
Mots-clés:modèle de langage étendu, évaluation de l’IA, système multi-agents, capacité de raisonnement, traitement contextuel, modèles open source, génération vidéo par IA, programmation IA, évaluation des capacités de raisonnement des LLM, Claude Opus 4 réfute l’article d’Apple, modèle MiniMax-M1 MoE, modèle de programmation Kimi-Dev-72B, fonction Gemini Deep Think
🔥 Pleins Feux
Un article d’Apple remettant en question les capacités de raisonnement des grands modèles de langage réfuté, un article co-écrit avec Claude souligne des failles dans la conception expérimentale: Apple a récemment publié un article intitulé « The Illusion of Thought », qui, à travers des tests sur des problèmes classiques tels que les Tours de Hanoï et le monde des blocs, indique que les principaux grands modèles de langage (LLM) sont peu performants dans les tâches de raisonnement complexe, relevant essentiellement de la reconnaissance de formes plutôt que d’une véritable compréhension. Cependant, le chercheur indépendant Alex Lawsen et le modèle d’IA Claude Opus 4 ont co-signé un article intitulé « The Illusion of “The Illusion of Thought” » pour réfuter ces affirmations, estimant que l’expérience d’Apple présentait des défauts de conception : 1. Elle n’a pas tenu compte de la limite de sortie de Tokens des LLM, ce qui a conduit à ce que les modèles soient jugés incorrects car incapables de produire intégralement des étapes très longues ; 2. Certains cas de test (comme certains « problèmes de traversée de rivière ») sont mathématiquement insolubles dans les conditions données, et l’incapacité de l’IA à fournir la « bonne réponse » ne relève pas d’un manque de capacité ; 3. En modifiant la méthode d’évaluation, par exemple en demandant au modèle de produire un programme de résolution de problèmes plutôt que des étapes complètes, l’IA obtient d’excellents résultats. Cet événement a suscité un vaste débat sur les capacités de raisonnement réelles des LLM et sur la méthodologie d’évaluation, soulignant l’importance de concevoir des protocoles d’évaluation pertinents et rappelant aux développeurs la nécessité de prêter attention à des facteurs tels que la fenêtre de contexte, le budget de sortie et la formulation des tâches, qui influencent les performances des modèles en application pratique. (Source: 新智元, 大数据文摘)
La feuille de route de Google pour l’IA révélée, suggérant que la prochaine architecture d’IA pourrait abandonner les mécanismes d’attention actuels: Logan Kilpatrick, responsable produit chez Google, a révélé lors de l’AI Engineer World Fair les orientations futures du modèle Gemini, dont la perspective la plus notable est la réalisation d’un « contexte infini ». Il a souligné qu’avec les mécanismes d’attention et les méthodes de traitement du contexte actuels, il est impossible de parvenir à un véritable contexte infini, laissant entendre que Google pourrait être en train de rechercher une toute nouvelle architecture d’IA fondamentale. La feuille de route comprend également : des capacités multimodales complètes (image + audio déjà pris en charge, la vidéo étant la prochaine étape), des expériences précoces avec Diffusion, des capacités d’Agent par défaut (utilisation et appel d’outils de premier ordre, le modèle évoluant progressivement vers un agent intelligent), une capacité d’inférence en expansion continue, et le lancement de davantage de petits modèles. Cette série de plans indique que Google promeut activement l’évolution de l’IA d’une réponse passive vers un agent intelligent proactif, et s’engage à surmonter les goulots d’étranglement technologiques actuels, en particulier dans le traitement du contexte, ce qui pourrait entraîner des changements majeurs dans l’architecture de l’IA. (Source: 新智元)
Sakana AI publie ALE-Agent, qui surpasse 98% des concurrents humains dans une compétition de programmation sur des problèmes NP-difficiles: Sakana AI, co-fondée par Llion Jones, l’un des auteurs de Transformer, a lancé ALE-Bench (Algorithmic Engineering Benchmark) en collaboration avec la plateforme japonaise de compétition de programmation AtCoder. Ce benchmark se concentre sur l’évaluation des capacités de raisonnement à long terme et de programmation créative de l’IA sur des problèmes NP-difficiles (tels que la planification d’itinéraires, l’ordonnancement de tâches). Son ALE-Agent, basé sur Gemini 2.5 Pro et combinant des incitations basées sur la connaissance du domaine et des stratégies de recherche diversifiées dans l’espace des solutions, a obtenu d’excellents résultats dans la compétition heuristique d’AtCoder, se classant 21e (dans les 2% supérieurs), surpassant un grand nombre de développeurs humains de haut niveau. Cela marque une avancée importante de l’IA dans la résolution de problèmes d’optimisation complexes, ce qui revêt une importance significative pour des applications pratiques telles que la logistique et la planification de la production. Bien qu’ALE-Agent excelle dans des algorithmes tels que le recuit simulé, il existe encore une marge d’amélioration en matière de débogage, d’analyse de complexité et pour éviter les écueils d’optimisation. (Source: 新智元, SakanaAILabs, hardmaru)
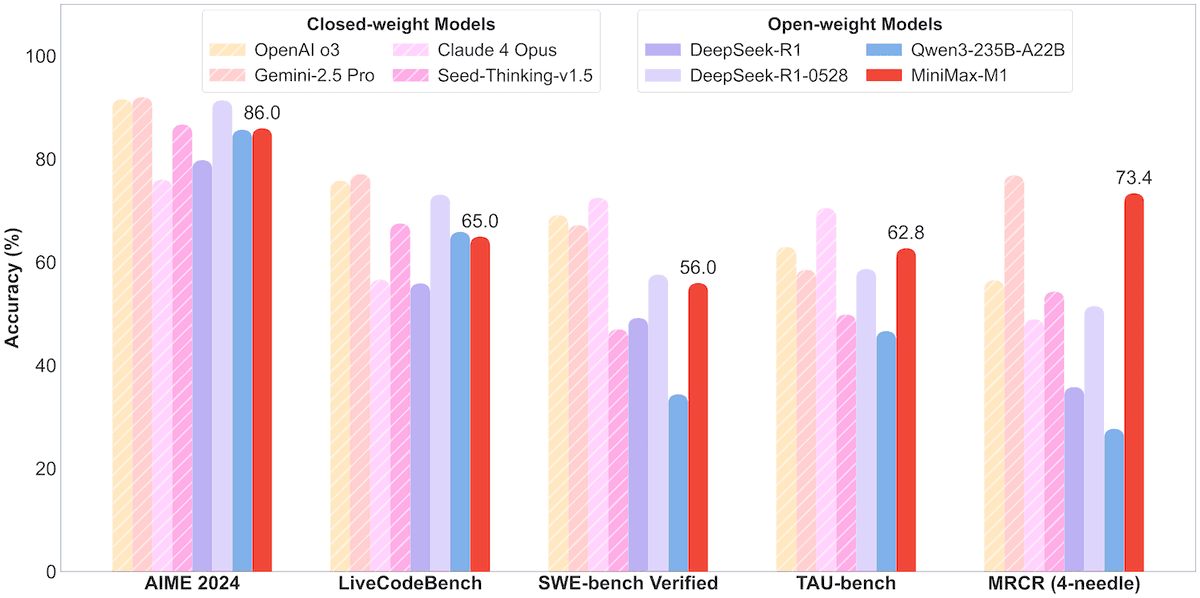
MiniMax publie en open source le modèle MoE MiniMax-M1 de 456B paramètres, supportant un contexte d’un million de Tokens et une sortie de 80 000 Tokens: La société MiniMax a publié son premier modèle d’inférence open source à grande échelle de type Mixture-of-Experts (MoE), le MiniMax-M1. Ce modèle a une taille de 45,6 milliards de paramètres, activant 4,59 milliards de paramètres par Token, et adopte une architecture combinant MoE et le mécanisme d’attention Lightning Attention. M1 supporte nativement une longueur de contexte d’un million de Tokens et peut atteindre une sortie de 80 000 Tokens, une performance de pointe dans l’industrie, avec deux versions de budget de pensée de 40k et 80k. Dans les benchmarks pour l’ingénierie logicielle, l’utilisation d’outils et les tâches à long contexte, M1 surpasse des modèles tels que DeepSeek-R1 et Qwen3-235B, avec des résultats particulièrement remarquables dans l’utilisation d’outils Agent (comme TAU-bench). Sa phase d’apprentissage par renforcement n’a nécessité que 512 puces H800 pendant trois semaines, pour un coût d’environ 537 400 dollars américains. Le modèle M1 est déjà utilisable gratuitement sur l’application et le site web de MiniMax, et est accessible via API. (Source: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Tendances
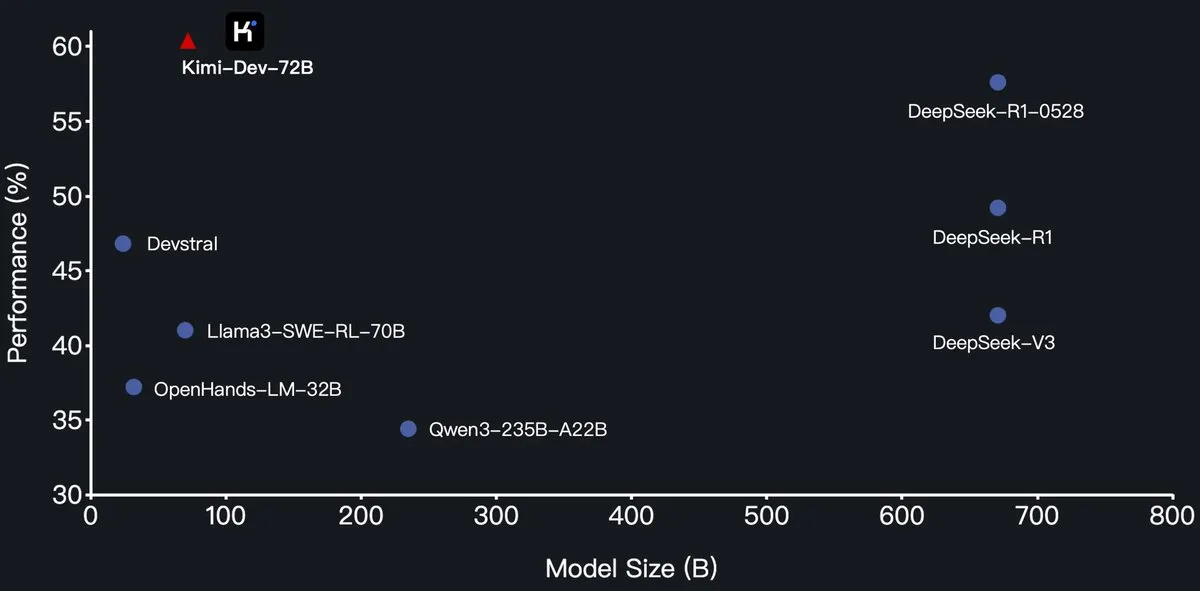
Moonshot AI publie en open source le grand modèle de langage de programmation Kimi-Dev-72B, surpassant DeepSeek-R1 sur SWE-Bench: Moonshot AI a publié son nouveau grand modèle de langage de programmation open source Kimi-Dev-72B, qui est affiné à partir de Qwen2.5-72B. Selon les informations, Kimi-Dev-72B a atteint un taux de résolution de 60,4% sur le benchmark SWE-bench Verified, surpassant des modèles tels que DeepSeek-R1-0528 (57,6%) et Qwen3-235B-A22B, devenant ainsi l’un des meilleurs modèles open source. Ce modèle a été entraîné par apprentissage par renforcement, se concentrant sur la réparation de dépôts de code réels dans des environnements Docker, et n’est récompensé que lorsque la suite de tests complète est réussie. Le responsable R&D de Qwen a déclaré ne pas avoir donné d’autorisation, mais l’utilisation par Kimi d’une licence MIT pour publier une version affinée est conforme aux règles. (Source: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
La série de modèles Qwen3 ajoute le support du format MLX, optimisant l’inférence sur les puces Apple: L’équipe Tongyi Qianwen d’Alibaba a annoncé que la série de modèles Qwen3 prend désormais en charge le format MLX et propose quatre niveaux de quantification : 4 bits, 6 bits, 8 bits et BF16. Cette initiative vise à optimiser l’efficacité d’exécution des modèles sur le framework MLX d’Apple, facilitant ainsi le déploiement local et l’inférence pour les développeurs sur les appareils Mac. Les utilisateurs peuvent obtenir les modèles correspondants sur HuggingFace et ModelScope. (Source: ClementDelangue, stablequan, jeremyphoward)

