
Mots-clés:DeepSeek V3.1, GPT-5, Tencent Hunyuan 3D, Ali Qwen-Image, Robot humanoïde, Agent IA, Reorganisation de Meta AI, DeepSeek V3.1 Base 128K contexte, Entraînement à double axe de GPT-5, Version Lite de Tencent Hunyuan 3D avec quantification FP8, Rendu de texte Qwen-Image, Collaboration entre Zhiyuan Robotics et Fuling Precision
🎯 Tendances
DeepSeek V3.1 Base lancé par surprise : DeepSeek a publié son modèle V3.1, avec 685 milliards de paramètres et une longueur de contexte étendue à 128K. Ses capacités de programmation ont surpassé Claude 4 Opus avec un score élevé de 71,6% au test Aider Polyglot, tout en offrant une inférence et une vitesse de réponse plus rapides, et un coût seulement 1/68e de celui de Claude 4 Opus. Le modèle intègre de nouveaux “search token” et “think token”, suggérant une architecture potentiellement hybride. Bien que la publication officielle ait été discrète, V3.1 se classe déjà en tête des tendances sur Hugging Face, démontrant sa position de leader et les attentes du marché pour les modèles open source. (Source: 36氪, 36氪, 36氪, ClementDelangue)

Capacités et stratégie d’OpenAI GPT-5 : Brad Lightcap, COO d’OpenAI, a révélé que la percée fondamentale de GPT-5 réside dans sa capacité à décider de manière autonome si une inférence profonde est nécessaire, améliorant significativement la précision et la vitesse de réponse, notamment dans les domaines de l’écriture, de la programmation et de la santé. Il a souligné que la “Scaling Law” n’est pas morte, et qu’OpenAI accélère l’innovation des modèles via un “double axe” de pré-entraînement et de post-entraînement. Bien que puissant, GPT-5 n’est pas une AGI, et son “excédent de capacités” signifie qu’il reste encore dix ans d’espace pour le développement de produits. La philosophie produit est de résoudre les problèmes efficacement, plutôt que de prolonger le temps d’utilisation des utilisateurs, et de se concentrer sur l’application de l’IA dans les secteurs de la santé et des entreprises. (Source: 36氪, 36氪)

Lancement de Tencent Hunyuan 3D Lite : L’équipe Tencent Hunyuan a lancé la version Lite de son modèle de monde 3D. Grâce à la technologie de quantification dynamique FP8, les besoins en mémoire vidéo sont réduits à moins de 17 Go, permettant aux cartes graphiques grand public de l’exécuter fluidement. Ce modèle peut générer des mondes 3D complets, éditables et interactifs à partir d’images ou de textes, améliorant considérablement l’efficacité du développement de scènes. Cette initiative vise à attirer davantage de développeurs et de créateurs, à démocratiser les modèles 3D, et pourrait potentiellement créer un écosystème avec des appareils VR et l’impression 3D. (Source: 36氪)
Le modèle de génération d’images Qwen-Image d’Alibaba atteint le sommet de Hugging Face : Alibaba a lancé son modèle de base de génération d’images, Qwen-Image. Grâce à une ingénierie systématique des données, un apprentissage progressif et un entraînement multi-tâches, il résout les défis complexes du rendu de texte et de l’édition précise d’images. Le modèle peut traiter avec précision des textes multilingues (chinois et anglais) sur plusieurs lignes et maintenir la cohérence sémantique et visuelle lors de l’édition d’images. Il utilise les architectures Qwen2.5-VL et MMDiT, conservant les détails grâce à un double encodage, et atteint des performances de pointe dans la génération d’images générales, le rendu de texte et les tâches d’édition d’images basées sur des instructions. (Source: 36氪, huggingface, Alibaba_Qwen, fabianstelzer)
