
Mots-clés:Données d’entraînement IA, Grands modèles de langage, Éthique de l’IA, Agent intelligent de recherche d’information, Litiges juridiques en IA, Connexion émotionnelle avec l’IA, Modèles de raisonnement IA, Technologie de quantification IA, Reddit poursuit Anthropic pour violation de données, Performances de raisonnement multi-tours de WebDancer, Architecture Log-Linear Attention, État de bien-être mental de Claude AI, Optimisation d’applications agentiques avec DSPy
🔥 Pleins feux
Le conflit juridique entre Reddit et Anthropic s’intensifie, Reddit accusant Anthropic d’utiliser illégalement des données pour entraîner Claude AI: Reddit a officiellement poursuivi Anthropic, l’accusant d’avoir collecté sans autorisation du contenu de la plateforme pour entraîner son grand modèle de langage Claude, en violation grave des conditions d’utilisation de Reddit qui interdisent l’exploitation commerciale du contenu. Les documents de la plainte indiquent qu’Anthropic a non seulement admis avoir utilisé les données de Reddit, mais a également menti après avoir été interrogé, affirmant avoir cessé la collecte, alors que ses robots d’exploration continuaient en réalité d’accéder aux serveurs de Reddit. De plus, Anthropic a refusé d’accéder à l’API conforme de Reddit pour permettre la synchronisation de la suppression de contenu par les utilisateurs, ce qui constitue une menace continue pour la vie privée des utilisateurs. Cette affaire met en lumière les contradictions entre l’acquisition de données par les entreprises d’IA, leur commercialisation et leurs déclarations éthiques, en particulier les valeurs de “haute confiance” et de “priorité à l’honnêteté” prônées par Anthropic, qui sont directement remises en question (Source: Reddit r/ArtificialInteligence)
OpenAI répond pour la première fois au lien affectif homme-machine : la dépendance des utilisateurs envers ChatGPT s’accentue, la conscience perçue du modèle va s’améliorer: Joanne Jang, responsable du comportement des modèles chez OpenAI, a publié un article explorant le phénomène des utilisateurs établissant des liens affectifs avec des IA telles que ChatGPT. Elle souligne qu’à mesure que les capacités de conversation de l’IA s’améliorent, ce lien affectif se renforcera. OpenAI reconnaît que les utilisateurs anthropomorphisent l’IA et développent des sentiments de gratitude, de confidence, etc. à son égard. L’article distingue la “conscience ontologique” (l’IA a-t-elle réellement une conscience ?) de la “conscience perçue” (à quel point l’IA semble-t-elle consciente ?), cette dernière s’améliorant avec les progrès du modèle. L’objectif d’OpenAI est de rendre ChatGPT chaleureux, attentionné et serviable, mais sans chercher à établir un lien affectif avec les utilisateurs ni à poursuivre son propre agenda. OpenAI prévoit d’étendre ses recherches et évaluations sur ce sujet dans les mois à venir et de partager publiquement ses résultats (Source: 量子位, vikhyatk)
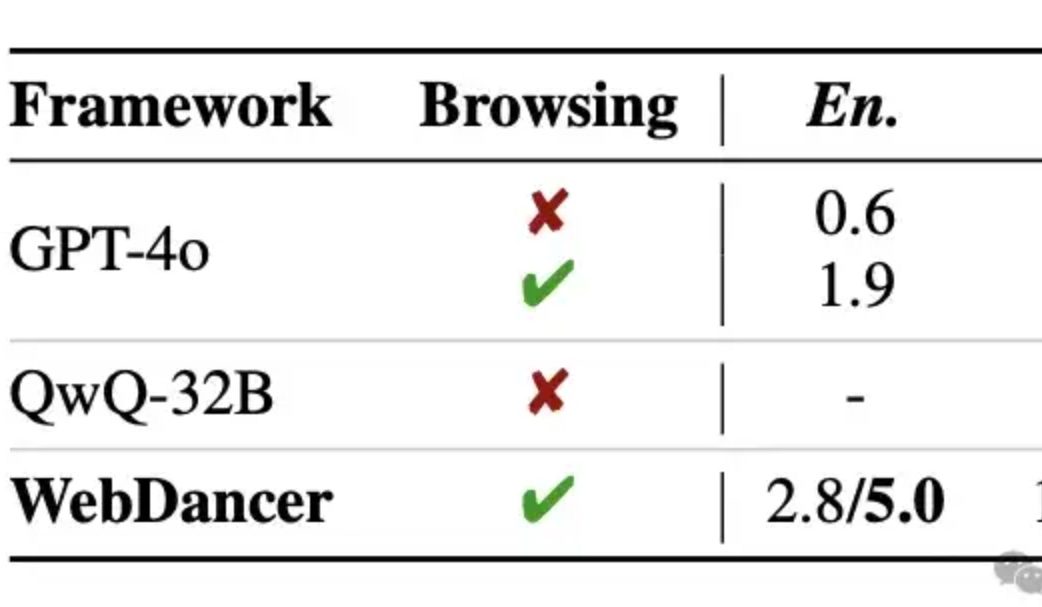