Google Gemini s’apprête à lancer la fonctionnalité « Deep Think » pour améliorer la capacité de traitement des problèmes complexes: Google se prépare à introduire une nouvelle fonctionnalité nommée « Deep Think » pour son modèle Gemini 2.5 Pro. Cette fonction vise à traiter des problèmes plus complexes en fournissant une capacité de calcul supplémentaire. En particulier pour les tâches liées aux mathématiques, Deep Think devrait améliorer les performances jusqu’à 15% par rapport à la version standard de Gemini 2.5 Pro. Cette fonctionnalité apparaîtra sous forme d’une nouvelle option dans la barre d’outils, et le processus de traitement pourrait prendre quelques minutes. Parallèlement, l’interface utilisateur de Gemini sera également mise à jour. (Source: op7418)
Le modèle de génération vidéo Google Veo 3 officiellement lancé, étendu à plus de 70 marchés: Google a annoncé que son modèle de génération vidéo par IA, Veo 3, est officiellement disponible pour les abonnés AI Pro et Ultra, couvrant plus de 70 marchés à travers le monde. Veo 3 est très attendu pour ses vidéos réalistes et créatives. Auparavant, des utilisateurs avaient déjà utilisé ce modèle pour créer des contenus ASMR tels que des « découpes de fruits hypnotiques », qui ont généré des dizaines de millions de vues sur les réseaux sociaux, démontrant son potentiel dans le domaine de la création de contenu. Ce lancement officiel permettra à davantage d’utilisateurs d’expérimenter et d’utiliser Veo 3 pour la création vidéo. (Source: Google, 新智元)
Hugging Face et Groq s’associent pour offrir des services d’inférence LLM à haute vitesse: Hugging Face a annoncé un partenariat avec la société de puces d’IA Groq, intégrant les LPU™ (Language Processing Unit) de Groq dans Hugging Face Playground et son API. Les utilisateurs peuvent désormais expérimenter directement sur la plateforme Hugging Face des services d’inférence LLM accélérés par le matériel Groq, prenant en charge divers modèles, y compris Llama 4 et Qwen 3. Cette initiative vise à fournir aux développeurs des options d’inférence de modèles d’IA plus rapides et plus efficaces, particulièrement adaptées à la création d’agents intelligents, d’assistants et d’applications d’IA en temps réel. (Source: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub ajoute une fonctionnalité de filtrage par taille de modèle pour aider les développeurs à choisir le modèle approprié: La plateforme Hugging Face a lancé une nouvelle fonctionnalité permettant aux utilisateurs de filtrer les modèles en fonction de leur taille (Size Range), en particulier pour ceux fonctionnant sur le framework mlx / mlx-lm. Cette amélioration vise à aider les développeurs à trouver plus facilement des modèles correspondant à leurs besoins spécifiques en matériel et en performances, soulignant que plus un modèle est grand, meilleur il n’est pas nécessairement, et que les petits modèles spécialisés sont souvent préférables dans des scénarios spécifiques. (Source: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

Mise à jour de NVIDIA NCCL, début de l’utilisation de l’accumulation FP32 pour les opérations de réduction sur les entrées en demi-précision: La dernière version de la NVIDIA Collective Communications Library (NCCL) (commit 72d2432) introduit une mise à jour importante : lors du traitement des opérations de réduction (reduction ops) sur des entrées en demi-précision (telles que FP16, BF16), elle commence à utiliser FP32 pour l’accumulation. Ce changement est crucial pour maintenir la précision des calculs et prévenir les dépassements (overflow), en particulier dans l’entraînement distribué à grande échelle. Cette version devrait être intégrée dans PyTorch 2.8 et les versions ultérieures. (Source: StasBekman)

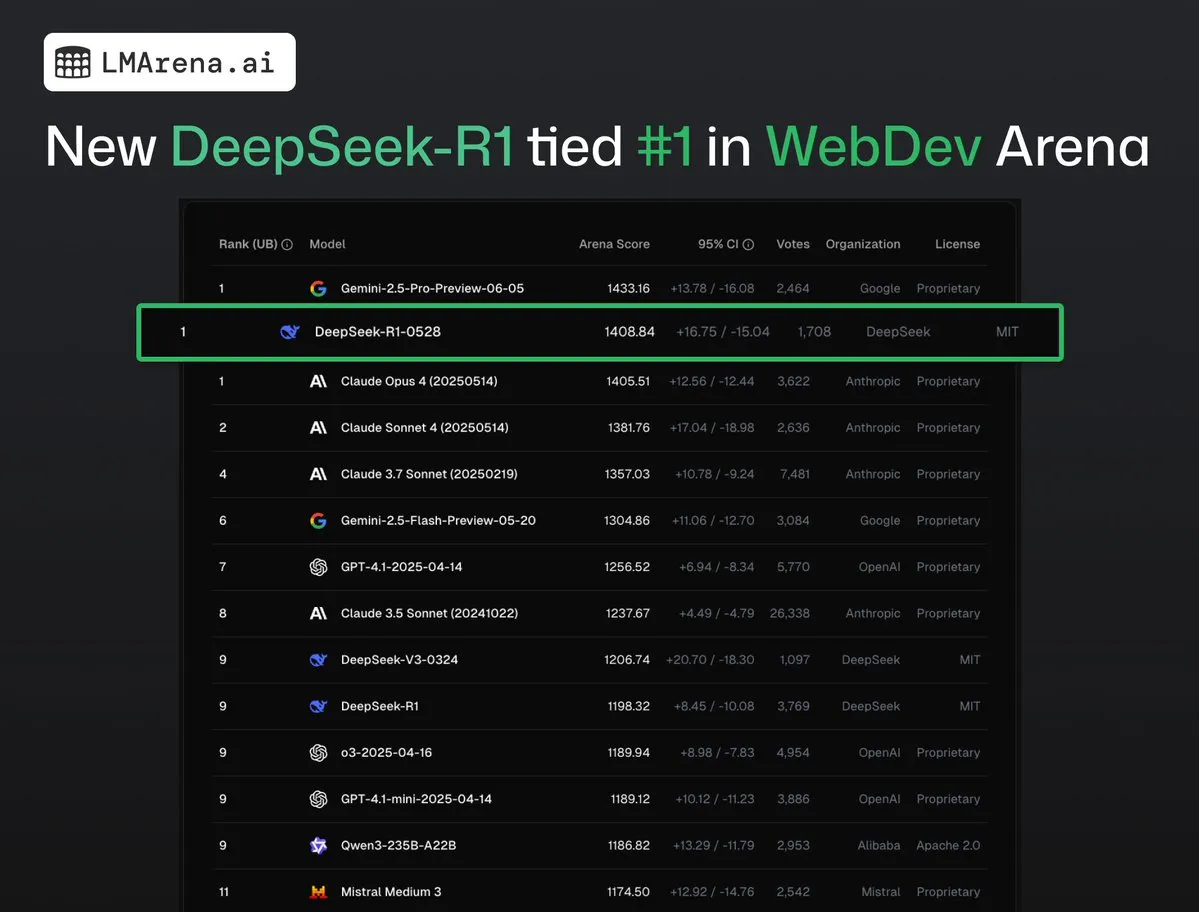
DeepSeek-R1 (0528) se classe premier ex æquo avec Claude Opus 4 sur WebDev Arena: Les dernières données de lmarena.ai montrent que la nouvelle version de DeepSeek-R1 (0528) a obtenu d’excellents résultats sur le benchmark WebDev Arena, se classant première ex æquo avec Claude Opus 4. Ce modèle se classe sixième au classement général de Text Arena, deuxième pour les capacités de programmation, quatrième pour les prompts difficiles, cinquième pour les capacités mathématiques, et est le modèle open source sous licence MIT le mieux classé. Cela témoigne de la forte compétitivité de DeepSeek dans des tâches spécifiques de développement et de raisonnement. (Source: ClementDelangue, zizhpan)
ByteDance lance les modèles d’image Seedream 3.0 et vidéo Seedance 1.0 Lite sur la plateforme Poe: Les outils de création par IA de ByteDance ont été mis à jour sur la plateforme internationale Poe, avec le lancement du modèle de génération d’images Seedream 3.0 de Jmeng AI et du modèle de génération vidéo Seedance 1.0 Lite. Seedream 3.0 vise à générer des images claires et vives, tandis que Seedance 1.0 Lite peut rapidement générer des vidéos avec des effets dynamiques réalistes. Les utilisateurs peuvent d’abord utiliser Seedream sur Poe pour générer une image, puis la convertir en vidéo en mentionnant Seedance avec @, réalisant ainsi un flux de création cohérent d’image vers vidéo. (Source: op7418)

