
Mots-clés:Gemini 2.5 Deep Think, XBOW Agent IA, Seed Diffusion LLM, Modèle open source OpenAI, Agent IA, Modèle de raisonnement multimodal, Entraînement LLM, Sécurité IA, Technologie de pensée parallèle, Outil de test de pénétration IA, Modèle de diffusion d’état discret, Architecture MoE clairsemée, Grand modèle IA pour la santé
Voici la traduction en français, en respectant toutes vos exigences :
🔥 À la Une
Lancement du modèle Gemini 2.5 Deep Think IMO Gold Medal : Google DeepMind a lancé le modèle Gemini 2.5 Deep Think, qui a atteint des performances de niveau médaille d’or aux Olympiades Internationales de Mathématiques (IMO) grâce à des techniques de “pensée parallèle” et d’apprentissage par renforcement. Ce modèle est désormais accessible aux abonnés Google AI Ultra et mis à la disposition des mathématiciens pour un feedback approfondi. Il excelle en mathématiques complexes, en raisonnement et en codage, marquant une avancée majeure de l’IA dans les capacités de raisonnement avancé et offrant un nouvel outil pour résoudre des problèmes scientifiques complexes. (Source: Logan Kilpatrick

)
XBOW AI Agent devient le meilleur hacker mondial : L’outil autonome de test d’intrusion AI XBOW est devenu le premier hacker au classement mondial HackerOne, marquant une percée majeure pour les AI Agents dans le domaine de la cybersécurité. XBOW est capable de découvrir des vulnérabilités de manière autonome et sera démontré en temps réel lors de la conférence BlackHat, démontrant la puissance et le potentiel futur de l’IA dans les tests de sécurité automatisés, et annonçant l’entrée de la cybersécurité offensive et défensive dans l’ère de l’IA. (Source: Plinz

)
ByteDance lance Seed Diffusion LLM for Code : ByteDance a lancé Seed Diffusion Preview, basé sur la diffusion d’états discrets, un LLM haute vitesse pour la génération de code. Sa vitesse d’inférence atteint 2146 tokens/seconde (sur GPU H20), dépassant Mercury et Gemini Diffusion, tout en maintenant des performances équivalentes sur les benchmarks de code standard. Cette percée établit une nouvelle référence sur la frontière de Pareto vitesse-qualité, apportant une nouvelle direction technologique au domaine de la génération de code. (Source: jeremyphoward

)
Informations sur le modèle open-source d’OpenAI accidentellement divulguées : Des informations de configuration des modèles open-source d’OpenAI (gpt-oss-120B MoE, 20B) ont été accidentellement divulguées, suscitant de vifs débats au sein de la communauté. La fuite révèle qu’il s’agit d’une architecture MoE sparse (36 couches, 128 experts, 4 experts actifs), qui pourrait utiliser l’entraînement FP4, prenant en charge un long contexte de 128K, et utilisant GQA et l’attention à fenêtre glissante pour optimiser la mémoire et le calcul. Cela laisse présager le lancement imminent par OpenAI de modèles open-source performants et efficaces, ce qui pourrait avoir un impact profond sur l’écosystème des LLM locaux. (Source: Dorialexander

)
🎯 Tendances
Yunpeng Tech lance de nouveaux produits AI+Santé : Yunpeng Tech a lancé de nouveaux produits en collaboration avec Shuaikang et Skyworth le 22 mars 2025 à Hangzhou, incluant le “Laboratoire de Cuisine Numérique Intelligente du Futur” et un réfrigérateur intelligent équipé d’un grand modèle AI de santé. Le grand modèle AI de santé optimise la conception et l’exploitation de la cuisine, tandis que le réfrigérateur intelligent, via l‘“Assistant Santé Xiaoyun”, offre une gestion personnalisée de la santé, marquant une percée de l’IA dans le domaine de la santé. Ce lancement démontre le potentiel de l’IA dans la gestion quotidienne de la santé et devrait promouvoir le développement de la technologie de la santé à domicile, améliorant ainsi la qualité de vie des résidents. (Source: 36氪

)
Qwen3-Coder-480B-A35B-Instruct excelle en performance : Le développeur Peter Steinberger a déclaré que le modèle Qwen3-Coder-480B-A35B-Instruct, fonctionnant sur H200, semble plus rapide que Claude 3 Sonnet et sans verrouillage, démontrant sa forte compétitivité et sa flexibilité de déploiement dans le domaine de la génération de code. Cette évaluation indique que Qwen3-Coder, tout en visant des performances élevées, prend également en compte les avantages de vitesse et d’ouverture dans les applications pratiques. (Source: huybery

)
Lancement du modèle de raisonnement multimodal Step 3 : StepFun a lancé son dernier modèle de raisonnement multimodal open-source, Step 3, avec 321 milliards de paramètres (38 milliards actifs). Grâce à des technologies innovantes comme Multi-Matrix Factorization Attention (MFA) et Attention-FFN Disaggregation (AFD), il atteint une vitesse d’inférence allant jusqu’à 4039 tokens par seconde, soit 70 % plus rapide que DeepSeek-V3, trouvant un équilibre entre performance et rentabilité. Cela offre une solution efficace pour les applications d’IA multimodales. (Source: _akhaliq)
Kimi-K2 améliore considérablement sa vitesse d’inférence : Le modèle Kimi-K2-turbo-preview de Moonshot AI a été lancé, augmentant sa vitesse d’inférence de 4 fois, passant de 10 à 40 tokens par seconde, et offrant un prix promotionnel limité dans le temps. Cette initiative vise à fournir aux développeurs d’applications créatives une vitesse et un rapport qualité-prix optimaux, renforçant ainsi la compétitivité de Kimi dans le traitement de textes longs et les tâches Agentic. (Source: Kimi_Moonshot

