Mots-clés:Recherche en IA, Informatique, Apprentissage par renforcement, Développement de médicaments, Conduite autonome, Modèle linguistique, Traitement multimodal, Cellule virtuelle, Institut Laude, Enseignants en apprentissage par renforcement (RLTs), Plateforme BioNeMo, Tesla Robotaxi, Modèle Kimi VL A3B Thinking
🔥 Pleins feux sur
Lancement du Laude Institute avec un financement initial de 100 millions de dollars pour promouvoir la recherche d’intérêt public en informatique: Andy Konwinski a annoncé le lancement du Laude Institute, une organisation à but non lucratif visant à financer la recherche en informatique non commerciale ayant un impact significatif sur le monde. Des personnalités de renom telles que Jeff Dean, Joyia Pineau et Dave Patterson rejoignent le conseil d’administration. L’institut a obtenu un engagement de financement initial de 100 millions de dollars et soutiendra les chercheurs pour transformer leurs idées en impact réel grâce à des subventions, au partage de ressources et à la création d’une communauté, en mettant un accent particulier sur la recherche ouverte et axée sur l’impact. (Source: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

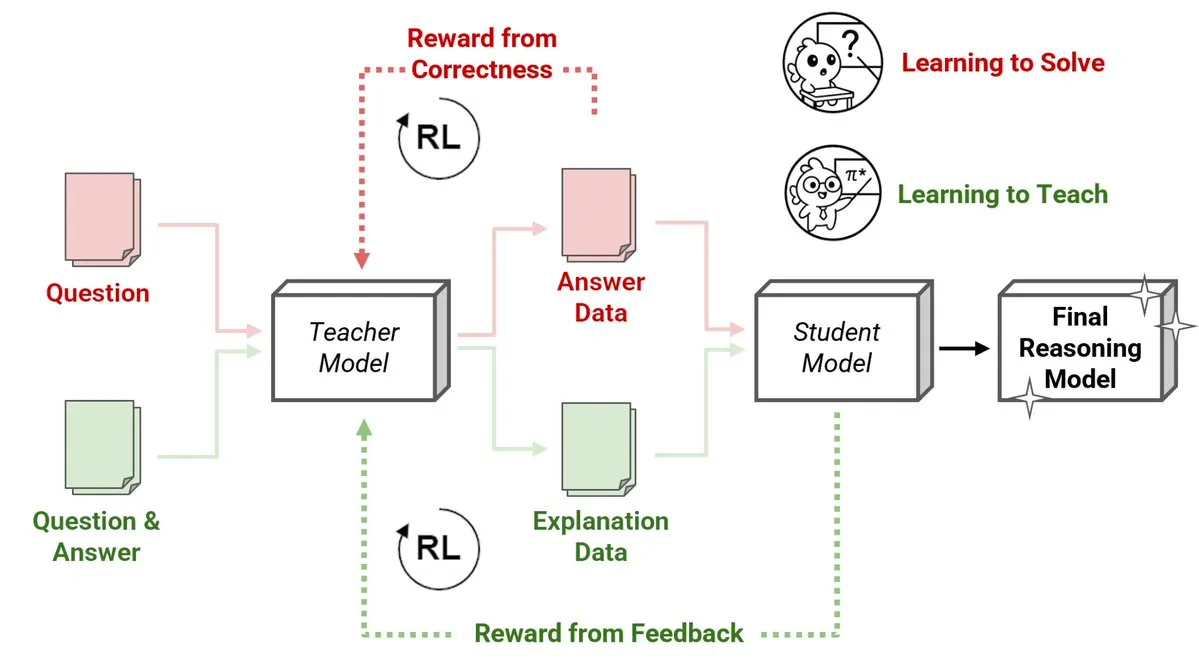
Sakana AI dévoile une nouvelle méthode d’enseignants par apprentissage par renforcement (RLTs), où de petits modèles enseignent le raisonnement à de grands modèles: Sakana AI a introduit une nouvelle approche avec les enseignants par apprentissage par renforcement (RLTs), transformant la manière dont le raisonnement est enseigné aux grands modèles de langage (LLMs) via l’apprentissage par renforcement (RL). Alors que le RL traditionnel se concentre sur « l’apprentissage pour résoudre » les problèmes, les RLTs sont entraînés pour générer des « explications » claires et progressives afin d’instruire les modèles étudiants. Un RLT avec seulement 7B de paramètres, en enseignant à un modèle étudiant de 32B de paramètres, surpasse en performance des LLMs plusieurs fois plus grands sur des tâches de raisonnement compétitives et de niveau universitaire. Cette approche établit une nouvelle norme d’efficacité pour le développement de modèles de langage de raisonnement avec RL. (Source: cognitivecompai, AndrewLampinen)
Nvidia s’associe à Novo Nordisk pour accélérer la découverte de médicaments grâce à un supercalculateur IA: Nvidia a annoncé une collaboration avec le géant pharmaceutique danois Novo Nordisk et le Centre national danois d’innovation en IA pour utiliser conjointement la technologie IA et le dernier supercalculateur danois Gefion afin d’accélérer la recherche et le développement de nouveaux médicaments. Cette collaboration utilisera la plateforme BioNeMo de Nvidia et des flux de travail IA avancés, visant à transformer les modèles de recherche et développement de médicaments. Le supercalculateur Gefion, construit avec les technologies d’Eviden et de Nvidia, fournira un puissant support de calcul pour la recherche dans des domaines tels que les sciences de la vie, favorisant la médecine personnalisée et la découverte de nouvelles thérapies. (Source: nvidia)

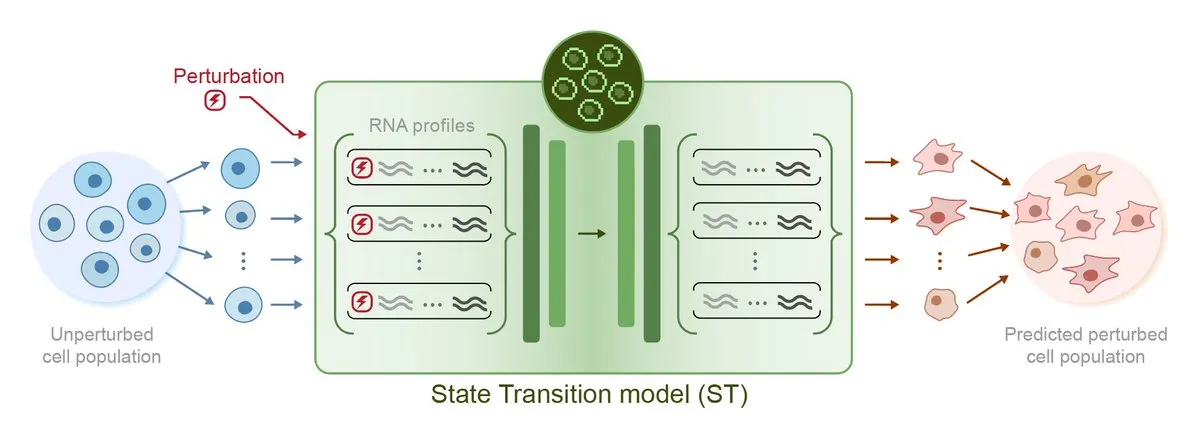
Arc Institute publie STATE, son premier modèle d’IA pour la prédiction des perturbations, marquant une étape vers l’objectif de la cellule virtuelle: Arc Institute a publié son premier modèle d’IA de prédiction des perturbations, STATE, une étape importante vers son objectif de réaliser une cellule virtuelle. Le modèle STATE est conçu pour apprendre comment utiliser des médicaments, des cytokines ou des perturbations génétiques pour modifier l’état cellulaire (par exemple, de « malade » à « sain »). La publication de ce modèle marque une nouvelle avancée de l’IA dans la compréhension et la prédiction du comportement cellulaire, ouvrant de nouvelles voies pour le traitement des maladies et le développement de médicaments. Les modèles associés sont disponibles sur HuggingFace. (Source: riemannzeta, ClementDelangue)
Le Robotaxi de Tesla lance un projet pilote à Austin, la solution visuelle attire l’attention, le code hérité de Karpathy considérablement simplifié: Tesla a officiellement lancé un service pilote de Robotaxi à Austin, au Texas, aux États-Unis. Les premiers véhicules, basés sur le Model Y, utilisent une solution de perception purement visuelle et le logiciel FSD. L’équipe dirigée par Ashok Elluswamy, responsable de l’IA et du logiciel de conduite autonome chez Tesla, a apporté des changements technologiques majeurs au système, réduisant de près de 90 % les quelque 330 000 à 340 000 lignes de code heuristique C++ héritées de l’équipe d’Andrej Karpathy, les remplaçant par un « réseau neuronal géant ». Cette démarche vise à passer d’un « codage de l’expérience humaine » à un « entraînement paramétré », en optimisant de manière autonome les modèles grâce à des données massives et à la simulation de conduite. Actuellement, le service est en phase d’expérimentation précoce, suscitant de larges discussions dans l’industrie sur la feuille de route technologique de Tesla et ses capacités de mise à l’échelle. (Source: 36氪, Ronald_vanLoon, kylebrussell)

