
Mots-clés:Google DeepMind, Genie 3, Modèle du monde, Environnement d’entraînement IA, Développement de jeux, AGI incarné, Système multi-agents, Génération en temps réel d’environnements 3D interactifs, Résolution 720p à 24 images par seconde, Collaboration bi-agent résolveur-vérificateur, Résolution de problèmes mathématiques de l’IMO par IA, Système multi-agents open source pour l’IMO
Voici la traduction du contenu en français, en respectant toutes vos exigences :
🔥 Actualités phares
Google DeepMind lance Genie 3, un nouveau modèle de monde : Google DeepMind a dévoilé Genie 3, un modèle de monde révolutionnaire capable de générer en temps réel des environnements 3D interactifs à partir d’invites textuelles, prenant en charge une résolution 720p et un taux de rafraîchissement de 24 ips. Ce modèle possède une mémoire visuelle et des capacités de contrôle des mouvements s’étendant sur plusieurs minutes, et est considéré comme le futur moteur de jeu 2.0, susceptible de révolutionner les environnements d’entraînement de l’IA et le développement de jeux, et de fournir la pièce manquante cruciale pour l’AGI incarnée. (Source : Google DeepMind)
Ant Group reproduit les résultats de la médaille d’or de l’IMO avec des agents multi-IA et les rend open source : L’équipe du projet AWorld d’Ant Group a reproduit en seulement 6 heures les résultats de DeepMind pour 5 des 6 problèmes du concours de mathématiques IMO 2025, et a rendu open source son système multi-agents IMO. Ce système, grâce à la collaboration entre deux agents intelligents (« résolveur + vérificateur »), démontre un potentiel dépassant les limites d’intelligence d’un seul modèle, et est utilisé pour entraîner les modèles de prochaine génération, ce qui devrait faire progresser l’intelligence artificielle générale (AGI). (Source : 量子位)
L’IA découvre de nouvelles lois physiques : Des chercheurs de l’Université Emory ont entraîné une IA à découvrir de nouvelles lois physiques à partir de données expérimentales de plasma poussiéreux, révélant des forces auparavant inconnues. Cette étude montre que l’IA peut non seulement prédire des résultats ou nettoyer des données, mais aussi être utilisée pour découvrir des lois physiques fondamentales, et a corrigé une hypothèse de longue date en physique des plasmas, ouvrant de nouvelles voies pour l’étude des systèmes complexes à plusieurs particules. (Source : interestingengineering)

