
Mots-clés:OpenAI, Meta, IBM, Mistral AI, Laboratoire de Super Intelligence, o3-pro, Magistral, Ordinateur quantique, Tarification o3-pro, Investissement Scale AI, Magistral-Small-2506, Ordinateur quantique Starling, Tests d’application militaire de l’IA
🔥 En Vedette
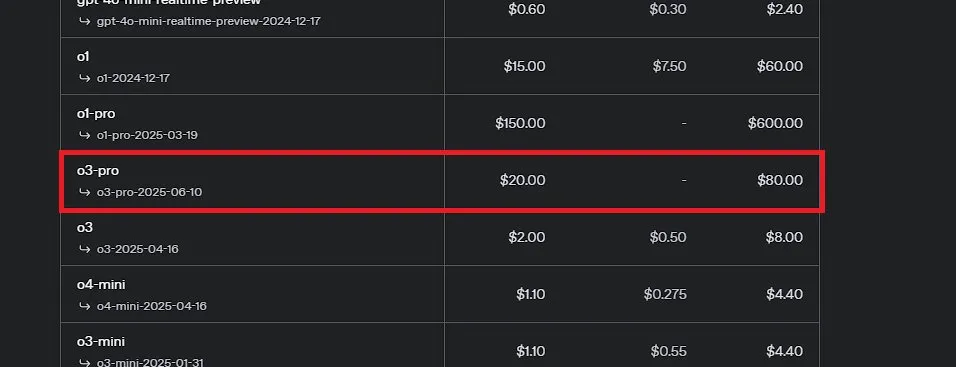
OpenAI lance o3-pro, présenté comme le modèle le plus puissant de son histoire, et réduit considérablement le prix de o3: OpenAI a officiellement lancé o3-pro, son modèle d’inférence le plus puissant à ce jour, désormais disponible pour les utilisateurs de ChatGPT Pro et Team, avec une API également mise en ligne simultanément. o3-pro surpasse les générations précédentes dans des domaines tels que la science, l’éducation, la programmation, les affaires et l’aide à la rédaction, et prend en charge divers outils tels que la recherche web, l’analyse de fichiers, l’entrée visuelle et la programmation Python. Son prix est de 20 dollars par million de tokens en entrée et de 80 dollars en sortie. Parallèlement, le prix du modèle o3 original a été considérablement réduit de 80 %, s’établissant après ajustement à 2 dollars par million de tokens en entrée et 8 dollars en sortie, au même niveau que GPT-4o. Cette décision pourrait déclencher une guerre des prix des modèles d’IA et favoriser l’application approfondie de l’IA dans les domaines professionnels, mais o3-pro présente également des limites telles qu’un temps de réponse plus long et l’absence temporaire de prise en charge des conversations éphémères. (Source: OpenAI, sama, OpenAIDevs, scaling01, dotey)
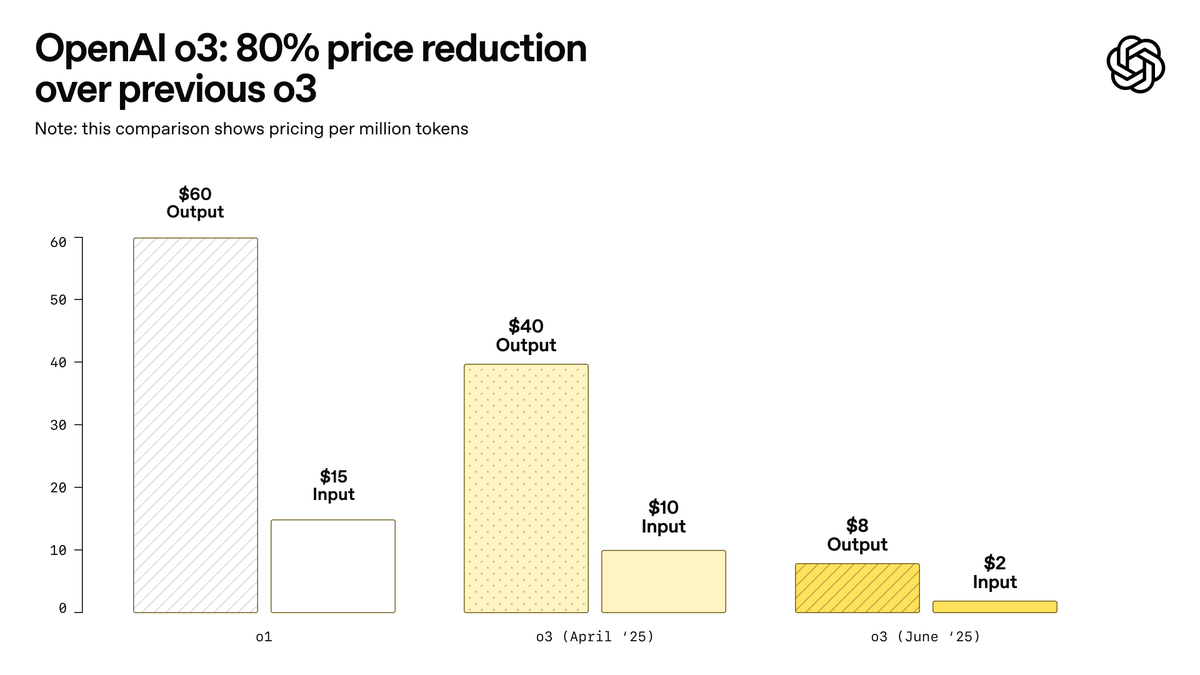
Meta crée un « Superintelligence Lab » et investit massivement dans Scale AI pour relancer sa compétitivité en IA: Selon le New York Times et d’autres sources, Meta Platforms réorganise sa division IA, crée un nouveau « Superintelligence Lab » et prévoit d’investir plus de 14 milliards de dollars pour acquérir 49 % des parts de la société d’annotation de données Scale AI. Alexandr Wang, cofondateur et PDG de Scale AI, rejoindra Meta et dirigera ce nouveau laboratoire. Cette initiative vise à accélérer la recherche et le développement de l’intelligence artificielle générale (AGI) et à renforcer la compétitivité globale de Meta dans le domaine de l’IA, notamment en matière de traitement de données de haute qualité et de recrutement de talents de premier plan. Cela marque un ajustement majeur de la stratégie IA de Meta et pourrait avoir un impact profond sur le paysage concurrentiel du secteur. (Source: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

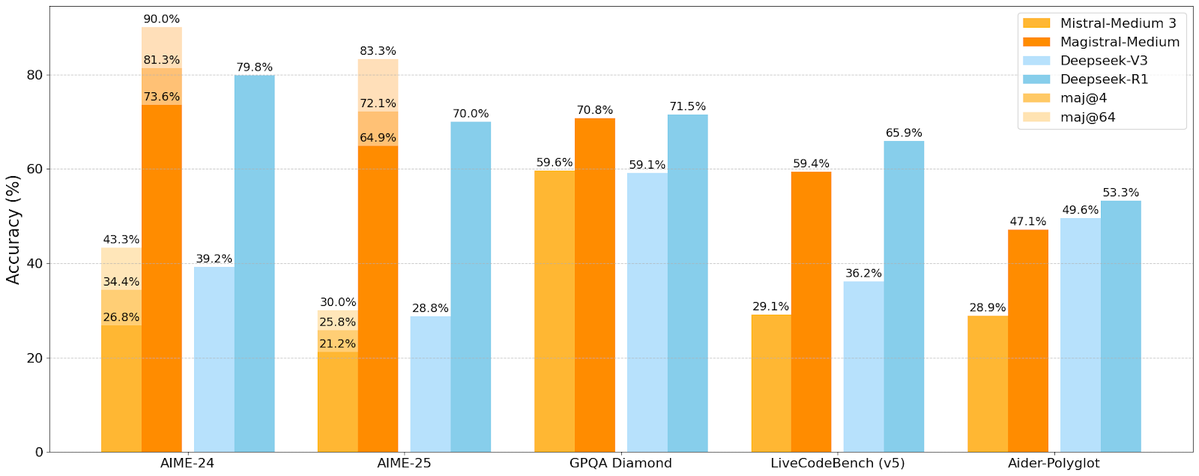
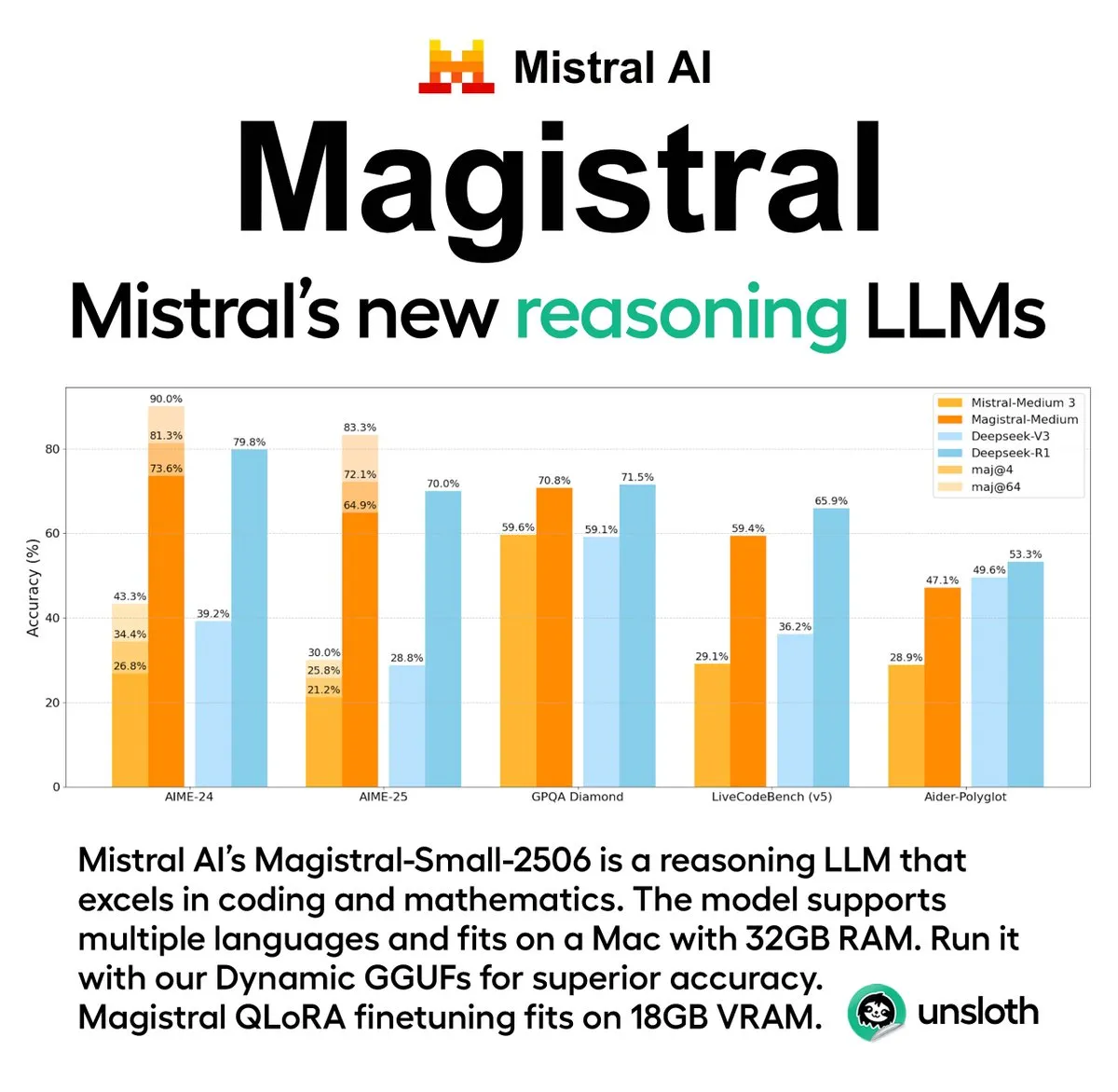
Mistral AI lance sa première série de modèles d’inférence Magistral, incluant une version open source: La start-up française d’IA Mistral AI a lancé Magistral, sa première série de modèles conçus spécifiquement pour l’inférence. Cette série comprend un modèle propriétaire plus puissant destiné aux entreprises, Magistral Medium, et un modèle open source de 24 milliards de paramètres, Magistral Small (Magistral-Small-2506), ce dernier étant publié sous licence Apache 2.0. Ces modèles excellent en mathématiques, en codage et en raisonnement multilingue, et visent à offrir des capacités d’inférence plus transparentes et spécifiques à certains domaines. La vitesse d’inférence de Magistral Medium sur la plateforme Le Chat serait 10 fois plus rapide que celle de ses concurrents, tandis que Magistral Small offre à la communauté une option puissante pour une exécution locale. (Source: Mistral AI, jxmnop, karminski3)
IBM prévoit de construire un ordinateur quantique tolérant aux pannes à grande échelle, Starling, d’ici 2028: IBM a dévoilé sa feuille de route pour le calcul quantique, prévoyant de construire d’ici 2028 un ordinateur quantique tolérant aux pannes à grande échelle nommé Starling, et espère le rendre accessible aux utilisateurs via des services cloud en 2029. Le système Starling devrait comprendre environ 100 modules et 200 qubits logiques, l’objectif principal étant de parvenir à une correction d’erreurs efficace, l’un des plus grands défis techniques actuels dans le domaine du calcul quantique. La machine utilisera les codes de parité à faible densité (LDPC) d’IBM pour la correction d’erreurs et s’efforcera de réaliser un diagnostic d’erreurs en temps réel. En cas de succès, ce serait une percée majeure dans le domaine du calcul quantique, susceptible d’accélérer son application à des problèmes complexes en science des matériaux, en développement de médicaments, etc. (Source: MIT Technology Review)

🎯 Tendances
Les avancées en IA d’Apple à la WWDC 2025 n’ont pas impressionné les développeurs: Apple a annoncé plusieurs mises à jour lors de la WWDC 2025, notamment un nouveau langage de design « liquid glass » et l’intégration de ChatGPT dans Xcode 26. Cependant, la communauté des développeurs a généralement estimé que ses progrès en matière d’intelligence artificielle étaient « en deçà des attentes ». Bien qu’Apple ait pour la première fois ouvert ses modèles d’IA sur appareil (on-device) aux développeurs et lancé le framework Foundation Models pour simplifier l’intégration des fonctionnalités d’IA, la mise à jour très attendue de Siri pourrait être reportée à l’année prochaine. L’analyste Ming-Chi Kuo a souligné que la stratégie d’IA d’Apple est centrale, mais qu’aucune avancée technologique majeure n’a été observée, la gestion des attentes du marché devenant cruciale. Apple semble se concentrer davantage sur l’amélioration de l’interface utilisateur et des fonctionnalités du système d’exploitation plutôt que sur une innovation disruptive des modèles d’IA eux-mêmes. (Source: MIT Technology Review, jonst0kes, rowancheung)
