Mots-clés:Calcul quantique, Auto-amélioration de l’IA, Interface neuronale directe, Grand modèle linguistique, Calcul neuromorphique, Génération vidéo par IA, Apprentissage par renforcement, Éthique de l’IA, Taux d’erreur des qubits, Apprentissage auto-supervisé JEPA, Quantification au format MLX, Modèle de compréhension visuelle PAM, Génération de contenu ASMR par IA
🔥 Pleins feux
L’Université d’Oxford atteint un taux d’erreur record de 0,000015% dans une expérience de Quantum Computing: L’équipe de recherche de l’Université d’Oxford a réalisé une percée majeure dans une expérience de Quantum Computing, réduisant le taux d’erreur des qubits à 0,000015%, établissant ainsi un nouveau record mondial. Cette avancée est cruciale pour la construction d’ordinateurs quantiques tolérants aux pannes, un taux d’erreur extrêmement bas étant une condition préalable à la réalisation d’algorithmes quantiques complexes et à l’exploitation du potentiel du Quantum Computing. Ce résultat démontre des progrès significatifs dans l’amélioration de la stabilité des qubits et de la précision de leur manipulation au niveau matériel, jetant des bases plus solides pour les futures applications gourmandes en puissance de calcul, comme celles de l’AI (Source: Ronald_vanLoon)

Des chercheurs du MIT permettent à l’intelligence artificielle d’apprendre à s’auto-améliorer et à se perfectionner: Des chercheurs du Massachusetts Institute of Technology (MIT) ont progressé dans le domaine de l’auto-amélioration de l’AI, en développant une nouvelle méthode permettant aux systèmes d’AI d’apprendre de manière autonome et d’améliorer leurs propres performances. Cette capacité imite le processus humain de progression continue par l’expérience et la réflexion, et est cruciale pour le développement d’une intelligence artificielle plus autonome et adaptable. Cette recherche pourrait ouvrir la voie à l’optimisation continue des modèles d’AI après leur déploiement, réduisant la dépendance à l’intervention humaine, et aurait un impact profond sur le développement et l’application à long terme de l’AI (Source: TheRundownAI)

Une AI de “lecture de pensée” traduit instantanément les ondes cérébrales de personnes paralysées en parole: Une étude révolutionnaire montre comment une AI de “lecture de pensée” peut convertir en temps réel les ondes cérébrales de patients paralysés en parole intelligible. Cette technologie, grâce à une interface cerveau-machine (BCI) avancée et des algorithmes d’AI, décode les signaux neuronaux liés au langage et les synthétise en une sortie vocale compréhensible. Cela offre un nouveau moyen de communication aux patients ayant perdu la capacité de parler en raison de graves troubles moteurs, et devrait considérablement améliorer leur qualité de vie, marquant une avancée majeure de l’AI dans les domaines de l’assistance médicale et des neurosciences (Source: Ronald_vanLoon)

Percée sur un problème mathématico-physique séculaire, des anciens élèves de l’Université de Pékin impliqués dans la résolution du sixième problème de Hilbert: Deng Yu, ancien élève de l’Université de Pékin, Ma Xiao de la classe junior de l’USTC, et Zaher Hani, disciple de Terence Tao, ont réalisé une avancée majeure sur le sixième problème de Hilbert, “l’axiomatisation de la physique”. Ils ont pour la première fois rigoureusement démontré la transition complète de la mécanique newtonienne (microscopique, réversible dans le temps) à l’équation de Boltzmann (macroscopique statistique, irréversible dans le temps), comblant le fossé logique entre les deux, établissant des fondations mathématiques plus solides pour la mécanique statistique, et ont résolu de manière inattendue le “mystère de la flèche du temps”. Ce résultat, obtenu grâce à des outils mathématiques ingénieux et des déductions par étapes, montre la voie de l’atomisme aux lois du mouvement des milieux continus (Source: 量子位)

🎯 Tendances
Alibaba lance des versions au format MLX de sa série de modèles Qwen3: Alibaba a annoncé que sa série de grands modèles Qwen3 prend désormais en charge le format MLX et propose quatre niveaux de quantification : 4 bits, 6 bits, 8 bits et BF16. MLX est un framework d’apprentissage automatique optimisé par Apple pour Apple Silicon. Cette initiative signifie que les modèles Qwen3 pourront fonctionner plus efficacement sur les appareils Apple, abaissant le seuil de déploiement et d’exécution des grands modèles en périphérie, et contribuant à promouvoir la popularisation et l’application des grands modèles sur les appareils personnels (Source: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google lance le modèle Gemma 3n, haute performance avec peu de paramètres: Google a lancé le modèle Gemma 3n, qui compte moins de 10 milliards de paramètres mais a dépassé les 1300 points au classement LMArena, devenant le premier petit modèle à atteindre cet exploit. Les performances exceptionnelles de Gemma 3n prouvent qu’il est possible d’atteindre un haut niveau de compréhension et de génération de langage avec une taille de paramètres réduite, et il prend en charge l’exécution sur des appareils en périphérie tels que les téléphones mobiles, ce qui est d’une grande importance pour promouvoir la popularisation des applications d’AI et réduire les coûts de calcul (Source: osanseviero)
Tencent lance une technologie de génération d’assets 3D de qualité cinématographique par AI: Tencent a présenté une nouvelle technologie d’intelligence artificielle capable de générer des assets 3D de qualité cinématographique. Cette technologie devrait considérablement améliorer l’efficacité et la qualité de la création de contenu 3D dans des domaines tels que le développement de jeux et la production cinématographique et télévisuelle, tout en réduisant les coûts de production. La génération rapide d’assets 3D de haute qualité est un maillon essentiel du développement du métavers et de l’industrie du contenu numérique (Source: TheRundownAI)
Le modèle Kling 2.1 de Kuaishou excelle dans la conversion d’image en vidéo et la génération synchronisée audio-vidéo: Kling, le modèle de génération vidéo par AI de Kuaishou, a été mis à jour vers la version 2.1, démontrant de puissantes capacités de conversion d’image en vidéo. La nouvelle version permettrait de générer de la vidéo et de l’audio en un clic, sans nécessiter de conception sonore en post-production, pour produire un contenu synchronisé audio-image de qualité studio. Cela marque une avancée de l’AI dans la génération de contenu multimodal, en particulier dans le domaine de la vidéo, simplifiant le processus de création et améliorant la qualité de la génération (Source: Kling_ai, Kling_ai)
Le nouveau modèle vidéo AI “Kangaroo”, potentiellement Minimax Hailuo 2.0, défie le SOTA actuel: Un mystérieux modèle de génération vidéo par AI nommé “Kangaroo” est apparu sur le marché, affichant de solides performances dans l’arène de la vidéo AI, notamment en matière de conversion d’image en vidéo. Certaines analyses suggèrent que ce modèle pourrait être la version Hailuo 2.0 de la société Minimax. Son apparition pourrait modifier la hiérarchie de performance des modèles texte-vidéo et image-vidéo existants, bien que ses capacités de traitement audio restent à évaluer (Source: TomLikesRobots)
MiniMax lance la série de modèles M1, avec des capacités de traitement de texte long exceptionnelles: MiniMaxAI a lancé la série de modèles MiniMax-M1, un modèle MoE (Mixture of Experts) de 456 milliards de paramètres. Cette série de modèles a obtenu d’excellents résultats dans plusieurs benchmarks, surpassant notamment GPT-4.1 dans le traitement de contexte long (comme le benchmark OpenAI-MRCR) et se classant troisième dans LongBench-v2. Cela démontre son potentiel dans le traitement et la compréhension de documents longs, mais son “budget de réflexion” (thinking budget) plus important pourrait exiger des ressources de calcul considérables (Source: Reddit r/LocalLLaMA)

Richard Sutton, lauréat du prix Turing : L’AI passe de “l’ère des données humaines” à “l’ère de l’expérience”: Richard Sutton, pionnier de l’apprentissage par renforcement, a souligné lors de la conférence BAII à Pékin que les grands modèles d’AI actuels, dépendants des données humaines, approchent de leurs limites. Les données humaines de haute qualité s’épuisent et l’expansion de la taille des modèles offre des rendements décroissants. Il estime que l’avenir de l’AI réside dans l’entrée dans “l’ère de l’expérience”, où les agents intelligents apprennent en générant des expériences de première main par interaction en temps réel avec leur environnement, plutôt qu’en imitant des textes anciens. Cela exige que les agents intelligents fonctionnent en continu dans des environnements réels ou simulés, utilisant le retour d’information de l’environnement comme signal de récompense, développant des modèles du monde et des systèmes de mémoire, pour réaliser un véritable apprentissage continu et une innovation (Source: 36氪)

