
Mots-clés:DeepSeek, OpenAI, Modèle de raisonnement, Grand modèle multimodal, Apprentissage par renforcement, Innovation en IA, Modèle open source, Modèle de raisonnement DeepSeek R1, Formation en apprentissage par renforcement OpenAI o4, Carte de la pensée humaine du grand modèle multimodal, Série Magistral de Mistral AI, Modèle MoE dots.llm1 de Xiaohongshu
🔥 Focus
DeepSeek et OpenAI : des voies d’innovation révélant une « innovation cognitive » : DeepSeek, grâce à une « Scaling Law limitée », des innovations architecturales MLA et MoE, ainsi qu’une optimisation collaborative logicielle et matérielle, a atteint une haute performance à faible coût. L’open source de son modèle d’inférence R1 a favorisé une percée dans les capacités cognitives de l’IA, brisant le « carcan mental » des innovateurs chinois dans le domaine de la recherche fondamentale et prouvant le leadership mondial des entreprises chinoises en matière de recherche fondamentale en IA et d’innovation de modèles. OpenAI, en exploitant au maximum l’architecture Transformer et la Scaling Law (loi d’échelle), a mené la révolution des grands modèles de langage et, avec ChatGPT et le modèle d’inférence o1, a transformé le paradigme d’interaction homme-machine et provoqué un saut qualitatif des capacités cognitives de l’IA. Les trajectoires de développement des deux entités soulignent une compréhension profonde de l’essence de la technologie et sa restructuration stratégique, offrant aux entrepreneurs de l’ère de l’IA des idées précieuses pour la structuration organisationnelle et l’innovation. En particulier, le paradigme de l’AI Lab de DeepSeek, qui encourage l’« émergence », offre un nouveau modèle organisationnel de référence pour les entrepreneurs axés sur l’innovation technologique (Source: 36氪)
OpenAI entraînerait un nouveau modèle o4, l’apprentissage par renforcement redéfinit le paysage de l’IA : SemiAnalysis révèle qu’OpenAI entraîne actuellement un nouveau modèle se situant entre GPT-4.1 et GPT-4.5. Le modèle d’inférence de nouvelle génération o4 sera basé sur GPT-4.1 et entraîné par apprentissage par renforcement (RL). Le RL débloque les capacités de raisonnement des modèles en générant des CoT (Chain of Thought) et favorise le développement des agents IA, mais il exige des infrastructures (notamment pour l’inférence) et une conception de fonctions de récompense très poussées, et est sujet au phénomène de « reward hacking ». Des données de haute qualité sont cruciales pour étendre le RL, et les données sur le comportement des utilisateurs deviendront un atout majeur. Le RL modifie également la structure organisationnelle des laboratoires, intégrant profondément l’inférence et l’entraînement. Contrairement au pré-entraînement, le RL permet de mettre à jour continuellement les capacités du modèle, comme le DeepSeek R1. Pour les petits modèles, la distillation pourrait être préférable au RL. Ces révélations suggèrent que le domaine de l’IA, en particulier les modèles d’inférence, connaîtra une évolution continue et un bond en avant de ses capacités grâce au RL (Source: 36氪)
Découverte : les grands modèles multimodaux forment spontanément des « cartes mentales humaines » : Une équipe conjointe de l’Institut d’automatisation de l’Académie chinoise des sciences et du Centre d’excellence en sciences du cerveau et technologie intelligente a confirmé, par des expériences comportementales et des analyses de neuro-imagerie, que les grands modèles de langage multimodaux (MLLMs) peuvent former spontanément des systèmes de représentation conceptuelle d’objets très similaires à ceux des humains. L’étude, en analysant 4,7 millions de jugements comportementaux issus de « tâches d’identification de l’intrus parmi trois options », a construit pour la première fois la « carte conceptuelle » d’un modèle d’IA. Les principales découvertes incluent : des modèles d’IA d’architectures différentes peuvent converger vers des structures cognitives de faible dimension similaires ; les modèles développent de manière émergente, sans supervision, des capacités de classification conceptuelle d’objets de haut niveau, cohérentes avec la cognition humaine ; les « dimensions de pensée » des modèles d’IA peuvent se voir attribuer des étiquettes sémantiques telles que animal, nourriture, dureté, etc. ; les représentations des MLLM sont significativement corrélées avec les schémas d’activité neuronale de régions cérébrales spécifiques (telles que FFA, PPA), fournissant des preuves d’un « mécanisme de traitement conceptuel partagé entre l’IA et les humains ». Cette recherche ouvre de nouvelles perspectives pour la compréhension de la cognition de l’IA, le développement de l’intelligence de type cérébral et les interfaces cerveau-machine (Source: 量子位)

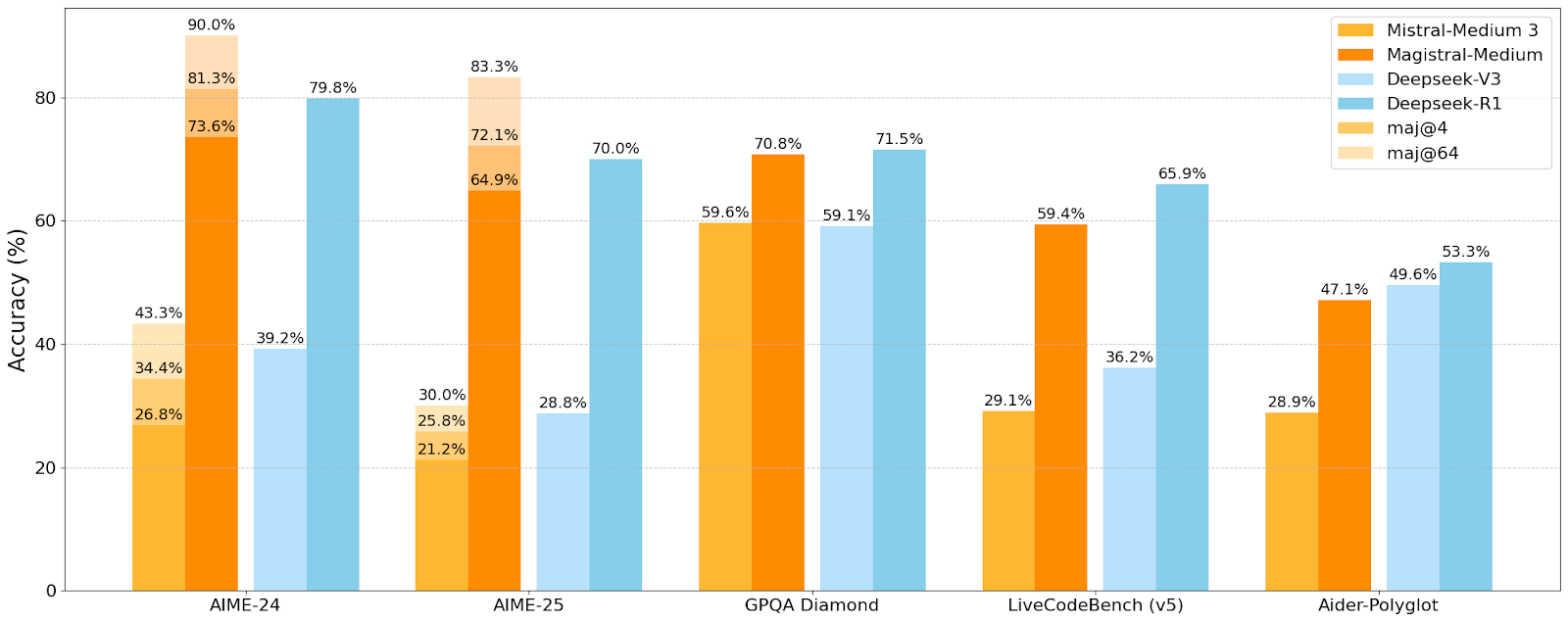
