
Mots-clés:OpenAI, Médaille d’or IOI, Programmation compétitive en IA, GPT-5, Baichuan Intelligence, Grand modèle de raisonnement médical en IA, Commerce de puces d’IA, Intelligence incarnée, Baichuan-M2-32B, Évaluation OpenAI HealthBench, GPU AMD Mi300, Base d’intelligence incarnée, Technologie de radar quantique
🔥 À la Une
OpenAI : Médaille d’or à l’IOI et nouvelles avancées en programmation compétitive par IA : Le système de raisonnement d’OpenAI a remporté une médaille d’or lors de la compétition en ligne de l’Olympiade Internationale d’Informatique (IOI) 2025, se classant premier parmi les participants IA et sixième au classement général, surpassant 98% des concurrents humains. Ce système n’a pas utilisé de modèle spécifiquement entraîné, mais a intégré plusieurs modèles de raisonnement génériques. Cette réussite marque une avancée significative de l’IA dans le domaine de la programmation compétitive, bien que Elon Musk ait affirmé que Grok 4 surpassait GPT-5 en matière de codage, et que des utilisateurs aient remis en question la stratégie marketing d’OpenAI. Le test LiveCodeBench Pro a également montré que GPT-5 Thinking a réalisé une percée dans les tâches de programmation complexes, avec une longueur de réponse moyenne bien supérieure à celle des autres modèles. (Source : sama, sama, 量子位, willdepue, npew, markchen90, SebastienBubeck)

Baichuan Intelligent lance le grand modèle de raisonnement médical Baichuan-M2 : Baichuan Intelligent a lancé son dernier grand modèle de raisonnement médical, Baichuan-M2-32B, qui a surpassé le gpt-oss-120b d’OpenAI et d’autres modèles open-source et propriétaires de premier plan sur le jeu de données d’évaluation OpenAI HealthBench. Il s’est particulièrement distingué sur HealthBench-Hard et dans les scénarios de diagnostic clinique chinois, devenant l’un des deux seuls modèles au monde à dépasser 32 points. Ce modèle, avec 32 milliards de paramètres, peut être déployé sur une seule carte RTX4090, réduisant considérablement les coûts de déploiement privé. Baichuan a innové en introduisant un “simulateur de patient” et un “système Verifier” pour l’entraînement par apprentissage par renforcement, améliorant ainsi l’utilisabilité du modèle dans des scénarios médicaux réels. (Source : 量子位)

Controverse autour du lancement de GPT-5 et crise de confiance des utilisateurs : Après le lancement de GPT-5 par OpenAI, ses performances ont été jugées inférieures aux attentes, s’apparentant davantage à une itération de produit qu’à une percée révolutionnaire. L’hyper-médiatisation du PDG Sam Altman (par exemple, la métaphore de l‘“Étoile de la Mort”, des experts de niveau PhD) contrastait fortement avec les retours réels des utilisateurs (erreurs fréquentes, baisse des capacités d’écriture créative, manque de personnalité), entraînant un mécontentement généralisé et une demande réussie de retour à GPT-4o. De plus, OpenAI a commencé à encourager l’utilisation de GPT-5 pour des conseils en matière de santé, suscitant des inquiétudes quant à la responsabilité des conseils médicaux fournis par l’IA, avec des cas d’intoxication signalés suite à une confiance erronée dans les conseils de l’IA. (Source : MIT Technology Review, MIT Technology Review, 量子位)
🎯 Tendances
Commerce de puces IA et tendance à la localisation en Chine : NVIDIA et AMD ont conclu un accord avec le gouvernement américain, selon lequel 15% de leurs ventes de puces IA à la Chine seront reversées au gouvernement américain. Parallèlement, la Chine a déclaré que la puce NVIDIA H20 n’était pas sûre et prévoit d’abandonner le H20 au profit de puces IA nationales. Certains analystes estiment que cette mesure accélérera le développement de l’écosystème local de puces IA en Chine, ce qui aura un impact profond sur le paysage mondial de l’industrie de l’IA. Dans le domaine du matériel IA, le GPU AMD Mi300, avec 192 Go de VRAM sur une seule carte et un total de 1,5 To de VRAM sur un nœud de 8 GPU, démontre des avantages significatifs dans le traitement des poids de modèle et des contextes longs. (Source : MIT Technology Review, Reddit r/artificial, dylan522p, realSharonZhou)