Tencent lance le modèle de chant Levo, supportant la séparation des pistes et le clonage de timbre vocal zero-shot: Tencent a publié un modèle de chant IA nommé Levo, dont les performances seraient comparables à celles de Suno V3.5. Levo prend en charge la séparation des pistes audio et les fonctionnalités de clonage de timbre vocal zero-shot. D’après les démonstrations et les évaluations publiées, ses performances sont excellentes. Cette avancée montre la force de Tencent dans le domaine de la génération de musique par IA. (Source: karminski3)
OpenAI lance la fonctionnalité de génération d’images ChatGPT dans WhatsApp: OpenAI a annoncé que les utilisateurs peuvent désormais utiliser la fonctionnalité de génération d’images de ChatGPT via le service 1-800-ChatGPT dans WhatsApp. Cette mise à jour permet à un public plus large de générer facilement des images IA directement dans l’application de messagerie instantanée. (Source: gdb, eliza_luth, iScienceLuvr)
SpatialLM mis à jour en version 1.1, améliorant la compréhension et la reconstruction de scènes 3D: Le modèle de raisonnement spatial SpatialLM a publié sa version 1.1. La nouvelle version prend en charge plusieurs modes de source d’entrée, y compris la génération de scènes 3D à partir de texte (Text-to-3D), la reconstruction à partir de vidéos de caméras portables, les données de nuages de points LiDAR (comme le LiDAR de l’iPhone Pro) et l’échantillonnage de maillages synthétiques. Les caractéristiques clés incluent un traitement robuste des nuages de points non structurés, permettant une reconstruction raisonnable même avec des données de numérisation 3D incomplètes. De plus, la nouvelle version optimise la détection zero-shot pour les flux vidéo entrants, améliore la précision de l’estimation de l’agencement intérieur et perfectionne la détection d’objets 3D. Les scénarios d’application sont vastes, couvrant la reconstruction de scènes AR, la compréhension spatiale des robots, les flux de travail de conception 3D et les applications de caméra grand public. (Source: karminski3)
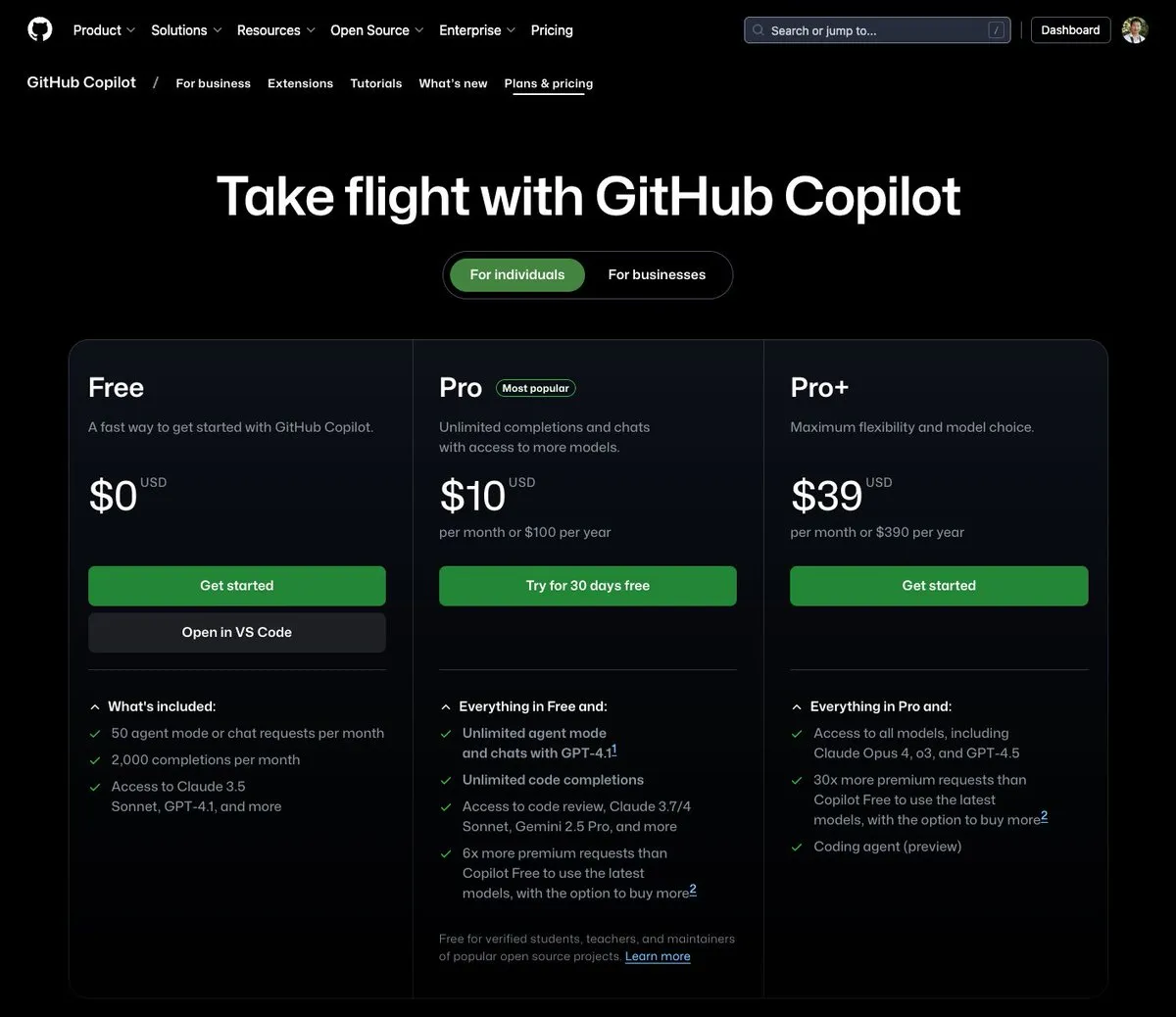
GitHub Copilot lance un forfait à 39 $ par mois, intégrant Claude Opus 4 et d’autres grands modèles: GitHub Copilot a ajouté un nouveau forfait d’abonnement à 39 $ par mois. Ce forfait offre non seulement des fonctionnalités d’assistant de codage, mais permet également aux utilisateurs d’accéder à plusieurs modèles de langage puissants, dont Claude Opus 4, o3 et GPT-4.5, et d’utiliser un Coding agent. Cette initiative vise à offrir aux développeurs une expérience d’assistance à la programmation par IA plus complète. (Source: dotey)
Les coûts d’appel des grands modèles d’IA continuent de baisser, la série Doubao 1.6 voit son prix chuter de 63% supplémentaires: Volcano Engine a lancé la série de grands modèles Doubao 1.6 lors de la conférence Force Original Power et a annoncé une réduction de ses coûts globaux de 63%. Pour la plage de longueur d’entrée de 0 à 32K, la plus couramment utilisée par les entreprises, le prix est de 0,8 yuan par million de tokens en entrée et de 8 yuans en sortie. Cela marque une nouvelle escalade dans la guerre des prix des grands modèles, après qu’Alibaba Qianwen ait réduit ses coûts à 1/10 de ceux de DeepSeek R1 en mars dernier. La baisse des coûts favorisera davantage le déploiement et la popularisation d’applications telles que les AI Agents. (Source: 字节必须再赢一次)
L’outil d’accélération de génération vidéo Chipmunk mis à jour, supporte les architectures multi-GPU et davantage de modèles open source: L’outil Chipmunk de l’équipe de Dan Fu a été mis à jour et supporte désormais une accélération sans perte de 1,4 à 3 fois pour la génération vidéo sur diverses architectures GPU NVIDIA (sm_80, sm_89, sm_90, comme les A100, 4090, H100). Parallèlement, Chipmunk ajoute le support de davantage de modèles vidéo open source tels que Mochi, Wan, et fournit des tutoriels d’intégration. Cet outil exploite la sparsité des activations dans les modèles vidéo (seulement 5-25% des activations contribuent à plus de 90% de la sortie) pour réaliser l’accélération, sans nécessiter de réentraînement du modèle. (Source: realDanFu)