Le Pentagone réduit la taille du bureau de test et d’évaluation des systèmes d’armes IA: Le secrétaire américain à la Défense, Pete Hegseth, a annoncé la réduction de moitié de la taille du Director, Operational Test and Evaluation (DOT&E) du ministère de la Défense, faisant passer ses effectifs de 94 à environ 45 personnes. Ce bureau est chargé de tester et d’évaluer la sécurité et l’efficacité des armes et des systèmes d’IA. Cet ajustement vise à « réduire la bureaucratie excessive et les dépenses inutiles, et à accroître la létalité ». Cette décision a suscité des inquiétudes quant à l’impact possible sur les tests de sécurité et d’efficacité des applications militaires de l’IA, en particulier dans un contexte où le Pentagone intègre activement les technologies d’IA (y compris les grands modèles de langage) dans divers systèmes militaires. (Source: MIT Technology Review)

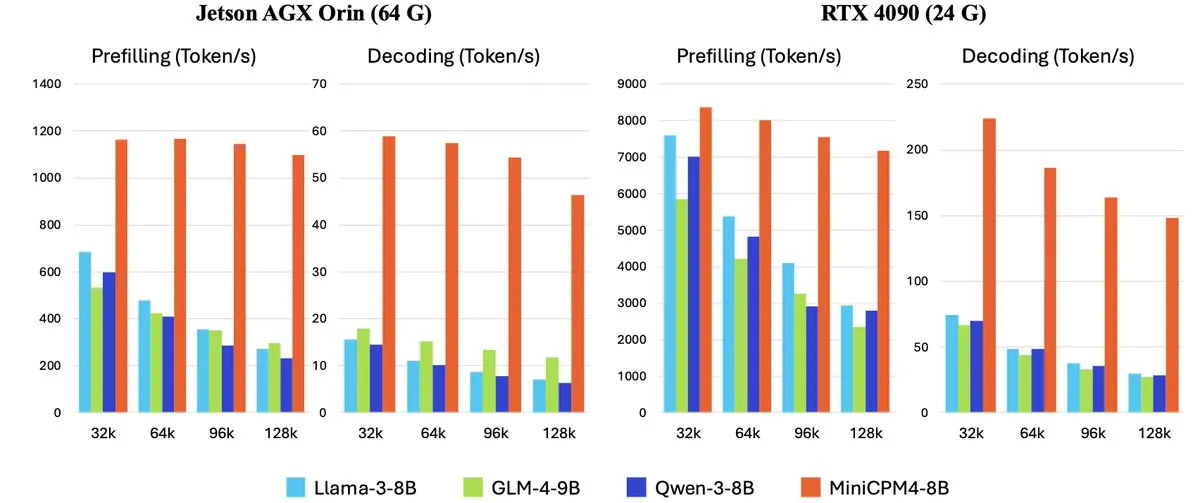
OpenBMB lance la série MiniCPM-4 de grands modèles de langage efficaces pour les appareils en périphérie: OpenBMB (Mianbi Intelligence) a lancé la série de modèles MiniCPM-4, conçue spécifiquement pour les appareils en périphérie (edge devices) afin d’atteindre une efficacité de fonctionnement ultra-élevée. La série comprend MiniCPM4-0.5B, MiniCPM4-8B (modèle phare), BitCPM4 (modèle quantifié à 1 bit), MiniCPM4-Survey dédié à la génération de rapports, et le modèle dédié MCP MiniCPM4-MCP. Le rapport technique détaille son architecture de modèle efficace (telle que le mécanisme d’attention sparse entraînable InfLLM v2), ses algorithmes d’apprentissage efficaces (tels que Model Wind Tunnel 2.0) et ses méthodes de traitement de données d’entraînement de haute qualité. Ces modèles sont désormais disponibles en téléchargement sur Hugging Face. (Source: _akhaliq, arankomatsuzaki, karminski3)
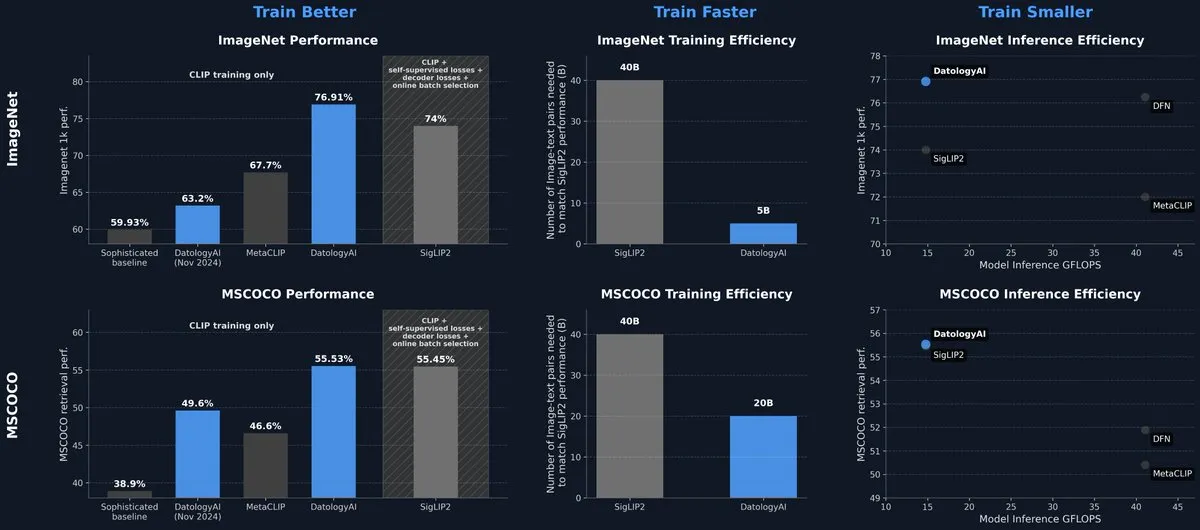
DatologyAI publie un modèle CLIP atteignant le niveau SOTA uniquement grâce à la gestion des données: DatologyAI a présenté ses derniers résultats de recherche dans le domaine multimodal, où, grâce à une gestion minutieuse des données (data curation) plutôt qu’à des innovations algorithmiques ou architecturales, son modèle CLIP ViT-B/32 a atteint une précision de 76,9 % sur ImageNet 1k, dépassant les 74 % rapportés par SigLIP2. Cette méthode a également permis une amélioration de 8 fois de l’efficacité de l’entraînement et de 2 fois de l’efficacité de l’inférence. Le modèle a été rendu public, soulignant l’énorme potentiel des données de haute qualité pour améliorer les performances des modèles. (Source: code_star, andersonbcdefg)
Krea AI lance son premier modèle d’image auto-développé Krea 1: Krea AI a lancé son premier modèle d’image, Krea 1, qui excelle dans le contrôle esthétique et la qualité d’image, possède une vaste réserve de connaissances artistiques et prend en charge la référence de style et l’entraînement personnalisé. Krea 1 vise à améliorer le réalisme des images, la finesse des textures et la richesse des expressions stylistiques. Actuellement, Krea 1 est ouvert en test bêta gratuit, permettant aux utilisateurs d’expérimenter ses puissantes capacités de génération d’images. (Source: _akhaliq, op7418)
NVIDIA lance GR00T N1, un modèle de robot humanoïde open source personnalisable: NVIDIA a lancé GR00T N1, un modèle de robot humanoïde open source personnalisable. Cette initiative vise à promouvoir la recherche et le développement dans le domaine de la robotique humanoïde, en fournissant aux développeurs une plateforme flexible pour construire et expérimenter diverses applications robotiques. La nature open source de GR00T N1 devrait attirer une participation communautaire plus large, accélérant les progrès de la technologie des robots humanoïdes. (Source: Ronald_vanLoon)
RoboBrain 2.0 lance des modèles robotiques multimodaux de 7B et 32B: RoboBrain 2.0 a lancé ses modèles robotiques multimodaux de 7 et 32 milliards de paramètres, visant à améliorer les capacités des robots en matière de perception, de réflexion et d’exécution de tâches. Les nouveaux modèles prennent en charge le raisonnement interactif, la planification à long terme, la rétroaction en boucle fermée, la perception spatiale précise (prédiction de points et de boîtes englobantes), la perception temporelle (estimation de trajectoires futures) et le raisonnement sur les scènes grâce à la construction et à la mise à jour d’une mémoire structurée en temps réel. L’amélioration de ces capacités devrait faire progresser le niveau d’opération autonome et de prise de décision des robots dans des environnements complexes. (Source: Reddit r/LocalLLaMA)
Kling AI partagera ses dernières recherches sur les modèles de génération vidéo au CVPR 2025: Pengfei Wan, responsable du modèle de génération vidéo Kling AI, prononcera un discours liminaire intitulé « Introduction à Kling et nos recherches sur des modèles de génération vidéo plus puissants » lors de la conférence de premier plan sur la vision par ordinateur, CVPR 2025. Il discutera avec des experts d’institutions telles que Google DeepMind des dernières percées et des avancées de pointe dans la technologie de génération vidéo. Ce partage présentera en détail les réalisations de Kling dans la promotion du développement de la technologie de génération vidéo. (Source: Kling_ai)

La technologie IA aide au Gaokao 2025 en Chine, plusieurs régions déploient des systèmes de surveillance intelligents: Le Gaokao 2025 en Chine a largement adopté des systèmes de surveillance intelligents par IA, avec une couverture complète de la surveillance par IA dans les centres d’examen de Tianjin, Jiangxi, Hubei, Yangjiang (Guangdong) et d’autres régions. Ces systèmes utilisent des caméras 4K, le suivi squelettique, la reconnaissance faciale, la surveillance audio et d’autres technologies pour détecter en temps réel les comportements frauduleux des candidats, tels que commencer à répondre avant l’heure, transmettre des objets, chuchoter, ou un regard anormalement dévié, et peuvent émettre des alertes. Cette mesure vise à renforcer l’équité des examens et à garantir la discipline dans les centres d’examen. L’application des systèmes de surveillance par IA marque l’entrée de la gestion des examens dans une ère intelligente, apportant une transformation aux méthodes de surveillance traditionnelles. (Source: 36氪)
