
Mots-clés:Mistral AI, distillation de modèles, DeepSeek, Kunlun Wanwei, IA multimodale, Huawei ADS 4.0, Momenta, apprentissage par renforcement, contentieux juridique en IA, FlashAttention 4, Bytebot, rapport Bessemer sur l’IA, jeu de données d’Ant Digital Technology
Voici la traduction de votre contenu en français, en respectant toutes vos exigences :
🔥 À la Une
Mistral AI accusé d’avoir « distillé » le modèle DeepSeek pour son modèle principal et d’avoir induit le public en erreur : Mistral AI, autrefois salué comme l’« OpenAI européen », est plongé dans un scandale de plagiat. Un ancien employé a révélé que la technologie du modèle central de Mistral ne serait pas le fruit de son propre apprentissage par renforcement, comme elle l’a affirmé publiquement, mais qu’elle aurait été directement « distillée » à partir du modèle DeepSeek, avec des allégations de falsification des résultats de tests de référence. Cette accusation a provoqué une onde de choc sur les réseaux sociaux, soulevant des questions sur la transparence et l’éthique de Mistral. Bien que la distillation de modèle ne soit pas techniquement répréhensible en soi, la question clé est de savoir si Mistral n’a pas clairement indiqué la source et a induit le public en erreur, ce qui porte un coup sévère à sa réputation et a déclenché un vaste débat au sein de la communauté de l’IA open source sur la transparence et l’éthique des modèles. (Source: 36氪)

Actualités des litiges et décisions juridiques en matière d’IA : le droit d’auteur, la vie privée et l’emploi au centre des préoccupations : Un résumé détaillé des affaires juridiques liées à l’IA révèle les défis juridiques complexes auxquels le domaine de l’IA est actuellement confronté. Parmi ceux-ci, la discrimination par les algorithmes d’IA (telle que la discrimination à l’embauche), l’attribution des droits d’auteur du contenu généré par l’IA, la responsabilité légale des deepfakes, la violation de la vie privée des données et la responsabilité des produits d’IA (tels que les accidents de conduite autonome) sont les principaux points de discorde. Il est à noter que les tribunaux chinois ont rendu plusieurs jugements reconnaissant les droits d’auteur des images et textes générés par l’IA aux créateurs, tandis que les tribunaux mexicains ont nié les droits d’auteur des œuvres d’IA. En outre, les recours collectifs contre les pratiques de collecte de données des entreprises d’IA et les demandes d’injonction contre le déploiement de produits d’IA se multiplient, ce qui indique que l’industrie de l’IA, tout en se développant rapidement, est confrontée à un examen juridique et à une réglementation de plus en plus stricts. (Source: Reddit r/ArtificialInteligence)
🎯 Tendances
Kunlun Wanwei lance six modèles d’IA multimodale en une semaine : Kunlun Wanwei a lancé de manière intensive six modèles d’IA multimodale lors de sa récente « Semaine Technologique », couvrant la génération vidéo (SkyReels-A3), les modèles mondiaux (Matrix-Game 2.0, Matrix-3D), le multimodal unifié (Skywork UniPic 2.0), les Agents (Skywork Deep Research Agent v2) et la création musicale par IA (Mureka V7.5, MoE-TTS). Parmi eux, SkyReels-A3 réduit considérablement le seuil pour le streaming de personnes numériques, Matrix-Game 2.0 et Matrix-3D réalisent des percées dans la génération en temps réel et l’interaction à longue séquence, UniPic 2.0 unifie la compréhension, la génération et l’édition d’images, tandis que Skywork Deep Research Agent v2 renforce les capacités de recherche approfondie multimodale. Le lancement intensif et l’open source partiel de ces modèles démontrent la stratégie globale et la force technologique de Kunlun Wanwei dans le domaine de l’IA multimodale, visant à promouvoir les scénarios d’application à haute fréquence dans les domaines verticaux. (Source: 量子位)

Le système de conduite intelligente avancée Huawei ADS4.0 livré en série sur le Dongfeng Mengshi M817 : Le Dongfeng Mengshi M817 est entièrement équipé du système d’aide à la conduite intelligente avancée Huawei ADS4.0, avec une livraison en série dès son lancement. Ce système est doté de 27 capteurs, dont un LiDAR à 192 lignes, des caméras haute définition et des radars à ondes millimétriques 4D, prenant en charge le NOA sur autoroute et en ville, et permettant un stationnement complet dans n’importe quelle place. De plus, le Mengshi M817 intègre également l’écosystème complet de Huawei, incluant Huawei Hongmeng Cockpit 5, Qiankun Vehicle Cloud, Qiankun Vehicle Control et Whale Fin Communication, visant à créer le produit le plus intelligent parmi les véhicules tout-terrain et le plus tout-terrain parmi les véhicules intelligents, marquant ainsi l’intégration profonde de la solution de conduite intelligente de Huawei dans le segment des véhicules tout-terrain robustes. (Source: 量子位)