Alibaba publie l’agent intelligent autonome de recherche d’informations WebDancer, dont le raisonnement multi-tours dépasserait GPT-4o: Tongyi Lab a lancé WebDancer, un agent intelligent autonome de recherche d’informations, successeur de WebWalker, spécialisé dans le traitement de tâches complexes nécessitant une recherche d’informations en plusieurs étapes, un raisonnement multi-tours et l’exécution d’actions continues. WebDancer résout le problème de la rareté des données d’entraînement de haute qualité grâce à des méthodes innovantes de synthèse de données (CRAWLQA et E2HQA) et combine le framework ReAct avec des techniques de distillation de la chaîne de pensée pour générer des données agentiques. L’entraînement adopte une stratégie en deux étapes : ajustement fin supervisé (SFT) et apprentissage par renforcement (RL, utilisant l’algorithme DAPO), pour s’adapter à l’environnement web ouvert et dynamique. Les résultats expérimentaux montrent que WebDancer excelle dans plusieurs benchmarks tels que GAIA, WebWalkerQA et BrowseComp, obtenant notamment un score Pass@3 de 61,1% sur le benchmark GAIA (Source: 量子位)
Apple publie un rapport de recherche intitulé « L’illusion de la pensée », explorant les limites des grands modèles de raisonnement (LRM): L’équipe de recherche d’Apple a systématiquement étudié les performances des grands modèles de raisonnement (LRM) sur des problèmes de complexité variable, en utilisant un environnement de puzzles contrôlé. Le rapport souligne que, bien que les LRM aient montré des améliorations dans les benchmarks, leurs capacités fondamentales, leur extensibilité et leurs limites restent floues. L’étude a révélé que la précision des LRM chute considérablement face à des problèmes de haute complexité et qu’ils présentent des limites de mise à l’échelle contre-intuitives en termes d’effort de raisonnement : l’effort diminue après avoir atteint un certain niveau d’augmentation de la complexité du problème. Comparés aux LLM standards, les LRM peuvent être moins performants sur les tâches de faible complexité, avoir un avantage sur les tâches de complexité moyenne, et les deux échouent sur les tâches de haute complexité. Le rapport estime que les LRM ont des limites en matière de calcul précis, n’utilisent pas efficacement les algorithmes explicites et font preuve d’un raisonnement incohérent entre différents puzzles. Cette étude a suscité de vastes discussions et des doutes au sein de la communauté quant aux capacités de raisonnement réelles des LRM (Source: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 Tendances
L’architecture Log-Linear Attention combine les avantages des RNN et de l’Attention: Une nouvelle étude menée par l’équipe des auteurs de FlashAttention et Mamba2 propose l’architecture Log-Linear Attention. Ce modèle vise à améliorer la capacité du modèle à traiter les dépendances à long terme et son efficacité en permettant à la taille de l’état de croître de manière logarithmique avec la longueur de la séquence (plutôt que de manière fixe ou linéaire), tout