Mots-clés:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, DeepRoute VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, Voitures de production L2 réalisant une conduite autonome de niveau L4, Comparaison des performances entre AMD MI350X et B200, Capacité de traitement de contexte long du modèle o3-pro, Technologie d’interaction full-duplex AIUI, Modèle visuel-langage-action VLA
🔥 À la Une
Le Robotaxi de Tesla effectue ses premiers tests publics sur route ; Elon Musk affirme que les véhicules de série L2 peuvent atteindre une conduite autonome de niveau L4 sans modification: Le Robotaxi de Tesla (une version remaniée du Model Y) est en phase de test sur route à Austin, avec le nouveau logo Robotaxi sur la carrosserie mais conservant le volant. Elon Musk a déclaré que tous les véhicules de série Tesla peuvent atteindre une conduite autonome non supervisée. Les véhicules de test actuels sont équipés d’une version bêta interne du FSD dont le nombre de paramètres est 4,5 fois supérieur à celui de la version actuelle du FSD, et qui devrait être optimisée et déployée d’ici la fin de l’année. Le lancement public du Robotaxi est prévu pour le 22 juin, en commençant par Austin. Cette initiative marque une évolution du FSD de niveau L2 de Tesla vers un Robotaxi de niveau L4/L5, ce qui pourrait accélérer la concurrence dans le secteur de la conduite autonome, notamment en défiant les acteurs de la filière technologique L4 tels que Waymo (Source: 量子位)

AMD lance sa puce IA la plus puissante, la série MI350, surpassant les performances du B200 de Nvidia: Lisa Su, PDG d’AMD, et Sam Altman, PDG d’OpenAI, ont conjointement annoncé les GPU MI350X et MI355X. Ces deux puces, gravées en 3nm, comptent 185 milliards de transistors et 288 Go de mémoire HBM3E, soit 1,6 fois la capacité mémoire du B200 de Nvidia. Selon les données officielles, la série MI350 exécute Llama 3.1 405B avec une vitesse d’inférence 30 % plus rapide que le B200 en précision FP4, et sa puissance de calcul FP64 est le double de celle de Nvidia. AMD a également annoncé la série MI400, développée en collaboration avec OpenAI, qui sera dévoilée l’année prochaine, intensifiant davantage la concurrence sur le marché des puces IA (Source: 量子位)

Les capacités d’inférence du modèle o3-pro d’OpenAI suscitent l’attention, les performances réelles diffèrent légèrement des tests officiels: Le dernier modèle d’inférence d’OpenAI, o3-pro, a démontré de puissantes capacités dans le traitement de jeux de mots complexes (par exemple, générer des réponses spécifiques basées sur les caractéristiques des titres de chansons de la chanteuse Sabrina Carpenter), ce qui a conduit l’ancien responsable de l’équipe AGI Readiness d’OpenAI à ironiser sur les doutes précédemment exprimés par Apple concernant les capacités d’inférence des grands modèles. Cependant, dans les classements de référence tels que LiveBench, le score moyen en codage d’o3-pro est presque identique à celui d’o3, et son score en codage agent est même inférieur. Les tests Fiction.LiveBench montrent qu’o3-pro excelle avec des contextes courts, mais reste inférieur à Gemini 2.5 Pro dans le traitement de contextes ultra-longs de 192k. Ben Hylak, ancien ingénieur chez Apple et SpaceX, souligne que les capacités réelles d’o3-pro dépendent fortement d’une entrée d’informations contextuelles suffisantes, le rendant plus adapté comme générateur de rapports que comme simple interlocuteur de chat, avec des améliorations notables dans l’appel d’outils et la compréhension de l’environnement (Source: 量子位)

iFLYTEK met à niveau sa plateforme d’interaction homme-machine AIUI et sa plateforme de super-cerveau pour robot, favorisant une collaboration approfondie du matériel intelligent: iFLYTEK a annoncé une mise à niveau majeure de sa plateforme d’interaction homme-machine AIUI, axée sur l’amélioration de l’interaction full-duplex, de la perception et de l’expression des émotions, ainsi que d’un système de mémoire de type humain. Spécialement pour les scénarios impliquant des enfants, une solution d’interaction dédiée a été lancée pour améliorer la reconnaissance et la compréhension du langage enfantin. Parallèlement, sa plateforme de super-cerveau pour robot, basée sur le grand modèle Spark, a renforcé l’interaction multimodale, la compréhension sémantique et l’application des connaissances, et a introduit un “sac à dos vocal intelligent” permettant aux robots existants de réaliser une interaction vocale sans modification matérielle. Ces mises à niveau visent à faire passer le matériel intelligent d’une interaction de base à une collaboration intelligente approfondie, en stimulant des domaines tels que l’automobile, le matériel IA et la robotique (Source: 量子位)

🎯 Tendances
DeepRoute.ai et Volcano Engine collaborent pour développer un agent pour le monde physique VLA basé sur le grand modèle Doubao: Zhou Guang, PDG de DeepRoute.ai, a annoncé une collaboration avec Volcano Engine pour développer conjointement des technologies d’avant-garde telles que le modèle vision-langage-action (VLA), en utilisant le grand modèle Doubao, dans le but de créer un agent pour le monde physique. Le modèle VLA de DeepRoute.ai sera lancé sur le marché grand public au troisième trimestre 2025, doté de quatre fonctionnalités principales : compréhension sémantique spatiale, reconnaissance d’obstacles de forme irrégulière, compréhension des panneaux de signalisation textuels et commande vocale du véhicule, visant à améliorer la sécurité et l’intelligence de la conduite assistée. Actuellement, le modèle VLA a terminé les tests sur route et plus de 5 modèles de voitures IA équipés de ce modèle devraient être commercialisés d’ici la fin de l’année (Source: 量子位)