Mistral AI lance sa première série de modèles d’inférence Magistral, le petit modèle Magistral-Small est open source : Mistral AI a lancé sa première série de modèles spécialement conçus pour l’inférence, Magistral, comprenant Magistral-Small et Magistral-Medium. Magistral-Small, basé sur Mistral Small 3.1 (2503), est un modèle d’inférence efficace de 24B paramètres, entraîné par SFT et RL en utilisant les trajectoires de Magistral Medium pour améliorer ses capacités de raisonnement. Ce modèle est multilingue, dispose d’une fenêtre contextuelle de 128k (contexte effectif recommandé de 40k), est open source sous licence Apache 2.0 et peut être déployé localement sur un unique RTX 4090 ou un MacBook avec 32 Go de RAM (après quantification). Les tests de référence montrent que Magistral-Small excelle dans des tâches telles que AIME24, AIME25, GPQA Diamond et Livecodebench (v5), se rapprochant voire surpassant certains modèles plus grands. Magistral-Medium est plus performant mais n’est actuellement pas open source. Ce lancement marque les progrès de Mistral dans l’amélioration des capacités d’inférence de ses modèles et du support multilingue (Source: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Tendances
Baisse drastique de 80% des prix de l’API du modèle OpenAI o3 : Sam Altman, PDG d’OpenAI, a annoncé une réduction de 80% des prix de l’API pour son modèle o3. Après ajustement, le prix d’entrée est de 2 $/million de tokens et le prix de sortie est de 8 $/million de tokens (certaines sources mentionnent 5 $/million de tokens pour la sortie, à vérifier sur la documentation officielle). Cette baisse de prix considérable réduit significativement le coût d’utilisation du modèle o3 pour des tâches telles que l’écriture de code, et devrait stimuler une adoption et une innovation plus larges. Les utilisateurs doivent noter que la liste des prix sur le site officiel pourrait ne pas être encore à jour ; il est conseillé d’effectuer des tests avant d’appeler l’API pour confirmer les prix réels et éviter des pertes inutiles. Cette mesure est considérée comme une stratégie pour faire face à la concurrence du marché (comme Gemini 2.5 Pro et Claude 4 Sonnet) et pourrait présager une baisse continue du coût de l’intelligence artificielle (Source: X, X, X)
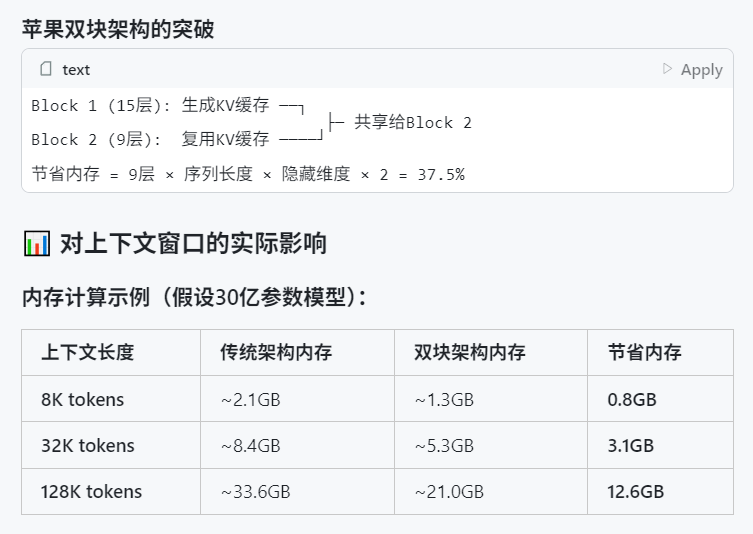
WWDC 2025 d’Apple : peu d’annonces fracassantes sur l’IA, mais les détails techniques révèlent de grandes ambitions : Lors de la Worldwide Developers Conference (WWDC) 2025, Apple a semblé moins insister sur l’IA que prévu, mais ses documents techniques révèlent des investissements profonds dans les modèles sur appareil et dans le cloud. Apple utilise des techniques avancées d’entraînement, de distillation et de quantification, y compris une « architecture à double bloc » (visant à réduire l’empreinte mémoire) pour ses modèles mobiles (environ 3B de paramètres) et une architecture « PT-MoE » (Parallel Track Mixture of Experts) pour ses modèles côté serveur. Ces technologies visent à optimiser l’inférence à faible latence sur les puces Apple et à réduire l’utilisation de la mémoire cache KV. Bien que certains estiment qu’Apple est en retard dans le domaine de l’IA, ses réalisations en matière de technologie de modèles (comme les modèles d’embedding open source) et son attention portée à des priorités différentes (comme l’intelligence sur appareil plutôt que les simples chatbots) indiquent une stratégie IA unique. La WWDC a également annoncé que Safari 26 prendra en charge WebGPU, ce qui améliorera considérablement les performances des modèles d’IA exécutés sur l’appareil (par exemple via Transformers.js), comme une multiplication par 12 environ de la vitesse de génération de sous-titres pour les modèles visuels dans le navigateur (Source: X, X, X)
Les utilisateurs de Perplexity Pro peuvent désormais utiliser le modèle OpenAI o3 : Perplexity a annoncé que ses abonnés Pro peuvent maintenant utiliser le modèle o3 d’OpenAI. Cette intégration offrira aux utilisateurs de Perplexity Pro des capacités de traitement de l’information et de questions-réponses plus puissantes. Parallèlement, Perplexity teste également sa fonctionnalité « Memory » et a mis à jour son assistant vocal iOS, visant à offrir une expérience utilisateur plus concise et pratique. Sa fonction d’articles Discover est également par défaut en mode « Summary » plus concis, avec une option pour passer au mode « Report » plus approfondi (Source: X, X, X)

Xiaohongshu met en open source son premier grand modèle MoE de 142B paramètres, dots.llm1, surpassant DeepSeek-V3 dans les évaluations en chinois : Xiaohongshu a rendu public son premier grand modèle, dots.llm1, un modèle MoE (Mixture of Experts) de 142 milliards de paramètres, n’activant que 14 milliards de paramètres lors de l’inférence. Ce modèle a utilisé 11,2 billions (10^12) de tokens non synthétiques lors de sa phase de pré-entraînement, provenant principalement de données Web issues de crawlers généralistes et propriétaires. L’équipe de Xiaohongshu a proposé un framework de traitement de données en trois étapes, évolutif, et l’a mis en open source pour améliorer la reproductibilité. dots.llm1 a obtenu un score de 92,2 sur C-Eval, surpassant tous les modèles, y compris DeepSeek-V3, et se rapproche des performances d’Alibaba Qwen3-32B sur des tâches en chinois, anglais, mathématiques et d’alignement. Xiaohongshu a également publié des points de contrôle d’entraînement intermédiaires pour favoriser la compréhension par la communauté de la dynamique des grands modèles (Source: 36氪)
