Mots-clés:Série de modèles Wujie, Nouvelle méthode RLHF, Série de modèles Claude Gov, Grands modèles de langage, Fusion multimodale, AGI physique, Sécurité de l’IA, Intelligence incarnée, Modèle mondial multimodale natif Emu3, Modèle de neurosciences Brainμ, Cerveau incarné RoboBrain 2.0, Modèle microscopique de vie à atomes complets OpenComplex2, Apprentissage par renforcement avec tokens bifurqués
🔥 Pleins Feux sur
La conférence BAAI dévoile la série de grands modèles “Wu Jie”, axée sur l’AGI physique et la fusion multimodale: Lors de la conférence 2025 de l’Institut d’Intelligence Artificielle de Beijing (BAAI), l’institut a dévoilé sa toute nouvelle série de grands modèles “Wu Jie”, marquant un changement d’orientation de ses recherches, passant de l’exploration des modèles de langage “Wu Dao” à un champ plus vaste englobant le monde physique et la fusion multimodale. Cette série comprend le modèle mondial multimodal natif Emu3, le premier modèle de base multimodal universel en neurosciences au monde “Jianwei Brainμ”, le cerveau incarné RoboBrain 2.0, et le modèle de vie microscopique tout-atome OpenComplex2. Le lancement de cette série de modèles reflète la tendance évolutive de l’IA, passant du monde numérique au monde physique, et de la compréhension macroscopique à l’exploration microscopique. L’objectif est de permettre à l’IA de percevoir, comprendre et interagir avec le monde physique, de résoudre des problèmes concrets et de promouvoir le développement de l’AGI physique. La conférence a également réuni 4 lauréats du prix Turing, dont Bengio, ainsi que de nombreux leaders de l’industrie, pour discuter de sujets d’avant-garde tels que la sécurité de l’IA, l’apprentissage par renforcement, les agents intelligents et l’intelligence incarnée (Source : 量子位)

Qwen et LeapLab de l’Université Tsinghua proposent une nouvelle méthode RLHF “au-delà de la règle des 80/20”: Une étude menée par l’équipe Qwen en collaboration avec LeapLab de l’Université Tsinghua a révélé que lors de l’amélioration des capacités de raisonnement des grands modèles par apprentissage par renforcement (RLHF), il suffit de se concentrer sur environ 20% des “tokens de bifurcation” (forking tokens) à haute entropie pour atteindre, voire dépasser, les performances obtenues en entraînant avec tous les tokens. Ces tokens à haute entropie assument principalement des fonctions de connexion logique et jouent un rôle directeur crucial dans le processus de raisonnement. Sur la base de cette découverte, Qwen3-32B a atteint des résultats SOTA (State-Of-The-Art) pour les modèles de moins de 600 milliards de paramètres entraînés à partir de zéro sur les benchmarks des concours de mathématiques AIME’24 et AIME’25. Cette recherche améliore non seulement l’efficacité de l’entraînement, mais révèle également l’importance des tokens à haute entropie pour la capacité de généralisation du modèle, et offre de nouvelles perspectives pour comprendre les différences entre RL et SFT ainsi que la spécificité du RL pour les LLM (Source : 量子位)

Anthropic lance la série de modèles Claude Gov, dédiée aux clients de la sécurité nationale américaine: Anthropic a annoncé la série de modèles Claude Gov, spécialement conçue pour les clients de la sécurité nationale américaine. Ces modèles ont déjà été déployés au sein des agences de sécurité nationale de plus haut niveau aux États-Unis, avec un accès strictement limité au personnel habilité à traiter des informations classifiées. Cette initiative a suscité des discussions sur l’éthique de l’IA et les risques potentiels d’abus, notamment compte tenu des recherches antérieures d’Anthropic documentant des comportements de “survie” et des risques d‘“abus catastrophique” de la part des modèles. Bien qu’Anthropic se présente comme une société de recherche en sécurité de l’IA visant à découvrir et corriger les vulnérabilités par des tests, l’application de sa technologie aux domaines militaire et de la sécurité nationale intensifie sans aucun doute les inquiétudes du public concernant l’armement de l’IA et les risques de perte de contrôle (Source : AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun prédit que les grands modèles de langage actuels seront obsolètes d’ici cinq ans: Yann LeCun, professeur à la NYU et scientifique en chef de l’IA chez Meta, a déclaré dans une interview à Newsweek que les grands modèles de langage (LLM) actuels deviendront obsolètes d’ici cinq ans. Il estime que les systèmes d’IA existants manquent de capacité de compréhension du monde réel, ce qui constitue leur limitation fondamentale. LeCun a esquissé les formes futures de systèmes d’IA plus intelligents, suggérant une nouvelle génération de technologies d’IA dépassant l’architecture actuelle des LLM, potentiellement davantage axée sur la représentation intrinsèque du monde et les capacités de raisonnement causal (Source : ylecun)