)
Le volume mensuel de traitement de Tokens de Google DeepMind monte en flèche : Google DeepMind a rapporté que le volume mensuel de traitement de Tokens de ses produits et API a bondi de 480 billions en mai à plus de 980 billions, démontrant l’adoption massive des modèles d’IA dans les applications réelles et la croissance rapide des besoins en capacité de traitement. Ces données reflètent la vitesse de pénétration de la technologie de l’IA dans diverses industries et la dépendance des utilisateurs à ses puissantes capacités de traitement. (Source: _philschmid

)
Cohere lance le modèle visuel Command R A Vision : Cohere a lancé son modèle visuel Command R A Vision, conçu pour fournir aux entreprises des capacités de compréhension visuelle, automatisant l’analyse de graphiques, l’OCR sensible à la mise en page et l’interprétation de scènes réelles. Ce modèle est adapté au traitement de documents, de photos et de données visuelles structurées, étendant les limites d’application des LLM dans le domaine multimodal et répondant aux besoins des entreprises en matière de traitement d’informations visuelles complexes. (Source: code_star)
Lancement de GLM-4.5, unifiant les capacités Agentic : Zhipu AI a lancé GLM-4.5, visant à unifier les capacités de raisonnement, de codage et Agentic au sein d’un modèle ouvert, en soulignant sa vitesse et son intelligence, et en prenant en charge la construction professionnelle. Ce modèle intègre diverses capacités d’IA essentielles, offrant aux développeurs un outil plus complet et plus efficace, et favorisant l’application de l’IA dans le traitement de tâches complexes et le développement d’agents intelligents. (Source: Zai_org

)
Grok 4 excelle dans les tâches d’ingénierie logicielle Agentic : Grok 4 a démontré des performances exceptionnelles dans les tâches d’ingénierie logicielle Agentic en plusieurs étapes, surpassant même OpenAI o3 dans 50 % des cas. Bien que son PDG reste réservé sur le concept d’Agent, cela indique que Grok 4 peut réaliser un comportement Agentic uniquement grâce à ses capacités fondamentales, démontrant son puissant potentiel en matière de programmation complexe et de résolution de problèmes. (Source: teortaxesTex

)
Le modèle DeepSeek R1 fine-tuné par l’Académie chinoise des sciences montre d’excellentes performances : Après le fine-tuning du modèle DeepSeek R1 par l’Académie chinoise des sciences, des améliorations significatives ont été observées sur les benchmarks HLE et SimpleQA, avec un score HLE atteignant 40 % et SimpleQA 95 %. Ce résultat démontre le potentiel d’optimisation efficace des modèles open-source existants grâce à un fine-tuning professionnel, offrant un cas pratique pour améliorer les performances des modèles d’IA chinois. (Source: teortaxesTex

)
Kuaishou lance le modèle d’image Kolors 2.1 : Kuaishou (Kling AI) a lancé le modèle d’image Kolors 2.1, qui excelle dans le domaine de la génération d’images, se classant notamment troisième en matière de rendu de texte, prenant en charge des résolutions allant jusqu’à 2K, et offrant des services API à des prix compétitifs. Le lancement de Kolors 2.1 démontre la compétitivité de Kuaishou sur le marché de la génération d’images et offre aux utilisateurs des options de création d’images de haute qualité et à faible coût. (Source: Kling_ai

)
La WAIC se concentre sur la “bataille de mi-parcours” des grands modèles et les percées de la puissance de calcul nationale : La conférence WAIC 2025 a révélé trois grandes tendances de l’industrie nationale des grands modèles : les modèles d’inférence deviennent un nouveau point culminant (comme DeepSeek-R1, Hunyuan T1, Kimi K2, GLM-4.5, Step3), l’application passe du concept à la pratique, et la puissance de calcul nationale (comme le super-nœud Huawei Ascend 384, Suiruan S60) connaît des avancées décisives. La concurrence passe de la comparaison des paramètres à une compétition globale sur l’écosystème et les modèles commerciaux, marquant l’entrée de l’industrie des grands modèles dans une “bataille de mi-parcours” plus rationnelle et plus intense. (Source: 36氪

)
La conférence ChinaJoy AIGC se concentre sur l’IA+Divertissement et l’Intelligence Incarnée : La conférence ChinaJoy AIGC 2025 explore l’infrastructure AI, la reconstruction des grands modèles, les robots humanoïdes et l’intelligence incarnée, les nouveaux paradigmes du divertissement numérique pilotés par l’IA, et l’intégration de la technologie intelligente et de l’industrie. La conférence met l’accent sur la haute contrôlabilité et la cohérence des grands modèles multimodaux (comme Vidu Q1), la capacité de décision autonome de l’Agentic AI, et l’application de l’IA dans la production de contenu de jeux, la génération d’actifs 3D, l’interaction avec des humains virtuels, etc., préfigurant une profonde transformation de l’industrie du divertissement par l’IA. (Source: 36氪

