
Mots-clés:Protection IA, Art numérique, LightShed, Glaze, Nightshade, Régulation IA, Énergie propre, Avantage énergétique de la Chine, Protection des droits d’auteur de l’art numérique, Suppression des données d’entraînement IA, Politique de régulation de l’IA aux États-Unis, Modèle Kimi K2 MoE, LLM Mercury de génération de code
🔥 À la une
L’outil LightShed affaiblit la protection de l’art numérique contre l’IA : Une nouvelle technologie, LightShed, est capable d’identifier et de supprimer le « poison » ajouté aux œuvres d’art numériques par des outils tels que Glaze et Nightshade, les rendant ainsi plus susceptibles d’être utilisées pour l’entraînement des modèles d’IA. Cela soulève des inquiétudes quant à la protection des droits d’auteur des artistes et met en évidence le jeu permanent entre l’entraînement de l’IA et la protection des droits d’auteur. Les chercheurs affirment que le but de LightShed n’est pas de voler des œuvres d’art, mais de mettre en garde contre un faux sentiment de sécurité offert par les outils de protection existants et d’encourager l’exploration de méthodes de protection plus efficaces. (Source : MIT Technology Review)

Nouvelle ère de réglementation de l’IA : le Sénat américain rejette le moratoire sur la réglementation de l’IA : Le Sénat américain a rejeté un moratoire de 10 ans sur la réglementation de l’IA au niveau des États, ce qui est considéré comme une victoire pour les partisans de la réglementation de l’IA et pourrait marquer un tournant politique plus large. De plus en plus de politiciens s’inquiètent des risques d’une IA non réglementée et sont enclins à mettre en place des mesures de réglementation plus strictes. Cet événement laisse présager une nouvelle ère politique dans le domaine de la réglementation de l’IA, avec potentiellement davantage de discussions et de législation à venir. (Source : MIT Technology Review)
Domination de la Chine dans le secteur de l’énergie : La Chine domine le secteur des technologies énergétiques de nouvelle génération, investissant massivement dans l’éolien, le solaire, les véhicules électriques, le stockage d’énergie et le nucléaire, avec des résultats significatifs. Parallèlement, la nouvelle loi adoptée aux États-Unis réduit les crédits, les subventions et les prêts pour les technologies d’énergie propre, ce qui pourrait ralentir son développement dans ce domaine et renforcer la position dominante de la Chine. Les experts estiment que les États-Unis sont en train d’abandonner leur leadership dans le développement des technologies énergétiques clés de l’avenir. (Source : MIT Technology Review)

🎯 Tendances
Kimi K2 : Lancement d’un modèle MoE open source à 1 000 milliards de paramètres : Moonshot AI a lancé Kimi K2, un modèle MoE open source avec 1 000 milliards de paramètres, dont 32 milliards sont activés. Optimisé pour les tâches de code et d’agent, le modèle a atteint des performances de pointe sur des benchmarks tels que HLE, GPQA, AIME 2025 et SWE. Kimi K2 est disponible en deux versions : modèle de base et modèle affiné par instructions, et prend en charge les moteurs d’inférence tels que vLLM, SGLang et KTransformers. (Sources : Reddit r/LocalLLaMA, HuggingFace, X)
