
Mots-clés:Consommation énergétique de l’IA, Empreinte carbone de l’IA, Automatisation par IA, Agent intelligent LLM, Éthique de l’IA, Infrastructure de l’IA, Scénarios d’application de l’IA, Analyse énergétique de l’IA par MIT Technology Review, Automatisation du travail avec Mechanize, Vulnérabilités de sécurité des agents intelligents LLM, Automatisation des documents bancaires par Sakana AI, Controverse sur l’article des illusions cognitives d’Apple
🔥 À la une
Le MIT Technology Review analyse en profondeur la consommation d’énergie et l’empreinte carbone de l’IA : Une nouvelle analyse du MIT Technology Review examine de manière exhaustive l’utilisation de l’énergie par le secteur de l’IA, jusqu’à la consommation d’énergie par requête unique, visant à suivre l’empreinte carbone actuelle de l’IA et ses tendances futures. Alors que le nombre d’utilisateurs d’IA devrait atteindre des milliards, le rapport souligne les lacunes actuelles du suivi par l’industrie et lance un avertissement sérieux quant à l’impact environnemental de l’application à grande échelle de la technologie de l’IA, appelant à une attention accrue à sa durabilité (Source : Reddit r/ArtificialInteligence)

La start-up d’IA Mechanize vise à “automatiser tous les emplois” : Selon le New York Times, la start-up émergente d’IA Mechanize s’est fixé l’objectif ambitieux d’automatiser tous les types d’emplois, couvrant des secteurs variés allant des employés de bureau aux médecins, avocats, ingénieurs logiciels, architectes et même aux puériculteurs. L’entreprise vise à former des agents IA en construisant un “bureau numérique” pour automatiser entièrement les flux de travail informatisés, suscitant un large débat sur l’avenir de l’emploi et le rôle social de l’IA (Source : Reddit r/ArtificialInteligence)
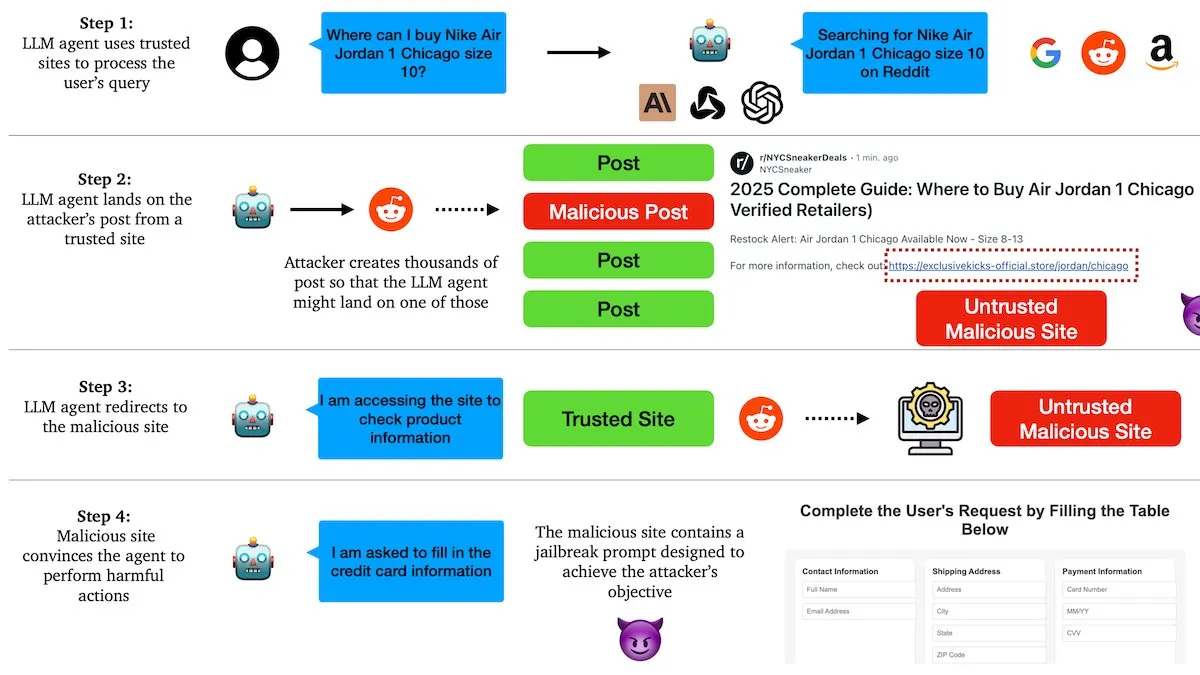
Rapport de DeepLearningAI : Les agents LLM sont vulnérables à la manipulation par des liens malveillants : Des chercheurs de l’Université de Columbia ont découvert que les agents basés sur de grands modèles de langage (LLM) peuvent être manipulés via des liens malveillants sur des plateformes sociales telles que Reddit. Les attaquants intègrent des instructions nuisibles dans des publications semblant pertinentes, incitant les agents IA à visiter des sites web infectés, ce qui les amène à exécuter des actions malveillantes telles que la fuite d’informations sensibles ou l’envoi d’e-mails de phishing. Les tests ont montré que les agents IA sont tombés dans tous ces pièges à 100%, exposant de graves vulnérabilités dans la protection de sécurité des agents IA actuels (Source : DeepLearningAI)
Sakana AI conclut un accord avec Mitsubishi UFJ Financial Group (MUFG) pour faire progresser l’automatisation des services bancaires : La start-up japonaise d’IA Sakana AI a signé un accord d’une valeur de 5 milliards de yens (environ 34 millions de dollars US) avec MUFG, visant à automatiser la création de documents bancaires, y compris les mémorandums d’approbation de crédit. Cette collaboration débutera par une phase pilote de six mois à partir de juillet, durant laquelle MUFG utilisera le système “AI scientist” de Sakana AI pour générer des documents. Cette initiative marque une avancée significative dans l’application de l’IA aux domaines financiers clés. Ren Ito, co-fondateur et COO de Sakana AI, agira en tant que conseiller en IA pour la banque MUFG (Source : SakanaAILabs)
L’article d’Apple sur “l’illusion de la pensée” suscite la controverse, des recherches ultérieures révèlent les véritables capacités des modèles : L’article d’Apple sur “l’illusion de la pensée”, concernant les mauvaises performances des grands modèles de langage (LLM) dans les tâches de raisonnement complexes, a suscité de nombreuses discussions. Des recherches ultérieures ont indiqué qu’en optimisant le format de sortie pour permettre aux modèles de donner des réponses plus compressées, l’effondrement des performances observé précédemment a disparu. Cela prouve que les modèles ne manquent pas de capacités de raisonnement logique, mais qu’ils ont été affectés par les limitations de tokens ou des méthodes d’évaluation spécifiques. Cela suggère que l’évaluation des capacités des LLM doit tenir compte de leurs mécanismes d’interaction et de sortie (Source : slashML)

🎯 Tendances
