Mots-clés:Meta V-JEPA 2, NVIDIA Cloud IA industriel, Sakana AI Texte-vers-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, Université de Princeton HistBench, Modèle mondial open source pour l’entraînement vidéo, Plateforme cloud IA pour la fabrication européenne, Adaptateur LLM pour la génération de texte, Réglage fin DPO pour GPT-4.1, Observabilité des agents IA
🔥 Pleins feux
Meta publie V-JEPA 2 : un modèle du monde open-source image/vidéo entraîné sur des vidéos : Meta a lancé V-JEPA 2, un nouveau modèle du monde open-source pour images/vidéos, basé sur l’architecture ViT, disponible en différentes tailles (L/G/H) et résolutions (286/384), avec jusqu’à 1,2 milliard de paramètres. V-JEPA 2 excelle dans la compréhension et la prédiction visuelles, permettant aux robots de planifier et d’exécuter des tâches en zero-shot dans des environnements inconnus. Meta souligne sa vision d’une IA utilisant des modèles du monde pour s’adapter à des environnements dynamiques et apprendre efficacement de nouvelles compétences. Parallèlement, Meta a également publié trois nouveaux benchmarks : MVPBench, IntPhys 2 et CausalVQA, destinés à évaluer la capacité des modèles existants à raisonner sur le monde physique à partir de vidéos. (Source: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia construit le premier cloud industriel d’IA en Europe pour promouvoir le développement de l’industrie manufacturière : Nvidia a annoncé la construction de la première plateforme cloud mondiale d’intelligence artificielle industrielle pour les fabricants européens. Cette usine d’IA vise à aider les leaders industriels à accélérer l’ensemble des applications de fabrication, de la conception et de la simulation d’ingénierie aux jumeaux numériques d’usines et à la robotique. Cette initiative fait partie d’une série d’annonces faites par Nvidia lors de GTC Paris et VivaTech 2025, visant à accélérer l’innovation en IA en Europe et au-delà. Jensen Huang a déclaré que la puissance de calcul de l’IA en Europe devrait décupler d’ici deux ans, et a souligné que “tous les objets en mouvement deviendront robotisés, les voitures étant les prochaines”. (Source: nvidia, nvidia, Jensen Huang : La puissance de calcul de l’IA en Europe décuplera en deux ans)

Sakana AI lance Text-to-LoRA : génération instantanée d’adaptateurs LLM spécifiques à une tâche à partir de descriptions textuelles : Sakana AI a publié la technologie Text-to-LoRA, un Hypernetwork capable de générer instantanément des adaptateurs LLM spécifiques à une tâche (LoRAs) à partir de la description textuelle de la tâche par l’utilisateur. Cette technologie vise à réduire la barrière à l’entrée pour la personnalisation des grands modèles, permettant aux utilisateurs non techniques de spécialiser les modèles de base via le langage naturel, sans nécessiter une expertise technique approfondie ou des ressources de calcul importantes. Text-to-LoRA peut encoder des centaines d’adaptateurs LoRA existants et, tout en maintenant les performances, généraliser à des tâches inédites. L’article de recherche et le code correspondants ont été publiés sur arXiv et GitHub, et seront présentés à l’ICML2025. (Source: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
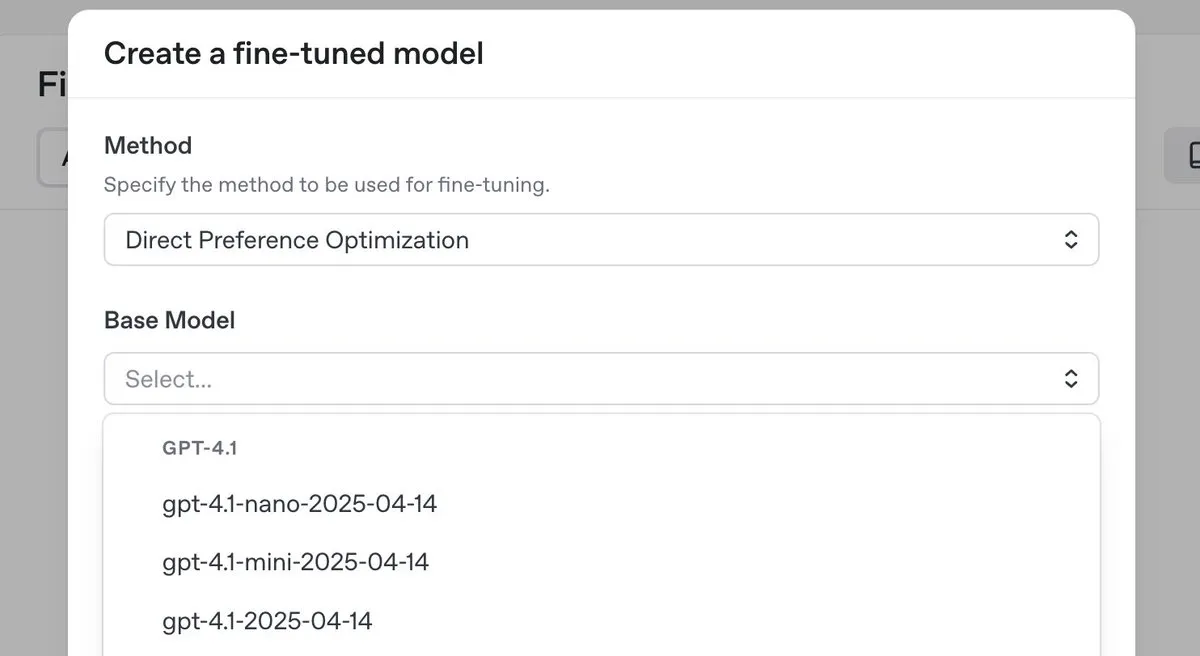
OpenAI lance le modèle d’inférence haut de gamme o3-pro avec une baisse de prix significative, et introduit la fonctionnalité de fine-tuning DPO pour la série GPT-4.1 : OpenAI a lancé son nouveau modèle d’inférence haut de gamme, o3-pro, et a considérablement réduit les prix des modèles de la série o3, visant à diminuer les coûts pour les développeurs. Parallèlement, OpenAI a annoncé que les utilisateurs peuvent désormais utiliser l’optimisation directe des préférences (DPO) pour le fine-tuning des modèles de la famille GPT-4.1 (y compris 4.1, 4.1-mini et 4.1-nano). Le DPO permet une personnalisation en comparant les réponses du modèle plutôt que des cibles fixes, ce qui est particulièrement adapté aux tâches ayant des exigences subjectives en matière de ton, de style et de créativité. ARC Prize a re-testé o3 après la baisse de prix, et les résultats montrent que ses performances sur ARC-AGI n’ont pas changé. (Source: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Mouvements
Databricks lance Lakebase, une version gratuite et Agent Bricks pour accélérer le développement d’applications de données et d’IA : Databricks a annoncé que Lakebase est entré en phase de prévisualisation publique. Il s’agit d’une base de données Postgres entièrement gérée, intégrée au lakehouse et conçue pour l’IA, combinant la facilité d’utilisation de Postgres, l’évolutivité du lakehouse et la technologie de branchement de la base de données Neon. Parallèlement, Databricks a lancé une version gratuite de sa plateforme et de nombreux supports de formation pour aider les développeurs à apprendre l’ingénierie des données, la science des données et l’IA. De plus, Databricks Apps est officiellement disponible (GA), permettant aux clients de créer et de déployer des applications interactives de données et d’IA sur la plateforme. Databricks a également lancé Agent Bricks, qui adopte une approche déclarative pour le développement d’agents IA, où l’utilisateur décrit la tâche et le système génère automatiquement une évaluation et optimise l’agent. (Source: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia s’associe à Mistral AI pour construire une plateforme cloud de bout en bout en Europe : Nvidia a annoncé un partenariat avec la startup française Mistral AI pour construire conjointement une plateforme cloud de bout en bout. La première phase de la collaboration verra le déploiement de 18 000 systèmes Nvidia Grace Blackwell, avec des plans d’expansion vers d’autres sites en 2026. Cette collaboration s’inscrit dans le cadre des efforts de Nvidia pour promouvoir la construction d’infrastructures d’IA en Europe et le concept d’« IA souveraine », visant à fournir à l’Europe des centres de données et des serveurs localisés. (Source: Jensen Huang : La puissance de calcul de l’IA en Europe décuplera en deux ans)
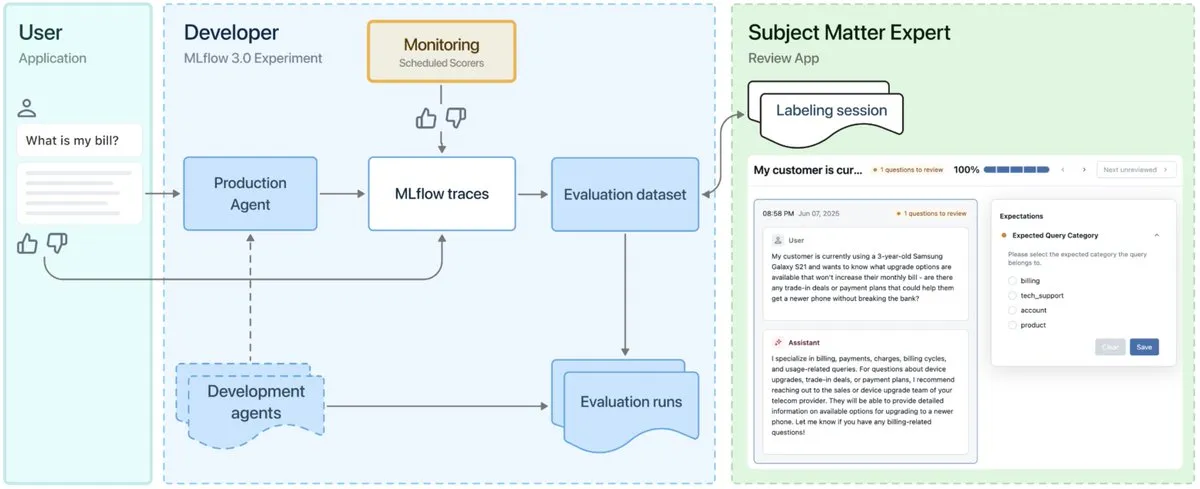
Lancement de MLflow 3.0, conçu pour l’observabilité et le développement d’agents IA : MLflow 3.0 a été officiellement lancé. Cette nouvelle version a été repensée spécifiquement pour l’observabilité et le développement d’agents IA, et met à jour les fonctionnalités traditionnelles de machine learning structuré. MLflow 3.0 vise à permettre l’amélioration continue des systèmes d’IA grâce aux données, en prenant en charge le suivi, l’évaluation et la surveillance des systèmes d’IA, et en tenant compte des besoins au niveau de l’entreprise, tels que la collaboration humaine, la gouvernance et la sécurité des données, ainsi que l’intégration avec l’écosystème de données Databricks. (Source: matei_zaharia, matei_zaharia, lateinteraction)
L’Université de Princeton et l’Université Fudan lancent conjointement HistBench et HistAgent pour promouvoir l’application de l’IA dans la recherche historique : Le laboratoire d’IA de l’Université de Princeton et le département d’histoire de l’Université Fudan ont collaboré pour lancer HistBench, le premier benchmark mondial d’évaluation de l’IA pour la recherche historique, et HistAgent, un assistant IA. HistBench comprend 414 questions historiques, couvrant 29 langues et l’histoire de multiples civilisations, visant à tester la capacité de l’IA à traiter des documents historiques complexes et sa compréhension multimodale. HistAgent est un agent intelligent spécialement conçu pour la recherche historique, intégrant des outils tels que la recherche documentaire, l’OCR et la traduction. Les tests montrent que les grands modèles généralistes ont un taux de précision inférieur à 20 % sur HistBench, tandis que HistAgent surpasse de loin les modèles existants. (Source: Premier benchmark historique mondial, Princeton et Fudan créent un assistant historique IA, l’IA perce dans les sciences humaines)

