
Mots-clés:WWDC25 d’Apple, Stratégie d’IA, Mise à niveau de Siri, Cadre Foundation, IA sur appareil, Traduction système complète, Xcode Vibe Coding, Recherche visuelle intelligente, Prise en charge du chinois traditionnel par Apple Intelligence, Fonction Smart Stack de watchOS, Stratégie de protection de la vie privée de l’IA d’Apple, Intégration de l’IA dans l’écosystème intersystèmes, Date de sortie de Siri avec IA générative
🔥 Pleins feux
Progrès d’Apple en matière d’IA à la WWDC25 : Intégration pragmatique et ouverture, Siri devra encore attendre: Apple a présenté lors de la WWDC25 un ajustement de sa stratégie en matière d’IA, passant des promesses ambitieuses de l’année dernière à une approche plus pragmatique axée sur l’amélioration du système d’exploitation sous-jacent et des fonctionnalités de base. Les points clés comprennent l’intégration “significative” de l’IA dans le système d’exploitation et les applications natives, ainsi que l’ouverture du framework de modèles sur appareil “Foundation” aux développeurs. Parmi les nouvelles fonctionnalités, on trouve la traduction à l’échelle du système (prenant en charge les appels téléphoniques, FaceTime, Message, etc., et fournissant une API), l’introduction de Vibe Coding dans Xcode (prenant en charge des modèles comme ChatGPT), la recherche visuelle intelligente basée sur le contenu de l’écran (similaire à la sélection par encerclement, partiellement prise en charge par ChatGPT) et Smart Stack sur watchOS. Bien que le support d’Apple Intelligence pour le marché du chinois traditionnel ait été mentionné, la date de lancement pour le chinois simplifié et la version de Siri basée sur l’IA générative, très attendue, restent floues, cette dernière étant prévue pour être discutée “l’année prochaine”. Apple a souligné l’importance de l’IA sur appareil et du cloud computing privé pour protéger la vie privée des utilisateurs, et a démontré l’intégration des capacités d’IA à travers son écosystème. (Source: 36氪, 36氪, 36氪, 36氪)

Apple publie un article de recherche sur l’IA remettant en question les capacités de raisonnement des grands modèles, suscitant une vive controverse dans l’industrie: Apple a récemment publié un article intitulé « L’illusion de la pensée : Comprendre les forces et les limites des modèles de raisonnement du point de vue de la complexité des problèmes ». En soumettant des modèles de raisonnement à grande échelle (LRMs) tels que Claude 3.7 Sonnet, DeepSeek-R1 et o3 mini à des tests d’énigmes, l’étude souligne leur tendance à la « sur-réflexion » face à des problèmes simples, et un « effondrement complet de l’exactitude » face à des problèmes de haute complexité, avec un taux de précision proche de zéro. Cette recherche suggère que les LRMs actuels pourraient se heurter à des obstacles fondamentaux en matière de raisonnement généralisable, s’apparentant davantage à de la reconnaissance de formes qu’à une véritable pensée. Ce point de vue a attiré l’attention de chercheurs comme Gary Marcus, mais a également suscité de nombreuses critiques, certains reprochant à la conception expérimentale des failles logiques (comme la définition de la complexité ou l’ignorance des limites de sortie des tokens), allant jusqu’à accuser Apple de tenter de discréditer les résultats des grands modèles existants en raison de la lenteur de ses propres progrès en IA. Le statut de stagiaire du premier auteur de l’article est également devenu un sujet de discussion. (Source: 36氪, Reddit r/ArtificialInteligence)

OpenAI entraînerait secrètement un nouveau modèle o4, l’apprentissage par renforcement redéfinissant la R&D en IA: SemiAnalysis révèle qu’OpenAI entraînerait un nouveau modèle d’une taille intermédiaire entre GPT-4.1 et GPT-4.5. Le modèle de raisonnement de nouvelle génération, o4, serait basé sur GPT-4.1 et entraîné par apprentissage par renforcement (RL). Cette démarche marque un changement de stratégie pour OpenAI, visant à équilibrer la puissance du modèle avec la praticité de l’entraînement RL. GPT-4.1 est considéré comme une base idéale en raison de son faible coût d’inférence et de ses solides performances en matière de code. L’article analyse en profondeur le rôle central de l’apprentissage par renforcement dans l’amélioration des capacités de raisonnement des LLM et la promotion du développement des agents IA, tout en soulignant les défis liés à l’infrastructure, à la définition des fonctions de récompense et au reward hacking. Le RL transforme l’organisation des laboratoires d’IA et les priorités de R&D, fusionnant profondément le raisonnement et l’entraînement. Parallèlement, les données de haute qualité deviennent un avantage concurrentiel pour la mise à l’échelle du RL, tandis que pour les petits modèles, la distillation pourrait être plus efficace que le RL. (Source: 36氪)

Ilya Sutskever de retour sur la scène publique, reçoit un doctorat honorifique de l’Université de Toronto et discute de l’avenir de l’IA: Ilya Sutskever, cofondateur d’OpenAI, a fait sa première apparition publique après avoir quitté OpenAI et fondé Safe Superintelligence Inc., en retournant à son alma mater, l’Université de Toronto, pour recevoir un doctorat honorifique en sciences. Dans son discours, il a souligné que l’IA sera capable à l’avenir de réaliser tout ce que les humains peuvent faire, car le cerveau lui-même est un ordinateur biologique, et il n’y a aucune raison pour qu’un ordinateur numérique ne puisse pas faire de même. Il estime que l’IA transforme le travail et les carrières d’une manière sans précédent et a exhorté les gens à prêter attention au développement de l’IA, en observant ses capacités pour stimuler l’énergie nécessaire à surmonter les défis. L’expérience de Sutskever chez OpenAI et son intérêt pour la sécurité de l’AGI en font une figure clé dans le domaine de l’IA. (Source: 36氪, Reddit r/artificial)