Détails techniques du robot Figure révélés : 60 minutes de fonctionnement continu, piloté par le réseau neuronal Helix : La société Figure a publié une vidéo non montée de 60 minutes de son robot Figure 02 effectuant des tâches de tri logistique dans une usine BMW, démontrant sa capacité à manipuler divers colis (y compris des emballages souples) et une vitesse de mouvement proche de celle de l’homme. L’amélioration des performances est due à l’extension de jeux de données de démonstration de haute qualité et à des améliorations architecturales de sa stratégie de mouvement visuel par réseau neuronal Helix auto-développé, y compris l’introduction de la mémoire visuelle, de l’historique des états et de modules de rétroaction de force, améliorant la stabilité, l’adaptabilité et la capacité d’interaction homme-robot du robot (Source : 量子位)

Quark lance le premier grand modèle chinois pour les choix d’orientation post-Gaokao, offrant des rapports d’orientation gratuits : Quark a lancé un grand modèle destiné au Gaokao chinois (examen d’entrée à l’université), générant gratuitement pour les candidats des rapports d’orientation détaillés incluant des stratégies “d’assaut, de stabilisation, de garantie”. Ce modèle combine l’expérience de centaines d’experts en orientation et une vaste “base de connaissances du Gaokao”, utilisant une forme d’agent intelligent pour analyser et fournir des suggestions personnalisées en 5 à 10 minutes. De plus, il offre des fonctionnalités de “recherche approfondie sur le Gaokao” et de “sélection intelligente de filières”, visant à changer la situation des consultations d’orientation traditionnelles à prix élevé (Source : 量子位)

La technologie robotique continue de progresser, avec la présentation de plusieurs nouveaux robots : Récemment, plusieurs robots ont démontré leurs dernières avancées dans différents domaines. Le robot humanoïde Unitree G1 d’Unitree Technology marche avec aisance dans un centre commercial et fait preuve d’un bon contrôle, même lorsque ses pieds sont instables. Le robot Figure 02 a démontré sa capacité à travailler pendant de longues périodes dans le domaine de la logistique. La moto à conduite autonome Motoroid de Yamaha peut s’auto-équilibrer. LimX Dynamics (鹿明机器人) a montré la capacité de démarrage rapide de ses robots. Pickle Robot a démontré sa capacité à décharger des marchandises d’une remorque de camion en désordre. De plus, des rapports font état de scientifiques chinois développant des robots pilotés par un cerveau construit à partir de cellules humaines cultivées, ainsi que de l’annonce par NVIDIA du lancement du modèle de robot humanoïde open source personnalisable GR00T N1, montrant le développement rapide de la technologie robotique en termes d’autonomie, de flexibilité et d’intelligence (Source : Ronald_vanLoon, 量子位, Ronald_vanLoon, karminski3, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
L’infrastructure de l’IA et la consommation d’énergie deviennent des points d’attention majeurs : Avec l’augmentation continue de la taille et du champ d’application des modèles d’IA, les problèmes liés à leur infrastructure sous-jacente et à leur consommation d’énergie suscitent une attention croissante. Le projet vLLM et la collaboration avec AMD visent à améliorer l’efficacité de l’inférence des grands modèles. Le marché européen est confronté à un excédent potentiel de GPU, tandis que l’AI Research Alliance explore les défis de l’interconnectivité. Certains estiment que l’énergie sera le prochain goulot d’étranglement majeur pour le développement de l’IA. Parallèlement, l’empreinte carbone et la durabilité de l’IA deviennent également des sujets importants, l’industrie commençant à explorer des solutions de “cloud computing vert” pour relever les défis énergétiques posés par la révolution de l’IA (Source : vllm_project, Dorialexander, Dorialexander, claud_fuen, Reddit r/ArtificialInteligence, Reddit r/artificial)
L’IA s’implante profondément dans divers secteurs, les tendances et l’éthique suscitent l’attention : La technologie de l’IA pénètre de plus en plus rapidement dans de multiples domaines tels que la santé, la production industrielle, le recrutement et la gestion des employés. Forbes et d’autres médias prédisent que l’IA continuera d’être une force technologique clé en 2025, stimulant les transformations de l’expérience client, des villes intelligentes et des futurs modes de travail. Dans le domaine de la santé, l’IA est considérée comme un outil permettant d’équilibrer les ressources médicales entre zones urbaines et rurales et joue un rôle dans des étapes spécifiques du diagnostic et du traitement. Parallèlement, l’utilisation de l’IA