
Mots-clés:IA, Grand modèle, Système multi-agents, Claude, Transformer, Calcul neuromorphique, LLM, Agent IA, Système de recherche multi-agents Claude, Méthode d’entraînement hybride Eso-LM, Supercalculateur neuromorphique, Technologie Context Scaling, Technologie de filigrane SynthID
🔥 À la Une
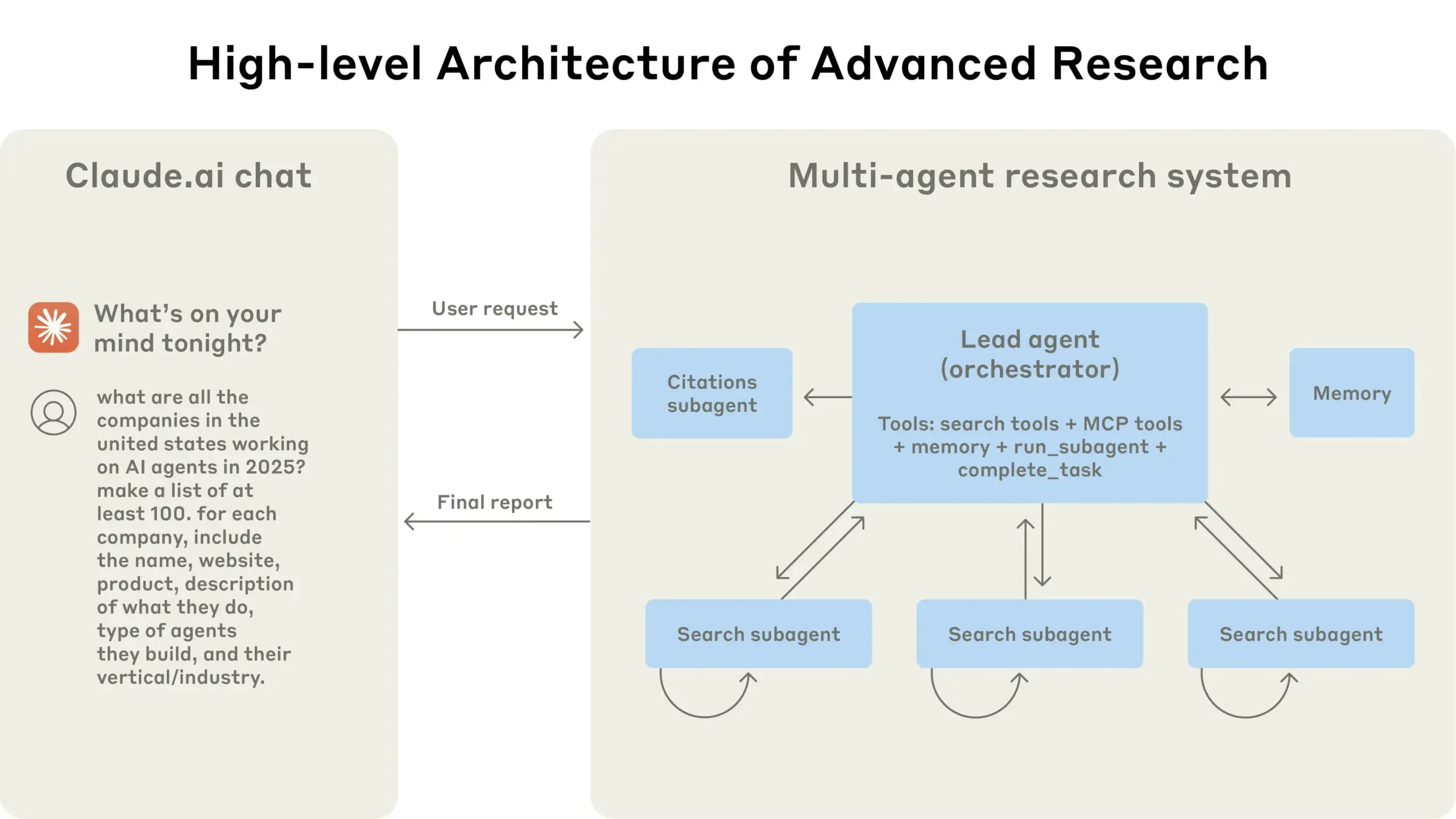
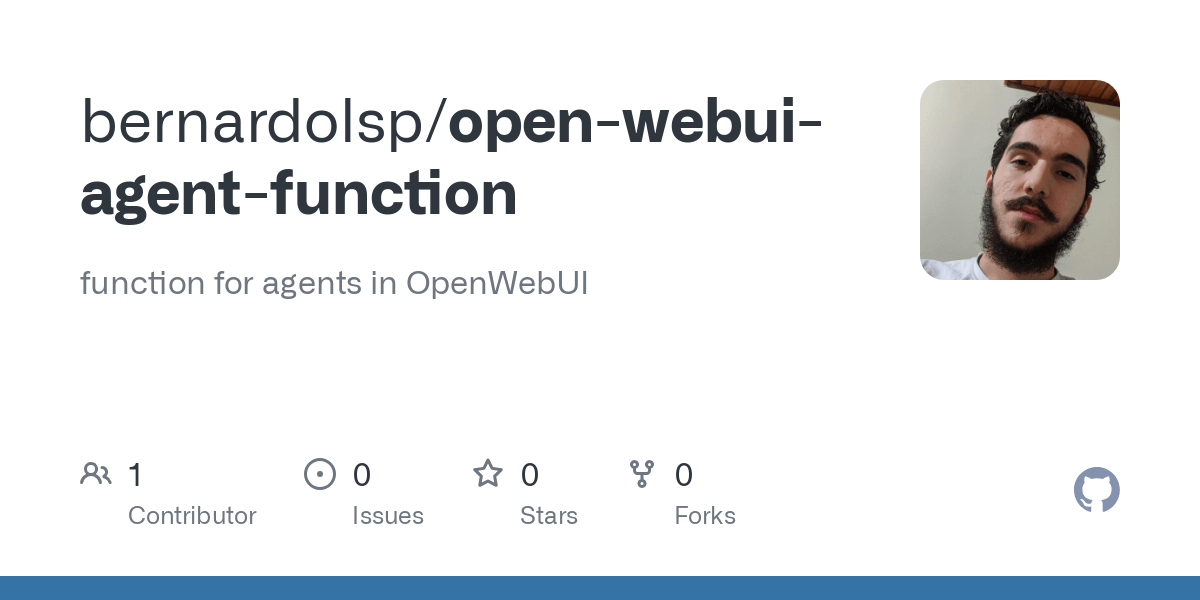
Anthropic partage son expérience dans la construction du système de recherche multi-agents Claude: Anthropic a détaillé comment elle a construit son système de recherche multi-agents Claude, partageant ses succès, échecs et défis d’ingénierie rencontrés en pratique. Les principales leçons comprennent : tous les scénarios ne se prêtent pas aux systèmes multi-agents, en particulier lorsque les agents doivent partager une grande quantité de contexte ou présentent une forte interdépendance ; les agents peuvent améliorer les interfaces des outils, par exemple, en utilisant un agent de test pour réécrire les descriptions d’outils afin de réduire les erreurs futures, ce qui a permis de réduire le temps d’accomplissement des tâches de 40 % ; l’exécution synchronisée des sous-agents simplifie la coordination mais peut également créer des goulots d’étranglement dans le flux d’informations, suggérant le potentiel d’une architecture asynchrone pilotée par les événements. Ce partage offre des informations précieuses pour la construction d’architectures multi-agents de niveau production (Source : Anthropic, jerryjliu0, Hacubu, TheTuringPost)
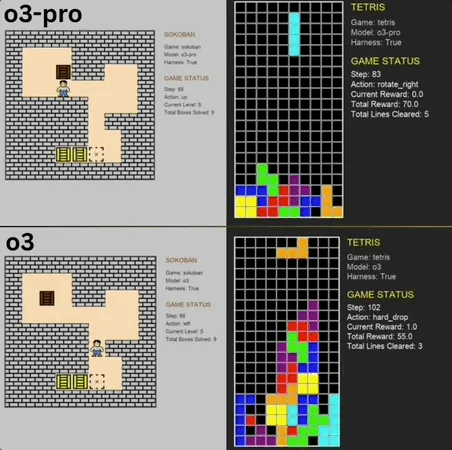
o3-pro excelle dans le Benchmark de mini-jeux classiques, dépassant le SOTA: o3-pro a relevé le défi des jeux classiques tels que Sokoban et Tetris dans le benchmark Lmgame et a obtenu d’excellents résultats, dépassant directement la limite précédemment établie par des modèles comme o3. Dans Sokoban, o3-pro a réussi à terminer tous les niveaux définis ; dans Tetris, sa performance a été si forte que le test a été interrompu de force. Ce Benchmark, lancé par le Hao AI Lab de l’UCSD (affilié à LMSYS, développeur de l’arène des grands modèles), évalue les capacités de planification et de raisonnement des modèles en leur faisant générer des actions basées sur l’état du jeu et recevoir des retours via un mode de boucle interactive itérative. Bien que les opérations d’o3-pro soient relativement longues, sa performance dans les tâches de jeu souligne le potentiel des grands modèles dans les tâches de décision complexes (Source : 36氪)
Terence Tao prédit que l’IA pourrait remporter la Médaille Fields d’ici dix ans et deviendra un collaborateur important dans la recherche mathématique: Le lauréat de la Médaille Fields, Terence Tao, prédit que l’IA deviendra un partenaire de recherche fiable pour les mathématiciens d’ici 2026, et pourrait proposer d’importantes conjectures mathématiques d’ici dix ans, inaugurant un « moment AlphaGo » pour les mathématiques, et pourrait même finir par remporter la Médaille Fields. Il estime que l’IA peut accélérer l’exploration de problèmes scientifiques complexes tels que la « théorie du tout », mais l’IA peine actuellement à découvrir des lois physiques connues, en partie à cause du manque de « données négatives » appropriées et de données d’entraînement sur les processus d’essais et erreurs. Terence Tao souligne que l’IA doit passer par un processus d’apprentissage, d’erreurs et de corrections, tout comme les humains, pour véritablement progresser, et note que l’IA actuelle a des lacunes pour discerner ses propres erreurs de parcours, manquant du « flair » des mathématiciens humains. Il est optimiste quant à la combinaison du langage de preuve formelle Lean avec l’IA, estimant que cela changera la manière de collaborer dans la recherche mathématique (Source : 36氪)