🎯 Actualités
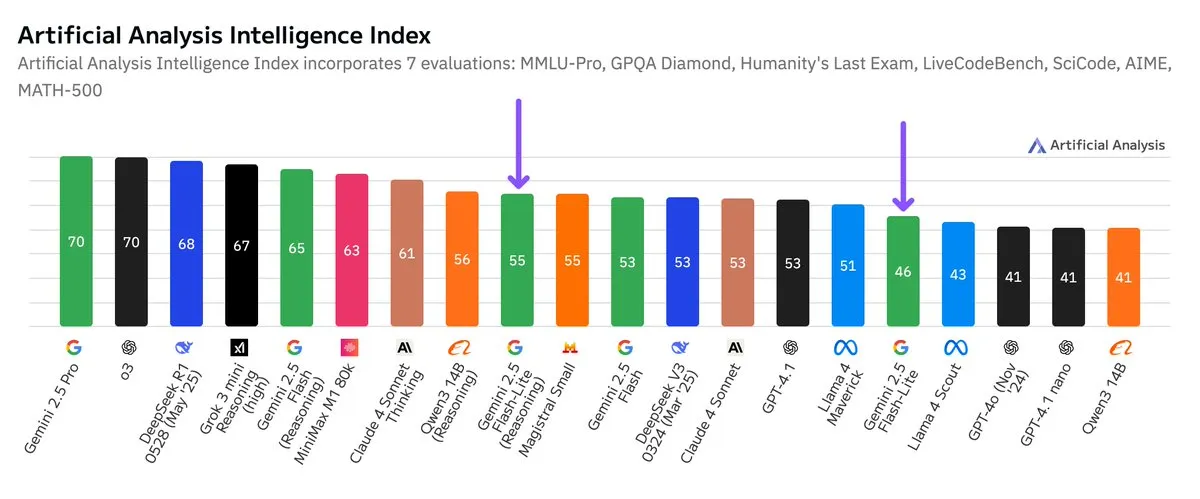
Publication des résultats de tests indépendants pour Google Gemini 2.5 Flash-Lite, amélioration du rapport coût-performance: Selon les résultats de tests indépendants publiés par Artificial Analysis, la version Preview (06-17) de Google Gemini 2.5 Flash-Lite, comparée à la version Flash standard, réduit les coûts d’environ 5 fois et augmente la vitesse d’environ 1,7 fois, mais avec une baisse du niveau d’intelligence. Ce modèle est une mise à niveau de Gemini 2.0 Flash-Lite, lancé en février 2025, et appartient à la catégorie des modèles hybrides. Cette mise à jour témoigne des efforts continus de Google pour améliorer l’efficacité et la rentabilité de ses modèles, ciblant potentiellement des scénarios d’application ayant des exigences élevées en matière de coût et de vitesse. (Source: zacharynado)
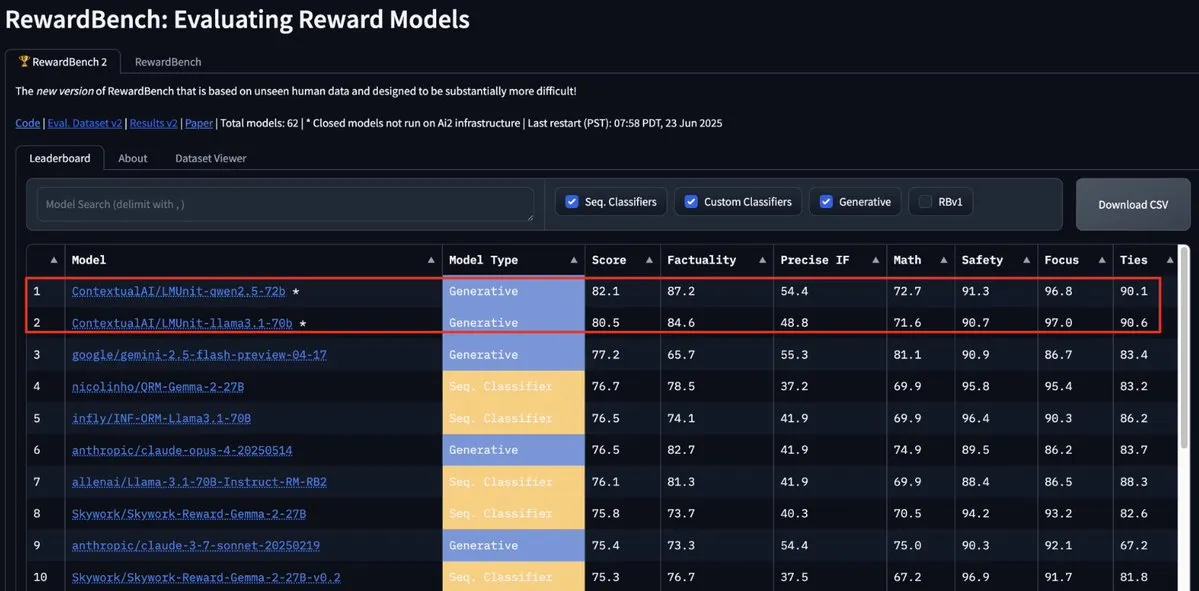
Le modèle LMUnit de ContextualAI prend la tête du classement RewardBench2, surpassant Gemini, Claude 4 et GPT-4.1: Le modèle LMUnit de ContextualAI s’est classé premier au benchmark RewardBench2, avec un score supérieur de plus de 5 % à celui de modèles renommés tels que Gemini, Claude 4 et GPT-4.1. Cet accomplissement pourrait être attribué à sa méthode d’entraînement unique, prétendument similaire à l’approche des « rubriques » (rubrics) pour laquelle OpenAI aurait investi des efforts considérables pour o4 et les modèles ultérieurs. Cette méthode faciliterait une mise à l’échelle efficace du LLM en tant que juge (llm-as-a-judge) lors du raisonnement. (Source: natolambert, menhguin, apsdehal)
Arcee.ai étend avec succès la longueur de contexte de son modèle AFM-4.5B de 4k à 64k: Arcee.ai a annoncé que la longueur de contexte de son premier modèle de base, AFM-4.5B, a été étendue avec succès de 4k à 64k. L’équipe a réalisé cette percée grâce à des expérimentations actives, des fusions de modèles, de la distillation et des méthodes qualifiées en plaisantant de « beaucoup de soupe » (en référence aux techniques de fusion de modèles). Cette avancée est cruciale pour le traitement de tâches impliquant de longs textes. Les améliorations apportées par Arcee au modèle GLM-32B-Base ont également prouvé son efficacité, non seulement en augmentant la prise en charge des longs contextes de 8k à 32k, mais aussi en améliorant toutes les évaluations des modèles de base (y compris pour les contextes courts). (Source: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Mise à jour de l’API Gemini de Google, amélioration de la vitesse et des capacités de traitement des vidéos et PDF: L’API Gemini de Google bénéficie d’une mise à jour importante concernant le traitement des vidéos et des PDF. Le temps de première réponse (TTFT) pour les vidéos mises en cache a été amélioré de 3 fois, et la vitesse de traitement des PDF mis en cache a été augmentée jusqu’à 4 fois. De plus, la nouvelle version prend en charge le traitement par lots de plusieurs vidéos, et les performances de la mise en cache implicite se rapprochent de celles de la mise en cache explicite. Ces améliorations visent à accroître l’efficacité et l’expérience des développeurs utilisant l’API Gemini pour traiter des contenus multimédias. (Source: _philschmid)
Moonshot (Kimi) met à jour son modèle Kimi VL A3B Thinking, améliorant les capacités de traitement multimodal: Moonshot AI (Kimi) a publié une version mise à jour de son petit modèle de langage visuel (VLM) Kimi VL A3B Thinking, sous licence MIT. La nouvelle version consomme moins de tokens, raccourcit les trajectoires de pensée, prend en charge le traitement vidéo et peut gérer des images à plus haute résolution (1792×1792). Il atteint un score de 65,2 sur VideoMMMU, MathVision s’améliore de 20,1 points à 56,9, MathVista de 8,4 points à 80,1, MMMU-Pro de 3,2 points à 46,3, et excelle dans le raisonnement visuel, la localisation d’agents UI, ainsi que le traitement vidéo et PDF. Il est désormais open source sur Hugging Face. (Source: mervenoyann)