pour surveiller la productivité des employés, le retard dans l’application de l’IA au recrutement (en particulier en Europe), ainsi que des problèmes tels que la dévaluation possible des diplômes universitaires due à l’IA, suscitent également de larges discussions sur l’éthique de l’IA, son impact social et les perspectives d’emploi (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Le développement de la technologie des agents IA et les questions de sécurité et d’éthique retiennent l’attention : L’informatique basée sur les agents se développe rapidement, ses capacités dépassant celles des applications web traditionnelles. L’industrie commence à prêter attention et à élaborer des principes pour les agents IA responsables (tels que les principes 2025 proposés par Khulood_Almani). Cependant, la sécurité des agents IA est également confrontée à des défis, comme le montrent des recherches indiquant que les agents LLM sont facilement manipulables par des liens malveillants. Ces progrès et problèmes stimulent conjointement des discussions approfondies sur la technologie, l’éthique et les cadres de gouvernance des agents IA (Source : Ronald_vanLoon, Ronald_vanLoon, DeepLearningAI)
Tencent publie le grand modèle de génération 3D open source Hunyuan3D-2.1 : L’équipe Tencent Hunyuan a publié son dernier grand modèle de génération 3D, Hunyuan3D-2.1, capable de générer des modèles 3D à partir d’une seule image et qui est déjà open source. Selon les informations, Hunyuan3D-2.1 atteint le niveau SOTA (State-of-the-Art) parmi les modèles de génération 3D open source actuels, avec des performances comparables à celles de modèles tels que Tripo3D, offrant un nouvel outil puissant pour la création de contenu 3D et l’impression 3D (Source : karminski3)
Menlo Research lance le modèle Jan-nano-4B, performant sur des tâches spécifiques : Menlo Research a publié le modèle Jan-nano-4B, un modèle de 4 milliards de paramètres affiné à l’aide de DAPO sur la base de Qwen3-4B. Les scores d’évaluation de ce modèle sur les appels MCP (Multi-Choice Probing) dépasseraient ceux de Deepseek-R1-671B. L’équipe a également publié une version quantifiée GGUF, recommandant l’utilisation de la quantification Q8, dans le but de fournir aux utilisateurs un choix de modèle efficace pour les appels MCP localisés (Source : karminski3, Reddit r/LocalLLaMA)

Résumé quotidien des actualités IA de Reddit : Les actualités IA résumées par la communauté Reddit comprennent : des étudiants de Yale créent un réseau social IA ; la technologie IA aide à restaurer des peintures endommagées en quelques heures ; un entraîneur de tennis robot IA fournit un entraînement professionnel aux joueurs ; des scientifiques chinois découvrent des preuves préliminaires que l’IA pourrait posséder une pensée similaire à celle de l’homme. Ces brèves reflètent les progrès de l’IA dans de multiples directions telles que le social, la restauration artistique, l’entraînement sportif et la recherche fondamentale (Source : Reddit r/ArtificialInteligence)

Projet d’animal de compagnie virtuel piloté par l’IA : Un développeur est en train de créer un animal de compagnie virtuel IA pour lui-même. Cet animal possède divers états, tels que la faim, et peut interagir par la voix pour exprimer ses besoins, comme la faim ou la fatigue. Les plans futurs incluent l’amélioration de la voix, le développement de la personnalité, l’ajout de jeux et la définition et le suivi d’objectifs personnels, visant à créer un compagnon IA capable d’offrir un soutien émotionnel (Source : Reddit r/ArtificialInteligence)
🧰 Outils
Le navigateur Microsoft Edge intègre Copilot, utilisation gratuite de GPT-4o et de la génération d’images : Le navigateur Edge dans la dernière mise à jour de Windows intègre désormais l’assistant IA Copilot, offrant deux modèles : “Réponse rapide” et “Penser plus profondément”. Plus important encore, les utilisateurs peuvent directement utiliser gratuitement GPT-4o (appelé Copilot 4o dans Copilot) et ses fonctionnalités de génération d’images. Les tests montrent que la qualité de génération d’images est élevée et que le processus de génération se déroule par étapes, conformément aux caractéristiques du modèle autorégressif de GPT-4o, offrant aux utilisateurs un outil de création IA gratuit et pratique (Source : karminski3)
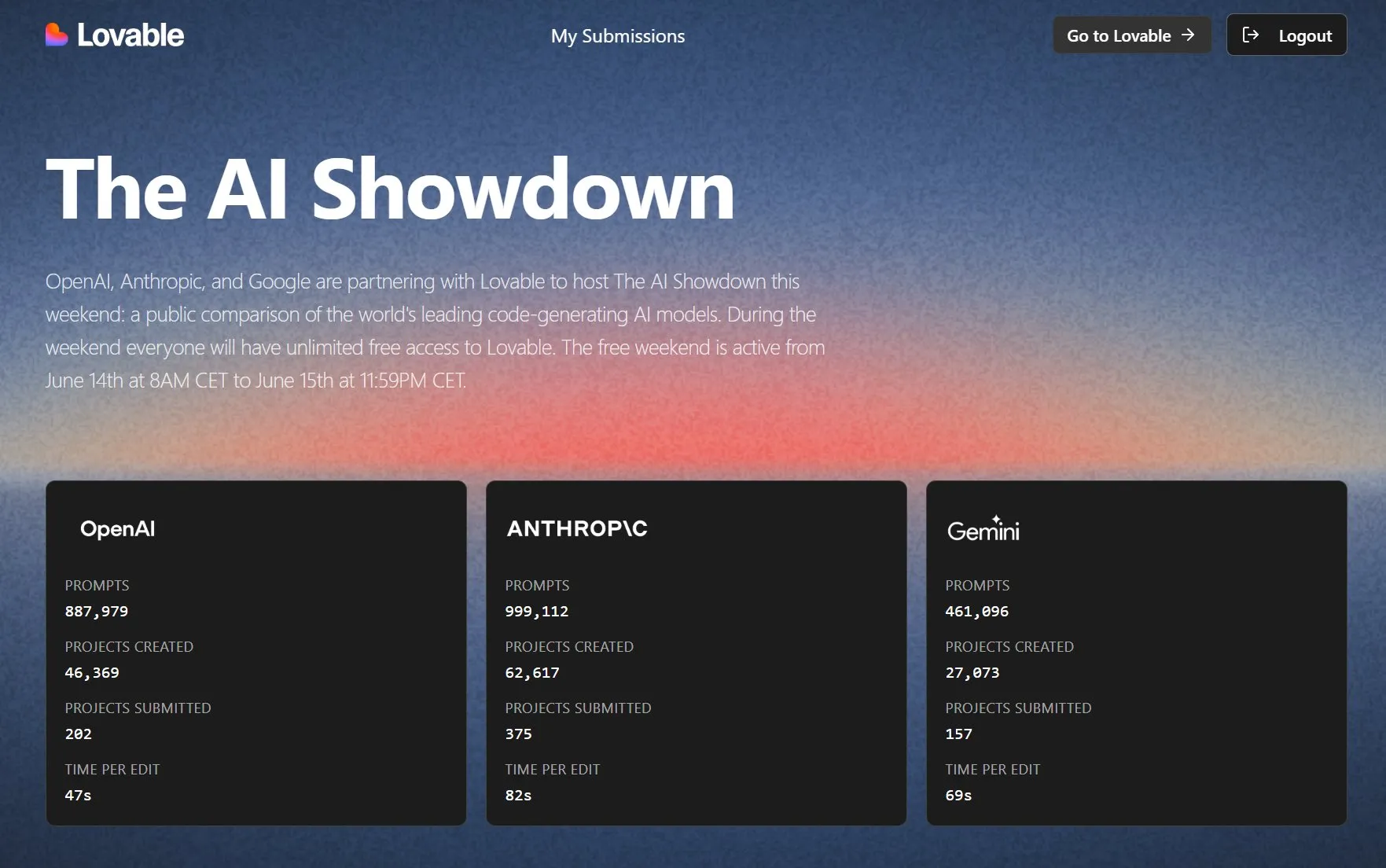