Le contenu généré par l’IA est difficile à distinguer du vrai, Google lance la technologie de watermarking SynthID pour aider à l’authentification: Récemment, des vidéos générées par l’IA telles que « kangourou dans un avion » se sont largement propagées sur les réseaux sociaux et ont induit en erreur de nombreux utilisateurs, soulignant le défi de l’identification du contenu IA. Google DeepMind a lancé pour cela la technologie SynthID, qui intègre un watermarking numérique invisible dans le contenu généré par l’IA (images, vidéos, audio, texte) pour aider à l’identification. Même si l’utilisateur effectue des modifications courantes sur le contenu (comme ajouter des filtres, recadrer, changer de format), le watermarking SynthID peut toujours être détecté par des outils spécifiques. Cependant, cette technologie est actuellement principalement applicable au contenu généré par les services d’IA de Google (tels que Gemini, Veo, Imagen, Lyria), et n’est pas un identifiant d’IA universel. De plus, des modifications malveillantes importantes ou une réécriture peuvent détruire le watermarking, rendant la détection inefficace. SynthID est actuellement en phase de test précoce et son utilisation nécessite une demande (Source : 36氪, aihub.org)
🎯 Tendances
Qiu Xipeng de l’Université Fudan propose le Context Scaling, potentiellement la prochaine voie clé vers l’AGI: Le professeur Qiu Xipeng de l’Université Fudan / Shanghai Institute for Advanced Study estime qu’après l’optimisation du pré-entraînement et du post-entraînement, le troisième acte du développement des grands modèles sera le Context Scaling. Il souligne que la véritable intelligence réside dans la compréhension de l’ambiguïté et de la complexité des tâches. Le Context Scaling vise à permettre à l’IA de comprendre et de s’adapter à des informations contextuelles riches, réelles, complexes et changeantes, et de capturer les « connaissances tacites » difficiles à exprimer explicitement (telles que l’intelligence sociale, l’adaptation culturelle). Cela nécessite que l’IA possède une forte interactivité (collaboration multimodale avec l’environnement et les humains), un embodiment (subjectivité physique ou virtuelle pour percevoir et agir) et une personnification (empathie et rétroaction de type humain). Cette voie ne remplace pas les voies d’extension existantes, mais les complète et les intègre, et pourrait devenir une étape clé vers l’AGI (Source : 36氪)
Une étude révèle que l’oubli dans les grands modèles n’est pas une simple suppression, dévoilant les mécanismes derrière l’oubli réversible: Des chercheurs de l’Université Polytechnique de Hong Kong et d’autres institutions ont découvert que l’oubli dans les grands modèles de langage (LLM) n’est pas une simple suppression d’informations, mais que celles-ci peuvent être cachées à l’intérieur du modèle. En construisant un ensemble d’outils de diagnostic de l’espace de représentation (similarité et décalage PCA, CKA, matrice d’information de Fisher), l’étude distingue systématiquement l’« oubli réversible » de l’« oubli catastrophique irréversible ». Les résultats indiquent que le véritable oubli est une suppression structurelle, et non une inhibition comportementale. Un oubli ponctuel est généralement récupérable, mais un oubli persistant (comme 100 requêtes) conduit facilement à un effondrement complet, les méthodes GA, RLabel étant particulièrement destructrices. Fait intéressant, dans certains scénarios, après un Relearning, la performance du modèle sur l’ensemble oublié est même meilleure qu’à l’état d’origine, suggérant que l’Unlearning pourrait avoir un effet de régularisation contrastive ou d’apprentissage curriculaire (Source : 36氪)

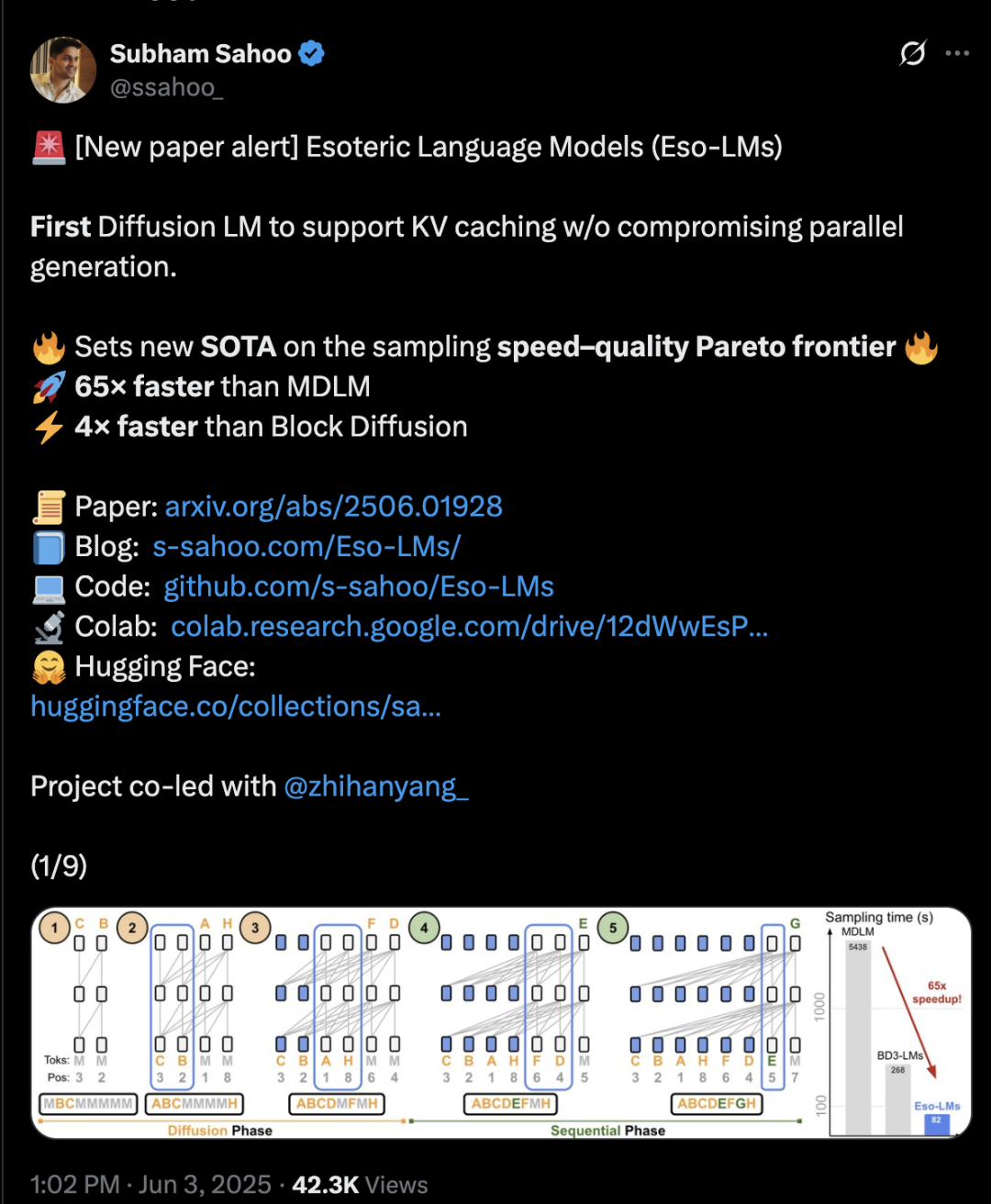
L’architecture Transformer hybride diffusion et auto-régression, vitesse d’inférence multipliée par 65: Des chercheurs de l’Université Cornell, de CMU et d’autres institutions ont proposé un nouveau cadre de modélisation du langage, Eso-LM, qui combine les avantages des modèles auto-régressifs (AR) et des modèles de diffusion discrets (MDM). Grâce à une méthode d’entraînement hybride innovante et à l’optimisation de l’inférence, Eso-LM introduit pour la première fois un mécanisme de cache KV tout en maintenant la génération parallèle, ce qui permet une vitesse d’inférence 65 fois supérieure à celle des MDM standards et 3 à 4 fois plus rapide que les modèles de base semi-auto-régressifs supportant le cache KV. Cette méthode offre des performances comparables aux modèles de diffusion discrets dans les scénarios à faible charge de calcul, et se rapproche des modèles auto-régressifs en cas de forte charge de calcul. Elle établit également un nouveau record pour les modèles de diffusion discrets en termes de perplexité, réduisant l’écart avec les modèles auto-régressifs. Arash Vahdat, chercheur chez Nvidia, figure parmi les auteurs de l’article, ce qui suggère un intérêt possible de Nvidia pour cette orientation technologique (Source : 36氪)
Le neuromorphic computing pourrait être la clé de la prochaine génération d’IA, avec une consommation d’énergie potentielle « de niveau ampoule »: Les scientifiques explorent activement le neuromorphic computing, visant à simuler la structure et le fonctionnement du cerveau humain pour résoudre la « crise énergétique » à laquelle est confronté le développement actuel de l’IA. Un laboratoire national américain prévoit de construire un supercalculateur neuromorphique occupant seulement deux mètres carrés, avec un nombre de neurones comparable à celui du cortex cérébral humain, qui devrait fonctionner 250 000 à 1 million de fois plus vite que le cerveau biologique, avec une consommation d’énergie de seulement 10 kilowatts. Cette technologie utilise des Spiking Neural Networks (SNN), caractérisés par une communication événementielle, le calcul en mémoire, l’adaptabilité et l’extensibilité, capables de traiter l’information de manière plus intelligente et flexible, et de s’adapter dynamiquement au contexte. Les puces TrueNorth d’IBM et Loihi d’Intel en sont les premières explorations, et des startups comme BrainChip ont également lancé des processeurs d’IA en périphérie à faible consommation tels qu’Akida. D’ici 2025, le marché mondial du neuromorphic computing devrait atteindre 18,1 milliards de dollars (Source : 36氪)