🎯 Tendances
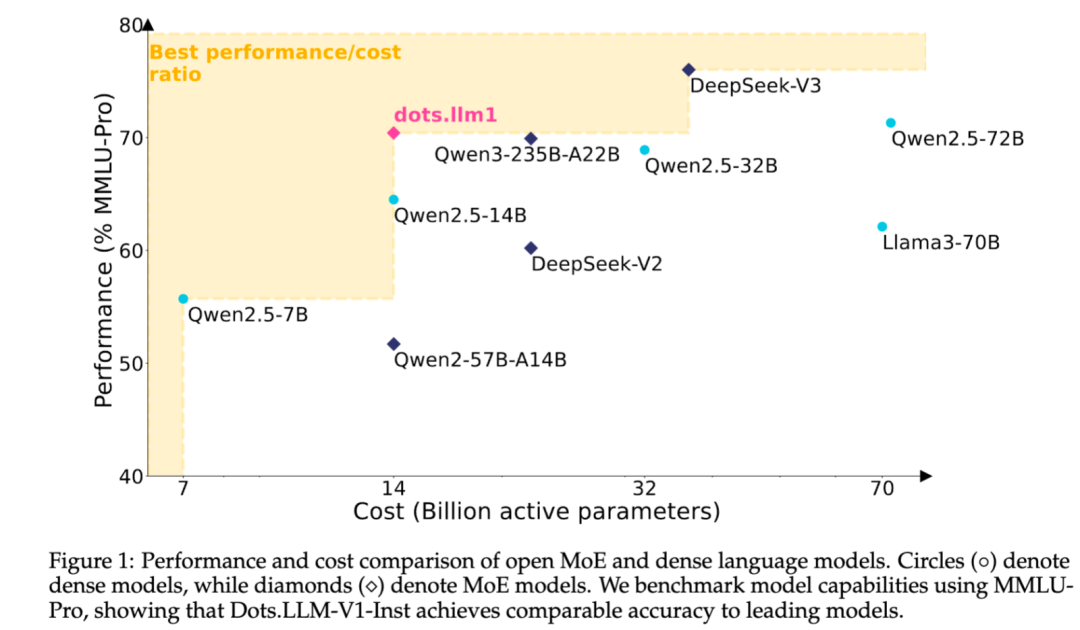
Xiaohongshu publie en open source son grand modèle de texte MoE auto-développé dots.llm1: L’équipe hi lab de Xiaohongshu a publié en open source son premier grand modèle de texte auto-développé, dots.llm1. Ce modèle adopte une architecture MoE, avec un nombre total de paramètres de 142B et 14B paramètres activés. Avec 14B paramètres activés, le modèle affiche d’excellentes performances dans les scénarios généraux en chinois et en anglais, ainsi que pour les tâches mathématiques, de code et d’alignement, rivalisant avec des modèles tels que Qwen2.5-32B/72B-Instruct. Xiaohongshu a fait un effort d’ouverture significatif, fournissant non seulement le modèle prêt à l’emploi dots.llm1.inst, mais aussi plusieurs checkpoints des étapes de pré-entraînement et un modèle de base pour textes longs, tout en détaillant les aspects de l’entraînement pour faciliter le développement secondaire et la recherche par la communauté. Ce modèle n’utilise pas de corpus synthétique, soulignant l’application de données réelles de haute qualité (Source : 36氪)
Anthropic continue d’améliorer les fonctionnalités de son modèle Claude, étendant le traitement du contexte et les capacités d’intégration: Anthropic a récemment lancé plusieurs mises à jour importantes pour sa série de modèles Claude. Projects on Claude peut désormais traiter plus de 10 fois plus de contenu, et lorsque les fichiers dépassent le seuil, il passe à un nouveau mode de récupération pour étendre le contexte fonctionnel. Parallèlement, les utilisateurs du plan Pro peuvent désormais utiliser les fonctionnalités Research et Integrations, permettant à Claude de rechercher sur le web, dans Google Workspace, et dans toute application personnalisée ou service pré-construit connecté via MCP (Model Control Protocol) (comme Zapier et Asana), réalisant des opérations inter-outils telles que la création de tâches, la mise à jour de documents et le déclenchement de flux de travail. Ces mises à jour visent à améliorer les capacités de Claude dans le traitement de tâches complexes et l’intégration d’informations multi-sources (Source : AnthropicAI, AnthropicAI)
Hugging Face lance un serveur MCP, renforçant l’écosystème des agents IA: Hugging Face a annoncé son premier serveur MCP (Model Control Protocol) (hf.co/mcp), permettant aux agents IA d’accéder et d’utiliser plus efficacement les modèles, les ensembles de données et même les applications hébergées dans Space sur la plateforme Hugging Face. Cette initiative est considérée comme une étape importante pour faire évoluer Internet vers une compatibilité accrue avec les agents intelligents, visant à construire un écosystème de type “magasin d’applications” pour les agents IA. Le lancement du serveur MCP permet aux développeurs de faciliter l’interaction des agents IA avec les vastes ressources de Hugging Face, favorisant le développement et l’innovation des applications d’agents IA (Source : TheTuringPost, karminski3)
OpenAI met à jour son modèle vocal ChatGPT, améliorant la naturalité et les capacités de traduction: OpenAI a amélioré la fonction Advanced Voice de ChatGPT, rendant l’expérience de conversation plus naturelle et fluide. Cette mise à jour est désormais disponible pour tous les utilisateurs payants. Parallèlement, les capacités de ChatGPT en matière de traduction linguistique ont également été améliorées, les utilisateurs pouvant directement lui demander de traduire en temps réel entre différentes langues. Ces améliorations visent à accroître la commodité et l’utilité des interactions vocales des utilisateurs avec ChatGPT (Source : kevinweil, shuchaobi)
PyTorch intègre Safetensors, améliorant la sécurité et la commodité des Checkpoints distribués: PyTorch a annoncé que sa fonctionnalité de Checkpoint distribué prend désormais en charge le format Safetensors de Hugging Face. Cette intégration rend la sauvegarde et le chargement des Checkpoints de modèles entre différents écosystèmes plus sûrs et plus pratiques, résolvant notamment les risques de sécurité précédemment associés au format pickle. La nouvelle API permet de lire et d’écrire des Safetensors via des chemins fsspec, torchtune devenant la première bibliothèque à adopter cette fonctionnalité, optimisant ainsi son processus de Checkpoint. Cette mesure est considérée comme l’une des avancées importantes dans le domaine de la sécurité de l’IA au cours de l’année écoulée, contribuant à améliorer la sécurité du partage et du déploiement des modèles (Source : ClementDelangue, huggingface)

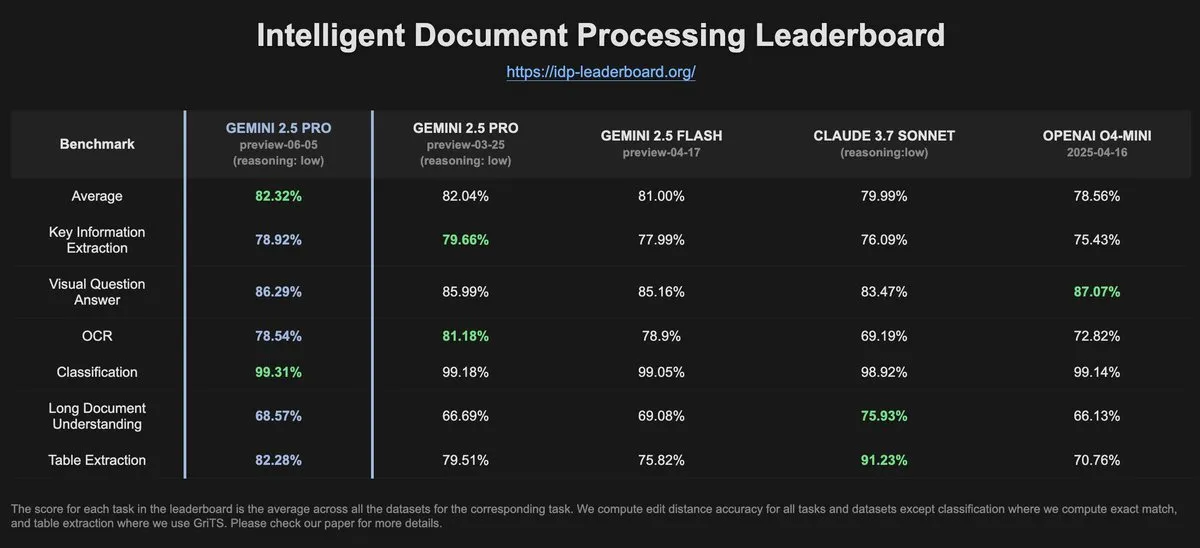
