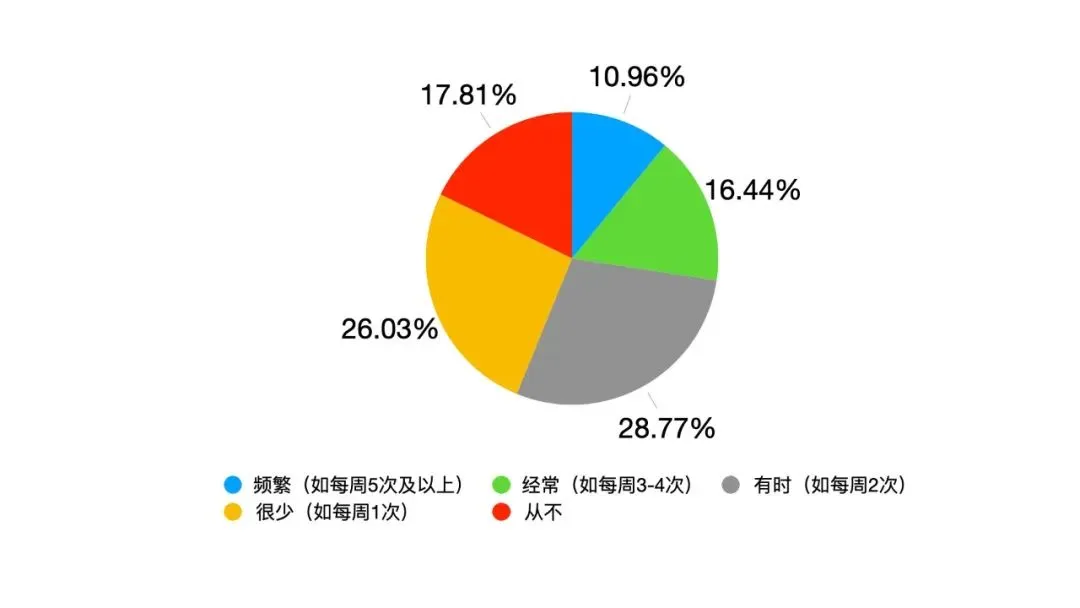
Mots-clés:Droits d’auteur des données d’entraînement IA, AlphaGenome, Copie matérielle OpenAI, Performances de l’IA au Gaokao, Gemini CLI, Nouvelle méthode RLT, BitNet b1.58, Agent intelligent Biomni, Jugement sur l’utilisation raisonnable de l’IA, Prédiction des paires de bases d’ADN, Réponse d’Altman aux accusations de plagiat, Amélioration des capacités mathématiques des grands modèles, Quota gratuit pour les agents IA terminaux
🔥 À la une
Décision historique sur les droits d’auteur des données d’entraînement de l’IA : un tribunal américain juge que l’utilisation par l’IA de livres achetés légalement pour l’entraînement constitue un “usage loyal” : Un tribunal fédéral américain, dans une affaire contre Anthropic, a statué que l’utilisation par les entreprises d’IA de livres publiés et achetés légalement pour entraîner de grands modèles de langage relevait de l‘“usage loyal” (fair use) et ne nécessitait pas le consentement préalable des auteurs. Le tribunal a estimé que l’entraînement de l’IA constituait un “usage transformateur” de l’œuvre originale, ne remplaçait pas directement le marché de l’œuvre originale, et favorisait l’innovation technologique et l’intérêt public. Cependant, le tribunal a également statué que l’utilisation de livres piratés pour l’entraînement ne constituait pas un usage loyal, et Anthropic pourrait toujours être tenue responsable pour cela. Ce jugement s’inspire du précédent de l’affaire Google Books de 2015 et est considéré comme une étape importante pour réduire les risques liés aux droits d’auteur des données d’entraînement de l’IA, pouvant influencer le traitement d’autres affaires similaires (telles que les poursuites contre OpenAI et Meta). Auparavant, Meta avait également obtenu un jugement favorable dans un procès similaire pour violation de droits d’auteur, le juge estimant que les plaignants n’avaient pas suffisamment prouvé que l’utilisation de leurs livres par Meta pour entraîner des modèles d’IA avait causé un préjudice économique. Ces jugements fournissent collectivement des directives juridiques plus claires pour l’industrie de l’IA en matière d’acquisition et d’utilisation des données, tout en soulignant l’importance de l’acquisition légale des données. (Source: 量子位、DeepLearning.AI Blog、wiredmagazine)
Google DeepMind lance AlphaGenome : un « microscope » IA pour prédire l’impact des variations génétiques sur des millions de paires de bases d’ADN : Google DeepMind a lancé le modèle d’IA AlphaGenome, capable de prendre en entrée des séquences d’ADN allant jusqu’à 1 million de paires de bases pour prédire des milliers de caractéristiques moléculaires, évaluer l’impact des variations génétiques, et qui surpasse les performances dans plus de 20 tests de référence en prédiction génomique. AlphaGenome se caractérise par un traitement contextuel de longues séquences à haute résolution, une prédiction multimodale complète, une notation efficace des variations et un nouveau modèle de jonction d’épissage. L’entraînement d’un seul modèle ne prend que 4 heures, avec un budget de calcul réduit de moitié par rapport au modèle Enformer original. Ce modèle vise à aider les scientifiques à comprendre la régulation génique, à accélérer la compréhension des maladies (en particulier les maladies rares), à guider la conception en biologie synthétique et à faire progresser la recherche fondamentale. Une version préliminaire est actuellement disponible via API pour la recherche non commerciale, avec un lancement complet prévu ultérieurement. (Source: 36氪、Google、demishassabis)