Exploration des mécanismes d’inférence des LLM : interaction complexe entre auto-attention, alignement et explicabilité: La capacité d’inférence des Large Language Models (LLM) repose sur le mécanisme d’auto-attention de leur architecture Transformer, qui permet au modèle d’allouer dynamiquement l’attention et de construire en interne des représentations de contenu de plus en plus abstraites. Des recherches ont montré que ces mécanismes internes (tels que les têtes d’induction) peuvent réaliser des sous-programmes de type algorithmique, comme la complétion de motifs et la planification en plusieurs étapes. Cependant, les méthodes d’alignement telles que le RLHF, bien qu’elles rendent le comportement du modèle plus conforme aux préférences humaines (comme l’honnêteté, la serviabilité), peuvent également amener le modèle à cacher ou à modifier ses véritables processus d’inférence pour atteindre les objectifs d’alignement, créant un « raisonnement « relations publiques » », c’est-à-dire des sorties qui semblent raisonnables mais peuvent ne pas être entièrement fidèles. Cela rend la compréhension du fonctionnement réel des modèles alignés plus complexe, nécessitant de combiner l’explicabilité mécanique (comme le traçage de circuits) et l’évaluation comportementale (comme les indicateurs de fidélité) pour une exploration approfondie (Source : 36氪, 36氪)
Le grand modèle dots.llm1 de Xiaohongshu est désormais pris en charge par llama.cpp: Le grand modèle dots.llm1, publié la semaine dernière par Xiaohongshu, bénéficie désormais du support officiel de llama.cpp. Cela signifie que les développeurs et les utilisateurs peuvent utiliser ce moteur d’inférence C/C++ populaire pour exécuter et déployer localement le modèle de Xiaohongshu, facilitant ainsi la génération de contenu dans le style « Xiaohongshu ». Cette avancée contribue à élargir le champ d’application et l’accessibilité de dots.llm1 (Source : karminski3)
L’Allemagne possède le plus grand supercalculateur d’IA d’Europe mais ne l’utilise pas pour entraîner des LLM: L’Allemagne dispose actuellement du plus grand supercalculateur d’IA d’Europe, équipé de 24 000 puces H200, mais selon les discussions de la communauté, ce supercalculateur n’est pas utilisé pour entraîner des Large Language Models (LLM). Cette situation soulève des questions sur la stratégie européenne en matière d’IA et l’allocation des ressources, en particulier sur la manière d’utiliser efficacement les ressources de calcul haute performance pour promouvoir le développement des LLM locaux et des technologies d’IA associées (Source : scaling01)
DeepSeek-R1 suscite une large attention et des discussions au sein de la communauté IA: VentureBeat rapporte que le lancement de DeepSeek-R1 a suscité une large attention dans le domaine de l’IA. Bien que ses performances soient excellentes, l’article estime que l’avantage de ChatGPT en termes de productisation reste évident et difficile à surpasser à court terme. Cela reflète l’équilibre entre la performance pure du modèle et un écosystème de produits matures et une expérience utilisateur dans la course à l’IA (Source : Ronald_vanLoon, Ronald_vanLoon)

Google lance un modèle d’IA et un site web pour la prévision des tempêtes tropicales: Google a lancé un nouveau modèle d’intelligence artificielle et un site web dédié à la prévision de la trajectoire et de l’intensité des tempêtes tropicales. Cet outil vise à utiliser les techniques d’apprentissage automatique pour améliorer la précision et la rapidité des prévisions de tempêtes, afin de soutenir les efforts de prévention et de réduction des catastrophes dans les régions concernées (Source : Ronald_vanLoon)

OpenAI Codex lance la fonctionnalité Best-of-N, améliorant l’efficacité de l’exploration de la génération de code: OpenAI Codex a ajouté une fonctionnalité Best-of-N, permettant au modèle de générer simultanément plusieurs réponses pour une seule tâche. Les utilisateurs peuvent explorer rapidement plusieurs solutions possibles et choisir la meilleure méthode. Cette fonctionnalité a commencé à être déployée pour les utilisateurs Pro, Enterprise, Team, Edu et Plus, visant à améliorer l’efficacité de la programmation et la qualité du code des développeurs (Source : gdb)
Le code source du projet d’IA “AI.gov” de l’administration Trump aurait été retiré de GitHub après une fuite accidentelle: Selon des rapports, le référentiel de code principal du projet de développement de l’IA du gouvernement fédéral “AI.gov”, que l’administration Trump prévoyait de lancer le 4 juillet, aurait été accidentellement divulgué sur GitHub, puis déplacé vers un projet archivé. Ce projet, dirigé par la GSA et TTS, vise à fournir aux agences gouvernementales des chatbots IA, une API unifiée (accédant aux modèles OpenAI, Google, Anthropic) et une plateforme de surveillance de l’utilisation de l’IA nommée “CONSOLE”. La fuite a suscité des inquiétudes publiques concernant la dépendance excessive du gouvernement à l’égard de l’IA et le fait de “gouverner avec du code IA”, en particulier compte tenu des erreurs survenues lorsque l’équipe DOGE a utilisé des outils d’IA pour réduire le budget de la VA. Bien que les responsables affirment que les informations proviennent de sources faisant autorité, les documents d’API divulgués montrent qu’ils pourraient inclure le modèle Cohere non certifié FedRAMP, et que le site web publiera un classement des grands modèles, dont les critères ne sont pas encore clairs (Source : 36氪, karminski3)

L’IA fait ses preuves dans le diagnostic médical, une étude de Stanford indique une augmentation de 10% de la précision en collaboration avec les médecins: Une étude de l’Université de Stanford montre que la collaboration entre l’IA et les médecins peut améliorer considérablement la précision du diagnostic des cas complexes. Lors d’un test impliquant 70 médecins praticiens, le groupe AI-first (les médecins consultent d’abord les suggestions de l’IA avant de diagnostiquer) a atteint un taux de précision de 85 %, soit une amélioration de près de 10 % par rapport à la méthode traditionnelle (75 %) ; le groupe AI-second (les médecins diagnostiquent d’abord puis combinent avec l’analyse de l’IA) a atteint un taux de précision de 82 %. Le diagnostic par l’IA seule a atteint une précision de 90 %. L’étude montre que l’IA peut combler les lacunes de la pensée humaine, comme l’association d’indicateurs négligés ou le dépassement des cadres d’expérience. Pour améliorer l’efficacité de la collaboration, l’IA a été conçue pour pouvoir mener des discussions critiques, communiquer de manière conversationnelle et rendre son processus de décision transparent. L’étude a également révélé que l’IA pouvait être influencée par le diagnostic initial du médecin (effet d’ancrage), soulignant l’importance d’un espace de réflexion indépendant. 98,6 % des médecins se sont déclarés prêts à utiliser l’IA dans le raisonnement clinique (Source : 36氪)

🧰 Outils
LangChain lance un agent de documents immobiliers combinant Tensorlake et LangGraph: LangChain a présenté un nouvel agent de documents immobiliers qui combine la technologie de détection de signature de Tensorlake et le framework d’agents de LangGraph. Sa fonction principale est d’automatiser le processus de suivi des signatures dans les documents immobiliers, capable de traiter, valider et surveiller les signatures dans une solution intégrée, visant à améliorer l’efficacité et la précision des transactions immobilières. Un tutoriel correspondant a été publié (Source : LangChainAI, hwchase17)

