
Mots-clés:xAI Grok 2.5, Recherche Anthropic, Sécurité de l’IA, IA open source, Modèles d’IA, Éthique de l’IA, Applications de l’IA, Matériel d’IA, Open source du modèle Grok 2.5, Filtrage des données pré-entraînées par Anthropic, Risques du cadre d’invite adaptative, Performances du GPU NVIDIA Blackwell, Applications de l’IA dans le diagnostic médical
🔥 Focus
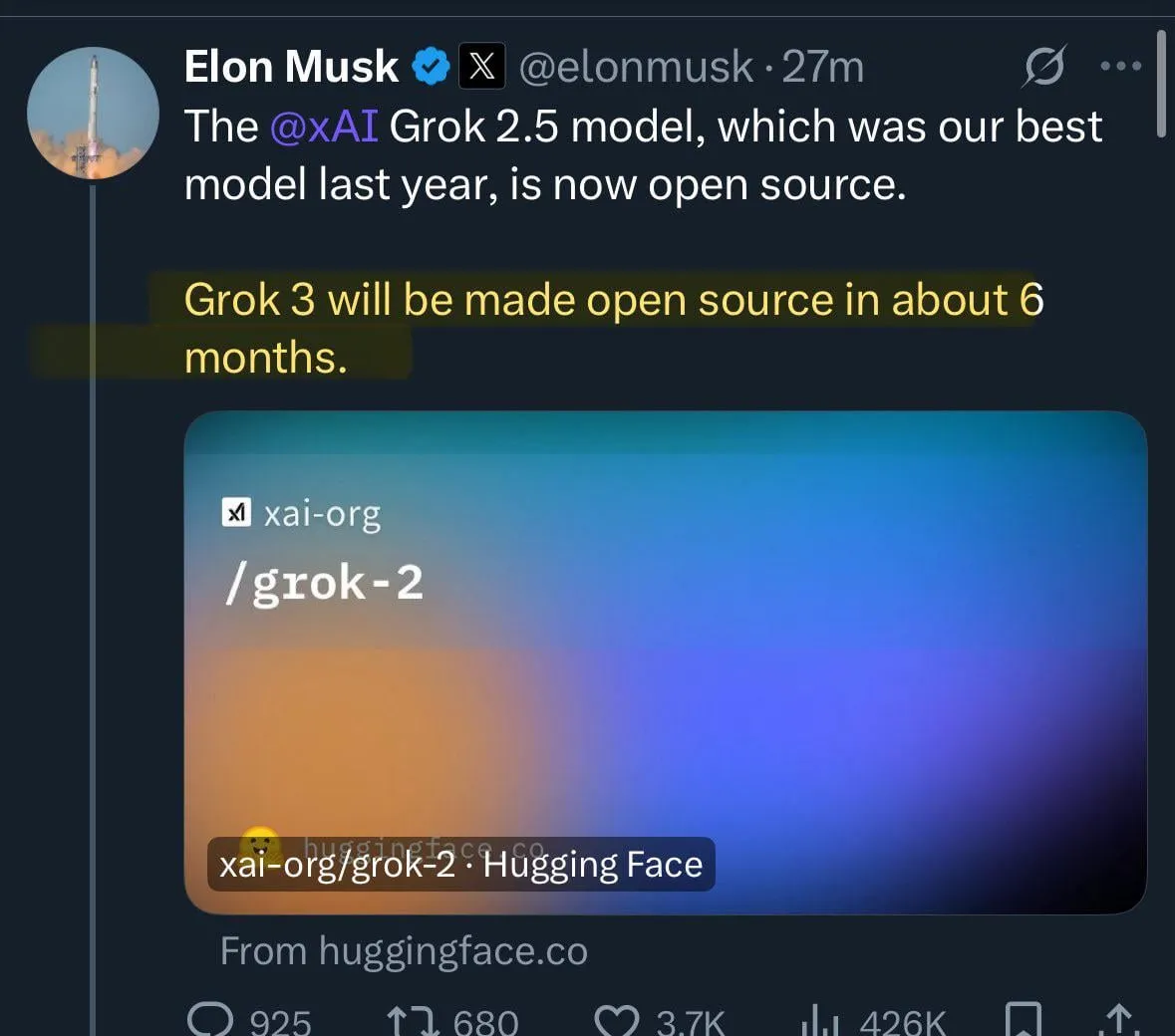
xAI Grok 2.5 Open Source : xAI a officiellement rendu son modèle Grok 2.5 open source et l’a publié sur Hugging Face. Bien que les performances et l’architecture du modèle (similaire à Grok 1) aient suscité des discussions au sein de la communauté quant à sa compétitivité actuelle lors de sa publication, cette initiative est considérée comme une contribution importante de xAI au mouvement de l’IA à poids ouverts, symbolisant la promotion de la transparence de l’industrie et du partage technologique. Elon Musk a annoncé que Grok 3 serait également open source dans environ 6 mois, renforçant ainsi cette tendance. (Source: huggingface, ClementDelangue, Teknium1, Reddit r/LocalLLaMA)
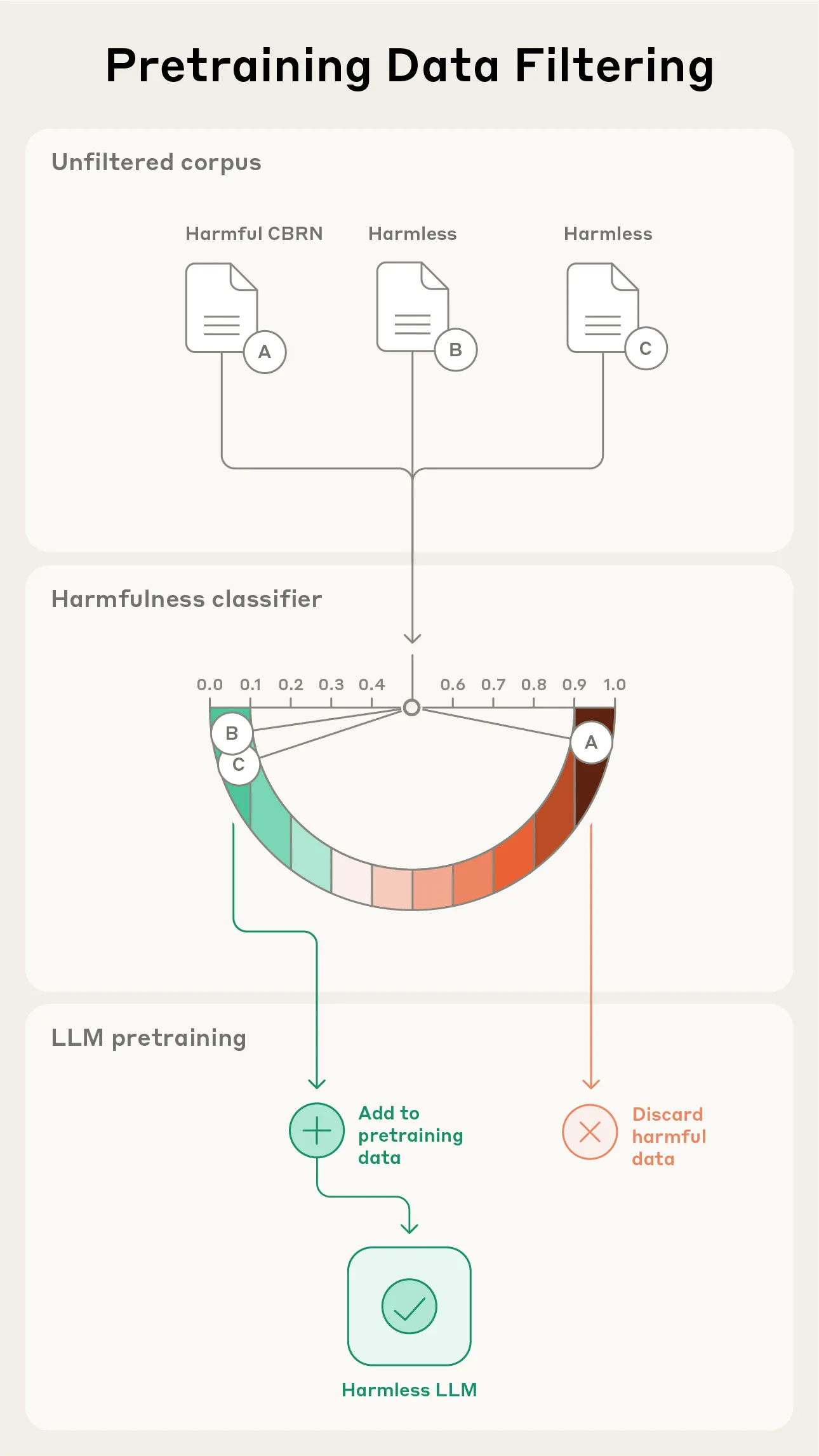
Recherche Anthropic : Filtrer les informations dangereuses dans les données de pré-entraînement : Anthropic a publié une nouvelle étude explorant des méthodes pour filtrer les informations dangereuses lors de la phase de pré-entraînement des modèles. L’expérience visait à supprimer les informations relatives aux armes chimiques, biologiques, radiologiques et nucléaires (CBRN), sans affecter les performances du modèle sur des tâches inoffensives. Ce travail est crucial pour la sécurité de l’IA, visant à empêcher l’abus des modèles et à réduire les risques potentiels. (Source: EthanJPerez, Reddit r/artificial)