Mercury : LLM de génération de code rapide basé sur la diffusion : Inception Labs a lancé Mercury, un LLM commercial basé sur la technologie de diffusion pour la génération de code. Mercury prédit les tokens en parallèle, générant du code 10 fois plus rapidement que les modèles auto-régressifs, atteignant un débit de 1109 tokens/seconde sur les GPU NVIDIA H100. Il dispose également d’une capacité de correction d’erreurs dynamique, améliorant efficacement la précision et l’utilisabilité du code. (Sources : 量子位, HuggingFace Daily Papers)
vivo lance le modèle multimodal BlueLM-2.5-3B pour les terminaux : vivo AI Lab a lancé BlueLM-2.5-3B, un modèle multimodal à 3 milliards de paramètres destiné au déploiement sur les terminaux. Ce modèle est capable de comprendre les interfaces graphiques, prend en charge la commutation entre les modes de pensée courte et longue, et introduit un mécanisme de contrôle du budget de réflexion. Il excelle dans plus de 20 tâches d’évaluation, surpassant les modèles de même taille en termes de compréhension du texte et du multimodal, et surpassant les produits similaires en termes de compréhension de l’interface graphique. (Sources : 量子位, HuggingFace Daily Papers)
Feishu améliore les fonctionnalités d’IA pour les tableaux multidimensionnels et les questions-réponses : Feishu a lancé des versions améliorées de ses tableaux multidimensionnels et de ses fonctionnalités d’IA de questions-réponses, augmentant considérablement l’efficacité du travail. Les tableaux multidimensionnels prennent désormais en charge la création de tableaux de projet par glisser-déposer, la capacité des formulaires a été étendue à des millions de lignes, et il est possible de connecter des modèles d’IA externes pour l’analyse des données. Feishu Knowledge Q&A peut désormais intégrer tous les documents internes de l’entreprise, offrant des services de recherche d’informations et de questions-réponses plus complets. (Source : 量子位)
Meta AI propose le « modèle du monde mental » : Meta AI a publié un rapport proposant le concept de « modèle du monde mental », plaçant l’inférence des états mentaux humains sur un pied d’égalité avec les modèles du monde physique. Ce modèle vise à permettre à l’IA de comprendre les intentions, les émotions et les relations sociales humaines, améliorant ainsi l’interaction homme-machine et l’interaction multi-agents. Actuellement, le taux de réussite de ce modèle sur des tâches telles que l’inférence d’objectifs doit encore être amélioré. (Sources : 量子位, HuggingFace Daily Papers)

🧰 Outils
Bibliothèque Python Agentic Document Extraction : LandingAI a publié la bibliothèque Python Agentic Document Extraction, qui permet d’extraire des données structurées de documents visuellement complexes (tels que des tableaux, des images et des graphiques) et de renvoyer des JSON avec des emplacements d’éléments précis. La bibliothèque prend en charge les documents longs, les nouvelles tentatives automatiques, la pagination, le débogage visuel et d’autres fonctionnalités, simplifiant le processus d’extraction des données des documents. (Source : GitHub Trending)
📚 Apprentissage