Lancement du modèle de bureau Gemma 3n, compatible multiplateforme et avec les appareils IoT: Google a lancé les modèles de bureau Gemma 3n, comprenant des versions de 2 et 4 milliards de paramètres, optimisés spécifiquement pour les ordinateurs de bureau (Mac/Windows/Linux) et les appareils de l’Internet des Objets (IoT). Ce modèle est alimenté par la nouvelle bibliothèque LiteRT-LM, conçue pour offrir des capacités d’exécution locale efficaces. Les développeurs peuvent prévisualiser et obtenir les ressources associées via Hugging Face et GitHub, favorisant ainsi davantage l’application de modèles d’IA légers sur les appareils en périphérie. (Source: ClementDelangue, demishassabis)
🧰 Outils
Yutori AI lance Scouts : un agent IA de surveillance web en temps réel: Yutori AI, fondée par d’anciens chercheurs de Meta AI, a lancé un produit d’agent IA nommé Scouts. Scouts peut surveiller les informations sur Internet en temps réel en fonction des thèmes ou des mots-clés définis par l’utilisateur, et notifier l’utilisateur lorsque du contenu pertinent apparaît. Cet outil vise à aider les utilisateurs à filtrer les informations précieuses pour eux parmi la masse d’informations en ligne, par exemple en suivant l’actualité d’un domaine spécifique, les tendances du marché, les offres de produits, ou même les réservations rares. Le lancement de Scouts marque une nouvelle avancée dans les outils d’acquisition d’informations personnalisées, faisant de l’IA l’« éclaireur » numérique de l’utilisateur. (Source: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit lance une nouvelle fonctionnalité : transformer en un clic des maquettes de Figma, etc., en applications fonctionnelles: Replit a lancé la fonctionnalité Replit Import, permettant aux utilisateurs d’importer directement des maquettes de plateformes telles que Figma, Lovable, Bolt, etc., et de les transformer en applications exécutables. Cette fonctionnalité vise à abaisser la barrière à l’entrée du développement, permettant même aux non-programmeurs de concrétiser rapidement leurs idées de design. Replit Import prend en charge le maintien de la fidélité du design et intègre des analyses de sécurité et la gestion des clés secrètes. Combiné avec Replit Agent, les bases de données, l’authentification et les services d’hébergement de Replit, il permet de créer des applications full-stack. (Source: amasad, pirroh)
Hugging Face lance AISheets : combiner les tableurs avec des milliers de modèles d’IA: Thomas Wolf, cofondateur de Hugging Face, a annoncé le lancement d’un produit expérimental, AISheets. Cet outil combine la facilité d’utilisation des tableurs avec la puissance de milliers de modèles d’IA open source (en particulier les LLM). Les utilisateurs peuvent construire, analyser et automatiser des tâches de traitement de données dans une interface de tableur familière, en utilisant des modèles d’IA pour obtenir des informations à partir des données et automatiser des tâches. L’objectif est de fournir une nouvelle manière rapide, simple et puissante d’analyser les données. (Source: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex prend en charge la conversion d’Agents en serveurs MCP pour interagir avec des modèles comme Claude: LlamaIndex a annoncé la prise en charge de la conversion de n’importe lequel de ses Agents en serveur Model Context Protocol (MCP). À l’aide d’exemples de code et de vidéos, il est démontré comment déployer un workflow personnalisé FidelityFundExtraction (pour extraire des données structurées de PDF complexes) en tant que serveur MCP et l’appeler depuis un modèle Claude. Cette fonctionnalité vise à améliorer le niveau d’agentification des outils, facilitant l’intégration avec des clients MCP tels que Claude Desktop et Cursor, et simplifiant le processus de connexion des workflows existants à un écosystème d’IA plus large. (Source: jerryjliu0)
GPT Researcher intègre le Model Context Protocol (MCP) de LangChain: GPT Researcher utilise désormais l’adaptateur Model Context Protocol (MCP) de LangChain pour la sélection intelligente d’outils et la recherche. Cette intégration combine de manière transparente le MCP avec les fonctionnalités de recherche sur le web pour une collecte de données complète. Les utilisateurs peuvent consulter la documentation d’intégration correspondante pour savoir comment configurer et utiliser cette nouvelle fonctionnalité, améliorant ainsi l’efficacité et la profondeur de la recherche. (Source: hwchase17)
Tesslate lance la série UIGEN-T3 de modèles de génération d’interface utilisateur, prenant en charge plusieurs tailles: L’équipe de Tesslate a lancé la série UIGEN-T3 de modèles de génération d’interface utilisateur (UI), comprenant diverses échelles de paramètres telles que 32B, 14B, 8B et 4B. Ces modèles sont spécialement conçus pour générer des composants d’interface utilisateur (tels que des fils d’Ariane, des boutons, des cartes) et du code frontal complet (comme des pages de connexion, des tableaux de bord, des interfaces de chat), et prennent en charge Tailwind CSS. Les modèles sont disponibles sur Hugging Face et visent à aider les développeurs à construire rapidement des interfaces utilisateur. Les développeurs signalent qu’une quantification standard réduit considérablement la qualité du modèle et recommandent une exécution en BF16 ou FP8 pour des résultats optimaux. (Source: Reddit r/LocalLLaMA)