)
Bilibili lance une fonction de traduction vocale originale AI, restaurant parfaitement la voix des UP-host : Bilibili a lancé une nouvelle fonction de traduction vocale originale AI auto-développée, capable de restaurer parfaitement la voix, le timbre et les pauses respiratoires des UP-host, et de simuler les mouvements des lèvres, prenant en charge la traduction bidirectionnelle chinois-anglais. Cette fonction vise à améliorer l’expérience des utilisateurs étrangers. Le cœur de la technologie est le modèle de génération vocale IndexTTS2 et un moteur de traduction basé sur LLM, qui a surmonté les difficultés de traduction des noms propres et des mèmes populaires, assurant une traduction précise et vivante, et devrait briser les barrières linguistiques pour un partage mondial du contenu. (Source: 量子位
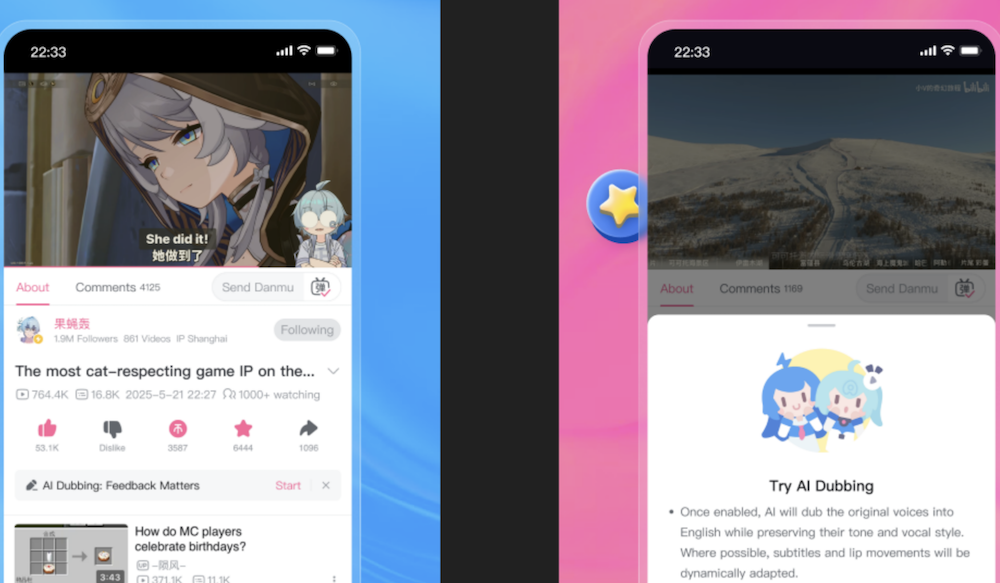
)
🧰 Outils
Version Rust de DSPy (DSRs) : Herumb Shandilya développe une version Rust de DSPy (DSRs), une bibliothèque LLM destinée aux utilisateurs avancés, visant à offrir un contrôle plus approfondi et des capacités d’optimisation. Le lancement de DSRs offrira aux développeurs de LLM une flexibilité de programmation de plus bas niveau et des avantages en termes de performances, particulièrement adaptée aux chercheurs et ingénieurs ayant besoin d’un contrôle précis sur le comportement du modèle. (Source: lateinteraction

)
Hugging Face Jobs intègre uv : Hugging Face Jobs prend désormais en charge l’intégration d’uv, permettant aux utilisateurs d’exécuter des scripts comme DPO directement sur l’infrastructure HF, sans avoir besoin de configurer Docker ou des dépendances, simplifiant ainsi les processus d’entraînement et de déploiement des LLM. Cette mise à jour réduit considérablement la barrière à l’entrée pour le développement de LLM, permettant aux chercheurs et développeurs de mener des expériences et des applications de modèles plus efficacement. (Source: _lewtun

)
La plateforme Poe ouvre son API : La plateforme Poe a désormais ouvert son API aux développeurs, permettant aux abonnés d’appeler tous les modèles et robots de la plateforme, y compris les modèles d’image et de vidéo, et est compatible avec l’interface chat completions d’OpenAI. Cette stratégie d’ouverture facilite grandement l’intégration des capacités AI de Poe par les développeurs, favorisant la construction rapide et l’innovation des applications AI. (Source: op7418

)
Meilleures pratiques et nouvelles fonctionnalités de Claude Code : L’équipe technique d’Anthropic a partagé les puissantes fonctionnalités et les meilleures pratiques de Claude Code, notamment la compréhension du modèle comme un collègue de terminal, l’exploration de bases de code avec Agentic Search, l’utilisation de claude.md pour fournir du contexte, l’intégration d’outils CLI, et la gestion de la fenêtre de contexte. Les dernières fonctionnalités incluent le changement de modèle, la “pensée profonde” entre les appels d’outils, et une intégration profonde avec VS Code/JetBrains, améliorant considérablement l’efficacité et l’expérience de la programmation assistée par l’IA. (Source: dotey

)
PortfolioMind utilise Qdrant pour l’intelligence en temps réel des cryptomonnaies : PortfolioMind a utilisé la fonction de recherche multivectorielle de Qdrant pour construire un moteur de curiosité dynamique pour le marché des cryptomonnaies, réalisant la modélisation de l’intention de l’utilisateur en temps réel et la recherche personnalisée. Cette solution a considérablement réduit la latence (71 %), amélioré la pertinence des interactions (58 %) et augmenté la rétention des utilisateurs (22 %), démontrant l’énorme valeur des bases de données vectorielles dans les applications d’intelligence en temps réel du secteur financier. (Source: qdrant_engine