Microsoft Research et l’Université de Pékin publient conjointement le framework Next-Frame Diffusion (NFD) pour améliorer l’efficacité de la génération vidéo auto-régressive : Microsoft Research et l’Université de Pékin ont conjointement lancé un nouveau framework, Next-Frame Diffusion (NFD), qui, grâce à l’échantillonnage parallèle intra-image et à l’auto-régression inter-image, a atteint une génération de vidéo auto-régressive de haute qualité à plus de 30 images par seconde sur un GPU A100 avec un modèle de 310M. NFD utilise un Transformer avec un mécanisme d’attention causale par blocs, et combine les techniques de distillation de cohérence et d’échantillonnage spéculatif pour améliorer davantage l’efficacité, promettant des applications dans des scénarios tels que les jeux interactifs en temps réel. (Source: Génération de plus de 30 images vidéo par seconde, prise en charge de l’interaction en temps réel, un nouveau framework de génération vidéo auto-régressive bat des records d’efficacité)

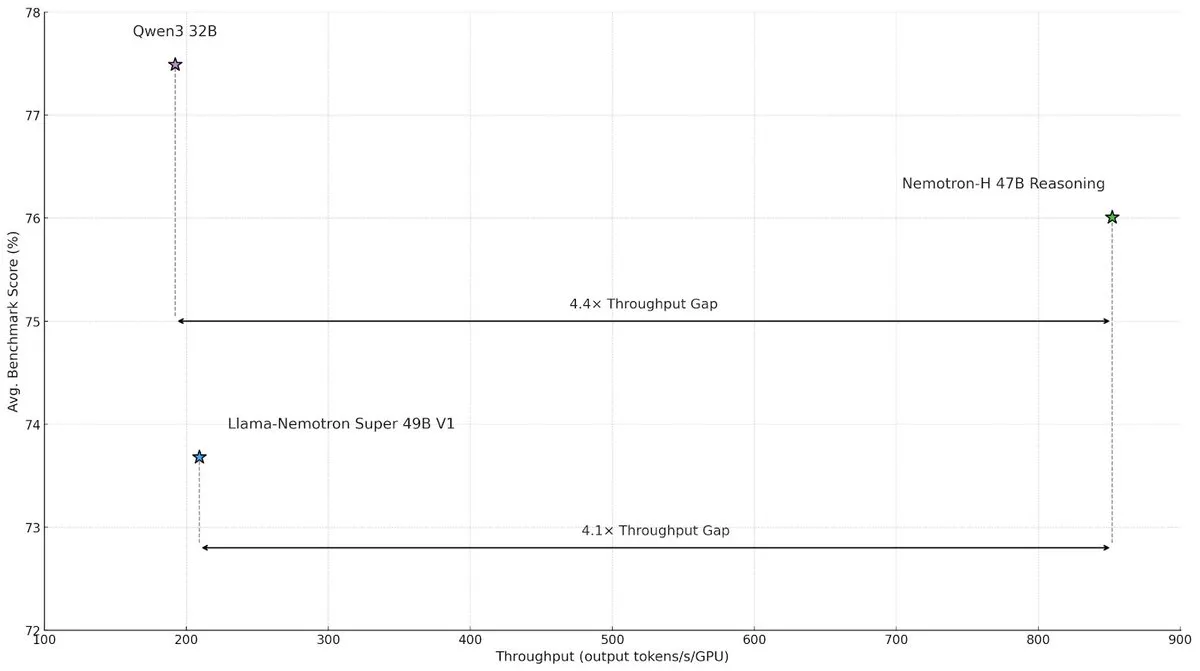
NVIDIA publie le modèle à architecture hybride Nemotron-H, améliorant la vitesse et l’efficacité de l’inférence à grande échelle : NVIDIA Research a lancé le modèle Nemotron-H, qui adopte une architecture hybride Mamba et Transformer, visant à résoudre les goulots d’étranglement de vitesse dans les tâches d’inférence à grande échelle. Ce modèle, tout en maintenant ses capacités d’inférence, atteint un débit 4 fois supérieur à celui des modèles Transformer de taille comparable. La recherche indique que les modèles hybrides peuvent maintenir les performances d’inférence même avec moins de couches d’attention, et que l’avantage en termes d’efficacité des architectures linéaires est particulièrement significatif dans les scénarios de longues chaînes d’inférence. (Source: _albertgu, tri_dao, krandiash)
Jack Rae, chercheur chez Google DeepMind, rejoint le groupe “Superintelligence” de Meta : Jack Rae, chercheur principal chez Google DeepMind, a confirmé avoir rejoint le nouveau groupe “Superintelligence” de Meta. Pendant son séjour chez DeepMind, Rae était responsable des capacités de “réflexion” du modèle Gemini et est l’un des principaux partisans de l’idée de “la compression, c’est l’intelligence”. Il avait précédemment participé au développement de GPT-4 chez OpenAI. Le PDG de Meta, Mark Zuckerberg, recrute personnellement les meilleurs talents en IA, offrant des packages de rémunération de plusieurs dizaines de millions de dollars à la nouvelle équipe, dans le but d’améliorer le modèle Llama et de développer des outils d’IA plus puissants pour rattraper les leaders du secteur. (Source: Le premier grand nom du groupe “Superintelligence” de Zuck, chercheur principal de Google DeepMind, figure clé de “la compression, c’est l’intelligence”, DhruvBatraDB)

Mistral AI lance son premier modèle d’inférence Magistral, prenant en charge le raisonnement multilingue : Mistral AI a lancé son premier modèle d’inférence, Magistral, comprenant une version open-source de 24 milliards de paramètres, Magistral Small, et Magistral Medium, destiné aux entreprises. Ce modèle a été spécifiquement affiné pour la logique multi-étapes et l’interprétabilité, prend en charge le raisonnement multilingue, particulièrement optimisé pour les langues européennes, et peut fournir un processus de pensée traçable. Magistral est entraîné à l’aide d’un algorithme GRPO amélioré par apprentissage par renforcement pur, sans dépendre des données de distillation des modèles d’inférence existants. Cependant, les résultats de ses benchmarks ont été partiellement remis en question car ils n’incluaient pas les données des dernières versions de Qwen et DeepSeek R1. (Source: Le nouveau modèle d’inférence “SOTA” évite-t-il Qwen et R1 ? L’OpenAI européen se fait critiquer)