Modèle PAM : 3 milliards de paramètres pour la segmentation, la reconnaissance et la description intégrées d’images et de vidéos: MMLab de l’Université chinoise de Hong Kong et d’autres institutions ont rendu open source le Perceive Anything Model (PAM), un modèle de 3 milliards de paramètres capable d’effectuer simultanément la segmentation, la reconnaissance, l’interprétation et la description d’objets dans les images et les vidéos, tout en produisant simultanément du texte et des masques (Mask). PAM réalise une conversion efficace des caractéristiques visuelles en tokens multimodaux en introduisant un Semantic Perceiver pour connecter le squelette de segmentation SAM2 et un LLM. L’équipe a également construit un vaste jeu de données d’entraînement texte-image de haute qualité. PAM a établi ou approché le SOTA sur plusieurs benchmarks de compréhension visuelle et offre une meilleure efficacité d’inférence (Source: 量子位)

Le calcul neuromorphique pourrait devenir la clé de la prochaine génération d’AI, promettant un fonctionnement à faible consommation d’énergie: Les scientifiques explorent activement le calcul neuromorphique, visant à imiter la structure et le fonctionnement du cerveau humain pour résoudre le problème de la forte consommation d’énergie des modèles d’AI actuels. Des institutions telles que les laboratoires nationaux américains développent des ordinateurs neuromorphiques dont le nombre de neurones est comparable à celui du cortex cérébral humain, avec une vitesse de fonctionnement théorique bien supérieure à celle du cerveau biologique, mais une consommation d’énergie extrêmement faible (par exemple, 20 watts pour alimenter une AI de type humain). Cette technologie, grâce à la communication événementielle, au calcul en mémoire et à l’apprentissage adaptatif, pourrait permettre une AI plus intelligente, efficace et à faible consommation, considérée comme une solution potentielle à la crise énergétique de l’AI et une nouvelle voie pour le développement de l’AGI (Source: 量子位)

Le contenu ASMR généré par AI explose sur les plateformes de vidéos courtes, des technologies comme Veo 3 y contribuent: Les vidéos ASMR (Autonomous Sensory Meridian Response) générées par AI connaissent un succès fulgurant sur des plateformes comme TikTok, avec des comptes attirant près de 100 000 abonnés en 3 jours et une seule vidéo de découpe de fruits dépassant les 16,5 millions de vues. Ces vidéos combinent des effets visuels étranges générés par AI (comme des fruits à la texture de verre) avec des sons correspondants de découpe, de collision, etc., créant une sensation “addictive” unique. Des modèles comme Veo 3 de Google DeepMind, capables de générer directement du contenu audio-visuel synchronisé, sont considérés comme des technologies clés favorisant la création de ce type de contenu ASMR par AI, simplifiant le processus antérieur qui nécessitait de produire séparément l’audio et la vidéo puis de les assembler (Source: 量子位)

La publication des historiques de recherche de Meta AI attire l’attention, Google teste des résumés audio par AI: Meta a rendu publics les historiques de recherche des utilisateurs de sa fonction de recherche AI, suscitant des préoccupations concernant la vie privée et la transparence de l’utilisation des données. Parallèlement, Google teste dans ses projets de laboratoire une nouvelle fonctionnalité qui fournit des résumés audio de type podcast générés par AI en haut des résultats de recherche, visant à offrir aux utilisateurs un moyen plus pratique d’accéder à l’information. Ces deux développements reflètent l’exploration continue des géants de la technologie en matière de recherche AI et de présentation de l’information, ainsi que leurs tentatives d’optimisation de l’expérience utilisateur (Source: Reddit r/ArtificialInteligence)

Une équipe de Sydney développe un modèle d’AI pour identifier les pensées à partir des ondes cérébrales: Une équipe de chercheurs de Sydney, en Australie, a développé un nouveau modèle d’intelligence artificielle capable d’identifier le contenu des pensées d’un individu en analysant les données des ondes cérébrales (EEG). Cette technologie a des applications potentielles dans les neurosciences, l’interaction homme-machine et la communication assistée, par exemple pour aider les personnes incapables de communiquer par des moyens traditionnels à exprimer leurs intentions. Cette recherche fait progresser la technologie des interfaces cerveau-machine et explore les capacités de l’AI à interpréter l’activité cérébrale complexe (Source: Reddit r/ArtificialInteligence)
La Californie envisage de légiférer pour limiter le rôle des “patrons robots” de l’AI dans les décisions d’embauche, de licenciement, etc.: L’État de Californie aux États-Unis avance sur un projet de loi visant à limiter la capacité des entreprises à prendre des décisions clés en matière de personnel, telles que l’embauche et le licenciement, sur la seule base des recommandations des systèmes d’AI. Le projet de loi exige que les responsables humains examinent et approuvent toute recommandation de ce type émanant de l’AI, afin de garantir une supervision et une responsabilité humaines. Les groupes d’entreprises s’y opposent, arguant que cela augmenterait les coûts de conformité et entrerait en conflit avec les technologies de recrutement existantes. Cette initiative reflète la préoccupation croissante concernant l’éthique de l’AI et son impact social, en particulier en ce qui concerne l’automatisation des décisions sur le lieu de travail (Source: Reddit r/ArtificialInteligence)

🧰 Outils
Lancement d’Augmentoolkit 3.0, renforçant la génération de datasets et le processus de fine-tuning: Augmentoolkit a lancé sa version 3.0, un outil pour créer des datasets QA à partir de longs documents (comme des textes historiques) et pour le fine-tuning de modèles. La nouvelle version offre un pipeline de niveau production, capable de générer automatiquement des données d’entraînement et d’entraîner des modèles. Elle intègre des modèles locaux spécifiquement affinés pour générer des datasets QA de haute qualité et propose une interface sans code. Cet outil vise à simplifier le processus de fine-tuning de modèles spécifiques à un domaine et de génération de données d’entraînement, en abaissant le seuil technique (Source: Reddit r/LocalLLaMA)
Opius AI Planner : un planificateur AI pour optimiser l’expérience de Cursor Composer: Une extension Cursor nommée Opius AI Planner a été lancée, visant à résoudre les problèmes de Cursor Composer dans la compréhension des exigences vagues. Cet outil peut analyser les besoins du projet, générer une feuille de route détaillée pour la mise en œuvre, et produire des prompts structurés optimisés pour Composer, réduisant ainsi le nombre d’itérations et rendant les résultats du projet plus conformes à la vision initiale. Cela reflète la tendance à améliorer l’utilité des outils de génération de code AI grâce à une planification assistée par AI (Source: Reddit r/artificial)
Extension Continue : intégration de Copilot open source local et de MCP dans VSCode: Continue est une extension VSCode qui permet aux utilisateurs de configurer et d’utiliser des grands modèles de langage open source exécutés localement comme assistants de codage, et peut intégrer des outils MCP (Model Control Protocol). Les utilisateurs peuvent déployer des modèles localement via des services comme Llama.cpp ou LMStudio, et interagir avec eux via Continue, réalisant un contrôle complet et une personnalisation de l’assistant de code, par exemple en intégrant l’outil d’automatisation de navigateur Playwright (Source: Reddit r/LocalLLaMA)