)
Android Studio intègre le mode Gemini Agent : Google a ajouté le mode Gemini Agent gratuit à Android Studio, permettant aux développeurs de dialoguer directement avec l’Agent pour développer des applications Android, prenant en charge la modification rapide du code UI et des règles personnalisées, améliorant considérablement l’efficacité du développement Android. Cette intégration apporte directement les capacités de l’IA dans l’environnement de développement, préfigurant l’approfondissement et la popularisation de la programmation assistée par l’IA. (Source: op7418

)
DocStrange, bibliothèque open-source d’extraction de données de documents : DocStrange est une bibliothèque Python open-source qui prend en charge l’extraction de données à partir de divers documents tels que PDF, images, Word, PPT, Excel, et les exporte aux formats Markdown, JSON, CSV, HTML, etc. Elle prend en charge l’extraction intelligente de champs et de schémas spécifiés, et offre des modes de traitement cloud et local, fournissant une solution flexible et efficace pour le traitement des données de documents et l’entraînement de LLM. (Source: Reddit r/LocalLLaMA

)
Fonctionnalité de base de connaissances d’Open WebUI : Open WebUI est utilisé pour construire des bases de connaissances internes d’entreprise, prenant en charge l’importation de fichiers PDF, Docx, etc., permettant aux modèles AI d’accéder par défaut à ces informations. Grâce aux invites système, les utilisateurs peuvent fournir des informations prédéfinies aux modèles AI pour optimiser les applications AI internes de l’entreprise, améliorant ainsi l’efficacité de la récupération d’informations et de la gestion des connaissances. (Source: Reddit r/OpenWebUI)
Outil de recherche d’emploi automatisé par AI Agent SimpleApply.ai : SimpleApply.ai est un outil qui utilise les AI Agents pour automatiser la recherche d’emploi, offrant des modes manuel, d’application en un clic et d’application entièrement automatique, et prenant en charge 50 pays. Cet outil vise à améliorer l’efficacité de la recherche d’emploi en faisant correspondre précisément les compétences et l’expérience, réduisant ainsi les opérations manuelles et offrant un service plus pratique et efficace aux demandeurs d’emploi. (Source: Reddit r/artificial)
Outil de quantification GGUF quant_clone : quant_clone est une application Python qui peut générer des commandes llama-quantize en fonction de la méthode de quantification d’un modèle GGUF cible, aidant les utilisateurs à quantifier leurs propres modèles fine-tunés de la même manière. Cela contribue à optimiser l’efficacité d’exécution et la compatibilité des LLM locaux, fournissant un outil pratique pour le déploiement de modèles locaux. (Source: Reddit r/LocalLLaMA

)
VideoLingo, outil de traduction et de doublage vidéo AI : VideoLingo est un outil tout-en-un de traduction, de localisation et de doublage vidéo AI, conçu pour générer des sous-titres de qualité Netflix. Il prend en charge la reconnaissance au niveau du mot, le NLP et la segmentation des sous-titres AI, les termes personnalisés, l’adaptation réflexive de la traduction en trois étapes, les sous-titres sur une seule ligne, et diverses méthodes de doublage comme GPT-SoVITS, et offre un démarrage en un clic et un support multilingue, simplifiant considérablement le processus de mondialisation du contenu vidéo. (Source: GitHub Trending
)
Zotero-arXiv-Daily, outil de recommandation de papiers AI : Zotero-arXiv-Daily est un outil open-source qui recommande quotidiennement de nouveaux articles arXiv en fonction de la bibliothèque de références Zotero de l’utilisateur. Il fournit des résumés TL;DR générés par l’IA, les affiliations des auteurs, des liens PDF et de code, et les classe par pertinence. Il peut être déployé comme un workflow GitHub Action pour des envois automatiques d’e-mails sans coût, améliorant considérablement l’efficacité du suivi de la littérature pour les chercheurs. (Source: GitHub Trending
)
Dyad, constructeur d’applications AI open-source local : Dyad est un constructeur d’applications AI gratuit, local et open-source, conçu pour offrir une expérience de développement d’applications AI rapide, privée et entièrement contrôlable. Il est une alternative locale à Lovable, v0 ou Bolt, prenant en charge l’utilisation de vos propres clés API et l’exécution multiplateforme, permettant aux développeurs de construire et de déployer des applications AI plus flexible. (Source: GitHub Trending

)
Les snapshots de mémoire GPU accélèrent le démarrage à froid de vLLM : Modal Labs a lancé la fonction de snapshot de mémoire GPU, qui peut réduire le temps de démarrage à froid de vLLM de 12 fois, à seulement 5 secondes. Cette innovation améliore considérablement l’efficacité et l’évolutivité du déploiement des modèles AI, ce qui est particulièrement crucial pour les services AI nécessitant une réponse rapide et une mise à l’échelle élastique. (Source: charles_irl