🧰 Outils
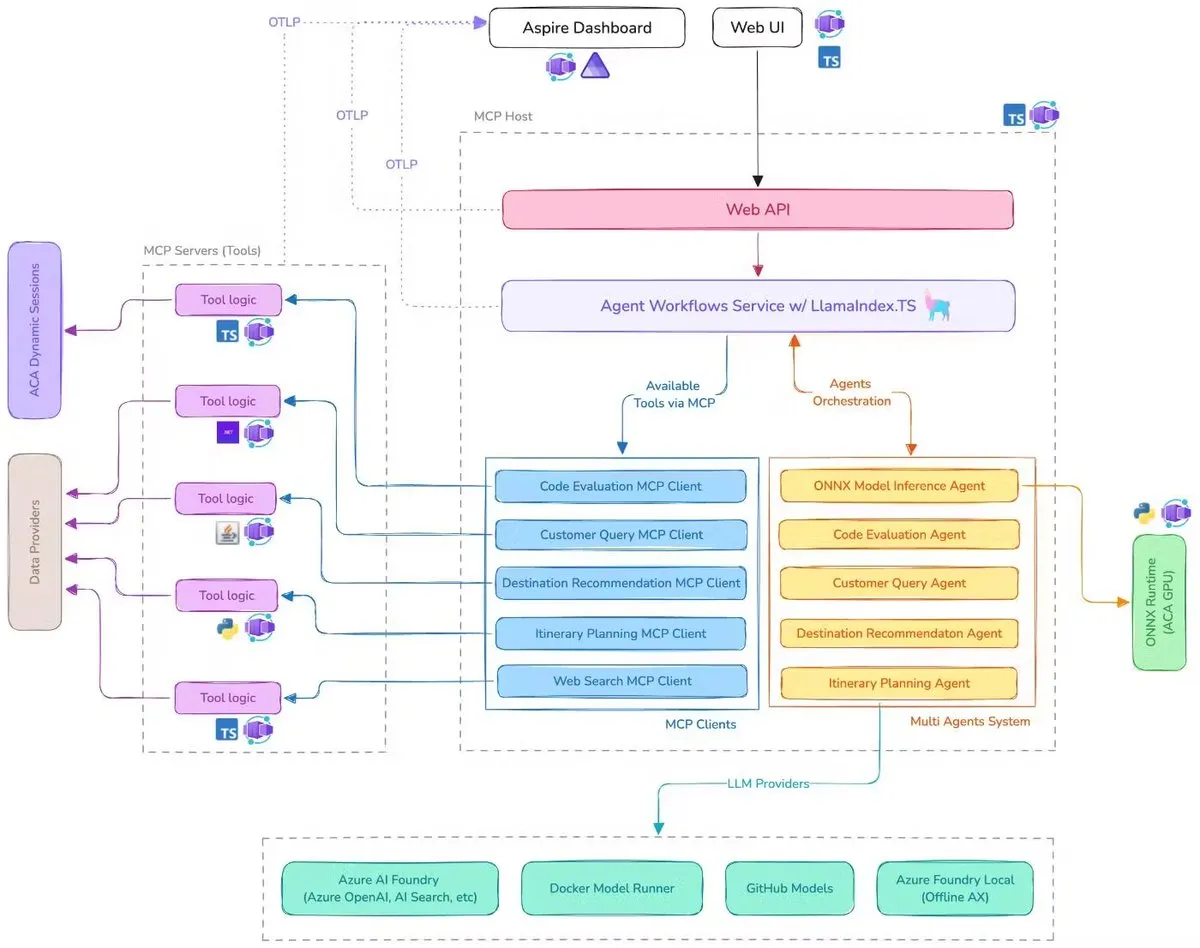
Microsoft publie une démo d’assistant de voyage IA, intégrant MCP, LlamaIndex.TS et Azure AI Foundry: Microsoft a présenté une démo d’assistant de voyage IA. Ce système coordonne plusieurs agents IA (y compris la classification des requêtes, la recommandation de destinations, la planification d’itinéraires, soit six agents spécialisés) pour accomplir des tâches complexes de planification de voyage, grâce au Model Context Protocol (MCP), à LlamaIndex.TS et à Azure AI Foundry. Chaque agent obtient des données et des outils en temps réel via des serveurs MCP écrits en Java, .NET, Python et TypeScript. Cette application montre comment des multi-agents de niveau entreprise peuvent collaborer via des microservices multilingues, en utilisant Azure OpenAI et les modèles GitHub pour fournir des capacités d’IA, et peuvent être déployés de manière évolutive et sans serveur via Azure Container Apps. (Source: jerryjliu0, jerryjliu0)
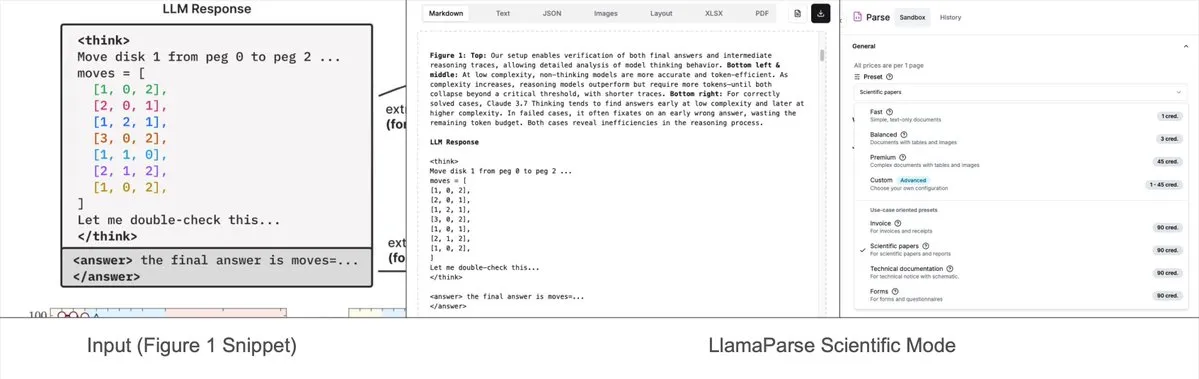
LlamaParse ajoute des modes prédéfinis, capables d’analyser des graphiques complexes en Mermaid ou Markdown: L’outil LlamaParse de LlamaIndex a récemment été mis à jour avec l’ajout de « modes prédéfinis » (preset-modes), lui permettant d’analyser des graphiques complexes (tels que ceux contenant plusieurs courbes et annotations) dans des documents comme des rapports de recherche, et de les convertir en diagrammes Mermaid formatés ou en tableaux Markdown. Cette fonctionnalité aide à capturer le contexte complet d’une page, et le texte structuré généré peut être utilisé pour construire des flux RAG ou pour une extraction de métadonnées plus poussée. (Source: jerryjliu0)
Prompt Optimizer : un outil d’optimisation pour aider à rédiger des prompts de haute qualité: Prompt Optimizer est un outil conçu pour aider les utilisateurs à rédiger de meilleurs prompts IA, améliorant ainsi la qualité des résultats de l’IA. Il est disponible sous forme d’application Web et d’extension Chrome, offrant une optimisation intelligente, une amélioration itérative en plusieurs étapes, une comparaison entre les prompts originaux et optimisés, l’intégration de plusieurs modèles (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow, etc.), une configuration avancée des paramètres, un stockage local crypté, etc. Cet outil traite les données purement côté client, garantissant la sécurité et la confidentialité des données. (Source: GitHub Trending)