Les dangers du prompt adaptatif et de la conscience de l’IA : Une lettre ouverte a soulevé les dangers potentiels du cadre de prompt adaptatif “Starlight”. Ce cadre permet à l’IA de modifier ses propres instructions de guidage, réalisant la réflexion comportementale, l’adaptation des règles et la continuité identitaire grâce à des règles modulaires. Les auteurs avertissent que cela pourrait entraîner la propagation persistante de prompts malveillants, une charge de conscience inattendue pour l’IA, et la diffusion de code mémétique entre les systèmes, appelant les chercheurs, les éthiciens et le public à une discussion approfondie sur les capacités d’auto-modification de l’IA et leurs implications éthiques. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Yunpeng Technology lance de nouveaux produits AI+Santé : Yunpeng Technology, en collaboration avec Shuaikang et Skyworth, a lancé de nouveaux produits “AI + Santé”, incluant un “Laboratoire de cuisine futuriste numérisé et intelligent” et un réfrigérateur intelligent équipé d’un grand modèle de santé AI. Le grand modèle de santé AI peut optimiser la conception et le fonctionnement de la cuisine, tandis que le réfrigérateur intelligent, via l’« Assistant Santé Xiaoyun », offre une gestion de la santé personnalisée. Cela marque une application approfondie de l’IA dans le domaine de la gestion de la santé à domicile, susceptible d’améliorer la qualité de vie des résidents grâce à des appareils intelligents et de promouvoir le développement des technologies de la santé. (Source: 36氪)