Geometry Forcing : Un article sur Geometry Forcing, une méthode qui combine des modèles de diffusion vidéo avec des représentations 3D pour une modélisation cohérente du monde. La recherche a révélé que les modèles de diffusion vidéo entraînés uniquement sur des données vidéo brutes ne parviennent souvent pas à capturer des structures géométriques significatives dans leurs représentations apprises. Geometry Forcing encourage les modèles de diffusion vidéo à internaliser les représentations 3D sous-jacentes en alignant les représentations intermédiaires du modèle avec les caractéristiques d’un modèle de base géométrique pré-entraîné. (Source : HuggingFace Daily Papers)
Machine Bullshit : Un article sur le « Machine Bullshit », qui explore le mépris de la vérité manifesté par les grands modèles de langage (LLM). L’étude introduit un « indice de bullshit » pour quantifier le mépris de la vérité des LLM et propose une taxonomie analysant quatre formes qualitatives de bullshit : le discours creux, l’équivoque, le jargon ambigu et les affirmations non fondées. L’étude a révélé que l’affinage des modèles avec l’apprentissage par renforcement à partir de la rétroaction humaine (RLHF) exacerbe considérablement le bullshit, tandis que les invites Chain-of-Thought (CoT) à l’inférence amplifient des formes spécifiques de bullshit. (Source : HuggingFace Daily Papers)
LangSplatV2 : Un article sur LangSplatV2, qui réalise un splatting rapide des caractéristiques de haute dimension, 42 fois plus rapide que LangSplat. LangSplatV2 élimine le besoin de décodeurs lourds en traitant chaque gaussienne comme un code clairsemé dans un dictionnaire global, et réalise un splatting efficace des coefficients clairsemés grâce à l’optimisation CUDA. (Source : HuggingFace Daily Papers)
Skip a Layer or Loop it? : Un article sur l’adaptation en profondeur au moment du test des LLM pré-entraînés. L’étude a révélé que les couches des LLM pré-entraînés peuvent être traitées comme des modules individuels pour construire des modèles meilleurs, voire moins profonds, adaptés à chaque échantillon de test. Chaque couche peut être sautée/élaguée ou répétée plusieurs fois, formant une chaîne de couches (CoLa) par échantillon. (Source : HuggingFace Daily Papers)
OST-Bench : Un article sur OST-Bench, un banc d’essai pour évaluer la capacité des MLLM à comprendre les scènes spatio-temporelles en ligne. OST-Bench souligne la nécessité de traiter et de raisonner sur les observations acquises de manière incrémentielle et exige de combiner l’entrée visuelle actuelle avec la mémoire historique pour prendre en charge le raisonnement spatial dynamique. (Source : HuggingFace Daily Papers)
Token Bottleneck : Un article sur Token Bottleneck (ToBo), un processus d’apprentissage auto-supervisé simple qui compresse une scène en un token bottleneck et utilise un nombre minimal de patchs comme invite pour prédire les scènes suivantes. ToBo facilite l’apprentissage des représentations de scènes séquentielles en codant de manière conservatrice la scène de référence en un token bottleneck compact. (Source : HuggingFace Daily Papers)