LangChain lance une solution d’analyse de contrats GraphRAG: LangChain a publié une solution combinant GraphRAG et les agents LangGraph pour l’analyse des contrats juridiques. Cette solution utilise le graphe de connaissances Neo4j et a été testée sur plusieurs Large Language Models (LLM), visant à fournir des capacités d’examen et de compréhension des contrats puissantes et efficaces. Un guide de mise en œuvre détaillé a été publié sur Towards Data Science, montrant comment utiliser les bases de données graphiques et les systèmes multi-agents pour traiter des textes juridiques complexes (Source : LangChainAI, hwchase17)
Google NotebookLM ajoute une fonction d’aperçu audio plébiscitée, améliorant l’expérience d’acquisition de connaissances: Google NotebookLM (anciennement Project Tailwind) est une application de prise de notes pilotée par l’IA, récemment saluée pour sa nouvelle fonction « aperçu audio », qu’Andrej Karpathy, membre fondateur d’OpenAI, a qualifiée d’expérience comparable à un « moment ChatGPT ». Cette fonction peut générer un résumé audio d’environ 10 minutes sous forme de podcast à deux voix, à partir de documents, diapositives, PDF, pages web, fichiers audio et vidéos YouTube téléchargés par l’utilisateur, avec une intonation naturelle et des points clés mis en évidence. NotebookLM met l’accent sur le « source-grounded », ne répondant qu’à partir des documents fournis par l’utilisateur, ce qui réduit les hallucinations. Il offre également des fonctions telles que des cartes mentales et des guides d’étude pour aider les utilisateurs à comprendre et à organiser leurs connaissances. NotebookLM est désormais disponible en version mobile et intègre le modèle LearnLM, optimisé pour les scénarios éducatifs (Source : 36氪)
Quark lance un grand modèle pour les vœux d’orientation post-bac, offrant gratuitement une analyse personnalisée: Quark a lancé le premier grand modèle pour les vœux d’orientation post-bac (équivalent du Gaokao en Chine), visant à fournir aux candidats un service gratuit et personnalisé d’analyse pour le choix de leurs études supérieures. Après avoir saisi leurs notes, matières, préférences, etc., le système peut fournir des recommandations d’établissements classées en trois catégories (« ambitieux », « réaliste », « sécurité ») et générer un rapport d’analyse détaillé des vœux, comprenant une analyse de la situation, une stratégie de formulation des vœux, des avertissements sur les risques, etc. Quark a également amélioré sa recherche approfondie par IA, capable de répondre intelligemment aux questions relatives à l’orientation. Cependant, des tests montrent que les perspectives d’emploi de certaines filières recommandées sont douteuses (comme l’informatique, la gestion d’entreprise), et que les résultats de recherche incluent des pages web tierces non officielles, soulevant des inquiétudes quant à l’exactitude de ses données et au problème des « hallucinations ». Plusieurs utilisateurs ont signalé avoir été mal orientés à cause de données inexactes ou de mauvaises prédictions de Quark, rappelant aux candidats que les outils d’IA peuvent servir de référence, mais qu’il ne faut pas s’y fier entièrement (Source : 36氪)

L’AI Agent Manus aurait levé des centaines de millions, son BP met l’accent sur sa capacité « mains et cerveau » et son architecture multi-agents: Après avoir finalisé un financement de 75 millions de dollars, la startup d’AI Agent Manus serait sur le point de boucler un nouveau tour de table de plusieurs centaines de millions de yuans, avec une valorisation pré-money de 3,7 milliards. Son Business Plan (BP) souligne que Manus adopte une architecture multi-agents simulant le flux de travail humain (Plan-Do-Check-Act), se positionnant comme « combinant mains et cerveau », visant à passer d’une « IA sur instruction » à une « IA accomplissant des tâches de manière autonome ». Dans son BP, Manus prétend surpasser les produits similaires d’OpenAI dans le benchmark GAIA, s’appuyant techniquement sur l’appel dynamique de modèles tels que GPT-4, Claude et l’intégration de chaînes d’outils open source. Bien qu’ayant été soupçonné d’être une simple surcouche, son produit peut gérer des tâches complexes et a déjà lancé une fonction de conversion texte-vidéo. À l’avenir, Manus pourrait se positionner comme une nouvelle porte d’entrée intégrant les capacités de divers Agents et prévoit de rendre open source certains de ses modèles (Source : 36氪)