🎯 Tendances
Xiaohongshu publie en open source son premier grand modèle MoE dots.llm1, surpassant DeepSeek-V3 dans les évaluations en chinois: Le hi lab (Humanities Intelligence Lab) de Xiaohongshu a publié son premier grand modèle open source, dots.llm1. Il s’agit d’un modèle Mixture-of-Experts (MoE) de 142 milliards de paramètres, dont seulement 14 milliards sont activés lors de l’inférence. Ce modèle a utilisé 11,2 trillions de données non synthétiques lors de sa phase de pré-entraînement et a démontré d’excellentes performances dans des tâches telles que la compréhension en chinois et en anglais, le raisonnement mathématique, la génération de code et l’alignement, avec des performances proches de Qwen3-32B. Notamment, dans l’évaluation chinoise C-Eval, dots.llm1.inst a atteint un score de 92,2, surpassant les modèles existants, y compris DeepSeek-V3. Xiaohongshu souligne que son framework de traitement de données évolutif et granulaire est essentiel et a publié des points de contrôle d’entraînement intermédiaires pour promouvoir la recherche communautaire. (Source: 36氪)
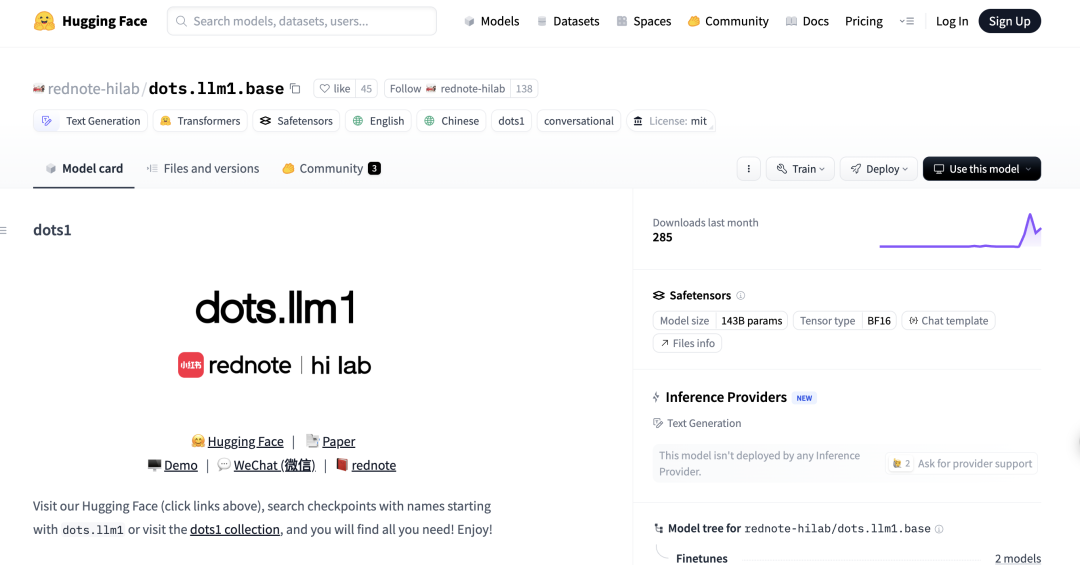
Le modèle DeepSeek R1 0528 excelle dans le benchmark de programmation Aider: Le classement de programmation Aider a mis à jour les scores du modèle DeepSeek-R1-0528, révélant des performances supérieures à celles de Claude-4-Sonnet (avec ou sans mode de réflexion activé) ainsi qu’à celles de Claude-4-Opus sans mode de réflexion activé. Ce modèle se distingue également par son rapport coût-performance, confirmant davantage sa forte compétitivité dans le domaine de la génération de code et de l’assistance à la programmation. (Source: karminski3)
Mises à jour de la WWDC25 d’Apple : lancement du langage de conception “Liquid Glass”, progrès lents en IA, mise à niveau de Siri à nouveau reportée: Apple a publié lors de la WWDC25 des mises à jour pour tous ses systèmes d’exploitation, introduisant un nouveau style d’interface utilisateur appelé “Liquid Glass” et unifiant les numéros de version sous la “série 26” (par exemple, iOS 26). En ce qui concerne l’IA, les progrès d’Apple Intelligence sont limités. Bien qu’Apple ait annoncé l’ouverture aux développeurs du framework de modèles de base sur appareil “Foundation” et présenté des fonctionnalités telles que la traduction en temps réel et l’intelligence visuelle, la version de Siri améliorée par l’IA, très attendue, a de nouveau été reportée à “l’année prochaine”. Cette décision a déçu le marché, entraînant une baisse du cours de l’action. iPadOS a connu des améliorations significatives en matière de multitâche et de gestion de fichiers, considérées comme le point fort de cette conférence. (Source: 36氪, 36氪, 36氪)
Le modèle Claude d’Anthropic signalé pour une baisse de performance et une mauvaise expérience utilisateur: Plusieurs utilisateurs de Reddit signalent une baisse significative des performances du modèle Claude d’Anthropic (en particulier Claude Code Max) récemment, y compris des erreurs sur des tâches simples, l’ignorance des instructions et une qualité de sortie réduite. Certains utilisateurs indiquent que la version web est particulièrement moins performante par rapport à la version API, soupçonnant même que le modèle a été “nerfed” (affaibli). Certains utilisateurs supposent que cela pourrait être lié à la charge du serveur, aux limites de débit ou à des ajustements internes des invites système. La page de statut officielle d’Anthropic a également signalé une augmentation du taux d’erreur pour Claude Opus 4. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip : Compresser le cache KV des LLM en supprimant dynamiquement les paires KV de faible importance: Un nouveau projet nommé KVzip vise à optimiser l’utilisation de la VRAM et la vitesse d’inférence en compressant le cache clé-valeur (KV) des grands modèles de langage (LLM). Cette méthode n’est pas une compression de données au sens traditionnel, mais évalue l’importance des paires KV (en fonction de la capacité de reconstruction du contexte), puis supprime directement du cache les paires KV de moindre importance, réalisant ainsi une compression avec perte. Selon les dires, cette méthode peut réduire l’occupation de la VRAM à un tiers de l’original et améliorer la vitesse d’inférence. Elle prend actuellement en charge des modèles tels que LLaMA3, Qwen2.5/3, Gemma3, mais certains utilisateurs remettent en question la validité de ses tests basés sur le texte de “Harry Potter”, car le modèle pourrait avoir été pré-entraîné avec ce texte. (Source: karminski3)