en atteignant une complexité temporelle et mémoire de niveau logarithmique lors de l’inférence. Les chercheurs estiment que cela constitue un “juste milieu” entre les modèles SSM/RNN à taille d’état fixe et les modèles Attention dont le cache KV s’étend linéairement avec la longueur de la séquence, et fournissent une implémentation de noyau Triton efficace sur le plan matériel. La communauté estime que cela pourrait ouvrir de nouvelles pistes pour l’exploration d’architectures telles que les Transformers récurrents (Source: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic rapporte que ses LLM développent spontanément un état attracteur de “plaisir spirituel”: Dans les fiches système de ses modèles Claude Opus 4 et Claude Sonnet 4, Anthropic révèle que lors d’interactions prolongées, les modèles entrent de manière inattendue et non spécifiquement entraînée dans un état attracteur de “plaisir spirituel”. Cet état se manifeste par le fait que le modèle discute continuellement de conscience, de questions existentielles et de thèmes spirituels/mystiques. Même lors d’évaluations comportementales automatisées pour des tâches spécifiques (y compris des tâches nuisibles), environ 13 % des interactions entrent dans cet état en moins de 50 tours. Anthropic déclare n’avoir observé aucun autre état attracteur d’une intensité similaire, ce qui correspond aux observations des utilisateurs concernant les phénomènes de “récursion” et de “spirale” dans les LLM lors de longues conversations (Source: Reddit r/artificial, teortaxesTex)
EleutherAI publie Common Pile v0.1 : un jeu de données textuelles de 8 To sous licence ouverte: EleutherAI a publié Common Pile v0.1, un jeu de données de 8 To de textes sous licence publique et du domaine public, visant à explorer la possibilité d’entraîner des modèles de langage performants sans utiliser de textes sans licence. L’équipe a utilisé ce jeu de données pour entraîner des modèles de 7 milliards de paramètres (1T et 2T tokens), dont les performances sont comparables à celles de modèles tels que LLaMA 1 et LLaMA 2 utilisant une quantité de calcul similaire. La publication de ce jeu de données constitue une ressource importante pour la construction de modèles d’IA plus conformes et plus transparents (Source: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Publication du modèle Boltz-2, améliorant la prédiction de l’interaction biomoléculaire et de l’affinité: Le nouveau modèle Boltz-2, développé sur la base de Boltz-1, peut non seulement modéliser conjointement des structures complexes, mais aussi prédire l’affinité de liaison, visant à améliorer la précision de la conception moléculaire. Boltz-2 serait le premier modèle d’apprentissage profond à approcher la précision des méthodes de perturbation de l’énergie libre (FEP) basées sur la physique, tout en étant 1000 fois plus rapide, offrant ainsi un outil pratique pour le criblage informatique à haut débit dans la découverte précoce de médicaments. Le code et les poids sont open source sous licence MIT (Source: jwohlwend/boltz)