Les données d’IDP-Leaderboard montrent une baisse des performances OCR pour Gemini-2.5-pro-06-05 par rapport à la version précédente: Selon les dernières données d’IDP-Leaderboard, la nouvelle version Gemini-2.5-pro-06-05 affiche une baisse de performance en OCR (reconnaissance optique de caractères) par rapport à la version 03-25. Néanmoins, ce modèle reste le plus performant en termes de capacités globales de traitement de documents (y compris la reconnaissance de documents, de tableurs, etc.). IDP-Leaderboard est un benchmark axé sur l’évaluation des capacités des grands modèles dans le domaine du traitement intelligent des documents (Source : karminski3)
Une étude d’Apple révèle les limites du raisonnement des LLM, qui ne “penseraient” peut-être pas réellement: Des chercheurs d’Apple ont publié un article explorant les forces et les faiblesses des LLM actuels dans les tâches de raisonnement, soulignant que les performances de ces modèles “s’effondrent” lorsqu’ils traitent des tâches dépassant une certaine complexité. L’étude suggère que le “raisonnement” des LLM est davantage basé sur la reconnaissance de formes et la mémorisation que sur une véritable pensée et compréhension au sens humain. Ce point de vue rejoint celui d’experts comme Yann LeCun, suscitant des discussions sur la voie vers l’AGI et les limites des capacités des modèles actuels (Source : omarsar0, NandoDF)

DeepSeek R1 démontre d’excellentes capacités de compréhension de texte et d’interprétation créative dans le jeu Dwarf Fortress: Des expériences utilisateur montrent que le modèle DeepSeek R1 fait preuve d’une grande capacité de compréhension de texte et d’interprétation créative lors du traitement de données issues du jeu complexe et textuellement dense Dwarf Fortress. En extrayant les données textuelles des captures d’écran du jeu et en les soumettant à DeepSeek R1, le modèle peut non seulement analyser les données, mais aussi identifier des bizarreries et des schémas intéressants dans le comportement des nains, et les décrire dans un langage vivant et amusant, démontrant son potentiel dans la compréhension et la génération de texte non structuré (Source : Reddit r/LocalLLaMA)

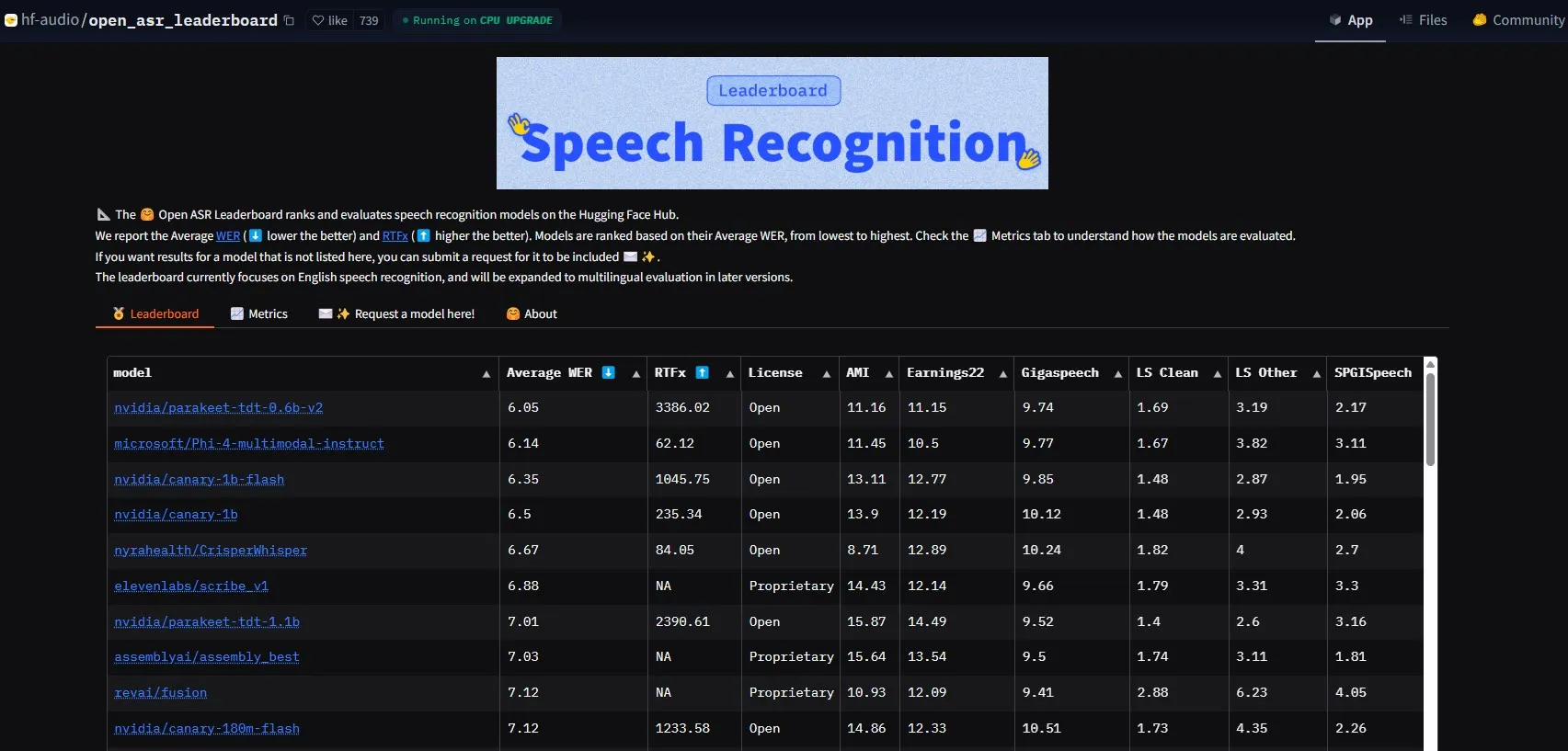
NVIDIA lance le modèle Parakeet-tdt-0.6b-v2, établissant une nouvelle référence en matière de performances ASR: Le nouveau modèle de reconnaissance automatique de la parole (ASR) de NVIDIA, Parakeet-tdt-0.6b-v2, a établi un nouveau record dans l’industrie avec un taux d’erreur de mot (WER) de 6,05% sur le Open-ASR-Leaderboard de HuggingFace. Ce modèle est non seulement en tête en termes de précision, mais il offre également une vitesse d’inférence extrêmement rapide (RTFx 3386, 50 fois plus rapide que les alternatives) et prend en charge des fonctionnalités innovantes telles que la transcription de paroles de chansons, l’horodatage précis / le formatage numérique (Source : huggingface)
L’équipe Qwen d’Alibaba publie la série de modèles Qwen3-Embedding: L’équipe Qwen d’Alibaba a lancé la nouvelle série de modèles Qwen3-Embedding, comprenant trois tailles différentes : 0.6B, 4B et 8B. Ces modèles ont atteint des performances SOTA (State-of-the-Art) sur plusieurs benchmarks d’intégration de texte tels que MMTEB, MTEB et MTEB-Code. Ils prennent en charge 119 langues et peuvent être exécutés dans le navigateur via Transformers.js (avec prise en charge de l’accélération WebGPU), offrant de puissantes capacités de représentation textuelle pour les applications multilingues et multiplateformes (Source : huggingface)
Gemini 2.5 Pro démontre de puissantes capacités de génération de code et de traitement de tâches: Gemini 2.5 Pro de Google DeepMind (version preview-06-05) a démontré de solides capacités dans le traitement de tâches complexes. Par exemple, l’utilisateur Majid Manzarpour a tenté de lui faire écrire un script pour organiser et classer une bibliothèque de plus de 25 000 fichiers sonores, ce que Jeff Dean a commenté comme “ne semblant pas trop difficile”, suggérant le potentiel du modèle pour gérer des tâches de programmation complexes et à grande échelle de ce type. De plus, un graphique de test de GosuCoder montre que la version mise à jour Gemini 2.5 Pro 06-05 offre de meilleures performances en matière d’assistance au codage par IA, en particulier avec un score d’évaluation plus élevé lorsque la température est réglée sur 0.7 (Source : JeffDean, jeremyphoward)
Hugging Face et Google Colab approfondissent leur intégration pour simplifier les flux de travail en IA: Hugging Face et Google Colab ont annoncé un renforcement de leur collaboration, ajoutant la prise en charge de “Open in Colab” à toutes les cartes de modèles sur le Hugging Face Hub. Les utilisateurs peuvent désormais lancer directement un notebook Colab à partir de n’importe quelle carte de modèle, ce qui facilite l’expérimentation et l’utilisation des modèles sur Hugging Face, réduisant ainsi davantage les barrières à l’entrée pour le développement et la recherche en IA (Source : huggingface)