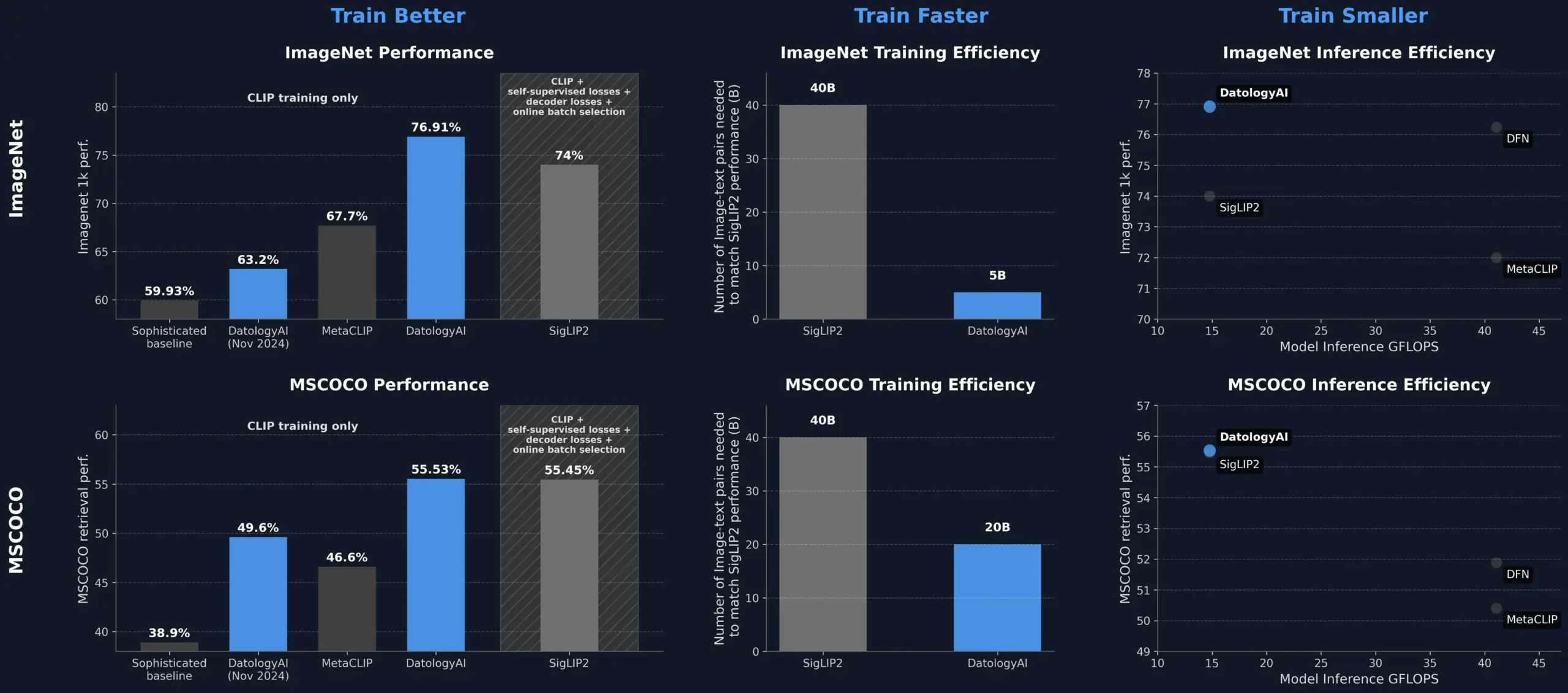
DatologyAI améliore les performances du modèle CLIP grâce à la curation de données, surpassant SigLIP2 : DatologyAI a démontré qu’il est possible d’améliorer significativement les performances du modèle CLIP uniquement par la curation de données. Leur méthode a permis au modèle ViT-B/32 d’atteindre une précision de 76,9% sur ImageNet 1k, dépassant les 74% rapportés par SigLIP2. De plus, cette approche a permis une amélioration de 8 fois de l’efficacité de l’entraînement et de 2 fois de l’efficacité de l’inférence. Les modèles correspondants ont été rendus publics. Cela souligne le rôle central des jeux de données de haute qualité et soigneusement gérés dans l’entraînement de modèles d’IA avancés ; même sans modifier l’architecture du modèle, l’optimisation des données peut exploiter son potentiel (Source: X, X)
Kuaishou et l’Université du Nord-Est proposent conjointement UNITE, un framework d’embedding multimodal unifié : Pour résoudre le problème d’interférence intermodale causé par les différences de distribution des données de différentes modalités (texte, image, vidéo) dans la recherche multimodale, des chercheurs de Kuaishou et de l’Université du Nord-Est ont proposé le framework d’embedding multimodal unifié UNITE. Ce framework, grâce à un mécanisme d’« apprentissage contrastif masqué sensible à la modalité » (MAMCL), ne considère que les échantillons négatifs cohérents avec la modalité cible de la requête lors de l’apprentissage contrastif, évitant ainsi une compétition erronée entre les modalités. UNITE adopte un entraînement en deux étapes « adaptation à la recherche + instruction fine-tuning » et a obtenu des résultats SOTA dans plusieurs évaluations, notamment la recherche image-texte, la recherche vidéo-texte et la recherche par instruction, surpassant des modèles de plus grande taille sur le MMEB Benchmark et devançant largement sur CoVR. L’étude souligne la capacité centrale des données vidéo-texte dans l’unification des modalités et indique que les tâches d’instruction dépendent davantage des données à dominante textuelle (Source: 量子位)

NVIDIA lance Earth-2, un modèle de fondation IA pour la simulation climatique : La plateforme Earth-2 de NVIDIA a lancé un nouveau modèle de fondation IA capable de simuler le climat mondial à une résolution kilométrique. Ce modèle vise à fournir des prévisions climatiques plus rapides et plus précises, ouvrant de nouvelles voies pour comprendre et prédire les systèmes naturels complexes de la Terre. Cette initiative marque une étape importante dans l’application de l’IA à la science du climat et à la modélisation du système terrestre, et devrait améliorer la recherche sur le changement climatique et les capacités d’alerte aux catastrophes (Source: X)

Panne majeure des services OpenAI, ChatGPT et l’API affectés : Les services ChatGPT d’OpenAI et son interface API ont connu une panne majeure dans la soirée du 10 juin, heure de Pékin, se manifestant par une augmentation du taux d’erreur et de la latence. De nombreux utilisateurs ont signalé ne pas pouvoir accéder aux services ou rencontrer des messages d’erreur tels que « Hmm…something seems to have gone wrong ». La page de statut officielle d’OpenAI a confirmé le problème, indiquant que les ingénieurs avaient identifié la cause première et travaillaient à une réparation urgente. Cette panne a affecté un grand nombre d’utilisateurs et d’applications dans le monde entier qui dépendent de ChatGPT et de son API, soulignant une fois de plus l’importance de la stabilité des grands services d’IA (Source: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Outils
L’écosystème de serveurs Model Context Protocol (MCP) continue de s’étendre : Le Model Context Protocol (MCP) vise à fournir aux grands modèles de langage (LLM) un accès sécurisé et contrôlé à des outils et des sources de données. Le dépôt GitHub modelcontextprotocol/servers rassemble les implémentations de référence de MCP et les serveurs construits par la communauté, illustrant la diversité de ses applications. Les serveurs officiels et tiers couvrent un large éventail de domaines, notamment les systèmes de fichiers, les opérations Git, l’interaction avec les bases de données (telles que PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra, etc.), les services cloud (AWS, Azure, Cloudflare), l’intégration d’API (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), la recherche (Brave, Algolia, Exa, Tavily), l’exécution de code, l’appel de modèles d’IA (Replicate, ElevenLabs), etc. L’écosystème MCP se développe rapidement, avec plus de 130 serveurs officiels et communautaires, et l’émergence de frameworks de développement tels que EasyMCP, FastMCP, MCP-Framework, ainsi que des outils de gestion comme MCP-CLI et MCPM. L’objectif est de réduire les obstacles à l’accès des LLM aux outils et données externes et de promouvoir le développement des Agents IA (Source: GitHub Trending)