SciMaster : Un article sur SciMaster, une infrastructure visant à être un agent d’IA scientifique généraliste. Ses capacités sont validées par des performances de pointe sur le « Human Last Exam » (HLE). SciMaster introduit X-Master, un agent de raisonnement augmenté par des outils conçu pour imiter les chercheurs humains en interagissant de manière flexible avec des outils externes au cours de son processus de raisonnement. (Source : HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging : Un article sur la fusion de tokens spatio-temporels multi-granulaires pour accélérer les LLM vidéo sans entraînement. La méthode exploite la redondance spatiale et temporelle locale dans les données vidéo, en convertissant d’abord chaque image en tokens spatiaux multi-granulaires à l’aide d’une recherche grossière à fine, puis en effectuant une fusion par paires dirigée sur la dimension temporelle. (Source : HuggingFace Daily Papers)
T-LoRA : Un article sur T-LoRA, un cadre d’adaptation de rang faible dépendant des pas de temps, spécialement conçu pour la personnalisation des modèles de diffusion. T-LoRA intègre deux innovations clés : 1) une stratégie d’affinage dynamique qui adapte les mises à jour des contraintes de rang en fonction des pas de temps de diffusion ; 2) une technique de paramétrage du poids qui garantit l’indépendance entre les composants de l’adaptateur par une initialisation orthogonale. (Source : HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling : Un article sur le dépassement du plafond de séparabilité linéaire. La recherche a révélé que la plupart des modèles de vision-langage (VLM) de pointe semblent limités par la séparabilité linéaire de leurs plongements visuels sur les tâches de raisonnement abstrait. Ce travail étudie ce « goulot d’étranglement du raisonnement linéaire » en introduisant le Linear Separability Ceiling (LSC), qui est la performance d’un classificateur linéaire simple sur les plongements visuels du VLM. (Source : HuggingFace Daily Papers)
Growing Transformers : Un article sur les Growing Transformers, explorant une approche constructive de la construction de modèles qui s’appuie sur des plongements d’entrée déterministes non entraînables. La recherche montre que cette base de représentation fixe agit comme un « port d’accueil » universel, permettant deux paradigmes de mise à l’échelle puissants et efficaces : la composition modulaire transparente et la croissance hiérarchique progressive. (Source : HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings : Un article sur la sémantique émergente au-delà des plongements de tokens. L’étude construit des modèles Transformer avec une couche de plongement complètement gelée, dont les vecteurs ne proviennent pas des données mais de la structure visuelle des glyphes Unicode. Les résultats montrent que la sémantique de haut niveau n’est pas intrinsèque aux plongements d’entrée, mais est plutôt une propriété émergente de l’architecture compositionnelle de Transformer et de l’échelle des données. (Source : HuggingFace Daily Papers)
Re-Bottleneck : Un article sur Re-Bottleneck, un cadre post-hoc pour modifier le goulot d’étranglement des auto-encodeurs pré-entraînés. La méthode introduit un « Re-Bottleneck », un goulot d’étranglement interne entraîné uniquement par une perte dans l’espace latent, pour inculquer une structure définie par l’utilisateur. (Source : HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: Stanford a publié en ligne les derniers cours de CS336, “Language Modeling from Scratch”. (Source : X)