Le grand modèle Doubao 1.6 de ByteDance est publié avec une nouvelle baisse de prix significative, le modèle vidéo Seedance 1.0 pro lancé simultanément : Volcano Engine a publié le grand modèle Doubao 1.6, innovant avec une tarification par tranches de “longueur d’entrée”. Pour la tranche d’entrée de 0 à 32K, le prix est de 0,8 yuan par million de tokens, et la sortie est de 8 yuans par million de tokens, soit une réduction de coût de 63 % par rapport à la version 1.5. Le nouveau modèle de génération vidéo Seedance 1.0 pro est tarifé à 0,015 yuan par millier de tokens, la génération d’une vidéo de 5 secondes en 1080P coûtant environ 3,67 yuans. Tan Dai, président de Volcano Engine, a déclaré que cette baisse de prix a été réalisée grâce à une optimisation ciblée des coûts pour la plage couramment utilisée de 32K par les entreprises et à une innovation du modèle commercial, visant à promouvoir l’application à grande échelle des Agents. (Source: Le grand modèle Doubao baisse à nouveau considérablement ses prix, Volcano Engine continue de lutter agressivement pour des parts de marché, Volcano Engine s’enflamme contre Baidu Cloud)
L’Université des Sciences et Technologies de Hong Kong et Huawei proposent conjointement le framework AutoSchemaKG, réalisant une construction de graphe de connaissances entièrement autonome : Le laboratoire KnowComp de l’Université des Sciences et Technologies de Hong Kong, en collaboration avec le département théorique de Huawei à Hong Kong, a proposé le framework AutoSchemaKG, capable de construire des graphes de connaissances de manière entièrement autonome sans schéma prédéfini. Ce système utilise de grands modèles de langage pour extraire directement des triplets de connaissances à partir de textes et induire des schémas d’entités et d’événements. Sur la base de ce framework, l’équipe a construit la série de graphes de connaissances ATLAS, contenant plus de 900 millions de nœuds et 5,9 milliards d’arêtes. Les expériences montrent que cette méthode, sans aucune intervention humaine, permet à l’induction de schémas d’atteindre un alignement sémantique de 95 % avec les schémas conçus par l’homme. (Source: Le plus grand GraphRag open-source : construction de graphes de connaissances entièrement autonome)

QJing Technology lance une solution de serveur intégré matériel-logiciel à 8 cartes, améliorant l’efficacité d’exécution du grand modèle DeepSeek : QJing Technology, en collaboration avec Intel, a organisé un salon de l’écosystème pour lancer sa dernière solution de serveur intégré matériel-logiciel à 8 cartes. Cette solution peut exécuter efficacement de grands modèles tels que DeepSeek-R1/V3-671B, avec des performances jusqu’à 7 fois supérieures à celles d’une seule carte. Parallèlement, son moteur d’inférence auto-développé KLLM, sa plateforme de gestion de grands modèles AMaaS et sa suite d’applications bureautiques “QJing·Zhiwen” ont également fait l’objet d’importantes mises à niveau, visant à relever les défis auxquels est confronté le déploiement privé de grands modèles, tels que la barrière d’entrée élevée et les performances d’exécution insuffisantes. (Source: Salon de l’écosystème QJing Technology & Intel, fusion de l’écosystème matériel, moteur d’inférence et applications de haut niveau, pour franchir le “dernier kilomètre” du déploiement privé de grands modèles)

Black Forest Labs publie la série de modèles d’image FLUX.1 Kontext, renforçant la cohérence des personnages et des styles : La société allemande Black Forest Labs a lancé la série de modèles texte-image FLUX.1 Kontext (versions max, pro, dev), axée sur le maintien de la cohérence des personnages et des styles lors de l’édition d’images. Cette série de modèles prend en charge les modifications locales et globales des images et peut générer des images à partir d’entrées textuelles et/ou d’images. La version FLUX.1 Kontext dev devrait être open-source. Lors de tests sur un benchmark propriétaire comprenant environ 1000 paires de prompts et d’images de référence, les versions FLUX.1 Kontext max et pro ont surpassé des modèles concurrents tels que OpenAI GPT Image 1 et Google Gemini 2.0 Flash. (Source: DeepLearning.AI Blog)

Nvidia, l’Université Rutgers et d’autres institutions proposent le framework STORM, utilisant des couches Mamba pour réduire les tokens nécessaires à la compréhension vidéo : Des chercheurs de Nvidia, de l’Université Rutgers, de l’UC Berkeley et d’autres institutions ont construit le système texte-vidéo STORM. Ce système introduit des couches Mamba entre le transformeur visuel SigLIP et le LLM de Qwen2-VL, en enrichissant les embeddings de tokens d’une seule image (contenant des informations d’autres images du même clip), moyennant ainsi les embeddings de tokens entre les images sans perdre d’informations cruciales. Cela permet au système de traiter les vidéos avec moins de tokens, surpassant GPT-4o et Qwen2-VL sur des benchmarks de compréhension vidéo tels que MVBench et MLVU, tout en améliorant la vitesse de traitement de plus de 3 fois. (Source: DeepLearning.AI Blog)

Le cofondateur de Google exprime des réserves quant aux robots humanoïdes, les perspectives de commercialisation des robots spécialisés sont prometteuses : Sergey Brin, cofondateur de Google, a déclaré ne pas être très enthousiaste à l’idée de robots humanoïdes reproduisant strictement la forme humaine, estimant que ce n’est pas une condition nécessaire pour un travail robotique efficace. Parallèlement, les robots spécialisés attirent l’attention en raison de leur caractéristique “prêt à l’emploi” et de leur voie de commercialisation claire. Par exemple, les robots sous-marins et les tondeuses à gazon robotisées présentent un potentiel énorme dans des scénarios spécifiques. L’analyse suggère qu’à ce stade, la forme du robot et la productivité capables de résoudre des problèmes réels sont essentielles, et les robots spécialisés, grâce à des modèles commerciaux clairs et à des scénarios de besoins réels, sont les premiers à atteindre la commercialisation. (Source: Les robots spécialisés tapent sur l’épaule des robots humanoïdes : “Frère, laisse-moi une place, je veux manger à table.”)

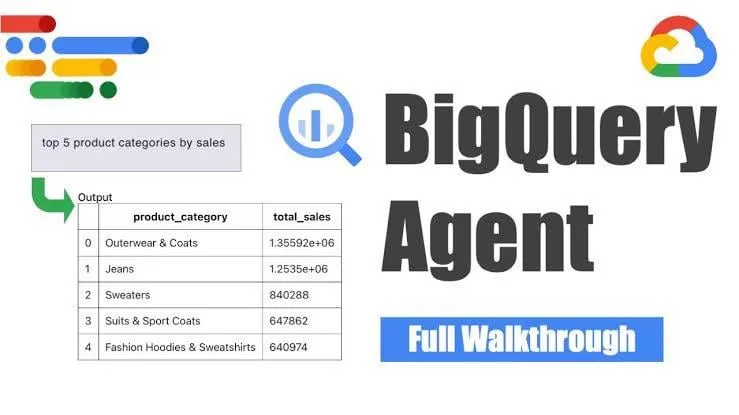
Google lance l’agent d’ingénierie des données BigQuery pour une génération intelligente de pipelines : Google a lancé l’agent d’ingénierie des données BigQuery, un outil qui utilise le raisonnement contextuel pour étendre efficacement la génération de pipelines de données. Les utilisateurs peuvent définir les exigences du pipeline via de simples instructions en ligne de commande ; l’agent utilise ensuite des prompts spécifiques au domaine pour générer du code de pipeline par lots personnalisé pour l’environnement de données de l’utilisateur, y compris les configurations d’ingestion de données, les requêtes de transformation, la logique de création de tables et les paramètres de planification via Dataform ou Composer. Cet outil vise à simplifier le travail répétitif des ingénieurs de données lorsqu’ils traitent plusieurs domaines de données, environnements et logiques de transformation grâce à l’assistance de l’IA. (Source: Reddit r/deeplearning)
Yandex publie Yambda, un vaste ensemble de données public contenant près de 5 milliards d’interactions utilisateur-piste audio : Yandex a publié un vaste ensemble de données public nommé Yambda, spécialement conçu pour la recherche sur les systèmes de recommandation. Cet ensemble de données contient près de 5 milliards d’interactions anonymes entre utilisateurs et pistes audio provenant de Yandex Music, offrant aux chercheurs une rare opportunité de travailler avec des données à l’échelle du monde réel. (Source: _akhaliq)