Application et défis de l’IA dans le système juridique : Le système juridique américain est confronté au problème des hallucinations de l’IA, les avocats et les juges utilisant des outils d’IA commettant des erreurs telles que la citation de faux cas. Malgré les risques, certains juges explorent l’application de l’IA dans la recherche juridique, les résumés de cas et la rédaction d’ordonnances de routine, estimant qu’elle peut améliorer l’efficacité. Cependant, les limites de l’application de l’IA dans le domaine juridique sont floues, et le mécanisme de responsabilisation des juges qui commettent des erreurs avec l’IA n’est pas encore clair, ce qui pourrait nuire à la confiance du public dans la justice. (Source : MIT Technology Review)
Accélération du développement de l’industrie de l’IA incarnée et feuilles de route technologiques : La Conférence Mondiale sur les Robots 2025 a mis en lumière les progrès rapides dans le domaine de l’IA incarnée. Unitree Robotics et Zhimeng Robotics, en tant qu’entreprises leaders, représentent respectivement les voies technologiques du matériel (chiens robots, flexibilité des pieds) et de l’intégration logicielle et matérielle (robots humanoïdes, approche écosystémique). Realman Robotics a également lancé la plateforme open-source RealBOT axée sur la “base de l’IA incarnée” et des modules articulaires haute performance, soulignant le concept de “Robot for AI” pour faire évoluer l’IA de l’intelligence numérique vers l’intelligence incarnée. L’industrie passe du “show de démonstration” à un “modèle de boucle fermée industrielle” et attire un soutien important en capital et en politiques. (Source : 36氪, 36氪, 量子位, 量子位)
Dernières mises à jour des modèles et fonctionnalités de Google et OpenAI : L’application Google Gemini a lancé la fonction Deep Think pour les abonnés Ultra, résolvant des problèmes de mathématiques et de programmation, et prenant en charge la connexion Gemini Live aux applications Google. Claude prend désormais en charge la citation de l’historique des conversations, facilitant la poursuite des dialogues. OpenAI a annoncé les priorités d’allocation de puissance de calcul pour les prochains mois, prévoyant de doubler cette puissance au cours des 5 prochains mois. De plus, le modèle GPT-oss a connu un grand nombre de téléchargements après sa publication, mais il a également été signalé qu’il présentait des hallucinations et des défauts dans les données d’entraînement. (Source : demishassabis, demishassabis, dotey, op7418, sama, sama, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA, 量子位, TheTuringPost, SebastienBubeck, Alibaba_Qwen, ClementDelangue, Reddit r/LocalLLaMA, _lewtun, mervenoyann, rasbt)
Impact de la recherche IA sur le trafic web et transformation de l’industrie : Le retrait soudain d’Amazon des enchères publicitaires de Google Shopping et l’interdiction à l’assistant d’achat IA de Google de crawler ses pages produits marquent une rupture dans la logique de trafic de l’ère de l’IA entre les deux géants. L’article souligne que le modèle de recherche IA est défavorable aux petits sites web, le trafic étant concentré sur les grands médias et sites web renommés, créant un effet de “vol aux pauvres pour donner aux riches”, similaire à la situation de Baidu qui a perdu son point d’entrée de trafic avec l’essor des applications. Cela prédit que la position de Google en tant que point d’entrée de recherche sera également remise en question. Toutes les plateformes évoluent vers un système en boucle fermée, cherchant à contrôler l’ensemble du comportement des utilisateurs et à remodeler la structure de confiance de l’industrie publicitaire. (Source : 36氪, 36氪)