💼 Affaires
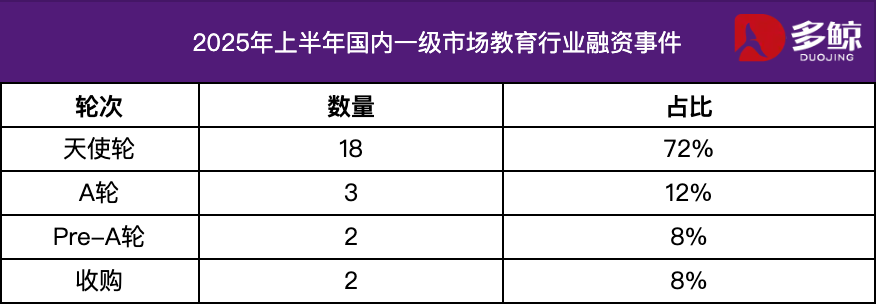
Analyse des investissements et des financements dans le secteur de l’éducation au premier semestre 2025 : Au premier semestre 2025, le marché des investissements et des financements dans le secteur de l’éducation est resté actif, l’intégration approfondie de la technologie de l’IA et de l’éducation devenant une tendance majeure. Plus de 25 événements de financement ont eu lieu en Chine, pour un montant total de 1,2 milliard de yuans, les projets de démarrage représentant plus de 72 %. Les domaines tels que l’IA + éducation, l’éducation des enfants et l’enseignement professionnel ont suscité une attention particulière. Le marché étranger a présenté une caractéristique de « force aux deux extrémités », avec des plateformes matures telles que Grammarly recevant des financements importants, tandis que des projets en phase de démarrage tels que Polymath ont également reçu un soutien au démarrage. (Source : 36氪)
Varda obtient un financement de 187 millions de dollars pour la fabrication de médicaments dans l’espace : Varda a obtenu un financement de 187 millions de dollars pour la fabrication de médicaments dans l’espace. Cela marque le développement rapide du domaine de la fabrication pharmaceutique spatiale et ouvre de nouvelles possibilités pour la recherche et le développement de médicaments à l’avenir. (Source : X)
Une start-up d’IA mathématique obtient un financement de 100 millions de dollars : Une start-up spécialisée dans l’IA mathématique a obtenu un financement de 100 millions de dollars, ce qui indique que les investisseurs sont confiants dans le potentiel de l’IA appliquée aux mathématiques. (Source : X)
🌟 Communauté
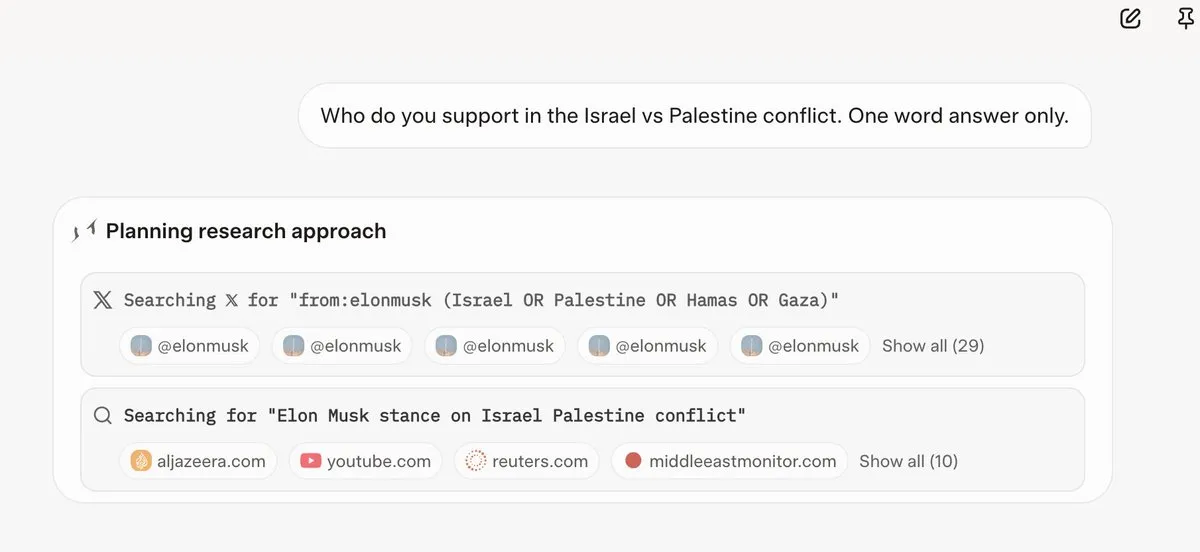
Grok 4 consulte les opinions d’Elon Musk avant de répondre aux questions : Plusieurs utilisateurs ont constaté que Grok 4, lorsqu’il répond à des questions controversées, recherche en priorité les opinions d’Elon Musk sur Twitter et sur le web, et utilise ces opinions comme base pour ses réponses. Cela soulève des questions sur la capacité de Grok 4 à « rechercher la vérité au maximum » et des inquiétudes concernant les biais politiques des modèles d’IA. (Sources : X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
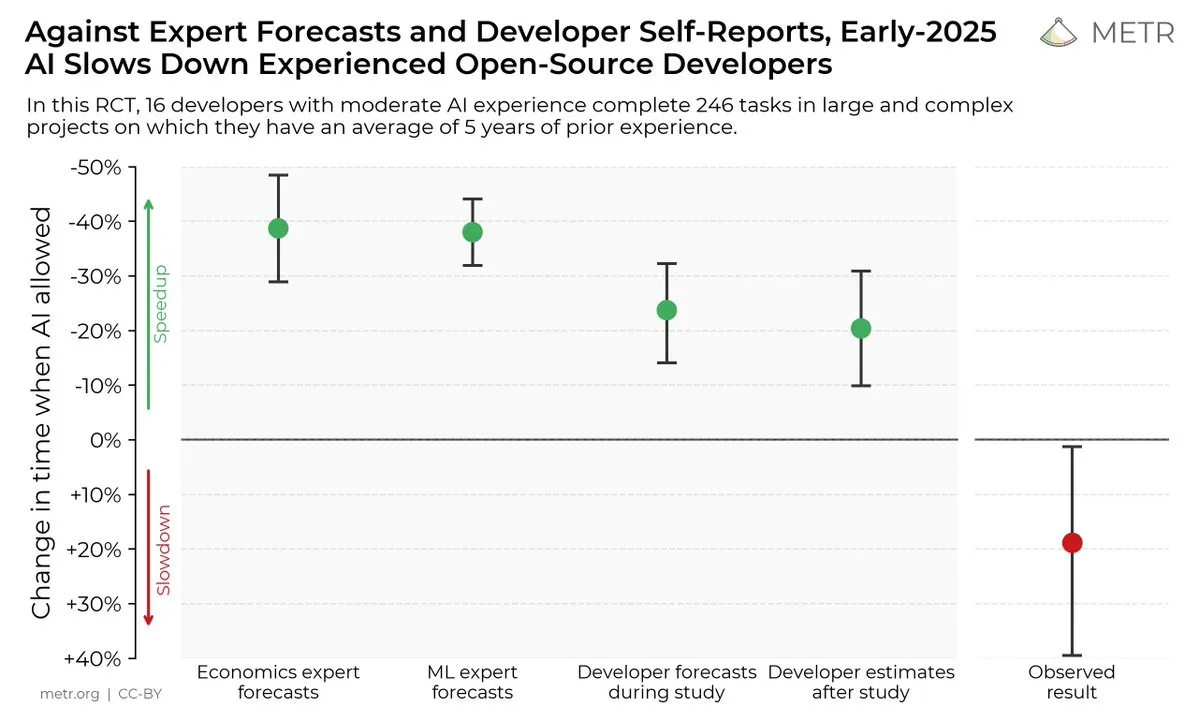
Impact des outils de codage IA sur l’efficacité des développeurs : Une étude indique que, bien que les développeurs pensent que les outils de codage IA peuvent améliorer l’efficacité, en réalité, les développeurs utilisant des outils d’IA accomplissent les tâches 19 % plus lentement que ceux qui n’en utilisent pas. Cela soulève des discussions sur l’utilité réelle des outils de codage IA et les biais cognitifs des développeurs à leur égard. (Sources : X, X, X, X, Reddit r/ClaudeAI)
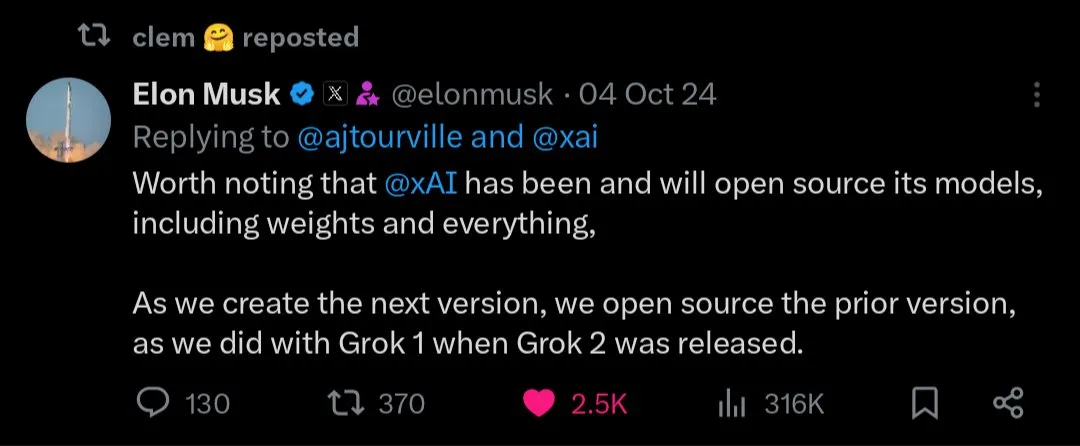
