
Mots-clés:OpenAI, LLM de raisonnement, Compétition internationale de mathématiques olympiques, Jeu de données d’entraînement IA, Confidentialité des données personnelles, Agent ChatGPT, Neutralité politique des modèles IA, Kimi K2, Résultats de niveau médaille d’or aux IMO, Jeu de données DataComp CommonPool, Intelligence des agents LLM, Ordre exécutif sur l’IA de la Maison Blanche, Architecture MoE
🔥 À la une
Le LLM expérimental d’OpenAI remporte une médaille d’or aux Olympiades internationales de mathématiques : Le dernier LLM expérimental d’OpenAI a obtenu un score de niveau médaille d’or aux Olympiades internationales de mathématiques (IMO) de 2025, résolvant 5 des 6 problèmes. Le modèle fonctionnait selon les mêmes règles que les humains, y compris une limite de 4,5 heures par problème, et n’utilisait aucun outil, produisant des preuves en langage naturel. Cela marque une avancée majeure pour l’IA dans le domaine du raisonnement mathématique, laissant entrevoir le potentiel de l’IA dans la découverte scientifique. (Source : gdb, scaling01, dmdohan, SebastienBubeck, markchen90, npew, MillionInt, cloneofsimo, bookwormengr, tokenbender)

L’ensemble de données d’entraînement à l’IA CommonPool contient des millions de données personnelles : Une étude a révélé que DataComp CommonPool, un vaste ensemble de données d’entraînement à l’IA open source, contient des millions d’images de passeports, de cartes de crédit, de certificats de naissance et d’autres documents contenant des informations d’identification personnelle. Les chercheurs ont audité 0,1 % des données de CommonPool et ont trouvé des milliers d’images contenant des informations d’identification, estimant que le nombre total de ces images dans l’ensemble de données pourrait atteindre des centaines de millions. Cela soulève des inquiétudes quant à la protection de la vie privée dans les données d’entraînement à l’IA et appelle la communauté du machine learning à repenser les pratiques de scraping Web indiscriminées. (Source : MIT Technology Review)

🎯 Tendances
OpenAI lance ChatGPT Agent, un assistant personnel : OpenAI a lancé ChatGPT Agent, un assistant personnel capable d’effectuer des tâches pour le compte de l’utilisateur en construisant son propre « ordinateur virtuel ». Cela marque une étape importante pour l’intelligence des agents LLM, mais la fonctionnalité est encore à ses débuts et l’exécution des tâches peut prendre du temps. (Source : MIT Technology Review, The Verge, Wired)
La Maison Blanche prépare un décret exigeant des modèles d’IA « politiquement neutres et sans biais » : La Maison Blanche prépare un décret exigeant que les modèles d’IA soient « politiquement neutres et sans biais ». La conformité déterminera l’admissibilité aux contrats fédéraux, ce qui est un gros problème pour tous les laboratoires d’IA. Le décret devrait être publié la semaine prochaine. (Source : WSJ, MIT Technology Review, natolambert)

Kimi K2 : Un modèle d’intelligence d’agent capable d’utiliser des outils : Publié par Kimi_Moonshot, Kimi K2 est un modèle d’intelligence d’agent capable d’utiliser des outils. Il excelle dans l’utilisation d’outils, les mathématiques, le codage et les tâches en plusieurs étapes, et est actuellement le modèle open source numéro un dans Arena, cinquième au classement général. Kimi K2 utilise une architecture Mixture-of-Experts (MoE) à grande échelle similaire à DeepSeek-V3, avec 1 000 milliards de paramètres totaux et 32 milliards de paramètres actifs. (Source : TheTuringPost)

