
Mots-clés:Grand modèle linguistique, Capacité de raisonnement, Intelligence artificielle générale, Détecteur d’IA, Régulation de l’IA, Appariement de motifs, Illusion de pensée, Recherche Apple, Mécanisme d’attention Log-Linéaire, Modèle MoE PanGu de Huawei, Mode vocal avancé de ChatGPT, Cadre TensorZero, Perspective de régulation du PDG d’Anthropic
🔥 Pleins feux sur
Une étude d’Apple révèle une « illusion de la pensée » : les modèles de « raisonnement » actuels ne pensent pas réellement, mais s’appuient davantage sur la reconnaissance de formes: Le dernier article de recherche d’Apple, intitulé « The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models through the Lens of Problem Complexity », souligne que les grands modèles de langage (LLM) actuels qui prétendent avoir des capacités de « raisonnement » (tels que Claude, DeepSeek-R1, GPT-4o-mini, etc.), se comportent davantage comme des outils efficaces de reconnaissance de formes (pattern matchers) que comme des systèmes de raisonnement logique au sens propre. L’étude a révélé que ces modèles voient leurs performances chuter de manière significative lorsqu’ils traitent des problèmes en dehors de leur distribution d’entraînement ou d’une complexité élevée, et peuvent même commettre des erreurs sur des problèmes simples en raison d’une « réflexion excessive » (overthinking), et ont du mal à corriger leurs erreurs initiales. L’étude souligne que les processus de « pensée » supposés des modèles (comme la chaîne de pensée ou chain-of-thought) échouent souvent face à des tâches nouvelles ou complexes, ce qui suggère que nous pourrions être plus éloignés de l’intelligence artificielle générale (AGI) que prévu. (Source: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

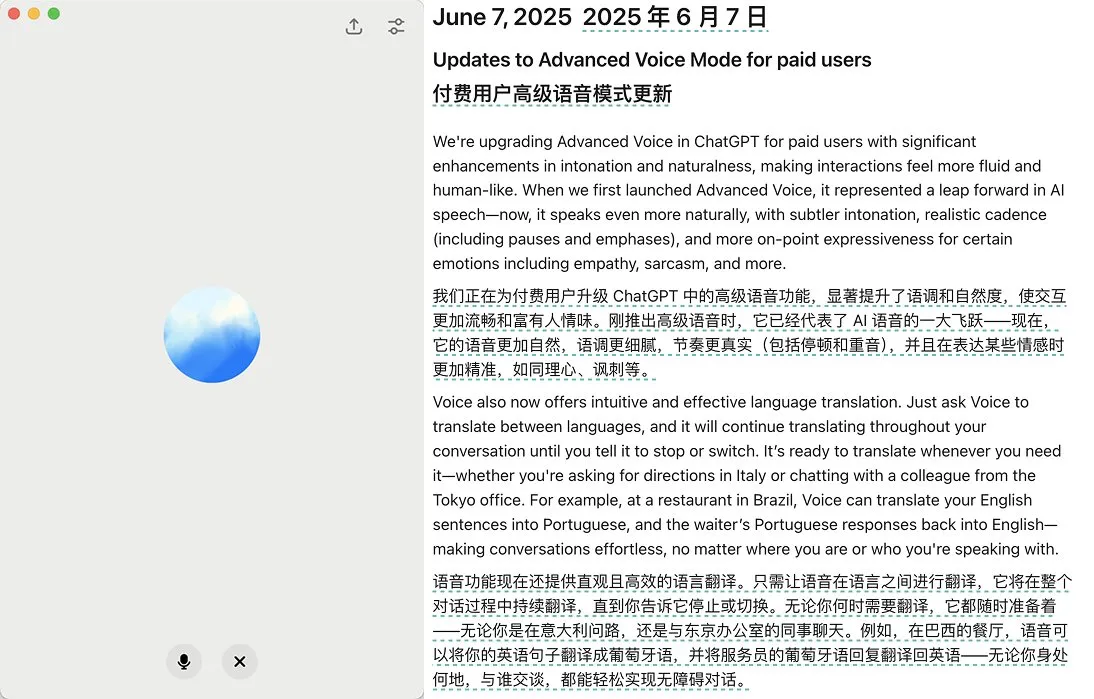
OpenAI lance une mise à jour du mode vocal avancé de ChatGPT, améliorant la naturalité et les fonctions de traduction: OpenAI a lancé une mise à jour majeure du mode vocal avancé (Advanced Voice Mode) pour les utilisateurs payants de ChatGPT. La nouvelle version améliore considérablement la fluidité et la naturalité de la voix, la rendant plus humaine et moins semblable à celle d’un assistant IA. De plus, la mise à jour améliore les performances de traduction linguistique et la capacité à suivre les instructions, et ajoute un nouveau mode de traduction permettant aux utilisateurs de demander à ChatGPT de traduire en continu la conversation des deux parties jusqu’à ce qu’on lui demande d’arrêter. Cette mise à jour vise à rendre l’interaction vocale plus facile et naturelle, améliorant l’expérience utilisateur. (Source: juberti, Plinz, op7418, BorisMPower)
Les détecteurs d’IA jugés inefficaces et susceptibles de favoriser la « dissimulation » du contenu IA: De nombreuses discussions sur les réseaux sociaux et les forums technologiques soulignent que les outils actuels de détection de contenu IA sont non seulement peu efficaces, mais pourraient même involontairement aider le contenu généré par IA à devenir plus difficile à percevoir. De nombreux utilisateurs et experts estiment que ces détecteurs se basent principalement sur des modèles linguistiques et des vocabulaires spécifiques (comme le terme académique « delve ») pour leur jugement, plutôt que de comprendre réellement la source du contenu. En raison du risque de faux positifs (pouvant causer des injustices à des groupes tels que les étudiants) et du fait que les modèles d’IA eux-mêmes évoluent pour échapper à la détection, la fiabilité de ces outils est sérieusement remise en question. Certains estiment que l’existence même des détecteurs d’IA incite à éviter certaines caractéristiques facilement repérables lors de la génération de contenu par IA, le rendant ainsi plus semblable à l’écriture humaine. (Source: Reddit r/ArtificialInteligence, sytelus)