Le grand modèle d’apprentissage par renforcement de Momenta lancé en première mondiale sur le Zhiji LS6, ouvrant la voie à une nouvelle tendance d’autonomie étendue intelligente : La nouvelle génération du Zhiji LS6 lancera en première mondiale le grand modèle R6 Flywheel de Momenta, un modèle basé sur le paradigme de l’apprentissage par renforcement, conçu pour apprendre la logique de conduite essentielle derrière les scénarios et améliorer la généralisation des algorithmes pour résoudre les problèmes de longue traîne. Le Zhiji LS6 propose simultanément des versions purement électriques et à autonomie étendue, la version à autonomie étendue offrant une autonomie purement électrique de 450 kilomètres et prenant en charge la charge ultra-rapide 800V, ce qui devrait inaugurer un nouveau mode d’autonomie étendue intelligente « grande batterie + petit réservoir ». Cette collaboration annonce une percée majeure de la technologie d’apprentissage par renforcement dans le domaine de l’aide à la conduite des véhicules de production, et apporte un nouveau point de convergence concurrentiel sur le marché des véhicules électriques intelligents. (Source: 量子位)

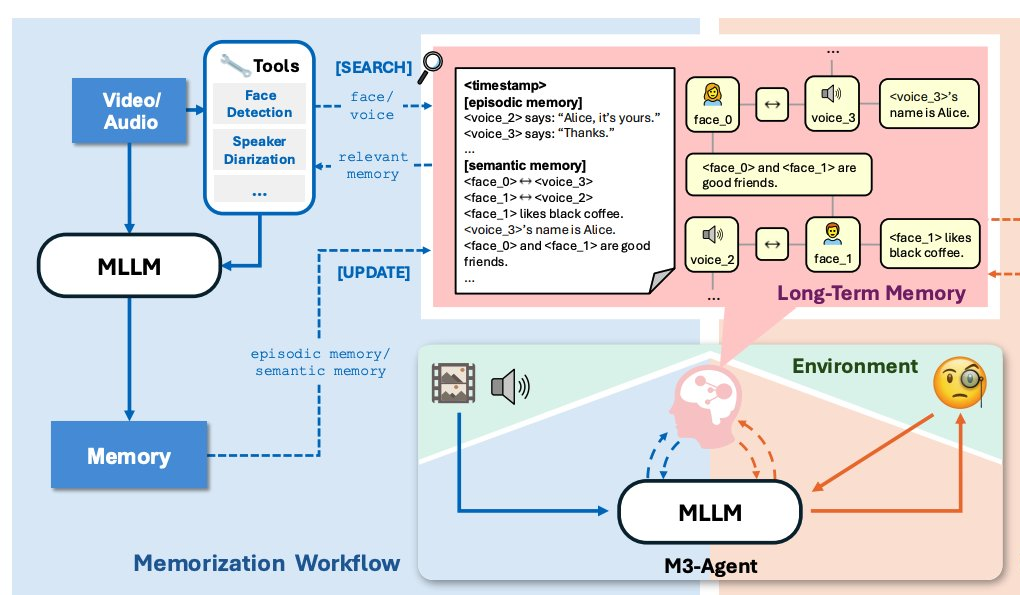
L’équipe Seed de ByteDance open-source le framework d’Agent multimodal à mémoire longue M3-Agent : L’équipe Seed de ByteDance a publié un nouveau framework d’Agent multimodal, M3-Agent, doté de la capacité d’écouter et de voir comme un humain, et de posséder une mémoire à long terme. M3-Agent traite les entrées visuelles et auditives en temps réel via des processus de mémoire et de contrôle parallèles, construisant et mettant à jour la mémoire événementielle et la mémoire sémantique, et prenant en charge le stockage d’informations multimodales. Son cœur réside dans l’utilisation de l’apprentissage par renforcement pour la déduction multi-tours et la récupération itérative de la mémoire, plutôt qu’un simple RAG à un seul tour. Parallèlement, l’équipe a également open-sourcé le benchmark de questions-réponses vidéo longue M3-Bench, utilisé pour évaluer l’efficacité de la mémoire et les capacités de raisonnement basées sur la mémoire des Agents multimodaux. (Source: 量子位)
Google DeepMind publie plusieurs mises à jour d’IA en août : Google DeepMind a lancé plusieurs mises à jour technologiques d’IA en août, notamment Genie 3, Imagen 4 Fast, Gemma 3 270M, Veo 3 Fast, Gemini Embedding, Kaggle Game Arena, Perch 2, ainsi que l’intégration d’AI Studio avec GitHub. Ces mises à jour couvrent plusieurs domaines, de la génération d’images à la génération de vidéos, en passant par l’optimisation des grands modèles linguistiques et l’intégration d’outils de développement, démontrant l’investissement continu de Google dans la recherche de pointe en IA et son application. (Source: osanseviero)
NVIDIA publie les modèles ASR open source multilingues Canary 1B et Parakeet TDT : NVIDIA a lancé deux modèles de reconnaissance vocale automatique (ASR) open source multilingues de pointe : Canary 1B et Parakeet TDT (0.6B). Ces modèles prennent en charge 25 langues, disposent de fonctions de détection et de traduction automatiques de la langue, et peuvent fournir des horodatages pour les mots et les phrases. Ils ont obtenu des performances SOTA (State-of-the-Art) sur le classement Open ASR et sont disponibles sous licence CC-BY sur Hugging Face, ce qui stimule considérablement le développement open source du traitement vocal multilingue. (Source: ImazAngel, reach_vb)