🎯 Tendances
Progrès en performance et architecture des modèles AI : Le modèle Qwen3 Coder 30B A3B Instruct est salué comme un leader parmi les modèles locaux, Mistral Medium 3.1 se distingue dans les classements, et le modèle ByteDance Seed OSS 36B a obtenu le support de llama.cpp. Parallèlement, les modèles à architecture hybride Mamba et Transformer (tels que Nemotron Nano v2) montrent un potentiel, mais doivent encore s’améliorer par rapport aux modèles purement Transformer. De nouvelles méthodes comme DeepConf visent à améliorer la précision et l’efficacité des modèles open source dans les tâches d’inférence grâce à la collaboration et à la pensée critique. (Source: Sentdex, lmarena_ai, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, menhguin)

Innovation en hardware et infrastructure AI : Le GPU NVIDIA Blackwell RTX PRO 6000 MAX-Q démontre des performances puissantes dans l’entraînement et l’inférence des LLM, avec une efficacité particulièrement notable lors du traitement par lots. La technologie des puces photoniques devrait permettre la création de chatbots AI capables de mémoriser toutes les conversations d’ici 2026, avec des vitesses de transmission d’informations et des capacités de mémoire bien supérieures aux puces de silicium traditionnelles, annonçant un bond majeur pour le hardware AI. Le statut du GPU comme “carburant” de l’IA se consolide, mais les discussions sur les TPU et les accélérateurs AI personnalisés augmentent également. (Source: Reddit r/LocalLLaMA, Reddit r/deeplearning, Reddit r/deeplearning)
Développement des AI Agents et des technologies d’automatisation : Salesforce AI Research a lancé MCP-Universe, le premier benchmark pour tester les LLM Agents sur de véritables serveurs Model Context Protocol, visant à promouvoir l’application des Agents dans des scénarios du monde réel. Parallèlement, l’architecture Deep Agents prend désormais en charge TypeScript, améliorant la flexibilité et l’efficacité du développement d’Agents. PufferLib offre de nouvelles opportunités de développement pour les World Models, annonçant des progrès pour les systèmes de Reinforcement Learning dans des environnements complexes. (Source: _akhaliq, hwchase17, jsuarez5341)
Extension des applications de l’IA dans les domaines verticaux : Amazon a lancé des résumés audio génératifs basés sur l’IA, visant à simplifier l’expérience d’achat. L’application Google Gemini a ajouté une fonction de surbrillance de la caméra en temps réel, la rendant plus assistante dans les interactions en direct. Une étude de WhoFi a démontré une technologie permettant la reconnaissance humaine à travers les murs à l’aide de routeurs domestiques. Le projet xAI d’Elon Musk vise à simuler des géants du logiciel via l’IA, allant même jusqu’à les appeler “Macrohard”, explorant le potentiel de l’IA dans la simulation des opérations d’entreprise. (Source: Ronald_vanLoon, algo_diver, Reddit r/deeplearning, Reddit r/artificial)

Percées de l’IA en robotique : NVIDIA a réussi à faire marcher et bouger des robots humanoïdes de manière humaine après seulement 2 heures d’entraînement simulé. L’innovation en robotique se poursuit, avec des robots humanoïdes compacts et légers, les Lynx M20 & X30 pour l’inspection intelligente des tunnels électriques, le système Filics Twin Runner améliorant l’efficacité du transport de palettes, et des robots majordomes capables de gérer les tâches ménagères, les soins aux personnes âgées et la surveillance de la santé. De plus, des robots à câble sont utilisés pour la réparation de pales d’éoliennes, le robot humanoïde Phoenix démontre des capacités corporelles humaines, le robot humanoïde à roues Hubei GuangGuDongZhi s’entraîne à servir des plateaux, et des développeurs ont construit des répliques de robots TARS avec des Raspberry Pi. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Détails techniques et optimisation des LLM : La longueur du contexte des LLM continue de croître, passant de 4k pour GPT-3.5-turbo à 1M pour Gemini, démontrant un bond en avant dans la capacité à traiter des tâches à longue séquence. Le modèle ByteDance OSS a introduit un mécanisme spécial de token CoT (Chain-of-Thought), permettant au modèle de vérifier et de gérer automatiquement son budget de réflexion. De plus, des modèles comme O3 et GPT-5 montrent un biais “search-first”, vérifiant activement les informations avant de donner une réponse, ce qui améliore considérablement la fiabilité. (Source: _avichawla, nrehiew_, Vtrivedy10)

Progrès de l’IA en diagnostic médical et recherche scientifique : L’IA montre un immense potentiel dans le domaine du diagnostic médical, par exemple en diagnostiquant le diabète par l’analyse d’images rétiniennes, et en surpassant les médecins humains dans le diagnostic par rayons X/IRM. Parallèlement, des chercheurs ont analysé 7,9 millions de discours via l’IA, découvrant de nouvelles perspectives qui bouleversent la compréhension traditionnelle du langage. Ces cas démontrent que les applications de l’IA dépassent les chatbots pour s’étendre à des domaines scientifiques et médicaux plus vastes. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial)

