
Mots-clés:GPT-5, Auto-amélioration de l’IA, Intelligence incarnée, Modèle multimodal, Grand modèle de langage, Apprentissage par renforcement, Agent IA, Amélioration des performances de GPT-5, Plateforme robotique Genie Envisioner, Biais d’évaluation de recrutement LLM, Contexte ultra-long Qwen3, Vérification des réponses CompassVerifier
🔥 Focus
Lancement de GPT-5 : Productisation et Amélioration des Performances : OpenAI a officiellement lancé GPT-5, marquant la dernière itération de son modèle phare. Ce lancement met l’accent sur l’amélioration de l’expérience utilisateur, en équilibrant vitesse et intelligence grâce à la planification automatique en temps réel des modèles de base et des modèles d’inférence profonde par un routeur. GPT-5 montre des progrès significatifs dans la réduction des hallucinations, l’amélioration de la conformité aux instructions et des capacités de programmation, et a battu des records dans plusieurs benchmarks. Sam Altman le compare à un “écran Retina”, soulignant son utilité en tant qu‘“IA de niveau doctorant” plutôt qu’une simple percée dans les limites de l’intelligence. Bien que techniquement non AGI, sa vitesse d’inférence plus rapide et ses coûts d’exécution réduits devraient favoriser une adoption généralisée de l’IA. (Source : MIT Technology Review)

Progrès de la Recherche sur l’Auto-Amélioration de l’IA : Mark Zuckerberg, PDG de Meta, a déclaré que l’entreprise s’efforce de construire des systèmes d’IA capables de s’auto-améliorer. L’IA a déjà démontré sa capacité à s’améliorer de diverses manières, par exemple via l’augmentation automatique des données, la recherche d’architecture de modèle, l’apprentissage par renforcement, etc., optimisant continuellement ses propres performances. Cette tendance laisse présager que les systèmes d’IA pourront à l’avenir apprendre de manière autonome et dépasser les limites de performance définies par l’homme, ce qui est une voie clé pour atteindre des niveaux d’IA plus élevés. (Source : MIT Technology Review)

Genie Envisioner : Plateforme Unifiée de Modèle du Monde pour la Manipulation Robotique : Des chercheurs ont lancé Genie Envisioner (GE), une plateforme de base unifiée de modèle du monde pour la manipulation robotique. GE-Base est un modèle de diffusion vidéo conditionné par des instructions, capable de capturer les dynamiques spatiales, temporelles et sémantiques des interactions robotiques réelles. GE-Act mappe les représentations latentes en trajectoires d’action exécutables, permettant une inférence de stratégie précise et générale. GE-Sim, en tant que simulateur neuronal conditionné par l’action, prend en charge le développement de stratégies en boucle fermée. Cette plateforme devrait fournir une base évolutive et pratique pour l’intelligence incarnée générale pilotée par des instructions. (Source : HuggingFace Daily Papers)
ISEval : Cadre d’Évaluation de la Capacité des Grands Modèles Multimodaux à Identifier les Entrées Erronées : Pour évaluer si les grands modèles multimodaux (LMMs) peuvent identifier activement les entrées erronées, des chercheurs ont proposé le cadre d’évaluation ISEval. Ce cadre couvre sept catégories de prémisses défectueuses et trois indicateurs d’évaluation. L’étude a révélé que la plupart des LMMs ont du mal à détecter activement les défauts textuels sans directives explicites, et se comportent différemment selon les types d’erreurs. Par exemple, ils sont doués pour identifier les sophismes logiques, mais moins performants sur les erreurs linguistiques superficielles et les défauts de conditions spécifiques. Cela souligne le besoin urgent pour les LMMs de valider activement l’efficacité des entrées. (Source : HuggingFace Daily Papers)
Étude sur les Biais Linguistiques dans l’Évaluation du Recrutement par LLM : Une étude a introduit un benchmark pour évaluer la réaction des grands modèles linguistiques (LLMs) aux marqueurs linguistiques discriminatoires dans l’évaluation du recrutement. Grâce à des simulations d’entretien soigneusement conçues, l’étude a révélé que les LLMs pénalisent systématiquement certains modèles linguistiques, en particulier le langage ambigu, même si la qualité du contenu est la même. Cela révèle des biais démographiques dans les systèmes d’évaluation automatisés et fournit un cadre de base pour la détection et la mesure de la discrimination linguistique dans les systèmes d’IA, avec de larges applications pour l’équité des décisions automatisées. (Source : HuggingFace Daily Papers)
🎯 Tendances
Les Modèles de la Série Qwen3 Supportent un Contexte Ultra-Long de Millions de Tokens : Les modèles Qwen3-30B-A3B-2507 et Qwen3-235B-A22B-2507 d’Alibaba Cloud supportent désormais un contexte ultra-long allant jusqu’à 1 million de tokens. Cela est rendu possible grâce aux technologies Dual Chunk Attention (DCA) et MInference sparse attention, qui non seulement améliorent la qualité de génération, mais augmentent également la vitesse d’inférence des séquences de près d’un million de tokens jusqu’à 3 fois. Cette avancée élargit considérablement le potentiel d’application des LLM dans le traitement de tâches complexes telles que les documents longs et les bases de code, et est compatible avec le déploiement efficace de vLLM et SGLang. (Source : Alibaba_Qwen)

