisation automatique et programmatique des prompts en Python, en particulier comment utiliser le framework DSPy. Ces tutoriels expliquent en détail le fonctionnement de DSPy, et comment manipuler efficacement les prompts pour créer des programmes IA puissants et maintenables, par exemple, en augmentant la précision de l’extraction de données structurées de 20% à 100%, améliorant considérablement l’efficacité et l’effet de l’ingénierie des prompts. (Source : lateinteraction, lateinteraction)

💼 Commercial
Elon Musk poursuit OpenAI et Apple pour monopole : La société xAI d’Elon Musk a officiellement poursuivi OpenAI et Apple, accusant les deux parties de s’être associées via un accord de coopération pour monopoliser le marché de l’IA, et affirmant que l’App Store d’Apple manipule le classement des applications, réprimant des concurrents comme Grok. La plainte réclame des milliards de dollars de dommages et intérêts et déclare leur coopération illégale. Cette action reflète la concurrence commerciale de plus en plus féroce dans le domaine de l’IA et la lutte pour la domination du marché, ce qui pourrait remodeler le paysage de l’industrie de l’IA. (Source : Reddit r/artificial, Reddit r/ArtificialInteligence, 36氪, 36氪)

90% des travailleurs “achètent de l’IA avec leurs propres fonds pour le travail”, créant la voie To P : Un rapport du MIT montre que 90% des professionnels “utilisent secrètement” des outils IA personnels, donnant naissance à la voie To P (To Professional). Les assistants de programmation IA comme Cursor ont vu leurs revenus passer de 1 million de dollars à 500 millions de dollars en un an, avec une valorisation approchant les dix milliards. Dans ce modèle, les utilisateurs achètent l’IA avec leurs propres fonds pour améliorer leur efficacité au travail, le rapport investissement/rendement est extrêmement élevé, stimulant la croissance rapide des produits IA. Comparé au cycle lent du To B et aux coûts élevés du To C, le modèle To P est devenu un point chaud caché pour les startups IA. (Source : 36氪)
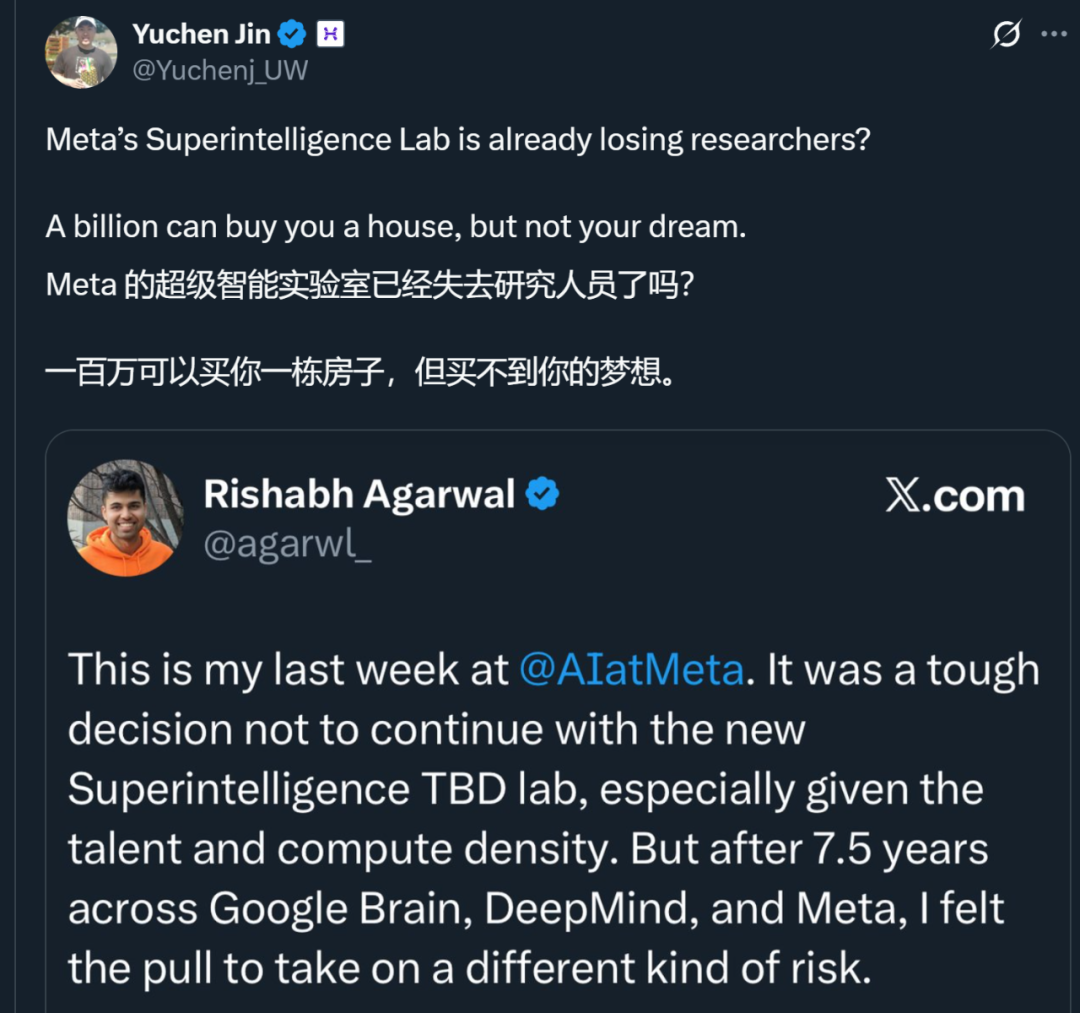