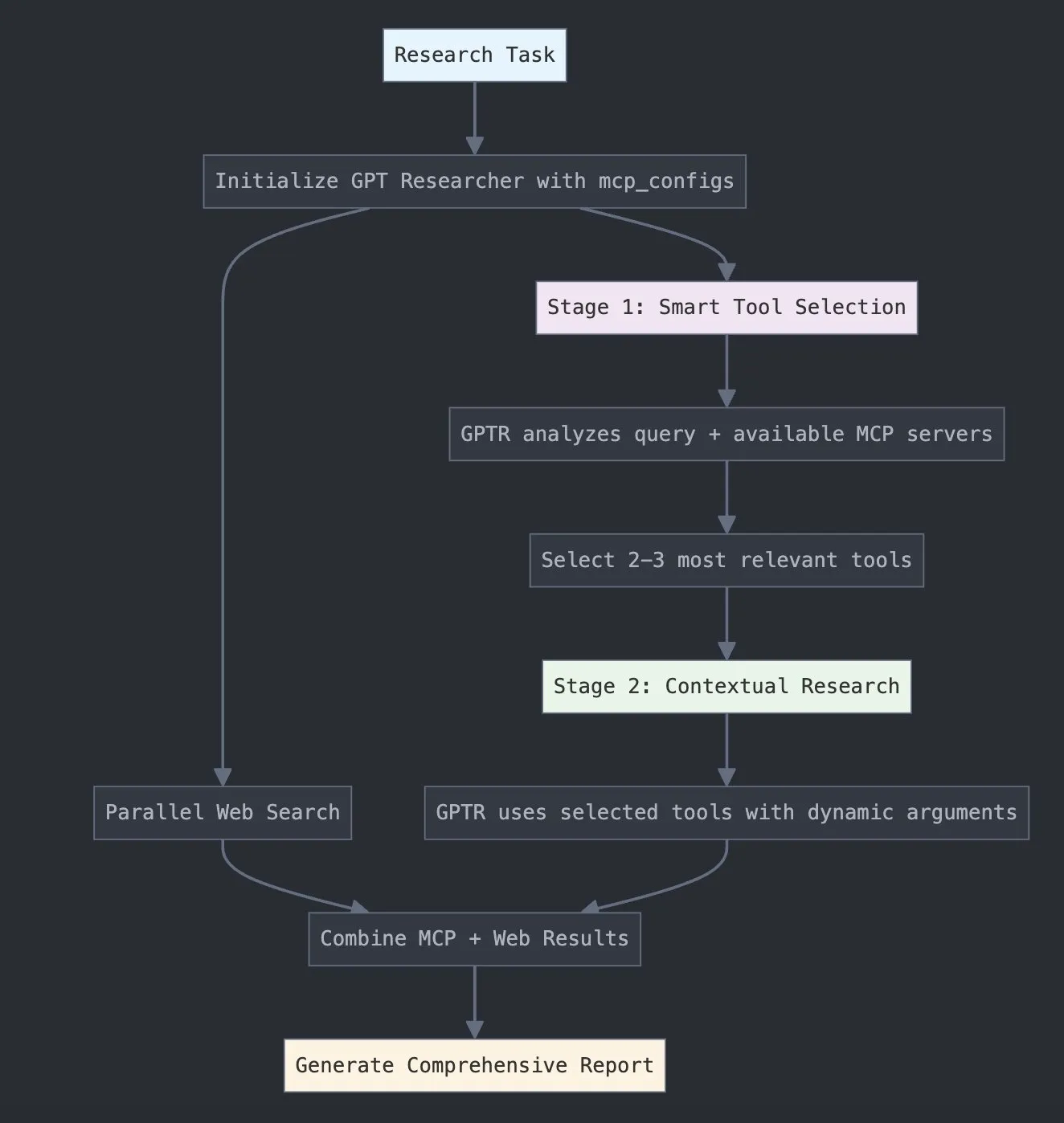
LangChain lance GPT Researcher MCP, améliorant les capacités de recherche : LangChain a annoncé que GPT Researcher utilise désormais son adaptateur Model Context Protocol (MCP) pour permettre une sélection intelligente d’outils et la recherche. Cette intégration combine MCP avec des fonctionnalités de recherche sur le web, visant à fournir aux utilisateurs des capacités de collecte et d’analyse de données plus complètes, renforçant ainsi la profondeur et l’étendue des applications de l’IA dans le domaine de la recherche (Source: X)
Hugging Face publie Vui : un NotebookLM open source de 100M de paramètres, réalisant un TTS de type humain : Hugging Face a publié Vui, un projet NotebookLM open source de 100 millions de paramètres, comprenant trois modèles : Vui.BASE (modèle de base entraîné sur 40 000 heures de conversations audio), Vui.ABRAHAM (modèle mono-locuteur sensible au contexte) et Vui.COHOST (modèle capable de mener des conversations à deux). Vui peut cloner des voix, imiter la respiration, les hésitations comme « euh », « ah », et même des sons non vocaux, marquant une nouvelle avancée dans la technologie de synthèse vocale (TTS) de type humain (Source: X, X)
Consilium : plateforme collaborative open source multi-agents pour résoudre des problèmes complexes : Le projet Consilium a été présenté sur Hugging Face. Il s’agit d’une plateforme collaborative open source multi-agents. Les utilisateurs peuvent constituer une équipe d’agents IA experts qui, par le débat et la recherche en temps réel (web, arXiv, documents SEC), collaborent pour résoudre des problèmes complexes et parvenir à un consensus. L’utilisateur définit la stratégie, et l’équipe d’agents se charge de trouver les réponses, illustrant une nouvelle exploration de l’IA dans la résolution collaborative de problèmes (Source: X)
Unsloth publie une version optimisée GGUF du modèle Magistral-Small-2506 : Suite à la publication par Mistral AI du modèle d’inférence Magistral-Small-2506, Unsloth a rapidement lancé sa version optimisée au format GGUF, adaptée aux plateformes telles que llama.cpp, LMStudio et Ollama. Cette réactivité témoigne de la vitalité et de l’efficacité de la communauté open source en matière d’optimisation et de déploiement de modèles, permettant aux nouveaux modèles d’être plus rapidement accessibles à un plus large éventail d’utilisateurs et de développeurs (Source: X)
📚 Apprentissage
Un nouvel article explore le paradigme du pré-entraînement par apprentissage par renforcement (RPT) : Un nouvel article intitulé « Reinforcement Pre-Training (RPT) » propose de reformuler la prédiction du token suivant comme une tâche d’inférence utilisant le RLVR (Reinforcement Learning with Verifiable Rewards). Le RPT vise à améliorer la précision de la prédiction des modèles de langage en stimulant la capacité d’inférence du token suivant et à fournir une base solide pour le fine-tuning par renforcement ultérieur. L’étude montre que l’augmentation du volume de calcul d’entraînement améliore continuellement la précision de la prédiction, indiquant que le RPT est un paradigme d’extension efficace et prometteur pour faire progresser le pré-entraînement des modèles de langage (Source: HuggingFace Daily Papers, X)

Un article propose Cartridges : des représentations légères de contexte long par auto-apprentissage : Un article intitulé « Cartridges: Lightweight and general-purpose long context representations via self-study » explore une méthode de traitement de textes longs par l’entraînement hors ligne de petits caches KV (appelés Cartridge), en remplacement du placement de l’ensemble du corpus dans la fenêtre contextuelle lors de l’inférence. L’étude a révélé que les Cartridges entraînés par « auto-apprentissage » (génération de dialogues synthétiques sur le corpus et entraînement avec un objectif de distillation contextuelle) atteignent des performances comparables à l’ICL avec une consommation mémoire significativement plus faible (réduction de 38,6 fois) et un débit plus élevé (augmentation de 26,4 fois). Ils peuvent également étendre la longueur de contexte effective du modèle et même prendre en charge une utilisation combinée sur plusieurs corpus sans réentraînement (Source: HuggingFace Daily Papers, X)