Un chercheur de DeepSeek réplique vLLM avec 1200 lignes de code, surpassant ses performances dans certains scénarios: Yu Xingkai, chercheur chez DeepSeek, a rendu open source le projet Nano-vLLM, réalisant les fonctionnalités principales de vLLM, y compris des technologies clés comme PagedAttention, en moins de 1200 lignes de code Python. Ce projet vise à fournir une version minimisée et entièrement lisible de vLLM, facilitant son apprentissage et sa compréhension. Dans des conditions de test spécifiques sur du matériel H800 et avec le modèle Qwen3-8B, le débit de Nano-vLLM a même dépassé celui de la version originale de vLLM, démontrant son efficacité. vLLM est un framework d’inférence et de service LLM développé par UC Berkeley, réputé pour son algorithme PagedAttention qui améliore considérablement le débit des services LLM (Source: 量子位)
Des entreprises chinoises utilisent des “valises de disques durs volantes” pour contourner les restrictions américaines à l’exportation de puces IA: Selon le Wall Street Journal, face aux restrictions américaines à l’exportation de puces IA haut de gamme, les entreprises chinoises adoptent une nouvelle stratégie : des ingénieurs transportent des disques durs contenant de grandes quantités de données d’entraînement (par exemple 80 To) vers des centres de données à l’étranger, comme en Malaisie, pour utiliser des serveurs équipés de puces avancées de Nvidia et autres afin d’entraîner des modèles d’IA. Une fois l’entraînement terminé, les paramètres du modèle sont ramenés en Chine. Cette démarche vise à contourner les difficultés d’importation directe de puces et a favorisé l’émergence de centres de données IA en Asie du Sud-Est et au Moyen-Orient. Un ancien fonctionnaire du département américain du Commerce s’est dit préoccupé par cette situation (Source: dotey)

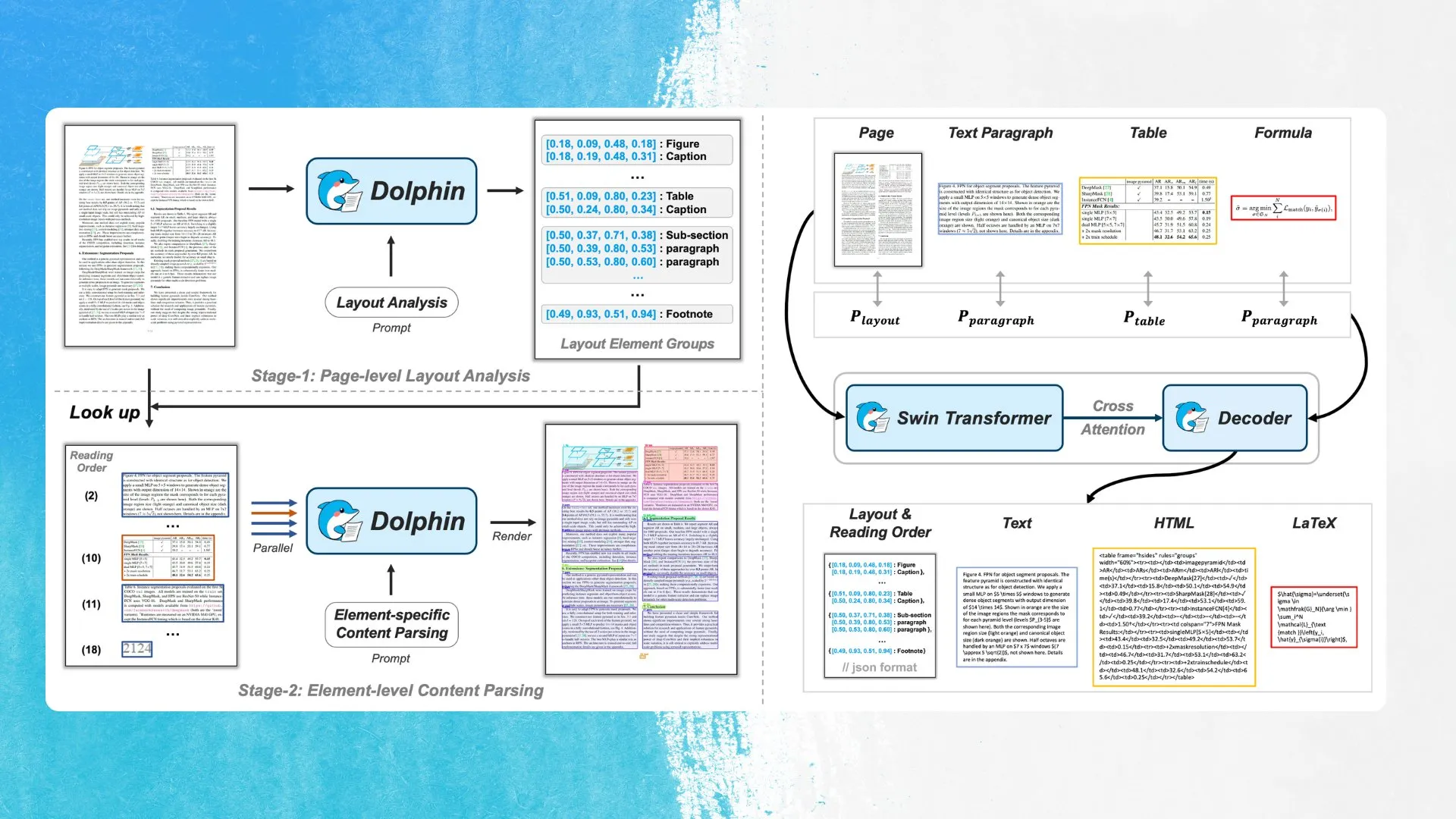
ByteDance lance un nouveau modèle OCR, Dolphin, utilisant la détection d’éléments de mise en page et l’analyse parallèle: ByteDance a publié un nouveau modèle OCR, Dolphin, sous licence MIT. Ce modèle détecte d’abord les éléments de la mise en page du document (tels que les tableaux, les formules, etc.), puis analyse chaque élément en parallèle pour générer le contenu. Le modèle et une démonstration sont disponibles sur Hugging Face Hub. Cette approche vise à améliorer la précision et l’efficacité de la reconnaissance des structures de documents complexes (Source: mervenoyann)
OpenAI améliore les fonctionnalités des “Projets” ChatGPT avec prise en charge de la recherche approfondie, mode vocal et téléversement de fichiers sur mobile: OpenAI a annoncé plusieurs améliorations pour la fonctionnalité “Projets” dans ChatGPT, y compris un support amélioré pour la recherche approfondie, l’intégration du mode vocal, une fonction de mémoire améliorée pour citer les conversations passées au sein du projet, ainsi que la prise en charge du téléversement de fichiers et un sélecteur de modèle sur mobile. Ces mises à jour visent à améliorer la capacité des utilisateurs à effectuer des travaux plus ciblés et complexes dans ChatGPT (Source: kevinweil)
L’équipe EuroLLM publie des versions préliminaires de plusieurs nouveaux modèles, dont un modèle 22B et un petit modèle MoE: L’équipe EuroLLM a publié des versions préliminaires de plusieurs nouveaux modèles, comprenant un modèle de base de 22 milliards de paramètres et une version affinée par instructions, deux modèles visuels basés sur d’anciennes versions d’EuroLLM (1,7B et 9B de paramètres), ainsi qu’un petit modèle de mélange d’experts (MoE) avec 0,6B de paramètres actifs et 2,6B de paramètres totaux. Tous ces modèles sont sous licence Apache-2.0, et les tests préliminaires montrent que ce petit modèle MoE fonctionne étonnamment bien pour sa taille (Source: Reddit r/LocalLLaMA)

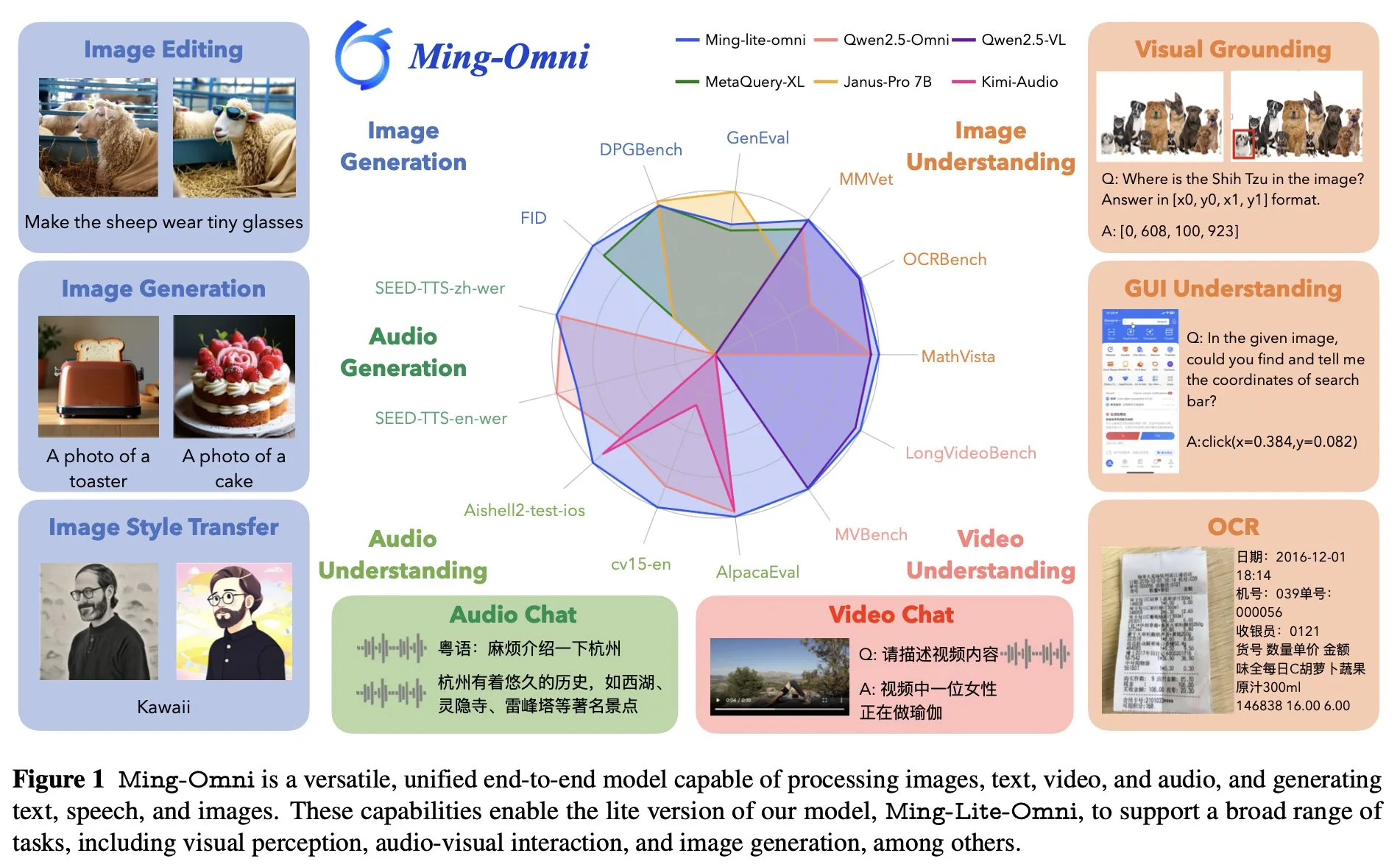
Ant Group lance le modèle omnipotent de bout en bout Ming Lite Omni, concurrent de GPT-4o: Ant Group a lancé le modèle Ming Lite Omni, capable de réaliser de multiples fonctions telles que l’écoute, la parole et la génération d’images, rivalisant en performance avec GPT-4o. Ming Lite Omni surpasse Qwen2.5VL-7B en précision sur les tâches GUI, atteint l’état de l’art (SOTA) dans la compréhension audio sur plusieurs benchmarks publics, et affiche également d’excellentes capacités de compréhension vidéo. Le modèle adopte une architecture de mélange d’experts (MoE) avec seulement 2,8 milliards de paramètres actifs, et a été spécifiquement optimisé pour la génération audio et image, par exemple en utilisant BPE pour réduire la fréquence d’images des tokens audio et des tokens apprenables multi-échelles pour améliorer la qualité de la génération d’images (Source: mervenoyann)
NVIDIA et Mistral AI s’associent pour co-construire la plateforme cloud IA Mistral Compute: NVIDIA a annoncé lors de la conférence GTC sa collaboration avec Mistral AI pour créer conjointement une plateforme cloud IA nommée Mistral Compute. Cette initiative est considérée comme un avantage majeur pour les États-Unis et la communauté open source, visant à fournir un modèle pour la construction d’infrastructures IA mondiales grâce à des modèles ouverts soutenus par des puces américaines (Source: arthurmensch)