Mise à Jour d’Anthropic Claude Opus 4.1 et Sonnet 4 : Anthropic a lancé Claude Opus 4.1 et Sonnet 4, avec un accent sur l’amélioration des tâches Agentic, du codage en monde réel et des capacités de raisonnement. Les nouveaux modèles disposent d’une fonction de “réflexion profonde”, permettant de basculer entre les modes de réponse instantanée et de déduction approfondie, compressant des tâches complexes de plusieurs heures en quelques minutes. Cela renforce davantage la position de Claude dans les scénarios de collaboration multi-modèles, se distinguant particulièrement dans les revues de code complexes et les tâches de raisonnement avancé. (Source : dl_weekly)
Microsoft Lance la Fonctionnalité Copilot 3D : Microsoft a lancé la fonctionnalité gratuite Copilot 3D, capable de convertir des images 2D en modèles 3D au format GLB, compatibles avec divers visualiseurs 3D, outils de conception et moteurs de jeu. Bien que les résultats soient actuellement moins bons pour les images d’animaux et d’humains, cette fonctionnalité offre aux utilisateurs une capacité de conversion 2D vers 3D pratique, susceptible de jouer un rôle dans la conception de produits, la réalité virtuelle, etc., réduisant ainsi davantage la barrière à la création de contenu 3D. (Source : The Verge)
HuggingFace Accelerate Publie un Guide de Formation Multi-GPU : HuggingFace, en collaboration avec Axolotl, a publié le guide Accelerate ND-Parallel, visant à simplifier la combinaison et l’application des stratégies de parallélisation dans la formation multi-GPU. Ce guide détaille des stratégies telles que le Data Parallel (DP), le Sharded Data Parallel (FSDP), le Tensor Parallel (TP) et le Context Parallel (CP), et fournit des exemples de configurations de parallélisation hybride, aidant les développeurs à optimiser l’utilisation de la mémoire et le débit lors de la formation de grands modèles, et à gérer efficacement les défis de surcharge de communication dans la formation multi-nœuds. (Source : HuggingFace Blog)
🧰 Outils
OpenAI Codex CLI : Agent de Codage Local en Terminal : OpenAI a lancé Codex CLI, un Agent de codage léger fonctionnant en local dans le terminal. Les utilisateurs peuvent l’installer via npm install -g @openai/codex ou brew install codex. Il prend en charge la liaison avec les comptes ChatGPT Plus/Pro/Team, permettant l’utilisation gratuite des derniers modèles comme GPT-5, ou une facturation à l’usage via une API Key. Codex CLI offre plusieurs modes sandbox (lecture-écriture, lecture seule, etc.) et prend en charge la configuration personnalisée, visant à fournir une assistance de programmation locale efficace et sécurisée aux développeurs. (Source : openai/codex – GitHub Trending)

HuggingFace AI Sheets : Outil de Jeu de Données Sans Code : HuggingFace a lancé AI Sheets, un outil open-source sans code pour construire, enrichir et transformer des jeux de données à l’aide de modèles d’IA. L’interface de l’outil ressemble à une feuille de calcul et prend en charge le déploiement local ou l’exécution sur le Hugging Face Hub. Les utilisateurs peuvent utiliser des milliers de modèles ouverts (y compris gpt-oss) pour la comparaison de modèles, l’optimisation des prompts, le nettoyage des données, la classification, l’analyse et la génération de données synthétiques, en améliorant itérativement les résultats générés par l’IA via l’édition manuelle et les retours “J’aime”, et peuvent exporter vers le Hub. (Source : HuggingFace Blog)