ByteDance publie le modèle de restauration vidéo SeedVR2 sur Hugging Face : L’équipe Seed de ByteDance a publié SeedVR2 sur Hugging Face, un modèle Transformer de diffusion en une seule étape pour la restauration vidéo. Ce modèle, sous licence Apache 2.0, se caractérise par une inférence en une seule étape, rapide et efficace, et prend en charge le traitement à n’importe quelle résolution, sans nécessiter de découpage en blocs ni être limité par la taille. (Source: huggingface)
Le grand modèle vidéo Doubao Seedance 1.0 Pro de ByteDance reçoit des critiques positives lors des tests pratiques : Le dernier grand modèle de génération d’images en vidéo de ByteDance, Seedance 1.0 Pro, a démontré une bonne capacité à suivre les instructions et une stabilité dans la génération d’objets lors des tests pratiques. Les utilisateurs ont rapporté une haute qualité de génération vidéo, une cinématographie et une synchronisation rythmique précises, se classant juste derrière Veo 2/3. Un inconvénient potentiel est que, lors de la génération de mouvements d’objets purs, le modèle ajoute parfois des mains pour rendre la scène plus plausible, ce qui peut être évité en limitant l’apparition des mains. (Source: karminski3, karminski3, karminski3)
Alibaba met en open source le framework d’avatar numérique Mnn3dAvatar, prenant en charge la capture faciale en temps réel et la création de personnages virtuels 3D : Alibaba a mis en open source sur GitHub un framework d’avatar numérique nommé Mnn3dAvatar. Ce projet permet la capture faciale en temps réel et le mappage des expressions sur des personnages virtuels 3D, et permet aux utilisateurs de créer leurs propres personnages virtuels 3D. Ce framework convient à des scénarios simples tels que le téléachat en direct et la présentation de contenu. (Source: karminski3)
Nvidia met en open source le modèle de base pour robot humanoïde Gr00t N 1.5 3B et fournit un tutoriel de fine-tuning : Nvidia a mis en open source le modèle Gr00t N 1.5 3B, un modèle de base ouvert conçu pour les compétences de raisonnement des robots humanoïdes, sous licence commerciale. Parallèlement, Nvidia a également publié un tutoriel complet de fine-tuning à utiliser avec LeRobotHF SO101, visant à promouvoir le développement et l’application de la technologie des robots humanoïdes. (Source: ClementDelangue)
Together AI lance l’API Batch, offrant un service d’inférence LLM à grande échelle avec une baisse de prix significative : Together AI a lancé sa nouvelle API Batch, spécialement conçue pour l’inférence LLM à grande échelle, prenant en charge des scénarios d’application à haut débit tels que la génération de données synthétiques, les tests de performance, la modération et le résumé de contenu, et l’extraction de documents. Cette API introduit un prix de lancement 50 % moins cher que l’API en temps réel, prend en charge le traitement par lots jusqu’à 50 000 requêtes ou 100 Mo à la fois, et est compatible avec 15 modèles de premier plan. (Source: vipulved)
Gemini 2.5 Pro de Google ajoute une fonctionnalité de génération d’art fractal interactif : Google a annoncé que Gemini 2.5 Pro prend désormais en charge la création instantanée d’art fractal interactif. Les utilisateurs peuvent générer des œuvres d’art visuelles uniques en fournissant des prompts tels que “crée-moi une belle œuvre d’art fractale, basée sur des particules, animée, sans fin, 3D, symétrique, inspirée par des formules mathématiques”. (Source: demishassabis)
La vitesse de génération vidéo de Veo3 Fast de Google a plus que doublé : Google Labs a annoncé que la vitesse de génération de la version Veo3 Fast de son outil de génération vidéo Flow a plus que doublé, tout en maintenant une résolution de 720p. Cette mise à jour vise à permettre aux utilisateurs de créer du contenu vidéo plus rapidement. (Source: op7418)
Hugging Face s’intègre à Google Colab et Kaggle, simplifiant le processus d’utilisation des modèles : Hugging Face est désormais intégré à Google Colab et Kaggle. Les utilisateurs peuvent lancer directement des notebooks Colab à partir de n’importe quelle carte de modèle, ou ouvrir le même modèle dans un Notebook Kaggle, et sont accompagnés d’exemples de code public exécutables, simplifiant ainsi le processus d’utilisation et d’expérimentation des modèles. (Source: ClementDelangue, huggingface)
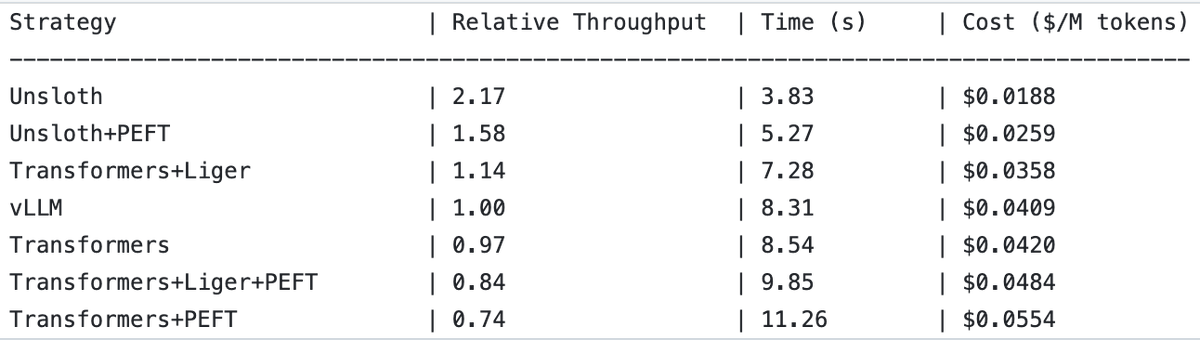
UnslothAI double le débit pour les services de modèles de récompense et l’inférence de classification de séquences : Il a été découvert qu’UnslothAI peut être utilisé pour fournir des services de modèles de récompense (RM) et que, pour l’inférence de classification de séquences, son débit est deux fois supérieur à celui de vLLM. Cette découverte a suscité l’intérêt de la communauté RL (apprentissage par renforcement), l’amélioration des performances d’UnslothAI étant susceptible d’accélérer la recherche et les applications associées. (Source: natolambert, danielhanchen)
Digua Robot lance le premier kit de développement robotique intégré calcul-contrôle sur SoC unique, RDK S100 : Digua Robot a lancé le RDK S100, le premier kit de développement robotique intégré calcul-contrôle sur SoC unique du secteur. Ce kit adopte une conception architecturale de type cerveau-cervelet humain, intégrant CPU+BPU+MCU sur un seul SoC, prenant en charge la collaboration efficace des grands et petits modèles d’IA incarnée, et bouclant la boucle “perception-décision-contrôle”. Le RDK S100 offre de multiples interfaces et une infrastructure de développement synergique matériel-logiciel et cloud-terminal, visant à accélérer la construction de produits d’IA incarnée et leur déploiement multi-scénarios. Il a déjà collaboré avec plus de 20 clients de premier plan et est commercialisé au prix de 2799 yuans. (Source: Digua Robot lance le premier kit de développement robotique intégré calcul-contrôle sur SoC unique, a déjà collaboré avec plus de 20 clients de premier plan | En première ligne)

🧰 Outils
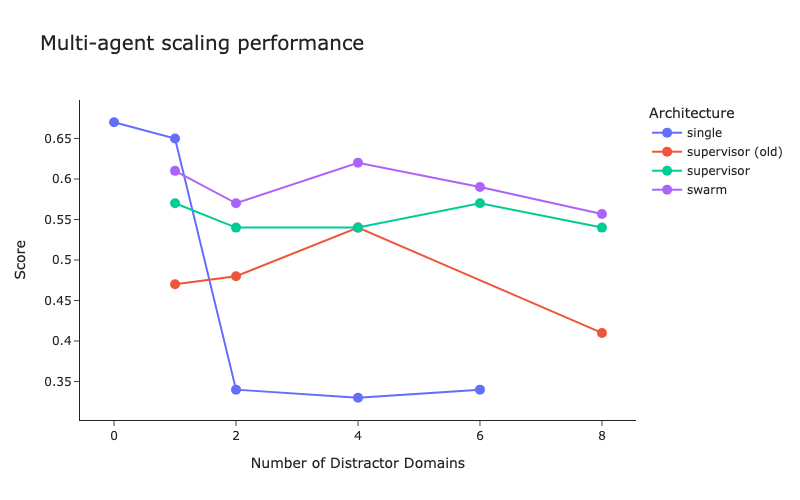
LangChain publie des benchmarks pour les architectures multi-agents et des améliorations de la méthode du superviseur : Face au nombre croissant de systèmes multi-agents, LangChain a effectué des tests de référence préliminaires pour explorer comment optimiser la coordination entre plusieurs agents. Parallèlement, LangChain a apporté quelques améliorations à sa méthode du superviseur (supervisor), et un article de blog à ce sujet a été publié. (Source: LangChainAI, hwchase17)
Cartesia lance Ink-Whisper : un modèle de transcription vocale en continu rapide et économique conçu pour les agents vocaux intelligents : Cartesia a publié Ink-Whisper, un modèle de transcription vocale en continu (STT) à haute vitesse et à faible coût, optimisé pour les agents vocaux intelligents. Ce modèle est spécialement conçu pour la précision dans des conditions réelles et peut être utilisé avec le modèle de synthèse vocale (TTS) Sonic de Cartesia pour permettre des interactions IA vocales rapides. Ink-Whisper prend en charge l’intégration avec des plateformes telles que VapiAI, PipecatAI et Livekit. (Source: simran_s_arora, tri_dao, krandiash)

MonkeyOCR : un modèle d’analyse de documents petit, rapide et open-source : Un modèle d’analyse de documents de 3 milliards de paramètres nommé MonkeyOCR a été publié sous licence Apache 2.0. Ce modèle est capable d’analyser divers éléments dans les documents, y compris les graphiques, les formules, les tableaux, etc., et vise à remplacer les pipelines d’analyse traditionnels pour offrir une meilleure solution de traitement des documents. (Source: mervenoyann, huggingface)
LlamaIndex s’intègre à Cleanlab pour améliorer la crédibilité des réponses des assistants IA : LlamaIndex a annoncé son intégration avec CleanlabAI. LlamaIndex est utilisé pour construire des assistants de connaissances IA et des agents de niveau production, générant des informations à partir des données d’entreprise. L’ajout de Cleanlab vise à améliorer la crédibilité des réponses de ces assistants IA, capable de noter chaque réponse du LLM, de capturer en temps réel les hallucinations ou les réponses incorrectes, et d’aider à analyser les raisons pour lesquelles une réponse n’est pas fiable (par exemple, mauvaise récupération, problèmes de données/contexte, requête difficile ou hallucination du LLM). (Source: jerryjliu0)