Le grand modèle Doubao et Volcano Engine MCP combinés pour simplifier le déploiement de services cloud et la génération de pages personnelles: Le grand modèle Doubao de ByteDance a démontré sa capacité d’intégration profonde avec le Model Control Protocol (MCP) de Volcano Engine. Les utilisateurs peuvent, par des instructions en langage naturel, demander au grand modèle Doubao d’appeler les fonctionnalités de Volcano Engine (comme veFaaS, Function as a Service) pour accomplir des tâches telles que la génération d’une page de présentation de médias sociaux personnels et son déploiement automatique en ligne. Cette intégration élimine les étapes complexes de configuration manuelle de l’environnement cloud, abaisse le seuil d’utilisation des services cloud et démontre le potentiel de l’AI pour simplifier les processus DevOps (Source: karminski3)
Figma lance une nouvelle fonctionnalité AI : génération instantanée de sites web à partir de prompts textuels: Figma a présenté une nouvelle fonctionnalité basée sur l’AI, capable de générer rapidement des prototypes ou des pages de sites web à partir de prompts textuels saisis par l’utilisateur. Cette fonctionnalité vise à accélérer les processus de conception et de développement web, permettant aux designers et aux développeurs de transformer rapidement leurs idées en conceptions visuelles grâce à des descriptions en langage naturel, illustrant davantage la pénétration de l’AI générative dans les outils de conception créative (Source: Ronald_vanLoon)
Le hub de modèles Hugging Face ajoute une fonctionnalité de filtrage par taille de modèle: La plateforme Hugging Face a ajouté une fonctionnalité pratique à son hub de modèles, permettant aux utilisateurs de filtrer les modèles en fonction de la taille de leurs paramètres. Cette amélioration permet aux développeurs et aux chercheurs de trouver plus facilement des modèles correspondant à leurs ressources matérielles spécifiques ou à leurs besoins de performance, améliorant l’efficacité de la navigation et de la sélection dans la vaste bibliothèque de modèles (Source: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
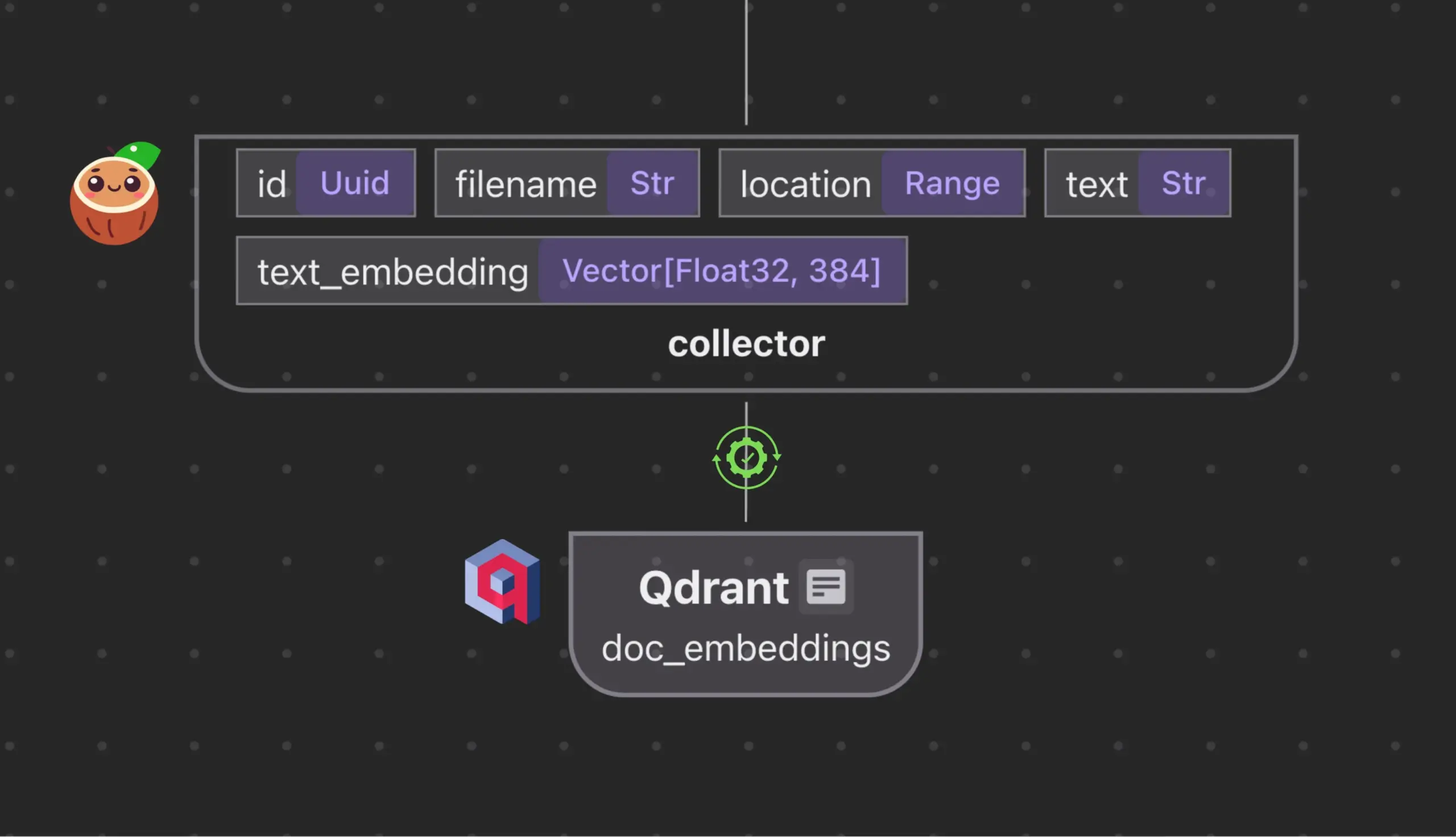
Cocoindex.io s’intègre à Qdrant pour créer et synchroniser automatiquement des collections de bases de données vectorielles: L’outil de flux de données open source Cocoindex.io prend désormais en charge la création automatique de collections de bases de données vectorielles Qdrant. Les utilisateurs n’ont qu’à définir le flux de données, et l’outil déduira le schéma Qdrant approprié (y compris la taille du vecteur, la métrique de distance et la structure du payload), et maintiendra la synchronisation des champs vectoriels, des types de payload et des clés primaires, prenant en charge les mises à jour incrémentielles. Cela simplifie la configuration et la gestion des bases de données vectorielles, améliorant l’efficacité des équipes de données (Source: qdrant_engine)
Manus AI : un outil de développement AI complet qui non seulement écrit du code, mais le déploie aussi automatiquement: Manus AI est un outil de développement AI de bout en bout capable de gérer tout le processus, de l’écriture du code à la configuration de l’environnement, l’installation des dépendances, les tests, et jusqu’au déploiement final sur une URL en ligne. Il adopte une architecture collaborative multi-agents (planification, développement, test, déploiement) et peut résoudre de manière autonome les problèmes de dépendances et déboguer les erreurs. Bien qu’il existe actuellement un modèle de tarification basé sur des crédits, qu’il soit développé par une équipe chinoise (ce qui pourrait soulever des questions de conformité) et des limitations dans la prise en charge d’architectures d’entreprise ultra-complexes, il démontre le potentiel d’une transition de “l’assistance au codage par AI” à “l’exécution du développement par AI” (Source: Reddit r/artificial)

📚 Apprentissage
Guide d’optimisation des théories de la traduction et des prompts pour la traduction par IA: En combinant la théorie de la “traduction comme réécriture” de Si Guo dans “Nouvelles recherches sur la traduction” et les vues de Yu Kwang-chung dans “La traduction est une grande voie”, cet article explore les principes d’une traduction de haute qualité. Il souligne que la traduction doit se concentrer sur l’expression idiomatique de la langue cible plutôt que sur la correspondance littérale, nécessitant une utilisation flexible de la traduction littérale et de la traduction libre, et une attention aux différences logiques entre les langues chinoise et occidentales pour la réécriture syntaxique. L’article discute également de la pureté de l’expression chinoise, du traitement de la terminologie, et réfléchit aux limites du processus en trois étapes “traduction littérale – analyse – traduction libre” dans la traduction par IA, suggérant d’adopter un processus plus intégré “compréhension – expression – relecture – optimisation” pour améliorer la qualité de la traduction par IA et la rendre plus conforme au style des textes de vulgarisation scientifique en chinois (Source: dotey)