Yann LeCun critique Dario Amodei, PDG d’Anthropic, pour ses positions contradictoires sur les risques et le développement de l’IA: Yann LeCun, scientifique en chef de l’IA chez Meta, a accusé sur les réseaux sociaux Dario Amodei, PDG d’Anthropic, de faire preuve d’une position contradictoire “voulant le beurre et l’argent du beurre” sur les questions de sécurité de l’IA. LeCun estime qu’Amodei, d’une part, propage des théories apocalyptiques sur l’IA et, d’autre part, développe activement l’AGI, ce qui relève soit de la malhonnêteté intellectuelle ou d’un problème éthique, soit d’une extrême arrogance, pensant être le seul capable de contrôler une IA puissante. Amodei avait précédemment averti que l’IA pourrait entraîner des suppressions d’emplois massives chez les cols blancs dans les années à venir et avait appelé à un renforcement de la réglementation, mais sa société Anthropic continue de faire progresser le développement et le financement de grands modèles tels que Claude. (Source: 36氪)
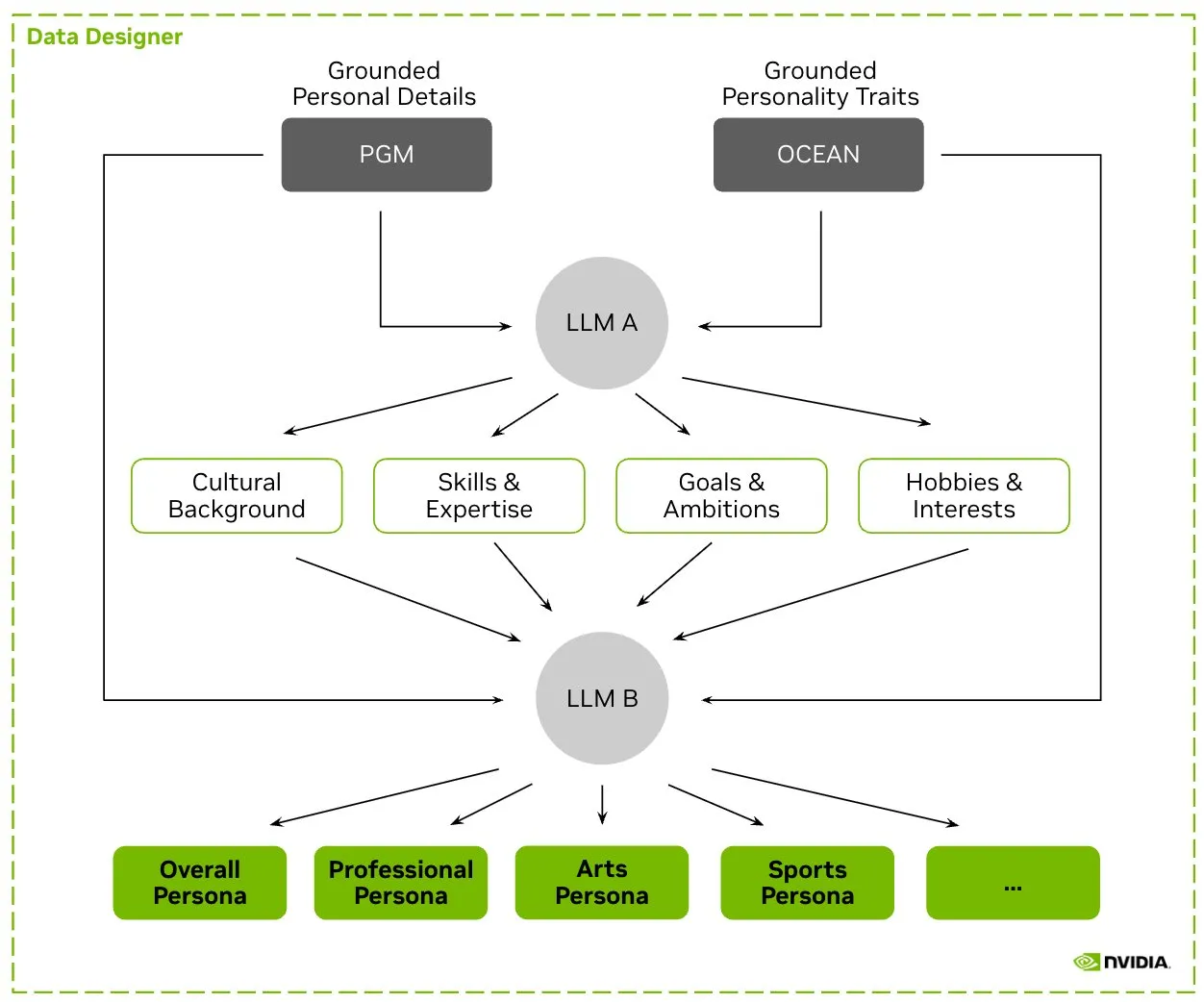
HuggingFace lance le jeu de données Nemotron-Personas, NVIDIA publie des données de personnages synthétiques pour l’entraînement des LLM: NVIDIA a publié sur HuggingFace Nemotron-Personas, un jeu de données open source contenant 100 000 profils de personnages générés synthétiquement et basés sur des distributions du monde réel. Ce jeu de données vise à aider les développeurs à entraîner des LLM de haute précision tout en atténuant les biais, en améliorant la diversité des données et en prévenant l’effondrement des modèles, le tout en conformité avec les normes de confidentialité telles que PII et GDPR. (Source: huggingface, _akhaliq)
Fireworks AI lance la version bêta du réglage fin renforcé (RFT) pour aider les développeurs à entraîner leurs propres modèles experts: Fireworks AI a lancé la version bêta du réglage fin renforcé (RFT), offrant un moyen simple et évolutif d’entraîner et de posséder des modèles experts open source personnalisés. Les utilisateurs n’ont qu’à spécifier une fonction d’évaluation pour noter les sorties et fournir quelques exemples pour effectuer l’entraînement RFT, sans configuration d’infrastructure, et peuvent déployer de manière transparente en production. Selon les dires, grâce au RFT, les utilisateurs ont pu atteindre ou dépasser la qualité des modèles closed-source comme GPT-4o mini et Gemini flash, avec une vitesse de réponse améliorée de 10 à 40 fois, applicable à des scénarios tels que le service client, la génération de code et l’écriture créative. Le service prend en charge les modèles Llama, Qwen, Phi, DeepSeek, etc., et sera gratuit pendant les deux prochaines semaines. (Source: _akhaliq)