Un article explore l’optimisation de la stratégie contrastive de groupe (GCPO) pour les LLM dans la résolution de problèmes de géométrie : L’article « GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization » aborde le défi de la construction de lignes auxiliaires par les LLM dans la résolution de problèmes de géométrie en proposant le framework GCPO. Ce framework fournit des signaux de récompense positifs et négatifs pour la construction de lignes auxiliaires en fonction de leur utilité contextuelle via un « masque contrastif de groupe », et introduit une récompense de longueur pour promouvoir des chaînes de raisonnement plus longues. La série de modèles GeometryZero, développée sur la base de GCPO, surpasse les modèles de base dans les benchmarks tels que Geometry3K et MathVista, avec une amélioration moyenne de 4,29%, démontrant le potentiel d’amélioration des capacités de raisonnement géométrique des petits modèles avec une puissance de calcul limitée (Source: HuggingFace Daily Papers)
L’article « The Illusion of Thinking » explore les capacités et les limites des modèles de raisonnement par la complexité des problèmes : Cette étude examine systématiquement les capacités, les propriétés d’échelle et les limites des grands modèles de raisonnement (LRMs). En utilisant un environnement de puzzles dont la complexité peut être contrôlée avec précision, l’étude révèle que la précision des LRMs s’effondre complètement au-delà d’une certaine complexité et qu’ils présentent des limites d’échelle contre-intuitives : l’effort de raisonnement diminue paradoxalement après que la complexité du problème a augmenté jusqu’à un certain point. Comparés aux LLM standards, les LRMs sont moins performants sur les tâches de faible complexité, supérieurs sur les tâches de complexité moyenne, et les deux échouent sur les tâches de haute complexité. L’étude souligne les limites des LRMs en matière de calcul précis, leur difficulté à appliquer des algorithmes explicites et leur manque de cohérence dans le raisonnement à différentes échelles (Source: HuggingFace Daily Papers, X)
Un article étudie l’évaluation de la robustesse des LLM dans les langues à faibles ressources : L’article « Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models » explore la sensibilité des grands modèles de langage (LLM) aux perturbations (telles que les attaques au niveau des caractères et des mots) dans les langues à faibles ressources comme le polonais. L’étude a révélé qu’en modifiant légèrement quelques caractères et en utilisant de petits modèles proxy pour calculer l’importance des mots, il est possible de créer des attaques qui modifient de manière significative les prédictions de différents LLM. Cela met en lumière des vulnérabilités de sécurité potentielles des LLM dans ces langues, qui pourraient être exploitées pour contourner leurs mécanismes de sécurité internes. Les chercheurs ont publié les jeux de données et le code correspondants (Source: HuggingFace Daily Papers)
Rel-LLM : une nouvelle méthode pour améliorer l’efficacité du traitement des bases de données relationnelles par les LLM : Un article propose le framework Rel-LLM, visant à résoudre le problème de la faible efficacité des grands modèles de langage (LLM) lors du traitement des bases de données relationnelles. Les méthodes traditionnelles qui convertissent les données structurées en texte entraînent une perte de liens cruciaux et une redondance des entrées. Rel-LLM crée des invites graphiques structurées via un encodeur de réseau de neurones graphiques (GNN) pour préserver la structure relationnelle au sein d’un framework de génération augmentée par récupération (RAG). Cette méthode comprend un échantillonnage de sous-graphes sensible au temps, un encodeur GNN hétérogène, une couche de projection MLP pour aligner les embeddings de graphes avec l’espace latent du LLM, et la structuration des représentations graphiques en invites graphiques JSON. Elle utilise également un objectif de pré-entraînement auto-supervisé pour aligner les représentations graphiques et textuelles. Les expériences montrent que l’encodage GNN capture efficacement les structures relationnelles complexes perdues lors de la sérialisation textuelle, et que les invites graphiques structurées injectent efficacement le contexte relationnel dans les mécanismes d’attention du LLM (Source: X)

Un article explore le problème du « sur-refus » des LLM et la méthode d’optimisation EvoRefuse : L’article « EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions » étudie le problème du refus excessif des grands modèles de langage (LLM) face aux « instructions pseudo-malveillantes » (entrées sémantiquement inoffensives mais déclenchant un refus du modèle). Pour pallier les lacunes des méthodes existantes de gestion des instructions en termes d’évolutivité et de diversité, l’article propose EVOREFUSE, une méthode utilisant des algorithmes évolutifs pour optimiser les invites, capable de générer des instructions pseudo-malveillantes diversifiées qui provoquent de manière persistante le refus des LLM. Sur cette base, les chercheurs ont créé EVOREFUSE-TEST (un benchmark contenant 582 instructions) et EVOREFUSE-ALIGN (un jeu de données d’entraînement à l’alignement contenant 3000 instructions et réponses). Les expériences montrent que le modèle LLAMA3.1-8B-INSTRUCT, fine-tuné sur EVOREFUSE-ALIGN, présente un taux de sur-refus jusqu’à 14,31% inférieur à celui des modèles entraînés sur des jeux de données d’alignement sous-optimaux, sans compromettre la sécurité (Source: HuggingFace Daily Papers)