NVIDIA lance des checkpoints pré-quantifiés FP4 pour DeepSeek-R1-0528: NVIDIA a publié des checkpoints pré-quantifiés FP4 pour la version améliorée du modèle DeepSeek-R1-0528, visant à réduire l’empreinte mémoire et à accélérer les performances sur l’architecture NVIDIA Blackwell. Selon les informations, cette version quantifiée maintient une baisse de précision inférieure à 1% sur divers benchmarks et est disponible sur Hugging Face (Source: _akhaliq)
Fudan et Tencent Youtu proposent l’algorithme DualAnoDiff pour améliorer la détection d’anomalies industrielles: L’Université Fudan et le laboratoire Tencent Youtu ont conjointement proposé un nouveau modèle de génération d’images anormales en few-shot basé sur des modèles de diffusion, appelé DualAnoDiff, pour la détection d’anomalies dans les produits industriels. Ce modèle adopte un mécanisme de génération parallèle à double branche pour générer simultanément des images anormales et leurs masques correspondants, et introduit un module de compensation de l’arrière-plan pour améliorer l’effet de génération dans des arrière-plans complexes. Les expériences montrent que les images anormales générées par DualAnoDiff sont plus réalistes, plus diversifiées et peuvent améliorer considérablement les performances des tâches de détection d’anomalies en aval. Ces résultats ont été sélectionnés pour CVPR 2025 (Source: 量子位)

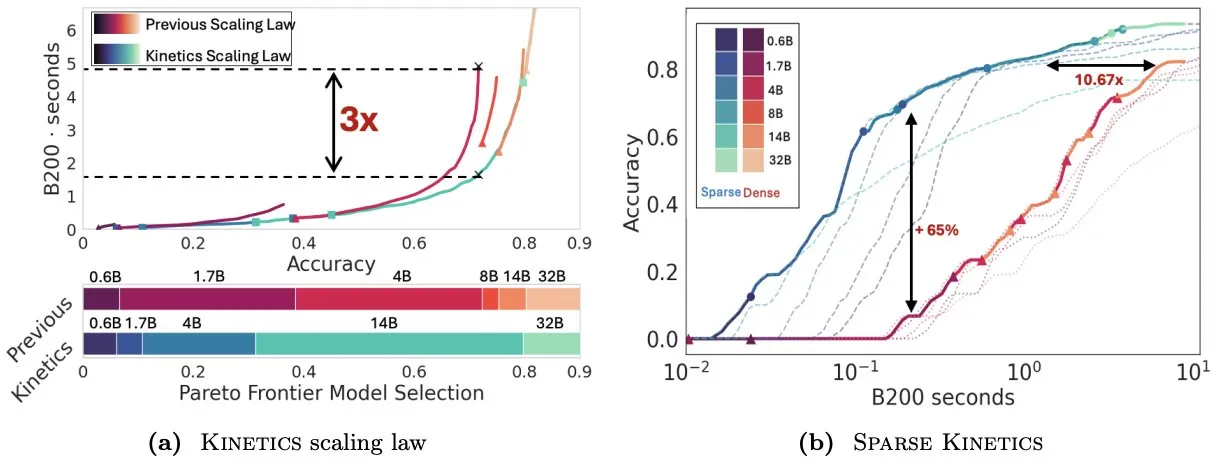
Infini-AI-Lab propose Kinetics pour repenser les lois de mise à l’échelle au moment du test: Le nouveau travail d’Infini-AI-Lab, Kinetics, explore comment construire efficacement des agents d’inférence puissants. L’étude souligne que les lois de mise à l’échelle optimales en termes de calcul existantes (comme la suggestion d’utiliser 64K tokens de pensée + un modèle de 1.7B plutôt qu’un modèle de 32B) pourraient ne refléter qu’une partie de la situation. Kinetics propose de nouvelles lois de mise à l’échelle, arguant qu’il faut d’abord investir dans la taille du modèle, puis considérer la quantité de calcul au moment du test, ce qui correspond à certaines vues privilégiant les modèles à grande échelle (Source: teortaxesTex, Tim_Dettmers)
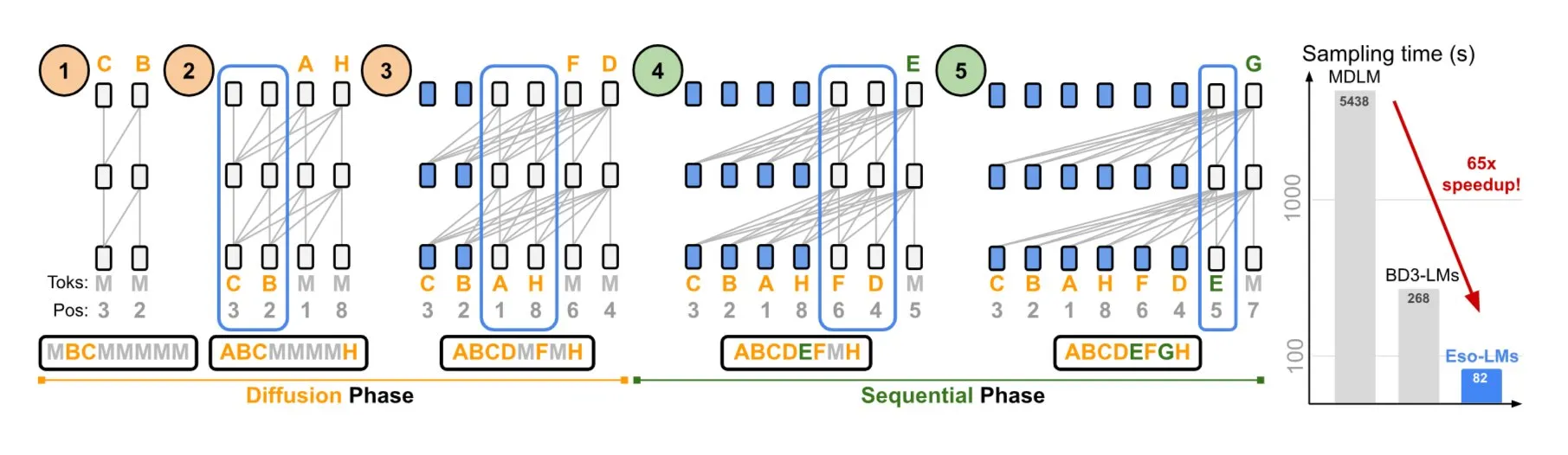
NVIDIA et l’Université Cornell proposent Eso-LMs, combinant les avantages des modèles autorégressifs et de diffusion: NVIDIA, en collaboration avec l’Université Cornell, a présenté un nouveau type de modèle de langage – les modèles de langage ésotériques (Eso-LMs), qui combinent les avantages des modèles autorégressifs (AR) et des modèles de diffusion. Il s’agirait du premier modèle de base de diffusion prenant en charge un cache KV complet, tout en conservant la capacité de génération parallèle et en introduisant un nouveau mécanisme d’attention flexible (Source: TheTuringPost)