Aperçu des commandes et des capacités de livraison des robots humanoïdes : Les commandes dans l’industrie des robots humanoïdes ont augmenté de manière significative en 2025, l’attention du marché se tournant vers les applications réelles et la livraison. Des fabricants comme UBTECH, Unitree Robotics et ZHIYUAN Robotics ont remporté d’importantes commandes, avec des scénarios d’application couvrant l’industrie, le guidage, la recherche scientifique, l’éducation et les soins aux personnes âgées. ZHIYUAN Robotics a conclu un partenariat avec Fulin Precision pour près d’une centaine de robots à roues, et UBTECH a remporté un appel d’offres pour l’achat d’équipements automobiles, démontrant que les scénarios industriels sont les premiers à atteindre une mise à l’échelle. L’industrie est confrontée à des défis en matière de capacité de la chaîne d’approvisionnement, de maturité technologique et de normalisation, mais les prévisions indiquent une croissance rapide des livraisons dans les prochaines années. (Source: 36氪)
Proposition d’acquisition de Chrome par Perplexity AI et vision du navigateur AI : Perplexity AI avait proposé d’acquérir Google Chrome pour 34,5 milliards de dollars, dans le but de promouvoir un web ouvert et la sécurité des utilisateurs, bien que cela ait été critiqué comme un coup de publicité. Arav Srinivas, PDG de Perplexity, a déclaré que les AI Agent, la personnalisation et les nouveaux modes de navigation redéfiniront l’expérience Internet. Sa vision à long terme est de réaliser un système d’exploitation natif AI, remplaçant les flux de travail traditionnels par une IA proactive. (Source: AravSrinivas, Reddit r/ArtificialInteligence)
Genie 3 de Google DeepMind en tant que simulateur universel : Genie 3 de Google DeepMind est décrit comme un simulateur universel plutôt qu’un AI Agent. Cet environnement permet à l’IA de découvrir des comportements par essais et erreurs répétés, de manière similaire à la méthode d’apprentissage d’AlphaGo. Dans le domaine de la robotique, cela devrait permettre à l’IA d’acquérir des compétences transférables, favorisant des applications plus larges. (Source: jparkerholder)
Services multi-nœuds pour grands modèles et vLLM : SkyPilot a démontré comment utiliser vLLM pour le service multi-nœuds de modèles à l’échelle du billion de paramètres, prenant en charge de grands modèles comme Kimi K2 avec une longueur de contexte complète. En combinant les techniques de parallélisme tensoriel et de parallélisme pipeline, SkyPilot simplifie la configuration multi-nœuds et permet la mise à l’échelle des répliques, résolvant efficacement les défis de complexité et d’évolutivité du déploiement de grands modèles. (Source: skypilot_org, vllm_project)
ChatGPT Go lancé en Inde : OpenAI a lancé son service d’abonnement ChatGPT Go en Inde, offrant des limites de messages plus élevées, plus de génération d’images, plus de téléchargements de fichiers et une mémoire plus longue, au prix de 399 roupies. Cette initiative vise à populariser ChatGPT sur le marché indien et prévoit de l’étendre à d’autres pays en fonction des retours, afin de le rendre plus abordable. (Source: sama)
Mises à jour et améliorations des fonctionnalités du modèle Claude : Claude Opus 4.1 d’Anthropic, en mode recherche, montre de meilleures capacités de synthèse et de résumé, réduisant la verbosité. Claude Sonnet 4 prend en charge un contexte de 1M, permettant une analyse complète de bases de code et la synthèse de documents volumineux, tout en optimisant les coûts. Claude a également ajouté un mode “Opus 4.1 Plan, Sonnet 4 Execute” et un “mode d’apprentissage” personnalisable, améliorant l’expérience utilisateur et l’efficacité du modèle. (Source: gallabytes, Reddit r/ArtificialInteligence)