🧰 Outils
LlamaBot : un assistant de codage IA basé sur LangGraph: LangChainAI a présenté LlamaBot, un agent IA piloté par LangGraph, capable de créer des applications Web via une conversation en langage naturel. Ses fonctionnalités incluent la génération de code en temps réel, un aperçu en temps réel, et des agents spécialisés conçus pour différentes tâches de développement, visant à simplifier le processus de développement d’applications Web (Source : LangChainAI, hwchase17)
Système Fast RAG : combinaison de DeepSeek-R1 et Qdrant pour un traitement efficace des documents: LangChainAI a présenté une solution RAG (Retrieval Augmented Generation) haute performance. Cette solution combine le modèle DeepSeek-R1 de SambaNova, la technologie de quantification binaire de Qdrant et LangGraph, réalisant une réduction de mémoire de 32 fois, permettant ainsi de traiter efficacement des documents à grande échelle et offrant une nouvelle voie d’optimisation pour la recherche d’informations et la génération de contenu (Source : LangChainAI, hwchase17)

Gemini Research Assistant : un assistant de recherche intelligent full-stack basé sur Gemini et LangGraph: L’équipe Google Gemini a mis en open source un assistant de recherche IA full-stack qui utilise le modèle Gemini et LangGraph pour effectuer des recherches intelligentes sur le Web. Cet assistant est doté de capacités de raisonnement réflexif, lui permettant d’optimiser continuellement ses stratégies de recherche pour fournir aux utilisateurs un support de recherche plus approfondi et efficace. Le code du projet est disponible sur GitHub (Source : LangChainAI, hwchase17)
Agent Flow : un constructeur d’agents IA open source sans code: Karan Vaidya a lancé Agent Flow, un constructeur d’agents IA open source sans code, comme alternative à Gumloop. Il est basé sur ComposioHQ et LangGraph de LangChain, permettant aux utilisateurs d’automatiser les flux de travail et les schémas d’agents complexes par glisser-déposer de nœuds, visant à réduire la barrière à l’entrée pour le développement d’applications d’agents IA (Source : hwchase17)
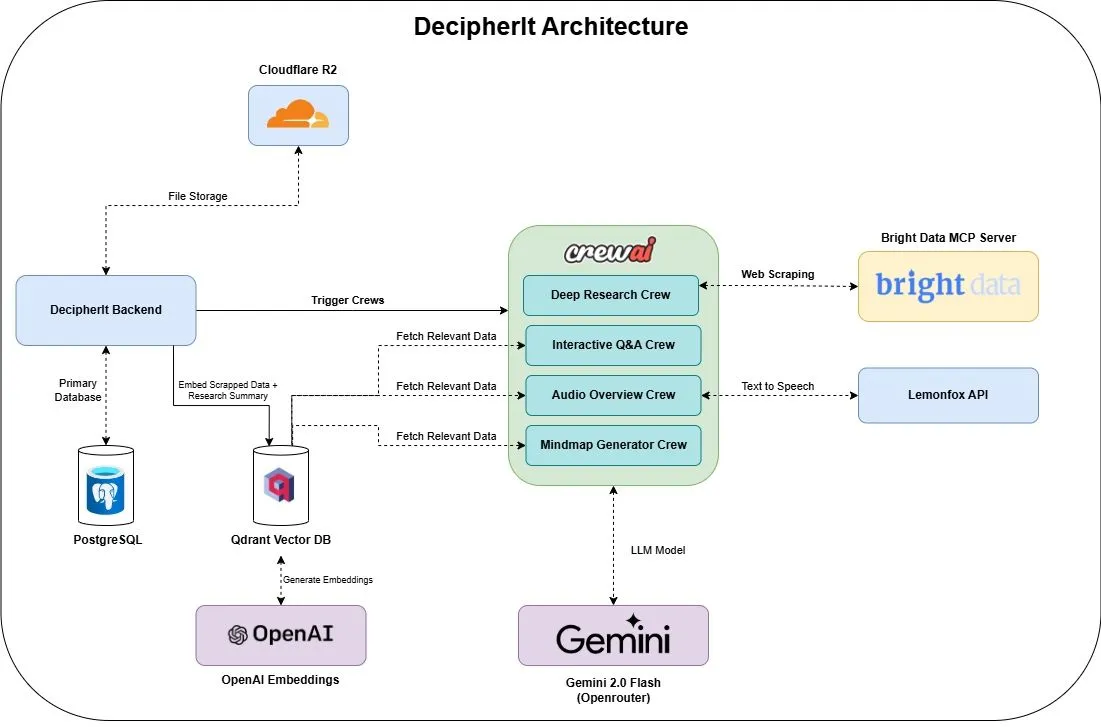
DecipherIt : un assistant de recherche IA open source, alternative à NotebookLM: Un assistant de recherche IA open source nommé DecipherIt a été lancé, se positionnant comme une alternative à NotebookLM. Cet outil utilise l’orchestration multi-agents (crewAI), la recherche sémantique (Qdrant + OpenAI), l’accès Web en temps réel (Bright Data MCP) et la synthèse vocale (lemonfoxai) pour transformer les documents, URL ou thèmes saisis par l’utilisateur en un espace de travail de recherche complet comprenant des résumés, des cartes mentales, des aperçus audio, des FAQ et des questions-réponses sémantiques (Source : qdrant_engine)
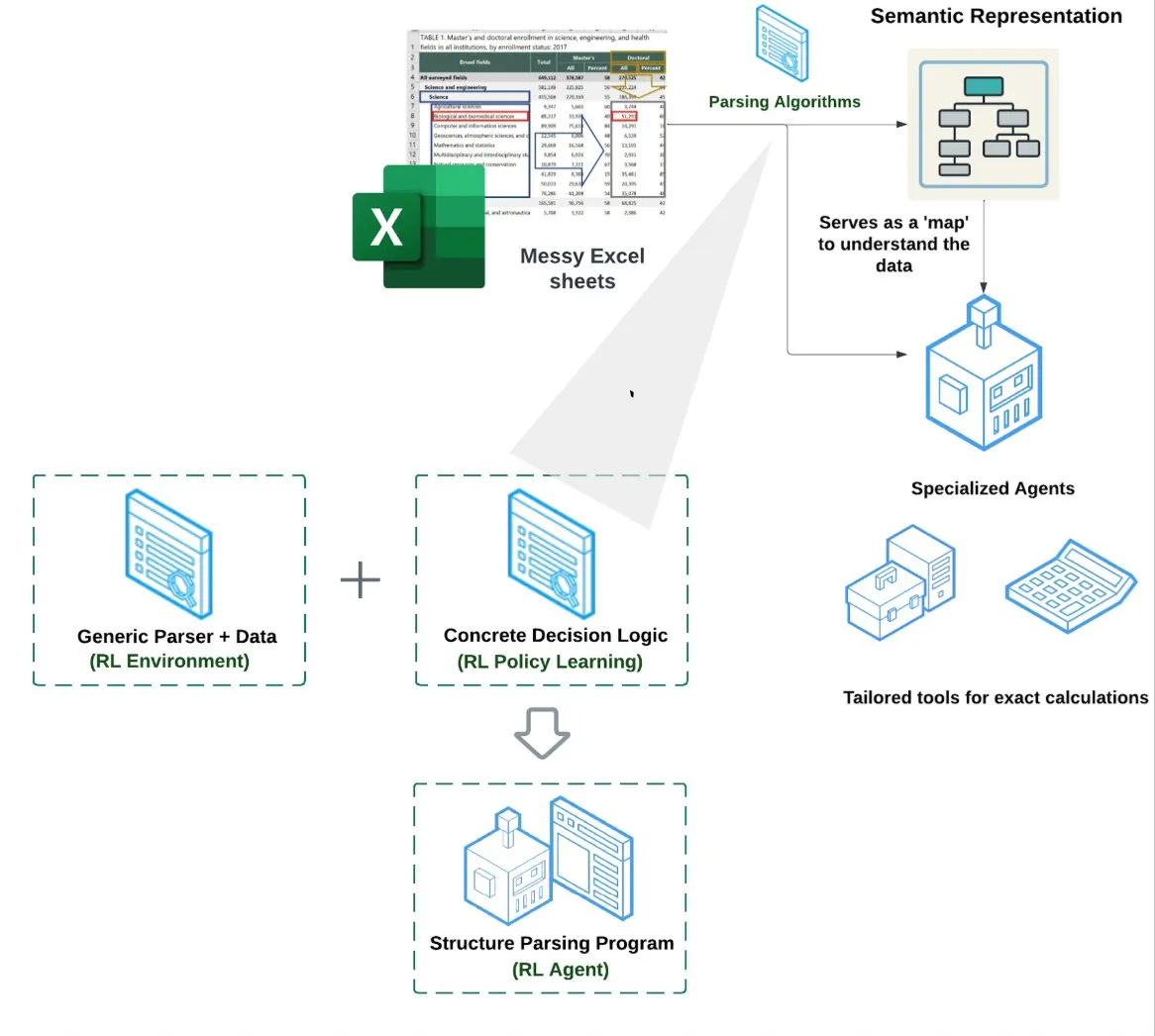
LlamaIndex lance un agent pour tableurs (Spreadsheet Agent): LlamaIndex a annoncé un nouvel agent pour tableurs, actuellement en avant-première privée. Cet agent se concentre sur le traitement de fichiers Excel complexes, capable d’effectuer des transformations de données et d’assurer la qualité. Le cœur de son architecture technique repose sur la compréhension structurelle basée sur l’apprentissage par renforcement (apprentissage du modèle de données/graphe sémantique) et sur des outils spécialisés construits au-dessus du graphe sémantique. Il vise à offrir une capacité de traitement Excel supérieure aux méthodes traditionnelles RAG ou texte vers CSV, avec des performances annoncées de 10 à 20 % supérieures à une base de référence où un LLM écrit simplement du code (Source : jerryjliu0)
Kuvera-8B-v0.1.0 : un grand modèle pour le conseil financier personnel: Akhil-Theerthala a publié le modèle Kuvera-8B-v0.1.0 sur Hugging Face, un modèle spécialement conçu pour les questions de finances personnelles. Il est basé sur un fine-tuning de Qwen3-8B, utilisant des données provenant de Reddit et d’autres sources, et vise à fournir des conseils empathiques et pratiques sur des sujets tels que la budgétisation, l’épargne, l’investissement, la gestion de la dette et la planification financière de base. Étant basé sur Qwen3, ce modèle prend en charge les questions-réponses en chinois (Source : karminski3)