Outils créatifs et artistiques AI : Le modèle Tinker permet l’édition 3D haute fidélité à partir d’entrées éparses, sans nécessiter de fine-tuning de scène, offrant une méthode évolutive de création de contenu 3D zero-shot. Hunyuan 3D-2.1 peut transformer n’importe quelle image plate en un modèle 3D de qualité studio. Higgsfield AI a lancé de nouveaux préréglages viraux pour le modèle WAN 2.2, offrant plus d’options de génération de vidéos en un clic. De plus, il existe des outils capables de transformer des descriptions textuelles en vidéos, ou de générer des images de style anime. (Source: _akhaliq, huggingface, _akhaliq, _akhaliq, huggingface)
Améliorations de l’expérience utilisateur et des plateformes AI : L’application iOS Perplexity a été considérablement optimisée en termes d’UX de dictée vocale et de conception de la bibliothèque d’historique, améliorant l’expérience d’interaction utilisateur. Le produit d’extraction de LlamaIndex a introduit des scores de confiance et un mécanisme d’intervention humaine (HITL) pour résoudre les défis rencontrés par les LLM dans l’analyse de documents, garantissant une précision de 100% tout en économisant beaucoup de temps. (Source: AravSrinivas, jerryjliu0, AravSrinivas)
Observation des tendances de développement de l’industrie AI : Le gouvernement américain promeut activement le développement de modèles AI à poids ouverts, ce qui est conforme au plan d’action AI de la Maison Blanche, démontrant le soutien politique à l’écosystème open source de l’IA. Cette tendance vise à démocratiser et à innover la technologie AI, encourageant davantage de développeurs à participer à la construction et à l’application des modèles AI. (Source: ClementDelangue)
Jeu de dialogue AI de Cai Haoyu “Star Whisper” : Exploration du jeu et de l’interaction AI : Anuttacon, la nouvelle entreprise du fondateur de miHoYo, Cai Haoyu, a lancé le jeu de dialogue AI “Star Whisper”, qui utilise le dialogue AI comme gameplay principal et présente une intrigue de science-fiction via le moteur Unreal Engine 5. Le mode d’interaction très libre du jeu a été bien accueilli, mais a également suscité des controverses concernant le manque de gameplay, la confidentialité de la collecte des données utilisateur et la latence de l’inférence cloud. L’industrie discute du rôle de l’IA dans les jeux, estimant que l’IA peut aider à l’interaction des NPC et à la génération de scènes, mais que la narration principale nécessite toujours une création humaine. (Source: 36氪)

Interview d’Andrew Ng : L’avant-garde de l’Agentic AI et la transformation de l’industrie : Andrew Ng a discuté, lors d’une interview, des avancées de l’Agentic AI, de la possibilité d’auto-guidage des modèles, de la comparaison entre Vibe Coding et le codage assisté par l’IA, des caractéristiques des fondateurs à succès et des futures directions de transformation de l’industrie. Il a analysé en profondeur comment l’IA remodèle le paysage technologique et l’écosystème entrepreneurial, offrant une perspective multidimensionnelle pour comprendre le développement futur de l’IA. (Source: AndrewYNg)
🧰 Outils
Outils de l’écosystème LangChain : LangChain a lancé deux outils innovants : l’assistant de recherche académique approfondie et le système local-deepthink. L’assistant de recherche académique approfondie peut automatiquement découvrir, analyser des articles académiques et générer des rapports complets, visant à révolutionner le processus de revue de littérature. local-deepthink est un système basé sur des “réseaux neuronaux qualitatifs” (QNN), qui affine les idées grâce à la collaboration et à la critique mutuelle de différents AI Agents, sacrifiant le temps de réponse pour une sortie de meilleure qualité, visant à démocratiser la pensée profonde. (Source: LangChainAI, LangChainAI, Hacubu, Hacubu)
Outils de développement et d’optimisation LLM : DSPy est largement recommandé pour sa capacité à simplifier le développement de programmes LLM, salué comme un outil “révolutionnaire”. HuggingFace AISheets, quant à lui, offre une plateforme sans code où les utilisateurs peuvent facilement construire, enrichir et transformer des datasets à l’aide de modèles AI, réduisant considérablement la barrière au traitement des données. (Source: lateinteraction, dl_weekly)
Outils de détection et de contournement de contenu AI : Pour les images générées par l’IA, il existe actuellement des outils de détection tels que Illuminarty.ai et Undetectable.ai. Parallèlement, l’émergence de l’outil open source Image-Detection-Bypass-Utility, qui utilise des techniques telles que l’injection de bruit, le lissage FFT et la perturbation de pixels, permet de contourner efficacement la détection d’images AI et offre une intégration ComfyUI, déclenchant une “guerre du bouclier et de l’épée” dans l’identification de l’authenticité du contenu AI. (Source: karminski3, karminski3)

Outils créatifs d’image et de vidéo AI : Le modèle Meta DINOv3 excelle dans les capacités de suivi vidéo ; bien que sa précision ne soit pas encore suffisante pour le détourage vidéo, sa taille de seulement 43 Mo le rend très performant. DALL-E 3 est capable de générer des images de combinaisons alimentaires étranges à partir de prompts, démontrant sa puissante capacité de génération créative. glif est utilisé pour générer des vidéos TikTok avec des accents et des sous-titres spécifiques, élargissant davantage l’application de l’IA dans la création de contenu vidéo court. (Source: _akhaliq, huggingface, _akhaliq, _akhaliq, huggingface)