Lancement du modèle Doubao Podcast, génération en un clic de podcasts IA humanisés: Volcengine a lancé le modèle Doubao Podcast, capable de générer rapidement des podcasts avec un style de dialogue hautement humanisé à partir de textes saisis par l’utilisateur (comme des liens d’articles ou des prompts). L’audio généré par le modèle est proche de la parole humaine en termes de ton, de pauses et d’expressions familières, et peut même engager des discussions argumentées basées sur le contenu. Cette technologie est basée sur le modèle de parole en temps réel de bout en bout de l’équipe de technologie vocale de ByteDance, réalisant une compréhension et un raisonnement directs au niveau de la modalité vocale. Actuellement, cette fonctionnalité est disponible sur la version PC de Doubao et sur l’espace Kouzi, visant à abaisser le seuil de création de contenu audio et à fournir un moyen efficace et personnalisé d’accéder à l’information. (Source: 量子位)

Unsloth AI fournit une version quantifiée GGUF de Magistral-Small-2506: En réponse au nouveau modèle d’inférence Magistral-Small-2506 récemment publié par Mistral AI, Unsloth AI propose une version quantifiée GGUF. Cela permet aux utilisateurs d’exécuter ce modèle de 24 milliards de paramètres localement, par exemple sur un appareil avec seulement 32 Go de RAM. Cette initiative réduit les exigences matérielles pour les modèles d’inférence haute performance, facilitant l’expérimentation et l’utilisation du modèle Magistral par un plus large éventail de développeurs et de chercheurs dans des environnements locaux. (Source: ImazAngel)
📚 Apprentissage
Analyse technique approfondie de la construction de l’assistant visuel LLaVA-1.5: LearnOpenCV a publié un article d’analyse technique approfondie de l’architecture LLaVA-1.5. L’article détaille comment LLaVA-1.5 construit des assistants visuels IA de pointe, y compris sa technologie révolutionnaire de Visual Instruction Tuning et les jeux de données open source qui ont transformé le domaine de l’IA multimodale. Ce guide est une référence précieuse pour les ingénieurs et chercheurs en IA/ML qui souhaitent comprendre le fonctionnement et les méthodes d’entraînement des grands modèles de langage multimodaux. (Source: LearnOpenCV)
Publication d’un guide d’introduction à l’apprentissage automatique pour les protéines: DL Weekly a partagé un guide complet sur l’apprentissage automatique pour les protéines, destiné aux débutants. Ce guide couvre les types de données fondamentaux liés aux protéines, les modèles d’apprentissage profond, les méthodes de calcul et les concepts biologiques de base, visant à aider les chercheurs et les développeurs intéressés par ce domaine interdisciplinaire à démarrer rapidement. (Source: dl_weekly)
Qdrant s’associe à DataTalksClub pour lancer un cours gratuit sur le RAG et la recherche vectorielle: Qdrant a annoncé un partenariat avec DataTalksClub pour offrir un cours en ligne gratuit de 10 semaines. Le contenu du cours comprend la génération augmentée par récupération (RAG), la recherche vectorielle, la recherche hybride, les méthodes d’évaluation, et inclut un projet pratique de bout en bout. Les experts de Qdrant, Kacper Łukawski et Daniel Wanderung, dispenseront personnellement les cours, visant à aider les apprenants à maîtriser les compétences pratiques pour construire des applications d’IA avancées. (Source: qdrant_engine)
Le podcast Weaviate explore la sortie structurée des LLM et le décodage contraint: Le dernier épisode du podcast Weaviate a invité Will Kurt et Cameron Pfiffer de dottxt.ai, qui ont discuté avec l’animateur Connor Shorten de la question de la sortie structurée des grands modèles de langage (LLM). L’émission a examiné en profondeur comment, grâce à des techniques de décodage contraint, garantir que les LLM génèrent des résultats fiables et prévisibles (tels que des JSON valides, des e-mails, des tweets, etc.), allant au-delà de la simple validation du format JSON. Ils ont également présenté l’outil open source Outlines et son application dans des cas d’utilisation réels de l’IA, envisageant l’impact de cette technologie sur les futurs systèmes d’IA. (Source: bobvanluijt)
Article NLP à l’ACL2025 SynthesizeMe! : Générer des prompts personnalisés à partir des interactions utilisateur: Un article de la conférence NLP ACL 2025 intitulé “SynthesizeMe!” propose une nouvelle méthode pour créer des modèles utilisateur personnalisés en langage naturel en analysant les interactions de l’utilisateur avec l’IA (y compris les retours implicites et explicites). La méthode génère et valide d’abord les processus de raisonnement expliquant les préférences de l’utilisateur, puis en déduit des profils utilisateur synthétiques, filtre les interactions utilisateur antérieures riches en informations, et construit finalement des prompts personnalisés pour des utilisateurs spécifiques, dans le but d’améliorer la modélisation des récompenses personnalisées et la réactivité des LLM. DSPy a également relayé et mentionné qu’il s’agit d’un excellent cas d’application de dspy.MIPROv2. (Source: lateinteraction, stanfordnlp)
Nouvel article explorant la surveillance et l’overclocking des LLM avec mise à l’échelle au moment du test (Test-Time Scaling): Un nouvel article se penche sur la technique de mise à l’échelle au moment du test (Test-Time Scaling) adoptée par des modèles tels que o3 et DeepSeek-R1. Cette technique permet aux LLM d’effectuer davantage de raisonnements avant de répondre, mais les utilisateurs sont souvent incapables de connaître leur progression interne ou de la contrôler. Les chercheurs proposent d’exposer l’« horloge » interne des LLM et montrent comment surveiller leur processus de raisonnement et les « overclocker » pour les accélérer. Cela offre de nouvelles perspectives pour comprendre et optimiser l’efficacité des grands modèles d’inférence. (Source: arankomatsuzaki)