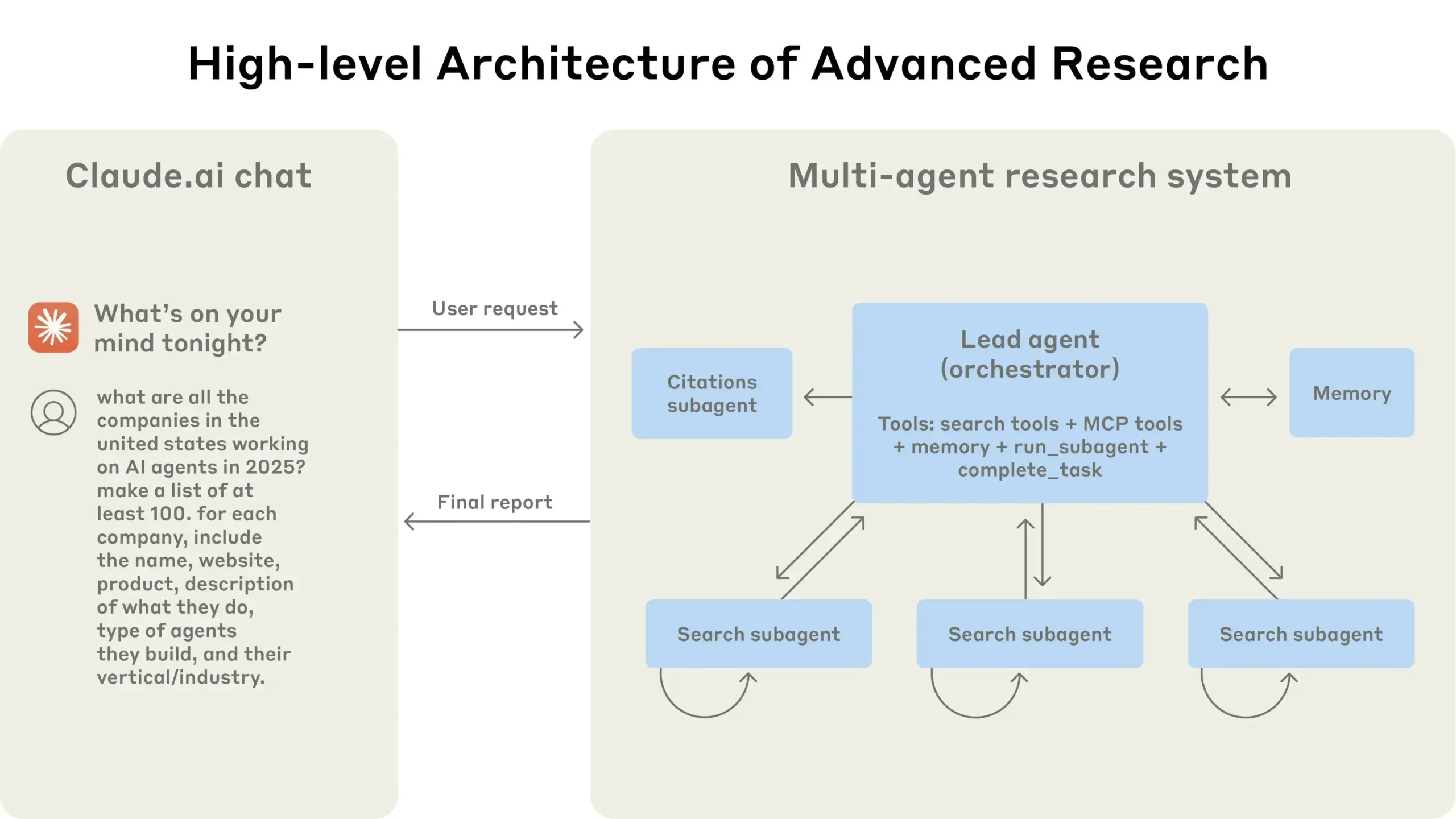
Anthropic partage son expérience dans la construction de son système de recherche multi-agents: AnthropicAI a publié un guide gratuit détaillant la manière dont ils ont construit leur système de recherche multi-agents. Le contenu comprend le fonctionnement de l’architecture du système, les méthodes de prompt engineering et de test, les défis rencontrés en production et les avantages des systèmes multi-agents. Ce guide offre une expérience pratique et des aperçus précieux aux chercheurs et développeurs intéressés par les systèmes multi-agents (Source: TheTuringPost, TheTuringPost)
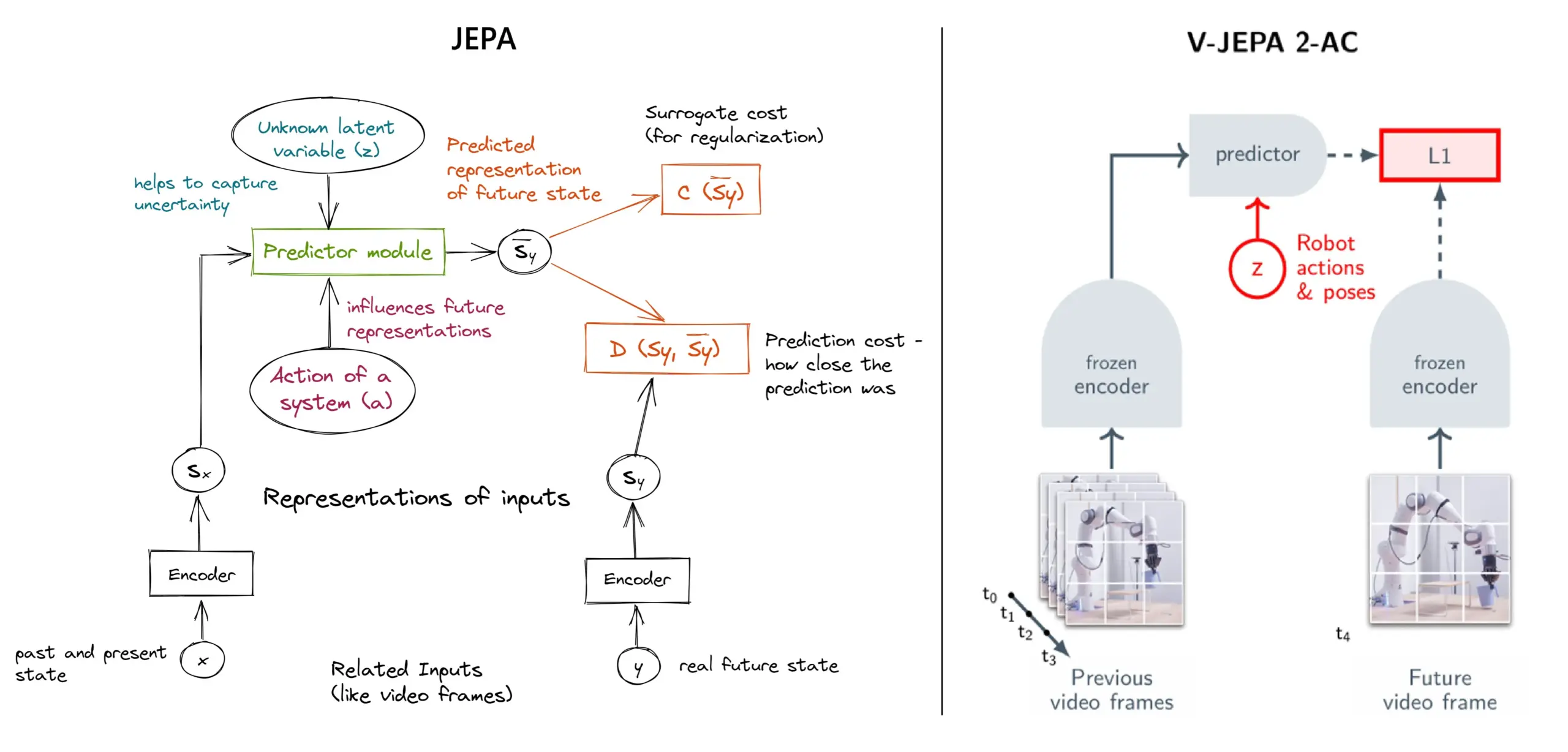
Explication détaillée du framework d’apprentissage auto-supervisé JEPA : aperçu de 11 types: JEPA (Joint Embedding Predictive Architecture), proposé par Yann LeCun de Meta et d’autres chercheurs, est un framework d’apprentissage auto-supervisé qui apprend en prédisant les représentations latentes des parties manquantes des données d’entrée. L’article présente 11 types différents de JEPA, y compris V-JEPA 2, TS-JEPA, D-JEPA, etc., et fournit plus d’informations et des liens vers des ressources connexes, aidant à comprendre cette méthode d’apprentissage auto-supervisé de pointe (Source: TheTuringPost, TheTuringPost)
Framework DSPy : découpler les tâches et les LLM, améliorer la maintenabilité du code: Un article d’analyse sur DSPy souligne que le framework DSPy réduit la complexité de l’utilisation des LLM en découplant les tâches des grands modèles de langage (LLM). Même avant l’optimisation, DSPy peut aider les développeurs à démarrer plus rapidement leurs projets et à générer un code plus facile à maintenir et à étendre. Ceci est d’une grande valeur pour les projets nécessitant de gérer un prompt engineering complexe et l’intégration de LLM (Source: lateinteraction, stanfordnlp)

Discussion d’article : Les Vision Transformers n’ont pas besoin de registres entraînés (Vision Transformers Don’t Need Trained Registers): Un nouvel article de recherche explore le mécanisme par lequel les cartes d’attention et les cartes de caractéristiques des Vision Transformers produisent des artefacts, un phénomène également présent dans les grands modèles de langage. L’article propose une méthode sans entraînement pour atténuer ces artefacts, visant à améliorer les performances et l’interprétabilité des Vision Transformers. Cette recherche est pertinente pour comprendre et améliorer l’application des architectures Transformer aux tâches visuelles (Source: Reddit r/MachineLearning)
Partage de tutoriel : Construire la série DeepSeek à partir de zéro (29 épisodes au total): Un créateur de contenu a publié une série de tutoriels vidéo intitulée “Comment construire DeepSeek à partir de zéro”, comprenant 29 épisodes. Le contenu couvre les bases du modèle DeepSeek, les détails de l’architecture (tels que le mécanisme d’attention, l’attention multi-têtes, le KV cache, MoE), l’encodage positionnel, la prédiction multi-tokens et des techniques clés comme la quantification. Cette série de tutoriels offre une ressource vidéo précieuse aux apprenants souhaitant comprendre en profondeur le fonctionnement interne de DeepSeek et de grands modèles similaires (Source: Reddit r/LocalLLaMA)