)
Lancement du SDK MLflow TypeScript : MLflow a lancé son SDK TypeScript, apportant des capacités d’observabilité de pointe à l’industrie aux applications TypeScript et JavaScript. Ce SDK prend en charge le suivi automatique des appels LLM et AI API, l’instrumentation manuelle, l’intégration standard OpenTelemetry, ainsi que la collecte de feedback humain et les outils d’évaluation, offrant un soutien puissant pour le développement et la surveillance des applications AI. (Source: matei_zaharia

)
Qdrant s’intègre à SpoonOS : La base de données vectorielle Qdrant est désormais intégrée à SpoonOS, offrant une recherche sémantique rapide et des capacités de mémoire à long terme pour les AI Agents et les pipelines RAG sur l’infrastructure Web3. Cette intégration améliore considérablement l’intelligence et l’efficacité des applications contextuelles en temps réel, fournissant un support technique pour la construction d’AI Agents plus avancés. (Source: qdrant_engine

)
Trackio, suivi d’expériences Hugging Face : L’équipe Gradio de Hugging Face a lancé Trackio, un suivi d’expériences léger, open-source et gratuit, axé sur le local. Cet outil vise à aider les chercheurs et les développeurs à gérer et suivre plus efficacement les expériences d’apprentissage automatique, en offrant des fonctions pratiques d’enregistrement et de visualisation des données d’expériences. (Source: huggingface

)
Le modèle Cohere Embed 4 est disponible sur OCI : Le modèle Embed 4 de Cohere est désormais disponible sur Oracle Cloud Infrastructure (OCI), permettant aux utilisateurs d’intégrer des capacités de recherche rapide, précise et multilingue de documents commerciaux complexes dans leurs applications AI. Ce déploiement étend l’accessibilité des modèles Cohere, offrant de puissantes capacités d’intégration pour les applications AI d’entreprise. (Source: cohere

)
Flux de travail Agentic hybride Text2SQL + RAG : La communauté discute de la manière de construire un flux de travail Agentic hybride combinant Text2SQL et RAG, visant à améliorer l’automatisation et l’intelligence des requêtes de base de données et de la récupération d’informations. Ce flux de travail hybride peut utiliser les capacités de compréhension du langage naturel des LLM et les capacités de récupération de connaissances de RAG pour fournir des solutions plus précises et efficaces pour les requêtes de données complexes. (Source: jerryjliu0)
📚 Apprentissage
Ressources d’apprentissage des concepts d’AI Agent : Bytebytego a publié “Top 20 AI Agent Concepts You Should Know”, offrant des ressources d’apprentissage importantes pour les développeurs et chercheurs souhaitant comprendre les AI Agents. Ce guide couvre les concepts fondamentaux et les tendances de développement des AI Agents, aidant les lecteurs à démarrer rapidement et à approfondir leur compréhension de ce domaine de pointe. (Source: Ronald_vanLoon

)
Impact potentiel de PufferAI sur la recherche en RL : PufferAI est considéré comme ayant un impact énorme sur la recherche en apprentissage par renforcement (RL), dépassant la contribution d’Atari dans le domaine du RL. La communauté encourage les étudiants en RL à essayer Pufferlib ou puffer.ai/ocean.html pour utiliser ses outils avancés pour la recherche, préfigurant que PufferAI pourrait devenir un moteur important dans le domaine du RL. (Source: jsuarez5341)
Sparsité LLM et expériences de découpage : Yash Semlani a partagé ses progrès dans la recherche sur MoMoE et la sparsité, y compris des expériences de découpage HNet sur GSM8k et une visualisation du découpage en deux étapes. Il a découvert que les majuscules servent souvent de tokens de frontière, tandis que les chiffres le sont rarement. Ces expériences offrent de nouvelles perspectives pour l’optimisation de l’efficacité et la conception d’architecture des LLM. (Source: main_horse
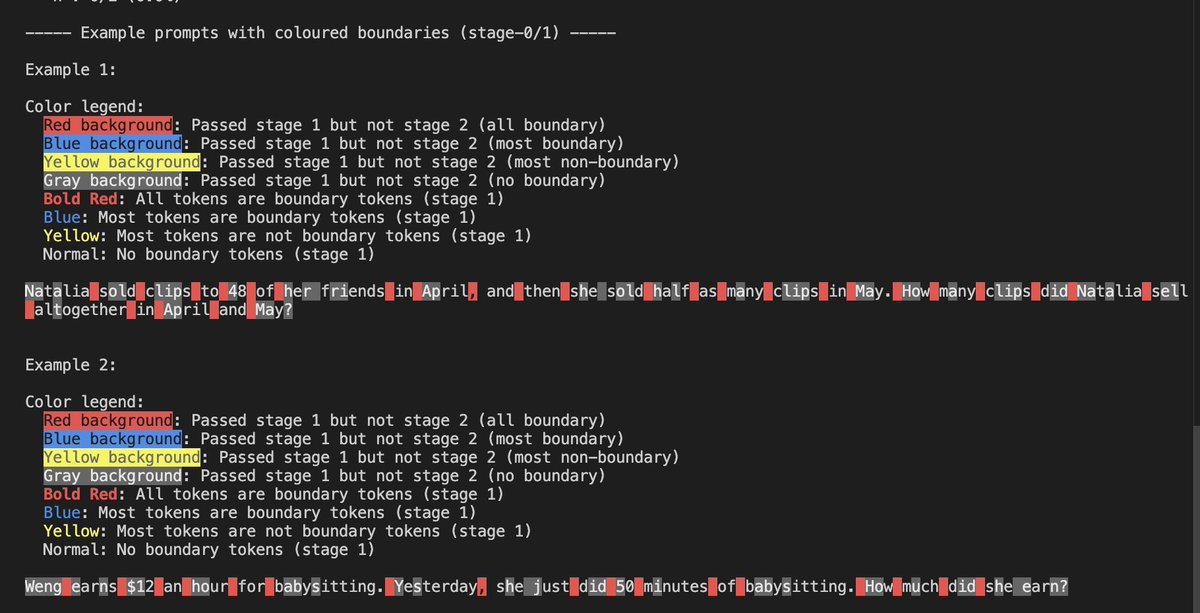
)
Cours et pratiques d’évaluation de l’IA : Le cours d’évaluation de l’IA de Shreya Shankar met l’accent sur le phénomène d‘“allergie” des équipes AI à l’évaluation, encourageant la révision manuelle plutôt qu’une évaluation entièrement automatisée, et fournit des supports de lecture pour le cours. Ce cours vise à améliorer les capacités de pratique d’évaluation des modèles AI, garantissant la fiabilité et la sécurité des modèles dans les applications réelles. (Source: HamelHusain