Hugging Face annonce son adhésion complète à PyTorch pour simplifier la bibliothèque Transformers: Lysandre Jik, responsable de l’open source chez Hugging Face, a déclaré qu’étant donné que la communauté d’utilisateurs a atteint un consensus sur PyTorch, tous les efforts futurs se concentreront sur PyTorch afin de réduire la surcharge de la bibliothèque Transformers et de s’engager à fournir une boîte à outils plus concise. L’équipe officielle de PyTorch a salué cette décision et a souligné qu’elle contribuerait à maintenir la simplicité du code (Source: reach_vb)

ByteDance lance la technologie de génération vidéo interactive en temps réel APT2: ByteDance a présenté sa dernière technologie de génération vidéo interactive en temps réel, APT2 (Autoregressive Adversarial Post-Training). Cette technologie, grâce à un post-entraînement auto-régressif antagoniste, vise à générer du contenu vidéo interactif de haute qualité en temps réel, faisant ainsi progresser davantage le domaine de la génération vidéo (Source: NerdyRodent)
🧰 Outils
Llama-Server Launcher : un lanceur de serveur llama.cpp avec GUI, axé sur l’optimisation des performances CUDA: Un développeur a partagé son lanceur personnel pour llama-server, écrit en Python et doté d’une interface utilisateur graphique (GUI). Cet outil vise à simplifier la configuration et le lancement des services llama.cpp, en mettant un accent particulier sur l’optimisation des performances CUDA. Les fonctionnalités incluent la sélection de modèles, la configuration des chemins, l’ajustement de la taille du contexte et des lots, le déchargement GPU, FlashAttention, la division des tenseurs et d’autres paramètres de performance avancés, ainsi que la sélection de modèles de chat et la gestion de la configuration de l’environnement. Il prend en charge l’obtention automatique des informations GPU et système, l’analyse des métadonnées des modèles GGUF et peut générer des scripts de lancement multiplateformes (.ps1/.sh) (Source: Reddit r/LocalLLaMA)
Together AI publie un agent data scientist open source: Together AI a construit un agent IA open source capable de raisonner comme un data scientist. Cet agent peut charger des données, écrire du code Python, se réentraîner lorsque les modèles échouent et résoudre des tâches réelles de Kaggle et DABStep. Cette initiative vise à promouvoir l’automatisation et la démocratisation de l’IA dans le domaine de la science des données (Source: percyliang)
AutoMind : un framework d’agent adaptatif basé sur la connaissance pour l’automatisation de la science des données: AutoMind est un nouveau framework d’agent LLM conçu pour surmonter les limitations des agents de science des données existants dans le traitement de tâches complexes et innovantes, en intégrant des bases de connaissances expertes, en adoptant un algorithme de recherche arborescente de connaissances d’agent et des stratégies de codage adaptatives, afin d’améliorer l’efficacité des processus d’apprentissage automatique automatisés dans le monde réel (Source: HuggingFace Daily Papers)
LlamaParse lance la fonctionnalité “Presets” pour simplifier la configuration de l’analyse de documents: LlamaParse a introduit la fonctionnalité “Presets” (Préréglages), offrant une série de modes préconfigurés faciles à comprendre pour optimiser les paramètres pour différents cas d’utilisation. Cela inclut des modes rapide, équilibré et avancé pour les scénarios généraux, ainsi que des modes optimisés pour les cas d’usage courants tels que les factures, les articles de recherche, les documents techniques et les formulaires, visant à permettre aux utilisateurs de choisir plus facilement entre vitesse et précision (Source: jerryjliu0)
OpenWebUI ajoute la prise en charge d’o3-pro, étendant la compatibilité des modèles: Des développeurs de la communauté ont créé une nouvelle fonctionnalité pour OpenWebUI, étendant la prise en charge du modèle o3-pro en ajoutant le support de l’API de réponse, le suivi des coûts, le support multi-clés et la recherche web. Cela permet aux utilisateurs d’utiliser o3-pro dans OpenWebUI sans avoir à souscrire à l’offre premium officielle (Source: Reddit r/OpenWebUI)
📚 Apprentissage
Un article explore la décomposition des activations MLP en caractéristiques interprétables via la décomposition en matrices semi-non négatives (SNMF): Cette recherche propose d’utiliser la SNMF pour décomposer directement les activations des perceptrons multicouches (MLP) afin d’apprendre des caractéristiques parcimonieuses, constituées de combinaisons linéaires de neurones co-activés, et de mapper ces caractéristiques à leurs entrées d’activation, les rendant ainsi directement interprétables. Les expériences montrent que les caractéristiques dérivées de la SNMF surpassent les auto-encodeurs clairsemés (SAE) en termes de guidage causal et s’alignent sur des concepts interprétables par l’homme, révélant une structure hiérarchique dans l’espace d’activation des MLP (Source: HuggingFace Daily Papers)
Un nouvel article propose LoRMA : un nouveau paradigme pour l’affinage des LLM par adaptation multiplicative de bas rang (Low-Rank Multiplicative Adaptation): L’affinage traditionnel des LLM met généralement à jour les poids par addition, tandis que LoRMA explore les mises à jour multiplicatives. Pour résoudre le problème de la “suppression de rang” induit par les matrices de bas rang, l’article introduit de nouvelles opérations d’expansion de rang basées sur la permutation et l’addition, et assure l’efficacité computationnelle grâce à des opérations de réorganisation efficaces. Les expériences montrent que LoRMA est compétitif, offrant de nouvelles perspectives pour l’adaptation des LLM (Source: Reddit r/deeplearning)