Article proposant CARTRIDGES : compresser le cache KV des LLM à long contexte par auto-apprentissage hors ligne: Des chercheurs de HazyResearch à l’Université de Stanford ont proposé une nouvelle méthode appelée CARTRIDGES, visant à résoudre le problème de l’occupation excessive de la mémoire par le cache KV dans les LLM à long contexte. Cette méthode, grâce à un mécanisme d’entraînement au moment du test par « auto-apprentissage », entraîne hors ligne un cache KV plus petit (appelé cartridge) pour stocker les informations des documents. Cela permet de réduire en moyenne de 39 fois la mémoire cache et d’augmenter de 26 fois le débit de pointe, tout en maintenant les performances sur les tâches. Une fois entraînée, cette cartridge peut être réutilisée par différentes requêtes utilisateur, offrant une nouvelle approche d’optimisation pour le traitement de longs contextes. (Source: gallabytes, simran_s_arora, stanfordnlp)

Nouvel article Grafting : édition à faible coût de l’architecture des Transformers de diffusion pré-entraînés: Des chercheurs de l’Université de Stanford ont proposé une nouvelle méthode appelée Grafting pour éditer l’architecture des modèles Transformers de diffusion pré-entraînés. Cette technique permet, avec seulement 2 % du coût de calcul du pré-entraînement, de remplacer les mécanismes d’attention et autres primitives de calcul dans le modèle par de nouvelles, permettant ainsi une conception personnalisée de l’architecture du modèle avec un petit budget de calcul. Ceci est important pour explorer de nouvelles architectures de modèles et améliorer l’efficacité des modèles existants. (Source: realDanFu, togethercompute)
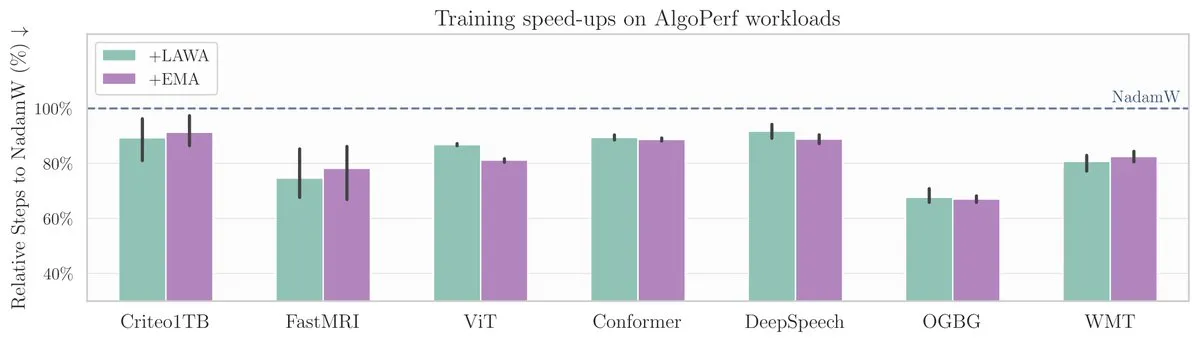
Nouvel article à l’ICML : la méthode de moyennage des points de contrôle accélère l’entraînement des modèles sur le benchmark AlgoPerf: Un nouvel article de l’ICML étudie l’application de la méthode classique de moyennage des points de contrôle (Averaging Checkpoints) pour améliorer la vitesse d’entraînement et les performances des modèles d’apprentissage automatique. Les chercheurs ont testé cette méthode sur AlgoPerf, un benchmark structuré et diversifié d’algorithmes d’optimisation, explorant ses avantages pratiques sur différentes tâches et fournissant une référence pratique pour accélérer l’entraînement des modèles. (Source: aaron_defazio)
Outil open source de visualisation et d’explication des Transformers: DL Weekly présente un outil de visualisation interactif conçu pour aider les utilisateurs à comprendre le fonctionnement des modèles basés sur l’architecture Transformer (comme GPT). Cet outil décompose les mécanismes internes du modèle de manière visuelle, rendant les concepts complexes plus faciles à comprendre. Il convient aux apprenants et aux chercheurs intéressés par les modèles Transformer. Le projet est open source sur GitHub. (Source: dl_weekly)
L’Université du Zhejiang propose InftyThink : segmentation et résumé pour un raisonnement de profondeur infinie: Une équipe de recherche de l’Université du Zhejiang, en collaboration avec l’Université de Pékin, a proposé un nouveau paradigme de raisonnement pour les grands modèles, InftyThink. Cette méthode décompose les longs raisonnements en plusieurs segments courts et introduit des résumés entre les segments pour relier le contexte, permettant ainsi théoriquement un raisonnement de profondeur infinie tout en maintenant un débit de génération élevé. Cette méthode ne nécessite pas d’ajustement de la structure du modèle et est compatible avec les processus de pré-entraînement et de fine-tuning existants en restructurant les données d’entraînement en un format de raisonnement multi-tours. Les expériences montrent qu’InftyThink peut améliorer considérablement les performances du modèle sur des benchmarks tels qu’AIME24 et augmenter le débit de génération. (Source: 量子位)

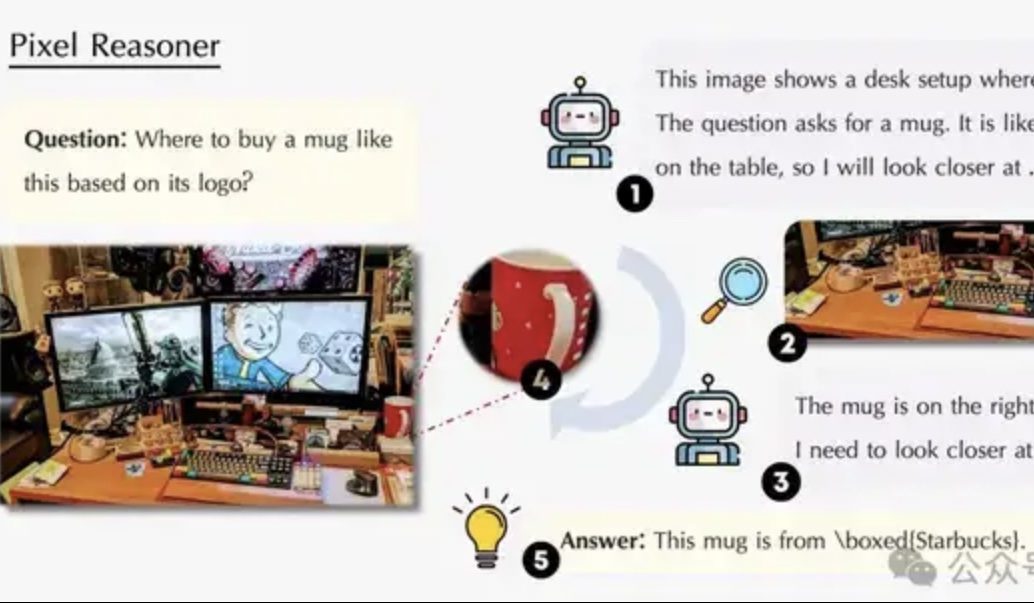
Un article explore le raisonnement dans l’espace pixel : permettre aux VLM d’« utiliser leurs yeux et leur cerveau » comme les humains: Une équipe de chercheurs de l’Université de Waterloo, de HKUST et de l’USTC propose le paradigme du « raisonnement dans l’espace pixel » (Pixel-Space Reasoning), permettant aux modèles de langage visuel (VLM) d’opérer et de raisonner directement au niveau des pixels, comme le zoom visuel, le marquage spatio-temporel, etc., plutôt que de dépendre des tokens textuels comme intermédiaires. Grâce à un schéma d’apprentissage par renforcement motivé par la curiosité intrinsèque et l’exactitude extrinsèque, il surmonte l’« inertie cognitive » des modèles. Le Pixel-Reasoner, construit sur la base de Qwen2.5-VL-7B, excelle sur plusieurs benchmarks tels que V*Bench, le modèle 7B surpassant les performances de GPT-4o. (Source: 量子位)
DeepLearning.AI lance le cinquième cours de son certificat professionnel en analyse de données : la narration de données (Data Storytelling): DeepLearning.AI a lancé le cinquième cours de son certificat professionnel en analyse de données, sur le thème de la « narration de données ». Le cours enseigne comment choisir le support approprié (tableaux de bord, mémos, présentations) pour présenter les informations, utiliser Tableau pour concevoir des tableaux de bord interactifs, aligner les découvertes sur les objectifs commerciaux et les communiquer efficacement, ainsi que des conseils pour la recherche d’emploi. Il souligne l’importance de la narration de données pour améliorer les performances commerciales et communiquer efficacement les informations. (Source: DeepLearningAI)