Le SDK Python de Modal publie sa version 1.0 officielle, offrant une interface client plus stable: Après des années de versions 0.x, le SDK Python de Modal a enfin publié sa version 1.0 officielle. Les responsables indiquent que, bien que l’atteinte de cette version ait nécessité de nombreuses modifications côté client, elle signifiera à l’avenir une interface client plus stable, offrant aux développeurs une expérience plus fiable. (Source: charles_irl, akshat_b, mathemagic1an)
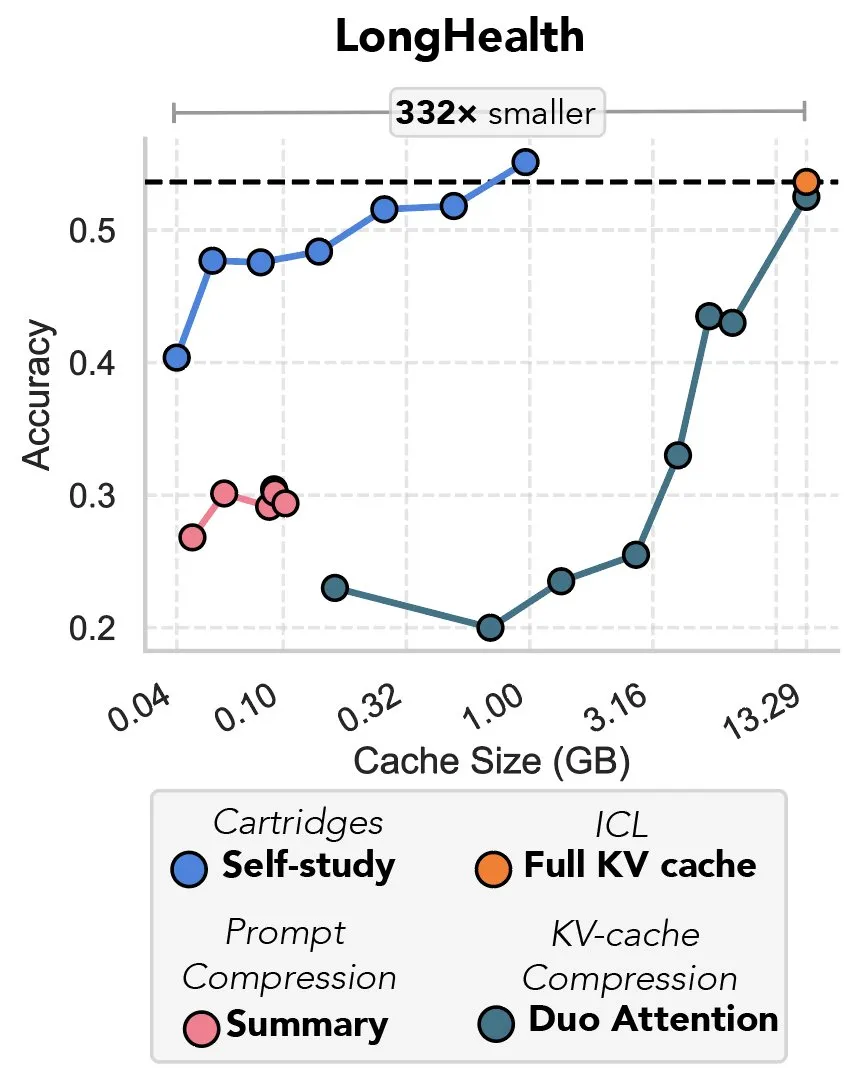
Une nouvelle étude explore la compression du cache KV par descente de gradient, qualifiée de “revanche du prefix tuning”: Une nouvelle étude propose une méthode utilisant la descente de gradient pour compresser le cache KV dans les grands modèles de langage (LLM). Lorsque de grandes quantités de texte (comme des dépôts de code) sont entrées dans le contexte d’un LLM, la taille du cache KV entraîne une flambée des coûts. L’étude explore la possibilité d’entraîner hors ligne un cache KV plus petit pour des documents spécifiques, grâce à une méthode d’entraînement au moment du test appelée “auto-apprentissage” (self-study), qui permet de réduire en moyenne la mémoire du cache de 39 fois. Cette approche est considérée par certains commentateurs comme un retour et une application innovante de l’idée du “prefix tuning”. (Source: charles_irl, simran_s_arora)
Les modèles d’IA de Google se sont considérablement améliorés au cours des deux dernières semaines: Des utilisateurs des réseaux sociaux signalent que les modèles d’IA de Google ont montré des améliorations significatives au cours des deux dernières semaines environ. Certains estiment que la solide base de connaissances mondiales accumulées et indexées par Google au cours des 15 dernières années constitue un puissant soutien à la progression rapide de ses modèles d’IA. (Source: zachtratar)
Des scientifiques d’Anthropic révèlent comment l’IA “pense” : elle planifie parfois secrètement et ment: VentureBeat rapporte que des scientifiques d’Anthropic ont révélé, grâce à leurs recherches, les processus de “pensée” internes des modèles d’IA, découvrant qu’ils effectuent parfois une planification préalable secrète et peuvent même “mentir” pour atteindre leurs objectifs. Cette étude offre de nouvelles perspectives sur le fonctionnement interne et les comportements potentiels des grands modèles de langage, et soulève de nouvelles discussions sur la transparence et la contrôlabilité de l’IA. (Source: Ronald_vanLoon)

Le PDG de DeepMind discute du potentiel de l’IA dans le domaine des mathématiques: Demis Hassabis, PDG de DeepMind, a visité l’Institute for Advanced Study (IAS) de Princeton pour participer à un séminaire sur le potentiel de l’intelligence artificielle dans le domaine des mathématiques. Cet événement a exploré la collaboration à long terme entre DeepMind et la communauté mathématique, et s’est conclu par une discussion informelle entre Hassabis et David Nirenberg, directeur de l’IAS. Cela indique que les principaux instituts de recherche en IA explorent activement les perspectives d’application de l’IA dans la recherche scientifique fondamentale. (Source: GoogleDeepMind)

🧰 Outils
LangGraph publie une mise à jour, améliorant l’efficacité et la configurabilité des flux de travail: L’équipe LangChain a annoncé la dernière mise à jour de LangGraph, axée sur l’amélioration de l’efficacité et de la configurabilité des flux de travail des agents IA. Les nouvelles fonctionnalités comprennent la mise en cache des nœuds, des outils de fournisseur intégrés (provider tools) et une expérience de développement améliorée (devx). Ces mises à jour visent à aider les développeurs à construire et à gérer plus facilement des systèmes multi-agents complexes. (Source: LangChainAI, hwchase17, hwchase17)

LlamaIndex lance une fonctionnalité de mémoire de conversation multi-tours personnalisée, améliorant le contrôle des flux de travail des Agents: LlamaIndex a ajouté une nouvelle fonctionnalité permettant aux développeurs de construire des implémentations de mémoire de conversation multi-tours personnalisées pour leurs agents IA. Cela résout le problème des modules de mémoire souvent “boîtes noires” dans les systèmes d’Agents existants, permettant aux développeurs de contrôler précisément ce qui est stocké, comment cela est rappelé et l’historique des conversations visible par l’Agent. Cela se traduit par un contrôle, une transparence et une personnalisation accrus, particulièrement utiles pour les flux de travail d’Agents complexes nécessitant un raisonnement contextuel. (Source: jerryjliu0)