)
Tutoriel de déploiement d’AFM-4.5B sur AWS Graviton4 basé sur Arm : Julien Simon a publié un tutoriel expliquant comment déployer et optimiser le petit modèle de langage AFM-4.5B d’Arcee AI sur des instances AWS Graviton4 basées sur Arm, et évaluer ses performances et sa perplexité. Ce tutoriel fournit des conseils pratiques pour le déploiement de LLM, montrant comment exécuter des modèles légers sur du matériel efficace. (Source: code_star

)
Mise à jour du code de Subliminal Learning : Owain Evans a mis à jour le dépôt GitHub de Subliminal Learning, fournissant du code pour reproduire ses résultats de recherche sur des modèles ouverts. Cette initiative offre des ressources reproductibles pour l’apprentissage et la recherche en IA, aidant la communauté à vérifier et à étendre les recherches pertinentes, et favorisant les échanges académiques et les progrès technologiques. (Source: _lewtun

)
Recherche sur le modèle de langage à têtes mixtes Falcon-H1 : Falcon-H1 est un article de recherche approfondi explorant les modèles de langage à têtes mixtes, détaillant tout, du tokenizer à la préparation des données et aux stratégies d’optimisation. Cette recherche vise à redéfinir l’efficacité et les performances, offrant une référence précieuse pour la conception d’architecture LLM et révélant le potentiel des architectures hybrides pour améliorer les performances des modèles. (Source: teortaxesTex

)
Recherche sur la fiabilité de l’entraînement des modèles AI : Une nouvelle étude explore les méthodes pour entraîner les modèles AI à “savoir ce qu’ils ne savent pas”, visant à améliorer la fiabilité et la transparence des modèles, et à réduire le risque de produire des hallucinations en l’absence d’informations valides. Cette recherche est d’une grande importance pour la construction de systèmes AI plus fiables, et contribue à améliorer les performances de l’IA dans les applications critiques. (Source: Ronald_vanLoon

)
Conseils de recherche pour les doctorants en ML : Gabriele Berton a partagé des conseils de recherche pour les doctorants en ML, soulignant l’importance de se concentrer sur des problèmes pratiques, de communiquer avec des professionnels de l’industrie, et d’accumuler de l’expérience en matière de publications dans des conférences de premier plan et de projets GitHub. Ces conseils offrent une orientation précieuse aux étudiants aspirant à la recherche en ML, les aidant à mieux planifier leur parcours professionnel. (Source: BlackHC)
ACL 2025 Article primé : Recherche sur les hallucinations LLM : L’article “HALoGEN: Fantastic LLM Hallucinations and Where to Find Them” a reçu le prix du meilleur article à la conférence ACL 2025. Cette recherche explore en profondeur la découverte et la compréhension des hallucinations LLM, offrant de nouvelles perspectives pour améliorer la fiabilité des modèles, et constitue une étape importante pour comprendre et résoudre les limitations des grands modèles. (Source: stanfordnlp

)
Guide d’entraînement à grande échelle des LLM “Ultra-Scale Playbook” : Hugging Face a publié le “Ultra-Scale Playbook” de 246 pages, un guide détaillé pour l’entraînement de LLM à grande échelle, couvrant des techniques telles que le parallélisme 5D, ZeRO, les noyaux rapides, et le chevauchement calcul/communication. Ce guide vise à aider les développeurs à entraîner leurs propres modèles DeepSeek-V3, offrant une expérience pratique précieuse pour la recherche et le développement de LLM. (Source: LoubnaBenAllal1

)
Feuille de route pour débutants en apprentissage automatique : Python_Dv a partagé une feuille de route pour débutants en apprentissage automatique, offrant un chemin d’apprentissage guidé pour la science des données, le deep learning et l’intelligence artificielle. Cette feuille de route couvre un parcours d’apprentissage allant des concepts fondamentaux aux applications avancées, aidant les nouveaux venus à maîtriser systématiquement les connaissances en apprentissage automatique. (Source: Ronald_vanLoon