Claude Code d’Anthropic ajoute un “mode Plan” pour améliorer la contrôlabilité des modifications de code complexes : Claude Code d’Anthropic a introduit un “mode Plan”. Cette fonctionnalité permet aux utilisateurs d’examiner le plan de mise en œuvre avant de modifier réellement le code, garantissant que chaque étape est mûrement réfléchie, ce qui est particulièrement utile pour les modifications de code complexes. Les utilisateurs peuvent entrer en mode Plan en appuyant deux fois sur Maj + Tab ; Claude Code fournira alors un plan de mise en œuvre détaillé et demandera confirmation avant exécution. Cette fonctionnalité est désormais disponible pour tous les utilisateurs de Claude Code (y compris les abonnés Pro ou Max). (Source: dotey, kylebrussell)
rvn-convert : un outil de conversion de SafeTensors vers GGUF v3 implémenté en Rust : Un outil open-source nommé rvn-convert a été publié. Écrit en Rust, il sert à convertir les fichiers de modèles au format SafeTensors vers le format GGUF v3. Cet outil se caractérise par la prise en charge du traitement en un seul fragment (single-shard), sa rapidité, l’absence de nécessité d’un environnement Python, sa capacité à mapper en mémoire les fichiers safetensors et à écrire directement dans les fichiers gguf, évitant ainsi les pics de RAM et les problèmes de rotation du disque. Il prend actuellement en charge le suréchantillonnage de BF16 vers F32, l’intégration de tokenizer.json, etc. (Source: Reddit r/LocalLLaMA)
L’API Runway ajoute la fonctionnalité de super-résolution vidéo 4K : Runway a annoncé que son API prend désormais en charge la fonctionnalité de super-résolution vidéo 4K. Les développeurs peuvent intégrer cette fonctionnalité dans leurs propres applications, produits, plateformes et sites web pour améliorer la clarté et la qualité du contenu vidéo. (Source: c_valenzuelab)
You.com lance la fonctionnalité “Projects” pour organiser et gérer les documents de recherche : You.com a lancé un nouvel outil appelé “Projects”, conçu pour aider les utilisateurs à organiser leurs documents de recherche dans des dossiers faciles d’accès. Cette fonctionnalité permet aux utilisateurs de contextualiser et de structurer leurs conversations, évitant la dispersion des historiques de chat et la perte d’informations, simplifiant ainsi le processus de gestion des connaissances. (Source: RichardSocher)
LlamaIndex lance le service d’extraction de documents par agent LlamaExtract : LlamaIndex a lancé LlamaExtract, un service d’extraction de documents piloté par un agent, conçu pour extraire des données structurées à partir de documents complexes et de schémas d’entrée. Ce service est non seulement capable d’extraire des paires clé-valeur, mais aussi de fournir pour chaque élément extrait un raisonnement précis sur sa source, des références de page et le texte correspondant. LlamaExtract est fourni sous forme d’API et peut être facilement intégré dans des flux de travail d’agents en aval. (Source: jerryjliu0)

Mise à jour de langchain-google-vertexai, amélioration du cache client et de la prise en charge des outils : langchain-google-vertexai a publié une nouvelle version. Les principales mises à jour incluent : le cache du client de prédiction, qui accélère l’instanciation des nouveaux clients de 500 fois ; la prise en charge des outils d’exécution de code intégrés. (Source: LangChainAI, Hacubu)
Perplexity Finance ajoute la fonctionnalité de téléchargement direct de modèles Excel : Perplexity Finance a annoncé que les utilisateurs peuvent désormais télécharger directement des modèles Excel depuis sa page, offrant un point de départ plus rapide pour la modélisation financière et la recherche. Cette fonctionnalité est gratuite pour tous les utilisateurs ; auparavant, seul le téléchargement au format CSV était pris en charge. (Source: AravSrinivas)
Viwoods lance la tablette à encre électronique AI Paper Mini, intégrant GPT-4o et d’autres fonctionnalités IA : Viwoods, un nouveau fabricant d’écrans à encre électronique, a lancé l’AI Paper Mini, une tablette à encre électronique dotée de fonctionnalités IA. Cet appareil prend en charge GPT-4o, DeepSeek et d’autres modèles d’IA, offre un mode Chat et des assistants IA prédéfinis (analyse de contenu, génération d’e-mails, transcription IA). Ses fonctionnalités distinctives incluent la gestion des tâches en vue calendrier, des notes rapides via une fenêtre flottante, etc. Côté matériel, le Paper Mini est équipé d’un écran Carta 1000 de 292 ppi, de 4 Go + 128 Go de stockage, et d’un stylet. Parallèlement, Viwoods a également lancé l’AI Paper, de plus grande taille, doté d’un écran flexible Carta 1300 de 300 ppi, avec un temps de réponse plus rapide. (Source: J’ai dépensé la moitié du prix d’un iPhone pour acheter une “tablette à encre électronique” avec IA…)

360 lance l’agent de super recherche IA Nano, avec le soutien personnel de Zhou Hongyi : Zhou Hongyi, fondateur du groupe 360, a présidé au lancement de l’agent de super recherche IA Nano. Cet agent vise à réaliser la recherche universelle en une seule phrase (“une phrase, tout peut être recherché”), capable de penser de manière autonome, d’appeler des navigateurs et des outils externes pour exécuter des tâches sans intervention humaine, et prend en charge la visualisation complète du processus et la traçabilité des étapes. Zhou Hongyi a déclaré que la conférence de lancement elle-même a tenté d’utiliser Nano AI pour sa préparation, et a également lancé le matériel d’enregistrement audio intelligent Nano AI Note ainsi que des lunettes IA en collaboration avec Rokid. (Source: Zhou Hongyi veut “éliminer” le département marketing avec l’IA, “Nano” y est-il parvenu ?)
📚 Apprentissage
DeepLearning.AI lance un nouveau cours court : Orchestrer les flux de travail GenAI avec Apache Airflow : DeepLearning.AI, en collaboration avec Astronomer, a lancé un nouveau cours court qui enseigne comment utiliser Apache Airflow 3.0 pour transformer des prototypes RAG en flux de travail prêts pour la production. Le contenu du cours comprend : décomposer les flux de travail en tâches modulaires, planifier les pipelines à l’aide de déclencheurs temporels et événementiels, mapper dynamiquement les tâches pour une exécution parallèle, ajouter des tentatives/alertes/remplissages pour la tolérance aux pannes, et des techniques pour mettre à l’échelle les pipelines. Aucune expérience préalable d’Airflow n’est requise pour ce cours. (Source: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain lance un mini-cours sur l’optimisation et l’évaluation de RAG : Hamel Husain a annoncé le lancement d’un mini-cours en quatre parties sur l’optimisation et l’évaluation de RAG (Retrieval Augmented Generation). La première partie, animée par @bclavie, a discuté du point de vue “la récupération est RAG”, visant à répondre aux discussions antérieures selon lesquelles RAG est un “virus mental qui doit être éradiqué”. Cette série de cours est gratuite et vise à aider les praticiens à résoudre les difficultés rencontrées dans l’évaluation de RAG. (Source: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