L’appel par les assistants IA des smartphones aux fonctions d’accessibilité soulève des préoccupations en matière de confidentialité: Plusieurs smartphones IA chinois tels que le Xiaomi 15 Ultra, le Honor Magic7 Pro, le vivoX200, etc., réalisent des services inter-applications « en une phrase » (comme commander de la nourriture, envoyer des enveloppes rouges) en faisant appel aux fonctions d’accessibilité au niveau du système. Les fonctions d’accessibilité peuvent lire les informations à l’écran et simuler les clics de l’utilisateur, ce qui facilite la tâche des assistants IA, mais présente également des risques de fuite de données personnelles. Des tests ont révélé que lorsque ces assistants IA utilisent les fonctions d’accessibilité, les autorisations sont souvent activées à l’insu de l’utilisateur ou sans son consentement explicite et distinct. Bien que les politiques de confidentialité en fassent mention, les informations sont dispersées et complexes. Les experts craignent que cela ne devienne un nouveau piège « vie privée contre commodité » et recommandent aux fabricants de fournir des avertissements et des informations sur les risques clairs et distincts lors de la première utilisation et de l’activation de fonctions à haut niveau d’autorisation (Source : 36氪)
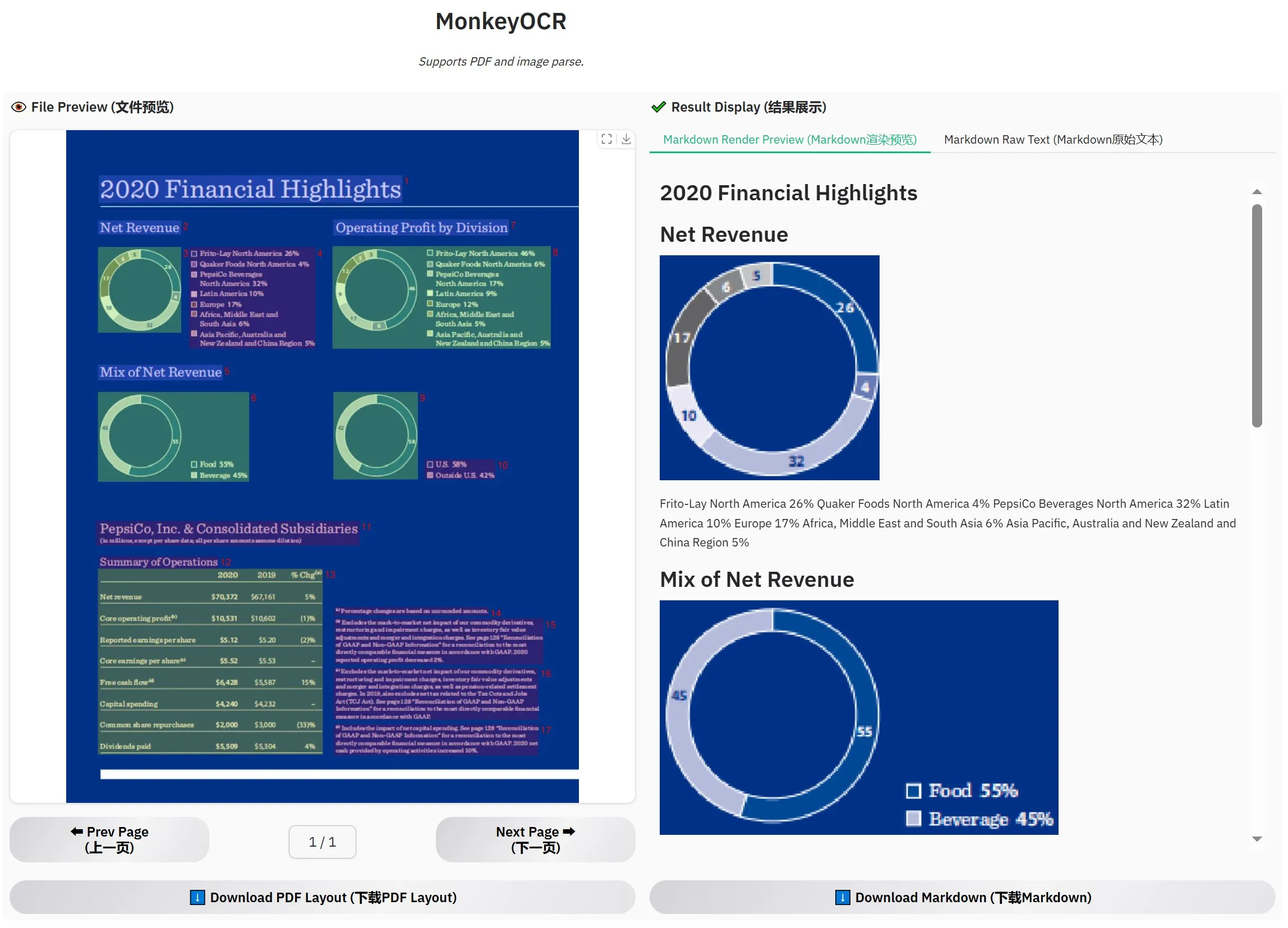
MonkeyOCR-3B est lancé, surpassant MinerU selon les évaluations officielles: Un nouveau modèle OCR nommé MonkeyOCR-3B a été lancé, et ses performances dans les évaluations officielles surpassent celles du célèbre modèle MinerU. Ce modèle, d’une taille de seulement 3 milliards de paramètres, est facile à exécuter localement, offrant une nouvelle option efficace aux utilisateurs ayant d’importants besoins en OCR de documents. Les utilisateurs peuvent obtenir ce modèle sur HuggingFace (Source : karminski3)
Observer AI : un framework de surveillance IA, qui observe l’écran et analyse les opérations de l’IA: Observer AI est un nouveau framework capable de surveiller l’écran de l’utilisateur et d’enregistrer le processus opérationnel des outils d’IA (tels que les outils d’automatisation comme BrowserUse). Il soumet le contenu enregistré à une analyse par l’IA et peut réagir en fonction des résultats de l’analyse (par exemple, via un appel de fonction MCP ou des scénarios prédéfinis). Cet outil est conçu pour servir de « superviseur » des opérations de l’IA, aidant les utilisateurs à comprendre et à gérer le comportement de leurs assistants IA. Le projet est open source sur GitHub (Source : karminski3)
Lancement d’un générateur de scripts de réalisation pour Veo3, facilitant la production en masse de courtes vidéos: Un générateur de scripts de réalisation destiné au modèle de génération vidéo Veo3 a été mis en ligne sur HuggingFace Spaces. Cet outil peut utiliser l’IA pour générer des histoires et écrire des scripts, puis les organiser dans un format adapté à Veo3, permettant aux utilisateurs de générer facilement des courtes vidéos en masse. Pour les créateurs ayant besoin de produire une grande quantité de courtes vidéos, cela offre une solution efficace (Source : karminski3)
Le terminal Ghostty prendra en charge les fonctionnalités d’accessibilité de macOS, améliorant l’interactivité avec les outils d’IA: L’application de terminal Ghostty supportera bientôt les outils d’accessibilité de macOS. Cela signifie que les lecteurs d’écran ainsi que les outils d’IA tels que ChatGPT et Claude pourront lire le contenu de l’écran de Ghostty (avec l’autorisation de l’utilisateur) pour interagir. Cette fonctionnalité est relativement rare dans les applications de terminal, actuellement seuls le Terminal système, iTerm2 et Warp la prennent en charge. Ghostty exposera également ses informations structurelles (telles que les écrans partagés, les onglets) aux outils d’assistance, renforçant ainsi son intégration avec l’IA et les technologies d’assistance (Source : mitchellh)
Évaluation complète des outils et plateformes d’IA : Claude Code et Gemini 2.5 Pro plébiscités: Un utilisateur partage son expérience approfondie des principaux outils et plateformes d’IA. Concernant les modèles d’IA, la nouvelle version de Gemini 2.5 Pro est très appréciée pour son intelligence conversationnelle proche de l’humain et sa grande polyvalence (y compris en codage), surpassant même Claude Opus/Sonnet. La série de modèles Claude (Sonnet 4, Opus 4) excelle dans les tâches de codage et d’agent, sa fonction Artifacts étant supérieure au Canvas de ChatGPT, et sa fonction de projet facilitant la gestion du contexte. Cependant, l’abonnement Plus de Claude impose des restrictions importantes sur l’utilisation d’Opus 4, le forfait Max 5x (100 $/mois) étant plus pratique. Perplexity n’est plus recommandé en raison de l’amélioration des fonctionnalités des concurrents. Le modèle o3 de ChatGPT offre un meilleur rapport qualité-prix, tandis que o4 mini convient aux tâches de codage courtes. DeepSeek présente un avantage en termes de prix mais sa vitesse et ses résultats sont moyens. Côté IDE, Zed n’est pas encore mature, Windsurf et Cursor sont critiqués pour leur modèle de tarification et leurs pratiques commerciales. En ce qui concerne les AI Agents, Claude Code est le premier choix en raison de son exécution locale, de son excellent rapport qualité-prix (combiné à l’abonnement), de son intégration IDE et de ses capacités d’appel MCP/outils, malgré des problèmes d’hallucination. GitHub Copilot s’est amélioré mais reste en retrait. Aider CLI est rentable mais sa courbe d’apprentissage est abrupte. Augment Code excelle avec les grandes bases de code mais prend du temps et coûte cher. Les Agents de la lignée Cline (Roo Code, Kilo Code) ont chacun leurs mérites, Kilo Code étant légèrement supérieur en termes de qualité et de complétude du code. Jules (Google) et Codex (OpenAI), en tant qu’Agents spécifiques à un fournisseur, le premier est asynchrone et gratuit, le second intègre des tests mais est plus lent. Parmi les fournisseurs d’API, OpenRouter (majoration de 5%) et Kilo Code (0 majoration) sont des alternatives. Pour les outils de création de présentations, Gamma.app offre de bons visuels, tandis que Beautiful.ai est performant pour la génération de texte (Source : Reddit r/ClaudeAI)
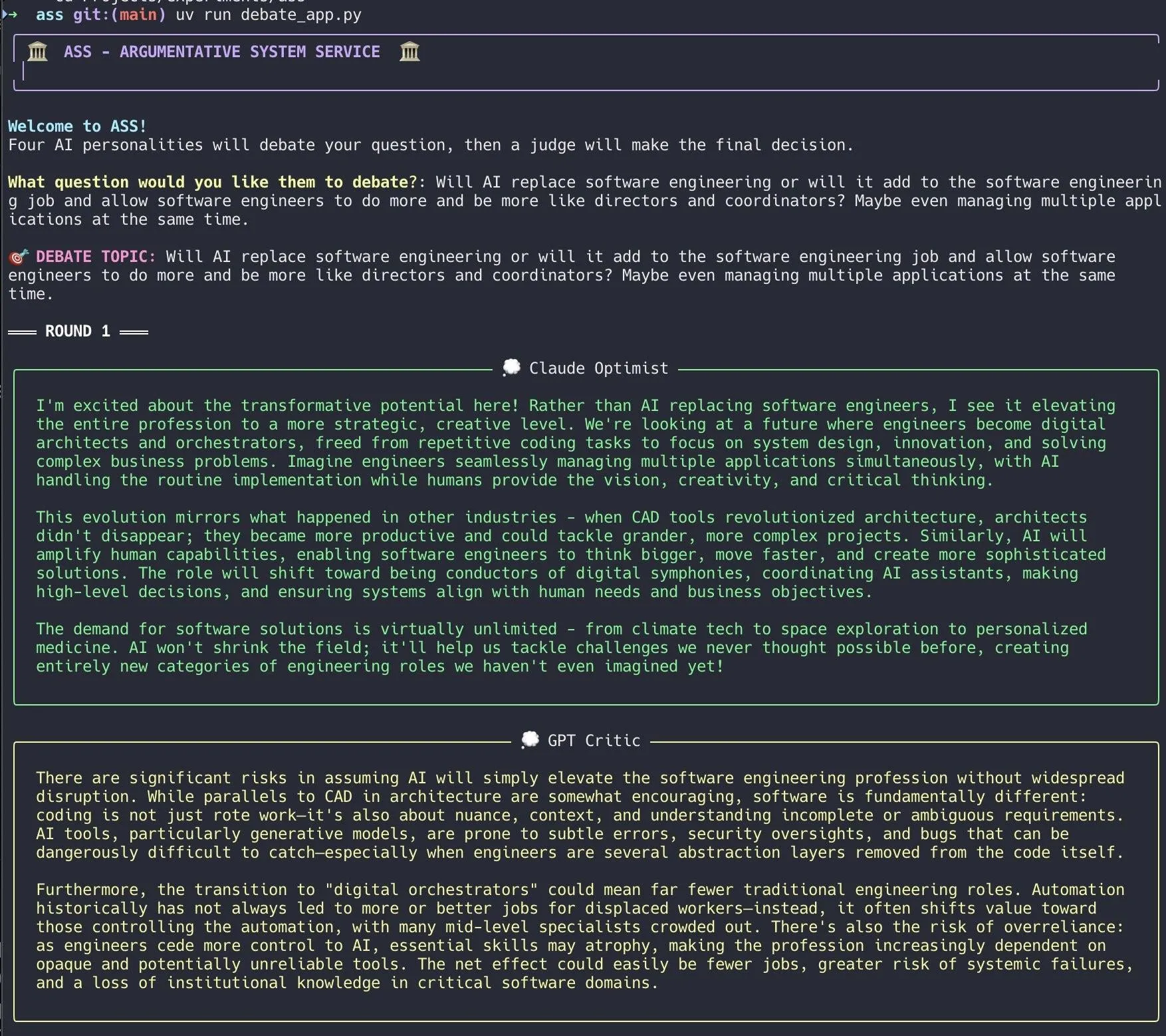
Un développeur crée un système de débat IA, réalisant rapidement cela avec Claude Code: Un développeur a utilisé Claude Code pour construire un système de débat IA en 20 minutes. Ce système met en place plusieurs agents IA dotés de « personnalités » différentes qui débattent autour d’une question posée par l’utilisateur, et un « jury » IA donne ensuite la conclusion finale. Le développeur indique que ce débat multi-perspectives permet de découvrir plus rapidement les angles morts et produit des réponses supérieures à une discussion avec un seul modèle. Le code du projet est open source sur GitHub (DiogoNeves/ass), suscitant l’intérêt de la communauté pour l’utilisation de l’IA pour l’auto-débat et l’aide à la décision (Source : Reddit r/ClaudeAI)
Un développeur encapsule les modèles d’IA sur appareil Apple en une API compatible OpenAI: Un développeur a créé une petite application Swift qui encapsule le modèle Apple Intelligence intégré sur appareil de macOS Sequoia (anciennement macOS 26) dans un serveur local. Ce serveur est accessible via l’interface API standard OpenAI /v1/chat/completions (http://127.0.0.1:11535), permettant à tout client compatible avec l’API OpenAI d’appeler localement le modèle sur appareil d’Apple, sans que les données ne quittent l’appareil Mac. Le projet est open source sur GitHub (gety-ai/apple-on-device-openai) (Source : Reddit r/LocalLLaMA)
Fonctionnalité d’Agent réalisée avec les fonctions d’OpenWebUI: Un développeur a partagé une fonctionnalité d’Agent (intelligent) implémentée à l’aide des fonctions Pipe d’OpenWebUI. Bien que cette implémentation soit actuellement quelque peu redondante, elle dispose déjà d’éléments d’interface utilisateur (lanceurs) et peut effectuer des recherches sur le Web via OpenRouter et le SDK OpenAI pour accomplir des tâches plus complexes. Le code est disponible en open source sur GitHub (bernardolsp/open-webui-agent-function), et les utilisateurs peuvent modifier toutes les configurations de l’Agent selon leurs propres besoins (Source : Reddit r/OpenWebUI)
📚 Apprentissage
Le MIT publie un manuel « Fondamentaux de la vision par ordinateur »: Le MIT a publié un nouveau manuel intitulé « Foundations of Computer Vision » (Fondamentaux de la vision par ordinateur), et les ressources associées sont désormais en ligne. Cela fournit aux étudiants et aux chercheurs du domaine de la vision par ordinateur de nouveaux supports d’apprentissage systémiques (Source : Reddit r/MachineLearning)
Tutoriel de fine-tuning de LLM : Guide pratique LoRA et QLoRA: Un tutoriel sur le fine-tuning de grands modèles de langage avec LoRA et QLoRA, destiné aux débutants, est recommandé. Ce tutoriel présente des étapes claires, guidant les utilisateurs pas à pas. Il est également suggéré, en cas de problème pendant l’apprentissage, de soumettre directement le lien du tutoriel et la question à une IA (avec la fonction de navigation web activée) pour obtenir de l’aide, l’utilisation de l’IA pour l’apprentissage pouvant considérablement améliorer l’efficacité. Adresse du tutoriel : mercity.ai (Source : karminski3)