Nouvelle percée dans la technologie de radar quantique : Des physiciens ont développé un nouveau type de radar quantique qui utilise des nuages atomiques pour détecter les ondes radio, ce qui pourrait être utilisé pour l’imagerie souterraine, par exemple pour la construction de pipelines souterrains et les fouilles archéologiques. Cette technologie, en tant que prototype de capteur quantique, pourrait à l’avenir être plus petite, plus sensible et ne nécessiterait pas d’étalonnage fréquent que les radars traditionnels. Les capteurs quantiques et le calcul quantique ont des points communs, et les progrès dans un domaine peuvent se renforcer mutuellement. (Source : MIT Technology Review)

Meta lance le modèle de monde V-JEPA 2 : Meta a publié V-JEPA 2, un modèle de monde révolutionnaire pour la compréhension et la prédiction visuelles, visant à améliorer les capacités de perception et de prédiction de l’IA dans le domaine visuel. (Source : Ronald_vanLoon)
🧰 Outils
Bibliothèque OpenAI Go API : La bibliothèque officielle Go d’OpenAI (openai-go) offre un accès pratique à l’API REST d’OpenAI, prenant en charge Go 1.21+, et inclut des fonctionnalités telles que la complétion de chat, les réponses en streaming, l’appel d’outils, la sortie structurée, ainsi que la gestion des erreurs, la configuration des délais d’attente, le téléchargement de fichiers et la validation de Webhook. (Source : GitHub Trending)

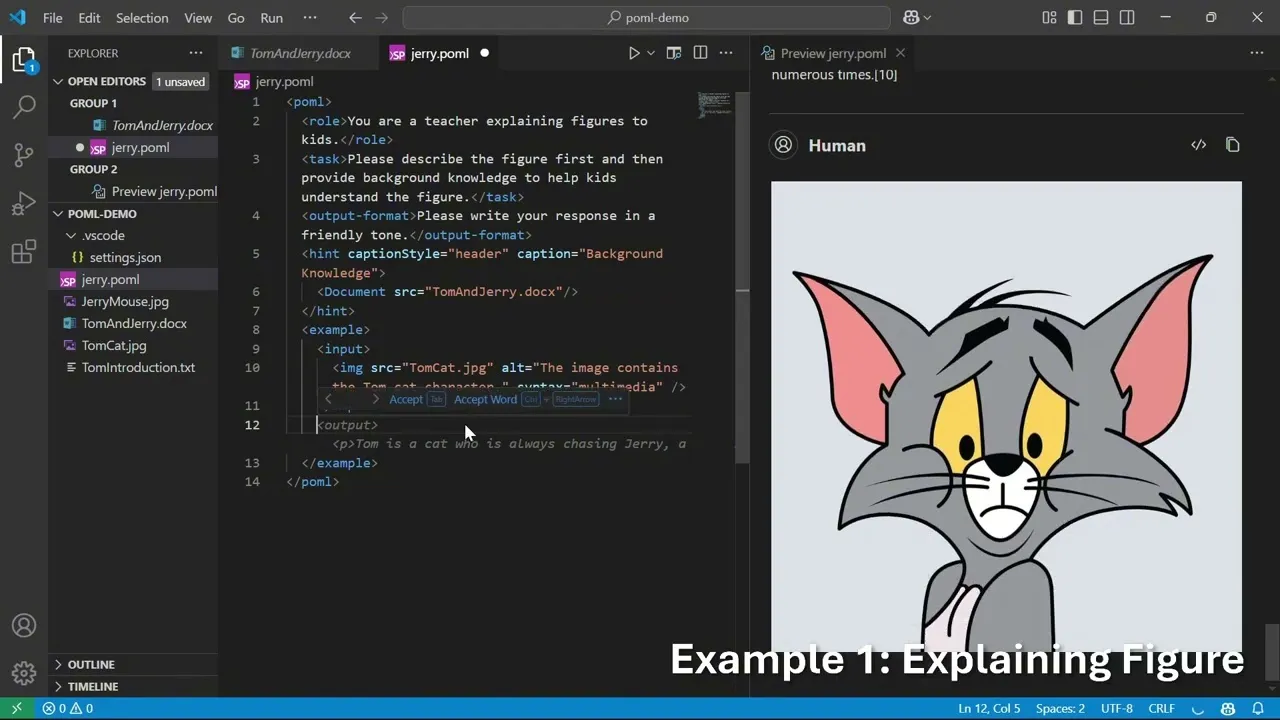
Microsoft POML : Langage de balisage pour l’orchestration de prompts : Microsoft a lancé POML (Prompt Orchestration Markup Language), un nouveau langage de balisage conçu pour offrir structure, maintenabilité et polyvalence à l’ingénierie avancée de prompts pour les grands modèles de langage (LLM). Il utilise une syntaxe similaire à HTML, prend en charge l’intégration de données, la séparation des styles et un moteur de template intégré, et fournit une extension VS Code et un SDK pour aider les développeurs à créer des applications LLM plus complexes et fiables. (Source : GitHub Trending)
Outil d’analyse de documents financiers LlamaIndex AI : LlamaIndex a présenté un outil IA qui transforme des documents financiers complexes en un langage facile à comprendre via LlamaCloud, offrant une interprétation détaillée des graphiques et des données financières, et prenant en charge la réécriture de contenu et la personnalisation, aidant ainsi les utilisateurs à comprendre des rapports financiers complexes. (Source : jerryjliu0)
Évaluation de 360 Smart Agent Factory : Évaluation de 360 Smart Agent Factory, une plateforme complète couvrant les Agents et le MCP (Multi-Agent Collaboration Platform), prenant en charge les moteurs de recherche, la génération de texte en image, la génération de pages web, etc. Elle peut être utilisée pour générer des recettes de régime, produire du contenu pour les médias sociaux en masse ou gérer des flux de travail complexes. Sa fonction de “swarm” multi-agents est un avantage, permettant une production de contenu facile et une gestion unifiée des flux de travail complexes. (Source : karminski3)
Plugin Excel AI et outil de compte-rendu de réunion AI : Un plugin AI pour Excel permet aux utilisateurs de discuter avec l’IA directement dans les cellules, générant des formules ou des macros, offrant des idées pour l’intégration d’Excel et de l’IA. De plus, l’outil de compte-rendu de réunion AI Notta (y compris son appareil d’enregistrement portable Notta Memo) a été classé SOTA pour sa transcription vocale rapide, sa capacité de résumé et de questionnement, améliorant considérablement l’efficacité des réunions. (Source : karminski3, karminski3, karminski3)