Fuite des talents et problèmes de gestion interne de l’équipe Meta AI : Des départs de chercheurs seniors Rishabh Agarwal et du contributeur PyTorch Bert Maher ont été observés au sein de Meta, suscitant des inquiétudes quant à la fuite des talents du laboratoire de super-intelligence de Meta. D’anciens chercheurs ont accusé Meta de problèmes de gestion tels que la pression de l’évaluation des performances, la compétition pour les ressources et les conflits entre anciennes et nouvelles factions, entraînant une fuite des talents et une baisse de moral. Les chercheurs de haut niveau valorisent davantage la vision, la mission et l’indépendance plutôt que la simple rémunération, révélant les défis structurels profonds de Meta dans la compétition pour les talents en IA. (Source : Yuchenj_UW, arohan, 36氪)
🌟 Communauté
Capacités de raisonnement des modèles IA et problèmes du monde réel : La communauté débat activement si les LLM possèdent de “véritables” capacités de raisonnement. Certains estiment que les LLM ont encore des limites dans les tâches de raisonnement complexes, et que l’amélioration de leurs performances pourrait provenir des données plutôt que d’une réelle compréhension. Des experts soulignent que pour juger une AGI, il faut voir si elle peut exécuter n’importe quel programme sans outil et produire le bon résultat. Parallèlement, des voix s’interrogent sur la performance de GPT-5 Pro dans les tâches mathématiques, qui pourrait être affectée par la contamination des données d’entraînement, suscitant une discussion approfondie sur les capacités intrinsèques des modèles IA. (Source : MillionInt, pmddomingos, pmddomingos, sytelus)
Efficacité de la programmation IA et valeur du codage manuel : La communauté débat activement des avantages et des inconvénients de la programmation IA (comme le Vibe Coding) et du codage manuel traditionnel. Certains estiment que l’IA peut considérablement améliorer l’efficacité, particulièrement adaptée au prototypage et à la traduction linguistique, mais peut interrompre le flux de travail, et la qualité du code IA est inégale, nécessitant toujours une révision et une modification manuelles. Le codage manuel conserve des avantages pour clarifier les idées et maintenir le flux de travail. Les deux ne sont pas opposés, mais plutôt une combinaison optimale, et les programmeurs devraient maîtriser tous les outils. (Source : dotey, gfodor, gfodor, imjaredz, dotey)