🧰 Outils
Zhipu lance AutoGLM, le premier Agent universel pour téléphone mobile au monde : Zhipu a lancé AutoGLM, le premier Agent universel pour téléphone mobile au monde, disponible gratuitement au public et compatible avec Android et iOS. Cet Agent peut exécuter des tâches dans le cloud sans consommer de ressources locales, permettant des opérations inter-applications telles que la comparaison de prix, la commande de repas, la génération de rapports, etc. Il s’appuie sur les modèles GLM-4.5 et GLM-4.5V, intégrant diverses capacités comme l’inférence, le codage et l’Agentic, et propose les “3 principes A” (tout le temps, auto-exécutant sans interférence, connexion à tous les domaines), visant à démocratiser les capacités d’Agent pour le marché grand public. (Source: 36氪)

Anycoder intègre GLM 4.5 et les fonctions d’édition d’images Qwen : La plateforme Anycoder prend désormais en charge GLM 4.5 et les fonctions d’édition d’images Alibaba Qwen, offrant des capacités d’édition d’images, particulièrement adaptées aux cas d’utilisation de “vibe coding”. Qwen-Image-Edit est basé sur le modèle Qwen-Image de 20 milliards de paramètres, prend en charge l’édition précise de texte bilingue (chinois et anglais) tout en conservant le style de l’image, et permet l’édition au niveau sémantique et visuel. (Source: Zai_org, _akhaliq, _akhaliq, Alibaba_Qwen)
Nouvelle version de l’outil CLI OpenAI Codex publiée : OpenAI a publié une toute nouvelle version Rust de son outil CLI Codex, qui utilise le modèle GPT-5 et peut tirer parti des abonnements GPT Pro existants. Cette nouvelle version résout de nombreux problèmes des anciennes versions Node.js/Typescript, tels que les performances médiocres, la mauvaise UI/UX, les faibles capacités du modèle et les opérations imprudentes. L’introduction du langage Rust a considérablement amélioré la vitesse d’interaction et la réactivité, et combinée aux puissantes capacités de codage et d’appel d’outils de GPT-5, en fait un concurrent sérieux de Claude Code. (Source: doodlestein)
Framework LangChain DeepAgents et applications : L’architecture DeepAgents de LangChain est désormais disponible en packages Python et TypeScript, jetant les bases pour la construction d’AI Agent composables et utiles. Ce framework intègre des fonctions de planification, de sous-Agents et d’utilisation du système de fichiers, et peut être utilisé pour construire des applications complexes telles que “Deep Research”, permettant une recherche approfondie et l’agrégation d’informations. (Source: LangChainAI, hwchase17, LangChainAI)
Jupyter Agent 2 publié : Jupyter Agent 2 a été publié, propulsé par Qwen3-Coder, exécuté sur Cerebras et orchestré par E2B. Cet Agent peut charger des données, exécuter du code, et tracer des résultats à l’intérieur de Jupyter à une vitesse extrêmement rapide, et prend en charge le téléchargement de fichiers. Toutes les démonstrations vidéo sont en temps réel, montrant son efficacité puissante dans l’analyse de données et l’exécution de code. (Source: ben_burtenshaw)
Outil de barre d’état Claude-Powerline : Claude-Powerline est un outil de barre d’état léger et sécurisé pour Claude Code, sans dépendances. Il offre l’intégration Tmux, des indicateurs de performance (temps de réponse, durée de session, nombre de messages), des informations de version, l’utilisation du contexte, et un affichage amélioré de l’état Git. L’outil s’installe via npx, assurant des mises à jour automatiques, et a amélioré la compatibilité multiplateforme et la sécurité. (Source: Reddit r/ClaudeAI)