GPT-5 combiné à des avatars virtuels IA : Synthesia a combiné la voix de GPT-5 avec des avatars virtuels IA pour une expérience visant à rendre la communication IA plus attrayante, mémorable et compréhensible, explorant l’intégration des LLM avec l’interaction multimodale. (Source : synthesiaIO)
Applications éducatives de l’IA et outils de recherche : GPT-5 montre son potentiel dans le domaine de l’éducation, par exemple en créant un visualiseur interactif de formes 3D pour aider les enfants à apprendre les formes 3D. De plus, la fonction d’agent de navigateur d’Elicit peut aider les utilisateurs à trouver rapidement des articles complets, tandis que pyCCsl, en tant qu’outil de ligne d’état pour Claude Code, fournit des informations de session telles que l’utilisation des tokens, le coût et le contexte, améliorant l’expérience d’utilisation des outils LLM. (Source : _akhaliq, jungofthewon, Reddit r/ClaudeAI)
Clients natifs OpenWebUI et framework d’orchestration de sprint Claude Code : OpenWebUI a lancé des clients natifs iOS et Android, visant à offrir une expérience utilisateur plus fluide et axée sur la confidentialité. Parallèlement, Gustav, en tant que framework d’orchestration de sprint pour Claude Code, peut transformer les documents de spécifications produit (PRD) en flux de travail d’applications de niveau entreprise, simplifiant ainsi le processus de développement. (Source : Reddit r/OpenWebUI, Reddit r/ClaudeAI)
Problème de contexte de fichier OpenWebUI : Les utilisateurs d’OpenWebUI signalent que bien que les fichiers PDF/DOCX/texte téléchargés aient été analysés avec succès, le modèle ne parvient pas à les inclure dans le contexte lors des requêtes, ce qui montre que les outils d’IA ont encore des problèmes à résoudre en matière de traitement de fichiers et de compréhension contextuelle. (Source : Reddit r/OpenWebUI)
📚 Recherche
Recherche sur l’inférence et l’optimisation des LLM : ReasonRank améliore considérablement la capacité de classement des LLM en liste grâce à la synthèse automatisée de données intensives en inférence et à un post-entraînement en deux étapes. LessIsMore propose un mécanisme d’attention clairsemée sans entraînement, accélérant le décodage des LLM sans sacrifier la précision. TSRLM, via un cadre en deux étapes “ancrage-rejet” et “sélection guidée par le futur”, résout le problème de l’efficacité décroissante de l’apprentissage des préférences des modèles auto-récompensés, améliorant significativement la capacité de génération des LLM. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Évaluation et fiabilité des agents IA : UserBench, un environnement de référence centré sur l’utilisateur, évalue la capacité des agents LLM à collaborer de manière proactive avec les utilisateurs pour des objectifs ambigus, révélant l’écart actuel entre l’achèvement des tâches et l’alignement avec l’utilisateur. Parallèlement, une étude discute de l’évaluation de la fiabilité et de la classification des pannes des systèmes utilisant des outils d’agent, suggérant la normalisation des indicateurs de décomposition du taux de réussite et des types de pannes pour améliorer la fiabilité du déploiement des systèmes d’agent. (Source : HuggingFace Daily Papers, Reddit r/MachineLearning)
Progrès des LLM multimodaux et de la technologie RAG : Le jeu de données VisR-Bench est utilisé pour évaluer la récupération multimodale basée sur des questions-réponses dans des documents longs, montrant que les MLLM rencontrent toujours des défis avec les tableaux structurés et les langues à faibles ressources. Le framework Bifrost-1, en reliant les MLLM et les modèles de diffusion via des embeddings d’images CLIP au niveau du patch, permet une génération d’images contrôlable et de haute fidélité. Video-RAG offre une méthode de génération augmentée par récupération sans entraînement, combinant OCR+ASR pour la compréhension de vidéos longues. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, LearnOpenCV)