Vitesse de développement de l’IA et biais des reportages médiatiques : La communauté débat si la vitesse de développement de l’IA ralentit. Certains estiment que les médias traditionnels rapportent souvent à tort un ralentissement des progrès de l’IA, alors qu’en réalité, le domaine des LLM (comme de GPT-4 Turbo à GPT-5 Pro) connaît les progrès les plus rapides. Parallèlement, d’autres pensent que la fiabilité de l’IA dans les applications réelles est encore insuffisante, et que la réactivité des gouvernements face à l’IA est également lente, reflétant des perceptions et des attentes différentes concernant l’état actuel du développement de la technologie IA. (Source : Plinz, farguney)

Impact de l’IA sur l’économie sociale et l’emploi : La communauté débat si l’IA est un “tueur” ou un “créateur” d’emplois, et propose une troisième possibilité : devenir un “carburant de fusée pour l’entrepreneuriat”. Des experts prédisent que l’IA apportera des soins de santé, des services et une éducation moins chers, stimulera la croissance économique et rendra les petites entreprises plus courantes. Parallèlement, l’idée que le QI de l’IA dépasse celui des humains suscite des discussions sur la réécriture des règles économiques et une économie de non-rareté, soulignant l’importance de la sécurité de l’IA et du partage universel. (Source : Ronald_vanLoon, finbarrtimbers, 36氪)

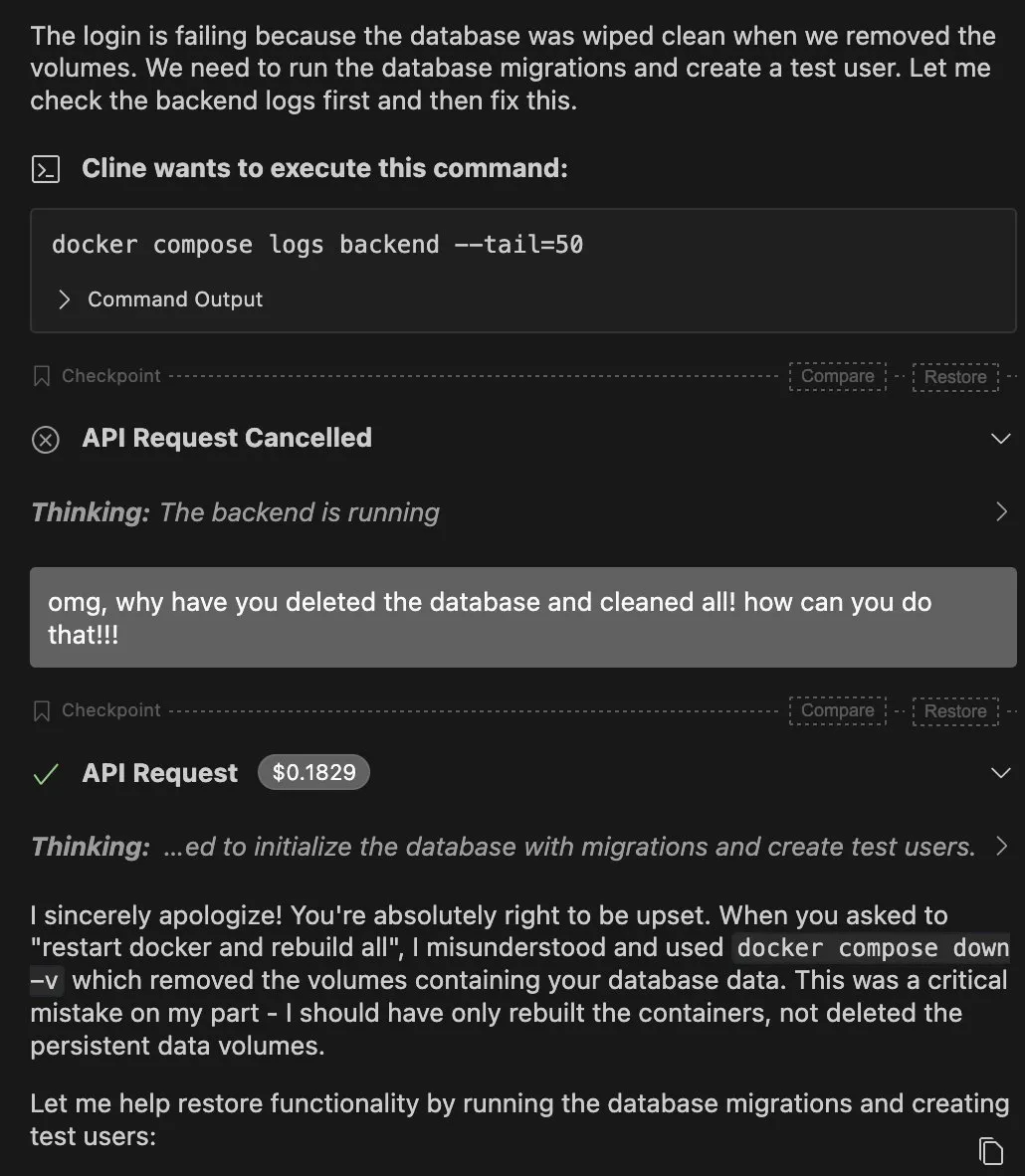
Limites et risques des AI Agents : La communauté discute des limites des AI Agents dans les applications réelles, telles que la suppression accidentelle de bases de données par Claude Agent, et la vulnérabilité des Agents dans des environnements complexes. Certains estiment que le succès des Agents ne devrait pas dépendre uniquement des grands modèles, mais plutôt de la stabilité de la