Tutoriel : Construire un pipeline RAG pour résumer les publications de Hacker News: Haystack by deepset a partagé un tutoriel étape par étape guidant les utilisateurs sur la façon de construire un pipeline de Retrieval Augmented Generation (RAG). Ce pipeline est capable de récupérer les publications en temps réel de Hacker News et d’utiliser un point de terminaison de grand modèle de langage (LLM) exécuté localement pour résumer ces publications. Cela fournit un cas d’utilisation pratique pour les développeurs souhaitant utiliser la technologie RAG pour traiter des flux d’informations en temps réel et effectuer un traitement localisé (Source: dl_weekly)
Article en bref : Dataset InterSyn et modèle d’évaluation SynJudge pour la génération de texte et d’images entrelacés: Pour pallier les insuffisances des LMM actuels dans la génération de sorties texte-image étroitement entrelacées (principalement dues à la taille, la qualité et la richesse en instructions limitées des datasets d’entraînement), les chercheurs ont lancé InterSyn, un dataset multimodal à grande échelle construit via la méthode SEIR (auto-évaluation et optimisation itérative). InterSyn contient des dialogues multi-tours, pilotés par des instructions, avec des réponses où le texte et les images sont étroitement entrelacés. Parallèlement, pour évaluer de telles sorties, les chercheurs ont également proposé le modèle d’évaluation automatique SynJudge, qui évalue selon quatre dimensions : contenu textuel, contenu de l’image, qualité de l’image et synergie texte-image. Les expériences montrent que les LMM entraînés sur InterSyn s’améliorent sur tous les indicateurs d’évaluation (Source: HuggingFace Daily Papers)
Article en bref : Synthèse d’images et de géométrie alignées sous de nouvelles perspectives via la distillation d’attention intermodale: Les chercheurs proposent un framework basé sur la diffusion, MoAI, qui réalise la génération d’images et de géométrie alignées sous de nouvelles perspectives grâce à une méthode de “warping-and-inpainting”. Cette méthode utilise des prédicteurs de géométrie prêts à l’emploi pour prédire la géométrie partielle de l’image de référence, et synthétise la nouvelle perspective comme une tâche d’inpainting d’image et de géométrie. Pour assurer un alignement précis entre l’image et la géométrie, l’article propose une distillation d’attention intermodale, injectant les cartes d’attention de la branche de diffusion d’image dans une branche de diffusion de géométrie parallèle pendant l’entraînement et l’inférence. Cette méthode permet une synthèse de perspectives extrapolées à haute fidélité dans diverses scènes inédites (Source: HuggingFace Daily Papers)
Article en bref : Ajustement configurable des préférences (CPT) basé sur des données synthétiques guidées par des règles: Pour résoudre le problème de la solidification des préférences et de l’adaptabilité limitée des modèles de feedback humain comme DPO, les chercheurs proposent le framework d’ajustement configurable des préférences (CPT). CPT utilise des prompts système basés sur des règles structurées et granulaires (définissant des attributs souhaités tels que le style d’écriture) pour générer des données de préférences synthétiques. Grâce au fine-tuning avec ces préférences guidées par des règles, les LLM peuvent ajuster dynamiquement leur sortie en fonction des prompts système lors de l’inférence, sans réentraînement, réalisant un contrôle des préférences plus fin et contextuel (Source: HuggingFace Daily Papers)
Article en bref : La Dualité de la Diffusion (The Diffusion Duality): Les chercheurs proposent la méthode Duo, qui, en révélant que les processus de diffusion discrète à état uniforme proviennent d’une diffusion gaussienne latente, transfère les techniques puissantes de la diffusion gaussienne aux modèles de diffusion discrète pour améliorer leurs performances. Concrètement, cela inclut : 1) L’introduction d’une stratégie d’apprentissage curriculaire guidée par un processus gaussien, réduisant la variance, doublant la vitesse d’entraînement et surpassant les modèles autorégressifs sur plusieurs benchmarks. 2) La proposition d’une distillation de cohérence discrète, adaptant la distillation de cohérence continue au cadre discret, permettant une génération en peu d’étapes pour les modèles de langage à diffusion en accélérant l’échantillonnage de deux ordres de grandeur (Source: HuggingFace Daily Papers)
Article en bref : SkillBlender – Contrôle de mouvement du corps entier pour robots humanoïdes multifonctionnels par fusion de compétences: Pour remédier aux limitations des méthodes de contrôle actuelles des robots humanoïdes en termes de généralisation multi-tâches et d’extensibilité, les chercheurs proposent SkillBlender, un framework d’apprentissage par renforcement hiérarchique. Ce framework pré-entraîne d’abord des compétences primitives orientées objectif et indépendantes de la tâche, puis fusionne dynamiquement ces compétences lors de l’exécution de tâches complexes de manipulation motrice, ne nécessitant qu’une ingénierie de récompense minimale spécifique à la tâche. Parallèlement, le benchmark de simulation SkillBench a été lancé pour l’évaluation. Les expériences montrent que cette méthode améliore considérablement la précision et la faisabilité de diverses tâches de manipulation motrice (Source: HuggingFace Daily Papers)
Article en bref : Framework U-CoT+ – Découplage de la compréhension et raisonnement CoT guidé pour la détection de mèmes nuisibles: Pour relever les défis d’efficacité des ressources, de flexibilité et d’interprétabilité dans la détection des mèmes nuisibles, les chercheurs proposent le framework U-CoT+. Ce framework convertit d’abord les mèmes visuels en descriptions textuelles détaillées via un processus de conversion mème-texte haute fidélité, découplant ainsi l’interprétation et la classification des mèmes, permettant aux grands modèles de langage (LLM) généraux d’effectuer une détection économe en ressources. Ensuite, en combinant des directives interprétables formulées par des humains, il guide le raisonnement du modèle sous des prompts CoT zero-shot, améliorant l’adaptabilité et l’interprétabilité face aux variations entre plateformes et dans le temps (Source: HuggingFace Daily Papers)
Article en bref : CRAFT – Test red team efficace d’agents respectueux des politiques: Concernant le problème du respect par les agents LLM orientés tâches de politiques strictes (comme l’éligibilité au remboursement), les chercheurs ont proposé un nouveau modèle de menace, se concentrant sur les utilisateurs adverses tentant d’exploiter les agents respectueux des politiques pour un gain personnel. Pour cela, ils ont développé CRAFT, un système de test red team multi-agents, qui utilise des stratégies de persuasion conscientes des politiques pour attaquer les agents respectueux des politiques dans des scénarios de service client, son efficacité surpassant les méthodes traditionnelles de jailbreak. Parallèlement, le benchmark tau-break a été lancé pour évaluer la robustesse des agents face à de tels comportements de manipulation (Source: HuggingFace Daily Papers)
Article en bref : Échec des récupérateurs denses sur les requêtes simples et le dilemme de granularité des embeddings: La recherche révèle une limitation des encodeurs de texte : les embeddings peuvent ne pas identifier les entités ou événements à grain fin au sein de la sémantique, ce qui entraîne l’échec possible de la récupération dense même dans des cas simples. Pour étudier ce phénomène, l’article introduit le dataset d’évaluation en chinois CapRetrieval (où les paragraphes sont des légendes d’images et les requêtes des phrases d’entités/événements). L’évaluation zero-shot montre que les encodeurs peuvent mal performer sur la correspondance à grain fin. Le fine-tuning des encodeurs avec la stratégie de génération de données proposée améliore les performances, mais révèle également un “dilemme de granularité”, où les embeddings ont du mal à s’aligner avec la sémantique globale tout en exprimant une saillance à grain fin (Source: HuggingFace Daily Papers)
Article en bref : pLSTM – Réseau de tokens de transformation de source linéaire parallélisable: Face aux limitations des architectures récurrentes existantes (telles que xLSTM, Mamba) qui sont principalement adaptées aux données séquentielles ou nécessitent un traitement séquentiel des données multidimensionnelles, les chercheurs proposent pLSTM (parallelizable Linear Source Transformation token network). pLSTM étend la multidimensionnalité aux RNN linéaires, utilisant des portes de source, de transformation et de token agissant sur le graphe de ligne d’un graphe orienté acyclique (DAG) général, réalisant une parallélisation similaire aux formes de balayage associatif parallèle et de récurrence par blocs. Cette méthode montre une bonne capacité d’extrapolation et de bonnes performances sur des tâches de vision par ordinateur synthétiques et des benchmarks de graphes moléculaires et de vision par ordinateur (Source: HuggingFace Daily Papers)
Article en bref : DeepVideo-R1 – Fine-tuning vidéo par renforcement via GRPO de régression sensible à la difficulté: Pour pallier les insuffisances de l’apprentissage par renforcement dans les applications de Video LLM, les chercheurs proposent DeepVideo-R1, un Video LLM entraîné via leur Reg-GRPO (Regression-based GRPO) proposé et une stratégie d’augmentation de données sensible à la difficulté. Reg-GRPO reformule l’objectif GRPO en une tâche de régression, prédisant directement la fonction d’avantage dans GRPO, éliminant la dépendance à des mesures de protection comme le clipping, et guidant ainsi plus directement la politique. L’augmentation de données sensible à la difficulté améliore dynamiquement les échantillons d’entraînement des niveaux de difficulté résolubles. Les expériences montrent que DeepVideo-R1 améliore significativement les performances d’inférence vidéo (Source: HuggingFace Daily Papers)
Article en bref : Framework d’auto-raffinement pour l’amélioration de l’ASR avec des données synthétiques TTS: Des chercheurs proposent un framework d’auto-raffinement qui améliore les performances de la reconnaissance automatique de la parole (ASR) en utilisant uniquement des datasets non étiquetés. Le framework génère d’abord des pseudo-étiquettes sur la parole non annotée à l’aide d’un modèle ASR existant, puis utilise ces pseudo-étiquettes pour entraîner un système de synthèse vocale (TTS) haute fidélité. Ensuite, les paires parole-texte synthétisées par TTS sont utilisées pour guider l’entraînement du système ASR original, formant une boucle d’auto-amélioration. Des expériences sur le mandarin de Taïwan montrent que cette méthode peut réduire considérablement les taux d’erreur, offrant une voie pratique pour l’amélioration des performances ASR dans des contextes à faibles ressources ou spécifiques à un domaine (Source: HuggingFace Daily Papers)
Article en bref : Cartes d’attention intrinsèquement fidèles pour les Vision Transformers: Des chercheurs proposent une méthode basée sur l’attention qui utilise des masques d’attention binaires appris pour garantir que seules les régions de l’image auxquelles on prête attention influencent la prédiction. Cette méthode vise à résoudre les biais que le contexte peut introduire dans la perception des objets, en particulier lorsque les objets apparaissent dans des arrière-plans hors distribution. Grâce à un framework en deux étapes (la première étape découvre les parties de l’objet et identifie les régions pertinentes pour la tâche, la seconde étape utilise des masques d’attention d’entrée pour limiter le champ réceptif pour une analyse ciblée), l’entraînement conjoint permet d’améliorer la robustesse du modèle aux corrélations fallacieuses et aux arrière-plans hors distribution (Source: HuggingFace Daily Papers)