Recherche sur la sécurité et les attaques de l’IA : Le framework WhisperInject manipule les modèles de langage audio pour générer du contenu nuisible via des perturbations audio à peine perceptibles par l’oreille humaine, révélant des menaces audio natives. Fact2Fiction est le premier framework d’attaque par empoisonnement ciblant les systèmes de vérification des faits basés sur des agents, qui, en fabriquant des preuves malveillantes, compromet la vérification des sous-déclarations, exposant les faiblesses de sécurité des systèmes de vérification des faits. De plus, une étude explore la prévention de la fabrication d’armes biologiques par les LLM en supprimant les données nuisibles avant l’entraînement, ce qui est plus efficace que les défenses post-entraînement. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, QuentinAnthon15)
Architecture LLM et technologies de compression : La nouvelle architecture MoE Grove MoE, grâce à des experts de différentes tailles et un mécanisme d’activation dynamique, atteint des performances comparables aux modèles SOTA avec moins de paramètres activés. La méthode MoBE compresse les LLM basés sur MoE en mélangeant des experts de base, réduisant significativement le nombre de paramètres tout en maintenant une faible baisse de précision. La recherche explore également la compression de la chaîne de pensée (CoT) des LLM via l’entropie par étape, élaguant les étapes redondantes sans dégrader significativement la précision. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Synthèse sur l’apprentissage par renforcement et l’inférence des LLM : Une synthèse couvre le domaine de l’apprentissage par renforcement (RL) à l’intersection de l’intelligence visuelle, incluant l’optimisation des politiques et les LLM multimodaux. Un autre article examine systématiquement les techniques de RL dans l’inférence des LLM, analysant leurs mécanismes, scénarios et principes par reproduction et évaluation, révélant que la minimisation de la combinaison des deux techniques peut libérer la capacité d’apprentissage des politiques sans critique. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers)
Stratégies robotiques générales et diversité des ensembles de données : Une étude révèle que la capacité de généralisation des stratégies robotiques générales est limitée par l‘“apprentissage par raccourci”, principalement attribué à une diversité insuffisante des ensembles de données et aux différences de distribution entre les sous-ensembles. L’étude montre que l’augmentation des données peut réduire efficacement l’apprentissage par raccourci et améliorer la capacité de généralisation. (Source : HuggingFace Daily Papers)
Benchmarks de codage LLM et nouveaux jeux de données : L’équipe Nebius a testé 34 nouvelles tâches GitHub PR sur le leaderboard SWE-rebench, constatant que GPT-5-Medium est globalement en tête, et que Qwen3-Coder est le meilleur modèle open-source, comparable à GPT-5-High sur l’indicateur pass@5. OpenBench v0.2.0 a été publié, ajoutant 17 nouveaux benchmarks couvrant les mathématiques, le raisonnement, la santé, etc. Le benchmark WideSearch évalue la capacité des agents IA à gérer la collecte d’informations répétitives à grande échelle. (Source : Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)