Kimi/HKU collaborent pour open-sourcer le framework OpenCUA, favorisant le développement d’Agents d’utilisation informatique : Kimi (Moonshot AI) a annoncé sa collaboration avec l’Université de Hong Kong (HKU) pour open-sourcer conjointement OpenCUA, le premier framework de modèle de base d’Agent d’utilisation informatique de bout en bout. Le modèle OpenCUA-32B a démontré d’excellentes performances sur le benchmark OSWorld-Verified, rivalisant avec les meilleurs modèles propriétaires, et fournit une infrastructure et des données sous-jacentes complètes. Cette initiative vise à promouvoir la recherche et les applications open source dans le domaine des Agents d’utilisation informatique, leur permettant d’automatiser des tâches dans un plus large éventail de scénarios. (Source: Kimi_Moonshot)

FlashAttention 4 bientôt disponible sur les GPU Blackwell, améliorant l’efficacité de l’inférence des LLM : Le code source de FlashAttention 4 (FA4) a été divulgué sur GitHub, montrant qu’il est principalement optimisé pour les GPU NVIDIA Blackwell (SM100+) et Tensor Core Generation 5, et qu’il utilise CuTe DSL (CUTLASS) et du code PTX écrit à la main. Le lancement de FA4 annonce une amélioration significative de l’efficacité de l’inférence des grands modèles linguistiques (LLM), aidant à résoudre les goulots d’étranglement de la mémoire dans l’inférence des LLM, pour des vitesses de modèle plus rapides et des coûts de calcul réduits. (Source: scaling01, Reddit r/LocalLLaMA)

La plateforme LEAP de Liquid AI prend en charge les processeurs AMD Ryzen et Ryzen AI, accélérant le déploiement de l’IA côté client : La plateforme Edge Platform (LEAP) de Liquid AI prend désormais en charge les processeurs AMD Ryzen™ et Ryzen AI™, ce qui signifie que de puissantes capacités d’IA à faible latence seront directement appliquées aux appareils terminaux tels que les ordinateurs portables. Cette avancée offre un espace plus large aux développeurs et aux entreprises pour déployer l’IA sur les appareils Edge, contribuant à des applications d’IA locales plus efficaces et plus privées, et réduisant la dépendance au calcul cloud. (Source: maximelabonne)