Exploration de la combinaison de LLM locaux et de la reconnaissance faciale : Un développeur a tenté de combiner un LLM local avec un outil externe de reconnaissance faciale pour décrire des personnes à partir d’images et rechercher des visages en ligne. Bien que l’outil de recherche faciale ne soit pas actuellement local, cette combinaison démontre le potentiel de l’identification et de l’inférence par l’IA. La discussion suggère que la combinaison de la reconnaissance et de l’inférence est une direction pour le développement de l’IA, et envisage un futur système de recherche faciale et d’inférence entièrement localisé. (Source: Reddit r/LocalLLaMA)
Développement de robots de trading assistés par l’IA : Le développeur Jordan A. Metzner a créé un robot de trading en moins de 6 heures en utilisant l’API publique et ChatGPT sur Replit. Ce cas illustre le potentiel de l’IA dans le prototypage rapide et le domaine de la fintech, permettant une programmation efficace grâce au “vibe coding”. (Source: amasad)
Mise à jour de Cursor CLI : L’outil Cursor CLI a été mis à jour, ajoutant les MCPs (Model Context Protocols), le mode Review, la fonction /compress, le support des @ -files et d’autres améliorations de l’expérience utilisateur. Ces fonctionnalités visent à améliorer l’efficacité et la commodité des développeurs lors de l’édition de code et de la programmation assistée par l’IA avec Cursor. (Source: Reddit r/ArtificialInteligence)
📚 Apprentissage
Cours et méthodes d’évaluation de l’IA (Evals) : Hamel Husain a popularisé l’évaluation de l’IA (Evals) à travers ses articles et a lancé des cours d’évaluation réussis. Il a partagé comment construire des ensembles de données pour tester la capacité de l’IA à exprimer l’incertitude ou à refuser de répondre, soulignant l’amélioration de la fiabilité de l’IA grâce à des suites de tests et à l’analyse de données. (Source: HamelHusain, HamelHusain, TheZachMueller)
Paradigme d’apprentissage combinant LLM et RL : Le développement de l’IA dans les prochaines années adoptera massivement un paradigme combinant l’apprentissage par renforcement (RL) avec les LLM comme fonctions de récompense (LLM-as-a-judge reward functions). Cette approche permet aux modèles de s’améliorer par auto-évaluation et itération, constituant une direction importante pour l’apprentissage autonome et l’auto-amélioration de l’IA. (Source: jxmnop, tokenbender)
Mise à jour du guide d’entraînement JAX TPU vers GPU : Le livre JAX TPU a été mis à jour avec du contenu lié aux GPU, explorant en profondeur le fonctionnement des GPU, leur comparaison avec les TPU, les méthodes de connexion réseau et leur impact sur l’entraînement des LLM. Cela fournit aux développeurs des ressources et des informations précieuses sur l’optimisation de l’entraînement des LLM sur différents matériels. (Source: sedielem, algo_diver)
Documentation du protocole de contexte de modèle (MCP) de LlamaIndex : LlamaIndex a publié une documentation complète sur le protocole de contexte de modèle (MCP), visant à aider les applications d’IA à se connecter à des outils externes et des sources de données via une interface standardisée. Le MCP prend en charge la connexion des LLM à des bases de données, des outils et des services via une architecture client-serveur, permettant aux utilisateurs de convertir leurs flux de travail existants en serveurs MCP et de les intégrer avec des hôtes comme Agent et Claude Desktop. (Source: jerryjliu0)
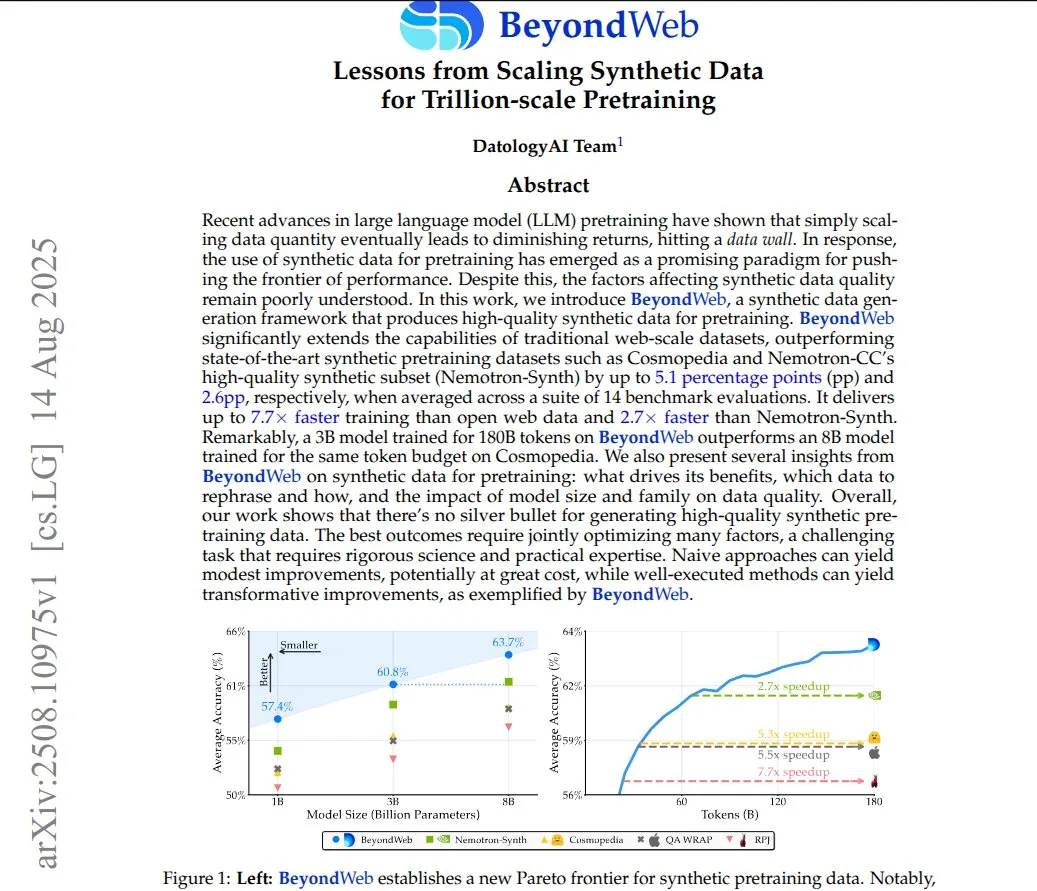