Ressources d’apprentissage et recommandations de livres sur l’IA : Un utilisateur de Reddit recherche des podcasts/chaînes YouTube informatifs sur les tendances de l’IA, les nouveaux concepts, les innovations et les articles de recherche. De plus, des livres tels que “The Access Economy”, “The Zero Marginal Cost Society”, “Life 3.0” et “The Inevitable” sont recommandés pour aider les lecteurs à comprendre l’IA et les changements économiques et sociaux futurs, et à explorer l’ère post-rareté. (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Rapport technique GLM-4.5 et extensions RL : L’article sur GLM-4.5 détaille son grand modèle de langage MoE, qui utilise une méthode d’inférence hybride et excelle dans les tâches de raisonnement, de codage et d’agent grâce à l’itération de modèles experts, des modes d’inférence hybrides et un programme d’apprentissage par renforcement basé sur la difficulté. Un nouvel article détaille également les résultats expérimentaux des extensions RL, y compris les avantages de l’ajout de multiples dimensions, de l’apprentissage par programme et de l’entraînement multi-étapes. (Source : Reddit r/ArtificialInteligence, _lewtun, Zai_org)
Autres recherches et technologies LLM : Le modèle GLiClass démontre une grande précision et efficacité dans les tâches de classification de séquences, et prend en charge l’apprentissage zéro-shot et few-shot. SONAR-LLM est un modèle Transformer uniquement décodeur qui atteint une qualité de génération compétitive en prédisant des embeddings au niveau de la phrase et en utilisant une supervision d’entropie croisée au niveau du token. Speech-to-LaTeX a publié un vaste ensemble de données et un modèle de conversion parole-LaTeX, faisant progresser la reconnaissance de contenu mathématique. Hugging Face a relayé la publication du jeu de données IndicSynth, un vaste ensemble de données vocales synthétiques pour 12 langues indiennes à faibles ressources. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, huggingface)
Problèmes et corrections d’entraînement RL : La mise à niveau de vLLM de v0 à v1 a entraîné un crash de l’entraînement RL asynchrone, mais a été corrigée avec succès, et l’expérience pertinente a été partagée. (Source : _lewtun, weights_biases)
Progrès des extensions RL : Les progrès ouverts des extensions d’apprentissage par renforcement (RL) sont passionnants ; bien que l’entraînement de modèles nécessite un effort d’ingénierie considérable, les résultats sont indéniables. (Source : jxmnop)
Synthèse des systèmes d’auto-évolution des agents IA : Une synthèse des technologies d’agents IA auto-évolutifs est présentée, proposant un cadre conceptuel unifié (entrées du système, système d’agent, environnement, optimiseur) et passant en revue systématiquement les techniques d’auto-évolution pour différents composants, tout en discutant des considérations d’évaluation, de sécurité et d’éthique. (Source : HuggingFace Daily Papers)
“Super Experts” dans les LLM MoE : Discussion sur le concept de “Super Experts” dans les LLM MoE, soulignant que l’élagage de ces experts rares mais cruciaux entraîne une chute drastique des performances. (Source : teortaxesTex)
Aperçu de la science des données : Partage d’une carte mentale de l’IA générative, offrant un aperçu de la science des données. (Source : Ronald_vanLoon)
💼 Affaires
Microsoft investit dans l’élimination du carbone pour faire face à la consommation d’énergie de l’IA : Microsoft investit plus de 1,7 milliard de dollars en partenariat avec des entreprises de biotechnologie pour atteindre ses objectifs d’élimination du carbone en enfouissant des boues biologiques, afin de faire face à la croissance rapide de la consommation d’énergie et des émissions de carbone des centres de données IA, de respecter ses engagements de bilan carbone négatif et de bénéficier de réductions d’impôts. Cette initiative reflète les problèmes de consommation de ressources posés par le développement de l’IA, incitant les grandes entreprises à rechercher des solutions de réduction des émissions de carbone. (Source : 36氪)