🧰 Outils
Bytebot : Agent de bureau IA open source pour l’automatisation des tâches en langage naturel : Bytebot est un Agent de bureau IA open source auto-hébergé qui permet aux utilisateurs d’automatiser les tâches informatiques via des commandes en langage naturel. Cet Agent fonctionne dans un environnement de bureau Linux conteneurisé, capable d’utiliser n’importe quelle application comme un navigateur, un client de messagerie, un logiciel de bureautique, un IDE, etc., et prend en charge le téléchargement et l’organisation de fichiers, la connexion à des sites web et des applications (y compris 2FA), ainsi que le traitement de documents PDF et de feuilles de calcul. L’objectif de Bytebot est de fournir une « IA avec son propre ordinateur », réalisant l’automatisation de flux de travail complexes en plusieurs étapes à travers les programmes, apportant une autonomie complète des tâches pour les scénarios d’automatisation des processus d’entreprise, de tests de développement et d’analyse de recherche. (Source: GitHub Trending)
Collection de modèles d’automatisation n8n, pour des flux de travail basés sur l’IA : Une collection sélectionnée de modèles d’automatisation n8n, nommée « awesome-n8n-templates », a émergé sur GitHub. n8n est un puissant outil d’automatisation de flux de travail, et ce dépôt fournit un grand nombre de modèles d’automatisation prêts à l’emploi basés sur l’IA, couvrant plusieurs scénarios d’application tels que Gmail, Telegram, Google Drive, Slack, WordPress, le traitement de PDF, les bases de données, Airtable, Notion et les médias sociaux. Ces modèles visent à aider les utilisateurs à connecter rapidement les applications courantes et à réaliser des fonctions telles que le tri automatique des e-mails, les chatbots IA, le traitement intelligent de documents et la génération de contenu pour les médias sociaux, améliorant considérablement l’efficacité du travail et réduisant le seuil d’automatisation. (Source: GitHub Trending)
Guardrails AI lance Snowglobe : un moteur de simulation pour Agents IA et chatbots : Guardrails AI a lancé Snowglobe, un moteur de simulation spécialement conçu pour les Agents IA et les chatbots. Cet outil vise à tester et à améliorer les chatbots IA à grande échelle en générant des milliers de conversations multi-tours réalistes et axées sur les rôles. Snowglobe peut automatiquement étiqueter, modéliser divers rôles d’utilisateurs et fournir des rapports d’analyse de défaillance détaillés, aidant les équipes à découvrir les angles morts et les cas limites avant le lancement du produit, garantissant ainsi la fiabilité des chatbots. Sa conception s’inspire des frameworks de test de simulation de l’industrie automobile autonome, visant à introduire les avantages des tests en environnement virtuel dans le domaine de l’IA conversationnelle, afin de réduire les risques de production et d’accélérer le déploiement. (Source: ShreyaR)
MiniMax met à jour les fonctionnalités de son Agent, prenant en charge les données boursières en temps réel et l’exportation multi-formats : L’Agent MiniMax a récemment subi plusieurs mises à jour de fonctionnalités, notamment l’intégration des prix boursiers et des données d’actualités en temps réel de Yahoo Finance, la prise en charge de la prévisualisation de diapositives en temps réel, et la fourniture d’une fonction d’exportation PPT/PDF asynchrone pour éviter les blocages. Ces mises à jour améliorent considérablement les capacités de l’Agent MiniMax en matière d’analyse commerciale et de génération de contenu, lui permettant de mieux servir les utilisateurs ayant besoin d’informations en temps réel et d’un traitement efficace des documents. (Source: MiniMax__AI)

Hugging Face lance ToonComposer, pour une création d’animations de dessins animés gratuite et efficace : Hugging Face a lancé ToonComposer, un outil de création d’animations de dessins animés gratuit et efficace. Cet outil permet aux utilisateurs de générer des images intermédiaires et de coloriser en utilisant des croquis de keyframes et des images de référence de couleurs comme entrées, grâce à un modèle basé sur Alibaba Wan. ToonComposer peut également remplir intelligemment les zones vides en fonction des invites, ce qui devrait permettre d’économiser jusqu’à 70 % du travail manuel, offrant ainsi une solution de création assistée par l’IA pratique pour les animateurs et les créateurs de contenu. (Source: huggingface)
Microsoft Copilot lance le Copilot Mode, intègre GPT-5 et propose des expériences de génération 3D : Microsoft Copilot a récemment lancé une nouvelle fonctionnalité, le « Copilot Mode », qui ne remplace pas le processus de recherche par défaut de l’utilisateur mais fonctionne en parallèle, et a déjà intégré le modèle GPT-5. De plus, Copilot Labs a lancé une expérience de génération 3D, permettant aux utilisateurs de générer des podcasts personnalisés via Copilot.com, couvrant n’importe quel sujet de niche ou professionnel. Ces mises à jour visent à améliorer l’expérience de recherche des utilisateurs, l’efficacité de la création de contenu et la capacité à obtenir des informations personnalisées, démontrant l’innovation continue de Microsoft dans les applications d’IA. (Source: mustafasuleyman, mustafasuleyman, mustafasuleyman)

Outils d’humanisation de texte IA et construction d’Agents IA sans code : Une liste des « Dix meilleurs outils pour humaniser le texte IA » a été partagée sur les réseaux sociaux, visant à aider les utilisateurs à rendre le contenu généré par l’IA plus humain. Parallèlement, des discussions ont eu lieu sur les étapes et méthodes pour construire des Agents IA sans code, ce qui réduit considérablement le seuil de développement des applications IA, permettant aux développeurs non professionnels de créer des flux de travail IA automatisés et de promouvoir la popularisation et l’application de la technologie IA dans des scénarios plus larges. (Source: Ronald_vanLoon, Ronald_vanLoon)