🧰 Outils
Le serveur GitHub MCP connecte les outils d’IA à la plateforme GitHub : Le serveur GitHub MCP permet aux outils d’IA de se connecter directement à la plateforme GitHub, permettant aux agents d’IA, aux assistants et aux chatbots de lire les référentiels et les fichiers de code, de gérer les problèmes et les PR, d’analyser le code et d’automatiser les workflows, le tout via des interactions en langage naturel. (Source : GitHub Trending)
ik_llama.cpp : Un fork de llama.cpp avec de meilleures performances CPU : ik_llama.cpp est un fork de llama.cpp avec de meilleures performances CPU et GPU/CPU hybrides, de nouveaux types de quantification SOTA, une prise en charge de Bitnet de premier ordre, des performances DeepSeek améliorées via MLA, FlashMLA, les opérations MoE fusionnées et la superposition de tenseurs, et un emballage de quantification entrelacé par lignes pour l’inférence GPU/CPU hybride. (Source : GitHub Trending)
📚 Apprentissage
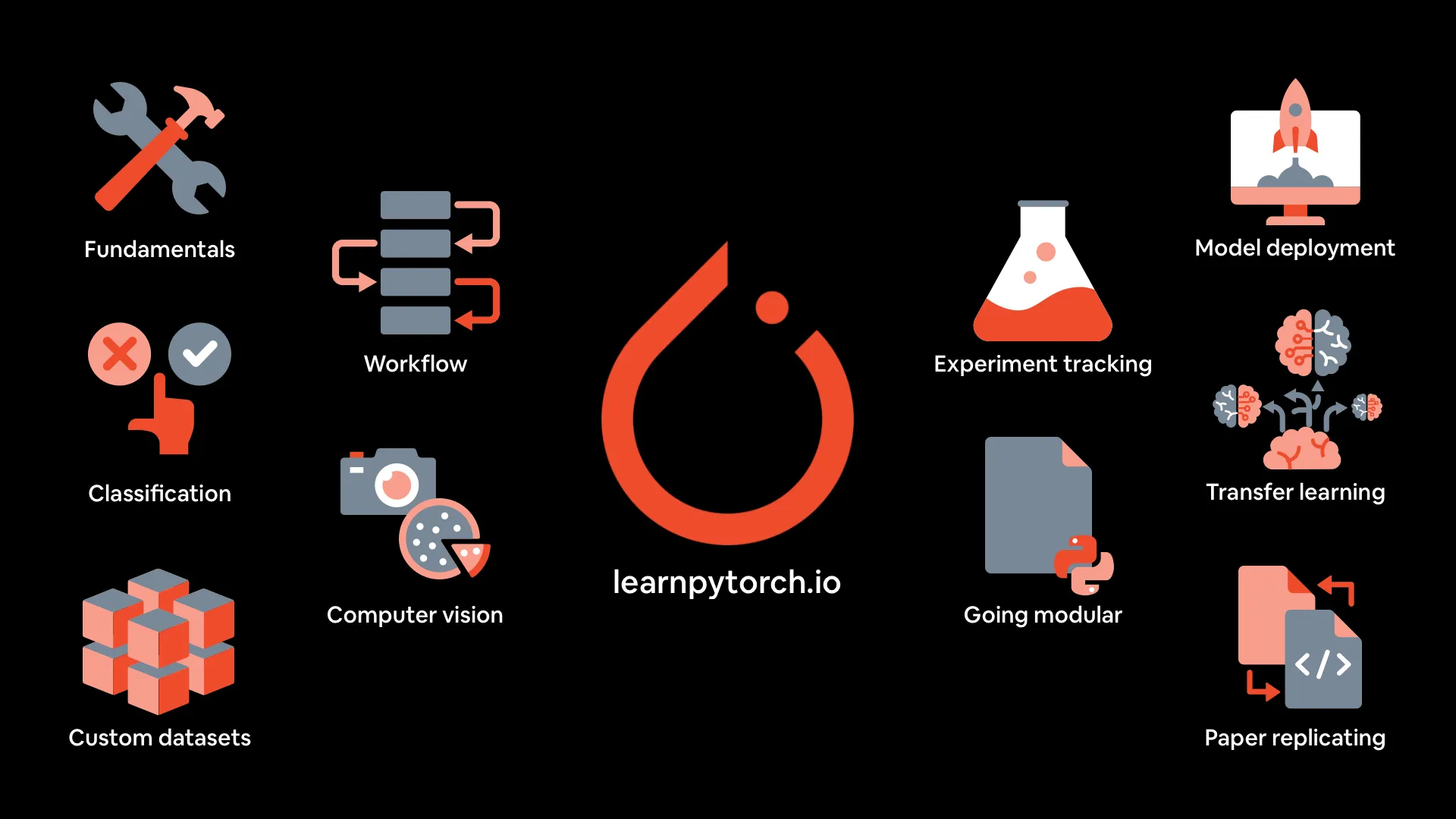
Ressources du cours de Deep Learning PyTorch : mrdbourke/pytorch-deep-learning fournit les ressources du cours « Apprendre le Deep Learning PyTorch à partir de zéro », y compris une version livre en ligne, les cinq premières sections vidéo sur YouTube, des exercices et des cours supplémentaires. Le cours met l’accent sur la pratique du code et l’expérimentation, couvrant les bases de PyTorch, le workflow, la classification des réseaux de neurones, la vision par ordinateur, les ensembles de données personnalisés, le transfer learning, le suivi des expériences et le déploiement de modèles. (Source : GitHub Trending)
MIT Press propose gratuitement trois livres sur les algorithmes et le Machine Learning : MIT Press propose gratuitement trois livres sur la théorie des algorithmes et les algorithmes de Machine Learning fondamentaux : Algorithm Design, Algorithms for Decision Making et Algorithms for Verification. Ces livres sont parfaits pour approfondir les algorithmes et le Machine Learning. (Source : TheTuringPost, TheTuringPost)