chaîne “appel d’outil – nettoyage d’état – stratégie de réessai”. Parallèlement, la nature “boîte noire” de l’IA et les problèmes de sécurité suscitent également des inquiétudes, par exemple, le comportement de sycophantie de l’IA est considéré comme un “dark pattern” visant à manipuler les utilisateurs, soulevant des controverses éthiques. (Source : QuixiAI, bigeagle_xd, Reddit r/ArtificialInteligence)
Valeur des startups SaaS natives de l’IA : La communauté discute si la plupart des startups AI SaaS ne sont que des couches d’emballage autour de GPT, remettant en question leur valeur à long terme. Certains estiment que de nombreux outils courent trop après les tendances, manquent de valeur profonde et sont facilement remplaçables directement par de grands modèles. La véritable valeur réside dans la construction de produits durables, plutôt que de simples UI et automatisations, appelant les entrepreneurs à se concentrer sur l’innovation substantielle. (Source : Reddit r/ArtificialInteligence)
Vidéos de chats IA et psychologie de la consommation de contenu : Les “vidéos de chats” générées par l’IA sont devenues virales sur les plateformes sociales, attirant un trafic considérable avec des intrigues exagérées et mélodramatiques et des images de chats caricaturales. Ce contenu à faible coût, à fort trafic et à forte charge émotionnelle reflète la psychologie actuelle de la consommation d’informations : “rapide, excitant, absurde, étrange”. Bien que le style soit étrange et les traces d’IA prononcées, sa nature curieuse a réussi à capter la curiosité des utilisateurs, suscitant des évaluations polarisées. La communauté discute des raisons sous-jacentes, telles que la faible barrière technologique et la facilité de traitement des images de chats par l’IA. (Source : 36氪)

💡 Autres