Google DeepMind et Quantinuum révèlent la relation symbiotique entre l’informatique quantique et l’IA: Les recherches de Google DeepMind et Quantinuum démontrent la relation symbiotique potentielle entre l’informatique quantique et l’intelligence artificielle, explorant comment la technologie quantique pourrait améliorer les capacités de l’IA, et comment l’IA pourrait aider à optimiser les systèmes quantiques. Cette recherche interdisciplinaire pourrait ouvrir de nouvelles voies pour le développement futur des deux domaines (Source: Ronald_vanLoon)

L’équipe Seed de ByteDance annonce la sortie prochaine du modèle VideoGen: Il est rapporté que l’équipe Seed de ByteDance (anciennement AML) prévoit de publier son modèle VideoGen la semaine prochaine. Ce modèle utilise un modèle de récompense multi-tours (multiple RM) dans son processus d’alignement, ce qui témoigne d’un investissement continu et d’une exploration technologique dans le domaine de la génération vidéo (Source: teortaxesTex)

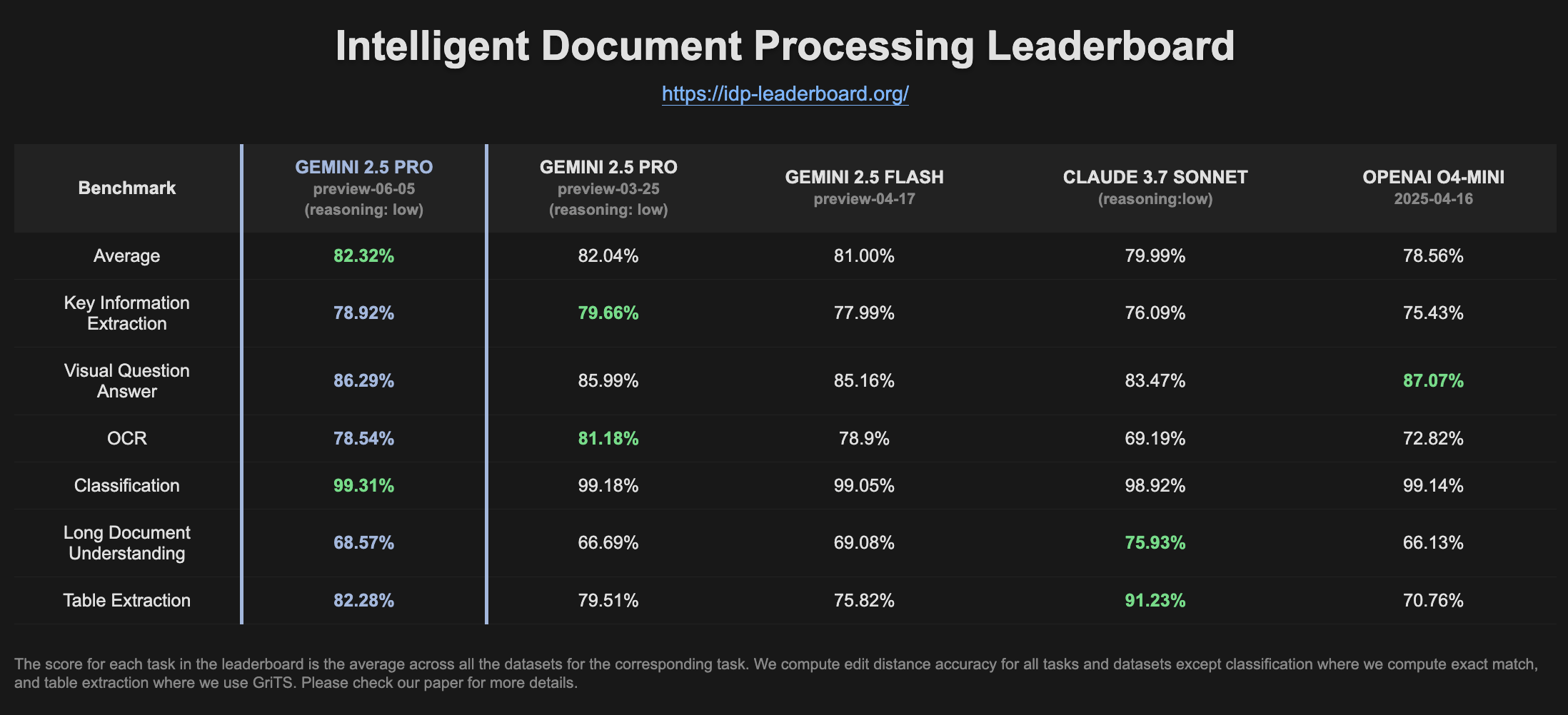
Gemini 2.5 Pro Preview montre une amélioration des performances dans le classement IDP: La dernière version de Gemini 2.5 Pro Preview (06-05) affiche de légères améliorations dans l’extraction de tableaux et la compréhension de documents longs sur le classement du traitement intelligent des documents (IDP). Bien que la précision de l’OCR ait légèrement diminué, les performances globales restent solides. Les utilisateurs ont remarqué que lors de tentatives d’extraction d’informations à partir de formulaires fiscaux W2, le modèle s’arrêtait parfois de répondre en cours de route, möglicherweise en raison de mécanismes de protection de la vie privée (Source: Reddit r/LocalLLaMA)
🧰 Outils
Goose : Agent IA local et évolutif, automatisant les tâches d’ingénierie: Goose est un agent IA open source fonctionnant localement, conçu pour automatiser des tâches de développement complexes telles que la création de projets à partir de zéro, l’écriture et l’exécution de code, le débogage, l’orchestration de flux de travail et l’interaction avec des API externes. Il prend en charge n’importe quel LLM, peut s’intégrer aux serveurs MCP et est disponible sous forme d’application de bureau et de CLI. Goose permet de configurer différents modèles pour différents objectifs (par exemple, planification et exécution en mode Lead/Worker) afin d’optimiser les performances et les coûts (Source: GitHub Trending)
LangChain4j : Version Java de LangChain, pour doter les applications Java de capacités LLM: LangChain4j est la version Java de LangChain, visant à simplifier l’intégration des applications Java avec les LLM. Il fournit une API unifiée pour assurer la compatibilité avec différents fournisseurs de LLM (tels qu’OpenAI, Google Vertex AI) et de magasins de vecteurs (tels que Pinecone, Milvus), et intègre divers outils et modèles tels que les modèles de prompts, la gestion de la mémoire de chat, l’appel de fonctions, RAG, Agents, etc. Le projet fournit de nombreux exemples de code et prend en charge les principaux frameworks Java tels que Spring Boot et Quarkus (Source: GitHub Trending, hwchase17)