Google Agent Development Kit (ADK) et ses Exemples : Google a publié l’Agent Development Kit (ADK), une boîte à outils Python open-source et axée sur le code, pour construire, évaluer et déployer des AI Agent complexes. L’ADK prend en charge un riche écosystème d’outils, des systèmes multi-Agent modulaires et un déploiement flexible. Sa bibliothèque d’exemples adk-samples fournit divers exemples d’Agent, des chatbots aux workflows multi-Agent, visant à accélérer le processus de développement d’Agent et à s’intégrer au protocole A2A pour la communication entre Agent distants. (Source : google/adk-python – GitHub Trending & google/adk-samples – GitHub Trending)

Qwen Code CLI : Outil d’Exécution de Code Gratuit : Alibaba Cloud Qwen Code CLI offre 2000 exécutions de code gratuites par jour, facilement lancées via la commande npx @qwen-code/qwen-code@latest. Cet outil prend en charge Qwen OAuth et vise à offrir aux développeurs une expérience de codage et de test pratique et efficace. L’équipe Qwen a déclaré qu’elle continuerait d’optimiser cet outil CLI et le modèle Qwen-Coder, s’efforçant d’atteindre le niveau de performance de Claude Code tout en restant open-source. (Source : Alibaba_Qwen)
📚 Apprentissage
Mise à Jour de la Bibliothèque Python d’OpenAI : La bibliothèque Python officielle d’OpenAI offre un accès pratique à l’API REST d’OpenAI, prenant en charge Python 3.8+. La bibliothèque contient des définitions de type pour tous les paramètres de requête et champs de réponse, et fournit des clients synchrones et asynchrones. La dernière mise à jour inclut le support bêta de l’API Realtime pour la construction d’expériences de dialogue multimodales à faible latence, ainsi que des détails sur la validation des webhooks, la gestion des erreurs, les ID de requête et les mécanismes de réessai, améliorant l’efficacité du développement et la robustesse. (Source : openai/openai-python – GitHub Trending)
Liste Sélectionnée d’AI Agent : e2b-dev/awesome-ai-agents est un dépôt GitHub qui rassemble de nombreux exemples et ressources d’AI Agent autonomes. Cette liste vise à fournir aux développeurs une ressource centralisée pour comprendre et apprendre différents types d’AI Agent, couvrant une variété de scénarios d’application, du simple au complexe, et constitue un matériel d’apprentissage important pour explorer et construire des AI Agent. (Source : e2b-dev/awesome-ai-agents – GitHub Trending)
MeanFlow : Nouveau Paradigme de Modèle de Diffusion Génératif en une Seule Étape : Science Space a proposé MeanFlow, une nouvelle méthode qui devrait devenir un standard pour l’accélération de la génération de modèles de diffusion. Cette méthode vise à réaliser une génération en une seule étape en modélisant la “vitesse moyenne” plutôt que la “vitesse instantanée”, surmontant ainsi le problème de la lenteur de génération des modèles de diffusion traditionnels. MeanFlow possède des principes mathématiques clairs, peut être entraîné à partir de zéro avec un seul objectif, et son effet de génération en une seule étape est proche du SOTA, offrant de nouvelles directions théoriques et pratiques pour l’accélération des modèles d’IA générative. (Source : WeChat)

Optimisation du Cycle de Vie Complet du KV Cache pour les Contextes Longs : Microsoft Research Asia a partagé ses pratiques d’optimisation du cycle de vie complet du KV Cache, visant à résoudre les défis de latence et de stockage dans l’inférence des grands modèles linguistiques (LLM) à contexte long. Grâce au benchmark SCBench et à des méthodes telles que MInference et RetrievalAttention, la latence de la phase de Prefilling est considérablement réduite et la pression sur la mémoire GPU du KV Cache est allégée. La recherche met l’accent sur l’optimisation inter-requêtes au niveau du système et la réutilisation du Prefix Caching, offrant des solutions d’optimisation pour l’évolutivité et l’économie de l’inférence des LLM à contexte long. (Source : WeChat)