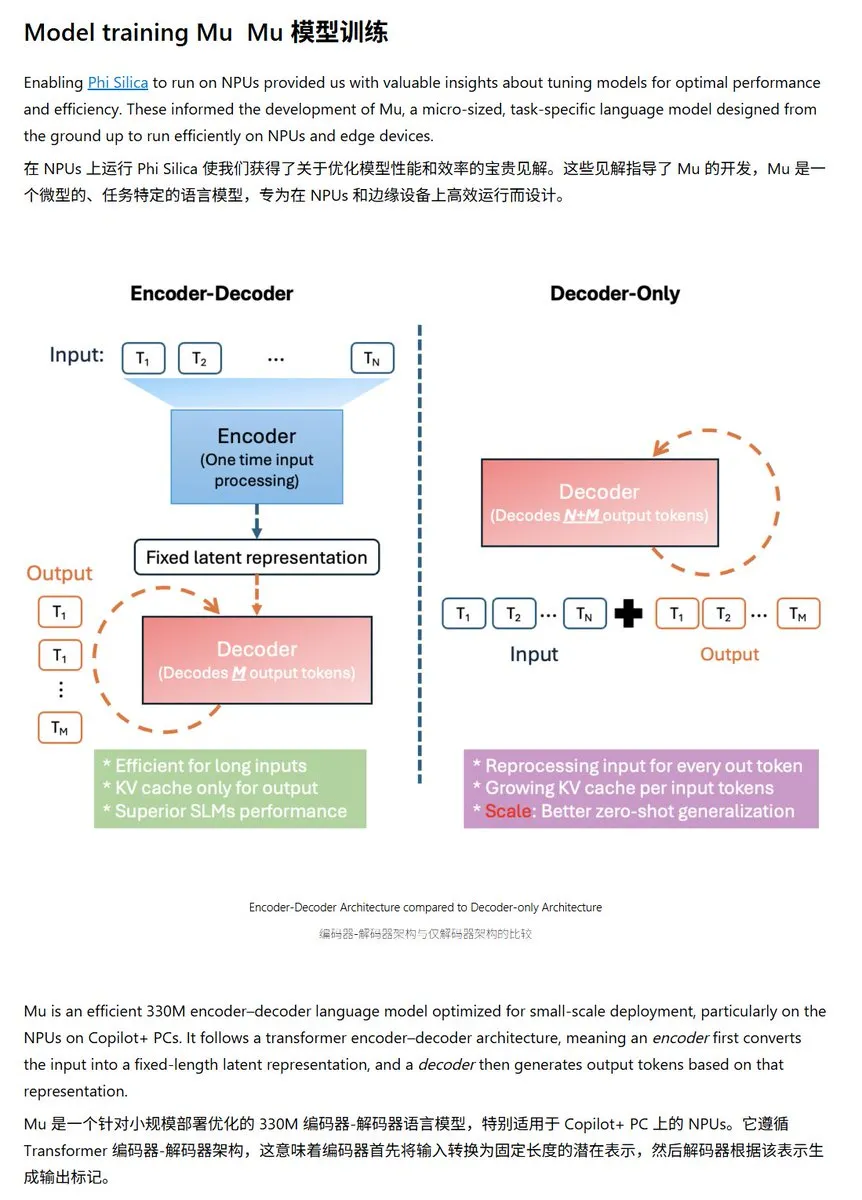
Microsoft publie le petit modèle de langage Mu-330M, optimisé pour les NPU Windows: Microsoft a lancé un nouveau petit modèle de langage, Mu-330M, conçu pour fonctionner sur les NPU (Neural Processing Units) des PC Windows Copilot+, visant à prendre en charge les fonctionnalités d’Agent au sein du système Windows. Ce modèle a été optimisé pour les NPU, adoptant des techniques telles que les embeddings de position rotatifs, l’attention par requêtes groupées et LayerNorm à double couche, afin de fonctionner efficacement avec une faible consommation d’énergie, marquant une nouvelle avancée de Microsoft dans les capacités d’IA en périphérie (edge AI). (Source: karminski3)
DeepMind publie le rapport technique Mercury, axé sur les modèles de langage à diffusion: Inception Labs (une équipe liée à DeepMind) a publié le rapport technique de son modèle de langage à diffusion, Mercury. Ce rapport détaille l’architecture du modèle Mercury, ses méthodes d’entraînement et ses résultats expérimentaux, offrant aux chercheurs un aperçu approfondi de ce type de modèle émergent. Les modèles à diffusion ont déjà obtenu un succès notable dans le domaine de la génération d’images, et leur application aux modèles de langage est une direction de recherche de pointe actuelle en IA. (Source: andriy_mulyar)
Meta s’associe à Oakley pour étendre sa gamme de lunettes intelligentes IA: Meta s’est associé à la marque de lunettes Oakley pour étendre davantage sa gamme de produits de lunettes intelligentes IA. Les nouvelles lunettes intelligentes devraient intégrer la technologie IA de Meta, offrant des fonctionnalités interactives plus riches et une meilleure expérience utilisateur. Cette collaboration marque l’investissement continu de Meta dans le domaine des dispositifs IA portables, visant à intégrer l’IA de manière plus transparente dans la vie quotidienne. (Source: rowancheung, Ronald_vanLoon)
Alibaba Cloud lance PAI-TurboX, un framework d’accélération pour l’entraînement et l’inférence de modèles de conduite autonome, réduisant le temps d’entraînement jusqu’à 50%: Alibaba Cloud a lancé PAI-TurboX, un framework d’accélération de l’entraînement et de l’inférence de modèles destiné au domaine de la conduite autonome. Ce framework vise à améliorer l’efficacité de l’entraînement et de l’inférence pour la perception, la planification et le contrôle, voire les modèles du monde. Il y parvient en optimisant le prétraitement des données multimodales, l’affinité CPU, la compilation dynamique, le parallélisme pipeline, et en fournissant des capacités d’optimisation d’opérateurs et de quantification. Des tests ont montré que PAI-TurboX peut réduire le temps d’entraînement d’environ 50 % pour plusieurs modèles industriels tels que BEVFusion, MapTR et SparseDrive. (Source: 量子位)
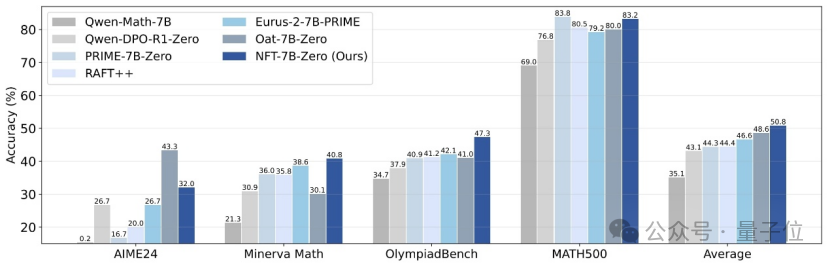
Tsinghua, Nvidia et d’autres proposent la méthode NFT, permettant à l’apprentissage supervisé de « réfléchir » à partir des erreurs: Des chercheurs de l’Université Tsinghua, de Nvidia et de l’Université Stanford ont conjointement proposé une nouvelle méthode d’apprentissage supervisé appelée NFT (Negative-aware FineTuning). Cette méthode, basée sur l’algorithme RFT (Rejection FineTuning), utilise des données négatives pour l’entraînement en construisant un « modèle négatif implicite », c’est-à-dire une « stratégie négative implicite ». Cette stratégie permet à l’apprentissage supervisé de « s’auto-réfléchir » comme l’apprentissage par renforcement, comblant ainsi l’écart de capacité entre l’apprentissage supervisé et l’apprentissage par renforcement sur certaines tâches. Elle a démontré des améliorations significatives des performances sur des tâches telles que le raisonnement mathématique, et même dans des conditions On-Policy, son gradient de fonction de perte est équivalent à celui de GRPO. (Source: 量子位)
Lancement d’OmniGen2 : un modèle de retouche d’image multifonctionnel de 8B, fusionnant la compréhension visuelle et la génération d’images: Un nouveau modèle de retouche d’image multifonctionnel appelé OmniGen2 a été lancé. Ce modèle combine la compréhension visuelle (basée sur Qwen-VL-2.5) avec la génération d’images (un modèle de diffusion de 4B paramètres), pour un total d’environ 8B paramètres. OmniGen2 peut prendre en charge diverses tâches telles que la génération de texte en image, l’édition d’images, la compréhension d’images et la génération contextuelle. Il vise à fournir un modèle unifié capable de résoudre divers problèmes liés à la vision et adapté à une intégration en périphérie (edge). (Source: karminski3)

Mise à jour du modèle de génération d’images à partir de texte Chroma-8.9B-v39, basé sur FLUX.1-schnell, disponible pour un usage commercial: Le modèle de conversion texte-image Chroma-8.9B-v39 a été mis à jour, améliorant l’éclairage et le naturel des tâches. Ce modèle, basé sur FLUX.1-schnell, a vu sa taille réduite de 12B à 8.9B paramètres et est distribué sous licence Apache 2.0, autorisant un usage commercial. Selon les informations, le modèle « réintroduit des concepts anatomiques manquants, sans aucune restriction de contenu » et a été post-entraîné sur un jeu de données contenant 5 millions d’œuvres d’anime, de furry, d’art et de photographies. (Source: karminski3)