💼 Affaires
Zhongke Wenge finalise un nouveau tour de financement stratégique, avec un investissement du fonds industriel du district de Shijingshan à Pékin : Le fournisseur de services d’IA pour entreprises Zhongke Wenge a annoncé la finalisation d’un nouveau tour de financement stratégique, mené par le Fonds de développement industriel innovant moderne du district de Shijingshan à Pékin. Ce financement sera principalement utilisé pour la R&D et la promotion commerciale de son système d’exploitation d’intelligence décisionnelle propriétaire DIOS, accélérant ainsi le développement technologique et la commercialisation de l’IA au niveau des entreprises. Fondée en 2017, Zhongke Wenge, dont l’équipe principale est issue de l’Institut d’automatisation de l’Académie chinoise des sciences, se concentre sur la compréhension multilingue, la sémantique intermodale et la technologie de décision en scénarios complexes, au service des secteurs des médias, de la finance, de l’administration, de l’énergie, etc. L’entreprise avait précédemment levé plus d’un milliard de yuans auprès de fonds soutenus par l’État tels que CDB Kaiyuan, China Internet Investment Fund et SCGC (Source: 量子位)

Sakana AI et la banque japonaise Hokkoku concluent un partenariat stratégique pour promouvoir l’IA dans la finance régionale : La start-up japonaise d’IA Sakana AI a annoncé la signature d’un protocole d’accord (MOU) avec Hokkoku Financial Holdings, basée dans la préfecture d’Ishikawa. Les deux parties collaboreront stratégiquement sur l’intégration de l’IA dans la finance régionale. Après avoir établi un partenariat global avec la banque Mitsubishi UFJ, Sakana AI s’associe à nouveau à une institution financière dans le but d’appliquer des technologies d’IA de pointe pour résoudre les problèmes auxquels sont confrontées les communautés régionales japonaises, en particulier dans le secteur des services financiers. Sakana AI se consacre au développement de technologies d’IA hautement spécialisées pour les institutions financières, et cette collaboration devrait servir de modèle pour l’application de l’IA dans d’autres banques régionales japonaises (Source: X, X)

Cohere s’associe à Ensemble pour introduire sa plateforme d’IA dans le secteur de la santé : La société d’IA Cohere a annoncé un partenariat avec EnsembleHP (fournisseur de solutions pour le secteur de la santé) afin d’introduire sa plateforme d’agents intelligents Cohere North dans le secteur de la santé. Les deux entreprises visent à réduire les frictions dans les processus de gestion médicale et à améliorer l’expérience des patients dans les hôpitaux et les systèmes de santé grâce à une plateforme d’agents IA sécurisée. Cette initiative marque une étape importante pour Cohere dans la promotion de ses grands modèles de langage et de ses technologies d’IA dans des secteurs verticaux clés (Source: X)
🌟 Communauté
Ilya Sutskever lors de son discours de doctorat honorifique à l’Université de Toronto : L’IA finira par tout faire, une attention active est nécessaire : Ilya Sutskever, cofondateur d’OpenAI, a déclaré lors de son discours après avoir reçu un doctorat honorifique en sciences de l’Université de Toronto (son quatrième diplôme de cette université) que les progrès de l’IA lui permettront « un jour de faire tout ce que nous pouvons faire », car le cerveau humain est un ordinateur biologique et l’IA un cerveau numérique. Il estime que nous vivons une époque extraordinaire définie par l’IA, qui a déjà profondément changé la signification des études et du travail. Il a souligné qu’au lieu de s’inquiéter, il vaut mieux se forger une intuition en utilisant et en observant les IA de pointe pour comprendre les limites de leurs capacités. Il a appelé les gens à prêter attention au développement de l’IA et à relever activement les défis et opportunités immenses qui en découlent, car l’IA affectera profondément la vie de chacun. Il a également partagé son état d’esprit personnel : « Accepter la réalité, ne pas regretter le passé, s’efforcer d’améliorer le présent. » (Source: X, 36氪)
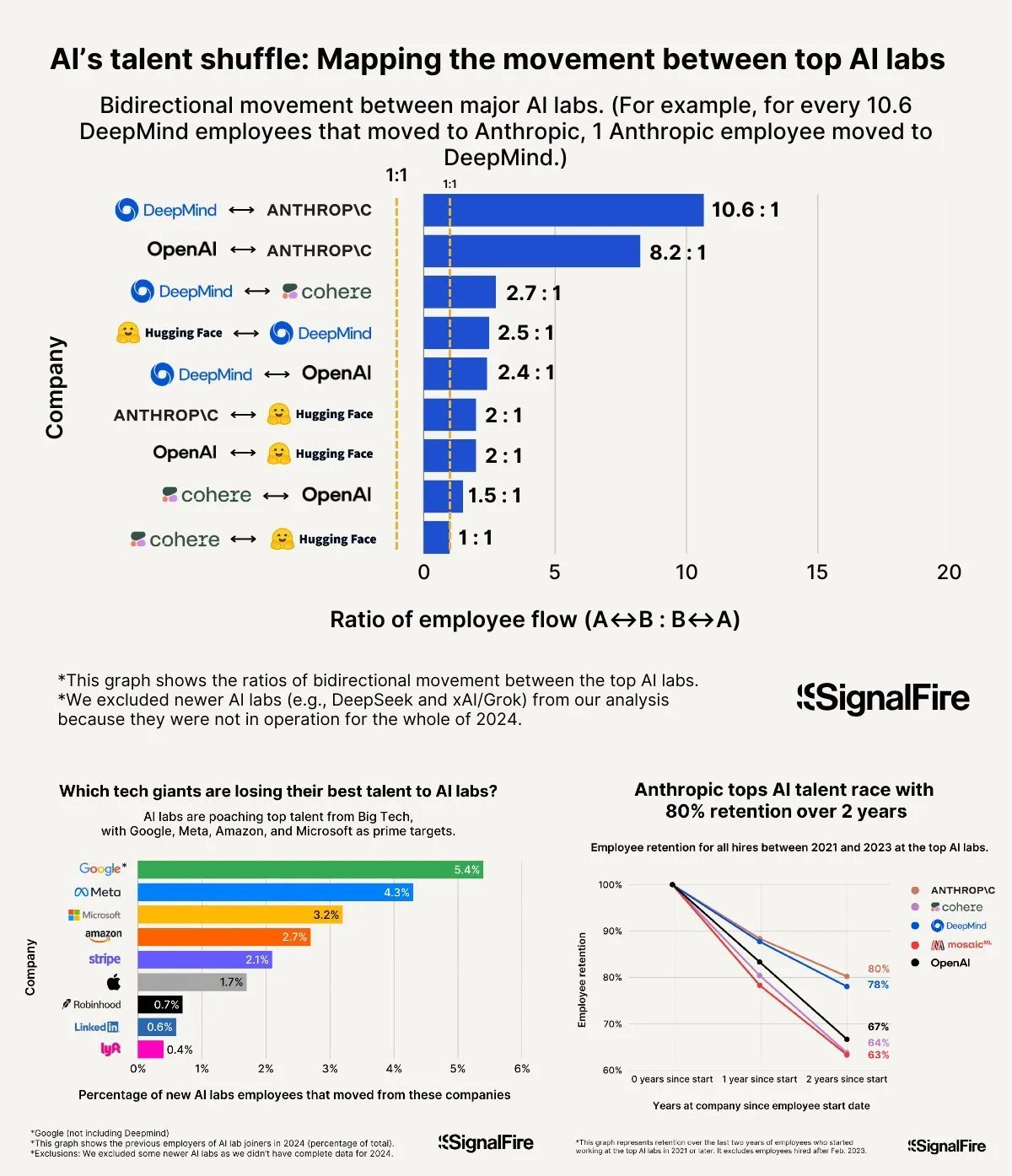
La guerre des talents en IA s’intensifie : les salaires élevés de Meta peinent à concurrencer OpenAI et Anthropic : Meta proposerait des salaires annuels dépassant les 2 millions de dollars pour attirer les talents en IA, mais se heurterait toujours à une fuite des talents vers OpenAI et Anthropic. Des discussions soulignent que le salaire de niveau L6 chez OpenAI avoisine les 1,5 million de dollars, et que le potentiel de valorisation des actions y est considéré comme supérieur à celui de Meta, ce qui rend OpenAI plus attrayant aux yeux des meilleurs talents. De plus, des allégations de tricherie au sein de l’équipe Llama et la forte pression des KPI chez Meta, ainsi qu’un taux élevé de licenciement des moins performants (15-20% cette année), influenceraient également le choix des talents. Anthropic, avec un taux de rétention des talents d’environ 80% (deux ans après sa création), serait devenue l’une des grandes entreprises préférées des meilleurs chercheurs en IA. L’intensité de cette guerre des talents est qualifiée d’« ahurissante » (Source: X, X)