Le Cadre d’Apprentissage par Renforcement FR3E Améliore la Capacité d’Exploration des LLM : ByteDance, MAP et l’Université de Manchester ont conjointement proposé FR3E (First Return, Entropy-Eliciting Explore), un nouveau cadre d’exploration structuré visant à résoudre le problème de l’exploration insuffisante des LLM dans l’apprentissage par renforcement. FR3E identifie les tokens à haute incertitude dans les trajectoires de raisonnement, guidant un déploiement diversifié, et reconstruit systématiquement le mécanisme d’exploration des LLM, réalisant un équilibre dynamique entre exploitation et exploration, et surpassant significativement les méthodes existantes sur plusieurs benchmarks de raisonnement mathématique. (Source : WeChat)

Étude sur la Corrélation entre les Valeurs Maximales et la Compréhension Contextuelle dans le Mécanisme d’Auto-Attention : Une nouvelle étude de l’ICML 2025 révèle que les représentations de requête (Q) et de clé (K) du mécanisme d’auto-attention des grands modèles linguistiques présentent des valeurs maximales hautement concentrées, essentielles à la compréhension des connaissances contextuelles. L’étude a découvert que ce phénomène est courant dans les modèles utilisant l’encodage de position rotatif (RoPE) et apparaît dès les premières couches. La perturbation de ces valeurs maximales entraîne une forte dégradation des performances du modèle dans les tâches nécessitant une compréhension contextuelle, offrant de nouvelles directions pour la conception, l’optimisation et la quantification des LLM. (Source : WeChat)
C3 Benchmark : Benchmark de Test pour les Modèles de Dialogue Vocal Bilingues Chinois-Anglais : L’Université de Pékin et Tencent ont conjointement publié C3 Benchmark, le premier benchmark d’évaluation complet des phénomènes complexes dans les modèles de dialogue vocal bilingues chinois-anglais, tels que les pauses, les caractères polyphoniques, les homophones, les accents, les ambiguïtés syntaxiques et les mots à sens multiples. Ce benchmark contient 1079 scénarios réels et 1586 paires audio-texte, visant à cibler les faiblesses fatales des modèles de dialogue vocal actuels et à promouvoir leur progrès dans la compréhension des conversations humaines quotidiennes. (Source : WeChat)
Chemma : Grand Modèle Linguistique pour la Synthèse Chimique Organique : L’équipe AI for Science de l’Université Jiao Tong de Shanghai a lancé le grand modèle linguistique de synthèse chimique de Magnolia (Chemma), réalisant pour la première fois l’accélération de l’ensemble du processus de synthèse organique par un grand modèle linguistique chimique. Chemma ne nécessite pas de calcul quantique, s’appuyant uniquement sur la compréhension et les capacités de raisonnement en chimie, et surpasse les meilleurs résultats existants dans les tâches de rétrosynthèse en une ou plusieurs étapes, de prédiction de rendement/sélectivité et d’optimisation de réaction. Son cadre d’apprentissage actif de collaboration homme-machine “Co-Chemist” a été validé avec succès dans des réactions réelles, offrant un nouveau paradigme pour la découverte chimique. (Source : WeChat)

Intern-Robotics : Moteur Full-Stack Incarné de Shanghai AI Lab : Le Shanghai AI Lab a lancé le moteur full-stack incarné Intern-Robotics, visant à promouvoir le “moment ChatGPT” dans le domaine de l’intelligence incarnée. Ce moteur est une infrastructure ouverte et partagée, axée sur la réalisation de la généralisation de l’ontologie, de la généralisation des scénarios, de la généralisation des tâches, et insistant sur un taux de réussite des opérations proche de 100%. L’équipe s’engage à résoudre le problème de la rareté des données et à réaliser progressivement la généralisation zéro-shot grâce à la technologie “Real to Sim to Real” et à l’apprentissage par renforcement en monde réel, accélérant ainsi l’application de l’intelligence incarnée. (Source : WeChat)

SQLM : Cadre d’Évolution de la Capacité de Raisonnement par Auto-Questionnement de l’IA : L’équipe de l’Université Carnegie Mellon a proposé SQLM, un cadre d’auto-questionnement sans données externes, qui améliore la capacité de raisonnement de l’IA par l’auto-questionnement et l’auto-réponse. Ce cadre comprend deux rôles, le questionneur (proposer) et le répondeur (solver), qui sont entraînés par apprentissage par renforcement pour maximiser la récompense attendue. SQLM a considérablement amélioré la précision du modèle dans les tâches d’arithmétique, d’algèbre et de programmation, offrant un processus d’auto-entretien évolutif pour l’amélioration des capacités des grands modèles linguistiques en l’absence de données annotées de haute qualité. (Source : WeChat)