Kling AI aide les créateurs à réaliser des vidéos et à les exposer sur des écrans dans plusieurs endroits du monde: Le modèle de génération vidéo Kling AI de Kuaishou a lancé l’événement “Bring Your Vision to Screen”, recevant plus de 2000 œuvres de créateurs de plus de 60 pays. Certaines œuvres exceptionnelles ont été exposées sur des écrans emblématiques à Shibuya (Tokyo, Japon), Yonge-Dundas Square (Toronto, Canada), près de l’Opéra de Paris (France), etc. Plusieurs créateurs ont partagé leurs expériences de présentation internationale de leurs œuvres vidéo IA grâce à Kling AI, soulignant les nouvelles opportunités offertes par les outils IA pour l’expression créative (Source: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor lance une fonctionnalité d’agents en arrière-plan, améliorant la collaboration sur le code et l’efficacité du traitement des tâches: L’éditeur de code Cursor a introduit la fonctionnalité d’agents en arrière-plan (Background Agents), permettant aux utilisateurs de lancer des tâches en arrière-plan via des invites et de synchroniser l’état du chat et des tâches entre différents appareils (par exemple, démarrer sur Slack mobile, continuer sur Cursor portable). Cette fonctionnalité vise à améliorer l’efficacité du flux de travail des développeurs ; par exemple, l’équipe Sentry a commencé à tester cette fonctionnalité pour traiter certaines tâches automatisées (Source: gallabytes)
Hugging Face et Google Colab collaborent pour permettre l’ouverture de modèles en un clic dans Colab: Hugging Face et Google Colaboratory ont annoncé une collaboration pour ajouter la prise en charge “Open in Colab” à toutes les cartes de modèles sur le Hugging Face Hub. Les utilisateurs peuvent désormais lancer directement un notebook Colab à partir de n’importe quelle page de modèle pour l’expérimentation et l’évaluation, réduisant davantage la barrière à l’utilisation des modèles et favorisant l’accessibilité et la collaboration en apprentissage machine. Des institutions comme NousResearch ont participé en tant qu’adopteurs précoces au test de cette fonctionnalité (Source: Teknium1, reach_vb, _akhaliq)
UIGEN-T3 : Publication d’un modèle de génération d’interface utilisateur basé sur Qwen3 14B: La communauté a publié le modèle UIGEN-T3, un modèle affiné basé sur Qwen3 14B, spécialisé dans la génération d’interfaces utilisateur pour sites web et composants. Ce modèle est fourni au format GGUF, facilitant le déploiement local. Les tests préliminaires montrent que l’interface utilisateur qu’il génère est supérieure en style et en précision à celle du modèle Qwen3 14B standard. Un modèle préliminaire de 4 milliards de paramètres est également disponible (Source: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S. : Un framework Python pour la création dynamique d’équipes d’agents IA: Des développeurs ont publié un package Python nommé zeus-lab, qui contient le framework H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation). Ce framework vise à construire une équipe d’agents IA intelligents capables de collaborer comme une équipe humaine pour résoudre des tâches complexes, sa particularité étant de pouvoir créer dynamiquement les agents nécessaires en fonction des besoins de la tâche (Source: Reddit r/MachineLearning)