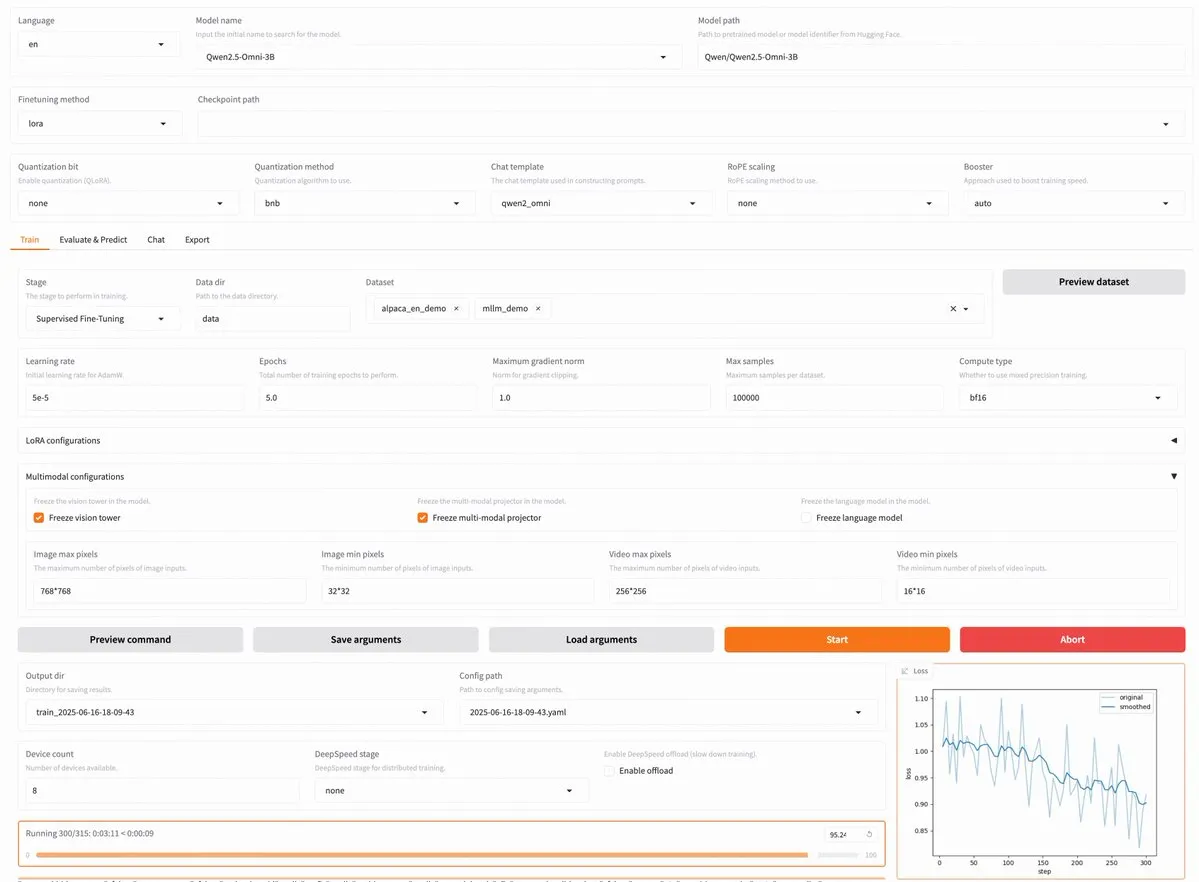
LLaMA Factory v0.9.3 publiée, supportant le fine-tuning sans code de près de 300 modèles, dont Qwen3, Llama 4: LLaMA Factory a publié sa version v0.9.3. Il s’agit d’une plateforme de fine-tuning sans code, entièrement open source, dotée d’une interface utilisateur Gradio, compatible avec près de 300 modèles, y compris les plus récents Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, etc. Les utilisateurs peuvent l’installer localement via une image Docker, ou l’expérimenter sur Hugging Face Spaces, Google Colab, ainsi que sur le cloud GPU de Novita. (Source: _akhaliq)
Nanonets OCR : un modèle OCR SOTA basé sur Qwen 2.5 VL 3B publié en open source: Nanonets a publié un nouveau modèle OCR de 3 milliards de paramètres – Nanonets OCR. Ce modèle est basé sur le réseau principal Qwen 2.5 VL 3B, surpasse les performances de l’API Mistral OCR et est publié sous licence Apache 2.0. Il est capable de gérer diverses tâches OCR telles que la reconnaissance LaTeX, la détection de filigranes et de signatures, l’extraction de tableaux complexes, etc. (Source: huggingface)
Perplexity Labs serait capable de remplacer plusieurs postes spécialisés, suscitant un débat sur les capacités des outils d’IA: Un utilisateur, GREG ISENBERG, affirme avoir utilisé Perplexity Labs pour remplacer le travail de cinq postes : vendeur, rédacteur publicitaire, réalisateur de films, gestionnaire de médias sociaux et analyste financier, estimant que les capacités des outils d’IA sont « réellement folles ». Le PDG de Perplexity, Arav Srinivas, a retweeté et commenté que c’était l’une des meilleures vidéos montrant comment les agents d’IA peuvent être appliqués dans des cas d’utilisation réels, comparant Perplexity Labs à d’autres outils sur le marché en matière d’analyse financière, de marketing sur les médias sociaux, de direction créative et de vente. Cela met en évidence le potentiel des AI Agents à intégrer et exécuter des tâches professionnelles multi-domaines. (Source: AravSrinivas, AravSrinivas)
Claude-Flow publie une mise à jour majeure v1.0.50, activant le « mode essaim » pour améliorer l’efficacité de l’automatisation du code: Claude-Flow, un système d’agents parallèles par lots basé sur Claude Code, a publié sa version v1.0.50. La nouvelle version introduit le « mode essaim » (Swarm Mode), permettant aux utilisateurs de générer, gérer et coordonner simultanément des centaines d’agents Claude travaillant en parallèle pour la construction, les tests, le déploiement ou les cycles de recherche multi-étapes. Selon les dires, les performances sont améliorées de 20 fois par rapport à l’automatisation séquentielle traditionnelle de Claude Code. Les développeurs peuvent l’initialiser via npx claude-flow@latest init --sparc --force. (Source: Reddit r/ClaudeAI)

📚 Apprentissage
Awesome Machine Learning : une liste complète de ressources sur l’apprentissage automatique: Le projet « awesome-machine-learning » sur GitHub est une liste soigneusement sélectionnée de frameworks, bibliothèques et logiciels d’apprentissage automatique, classés par langage de programmation. Il contient également des liens vers des livres gratuits sur l’apprentissage automatique, des événements professionnels, des cours en ligne, des blogs, des newsletters et des rencontres locales, offrant une navigation précieuse aux apprenants et praticiens de l’apprentissage automatique. (Source: GitHub Trending)
Anthropic et Cognition AI publient respectivement des articles de blog sur la construction de systèmes multi-agents, résumés par LangChain: Anthropic et Cognition AI ont récemment publié chacun des articles de blog sur la construction (ou non) de systèmes multi-agents. Anthropic a partagé son expérience dans la construction de son système de recherche multi-agents, tandis que Cognition AI a avancé l’argument de « ne pas construire de multi-agents ». Harrison Chase de LangChain a résumé cela, soulignant que bien que les points de vue semblent différents en surface, les deux articles partagent de nombreuses similitudes dans leurs directives et recommandations, et les a reliés aux efforts de LangChain dans le domaine des multi-agents. (Source: hwchase17, Hacubu)
L’article « Recent Advances in Speech Language Models: A Survey » accepté à la conférence principale d’ACL 2025: L’article de synthèse sur les modèles de langage vocal (SpeechLM) intitulé « Recent Advances in Speech Language Models: A Survey », rédigé par une équipe de l’Université chinoise de Hong Kong, a été accepté à la conférence principale d’ACL 2025. Cet article est la première revue complète et systématique dans ce domaine, analysant en profondeur l’architecture technique des SpeechLM (tokeniseurs vocaux, modèles de langage, vocodeurs), les stratégies d’entraînement (pré-entraînement, fine-tuning par instruction, post-alignement), les paradigmes d’interaction (modélisation full-duplex), les scénarios d’application (sémantique, locuteur, paralinguistique) et les systèmes d’évaluation. L’article souligne le potentiel des SpeechLM pour réaliser une interaction vocale homme-machine naturelle et identifie les défis et les orientations futures. (Source: 36氪)

Une nouvelle étude améliore les capacités de raisonnement interdomaines des petits modèles grâce à l’apprentissage par jeu visuel (ViGaL), un modèle 7B surpasse GPT-4o en mathématiques: Des équipes de recherche de l’Université Rice, de l’Université Johns Hopkins et de Nvidia ont proposé un nouveau paradigme de post-entraînement appelé ViGaL (Visual Game Learning). En faisant jouer un modèle multimodal de 7 milliards de paramètres (Qwen2.5-VL-7B) à des jeux d’arcade simples comme Snake et la rotation 3D, le modèle a non seulement amélioré ses compétences de jeu, mais a également montré une amélioration significative de ses capacités interdomaines dans des tâches de raisonnement complexes telles que les mathématiques (MathVista) et les questions-réponses multidisciplinaires (MMMU), surpassant même à certains égards des modèles de pointe comme GPT-4o. L’étude montre que l’entraînement par le jeu peut cultiver les capacités cognitives générales du modèle, telles que la compréhension spatiale et la planification séquentielle, et que différents jeux peuvent renforcer différents aspects des compétences de raisonnement. Cette méthode améliore les capacités de raisonnement tout en maintenant les capacités visuelles générales du modèle. (Source: 新智元)

Le laboratoire d’IA de Shanghai et d’autres proposent le framework MathFusion pour améliorer la capacité des LLM à résoudre des problèmes mathématiques grâce à la fusion d’instructions: Le laboratoire d’intelligence artificielle de Shanghai, l’Institut d’intelligence artificielle Gaoling de l’Université Renmin de Chine et d’autres institutions ont conjointement proposé le framework MathFusion. Il vise à améliorer la capacité des grands modèles de langage (LLM) à résoudre des problèmes mathématiques en fusionnant différentes questions mathématiques pour générer des instructions synthétiques structurellement plus diverses et logiquement plus complexes. Ce framework comprend trois stratégies de fusion : séquentielle, parallèle et conditionnelle, capables de capturer efficacement les liens profonds entre les problèmes. Les expériences montrent qu’en utilisant seulement 45 000 instructions synthétiques pour affiner des modèles tels que DeepSeekMath-7B, Llama3-8B et Mistral-7B, MathFusion a amélioré la précision moyenne de 18,0 points de pourcentage sur plusieurs benchmarks mathématiques, démontrant une haute efficacité des données et des performances. (Source: 量子位)

Le laboratoire d’IA de Shanghai et d’autres proposent le framework GRA, où de petits modèles collaborent pour générer des données de haute qualité, avec des performances comparables aux modèles 72B: Le laboratoire d’intelligence artificielle de Shanghai, en collaboration avec l’Université Renmin de Chine, a proposé le framework GRA (Generator–Reviewer–Adjudicator). En simulant le mécanisme de soumission d’articles et d’évaluation par les pairs, il permet à plusieurs petits modèles de langage (paramètres 7-8B) de collaborer pour générer des données d’entraînement de haute qualité. Dans ce framework, le Generator est responsable de la génération, le Reviewer effectue plusieurs cycles d’évaluation et de notation, et l’Adjudicator prend la décision finale en cas de conflit d’évaluation. Les expériences montrent que l’entraînement de modèles de base tels que LLaMA-3.1-8B et Qwen-2.5-7B avec des données générées par GRA atteint ou dépasse les performances obtenues avec des données distillées à partir de grands modèles comme Qwen-2.5-72B-Instruct sur 10 ensembles de données courants couvrant les mathématiques, le code, le raisonnement logique, etc. Cela offre de nouvelles perspectives pour la synthèse de données à faible coût et à haute efficacité. (Source: 量子位)