🎯 Tendances
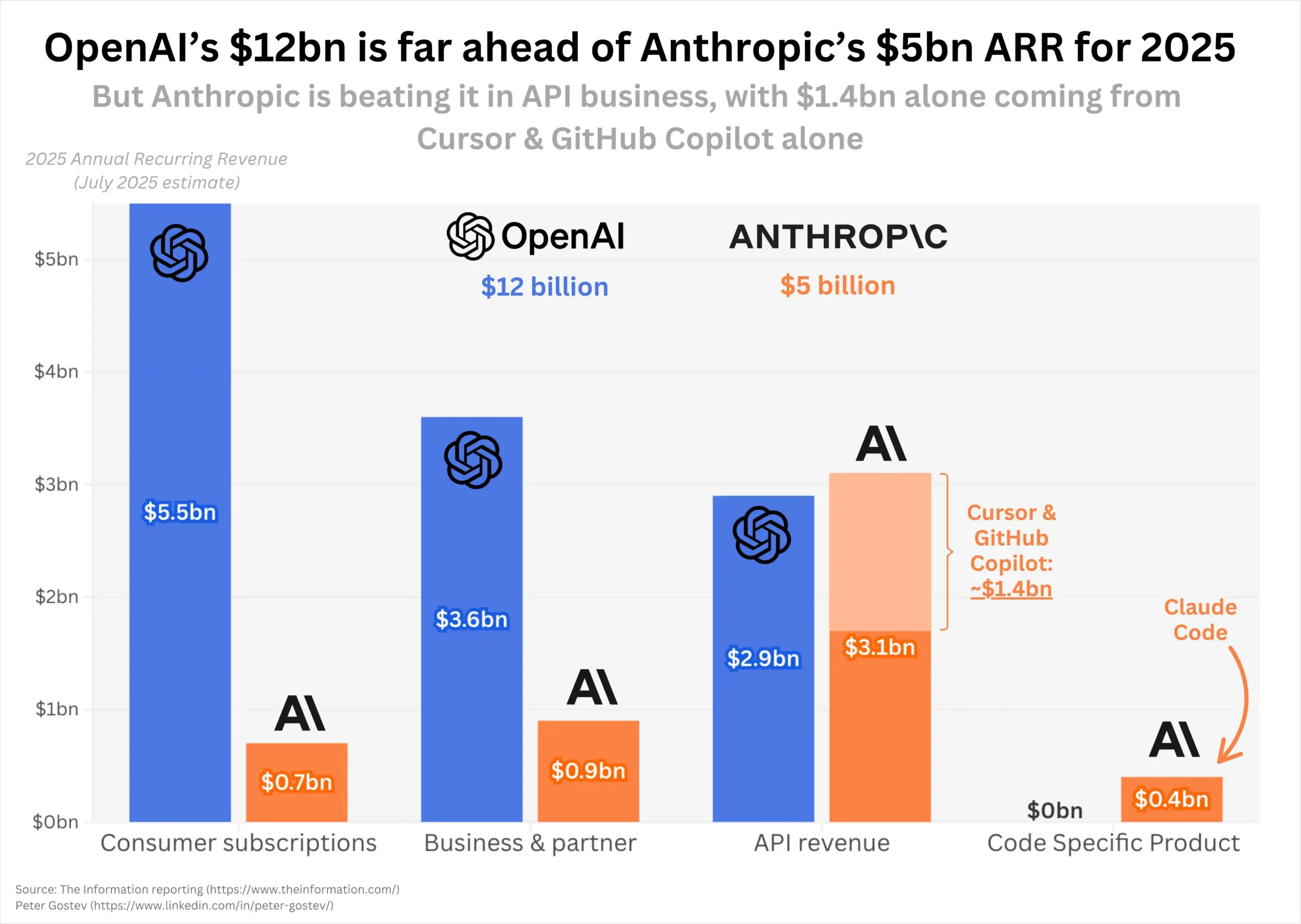
OpenAI et Anthropic connaissent une croissance rapide de leurs revenus, la dynamique du marché est sous surveillance : En 2025, OpenAI et Anthropic affichent une croissance impressionnante de leurs revenus : le revenu récurrent annuel d’OpenAI a doublé pour atteindre 12 milliards de dollars, et celui d’Anthropic a été multiplié par 5 pour atteindre 5 milliards de dollars. Anthropic montre une forte performance sur le marché des API de programmation, tandis que le nombre d’utilisateurs de ChatGPT continue de croître rapidement. Le marché se demande si le lancement futur de GPT-5 changera la dynamique actuelle du marché, en particulier la position dominante d’Anthropic dans le domaine de la programmation. (Source : dotey, nickaturley, xikun_zhang_)
Kaggle lance une plateforme de compétition de jeux d’échecs IA : Kaggle a annoncé le lancement de Game Arena, une plateforme de compétition open source visant à évaluer objectivement les performances des modèles d’IA de pointe en les faisant s’affronter directement (actuellement principalement aux échecs). Le premier championnat d’échecs IA a déjà commencé, et des maîtres d’échecs ont été invités à commenter, suscitant l’intérêt de la communauté pour les performances de modèles tels que Kimi K2. (Source : algo_diver, teortaxesTex, sirbayes, Reddit r/LocalLLaMA)

Détails de l’entraînement de GPT-5 d’OpenAI révélés : Des rapports indiquent qu’OpenAI utilise entre 170 000 et 180 000 GPU H100 pour entraîner GPT-5. Les capacités multimodales de ce modèle sont considérablement améliorées, et il pourrait déjà intégrer l’entrée vidéo, avec l’intention de créer des « moments Ghibli », ce qui suggère ses ambitions en matière de génération de contenu créatif. (Source : teortaxesTex)

GLM 4.5 entre dans le top 5 de LM Arena : Le modèle GLM 4.5 de Zai.org a excellé dans le vote communautaire de LM Arena, obtenant plus de 4000 voix, se classant ainsi dans le top 5 du classement général. Il est désormais aux côtés de DeepSeek-R1 et Kimi-K2 comme l’un des meilleurs modèles open source, démontrant sa compétitivité dans le domaine des grands modèles linguistiques. (Source : teortaxesTex, NandoDF)

Yunpeng Technology lance de nouveaux produits IA+santé : Yunpeng Technology, en collaboration avec Shuaikang et Skyworth, a lancé un réfrigérateur intelligent équipé d’un grand modèle de santé IA et un « laboratoire de cuisine future numérisée et intelligente ». Le grand modèle de santé IA, via l’« assistant de santé Xiaoyun », offre une gestion de la santé personnalisée et optimise la conception et le fonctionnement de la cuisine, marquant une application approfondie de l’IA dans la gestion quotidienne de la santé et la technologie domestique, et devrait améliorer la qualité de vie des résidents. (Source : 36氪)
Nouveau cadre de sécurité pour les systèmes d’IA publié : MITSloan a proposé un nouveau cadre visant à aider les entreprises à construire des systèmes d’IA plus sécurisés. Ce cadre se concentre sur les pratiques de sécurité de l’intelligence artificielle et de l’apprentissage automatique, fournissant des directives importantes pour la sécurité des applications d’IA de plus en plus complexes. (Source : Ronald_vanLoon)