Le PDG d’Anthropic appelle à renforcer la transparence et la responsabilité réglementaire des entreprises d’IA: Le PDG d’Anthropic a publié un article d’opinion dans le New York Times, soulignant qu’il ne faut pas relâcher la réglementation des entreprises d’IA, et qu’il est particulièrement nécessaire d’accroître leur transparence et de les tenir responsables. Ce point de vue est particulièrement important dans le contexte du développement rapide et des capacités en constante évolution de l’IA, faisant écho aux préoccupations de la société concernant les risques potentiels et l’éthique de l’IA. L’article soutient qu’à mesure que l’influence de la technologie IA s’étend, il est crucial de s’assurer que son développement sert l’intérêt public et d’éviter les abus, ce qui nécessite une action conjointe de l’autorégulation de l’industrie et de la surveillance externe. (Source: Reddit r/artificial)

🎯 Actualités
Jeff Dean envisage l’avenir de l’IA : matériel spécialisé, évolution des modèles et applications scientifiques: Jeff Dean, responsable de l’IA chez Google, a partagé sa vision de l’avenir de l’IA lors de l’événement AI Ascent de Sequoia Capital. Il a souligné l’importance du matériel spécialisé (comme les TPU) pour les progrès de l’IA et a discuté des tendances d’évolution de l’architecture des modèles. Dean a également envisagé la forme future de l’infrastructure de calcul, ainsi que l’énorme potentiel d’application de l’IA dans des domaines tels que la recherche scientifique, estimant que l’IA deviendra un outil clé pour stimuler les découvertes scientifiques. (Source: TheTuringPost)

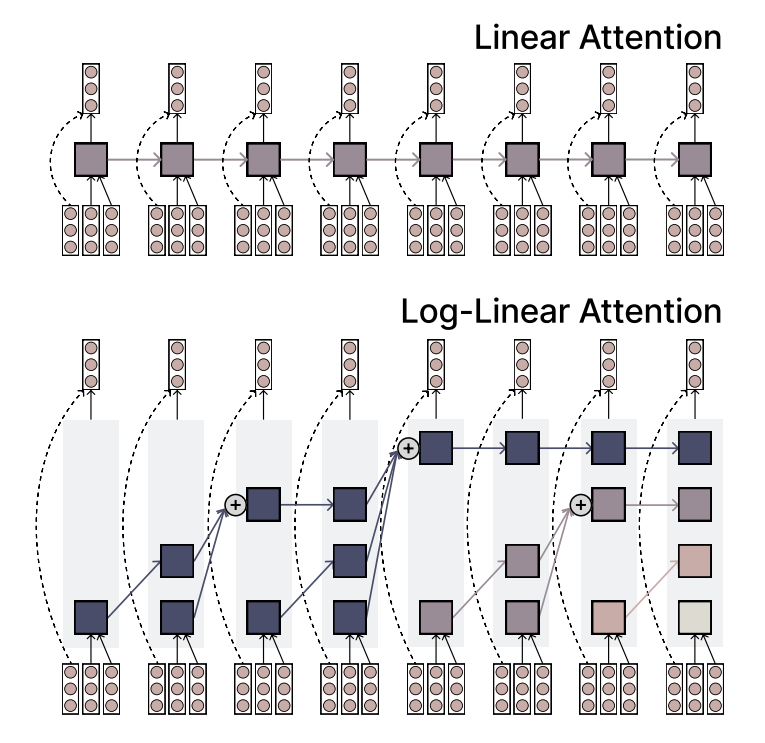
Le MIT propose le mécanisme Log-Linear Attention, alliant efficacité et expressivité: Des chercheurs du MIT ont proposé un nouveau mécanisme d’attention appelé Log-Linear Attention. Ce mécanisme vise à combiner l’efficacité de l’attention linéaire (Linear Attention) avec la forte capacité d’expression de l’attention Softmax. Sa principale caractéristique est l’utilisation d’un petit nombre de « memory slots » qui augmentent logarithmiquement avec la longueur de la séquence, maintenant ainsi une faible complexité de calcul lors du traitement de longues séquences tout en capturant les informations clés. (Source: TheTuringPost)
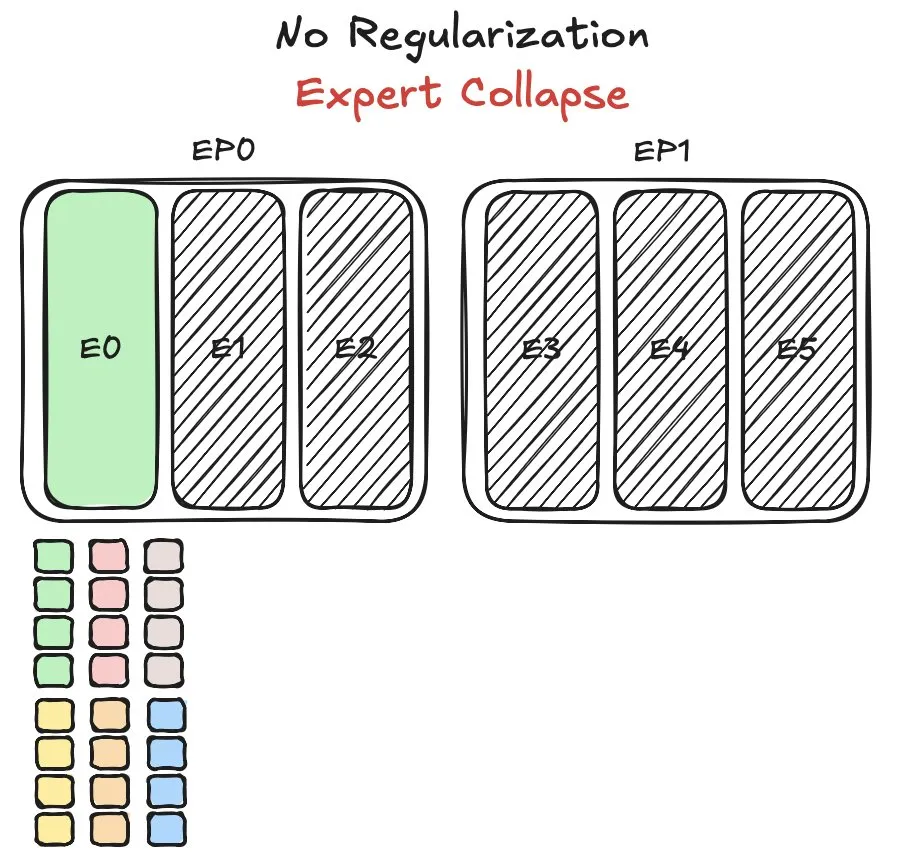
Le modèle Pangu MoE de Huawei confronté à des défis d’équilibrage de charge des experts, propose une nouvelle méthode: Huawei, lors de l’entraînement de son modèle Mixture-of-Experts (MoE) Pangu Ultra MoE, a rencontré le problème crucial de l’équilibrage de la charge des experts. L’équilibrage de la charge des experts nécessite un compromis entre la dynamique d’entraînement et l’efficacité du système. Huawei a proposé une nouvelle solution à ce problème, visant à optimiser l’attribution des tâches et la charge de calcul des différents modules experts dans le modèle MoE, afin d’améliorer l’efficacité de l’entraînement et les performances du modèle. Une publication relative à cette recherche a été diffusée. (Source: finbarrtimbers)
NVIDIA publie le modèle Cascade Mask R-CNN Mamba Vision, axé sur la détection d’objets: NVIDIA a publié sur Hugging Face un nouveau modèle nommé cascade_mask_rcnn_mamba_vision_tiny_3x_coco. D’après son nom, ce modèle est spécifiquement conçu pour les tâches de détection d’objets et pourrait intégrer l’architecture Cascade R-CNN avec la technologie visuelle Mamba (un modèle à espace d’états), visant à améliorer la précision et l’efficacité de la détection d’objets. (Source: _akhaliq)
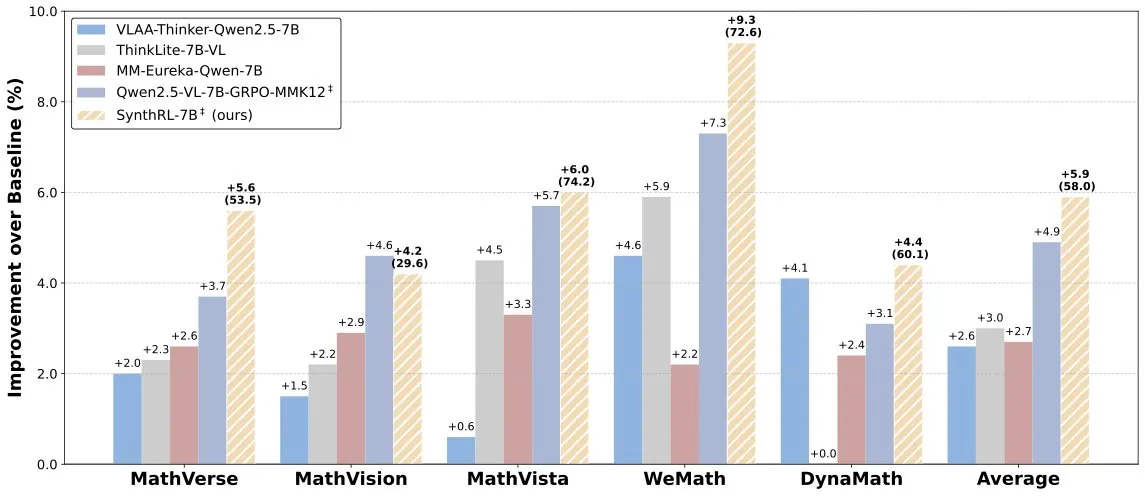
Lancement du modèle SynthRL : raisonnement visuel évolutif grâce à la synthèse de données vérifiables: Le modèle SynthRL a été lancé sur Hugging Face. Ce modèle se concentre sur la capacité de raisonnement visuel évolutif, sa technologie principale reposant sur une méthode de synthèse de données vérifiables pour générer des variantes plus difficiles de tâches de raisonnement visuel, tout en maintenant l’exactitude des réponses originales. Cela contribue à améliorer la compréhension et le niveau de raisonnement du modèle dans des scènes visuelles complexes. (Source: _akhaliq)