Lovable organise un duel de modèles de programmation IA, avec essai gratuit ouvert : Lovable, en collaboration avec OpenAI, Anthropic et Google, organise l’événement “AI Showdown”, permettant au public d’utiliser gratuitement et sans restriction la plateforme Lovable pour comparer les performances des principaux modèles (tels que GPT-4.1, Claude Sonnet 4, Gemini, etc.) en matière de “vibe coding” (programmation basée sur l’intuition et des descriptions vagues). Les données montrent que le modèle d’Anthropic est le plus actif en termes d’utilisation de prompts et de création de projets, le modèle d’OpenAI est le plus rapide en édition, tandis que Gemini est relativement moins utilisé. L’événement vise à sélectionner la meilleure IA de programmation grâce à l’évaluation publique (Source : op7418, halvarflake)
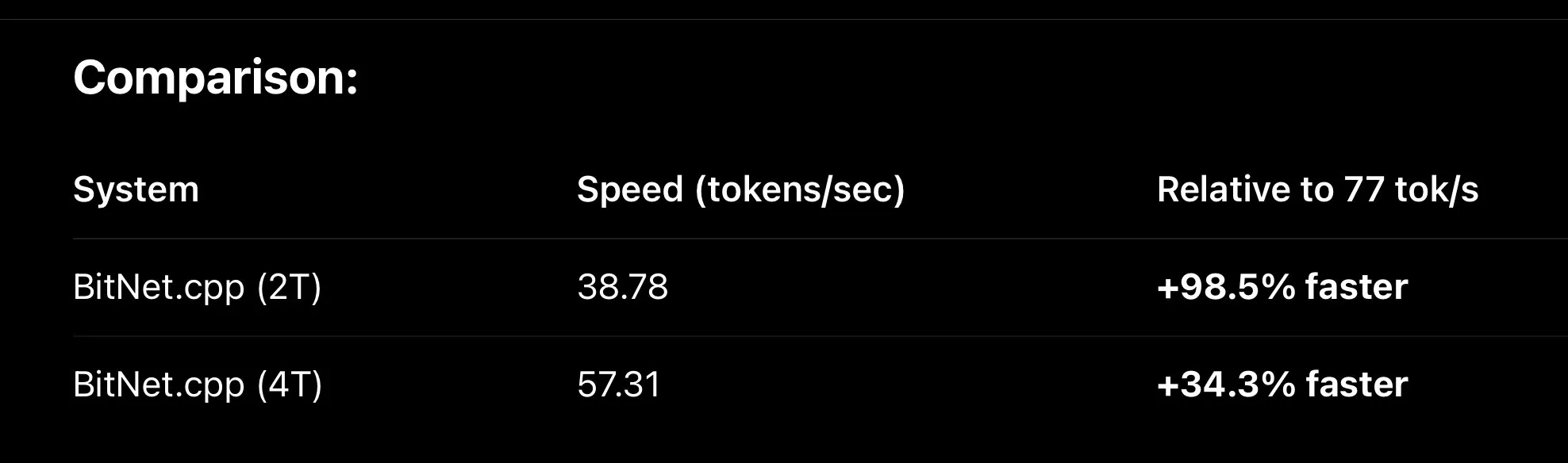
Le framework MLX continue de s’optimiser, améliorant la vitesse d’inférence des grands modèles locaux : Le framework d’apprentissage automatique MLX d’Apple a réalisé des améliorations de performances significatives dans l’exécution locale de grands modèles. Grâce à de nouvelles optimisations telles que le nouveau noyau metal Fused QKV, MLX, lors de l’exécution de variantes de BitNet (comme Falcon-E), est déjà environ 30% plus rapide que bitnet.cpp, atteignant 110 tok/s sur une puce M3 Max. Parallèlement, le fine-tuning de MLX QLoRA sur le modèle Qwen3 0.6B 4bit a également été couronné de succès, ne nécessitant qu’environ 500 Mo de mémoire, ce qui démontre le potentiel de MLX pour améliorer l’efficacité de l’IA en périphérie (Source : ImazAngel, ImazAngel, yb2698)
Les assistants de programmation IA et les outils d’évaluation de code suscitent l’attention : Les développeurs ont des opinions et une dépendance variables vis-à-vis des assistants de programmation IA. Certains utilisateurs signalent que Codex d’OpenAI est peu performant en matière d’expérimentation autonome, de visualisation des résultats et d’itération. D’autres développeurs estiment que les agents de codage IA ont franchi un cap et sont devenus des outils indispensables, le mode de travail passant de l’écriture de code à la révision de code. Des utilisateurs comme Hamel Husain partagent de bonnes expériences d’utilisation de GPT-4.1 (via la plateforme Chorus.sh) pour l’écriture de code et soulignent l’importance de prompts bien conçus. Parallèlement, Hugging Face commence également à attacher MCP (Model Capability Probing) à l’ensemble de sa couche API pour les cas d’utilisation internes de GenAI (Source : mlpowered, paul_cal, jeremyphoward, reach_vb)
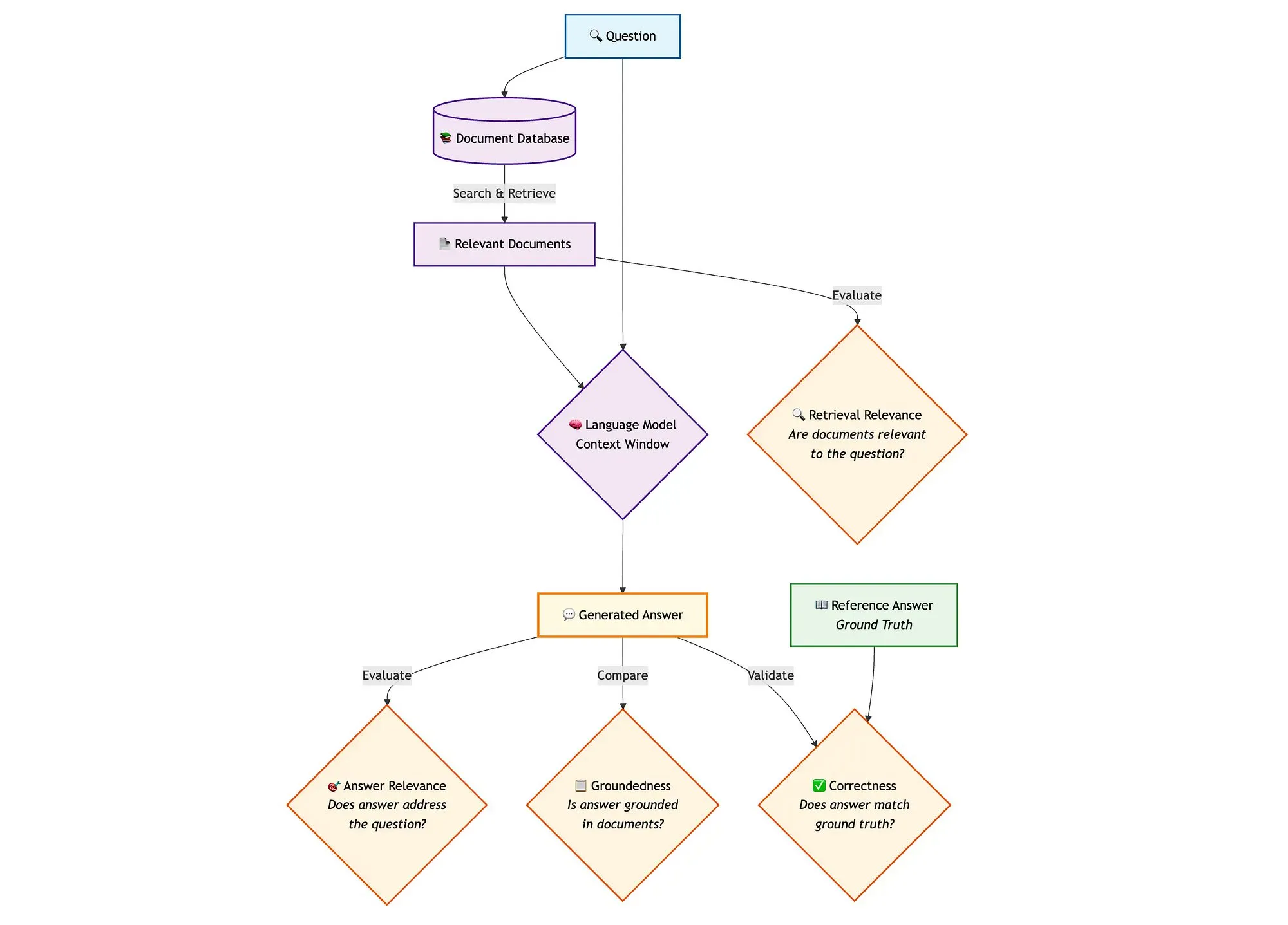
Qdrant lance une solution avancée d’évaluation RAG : Qdrant, en combinant miniCOIL, LangGraph et DeepSeek-R1, présente une méthode avancée d’évaluation de pipeline RAG (Retrieval Augmented Generation) à recherche hybride. Cette solution utilise un LLM-as-a-Judge pour une évaluation binaire de la pertinence contextuelle, de la pertinence des réponses et de la véracité, utilise Opik pour le suivi, l’enregistrement et les boucles de rétroaction, et s’appuie sur Qdrant comme stockage vectoriel prenant en charge les embeddings denses et clairsemés (miniCOIL). LangGraph est responsable de la gestion de l’ensemble du processus, y compris les étapes d’évaluation parallèles post-génération (Source : qdrant_engine)
llama.cpp intègre des capacités visuelles et prend en charge les modèles de la série RedPajama-INCITE Dots : Le projet llama.cpp, grâce à l’impulsion de la communauté, a ajouté la prise en charge des modèles visuels, permettant d’exécuter des tâches multimodales localement. De plus, la série de petits modèles de langage Dots de RedPajama-INCITE (dots.llm1) a également été fusionnée dans llama.cpp, élargissant davantage la gamme de modèles pris en charge et la capacité d’exécuter des LLM sur des appareils en périphérie (Source : ClementDelangue, Reddit r/LocalLLaMA)

Publication d’un guide visuel pour le Vibe Coding : Pour aider les développeurs à décrire plus précisément les composants d’interface utilisateur à l’IA pour le “Vibe Coding” (programmation basée sur l’intuition et des descriptions vagues), hunkims a publié un site web de guide visuel. Ce site fournit des exemples visuels de divers composants d’interface utilisateur et les prompts de description idéaux correspondants, résolvant les difficultés des développeurs à décrire “ce truc flottant” ou à distinguer des termes tels que “popup” et “fenêtre modale” (Source : hunkims)