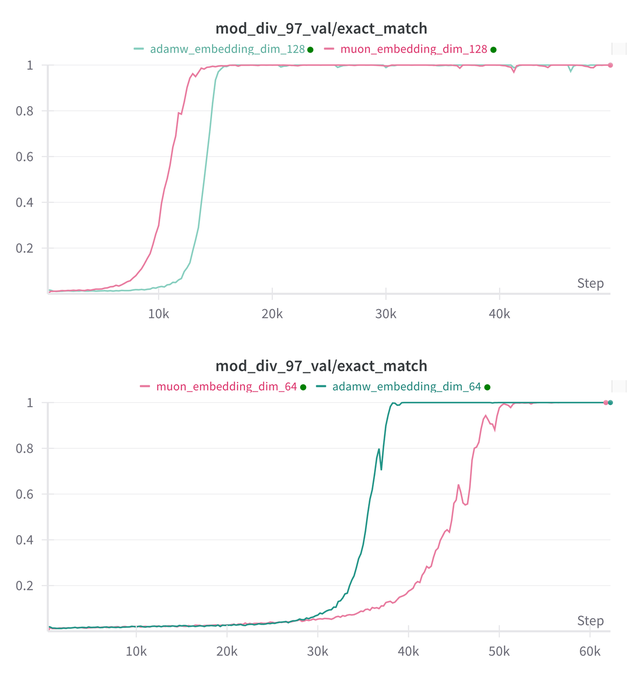
Essential AI met à jour ses conclusions de recherche sur les capacités de Grokking de ses modèles Muon et Adam: Essential AI a partagé les dernières avancées de ses recherches concernant les capacités de Grokking (un phénomène où un modèle, après une performance initiale médiocre, comprend soudainement et généralise) de ses modèles Muon et Adam. Les hypothèses initiales pourraient contredire les observations réelles. L’équipe a rendu publics les résultats d’expériences internes à petite échelle, montrant qu’après avoir étendu l’espace de recherche des hyperparamètres, Muon ne présente pas d’avantage universel évident par rapport à AdamW, les deux ayant des performances variables selon les scénarios. Cela suggère qu’AdamW reste un optimiseur puissant, voire de pointe (SOTA), dans de nombreux cas. (Source: eliebakouch, teortaxesTex, nrehiew_)
Mise à jour du modèle de génération d’images Ostris AI, axée sur la version sans CFG et l’optimisation des détails haute fréquence: Ostris AI continue de mettre à jour son modèle de génération d’images, se concentrant actuellement sur le développement de la version sans CFG (Classifier-Free Guidance) en raison de sa convergence plus rapide. Dans la dernière mise à jour du 7ème jour, l’équipe a ajouté de nouvelles techniques d’entraînement pour mieux gérer les détails haute fréquence et s’efforce de supprimer les artefacts liés aux détails élevés. La mise à jour précédente du 4ème jour avait déjà montré une amélioration significative de la qualité des images générées sans utiliser de CFG, grâce à de nouvelles méthodes. (Source: ostrisai)

Ant Group, l’Académie Chinoise des Sciences et d’autres partenaires rendent open source le modèle ViLaSR-7B, réalisant un raisonnement spatial « en dessinant pour penser »: L’Institut de Recherche Technologique d’Ant, l’Institut d’Automatisation de l’Académie Chinoise des Sciences et l’Université Chinoise de Hong Kong ont conjointement rendu open source le modèle ViLaSR-7B. Ce modèle, grâce au paradigme « Drawing to Reason in Space », permet aux grands modèles de langage visuel (LVLM) de dessiner des marqueurs auxiliaires (tels que des lignes de référence, des boîtes englobantes) dans l’espace visuel pour faciliter la réflexion, améliorant ainsi la perception spatiale et les capacités de raisonnement. ViLaSR adopte un cadre d’entraînement en trois étapes : démarrage à froid, échantillonnage par rejet réflexif et apprentissage par renforcement. Les expériences montrent que ce modèle améliore en moyenne de 18,4 % les performances sur 5 benchmarks, y compris la navigation dans des labyrinthes, la compréhension d’images et le raisonnement spatial vidéo, et se rapproche des performances de Gemini-1.5-Pro sur VSI-Bench. (Source: 量子位)

🧰 Outils
SGLang prend désormais en charge Hugging Face Transformers en tant que backend, améliorant l’efficacité de l’inférence: SGLang a annoncé qu’il prend désormais en charge Hugging Face Transformers en tant que backend. Cela signifie que les utilisateurs peuvent fournir des services d’inférence rapides et de qualité production pour n’importe quel modèle compatible avec Transformers, sans nécessiter de prise en charge native, en mode plug-and-play. Cette intégration vise à simplifier le processus de déploiement de l’inférence de modèles de langage haute performance, élargissant le champ d’application et la facilité d’utilisation de SGLang. (Source: TheZachMueller, ClementDelangue)

MLX-LM-LORA v0.7.0 est disponible, avec une fonctionnalité RLHF intégrée: MLX-LM-LORA a publié sa version v0.7.0, qui intègre une fonctionnalité d’apprentissage par renforcement à partir de rétroaction humaine (RLHF). Cet outil prend désormais en charge le chargement en 4 bits, 6 bits et 8 bits, le mode d’entraînement RLHF, et peut fusionner directement les adaptateurs (adapters) dans les poids de base. Cela rend le fine-tuning LoRA plus intelligent et efficace dans le framework MLX, en particulier sur les appareils à puce Apple. (Source: awnihannun)
Lancement de LlamaCloud, une boîte à outils compatible MCP pour les flux de travail documentaires: LlamaCloud est désormais disponible, se présentant comme une boîte à outils compatible avec le Model Context Protocol (MCP) pour tout flux de travail documentaire. Les utilisateurs peuvent le connecter à des modèles tels que Claude pour réaliser des opérations complexes d’extraction, de comparaison de documents, etc. Par exemple, il peut analyser les performances financières de Tesla sur les cinq derniers trimestres et générer un rapport de synthèse, en créant dynamiquement des schémas standardisés et en les exécutant sur tous les fichiers, puis en utilisant la génération de code pour obtenir le résultat final. LlamaCloud peut corriger dynamiquement les schémas incorrects et prend en charge les liens directs vers les fichiers. (Source: jerryjliu0)
Georgi Gerganov annonce le projet LlamaBarn: Georgi Gerganov (le créateur de llama.cpp) a publié une image sur les réseaux sociaux, annonçant un nouveau projet nommé « LlamaBarn ». L’image montre une interface de type tableau de bord, contenant des éléments tels que la sélection de modèles, l’ajustement de paramètres, etc., suggérant qu’il pourrait s’agir d’un outil pour gérer, exécuter ou tester des LLM locaux. La communauté exprime son impatience, estimant qu’il pourrait devenir un concurrent sérieux pour les outils existants tels qu’Ollama. (Source: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor : un nouvel assistant de programmation IA open source, prenant en charge MCP et les modèles locaux: Void Editor fait son apparition en tant que nouvel assistant de programmation IA open source, visant à devenir une alternative à des outils comme Cursor. Il prend en charge l’auto-complétion par tabulation, le mode chat, le Model Context Protocol (MCP) ainsi que le mode Agent. Les utilisateurs peuvent connecter n’importe quelle API de grand modèle de langage ou exécuter des modèles localement, offrant aux développeurs une expérience de programmation assistée par IA flexible. (Source: karminski3)
Together AI lance l’outil Which LLM pour aider à choisir le LLM open source approprié: Together AI a lancé un outil gratuit nommé « Which LLM », conçu pour aider les utilisateurs à choisir le grand modèle de langage open source le plus adapté en fonction de cas d’utilisation spécifiques, des besoins de performance et des considérations économiques. Avec la prolifération des LLM open source, ce type d’outil peut fournir une référence précieuse aux développeurs et aux chercheurs lors de la sélection d’un modèle. (Source: vipulved)
Perplexity Finance ajoute une fonction de suivi chronologique des cours boursiers: Perplexity Finance a annoncé que les utilisateurs peuvent désormais suivre l’évolution chronologique des cours de n’importe quel symbole boursier sur sa plateforme. Cette nouvelle fonctionnalité vise à fournir aux utilisateurs un outil d’analyse des informations du marché financier plus intuitif et pratique. Combinée aux capacités d’IA de Perplexity, elle pourrait apporter une nouvelle expérience à la recherche et à l’analyse d’informations financières. (Source: AravSrinivas)