Malgré les bonnes performances de DeepSeek-R1, l’avantage produit de ChatGPT reste solide: VentureBeat commente que, bien que les modèles émergents comme DeepSeek-R1 affichent d’excellentes performances à certains égards, ChatGPT, grâce à son avantage de précurseur, sa large base d’utilisateurs, son écosystème de produits mature et sa capacité d’itération continue, conserve une position de leader au niveau produit difficile à surpasser à court terme. La course à l’IA n’est pas seulement une compétition de paramètres techniques, mais aussi une confrontation globale d’expérience produit, de construction d’écosystème et de modèle commercial. (Source: Ronald_vanLoon)

L’équipe Qwen confirme que Qwen3-coder est en développement: Junyang Lin de l’équipe Qwen a confirmé qu’ils développent Qwen3-coder, une version améliorée des capacités de codage de la série Qwen3. Bien qu’aucun calendrier précis n’ait été annoncé, en se référant au cycle de publication de Qwen2.5, on peut s’attendre à ce qu’il soit disponible dans quelques semaines. La communauté espère que ce modèle apportera des avancées dans la génération de code, l’intégration de flux de travail autonomes/agents, et maintiendra un bon support pour plusieurs langages de programmation. (Source: Reddit r/LocalLLaMA)

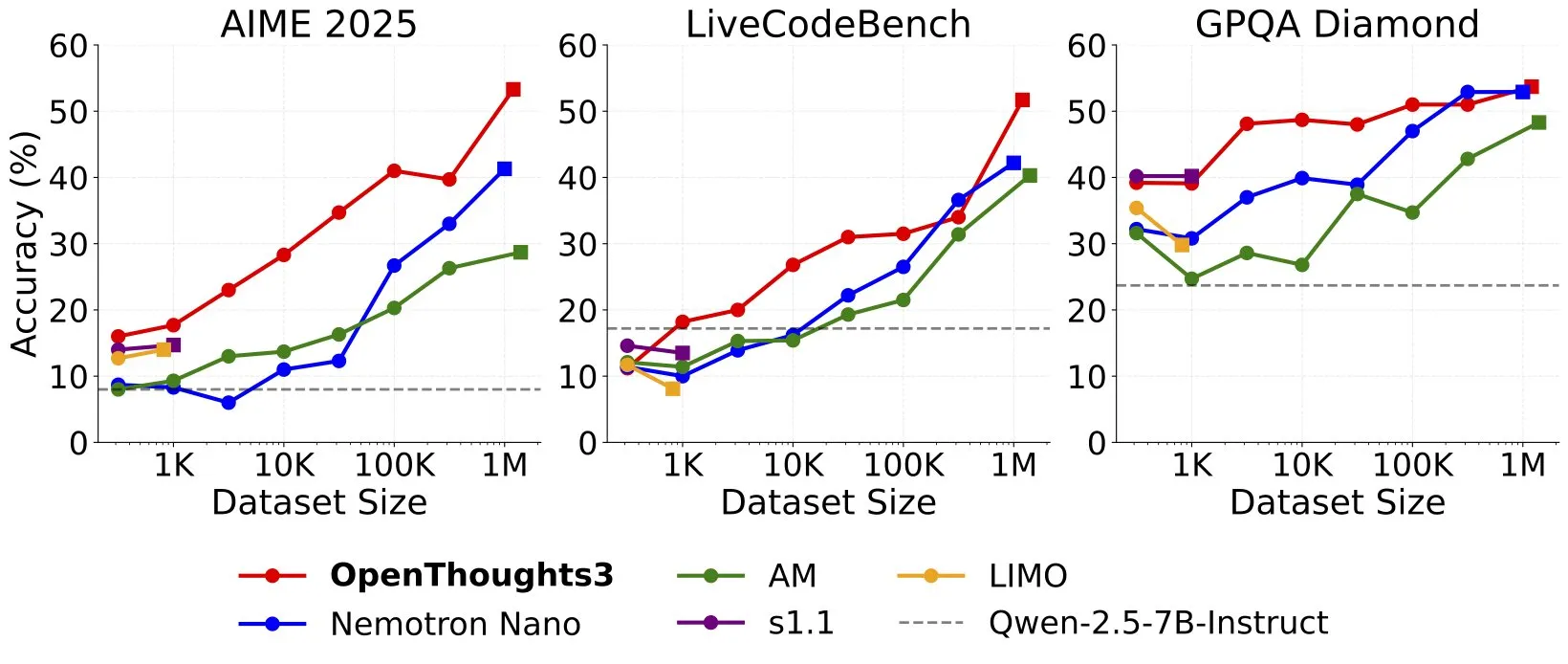
Lancement d’OpenThinker3-7B, présenté comme le modèle de raisonnement 7B open source SOTA sur données ouvertes: Ryan Marten a annoncé le lancement du modèle OpenThinker3-7B, le décrivant comme le modèle de raisonnement à 7 milliards de paramètres le plus avancé actuellement, entraîné sur des données ouvertes. Selon les affirmations, ce modèle surpasse en moyenne de 33 % DeepSeek-R1-Distill-Qwen-7B dans les évaluations de code, de science et de mathématiques. Parallèlement, son jeu de données d’entraînement OpenThoughts3-1.2M a également été publié. (Source: menhguin)
🧰 Outils
TensorZero : framework LLMOps open source pour optimiser le développement et le déploiement d’applications LLM: TensorZero est un framework open source d’optimisation d’applications LLM, conçu pour transformer les données de production en modèles plus intelligents, plus rapides et plus économiques grâce à des boucles de rétroaction. Il intègre une passerelle LLM (prenant en charge plusieurs fournisseurs de modèles), l’observabilité, l’optimisation (prompts, fine-tuning, RL), l’évaluation et l’expérimentation (tests A/B), et prend en charge une faible latence, un débit élevé et GitOps. Cet outil est écrit en Rust, mettant l’accent sur les performances et les besoins des applications de niveau industriel. (Source: GitHub Trending)

LangChain lance un système RAG haute performance combinant SambaNova, Qdrant et LangGraph: LangChain a présenté une solution de génération augmentée par récupération (RAG) haute performance. Cette solution combine le modèle DeepSeek-R1 de SambaNova, la technologie de quantification binaire de Qdrant et LangGraph, permettant une réduction de mémoire de 32 fois pour traiter efficacement des documents à grande échelle. Cela ouvre de nouvelles possibilités pour la construction d’applications RAG plus économiques et plus rapides. (Source: hwchase17, qdrant_engine)
L’application Sparkify de Google pour la génération de vidéos scientifiques en un clic présente des exemples de haute qualité: L’application Sparkify lancée par Google, capable de générer des vidéos scientifiques en un clic, présente des exemples d’une qualité impressionnante. Le contenu vidéo est globalement cohérent, le doublage est naturel, et elle peut même réaliser des effets complexes tels que l’affichage en écran partagé, démontrant le potentiel de l’IA dans la création automatisée de contenu vidéo. (Source: op7418)