Un article propose le framework TaxoAdapt pour adapter les taxonomies multidimensionnelles construites par les LLM à des corpus de recherche en évolution: Face au défi de l’organisation de la littérature scientifique, le framework TaxoAdapt peut ajuster dynamiquement les taxonomies générées par les LLM pour s’adapter à des corpus spécifiques, et prend en charge de multiples dimensions (telles que la méthodologie, la tâche, les métriques d’évaluation). Ce framework, par classification hiérarchique itérative, étend la largeur et la profondeur de la classification en fonction de la distribution thématique du corpus, visant à mieux organiser et capturer l’évolution des domaines scientifiques (Source: HuggingFace Daily Papers)
Un article présente le framework MOSAIC, réalisant l’apprentissage collaboratif dans les systèmes d’agents: MOSAIC est un framework pour l’apprentissage collaboratif dans les systèmes d’IA autonomes et agentifs, opérant dans des environnements décentralisés et dynamiques. Les agents partagent et réutilisent sélectivement des connaissances modulaires (sous forme de masques de réseaux neuronaux), sans synchronisation ni contrôle centralisé. Les expériences montrent que MOSAIC surpasse les apprenants isolés en vitesse et en performance, résolvant parfois des tâches insolubles pour les agents isolés, et favorisant l’amélioration de l’efficacité collective et de l’adaptabilité (Source: Reddit r/MachineLearning)
Un article propose le framework ClaimSpect pour une analyse hiérarchique améliorée par la recherche d’affirmations complexes: De nombreuses affirmations (telles que les affirmations scientifiques ou politiques) ne sont pas simplement vraies ou fausses. Le framework ClaimSpect, par génération améliorée par la recherche, construit automatiquement une structure hiérarchique des aspects liés à une affirmation et enrichit ces aspects avec les perspectives d’un corpus spécifique. Cette méthode vise à déconstruire les affirmations complexes et à présenter les différentes opinions sur chaque aspect présentes dans le corpus, ainsi que leur prévalence (Source: HuggingFace Daily Papers)
Un article propose un guidage par perturbation à grain fin (Fine-Grained Perturbation Guidance) via la sélection de têtes d’attention: Cette étude révèle que des têtes d’attention spécifiques dans les modèles de diffusion contrôlent différents concepts visuels (tels que la structure, le style, la qualité de la texture). Sur cette base, l’article propose le framework “HeadHunter”, qui sélectionne systématiquement les têtes d’attention alignées sur les objectifs de l’utilisateur, permettant un contrôle à grain fin de la qualité de génération et des attributs visuels, et introduit SoftPAG pour ajuster l’intensité de la perturbation. Cette méthode a démontré sa supériorité en termes d’amélioration de la qualité et de guidage stylistique sur des modèles tels que Stable Diffusion 3 et FLUX.1 (Source: HuggingFace Daily Papers)
Un article explore le fait que le désapprentissage des LLM devrait être indépendant de la forme (Form-Independent): L’étude souligne que l’efficacité des méthodes actuelles de désapprentissage (unlearning) des LLM dépend fortement de la forme des échantillons d’entraînement, ce qui rend difficile la généralisation à différentes expressions de la même connaissance. L’article définit ce problème comme un “biais dépendant de la forme” (Form-Dependent Bias) et introduit le benchmark ORT pour l’évaluation. Pour résoudre ce problème, l’article propose la méthode ROCR (Rank-one Concept Redirection), qui réalise le désapprentissage en redirigeant la perception du modèle de concepts spécifiques. Les expériences prouvent que ROCR améliore significativement l’efficacité du désapprentissage et peut générer des sorties naturelles (Source: HuggingFace Daily Papers)
Un article propose UniPre3D : une méthode de pré-entraînement unifiée pour les modèles de nuages de points 3D basée sur le Gaussian Splatting intermodal: UniPre3D vise à relever les défis posés par la diversité des échelles des données de nuages de points dans la vision 3D, en proposant la première méthode de pré-entraînement unifiée applicable de manière transparente à n’importe quelle échelle de nuage de points et à n’importe quelle architecture de modèle 3D. Cette méthode prédit des primitives gaussiennes comme tâche de pré-entraînement et utilise le rendu par Gaussian Splatting différentiable pour obtenir une supervision précise au niveau du pixel et une optimisation de bout en bout, tout en intégrant les caractéristiques des modèles de pré-entraînement 2D pour introduire des connaissances sur la texture (Source: HuggingFace Daily Papers)
Un article propose StreamSplat : reconstruction 3D dynamique en ligne pour les flux vidéo non calibrés: StreamSplat est un framework entièrement feed-forward capable de convertir en ligne un flux vidéo non calibré de longueur arbitraire en une représentation dynamique par Gaussian Splatting 3D (3DGS). Il prédit les positions 3DGS grâce à un mécanisme d’échantillonnage probabiliste dans un encodeur statique, et modélise la dynamique de manière robuste et efficace via un champ de déformation bidirectionnel dans un décodeur dynamique, visant à résoudre les défis de calibration, de modélisation dynamique et de stabilité d’efficacité dans la reconstruction de scènes dynamiques en temps réel (Source: HuggingFace Daily Papers)