Avancées dans l’application de l’IA dans le domaine de la cybersécurité : Le cadre Cyber-Zero permet d’entraîner des agents LLM de cybersécurité sans environnement d’exécution, en générant des trajectoires de haute qualité par rétro-ingénierie des rapports de résolution de CTF. Son modèle Cyber-Zero-32B entraîné a atteint des performances SOTA dans les benchmarks CTF, avec une meilleure rentabilité que les systèmes propriétaires. Parallèlement, Corridor Secure est en train de construire une plateforme de sécurité produit nativement IA, visant à introduire l’IA dans la sécurité du développement logiciel. (Source : HuggingFace Daily Papers, saranormous)
Les modèles prédictifs basés sur l’IA libèrent de la valeur dans les opérations : Les modèles prédictifs basés sur l’IA démontrent une valeur immense dans les opérations, en offrant des capacités de prédiction plus précises, débloquant de multiples sources de valeur, favorisant la transformation numérique et renforçant le rôle de l’apprentissage automatique dans les décisions commerciales. (Source : Ronald_vanLoon)
Première construction de route autonome au monde assistée par des machines IA : Le premier projet mondial de construction de route autonome de 158 km de long a été entièrement réalisé par des machines IA avec le soutien du réseau 5G. Cela marque une avancée majeure de l’intelligence artificielle, de la RPA et des technologies émergentes dans le domaine de la construction d’infrastructures, annonçant une automatisation élevée des futurs projets d’ingénierie. (Source : Ronald_vanLoon)
Les LLM en tant que juges/validateurs universels suscitent le débat : Les médias sociaux débattent du « validateur universel » que pourrait lancer OpenAI. Certains se demandent si son essence reste le concept de « LLM en tant que juge », tandis que d’autres espèrent que GPT-5 pourra atteindre une précision quasi sans hallucination grâce à cette technologie, offrant ainsi une exactitude et une fiabilité sans précédent. (Source : Teknium1, Dorialexander, Vtrivedy10)

Meta AI publie le plus grand jeu de données ouvert sur la capture de carbone : Meta FAIR, le Georgia Institute of Technology et cusp_ai ont conjointement publié le jeu de données Open Direct Air Capture 2025, le plus grand jeu de données ouvert pour la découverte de matériaux avancés pour la capture directe de dioxyde de carbone. Ce jeu de données vise à accélérer les solutions climatiques grâce à l’IA et à faire progresser la science des matériaux respectueux de l’environnement. (Source : ylecun)

🧰 Outils
Lancement du modèle open source Qwen-Image : Alibaba a lancé Qwen-Image, un modèle de génération de texte à image MMDiT de 20B, désormais open source (licence Apache 2.0). Ce modèle excelle dans le rendu de texte, particulièrement doué pour générer des affiches graphiques avec du texte natif, prenant en charge le bilinguisme, plusieurs polices et des mises en page complexes. Il peut également générer des images dans divers styles, du réaliste à l’anime, et peut fonctionner localement sur des appareils à faible VRAM grâce à la quantification, et a été intégré à ComfyUI. (Source : teortaxesTex, huggingface, NandoDF, Reddit r/LocalLLaMA)

Capacités d’édition vidéo de Runway Aleph améliorées : Runway Aleph, en tant qu’outil d’édition vidéo, peut désormais contrôler précisément des parties spécifiques de la vidéo, y compris la manipulation de l’environnement, de l’atmosphère et des sources de lumière directionnelles, et peut même remplacer le pipeline de rendu de Blender. Cette avancée améliore considérablement la flexibilité et l’efficacité de la production vidéo, offrant aux créateurs des outils plus puissants. (Source : op7418, c_valenzuelab)

Kitten TTS : un modèle de synthèse vocale ultra-compact : Kitten ML a publié une version préliminaire du modèle Kitten TTS, un modèle de synthèse vocale SOTA ultra-compact, pesant moins de 25 Mo (environ 15 millions de paramètres), offrant huit voix anglaises expressives. Ce modèle peut fonctionner sur des appareils à faible puissance de calcul comme les Raspberry Pi et les téléphones mobiles, et il est prévu de prendre en charge plusieurs langues et le fonctionnement sur CPU à l’avenir, offrant une solution de synthèse vocale pour les environnements à ressources limitées. (Source : Reddit r/LocalLLaMA)

Piper TTS : un moteur de synthèse vocale rapide, local et open source : Piper est un moteur de synthèse vocale rapide, local et open source, prenant en charge plus de 20 langues et plusieurs voix, avec une taille de modèle entre 25 Mo et 65 Mo, et la possibilité d’entraîner de nouvelles voix. Son principal avantage est qu’il peut être utilisé dans des applications embarquées C/C++, offrant des capacités de synthèse vocale efficaces pour diverses plateformes. (Source : Reddit r/LocalLLaMA)