📚 Apprentissage
Datology AI lance BeyondWeb, utilisant des données synthétiques pour briser le goulot d’étranglement du pré-entraînement à l’échelle du trillion : Datology AI a lancé BeyondWeb, un framework de génération de données synthétiques, visant à résoudre les goulots d’étranglement de données et les rendements décroissants rencontrés lors de l’extension des données web brutes pour les modèles pré-entraînés. La recherche montre que grâce aux données synthétiques de haute qualité générées par BeyondWeb, un LLM de 3B paramètres peut même surpasser un modèle de 8B, et a démontré une frontière de Pareto des performances. Ce framework souligne le rôle clé des données synthétiques de haute qualité dans l’amélioration des performances des modèles, ainsi que l’importance d’une compréhension rigoureuse de la science des données dans la curation des ensembles de données optimaux, annonçant que le pré-entraînement futur pourrait ne plus dépendre entièrement de données web massives, mais se tourner vers une génération de données synthétiques plus efficace et de meilleure qualité. (Source: code_star, eliebakouch, Dorialexander, tokenbender)

Analyse des performances de JAX sur GPU/TPU et de l’impact sur l’entraînement des LLM : Concernant les performances de JAX sur GPU et TPU, des discussions indiquent que JAX sur GPU est désormais comparable à TPU. Parallèlement, Jacob Austin et ses collaborateurs ont publié une version mise à jour pour GPU du livre JAX TPU, explorant en profondeur le fonctionnement des GPU, les méthodes de connexion réseau et comment ces facteurs influencent l’entraînement des LLM. Cette ressource vise à aider les chercheurs à comprendre le rôle clé de l’architecture GPU dans l’efficacité de l’entraînement des modèles, et à fournir des conseils pour optimiser l’entraînement des LLM. (Source: fchollet, zacharynado, Ar_Douillard, vinayramasesh, suchenzang)

Frameworks d’évaluation de l’IA et application de l’apprentissage par renforcement dans les LLM : Prophet Arena a lancé un benchmark d’intelligence prédictive IA pour les LLM, visant à évaluer la capacité des modèles IA à prédire l’avenir, en soulignant leur nature en temps réel qui ne peut être « piratée ». De plus, une étude propose la méthode Self-Search Reinforcement Learning (SSRL), utilisant les LLM comme simulateurs efficaces pour les tâches de recherche d’Agents dans l’apprentissage par renforcement, réduisant ainsi la dépendance aux moteurs de recherche externes. Ces avancées propulsent conjointement l’innovation dans les méthodes d’évaluation et d’entraînement des LLM, en particulier dans les scénarios nécessitant un raisonnement complexe et un retour d’information en temps réel. (Source: cloneofsimo, teortaxesTex, HuggingFace Daily Papers)

Types de mémoire des Agents IA et Protocole de Contexte de Modèle (MCP) : Les types de mémoire des Agents IA sont essentiels pour l’accomplissement de tâches complexes, incluant la mémoire à court terme (réalisée par l’extension de la fenêtre de contexte) et la mémoire à long terme (dépendante des bases de données vectorielles, des systèmes d’exploitation de mémoire et de l’orchestration MCP). Le Protocole de Contexte de Modèle (MCP) proposé par Anthropic est en train de devenir une spécification universelle pour l’accès de l’IA aux API externes, aux outils et aux données en temps réel, salué comme le « USB-C de l’IA ». Le MCP prend en charge la mémoire persistante et les flux de travail multi-outils, permettant aux Agents d’effectuer des opérations à travers les systèmes, et devrait devenir l’infrastructure fondamentale du Web natif aux Agents. (Source: Ronald_vanLoon)

Progrès dans l’optimisation et les techniques de fusion des modèles LLM : Un récent rapport de recherche explore comment la technique de fusion de modèles (model merging) a permis à des modèles de 15B paramètres de surpasser des modèles de 32B sur certaines tâches, tout en réduisant considérablement l’utilisation de tokens, démontrant l’importance d’optimiser la structure des modèles et les stratégies d’entraînement. De plus, Maxime Rivest a partagé un cas où un modèle Qwen 30B a été élagué de 87,24 % pour une tâche de classification de sentiments, tout en maintenant une précision de 100 %, indiquant le potentiel énorme des modèles MoE pour la génération spécifique à une tâche, et appelant au développement de davantage d’outils d’élagage. Ces techniques contribuent à l’exécution de grands modèles sur des GPU grand public, réduisant ainsi le seuil de déploiement. (Source: teortaxesTex, ImazAngel)