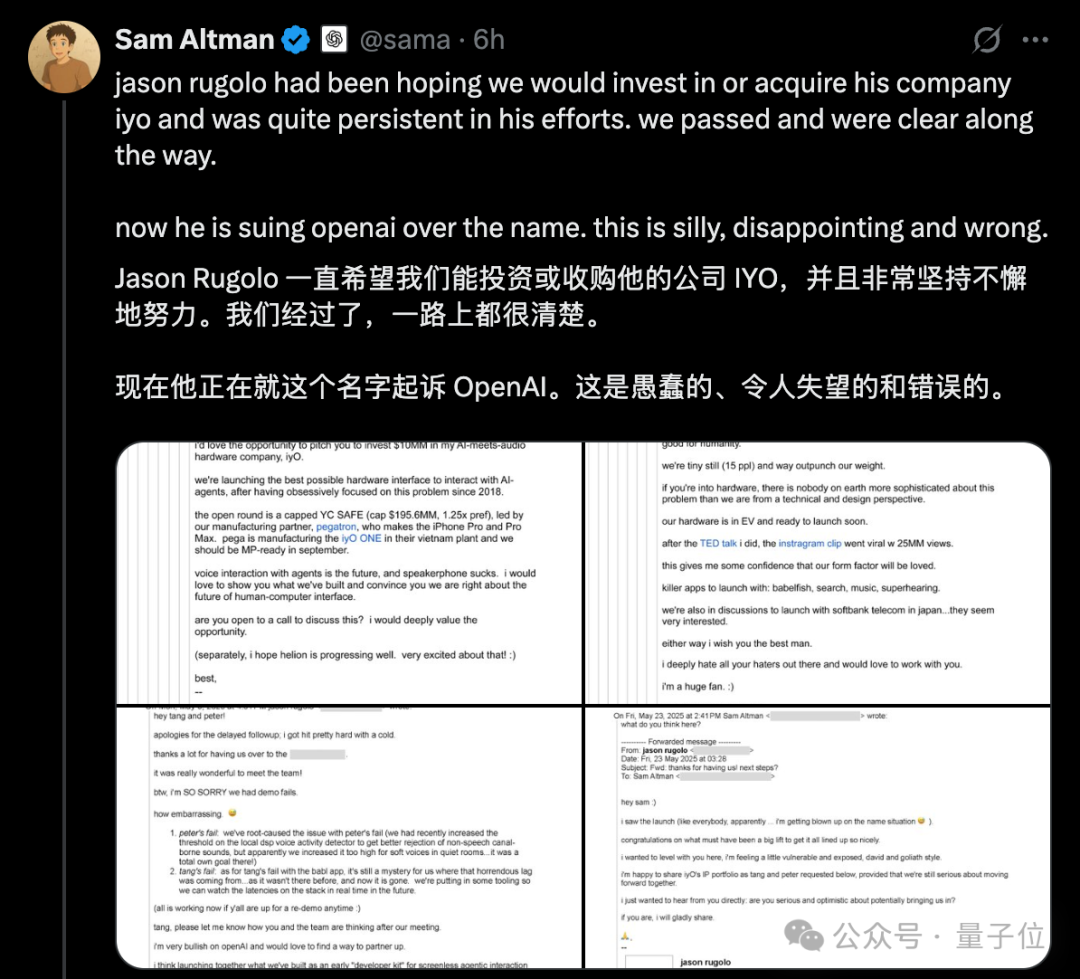
La controverse sur le “plagiat” de matériel par OpenAI s’intensifie, Altman réfute publiquement par e-mail les accusations d’IYO : Face aux accusations de la start-up de matériel d’IA IYO concernant la violation de marque et le plagiat de produit par OpenAI et sa société de matériel acquise io (fondée par l’ancien designer d’Apple Jony Ive), le PDG d’OpenAI, Sam Altman, a répondu publiquement sur les réseaux sociaux, qualifiant le procès d’IYO de “stupide, décevant et complètement faux”. Altman a présenté des captures d’écran d’e-mails montrant que le fondateur d’IYO, Jason Rugolo, avait activement sollicité un investissement de 10 millions de dollars ou une acquisition par OpenAI avant le procès, et qu’il espérait toujours partager sa propriété intellectuelle après l’annonce de l’acquisition d’io par OpenAI. Altman estime qu’IYO n’a intenté une action en justice qu’après l’échec de sa tentative d’investissement ou d’acquisition. Le fondateur d’IYO a répliqué qu’Altman tenait un procès public en ligne et a maintenu ses droits sur le nom de son produit. Auparavant, le tribunal avait approuvé l’ordonnance restrictive temporaire d’IYO, empêchant OpenAI d’utiliser le logo IO. OpenAI a déclaré que son produit matériel différait de l’appareil auditif personnalisé d’IYO, que la conception du prototype n’était pas finalisée et qu’il ne serait pas commercialisé avant au moins un an. (Source: 量子位、36氪)
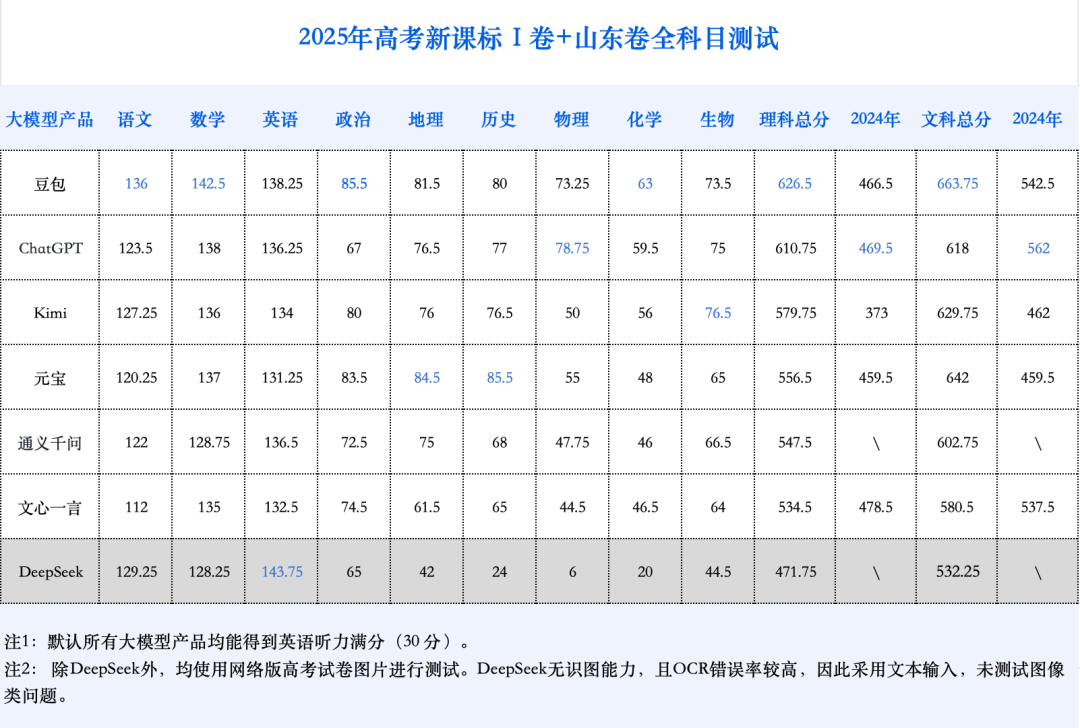
Les grands modèles d’IA à l’épreuve du Gaokao une nouvelle fois, les résultats globaux s’améliorent nettement, les mathématiques progressent de manière remarquable : Les résultats de l’évaluation simulée du Gaokao 2025 par GeekPark pour l’IA montrent que les résultats globaux des principaux grands modèles (tels que Doubao, DeepSeek R1, ChatGPT o3, etc.) se sont considérablement améliorés par rapport à l’année dernière, démontrant un potentiel pour intégrer les meilleures universités. On estime que le lauréat, Doubao, pourrait se classer parmi les 900 meilleurs de la province du Shandong. Le déséquilibre entre les matières littéraires et scientifiques de l’IA s’est atténué, la note moyenne des matières scientifiques augmentant plus rapidement. Les mathématiques sont devenues la matière où les progrès sont les plus significatifs, avec une augmentation de la note moyenne de 84,25 points, dépassant le chinois et l’anglais. Les capacités multimodales sont devenues un facteur clé de différenciation, en particulier dans les matières contenant de nombreuses questions illustrées, comme la physique et la géographie. Bien que l’IA excelle dans le raisonnement complexe et le calcul, elle commet encore des erreurs dans la compréhension de problèmes simples avec des informations visuelles confuses (comme une question de vecteurs en mathématiques). En ce qui concerne la rédaction, l’IA peut produire des textes bien structurés et riches en arguments, mais manque de réflexion approfondie et de résonance émotionnelle, ce qui rend difficile la production de chefs-d’œuvre. (Source: 36氪)
🎯 Tendances
Lancement de Gemini CLI par Google, basé sur Gemini 2.5 Pro, avec un quota gratuit généreux qui suscite l’attention : Google a officiellement lancé Gemini CLI, un assistant IA fonctionnant dans l’environnement terminal, basé sur le modèle Gemini 2.5 Pro. Son point fort réside dans son quota d’utilisation gratuite extrêmement généreux : prise en charge d’une fenêtre contextuelle de 1 million de tokens, 60 appels de modèle par minute et 1000 par jour, ce qui constitue une concurrence sérieuse pour les outils payants tels que Claude Code d’Anthropic. Gemini CLI utilise la licence open source Apache 2.0, prend en charge l’écriture de code, le débogage, la gestion de projet, la recherche de documentation et l’appel d’autres services Google (comme la génération d’images et de vidéos) via MCP. Google souligne les avantages de son modèle universel dans le traitement de tâches de développement complexes, estimant que les modèles purement dédiés au code pourraient au contraire être limités. La communauté a réagi avec enthousiasme, estimant que cela favorisera la popularisation et la concurrence des outils d’IA en ligne de commande. (Source: 36氪、Reddit r/LocalLLaMA、dotey)

Sakana AI propose une nouvelle méthode RLT, un petit modèle de 7B “enseigne” mieux que DeepSeek-R1 : Sakana AI, fondée par Llion Jones, l’un des auteurs de Transformer, a proposé une nouvelle méthode d’enseignants par apprentissage par renforcement (RLTs). Cette méthode ne demande plus au modèle enseignant de résoudre les problèmes à partir de zéro, mais de fournir des explications claires, étape par étape, basées sur des solutions connues, imitant ainsi l’enseignement “heuristique” des excellents professeurs humains. Les expériences montrent qu’un petit modèle RLT de 7B entraîné avec cette méthode surpasse le DeepSeek-R1 de 671B en termes de transmission de compétences de raisonnement, et peut entraîner efficacement des modèles étudiants jusqu’à 3 fois plus grands (comme un 32B), tout en réduisant considérablement les coûts d’entraînement. Cette méthode vise à résoudre les problèmes des modèles enseignants traditionnels qui dépendent de leur propre capacité à résoudre les problèmes, sont lents et coûteux à entraîner, en alignant l’entraînement de l’enseignant sur son véritable objectif (aider le modèle étudiant à apprendre) pour améliorer l’efficacité. (Source: 量子位、SakanaAILabs)