Un article explore l’impact des conflits de connaissances sur les grands modèles de langage: Un nouvel article évalue systématiquement le comportement des grands modèles de langage (LLM) lorsqu’ils sont confrontés à des conflits entre les entrées contextuelles et leurs connaissances paramétriques (c’est-à-dire la « mémoire » interne du modèle). L’étude révèle que les conflits de connaissances ont peu d’impact sur les tâches qui ne dépendent pas de l’utilisation des connaissances ; lorsque le contexte et les connaissances paramétriques sont cohérents, le modèle fonctionne mieux ; même lorsqu’on le lui demande, le modèle ne peut pas supprimer complètement ses connaissances internes ; fournir des raisons expliquant le conflit augmente la dépendance du modèle au contexte. Ces découvertes soulèvent des questions sur la validité de l’évaluation basée sur les modèles et soulignent la nécessité de prendre en compte les problèmes de conflits de connaissances lors du déploiement des LLM. (Source: HuggingFace Daily Papers)
Article CyberV : un cadre cybernétique pour l’extension au moment du test dans la compréhension vidéo: Pour résoudre les problèmes de demande de calcul, de robustesse et de précision auxquels sont confrontés les grands modèles de langage multimodaux (MLLM) lors du traitement de vidéos longues ou complexes, les chercheurs proposent le cadre CyberV. Ce cadre, inspiré des principes de la cybernétique, redéfinit les MLLM vidéo comme des systèmes adaptatifs, comprenant un système d’inférence MLLM, des capteurs et un contrôleur. Les capteurs surveillent le processus direct du modèle et collectent des interprétations intermédiaires (telles que la dérive de l’attention), le contrôleur décide quand et comment déclencher l’autocorrection et générer un retour d’information. Ce cadre d’extension adaptative au moment du test améliore les MLLM existants sans réentraînement, et les expériences montrent qu’il améliore considérablement les performances de modèles tels que Qwen2.5-VL-7B sur des benchmarks comme VideoMMMU. (Source: HuggingFace Daily Papers)
Article proposant LoRMA : adaptation multiplicative de bas rang pour le fine-tuning efficace des paramètres des LLM: Pour résoudre les problèmes d’effondrement de la représentation et de déséquilibre de la charge des experts existants dans les méthodes de fine-tuning efficace des paramètres (PEFT) basées sur LoRA et MoE, les chercheurs ont proposé l’adaptation multiplicative de bas rang (LoRMA). Cette méthode transforme la manière dont les mises à jour des experts de l’adaptateur PEFT sont effectuées, passant d’une addition à une transformation matricielle multiplicative plus riche, en utilisant une réorganisation efficace des opérations et en introduisant une stratégie d’expansion du rang pour faire face à la complexité de calcul et aux goulots d’étranglement du rang. Les expériences prouvent que la méthode hétérogène MoA (Mixture of Adapters) surpasse les méthodes homogènes MoE-LoRA en termes de performances et d’efficacité des paramètres. (Source: Reddit r/MachineLearning)
Article proposant FlashDMoE : implémentation rapide et distribuée de MoE sur un seul noyau: Des chercheurs ont lancé FlashDMoE, le premier système à fusionner entièrement la propagation avant d’un Mixture of Experts (MoE) distribué en un seul noyau CUDA. En écrivant une couche fusionnée à partir de zéro en pur CUDA, FlashDMoE atteint une amélioration de l’utilisation du GPU allant jusqu’à 9 fois, une réduction de la latence de 6 fois et une amélioration de l’efficacité de la mise à l’échelle faible de 4 fois. Ce travail offre de nouvelles idées et implémentations pour optimiser l’efficacité de l’inférence des modèles MoE à grande échelle. (Source: Reddit r/MachineLearning)
💼 Affaires
xAI et Polymarket s’associent pour fusionner les prédictions de marché et l’analyse de Grok: xAI, la société d’intelligence artificielle d’Elon Musk, a annoncé un partenariat avec la plateforme de marché de prédiction décentralisée Polymarket. Cette collaboration vise à combiner les données de prédiction de marché de Polymarket avec les données de X (anciennement Twitter) et les capacités d’analyse de Grok AI pour créer un « moteur de vérité hardcore » afin de révéler les facteurs qui façonnent le monde. xAI a déclaré que ce n’était que le début de la collaboration et que d’autres contenus de coopération suivraient. (Source: xai)
La société de puces d’inférence IA Groq obtient un engagement d’investissement de 1,5 milliard de dollars de l’Arabie Saoudite, se concentrant sur une stratégie d’intégration verticale: La société de puces d’inférence IA Groq a annoncé avoir obtenu un engagement d’investissement de 1,5 milliard de dollars de l’Arabie Saoudite pour étendre la livraison locale de son infrastructure d’inférence IA basée sur les LPU (Language Processing Units). Fondée par Jonathan Ross, l’un des inventeurs du TPU, Groq se concentre sur le calcul d’inférence IA. Ses puces LPU adoptent une architecture de pipeline programmable, avec la mémoire et les unités de calcul intégrées sur la même puce, améliorant considérablement la vitesse d’accès aux données et l’efficacité énergétique. Groq ne vend pas seulement des puces, mais propose également des clusters GroqRack (cloud privé/centre de calcul IA) et la plateforme cloud GroqCloud (Tokens-as-a-Service), et prend en charge les principaux modèles open source tels que Llama, DeepSeek, Qwen. La société a également développé le système d’IA composite Compound pour augmenter la valeur du cloud d’inférence IA. (Source: 36氪)