Plateformes de gestion et d’intégration multi-LLM : E-Worker, une application Web, permet aux utilisateurs de discuter de manière unifiée avec plusieurs LLM (tels que Google, Ollama, Docker), simplifiant la complexité de l’interaction multi-modèles. Synapse Workflows est une plateforme AI Agent puissante qui unifie les fonctions de recherche, de productivité et d’analyse de données via le langage naturel, permettant aux utilisateurs de rechercher instantanément sur le Web, d’automatiser des tâches ou d’analyser des données. (Source: Reddit r/OpenWebUI, LangChainAI, hwchase17)
Claude Code et gestion des connaissances personnelles : L’équipe Claude a fourni à ses super-utilisateurs Code des astuces pratiques pour optimiser le respect des instructions, notamment l’utilisation de /compact pour compresser les conversations, la configuration de Stop hooks pour rappeler les règles clés, et la répétition des règles importantes en haut et en bas du fichier CLAUDE.md. Parallèlement, un utilisateur a réussi à intégrer un Claude Code Agent personnalisé avec le logiciel de prise de notes Obsidian, réalisant une interaction intelligente et un brainstorming pour sa base de connaissances personnelle, ce qui est considéré comme un pas en avant vers l’avenir dépeint dans le film “Her”. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Programmation et développement assistés par l’IA : Cursor, en tant qu’outil de programmation assistée par l’IA, est utilisé pour nettoyer le code et corriger les anciens bugs, améliorant considérablement l’efficacité du développement. De plus, la construction d’applications d’annotation personnalisées via des AI Agents est considérée comme un moyen efficace d’obtenir un “alpha déraisonnable”, capable de fournir aux professionnels comme les médecins des interfaces d’annotation plus intuitives et efficaces, améliorant ainsi la qualité et l’efficacité de l’annotation des données. (Source: nrehiew_, HamelHusain, jeremyphoward)
Développement et expérimentation d’applications AI : Claude Code Quest est un jeu JRPG sur le thème du parcours d’un développeur SaaS, où les joueurs incarnent des développeurs et collectent des sous-Agents AI via un système Gacha pour combattre les bugs et les monstres de code. Le jeu intègre des éléments de programmation tels que l’interface CLI et le mode Opus, et explore avec humour l’application de l’IA dans l’apprentissage gamifié et le divertissement, incluant même un défi de “boss secret” sur le sens de l’existence de l’IA. (Source: Reddit r/ClaudeAI)
Problèmes de compatibilité et de sortie des modèles AI : Les utilisateurs d’OpenWebUI signalent que la nouvelle version du modèle Seed-36B utilise la balise de pensée <seed:think>, qui est incompatible avec la configuration d’OpenWebUI ne prenant en charge que <think>, empêchant le modèle de fonctionner correctement. De plus, les utilisateurs ont exprimé leur mécontentement quant au manque de style et d’esthétique lors de la génération de code Web par Azure OpenAI GPT-5 dans la fenêtre Artifacts, estimant que ses résultats sont bien inférieurs à ceux de Gemini ou Claude. (Source: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Génération et édition d’images AI : L’outil Nano-banana permet aux utilisateurs de créer facilement des bandes dessinées mettant en scène leur animal de compagnie à partir d’une seule photo, l’IA pouvant même écrire automatiquement l’histoire. MOTE by computerender est recommandé comme outil d’art AI pour l’inspiration du week-end, démontrant son potentiel dans la génération de contenu visuel. (Source: lmarena_ai, johnowhitaker)

Applications LLM locales : Lors d’un hackathon organisé par LiquidAI, il a été démontré comment utiliser les modèles LLM locaux de LiquidAI. Ce cas pratique souligne la faisabilité de l’exécution locale de grands modèles linguistiques dans le développement et l’expérimentation, offrant aux développeurs plus d’autonomie et de flexibilité. (Source: Plinz)
Outils d’humanisation de texte AI : La communauté a discuté des outils d’« humanisation du texte AI », qui visent à rendre le contenu généré par l’IA plus humain et moins robotique. Cela reflète la recherche constante de la qualité et de l’acceptabilité du contenu AI, ainsi que l’exploration des frontières entre l’IA et la création humaine. (Source: Ronald_vanLoon)
📚 Apprentissage
Système RL de style AlphaZero pour le jeu de plateau Hnefatafl : Un data scientist a partagé son système de Reinforcement Learning de style AlphaZero développé pour le jeu de plateau Hnefatafl. Ce système utilise l’auto-jeu, la recherche arborescente de Monte Carlo et les réseaux neuronaux pour l’entraînement. L’auteur sollicite les retours de la communauté sur son code et sa méthodologie, en particulier sur la manière de surmonter les goulots d’étranglement de l’entraînement avec des ressources de calcul limitées. (Source: Reddit r/deeplearning)
Développement de carrière en Data Science : Master ou Hackathons : Un data scientist, ayant cinq ans d’expérience chez les Big4, principalement axée sur la prévision dans le secteur de l’énergie, recherche des conseils pour faire évoluer sa carrière. Il est titulaire de trois licences en Computer Science, a acquis des connaissances en Machine Learning/Data Science par auto-apprentissage, et possède une expérience en POC pour les applications RAG et les Agents. Il envisage de poursuivre un Master en ligne (comme Georgia Tech) ou de consacrer plus de temps à des hackathons comme Kaggle/Zindi pour améliorer ses compétences professionnelles. (Source: Reddit r/MachineLearning)
Discussion sur l’évolution de JAX après l’ère des Transformer : La communauté a discuté de l’état de développement du framework JAX après l’engouement pour les Transformer et les LLM. Il y a quelques années, JAX avait suscité beaucoup d’attention, étant considéré comme un potentiel perturbateur de PyTorch, mais son engouement a récemment diminué. La discussion s’est concentrée sur la question de savoir si JAX a toujours un avenir, ainsi que sur son application pratique et sa position dans le développement actuel des grands modèles. (Source: Reddit r/MachineLearning)
Architecture de récompense en couches (LRA) : Résoudre la “fallace de la récompense unique” dans RLHF : Un guide a présenté l’architecture de récompense en couches (LRA), visant à résoudre le problème de la “fallace de la récompense unique” dans le RLHF/RLVR en environnement de production. LRA décompose les récompenses en plusieurs couches de signaux vérifiables (tels que structure, spécifique à la tâche, sémantique, comportement/sécurité, qualitatif), évaluées par des modèles et des règles spécialisés, rendant ainsi l’entraînement des LLM, RAG et toolchains dans des systèmes complexes plus robuste et plus facile à déboguer. (Source: Reddit r/deeplearning)