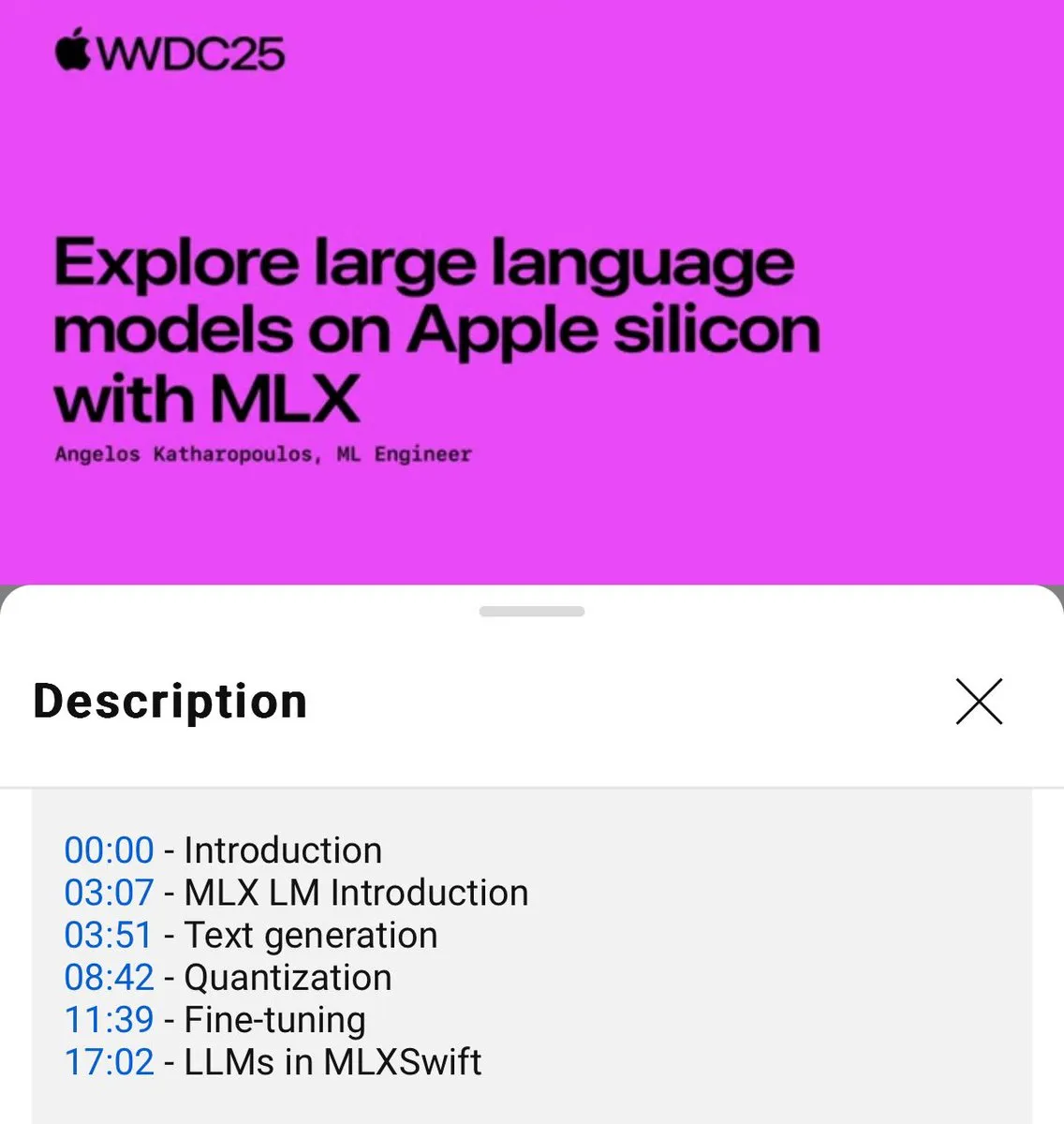
Publication d’un tutoriel sur l’utilisation locale des modèles de langage MLX (WWDC25) : Lors de la conférence WWDC25, Angelos Katharopoulos a présenté comment démarrer rapidement avec les modèles de langage locaux en utilisant MLX. Le tutoriel couvre l’utilisation de la CLI MLXLM pour des opérations en une seule ligne de commande, telles que la quantification de modèles (mlx_lm.convert), le fine-tuning LoRA (mlx_lm.lora), ainsi que la fusion de modèles et leur téléversement sur Hugging Face (mlx_lm.fuse). Le tutoriel complet sous forme de Jupyter Notebook est disponible sur GitHub. (Source: awnihannun)
LangChain partage la méthode de Harvey AI pour construire des agents IA juridiques : Ben Liebald de Harvey AI a partagé, lors de l’événement Interrupt de LangChain, leur méthode éprouvée pour construire des agents IA juridiques. Cette méthode combine l’évaluation LangSmith et une stratégie “lawyer-in-the-loop” (avocat dans la boucle), visant à fournir des outils d’IA fiables pour les avocats dans le cadre de travaux juridiques complexes. (Source: LangChainAI, hwchase17)