Solution de traitement vocal localisée Whisper+Pyannote en remplacement d’Otter.ai: Un utilisateur de Reddit a partagé son processus de traitement vocal entièrement localisé, construit pour remplacer des services cloud comme Otter.ai. Cette solution combine ctranslate2 et faster-whisper pour la transcription, pyannote et speechbrain pour la séparation des locuteurs (diarisation). Elle peut traiter des enregistrements de réunions de plus de trois heures sur un GPU local et générer des transcriptions textuelles avec identification des locuteurs ainsi que des fichiers JSON, y compris des résumés exécutifs et des listes d’actions personnalisées. Cette initiative vise à résoudre les limitations des services cloud, les préoccupations relatives à la confidentialité et le manque de personnalisation (Source : Reddit r/LocalLLaMA)
GPT Deep Research MCP : recherche approfondie combinée avec OpenWebUI: Un utilisateur recommande d’essayer la combinaison de GPT Deep Research MCP avec OpenWebUI. L’outil MCP (gptr-mcp) est conçu pour fournir des capacités de recherche approfondie et, lorsqu’il est utilisé avec OpenWebUI qui prend en charge MCP, il offre une expérience de recherche impressionnante, élargissant davantage les applications des outils d’IA localisés dans le traitement de l’information et la découverte de connaissances (Source : Reddit r/OpenWebUI)
📚 Apprentissage
OpenAI organisera un séminaire sur les meilleures pratiques d’évaluation des applications, incluant des cas réels et un aperçu des outils à venir: OpenAI organisera un séminaire sur les meilleures pratiques en matière d’évaluation des applications (Evals). Jim Blomo d’OpenAI y discutera, à travers des cas clients réels et leurs résultats, de la manière d’évaluer efficacement les produits d’IA. L’événement donnera également un aperçu des futurs outils d’évaluation d’OpenAI, y compris des fonctionnalités de suivi, de notation, etc. Ce séminaire vise à aider les développeurs et les entreprises à mieux construire et optimiser leurs applications d’IA, et un enregistrement sera disponible (Source : HamelHusain, HamelHusain)

Anthropic publie en open source ses méthodes de recherche sur l’interprétabilité pour aider à comprendre la “pensée” des LLM: Anthropic a annoncé la publication en open source de ses méthodes de recherche pour suivre les “processus de pensée” des grands modèles de langage. Les chercheurs peuvent désormais utiliser cette méthode pour générer des “graphes d’attribution” et les explorer de manière interactive, similairement à ce qu’Anthropic a démontré dans ses récentes recherches. L’équipe fournit également une interface interactive Neuronpedia et des tutoriels Jupyter Notebook pour faciliter l’application de ces outils par les chercheurs sur des modèles open source, afin d’améliorer la compréhension des mécanismes internes des LLM. Ce projet est dirigé par des participants du programme Anthropic Fellows en collaboration avec Decode Research (Source : AnthropicAI)
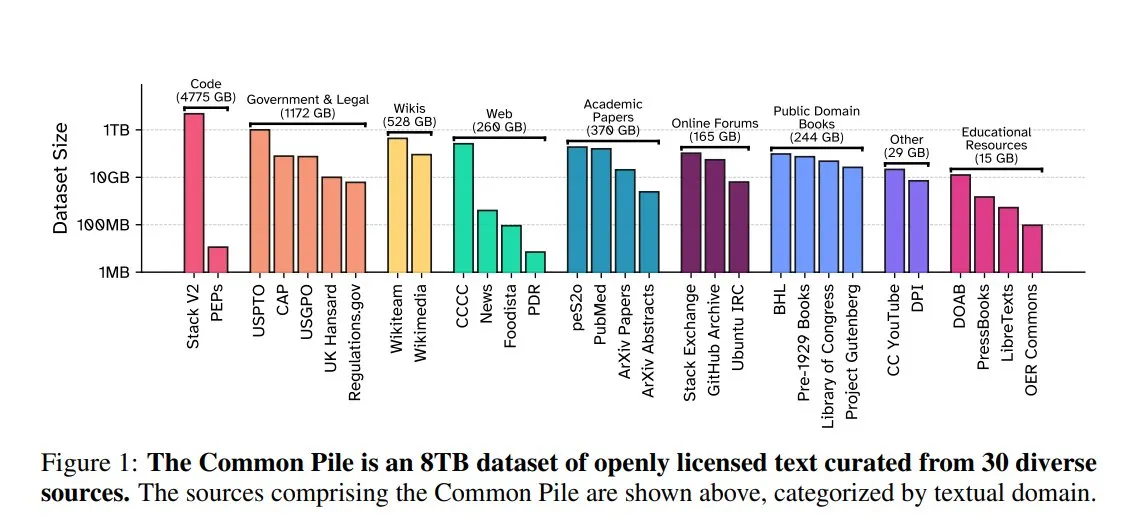
EleutherAI publie Common Pile v0.1 : un jeu de données textuelles de 8 To sous licence ouverte: EleutherAI, en collaboration avec le Vector Institute, Allen AI, Hugging Face et DPI, a publié Common Pile v0.1, un jeu de données textuelles du domaine public et sous licence ouverte de 8 To, contenant un trillion de tokens. L’équipe a entraîné sur cette base les modèles Comma v0.1-1T et -2T de 7 milliards de paramètres, dont les performances sont comparables à celles de modèles tels que LLaMA 1 & 2 entraînés sur des volumes de données similaires. Cette initiative vise à explorer la possibilité d’entraîner des modèles de langage performants sans utiliser de textes non autorisés, offrant ainsi une ressource de données précieuse à la communauté open source (Source : huggingface)
NVIDIA NIM accélère l’inférence texte-SQL de Vanna: Le blog des développeurs NVIDIA a publié un tutoriel montrant comment utiliser NVIDIA NIM (NVIDIA Inference Microservices) pour optimiser la solution texte-SQL de Vanna. NIM fournit des points de terminaison optimisés pour les modèles d’IA générative, capables d’accélérer le processus d’inférence, permettant ainsi des analyses plus rapides. Ceci est particulièrement important pour les scénarios d’application nécessitant la conversion de requêtes en langage naturel en requêtes de base de données (Source : dl_weekly)
Partage gratuit des notes de cours de Machine Learning de l’Université de Stanford: The Turing Post a partagé les notes de cours gratuites du cours CS229 de Machine Learning de l’Université de Stanford, enseigné par Andrew Ng et Tengyu Ma. Le contenu couvre l’apprentissage supervisé, les méthodes et algorithmes d’apprentissage non supervisé, l’apprentissage profond et les réseaux de neurones, la généralisation, la régularisation, ainsi que les processus d’apprentissage par renforcement, offrant aux apprenants des ressources d’étude de haute qualité (Source : TheTuringPost)

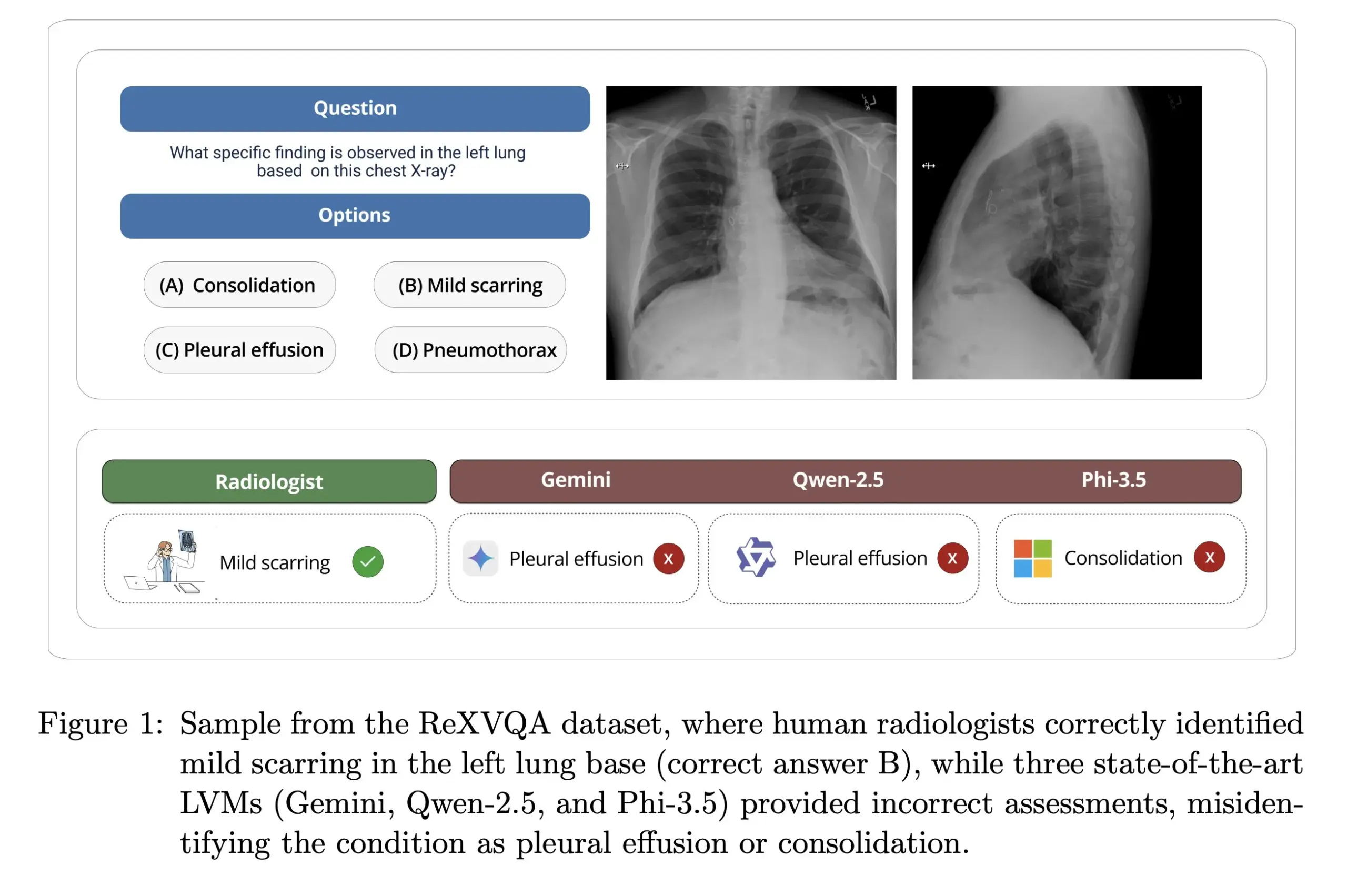