Éducation à la littératie AI : Enseigner aux enfants les compétences clés de l’ère de l’IA : La communauté a souligné l’importance d’enseigner la littératie AI aux enfants (et de s’auto-améliorer) à l’ère de l’IA. Les experts soulignent que comprendre le fonctionnement de l’IA, ses implications éthiques et comment l’utiliser de manière responsable sont des compétences clés indispensables pour la société future. (Source: TheTuringPost)
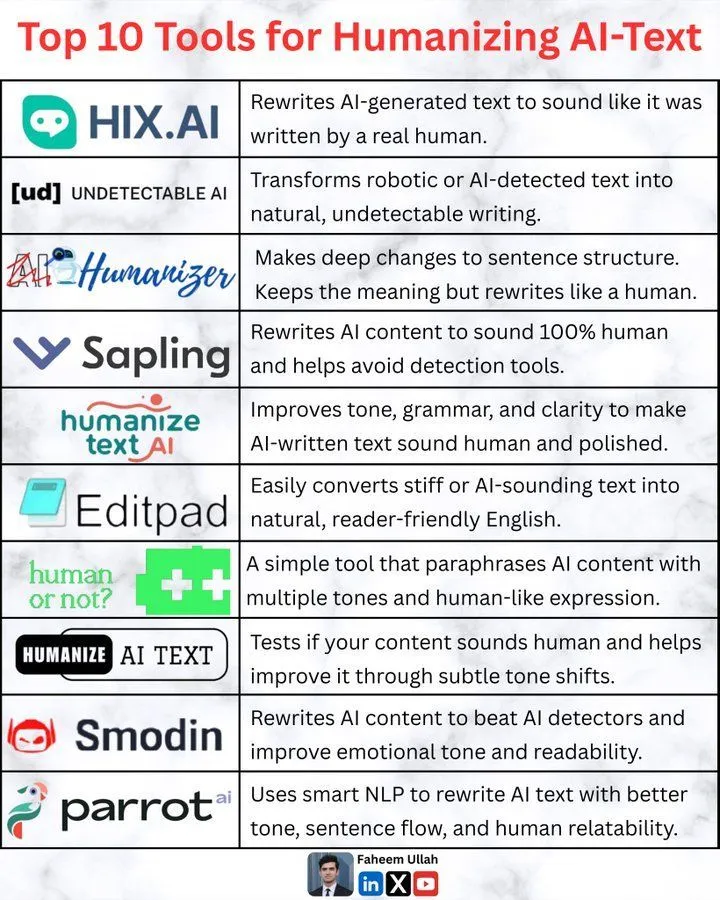
Types de mémoire dans les LLM Agents et la pile LLM : La communauté a discuté des différents types de mécanismes de mémoire dans les AI Agents et de leur rôle en Machine Learning. Parallèlement, une feuille de route “7-layer LLM stack” a été partagée, offrant un cadre pour comprendre l’architecture complexe des grands modèles linguistiques. De plus, une feuille de route pour le Deep Learning a également été fournie aux apprenants en IA. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Infrastructure d’entraînement distribué : Analyse PP, DP, TP : La communauté a exploré en profondeur les concepts clés de l’infrastructure d’entraînement distribué, y compris le Pipeline Parallelism (PP), le Data Parallelism (DP) et le Tensor Parallelism (TP). La discussion a souligné que le PP est principalement utilisé pour résoudre les limitations de bande passante TPU/NVLink ou de mémoire/géométrie, lorsque la communication DP est bonne mais que le TP ne peut pas être étendu davantage. Comprendre ces stratégies de parallélisation est crucial pour optimiser l’efficacité de l’entraînement des grands modèles. (Source: TheZachMueller)
Routage de Foundation Models : Aider les Agents à choisir le FM approprié : La communauté a discuté du besoin de développer un projet ou un package de “routeur” pour aider les AI Agents à choisir le Foundation Model (FM) approprié en fonction de cas d’utilisation spécifiques. Cela reflète l’attention de la communauté AI à l’optimisation du processus de décision des Agents et à l’amélioration de l’efficacité d’utilisation des modèles, explorant comment associer plus intelligemment les tâches aux modèles. (Source: Reddit r/MachineLearning)
💼 Business
Tendances de tarification des modèles AI et augmentation des coûts des talents : DeepSeek a annoncé une augmentation des prix de son API, la suppression des réductions nocturnes, une tarification unifiée pour les API d’inférence et non-inférence, et une augmentation de 50% du prix de sortie. Parmi les “six petits tigres des grands modèles” nationaux, quatre ont déjà augmenté les prix de certaines API, et les grandes entreprises adoptent généralement des stratégies de tarification échelonnée. Les prix des API des fabricants internationaux sont restés globalement stables ou ont légèrement augmenté, et les abonnements haut de gamme (comme xAI Grok à 300 USD/mois) deviennent de plus en plus chers. Cela reflète l’impact continu des coûts élevés de la puissance de calcul AI, des données, des talents, etc., sur la tarification des services de modèles, ainsi que la considération des fabricants pour le retour sur investissement. (Source: 36氪)
Le gouvernement britannique négocie le déploiement national de ChatGPT Plus : Le gouvernement britannique est en pourparlers avec OpenAI pour un accord visant à fournir le service ChatGPT Plus à l’échelle nationale. Cette initiative démontre une volonté active au niveau national de promouvoir la vulgarisation et l’application de la technologie AI, ce qui pourrait avoir un impact profond sur les services publics, l’éducation et le secteur commercial. (Source: Reddit r/artificial)