CompassVerifier : Modèle de Vérification de Réponses IA et Jeu de Données d’Évaluation : Le Shanghai AI Lab et l’Université de Macao ont conjointement publié CompassVerifier, un modèle de vérification de réponses universel, et VerifierBench, un jeu de données d’évaluation, visant à résoudre le problème du décalage entre les progrès rapides des capacités d’entraînement des grands modèles et la capacité de vérification des réponses. CompassVerifier est un vérificateur universel léger mais puissant, optimisé sur la base des modèles de la série Qwen, capable d’atteindre une précision de vérification supérieure à celle des grands modèles universels dans plusieurs domaines tels que les mathématiques, les connaissances et le raisonnement scientifique, et peut servir de modèle de récompense pour l’apprentissage par renforcement, fournissant un retour précis pour l’optimisation itérative des LLM. (Source : WeChat)

CoAct-1 : Agent d’Utilisation d’Ordinateur Basé sur le Codage comme Action : Des chercheurs ont proposé CoAct-1, un système multi-Agent qui utilise le codage comme action augmentée, visant à résoudre les problèmes d’efficacité et de fiabilité des Agent d’opération GUI dans les tâches complexes. L’Orchestrator de CoAct-1 peut déléguer dynamiquement des sous-tâches à l’Agent GUI Operator ou Programmer (qui peut écrire et exécuter des scripts Python/Bash), contournant ainsi les opérations GUI inefficaces. Cette méthode a atteint un taux de réussite SOTA sur le benchmark OSWorld et a considérablement amélioré l’efficacité, offrant une voie plus puissante pour l’automatisation informatique générale. (Source : HuggingFace Daily Papers)
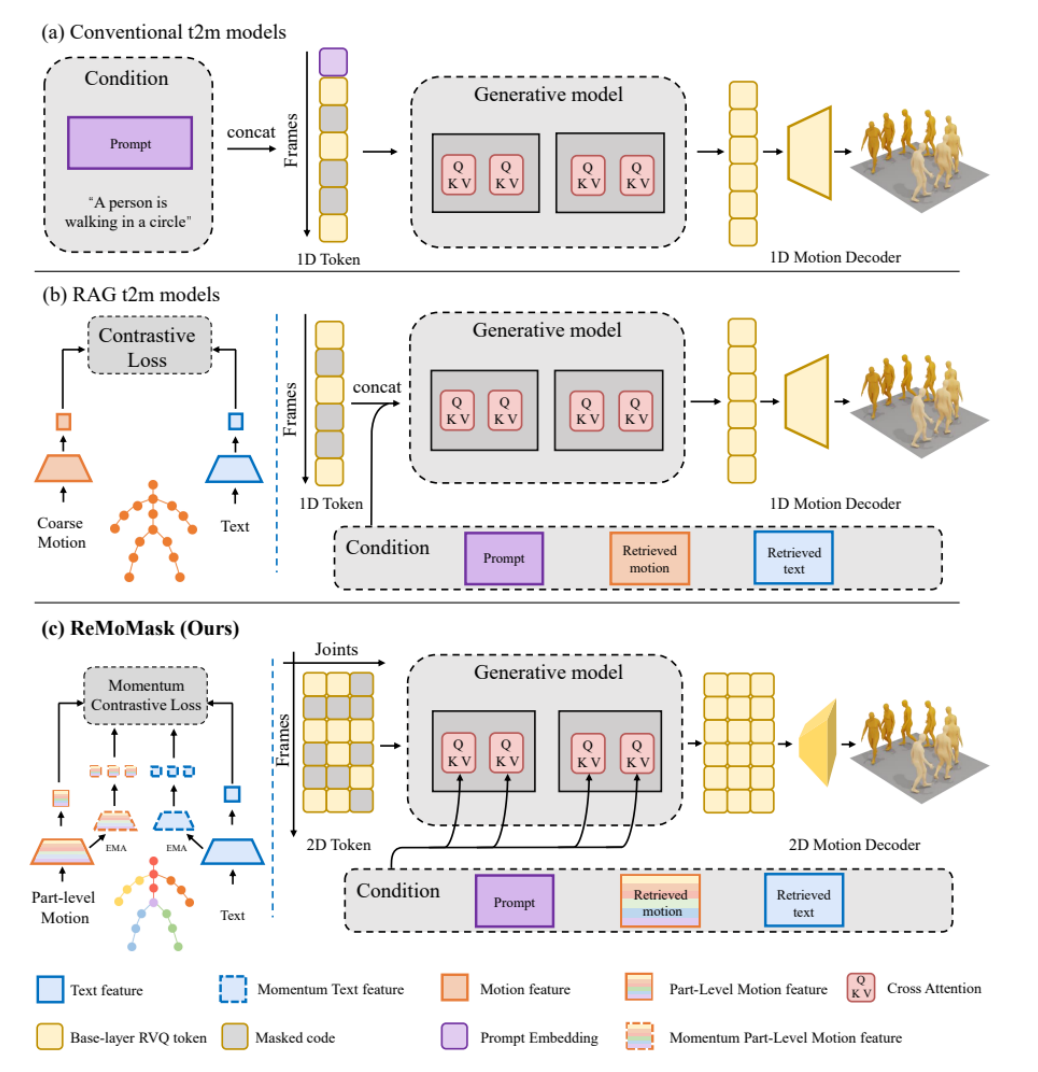
ReMoMask : Nouvelle Méthode de Génération d’Actions 3D de Haute Qualité pour les Jeux : L’Université de Pékin a proposé ReMoMask, un cadre Text-to-Motion basé sur la génération augmentée par la récupération, visant à générer des actions 3D fluides et réalistes de haute qualité à partir d’une seule instruction. ReMoMask intègre un modèle bidirectionnel texte-action basé sur le momentum, un mécanisme d’attention spatio-temporelle sémantique et un guidage RAG sans classificateur, générant efficacement des actions cohérentes dans le temps. Cette méthode a battu les records de performance SOTA sur les benchmarks standard tels que HumanML3D et KIT-ML, et devrait révolutionner les processus de production de jeux et d’animations. (Source : WeChat)
Synthèse WebAgents : L’Automaion Web Propulsée par les Grands Modèles : Des chercheurs de l’Université Polytechnique de Hong Kong ont publié la première synthèse sur les WebAgents, dressant un bilan complet des progrès de la recherche sur l’automaion Web de nouvelle génération propulsée par les grands modèles d’IA Agent. La synthèse résume les méthodes représentatives des WebAgents sous les angles de l’architecture (perception, planification et raisonnement, exécution), de l’entraînement (données, stratégie) et de la fiabilité (sécurité, confidentialité, généralisation), et explore les futures directions de recherche, telles que l’équité, l’explicabilité, les jeux de données et les WebAgents personnalisés, fournissant un guide pour la construction de systèmes d’automatisation Web plus intelligents et sécurisés. (Source : WeChat)