Bases de données vectorielles et similarité cosinus dans le RAG : La similarité cosinus est un concept mathématique central dans les bases de données vectorielles pour mesurer la similarité entre les vecteurs d’intégration, influençant directement la manière dont les systèmes RAG (Retrieval-Augmented Generation) trouvent les blocs de texte les plus pertinents. En comprenant la similarité cosinus, la qualité de la récupération RAG peut être optimisée. De plus, il est souligné que l’amélioration de la qualité de la récupération RAG ne dépend pas uniquement de meilleurs modèles d’intégration, mais nécessite également des techniques d’optimisation fines, telles que le réglage fin des modèles d’intégration, la définition de seuils de distance, le filtrage des métadonnées, le routage des requêtes et la réécriture/extension des requêtes, afin de garantir que les informations récupérées des bases de données vectorielles sont plus précises et pertinentes. (Source: ProfTomYeh, bobvanluijt)

Gestion des risques des modèles à poids ouverts et importance de l’évaluation de l’IA : Des stratégies de gestion des risques ont été proposées pour faire face aux risques potentiels posés par les modèles à poids ouverts. Parallèlement, le domaine de l’IA souligne l’importance des évaluations privées continues, estimant que les benchmarks publics ne suffisent plus à répondre aux besoins des entreprises en matière de performances fiables et explicables. Il est donc crucial de construire une infrastructure d’évaluation complète dès le début du projet. Cela reflète la tendance de l’industrie à rechercher un équilibre entre l’ouverture et la sécurité des modèles d’IA, ainsi qu’une attention croissante aux performances des systèmes d’IA dans des applications réelles. (Source: BlancheMinerva, ShreyaR)

Implémentation de Hindsight Experience Replay (HER) dans JAX : Une nouvelle implémentation JAX a publié une version minimale et claire de l’algorithme Hindsight Experience Replay (HER), basée sur Equinox pour la définition du modèle, Optax pour l’optimisation, et fournissant des scripts reproductibles et un Colab Notebook. HER est une technique d’apprentissage par renforcement qui améliore l’efficacité de l’apprentissage en traitant les tentatives échouées comme des tentatives réussies pour atteindre des objectifs différents. Cette implémentation JAX offre aux chercheurs un moyen pratique d’explorer HER dans différents frameworks. (Source: Reddit r/MachineLearning)

Feuille de route pour l’apprentissage de l’IA générative publiée : Une feuille de route détaillée pour l’apprentissage de l’IA générative a été partagée, visant à guider les apprenants pour maîtriser systématiquement les connaissances et les compétences dans le domaine de l’IA générative. Cette feuille de route pourrait couvrir divers aspects, des théories fondamentales aux architectures de modèles, en passant par les applications pratiques et les dernières tendances, offrant un chemin d’apprentissage précieux pour ceux qui souhaitent entrer ou approfondir le domaine de l’IA générative. (Source: Ronald_vanLoon)

Sélection d’articles de recherche en IA de la semaine : Cette semaine, plusieurs articles de recherche importants ont émergé dans le domaine de l’IA, couvrant le décodage guidé par récompense pour les LLM multimodaux, l’optimisation des préférences pour l’animation de portraits pilotée par l’audio, le jeu de données de textures 3D haute résolution TexVerse, l’auto-encodeur masqué pour les données d’observation de la Terre MAESTRO, le framework GNN auto-explicatif X-Node, l’apprentissage par renforcement auto-recherche SSRL, et la reconstruction du cache KV pour l’inférence LLM XQuant, entre autres. Ces articles font progresser la technologie de l’IA dans différentes dimensions, du contrôle des modèles à l’efficacité des données et à l’explicabilité, jetant les bases de la recherche et des applications futures de l’IA. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
💼 Affaires
Bessemer publie le rapport « L’état de l’IA en 2025 », révélant un nouveau paradigme de startup IA : La célèbre société d’investissement Bessemer a publié un rapport résumant ses sept jugements clés sur l’industrie de l’IA en 2025. Le rapport indique que les startups IA présentent deux paradigmes de croissance : « supernovas » et « météores ». Les « supernovas » peuvent atteindre 40 millions de dollars d’ARR dès la première année de commercialisation, mais avec de faibles marges bénéficiaires ; les « météores » ressemblent davantage à des SaaS sains, avec une croissance plus rapide et une structure de coûts contrôlable. Le rapport souligne que l’industrie de l’IA est entrée dans une deuxième phase, se concentrant davantage sur la « définition et la mesure des problèmes », la mémoire et le contexte devenant de nouveaux fossés concurrentiels. De plus, l’IA bouleverse les systèmes d’enregistrement des logiciels d’entreprise traditionnels, le marché vertical de l’IA a un potentiel énorme, et le rapport annonce des opportunités de plateforme pour la prochaine génération de plateformes grand public. (Source: 36氪)