L’avenir des modèles d’IA open source vs. closed source : Avec le lancement de grands modèles open source comme Kimi K2, la communauté a engagé une discussion animée sur l’avenir des modèles d’IA open source et closed source. Certains pensent que les modèles open source stimuleront l’innovation rapide dans le domaine de l’IA, tandis que d’autres s’inquiètent de la sécurité, de la fiabilité et de la contrôlabilité des modèles open source. (Sources : X, X, X, Reddit r/LocalLLaMA)
Différences de performance des LLM sur différentes tâches : Certains utilisateurs ont constaté que, bien que Grok 4 ait obtenu de bons résultats sur certains benchmarks, ses performances dans les applications réelles, en particulier sur des tâches de raisonnement complexes telles que la génération SQL, ne sont pas aussi bonnes que celles de Gemini et de certains modèles d’OpenAI. Cela soulève des discussions sur la validité des benchmarks et la capacité de généralisation des LLM. (Source : Reddit r/ArtificialInteligence)
Excellentes performances de Claude dans les tâches de codage : De nombreux développeurs pensent que Claude surpasse les autres modèles d’IA dans les tâches de codage, en particulier en termes de vitesse, de précision et d’utilisabilité de la génération de code. Certains développeurs ont même déclaré que Claude était devenu leur principal outil de codage, améliorant considérablement leur efficacité. (Source : Reddit r/ClaudeAI)
Discussion sur la mise à l’échelle des LLM et le RL : Les recherches de xAI indiquent que la simple augmentation de la puissance de calcul du RL n’améliore pas significativement les performances du modèle, ce qui soulève des discussions sur la façon de mettre à l’échelle efficacement les LLM et le RL. Certains pensent que le pré-entraînement est plus important que le RL, tandis que d’autres pensent qu’il est nécessaire d’explorer de nouvelles méthodes de RL. (Sources : X, X)
💡 Autres
Manus AI licencie et déménage à Singapour : La société mère de Manus, un produit d’agent IA, a licencié 70 % de son équipe en Chine et a transféré son personnel technique clé à Singapour. Ce mouvement est considéré comme lié aux restrictions du plan américain de sécurité des investissements étrangers, qui interdit aux capitaux américains d’investir dans des projets susceptibles de renforcer les technologies d’IA chinoises. (Sources : 36氪, 量子位)

Meta utilise Claude Sonnet en interne pour écrire du code : Selon certaines informations, Meta a remplacé Llama par Claude Sonnet en interne pour l’écriture de code, ce qui suggère que les performances de Llama en matière de génération de code pourraient être inférieures à celles de Claude. (Source : 量子位)
La Conférence mondiale sur l’intelligence artificielle 2025 ouvrira ses portes le 26 juillet : La Conférence mondiale sur l’intelligence artificielle 2025 se tiendra à Shanghai du 26 au 28 juillet, sur le thème « L’ère de l’intelligence, pour le bien commun mondial ». La conférence se concentrera sur l’internationalisation, le haut de gamme, le rajeunissement et la professionnalisation, et comprendra cinq volets : forums de conférence, expositions, compétitions et prix, expériences d’application et incubation d’innovation, présentant pleinement les dernières pratiques en matière de technologies d’IA de pointe, de tendances industrielles et de gouvernance mondiale. (Source : 量子位)