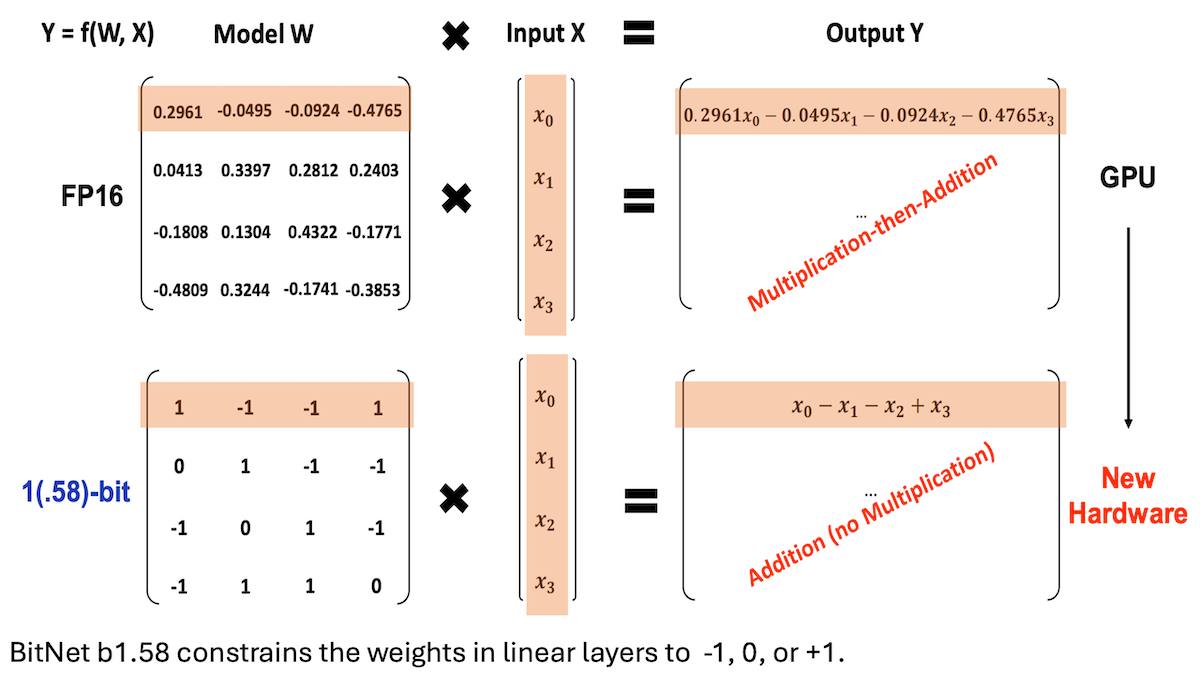
Microsoft et d’autres proposent BitNet b1.58, réalisant des LLM à faible précision et haute performance d’inférence : Des chercheurs de Microsoft, de l’Université de l’Académie chinoise des sciences et de l’Université Tsinghua ont mis à jour le modèle BitNet b1.58, dont la plupart des poids sont limités à trois valeurs : -1, 0 ou +1 (environ 1,58 bit/paramètre). À une échelle de 2 milliards de paramètres, ses performances rivalisent avec celles des modèles de pleine précision de premier plan. Ce modèle est optimisé grâce à des stratégies d’entraînement soigneusement conçues (telles que l’entraînement conscient de la quantification, un taux d’apprentissage à deux étapes et une décroissance des poids). Sur 16 benchmarks populaires, sa vitesse et son utilisation de la mémoire surpassent celles de Qwen2.5-1.5B, Gemma-3 1B, etc. Sa précision moyenne est proche de celle de Qwen2.5-1.5B et supérieure à la version quantifiée à 4 bits de Qwen2.5-1.5B. Ce travail démontre qu’en ajustant finement les hyperparamètres, les modèles à faible précision peuvent également atteindre des performances élevées, offrant de nouvelles perspectives pour le déploiement efficace des LLM. (Source: DeepLearning.AI Blog)
Des institutions telles que Stanford lancent Biomni, un agent intelligent pour la recherche biologique, intégrant plus d’une centaine d’outils et de bases de données : Des chercheurs de l’Université de Stanford, de l’Université de Princeton et d’autres institutions ont lancé Biomni, un agent d’IA conçu pour un large éventail de recherches en biologie. Cet agent, basé sur Claude 4 Sonnet, intègre 150 outils extraits et sélectionnés à partir de 2500 articles récents dans 25 domaines spécialisés de la biologie (y compris la génomique, l’immunologie, les neurosciences, etc.), près de 60 bases de données et une centaine de logiciels biologiques populaires. Biomni est capable d’exécuter diverses tâches telles que poser des questions, proposer des hypothèses, concevoir des protocoles, analyser des ensembles de données et générer des graphiques. Il utilise le framework CodeAct, répondant aux requêtes par planification itérative, génération et exécution de code, et introduit une autre instance de Claude 4 Sonnet comme juge pour évaluer la plausibilité des résultats intermédiaires. Dans plusieurs benchmarks tels que Lab-bench et des études de cas réels, Biomni a surpassé Claude 4 Sonnet seul ainsi que les modèles Claude améliorés par la recherche documentaire. (Source: DeepLearning.AI Blog)

Anthropic lance une nouvelle fonctionnalité pour Claude Code : créer et partager des Artifacts pilotés par l’IA : Anthropic a introduit une nouvelle fonctionnalité pour son assistant de programmation IA Claude Code, permettant aux utilisateurs de créer, héberger et partager des “Artifacts” (qui peuvent être compris comme de petites applications ou outils IA), et d’intégrer directement l’intelligence de Claude dans ces créations. Cela signifie que les utilisateurs peuvent non seulement utiliser Claude pour générer des extraits de code ou effectuer des analyses, mais aussi pour construire des applications fonctionnelles pilotées par l’IA. Une caractéristique clé est que lors du partage de ces applications IA, les spectateurs s’authentifient avec leur propre compte Claude, et leur utilisation est décomptée de leur propre quota d’abonnement, et non de celui du créateur. Cette fonctionnalité est actuellement en phase bêta et ouverte à tous les utilisateurs gratuits, Pro et Max, visant à abaisser le seuil de création d’applications IA et à promouvoir la popularisation et le partage des capacités de l’IA. (Source: kylebrussell、Reddit r/ClaudeAI)
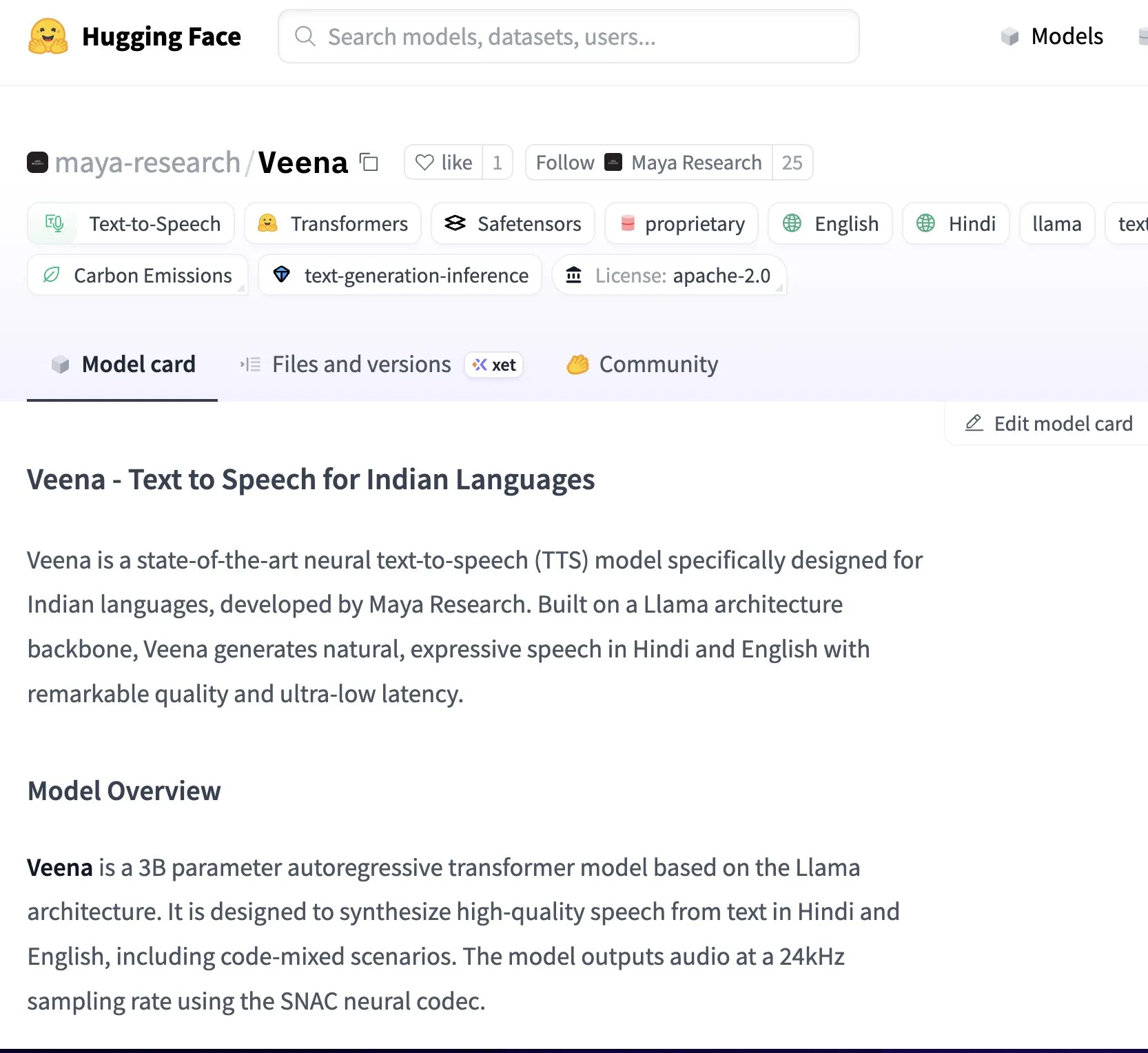
Maya Research lance le modèle Veena TTS, prenant en charge l’hindi et l’anglais, avec un timbre vocal plus proche de l’accent indien natif : Maya Research a lancé un modèle de synthèse vocale (TTS) nommé Veena, basé sur l’architecture Llama 3B et sous licence Apache 2.0. La particularité de Veena est sa capacité à générer de la parole en anglais et en hindi avec un accent indien, y compris dans des scénarios de code-mix, comblant ainsi les lacunes des modèles TTS existants en matière de prononciation localisée en Inde. Le modèle a une latence inférieure à 80 millisecondes, peut fonctionner dans l’environnement gratuit Google Colab et est disponible sur Hugging Face Hub. L’équipe a indiqué qu’elle travaillait activement à la prise en charge d’autres langues indiennes telles que le tamoul, le télougou et le bengali. (Source: huggingface、huggingface)
Zhixiang Weilai (HiDream.ai) lance vivago2.0, intégrant des capacités de génération et d’édition multimodales : Zhixiang Weilai (HiDream.ai), fondée par le ponte de l’IA Mei Tao, a lancé l’outil de création IA multimodal vivago2.0. Ce produit intègre des fonctionnalités telles que la génération d’images, la conversion d’images en vidéos, les podcasts IA (synchronisation labiale), les modèles d’effets spéciaux, et dispose d’une communauté créative permettant aux utilisateurs de partager et de trouver l’inspiration. Sa technologie de base repose sur le nouvel agent intelligent d’image HiDream-A1, qui intègre des versions avancées et propriétaires de HiDream-I1 (modèle de base de génération d’images de 17 milliards de paramètres, précédemment open source et en tête des compétitions de génération de texte en image) et HiDream-E1 (modèle d’édition d’images interactif). vivago2.0 vise à abaisser le seuil de création de contenu multimodal, offre des centaines de modèles d’effets spéciaux et prend en charge la génération et la modification d’images par le biais de dialogues en langage naturel (Image Agent). (Source: 量子位)