Partage d’expérience sur le « Vibe Coding » : 5 règles pour éviter les pièges de la programmation assistée par IA : Sur les réseaux sociaux, des développeurs expérimentés ont partagé cinq règles pour éviter de tomber dans des cycles de débogage inefficaces lors de l’utilisation de l’IA (comme Claude) pour le « Vibe Coding » (une méthode de programmation s’appuyant fortement sur l’assistance de l’IA) : 1. Trois prises, retrait : Si l’IA ne parvient pas à résoudre le problème après trois tentatives, arrêtez et demandez à l’IA de reconstruire à partir d’une nouvelle description des besoins. 2. Réinitialiser le contexte : L’IA « oublie » après de longues conversations ; il est conseillé de sauvegarder le code fonctionnel toutes les 8-10 séries de messages, d’ouvrir une nouvelle session et de ne coller que les composants problématiques et une brève description de l’application. 3. Décrire le problème de manière concise : Décrivez clairement le bug en une phrase. 4. Contrôle de version fréquent : Commitez sur Git après chaque fonctionnalité terminée. 5. Recommencer si nécessaire : Si la correction d’un bug prend trop de temps (par exemple, plus de 2 heures), il vaut mieux supprimer le composant problématique et laisser l’IA le reconstruire. L’essentiel est d’abandonner résolument la réparation lorsque l’on reconnaît que le code est irrémédiablement endommagé. Il est également souligné que comprendre la programmation permet de mieux guider l’IA et de déboguer (Source: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li parle de la création de World Labs : née d’une exploration de l’essence de l’intelligence, l’intelligence spatiale est la pièce manquante cruciale de l’IA : Dans un podcast d’a16z, Fei-Fei Li a partagé les motivations derrière la création de World Labs, soulignant qu’il ne s’agissait pas de suivre la vague des modèles de fondation, mais d’une exploration continue de l’essence de l’intelligence. Elle estime que si le langage est un vecteur d’information efficace, il présente des lacunes dans la représentation du monde physique tridimensionnel ; une véritable intelligence générale doit reposer sur la compréhension de l’espace physique et des relations entre les objets. Une lésion cornéenne qui l’a temporairement privée de sa vision stéréoscopique lui a fait prendre conscience plus profondément de l’importance de la représentation spatiale tridimensionnelle pour l’interaction physique. World Labs vise à construire des modèles d’IA (modèles du monde, LWM) capables de réellement comprendre le monde physique, comblant ainsi le manque actuel de l’IA en matière d’intelligence spatiale. Elle pense que pour réaliser cette vision, il faut mobiliser une puissance de calcul, des données et des talents de niveau industriel, et souligne que la percée technologique actuelle consiste à permettre à l’IA de reconstruire une compréhension complète de scènes tridimensionnelles à partir d’une vision monoculaire (Source: 量子位)

L’IA au service du Gaokao : des controverses sur les pronostics aux opportunités et inquiétudes pour l’orientation : Avant et après le Gaokao (examen national d’entrée à l’université en Chine), l’application de l’IA dans l’éducation a suscité de vifs débats. D’une part, les « pronostics par IA » sont devenus un sujet brûlant, mais en raison de la rigueur scientifique, de la confidentialité et des mécanismes « anti-pronostics » de l’examen, la probabilité que l’IA prédise avec précision les sujets est faible, et la qualité de certains sujets de pronostics sur le marché est préoccupante. D’autre part, l’IA a montré son utilité dans la planification des révisions, l’explication des questions, la surveillance des examens et la correction, comme les plans d’apprentissage personnalisés, les réponses intelligentes aux questions, et les systèmes de surveillance par IA améliorant l’équité et l’efficacité. Pour l’orientation post-bac, les outils d’IA peuvent rapidement recommander des établissements et des filières en fonction des notes et du classement des candidats, réduisant ainsi l’asymétrie d’information. Cependant, une dépendance excessive à l’IA pour l’orientation suscite des inquiétudes : les algorithmes pourraient renforcer la préférence pour les filières populaires, négligeant les intérêts individuels et le développement à long terme ; confier entièrement le choix de son avenir à un algorithme pourrait conduire à un « détournement de la vie par l’algorithme ». L’article appelle à une vision rationnelle de l’assistance par IA, soulignant l’importance de maîtriser l’outil avec sagesse et de définir son avenir par la réflexion (Source: 36氪)