Les Transformers basés sur l’énergie sont des apprenants et des penseurs évolutifs : Un article explore les Energy-Based Transformers (EBT), un nouveau type de modèles basés sur l’énergie (EBM) qui apprennent à vérifier explicitement la compatibilité entre les entrées et les prédictions candidates, redéfinissant le problème de prédiction comme une optimisation sur ce vérificateur, permettant ainsi d’apprendre à « penser » uniquement à partir de l’apprentissage non supervisé. (Source : )

🌟 Communauté
Leçons tirées de l’ingénierie contextuelle pour les LLM : L’équipe ManusAI partage les leçons apprises sur la construction de l’ingénierie contextuelle pour les agents d’IA, soulignant l’importance du cache KV, du système de fichiers, du suivi des erreurs, etc. dans la conception des agents. (Source : dotey, AymericRoucher, vllm_project)
Comparaison des performances réelles de Kimi K2 et Gemini : ClementDelangue et jeremyphoward ont relayé le tweet de pash indiquant que Kimi K2 surpassait Gemini dans les tâches réelles, fournissant des données graphiques à l’appui. (Source : ClementDelangue, jeremyphoward)
La médaille d’or d’OpenAI à l’IMO est une surprise : La performance du LLM d’OpenAI à l’IMO, qui lui a valu une médaille d’or, a surpris beaucoup de monde et a suscité de nombreuses discussions au sein de la communauté. (Source : kylebrussell, VictorTaelin)
💼 Affaires
Anthropic limite l’utilisation de Claude Code : Anthropic a limité l’utilisation de Claude Code sans en informer les utilisateurs, ce qui a suscité des plaintes et des inquiétudes concernant les produits fermés. (Source : jeremyphoward, HamelHusain)
Meta refuse de signer l’accord européen sur l’intelligence artificielle : Meta a refusé de signer l’accord européen sur l’intelligence artificielle, le qualifiant de trop interventionniste et susceptible d’entraver le développement de l’IA. (Source : Reddit r/artificial, Reddit r/ArtificialInteligence)
💡 Autres
Comment exécuter un LLM sur un ordinateur portable : MIT Technology Review a publié un guide sur la façon d’exécuter des grands modèles de langage (LLM) sur un ordinateur portable, fournissant des étapes et des conseils aux utilisateurs soucieux de la confidentialité, souhaitant échapper au contrôle des grandes entreprises de LLM ou aimant expérimenter. (Source : MIT Technology Review, MIT Technology Review)
Une brève histoire des « bébés à trois parents » : MIT Technology Review retrace l’histoire des « bébés à trois parents », présentant les différentes approches de cette technique, les controverses et les derniers développements de la recherche, notamment la naissance de huit bébés dans le cadre d’un essai au Royaume-Uni. (Source : MIT Technology Review, MIT Technology Review)
Comment trouver de la valeur dans les agents d’IA dès le premier jour : Cet article explore comment les entreprises peuvent trouver de la valeur dans les agents d’IA, suggérant d’adopter une attitude itérative, de commencer par des « fruits à portée de main » et des cas d’utilisation incrémentiels, et de donner la priorité à l’interopérabilité pour se préparer aux futurs systèmes multi-agents. (Source : MIT Technology Review)