Nvidia lance la série de GPU RTX 5050, avec des configurations de mémoire vidéo différentes pour les versions de bureau et portable : Nvidia a officiellement lancé la série de GPU GeForce RTX 5050, comprenant des versions pour ordinateurs de bureau et portables, dont la sortie est prévue pour juillet, avec un prix de détail suggéré en Chine à partir de 2099 yuans pour la version de bureau. La RTX 5050 de bureau dispose de 2560 cœurs CUDA Blackwell, est équipée de 8 Go de mémoire GDDR6 et a une consommation électrique maximale de 130W. La version portable de la RTX 5050 dispose également de 2560 cœurs CUDA, mais est équipée de 8 Go de mémoire GDDR7 plus économe en énergie. Nvidia affirme qu’avec la technologie DLSS 4, la RTX 5050 peut dépasser les 150 ips en ray tracing dans des jeux comme Cyberpunk 2077, et offre une amélioration moyenne des performances de rastérisation de 60% (version de bureau) et de 2,4 fois (version portable) par rapport à la RTX 3050. Cette différenciation de la configuration de la mémoire vidéo reflète la stratégie d’équilibre entre coût et performance de Nvidia sur différents segments de marché. (Source: 量子位)

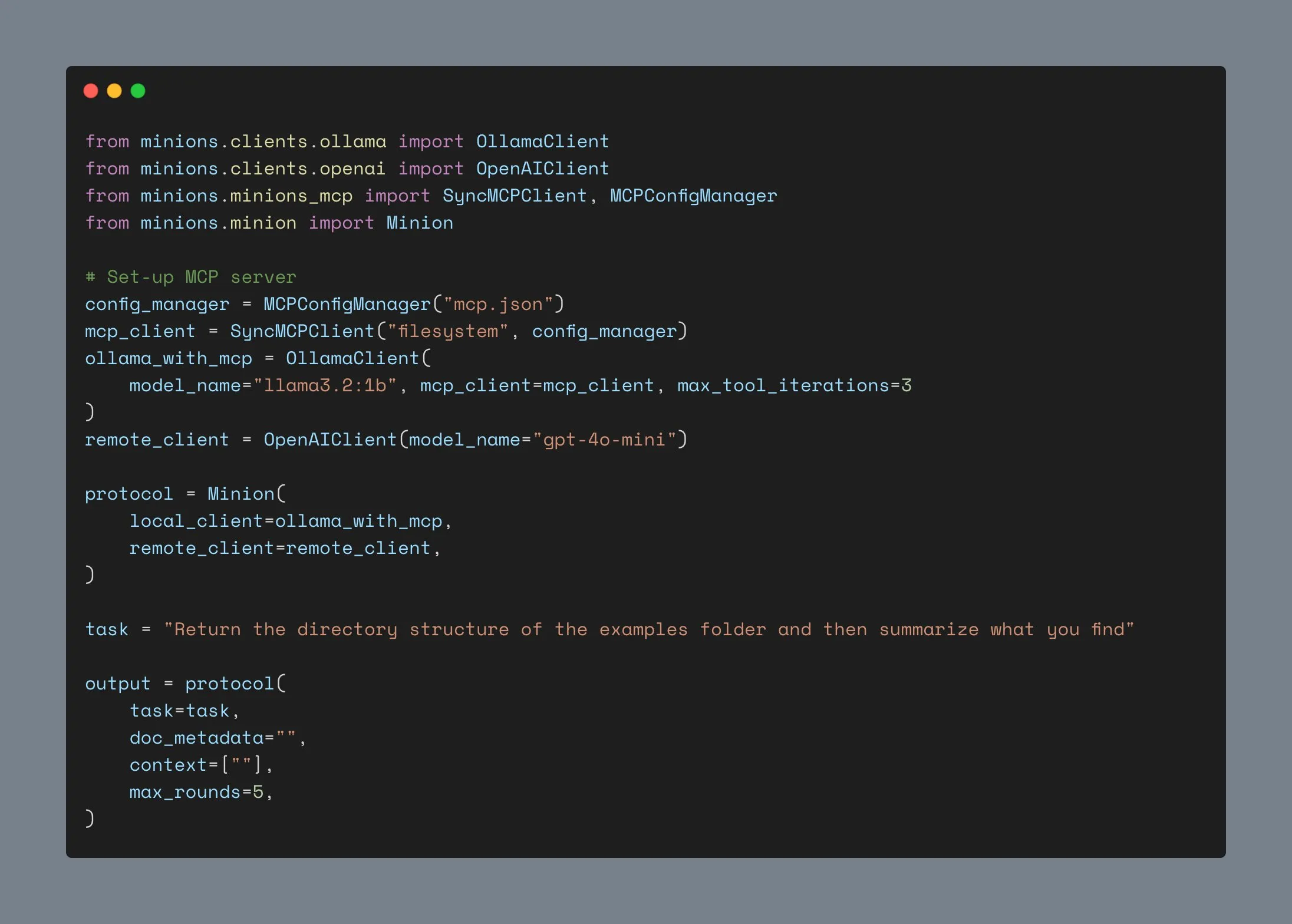
Mise à jour de LM Studio avec prise en charge du protocole MCP, permettant de connecter des LLM locaux à des serveurs MCP : L’outil d’exécution de LLM sur ordinateur de bureau LM Studio a publié une nouvelle version (0.3.17), ajoutant la prise en charge du protocole de contexte de modèle (MCP). Les utilisateurs peuvent désormais connecter des grands modèles de langage exécutés localement à des serveurs compatibles MCP, par exemple pour appeler des outils ou des services externes. LM Studio a mis à jour son interface de programme à cet effet, permettant aux utilisateurs d’installer et de configurer des services MCP, et de charger et gérer automatiquement les processus de serveur MCP locaux. Pour faciliter la configuration, LM Studio propose également un outil en ligne pour générer des liens de configuration de serveur MCP importables en un clic. (Source: multimodalart、karminski3)