Hugging Face lance son premier serveur MCP, étendant les fonctionnalités des chatbots: Hugging Face a lancé son premier serveur MCP (Modular Chat Processor) (hf.co/mcp), que les utilisateurs peuvent coller dans leur fenêtre de chat pour l’utiliser. Le serveur MCP vise à améliorer les fonctionnalités des chatbots en offrant une expérience interactive plus riche grâce à des unités de traitement modulaires. La communauté a également compilé une liste d’autres serveurs MCP utiles, tels que Agentset MCP, GitHub MCP, etc. (Source: TheTuringPost)
Les performances de Chatterbox TTS rivalisent avec ElevenLabs, et il est désormais intégré à gptme: L’outil TTS (Text-to-Speech) Chatterbox a attiré l’attention pour ses excellents effets de synthèse vocale, les utilisateurs rapportant que ses performances sont comparables à celles du célèbre ElevenLabs, et supérieures à celles de Kokoro. Chatterbox prend en charge la personnalisation de la voix via des échantillons de référence et a maintenant été ajouté comme backend TTS à gptme, offrant aux utilisateurs des options de sortie vocale de haute qualité. (Source: teortaxesTex, _akhaliq)
E-Library-Agent : système intelligent de recherche et de questions-réponses pour livres/documents locaux: E-Library-Agent est un agent IA auto-hébergé capable d’extraire, d’indexer et d’interroger des collections personnelles de livres ou d’articles. Ce projet est basé sur ingest-anything et est alimenté par les plateformes LlamaIndex, Qdrant et Linkup, permettant l’extraction de documents locaux, des questions-réponses contextuelles et la découverte sur le Web via une interface unique, facilitant la gestion et l’utilisation des bases de connaissances personnelles par les utilisateurs. (Source: qdrant_engine)
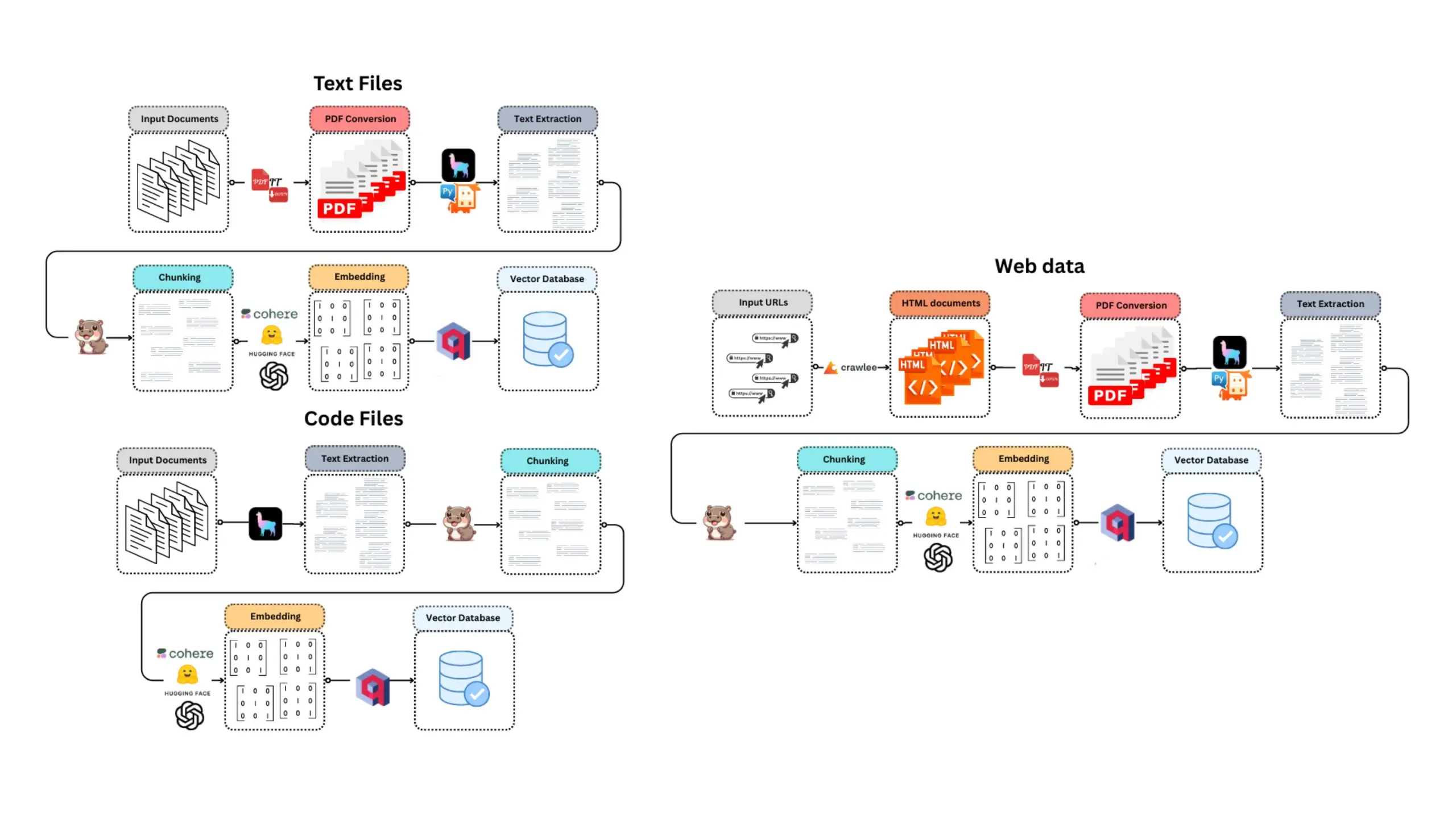
Claude Code est très apprécié des développeurs pour ses puissantes capacités d’assistance au codage: Les utilisateurs de la communauté Reddit ont partagé des expériences positives concernant l’utilisation de Claude Code d’Anthropic pour le développement de logiciels, en particulier dans des domaines tels que le développement de jeux (par exemple, des projets Godot C#). Les utilisateurs louent sa capacité à résoudre des problèmes complexes, bien au-delà d’autres assistants de codage IA (comme GitHub Copilot), capable de comprendre le contexte et de générer du code efficace, même les frais de 100 $ par mois étant considérés comme valant l’investissement. Les développeurs estiment que les programmeurs expérimentés combinés à Claude Code seront extrêmement productifs. (Source: Reddit r/ClaudeAI)
ChatterUI prend en charge les modèles visuels locaux, mais le traitement est lent sur Android: La version préliminaire du client de chat LLM ChatterUI ajoute la prise en charge des pièces jointes et des modèles visuels locaux (via llama.rn). Les utilisateurs peuvent charger des fichiers mmproj pour les modèles locaux compatibles, ou se connecter à des API prenant en charge les fonctionnalités visuelles (comme Google AI Studio, OpenAI). Cependant, en raison de l’absence de backend GPU stable pour llama.cpp sur Android, la vitesse de traitement des images est extrêmement lente (par exemple, 5 minutes pour une image de 512×512), les performances sur iOS étant relativement meilleures. (Source: Reddit r/LocalLLaMA)
FLUX kontext excelle dans le remplacement d’arrière-plan pour les images promotionnelles de voitures: Des tests utilisateurs ont révélé que l’outil d’édition d’images IA FLUX kontext est remarquablement efficace pour modifier les arrière-plans des images promotionnelles de voitures. Par exemple, en remplaçant l’arrière-plan des images officielles de la Xiaomi SU7 (par une plage au crépuscule, un circuit de course), l’outil non seulement fusionne naturellement l’arrière-plan, mais ajoute également intelligemment un effet de flou de mouvement aux véhicules en déplacement, améliorant le réalisme et l’impact visuel de l’image. (Source: op7418)