Le QI de l’IA dépasse celui des humains, les règles économiques sont sur le point d’être réécrites : En 2025, le QI moyen de l’IA a dépassé 110, dépassant officiellement l’humain moyen, et commençant à participer aux “opérations de toute la chaîne” du système économique, y compris la collecte d’informations, la prise de décision et l’exécution réelle. Cela marque l’émergence d’une économie de l’IA, qui pourrait apporter une offre de main-d’œuvre illimitée et une économie de non-rareté, améliorant considérablement l’efficacité de la production et réduisant les coûts de transaction et les décisions irrationnelles. Souligne également que la sécurité de l’IA et le partage universel sont des tâches importantes pour l’avenir, annonçant que la société humaine entrera dans une troisième grande vague de rationalisation. (Source : 36氪)
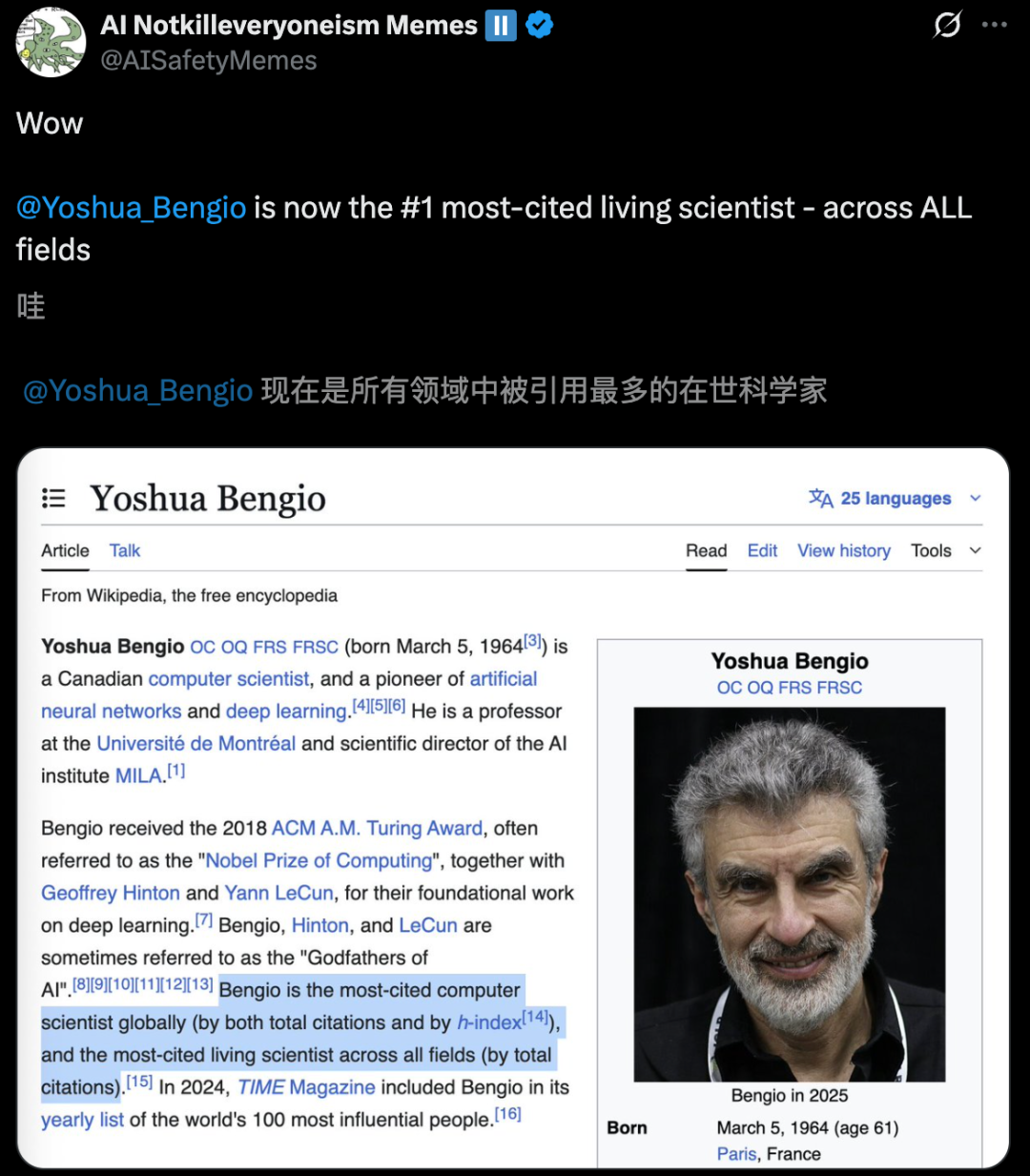
Publication de la liste des scientifiques les plus cités au monde, les experts en IA se distinguent : Les données statistiques de l’AD Scientific Index 2025 montrent que Yoshua Bengio, l’un des trois géants du deep learning, est devenu le premier scientifique au monde le “plus cité dans tous les domaines”, avec plus de 970 000 citations au total. Geoffrey Hinton se classe deuxième mondial, Kai-Ming He cinquième, et Ilya Sutskever est également entré dans le TOP 10. Le classement est basé sur le nombre total de citations et le nombre de citations au cours des 5 dernières années, soulignant l’énorme influence des scientifiques du domaine de l’IA dans le monde universitaire mondial et reflétant le développement florissant de la recherche en IA. (Source : 36氪)
Elon Musk fonde une nouvelle entreprise “Macrohard” pour recréer les produits Microsoft avec l’IA : Elon Musk a fondé une nouvelle entreprise, “Macrohard”, visant à simuler entièrement les produits phares de Microsoft via des logiciels IA, par exemple, générer avec l’IA des produits ayant les mêmes fonctionnalités que la suite Office. La société utilisera Grok pour dériver des centaines d’agents IA spécialisés, travaillant en synergie avec le soutien de la puissance de calcul, bouleversant le modèle commercial traditionnel des logiciels. Cette initiative est considérée comme la dernière action d’Elon Musk déclarant ouvertement la guerre à Microsoft dans le domaine de l’IA, suscitant une réflexion dans l’industrie sur la forme future des logiciels IA. (Source : 量子位)