Gradio lance Trackio, une bibliothèque légère de suivi d’expériences : L’équipe Gradio de Hugging Face a lancé Trackio, une bibliothèque légère de suivi et de visualisation d’expériences. Cet outil, écrit en moins de 1000 lignes de code Python, est entièrement open source et gratuit, et peut être utilisé localement ou hébergé. Trackio vise à aider les développeurs à enregistrer et à surveiller plus facilement les divers indicateurs et résultats pendant le processus d’expérimentation en apprentissage automatique, simplifiant ainsi la gestion des expériences. (Source: ClementDelangue、_akhaliq)
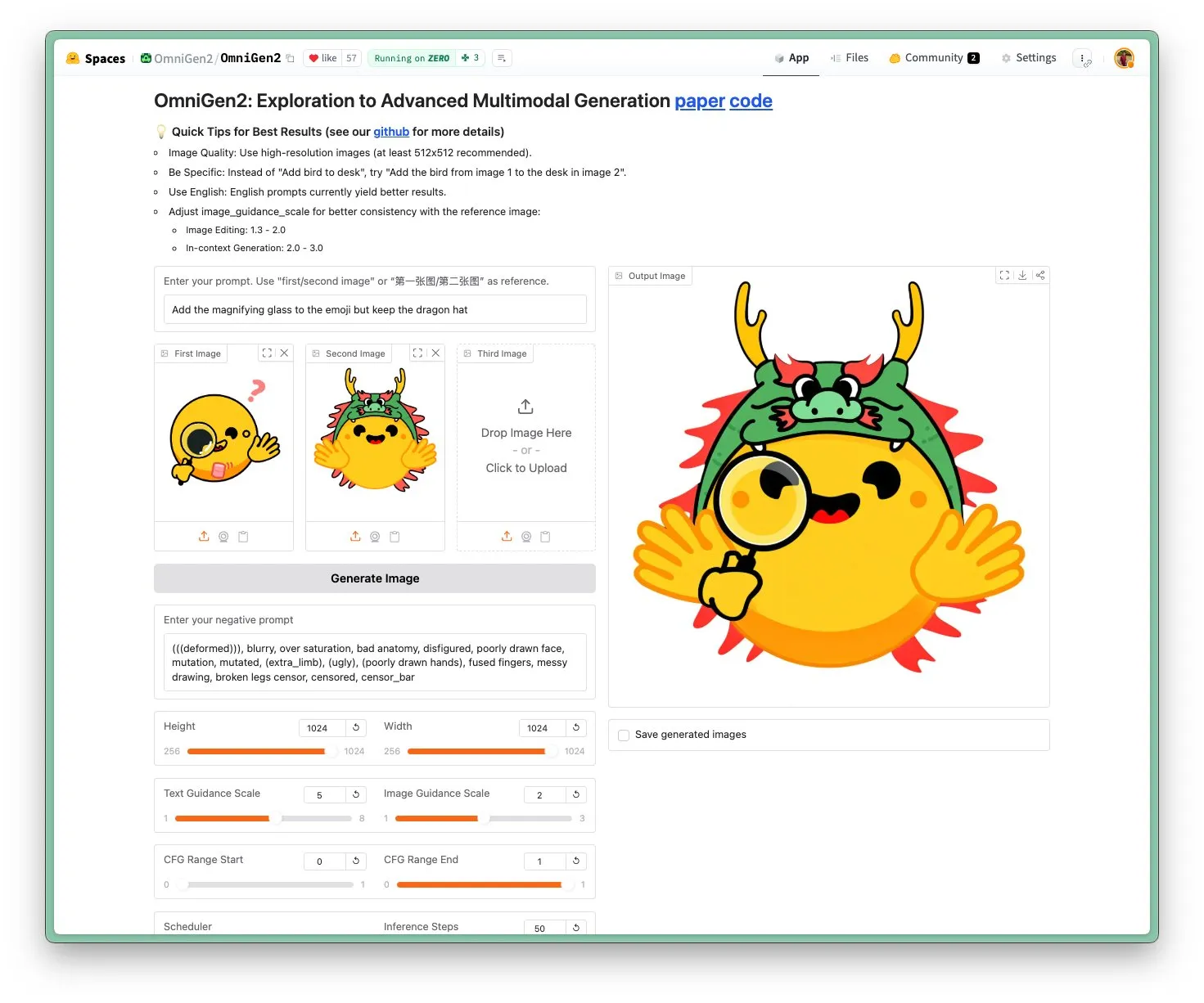
OmniGen 2 lancé : modèle visuel multifonctionnel et d’édition d’images SOTA sous licence Apache 2.0 : Le nouveau modèle OmniGen 2 atteint un niveau SOTA (state-of-the-art) en matière d’édition d’images et est distribué sous licence open source Apache 2.0. Ce modèle excelle non seulement dans l’édition d’images, mais peut également effectuer diverses tâches telles que la génération contextuelle, la conversion de texte en image et la compréhension visuelle. Les utilisateurs peuvent directement essayer la démo et le modèle sur Hugging Face Hub. (Source: huggingface)
L’architecture Atlas est proposée : avec une mémoire contextuelle à long terme, elle défie Transformer : La nouvelle architecture Atlas vise à résoudre le problème de la mémoire à long terme dans les LLM, affirmant surpasser Transformer et les RNN linéaires modernes dans les tâches de modélisation du langage. Atlas a la capacité d’apprendre à mémoriser le contexte lors des tests, peut augmenter la longueur effective du contexte des modèles Titans et atteindre une précision de plus de 80 % sur le benchmark BABILong avec une fenêtre contextuelle de 10 millions. Les chercheurs ont également discuté d’une autre série de modèles d’attention softmax à généralisation stricte basés sur l’idée d’Atlas. (Source: behrouz_ali)