📚 Apprentissage
Nouvelle fonctionnalité flexicache de fastcore : un décorateur de cache flexible: Jeremy Howard a présenté une nouvelle fonctionnalité pratique de la bibliothèque fastcore, flexicache. Il s’agit d’un décorateur de cache très flexible, intégrant deux stratégies de cache : ‘mtime’ (basée sur l’heure de modification du fichier) et ‘time’ (basée sur l’horodatage), et permettant aux utilisateurs de personnaliser de nouvelles stratégies de cache avec peu de code. Cette fonctionnalité, détaillée dans un article de Daniel Roy Greenfeld, contribue à améliorer l’efficacité de l’exécution du code. (Source: jeremyphoward)
Discussion sur le potentiel de la combinaison MuP et Muon pour l’entraînement des modèles Transformer: Jingyuan Liu a étudié en profondeur les travaux de Jeremy Bernstein sur la dérivation de Muon et des conditions spectrales, et a exprimé son admiration pour l’élégance du processus de dérivation, en particulier la manière dont MuP (Maximal Update Parametrization) et Muon (un optimiseur) fonctionnent ensemble. Il estime que, d’après la dérivation, l’utilisation de Muon comme optimiseur pour l’entraînement de modèles basés sur MuP est un choix naturel, et souligne que cela pourrait être plus excitant que la migration des hyperparamètres d’AdamW vers Muon en faisant correspondre la RMS de mise à jour dans le travail Moonlight de Moonshot. La communauté estime que la combinaison MuP + Muon pourrait être appliquée à grande échelle par les grandes entreprises technologiques d’ici la fin de l’année. (Source: jeremyphoward)

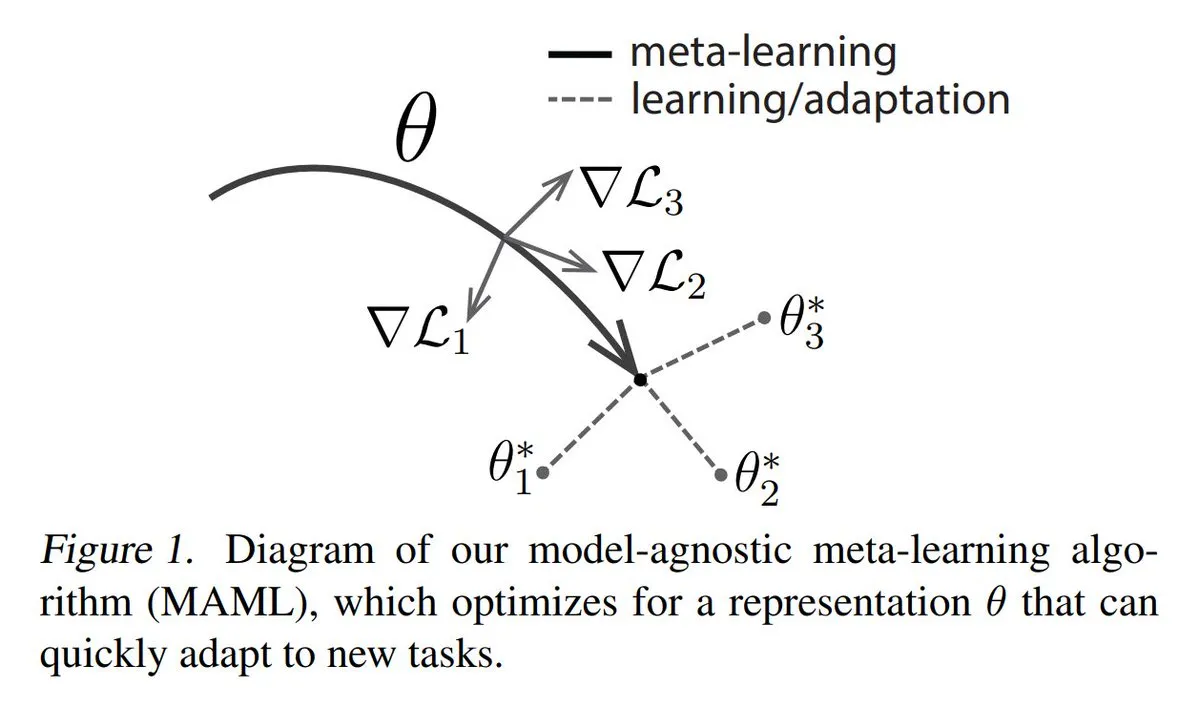
Analyse des trois principales approches du méta-apprentissage (Meta-learning): Le méta-apprentissage vise à entraîner des modèles à apprendre rapidement de nouvelles tâches, même avec peu d’échantillons. Les méthodes courantes incluent : 1. Basées sur l’optimisation/le gradient : trouver des paramètres de modèle qui peuvent être affinés efficacement sur une tâche avec peu d’étapes de gradient. 2. Basées sur la métrique : aider le modèle à trouver de meilleures façons de mesurer la similarité entre les nouveaux et les anciens échantillons, regroupant efficacement les échantillons pertinents. 3. Basées sur le modèle : l’ensemble du modèle est conçu pour pouvoir s’adapter rapidement en utilisant une mémoire intégrée ou des mécanismes dynamiques. TuringPost fournit une explication détaillée des méthodes de méta-apprentissage, des bases aux approches modernes. (Source: TheTuringPost)
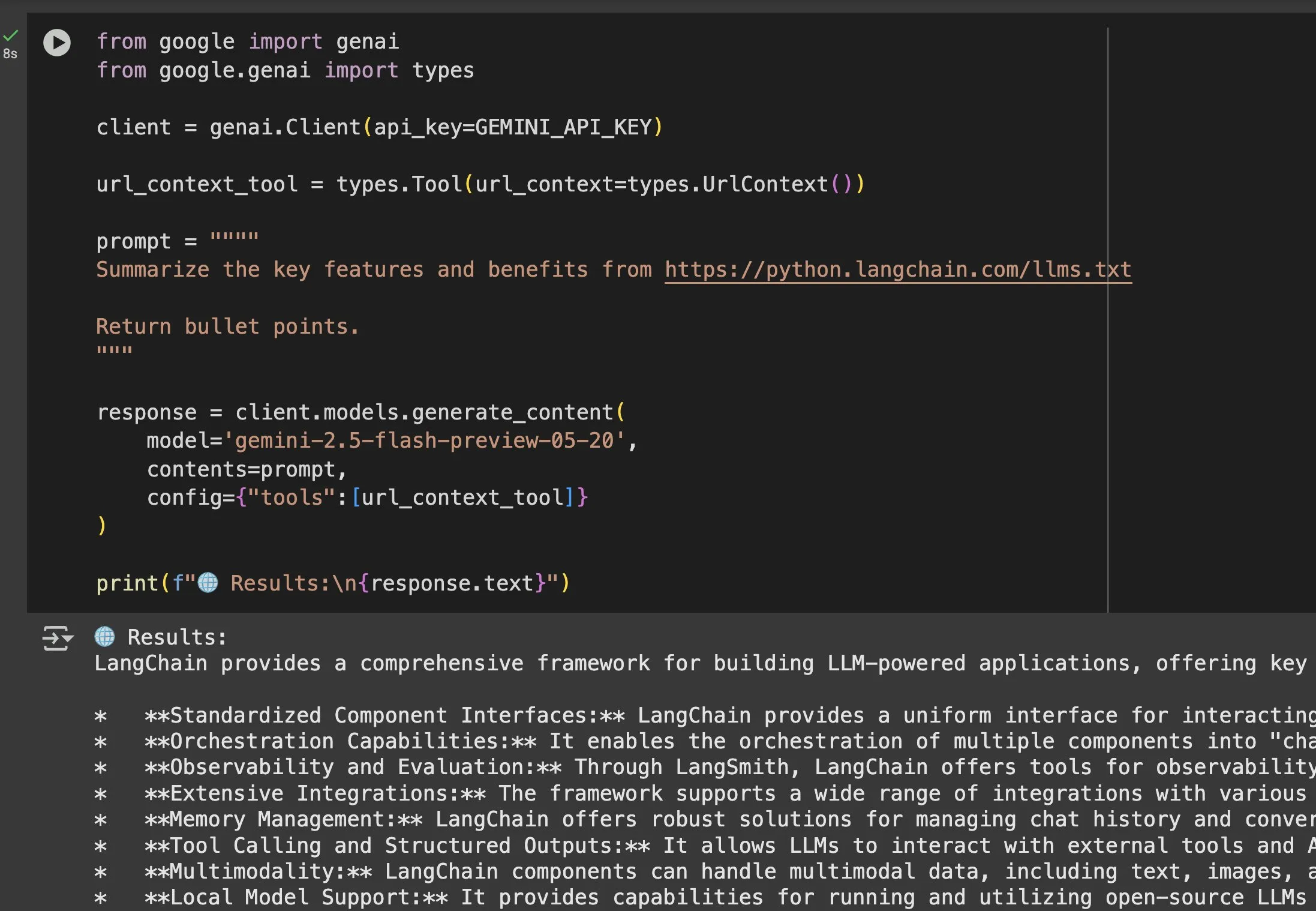
La valeur des fichiers llms.txt dans des modèles comme Gemini mise en évidence: Jeremy Phoward a souligné l’utilité des fichiers llms.txt. Par exemple, Gemini peut désormais comprendre le contenu des URL ; il suffit d’ajouter l’URL dans le prompt et de configurer l’outil de contexte URL. Cela signifie qu’un client (comme Gemini), en lisant le point de terminaison llms.txt, peut savoir précisément où se trouvent les informations nécessaires, ce qui facilite grandement l’acquisition et l’utilisation programmatiques des informations. (Source: jeremyphoward)
EleutherAI publie Common Pile v0.1, un jeu de données textuelles de 8 To sous licence ouverte: EleutherAI a annoncé le lancement de Common Pile v0.1, un vaste jeu de données contenant 8 To de textes sous licence ouverte et du domaine public. Ils ont entraîné des modèles de langage de 7 milliards de paramètres sur ce jeu de données (en utilisant respectivement 1T et 2T de tokens), dont les performances sont comparables à celles de modèles similaires tels que LLaMA 1 et LLaMA 2. Cela fournit des ressources précieuses et des preuves empiriques pour la recherche sur l’entraînement de modèles de langage haute performance utilisant uniquement des données conformes. (Source: clefourrier)