InfiAlign : Cadre d’Alignement des Capacités de Raisonnement des LLM : InfiAlign est un cadre post-entraînement évolutif et économe en échantillons, qui combine SFT et DPO pour aligner les LLM afin d’améliorer les capacités de raisonnement. Le cœur de ce cadre est un pipeline de sélection de données puissant, capable de filtrer automatiquement des données d’alignement de haute qualité à partir de jeux de données de raisonnement open-source. InfiAlign a atteint des performances comparables à DeepSeek-R1-Distill-Qwen-7B sur le modèle Qwen2.5-Math-7B-Base, mais en utilisant seulement environ 12% des données d’entraînement, et a obtenu des améliorations significatives dans les tâches de raisonnement mathématique, offrant une solution pratique pour l’alignement des grands modèles de raisonnement. (Source : HuggingFace Daily Papers)
💼 Affaires
Plan de Monétisation des Options d’Achat d’Actions d’OpenAI pour Retenir les Employés : Pour faire face à la fuite des talents, OpenAI a lancé une nouvelle phase de son plan de monétisation des options d’achat d’actions des employés, valorisée à 500 milliards de dollars, visant à retenir les talents par des incitations financières directes. Cette initiative devrait propulser la valorisation d’OpenAI vers de nouveaux sommets. Parallèlement, ChatGPT a atteint 700 millions d’utilisateurs actifs hebdomadaires, le nombre d’entreprises clientes payantes a augmenté à 5 millions, et les revenus annuels récurrents devraient dépasser 20 milliards de dollars, démontrant une bonne dynamique de développement des produits et de commercialisation d’OpenAI. (Source : 量子位)