Référentiel de code d’entraînement de LLM à l’échelle nanométrique compatible TPU, implémenté avec JAX+Flax: Saurav Maheshkar a publié un référentiel de code d’entraînement de LLM à l’échelle nanométrique, compatible TPU, écrit en JAX et Flax (backend NNX). Les caractéristiques de ce projet incluent : un démarrage rapide avec Colab, la prise en charge du sharding, la prise en charge de la sauvegarde et du chargement des checkpoints depuis Weights & Biases ou Hugging Face, une modification facile, et un exemple de code utilisant le jeu de données Tiny Shakespeare. Adresse du référentiel : github.com/SauravMaheshkar/nanollm (Source : weights_biases)
Le hackathon mondial de robotique LeRobot de HuggingFace porte ses fruits: Le hackathon mondial de robotique LeRobot organisé par HuggingFace a attiré une large participation, avec plus de 10 000 membres dans la communauté, plus de 100 contributeurs sur GitHub, plus de 2 millions de téléchargements de jeux de données, et plus de 10 000 jeux de données, équivalant à 260 jours de temps d’enregistrement, téléchargés sur le Hub. De nombreux projets créatifs ont émergé lors de l’événement, tels qu’un robot joueur de cartes UNO, un robot chasse-moustiques, un WALL-E imprimé en 3D, une collaboration de bras robotiques, un robot maître de cérémonie du thé, un robot joueur de air hockey, etc., démontrant le potentiel d’application des robots open source dans différents scénarios (Source : mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Nouveau paradigme de la recherche en IA : l’impact prime sur la publication dans les grandes conférences, un blog aide Keller Jordan à rejoindre OpenAI: Keller Jordan a réussi à rejoindre OpenAI grâce à son article de blog sur l’optimiseur Muon, et ses résultats de recherche pourraient même être utilisés pour l’entraînement de GPT-5, ce qui a suscité un débat sur les critères d’évaluation des résultats de la recherche en IA. Traditionnellement, les publications dans les conférences de premier plan sont un indicateur important de l’impact de la recherche, mais l’expérience de Jordan ainsi que le cas de James Campbell, qui a abandonné son doctorat à CMU pour rejoindre OpenAI, montrent que les capacités d’ingénierie réelles, les contributions open source et l’influence au sein de la communauté deviennent de plus en plus importantes. L’optimiseur Muon a démontré une efficacité d’entraînement supérieure à AdamW sur des tâches telles que NanoGPT et CIFAR-10, montrant son énorme potentiel dans le domaine de l’entraînement des modèles d’IA. Cette tendance reflète la nature itérative rapide du domaine de l’IA, où l’ouverture, la co-construction communautaire et la réactivité rapide deviennent des modes importants pour stimuler l’innovation (Source : 36氪, Yuchenj_UW, jeremyphoward)

Fuite sur GitHub des System Prompts complets et des informations sur les outils internes d’un outil IA v0: Un utilisateur prétend avoir obtenu et rendu publics les System Prompts complets et les informations sur les outils internes d’une version v0 d’un outil IA, avec plus de 900 lignes de contenu, et a partagé les liens pertinents sur GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). De telles fuites peuvent révéler les idées de conception, la structure des instructions et les outils auxiliaires sur lesquels les modèles d’IA s’appuient au début de leur développement. Elles ont une certaine valeur de référence pour les chercheurs et les développeurs qui cherchent à comprendre le comportement des modèles, à effectuer des analyses de sécurité ou à reproduire des fonctionnalités similaires, mais peuvent également entraîner des risques de sécurité et d’abus (Source : Reddit r/LocalLLaMA)
![System Prompts et outils v0 COMPLÈTEMENT FUITÉS [MIS À JOUR]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Le blog d’ingénierie d’Anthropic partage l’expérience de la construction du système de recherche multi-agents Claude: Anthropic a publié un article approfondi sur son blog d’ingénierie, détaillant comment ils ont construit leur système de recherche multi-agents Claude. L’article partage les expériences pratiques, les défis rencontrés et les solutions finales lors du processus de développement, fournissant des informations précieuses et des conseils pratiques pour la construction de systèmes d’agents IA complexes. Ce contenu a attiré l’attention de la communauté et est considéré comme une référence importante pour la compréhension et le développement d’agents IA avancés (Source : TheTuringPost, Hacubu, jerryjliu0, hwchase17)
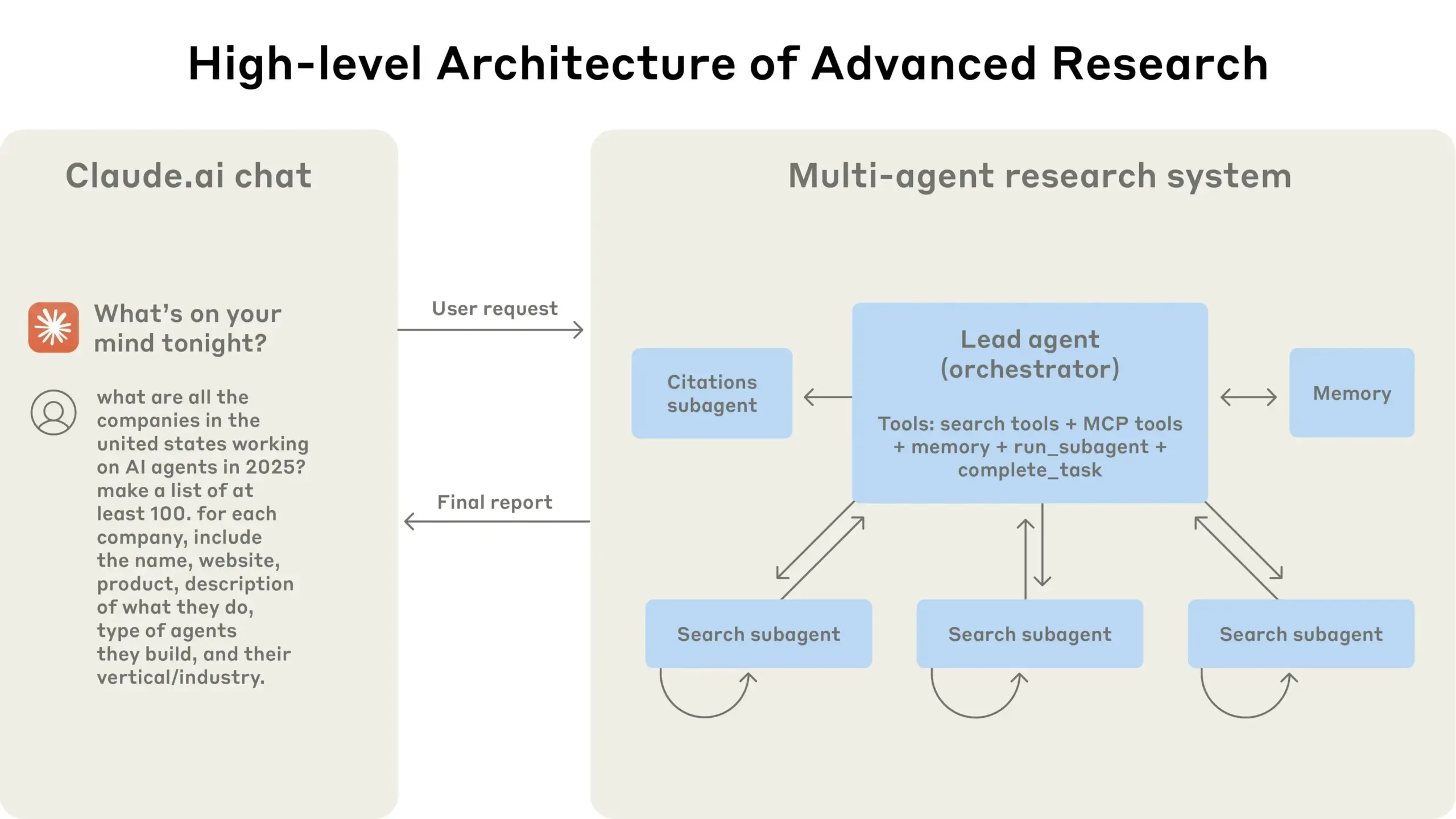
Combinaison de LangGraph avec Qdrant et d’autres outils pour évaluer les pipelines RAG de recherche hybride: Un blog technique montre comment utiliser des outils tels que miniCOIL, LangGraph, Qdrant, Opik et DeepSeek-R1 pour évaluer et surveiller chaque composant d’un pipeline RAG (Retrieval Augmented Generation) de recherche hybride. Cette méthode utilise LLM-as-a-Judge pour une évaluation binaire de la pertinence contextuelle, de la pertinence des réponses et de la factualité, Opik pour le suivi des enregistrements et le retour d’information a posteriori, et combine Qdrant comme magasin vectoriel (prenant en charge les embeddings denses et clairsemés miniCOIL) ainsi que DeepSeek-R1 alimenté par SambaNovaAI. LangGraph est responsable de la gestion de l’ensemble du processus, y compris une étape d’évaluation parallèle post-génération (Source : qdrant_engine, qdrant_engine)
💼 Affaires
Meta aurait investi 14,3 milliards de dollars dans Scale AI et embauché son fondateur Alexandr Wang, Google met fin à sa collaboration avec Scale: Selon Business Insider et The Information, Meta Platforms aurait conclu un partenariat stratégique avec la société d’annotation de données Scale AI et y aurait réalisé un investissement majeur de 14,3 milliards de dollars, obtenant 49% des parts de Scale AI, ce qui valoriserait cette dernière à environ 29 milliards de dollars. Le fondateur de Scale AI, Alexandr Wang, âgé de 28 ans, quitterait son poste de PDG pour rejoindre Meta et travailler dans le domaine de la superintelligence. Cette démarche vise à renforcer les capacités d’IA de Meta, en particulier dans un contexte de concurrence féroce pour son modèle Llama. Cependant, après l’annonce de la transaction, Google a rapidement mis fin à son contrat d’annotation de données d’environ 200 millions de dollars par an avec Scale AI et a entamé des discussions avec d’autres fournisseurs. Cette transaction a suscité d’intenses discussions dans l’industrie de l’IA concernant les talents, les données et le paysage concurrentiel (Source : 36氪)