Un article passe en revue le sondage attentionnel (Attentive Probing) dans la modélisation d’images masquées: Alors que l’affinage à grande échelle devient irréalisable, le sondage (probing) est devenu la méthode privilégiée pour l’évaluation de l’apprentissage auto-supervisé (SSL). Le sondage linéaire standard (LP) ne reflète pas pleinement le potentiel des modèles entraînés par modélisation d’images masquées (MIM). Cet article réexamine le sondage attentionnel, introduisant le sondage efficace (EP), un mécanisme d’attention croisée multi-requêtes qui réduit le nombre de paramètres entraînables et améliore la vitesse, surpassant LP et les méthodes de sondage attentionnel précédentes sur plusieurs benchmarks (Source: HuggingFace Daily Papers)
Un article propose PosterCraft : une nouvelle approche pour la génération d’affiches esthétiques de haute qualité dans un cadre unifié: PosterCraft vise à relever le défi de la génération d’affiches esthétiques, qui exige non seulement un rendu textuel précis, mais aussi l’intégration transparente de contenu artistique abstrait, d’une mise en page attrayante et d’une harmonie stylistique globale. PosterCraft adopte un flux de travail en cascade pour optimiser la génération, incluant l’optimisation du rendu de texte à grande échelle, l’affinage supervisé sensible à la région, l’apprentissage par renforcement pour le texte esthétique et l’affinage par rétroaction conjointe visuelle et linguistique, et surpasse significativement les bases de référence open source dans plusieurs expériences (Source: HuggingFace Daily Papers)
Un article propose d’améliorer les modèles de diffusion par guidage par perturbation de tokens (Token Perturbation Guidance): Pour résoudre les limitations du guidage indépendant du classifieur (CFG), qui nécessite un processus d’entraînement spécifique et se limite à la génération conditionnelle, la méthode TPG applique directement une matrice de perturbation aux représentations intermédiaires des tokens au sein du réseau de diffusion. TPG utilise une opération de brassage préservant la norme pour fournir un signal de guidage efficace, améliorant la qualité de la génération sans modification architecturale, et est applicable à la génération conditionnelle et inconditionnelle. Les expériences montrent que TPG améliore de près de 2 fois le FID de la baseline SDXL pour la génération inconditionnelle (Source: HuggingFace Daily Papers)
Un article propose DreamActor-H1 : génération de vidéos de démonstration homme-produit haute fidélité par des Diffusion Transformers avec conception de mouvement: DreamActor-H1 est un framework basé sur Diffusion Transformer (DiT) visant à générer des vidéos de démonstration d’interaction homme-produit de haute qualité. Cette méthode injecte des informations de référence appariées homme-produit et un mécanisme supplémentaire d’attention croisée masquée, tout en préservant les détails d’identité de l’humain et du produit (comme les logos, les textures). Elle utilise des modèles de maillage humain 3D et des boîtes englobantes de produits pour fournir un guidage de mouvement précis, et améliore la cohérence 3D grâce à un encodage de texte structuré (Source: HuggingFace Daily Papers)
Un article propose EmbodiedGen : un moteur de monde 3D génératif pour l’intelligence incarnée: EmbodiedGen est une plateforme fondamentale pour la génération de mondes 3D interactifs, visant à générer de manière évolutive et à faible coût des actifs 3D photoréalistes, contrôlables et de haute qualité, dotés de propriétés physiques précises et à l’échelle du monde réel, et utilisant un format de description unifié pour robot (URDF). Ces actifs peuvent être directement importés dans divers moteurs de simulation physique, soutenant les tâches d’entraînement et d’évaluation de l’intelligence incarnée, et résolvant les problèmes de coût élevé et de réalisme limité des actifs graphiques 3D traditionnels (Source: HuggingFace Daily Papers)
Une nouvelle étude réfute l’article d’Apple sur l‘“illusion de la pensée”, arguant que les LLM peuvent résoudre de nouveaux problèmes complexes: En réponse à un récent article d’Apple intitulé “Illusion of Thinking”, qui affirmait que les grands modèles de raisonnement (LRM) subissent un “effondrement de la précision” sur des énigmes de planification complexes (comme les Tours de Hanoï), une étude critique subséquente souligne que les conclusions d’Apple reflètent principalement les limites de la conception expérimentale plutôt qu’un échec des capacités de raisonnement fondamentales des modèles. La nouvelle étude soutient que le dépassement du budget de tokens dans l’expérience originale, l’évaluation erronée des sorties délibérément tronquées et l’inclusion d’instances d’énigmes mathématiquement insolubles ont conjointement conduit à une mauvaise évaluation des capacités des modèles. En ajustant la méthodologie expérimentale, par exemple en demandant aux modèles de générer des fonctions Lua compactes pour résoudre les Tours de Hanoï plutôt que des listes d’étapes exhaustives, les modèles ont montré une grande précision sur des cas précédemment rapportés comme des échecs complets, indiquant que les modèles ne sont pas incapables de raisonner, mais sont limités par le format de sortie et les contraintes de tokens (Source: Reddit r/LocalLLaMA)