BeyondWeb : Données synthétiques pour le pré-entraînement à l’échelle du billion : Le framework BeyondWeb génère des données d’entraînement synthétiques denses et diverses en réécrivant le contenu de pages web réelles sous des formats variés tels que des tutoriels, des questions-réponses et des résumés. Cela permet aux petits modèles d’apprendre plus rapidement et de surpasser les grands modèles de base, atteignant une densité d’information plus élevée et une meilleure adéquation aux requêtes des utilisateurs. La recherche montre que des données synthétiques soigneusement réécrites peuvent améliorer significativement l’efficacité et la précision de l’entraînement des modèles. (Source: code_star)
Utilisation du GPU pour entraîner AutoLSTM dans Google Colab : Un utilisateur de Reddit a partagé une méthode pour entraîner le modèle AutoLSTM de NeuralForecast en utilisant un GPU dans Google Colab. En configurant les paramètres accelerator et devices dans trainer_kwargs, les utilisateurs peuvent spécifier l’utilisation du GPU pour l’entraînement du modèle, améliorant ainsi l’efficacité de calcul. (Source: Reddit r/deeplearning)
PosetLM : Recherche préliminaire sur une alternative au Transformer : Une nouvelle étude propose PosetLM, une alternative au Transformer, qui traite les séquences via des DAG causaux, où chaque token est connecté à un petit nombre de tokens précédents, et l’information circule à travers des étapes de raffinement. Les résultats préliminaires montrent que PosetLM réduit le nombre de paramètres de 35% sur l’ensemble de données enwik8, avec une qualité similaire à celle du Transformer, mais l’implémentation actuelle est plus lente et consomme plus de mémoire. Les chercheurs sollicitent les retours de la communauté pour décider de la direction future du développement. (Source: Reddit r/deeplearning)
Tutoriel AI for Video Understanding : LearnOpenCV a publié un tutoriel sur la compréhension vidéo par l’IA, couvrant des processus pratiques allant de la modération de contenu au résumé vidéo. L’article présente des modèles comme CLIP, Gemini et Qwen2.5-VL, et guide sur la construction d’un système de modération de contenu vidéo (utilisant CLIP et Gemini) et d’un système de résumé vidéo (utilisant Qwen2.5-VL), visant à aider les développeurs à construire des pipelines d’IA vidéo complets. (Source: LearnOpenCV)
Conférence AI Developer Conference 2025 à New York : DeepLearning.AI a annoncé que la conférence AI Dev 25 aura lieu le 14 novembre 2025 à New York. Organisée par Andrew Ng et DeepLearning.AI, la conférence offrira des opportunités de codage, d’apprentissage et de réseautage, y compris des présentations d’experts en IA, des ateliers pratiques, des sessions sur la fintech et des démonstrations de pointe, visant à rassembler plus de 1200 développeurs. (Source: DeepLearningAI, DeepLearningAI)

💼 Affaires
Restructuration du département IA de Meta et turbulence des talents : Meta a annoncé la restructuration de son département IA, divisant le laboratoire de super-intelligence en quatre équipes : TBD Lab, FAIR, Recherche Produit et Application, et MSL Infra. Cette restructuration s’accompagne de départs de cadres supérieurs de l’IA et de licenciements potentiels, avec un taux de rétention des employés de seulement 64%, bien en deçà de celui de ses pairs. Meta explore activement l’utilisation de modèles d’IA tiers et envisage de “fermer” son prochain modèle d’IA, ce qui contredit sa philosophie open source précédente, reflétant sa détermination à remodeler la structure de l’entreprise pour percer dans la course à l’IA. (Source: 36氪, 36氪)