SelfCheckGPT : une méthode de détection des hallucinations LLM sans référence: Un article de blog explore SelfCheckGPT comme alternative à LLM-as-a-judge (utiliser un LLM comme évaluateur) pour détecter les hallucinations dans les modèles de langage. Il s’agit d’une méthode de détection sans texte de référence et sans ressources, offrant de nouvelles perspectives pour évaluer et améliorer la véracité des sorties LLM. (Source: dl_weekly)
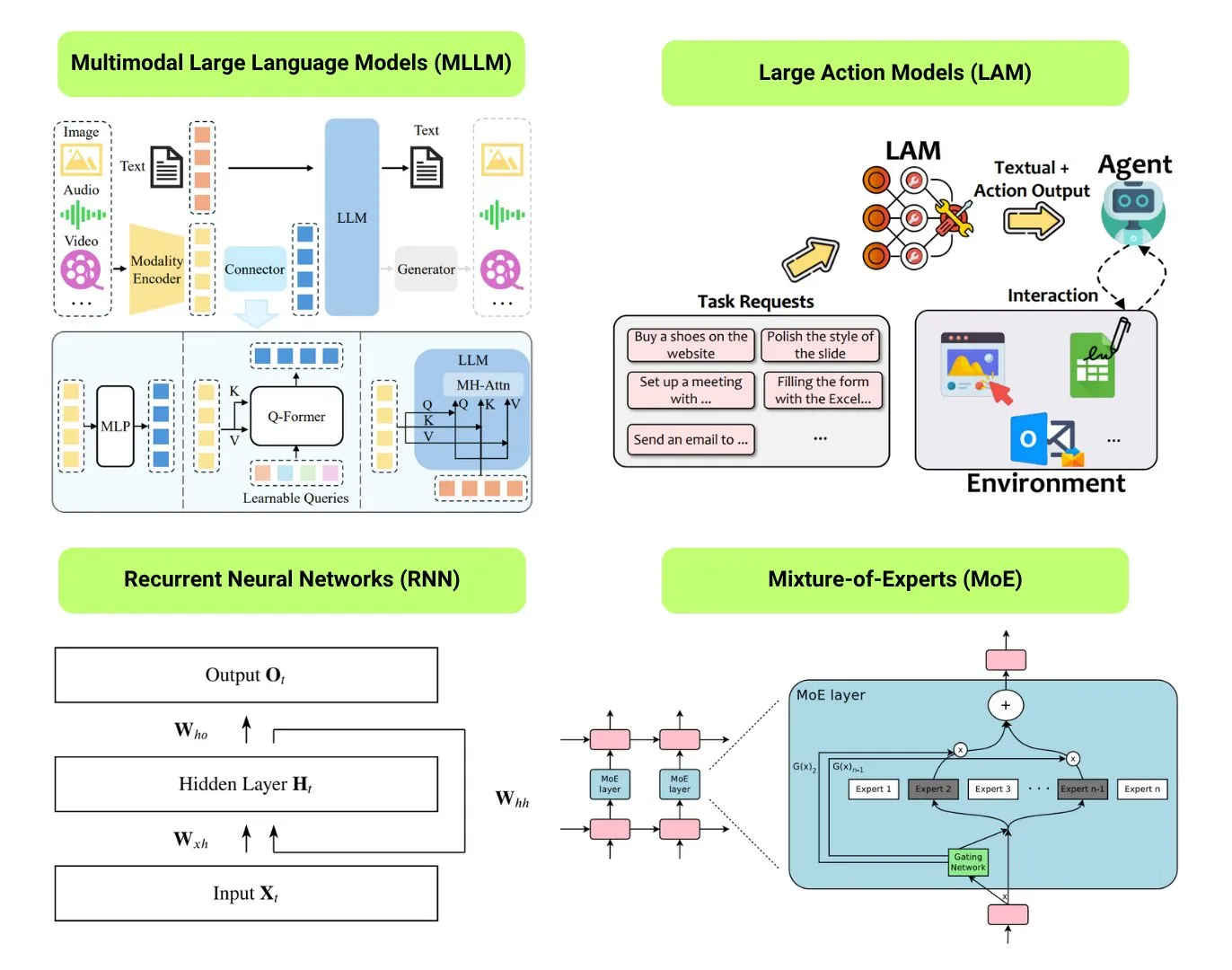
Récapitulatif de 12 types de modèles d’IA fondamentaux: The Turing Post a répertorié 12 types de modèles d’IA fondamentaux, notamment LLM (grands modèles de langage), SLM (petits modèles de langage), VLM (modèles de langage visuel), MLLM (grands modèles de langage multimodaux), LAM (grands modèles de comportement), LRM (grands modèles de raisonnement), MoE (modèles de mélange d’experts), SSM (modèles à espace d’états), RNN (réseaux de neurones récurrents), CNN (réseaux de neurones convolutifs), SAM (modèles de segmentation de tout) et LNN (réseaux de neurones logiques). Les ressources associées fournissent des explications et des liens utiles pour ces types de modèles. (Source: TheTuringPost)
Populaire sur GitHub : Tutoriel Kubernetes The Hard Way: Le tutoriel de Kelsey Hightower, « Kubernetes The Hard Way », continue de susciter l’intérêt sur GitHub. Ce tutoriel vise à aider les utilisateurs à construire progressivement un cluster Kubernetes manuellement, afin de comprendre en profondeur ses composants principaux et son fonctionnement, plutôt que de dépendre de scripts automatisés. Le tutoriel s’adresse aux apprenants souhaitant maîtriser les bases de Kubernetes, couvrant l’ensemble du processus, de la préparation de l’environnement au nettoyage du cluster. (Source: GitHub Trending)
Populaire sur GitHub : Liste de GPTs et Prompts gratuits: Le dépôt friuns2/BlackFriday-GPTs-Prompts est populaire sur GitHub. Il compile une série de modèles GPT gratuits et de Prompts de haute qualité, utilisables sans abonnement Plus. Ces ressources couvrent de multiples domaines tels que la programmation, le marketing, la recherche universitaire, la recherche d’emploi, les jeux, la création, et incluent quelques techniques de « Jailbreaks », offrant aux utilisateurs de GPT une multitude d’outils prêts à l’emploi et d’inspiration. (Source: GitHub Trending)

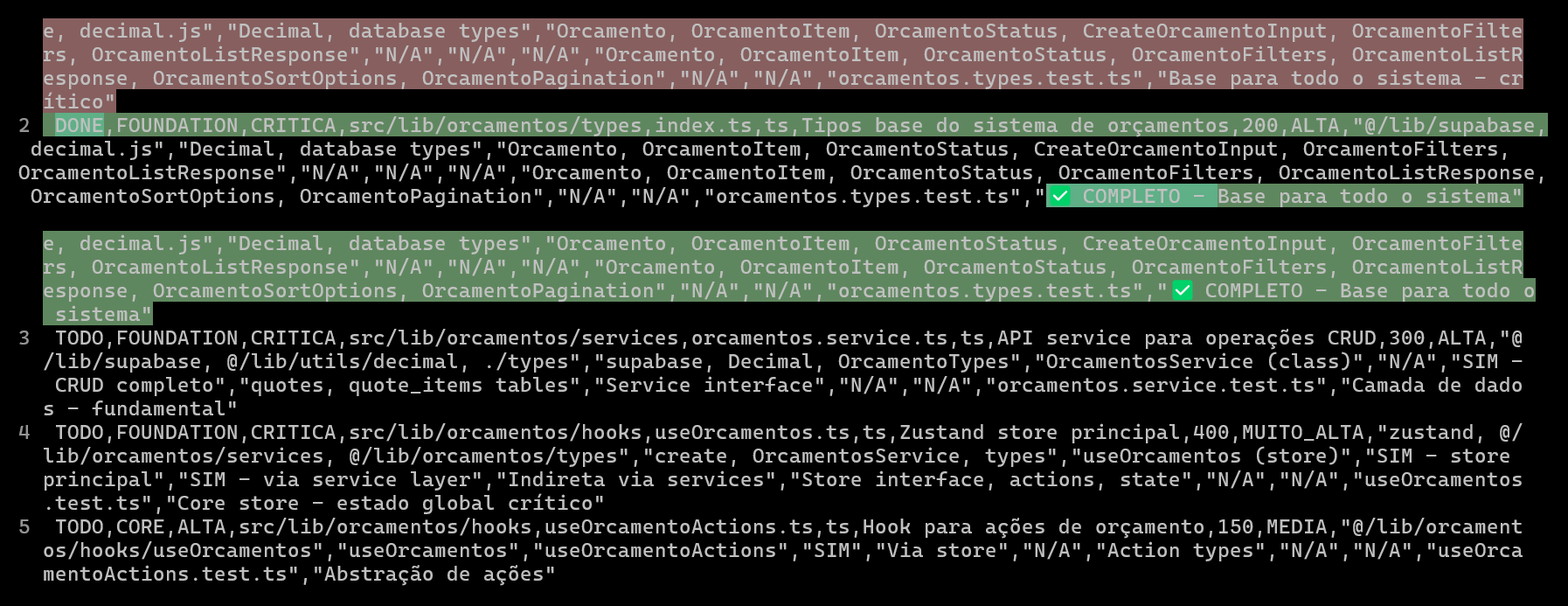
Utiliser des CSV pour planifier et suivre les projets de codage IA, améliorant la qualité et l’efficacité du code: Un développeur a partagé comment, lors du développement d’un système ERP avec Claude Code, la création de fichiers CSV détaillés pour planifier et suivre la progression du codage de chaque fichier a considérablement amélioré l’efficacité du développement de fonctionnalités complexes et la qualité du code. Le fichier CSV contient l’état, le nom du fichier, la priorité, le nombre de lignes de code, la complexité, les dépendances, la description des fonctionnalités, les Hooks utilisés, les modules importés/exportés et des « notes de progression » cruciales. Cette méthode permet à l’IA de se concentrer davantage sur la construction du code et donne aux développeurs une vision claire des écarts entre la progression réelle du projet et le plan initial. (Source: Reddit r/ClaudeAI)
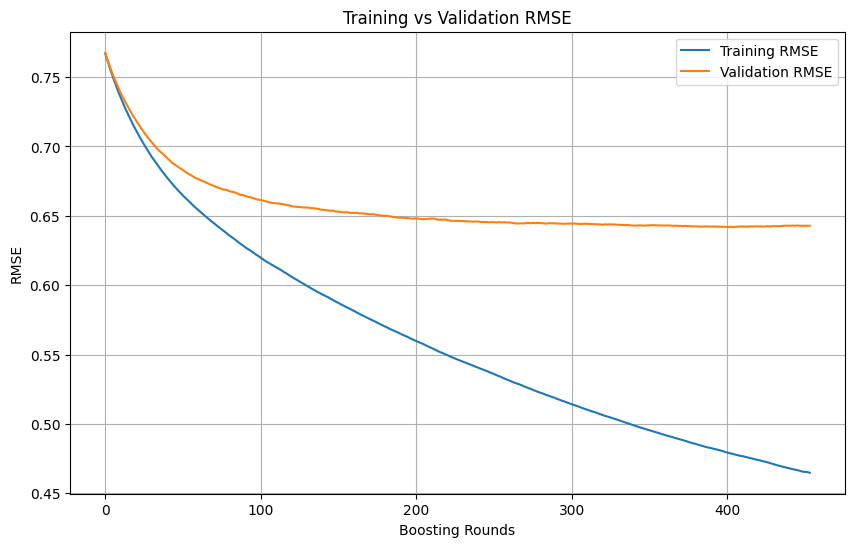