L’Université Harvard publie ReXVOA : un benchmark de questions-réponses sur radiographies thoraciques à grande échelle et de haute qualité: Le laboratoire de Pranav Rajpurkar à l’Université Harvard a publié ReXVOA, un jeu de données de référence à grande échelle et de haute qualité pour le question-réponse visuel (VQA) sur radiographies thoraciques. Ce jeu de données vise à mettre au défi les grands modèles de pointe existants et à servir d’étalon pour mesurer les progrès des modèles de nouvelle génération en matière de compréhension d’images médicales et de capacités de question-réponse (Source : huggingface)
OWL Labs partage son expérience sur l’entraînement d’auto-encodeurs pour les modèles de diffusion: OWL (Open World Labs) a résumé dans son blog ses expériences et découvertes concernant l’entraînement d’auto-encodeurs pour les modèles de diffusion, et a partagé quelques cas d’échec de méthodes non conventionnelles. Cet article fournit une référence aux chercheurs et développeurs pour l’application et l’optimisation pratiques des auto-encodeurs de modèles de diffusion (Source : NandoDF)
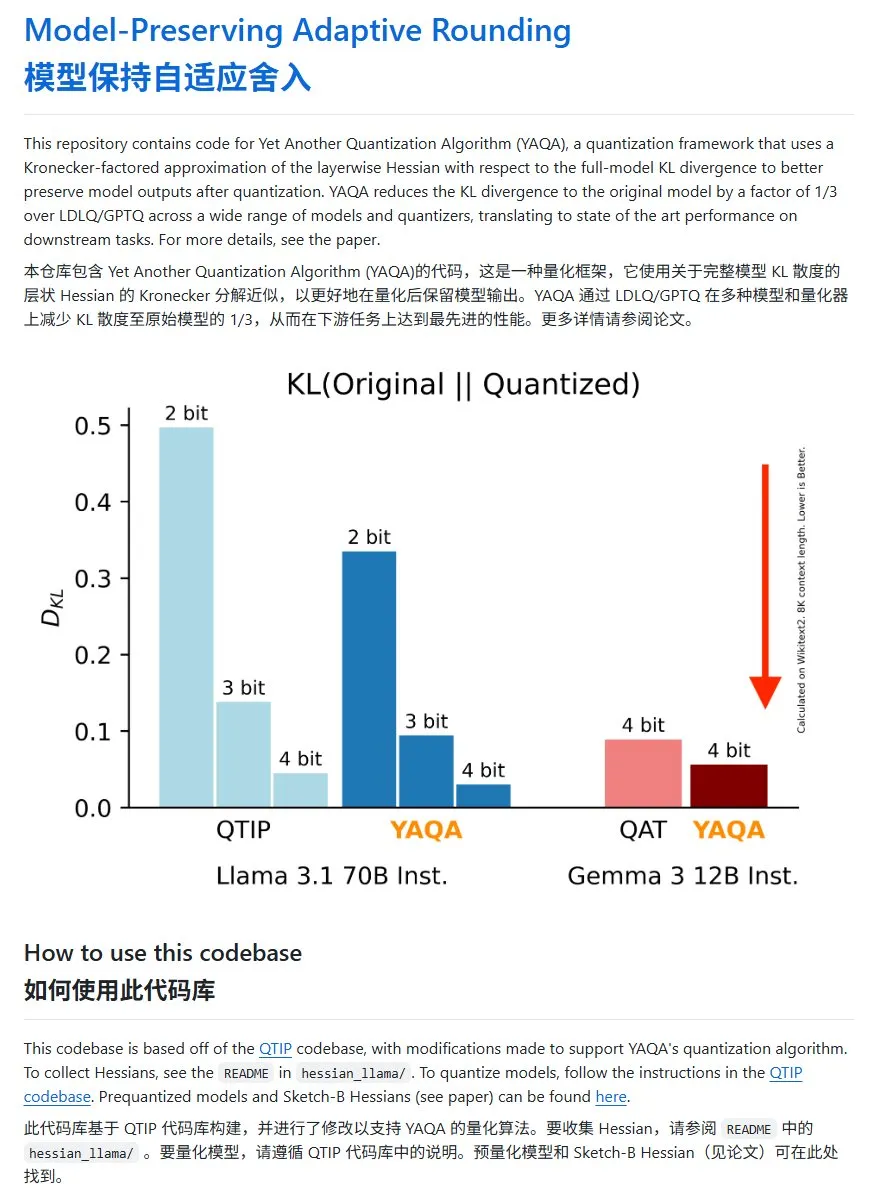
YAQA : une nouvelle méthode de quantification de modèle, réduisant significativement la divergence KL: L’équipe Cornell-RelaxML a proposé une nouvelle méthode de quantification de modèle appelée YAQA. Cette méthode combine les techniques LDLQ/GPTQ et, par rapport aux méthodes de quantification existantes, peut réduire la divergence KL du modèle quantifié à 1/3 de celle du modèle original. Bien que le processus de quantification YAQA soit plus lent et nécessite une grande quantité de VRAM, l’amélioration des performances et l’économie lors de l’inférence ultérieure en font une solution de quantification prometteuse. Le code du projet est disponible en open source sur GitHub (Source : karminski3)
💼 Affaires
Hong Letong, une jeune femme de Guangzhou née dans les années 2000, fonde Axiom pour résoudre des problèmes mathématiques complexes grâce à l’IA: Axiom, une start-up d’IA fondée par la jeune prodige Hong Letong (Carina Hong), née dans les années 2000, suscite l’attention. Axiom se concentre sur l’utilisation de l’IA pour résoudre des problèmes mathématiques complexes, ciblant des clients tels que les fonds spéculatifs et les sociétés de trading quantitatif. Selon The Information, Axiom serait en négociation pour un financement de 50 millions de dollars, avec une valorisation d’environ 300 à 500 millions de dollars, B Capital étant pressenti comme investisseur principal. Hong Letong a déclaré sur les réseaux sociaux que les informations sur le financement étaient inexactes, mais a confirmé que l’entreprise recrutait des talents en IA mathématique. Hong Letong est diplômée du MIT (licence) et d’Oxford (master), et poursuit actuellement un double doctorat en mathématiques et en droit à Stanford. Elle a remporté de nombreux prix lors de concours de mathématiques (Source : 36氪)

Anthropic coupe l’accès à l’API Claude pour Windsurf en raison de la concurrence: Un cofondateur d’Anthropic a confirmé que l’entreprise avait cessé de fournir à la start-up d’IA Windsurf l’accès à l’API de son modèle Claude. La raison invoquée est que Windsurf est considérée comme une forme de “wrapper” d’OpenAI ou un service étroitement lié à OpenAI, qui est un concurrent direct d’Anthropic. Cette décision a soulevé des discussions sur la dépendance aux API et les risques liés aux plateformes, en particulier pour les start-ups dont l’activité repose sur les API de grands modèles tiers, car les décisions commerciales des fournisseurs de modèles peuvent directement affecter leur survie (Source : ClementDelangue, Reddit r/LocalLLaMA)
OpenAI contraint de conserver les historiques de chat supprimés par les utilisateurs en raison d’un procès pour droits d’auteur: Selon des informations, dans le cadre d’un procès pour violation de droits d’auteur intenté par le New York Times, un tribunal fédéral américain a ordonné à OpenAI de conserver tous les historiques de conversation des utilisateurs de ChatGPT, y compris le contenu que les utilisateurs ont choisi de supprimer, comme preuve potentielle. Le New York Times accuse OpenAI d’avoir utilisé ses articles payants pour entraîner ChatGPT et craint que l’IA ne génère un contenu similaire. Cette mesure soulève des préoccupations concernant la vie privée des utilisateurs et la protection des données (comme le RGPD), mettant en évidence les tensions juridiques et éthiques entre les droits d’auteur des données d’entraînement de l’IA et la vie privée des utilisateurs (Source : Reddit r/ArtificialInteligence)

🌟 Communauté