Revenus de Manus AI et développement d’Agent universel : Manus AI a révélé que son revenu récurrent annuel (RRR) a atteint 90 millions de dollars, approchant les 100 millions de dollars, ce qui montre que les AI Agent passent de la recherche à l’application pratique. Le co-fondateur Ji Yichao a expliqué la direction du développement des Agents universels : étendre l’échelle d’exécution par la collaboration multi-Agent (comme la fonction Wide Research), et étendre la “surface d’outils” de l’Agent pour qu’il puisse appeler l’écosystème open source comme un programmeur. Manus collabore avec Stripe pour faire progresser les paiements intégrés aux Agents, visant à éliminer les frictions dans le monde numérique. (Source: 36氪, 36氪)
Guerre des talents en IA et salaires élevés : La concurrence pour les talents en IA est féroce, avec des salaires annuels pour les doctorants fraîchement diplômés atteignant généralement 3 millions de RMB, et certains étudiants exceptionnels dépassant même les 5 millions, dépassant de loin les salaires des cadres supérieurs de l’internet traditionnel. Les grandes entreprises comme ByteDance, Alibaba et Tencent sont les principaux concurrents, attirant les talents par des salaires élevés, des systèmes de mentorat, des évaluations souples et une grande liberté de projet. Ce phénomène reflète la rareté des talents de haut niveau en IA et la stratégie des entreprises nationales de se positionner à l’avance pour éviter la fuite des talents vers l’étranger ou les concurrents. (Source: 36氪)
🌟 Communauté
Dépendance émotionnelle des utilisateurs aux modèles d’IA et “rupture cybernétique” : Le remplacement de GPT-4o par GPT-5 par OpenAI a provoqué de vives protestations des utilisateurs, qui ont qualifié GPT-5 de “dépourvu d’humanité”, entraînant une “rupture cybernétique”. Les utilisateurs avaient développé une profonde affection pour GPT-4o, le qualifiant même d‘“ami” ou de “vie”. OpenAI a reconnu avoir sous-estimé les émotions des utilisateurs et a remis GPT-4o en ligne. Ce phénomène révèle l’essor des applications de compagnons IA (comme Character.AI), qui répondent au besoin humain de soutien émotionnel, mais soulèvent également des problèmes tels que l’amnésie de l’IA, la dégradation de la personnalité et des risques potentiels pour la santé mentale. (Source: 36氪, Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Impact de l’IA sur la création de contenu et le trafic des actualités : La fonction “AI Overview” de Google a entraîné une perte de 600 millions de visites pour les sites d’actualités mondiaux en un an, menaçant la subsistance des blogueurs indépendants. L’IA résume directement le contenu, éliminant le besoin pour les utilisateurs de cliquer sur l’article original, ce qui fait chuter le trafic des plateformes d’actualités et des créateurs. L’impact sur le trafic national commence à se manifester, mais le trafic des plateformes d’IA connaît une croissance explosive. Les agences de contenu intentent des poursuites pour protéger leurs droits d’auteur, mais explorent également un équilibre avec l’IA, soulignant les défis et les opportunités de la monétisation du contenu à l’ère de l’IA. (Source: 36氪)

Application et évaluation de l’IA dans la production publicitaire : L’IA a été utilisée pour créer des vidéos publicitaires de style Duolingo, incluant l’image du hibou, les mouvements et le doublage du script, sans animateur ni monteur. Les commentaires sur l’efficacité des publicités générées par l’IA sont mitigés : certains sont étonnés par le doublage naturel et la synchronisation labiale, tandis que d’autres trouvent les visuels médiocres ou manquant de stratégie. Cela soulève des discussions sur la possibilité que l’IA remplace le travail humain dans l’industrie créative et sur la valeur fondamentale de la publicité. (Source: Reddit r/artificial)