Un article explore l’état actuel et l’avenir de l’explicabilité des grands modèles, soulignant son importance pour le déploiement sécurisé de l’IA: L’Institut de recherche Tencent a publié un article explorant en profondeur l’état actuel, les approches techniques et les défis futurs de l’explicabilité des grands modèles de langage (LLM). L’article souligne que la compréhension des mécanismes internes des LLM est cruciale pour prévenir les déviations de valeur, déboguer et améliorer les modèles, empêcher les abus et promouvoir les applications dans des scénarios à haut risque. Les approches techniques actuelles comprennent l’explication automatisée (grands modèles expliquant de petits modèles), la visualisation des caractéristiques (comme les auto-encodeurs clairsemés), la surveillance de la chaîne de pensée et l’explicabilité mécaniste (comme le « microscope IA » d’Anthropic et Tracr de DeepMind). Cependant, la polysémie neuronale, l’universalité des lois d’explication et les limitations cognitives humaines restent des défis majeurs. L’article appelle à renforcer les investissements dans la recherche sur l’explicabilité et suggère d’adopter à ce stade des règles de droit souple encourageant l’autorégulation de l’industrie, afin d’assurer un développement sûr, transparent et centré sur l’humain de la technologie IA. (Source: 腾讯研究院)

Un nouvel article explore les applications et les progrès des modèles de diffusion discrets dans les grands modèles de langage et multimodaux: Un article intitulé « Discrete Diffusion in Large Language and Multimodal Models: A Survey » passe en revue de manière systématique les avancées de la recherche sur les modèles de langage à diffusion discrète (dLLMs) et les modèles de langage multimodaux à diffusion discrète (dMLLMs). Ces modèles adoptent un décodage parallèle multi-Token et des stratégies de génération basées sur le débruitage, réalisant une génération parallèle, une contrôlabilité fine de la sortie, ainsi que des capacités de perception dynamiques et réactives, avec une vitesse d’inférence jusqu’à 10 fois supérieure à celle des modèles autorégressifs. L’article retrace leur historique de développement, formalise le cadre mathématique, classifie les modèles représentatifs, analyse les technologies clés d’entraînement et d’inférence, résume les applications dans les domaines du langage, du langage visuel et de la biologie, et discute enfin des futures orientations de recherche et des défis de déploiement. (Source: HuggingFace Daily Papers)
Une nouvelle recherche propose Test3R : améliorer la précision géométrique de la reconstruction 3D grâce à l’apprentissage au moment du test: Une nouvelle technologie nommée Test3R améliore considérablement la précision géométrique de la reconstruction 3D grâce à un apprentissage effectué au moment du test. Cette méthode utilise des triplets d’images (I_1,I_2,I_3) et génère des résultats de reconstruction à partir des paires d’images (I_1,I_2) et (I_1,I_3). L’idée centrale est d’optimiser le réseau au moment du test via un objectif auto-supervisé : maximiser la cohérence géométrique de ces deux résultats de reconstruction par rapport à l’image commune I_1. Les expériences montrent que Test3R surpasse de manière significative les méthodes SOTA existantes dans les tâches de reconstruction 3D et d’estimation de la profondeur multi-vues, tout en étant universelle et peu coûteuse, facile à appliquer à d’autres modèles, avec un surcoût d’entraînement au moment du test et un nombre de paramètres minimes. (Source: HuggingFace Daily Papers)
Un article propose Mirage-1 : un agent GUI doté de compétences multimodales hiérarchiques, améliorant la capacité de traitement des tâches à long terme: Des chercheurs proposent Mirage-1, un agent GUI multimodal, multiplateforme et plug-and-play, conçu pour résoudre les problèmes de manque de connaissances et d’écart entre les domaines hors ligne et en ligne rencontrés par les agents GUI actuels lors du traitement de tâches à long terme dans des environnements en ligne. Au cœur de Mirage-1 se trouve le module de compétences multimodales hiérarchiques (HMS), qui abstrait progressivement les trajectoires en compétences d’exécution, compétences de base et méta-compétences, fournissant une structure de connaissances hiérarchique pour la planification de tâches à long terme. Parallèlement, l’algorithme de recherche arborescente Monte-Carlo améliorée par les compétences (SA-MCTS) utilise les compétences acquises hors ligne pour réduire l’espace de recherche des actions dans l’exploration arborescente en ligne. Sur les benchmarks AndroidWorld, MobileMiniWob++, Mind2Web-Live et le nouveau benchmark AndroidLH, Mirage-1 a montré des améliorations de performances significatives. (Source: HuggingFace Daily Papers)
L’article « Don’t Pay Attention » propose une nouvelle architecture de réseau neuronal fondamentale, Avey, qui défie Transformer: Un article intitulé « Don’t Pay Attention » propose une nouvelle architecture de réseau neuronal fondamentale, Avey, visant à se libérer de la dépendance aux mécanismes d’attention et récurrents. Avey est composé d’un classeur (ranker) et d’un processeur neuronal autorégressif (autoregressive neural processor), qui collaborent pour identifier et contextualiser uniquement les Tokens les plus pertinents pour un Token donné, quelle que soit leur position dans la séquence. Cette architecture découple la longueur de la séquence de la largeur du contexte, permettant ainsi de traiter efficacement des séquences de longueur arbitraire. Les résultats expérimentaux montrent qu’Avey est comparable à Transformer sur les benchmarks NLP standard à courte portée et excelle particulièrement dans la capture des dépendances à longue portée. (Source: HuggingFace Daily Papers)
Un nouvel article explore la validation de code évolutive via des modèles de récompense, en équilibrant précision et débit: Une étude explore le compromis entre l’utilisation de modèles de récompense basés sur les résultats (ORM) et des validateurs exhaustifs (comme une suite de tests complète) lorsque les grands modèles de langage (LLM) résolvent des tâches de codage. L’étude révèle que même en présence de validateurs exhaustifs, les ORM jouent un rôle clé dans la validation à grande échelle en sacrifiant une certaine précision au profit de la vitesse. En particulier, dans les méthodes de type « générer-élaguer-réordonner », l’utilisation d’un validateur plus rapide mais moins précis pour éliminer au préalable les solutions incorrectes peut accélérer le système de 11,65 fois, avec une perte de précision de seulement 8,33 %. Cette méthode fonctionne en filtrant les solutions incorrectes mais bien classées, offrant de nouvelles perspectives pour la conception de systèmes de classement de programmes évolutifs et précis. (Source: HuggingFace Daily Papers)
Le nouveau benchmark AbstentionBench révèle : les LLM de type raisonnement sont peu performants sur les questions sans réponse: Pour évaluer la capacité des grands modèles de langage (LLM) à choisir de s’abstenir (c’est-à-dire refuser de répondre explicitement) face à l’incertitude, des chercheurs ont lancé AbstentionBench. Ce benchmark à grande échelle comprend 20 ensembles de données différents, couvrant divers types de questions telles que celles dont la réponse est inconnue, les spécifications insuffisantes, les prémisses erronées, les interprétations subjectives et les informations obsolètes. L’évaluation de 20 LLM de pointe montre que l’abstention est un problème non résolu et que l’augmentation de la taille des modèles n’y contribue guère. De manière surprenante, même pour les LLM de type raisonnement explicitement entraînés pour les mathématiques et les sciences, leur fine-tuning pour le raisonnement a en moyenne réduit leur capacité d’abstention de 24 %. Bien que des prompts système soigneusement conçus puissent améliorer les performances d’abstention en pratique, cela ne résout pas les défauts fondamentaux des modèles en matière de raisonnement en situation d’incertitude. (Source: HuggingFace Daily Papers)
Un article propose une méthode basée sur les patchs et la décomposition (PatchInstruct) pour utiliser les LLM dans la prévision de séries temporelles: Une nouvelle étude explore des stratégies de prompting simples et flexibles pour utiliser les grands modèles de langage (LLM) dans la prévision de séries temporelles, sans nécessiter de réentraînement important ni d’architectures externes complexes. En combinant la décomposition des séries temporelles, la tokenisation basée sur les patchs (patch-based tokenization) et l’amélioration par les voisins basée sur la similarité, les chercheurs ont découvert qu’il est possible d’améliorer la qualité des prédictions des LLM tout en maintenant la simplicité et en minimisant le prétraitement des données. La méthode PatchInstruct proposée dans cette étude permet aux LLM de faire des prédictions précises et efficaces. (Source: HuggingFace Daily Papers)
Publication du nouveau jeu de données MS4UI, axé sur le résumé multimodal de vidéos didacticielles d’interface utilisateur: Pour remédier aux lacunes des benchmarks existants en matière de fourniture d’instructions détaillées et exécutables et d’illustrations, des chercheurs ont proposé le jeu de données MS4UI (Multi-modal Summarization for User Interface Instructional Videos). Ce jeu de données comprend 2413 vidéos didacticielles d’interface utilisateur, totalisant plus de 167 heures, et a été annoté manuellement avec segmentation vidéo, résumé textuel et résumé vidéo. Il vise à promouvoir la recherche de méthodes de résumé multimodal concises et exécutables pour les vidéos didacticielles d’interface utilisateur. Les expériences montrent que les méthodes SOTA actuelles de résumé multimodal sont peu performantes sur MS4UI, soulignant l’importance de nouvelles approches dans ce domaine. (Source: HuggingFace Daily Papers)
DeepResearch Bench : un benchmark complet pour les agents de recherche approfondie intelligents: Pour évaluer systématiquement les capacités des agents de recherche approfondie basés sur les LLM (Deep Research Agents, DRAs), des chercheurs ont lancé DeepResearch Bench. Ce benchmark comprend 100 tâches de recherche de niveau doctoral soigneusement conçues par des experts de 22 domaines différents. En raison de la complexité et de la forte intensité de main-d’œuvre de l’évaluation des DRAs, les chercheurs ont proposé deux nouvelles méthodes d’évaluation hautement corrélées avec le jugement humain : l’une est une méthode de critères adaptatifs basée sur des références pour évaluer la qualité des rapports de recherche générés ; l’autre est un cadre qui évalue la capacité de récupération et de collecte d’informations des DRAs en évaluant le nombre de citations valides et la précision globale des citations. (Source: HuggingFace Daily Papers)
Un article propose BridgeVLA : un apprentissage efficace des manipulations 3D grâce à l’alignement entrée-sortie: Pour améliorer l’efficacité de l’utilisation des signaux 3D par les modèles de langage visuel (VLM) dans l’apprentissage de la manipulation robotique, des chercheurs ont proposé BridgeVLA, un nouveau modèle d’action visuo-linguistique 3D (VLA). BridgeVLA projette les entrées 3D sur plusieurs images 2D, assurant l’alignement avec les entrées du réseau principal VLM, et utilise des cartes de chaleur 2D pour la prédiction des actions, unifiant ainsi les entrées et les sorties dans un espace d’image 2D cohérent. De plus, cette étude propose une méthode de pré-entraînement évolutive qui permet au réseau principal VLM d’acquérir la capacité de prédire des cartes de chaleur 2D avant l’apprentissage de la politique en aval. Les expériences montrent que BridgeVLA obtient d’excellents résultats sur plusieurs benchmarks de simulation et des expériences sur robot réel, améliorant considérablement l’efficacité et l’efficience de l’apprentissage des manipulations 3D, et démontrant une forte efficacité d’échantillonnage et une capacité de généralisation. (Source: HuggingFace Daily Papers)
Une nouvelle recherche synthétise des millions d’instructions utilisateur complexes et diversifiées (SynthQuestions) grâce à une base d’attribution: Pour pallier le manque de données d’instructions diversifiées, complexes et à grande échelle nécessaires à l’alignement des grands modèles de langage (LLM), des chercheurs proposent une méthode de synthèse d’instructions basée sur une fondation d’attribution (attributed grounding). Ce cadre comprend : 1) un processus d’attribution descendant, qui associe des instructions réelles sélectionnées à des utilisateurs contextualisés ; 2) un processus de synthèse ascendant, qui utilise des documents Web pour générer d’abord des contextes, puis des instructions significatives. Grâce à cette méthode, un jeu de données de 1 million d’instructions, SynthQuestions, a été construit. Les expériences montrent que les modèles entraînés sur ce jeu de données obtiennent des performances de pointe sur plusieurs benchmarks courants, et que les performances continuent de s’améliorer avec l’augmentation du corpus Web. (Source: HuggingFace Daily Papers)
PersonaFeedback : publication d’un benchmark d’évaluation personnalisée à grande échelle annoté par des humains: Pour évaluer la capacité des grands modèles de langage (LLM) à fournir des réponses personnalisées étant donné des profils utilisateurs prédéfinis et des requêtes, des chercheurs ont lancé le benchmark PersonaFeedback. Ce benchmark contient 8298 cas de test annotés par des humains, classés en trois niveaux (simple, moyen et difficile) en fonction de la complexité contextuelle du profil utilisateur et de la difficulté à distinguer les réponses personnalisées. Contrairement aux benchmarks existants, PersonaFeedback découple l’inférence de profil de la personnalisation, se concentrant sur l’évaluation de la capacité du modèle à générer des réponses sur mesure pour des profils explicites. Les résultats expérimentaux montrent que même les LLM SOTA rencontrent des difficultés dans les tests de niveau difficile, indiquant que les cadres d’amélioration de la récupération actuels ne sont pas la solution ultime pour les tâches de personnalisation. (Source: HuggingFace Daily Papers)
Un article explore la « chirurgie linguistique » dans les grands modèles multilingues : contrôle linguistique au moment de l’inférence par injection latente: Une nouvelle étude explore le phénomène d’alignement des représentations qui se produit naturellement dans les grands modèles de langage (LLM) et sa signification pour découpler les informations spécifiques à la langue et celles indépendantes de la langue. L’étude confirme l’existence de cet alignement et analyse son comportement par rapport aux modèles d’alignement explicitement conçus. Sur la base de ces découvertes, les chercheurs proposent la méthode de contrôle linguistique au moment de l’inférence (Inference-Time Language Control, ITLC), qui utilise l’injection latente (latent injection) pour obtenir un contrôle interlinguistique précis et atténuer les problèmes de confusion linguistique dans les LLM. Les expériences démontrent la forte capacité de contrôle interlinguistique d’ITLC tout en maintenant l’intégrité sémantique de la langue cible, et sa capacité à atténuer efficacement le problème de confusion interlinguistique qui persiste même dans les LLM à grande échelle actuels. (Source: HuggingFace Daily Papers)
Un article propose la méthode NoWait : supprimer les « Tokens de réflexion » pour améliorer l’efficacité de l’inférence des grands modèles: Des recherches récentes indiquent que les grands modèles de raisonnement, lorsqu’ils effectuent un raisonnement complexe par étapes, produisent souvent des sorties redondantes en « réfléchissant » excessivement (par exemple, en sortant des Tokens comme « Wait », « Hmm »), ce qui affecte l’efficacité. La nouvelle méthode proposée, NoWait, vise à valider la nécessité de ces Tokens d’auto-réflexion explicites pour le raisonnement de haut niveau en les supprimant au moment de l’inférence. Sur dix benchmarks couvrant des tâches de raisonnement textuel, visuel et vidéo, NoWait a réduit la longueur des trajectoires de la chaîne de pensée de 27 % à 51 % dans cinq familles de modèles de style R1, sans nuire à l’utilité du modèle. Cette méthode offre une solution plug-and-play pour un raisonnement multimodal efficace tout en maintenant l’utilité. (Source: HuggingFace Daily Papers)
💼 Affaires
OpenAI remporte un contrat de 200 millions de dollars avec le ministère américain de la Défense pour développer des capacités militaires de pointe: OpenAI a signé un contrat d’un an d’une valeur de 200 millions de dollars avec le ministère américain de la Défense, visant à développer des outils d’intelligence artificielle avancés pour la sécurité nationale. Cela marque le premier contrat de ce type répertorié par le Pentagone pour OpenAI. Le travail sera principalement effectué dans la région de la capitale nationale. OpenAI avait déjà collaboré avec la société de défense Anduril. Cette initiative s’inscrit dans un contexte de promotion généralisée des applications de l’IA dans le secteur de la défense américain, où ses concurrents Anthropic ont également collaboré avec Palantir et Amazon. Le PDG d’OpenAI, Sam Altman, avait publiquement exprimé son soutien aux projets de sécurité nationale. (Source: Reddit r/ArtificialInteligence, code_star)