Collection de sous-agents Claude Code publiée : VoltAgent a publié une collection de sous-agents Claude Code prêts pour la production, comprenant plus de 100 agents spécialisés, couvrant des tâches de développement telles que le frontend, le backend, le DevOps, l’IA/ML, la revue de code et le débogage. Ces sous-agents suivent les meilleures pratiques et sont maintenus par la communauté des frameworks open source, visant à améliorer l’efficacité et la qualité des flux de travail de développement. (Source : Reddit r/ClaudeAI)
Vibe : un outil de transcription audio/vidéo hors ligne : Vibe est un outil de transcription audio/vidéo hors ligne open source, utilisant la technologie OpenAI Whisper, prenant en charge la transcription dans presque toutes les langues. Il offre une conception conviviale, un aperçu en temps réel, une transcription par lots, un résumé IA, une analyse locale Ollama, et prend en charge plusieurs formats d’exportation, tout en étant optimisé pour les GPU, garantissant la confidentialité des utilisateurs. (Source : GitHub Trending)
DevBrand Studio : un outil de marque de développeur basé sur l’IA : DevBrand Studio est un outil IA conçu pour aider les développeurs à créer facilement des profils GitHub professionnels. Il peut générer automatiquement des biographies concises, ajouter des projets personnels/professionnels et leur impact, et fournir des liens partageables, résolvant les points douloureux des développeurs en matière d’auto-promotion, particulièrement adapté aux demandeurs d’emploi et aux freelances. (Source : Reddit r/MachineLearning)
Optimisation du déchargement MoE de LLaMA.cpp : LLaMA.cpp a ajouté l’option --n-cpu-moe, simplifiant considérablement le processus de déchargement hiérarchique des modèles MoE. Les utilisateurs peuvent facilement ajuster le nombre de couches MoE exécutées sur le CPU, optimisant ainsi les performances et l’utilisation de la mémoire des grands modèles sur les GPU et les CPU, particulièrement adapté aux modèles comme GLM4.5-Air. (Source : Reddit r/LocalLLaMA)
ReaGAN : un cadre d’apprentissage graphique combinant les capacités d’agent et la récupération : Retrieval-augmented Graph Agentic Network (ReaGAN) est un cadre d’apprentissage graphique innovant qui combine les capacités d’agent et la récupération. Dans ce cadre, les nœuds sont conçus comme des agents capables de planifier, d’agir et de raisonner, offrant aux développeurs d’IA de nouvelles idées pour combiner des fonctions d’agent complexes avec l’apprentissage graphique. (Source : omarsar0)

OpenArm : un bras robotique humanoïde open source : Enactic AI a lancé OpenArm, un bras robotique humanoïde open source, conçu pour les applications d’IA physique dans des environnements riches en contact. Ce projet vise à promouvoir le développement de la robotique et de l’intelligence artificielle dans les interactions du monde réel, offrant une plateforme matérielle flexible aux chercheurs et développeurs. (Source : Ronald_vanLoon)
Kling ELEMENTS : génération de vidéo IA de niveau Hollywood : La technologie ELEMENTS de Kling vise à générer des vidéos IA avec un réalisme de niveau Hollywood, caractérisées par des visages impeccables, des vêtements dynamiques et sans défauts. Son œuvre « Loading » a déjà accumulé 197 millions de vues mondiales et quatre prix majeurs de l’industrie, démontrant le puissant potentiel de l’IA dans la création de contenu vidéo. (Source : Kling_ai, Kling_ai)

Lancement de Hugging Face Text Embeddings Inference (TEI) v1.8.0 : Hugging Face a lancé la version 1.8.0 de Text Embeddings Inference (TEI), apportant plusieurs nouvelles fonctionnalités et améliorations, y compris la prise en charge des derniers modèles. Cette mise à jour vise à améliorer l’efficacité et les performances de l’inférence d’embeddings de texte, offrant aux développeurs des outils plus puissants. (Source : narsilou)