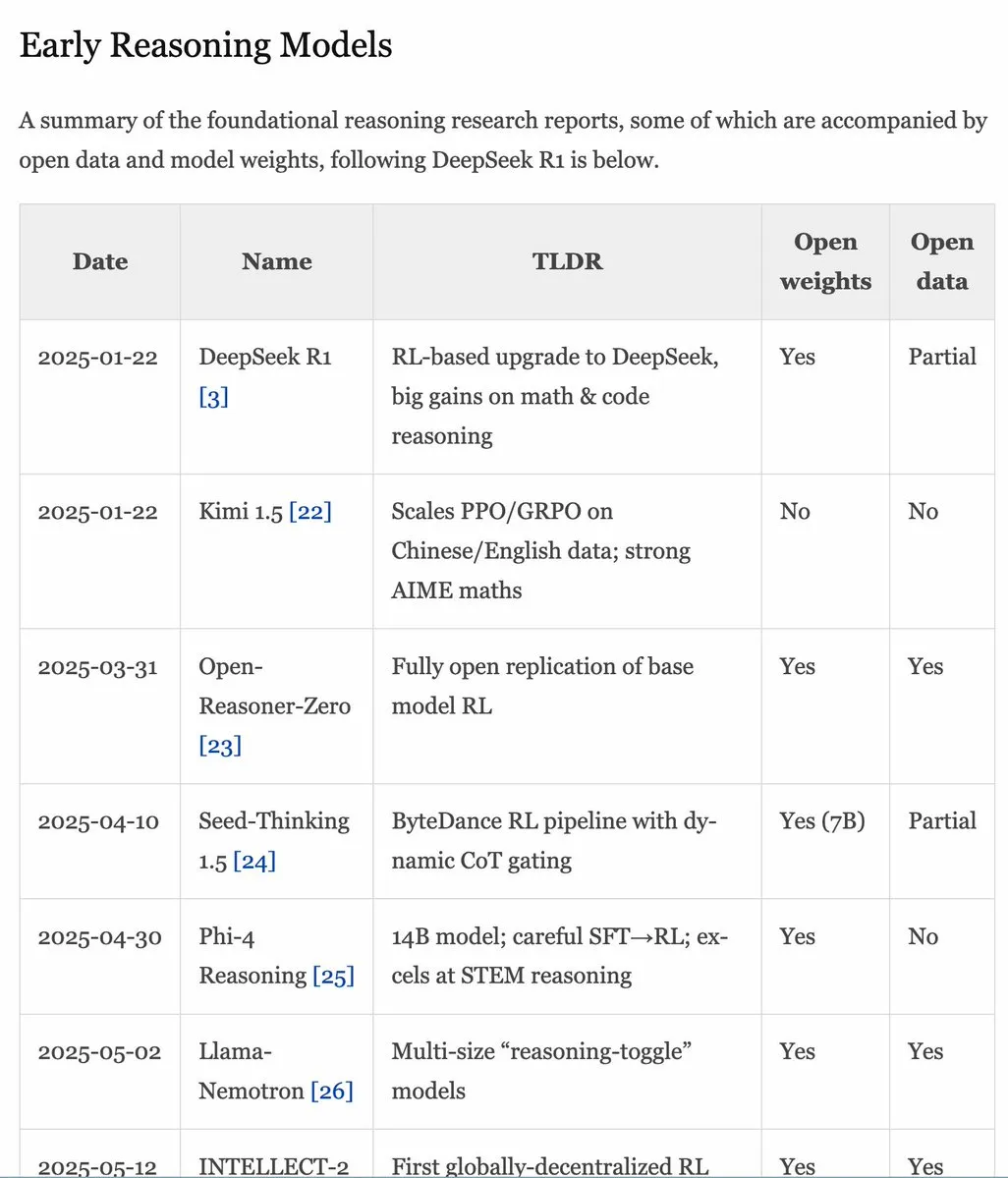
Mise à jour du manuel RLHF v1.1, extension du contenu sur RLVR/modèles d’inférence : Le manuel RLHF (rlhfbook.com) a été mis à jour à la version v1.1, ajoutant un contenu étendu sur RLVR (Reinforcement Learning from Video Representations) et les modèles de raisonnement. Les mises à jour comprennent un résumé des principaux rapports sur les modèles de raisonnement, les pratiques/astuces courantes et leurs utilisateurs, les travaux de raisonnement pertinents antérieurs à o1, ainsi que des améliorations telles que l’RL asynchrone. (Source: menhguin)
Article SWE-Flow : Synthèse de données pour l’ingénierie logicielle par une approche pilotée par les tests : Un nouvel article intitulé SWE-Flow propose un nouveau framework de synthèse de données basé sur le développement piloté par les tests (TDD). Ce framework déduit automatiquement les étapes de développement incrémentiel en analysant les tests unitaires, et construit un graphe de dépendances d’exécution (RDG) pour générer un plan de développement structuré. Chaque étape produit une base de code partielle, les tests unitaires correspondants et les modifications de code nécessaires, créant ainsi des tâches TDD vérifiables. L’ensemble de données de référence SWE-Flow-Eval a été généré sur la base de cette méthode. (Source: HuggingFace Daily Papers)
Article PlayerOne : Le premier simulateur du monde réel construit à la première personne : PlayerOne est proposé comme le premier simulateur du monde réel construit à la première personne (égocentrique), capable d’exploration immersive dans des environnements dynamiques. Étant donné une image de la scène à la première personne de l’utilisateur, PlayerOne peut construire le monde correspondant et générer une vidéo à la première personne strictement alignée sur les mouvements réels de l’utilisateur capturés par une caméra externe. Ce modèle adopte un processus d’entraînement allant du grossier au fin, et conçoit un schéma d’injection de mouvement découplé par composant ainsi qu’un cadre de reconstruction conjoint. (Source: HuggingFace Daily Papers)
Article ComfyUI-R1 : Exploration de modèles de raisonnement pour la génération de workflows : ComfyUI-R1 est le premier grand modèle de raisonnement pour la génération automatisée de workflows. Les chercheurs ont d’abord construit un ensemble de données contenant 4K workflows et ont créé des données de raisonnement Chain-of-Thought (CoT) longues. ComfyUI-R1 est entraîné via un framework en deux étapes : le fine-tuning CoT pour le démarrage à froid, et l’apprentissage par renforcement pour stimuler les capacités de raisonnement. Les expériences montrent que le modèle à 7 milliards de paramètres surpasse de manière significative les méthodes existantes en termes de validité du format, de taux de réussite et de scores F1 au niveau des nœuds/graphes. (Source: HuggingFace Daily Papers)
Article SeerAttention-R : Un framework d’adaptation d’attention éparse pour le raisonnement long : SeerAttention-R est un framework d’attention éparse spécialement conçu pour le long décodage des modèles de raisonnement. Il apprend la sparsité de l’attention grâce à un mécanisme de portail par auto-distillation et supprime le pooling des requêtes pour s’adapter au décodage auto-régressif. Ce framework peut être intégré comme un plugin léger dans les modèles pré-entraînés existants, sans modifier les paramètres d’origine. Dans les tests du benchmark AIME, SeerAttention-R, entraîné avec seulement 0,4 milliard de tokens, maintient une précision de raisonnement quasi sans perte avec un budget de 4K tokens dans de grands blocs d’attention épars (64/128). (Source: HuggingFace Daily Papers)
Article SAFE : Détection d’échecs multi-tâches pour les modèles vision-langage-action : L’article propose SAFE, un détecteur d’échecs conçu pour les politiques robotiques générales (telles que les VLA). En analysant l’espace des caractéristiques des VLA, SAFE apprend à prédire la probabilité d’échec d’une tâche à partir des caractéristiques internes du VLA. Ce détecteur est entraîné sur des déploiements réussis et échoués, et évalué sur des tâches inédites ; il est compatible avec différentes architectures de politiques et vise à améliorer la sécurité des VLA lors de leurs interactions avec l’environnement. (Source: HuggingFace Daily Papers)
Article Branched Schrödinger Bridge Matching : Apprentissage des ponts de Schrödinger ramifiés : Cette recherche introduit le framework Branched Schrödinger Bridge Matching (BranchSBM) pour apprendre les ponts de Schrödinger ramifiés, afin de prédire les trajectoires intermédiaires entre une distribution initiale et une distribution cible. Contrairement aux méthodes existantes, BranchSBM peut modéliser des évolutions ramifiées ou divergentes partant d’un point de départ commun vers plusieurs résultats distincts, en paramétrant plusieurs champs de vitesse dépendant du temps et des processus de croissance. (Source: HuggingFace Daily Papers)
💼 Affaires
Meta envisagerait d’acquérir la société d’annotation de données Scale AI pour 150 milliards de dollars, son fondateur pourrait rejoindre Meta : Selon des informations, Meta prévoirait de dépenser 150 milliards de dollars pour acquérir Scale AI, une société leader dans le domaine de l’annotation de données. Si l’accord est conclu, Alexandr Wang, le fondateur sino-américain de 28 ans de Scale AI, et son équipe rejoindraient directement Meta. Cette démarche est considérée comme une initiative majeure du PDG de Meta, Mark Zuckerberg, pour renforcer les capacités de son équipe AGI (Intelligence Artificielle Générale) et rattraper ses concurrents tels qu’OpenAI et Google. Meta a récemment multiplié les recrutements de talents en IA, offrant des packages de rémunération de plusieurs dizaines de millions de dollars aux meilleurs ingénieurs. (Source: Le premier grand nom du groupe “Superintelligence” de Zuck, chercheur principal de Google DeepMind, figure clé de “la compression, c’est l’intelligence”, dylan522p, sarahcat21, Dorialexander)
Disney et Universal Pictures poursuivent la société d’images IA Midjourney pour violation de droits d’auteur : Disney et Universal Pictures ont intenté une action en justice contre la société de génération d’images IA Midjourney, l’accusant d’utilisation non autorisée d’œuvres de propriété intellectuelle renommées telles que “Star Wars” et “Les Simpson”. Cette affaire suscite l’attention ; si Disney obtient gain de cause, cela pourrait avoir des répercussions en chaîne sur d’autres entreprises d’IA qui dépendent de l’entraînement sur de vastes ensembles de données, exacerbant davantage les litiges relatifs aux droits d’auteur dans le domaine de l’IA. (Source: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google lance un nouveau “plan de départs volontaires” face à l’impact de la recherche IA, affectant plusieurs équipes importantes dont la recherche et la publicité : Face à l’impact de la recherche IA, Google a de nouveau proposé un “plan de départs volontaires” aux employés de plusieurs départements aux États-Unis, affectant des équipes clés telles que la recherche, la publicité et l’ingénierie de base, tout en renforçant sa politique de retour au bureau. Cette démarche vise à réorganiser les ressources et à consacrer davantage d’efforts au développement du projet phare d’IA Gemini et de l’expérience de recherche en “mode IA”. L’activité de recherche traditionnelle de Google est confrontée à d’énormes défis en raison de l’essor de l’IA, tandis que l’entreprise fait également face à des pressions réglementaires. (Source: Face à l’impact de la recherche IA, Google lance un nouveau “plan de départs volontaires”, affectant plusieurs équipes importantes, jpt401)
🌟 Communauté
L’IA révèle des biais dans une expérience de détection de fraude aux allocations à Amsterdam, le projet est interrompu : Amsterdam a tenté d’utiliser un système d’IA (Smart Check) pour évaluer les demandes d’allocations afin de détecter les fraudes. Bien qu’ayant suivi les meilleures pratiques en matière d’IA responsable, y compris des tests de biais et des garanties techniques, lors du projet pilote, le système n’a toujours pas réussi à atteindre l’équité et l’efficacité. Le modèle initial présentait des biais envers les demandeurs non néerlandais et les hommes ; après ajustement, il a développé des biais envers les Néerlandais et les femmes. Finalement, le projet a été arrêté car il était impossible de garantir l’absence de discrimination. Cette affaire a suscité un large débat sur l’équité algorithmique, l’efficacité des pratiques d’IA responsable et l’application de l’IA dans la prise de décision des services publics. (Source: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Système d’identification du contenu généré par l’IA : discussion sur la valeur, les limites et la logique de gouvernance : Avec l’augmentation des rumeurs et de la fausse propagande générées par l’IA, le système d’identification de l’IA attire l’attention en tant que moyen de gouvernance. En théorie, l’identification explicite et implicite peut améliorer l’efficacité de la reconnaissance et renforcer la vigilance des utilisateurs. Cependant, en pratique, l’identification est facilement contournée, falsifiée et mal interprétée, et son coût est élevé. L’article suggère que l’étiquetage de l’IA devrait être intégré dans les systèmes de gouvernance de contenu existants, se concentrer sur les domaines à haut risque (tels que les rumeurs, la fausse propagande), définir raisonnablement les responsabilités des plateformes de génération et de diffusion, et renforcer l’éducation du public à la maîtrise de l’information. (Source: Quand les rumeurs prennent le train de l‘“IA”)
Les outils de codage assisté par IA (comme Claude Code) améliorent considérablement l’efficacité des développeurs et réduisent le stress au travail : De nombreux développeurs de la communauté ont partagé leurs expériences positives avec les outils de codage assisté par IA (en particulier Claude Code d’Anthropic). Ces outils aident non seulement à écrire, tester et déboguer du code, mais peuvent également fournir un soutien pour la planification de projets et la résolution de problèmes complexes, améliorant ainsi considérablement l’efficacité du développement, réduisant le stress au travail et l’anxiété liée aux délais. Certains utilisateurs ont déclaré que l’assistance de l’IA leur donnait le sentiment d’être devenus une “force imparable”. (Source: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

La consommation d’énergie et d’eau par le contenu généré par l’IA suscite l’attention, Sam Altman affirme que chaque requête ChatGPT consomme environ 1/15e de cuillère à café d’eau : Sam Altman, PDG d’OpenAI, a révélé que chaque requête ChatGPT consomme environ “un quinzième de cuillère à café” d’eau. Cette donnée a suscité des discussions sur l’impact environnemental de l’entraînement et de l’inférence des modèles d’IA. Bien que la méthode de calcul spécifique et l’inclusion ou non des coûts d’entraînement ne soient pas encore claires, l’empreinte énergétique et la consommation d’eau de l’IA sont devenues des sujets de préoccupation dans les milieux technologiques et environnementaux. (Source: MIT Technology Review, Reddit r/ChatGPT)