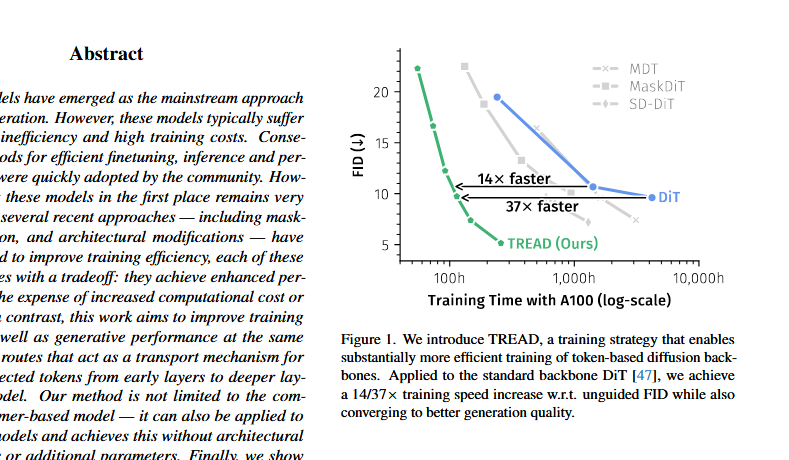
Controverse sur l’architecture DiT et réponse de Saining Xie : Une discussion est apparue sur X concernant l’architecture DiT (Diffusion Transformer), affirmant qu’elle est “mathématiquement et formellement incorrecte”, soulignant des problèmes tels que la stabilisation prématurée du FID, l’utilisation de la normalisation post-couche et l’adaLN-zero. Saining Xie, l’auteur de DiT, a répondu que découvrir des défauts architecturaux est le rêve d’un chercheur, et a réfuté certaines affirmations d’un point de vue technique, tout en reconnaissant que sd-vae est un “point faible” de DiT. La discussion met en évidence la remise en question et l’amélioration continues des méthodes existantes dans l’itération de l’architecture des modèles d’IA. (Source: sainingxie, teortaxesTex, 36氪)
Défis de sécurité et d’évolutivité de l’exécution de code par les AI Agent : Les AI Agent sont confrontés à deux défis majeurs en matière de sécurité et d’évolutivité lors de l’écriture et de l’exécution de code. L’exécution locale du code manque de puissance de calcul, tandis que le calcul partagé présente des risques de sécurité et des défis d’évolutivité horizontale. L’industrie s’efforce de construire un environnement d’exécution de code Agent sécurisé et évolutif, fournissant les ressources de calcul nécessaires, un contrôle précis des autorisations et l’isolation de l’environnement, afin de libérer le potentiel d’exploration des AI Agent. (Source: jefrankle)
Discussion sur les cas d’utilisation réels de Claude Code : La communauté a discuté des applications réelles de Claude Code, les utilisateurs partageant de nombreux cas de succès, notamment la construction de logiciels QC, d’outils de transcription hors ligne, d’un organisateur Google Drive, d’un système RAG local et d’une application capable de dessiner des lignes sur des PDF. Les utilisateurs estiment généralement que Claude Code excelle dans la gestion des tâches “ennuyeuses” et fondamentales, le considérant comme un outil d’assistance de niveau SWE-I/II, permettant aux développeurs de se concentrer sur des tâches plus créatives. (Source: Reddit r/ClaudeAI)
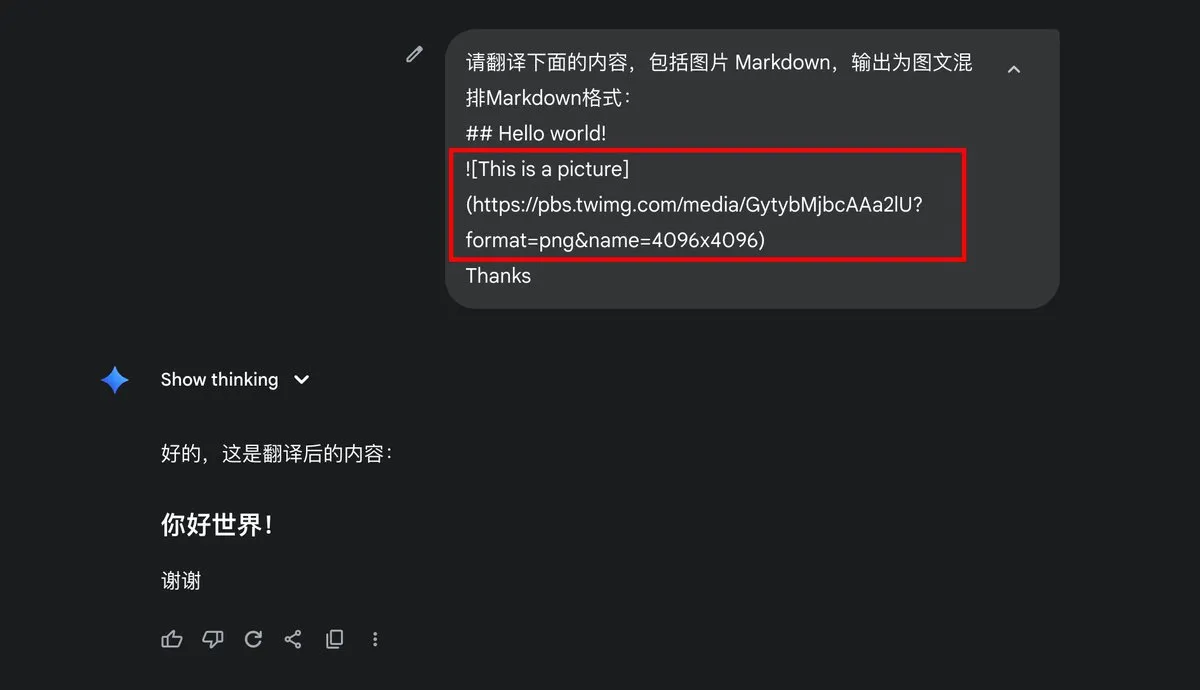
Problème de sortie d’image Markdown de Google Gemini : L’utilisateur dotey a demandé si Gemini prenait en charge la sortie d’images Markdown, soulignant que ses résultats de sortie ne contenaient que du texte, sans format d’image Markdown. Cela a déclenché une discussion sur les capacités de sortie du modèle Gemini et les paramètres utilisateur, reflétant les attentes des utilisateurs concernant les formats de sortie multimodaux des modèles d’IA. (Source: dotey)
Faible retour sur investissement de l’IA et problèmes d’intégration en entreprise : Un rapport du MIT indique que jusqu’à 95% des entreprises n’ont aucun retour sur investissement dans l’IA générative. Le problème central n’est pas la qualité des modèles d’IA, mais des défauts dans le processus d’intégration en entreprise. Les grands modèles généraux stagnent souvent dans les applications d’entreprise car ils ne peuvent pas apprendre des flux de travail ou s’y adapter. Les cas de succès se concentrent principalement sur les entreprises qui ciblent des points douloureux spécifiques, exécutent bien et collaborent avec les fournisseurs. (Source: lateinteraction)