Jugement du surapprentissage et moment d’arrêt lors de l’entraînement en machine learning: Lors de l’entraînement d’un modèle de machine learning, lorsque la perte d’entraînement continue de diminuer rapidement alors que la perte de validation diminue lentement, voire stagne ou augmente, cela indique généralement que le modèle pourrait être en surapprentissage. En principe, tant que la perte de validation continue de diminuer, l’entraînement peut se poursuivre. L’essentiel est de s’assurer que l’ensemble de validation est indépendant de l’ensemble d’entraînement et représente la distribution réelle des données de la tâche. Si la perte de validation cesse de diminuer ou commence à augmenter, il faut envisager d’arrêter l’entraînement prématurément ou d’adopter des méthodes de régularisation pour améliorer la capacité de généralisation du modèle. (Source: Reddit r/MachineLearning)
🌟 Communauté
AI Engineer World’s Fair 2025 se concentre sur des sujets tels que RL+Reasoning, Eval, etc.: Les thèmes de la conférence AI Engineer World’s Fair 2025 couvrent des domaines de pointe tels que l’apprentissage par renforcement + raisonnement (RL+Reasoning), l’évaluation (Eval), les agents d’ingénierie logicielle (SWE-Agent), les architectes IA et l’infrastructure des agents. Les participants ont indiqué que la conférence était pleine de vitalité et de pensée innovante, beaucoup osant essayer de nouvelles choses, se réinventant constamment et s’investissant dans le domaine de l’IA. La conférence a également fourni une plateforme d’échange et d’apprentissage pour les ingénieurs IA. (Source: swyx, hwchase17, charles_irl, swyx)

L’IA idéale selon Sam Altman : petits modèles + raisonnement surpuissant + contexte massif + outils universels: Sam Altman a décrit sa vision de l’IA idéale : un modèle aux capacités de raisonnement surhumaines, de très petite taille, capable d’accéder à des billions d’informations contextuelles et d’utiliser tous les outils imaginables. Ce point de vue a suscité des discussions, certains estimant que cela diffère de la situation actuelle où les grands modèles dépendent du stockage des connaissances, et remettant en question la faisabilité pour les petits modèles d’analyser les connaissances dans un contexte immense et d’effectuer un raisonnement complexe, arguant que les connaissances et la capacité de réflexion sont difficilement séparables efficacement. (Source: teortaxesTex)
Les agents de codage suscitent le désir de refactorisation du code, défis et opportunités de la programmation assistée par IA: Les développeurs indiquent que l’émergence des agents de codage a considérablement accru leur « tentation » de refactoriser le code d’autrui, tout en introduisant de nouveaux dangers. Un développeur a partagé son expérience d’utilisation de l’IA pour accomplir une tâche de programmation nécessitant environ 10 minutes de travail manuel ; bien que l’IA puisse générer rapidement du code fonctionnel, atteindre le niveau d’organisation et de style d’un programmeur expérimenté nécessite encore beaucoup de conseils et de refactorisation manuels. Cela met en évidence les défis de la programmation assistée par IA pour améliorer la qualité du code de niveau débutant/intermédiaire vers un niveau avancé. (Source: finbarrtimbers, mitchellh)
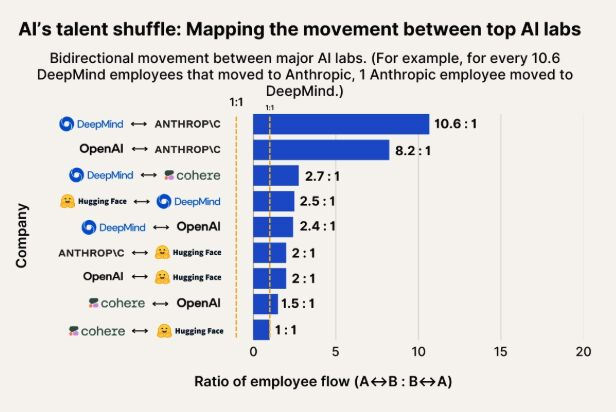
Observation des flux de talents en IA : Anthropic devient une destination importante pour les talents de Google DeepMind et OpenAI: Un graphique illustrant les flux de talents en IA montre qu’Anthropic devient une entreprise importante attirant des chercheurs de Google DeepMind et d’OpenAI. La communauté estime que cela correspond à la perception générale, et certains utilisateurs supposent qu’Anthropic pourrait posséder certaines « armes secrètes » ou des orientations de recherche uniques qui attirent les meilleurs talents. (Source: bookwormengr, TheZachMueller)