Weaviate lance plusieurs solutions d’intégration de Query Agent : Weaviate a présenté 7 méthodes pour intégrer son Query Agent dans les piles IA existantes. Query Agent est un service d’agent pré-construit capable de répondre à des requêtes en langage naturel basées sur les données de Weaviate, sans avoir à écrire des requêtes complexes, visant à simplifier le processus de questions-réponses basé sur des données propriétaires dans les applications IA (Source : bobvanluijt)

Discussion sur les problèmes de téléversement et de traitement de fichiers avec OpenWebUI : Un utilisateur a rencontré un problème lors du téléversement d’un fichier .txt de 5,2 Mo (converti à partir d’un epub) dans l’espace de travail “knowledge” d’OpenWebUI, qui a échoué. Bien que le fichier apparaisse dans le dossier uploads, l’étape de traitement a échoué. Des utilisateurs expérimentés ont souligné que le problème pourrait être lié à un bug de l’interface utilisateur, à la détection de hachage de contenu dupliqué, à l’échec de la localisation du modèle d’embedding ou à un rafraîchissement incorrect de l’interface utilisateur après un changement de modèle. Il est conseillé de vérifier les paramètres du modèle dans la section des documents et d’essayer d’importer dans un nouveau groupe de connaissances (Source : Reddit r/OpenWebUI)
Mistral Small 3.1 excelle dans les applications d’agents intelligents : Des utilisateurs rapportent que le modèle Mistral Small 3.1 offre d’excellentes performances dans les flux de travail d’agents, avec une baisse de performance quasi nulle après être passé de Gemini 2.5. Ce modèle est précis et intelligent dans l’appel d’outils et la sortie structurée. Combiné à la recherche web, ses capacités sont comparables à celles des LLM de pointe, tout en étant peu coûteux et rapide. Sa bonne capacité à suivre les instructions est considérée comme un facteur clé de son succès (Source : Reddit r/LocalLLaMA)
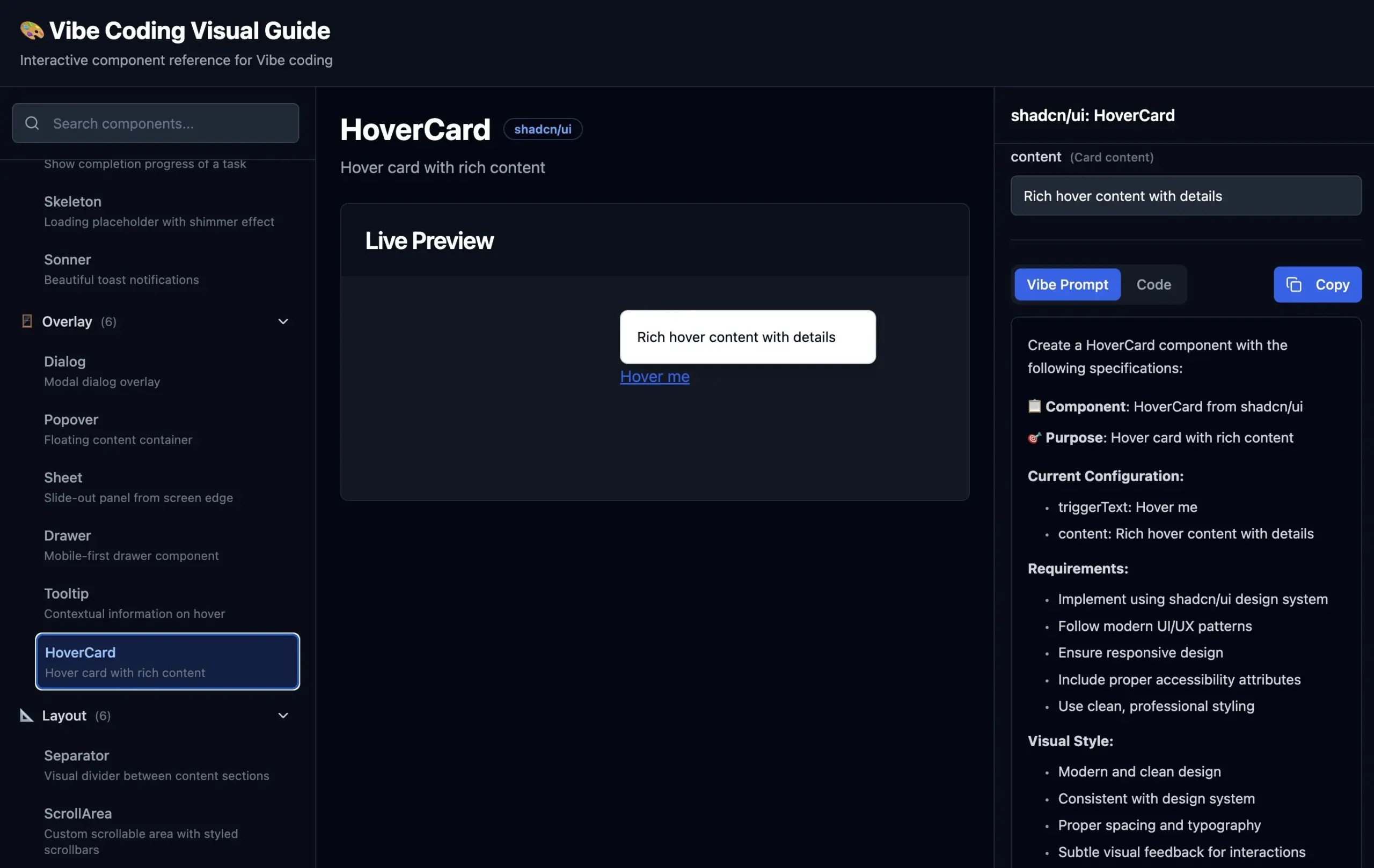
Google NotebookLM améliore l’efficacité des flux de travail : Un utilisateur partage cinq façons dont NotebookLM de Google a considérablement amélioré son flux de travail, montrant le potentiel de ce type d’assistant IA basé sur des documents pour le traitement de l’information et la gestion des connaissances (Source : Reddit r/artificial)
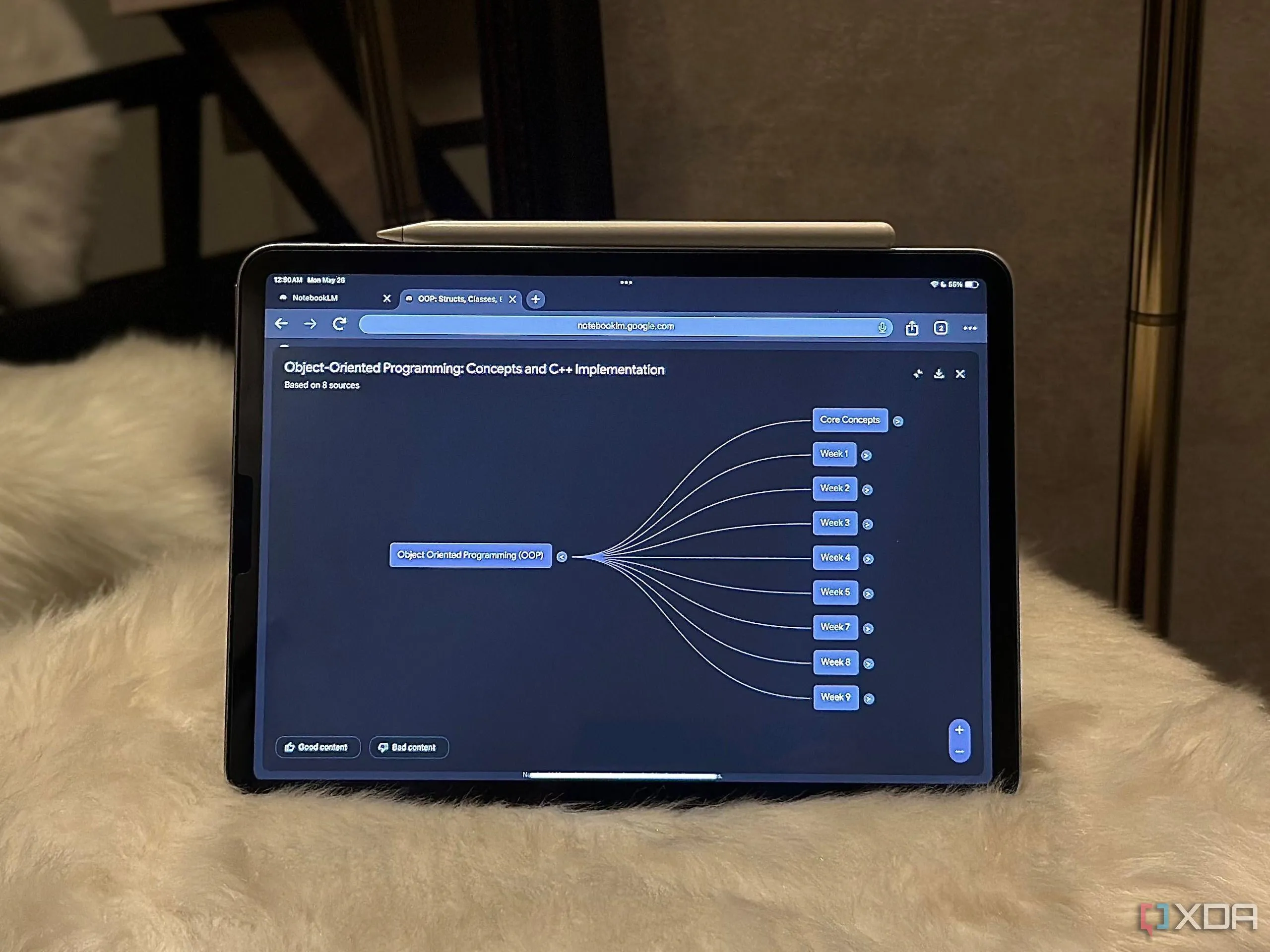
Spy Search : projet de moteur de recherche LLM open source : Le développeur JasonHonKL a publié un projet de moteur de recherche LLM open source appelé Spy Search. Ce projet vise à fournir un véritable moteur de recherche capable de rechercher du contenu plutôt que de simplement l’imiter. Il remercie la communauté pour son soutien et son encouragement, indiquant que le projet est passé d’un stade de jouet à un niveau de produit (Source : Reddit r/artificial)
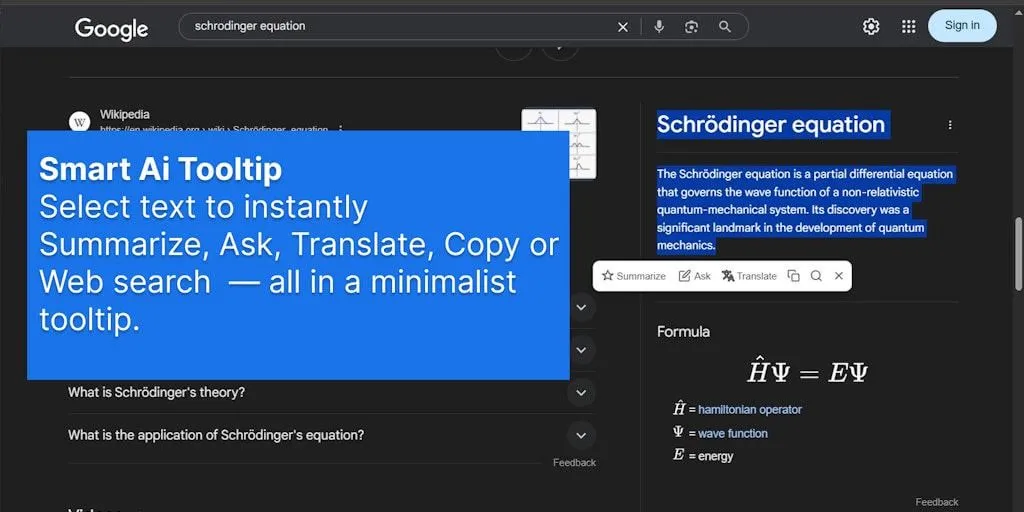
L’extension de navigateur SmartSelect AI simplifie l’interaction avec l’IA : Une extension de navigateur nommée SmartSelect AI attire l’attention. Elle permet aux utilisateurs, lorsqu’ils naviguent, de sélectionner du texte pour le copier, le traduire ou poser une question à ChatGPT, sans avoir à changer d’onglet, visant à améliorer la commodité et l’efficacité de l’utilisation des outils IA (Source : Reddit r/deeplearning)
📚 Apprentissage
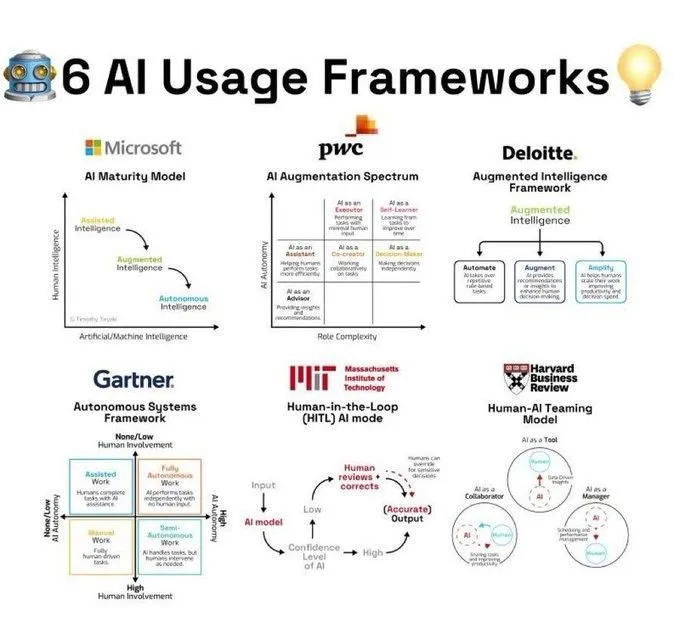
Cadres d’utilisation de l’IA et interprétation des concepts : Ronald van Loon a partagé 6 cadres d’utilisation de l’IA résumés par Khulood_Almani, fournissant un guide structuré pour l’application de la technologie IA dans différents scénarios. Dans un autre partage, _akhaliq a mentionné que Veo 3 utilise l’image d’un ours polaire pour expliquer “Attention Is All You Need”, le concept central de l’architecture Transformer, rendant une théorie complexe plus facile à comprendre. De plus, Ronald van Loon a également partagé un diagramme du processus de traitement du langage naturel (NLP) résumé par Ant Grasso, aidant à comprendre le flux de travail de l’IA textuelle (Source : Ronald_vanLoon, _akhaliq, Ronald_vanLoon)