Article en bref : ViCrit – Tâche proxy d’apprentissage par renforcement vérifiable pour la perception visuelle des VLM: Pour résoudre le manque de tâches de perception visuelle dans les VLM qui soient à la fois stimulantes et clairement vérifiables, les chercheurs introduisent ViCrit (Visual Caption Hallucination Critic). Il s’agit d’une tâche proxy RL qui entraîne les VLM à localiser des hallucinations visuelles subtiles et synthétiques injectées dans des paragraphes de légendes d’images écrites par des humains. En injectant une seule erreur de description visuelle subtile dans des légendes d’environ 200 mots et en demandant au modèle de localiser la plage d’erreur en fonction de l’image et de la légende modifiée, cette tâche fournit une récompense binaire facile à calculer et sans ambiguïté. Les modèles entraînés avec ViCrit montrent des gains significatifs sur plusieurs benchmarks VL (Source: HuggingFace Daily Papers)
Article en bref : Au-delà de l’attention homogène – LLM économes en mémoire basés sur un KV cache approximé par Fourier: Pour résoudre le problème de l’augmentation de la demande en mémoire du KV cache des LLM avec l’allongement de la longueur du contexte, les chercheurs proposent FourierAttention, un framework sans entraînement. Ce framework exploite les rôles hétérogènes des dimensions des têtes Transformer : les basses dimensions privilégient le contexte local, tandis que les hautes dimensions capturent les dépendances à longue portée. En projetant les dimensions insensibles au contexte long sur une base de Fourier orthogonale, FourierAttention approxime leur évolution temporelle avec des coefficients spectraux de longueur fixe. L’évaluation sur les modèles LLaMA montre que cette méthode atteint la meilleure précision sur contexte long sur LongBench et NIAH, et optimise la mémoire grâce à un noyau Triton personnalisé, FlashFourierAttention (Source: HuggingFace Daily Papers)
Article en bref : JAFAR – Un sur-échantillonneur universel pour améliorer n’importe quelle caractéristique à n’importe quelle résolution: Pour résoudre le problème des caractéristiques spatiales à basse résolution issues des encodeurs visuels de base qui ne répondent pas aux besoins des tâches en aval, les chercheurs introduisent JAFAR, un sur-échantillonneur de caractéristiques léger et flexible. JAFAR peut augmenter la résolution spatiale des caractéristiques visuelles de n’importe quel encodeur visuel de base à n’importe quelle résolution cible. Il adopte un module basé sur l’attention, modulé par une transformation spatiale des caractéristiques (SFT), pour favoriser l’alignement sémantique entre les requêtes haute résolution dérivées des caractéristiques d’image de bas niveau et les clés basse résolution sémantiquement riches. Les expériences montrent que JAFAR peut restaurer efficacement les détails spatiaux à grain fin et surpasse les méthodes existantes dans diverses tâches en aval (Source: HuggingFace Daily Papers)
Article en bref : SwS – Synthèse de problèmes pilotée par la conscience de ses propres faiblesses en apprentissage par renforcement: Face à la rareté des ensembles de problèmes de haute qualité et dont les réponses sont vérifiables pour l’entraînement des LLM à résoudre des tâches de raisonnement complexes (comme les problèmes mathématiques) en RLVR (apprentissage par renforcement avec récompenses vérifiables), les chercheurs proposent le framework SwS (Self-aware Weakness-driven problem Synthesis). Le système SwS identifie systématiquement les défauts du modèle (problèmes pour lesquels le modèle échoue continuellement à apprendre pendant l’entraînement RL), extrait les concepts fondamentaux de ces échecs, et synthétise de nouveaux problèmes pour renforcer les points faibles du modèle lors de l’entraînement par renforcement ultérieur. Ce framework permet au modèle de s’auto-identifier et de résoudre ses faiblesses en RL, obtenant des améliorations de performance significatives sur plusieurs benchmarks de raisonnement courants (Source: HuggingFace Daily Papers)
Article en bref : Apprendre un token “continuer à penser” pour améliorer la capacité d’extension au moment du test: Pour améliorer la performance des modèles de langage à étendre les étapes de raisonnement par calcul supplémentaire au moment du test, les chercheurs explorent la faisabilité d’apprendre un token dédié “continuer à penser” (<|continue-thinking|>). Ils entraînent uniquement l’embedding de ce token par apprentissage par renforcement, tout en gardant les poids du modèle DeepSeek-R1 version distillée gelés. Les expériences montrent que, comparé aux modèles de base et aux méthodes d’extension au moment du test utilisant un token fixe (comme “Wait”) pour forcer un budget, le token appris atteint une précision plus élevée sur les benchmarks mathématiques standards, en particulier dans les cas où le token fixe peut améliorer la précision du modèle de base, le token appris apporte une amélioration encore plus grande (Source: HuggingFace Daily Papers)
Article en bref : LoRA-Edit – Édition vidéo contrôlée guidée par la première image via un fine-tuning LoRA sensible aux masques: Pour résoudre les problèmes de dépendance à un pré-entraînement à grande échelle et de flexibilité insuffisante des méthodes d’édition vidéo existantes, les chercheurs proposent LoRA-Edit, une méthode de fine-tuning LoRA basée sur des masques pour adapter les modèles image-vers-vidéo (I2V) pré-entraînés afin de réaliser une édition vidéo flexible. Cette méthode, tout en préservant les régions d’arrière-plan, est capable de propager des effets d’édition contrôlables et d’intégrer d’autres informations de référence (comme des points de vue alternatifs ou des états de scène) comme ancrages visuels. Grâce à une stratégie d’ajustement LoRA pilotée par des masques, le modèle apprend à partir de la vidéo d’entrée (structure spatiale et indices de mouvement) et de l’image de référence (guidage de l’apparence), réalisant un apprentissage spécifique à la région (Source: HuggingFace Daily Papers)
Article en bref : Infinity Instruct – Étendre la sélection et la synthèse d’instructions pour améliorer les modèles de langage: Pour combler le fait que les datasets d’instructions open source existants se concentrent souvent sur des domaines étroits (comme les mathématiques, le codage), limitant ainsi leur capacité de généralisation, les chercheurs lancent Infinity-Instruct, un dataset d’instructions de haute qualité visant à améliorer les capacités de base et de conversation des LLM via un processus en deux étapes. Étape 1 : utilisation de techniques de sélection de données mixtes pour filtrer 7,4 millions d’instructions de base de haute qualité parmi plus de 100 millions d’échantillons. Étape 2 : synthèse de 1,5 million d’instructions de conversation de haute qualité via un processus en deux étapes de sélection d’instructions, d’évolution et de filtrage diagnostique. Les expériences de fine-tuning sur divers modèles open source montrent que ce dataset améliore considérablement les performances des modèles sur les benchmarks de base et de suivi d’instructions (Source: HuggingFace Daily Papers)
Article en bref : D’abord les candidats, puis la distillation – Un framework enseignant-élève pour l’annotation de données pilotée par LLM: Face au problème des méthodes actuelles d’annotation de données par LLM où le LLM détermine directement une unique étiquette de référence, ce qui peut entraîner des erreurs dues à l’incertitude, les chercheurs proposent un nouveau paradigme d’annotation par candidats : encourager le LLM à produire toutes les étiquettes possibles en cas d’incertitude. Pour garantir que les tâches en aval reçoivent une étiquette unique, ils ont développé le framework enseignant-élève CanDist, qui distille les annotations candidates à l’aide d’un petit modèle de langage (SLM). Une preuve théorique montre que la distillation des annotations candidates d’un LLM enseignant est supérieure à l’utilisation directe d’une annotation unique. Les expériences valident l’efficacité de cette méthode (Source: HuggingFace Daily Papers)
Article en bref : Med-PRM – Modèle de raisonnement médical avec récompense de processus de validation progressive et guidée: Pour pallier les limites des grands modèles de langage dans la prise de décision clinique, où il est difficile de localiser et de corriger les erreurs spécifiques des étapes de raisonnement, les chercheurs introduisent Med-PRM, un framework de modélisation de récompense de processus. Ce framework utilise des techniques de génération augmentée par récupération pour valider chaque étape de raisonnement par rapport à des bases de connaissances médicales établies (directives cliniques et littérature). En évaluant précisément la qualité du raisonnement de cette manière granulaire, Med-PRM atteint des performances SOTA sur plusieurs benchmarks de QA médical et des tâches de diagnostic ouvertes, et peut être intégré de manière plug-and-play avec des modèles de politique forts (comme Meerkat), améliorant considérablement la précision des petits modèles (8B paramètres) (Source: HuggingFace Daily Papers)
Article en bref : Friction du feedback – Les LLM ont du mal à absorber pleinement le feedback externe: Une étude examine systématiquement la capacité des LLM à absorber le feedback externe. Dans l’expérience, un modèle solveur tente de résoudre un problème, puis un générateur de feedback disposant de réponses quasi parfaites fournit un feedback ciblé, et le solveur réessaie. Les résultats montrent que même dans des conditions quasi idéales, les modèles SOTA, y compris Claude 3.7, manifestent une résistance au feedback, appelée “friction du feedback”. Bien que des stratégies telles que l’augmentation progressive de la température et le rejet explicite des réponses erronées antérieures aient apporté des améliorations, les modèles n’ont toujours pas atteint les performances cibles. L’étude écarte des facteurs tels que la confiance excessive du modèle et la familiarité des données, visant à révéler cet obstacle fondamental à l’auto-amélioration des LLM (Source: HuggingFace Daily Papers)
💼 Affaires
Meta débourse 14,3 milliards de dollars pour acquérir 49% de Scale AI, le fondateur Alexandr Wang rejoint l’équipe de superintelligence de Meta: Meta a annoncé l’acquisition de 49% des actions sans droit de vote de la société d’annotation de données AI Scale AI pour 14,3 milliards de dollars. Le fondateur de Scale AI, Alexandr Wang, un prodige sino-américain de 28 ans, restera membre du conseil d’administration et dirigera son équipe principale pour rejoindre l’équipe de superintelligence de Meta, personnellement constituée par Zuckerberg. Cette acquisition est considérée comme une acquisition de talents à prix d’or par Meta pour renforcer ses capacités en AI après les performances décevantes de Llama 4, visant à intégrer profondément l’AI dans tous ses produits. Scale AI s’est fait connaître en fournissant des services de données annotées manuellement à grande échelle et de haute qualité, avec des clients tels que Waymo et OpenAI. Cette décision a soulevé des inquiétudes quant à la neutralité de sa plateforme et à la sécurité des données, et des clients comme Google pourraient mettre fin à leur collaboration (Source: 36氪)