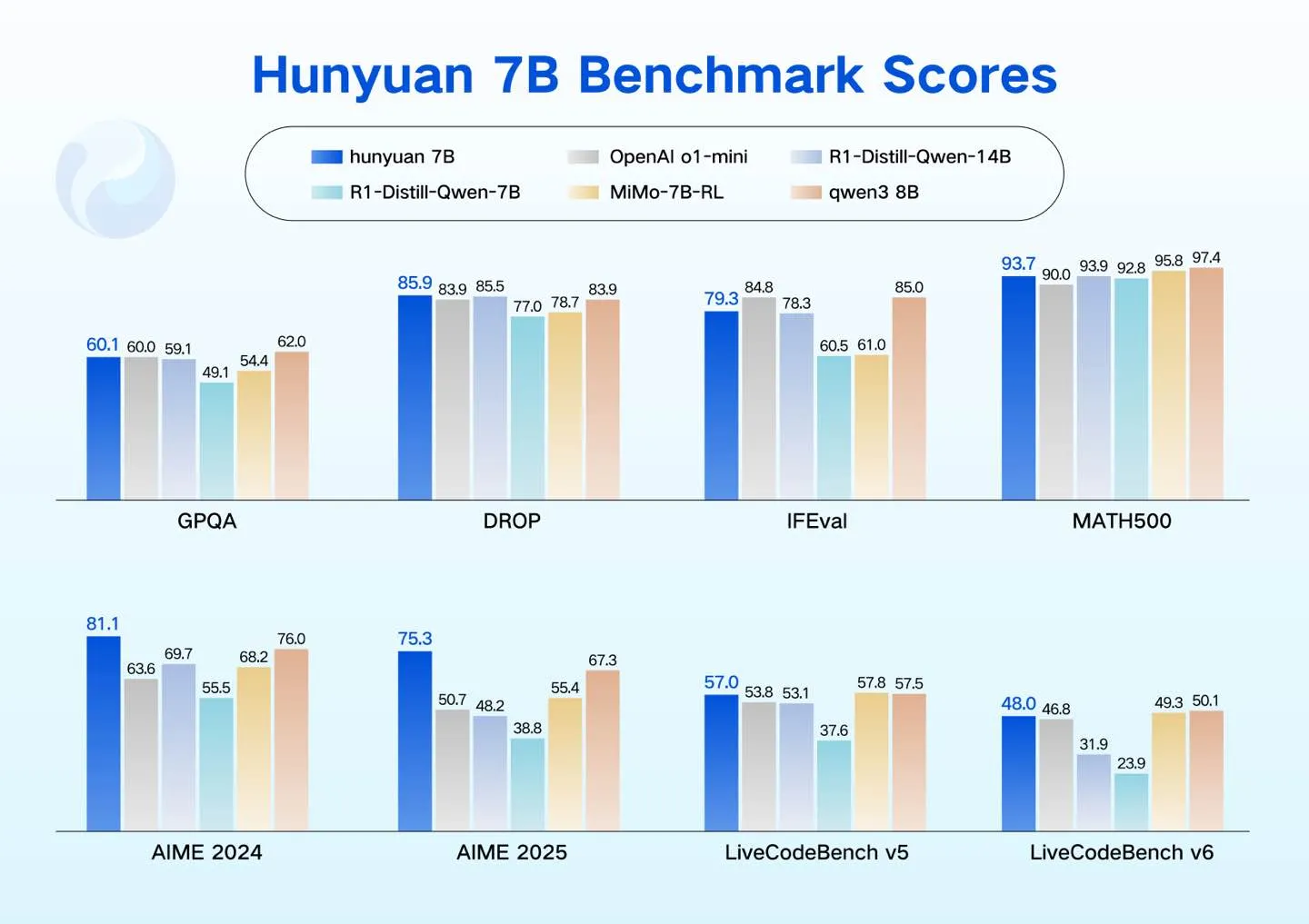
Tencent Hunyuan lance des modèles LLM compacts : Tencent Hunyuan a lancé quatre modèles LLM compacts (0.5B, 1.8B, 4B, 7B), conçus pour prendre en charge les scénarios à faible consommation d’énergie, tels que les GPU grand public, les voitures intelligentes, les appareils domestiques intelligents, les téléphones mobiles et les PC. Ces modèles prennent en charge un réglage fin rentable, élargissant l’écosystème LLM open source de Hunyuan. (Source : awnihannun)
Outil de génération de vidéo IA Topviewofficial : Topviewofficial a lancé un outil de génération de vidéo IA, affirmant pouvoir créer des vidéos virales en quelques minutes. Cet outil vise à simplifier le processus de création de contenu, en permettant aux utilisateurs de produire rapidement des vidéos créatives grâce à la technologie d’IA générative. (Source : Ronald_vanLoon)
Le navigateur Comet AI améliore l’efficacité : Le navigateur Comet est salué par les utilisateurs comme un exemple de navigation IA, sa consommation de mémoire est réduite de près de trois fois par rapport à Chrome, et il fonctionne plus efficacement avec le même nombre d’onglets. Les utilisateurs affirment que Comet est devenu leur navigateur par défaut, car il montre comment un navigateur IA devrait fonctionner, et le considèrent comme un IDE pour les non-développeurs. (Source : AravSrinivas)

📚 Apprentissage
Bootcamp GStar du New Turing Institute : Le New Turing Institute a lancé le bootcamp GStar, un programme mondial de talents de 12 semaines visant à former les participants aux technologies de pointe des LLM, à la recherche et au leadership. Ce programme est conçu par des experts de premier plan en IA, et des universitaires renommés participent à l’encadrement. (Source : YiTayML)