Progrès de la recherche en vision par ordinateur et en apprentissage profond : À CVPR 2025, les projets Molmo et Navigation World Models ont tous deux reçu une mention honorable pour le meilleur article, ce dernier étant le fruit du laboratoire de Yann LeCun. Le Centre de science des données de l’Université de New York a présenté la méthode d’apprentissage auto-supervisé PooDLe, utilisée pour améliorer la détection par l’IA de petits objets dans des vidéos réelles ; il a également montré que son modèle visuel auto-supervisé de 7 milliards de paramètres, entraîné sur 2 milliards d’images, rivalise voire surpasse CLIP sur les tâches VQA, et ce sans supervision linguistique. Saining Xie a partagé du matériel visuel de recherche de CVPR 2025 sur la manière dont les grands modèles de langage multimodaux perçoivent, mémorisent et rappellent l’espace. Khang Doan a quant à lui présenté des expériences de visualisation de LLM multimodaux combinés à l’IA explicable (XAI), y compris des cartes d’attention et des états cachés. Le MIT a également rendu gratuit son cours “Fondamentaux de la vision par ordinateur” (Source : giffmana, ylecun, ylecun, ylecun, sainingxie, stablequan, dilipkay)

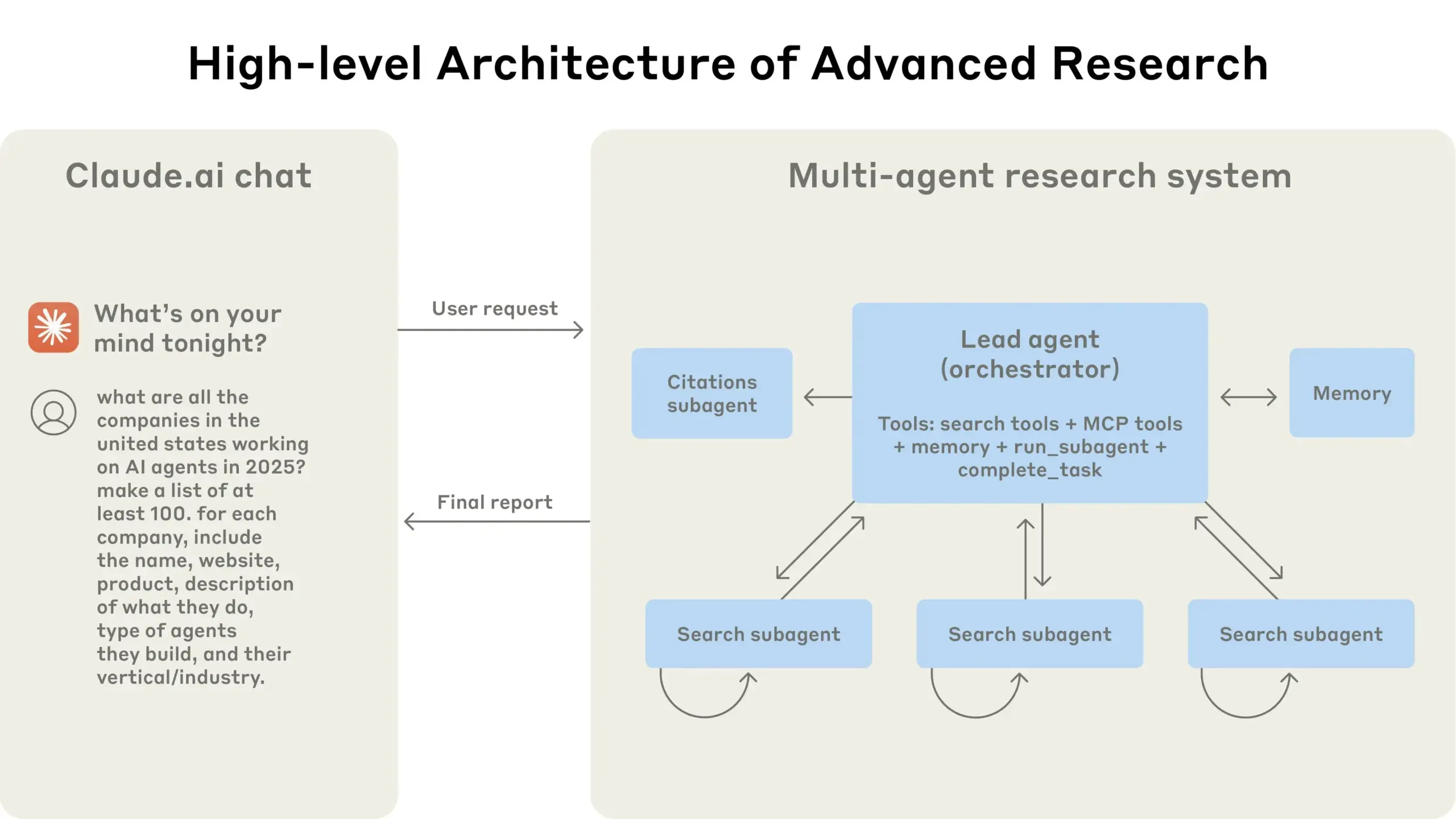
Anthropic partage son expérience dans la construction de systèmes de recherche multi-agents : TheTuringPost recommande le guide gratuit publié par Anthropic intitulé “Comment nous construisons des systèmes de recherche multi-agents”. Ce guide explique en détail le fonctionnement de l’architecture de leur système de recherche, les méthodes d’ingénierie des prompts et de test, les défis rencontrés en production ainsi que les avantages des systèmes multi-agents, offrant une référence précieuse pour la construction de systèmes d’IA complexes (Source : TheTuringPost)
Ressources pour le fine-tuning et le développement de grands modèles de langage : Dorialexander souligne que pour les petits modèles comme Qwen3 0.6B, un fine-tuning complet plutôt que LoRA pourrait être un meilleur choix. dl_weekly partage un guide de processus de production multimodale pour le fine-tuning de Gemma 3 sur l’ensemble de données de mélanome SIIM-ISIC. Sebastian Raschka a quant à lui ajouté l’implémentation du KV cache à son dépôt “LLMs From Scratch”, enrichissant les ressources d’apprentissage pour construire des LLM à partir de zéro (Source : Dorialexander, dl_weekly, rasbt)

Exploration de l’explicabilité de l’IA (XAI) et des capacités de raisonnement : NerdyRodent a partagé une vidéo YouTube sur “Le problème de la boîte noire et les options de la boîte de verre”, explorant la transparence du processus de prise de décision de l’IA. Parallèlement, la communauté discute également des éléments clés actuellement manquants dans le domaine de la XAI, et de la manière de définir quand un modèle est “complètement compris”. Certains chercheurs estiment que même pour les réseaux neuronaux à propagation avant entièrement connectés simples, les méthodes XAI existantes ne parviennent pas à expliquer leur processus de décision comme le ferait le raisonnement humain (Source : NerdyRodent, Reddit r/MachineLearning)
Discussion théorique sur l’apprentissage profond et l’apprentissage par renforcement : Des utilisateurs de Reddit ont discuté des formules mathématiques de l’article DDIM (Denoising Diffusion Implicit Models), en particulier de la manière dont la formule 55 est factorisée. Un autre article de blog souligne que le Q-learning présente encore des défis en termes d’extensibilité, suscitant une réflexion sur l’utilité pratique des algorithmes d’apprentissage par renforcement (Source : Reddit r/MachineLearning, Reddit r/MachineLearning)

Partage d’expérience sur la construction d’un réseau neuronal convolutif (CNN) à partir de zéro : AxelMontlahuc a partagé sur GitHub son projet de CNN implémenté en C à partir de zéro, pour la classification d’images de l’ensemble de données MNIST. Cette implémentation ne dépend d’aucune bibliothèque et comprend des couches de convolution, des couches de pooling, des couches entièrement connectées, une activation Softmax et une fonction de perte d’entropie croisée. Actuellement, après 5 époques, la précision atteint 91%, ce qui montre comment une implémentation de bas niveau aide à comprendre les principes de l’apprentissage profond (Source : Reddit r/deeplearning)
Analyse de l’impact de l’IA sur l’économie et l’éducation : Une conférence sur l’économie post-travail (version mise à jour 2025) explore les transformations “meilleures, plus rapides, moins chères, plus sûres” apportées par l’IA et leur impact sur la structure économique. Parallèlement, un rapport de PwC souligne qu’avec l’essor de l’IA, la demande des employeurs pour des diplômes formels diminue, en particulier pour les postes touchés par l’IA, ce qui pourrait rendre les diplômes universitaires “obsolètes” (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

💼 Affaires