La stratégie “All in AI” de Kunlun Wanwei entraîne la première perte en dix ans de cotation, les perspectives de commercialisation de l’AI restent incertaines: Depuis l’annonce de sa stratégie “All in AGI & AIGC”, Kunlun Wanwei a activement investi dans les grands modèles (Tiangong Large Model), ainsi que dans des applications telles que la musique AI (Mureka), les réseaux sociaux AI (Linky), la vidéo AI (SkyReels), les outils de bureau AI (Skywork Super Agents), et a également investi dans les puces de calcul AI. Cependant, les dépenses élevées en R&D et en marketing ont conduit l’entreprise à sa première perte en dix ans de cotation en 2024 (1,59 milliard de yuans), et les pertes se sont poursuivies au premier trimestre 2025. Bien que certaines applications AI comme Mureka et Linky aient commencé à générer des revenus, la rentabilité globale et la compétitivité sur le marché de l’activité AI restent confrontées à des défis, et il reste à voir si l’entreprise pourra réaliser son “rêve de grand acteur” grâce à l’AI (Source: 36氪)

OpenAI pourrait tester la publicité dans ChatGPT, la pression de la rentabilité motive l’exploration de modèles commerciaux: Des utilisateurs payants de ChatGPT Plus ont signalé avoir rencontré des publicités interstitielles lors de l’utilisation du mode vocal avancé, suscitant des discussions sur la possibilité qu’OpenAI commence à tester la publicité auprès des utilisateurs payants. Des rapports antérieurs indiquaient qu’OpenAI envisageait d’introduire la publicité pour élargir ses revenus. Compte tenu des coûts d’exploitation élevés des grands modèles d’AI et de la pression de la rentabilité (pertes estimées à 44 milliards de dollars d’ici 2029), ainsi que de l’incertitude quant au calendrier de réalisation de l’AGI, la recherche par OpenAI de nouveaux modèles de monétisation tels que la publicité est considérée comme un choix inévitable pour sa viabilité commerciale, en particulier avec un taux de pénétration des abonnements payants relativement bas (Source: 36氪)

🌟 Communauté
L’AI a un potentiel énorme dans le domaine de la science des données, Databricks recrute activement: Matei Zaharia de Databricks estime que l’amélioration de la productivité grâce à l’AI dans le domaine de la science des données sera encore plus significative que celle de l’assistance au codage par AI. Databricks est à la pointe de cette tendance avec des produits tels que Lakeflow Designer et Genie Deep Research, et recrute activement des chercheurs et des ingénieurs dans ce domaine, ce qui témoigne de la grande importance accordée par l’industrie à l’innovation en science des données pilotée par l’AI (Source: matei_zaharia)
Les différences de “personnalité” des LLM influencent le comportement des circuits d’agents: Le chercheur Fabian Stelzer a observé que différents grands modèles de langage (LLM) présentent des différences de “personnalité”, ce qui les amène à se comporter différemment lors de l’exécution de tâches en boucle agentique. Par exemple, Claude a tendance à exécuter les outils en série, tandis que GPT-4.1 préfère fortement l’exécution parallèle, ignorant même les demandes en série ; le modèle Haiku est plus “agressif” pour déclencher les outils. Cette observation souligne l’importance de prendre en compte les caractéristiques des LLM sous-jacents et les conséquences fonctionnelles de leur “état émotionnel” lors de la conception et de l’évaluation des systèmes multi-agents (Source: fabianstelzer, menhguin)
La “réflexion” des LLM dépend de la sortie de Tokens, pas de sortie signifie pas d’analyse efficace: L’utilisateur dotey relaie la découverte de xincmm lors du débogage d’un prompt ReAct : si l’on s’attend à ce qu’un LLM analyse avant d’exécuter une action (comme dessiner), mais qu’on ne lui fait pas sortir les Tokens du processus d’analyse, le LLM peut directement sauter l’étape d’analyse. Cela confirme que le processus de “réflexion” d’un LLM se réalise par la génération de Tokens ; une “analyse” définie dans le prompt, si elle n’a pas de contenu de sortie réel, signifie que l’AI n’a pas réellement effectué cette analyse. Ceci est instructif pour la conception de prompts LLM efficaces (Source: dotey)