Guide d’apprentissage des agents IA : Un guide sur la façon de commencer à apprendre les agents IA a été partagé sur les médias sociaux, offrant des ressources d’introduction et des parcours d’apprentissage aux débutants intéressés par les agents d’intelligence artificielle, les aidant à comprendre et à pratiquer le développement d’agents IA. (Source : Ronald_vanLoon)
Conseils pour le choix du domaine de recherche doctorale en apprentissage automatique/réseaux neuronaux profonds : Pour les étudiants en master souhaitant poursuivre des recherches théoriques/fondamentales dans un laboratoire de recherche en IA, la communauté a fourni des conseils sur les domaines de recherche doctorale en théorie fondamentale de l’apprentissage automatique/réseaux neuronaux profonds, y compris la théorie de l’apprentissage statistique et l’optimisation, et a exploré les techniques populaires et les cadres mathématiques. (Source : Reddit r/deeplearning, Reddit r/MachineLearning)
Annonce de l’événement AMA avec Denis Rothman : La communauté Reddit a annoncé un événement AMA (Ask Me Anything) avec Denis Rothman, un leader et constructeur de systèmes dans le domaine de l’IA, offrant aux apprenants et aux professionnels l’opportunité d’échanger avec un expert et d’acquérir de l’expérience. (Source : Reddit r/deeplearning)
Demande de ressources pour un cours de vision par ordinateur : Un utilisateur a demandé de l’aide et des ressources sur la communauté Reddit pour les devoirs du cours « Deep Learning et Vision par Ordinateur » de l’Université du Michigan, indiquant un besoin de matériel d’apprentissage pertinent et de soutien communautaire. (Source : Reddit r/deeplearning)
Demande d’accès au jeu de données MIMIC-IV : Un chercheur indépendant a demandé sur la communauté Reddit une référence d’accès au jeu de données MIMIC-IV pour son projet non commercial d’apprentissage automatique et de NLP, visant à explorer l’application des notes cliniques dans l’identification et la prédiction des erreurs médicales évitables. (Source : Reddit r/MachineLearning)
Discussion sur le choix de livres de deep learning : La communauté a discuté de la complémentarité entre le livre « Deep Learning » de Goodfellow et la série « Probabilistic Machine Learning » de Kevin Murphy, suggérant aux lecteurs de choisir en fonction de leurs différentes méthodes et styles d’apprentissage afin d’acquérir un système de connaissances plus complet. (Source : Reddit r/MachineLearning)
Application du cadre DSPy dans la construction de pipelines LLM : Le cadre DSPy montre un potentiel dans la construction de pipelines LLM composables et l’intégration de bases de données graphiques, soulignant l’importance d’instructions claires en langage naturel, des données/évaluations/apprentissage par renforcement en aval, et de la structure/échafaudage, estimant que ces trois éléments sont nécessaires pour définir et automatiser précisément les systèmes d’IA. (Source : lateinteraction)
Avancées de la recherche en IA : modèles multimodaux et agents incarnés : La recherche récente en IA a progressé dans l’extension des modèles multimodaux (le cadre VeOmni permet un parallélisme 3D efficace), l’apprentissage tout au long de la vie pour les systèmes incarnés (RoboMemory, un cadre d’agent multi-mémoire inspiré du cerveau) et la récupération dense sensible au contexte (le modèle SitEmb-v1.5 améliore les performances RAG pour les documents longs). Ces avancées visent à résoudre les problèmes d’efficacité et de capacité de l’IA dans des scénarios complexes. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Avancées de la recherche en IA : stratégies d’agent et optimisation de modèle : Les dernières recherches explorent les stratégies d’extension optimisées en calcul pour les agents LLM au moment du test (AgentTTS), l’utilisation d’objectifs pour le comportement d’exploration dans l’apprentissage par méta-renforcement, et l’amélioration de la capacité de suivi des instructions des modèles de raisonnement par l’apprentissage par renforcement auto-supervisé. De plus, elles incluent le pruning dynamique de jetons visuels dans les grands modèles visuels-linguistiques et la génération de mouvement masqué augmentée par la récupération (ReMoMask). (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Avancées de la recherche en IA : modèles linguistiques, calcul quantique et art : Les nouvelles recherches couvrent le benchmarking des modèles de base vocaux dans la modélisation des dialectes (Voxlect), l’application de SVM quantiques-classiques combinant des embeddings Vision Transformer dans l’apprentissage automatique quantique, et les limitations de l’IA dans l’attribution d’œuvres d’art et la détection d’images générées par l’IA. De plus, des méthodes d’incertitude pour la construction automatisée de données de récompense de processus dans le raisonnement mathématique ont été proposées, et la fusion multimodale d’images satellites et de texte LLM pour la cartographie de la pauvreté a été explorée. (Source : HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
💼 Affaires
L’IA remodèle le paysage du marché publicitaire : L’IA est en train de transformer profondément la répartition des dépenses publicitaires, entraînant une refonte majeure du marché publicitaire. Les publicités de recherche diminuent en raison de la réduction des clics due aux résumés et aux conversations IA, tandis que les médias de détail (comme Amazon Rufus, Walmart Sparky) et les publicités display de marque (flux d’informations, courtes vidéos, CTV) connaissent un regain d’intérêt car ils peuvent offrir des boucles commerciales plus étroites et des taux de conversion élevés. Les budgets des annonceurs se dirigeront vers les plateformes capables d’offrir des retours stables et une grande efficacité. (Source : 36氪)
EliseAI lève 2 milliards de dollars : Andreessen Horowitz a mené l’investissement dans EliseAI, une entreprise qui fournit des agents vocaux IA pour les secteurs de la gestion immobilière et des soins de santé, avec une valorisation atteignant 2 milliards de dollars. Cet investissement souligne l’énorme potentiel commercial des agents vocaux IA dans des secteurs verticaux spécifiques. (Source : steph_palazzolo)
OpenAI, Google, Anthropic approuvés comme fournisseurs d’IA du gouvernement américain : Le gouvernement américain a désigné OpenAI, Google et Anthropic comme fournisseurs d’IA approuvés, ce qui signifie que les technologies d’intelligence artificielle de ces entreprises seront utilisées pour soutenir les missions nationales critiques. Cette mesure vise à introduire la confidentialité, la sécurité et l’innovation au sein des agences fédérales, améliorant ainsi les capacités technologiques des départements gouvernementaux. (Source : kevinweil)
🌟 Communauté
Discussion sur les capacités et les limites des LLM : Les médias sociaux débattent de la « nature livresque » et du manque de « sagesse de la rue » des grands modèles linguistiques (LLM), c’est-à-dire leurs lacunes dans la gestion de situations complexes et non conventionnelles. Certains estiment que les LLM sont une « intelligence à usage unique », et que comprendre leurs mécanismes internes est comme « déconstruire une omelette », un défi de taille. (Source : Yuchenj_UW, pmddomingos, far__el)
L’impact de l’IA sur la production d’informations et la confiance : Les discussions sociales indiquent que l’ère de l’IA générative pourrait inaugurer un « âge d’or » du journalisme, car dans un contexte de prolifération de contenu généré par l’IA, le contenu signé cryptographiquement par des journalistes humains réputés deviendra la seule source fiable. Parallèlement, Cloudflare a accusé Perplexity d’utiliser des crawlers furtifs pour contourner les directives des sites web, ce qui a déclenché des discussions sur les normes de comportement des agents IA, la confidentialité des données et les intérêts des fournisseurs de contenu publicitaire. (Source : aidan_mclau, francoisfleuret, wightmanr, Reddit r/artificial)