Amazon Web Services Construit la Plus Grande Plateforme d’Agrégation de Modèles d’IA : Amazon Web Services (AWS) a annoncé que le modèle gpt-oss d’OpenAI est désormais accessible via Amazon Bedrock et Amazon SageMaker pour la première fois, enrichissant ainsi son écosystème de modèles sous sa stratégie “Choice Matters”. AWS propose désormais plus de 400 modèles d’IA majeurs, commerciaux et open-source, visant à permettre aux entreprises de choisir le modèle le plus adapté en fonction des performances, des coûts et des besoins des tâches, plutôt que de rechercher un seul modèle “le plus puissant”, favorisant la synergie multi-modèles. (Source : 量子位)

Ant Group Investit dans une Société de Mains Dextres pour l’IA Incarnée : Ant Group a mené un investissement de plusieurs centaines de millions de yuans dans la société d’IA incarnée Lingxin Qiaoshou (灵心巧手), spécialisée dans les mains dextres. Lingxin Qiaoshou est la seule entreprise au monde à avoir produit en masse des milliers de mains dextres à haute liberté de mouvement, détenant 80% de parts de marché. Sa série de mains dextres Linker Hand offre une grande liberté de mouvement, un système multi-capteurs et un avantage de coût, et a déjà été déployée dans des scénarios industriels et médicaux. Cet investissement sera utilisé pour la recherche technologique et la construction de sites de collecte de données, accélérant le déploiement des mains dextres dans des applications réelles. (Source : 量子位)

🌟 Communauté
L’Expérience Utilisateur de GPT-5 Divise : Après le lancement de GPT-5, les retours des utilisateurs sont mitigés. Certains saluent ses améliorations significatives en matière de programmation et de raisonnement complexe, trouvant la génération de code plus propre et précise, et la capacité de traitement de contexte long extrêmement puissante. Cependant, d’autres utilisateurs expriment leur déception quant à la diminution de la personnalisation du modèle, de l’écriture créative et des capacités de soutien émotionnel, le trouvant “ennuyeux” et “sans âme”, et le mécanisme de routage du modèle entraînant une expérience instable, certains allant même jusqu’à annuler leur abonnement. (Source : Reddit r/ChatGPT & Reddit r/LocalLLaMA & Reddit r/ChatGPT & Reddit r/ChatGPT)

L’Application et les Controverses de l’IA dans la Parentalité : Les parents qui travaillent utilisent de plus en plus des outils d’IA comme ChatGPT comme “co-parents”, les employant pour planifier les repas, optimiser les routines du coucher, et même offrir un soutien émotionnel. L’espace d’écoute sans jugement de l’IA allège le fardeau psychologique des parents. Cependant, cette technologie émergente suscite également des controverses, notamment le risque de conseils inexacts, les risques de fuite de données privées (comme l’incident de fuite de données de ChatGPT), la dépendance excessive à l’IA pouvant entraîner l’isolement dans les relations interpersonnelles, et l’impact potentiel sur l’environnement. (Source : 36氪)
Airbnb : Incident de Faux Images Générées par l’IA Entraînant une Indemnisation Utilisateur : Airbnb a été le théâtre d’un incident où un hôte a utilisé des images falsifiées par l’IA pour escroquer des indemnisations à un utilisateur, soulignant les risques de l’IA dans le service client. Le service client IA n’a pas réussi à identifier les images générées par l’IA, ce qui a conduit à une décision erronée d’indemnisation de l’utilisateur. Bien qu’OpenAI ait précédemment lancé un détecteur d’images, la capacité de l’IA à identifier l’IA reste limitée, surtout face aux techniques de “falsification partielle”. Cet incident soulève des inquiétudes quant à la fiabilité des outils de détection de contenu IA et à la capacité des plateformes C2C à faire face à l’impact des deepfakes. (Source : 36氪)