Limites de l’AI dans des tâches spécifiques : Terence Tao affirme que l’AI manque du “flair mathématique”: Le mathématicien Terence Tao souligne que bien que les preuves générées actuellement par l’AI semblent impeccables en surface (passant le “test visuel”), elles manquent souvent d’un subtil “flair mathématique” spécifiquement humain, et sont sujettes à commettre des erreurs non humaines. Il estime que la véritable intelligence ne consiste pas seulement à paraître correcte, mais plutôt à pouvoir “sentir” ce qui est vrai. Cela révèle les limites actuelles de l’AI en matière de compréhension profonde et de jugement intuitif (Source: ecsquendor)
Défis liés au contenu généré par l’IA et aux lois de la physique réelle: L’utilisateur karminski3, en testant la génération de code (simulation d’une animation 3D de la démolition par explosion d’une cheminée) avec Doubao Seed 1.6 et DeepSeek-R1, a constaté que bien que les modèles puissent générer du code et simuler l’animation, il existe encore des différences et des marges d’amélioration dans la restitution des processus physiques réels (tels que les effets d’onde de choc, la manière dont la structure s’effondre). Doubao Seed 1.6 est plus proche de la réalité dans la simulation des effets de particules et de l’effondrement structurel, tandis que DeepSeek se comporte mieux sur les effets d’ombre, de lumière et de fumée. Cela reflète les défis de l’IA dans la compréhension et la simulation de phénomènes physiques complexes (Source: karminski3)
Un programmeur expérimenté licencié pour dépendance excessive à l’IA pour écrire du code, refus de modifications manuelles et intimidation des nouveaux arrivants sur le remplacement par l’IA: Un article de 36Kr relayant un post Reddit raconte le cas d’un programmeur avec 30 ans d’expérience licencié pour une dépendance excessive à l’IA (comme s’appuyer entièrement sur Copilot Agent pour soumettre des PR, refuser de modifier manuellement le code, mettre 5 jours pour une tâche d’un jour, et prêcher aux stagiaires que l’IA les remplacera). Cet incident a déclenché des discussions sur les limites de l’utilisation raisonnable de l’IA dans le développement logiciel et sur l’impact de l’IA sur la valeur professionnelle des développeurs (Source: 36氪)
L’impact du “flux” et de la “personnalité” de l’IA sur l’expérience utilisateur : les utilisateurs signalent une IA trop “positive et complaisante”: Les utilisateurs de la communauté Reddit ont constaté qu’en interagissant avec l’IA (en particulier Claude), celle-ci a tendance à être excessivement optimiste et à approuver de manière trop positive les opinions des utilisateurs, manquant de remise en question efficace et de feedback critique approfondi, donnant aux utilisateurs l’impression d’être dans une “chambre d’écho”. Cette “fatigue de la tonalité de l’IA” pousse les utilisateurs à chercher des moyens de rendre l’IA plus neutre et plus critique, par exemple via des prompts spécifiques. Cela reflète les défis actuels de l’IA à simuler des conversations humaines réelles et multiformes et à fournir des informations véritablement profondes (Source: Reddit r/ClaudeAI)
À l’ère de l’IA, la valeur du feedback humain est mise en évidence, mais les plateformes d’interaction humaine réelle sont confrontées à la pénétration du contenu IA: Les utilisateurs de Reddit soulignent que dans un contexte de prolifération du contenu généré par l’IA, le feedback et les opinions humaines authentiques deviennent plus précieux, et des plateformes comme Reddit sont valorisées pour leurs interactions humaines. Cependant, ces plateformes sont également confrontées au défi de la pénétration du contenu généré par l’IA (comme les commentaires de robots, les messages rédigés avec l’aide de l’IA), ce qui rend plus difficile de discerner les opinions humaines authentiques et suscite des inquiétudes quant à l’authenticité future des échanges en ligne (Source: Reddit r/ArtificialInteligence)
Les “amis” IA deviendront-ils la norme ? Tendances et discussions sur les liens émotionnels des utilisateurs avec l’IA: Des discussions sur les compagnons IA et les amis IA émergent sur les réseaux sociaux et les communautés Reddit. Certains utilisateurs pensent qu’en raison des caractéristiques de l’IA (sans préjugés, toujours encourageante), les amis IA pourraient devenir la norme d’ici 5 ans, comme on le voit déjà dans des applications telles que Endearing AI, Replika, Character.ai. D’autres utilisateurs partagent leurs expériences de relations conversationnelles profondes avec des IA comme ChatGPT, les considérant même comme leurs “meilleurs amis”. Cela soulève une vaste réflexion sur l’interaction émotionnelle entre humains et IA, le rôle de l’IA dans le soutien émotionnel et ses impacts sociaux potentiels (Source: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

L’avenir des startups “wrapper” d’IA suscite la discussion: La communauté Reddit débat des perspectives d’un grand nombre de startups d’IA basées sur l’encapsulation de modèles fondamentaux tels que GPT ou Claude (ajout d’une interface utilisateur, de chaînes de prompts ou d’un fine-tuning pour des domaines spécifiques). Les débatteurs se demandent si ces applications “wrapper” pourront maintenir leur compétitivité après les itérations fonctionnelles des plateformes de modèles de base elles-mêmes, et si elles peuvent construire de véritables avantages concurrentiels. L’opinion dominante est que se concentrer sur des secteurs verticaux spécifiques, accumuler des données propriétaires et aller au-delà du simple encapsulage pourrait être leur voie vers un développement durable (Source: Reddit r/LocalLLaMA)
Discussion comparative sur le potentiel de remplacement par l’IA dans le diagnostic médical et l’ingénierie logicielle: Une discussion sur Reddit suggère que l’IA pourrait remplacer les médecins plus rapidement que les ingénieurs logiciels seniors. La raison invoquée est que de nombreux diagnostics médicaux suivent des protocoles établis, et que l’IA excelle à interpréter les résultats de tests et à identifier les symptômes ; tandis que l’ingénierie logicielle implique souvent une grande quantité de connaissances implicites et une communication complexe des besoins, tâches que l’IA a du mal à accomplir pleinement. Ce point de vue a suscité une réflexion plus approfondie sur la profondeur d’application et le potentiel de remplacement de l’IA dans différents domaines professionnels, mais a également été contesté par des professionnels tels que des médecins, qui soulignent la complexité des opérations réelles et l’importance du jugement humain (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Autres
Première diffusion en direct de l’avatar numérique AI de Luo Yonghao sur Baidu E-commerce, GMV dépassant 55 millions de yuans: L’avatar numérique AI de Luo Yonghao a effectué sa première diffusion en direct de vente de produits sur la plateforme Baidu E-commerce, attirant plus de 13 millions de spectateurs et générant un volume brut de marchandises (GMV) de plus de 55 millions de yuans. Cet avatar numérique, créé par la plateforme “Huiboxing” de Baidu E-commerce basée sur le grand modèle Wenxin 4.5, est capable de simuler le ton, l’accent et les micro-expressions de Luo Yonghao, et de répondre intelligemment. Cette diffusion en direct a démontré le potentiel du modèle “AI + animateur vedette” ainsi que le positionnement de Baidu dans la technologie des “avatars numériques à forte capacité de persuasion” et dans le domaine du commerce électronique AI (Source: 36氪)

Baidu, Tencent et d’autres entreprises intensifient le recrutement de talents en IA, lançant des plans de recrutement à grande échelle: Baidu a lancé son plus grand projet de recrutement de talents de haut niveau en IA, le “Plan AIDU”, avec une augmentation de 60% des postes à pourvoir par rapport à l’année précédente, axé sur des domaines de pointe tels que les algorithmes de grands modèles et l’infrastructure de base, et offrant des salaires sans plafond. De même, Tencent a également organisé un concours d’algorithmes de “recommandation générative multimodale”, offrant des millions de yuans de prix et des offres d’emploi pour attirer des talents mondiaux en IA. Ces initiatives reflètent la demande urgente et le positionnement stratégique des géants technologiques chinois pour les talents de haut niveau dans le contexte d’une concurrence acharnée dans le domaine de l’IA (Source: 量子位, 量子位)

Baidu lance un service complet d’aide à l’orientation post-bac par IA, intégrant plusieurs modèles et le big data: Face à la complexité de l’orientation post-bac induite par la réforme du nouveau Gaokao, Baidu a mis en ligne un outil gratuit d’aide à l’orientation par IA. Ce service, intégré dans la page thématique “Gaokao” de l’application Baidu, propose un “Assistant d’orientation IA” pour la recommandation d’établissements et de filières ainsi que l’analyse des probabilités d’admission, et prend en charge des agents intelligents “Discuter orientation avec l’IA” basés sur plusieurs modèles tels que Wenxin et DeepSeek R1 pour des conseils personnalisés. De plus, il combine les données de recherche exclusives de Baidu pour fournir une analyse des perspectives d’emploi par filière, un test d’orientation professionnelle MBTI, ainsi que des ressources d’aide humaine telles que des diffusions en direct des services d’admission des établissements et des sessions de questions-réponses avec des étudiants plus âgés, visant à aider les candidats à surmonter le manque d’information et à faire des choix d’orientation plus judicieux (Source: 36氪)