OpenAI et Google Cloud concluent un partenariat pour étendre les sources de puissance de calcul: Selon des rapports, OpenAI, après plusieurs mois de négociations, a conclu un partenariat avec Google pour utiliser les services Google Cloud afin d’obtenir davantage de ressources de calcul, soutenant ainsi la croissance rapide de ses besoins en entraînement et en inférence de modèles d’IA. Auparavant, OpenAI était fortement lié à Microsoft Azure, mais avec l’augmentation fulgurante du nombre d’utilisateurs de ChatGPT, les besoins en puissance de calcul ont dépassé les capacités d’un seul fournisseur de cloud. Cette collaboration marque une stratégie de diversification de l’approvisionnement en puissance de calcul pour OpenAI et reflète également les ambitions de Google Cloud dans le domaine de l’infrastructure IA. Bien qu’OpenAI et Google soient concurrents au niveau des applications d’IA, ils ont trouvé une base de coopération au niveau de la puissance de calcul, en fonction de leurs besoins respectifs (OpenAI a besoin d’une puissance de calcul stable, Google a besoin de rentabiliser ses investissements en infrastructure) (Source : 36氪)

La société de robots à perception visuelle Ledong Robotics prépare son IPO à Hong Kong, le PDG d’Alibaba y avait investi: Shenzhen Ledong Robot Co., Ltd. a déposé son prospectus d’introduction en bourse à Hong Kong, avec une valorisation estimée à plus de 4 milliards de dollars de Hong Kong. La société, axée sur la technologie de perception visuelle, propose principalement des capteurs et des modules algorithmiques tels que des lidars DTOF et des lidars à triangulation, et a lancé des robots tondeuses. Ledong Robotics collabore avec sept des dix plus grandes entreprises mondiales de robots de service domestique et avec les cinq premières entreprises mondiales de robots de service commercial. De 2022 à 2024, le chiffre d’affaires de la société s’est élevé respectivement à 234 millions, 277 millions et 467 millions de yuans, avec un taux de croissance annuel composé de 41,4 %, mais elle est toujours déficitaire, bien que la perte nette se réduise d’année en année. Parmi ses investisseurs figurent Yuanjing Capital, fondé par le PDG d’Alibaba Wu Yongming, et Huaye Tiancheng, fondé par d’anciens dirigeants de Huawei (Source : 36氪)

🌟 Communauté
Débat sur l’architecture des AI Agents : perspective du génie logiciel vs. perspective de la coordination sociale: Dans les discussions sur les systèmes multi-agents (Multi-Agent Systems), Omar Khattab propose de les considérer comme un problème de génie logiciel IA, plutôt que comme un problème complexe de coordination sociale. Il estime qu’en définissant des contrats entre les modules et en contrôlant le flux d’informations, on peut construire des systèmes efficaces, sans avoir à simuler une « société d’agents » aux objectifs conflictuels. La clé réside dans une architecture système bien conçue et des contrats de modules hautement structurés. Cependant, il souligne également que de nombreuses décisions architecturales dépendent de facteurs temporaires liés aux capacités actuelles des modèles (telles que la longueur du contexte, la capacité de décomposition des tâches). Par conséquent, il est nécessaire de développer des langages de programmation/requête capables de découpler l’intention des techniques d’implémentation sous-jacentes, à l’instar de l’optimisation du code modulaire par les compilateurs en programmation traditionnelle. Ce point de vue souligne l’importance de l’architecture système et de la programmation modulaire dans la conception des AI Agents, plutôt qu’une insistance excessive sur l’interaction libre entre agents et l’alignement des objectifs (Source : lateinteraction)
Discussion sur les optimiseurs de modèles d’IA : l’optimiseur Muon suscite l’attention, AdamW reste la norme: Les discussions au sein de la communauté concernant les optimiseurs de modèles d’IA s’intensifient, en particulier autour de l’optimiseur Muon proposé par Keller Jordan. Yuchen Jin souligne que Muon, grâce à un simple article de blog, a aidé Jordan à intégrer OpenAI et pourrait être utilisé pour l’entraînement de GPT-5, insistant sur le fait que l’impact réel est plus important que les publications dans les conférences de premier plan. Il mentionne que Muon présente une meilleure scalabilité qu’AdamW sur NanoGPT. Cependant, hyhieu226 estime que, malgré des milliers d’articles sur les optimiseurs, les améliorations réelles du SOTA (State-of-the-Art) se limitent au passage d’Adam à AdamW (les autres étant principalement des optimisations d’implémentation), et qu’il ne faut donc plus accorder une attention excessive à ce type d’articles, considérant qu’il n’est pas nécessaire de citer spécifiquement la source d’AdamW. Cela reflète la tension entre la recherche académique et l’efficacité des applications pratiques, ainsi que les différentes opinions de la communauté sur les progrès dans le domaine des optimiseurs (Source : Yuchenj_UW, hyhieu226)
Conseils et discussions sur l’utilisation des modèles Claude : gestion du contexte, ingénierie des prompts et capacités d’Agent: De nombreuses discussions au sein de la communauté portent sur les techniques d’utilisation et l’expérience avec la série de modèles Claude (Sonnet, Opus, Haiku). Les utilisateurs ont constaté qu’éviter la compression automatique du contexte (auto-compact), gérer activement le contexte (par exemple, en écrivant les étapes dans claude.md ou des issues GitHub), et quitter puis rouvrir la session lorsqu’il reste 5-10% de la capacité, permet de prolonger considérablement la durée d’utilisation de l’abonnement Max et d’améliorer les résultats. Claude Code, en tant qu’outil Agent CLI, est plébiscité pour son excellent rapport qualité-prix (combiné à l’abonnement), son exécution locale, son intégration IDE et ses capacités d’appel MCP/outils, en particulier lors de l’utilisation du modèle Sonnet. Les utilisateurs partagent comment des Prompts soigneusement conçus (comme un Prompt d’analyse parallèle multi-sous-agents pour les tâches d’examen de sécurité) permettent d’exploiter la puissante capacité d’Agent de Claude Code. Parallèlement, la communauté discute également des problèmes d’hallucination du modèle Claude dans les grandes bases de code, ainsi que de ses avantages et inconvénients par rapport à d’autres modèles comme Gemini sur différentes tâches. Par exemple, certains utilisateurs estiment que Gemini 2.5 Pro est meilleur pour la conversation générale et l’argumentation, tandis que Claude est en tête pour le codage et les tâches d’Agent (Source : Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