La société de robots interactifs humanoïdes de Shenzhen « Digital China » finalise un tour de financement providentiel+ de plusieurs dizaines de millions de yuans: Digital China (Shenzhen) Technology Co., Ltd. a récemment finalisé un tour de financement providentiel+ de plusieurs dizaines de millions de yuans, avec un investissement exclusif de Co-Stone Capital. La société se concentre sur la commercialisation à grande échelle de robots AGI. Ses produits phares comprennent le robot humanoïde « Xia Lan », le robot humanoïde polyvalent « Xia Qi » et le robot de la série IP « Xing Hang Xia ». Le robot « Xia Lan », basé sur une technologie bionique de précision, peut imiter la plupart des expressions humaines et possède des capacités d’interaction multimodale. La société a obtenu des commandes de plusieurs centaines de millions de yuans de la part de clients tels que des fabricants TIC de premier plan et des réseaux électriques locaux. (Source: 36氪)

🌟 Communauté
Sam Altman publie un article de blog « La singularité douce », explorant la révolution progressive de l’IA et son avenir: Le PDG d’OpenAI, Sam Altman, a publié un article de blog affirmant que la singularité technologique se produit de manière plus douce et « graduelle » que prévu, sous la forme d’un processus continu et exponentiellement accéléré. Il prédit que d’ici 2025, les agents IA capables d’accomplir de manière indépendante des tâches intellectuelles complexes (comme la programmation) remodèleront l’industrie logicielle ; d’ici 2026, des systèmes capables de découvrir de nouvelles connaissances scientifiques pourraient apparaître ; et d’ici 2027, des robots capables d’accomplir des tâches dans le monde réel pourraient voir le jour. Altman souligne que la résolution du problème d’alignement de l’IA et la garantie de l’accessibilité de la technologie sont essentielles pour un avenir prospère. Il a également révélé que le premier modèle de poids open source d’OpenAI sera reporté à la fin de l’été, car l’équipe de recherche a obtenu des « résultats étonnamment incroyables ». (Source: dotey, scaling01, sama)
La communauté débat sur OpenAI o3-pro : puissant mais coûteux, la baisse de prix de o3 déclenche des réactions en chaîne: Le lancement d’OpenAI o3-pro et son prix élevé (80 $/M de tokens en sortie) sont devenus un sujet de discussion central dans la communauté. Les utilisateurs reconnaissent généralement ses puissantes capacités dans des tâches complexes de raisonnement, de programmation, etc., mais s’inquiètent également de sa vitesse de réponse et de son coût, certains utilisateurs plaisantant qu’un simple « Hi » pourrait coûter 80 dollars. Parallèlement, la baisse de prix de 80 % du modèle o3 est considérée comme susceptible de déclencher une guerre des prix des modèles d’IA, en concurrence avec GPT-4o et d’autres produits. La communauté est partagée sur la question de savoir si les performances de o3 ont été « dégradées » après la baisse de prix. OpenAI a ensuite annoncé le doublement du quota d’utilisation de o3 pour les utilisateurs de ChatGPT Plus afin de répondre à la demande des utilisateurs. (Source: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Les salaires élevés de Meta pour attirer les talents et les investissements dans l’organisation de l’IA suscitent un vif débat: Les rémunérations élevées offertes par Meta aux chercheurs en IA (qui atteindraient neuf chiffres en dollars) ont suscité des discussions au sein de la communauté. Nat Lambert a commenté que de tels salaires pourraient financer une institution de recherche entière de la taille d’AI2, soulignant le coût exorbitant des meilleurs talents. Combiné à la création par Meta du « Superintelligence Lab » et à ses investissements massifs dans Scale AI, la communauté estime généralement que Meta est prête à tout pour remodeler sa compétitivité en IA, mais s’interroge également sur sa politique organisationnelle interne et son efficacité. Helen Toner a relayé un contenu de ChinaTalk indiquant que cette initiative de Meta vise à surmonter les problèmes de politique interne et d’ego au sein de l’organisation. (Source: natolambert, natolambert)
Le nouveau style d’interface utilisateur « Liquid Glass » d’Apple à la WWDC suscite des discussions sur le design et l’ergonomie: Le nouveau style de design d’interface utilisateur « Liquid Glass » présenté par Apple à la WWDC 2025 a suscité de nombreuses discussions au sein des communautés de développeurs et de designers. Certains estiment que son effet visuel est novateur et reflète l’exploration par Apple du design d’interface 3D. Cependant, des personnalités expérimentées comme ID_AA_Carmack (John Carmack) ont souligné que les interfaces utilisateur semi-transparentes posent généralement des problèmes d’ergonomie, créant facilement des interférences visuelles et un faible contraste, ce qui affecte la lecture et l’utilisation. Ils ont rappelé que Windows et Mac avaient par le passé tenté des designs similaires, mais les avaient finalement ajustés en raison de problèmes d’ergonomie. L’expérience utilisateur (UX) devrait primer sur l’effet visuel de l’interface utilisateur (UI), tel est le cœur du débat. (Source: gfodor, ID_AA_Carmack, ReamBraden, dotey)
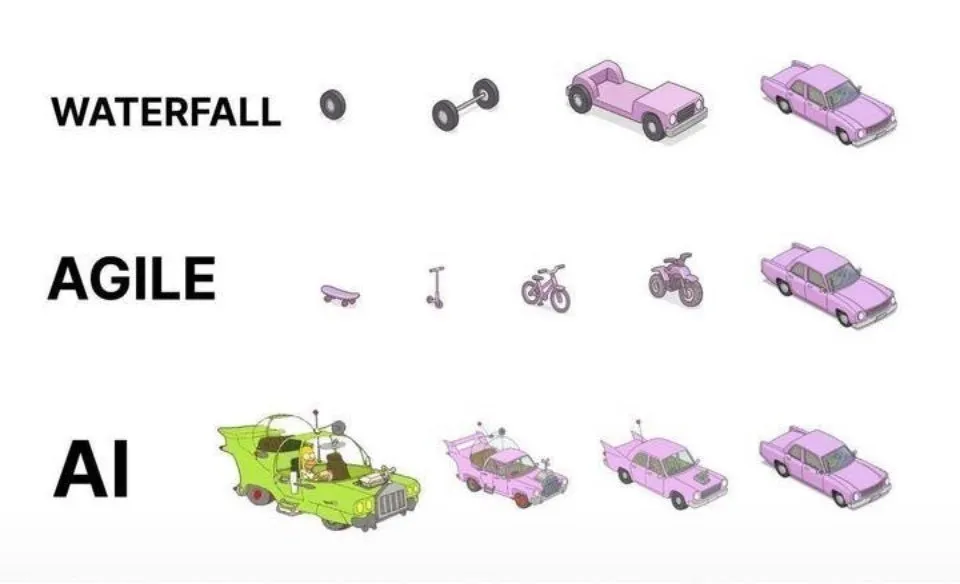
Pratiques de programmation assistée par IA : l’itération agile est préférable à la génération unique: Sur les réseaux sociaux, dotey a exprimé son point de vue sur les meilleures pratiques d’utilisation de l’IA (comme Claude Code) pour la programmation. Il estime qu’il ne faut pas adopter une approche consistant à fournir des exigences complètes en une seule fois pour que l’IA génère un vaste produit semi-fini (modèle en cascade) ou à générer d’abord un produit imparfait puis à l’optimiser (similaire au troisième mode illustré). En effet, il est difficile de contrôler la qualité et la maintenance ultérieure est compliquée. Il préconise l’adoption d’un modèle d’itération agile (similaire au premier mode illustré), consistant à décomposer les grands projets (comme un système ERP) en plusieurs petites versions stables et indépendantes, développées progressivement par itérations, afin de garantir l’exhaustivité fonctionnelle et la contrôlabilité de chaque version. Cela correspond aux meilleures pratiques traditionnelles de l’ingénierie logicielle. (Source: dotey)