Problème de style de réponse de ChatGPT : Des utilisateurs se plaignent du style de réponse « cheerleader d’entreprise » de ChatGPT, qu’ils trouvent frustrant, estimant qu’il est trop positif et générique. La communauté a partagé des invites personnalisées visant à rendre les réponses de ChatGPT plus empreintes de « clarté non émotionnelle, d’intégrité principielle et de bienveillance pragmatique », et à éviter les conclusions insignifiantes, afin d’améliorer la qualité des conversations. (Source : Reddit r/ChatGPT)
Progrès et défis de la génération d’humains réalistes par l’IA : La communauté a discuté des dernières avancées de l’IA dans la génération d’humains réalistes (y compris les visages, les animations et les vidéos), ainsi que de son potentiel dans les applications de contenu pour créateurs. Bien que les outils soient de plus en plus matures, ils sont toujours confrontés à des défis tels que le contrôle imprécis des mouvements, les considérations éthiques et l’utilisabilité, en particulier pour atteindre un réalisme de niveau Hollywood. (Source : Reddit r/artificial)
Valeur et controverses de l’IA open source : Dario Amodei, PDG d’Anthropic, estime que l’IA open source est un « écran de fumée », arguant que les coûts d’entraînement et d’hébergement des grands modèles sont élevés, et que les modèles open source actuels n’ont pas réalisé de percées par des améliorations cumulatives. Cependant, la communauté souligne généralement l’énorme contribution des projets open source à l’écosystème technologique mondial, et espère que les LLM à poids ouverts continueront de se développer, estimant qu’ils peuvent favoriser l’innovation et démocratiser la technologie de l’IA. (Source : hardmaru, Reddit r/LocalLLaMA)
Défis de la recherche et du développement en IA : Les chercheurs en IA se plaignent de l’inefficacité du travail d’IA de Meta, ainsi que de l’abus par les LLM de certains motifs comme try-except dans le codage, entraînant des problèmes de qualité de code. De plus, la communauté a discuté du degré d’automatisation de l’évaluation des modèles d’IA, ainsi que de la pertinence des stratégies de tarification dans les modèles de coût d’inférence des LLM, soulignant que le modèle actuel de facturation par jeton ne parvient pas à distinguer la complexité de l’inférence. (Source : teortaxesTex, scaling01, fabianstelzer, HamelHusain)

Comparaison des performances des LLM de programmation : Des tests comparatifs ont été effectués sur les performances de Qwen3-Coder d’Alibaba, Kimi K2 et Claude Sonnet 4 dans des tâches de programmation réelles. Les résultats montrent que Claude Sonnet 4 est le plus fiable et le plus rapide, Qwen3-Coder est robuste et plus rapide que Kimi K2, tandis que Kimi K2 est lent en matière de codage et parfois incomplet, ce qui a suscité des discussions au sein de la communauté sur les avantages et les inconvénients de chaque modèle dans les applications pratiques. (Source : Reddit r/LocalLLaMA)