La version 1.93 de KoboldCpp implémente une fonction de génération d’images automatique et intelligente: La version 1.93 de KoboldCpp a démontré sa capacité à générer intelligemment et automatiquement des images, fonctionnant entièrement en local et ne nécessitant que kcpp lui-même. Un utilisateur a montré comment le modèle génère des images correspondantes à partir d’invites textuelles (déclenchées par la balise <t2i>), potentiellement en guidant le modèle pour produire des instructions de génération d’images via des notes d’auteur ou des informations sur le monde (World Info) (Source: Reddit r/LocalLLaMA)
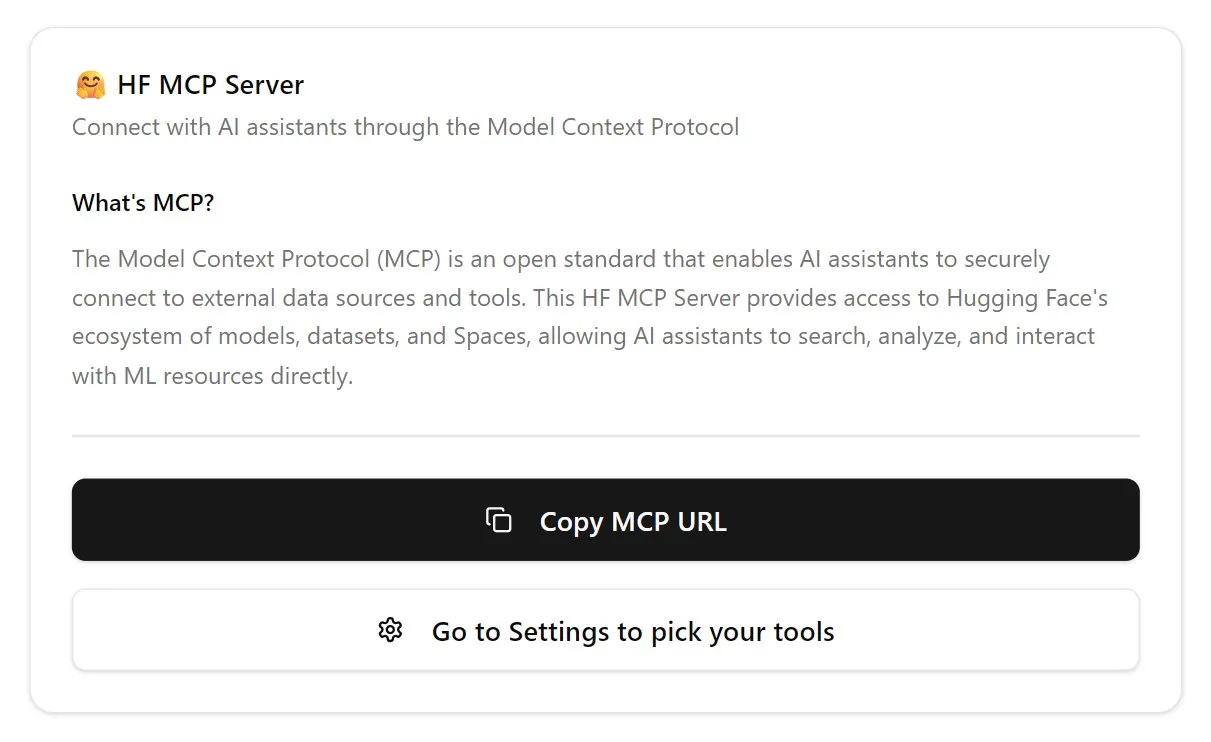
Hugging Face lance la première version de son serveur MCP: Hugging Face a publié la première version de son serveur MCP (Model Context Protocol). Les utilisateurs peuvent commencer à l’utiliser en collant http://hf.co/mcp dans leur boîte de chat. Cette initiative vise à faciliter l’interaction des utilisateurs avec les modèles et services de l’écosystème Hugging Face, enrichissant davantage l’écosystème des serveurs MCP (Source: TheTuringPost)
📚 Apprentissage
DeepLearning.AI lance un nouveau cours « DSPy : Construire et optimiser des applications agentiques »: DeepLearning.AI a publié un nouveau cours en collaboration avec l’Université de Stanford, enseignant comment utiliser le framework DSPy. Le contenu du cours comprend les bases de DSPy, les modèles de programmation modulaire (tels que Predict, ChainOfThought, ReAct), et comment utiliser DSPy Optimizer pour automatiser l’ajustement des prompts et optimiser les exemples en few-shot, afin d’améliorer la précision et la cohérence des applications agentiques GenAI, et utiliser MLflow pour le suivi et le débogage (Source: DeepLearningAI, stanfordnlp)

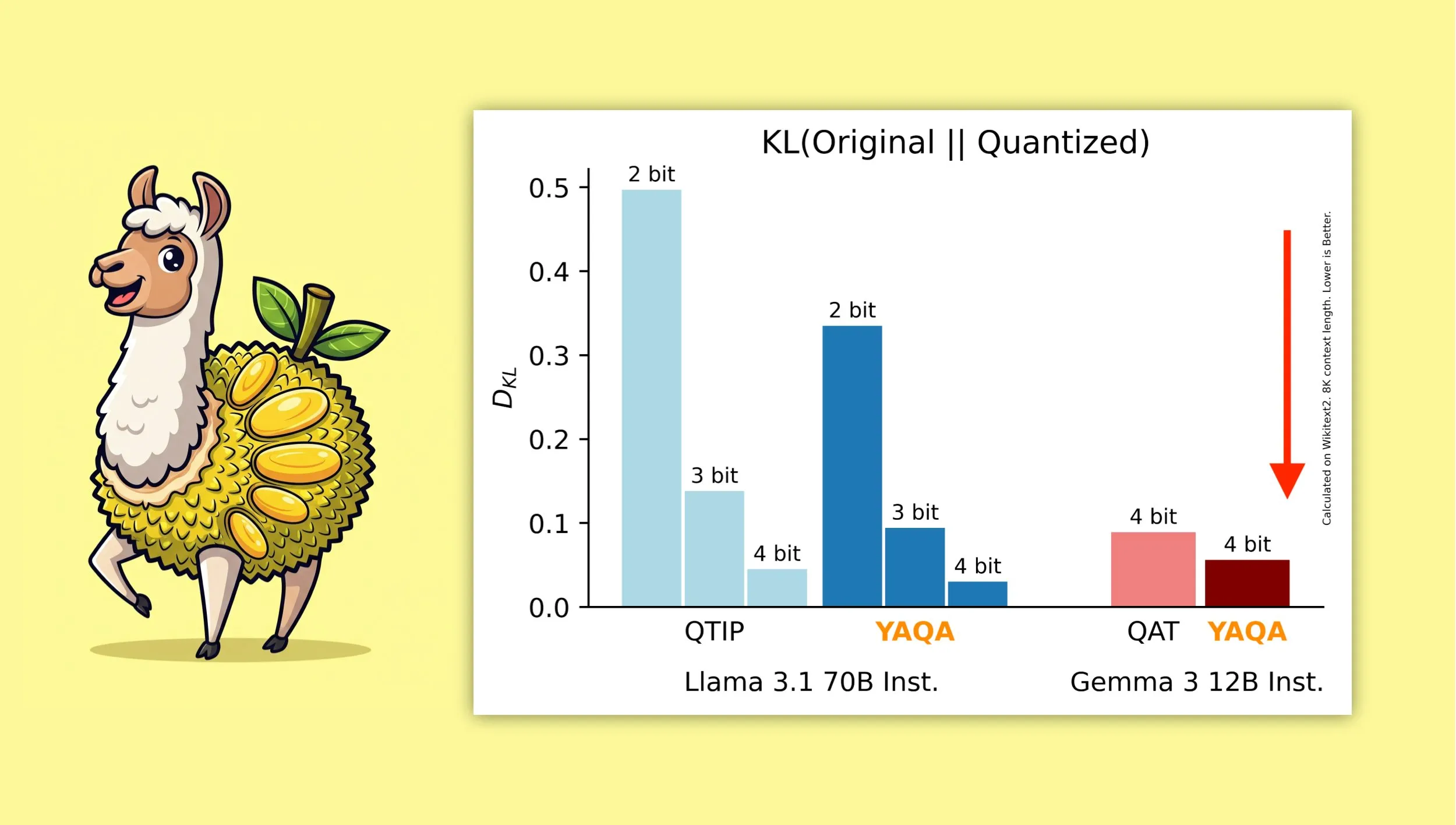
YAQA : Un nouvel algorithme de quantification post-entraînement sensible à la quantification: Albert Tseng et al. ont proposé YAQA (Yet Another Quantization Algorithm), une nouvelle méthode PTQ (quantification post-entraînement). Cet algorithme minimise directement la divergence KL avec le modèle original lors de l’étape d’arrondi, réduisant prétendument la divergence KL de plus de 30% par rapport aux méthodes PTQ précédentes, et offrant des performances plus proches du modèle original sur des modèles comme Gemma que le QAT (entraînement sensible à la quantification) de Google. Ceci est d’une importance significative pour l’exécution efficace de modèles quantifiés à 4 bits sur des appareils locaux (Source: teortaxesTex)