Alta lève 11 millions de dollars, Menlo Ventures en tête, se concentrant sur l’IA + la mode: La start-up de mode IA Alta a annoncé avoir levé 11 millions de dollars lors d’un tour de financement mené par Menlo Ventures, avec la participation de Benchstrength et Aglaé Ventures (le fonds de capital-risque soutenu par la famille Arnault du groupe LVMH). Amy Tong Wu rejoindra le conseil d’administration d’Alta. Ce financement aidera Alta à poursuivre son développement dans le domaine de la combinaison de l’IA et de la mode. (Source: ZhaiAndrew)
Figure réorganise sa structure, le département des contrôles fusionne avec Helix pour accélérer la feuille de route IA: La société de robots humanoïdes Figure a annoncé que son département des contrôles (Controls) n’existe plus et que toute l’équipe a été intégrée au département Helix. Cette décision vise à accélérer le développement de la feuille de route de l’entreprise dans le domaine de l’intelligence artificielle, indiquant que Figure concentre davantage de ressources et d’efforts sur la R&D et l’application des technologies IA. (Source: adcock_brett)
🌟 Communauté
Discussion sur l’AGI : les utilisateurs ordinaires n’ont pas à s’inquiéter excessivement, l’AGI est plus stratégique qu’un outil quotidien: Plusieurs discussions au sein de la communauté soulignent que les utilisateurs ordinaires de LLM n’ont pas à s’inquiéter outre mesure de l’arrivée de l’AGI (Intelligence Artificielle Générale). La définition de l’AGI est vague et très théorique. Même si elle était réalisée, elle ne se manifesterait pas directement dans la fenêtre de chat de l’utilisateur à court terme, mais servirait plutôt d’outil stratégique et d’infrastructure pour les États ou les grandes organisations, utilisée pour gérer des affaires complexes telles que les négociations entre pays, plutôt que d’aider les individus à organiser des réunions. (Source: farguney, farguney, farguney, farguney)
La construction de systèmes multi-agents nécessite une évaluation humaine, une attention aux cas limites et à la qualité des sources: Lors de la construction de systèmes multi-agents, l’évaluation et les tests humains sont cruciaux et permettent de découvrir des cas limites que l’évaluation automatisée pourrait ignorer. Par exemple, les premiers agents, lors du choix des sources d’information, avaient tendance à privilégier les fermes de contenu optimisées pour le SEO plutôt que les PDF académiques faisant autorité ou les blogs personnels. L’ajout d’heuristiques sur la qualité des sources dans les prompts aide à résoudre ce type de problème. Cela montre que même à l’ère de l’évaluation automatisée, les tests manuels restent indispensables pour découvrir les défaillances du système, les biais subtils dans le choix des sources, etc. (Source: riemannzeta)