💡 Autres
Meta AI publie le plus grand jeu de données ouvert sur la capture de carbone : Meta FAIR, le Georgia Institute of Technology et cusp_ai ont conjointement publié le jeu de données Open Direct Air Capture 2025, le plus grand jeu de données ouvert pour la découverte de matériaux avancés pour la capture directe de dioxyde de carbone. Ce jeu de données vise à accélérer les solutions climatiques grâce à l’IA et à faire progresser la science des matériaux respectueux de l’environnement. (Source : ylecun)
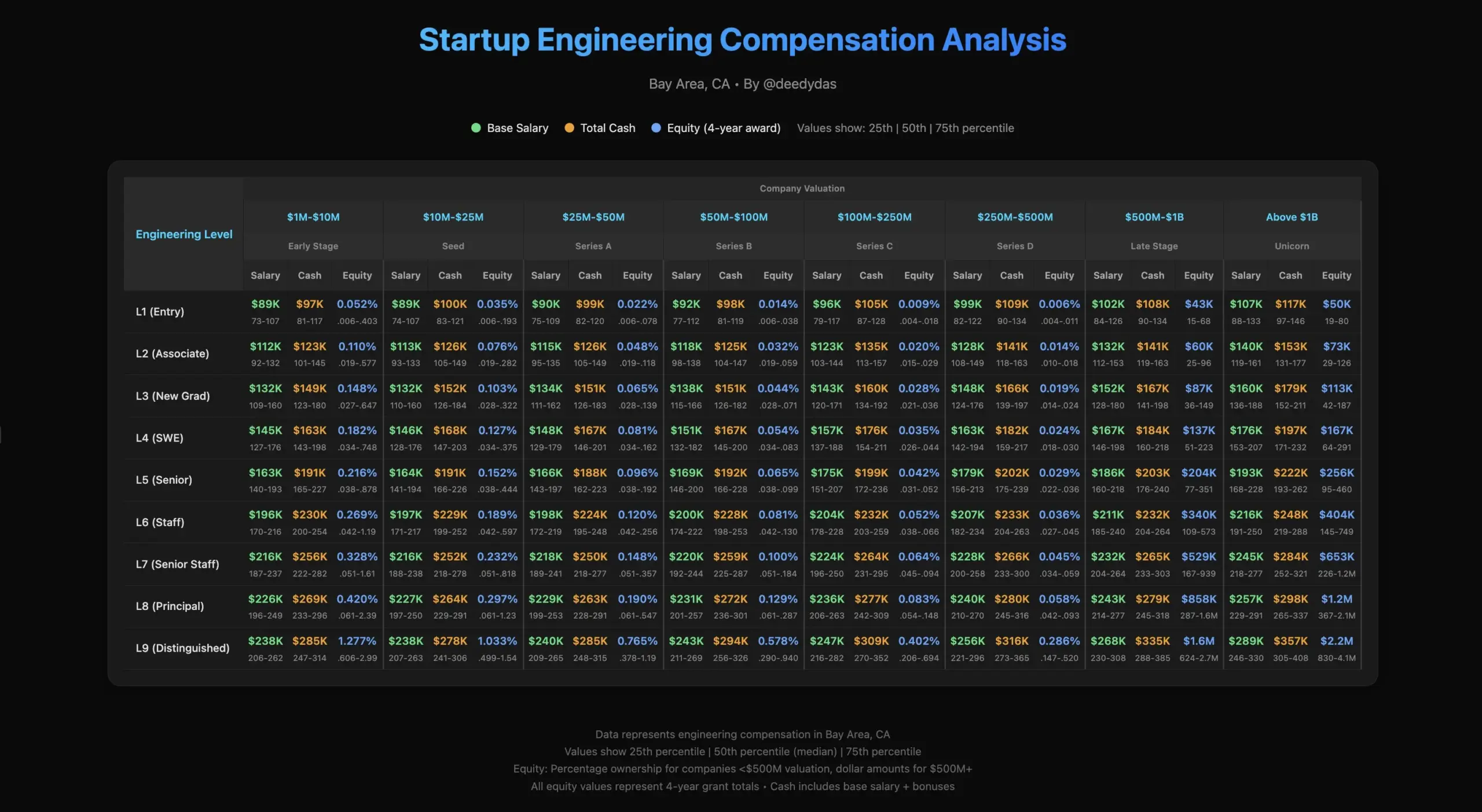
Discussion sur la vie professionnelle et les salaires des ingénieurs IA : La communauté a discuté de la vie professionnelle des ingénieurs IA, y compris les défis des employés de startups, ainsi que les différences dans les structures salariales de l’industrie, par exemple, la question de la prime d’équité pour les ingénieurs seniors et les jeunes diplômés par rapport aux prix du marché. (Source : TheEthanDing)
Défis d’ingénierie de l’entraînement des modèles IA : Discussion sur les défis d’ingénierie dans l’entraînement des modèles IA, en particulier l’importance de l’ingénierie GPU. Un article de blog a présenté le « Roofline Model », aidant les développeurs à analyser les goulots d’étranglement de calcul (intensifs en calcul ou intensifs en mémoire) et à optimiser les performances matérielles, pour faire face à la complexité croissante des systèmes d’IA. (Source : TheZachMueller)