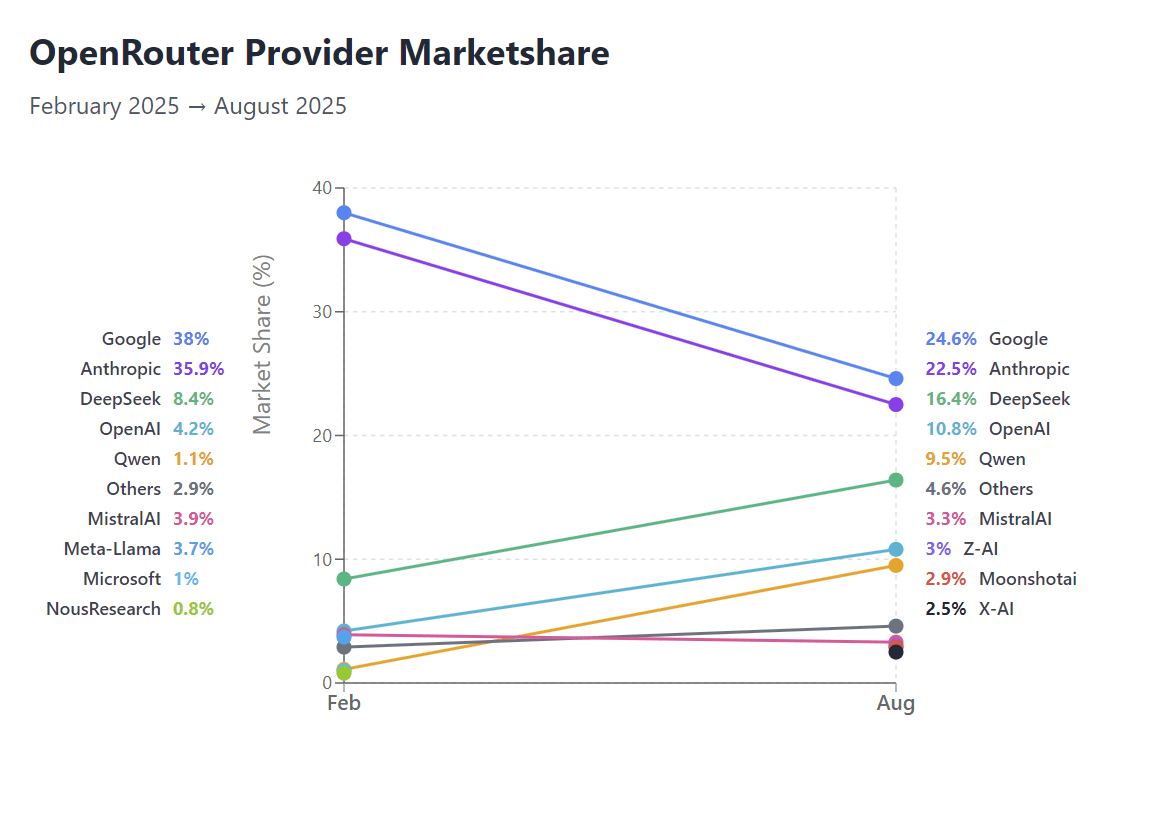
Changements de parts de marché d’OpenRouter et défis des domaines verticaux de l’IA : Selon les données d’OpenRouter, les parts de marché de Google et Anthropic sont mises à l’épreuve, ce qui témoigne de l’essor des modèles ouverts dans la concurrence du marché. Parallèlement, des entreprises dans des domaines verticaux spécifiques de l’IA, tels que Text-to-SQL, sont confrontées à des “ventes à bas prix”, reflétant l’intensification de la concurrence sur le marché et les défis des modèles commerciaux pour des applications spécifiques. (Source: Reddit r/LocalLLaMA, TheEthanDing)
🌟 Communauté
Perspectives et discussions éthiques sur le développement de l’IA : La communauté débat vivement des “leçons amères” de la recherche en IA, à savoir que les méthodes générales sont supérieures à l’intuition humaine. Les risques potentiels de l’AGI et les questions de survie humaine, ainsi que l’impact de l’IA sur la conscience et la réinvention de l’identité humaine, ont suscité de vastes réflexions philosophiques. Parallèlement, les questions de la régulation de l’IA, de l’éthique de l’IA (comme le respect des droits des robots) et de la décontextualisation historique et artistique due à la censure du contenu AI sont également devenues des points centraux de l’attention de la communauté. (Source: riemannzeta, Reddit r/ArtificialInteligence, Reddit r/artificial, Ronald_vanLoon, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Impact de l’IA sur la cognition humaine et la société : La communauté discute de la possibilité qu’une dépendance excessive à l’IA puisse entraîner une “charge cognitive” et une dégradation des capacités de réflexion, soulevant des inquiétudes quant aux applications de l’IA dans la santé mentale (comme les thérapies AI) et l’éducation. Parallèlement, les déclarations contradictoires des milliardaires de la technologie sur l’impact de l’IA sont critiquées, reflétant l’incertitude du public quant à l’orientation future de l’IA et le questionnement de la crédibilité des leaders. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Anxiété professionnelle et d’emploi à l’ère de l’IA : L’impact de l’IA sur les professions de cols blancs traditionnelles (comme la comptabilité) a provoqué de l’anxiété professionnelle chez les étudiants, beaucoup craignant que l’automatisation par l’IA ne “détruise” les emplois non liés à l’ingénierie logicielle. Jad Tarifi, pionnier de l’IA générative chez Google, conseille d’éviter les longs cursus universitaires comme le droit ou la médecine, et de s’engager plus activement dans le monde réel pour s’adapter aux changements rapides apportés par l’IA. Parallèlement, la communauté appelle à ce que le développement de l’IA priorise l’automatisation du travail physique plutôt que les emplois créatifs ou de cols blancs. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial)