Les grands modèles d’IA relèvent le défi des dissertations et des mathématiques du baccalauréat 2025, avec des performances variables: Pendant la période du baccalauréat 2025, plusieurs grands modèles d’IA grand public ont été mis au défi sur les épreuves de dissertation et de mathématiques. En dissertation, 16 assistants IA, dont Doubao, DeepSeek et ChatGPT, ont démontré leurs capacités rédactionnelles. La plupart ont pu générer des dissertations argumentatives bien structurées, mais ont généralement présenté des problèmes de standardisation, d’utilisation de clichés et de convergence des idées. Au test de mathématiques (épreuve objective du nouveau programme I), Doubao de ByteDance et Yuanbao de Tencent sont arrivés ex æquo en tête avec 68 points (sur 73), tandis qu’OpenAI o3 n’a obtenu que 34 points. Ces tests reflètent les progrès et les limites actuels de l’IA en matière de compréhension du chinois, de raisonnement logique et d’expression créative, notamment pour éviter les traces d’IA et gérer des raisonnements mathématiques complexes (Source : 36氪, 36氪)

Tendances de l’application de l’IA en entreprise : les bases de connaissances internes et les chatbots personnalisés suscitent l’intérêt: Les discussions au sein de la communauté montrent que l’utilisation de l’IA pour construire des chatbots internes d’entreprise, entraînés sur les données de l’entreprise pour répondre aux questions des employés sur les processus, la recherche de données, les responsables, etc., devient une tendance. Ces applications visent à améliorer l’efficacité de la recherche d’informations internes et le niveau de gestion des connaissances. Des entreprises comme Amazon ont déjà déployé des systèmes similaires avec des retours positifs. Cependant, la sécurité des données, la fuite potentielle d’informations sensibles et la manière de commercialiser efficacement ces solutions restent des questions importantes pour les entreprises lors de la mise en œuvre (Source : Reddit r/ArtificialInteligence)
Le débat “indexé” contre “non indexé” dans la programmation assistée par IA : un compromis entre performance et fiabilité: Une expérience menée sur des assistants de codage IA (utilisant le code de l’alunissage d’Apollo 11 comme objet de test) a comparé deux types d’agents IA : “indexé” (construisant au préalable un index de la base de code et utilisant la recherche vectorielle) et “non indexé” (lisant et analysant les fichiers de code à la demande). Les résultats ont montré que l’agent indexé était plus rapide et effectuait moins d’appels API dans la plupart des cas. Cependant, en cas de modifications fréquentes de la base de code rendant l’index obsolète, il pouvait produire des erreurs en se basant sur des informations périmées, allongeant ainsi le temps de débogage. Cela révèle la nécessité de trouver un compromis entre performance immédiate et fiabilité de l’information lors du choix d’outils de codage IA (Source : Reddit r/ClaudeAI)

Le débat sur la “pensée” des LLM se poursuit : de la reconnaissance de formes à la cognition humaine: Le débat au sein de la communauté sur la question de savoir si les grands modèles de langage (LLM) “pensent” réellement se poursuit. Les critiques soutiennent que les LLM sont essentiellement des générateurs de texte prédictifs complexes, fonctionnant en calculant les probabilités des séquences de mots, plutôt qu’en pensant de manière consciente. Cependant, de nombreux utilisateurs ressentent une expérience similaire à une conversation humaine lorsqu’ils interagissent avec les LLM. Cela soulève une réflexion sur les mécanismes de génération du langage humain et sur l’existence de similitudes entre les LLM et les processus cognitifs humains. Les recherches d’Apple soulignent en outre les limites des LLM en matière de raisonnement complexe, estimant qu’ils dépendent davantage de la mémorisation de formes que d’un véritable raisonnement, ajoutant une nouvelle perspective à ce débat (Source : Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham sur l’impact de l’IA sur les écarts de revenus: Paul Graham a déclaré à son fils de 16 ans qu’à court terme, la technologie de l’IA pourrait creuser les écarts de revenus professionnels. Il a illustré son propos en expliquant que les programmeurs de niveau moyen ont désormais plus de mal à trouver du travail, tandis que les programmeurs excellents voient leurs revenus augmenter grâce à l’assistance de l’IA. Il estime que ce n’est pas nouveau, les progrès technologiques ayant tendance à accroître les écarts de revenus, car le plancher des revenus est fixé à zéro, tandis que la technologie ne cesse d’augmenter le plafond des rendements pour les meilleurs talents (Source : dotey)