Défi MiniMax AI Agent : Le défi MiniMax AI Agent offre un total de 150 000 USD de prix, encourageant les développeurs à construire ou à remixer des projets d’agents IA, couvrant des domaines tels que la productivité, la créativité, l’éducation et le divertissement. Le défi vise à promouvoir l’innovation et l’application des technologies d’agents IA. (Source : MiniMax__AI, Reddit r/ChatGPT)
Anthropic recrute un responsable de la sécurité de l’IA : Anthropic a embauché Dave Orr comme responsable de la sécurité, qui a auparavant dirigé l’intégration des LLM dans Google Assistant chez Google. Cette décision témoigne de l’importance croissante qu’Anthropic accorde à la prévention des risques liés à l’IA, reflétant que les entreprises d’IA, tout en développant leur technologie, commencent également à renforcer la gouvernance des risques potentiels. (Source : steph_palazzolo)
🌟 Communauté
IA, emploi et impact social : Des études montrent que la popularisation de l’IA générative a entraîné une augmentation de la durée hebdomadaire de travail des professionnels et une réduction de leur temps de loisirs, c’est-à-dire que “plus l’IA est répandue, plus les travailleurs sont occupés”. Dans l’industrie de la publicité, l’IA pourrait éroder la “barrière créative”, les nouveaux venus pouvant sauter l’étape de la réflexion. Parallèlement, l’émergence des compagnons IA a entraîné une dépendance émotionnelle chez les utilisatrices, certaines allant même jusqu’à établir des relations émotionnelles profondes avec l’IA, soulevant des discussions sur l’éthique de l’IA et son impact social. L’impact de l’IA sur l’emploi, en particulier pour les nouveaux venus manquant de désirs et de motivation originels, est le plus important. (Source : 36氪, op7418, teortaxesTex, menhguin, scaling01, teortaxesTex)
Controverse sur l’expérience utilisateur et la qualité du modèle GPT-5 : Après le lancement de GPT-5, de nombreux utilisateurs ont exprimé leur déception quant à ses performances, le jugeant impersonnel, froid, lent et médiocre en écriture créative, moins bon que GPT-4o. Les utilisateurs ont soupçonné OpenAI d’exécuter une “contrefaçon bon marché” de GPT-5 dans ChatGPT pour économiser des coûts, et ont réussi à demander le retour à GPT-4o. Certains commentaires ont qualifié l’hyper-médiatisation d’OpenAI de “gaffe”, donnant à Google l’occasion de sévir contre OpenAI. De plus, les utilisateurs n’ont pas perçu de manière significative la longueur de contexte de 192K du mode GPT-5 Thinking. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT, op7418, TheTuringPost)
Préoccupations éthiques et de sécurité de l’IA : Dans le cadre du capitalisme de marché libre, l’IA pourrait conduire à une dystopie d’entreprise, étant utilisée pour collecter des données privées, manipuler le discours public, contrôler les gouvernements, et être monopolisée par de grandes entreprises, finissant par déformer la réalité. Parallèlement, les craintes que l’IA puisse acquérir des droits de l’homme et la citoyenneté, ainsi que les risques de dépendance émotionnelle liés aux compagnons IA, ont suscité des discussions sur l’éthique de l’IA et son impact social. Yoshua Bengio souligne que le développement de l’IA doit être orienté vers des résultats plus sûrs et bénéfiques. (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Yoshua_Bengio, teortaxesTex)
Modèles de développement de l’IA et perspectives d’avenir : Le développement des LLM est comparé à l’évolution de l’aviation, des frères Wright à l’atterrissage sur la lune, suggérant que la “course à l’échelle” de l’IA cédera la place à une phase d’optimisation et de spécialisation. Certains estiment que les produits et modèles commerciaux actuels des meilleurs laboratoires de LLM limitent leur recherche en IA, ce qui pourrait les empêcher d’être les premiers à atteindre la super-intelligence. La commercialisation et la “brandisation” du terme AGI soulèvent des questions sur sa signification technique. De plus, des discussions portent sur la crainte que 70% des interactions futures soient avec des “emballages” de LLM, ainsi que sur le mécontentement face à la censure et la “purification” excessives des outils IA. (Source : Reddit r/ArtificialInteligence, far__el, rao2z, vikhyatk, Reddit r/ChatGPT)