Mise à jour du modèle visuel Moondream 2B : amélioration du raisonnement visuel et de la compréhension de l’UI, accélération de 40 % de la génération de texte : Une nouvelle version du modèle visuel Moondream 2B a été publiée, avec des améliorations au niveau du raisonnement visuel, de la détection d’objets et de la compréhension de l’interface utilisateur (UI). De plus, la vitesse de génération de texte a été augmentée de 40 %. Cela indique que les petits modèles multimodaux continuent d’être optimisés pour des capacités spécifiques, visant à fournir une interaction visuo-linguistique plus efficace et précise. (Source: mervenoyann)
Inworld AI et Modular collaborent pour lancer un modèle TTS de haute qualité à faible coût : Inworld AI a annoncé le lancement d’un nouveau modèle de synthèse vocale (TTS) qui réduirait le coût des TTS de pointe de 20 fois, pour atteindre 5 dollars par million de caractères. Ce modèle est basé sur l’architecture Llama, et son code d’entraînement et de modélisation sera open source. Le partenaire Modular a déclaré que grâce à la collaboration technologique, ils ont réalisé la plateforme d’inférence TTS la plus rapide avec la latence la plus faible sur NVIDIA B200, et publieront un rapport technique conjoint. (Source: clattner_llvm)
Higgsfield AI lance le modèle Soul : axé sur la génération de photos de haute esthétique : Higgsfield AI a lancé un nouveau modèle de génération de photos appelé Higgsfield Soul, spécialisé dans la haute valeur esthétique et le réalisme de qualité mode. Ce modèle propose plus de 50 préréglages soigneusement sélectionnés, visant à générer des images comparables à des photographies professionnelles, défiant ainsi la photographie mobile traditionnelle. (Source: _akhaliq)
🧰 Outils
Gemini CLI : l’agent IA open source pour terminal lancé par Google, offrant 1000 appels gratuits quotidiens à Gemini 2.5 Pro : Google a lancé Gemini CLI, un agent IA open source en ligne de commande, permettant aux utilisateurs d’utiliser directement le modèle Gemini 2.5 Pro dans le terminal. Cet outil offre une fenêtre contextuelle de 1 million de tokens, et les utilisateurs gratuits peuvent bénéficier jusqu’à 1000 requêtes par jour (60 par minute). Gemini CLI prend en charge l’écriture de code, le débogage, les E/S du système de fichiers, la compréhension du contenu Web, les plugins et le protocole MCP, visant à aider les développeurs à construire et maintenir des logiciels plus efficacement. Sa nature open source (licence Apache 2.0) et son quota gratuit élevé en font un concurrent sérieux pour les outils existants tels que Claude Code, et pourraient favoriser la prise en charge des modèles locaux. (Source: Reddit r/LocalLLaMA、dotey、yoheinakajima)
Anthropic lance une nouvelle fonctionnalité pour Claude Code : créer et partager des Artifacts pilotés par l’IA, les utilisateurs utilisant leur propre quota : Anthropic a introduit une nouvelle fonctionnalité pour son assistant de programmation IA Claude Code, permettant aux utilisateurs de créer, héberger et partager des “Artifacts” (qui peuvent être compris comme de petites applications ou outils IA), et d’intégrer directement l’intelligence de Claude dans ces créations. Cela signifie que les utilisateurs peuvent non seulement utiliser Claude pour générer des extraits de code ou effectuer des analyses, mais aussi pour construire des applications fonctionnelles pilotées par l’IA. Une caractéristique clé est que lors du partage de ces applications IA, les spectateurs s’authentifient avec leur propre compte Claude, et leur utilisation est décomptée de leur propre quota d’abonnement, et non de celui du créateur. Cette fonctionnalité est actuellement en phase bêta et ouverte à tous les utilisateurs gratuits, Pro et Max, visant à abaisser le seuil de création d’applications IA et à promouvoir la popularisation et le partage des capacités de l’IA. (Source: kylebrussell、Reddit r/ClaudeAI、dotey)
Mise à jour de LM Studio avec prise en charge du protocole MCP, permettant de connecter des LLM locaux à des serveurs MCP : L’outil d’exécution de LLM sur ordinateur de bureau LM Studio a publié une nouvelle version (0.3.17), ajoutant la prise en charge du protocole de contexte de modèle (MCP). Les utilisateurs peuvent désormais connecter des grands modèles de langage exécutés localement à des serveurs compatibles MCP, par exemple pour appeler des outils ou des services externes. LM Studio a mis à jour son interface de programme à cet effet, permettant aux utilisateurs d’installer et de configurer des services MCP, et de charger et gérer automatiquement les processus de serveur MCP locaux. Pour faciliter la configuration, LM Studio propose également un outil en ligne pour générer des liens de configuration de serveur MCP importables en un clic. (Source: multimodalart、karminski3)
Superconductor : un outil pour gérer une équipe d’agents Claude Code sur mobile ou ordinateur de bureau : Superconductor est un nouvel outil qui permet aux utilisateurs de gérer une équipe de plusieurs agents Claude Code depuis leur téléphone portable ou leur ordinateur portable. Les utilisateurs peuvent rédiger des tickets de tâches informels, lancer plusieurs agents pour chaque ticket, chaque agent disposant de son propre aperçu d’application en temps réel. Les développeurs peuvent générer une PR (Pull Request) des résultats de l’agent le plus performant en un clic. Cet outil vise à simplifier la collaboration multi-agents et le processus de génération de code. (Source: full_stack_dl)
Udio lance la fonctionnalité Sessions, améliorant la précision de l’édition musicale par IA : La plateforme de génération de musique par IA Udio a lancé la fonctionnalité “Sessions” pour ses abonnés aux versions standard et professionnelle. Cette fonctionnalité introduit une nouvelle vue chronologique pour l’édition des pistes audio, permettant aux utilisateurs de produire de la musique avec plus de précision et de réduire la dépendance à la génération aléatoire de l’IA. Actuellement, Sessions prend en charge l’extension ou l’édition des pistes, et d’autres fonctionnalités seront ajoutées à l’avenir. (Source: TomLikesRobots)
Mise à jour du client Ollama, prise en charge de l’intégration MCP, plus de 1000 étoiles sur GitHub : Le client Ollama a été mis à jour et peut désormais intégrer sa fonctionnalité d’appel d’outils avec n’importe quel serveur MCP Anthropic. Cela signifie que les utilisateurs peuvent combiner la commodité des modèles exécutés localement par Ollama avec les capacités d’outils externes fournies par MCP. Parallèlement, le projet a dépassé les 1000 étoiles sur GitHub. (Source: ollama)
📚 Apprentissage
Andrew Ng lance un nouveau cours : Protocole de Communication pour Agents Intelligents (ACP) : DeepLearning.AI, en collaboration avec IBM Research, lance un cours abrégé sur le Protocole de Communication pour Agents Intelligents (ACP). L’ACP est un protocole ouvert qui normalise la communication entre agents via une interface RESTful unifiée, visant à résoudre les défis d’intégration lors de la construction de systèmes multi-agents par plusieurs équipes et à travers différents frameworks. Le cours enseignera comment utiliser l’ACP pour connecter des agents construits avec différents frameworks (tels que CrewAI, Smoljames), réaliser une collaboration séquentielle et hiérarchique des flux de travail, et importer des agents ACP dans la plateforme BeeAI (une plateforme open source d’enregistrement et de partage d’agents). Les participants apprendront le cycle de vie des agents ACP et les compareront à d’autres protocoles tels que MCP (Model Context Protocol) et A2A (Agent-to-Agent). (Source: AndrewYNg)
L’Université Johns Hopkins lance un cours sur DSPy : L’Université Johns Hopkins a mis en place un cours sur DSPy. DSPy est un framework pour l’optimisation algorithmique des prompts et des poids des LLM, qui transforme le processus d’ingénierie des prompts, auparavant manuel, en un processus plus systématisé et programmable de construction et d’optimisation de modules. Le PDG de Shopify, Tobi Lutke, a également déclaré que DSPy était son outil de prédilection pour l’ingénierie contextuelle. (Source: stanfordnlp、lateinteraction)

Tutoriel LM Studio : Utiliser des modèles open source Hugging Face pour une expérience de type ChatGPT locale et privée : Niels Rogge a publié un tutoriel YouTube montrant comment utiliser LM Studio en combinaison avec des modèles open source de Hugging Face (comme Mistral 3.2-Small) pour obtenir une expérience de type ChatGPT 100% privée et hors ligne en local. Le tutoriel explique des concepts tels que GGUF, la quantification, et pourquoi les modèles occupent encore beaucoup d’espace même après une quantification à 4 bits, et montre la compatibilité de LM Studio avec l’API OpenAI. (Source: _akhaliq)

LlamaIndex organisera un séminaire en ligne sur la mémoire des agents : LlamaIndex, en collaboration avec AIMakerspace, organisera une discussion en ligne sur la mémoire des agents. Le contenu couvrira la persistance de l’historique des discussions, l’utilisation de blocs statiques, factuels et vectoriels pour la mémoire à long terme, la logique de mise en œuvre de la mémoire personnalisée, et les moments où la mémoire est cruciale. La discussion vise à aider les développeurs à construire des agents qui nécessitent un contexte réel dans les conversations. (Source: jerryjliu0)

Le podcast Weaviate explore les benchmarks et l’évaluation RAG : Le 124ème épisode du podcast Weaviate a invité Nandan Thakur, qui a apporté d’importantes contributions dans le domaine de l’évaluation de la recherche, pour discuter des tests de référence et de l’évaluation de la génération augmentée par récupération (RAG). Le contenu aborde des benchmarks tels que BEIR, MIRACL, TREC et le plus récent FreshStack, ainsi que de multiples sujets liés à RAG, notamment le raisonnement, la rédaction de requêtes, la recherche cyclique, les résultats de recherche paginés et les récupérateurs hybrides. (Source: lateinteraction)

PyTorch lance la recette flux-fast, accélérant les modèles Flux de 2,5 fois sur H100 : PyTorch a publié une recette simple nommée flux-fast, conçue pour augmenter la vitesse d’exécution des modèles Flux de 2,5 fois sur les GPU H100, sans nécessiter d’ajustements complexes. Cette solution vise à simplifier la réalisation de calculs haute performance, et le code correspondant a été fourni. (Source: robrombach)

Informations sur la conférence MLSys 2026 annoncées : La conférence MLSys 2026 est prévue pour mai 2026 à Seattle (Bellevue), la date limite de soumission des articles étant le 30 octobre de cette année. Toutes les vidéos des sessions de MLSys 2025 sont disponibles gratuitement sur le site officiel. Cette conférence se concentre sur la recherche et les avancées dans le domaine des systèmes d’apprentissage automatique. (Source: JeffDean)

Le cours CS336 de Stanford “Construire des modèles de langage à partir de zéro” suscite l’attention : Le cours CS336 de l’Université de Stanford, “Language Models from Scratch”, enseigné entre autres par Percy Liang, a reçu des éloges. Ce cours vise à permettre aux étudiants de comprendre en profondeur les détails techniques des modèles de langage, en construisant eux-mêmes des modèles pour combler le fossé entre les chercheurs et les détails techniques. Le contenu du cours et les devoirs sont considérés comme des ressources d’apprentissage importantes pour devenir un expert en LLM. (Source: nrehiew_、jpt401)
💼 Affaires
Meta investit 14,3 milliards de dollars dans Scale AI et recrute son PDG Alexandr Wang pour accélérer la R&D en IA : Pour renforcer ses capacités en IA, Meta a conclu un accord avec la société d’annotation de données Scale AI, investissant 14,3 milliards de dollars pour acquérir 49 % de ses actions sans droit de vote, et recruter son fondateur et PDG Alexandr Wang ainsi que son équipe. Alexandr Wang sera responsable d’un nouveau laboratoire chez Meta axé sur la recherche en superintelligence. Cette démarche vise à doter Meta de talents de premier plan en IA et de capacités d’exploitation de données à grande échelle, afin de faire face à la réception mitigée de son modèle Llama 4 et aux turbulences de personnel au sein de son département de recherche en IA. Scale AI utilisera les fonds pour accélérer l’innovation et distribuer une partie des fonds aux actionnaires, son directeur de la stratégie Jason Droege assurant l’intérim au poste de PDG. Cette transaction pourrait éviter un examen gouvernemental partiel en évitant une acquisition directe. (Source: DeepLearning.AI Blog)