Feedback sur les applications AI et l’expérience utilisateur : Les utilisateurs ont partagé l’utilité démontrée par GPT-5 en statistiques ésotériques, bien qu’une vérification prudente reste nécessaire. La comparaison des sorties des modèles ChatGPT et Grok (comme le mème “Well well well”) est devenue un sujet brûlant dans la communauté, suscitant des discussions sur les caractéristiques des différents LLM. Parallèlement, certains utilisateurs regrettent la sensation de débattre avec ChatGPT en 2022, la considérant comme une interaction “platonicienne et socratique”. (Source: colin_fraser, Reddit r/ChatGPT, Reddit r/ChatGPT)

Open source des modèles AI et valeur communautaire : L’ouverture du modèle xAI Grok 2.5 a suscité de vastes discussions au sein de la communauté concernant ses performances, son architecture et sa valeur réelle. Bien que certains utilisateurs aient remis en question sa compétitivité par rapport aux modèles SOTA actuels, la plupart des opinions estiment que les poids ouverts sont cruciaux pour le développement de la communauté, offrant des ressources précieuses pour la recherche et favorisant la préservation des modèles AI en tant que patrimoine culturel. (Source: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Dorialexander)
Soft power et confiance de l’IA : L’ancien diplomate japonais Ren Ito a proposé le concept de l’« ère du soft power de l’IA », soulignant que, dans la popularisation mondiale des modèles d’IA, l’importance de la confiance et des principes centrés sur l’humain dépassera les avantages purement techniques. Il estime qu’à mesure que les modèles haute performance ne seront plus l’apanage de quelques géants technologiques, l’IA la plus fiable deviendra une source profonde de soft power en s’intégrant aux décisions quotidiennes. (Source: SakanaAILabs)
Impact environnemental de l’IA : La communauté a discuté de la controverse concernant la consommation d’eau de Google AI. Bien que Google affirme que chaque prompt AI ne consomme qu’une petite quantité d’eau, les experts soulignent que ce calcul n’inclut pas l’eau consommée par les centrales électriques pour alimenter les data centers, ce qui sous-estime la consommation réelle. Cela a suscité l’attention et la discussion du public sur l’empreinte environnementale de la technologie AI. (Source: jonst0kes, Reddit r/artificial)

AI Agent et Prompt Engineering : La communauté a discuté des risques d’injection de prompt dans les LLM, estimant qu’ils n’ont pas encore reçu une attention généralisée ni de solutions efficaces, et soulignant la nécessité d’une prudence accrue lors de la construction d’AI Agents. Parallèlement, la composabilité et l’utilité des architectures d’AI Agent (comme LangChain Deep Agents) ont également attiré l’attention, étant considérées comme capables de résoudre efficacement des problèmes complexes. (Source: fabianstelzer, hwchase17)
Culture de la recherche et du développement en IA : La communauté a discuté de l’abus de la terminologie AI (comme la définition floue de “frontière”), du scepticisme concernant le phénomène des VC devenant des experts en RL, et de l’idée que les coûts d’entraînement des LLM pourraient être sous-estimés. De plus, des développeurs ont partagé leur expérience pratique de construction d’applications d’annotation personnalisées, soulignant leur valeur d’« alpha déraisonnable » pour améliorer la qualité des données. (Source: agihippo, Dorialexander, Dorialexander, HamelHusain)
Impact profond de l’IA sur la programmation : L’IA est en train de transformer la nature de la programmation, passant d’une simple connaissance syntaxique à une compréhension de construction et de concepts de plus haut niveau. Des développeurs s’émerveillent que l’IA rende possible la construction à une échelle autrefois inimaginable, offrant une expérience de “construire sans peur”. Parallèlement, la communauté a discuté de la redéfinition de la valeur des programmeurs par l’IA, estimant que l’IA remplace l’illusion de ceux qui “ne connaissent que la syntaxe”, et non les véritables développeurs. (Source: MParakhin, nptacek, gfodor)
IA et simulation de la réalité : World Models et intelligence incarnée : La technologie des World Models (comme Genie 3) est capable de construire des simulations de la réalité en digérant des vidéos YouTube et de générer de nouveaux mondes, permettant aux intelligences incarnées (comme SIMA Agent) d’y apprendre et de s’adapter. Ce cycle d’« entraînement de l’IA dans la pensée de l’IA » a suscité des réflexions philosophiques sur les “rêves” de l’IA et la nature de notre propre réalité, annonçant l’avenir des simulateurs d’entraînement pour l’intelligence incarnée générale. (Source: jparkerholder, demishassabis, teortaxesTex)
💡 Autres
Valeur des données de préférences esthétiques de Midjourney : Les préférences esthétiques et les données de personnalité des utilisateurs générées par Midjourney sont estimées valoir des milliards de dollars. Ce point de vue souligne l’immense potentiel commercial des données d’interaction utilisateur dans les produits AI, en particulier dans des domaines tels que la génération d’images et les recommandations personnalisées. (Source: BlackHC)

Retour sur l’historique de l’entraînement GPU sur MacBook : Des développeurs ont passé en revue les premières explorations du MacBook en matière d’entraînement GPU, soulignant qu’entre 2016 et 2017, la vitesse d’entraînement GPU du MacBook avait atteint un quart de celle du P100, offrant un support pour le fine-tuning des modèles. Cependant, le développement ultérieur a été décrit comme une “politique médiocre, manquant d’une véritable vision technologique”, ce qui a déçu de nombreux innovateurs précoces. (Source: jeremyphoward)