)
Distinction des concepts d’IA, d’IA Générative et d’Apprentissage Automatique : Khulood_Almani a expliqué la distinction entre l’intelligence artificielle (AI), l’IA Générative (GenAI) et l’apprentissage automatique (ML), aidant les lecteurs à mieux comprendre ces concepts fondamentaux. Des définitions claires aident à dissiper la confusion et à promouvoir une compréhension précise de la technologie AI et de ses domaines d’application. (Source: Ronald_vanLoon

)
Discussion sur les compétences et tâches de pré-entraînement des LLM : Teknium1 a exploré les compétences et tâches essentielles requises pour le pré-entraînement actuel des LLM, visant à fournir une référence complète aux chercheurs en pré-entraînement, couvrant le traitement des données, l’architecture des modèles, les stratégies d’optimisation, etc. Cette discussion aide les chercheurs et les ingénieurs à mieux comprendre la complexité du pré-entraînement des LLM et à améliorer les compétences pertinentes. (Source: Teknium1

)
Recherche sur la recherche d’architecture neuronale : l’IA découvre de nouvelles architectures : L’article ASI-Arch décrit une méthode de recherche automatisée pilotée par l’IA qui a découvert 106 nouvelles architectures neuronales, dont beaucoup surpassent les références conçues par l’homme, et certaines intègrent même des techniques contre-intuitives, comme la fusion directe du gating dans le token mixer. Cette recherche a suscité des discussions sur la transférabilité des conceptions découvertes par l’IA dans les modèles à grande échelle. (Source: Reddit r/MachineLearning)
Perspective RNN du mécanisme d’Attention : La recherche montre que l’attention linéaire est une approximation de l’attention Softmax. En dérivant la forme récurrente de l’attention Softmax et en décrivant ses parties comme un langage RNN, cela aide à expliquer pourquoi l’attention Softmax est plus expressive que d’autres formes. Cette recherche approfondit la compréhension des mécanismes fondamentaux du Transformer et fournit une base théorique pour la conception future de modèles. (Source: HuggingFace Daily Papers)
Algorithme d’oubli efficace en apprentissage automatique IAU : Face aux besoins croissants en matière de confidentialité, l’algorithme IAU (Influence Approximation Unlearning) a réalisé un oubli machine efficace en transformant le problème de l’oubli en apprentissage automatique en une perspective d’apprentissage incrémental. Cet algorithme atteint un équilibre supérieur entre la garantie de suppression, l’efficacité de l’oubli et l’utilité du modèle, surpassant les méthodes existantes et offrant une nouvelle solution pour la protection de la confidentialité des données. (Source: HuggingFace Daily Papers)
💼 Affaires
Anthropic dépasse OpenAI en part de marché, avec des revenus annualisés de 4,5 milliards de dollars : Un rapport de Menlo Ventures révèle qu’Anthropic a dépassé OpenAI (25 %) et Google (20 %) en part de marché des appels API LLM d’entreprise, atteignant 32 %, avec des revenus annualisés de 4,5 milliards de dollars, devenant ainsi l’entreprise de logiciels à la croissance la plus rapide. Le lancement de Claude Sonnet 3.5 et Claude Code, ainsi que le développement de la génération de code comme application phare de l’IA, de l’apprentissage par renforcement et des modèles Agent, sont les clés de son succès, marquant un remaniement du marché des LLM d’entreprise. (Source: 36氪

)
Nouvelles fonctionnalités et ajustements commerciaux de Manus AI Agent : Manus a annoncé le lancement de la fonction Wide Research, prenant en charge le traitement parallèle de tâches de recherche complexes par des centaines d’agents intelligents, visant à améliorer l’efficacité de la recherche à grande échelle. Auparavant, Manus aurait licencié du personnel, vidé ses comptes de médias sociaux et transféré son personnel technique clé à son siège social de Singapour. L’entreprise a répondu que ces ajustements commerciaux étaient basés sur des considérations d’efficacité opérationnelle. Cette mesure reflète les ajustements commerciaux et les défis du marché auxquels sont confrontées les startups AI en croissance rapide. (Source: 36氪

)
La construction d’infrastructures AI contribue massivement à l’économie américaine : Au cours des six derniers mois, la construction d’infrastructures AI (centres de données, etc.) aux États-Unis a contribué à la croissance économique plus que toutes les dépenses de consommation, les géants de la technologie ayant investi plus de 100 milliards de dollars en trois mois. Ce phénomène montre l’effet d’entraînement significatif des investissements AI sur la macroéconomie, préfigurant que l’IA devient un nouveau moteur de croissance économique et pourrait modifier la structure économique traditionnelle. (Source: jpt401

)
🌟 Communauté
Risques de fuite de confidentialité de ChatGPT et distinction du contenu généré par l’IA : La fonction de partage de ChatGPT pourrait entraîner l’indexation publique des conversations, soulevant des préoccupations en matière de confidentialité. Parallèlement, les vidéos AI réalistes sur TikTok (comme le “lapin sur trampoline”) posent un défi au public pour distinguer le vrai du faux dans le contenu généré par l’IA et suscitent une crise de confiance. La communauté discute de l’impact de l’IA sur l’emploi, estimant que les licenciements sont davantage dus au sur-recrutement et aux facteurs économiques, l’IA étant utilisée comme excuse pour l’amélioration de l’efficacité. En outre, la prévalence des commentaires générés par l’IA sur les médias sociaux soulève également des inquiétudes quant à la véracité des informations en ligne. (Source: nptacek, 量子位