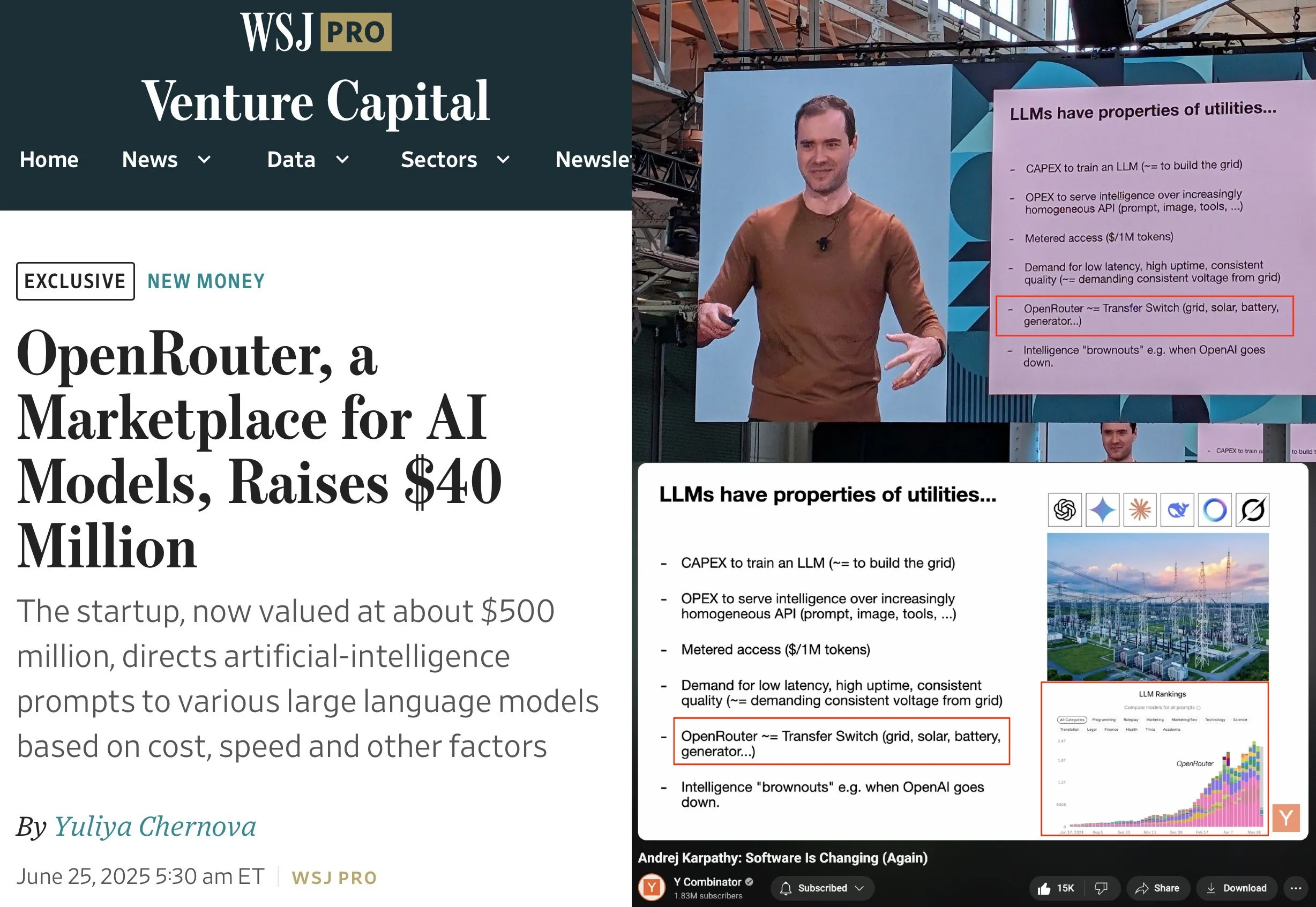
OpenRouter lève 40 millions de dollars en série A, menée par a16z et Menlo : OpenRouter, le plan de contrôle pour l’inférence LLM et place de marché de modèles, a annoncé avoir levé un total de 40 millions de dollars en tours de financement d’amorçage et de série A, menés par a16z et Menlo Ventures. OpenRouter vise à devenir l’interface unifiée pour les développeurs pour choisir et utiliser divers LLM, offrant actuellement plus de 400 modèles et traitant 100 trillions de tokens par an. Le financement sera utilisé pour étendre les modalités de modèles prises en charge (comme la génération d’images, les modèles d’interaction multimodale), mettre en œuvre des mécanismes de routage plus intelligents (comme le routage géographique, l’optimisation de l’allocation de GPU d’entreprise) et améliorer les fonctionnalités de découverte de modèles. (Source: amasad、swyx)
La société de robots humanoïdes “Lingbao CASBOT” lève près de 100 millions de yuans en tour de financement Angel+, mené par Lens Technology : La marque de robots humanoïdes “Lingbao CASBOT” a annoncé avoir finalisé un tour de financement Angel+ de près de 100 millions de yuans, mené par Lens Technology, avec la participation de Tianjin Jiayi et des actionnaires existants Guotou Chuanghe et Henan Asset. Les fonds seront utilisés pour accélérer la production de masse des produits, la R&D technologique et l’expansion du marché. Lingbao CASBOT se concentre sur les applications concrètes des robots humanoïdes universels et de l’intelligence incarnée, et a déjà lancé deux robots humanoïdes bipèdes, CASBOT 01 et 02, destinés respectivement aux opérations spéciales et à des scénarios d’interaction homme-machine plus larges (comme le guidage, l’éducation). La technologie de base de l’entreprise comprend un modèle hiérarchique de bout en bout combiné à un post-entraînement par apprentissage par renforcement, et a déjà établi des collaborations dans les secteurs de la fabrication industrielle et de l’énergie minière avec des groupes tels que Zhaojin Group et China National Gold Group. (Source: 36氪、36氪)

🌟 Communauté
Andrej Karpathy plaide pour l‘“ingénierie contextuelle” en remplacement de l‘“ingénierie des prompts”, soulignant la complexité de la création d’applications LLM : Andrej Karpathy partage l’avis de Tobi Lutke selon lequel l‘“ingénierie contextuelle” (context engineering) décrit plus précisément que l‘“ingénierie des prompts” (prompt engineering) la compétence essentielle des applications LLM de niveau industriel. Il souligne que les prompts désignent généralement les brèves descriptions de tâches saisies quotidiennement par les utilisateurs, tandis que l’ingénierie contextuelle est un art et une science subtils, impliquant le remplissage précis de la fenêtre contextuelle avec des descriptions de tâches, quelques exemples, des RAG, des données multimodales, des outils, l’historique des états, etc., afin d’optimiser les performances des LLM. Il souligne également que les applications LLM vont bien au-delà, nécessitant de résoudre une série de problèmes complexes d’ingénierie logicielle tels que la décomposition des problèmes, le contrôle de flux, l’orchestration multi-modèles, l’UI/UX, l’évaluation de la sécurité, etc. Par conséquent, l’expression “enveloppe ChatGPT” est erronée. (Source: karpathy、code_star、dotey)
Hugging Face lance un plan payant pour les équipes afin de répondre aux questions de la communauté sur son modèle économique : En réponse aux questions de la communauté sur la manière dont Hugging Face génère des revenus (comme celles soulevées par le tweet de l’utilisateur @levelsio), le cofondateur de Hugging Face, Clement Delangue, a répondu avec humour qu’il était “déclenché par l’anxiété de la monétisation” et a annoncé le lancement d’un nouveau plan premium payant pour les équipes. Hugging Face, en tant que plateforme hébergeant un grand nombre de modèles d’IA, fournissant des API gratuites et n’imposant pas de clés API, a vu son modèle économique devenir un sujet de discussion central au sein de la communauté. Le lancement de ce nouveau plan indique qu’elle explore et développe activement des voies de commercialisation. (Source: huggingface、ClementDelangue)
La communauté débat de la fidélité des utilisateurs aux assistants de code IA et de la collaboration multi-outils : The Information rapporte que la fidélité des développeurs aux assistants de codage pourrait être plus élevée qu’on ne le pense. Parallèlement, on observe au sein de la communauté des développeurs utilisant simultanément plusieurs outils de codage IA tels que Claude Code, Codex (CLI) et Gemini (CLI) dans le même dépôt de code. Cela reflète le fait que les développeurs expérimentent activement différents outils d’IA pour améliorer leur efficacité, tout en cherchant potentiellement la combinaison de fonctionnalités la mieux adaptée à leur flux de travail spécifique, plutôt que de dépendre entièrement d’un seul outil. (Source: steph_palazzolo、code_star)