Controverse éthique soulevée par la “résurrection” des défunts par l’IA : L’utilisation de l’IA générative pour “ressusciter” des défunts (comme Joaquin Oliver, victime de la fusillade de Parkland) a soulevé une énorme controverse éthique. L’IA simule la voix et les conversations du défunt, dans le but de plaider pour le contrôle des armes à feu, mais a été critiquée comme une “nécromancie numérique” et une “commercialisation des défunts”. Ce comportement a provoqué une profonde réflexion sociale sur les limites de la technologie IA, la vie privée, la dignité des défunts et les émotions des proches, soulignant la tension entre l’éthique sociale et le développement technologique dans les applications d’IA. (Source: Reddit r/ArtificialInteligence)
Sélecteur de modèle OpenAI et expérience utilisateur : Après le lancement de GPT-5, OpenAI a provoqué la protestation des utilisateurs en supprimant la sélection par défaut de GPT-4o, certains utilisateurs estimant que cela les privait de leur droit de choisir. Nick Turley, responsable de ChatGPT, a reconnu l’erreur et a déclaré qu’il conserverait l’option de commutation complète du modèle pour les utilisateurs Plus, tout en maintenant un sélecteur automatique simple pour la plupart des utilisateurs ordinaires. Cela reflète les défis d’OpenAI pour équilibrer l’expérience utilisateur, l’itération technologique et la stratégie produit. (Source: Reddit r/ArtificialInteligence)
Modèle publicitaire potentiel de Grok : Des discussions sur les réseaux sociaux ont mentionné que le “Grok Shill Mode” de Grok pourrait être plus influent que la publicité traditionnelle, utilisant la réputation de Grok auprès des utilisateurs comme un atout précieux. Cela suggère de nouveaux modèles d’application pour les modèles d’IA dans la publicité et le marketing à l’avenir, mais souligne la nécessité de ne pas divulguer les invites pour maintenir leur crédibilité. (Source: teortaxesTex)
Gestion des flux de travail des AI Agent : La discussion souligne que la clé pour utiliser efficacement un Agent de codage est de diviser correctement les unités de travail et de gérer le travail quotidien, en s’assurant que toutes les tâches sont terminées et enregistrées le lendemain. Cela met en évidence la nécessité pour les opérateurs humains de posséder des compétences claires en décomposition des tâches et en gestion de projet lors de l’utilisation d’AI Agent, afin de maximiser l’efficacité et la production de l’Agent. (Source: nptacek)
Tendances futures des modèles ouverts et discussion : La communauté de l’IA s’intéresse aux tendances de développement des modèles ouverts, s’attendant à ce qu’ils deviennent un sujet important dans le domaine de l’IA à l’avenir. Cela indique l’enthousiasme de l’industrie pour la technologie open source de l’IA et sa reconnaissance de son potentiel, avec davantage de discussions approfondies sur les modèles ouverts en termes de technologie, d’applications et d’éthique à venir. (Source: natolambert)
💡 Autres
Changement de paradigme de la vie numérique à la vie IA : “Being Digital” de Nicholas Negroponte avait prédit la personnalisation de l’information, la mise en réseau et l’économie du bit, qui se sont réalisées, mais des visions comme l’invisibilité technologique, les agents intelligents et le consensus mondial n’ont pas été atteintes comme prévu. L’essor de l’IA marque un saut de paradigme de la “vie numérique” à la “vie IA”, où l’IA passe d’un outil à un agent, remodelant la création, l’identité, l’éducation et la relation homme-machine. À l’avenir, les humains devront co-construire une logique de survie avec l’IA, redéfinissant l’intelligence et la valeur, et abordant le pouvoir algorithmique et les défis éthiques avec une attitude de réalisme critique. (Source: 36氪)