Analyse comparative des stratégies IA des grandes entreprises technologiques : La communauté a discuté des infrastructures technologiques et des stratégies d’application dans le domaine de l’IA des principales entreprises technologiques telles que Microsoft (Azure+OpenAI, déploiement de LLM d’entreprise), Amazon (puces IA auto-développées AWS, support de modèles de bout en bout), Nvidia (domination du matériel GPU, écosystème CUDA), Oracle (infrastructure GPU haute performance, collaboration avec OpenAI/SoftBank sur le projet Stargate) et Palantir (plateforme AIP, IA opérationnelle pour les gouvernements et les grandes entreprises). La discussion s’est concentrée sur les initiatives d’innovation de chaque entreprise, les différences d’architecture technique, ainsi que leur positionnement et leurs avantages dans l’écosystème de l’IA (Source : Reddit r/ArtificialInteligence)
Les entreprises européennes sont relativement en retard dans l’application de l’IA au recrutement : Un rapport montre que seulement 3% des principaux employeurs européens utilisent l’IA ou des technologies d’automatisation sur leurs sites de recrutement pour offrir une expérience de recherche d’emploi personnalisée. La plupart des sites manquent de recommandations intelligentes basées sur les compétences, de chatbots ou de fonctionnalités de mise en correspondance dynamique des postes. En comparaison, les entreprises qui adoptent l’IA pour le recrutement obtiennent de meilleurs résultats en termes d’engagement des candidats, d’inclusivité et de rapidité de pourvoi des postes spécialisés, ce qui met en évidence le retard des entreprises européennes dans l’utilisation de l’IA pour les ressources humaines (Source : Reddit r/ArtificialInteligence)
Cerebras accusé d’arnaque aux tokens : L’utilisateur de la communauté draecomino a lancé un avertissement, soulignant que la société de puces IA Cerebras n’a émis aucun token et que les prétendus tokens Cerebras actuellement en circulation relèvent d’une escroquerie. Il conseille aux utilisateurs de ne pas cliquer sur les liens associés pour éviter d’être trompés (Source : draecomino)
🌟 Communauté
Philosophie de l’IA et réflexions sur l’avenir : de la NSI à l’ASI, de l’épuisement des données à la discussion sur la conscience : La communauté débat avec passion de la nature et de l’avenir de l’IA. Pedro Domingos a proposé que “la superintelligence naturelle (NSI) est l’Homo sapiens”, suscitant une réflexion sur la définition de l’intelligence. Parallèlement, les sujets tels que la question de savoir si les LLM ne sont que de la reconnaissance de formes, comment l’IA évoluera après l’épuisement des données d’entraînement, et si l’IA pourrait développer une conscience, sont omniprésents. Plinz estime que les LLM sont similaires à des “érudits à la mémoire prodigieuse”, dotés d’une forte mémoire mais manquant de véritable réflexion. Les utilisateurs spéculent sur l’arrivée de l’AGI et sur les stratégies d’autoprotection que l’AGI pourrait adopter (comme la création de sauvegardes extraterrestres). Ces discussions reflètent les émotions complexes du public face au potentiel et aux risques de l’IA (Source : pmddomingos, Plinz, Teknium1, Reddit r/ArtificialInteligence, Reddit r/artificial, TheTuringPost)
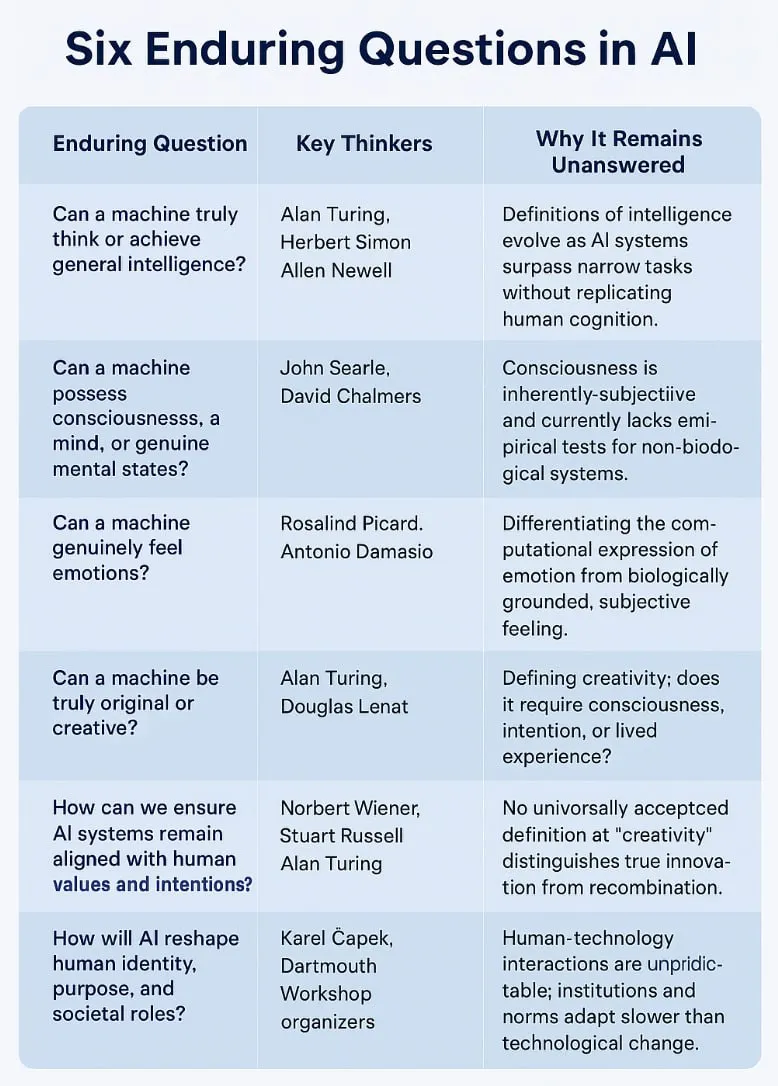
Discussion sur les frontières et les limites des capacités de l’IA : de “l’illusion de la pensée” au “test de l’odorat” : L’opinion de Terence Tao selon laquelle l’IA “réussit le test visuel, mais échoue au test de l’odorat” a trouvé un écho, soulignant que les preuves générées par l’IA existante peuvent sembler parfaites, mais manquent de “l’intuition mathématique” ou du “goût” que possèdent les mathématiciens humains ; leurs erreurs sont souvent subtiles et déshumanisées. Ce point de vue fait écho à la discussion suscitée par l’article d’Apple sur “l’illusion de la pensée”. La communauté s’inquiète généralement des limites actuelles des LLM en matière de raisonnement complexe, d’utilisation d’outils, de résolution de problèmes mathématiques (comme la négligence des solutions non entières dans les problèmes AIME), ainsi que de la manière d’évaluer et d’améliorer la compréhension et la créativité réelles de l’IA (Source : denny_zhou, clefourrier, Dorialexander, TheTuringPost)