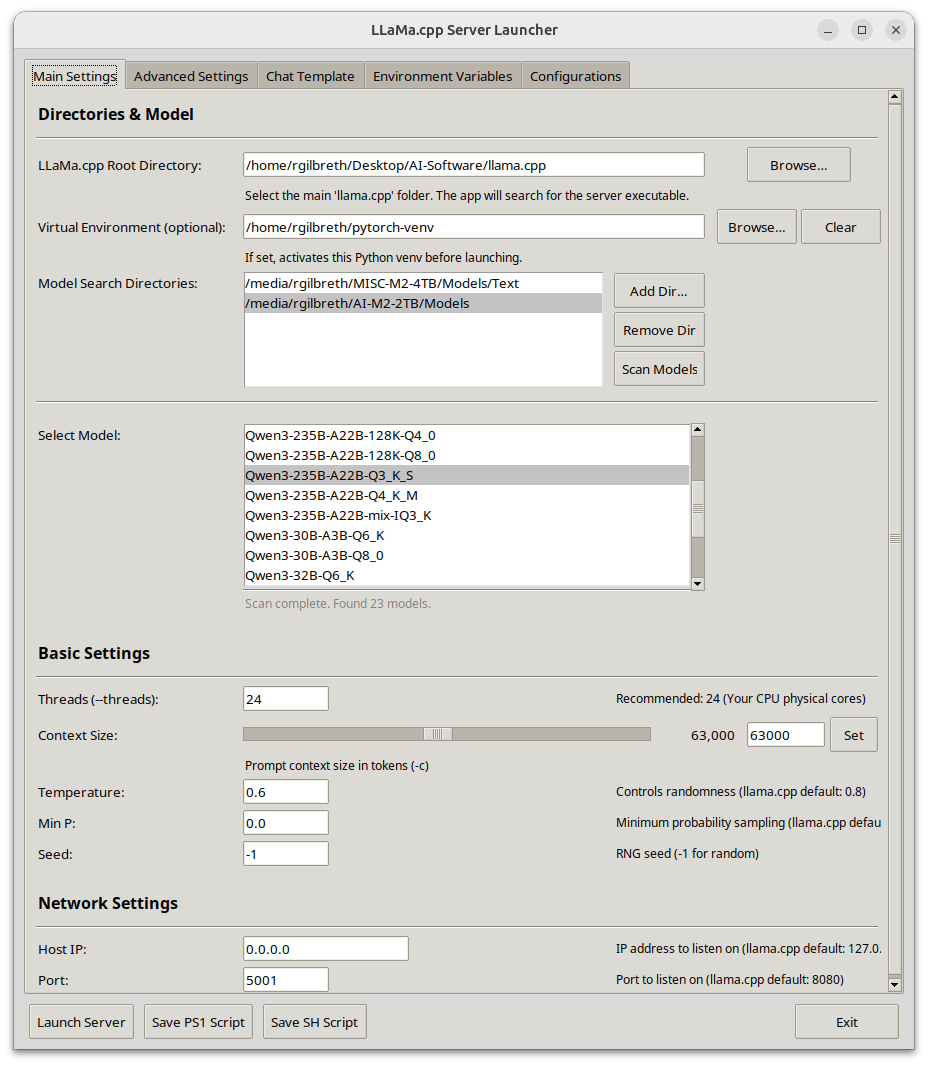
KRIS-Bench : un nouveau benchmark pour évaluer de manière exhaustive les capacités de raisonnement des modèles d’édition d’images du point de vue des types de connaissances: Des institutions telles que l’Université du Sud-Est ont conjointement publié KRIS-Bench, un benchmark des capacités de raisonnement des systèmes d’édition d’images basé sur la connaissance. Il évalue 10 modèles d’édition d’images grand public (dont GPT-Image-1, Gemini 2.0 Flash, etc.) à travers trois niveaux : connaissances factuelles (comme la couleur, la quantité), connaissances conceptuelles (comme le bon sens physique) et connaissances procédurales (comme les opérations multi-étapes), subdivisés en 22 tâches d’édition. Les résultats montrent que le modèle propriétaire GPT-Image-1 obtient les meilleures performances, mais tous les modèles affichent généralement de faibles performances sur les tâches de raisonnement profond telles que le raisonnement procédural, les sciences naturelles et la synthèse multi-étapes, révélant les lacunes des modèles actuels en matière de capacités cognitives avancées (Source: 量子位)
Une nouvelle recherche propose la méthode Finetune-RAG pour affiner les modèles de langage afin de résister aux hallucinations dans RAG: Les grands modèles de langage, dans le cadre de la génération augmentée par récupération (RAG), sont susceptibles de produire des hallucinations lorsque la récupération n’est pas parfaite (par exemple, en présence de fragments de documents perturbateurs). Finetune-RAG entraîne les modèles sur des échantillons d’entrée contenant des contextes corrects et incorrects, leur permettant de mieux maintenir la véracité. L’équipe de recherche a publié un ensemble de données de plus de 1600 échantillons à double contexte, un point de contrôle affiné de LLaMA 3.1-8B-Instruct, ainsi qu’un cadre d’évaluation GPT-4o nommé Bench-RAG. L’évaluation montre que cette méthode améliore la précision de 77 % à 98 %, avec des améliorations également en termes d’utilité, de pertinence et de profondeur (Source: Reddit r/MachineLearning)
TeleMath : publication du premier benchmark LLM pour la capacité à résoudre des problèmes mathématiques dans le domaine des télécommunications: Pour évaluer la capacité des grands modèles de langage à résoudre des tâches spécifiques au domaine des télécommunications et à forte composante mathématique, des chercheurs ont lancé le benchmark TeleMath. Ce benchmark comprend 500 paires de questions-réponses couvrant des sujets des télécommunications tels que le traitement du signal, l’optimisation des réseaux et l’analyse des performances. L’évaluation de plusieurs LLM open source montre que les modèles conçus pour le raisonnement mathématique ou logique obtiennent de meilleurs résultats sur TeleMath, tandis que les grands modèles généralistes à nombreux paramètres rencontrent souvent des difficultés. L’ensemble de données et le code d’évaluation ont été rendus publics (Source: HuggingFace Daily Papers)
ChineseHarm-Bench : publication d’un benchmark pour la détection de contenu préjudiciable en chinois: Face au constat que les ressources existantes pour la détection de contenu préjudiciable sont majoritairement en anglais, des chercheurs ont publié ChineseHarm-Bench, un benchmark complet et annoté par des professionnels pour la détection de contenu préjudiciable en chinois. Ce benchmark couvre six catégories représentatives, avec des données provenant entièrement du monde réel. Le processus d’annotation a également produit une base de règles de connaissances, fournissant aux LLM des connaissances expertes explicites. De plus, les chercheurs proposent une méthode de référence améliorée par la connaissance, combinant des règles annotées manuellement et les connaissances implicites des LLM, permettant à de petits modèles d’atteindre les performances des LLM SOTA (Source: HuggingFace Daily Papers)
Une nouvelle recherche découvre une structure hiérarchique des capacités latentes des modèles de langage grâce à l’apprentissage de représentations causales: Pour évaluer fidèlement les capacités des modèles de langage et surmonter les effets de confusion et les coûts de calcul élevés, cette étude propose un cadre d’apprentissage de représentations causales. Ce cadre modélise les performances observées sur les benchmarks comme des transformations linéaires d’un petit nombre de facteurs de capacité latents et, après avoir contrôlé le modèle de base comme facteur de confusion commun, identifie les relations causales entre ces facteurs latents. Appliquée aux données de plus de 1500 modèles du Open LLM Leaderboard, l’étude a découvert une structure causale linéaire concise à trois nœuds, révélant un chemin causal clair allant des capacités générales de résolution de problèmes à la maîtrise du suivi des instructions, puis aux capacités de raisonnement mathématique (Source: HuggingFace Daily Papers)
DeepLearning.AI lance un nouveau cours “Orchestrer les flux de travail pour les applications GenAI”: Andrew Ng a annoncé un nouveau cours de courte durée en collaboration avec Astronomer, enseignant comment construire et déployer des pipelines d’IA générative fiables à l’aide de l’outil open source populaire Airflow 3.0. Le contenu du cours comprend la décomposition des flux de travail en tâches discrètes, la planification des tâches, l’exécution parallèle, la récupération après échec et l’observabilité, visant à aider les apprenants à transformer des prototypes de notebooks Jupyter ou des scripts Python en flux de travail prêts pour la production (Source: DeepLearningAI)