Mustafa Suleyman : La technologie de l’IA évolue d’un modèle fixe et unifié vers un modèle dynamique et personnalisé: Mustafa Suleyman, cofondateur d’Inflection AI et ancien de DeepMind, a commenté que les technologies traditionnelles sont généralement fixes, unifiées et « taille unique », tandis que la technologie actuelle de l’intelligence artificielle présente des caractéristiques dynamiques, personnalisées et émergentes. Il estime que cela signifie que la technologie passe de la fourniture de résultats uniques et répétitifs à l’exploration de voies aux possibilités infinies, soulignant l’énorme potentiel de l’IA dans les services personnalisés et les applications créatives. (Source: mustafasuleyman)
Perplexity AI rencontre des problèmes d’infrastructure, le PDG intervient pour s’expliquer: Arav Srinivas, PDG de Perplexity AI, a répondu sur les réseaux sociaux aux utilisateurs concernant l’instabilité du service, indiquant qu’en raison de problèmes d’infrastructure, ils avaient dû activer une expérience utilisateur dégradée (degraded UX) pour une partie du trafic. Il a souligné que les données des utilisateurs (telles que la bibliothèque ou les fils de discussion) n’étaient pas perdues et que toutes les fonctionnalités seraient restaurées une fois le système stabilisé. Cela reflète les défis de stabilité et d’évolutivité de l’infrastructure auxquels sont confrontés les services d’IA en pleine croissance. (Source: AravSrinivas)
Sergey Levine explore les différences d’apprentissage entre les modèles de langage et les modèles vidéo: Le professeur Sergey Levine de UC Berkeley, dans son article « Les modèles de langage dans la caverne de Platon », soulève une question profonde : pourquoi les modèles de langage apprennent-ils tant en prédisant le mot suivant, alors que les modèles vidéo apprennent relativement peu en prédisant l’image suivante ? Il estime que les LLM, en apprenant les « ombres » de la connaissance humaine (données textuelles), ont acquis de puissantes capacités de raisonnement, ce qui s’apparente davantage à une « ingénierie inverse » de la cognition humaine qu’à une véritable exploration autonome du monde physique. Les modèles vidéo observent directement le monde physique, mais sont actuellement inférieurs aux LLM en matière de raisonnement complexe. Il suggère que l’objectif à long terme de l’IA devrait être de dépasser la dépendance aux « ombres » de la connaissance humaine, en interagissant directement avec le monde physique via des capteurs pour réaliser une exploration autonome. (Source: 36氪)
💡 Autres
Débat sur l’éthique et la conscience de l’IA : l’IA peut-elle posséder une véritable conscience ?: MIT Technology Review se penche sur la question complexe de la conscience de l’IA. L’article souligne que la conscience de l’IA n’est pas seulement un casse-tête intellectuel, mais aussi une question à forte portée morale. Une erreur de jugement sur la conscience de l’IA pourrait conduire à l’esclavage involontaire d’IA sensibles, ou au sacrifice du bien-être humain pour des machines non sensibles. La communauté des chercheurs a progressé dans la compréhension de la nature de la conscience, et ces résultats pourraient guider l’exploration et la gestion de la conscience artificielle. Cela soulève des réflexions profondes sur les droits de l’IA, ses responsabilités et les relations homme-machine. (Source: MIT Technology Review)
Joseph Sifakis, lauréat du prix Turing : l’IA actuelle n’est pas une véritable intelligence, il faut se méfier de la confusion entre connaissance et information: Joseph Sifakis, lauréat du prix Turing, souligne dans ses écrits et interviews que la société actuelle a une compréhension erronée de l’IA, confondant accumulation d’informations et création de sagesse, et surestimant l’« intelligence » des machines. Il estime qu’il n’existe pas encore de véritables systèmes intelligents et que l’impact réel de l’IA sur l’industrie est minime. L’IA manque de compréhension du sens commun, son « intelligence » est le produit de modèles statistiques, et il lui est difficile de peser les valeurs et les risques dans des contextes sociaux complexes. Il souligne que le cœur de l’éducation est de cultiver la pensée critique et la créativité, et non la transmission de connaissances, et appelle à l’établissement de normes mondiales pour les applications de l’IA, à la définition claire des frontières de responsabilité, afin que l’IA devienne un partenaire qui augmente les capacités humaines plutôt qu’un substitut. (Source: 36氪)
Restructuration de l’industrie publicitaire à l’ère de l’IA : de la génération créative à la diffusion personnalisée: La conférence Google I/O 2025 a montré comment l’IA restructure en profondeur l’industrie publicitaire. Les tendances comprennent : 1) L’automatisation créative pilotée par l’IA, des images aux scripts vidéo, tout peut être généré par l’IA, des outils comme Veo 3, Imagen 4 et Flow abaissant le seuil de création de contenu de haute qualité. 2) Le paradigme de la personnalisation passe de « mille visages pour mille personnes » à « mille visages pour une personne », les agents intelligents IA pouvant comprendre activement les besoins des utilisateurs et faciliter les transactions. 3) La frontière entre publicité et contenu s’estompe, la publicité s’intégrant directement dans les résultats de recherche générés par l’IA, devenant une partie de l’information. Les marques doivent construire des agents intelligents exclusifs, fournir des services orientés IA et adhérer à une stratégie à long terme « d’intégration de la marque et de l’efficacité » pour s’adapter au changement. (Source: 36氪)