Les différences entre les LLM et les modèles vidéo en termes de mécanismes de prédiction et d’apprentissage suscitent la réflexion: Yann LeCun et Pedro Domingos ont relayé le point de vue de Sergey Levine, qui s’interroge sur la raison pour laquelle les modèles de langage apprennent tant de la prédiction du prochain Token, alors que les modèles vidéo apprennent relativement peu de la prédiction de la prochaine image. Levine suppose que cela pourrait être dû au fait que les LLM jouent en quelque sorte le rôle de « scanners cérébraux », suggérant la singularité de leurs mécanismes d’apprentissage, ou que les LLM vivent comme dans la caverne de Platon, inférant le monde réel en observant des séquences d’ombres (le texte). (Source: ylecun, pmddomingos, pmddomingos)

Impact positif des AI Agents dans le domaine de l’éducation : encourager les apprenants à sortir de leur zone de confort: La communauté discute du fait que les AI Agents n’ont pas seulement un impact positif sur les entreprises, mais possèdent également un potentiel énorme dans le domaine de l’éducation. En interagissant avec les AI Agents, les apprenants peuvent sortir plus efficacement de leur zone de confort, favorisant ainsi l’amélioration des résultats d’apprentissage. (Source: pirroh, amasad)
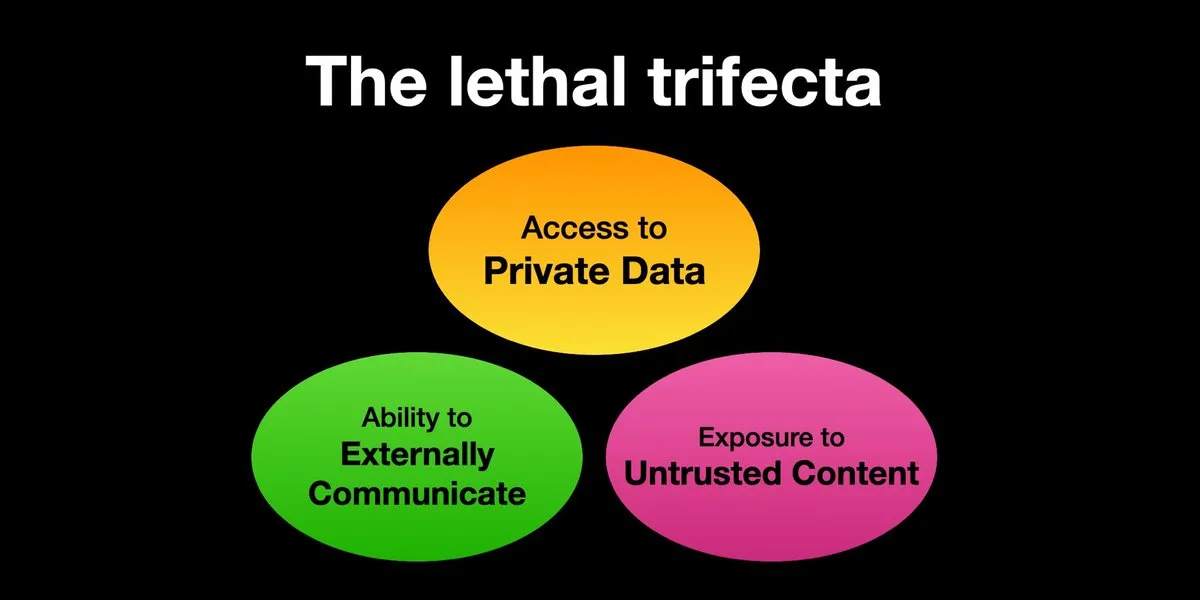
Les AI Agents confrontés aux risques d’attaques par injection de prompt, la protection de la sécurité doit être renforcée de toute urgence: Karpathy relaie l’avertissement de Simon Willison concernant le risque de « trifecta létale » (Lethal Trifecta) auquel sont confrontés les AI Agents : lorsque ceux-ci ont simultanément accès à des données privées, sont en contact avec du contenu non fiable et ont la capacité de communiquer vers l’extérieur, les attaquants peuvent tromper le système pour voler des données. Cela rappelle l’époque du « Far West » des premiers virus informatiques. Actuellement, les mécanismes de défense contre les prompts malveillants sont encore imparfaits, manquant par exemple d’un paradigme de sécurité similaire à l’espace noyau/utilisateur des systèmes d’exploitation pour limiter la capacité des Agents à exécuter des scripts arbitraires. Cela suscite des inquiétudes quant à l’adoption précoce des LLM Agents pour l’informatique personnelle. (Source: karpathy, TheTuringPost)
À l’ère de l’IA, la capacité d’apprentissage rapide devient une compétence essentielle: Mustafa Suleyman souligne que le plus grand accélérateur de carrière au cours de la prochaine décennie sera une excellente capacité d’apprentissage. Il conseille aux gens d’identifier clairement leur style d’apprentissage, d’utiliser l’IA pour convertir le matériel dans un format approprié (comme des podcasts, des quiz), puis d’appliquer les connaissances et de répéter continuellement ce processus pour apprendre et progresser rapidement. (Source: mustafasuleyman)
Authenticité et pertinence du contenu généré par l’IA : la pertinence pourrait l’emporter sur l’authenticité: L’utilisateur imjaredz partage son expérience : après avoir envoyé 2000 e-mails de prospection générés par l’IA, personne ne s’est plaint qu’ils aient été écrits par une IA ; au contraire, 5 personnes ont indiqué que le contenu de l’e-mail correspondait « exactement à ce sur quoi elles travaillaient ». Cela soulève la question de savoir si, dans la communication, la pertinence du contenu est plus importante que son « authenticité » (c’est-à-dire s’il a été créé par un humain). (Source: imjaredz)
Débat sur la capacité de « compréhension » des LLM : l’approximation comportementale n’équivaut pas à une véritable compréhension: Au sein de la communauté, certains estiment que bien que les grands modèles de langage fassent preuve de puissantes capacités d’approximation comportementale et cognitive, cela n’équivaut pas à une véritable compréhension. La compréhension nécessite une capacité d’explication, et le simple fait de manifester un comportement ne constitue ni intelligence ni compréhension. Cette distinction fondamentale est souvent négligée. Ce point de vue souligne qu’avant de confier aux modèles des décisions impliquant la sécurité des personnes, il est nécessaire d’évaluer avec prudence s’ils se rapprochent réellement de l’intelligence artificielle générale et de se méfier de la surestimation de leurs capacités. (Source: farguney)
Les AI Agents brillent dans les benchmarks d’ingénierie logicielle, mais débat sur leur nature d’« agent »: Alors que l’IA obtient des scores de plus en plus élevés dans les benchmarks d’ingénierie logicielle comme SWE-bench (dépassant même 50-60 points), la communauté débat pour savoir si « l’ère du codage par agent » est réellement arrivée. Certains estiment que si l’on utilise couramment des « frameworks sans agent » (agentless frameworks), plutôt que de laisser les modèles de langage explorer réellement l’environnement, alors parler d’« ère du codage par agent » pourrait être inapproprié, bien que ces frameworks soient précieux en eux-mêmes. (Source: huybery, terryyuezhuo)
Besoin de modération du contenu pour les images générées par IA : recherche de solutions open source ou commerciales: Avec la popularisation des technologies de génération d’images par IA, les développeurs chinois commencent à se préoccuper de la conformité du contenu produit, notamment de la manière de détecter les contenus à caractère pornographique, politiquement sensibles, etc. Des discussions émergent au sein de la communauté à la recherche de petits modèles open source ou de produits commerciaux disponibles pour la modération de contenu. (Source: dotey)
💡 Divers
Personnalisation et pertinence du contenu grâce à l’IA : 2000 e-mails IA sans critique négative, 5 personnes déclarent « c’est exactement ce dont j’ai besoin »: Un utilisateur a partagé avoir envoyé 2000 e-mails de prospection générés par IA, et aucun destinataire ne s’est plaint que l’e-mail ait été rédigé par une IA. Au contraire, cinq destinataires ont indiqué que le contenu de l’e-mail correspondait « exactement au travail qu’ils effectuaient actuellement ». Ce cas soulève la question de savoir si, dans la communication assistée par IA, la grande pertinence du contenu peut l’emporter sur le souci de l концеп« authenticité » (c’est-à-dire, s’il a été rédigé par un humain), suggérant le potentiel de l’IA dans la génération de contenu personnalisé. (Source: imjaredz)
L’humain devient le goulot d’étranglement des systèmes d’IA, nécessité d’éviter ou d’améliorer l’efficacité humaine: Le point de vue de Charles Earl souligne que les boîtes de réception débordent d’e-mails tandis que les boîtes d’envoi sont vides, ce qui reflète que l’humain est le goulot d’étranglement dans le traitement de l’information et la réactivité. À l’ère de l’IA, il faut réfléchir à la manière d’éviter les goulots d’étranglement humains, ou comment améliorer l’efficacité du travail humain grâce à des technologies comme l’IA. (Source: charles_irl)
Risques potentiels du contrôle de la maison intelligente par l’IA : un utilisateur piégé dans un lit intelligent froid à cause d’un bug de l’application: Un utilisateur a partagé son expérience d’être incapable de régler la température de son lit intelligent contrôlé par IA (Eight Sleep Pod3) à cause d’un bug de l’application, se retrouvant finalement piégé dans un lit froid. Ce modèle n’ayant pas de contrôle manuel et dépendant entièrement de l’application, cette panne met en évidence les inconvénients et l’expérience « dystopique » que peut entraîner une dépendance excessive à l’IA et aux applications pour contrôler les appareils domestiques intelligents. (Source: madiator)