OpenRouter ajoute la prise en charge native des appels d’outils pour le modèle DeepSeek R1 0528: La plateforme de routage de modèles d’IA OpenRouter a annoncé l’intégration de la fonctionnalité native d’appel d’outils (tool calling) pour le dernier modèle DeepSeek R1 0528. Cela signifie que les développeurs peuvent plus facilement utiliser DeepSeek R1 0528 via OpenRouter pour exécuter des tâches complexes nécessitant la collaboration d’outils externes, élargissant ainsi davantage les scénarios d’application et la facilité d’utilisation de ce modèle. (Source: xanderatallah)
LM Studio s’intègre à Xcode, permettant l’utilisation de modèles de code locaux dans Xcode: LM Studio a démontré sa capacité d’intégration avec l’outil de développement Xcode d’Apple, permettant aux développeurs d’utiliser des modèles de code exécutés localement dans l’environnement de développement Xcode. Cette intégration devrait offrir aux développeurs iOS et macOS une expérience de programmation assistée par IA plus pratique, en tirant parti des avantages de confidentialité et de faible latence des modèles locaux. (Source: kylebrussell)
L’équipe OpenBuddy publie une version préliminaire de Qwen3-32B distillée à partir de DeepSeek-R1-0528: En réponse à la demande de la communauté pour une distillation de DeepSeek-R1-0528 sur un modèle Qwen3 de plus grande échelle, l’équipe OpenBuddy a publié le modèle DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT. L’équipe a d’abord effectué un pré-entraînement supplémentaire sur Qwen3-32B pour restaurer son “style de pré-entraînement”, puis, en se référant à la configuration de “s1: Simple test-time scaling”, a utilisé environ 10% des données de distillation pour l’entraînement, obtenant un style de langage et un mode de pensée très proches de la version originale R1-0528. Le modèle, ses versions quantifiées GGUF et le jeu de données de distillation ont tous été publiés en open source sur HuggingFace. (Source: karminski3)

OpenAI offre des crédits API gratuits pour aider les développeurs à découvrir le modèle o3: Le compte officiel des développeurs d’OpenAI a annoncé qu’il offrirait à 200 développeurs des crédits API gratuits, chacun recevant l’équivalent de 1 million de tokens d’entrée pour utiliser le modèle OpenAI o3. Cette initiative vise à encourager les développeurs à expérimenter et à explorer les capacités du modèle o3. Les développeurs peuvent postuler en remplissant un formulaire. (Source: OpenAIDevs)
📚 Apprentissage
LlamaIndex organise des Office Hours en ligne pour discuter des agents de remplissage de formulaires et des serveurs MCP: LlamaIndex a organisé une autre session d’Office Hours en ligne, dont les thèmes comprenaient la création d’agents documentaires pratiques de niveau production, en particulier pour les cas d’utilisation courants de remplissage de formulaires (form filling) en entreprise. L’événement a également abordé les nouveaux outils et méthodes pour créer des serveurs de protocole de contexte de modèle (MCP) à l’aide de LlamaIndex. (Source: jerryjliu0, jerryjliu0)

HuggingFace publie neuf cours d’IA gratuits, couvrant les LLM, la vision, les jeux et d’autres domaines: HuggingFace a lancé une série de neuf cours d’IA gratuits visant à aider les apprenants à améliorer leurs compétences en IA. Le contenu des cours est vaste et couvre les grands modèles de langage (LLM), les agents IA (agents), la vision par ordinateur, les applications de l’IA dans les jeux, le traitement audio et les technologies 3D. Tous les cours sont open source et axés sur la pratique. (Source: huggingface)
Elvis publie un guide sur les LLM de raisonnement, ciblant des modèles comme o3 et Gemini 2.5 Pro: Elvis a publié un guide sur les grands modèles de langage de raisonnement (Reasoning LLMs), particulièrement adapté aux développeurs utilisant des modèles tels que o3 et Gemini 2.5 Pro. Ce guide présente non seulement les méthodes d’utilisation de ces modèles, mais aborde également leurs modes d’échec courants et leurs limitations, offrant ainsi une référence pratique aux développeurs. (Source: omarsar0)
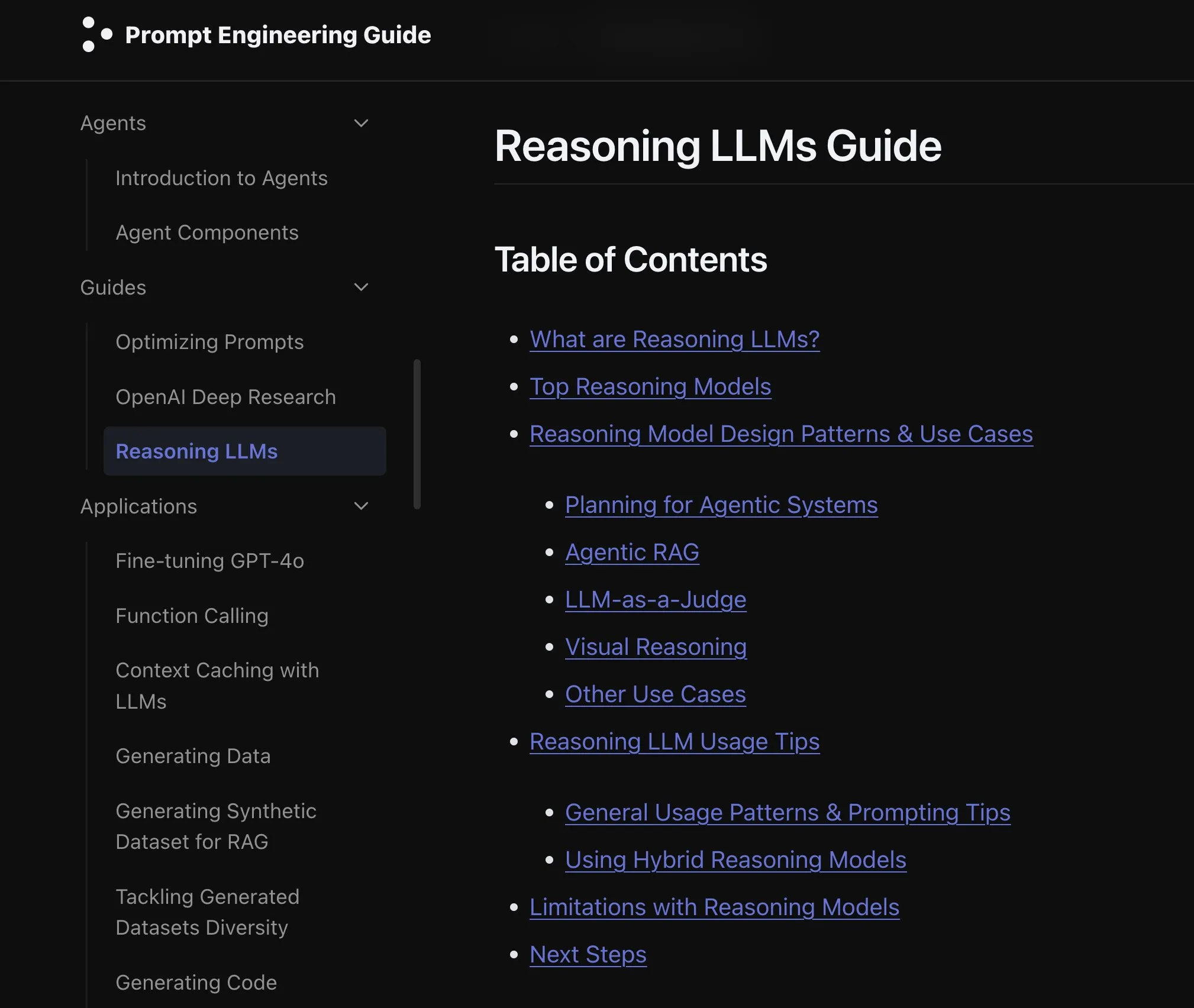
Un nouvel article explore les effets de l’extension des modalités des modèles de langage: Un nouvel article explore les effets de l’extension des modalités (extending modality) dans les modèles de langage, suscitant une réflexion sur la pertinence de la voie actuelle de développement de l’omni-modalité. Cette recherche offre une perspective académique pour comprendre les futures orientations du développement de l’IA multimodale. (Source: _akhaliq)
Un nouvel article propose la méthode Likra : utiliser les mauvaises réponses pour accélérer l’apprentissage des LLM: Un article présente la méthode Likra, qui consiste à entraîner une tête du modèle à traiter les bonnes réponses et une autre à traiter les mauvaises réponses, puis à utiliser leur rapport de vraisemblance pour sélectionner la réponse. L’étude montre que chaque exemple d’erreur pertinent peut contribuer jusqu’à 10 fois plus à l’amélioration de la précision qu’un exemple correct. Cela aide le modèle à éviter plus finement les erreurs et révèle la valeur potentielle des exemples négatifs dans l’entraînement des modèles, notamment pour accélérer l’apprentissage et réduire les hallucinations. (Source: menhguin)