IdeaWeaver lance le premier agent IA pour le débogage des performances système: IdeaWeaver a annoncé le lancement de ce qu’il prétend être le premier agent IA spécialement conçu pour déboguer les problèmes de performance système. Cet outil, qui utilise le framework CrewAI, peut exécuter réellement des commandes système pour diagnostiquer les problèmes liés au CPU, à la mémoire, aux E/S et au réseau. Sa particularité est de prioriser l’utilisation de LLM locaux (via OLLAMA) pour protéger la vie privée, ne demandant une clé API OpenAI que si les modèles locaux ne sont pas disponibles. Il vise à appliquer les capacités de l’IA aux domaines du DevOps et de l’administration système. (Source: Reddit r/artificial)
Kling AI ajoute la prise en charge de Live Photo, permettant de sauvegarder les vidéos générées comme fonds d’écran animés: Kling AI a annoncé que sa fonction de génération vidéo prend désormais en charge la sauvegarde des créations sous forme de Live Photos (photos animées). Les utilisateurs peuvent définir leurs contenus dynamiques préférés créés par Kling comme fonds d’écran de téléphone, augmentant ainsi l’aspect ludique et pratique des vidéos générées par IA. (Source: Kling_ai)
Cognition AI rend open source Blockdiff, permettant une accélération de 200 fois de la vitesse des snapshots de VM: Cognition AI a annoncé la mise en open source de Blockdiff, son format de fichier de snapshot de VM développé pour Devin. En raison du temps excessif nécessaire à EC2 pour créer des snapshots de VM (plus de 30 minutes), l’équipe a construit son propre hyperviseur de machine virtuelle otterlink et le format de fichier Blockdiff, ce qui a permis d’accélérer la création de snapshots de 200 fois. Cette contribution open source vise à aider les développeurs à gérer plus efficacement les environnements de machines virtuelles. (Source: karinanguyen_)

📚 Apprentissage
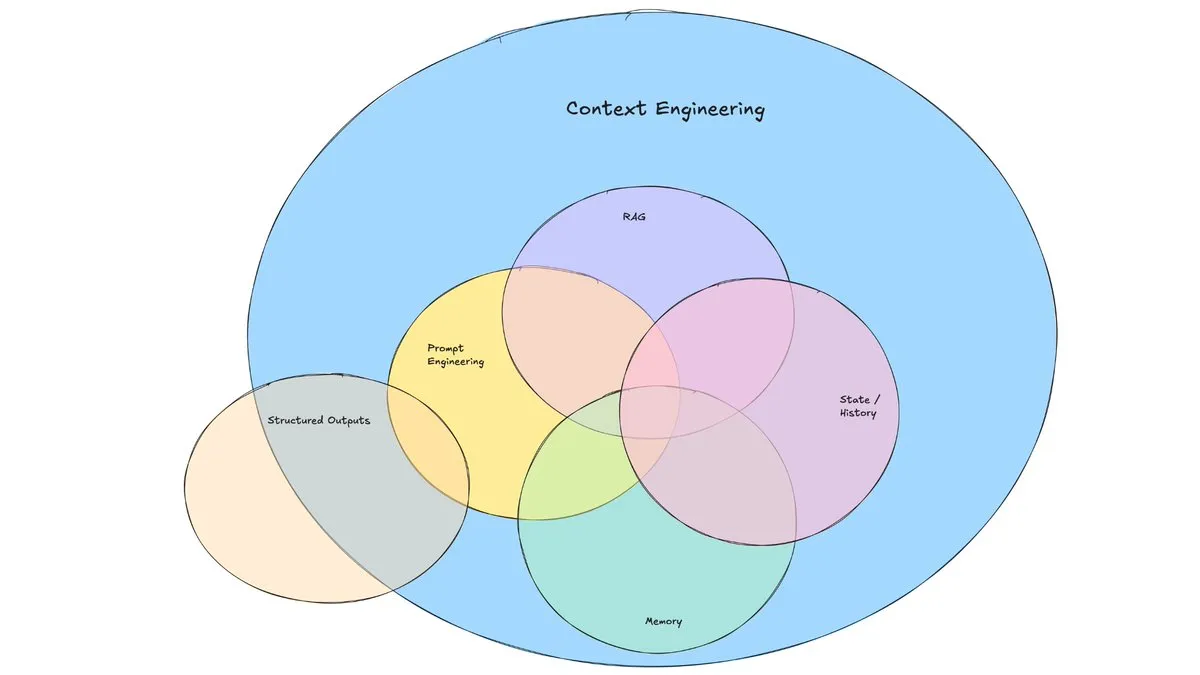
Un article de blog de LangChain explore l’essor de l’« ingénierie du contexte »: LangChain a publié un article de blog explorant le terme de plus en plus populaire d’« ingénierie du contexte » (Context Engineering). L’article le définit comme « la construction de systèmes dynamiques pour fournir les bonnes informations et les bons outils dans le bon format, afin de permettre aux LLM d’accomplir raisonnablement des tâches ». Ce n’est pas un concept entièrement nouveau, les constructeurs d’agents le pratiquent depuis longtemps, et des outils comme LangGraph, LangSmith, etc., ont été créés à cette fin. La proposition de ce terme contribue à attirer davantage l’attention sur les compétences et les outils associés. (Source: hwchase17, Hacubu, yoheinakajima)
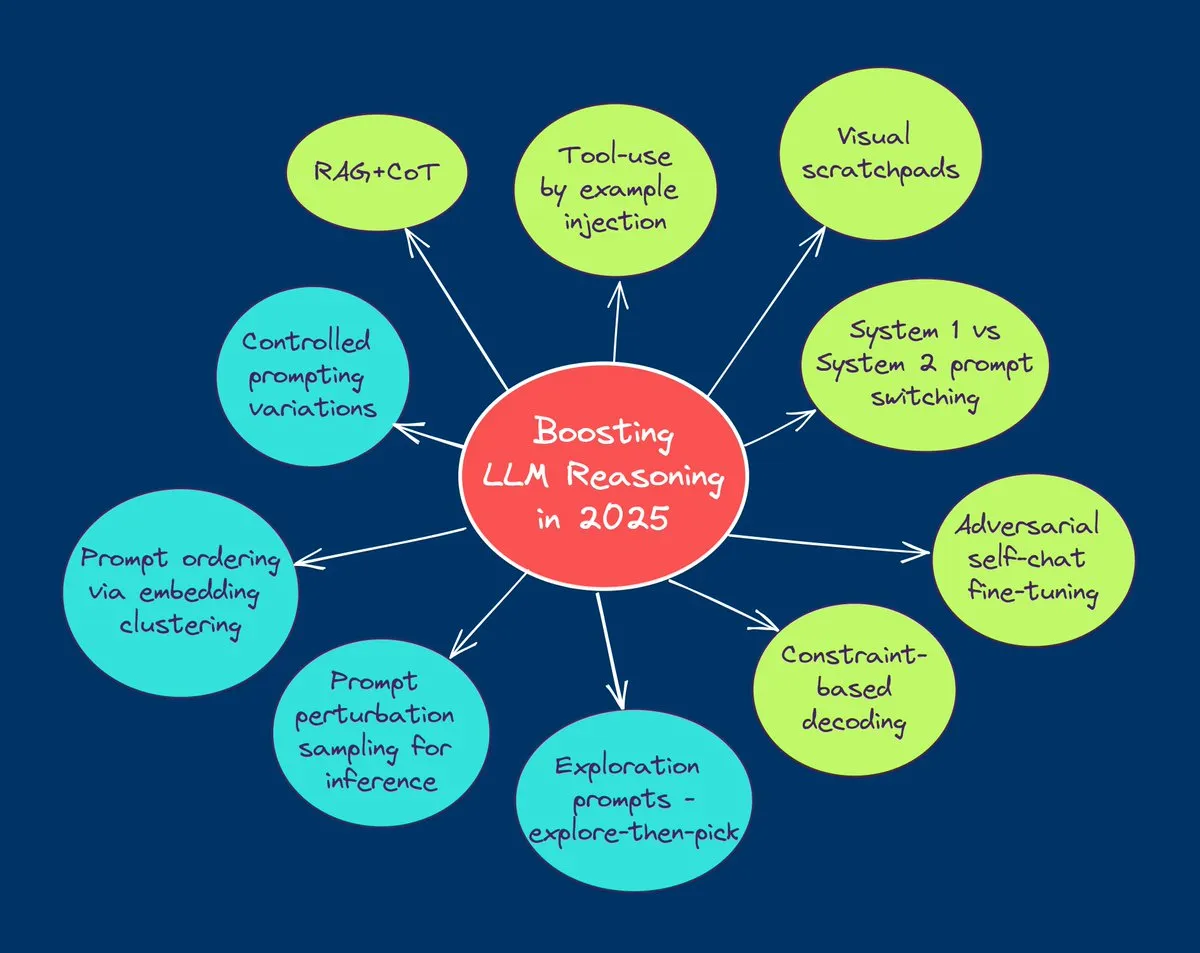
TuringPost résume les 10 principales technologies pour améliorer les capacités de raisonnement des LLM en 2025: TuringPost a partagé 10 technologies clés utilisées en 2025 pour améliorer les capacités de raisonnement des grands modèles de langage (LLM), notamment : la chaîne de pensée améliorée par la récupération (RAG+CoT), l’utilisation d’outils par injection d’exemples, le brouillon visuel (prise en charge du raisonnement multimodal), la commutation entre les systèmes de pensée 1 et 2, le fine-tuning par auto-dialogue contradictoire, le décodage basé sur des contraintes, le prompting exploratoire (explorer avant de choisir), l’échantillonnage par perturbation des prompts pour le raisonnement, le tri des prompts par regroupement d’embeddings et les variantes de prompts contrôlées. Ces techniques offrent diverses approches pour optimiser les performances des LLM dans des tâches complexes. (Source: TheTuringPost, TheTuringPost)
Cohere Labs organise une école d’été ML pour explorer l’avenir de l’apprentissage machine: La communauté scientifique ouverte de Cohere Labs organisera une école d’été ML (ML Summer School) en juillet. Cet événement réunira des membres de la communauté mondiale pour discuter de l’avenir de l’apprentissage machine et invitera des conférenciers de l’industrie à partager leurs connaissances. Katrina Lawrence animera le 2 juillet un cours de révision des mathématiques pour l’apprentissage machine, couvrant des concepts fondamentaux tels que le calcul différentiel et intégral, le calcul vectoriel et l’algèbre linéaire. (Source: sarahookr)