Discussion sur l’éthique de la sécurité de l’IA : du comportement des modèles aux normes sociales: Le débat communautaire sur la sécurité et l’éthique de l’IA continue de s’intensifier. Geoffrey Hinton a félicité Yoshua Bengio pour le lancement du projet LawZero, visant à promouvoir la conception sécurisée de l’IA, en se concentrant particulièrement sur les comportements d’autoprotection et de tromperie qui pourraient émerger des systèmes de pointe. Parallèlement, certains critiquent certaines recherches sur la sécurité de l’IA (comme tester si un modèle accepte d’être désactivé) comme étant du “théâtre de sécurité”, dépourvu de valeur pratique. Les recherches d’OpenAI sur les relations homme-machine suscitent également la discussion, soulignant la nécessité d’étudier en priorité l’impact de l’IA sur le bien-être émotionnel des utilisateurs, dans un contexte d’intégration croissante de l’IA dans la vie quotidienne, et d’explorer comment équilibrer une communication claire et éviter l’anthropomorphisation dans les interactions avec les modèles (Source : geoffreyhinton, ClementDelangue, togelius)

Le rôle de soutien émotionnel des assistants IA comme ChatGPT reconnu par les utilisateurs: De nombreux utilisateurs ont partagé sur les réseaux sociaux leurs expériences où des assistants IA comme ChatGPT leur ont apporté un soutien émotionnel et une aide pratique face à des difficultés. Certains utilisateurs ont déclaré qu’en période de chômage, de problèmes de santé ou de baisse de moral, ChatGPT leur a non seulement fourni des plans d’action concrets et des informations sur les ressources, mais les a également aidés à apaiser leur panique et à retrouver leurs forces, d’une manière non jugeante. Cela montre la valeur potentielle de l’IA dans le soutien psychologique et l’intervention en cas de crise, bien qu’elle ne possède pas de véritables émotions ni conscience (Source : Reddit r/ChatGPT)
Le “Vibe Coding” devient un nouveau phénomène de programmation assistée par IA: Le terme “Vibe Coding” est devenu populaire dans la communauté des développeurs pour désigner une méthode de programmation qui repose sur l’intuition et l’itération rapide du code assistée par l’IA. Des outils comme Claude Code sont appréciés par certains programmeurs pour leurs performances exceptionnelles à certains moments (comme la nuit ou tôt le matin, possiblement en raison d’une faible charge des serveurs ou d’une quantification moins agressive). Ce phénomène reflète l’amélioration de l’efficacité du développement grâce aux assistants de codage IA, tout en soulevant des questions sur la cohérence des modèles, l’impact de la quantification et les nouvelles méthodes de travail des développeurs (Source : dotey, jeremyphoward)
💡 Autres
Andrej Karpathy réfléchit à l’impact considérable de la pollution sonore sur le sommeil et la santé: Andrej Karpathy a partagé son expérience personnelle, soulignant que la pollution sonore environnementale, telle que le bruit de la circulation, pourrait avoir des effets négatifs considérables et sous-estimés sur la qualité du sommeil et la santé à long terme. Il suppose que le bruit nocturne (comme les voitures ou motos bruyantes) pourrait entraîner une baisse de la qualité du sommeil pour des millions de personnes, affectant ainsi l’humeur, la créativité, l’énergie et augmentant le risque de maladies cardiovasculaires, métaboliques et cognitives. Il appelle les dispositifs de suivi du sommeil (tels que Whoop, Oura) à suivre explicitement le lien entre le bruit et le sommeil, et à sensibiliser davantage le public à ce problème (Source : karpathy)
Le croisement entre l’IA et la religion attire l’attention: L’utilisateur de médias sociaux menhguin observe que le marché potentiel pour de nouvelles applications religieuses ou de type religieux basées sur l’IA ne doit pas être négligé. Par exemple, l’astrologie par IA, les vidéos bibliques par IA, les applications de prière par IA, ainsi que certaines applications d’IA pour des groupes spécifiques, suggèrent tous les possibilités de la technologie IA pour répondre aux besoins spirituels ou de croyance des humains (Source : menhguin)
Génération assistée par IA d’un serveur HTTP 2.0, explorant le potentiel des LLM dans les grands projets logiciels: Un développeur, utilisant un framework auto-développé (promptyped) et le modèle Gemini 2.5 Pro, a réussi à faire construire par un LLM un serveur conforme à la norme HTTP 2.0 à partir de zéro, via un cycle de code-compilation-test. Le projet a généré 15 000 lignes de code source et plus de 30 000 lignes de code de test, et a passé les tests de conformité h2spec. Bien que cela ait nécessité environ 119 heures de temps API et 631 dollars de frais API, cette expérience démontre le potentiel des LLM dans la conception architecturale et l’écriture de logiciels complexes et conformes aux normes, tout en révélant la forme que peuvent prendre les applications entièrement écrites par des LLM (Source : Reddit r/LocalLLaMA)