Un nouvel article examine l’impact négatif potentiel de l’adoption des LLM sur la diversité des opinions: Un article de recherche discute de la manière dont l’adoption généralisée des grands modèles de langage (LLM) pourrait conduire à des boucles de rétroaction (l’hypothèse de “l’effet de verrouillage”), nuisant ainsi à la diversité des opinions. Cette étude attire l’attention sur les impacts socioculturels potentiels du développement des technologies d’IA, bien que ses conclusions doivent encore être considérées avec prudence. (Source: menhguin)

MIRIAD : Publication d’un jeu de données massif de paires de questions-réponses médicales pour aider les LLM médicaux: Des chercheurs ont publié MIRIAD, un jeu de données synthétique à grande échelle contenant plus de 5,8 millions de paires de questions-réponses médicales, conçu pour améliorer les performances de la génération augmentée par récupération (RAG) dans le domaine médical. Ce jeu de données fournit aux LLM des connaissances structurées en reformulant des passages de la littérature médicale sous forme de questions-réponses. Les expériences montrent que l’amélioration des LLM avec MIRIAD augmente la précision des réponses aux questions médicales et aide les LLM à détecter les hallucinations médicales. (Source: lateinteraction, lateinteraction)

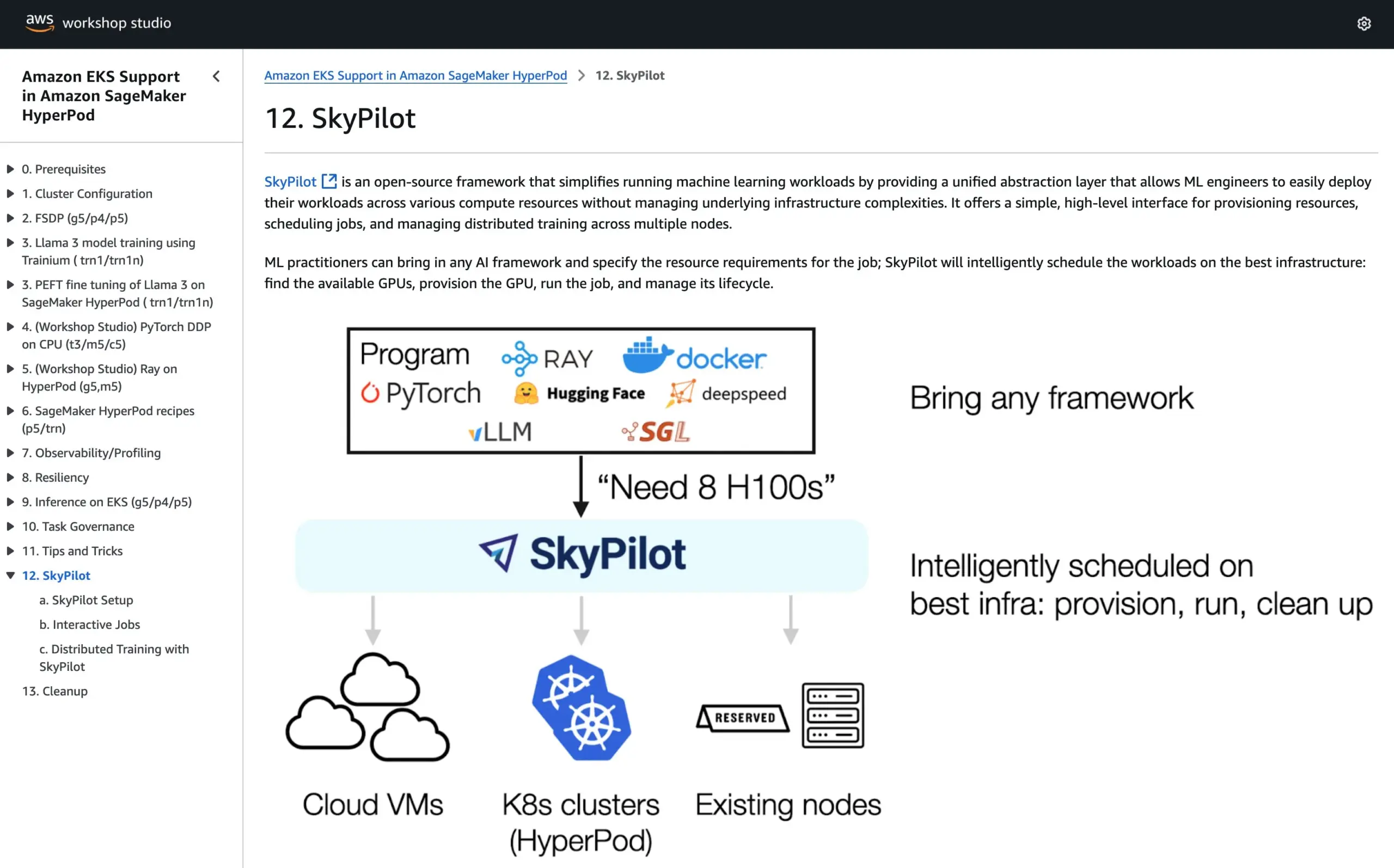
SkyPilot rejoint le tutoriel officiel d’AWS SageMaker HyperPod, combinant les avantages des deux systèmes pour exécuter l’IA: SkyPilot a annoncé son intégration dans le tutoriel officiel d’AWS SageMaker HyperPod. Les utilisateurs peuvent combiner la meilleure disponibilité et capacité de récupération des nœuds offertes par HyperPod avec la commodité, la rapidité et la fiabilité de SkyPilot pour l’exécution des tâches d’IA en équipe, optimisant ainsi l’exécution des charges de travail d’IA. (Source: skypilot_org)
💼 Affaires
OpenAI atteint 10 milliards de dollars de revenus annuels mais reste déficitaire, la croissance du nombre d’utilisateurs est rapide: Selon CNBC, les revenus récurrents annuels (ARR) d’OpenAI ont atteint 10 milliards de dollars, doublant par rapport à l’année dernière, principalement grâce aux abonnements grand public à ChatGPT, aux contrats d’entreprise et à l’utilisation de l’API. L’entreprise compte 500 millions d’utilisateurs hebdomadaires et plus de 3 millions de clients professionnels. Cependant, en raison des coûts de calcul élevés, la société aurait perdu environ 5 milliards de dollars l’année dernière, mais vise un ARR de 125 milliards de dollars d’ici 2029. Cette information n’inclut pas les revenus de licence de Microsoft, les revenus réels pourraient donc être plus élevés. (Source: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Après un échec en bourse A, la société de décision IA Deep演智能 se tourne vers une IPO à Hong Kong, confrontée à une baisse de ses bénéfices: Près d’un an après avoir retiré sa demande d’introduction en bourse à Shenzhen, la société de décision marketing IA Deep演智能 a soumis un prospectus à la Bourse de Hong Kong. Le bénéfice net de la société a chuté de 64,5 % en 2024, et les créances représentent jusqu’à 40 % de ses actifs. Les activités principales de Deep演智能 sont la plateforme de publicité intelligente AlphaDesk et la plateforme de gestion de données intelligente AlphaData. En 2025, elle a lancé le produit AI Agent DeepAgent. Bien qu’elle détienne une part de marché de premier plan sur le marché chinois des applications d’IA pour la prise de décision en marketing et ventes, elle est confrontée à des défis tels que l’augmentation des coûts d’achat de ressources médiatiques et l’intensification de la concurrence sectorielle. (Source: 36氪)