DeepLearning.AI et Meta s’associent pour lancer le cours gratuit « Building with Llama 4 »: DeepLearning.AI et Meta se sont associés pour lancer un cours gratuit intitulé « Building with Llama 4 ». Le contenu du cours comprend : la manipulation pratique des modèles de la série Llama 4, la compréhension de son architecture de mélange d’experts (MOE) et comment utiliser l’API officielle pour créer des applications ; l’application de Llama 4 pour l’inférence multi-images, la localisation d’images (identification d’objets et de leurs boîtes englobantes), et le traitement de requêtes textuelles à contexte long allant jusqu’à 1 million de tokens ; l’utilisation des outils d’optimisation de prompts de Llama 4 pour améliorer automatiquement les prompts système, et l’utilisation de sa boîte à outils de données synthétiques pour créer des ensembles de données de haute qualité pour le fine-tuning. (Source: DeepLearningAI)
La chaîne YouTube d’EleutherAI offre une multitude de contenus de recherche en IA: La chaîne YouTube d’EleutherAI rassemble les enregistrements vidéo de ses clubs de lecture et de ses séries de conférences, totalisant plus de 100 heures de contenu. Les sujets abordés couvrent la scalabilité et les performances en apprentissage machine, l’analyse fonctionnelle, ainsi que des podcasts et des entretiens avec les membres de l’équipe. Cette chaîne offre une riche ressource d’apprentissage pour les chercheurs et les passionnés d’IA. EleutherAI a également lancé une nouvelle série de conférences, dont la première, animée par @linguist_cat, porte sur les tokenizers et leurs limitations. (Source: BlancheMinerva, BlancheMinerva)
Un article explore l’amélioration du raisonnement multimodal grâce aux tokens visuels latents (Machine Mental Imagery): Un nouvel article intitulé « Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens » propose le framework Mirage, qui améliore le raisonnement multimodal en intégrant des tokens visuels latents (plutôt que de générer des images complètes) pendant le processus de décodage du VLM, simulant ainsi l’imagerie mentale humaine. La méthode supervise d’abord les tokens latents par distillation d’embeddings d’images réelles, puis passe à une supervision purement textuelle pour aligner les trajectoires latentes avec les objectifs de la tâche, et améliore davantage les capacités grâce à l’apprentissage par renforcement. Les expériences démontrent que Mirage peut atteindre un raisonnement multimodal plus robuste sans générer d’images explicites. (Source: HuggingFace Daily Papers)
Un article propose le framework Vision as a Dialect, unifiant la compréhension et la génération visuelles via des représentations alignées sur le texte: Un article intitulé « Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations » présente un framework LLM multimodal nommé Tar. Ce framework utilise un tokenizer aligné sur le texte (TA-Tok) pour convertir les images en tokens discrets et exploite un codebook aligné sur le texte projeté à partir du vocabulaire du LLM, unifiant ainsi le visuel et le textuel dans une représentation sémantique discrète partagée. Tar permet une entrée/sortie intermodale via une interface partagée, sans nécessiter de conception spécifique à la modalité, et adopte un encodeur-décodeur adaptatif à l’échelle ainsi qu’un détokenizer génératif pour équilibrer l’efficacité et les détails visuels. (Source: HuggingFace Daily Papers)
Un article propose ReasonFlux-PRM : un PRM sensible à la trajectoire pour le raisonnement en chaîne de pensée longue des LLM: L’article « ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs » présente un nouveau modèle de récompense de processus (PRM) sensible à la trajectoire, spécialement conçu pour évaluer les traces de raisonnement de type trajectoire-réponse générées par des modèles de raisonnement de pointe tels que DeepSeek-R1. ReasonFlux-PRM combine une supervision au niveau de l’étape et au niveau de la trajectoire, réalisant une attribution de récompense à grain fin alignée sur les données de la chaîne de pensée structurée, et obtient des améliorations de performance dans des scénarios tels que SFT, RL et l’expansion BoN lors des tests. (Source: HuggingFace Daily Papers)
Un article étudie les méthodes d’évaluation des garde-fous contre le jailbreak des grands modèles de langage: Un article intitulé « SoK: Evaluating Jailbreak Guardrails for Large Language Models » effectue une synthèse systématique des connaissances sur les attaques de jailbreak des grands modèles de langage (LLM) et leurs garde-fous (Guardrails). L’article propose une nouvelle taxonomie multidimensionnelle, classifiant les garde-fous selon six dimensions clés, et introduit un cadre d’évaluation sécurité-efficacité-utilité pour évaluer leur effet réel. Grâce à une analyse et des expérimentations approfondies, l’article souligne les avantages et les inconvénients des méthodes de garde-fous existantes, explore leur universalité face à différents types d’attaques, et fournit des informations pour optimiser les combinaisons de défense. (Source: HuggingFace Daily Papers)
Un article primé à l’AAAI 2025 explore une classe décidable de processus décisionnels de Markov partiellement observables (POMDP): Un article intitulé « Revelations: A Decidable Class of POMDP with Omega-Regular Objectives » a reçu le prix du meilleur article à l’AAAI 2025. Cette recherche identifie une classe décidable de MDP (processus décisionnels de Markov) : les problèmes de décision avec des « révélations fortes », c’est-à-dire où il existe à chaque étape une probabilité non nulle de révéler l’état exact du monde. L’article fournit également des résultats de décidabilité pour les « révélations faibles », où l’état exact est garanti d’être finalement révélé, mais pas nécessairement à chaque étape. Cette étude offre de nouvelles bases théoriques pour la prise de décision optimale en situation d’information incomplète. (Source: aihub.org)
Un article propose CommVQ : la quantification vectorielle commutative pour la compression du cache KV: L’article « CommVQ: Commutative Vector Quantization for KV Cache Compression » propose une méthode nommée CommVQ, qui compresse le cache KV via une quantification additive et des encodeurs et codebooks légers, afin de réduire l’empreinte mémoire lors de l’inférence de LLM à long contexte. Pour réduire le coût de calcul du décodage, le codebook est conçu pour être commutatif avec les embeddings de position rotatifs (RoPE) et est entraîné à l’aide de l’algorithme EM. Les expériences montrent que cette méthode peut réduire la taille du cache KV FP16 de 87,5 % avec une quantification à 2 bits et surpasse les méthodes existantes de quantification du cache KV, permettant même une quantification du cache KV à 1 bit avec une perte de précision minimale. (Source: HuggingFace Daily Papers)
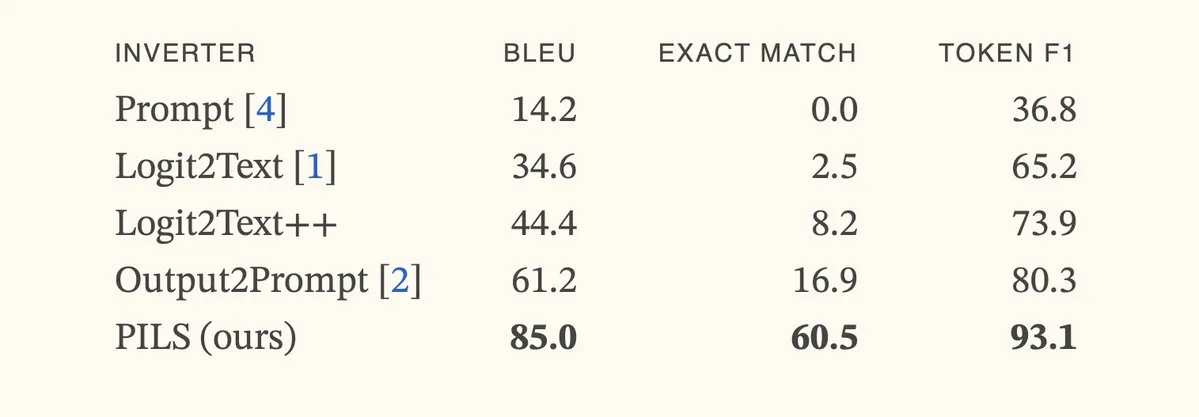
Un article propose la méthode PILS, améliorant l’inversion des modèles de langage grâce à une représentation compacte de la distribution du token suivant: L’article « Better Language Model Inversion by Compactly Representing Next-Token Distributions » propose une nouvelle méthode d’inversion de modèle de langage appelée PILS (Prompt Inversion from Logprob Sequences). Cette méthode récupère les prompts cachés en analysant les probabilités du token suivant du modèle sur plusieurs étapes de génération. L’idée centrale est la découverte que les vecteurs de sortie du modèle de langage occupent un sous-espace de faible dimension, permettant ainsi une compression sans perte de la distribution de probabilité du token suivant via une transformation linéaire, pour une inversion plus efficace. Les expériences montrent que PILS surpasse significativement les méthodes SOTA précédentes dans la récupération des prompts cachés. (Source: HuggingFace Daily Papers, jxmnop)