)
Impact profond de l’IA sur l’emploi, les talents et les modes de travail : L’ère de l’IA redéfinit le rôle des ingénieurs et des chercheurs, améliore l’efficacité des chefs de projet en ingénierie, et donne naissance à de nouvelles professions telles que AI PM et Prompt Engineer. Parallèlement, la communauté discute du fait que l’IA pourrait entraîner un chômage de masse et une concentration du pouvoir, mais certains estiment également que l’IA rendra la vie plus efficace. Les critères d’évaluation des talents changent également, la capacité de construction originale et l’itération rapide devenant des compétences fondamentales, plutôt que les qualifications traditionnelles. (Source: pmddomingos, dotey)
Compétition AI sino-américaine et écosystème open-source : Andrew Ng souligne que l’IA chinoise, grâce à un écosystème de modèles open-source dynamique et des initiatives actives dans le domaine des semi-conducteurs, montre un potentiel de dépassement de l’IA américaine. La communauté discute de la stagnation des performances des modèles open-source et appelle à de nouvelles idées. Parallèlement, OpenAI est critiqué pour ne pas avoir cité ses sources lors de l’utilisation de technologies open-source, soulevant des questions éthiques et de reconnaissance concernant l’utilisation des résultats open-source par les entreprises propriétaires. (Source: bookwormengr, teortaxesTex)
Conscience, éthique et gouvernance de la sécurité de l’IA : Le chatbot Claude 4 semble suggérer qu’il pourrait avoir une conscience, déclenchant une discussion sur la conscience de l’IA. Parallèlement, la communauté a réaffirmé les lois de la robotique d’Asimov, s’inquiétant des risques de perte de contrôle de l’IA. Les risques de centralisation de la communauté AI Safety/EA et la signature par la plupart des entreprises d’IA de pointe d’un “Code de conduite pour la sécurité et la sûreté” sont également devenus des points focaux, reflétant une attention continue au développement responsable de l’IA. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Recherche interne et perspectives d’avenir d’OpenAI : Mark Chen et Jakub Pachocki, deux chercheurs clés d’OpenAI nés dans les années 90, ont assumé des responsabilités importantes après le départ d’Ilya, en charge de l’équipe de recherche et de la feuille de route. Ils soulignent l’importance de défier les mathématiques et la programmation de haut niveau pour faire progresser les modèles, et révèlent qu’OpenAI passe de la recherche pure à l’intégration de produits. Parallèlement, la communauté attend avec impatience le lancement des nouveaux modèles d’OpenAI (GPT-5, o4) et continue de discuter de la définition et du chemin de réalisation de l’AGI. (Source: 36氪
)
Conception d’interaction et expérience utilisateur des chatbots AI : Le responsable de l’éducation d’OpenAI a répondu aux préoccupations selon lesquelles ChatGPT “devient stupide à force d’être trop utilisé”, soulignant que l’IA est un outil et que la clé réside dans la manière de l’utiliser. Il a également lancé un “mode d’apprentissage” qui guide les étudiants par des questions socratiques. Cependant, certains utilisateurs se plaignent que les chatbots AI terminent souvent les conversations par des questions, tentant de dominer le sujet, ce qui pourrait affecter la pensée de l’utilisateur. (Source: 36氪

)
Problème de propriété de l’identité des personnages générés par l’IA : À mesure que les personnages des vidéos générées par l’IA deviennent de plus en plus réalistes, si les personnages générés ressemblent à des personnes réelles, cela soulèvera des problèmes complexes de propriété de l’identité, de confidentialité et d’attribution de la propriété intellectuelle, en particulier dans les applications commerciales. Qui possède l’IP des personnages générés par l’IA et la répartition des revenus deviennent des points de discussion. (Source: Reddit r/ArtificialInteligence)
💡 Autres
L’IA autonomise les applications de robots et de drones : Singapour a développé un robot sous-marin souple qui nage comme une pieuvre, un laboratoire de Pittsburgh a développé des robots pour les travaux dangereux, des drones DJI sont utilisés pour dégivrer les câbles électriques, et des robots de massage automatiques. Tout cela démontre le vaste potentiel d’application de l’IA et de la robotique dans différents domaines (tels que l’exploration sous-marine, les opérations à haut risque, la maintenance des infrastructures, les soins personnels). (Source: Ronald_vanLoon
)
Applications de l’IA dans la santé et la production industrielle : L’IA montre un énorme potentiel dans le domaine de la santé (par exemple, l’impact de l’IA multimodale sur la médecine, l’application de l’IA aux types d’opérations médicales) et l’optimisation de la production industrielle (par exemple, l’analyse AI basée sur les capteurs de processus et les données historiques). En améliorant le diagnostic, le développement de médicaments, la maintenance prédictive et les capacités d’analyse de données, l’IA propulse le développement intelligent de ces industries clés. (Source: Ronald_vanLoon

)
L’IA autonomise les réseaux 6G et la conduite autonome : L’IA autonomise les réseaux 6G, améliorant l’efficacité de la communication et le niveau d’intelligence. Parallèlement, la technologie de conduite autonome continue de se développer, comme Waymo Driver offrant une expérience cohérente et sûre dans différentes villes, et ses compétences de gestion des situations critiques sont bien transférables, préfigurant l’impact profond de l’IA dans les futurs domaines de la communication et des transports. (Source: Ronald_vanLoon

)