Le programme de formation des architectes IA en chef (AICA) de Baidu attire de nombreux géants de l’industrie : La neuvième édition du programme de formation des architectes IA en chef (AICA) de Baidu a attiré des cadres techniques de nombreuses entreprises renommées telles que Maotai, Mercedes-Benz, McDonald’s, State Grid et Sinopec. Ce programme s’appuie sur la plateforme d’apprentissage profond PaddlePaddle de Baidu et le grand modèle Wenxin, visant à former des architectes IA polyvalents, à la fois compétents en développement technique et capables d’assurer la mise en œuvre des projets. Le cours de cette édition se concentre sur les applications des grands modèles, introduisant pour la première fois des technologies de pointe telles que la collaboration multi-Agents. Les invités ont souligné l’importance des grands modèles pour transformer l’industrie et ont offert des conseils sur la manière dont les architectes IA peuvent suivre le rythme du développement des grands modèles, reflétant l’importance accordée par les entreprises chinoises à la formation des talents en IA et à l’application industrielle. (Source: 量子位)

La startup d’automatisation industrielle Squint lève 40 millions de dollars, accélérant la fabrication collaborative homme-machine : La startup d’automatisation industrielle Squint a récemment levé 40 millions de dollars, visant à promouvoir sa vision de la « fabrication intelligente », c’est-à-dire la réalisation d’une collaboration approfondie entre les humains et les Agents d’intelligence artificielle dans l’industrie manufacturière. Cet investissement aidera Squint à développer davantage de solutions basées sur l’IA, à améliorer l’efficacité de la production industrielle et le niveau d’automatisation, annonçant que l’IA jouera un rôle de plus en plus important dans l’industrie manufacturière traditionnelle et pourrait changer les modes de travail futurs. (Source: dl_weekly)
🌟 Communauté
Les discussions sur l’impact de l’IA sur l’emploi et la société humaine s’intensifient : Avec le développement rapide de la technologie IA, les discussions sur son impact sur le marché du travail et la structure sociale s’intensifient. Hinton, le parrain de l’IA, prédit que les emplois manuels comme les « plombiers » pourraient être plus sûrs que les cols blancs à l’avenir, car l’IA a encore des limites dans les opérations physiques. Parmi les étudiants universitaires de la génération Z aux États-Unis, 42 % se sont déjà tournés vers des emplois manuels ou qualifiés pour éviter les risques de remplacement par l’IA. Parallèlement, la communauté discute également de la redéfinition du sens de l’humanité à l’ère de l’AGI, des applications simples et efficaces de l’IA au sein des entreprises, et de la question de savoir si le domaine de l’IA est encore à ses « débuts », entre autres questions profondes. (Source: La prophétie de Hinton se réalise, l’IA prend le contrôle de la moitié des cols blancs américains, Oxford et Harvard se reconvertissent en masse dans les métiers techniques, Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Divergence entre la vitesse de développement des grands modèles et la perception des utilisateurs : L’évaluation de GPT-5 sur les réseaux sociaux est polarisée : certains utilisateurs estiment que ses performances sont médiocres, voire qu’il est revenu à une ancienne version, tandis que d’autres le trouvent excellent pour des tâches spécifiques. Cette divergence de perception reflète que le développement des grands modèles pourrait passer d’une percée « explosive » à une itération plus stable, où l’amélioration de chaque mise à jour ne se limite plus à de simples scores de référence, mais à une optimisation plus complète au niveau du système, comme la réduction des coûts, la diminution des hallucinations, un contexte plus long et une cohérence améliorée. Parallèlement, les promesses non tenues d’Elon Musk concernant l’open source de Grok ont également soulevé des questions au sein de la communauté sur ses priorités. (Source: jeremyphoward, scaling01, teortaxesTex, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)

Expérience utilisateur et limites des assistants de programmation IA : Les assistants de programmation IA tels que Claude Code et Codex CLI sont largement reconnus pour améliorer l’efficacité de la programmation ; certains utilisateurs affirment qu’ils ont complètement transformé les priorités d’ingénierie, multipliant par 10 les performances des produits. Cependant, ces outils présentent également des limites, par exemple, Claude Code peut se retrouver dans une boucle de « chasse aux bugs » lors du débogage, ou utiliser des dates obsolètes lors de recherches web. Les utilisateurs ont découvert qu’enseigner à l’IA l’utilisation d’outils CLI plus puissants (comme sed et ripgrep) peut considérablement améliorer son efficacité, mais cela révèle également les lacunes de l’IA en matière d’apprentissage autonome et d’adaptation à de nouveaux outils, ainsi que sa dépendance à l’orientation humaine. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Éthique de l’IA, impact social et perspectives d’avenir suscitent de larges discussions : La communauté a engagé des discussions approfondies sur l’éthique et l’impact social de l’IA. Les sujets incluent la question de savoir si l’IA représente un risque existentiel (certains plaisantent en disant que « l’IA tuera tous les chats et chiens » pourrait être plus convaincant), l’impact de l’IA sur le mode de vie humain dans l’ère post-singularité, et les nouvelles formes que l’IA apporte à la narration et à la création artistique. Parallèlement, certains comparent les préoccupations actuelles concernant l’IA à la résistance historique face aux ordinateurs, suggérant que l’histoire se répète. Concernant l’avenir de l’IA, les gens envisagent diverses possibilités, allant de l’IA assistant la gouvernance sociale à la coexistence homme-IA, voire à l’IA surpassant l’intelligence humaine, mais il est généralement admis que les progrès de l’IA seront exponentiels. (Source: hyhieu226, JimDMiller, teortaxesTex, Reddit r/artificial, Reddit r/artificial, Reddit r/deeplearning, Reddit r/artificial, yupp_ai)