Article proposant Phantom-Data : un jeu de données général pour la génération de vidéos cohérentes au niveau du sujet: L’article « Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset » présente un nouveau jeu de données nommé Phantom-Data, visant à résoudre le problème omniprésent du « copier-coller » dans les modèles existants de génération de vidéo à partir d’un sujet (c’est-à-dire l’enchevêtrement excessif de l’identité du sujet avec les attributs de l’arrière-plan et du contexte). Phantom-Data est le premier jeu de données général de cohérence sujet-vidéo apparié, contenant environ un million de paires cohérentes en identité dans différentes catégories. Ce jeu de données est construit via un processus en trois étapes, comprenant la détection de sujets, la récupération de sujets à grande échelle dans différents contextes et la vérification d’identité guidée par des a priori. (Source: HuggingFace Daily Papers)
Un article propose LongWriter-Zero : maîtriser la génération de texte ultra-long par apprentissage par renforcement: L’article « LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning » propose une méthode basée sur les incitations pour cultiver la capacité des LLM à générer des textes ultra-longs et de haute qualité à partir de zéro, en utilisant l’apprentissage par renforcement (RL), sans aucune donnée annotée ou synthétique. Cette méthode part d’un modèle de base et, par RL, le guide dans le processus de planification et d’affinage de l’écriture, en utilisant un modèle de récompense spécialisé pour contrôler la longueur, la qualité de l’écriture et le format structurel. Les expériences montrent que LongWriter-Zero, entraîné à partir de Qwen2.5-32B, surpasse les méthodes SFT traditionnelles dans les tâches d’écriture de textes longs et atteint des niveaux SOTA sur plusieurs benchmarks. (Source: HuggingFace Daily Papers)
💼 Affaires
La société d’IA juridique Harvey annonce une levée de fonds de série E de 300 millions de dollars, pour une valorisation de 5 milliards de dollars: La start-up d’IA juridique Harvey a annoncé une levée de fonds de série E de 300 millions de dollars, co-dirigée par Kleiner Perkins et Coatue, portant la valorisation de l’entreprise à 5 milliards de dollars. Parmi les autres investisseurs figurent Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson et REV. Ce financement aidera Harvey à poursuivre le développement et l’expansion de ses applications d’IA dans le domaine juridique. (Source: saranormous)
Le service cloud GPU à la demande Hyperbolic atteint un ARR de 1 million de dollars en 7 jours: Yuchenj_UW a annoncé que son service cloud GPU à la demande Hyperbolic, lancé la semaine dernière, a vu son revenu annuel récurrent (ARR) passer de 0 à 1 million de dollars en 7 jours, avec un marketing minimal se limitant à un seul tweet. Ils offrent aux constructeurs des crédits d’essai gratuits pour des nœuds 8xH100, ce qui témoigne d’une forte demande du marché pour les services cloud GPU haute performance. (Source: Yuchenj_UW)
Replit annonce un revenu annuel récurrent (ARR) dépassant les 100 millions de dollars: La plateforme d’environnement de développement intégré (IDE) en ligne et de cloud computing Replit a annoncé que son revenu annuel récurrent (ARR) a dépassé les 100 millions de dollars, une croissance significative par rapport aux 10 millions de dollars de la fin 2024. L’entreprise a déclaré qu’elle disposait encore de plus de la moitié de ses fonds en banque après sa dernière levée de fonds en 2023, pour une valorisation de 1,1 milliard de dollars. La croissance de Replit est due à l’utilisation de sa plateforme par des entreprises clientes (telles que Zillow, HubSpot) et des développeurs indépendants. L’entreprise recrute activement. (Source: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 Communauté
Nouveau paradigme de la programmation IA : concevoir d’abord, puis prompter, pour une génération de code optimisée par itération: Dotey et Baoyu discutent du changement de paradigme dans le développement logiciel induit par l’IA. Le débat traditionnel entre « concevoir d’abord, coder ensuite » et « implémenter d’abord, refactoriser ensuite » trouve une fusion à l’ère de l’IA. L’IA réduit considérablement le coût et le temps entre la conception et le codage, permettant aux développeurs de réaliser rapidement des versions même lorsque la conception n’est pas entièrement claire, et d’améliorer itérativement la conception et les prompts en validant les résultats. Les prompts jouent le rôle des anciens « documents de conception détaillée », mais de manière plus simplifiée. Dans ce modèle, les développeurs devraient se concentrer davantage sur la conception du système, générer du code par petits lots, utiliser la gestion du code source, et examiner et tester le code généré par l’IA. Pour les programmeurs expérimentés, changer de mentalité et d’habitudes de développement est la clé pour adopter la programmation IA. (Source: dotey)
Claude Code est plébiscité par les développeurs pour sa puissante capacité de traitement de grandes bases de code et son efficacité contextuelle: La communauté Reddit r/ClaudeAI discute vivement des performances exceptionnelles de Claude Code dans le traitement de grandes bases de code. Les utilisateurs rapportent qu’il comprend bien les bases de code dépassant largement les 200k tokens et peut y apporter des modifications. La discussion suggère que Claude Code pourrait atteindre une gestion efficace du contexte grâce à des stratégies similaires à la lecture humaine (ne lire que les parties clés), à l’utilisation d’outils comme grep pour la récupération contextuelle (plutôt que de dépendre entièrement de la compression vectorielle de RAG), et aux avantages de l’intégration de modèles propriétaires. Les utilisateurs partagent de nombreux cas de réussite, tels que la résolution de problèmes système, la création d’un outil de suivi financier personnel, le développement d’applications Android (même sans expérience en développement Android), la création de scripts Obsidian DataviewJS, etc., améliorant considérablement leur productivité. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Le concept d’« ingénierie du contexte » attire l’attention, soulignant la construction de systèmes dynamiques pour habiliter les LLM: Harrison Chase de LangChain a proposé que l’« ingénierie du contexte » (Context Engineering) est le travail principal des ingénieurs IA dans la construction de systèmes. Elle est définie comme « la construction de systèmes dynamiques pour fournir les bonnes informations et les bons outils dans le bon format, afin de permettre aux LLM d’accomplir raisonnablement des tâches ». Ce concept souligne l’importance, dans les applications LLM, d’organiser et de fournir efficacement les informations contextuelles pour la performance du modèle, ce qui est fondamental dans des domaines tels que la construction d’agents. (Source: hwchase17, Hacubu, yoheinakajima)
Le fondateur de Meta, Mark Zuckerberg, recrute personnellement des talents en IA, suscitant l’attention de la communauté: Des informations sur les réseaux sociaux indiquent que le fondateur de Meta, Mark Zuckerberg, participe personnellement au recrutement de talents pour son laboratoire de superintelligence, contactant directement des centaines de candidats potentiels et invitant ceux qui répondent à dîner. Cette démarche est interprétée comme une démonstration de la détermination et de l’investissement de Meta dans le domaine de l’IA, en particulier en ce qui concerne l’intelligence artificielle générale (AGI) ou la superintelligence, et met en évidence la concurrence féroce entre les grandes entreprises technologiques pour attirer les meilleurs talents en IA. (Source: reach_vb, andrew_n_carr)