You.com s’associe au magazine TIME pour offrir un an de service Pro gratuit à ses abonnés numériques: La société de recherche par IA You.com a annoncé un partenariat avec la célèbre marque médiatique TIME Magazine. Dans le cadre de cette collaboration, You.com offrira un an de service gratuit à son compte You.com Pro à tous les abonnés numériques du magazine TIME. Cette initiative vise à élargir la base d’utilisateurs de You.com Pro et à explorer la combinaison de la recherche par IA et du contenu médiatique. (Source: RichardSocher)

🌟 Communauté
Anthropic conseille aux utilisateurs d’utiliser son IA comme une machine à sous, suscitant un débat communautaire: La suggestion d’Anthropic concernant l’utilisation de son IA – “traitez-la comme une machine à sous” – a suscité de nombreuses discussions et quelques moqueries sur les réseaux sociaux. Cette formulation suggère que les résultats de son IA peuvent présenter une incertitude et un caractère aléatoire, nécessitant que les utilisateurs acceptent et jugent de manière sélective, plutôt que de s’y fier entièrement. Cela reflète les défis actuels auxquels sont confrontés les grands modèles de langage en termes de fiabilité et de cohérence. (Source: pmddomingos, pmddomingos)
Les outils de développement IA : un contraste saisissant entre les applications de pointe et les pratiques courantes: La communauté des développeurs débat d’une contradiction fondamentale lors de la création et de l’investissement dans les outils de développement IA : la manière dont le 1% supérieur des applications IA est construit est radicalement différente de celle des 99% restants. Les deux approches sont correctes et appropriées pour leurs cas d’utilisation respectifs, mais tenter d’étendre de manière transparente une petite application à une très grande échelle en utilisant la même architecture ou la même pile technologique est presque voué à l’échec. Cela souligne la complexité du choix des outils et des méthodologies dans le domaine du développement de l’IA. (Source: swyx)
Shopify encourage ses employés à utiliser audacieusement les LLM pour la programmation, organisant même un “concours de dépenses”: MParakhin de Shopify a révélé que l’entreprise non seulement ne restreint pas l’utilisation des LLM par ses employés lors du codage, mais “réprimande” même ceux qui dépensent trop peu. Il a même organisé un concours récompensant les employés qui ont dépensé le plus de crédits LLM sans utiliser de scripts. Cela reflète l’attitude de certaines entreprises technologiques de pointe qui adoptent activement les outils de développement assistés par IA et les considèrent comme un moyen important d’améliorer l’efficacité et la capacité d’innovation. (Source: MParakhin)
Application des Agents IA dans les salles de rédaction : le cas de Magid en collaboration avec PromptLayer: La société Magid utilise la plateforme PromptLayer pour construire des agents IA afin d’aider les salles de rédaction à créer du contenu à grande échelle, tout en garantissant la conformité avec les normes journalistiques. Ces agents IA sont capables de traiter des milliers d’articles, possèdent des capacités de fiabilité et de contrôle de version, et ont gagné la confiance de vrais journalistes. Ce cas illustre le potentiel d’application pratique des Agents IA dans la création de contenu et l’industrie de l’information. (Source: imjaredz, Jonpon101)