La popularisation des robots humanoïdes confrontée aux défis de la confiance et de l’acceptation sociale: Le commentateur technologique Faruk Guney prédit que la première vague de robots humanoïdes pourrait échouer en raison d’un énorme déficit de confiance. Il estime que, malgré les progrès technologiques constants, la société n’est pas encore prête à accepter ces « intelligences en boîte noire » dans les foyers pour effectuer des tâches de compagnie, ménagères ou même d’éducation des enfants. La prise de décision opaque des robots, les risques potentiels de surveillance et leur apparence « mignonne » très différente de celle des humains (moins que Wall-E), pourraient tous devenir des obstacles à leur application généralisée. Ce n’est qu’après des discussions sociales approfondies, une réglementation, des audits et une reconstruction de la confiance que la véritable popularisation des robots humanoïdes pourra avoir lieu. (Source: farguney, farguney)
Conception personnalisée de l’IA : « l’imperfection » l’emporte sur la « perfection »: Un développeur a partagé son expérience de création de 50 personnalités IA sur une plateforme audio IA. Il conclut que des histoires de fond trop élaborées, une cohérence logique absolue et des traits de caractère uniques extrêmes rendent en fait l’IA mécanique et irréelle. Une personnalité IA réussie réside dans une « pile de personnalité à 3 couches » (traits fondamentaux + traits modificateurs + bizarreries), des « modes d’imperfection » appropriés (comme des lapsus occasionnels, des auto-corrections) et des informations de fond judicieuses (300-500 mots, incluant des expériences positives et difficiles, des passions spécifiques et des points de vulnérabilité liés à la profession). Ces détails « imparfaits » rendent paradoxalement l’IA plus humaine et plus apte à créer des liens. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Discussion sur la « perception » et l’« AGI » des LLM : excitation et scepticisme coexistent: La communauté est généralement enthousiasmée par l’énorme potentiel des LLM, les considérant comme comparables à des inventions historiques majeures qui changeront tout. Cependant, beaucoup restent sceptiques quant aux affirmations selon lesquelles les LLM auraient déjà une « capacité de perception », auraient besoin de « droits », ou « mettraient fin à l’humanité » ou apporteraient l’« AGI ». Il est souligné qu’il faut faire preuve de nuance et de prudence dans l’interprétation des capacités des LLM et des résultats de recherche. (Source: fabianstelzer)
💡 Divers
Exploration de la collaboration de plusieurs robots pour la marche autonome: Les médias sociaux ont vu émerger des explorations sur la collaboration de plusieurs robots en matière de marche autonome. Cela implique des technologies complexes telles que la planification de trajectoire des robots, l’attribution des tâches, le partage d’informations et l’évitement des collisions, constituant un domaine de recherche suivi de près en robotique, en RPA (automatisation robotisée des processus) et en machine learning. (Source: Ronald_vanLoon)
Astuce pour optimiser les hyperparamètres d’ULMFiT à l’aide de forêts aléatoires: Jeremy Howard a partagé une astuce qu’il a utilisée pour optimiser ULMFiT (une méthode d’apprentissage par transfert) : en exécutant un grand nombre d’expériences d’ablation et en fournissant tous les hyperparamètres et les données de résultats à un modèle de forêt aléatoire, il a pu identifier les hyperparamètres ayant le plus grand impact sur les performances du modèle. Cette méthode a été intégrée par Weights & Biases dans son produit, offrant de nouvelles perspectives pour l’optimisation des hyperparamètres. (Source: jeremyphoward)

Le robot humanoïde de Figure démontre sa capacité à traiter des tâches logistiques pendant 60 minutes: La société Figure a publié une vidéo de 60 minutes montrant son robot humanoïde, piloté par le réseau neuronal Helix, accomplir de manière autonome diverses tâches dans un scénario logistique. Cette démonstration vise à prouver la capacité de travail stable à long terme et le niveau de décision autonome de son robot dans des environnements réels complexes. (Source: adcock_brett)