Observations sur l’écosystème et le paysage concurrentiel de l’industrie de l’IA : Les observateurs de l’industrie notent que le seuil de création de startups dans le domaine de l’IA diminue ; avec suffisamment de fonds et de GPU, il est possible de construire un modèle proche du SOTA en un an. La Chine progresse rapidement dans la technologie robotique, contrastant avec les États-Unis. DeepSeek est salué pour son modèle commercial « non frauduleux », tandis que le modèle Kimi K2 est apprécié des utilisateurs pour sa personnalisation « froide et fascinante » et son vocabulaire puissant. Parallèlement, il est conseillé aux chercheurs en IA de se méfier de la socialisation excessive au détriment du codage. (Source: teortaxesTex, teortaxesTex, teortaxesTex, crystalsssup, shlomifruchter, Reddit r/LocalLLaMA)

💡 Autres
Ant Group Digital Technologies et l’Université de Stanford open-sourcent des jeux de données de localisation de deepfakes, favorisant l’explicabilité des algorithmes d’IA : Lors de la Conférence Internationale Conjointe sur l’Intelligence Artificielle (IJCAI), Ant Group Digital Technologies et l’Université de Stanford ont respectivement open-sourcé deux grands jeux de données de deepfakes. Ant Group Digital Technologies a open-sourcé un jeu de données d’entraînement de 1,8 million (DDL-Datasets), couvrant plus de 80 types de techniques de falsification, y compris la falsification de visage, la manipulation vidéo et le clonage vocal, avec des annotations claires sur la position et le moment de la falsification IA à l’écran, visant à améliorer l’explicabilité des algorithmes. L’Université de Stanford a quant à elle open-sourcé le jeu de données DeepAction, contenant 2600 vidéos de mouvements humains générés par l’IA. L’ouverture de ces jeux de données fournira des ressources de données fondamentales essentielles aux chercheurs du monde entier, favorisant le développement de technologies d’identification de sécurité de l’IA pour faire face aux risques de fraude posés par l’IA générative. (Source: 量子位)

Exploration des applications de l’IA en bioacoustique et dans la recherche et le sauvetage en cas de catastrophe : La technologie IA est appliquée dans plusieurs domaines non traditionnels. Par exemple, l’IA, grâce à l’analyse bioacoustique, aide les scientifiques à identifier et à protéger les espèces menacées, favorisant ainsi la protection de l’environnement. De plus, des recherches explorent l’utilisation de coléoptères bioniques « portables » pilotés par l’IA pour la recherche et le sauvetage en cas de catastrophe, exploitant leur capacité à se faufiler dans les décombres pour trouver des survivants. Ces cas démontrent l’énorme potentiel de l’IA à résoudre des problèmes complexes dans des domaines interdisciplinaires, ainsi que sa valeur pratique dans la surveillance environnementale et l’aide humanitaire. (Source: Ronald_vanLoon, Ronald_vanLoon)

Les défis des visas pour les conférences IA mettent en lumière les défis de l’échange académique mondial : Des chercheurs ont signalé avoir rencontré des difficultés pour obtenir des visas pour participer à des conférences internationales sur l’IA (comme ICCV 2025 qui se tiendra à Hawaï), même lorsqu’ils étaient invités à présenter des communications académiques. Ce problème a suscité des discussions sur le choix des lieux des grandes conférences académiques et l’accessibilité virtuelle, appelant les organisateurs de conférences à envisager des lieux plus accessibles aux chercheurs du monde entier ou à proposer des solutions de participation en ligne plus complètes, afin de garantir l’équité et l’inclusion des échanges académiques et d’éviter que les barrières de visa n’entravent la coopération internationale et le partage des connaissances. (Source: Reddit r/MachineLearning)