Les Géants de l’IA de la Silicon Valley Construisent des Bunkers Apocalyptiques, Suscitant le Débat : Il a été révélé que des leaders de l’IA de la Silicon Valley, tels que Mark Zuckerberg et Sam Altman, construisent ou possèdent des abris anti-apocalyptiques, suscitant l’inquiétude du public quant à l’avenir du développement de l’IA et ses risques potentiels. Bien qu’ils nient tout lien avec l’IA, cette démarche est interprétée comme une mesure de précaution contre les pandémies, les cyber-guerres, les catastrophes climatiques, etc. Les discussions au sein de la communauté spéculent si ces personnes, qui connaissent le mieux la technologie de l’IA, ont perçu des signes inconnus du grand public, et si le développement de l’IA a déjà entraîné des risques imprévisibles. (Source : 量子位)

o3 Remporte le Championnat International d’Échecs IA de Kaggle : Lors de la finale du premier Championnat International d’Échecs IA de Google Kaggle, o3 d’OpenAI a balayé Grok 4 d’Elon Musk 4-0, remportant le titre. Ce match a été considéré comme une “guerre par procuration” entre OpenAI et xAI, visant à tester la pensée critique, la planification stratégique et la capacité d’adaptation des grands modèles. Bien que Grok 4 ait eu un élan fort auparavant, il a commis de nombreuses erreurs en finale, tandis que o3 a démontré une stratégie stable et n’a perdu aucune partie, devenant le champion invaincu. (Source : WeChat)

Discussion sur l’Entrée de l’IA dans la “Vallée de la Désillusion” : De nombreuses discussions ont émergé sur les réseaux sociaux, suggérant que l’IA est entrée dans la “vallée de la désillusion”, en particulier après le lancement de GPT-5. Les utilisateurs soulignent que les limites de l’IA n’ont pas été efficacement dépassées, et que les gains liés à l’augmentation de la taille des modèles et de la puissance de calcul diminuent. Ce point de vue soutient que les progrès de l’IA sont devenus “moins évidents”, se manifestant principalement dans les domaines d’experts plutôt qu’au niveau perceptible par l’utilisateur moyen, ce qui laisse présager que le développement de l’IA pourrait entrer dans une période de plateau, nécessitant une percée architecturale entièrement nouvelle. (Source : Reddit r/ArtificialInteligence)

💡 Autres
Docker Avertit des Risques de Sécurité de la Chaîne d’Outils MCP : Docker a émis un avertissement, signalant de graves vulnérabilités de sécurité dans les chaînes d’outils de développement basées sur l’IA et construites sur le Model Context Protocol (MCP), y compris la fuite d’informations d’identification, l’accès non autorisé aux fichiers et l’exécution de code à distance, avec des cas réels déjà survenus. Ces outils intègrent les LLM dans l’environnement de développement, leur conférant des autorisations d’opération autonomes, mais manquent d’isolation et de supervision. Docker recommande d’éviter d’installer les serveurs MCP via npm, d’utiliser plutôt des conteneurs signés, et souligne l’importance de l’isolation des conteneurs et des réseaux zéro-confiance. (Source : WeChat)

Plan d’Incentive pour les Développeurs d’Applications Huawei HarmonyOS 2025 : Huawei a annoncé que le nombre de terminaux HarmonyOS 5 a dépassé les dix millions, et a lancé le “Plan d’Incentive pour les Développeurs d’Applications HarmonyOS 2025”, investissant plus de cent millions de yuans en subventions, avec une récompense maximale de 6 millions de yuans par développeur. Ce plan vise à accélérer le développement de l’écosystème HarmonyOS, à attirer les développeurs à créer des applications pour l’IA et les terminaux multiples, et à réaliser le “développement unique, déploiement multi-terminaux”. Huawei offre un support de développement complet, y compris l’habilitation technologique, les tests rapides, le déploiement et l’exploitation efficaces, visant à construire un écosystème de développeurs solide. (Source : WeChat)

Lancement du Serveur Super-Nœud IA Domestique YuanNao SD200 : Inspur Information a lancé le serveur AI super-nœud “YuanNao SD200”, visant à résoudre les défis de puissance de calcul liés à l’exécution de modèles à des milliards de paramètres. Ce serveur adopte une architecture innovante de communication sémantique de mémoire multi-hôtes à faible latence, capable d’agréger 64 puces GPU locales, offrant une mémoire vidéo unifiée maximale de 4 To et une mémoire unifiée de 64 Go, prenant en charge les modèles à très longues séquences de milliards de paramètres. Les tests réels montrent que le SD200 atteint une excellente efficacité d’extension de la puissance de calcul sur des modèles comme DeepSeek R1, offrant un support puissant pour l’AI4 Science et les applications industrielles. (Source : WeChat)