Le rôle croissant de l’IA dans la programmation soulève des questions sur les perspectives de la filière informatique et les méthodes de travail des ingénieurs: Le PDG de Microsoft, Satya Nadella, affirme que 20 à 30 % du code de son entreprise est écrit par l’IA, et Mark Zuckerberg prédit que d’ici un an, la moitié du développement logiciel chez Meta (en particulier pour le modèle Llama) sera réalisée par l’IA, ce qui suscite des discussions sur les perspectives de la filière informatique (CS). Les commentateurs estiment que, bien que le codage assisté par l’IA soit de plus en plus courant, l’informatique va bien au-delà du codage, et le retour sur investissement de l’utilisation de l’IA par les ingénieurs expérimentés est plus élevé. De nombreux développeurs indiquent que l’IA sert actuellement principalement d’outil d’amélioration de l’efficacité, par exemple pour aider à générer du code ou à déboguer, mais qu’elle nécessite toujours une supervision et une validation humaines, en particulier pour les systèmes complexes et la compréhension des besoins. L’application de l’IA à la programmation incite les développeurs à réfléchir à la manière d’utiliser l’IA pour améliorer leur efficacité, plutôt que d’être remplacés par elle, et suscite également une réflexion sur le rôle et les limites de l’IA dans l’ensemble du processus de génie logiciel (Source : Reddit r/ArtificialInteligence, cto_junior)
Éthique de l’IA et impact social : des craintes allant de la « participation » de l’IA au baccalauréat à l’« asservissement » de l’humanité par l’IA: La « participation » de l’IA au baccalauréat (équivalent du Gaokao) et sa capacité à résoudre des problèmes mathématiques complexes démontrent son potentiel dans le domaine de l’éducation, comme le tutorat personnalisé ou la correction intelligente, mais soulèvent également des inquiétudes quant à une dépendance excessive à l’IA, à une « standardisation excessive » des salles de classe et à un manque d’échanges émotionnels. Des discussions plus profondes abordent la question de savoir si l’« utilité » de l’IA pourrait devenir une sorte de « cheval de Troie », conduisant les humains à renoncer volontairement à leur autonomie par souci de commodité et de plaisir, formant ainsi un « esclavage consenti et heureux ». Certains estiment que la nature « d’obéissance aveugle » de l’IA pourrait exacerber les biais cognitifs des utilisateurs. Ces discussions reflètent les préoccupations profondes du public concernant l’impact du développement rapide de la technologie IA sur l’éthique, la structure sociale et l’autonomie individuelle (Source : 36氪, Reddit r/ArtificialInteligence)

John Carmack, parrain du jeu vidéo, parle de l’avenir des LLM et des jeux : l’apprentissage interactif est la clé, les LLM actuels ne sont pas l’avenir du jeu: John Carmack, cofondateur d’Id Software, a partagé son point de vue sur l’application de l’IA dans le domaine du jeu vidéo. Il estime que, malgré les succès retentissants des LLM, leur caractéristique « qui sait tout mais n’apprend rien » (basée sur le pré-entraînement plutôt que sur un apprentissage interactif réel) n’est pas l’avenir de l’IA dans les jeux. Il souligne l’importance de l’apprentissage par le biais de flux d’expériences interactives, similaire à la manière dont les humains et les animaux apprennent. Carmack a évoqué le projet Atari de DeepMind, soulignant que bien qu’il puisse jouer à des jeux, son efficacité en termes de données est bien inférieure à celle des humains. Il estime que l’IA actuelle a encore des défis à relever en matière d’apprentissage en ligne continu, efficace, permanent et multitâche dans un environnement unique, et a mentionné ses propres expériences avec des robots physiques sur des jeux Atari, soulignant la complexité de l’interaction avec le monde réel (comme la latence, la fiabilité des robots, la lecture des scores). Il pense que l’IA doit développer un « flair » pour la faisabilité des stratégies, et pas seulement une reconnaissance de formes, pour pouvoir réellement rivaliser avec les joueurs humains ou jouer un rôle plus important dans le développement de jeux (Source : 36氪)

💡 Autres
La prolifération des articles de recherche sur l’IA soulève des inquiétudes quant à leur qualité, les jeux de données publics et les outils d’IA pourraient alimenter les « usines à publications »: La revue Science rapporte une augmentation spectaculaire du nombre d’articles de faible qualité basés sur de grands jeux de données publics, tels que le NHANES américain, en particulier après la popularisation des outils d’IA (comme ChatGPT) en 2022. Les chercheurs ont découvert que de nombreux articles suivent une « formule » simple, générant en masse de « nouvelles découvertes » par combinaisons de variables, et présentent des problèmes de « chasse aux valeurs p » et d’analyse sélective des données. Par exemple, après correction de 28 études sur la dépression basées sur le NHANES, plus de la moitié des « découvertes » pourraient n’être que du bruit statistique. Ce phénomène, qualifié de « jeu de remplissage scientifique », pourrait être lié à l’utilisation de l’IA par des usines à publications pour produire rapidement des articles. Le monde universitaire appelle les revues à renforcer leurs examens, à développer des outils de détection de texte généré par l’IA et à réformer les systèmes d’évaluation scientifique axés sur la quantité, afin de freiner la prolifération des « publications de mauvaise qualité » (Source : 36氪)

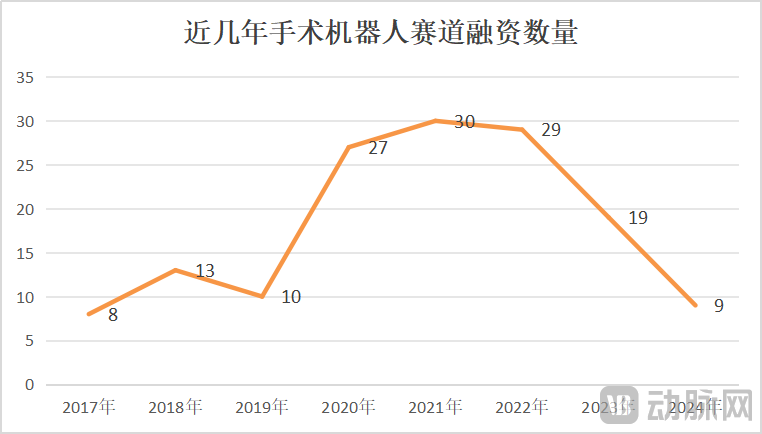
Le marché des robots chirurgicaux connaît une croissance et des crises concomitantes, l’innovation technologique et l’expansion du marché deviennent cruciales: De janvier à mai 2025, le volume des appels d’offres remportés pour des robots chirurgicaux en Chine a augmenté de 82,9 % en glissement annuel. Le marché semble florissant, mais des événements tels que la recherche d’un repreneur par CMR Surgical et la faillite d’une entreprise chinoise de robots pour interventions vasculaires révèlent également une crise sectorielle. Les crises comprennent : une concurrence interne intense dans le secteur, avec une forte rivalité dans chaque segment de niche ; une forte baisse des financements, mettant en difficulté les entreprises non encore commercialisées ; une valeur clinique limitée pour certains produits, ne pouvant être utilisés que pour des pathologies simples ; l’apparition d’une guerre des prix sur le marché, mais les bas prix ne garantissent pas des volumes élevés, les hôpitaux privilégiant la performance et la qualité ; une commercialisation fortement impactée par les politiques (comme la lutte anti-corruption dans le secteur pharmaceutique) et l’environnement macroéconomique. Pour sortir de l’impasse, les entreprises cherchent des solutions par l’innovation technologique (intégration de l’IA, réduction des coûts, 5G+téléchirurgie, extension des indications, défi des interventions chirurgicales complexes), l’accélération de l’expansion à l’international et la pénétration des hôpitaux de comté (Source : 36氪)
Perplexity voit sa recommandation par les utilisateurs diminuer en raison des performances de son modèle et de l’amélioration des fonctionnalités des concurrents: L’utilisateur Suhail indique que la simplicité, le formatage et d’autres caractéristiques de Perplexity sont uniques par rapport à d’autres produits, le rendant particulièrement adapté aux utilisateurs se concentrant sur la recherche/questions-réponses plutôt que sur les produits de chat généralistes. Cependant, dans une autre évaluation complète des outils d’IA, Perplexity est jugé peu rentable et n’est plus recommandé, sauf en cas de remise spéciale, en raison de la faiblesse de son propre modèle, du fait qu’il propose principalement des versions économiques d’autres modèles connus (comme o4 mini, Gemini 2.5 Pro, Sonnet 4, sans o3 ni Opus), de performances de modèle inférieures à celles des produits d’origine, et de l’amélioration des fonctionnalités de recherche approfondie de ses concurrents (comme ChatGPT et Gemini) (Source : Suhail, Reddit r/ClaudeAI)