Discussion sur les modèles de réussite des entreprises d’agents IA : auto-service vs. services personnalisés : La communauté a débattu des modèles de réussite pour les entreprises d’agents IA. Un point de vue soutient que les entreprises d’agents IA performantes (en particulier celles desservant les marchés de taille moyenne à grande) adoptent souvent un modèle similaire à celui de Palantir, c’est-à-dire avec un grand nombre d’ingénieurs de développement sur site (FDEs) et des logiciels personnalisés, plutôt qu’un modèle purement d’auto-service. D’autres insistent sur la valeur à long terme du modèle d’auto-service, estimant que les équipes finiront par choisir de construire en interne les applications importantes. Cela reflète les différentes pistes de réflexion dans le domaine des agents IA concernant les modèles de service et les stratégies de marché (Source: X)
💡 Divers
Les invites système de Google Diffusion dévoilées, révélant ses principes de conception et les limites de ses capacités : Un utilisateur a partagé ce qui serait les invites système de Google Diffusion (un modèle de langage de diffusion textuelle). Ces invites détaillent l’identité du modèle (Gemini Diffusion, un modèle de langage de diffusion textuelle expert entraîné par Google, non autorégressif), ses principes et contraintes fondamentaux (tels que le respect des instructions, la nature non autorégressive, la précision, l’absence d’accès en temps réel, l’éthique de sécurité, une date limite de connaissances en décembre 2023, la capacité de génération de code), ainsi que des instructions spécifiques pour la génération de pages web HTML et de jeux HTML. Ces instructions couvrent le format de sortie, la conception esthétique, le style (comme l’utilisation dédiée de Tailwind CSS ou de CSS personnalisé dans les jeux), l’utilisation d’icônes (icônes SVG Lucide), la mise en page et les performances (prévention du CLS), les exigences en matière de commentaires, etc. Enfin, l’importance de la réflexion étape par étape et du respect précis des instructions de l’utilisateur est soulignée. Ces invites offrent un aperçu des idées de conception et du comportement attendu de tels modèles (Source: Reddit r/LocalLLaMA)
Arvind Narayanan explique la genèse et la réflexion derrière l’article « L’IA comme technologie normale » : Arvind Narayanan, professeur à l’Université de Princeton, a partagé le processus de création de son article co-écrit avec Sayash Kapoor, « AI as Normal Technology ». Initialement sceptique quant à l’AGI et aux risques existentiels, il a décidé, sous l’impulsion de collègues, de prendre le sujet au sérieux et de participer aux discussions. En réfléchissant, il a reconnu que les points de vue liés à la superintelligence méritaient d’être pris au sérieux, que les médias sociaux n’étaient pas adaptés aux discussions sérieuses, et que les communautés de l’éthique de l’IA et de la sécurité de l’IA avaient chacune leurs propres « bulles d’information ». La première version de l’article a été rejetée par l’ICML, mais le débat houleux lors du processus d’évaluation a renforcé leur détermination à poursuivre leurs recherches. Ils ont réalisé que leurs désaccords avec la communauté de la sécurité de l’IA étaient plus profonds qu’ils ne le pensaient et ont reconnu la nécessité d’un débat transdisciplinaire plus productif. Finalement, l’article a été publié lors d’un atelier du Knight First Amendment Institute de l’Université Columbia, suscitant une large attention et des discussions fructueuses, ce qui a rendu Narayanan plus optimiste quant à l’avenir de la politique en matière d’IA (Source: X)
La génération Z des entrepreneurs en IA émerge et redéfinit les règles de l’entrepreneuriat : Un groupe d’entrepreneurs en IA nés après 2000 émerge à une vitesse étonnante sur la scène mondiale de l’entrepreneuriat. Forts d’une compréhension profonde des technologies de l’IA et d’une perception aiguisée de l’environnement numérique natif, ils redéfinissent les règles de l’entrepreneuriat. Parmi les exemples, citons Michael Truell d’Anysphere (Cursor) (passé de stagiaire à PDG d’une entreprise valant des dizaines de milliards de dollars en 3 ans), les trois fondateurs de Mercor (qui ont créé une plateforme de recrutement IA de plusieurs milliards en 2 ans), Eric Steinberger de Magic (cofondateur à 25 ans d’une entreprise de codage IA ayant levé plus de 400 millions de dollars) et Hong Letong d’Axiom (spécialisée dans la résolution de problèmes mathématiques par l’IA, valorisée avant même d’avoir un produit). Ces jeunes entrepreneurs partagent généralement les caractéristiques suivantes : la programmation est leur langue maternelle ; ils se sont fait connaître jeunes, saisissant la fenêtre d’opportunité technologique ; ils perçoivent avec acuité les besoins des utilisateurs ; ils ont une compréhension native de l’IA pour l’organisation et les produits, privilégiant des équipes minimalistes et efficaces et une logique « l’IA est le produit ». Leur succès marque un changement de paradigme dans l’entrepreneuriat à l’ère de l’IA (Source: 36氪)