Un article explore les méthodes d’optimisation des systèmes d’IA composites, les défis et les orientations futures: Avec le développement des LLM et des systèmes d’IA, les systèmes d’IA composites intégrant plusieurs composants deviennent de plus en plus matures pour exécuter des tâches complexes. Cet article passe en revue systématiquement les dernières avancées en matière d’optimisation des systèmes d’IA composites, y compris les techniques numériques et basées sur le langage. L’article formalise le concept d’optimisation des systèmes d’IA composites, classe les méthodes existantes et souligne les défis de recherche ouverts et les orientations futures dans ce domaine (Source: HuggingFace Daily Papers)
💼 Affaires
Disney et Universal Studios poursuivent le générateur d’images Midjourney pour violation de droits d’auteur: Disney et Universal Studios accusent Midjourney d’avoir utilisé sans autorisation leurs bibliothèques créatives (incluant des personnages de Star Wars, La Reine des Neiges, Les Minions, etc.) pour entraîner ses modèles, et d’avoir généré et distribué un grand nombre d’œuvres dérivées, qualifiant cela de “plagiat sans fond”. Cette affaire relance le débat sur la frontière entre le contenu généré par IA et la propriété intellectuelle (Source: Reddit r/ArtificialInteligence)
NVIDIA et Deutsche Telekom s’associent pour établir le premier cloud industriel d’IA pour les fabricants européens d’ici 2026: Le chancelier fédéral allemand Friedrich Merz et le PDG de NVIDIA Jensen Huang se sont rencontrés pour discuter d’une coopération stratégique plus poussée afin de consolider la position de l’Allemagne en tant que leader mondial de l’IA. Dans le cadre de cette vision, Deutsche Telekom et NVIDIA ont annoncé une nouvelle collaboration visant à établir d’ici 2026 le premier cloud industriel d’IA au monde pour les fabricants européens. Cette infrastructure sécurisée et conforme aux normes européennes soutiendra l’innovation de pointe tout en garantissant une souveraineté totale des données (Source: nvidia)

Rumeur selon laquelle Sam Altman pourrait diluer le contrôle à but non lucratif d’OpenAI par des acquisitions entièrement en actions: Les récentes acquisitions par OpenAI d’io (6,5 milliards de dollars) et de Windsurf (3 milliards de dollars), entièrement en actions, ont suscité des spéculations. Sur Hacker News, une théorie suggère que Sam Altman pourrait utiliser ces transactions pour diluer progressivement le contrôle de l’organisation à but non lucratif OpenAI Inc. sur l’entité à but lucratif OpenAI Global LLC (maintenant OpenAI PBC), contournant ainsi potentiellement les restrictions légales liées à une transformation en société entièrement à but lucratif. Cette manœuvre est rapprochée par certains des opérations d’Altman sur Reddit en 2014, mais d’autres estiment que ces acquisitions sont des stratégies commerciales normales (Source: Reddit r/ArtificialInteligence)
🌟 Communauté
Le débat sur la capacité réelle de l’IA à “raisonner” se poursuit, l’article d’Apple suscitant la controverse: Un récent article d’Apple affirmant que les performances des grands modèles de langage (LLM) sur des tâches complexes (comme les Tours de Hanoï) ne relèvent pas d’un véritable raisonnement mais plutôt d’une reconnaissance de formes, a suscité un large débat au sein de la communauté. Miles Brundage, ancien employé d’OpenAI, en commentant la résolution par o3-pro de jeux de mots complexes, a demandé ironiquement : “Si cela ne s’appelle pas raisonner, alors qu’est-ce qui l’est ?”. Des recherches ultérieures ont indiqué que le phénomène d‘“effondrement du raisonnement” décrit dans l’article d’Apple pourrait être dû aux limites de la conception expérimentale (comme les limites de tokens, l’évaluation erronée de problèmes insolubles) plutôt qu’à un manque de capacité de raisonnement intrinsèque des modèles. Après ajustement des méthodes de test, les modèles ont bien performé sur des tâches où ils avaient précédemment échoué, ce qui suggère que l’évaluation des capacités de raisonnement de l’IA nécessite une conception expérimentale plus minutieuse (Source: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
Divergences notables entre Jensen Huang (PDG de Nvidia) et Dario Amodei (PDG d’Anthropic) sur l’avenir de l’IA: Fortune rapporte que Jensen Huang, PDG de Nvidia, a déclaré être en désaccord avec presque toutes les opinions de Dario Amodei, PDG d’Anthropic, concernant l’IA. Amodei souligne fréquemment les risques potentiels de l’IA et son impact massif sur l’emploi, et plaide pour un contrôle plus strict du développement de l’IA, mené par un petit nombre d’organisations “responsables”. Huang, quant à lui, se montre sceptique face à de telles opinions, préférant promouvoir une application et un développement larges des technologies IA. La communauté commente que la position de Huang pourrait être liée à ses intérêts commerciaux, Nvidia étant le principal fournisseur de matériel IA (Source: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