Débat sur la question de savoir si les LLM comprennent réellement les preuves mathématiques : le benchmark IneqMath révèle les faiblesses des modèles : Le nouveau benchmark IneqMath, axé sur les preuves d’inégalités mathématiques de niveau olympique, révèle que si les LLM peuvent parfois trouver la bonne réponse, il existe des lacunes importantes dans leur capacité à construire des preuves rigoureuses et valides. Cela a suscité un débat sur la question de savoir si les LLM, dans des domaines tels que les mathématiques, comprennent réellement ou se contentent de “deviner”. Sathya souligne que ce phénomène de “réponse correcte – raisonnement erroné” se manifeste également dans des benchmarks tels que PutnamBench. (Source: lupantech, lupantech, _akhaliq, clefourrier)
Applications et discussions sur les agents IA dans le développement logiciel, la recherche et les tâches quotidiennes : La communauté discute largement des applications des agents IA dans différents domaines. Par exemple, des utilisateurs partagent leur expérience de la construction de workflows d’agents de recherche approfondie avec n8n et Claude ; LlamaIndex montre comment réaliser un agent de remplissage de formulaires incrémentiel grâce à Artifact Memory Block ; la discussion a également porté sur l’utilisation du MCP (Model Context Protocol) pour concevoir des interfaces d’outils orientées IA, ainsi que sur les applications des agents IA dans des domaines tels que le droit et l’automatisation des infrastructures (par exemple, JARVIS de Cisco). (Source: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Les normes de sécurité pour les robots humanoïdes attirent l’attention, nécessitant de prendre en compte à la fois les impacts physiques et psychologiques : Alors que les robots humanoïdes entrent progressivement dans les applications industrielles et visent des scénarios tels que les foyers, leurs normes de sécurité deviennent un sujet de discussion central. Le groupe de recherche sur les robots humanoïdes de l’IEEE souligne que les robots humanoïdes possèdent des caractéristiques uniques telles que la stabilité dynamique, nécessitant de nouvelles règles de sécurité. Outre la sécurité physique (comme la prévention des chutes et des collisions), il faut également tenir compte des défis de communication dans l’interaction homme-robot (comme l’expression de l’intention, la coordination multi-robots) et des impacts psychologiques (comme les attentes excessives dues à une anthropomorphisation excessive, la sécurité émotionnelle). L’élaboration de normes doit équilibrer innovation et sécurité, et prendre en compte les besoins des différents scénarios d’application. (Source: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Autres
Docker annonce que docker run --gpus prend désormais en charge les GPU AMD : Docker a officiellement annoncé que la commande docker run --gpus prend désormais également en charge l’exécution sur les GPU AMD. Cette amélioration accroît la facilité d’utilisation des GPU AMD pour les charges de travail IA/ML conteneurisées, ce qui est positif pour promouvoir l’adoption d’AMD dans l’écosystème de l’IA. (Source: dylan522p)
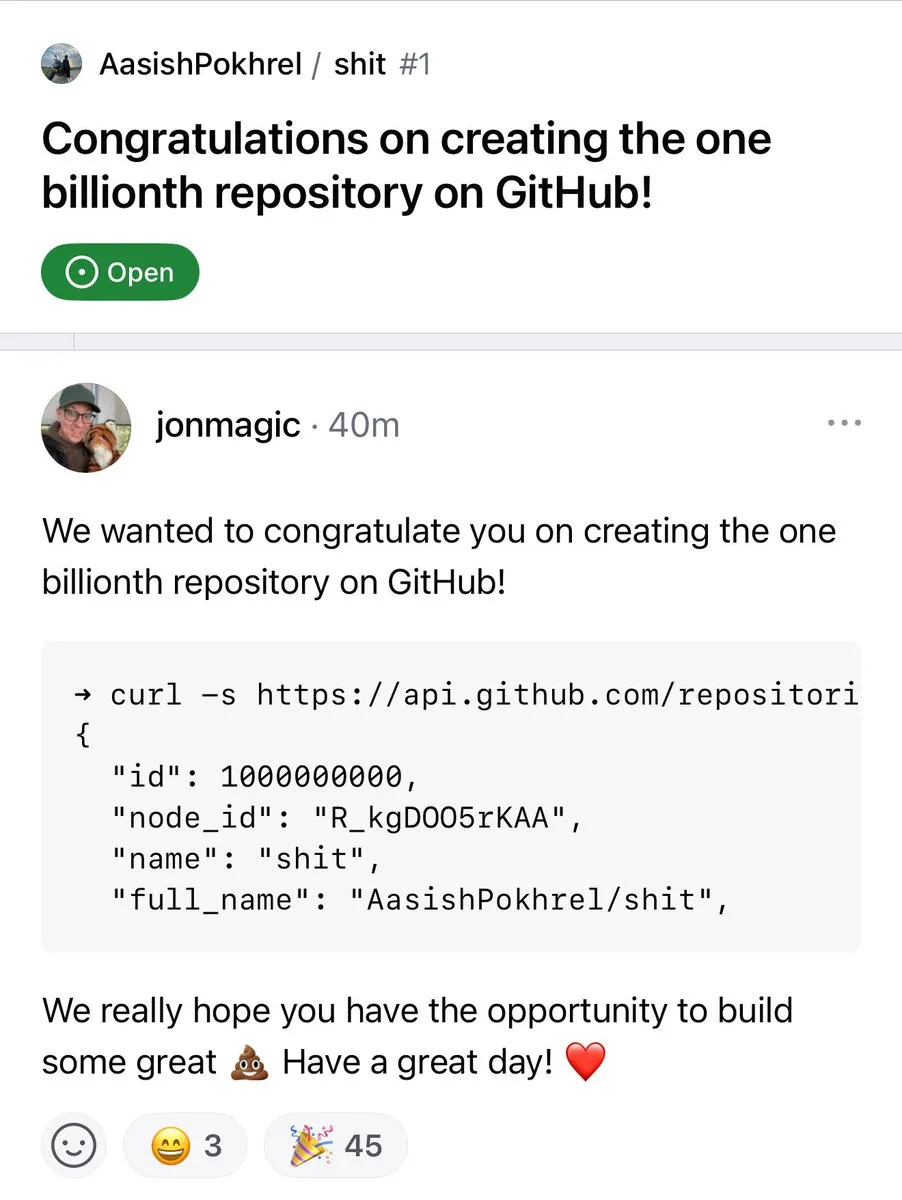
Le nombre de dépôts GitHub dépasse le milliard : Le nombre de dépôts de code sur la plateforme GitHub a officiellement franchi le cap du milliard. Cet événement marquant témoigne de la prospérité et de la croissance continues de la communauté open source et des plateformes d’hébergement de code. (Source: karminski3, zacharynado)
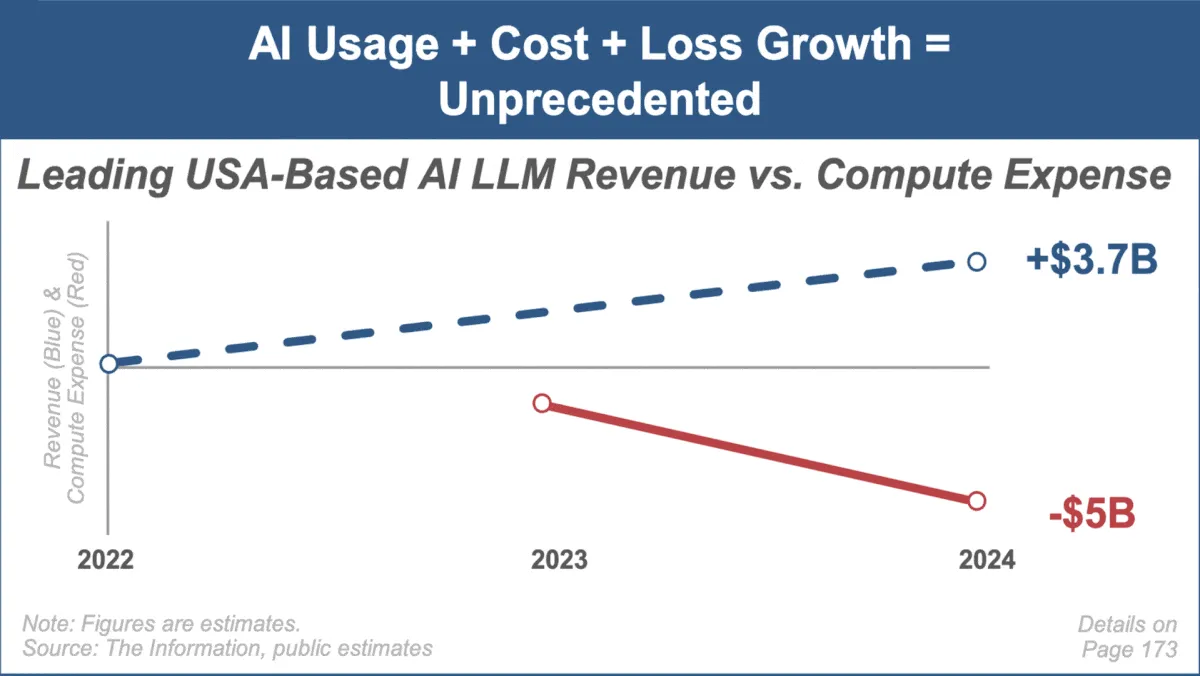
Mary Meeker publie son dernier rapport sur les tendances de l’IA, se concentrant sur la croissance rapide du marché et ses défis : Mary Meeker, analyste d’investissement de renom, a publié son premier rapport sur les tendances du marché de l’intelligence artificielle, intitulé “Trends — Artificial Intelligence (May ‘25)”. Le rapport souligne la vitesse de croissance sans précédent dans le domaine de l’IA, l’explosion du nombre d’utilisateurs (par exemple, ChatGPT atteignant 800 millions d’utilisateurs), l’augmentation massive des dépenses d’investissement liées à l’IA, ainsi que les percées continues de l’IA en termes de performances et de capacités émergentes. Le rapport souligne également les défis auxquels sont confrontés les modèles économiques de l’IA, tels que l’augmentation des coûts de calcul, l’itération rapide des modèles et la concurrence des alternatives open-source. (Source: DeepLearning.AI Blog)