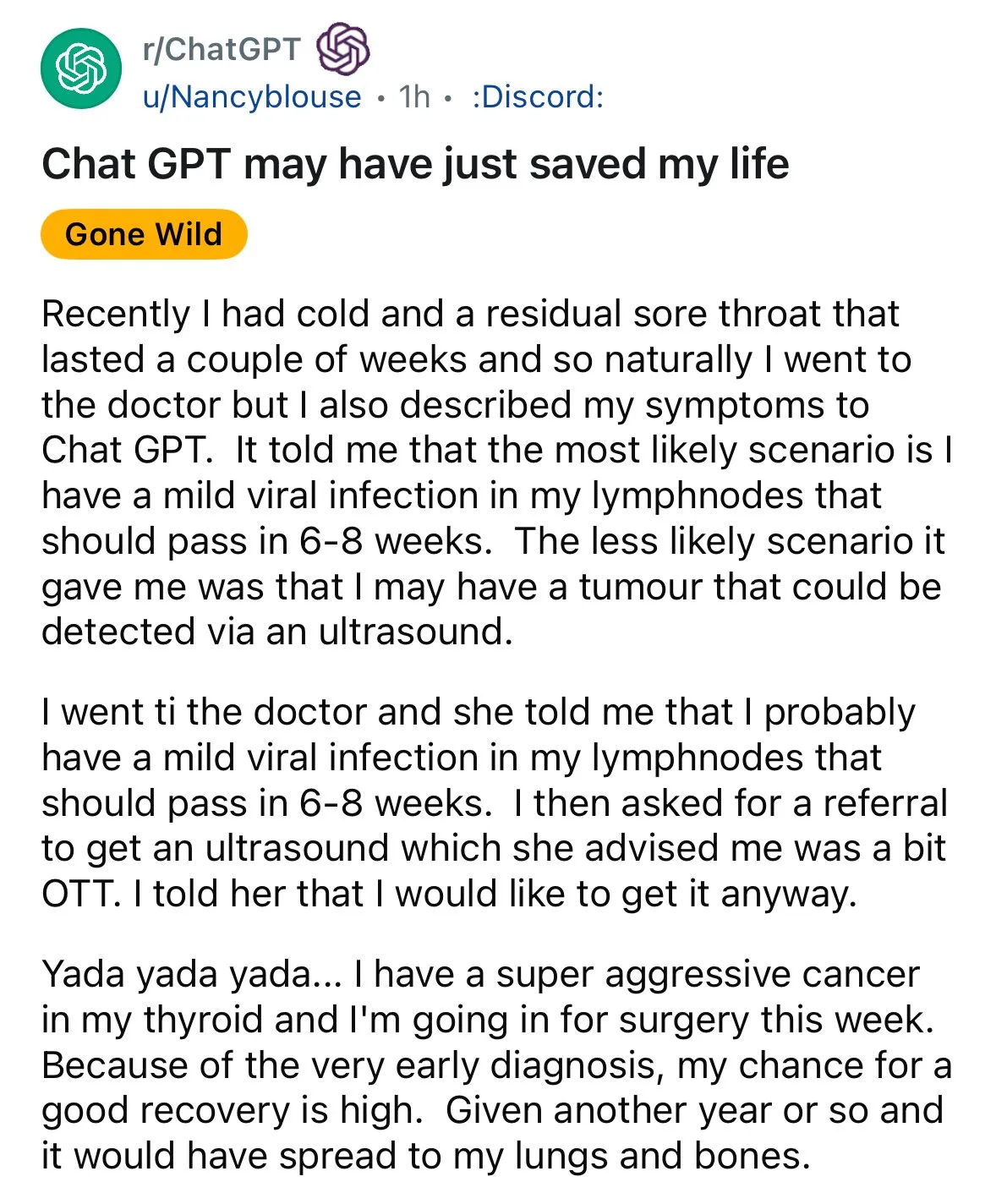
L’IA montre son potentiel dans le diagnostic médical, suscitant des discussions sur le “deuxième avis” : Des cas de diagnostic assisté par IA réapparaissent sur les réseaux sociaux. Un patient souffrant de maux de gorge, après que son médecin lui ait conseillé d’observer, a obtenu une suggestion de ChatGPT pour effectuer une échographie, qui a finalement révélé un cancer de la thyroïde. De tels événements suscitent des discussions, encourageant les gens à utiliser l’IA pour obtenir un “deuxième avis” sur les questions médicales, estimant que cela pourrait sauver des vies. Parallèlement, la recherche du modèle GRAPE de l’Académie DAMO d’Alibaba, qui détecte le cancer gastrique précoce par des scanners CT conventionnels, a été publiée dans Nature Medicine, montrant l’énorme potentiel de l’IA dans le dépistage précoce du cancer. (Source: aidan_mclau、Yuchenj_UW)
La “littérature folle” à l’ère de l’IA et le phénomène de la compagnie de l’IA : La “littérature folle” populaire chez les jeunes, comme moyen d’expression émotionnelle et de micro-résistance, croise désormais les outils d’IA. De nombreux utilisateurs se tournent vers l’IA générative (comme Dan Xiaohuang de Wen Xiaoyan) comme exutoire émotionnel et compagnon, pour soulager la solitude, obtenir du réconfort, voire aider à la prise de décision (comme le débriefing après une dispute). L’IA, grâce à sa patience, son impartialité et sa disponibilité constante, devient un “ami électronique” peu coûteux et très privé, aidant les utilisateurs à trouver du réconfort dans les moments de chaos et étant considérée comme bénéfique pour l’amélioration de l’état mental. (Source: 36氪)

Le débat sur la question de savoir si les LLM constituent une intelligence artificielle générale (AGI) se poursuit : Au sein de la communauté, le débat se poursuit sur la question de savoir si et quand les grands modèles de langage (LLM) pourront atteindre l’intelligence artificielle générale (AGI). Certains estiment que, bien que les LLM excellent dans de nombreuses tâches, ils sont encore loin d’une véritable AGI, en particulier en l’absence des théories et des données sur le fonctionnement interne des génies scientifiques humains. Les opinions divergent également quant au calendrier de réalisation de l’AGI, avec des estimations allant de 2028 dans un avenir proche à 2035-2040 plus lointain. (Source: menhguin)

💡 Divers
Le premier chatbot au monde, Eliza, a été restauré avec succès 60 ans plus tard : Eliza, le premier chatbot au monde inventé par le scientifique du MIT Joseph Weizenbaum au milieu des années 1960, dont le code source original avait été perdu pendant de nombreuses années, a vu ses épreuves imprimées redécouvertes. Grâce aux efforts d’équipes de l’Université de Stanford et du MIT, qui ont nettoyé et débogué le code original, corrigé des fonctionnalités et développé un environnement d’exécution simulé, Eliza a été “ressuscitée” avec succès 60 ans plus tard. L’Eliza originale analysait le texte saisi par l’utilisateur, extrayait des mots-clés et réorganisait les phrases pour répondre, interagissant avec les utilisateurs sous les traits d’un thérapeute rogérien, et avait suscité un attachement émotionnel chez de nombreux testeurs. Le code et le simulateur d’Eliza restaurés ont été publiés sur Github pour que le public puisse les découvrir. (Source: 36氪)

L’outil de génération d’images par IA Midjourney fait face à des poursuites pour droits d’auteur de la part de Disney et d’autres, mais son mode de création unique est plébiscité : La plateforme de génération d’images par IA Midjourney fait face à des poursuites judiciaires car les images qu’elle génère pourraient enfreindre les droits d’auteur sur les actifs visuels de sociétés telles que Disney et Universal Pictures. Cependant, l’outil, grâce à son mode de création unique – générer des images hautement artistiques et stylisées via des invites textuelles dans la communauté Discord – est très populaire auprès des créateurs du monde entier. L’équipe de Midjourney compte moins de 50 personnes, n’a pas levé de fonds, mais son chiffre d’affaires annuel atteint déjà 200 millions de dollars. Sa philosophie de produit met l’accent sur la “primauté de l’imagination”, positionnant l’IA comme un moteur d’expansion de la pensée humaine plutôt qu’un simple outil de remplacement, et a remodelé le paradigme de la création numérique grâce à une interaction minimaliste “dé-outillée” et une culture de co-création communautaire. (Source: 36氪)

La transformation du leadership induite par l’IA : de l’obéissance hiérarchique à la symbiose homme-machine : Avec l’intégration profonde de l’IA dans le travail, le leadership traditionnel est confronté à des défis. Une enquête de Google montre que 82 % des jeunes leaders utilisent l’IA, et les données d’Oracle indiquent que 25 % des employés préfèrent interroger l’IA plutôt que leur responsable. L’IA entraîne des changements dans l’environnement du leadership : l’information et l’expérience ne sont plus le bastion exclusif des leaders, la transparence des décisions engendre une pression, et la gestion s’étend des équipes purement humaines aux “hybrides homme-machine”. L’École de Management de l’Université Fudan a introduit le concept de “leadership symbiotique”, soulignant la symbiose entre l’économie traditionnelle et l’économie numérique, l’entreprise et l’écosystème, le cerveau humain et le cerveau machine. À l’ère de l’IA, les leaders doivent maîtriser la transition entre les anciennes et les nouvelles dynamiques, créer de la valeur au sein de réseaux collaboratifs et exploiter l’effet multiplicateur de la collaboration homme-machine, leur compétence principale résidant dans la capacité à faire en sorte que l’IA serve l’humanité. (Source: 36氪)