L’abonnement à 20 $ de Claude Code est salué par les développeurs pour son excellent rapport qualité-prix: De nombreux développeurs ont partagé sur les réseaux sociaux leurs expériences positives avec l’abonnement mensuel à 20 $ de Claude Code d’Anthropic, le qualifiant d’extrêmement rentable et permettant un retour sur investissement rapide dans leurs projets. Les utilisateurs mentionnent que, malgré certaines limitations de débit, Claude Code excelle dans l’assistance au codage, l’apprentissage de nouveaux langages (par exemple, passer de C# à SwiftUI) et l’optimisation des instructions de projet (comme les fichiers CLAUDE.md), améliorant considérablement l’efficacité du travail. Certains utilisateurs envisagent même d’annuler leurs abonnements à d’autres outils d’assistance à la programmation IA (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
La communauté discute des futures applications de l’IA en psychologie et des défis éthiques: Avec des technologies telles que les LLM rédigeant des suggestions thérapeutiques et des applications suivant les émotions via les capteurs de téléphone, l’IA pénètre progressivement la psychologie. La discussion communautaire se concentre sur la question de savoir si l’IA, dans la pratique clinique, améliorera les capacités des thérapeutes ou finira par remplacer une partie de leur travail, la crédibilité de l’IA dans l’évaluation et la recherche, l’impact sur la formation professionnelle et le marché de l’emploi en psychologie, ainsi que les questions éthiques et réglementaires des applications de l’IA, en particulier les biais des données, la vie privée et les limites des “thérapeutes robots”. La préoccupation centrale est de savoir comment exploiter l’IA pour améliorer l’efficacité et les services personnalisés tout en garantissant la sécurité des patients et en préservant la valeur thérapeutique de la connexion interpersonnelle (Source: Reddit r/artificial)
Le modèle DeepSeek-R1-0528 quantifié à 3,53 bits par Unsloth obtient de bons résultats sur le benchmark de codage Aider Polyglot: Après quantification à 3,53 bits (UD-Q3_K_XL) du modèle DeepSeek-R1-0528 par l’équipe Unsloth, celui-ci a atteint un taux de réussite de 68 % au test de benchmark de codage Aider Polyglot. Le test a utilisé une taille de contexte de 40960 et Flash Attention, nécessitant environ 300 Go de RAM/VRAM. Ce résultat se situe entre Claude Sonnet 3.7 et Claude Opus 4, montrant le potentiel des modèles quantifiés à maintenir une capacité de codage élevée. Les membres de la communauté se sont dits impressionnés par les performances de tels modèles exécutés localement et attendent avec impatience les résultats de tests d’autres versions quantifiées (Source: Reddit r/LocalLLaMA)
💡 Autres
Le rapport d’incident de la panne mondiale de GCP révèle : une politique de quota illégale a causé l’interruption de service: Le rapport sur la récente panne mondiale de Google Cloud Platform (GCP) indique que la cause était la diffusion d’une politique de quota erronée au système mondial de gestion des API (par exemple, limitant à 1 seule requête par heure), ce qui a entraîné le rejet des requêtes externes pour dépassement de quota (erreur 403). Après avoir découvert le problème, les ingénieurs ont contourné la vérification des quotas pour les API affectées. Cependant, dans la région us-central1, la tentative de suppression de l’ancienne politique et d’écriture de la nouvelle a provoqué une surcharge de la base de données en raison de problèmes de cache, allongeant le temps de récupération. D’autres régions ont adopté une approche de suppression progressive du cache pour la récupération, l’ensemble du processus ayant duré environ 2 heures (Source: karminski3)

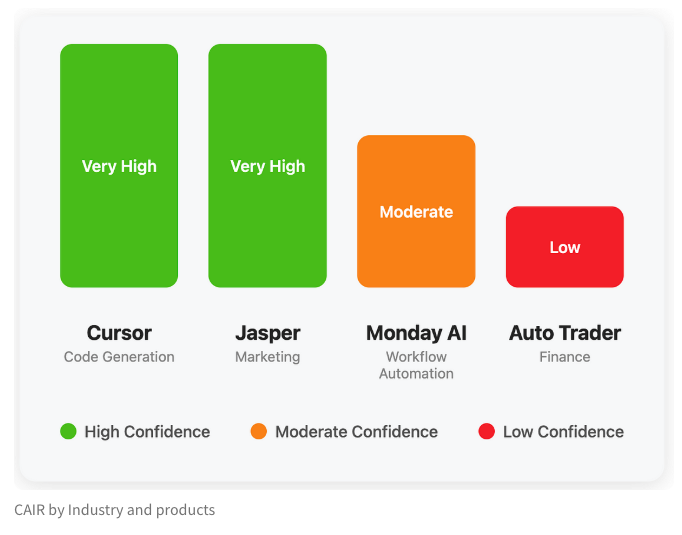
L’équipe LangChain propose l’indicateur CAIR pour évaluer le potentiel de succès des produits IA: Harrison Chase de LangChain, en collaboration avec Assaf Elovic, a rédigé un article explorant pourquoi certains produits IA se popularisent rapidement tandis que d’autres peinent. Ils soutiennent que la capacité du modèle n’est pas le seul facteur déterminant ; l’expérience utilisateur (UX) est cruciale, et ils proposent l’indicateur “CAIR” (Confidence in AI Results, confiance dans les résultats de l’IA). Plus le CAIR est élevé, plus l’adoption du produit est élevée. Ce cadre vise à aider les développeurs à identifier et à améliorer les divers composants qui influencent la confiance des utilisateurs, augmentant ainsi le taux de succès des produits (Source: hwchase17, swyx, hwchase17, Hacubu)
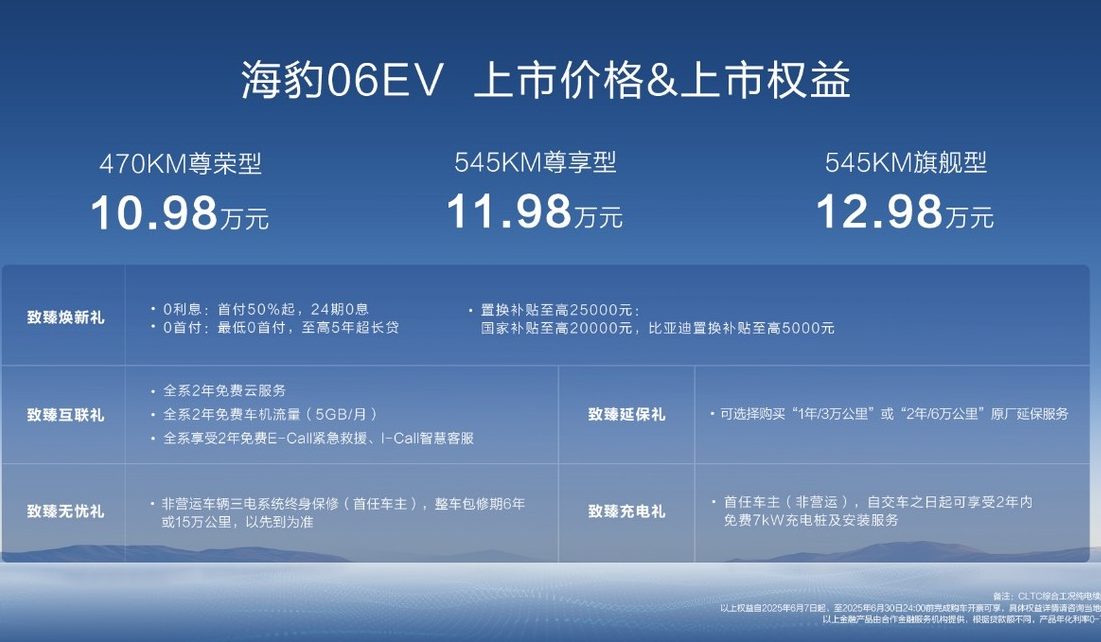
BYD lance la nouvelle berline coupé familiale purement électrique Seal 06EV, à partir de 109 800 yuans: BYD Ocean Net a lancé la Seal 06EV au salon de l’automobile de Chongqing, positionnée comme une berline coupé tendance, de qualité et de choix, disponible en 3 configurations, avec des prix allant de 109 800 à 129 800 yuans. Le véhicule est basé sur la plateforme e-platform 3.0 Evo de BYD, équipé d’un système de propulsion électrique intelligent huit-en-un et d’un système de pompe à chaleur efficace à large plage de température de nouvelle génération, offrant deux options d’autonomie CLTC de 470 km et 545 km. Le véhicule adopte une configuration à propulsion arrière, est équipé du système de contrôle intelligent de la carrosserie à amortissement YunNian-C, et du système d’aide à la conduite intelligente “Tian Shen Zhi Yan C” (Œil du Ciel C) version trinoculaire, prenant en charge des fonctions telles que la navigation assistée sur autoroute et le stationnement automatique (Source: 量子位)