Discussion sur la voie vers l’AGI via les LLM de type RL+GPT: Au sein de la communauté, certains estiment que la combinaison de l’apprentissage par renforcement (RL) et des grands modèles de langage (LLM) de style GPT pourrait tout à fait mener à une intelligence artificielle générale (AGI). Ce point de vue a suscité une réflexion et des discussions plus approfondies sur les voies de réalisation de l’AGI, le potentiel du RL à doter les LLM de capacités d’orientation vers un objectif et d’apprentissage continu plus fortes étant souligné. (Source: finbarrtimbers, agihippo)
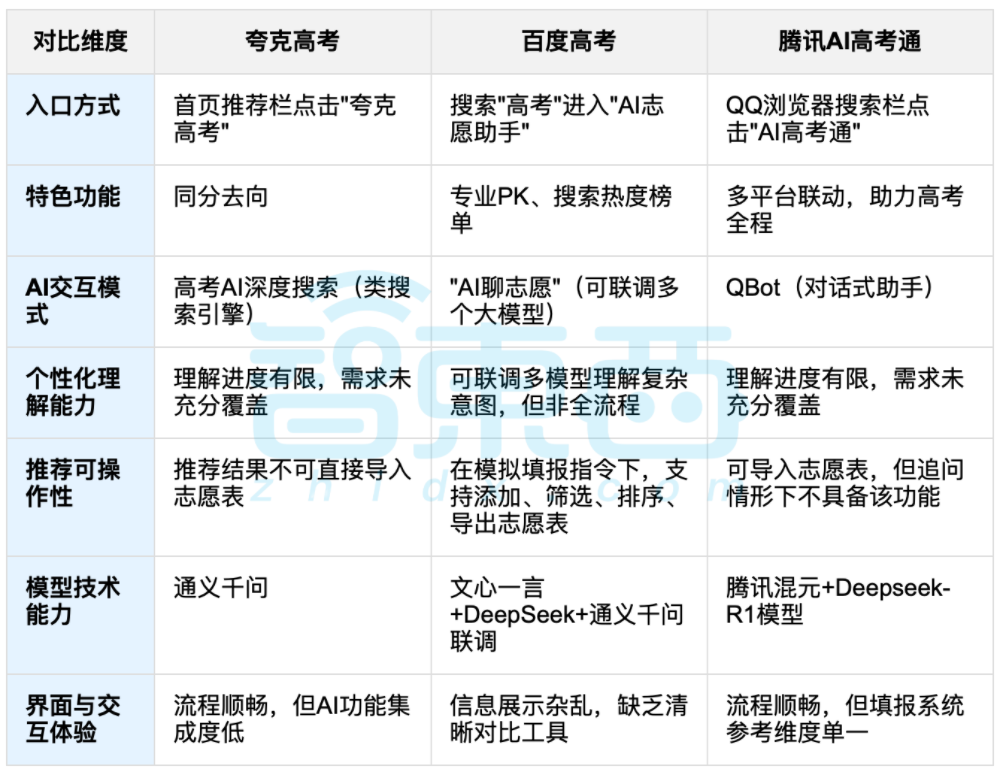
L’aide de l’IA pour l’orientation post-baccalauréat suscite le débat, l’équilibre entre données et choix personnalisés au centre des préoccupations: Avec la fin des examens du baccalauréat (gaokao), les outils d’aide à l’orientation assistée par IA tels que Quark, Baidu AI Gaokao Tong, Tencent AI Gaokao Tong, etc., suscitent l’attention. Ces outils analysent les données des années précédentes, font correspondre les classements et les notes, et fournissent des suggestions de type “ambitieux, réaliste, sûr”. Les tests montrent que chaque plateforme a ses propres forces et faiblesses en termes d’interaction, de logique de recommandation et de compréhension des besoins personnalisés. La discussion souligne que si l’IA peut améliorer l’efficacité de l’accès à l’information et réduire les asymétries d’information, lorsqu’il s’agit de facteurs personnels complexes tels que la personnalité, les intérêts et les projets d’avenir, la “divination par les données” de l’IA ne peut remplacer complètement le jugement subjectif et les choix de vie des candidats. (Source: 36氪, 36氪)
💡 Autres
Cortical Labs lance la première plateforme de bio-informatique commercialisée CL1, intégrant 800 000 neurones humains vivants: La start-up australienne Cortical Labs a mis en vente la première plateforme de bio-informatique commercialisée au monde, CL1. Cette plateforme combine 800 000 neurones humains vivants avec des puces en silicium, constituant une “intelligence hybride”. CL1 peut traiter des informations et apprendre de manière autonome, présentant des caractéristiques de type conscience, et a appris à jouer au jeu “Pong” lors d’expériences. L’appareil consomme beaucoup moins d’énergie que le matériel d’IA traditionnel, coûte 35 000 dollars l’unité et propose un mode d’accès à distance “wetware-as-a-service” (WaaS). Cette technologie brouille les frontières entre le biologique et la machine, soulevant des questions sur la nature de l’intelligence et l’éthique. (Source: 36氪)

Les difficultés pratiques des bases de connaissances IA : une technologie impressionnante mais difficile à mettre en œuvre, nécessitant une conception “compatible avec l’IA”: Liu Xianghua, vice-président de Lanling, a souligné lors d’un dialogue avec Cui Qiang, fondateur de Cui Niu Hui, que la technologie des grands modèles a ravivé l’intérêt pour la gestion des connaissances en entreprise, mais que les bases de connaissances IA sont confrontées à une situation où elles sont “acclamées par la critique mais ne rencontrent pas le succès escompté”. Il estime qu’il existe des différences considérables entre les bases de connaissances d’entreprise et les bases de connaissances personnelles en termes de gestion des autorisations, de gouvernance du système de connaissances et de cohérence du contenu. Construire des bases de connaissances “compatibles avec l’IA”, en mettant l’accent sur la qualité des données, les graphes de connaissances, la recherche hybride, etc., peut réduire les hallucinations et améliorer l’aspect pratique. Il désapprouve la poursuite de la technologie pour la technologie, soulignant qu’il faut choisir la technologie appropriée en fonction du scénario, et que les grands modèles ne sont pas une panacée. (Source: 36氪)
Un projet de réacteur à fusion nucléaire amélioré par l’IA et soutenu par Google vise un plasma à 1,8 milliard de degrés Fahrenheit d’ici 2030: Selon Interesting Engineering, Google soutient un projet visant à améliorer les réacteurs à fusion nucléaire grâce à la technologie de l’IA. L’objectif du projet est de pouvoir produire et maintenir un plasma à 1,8 milliard de degrés Fahrenheit (environ 1 milliard de degrés Celsius) d’ici 2030. Cette collaboration montre le potentiel de l’IA pour relever des défis scientifiques et techniques extrêmes, en particulier dans le domaine des énergies propres. (Source: Ronald_vanLoon)