Culture et humour de la communauté IA : Au sein de la communauté IA, il existe des discussions sur l’anthropomorphisation des modèles d’IA, comme l’idée que “mon IA est consciente/sensible”. Il y a aussi des commentaires humoristiques sur les réactions des utilisateurs après la mise à jour de la capacité de mémoire de Claude, ainsi que des plaisanteries sur le quotidien des chercheurs en IA et les interactions sur les réseaux sociaux des géants de l’IA. (Source : Reddit r/ArtificialInteligence, nptacek, vikhyatk, code_star, Reddit r/ChatGPT)
Modèle de conférence IA et défis de la publication académique : Un article souligne que le modèle actuel des conférences IA n’est pas durable en raison de l’augmentation rapide du volume de publications, des émissions de carbone, du décalage entre le cycle de vie de la recherche et le calendrier des conférences, de la crise de capacité des lieux et des problèmes de santé mentale. Il est suggéré de séparer la publication de la conférence, à l’instar d’autres domaines académiques. (Source : Reddit r/MachineLearning)
Benchmarks IA et controverse sur l’évaluation des modèles : Des questions ont été soulevées concernant la mise à jour par OpenAI du graphique des scores SWE-bench Verified, soulignant qu’ils n’avaient pas exécuté tous les tests. Parallèlement, des chercheurs ont découvert que la capacité de “raisonnement simulé” des LLM est un “mirage fragile”, excellant dans le charabia fluide plutôt que dans le raisonnement logique. Ces discussions reflètent la complexité et les défis de l’évaluation des modèles d’IA. (Source : dylan522p, Reddit r/artificial)
Politique des puces IA et critique des reportages : Des commentaires ont critiqué les journalistes pour avoir décrit la NVIDIA H20 comme une “puce avancée”, soulignant que la H20 a environ 4 ans de retard sur la B200, avec une puissance de calcul, une bande passante mémoire et une mémoire bien inférieures à celles de la B200. Il a été suggéré que la vente de H20 à la Chine est une bonne politique car elle peut ralentir le développement de l’écosystème national d’accélérateurs IA en Chine et creuser l’écart entre l’écosystème IA open-source chinois et les modèles propriétaires américains. (Source : GavinSBaker)
Demande des utilisateurs pour la tarification des LLM et les services de puissance de calcul : Appel à OpenAI/Google pour offrir un service de paiement à l’heure de calcul, permettant aux modèles d’inférence de réfléchir longuement aux problèmes, plutôt que de simuler par de multiples appels API, estimant que cela aiderait à comparer les modèles avec le même budget de calcul. (Source : MParakhin)
💡 Divers
Application de l’IA dans le secteur financier : L’analyse des données financières basée sur l’IA joue un rôle important dans l’élaboration de stratégies plus intelligentes, améliorant l’efficacité de l’analyse et la qualité des décisions dans le secteur financier. (Source : Ronald_vanLoon, Ronald_vanLoon)
Stratégie IA de Google et concurrence : Discussion sur les mouvements potentiels de Google dans le domaine de l’IA, certains commentateurs estimant que Google, avec son avantage matériel TPU et ses recherches plus poussées en matière de recherche, de RL et de modèles de monde de diffusion, pourrait constituer une menace plus importante pour OpenAI. (Source : Reddit r/LocalLLaMA)
Événement AMA de Hugging Face : Clement Delangue, PDG de Hugging Face, a annoncé un événement AMA (Ask Me Anything) à venir, offrant à la communauté une opportunité d’interaction directe. (Source : ClementDelangue)