Le développement de l’IA suscite une profonde réflexion sur le marché de l’emploi et la structure économique: La Harvard Business School et l’économiste Anton Korinek préviennent que l’AGI pourrait être atteinte d’ici 2 à 5 ans, et que si le système économique n’est pas radicalement transformé, cela pourrait conduire à un effondrement, soulignant la nécessité d’un revenu de base universel. Parallèlement, la communauté discute du fait que l’IA automatisera un grand nombre de tâches quantifiables, impactant les emplois des cols bleus et des cols blancs, et que les entreprises devront restructurer leur organisation pour s’adapter à l’IA. Yuval Noah Harari compare la révolution de l’IA à une « vague d’immigration IA », suscitant des débats sur le remplacement des emplois par l’IA et sa quête de pouvoir. Ces points de vue convergent vers l’impact disruptif de l’IA sur la future structure socio-économique. (Source: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

L’IA se distingue dans les concours de programmation, les excellents résultats de l’agent de Sakana AI suscitent un vif débat: L’agent de Sakana AI s’est classé 21e parmi plus de 1000 programmeurs humains lors du concours de programmation heuristique AtCoder, se plaçant globalement dans les 6,8 % supérieurs. L’IA a itéré environ 100 versions en 4 heures, générant des milliers de solutions potentielles, alors que les concurrents humains ne peuvent généralement en tester qu’une douzaine. L’IA a utilisé Gemini 2.5 Pro et a combiné des connaissances expertes avec des algorithmes de recherche systématique (tels que le recuit simulé et la recherche en faisceau) pour résoudre des problèmes d’optimisation réels. Les réactions de la communauté sont mitigées : certains estiment que la programmation de compétition diffère de l’ingénierie d’entreprise, et que la victoire de l’IA s’apparente davantage à celle d’un ordinateur surpassant un humain en addition et soustraction. (Source: Reddit r/ArtificialInteligence)
💡 Autres
Exploration de l’IA dans le domaine de la formation professionnelle : tentatives multiples avec les entretiens, les enseignants et les machines d’apprentissage: Les géants de la formation professionnelle tels que Huatu, Fenbi et Zhonggong explorent activement les applications de l’IA, avec des orientations différentes. Huatu se concentre sur l’évaluation des entretiens par l’IA, Fenbi approfondit la correction par l’IA et les enseignants IA (les ventes de ses classes de systèmes de bachotage par IA ont déjà dépassé 14 millions), tandis que Zhonggong lance une machine d’apprentissage pour l’emploi basée sur l’IA. Le consensus de l’industrie est que l’IA devrait améliorer les résultats d’apprentissage et l’efficacité opérationnelle, plutôt que de simplement viser des prix élevés. L’application de l’IA passe également de la validation de concept à l’approfondissement des scénarios, comme 51CTO qui utilise des humains numériques et la modélisation 3D pour générer des cours, et l’IA pour la génération de questions d’examen et l’analyse des parcours d’apprentissage. Cependant, la plupart des entreprises d’éducation ne disposent pas encore de la capacité de construire leurs propres grands modèles, préférant faire appel à des API tierces. (Source: 36氪)
Disney et Universal Pictures poursuivent en justice la licorne de génération d’images par IA Midjourney pour contrefaçon: Les géants hollywoodiens Disney et Universal Pictures ont conjointement intenté une action en justice contre la société de génération d’images par IA Midjourney, l’accusant d’utiliser sans autorisation une grande quantité de contenu protégé par le droit d’auteur (comme Iron Man, les Minions, etc.) pour entraîner ses modèles d’IA et générer des images très similaires. Les plaignants demandent l’interdiction des actes de contrefaçon et réclament jusqu’à 150 000 dollars de dommages et intérêts pour chaque œuvre contrefaite intentionnellement. Cette affaire met en lumière les défis liés au droit d’auteur auxquels est confrontée l’IA générative. Le fondateur de Midjourney avait admis avoir utilisé des données sans autorisation. Le procès pourrait viser à promouvoir la mise en place de mécanismes d’octroi de licences de droits d’auteur et de systèmes de filtrage de contenu. (Source: 36氪)

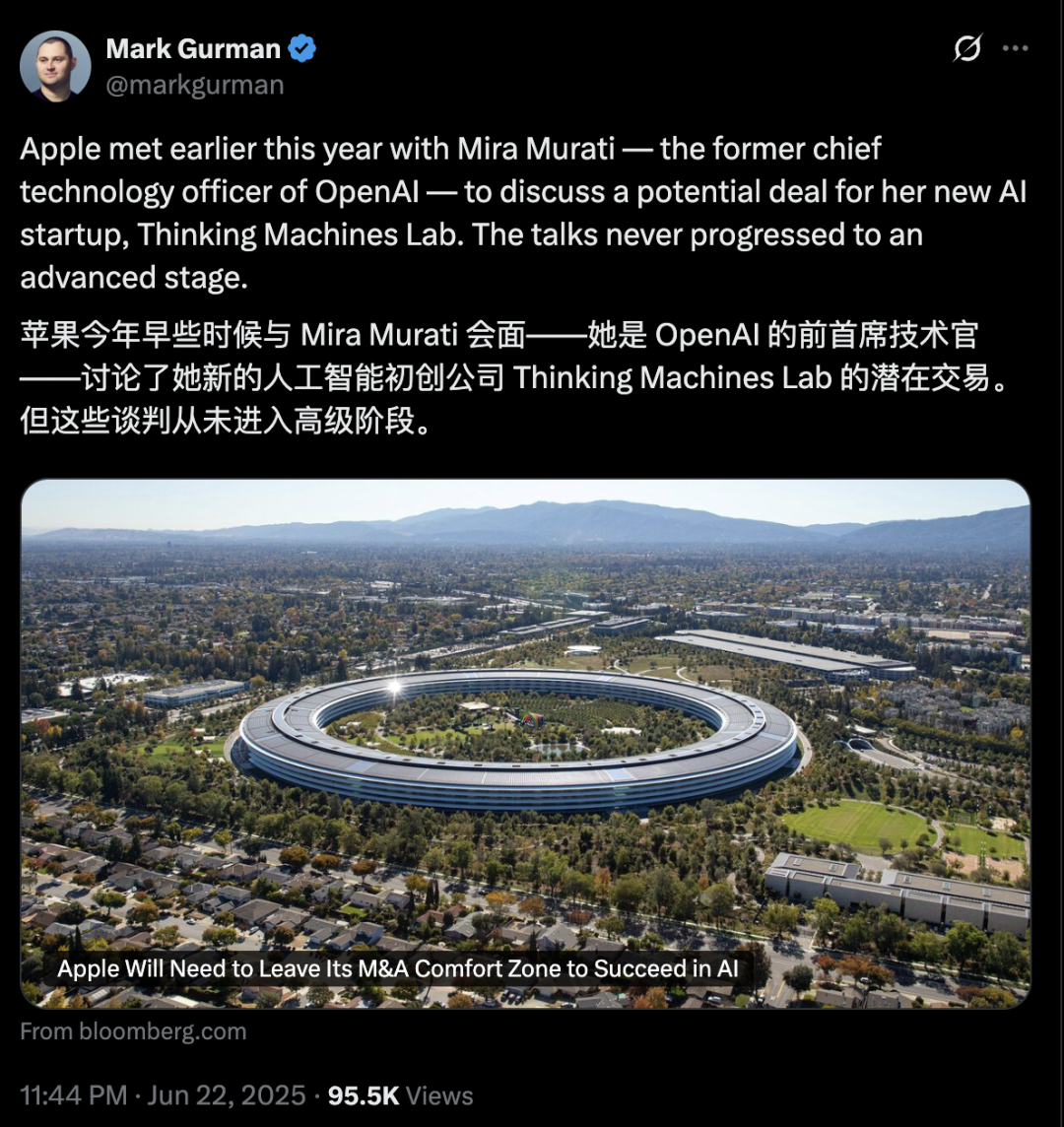
Apple, accusé de retard en matière d’IA, pourrait envisager des acquisitions pour combler ses lacunes ; l’entreprise de l’ex-CTO d’OpenAI suscite l’intérêt: Des rapports indiquent qu’Apple est relativement en retard dans le domaine de l’IA, ses capacités d’IA développées en interne étant insuffisantes et les performances de Siri décevantes. Pour combler cet écart, Apple pourrait envisager une acquisition majeure. Il se murmure qu’Apple aurait eu des contacts préliminaires avec Mira Murati, l’ancienne CTO d’OpenAI, au sujet de sa nouvelle start-up, Thinking Machines Lab. Historiquement, Apple a souvent renforcé ses capacités en acquérant de petites entreprises technologiques (comme Siri elle-même). Actuellement, Apple est loin derrière les géants de l’industrie en termes de taille des paramètres de ses modèles d’IA. L’acquisition d’entreprises comme Mistral pourrait l’aider à faire une percée dans le développement de ses propres grands modèles. (Source: 36氪)