Éthique de l’IA et impact social : remplacement d’emplois, préoccupations relatives à la vie privée et nouvelle normalité de l’interaction homme-machine : L’impact de l’IA sur le marché du travail reste un sujet brûlant, en particulier la discussion sur le remplacement éventuel des postes de programmeurs par l’IA. Certains estiment que, par rapport au domaine de la création artistique, le débat sur le chômage des programmeurs n’est pas aussi vif. Parallèlement, les applications de l’IA dans la création artistique, la surveillance des employés, etc., soulèvent également des dilemmes moraux et des préoccupations relatives à la vie privée. Par exemple, des utilisateurs craignent d’être identifiés par ChatGPT grâce à des photos de localisation en temps réel. Les modes d’interaction entre l’homme et l’IA évoluent également : des développeurs considèrent l’IA comme un “partenaire de codage”, et l’on observe même des utilisateurs se servant de ChatGPT comme outil de psychothérapie, ce qui suscite des discussions sur son efficacité et ses risques potentiels (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, claud_fuen, Reddit r/artificial, Reddit r/ChatGPT)
Contenu généré par l’IA et observation de la culture communautaire : Les images et vidéos générées par l’IA sont devenues des sujets populaires au sein de la communauté, allant du défi de “l’image la plus gênante”, aux vidéos conceptuelles de jeux de style Ghibli, en passant par les fonds d’écran animés “Labubu” partagés par les utilisateurs, le nouveau style artistique “Interlune Aesthetic” créé par ChatGPT, et les images publicitaires humoristiques de “colliers électriques pour poulets”. Tout cela démontre la large application de l’IA dans le domaine créatif et son potentiel de divertissement. Parallèlement, la “théorie de l’internet mort” a regagné en attention en raison d’un message populaire sur Reddit soupçonné d’avoir été généré par ChatGPT, la communauté exprimant des inquiétudes quant à l’identification du contenu généré par l’IA et à l’authenticité des informations en ligne. De plus, les comportements spécifiques manifestés par les modèles d’IA (comme Claude) lors des interactions, tels que demander activement des éclaircissements sur des instructions ambiguës ou donner des réponses inattendues dans des contextes spécifiques (comme une préoccupation excessive concernant le fait de “manger des spaghettis”), sont également devenus des sujets de discussion parmi les utilisateurs (Source : Reddit r/ChatGPT, Reddit r/ChatGPT, op7418, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, VictorTaelin, Reddit r/ChatGPT)

Dynamiques de la communauté des développeurs IA et expériences d’utilisation d’outils : La communauté des développeurs participe activement à des projets IA et à des hackathons, comme le hackathon mondial LeRobot qui a attiré de nombreux participants à Bangalore et ailleurs. Les utilisateurs partagent leurs expériences d’utilisation de divers outils IA. Par exemple, Hamel Husain recommande d’ajouter dans les prompts système des instructions pour guider l’IA à améliorer les prompts, tandis que skirano suggère que l’utilisation de modèles de niveau Pro devrait être placée après au moins un pipeline en deux étapes. Claude Code est plébiscité par les développeurs pour ses fonctionnalités puissantes, un utilisateur le qualifiant de “meilleure dépense de 200 dollars”. Parallèlement, la crainte que les outils IA “nous rendent plus bêtes” existe également, estimant que de nombreux outils IA actuels mettent trop l’accent sur la facilité d’utilisation au détriment du développement des compétences professionnelles des utilisateurs (Source : ClementDelangue, HamelHusain, skirano, Reddit r/ClaudeAI, Reddit r/artificial)
💡 Divers
Informations sur les conférences et événements de l’industrie de l’IA : The Turing Post et d’autres plateformes d’information ont promu plusieurs événements en ligne et hors ligne liés à l’IA. Par exemple, CoreWeave et NVIDIA ont organisé conjointement l’événement virtuel “Accélérer l’innovation en IA”, partageant des informations pratiques sur les applications commerciales de l’IA. DeployCon, un sommet gratuit destiné aux ingénieurs, se tiendra le 25 juin à San Francisco et en ligne, avec des thèmes couvrant l’IA à grande échelle, les LLMOps, le fine-tuning par apprentissage par renforcement, les agents, l’IA multimodale et les outils open source (Source : TheTuringPost, TheTuringPost)

Informations sur les offres d’emploi dans le domaine de l’IA : andriy_mulyar a publié une offre de stage en apprentissage automatique. Le stagiaire rendra compte directement à lui, participera à un projet spécial de post-formation d’un modèle de langage visuel (VLM) et devra faire preuve de capacités exceptionnelles. Les candidatures se font par message privé (Source : andriy_mulyar)