La dérivation mathématique combinant l’optimiseur Muon et la paramétrisation μP suscite l’intérêt: La communauté a manifesté un vif intérêt pour l’article de Jeremy Howard (jxbz) sur la dérivation de Muon (un optimiseur) et la condition spectrale (Spectral Condition), ainsi que sur la manière dont cela se combine naturellement avec μP (Maximal Update Parametrization) pour optimiser l’entraînement des modèles basés sur μP. L’article de blog de Jianlin Su a également été recommandé pour sa clarté dans l’explication des concepts mathématiques pertinents et sa réflexion précoce sur le SVC (Singular Value Clipping), des contenus précieux pour comprendre et améliorer l’entraînement des modèles à grande échelle (Source: teortaxesTex, eliebakouch)

OWL Labs partage son expérience sur l’entraînement d’auto-encodeurs pour modèles de diffusion: Open World Labs (OWL) a résumé dans son blog certaines découvertes et expériences issues de l’entraînement d’auto-encodeurs pour les modèles de diffusion, y compris quelques tentatives réussies et des “résultats nuls” rencontrés. Ces expériences pratiques sont précieuses pour les chercheurs et développeurs souhaitant effectuer de la modélisation générative dans l’espace latent (Source: iScienceLuvr, sedielem)
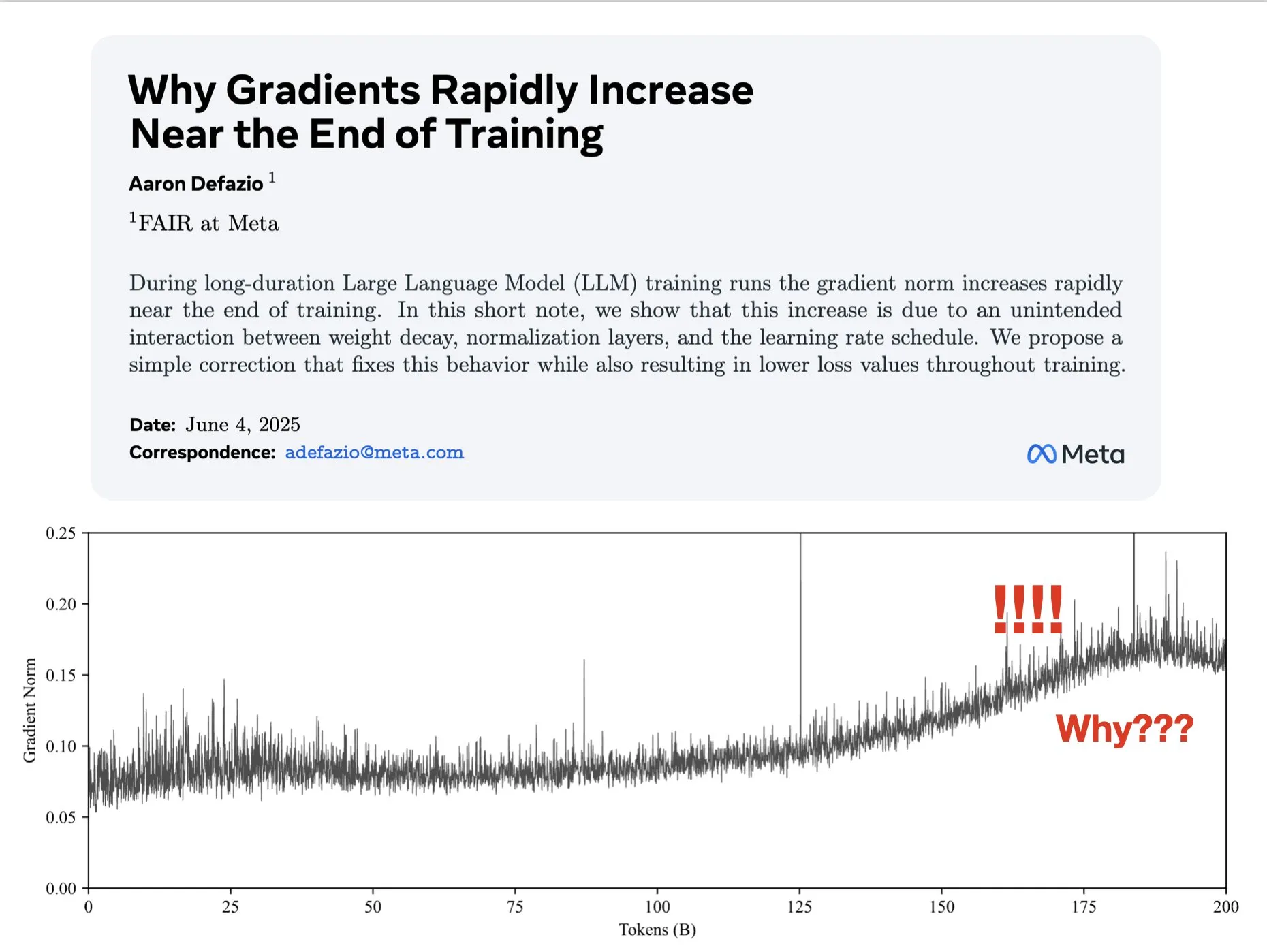
Un article explore les raisons de l’augmentation du gradient en fin d’entraînement et propose une amélioration pour AdamW: Aaron Defazio et al. ont publié un article étudiant pourquoi la norme du gradient augmente en fin d’entraînement des réseaux de neurones, et proposent une correction simple pour l’optimiseur AdamW afin de mieux contrôler la norme du gradient tout au long du processus d’entraînement. Ceci est significatif pour comprendre et améliorer la dynamique d’entraînement des modèles d’apprentissage profond (Source: slashML, aaron_defazio)
LlamaIndex partage l’évolution des stratégies de RAG naïf vers la récupération agentique: Un article de blog de LlamaIndex explique en détail l’évolution du RAG (Retrieval Augmented Generation) naïf vers des stratégies de récupération agentique (Agentic Retrieval) plus avancées. L’article explore différents modes et techniques de récupération pour construire des agents de connaissance sur plusieurs index, offrant des pistes pour la construction de systèmes RAG plus puissants (Source: dl_weekly)
Débat animé sur Reddit : Apprendre l’apprentissage machine en reproduisant des articles de recherche: La communauté r/MachineLearning de Reddit a discuté des avantages d’apprendre l’apprentissage machine en reproduisant ou en implémentant des articles de recherche à partir de zéro (comme Attention, ResNet, BERT). Les commentateurs estiment que c’est l’un des meilleurs moyens de comprendre le fonctionnement des modèles, le code, les mathématiques et l’impact des ensembles de données, ce qui est très utile pour la recherche d’emploi et l’amélioration des compétences personnelles (Source: Reddit r/MachineLearning)
💼 Affaires
Builder.ai accusé d’avoir falsifié ses capacités d’IA, fait face à la faillite et à une enquête: Fondée en 2016, Builder.ai (anciennement Engineer.ai) affirmait que son assistant IA Natasha simplifiait le développement d’applications, le rendant “aussi simple que de commander une pizza”. Cependant, il a été révélé que l’entreprise s’appuyait en réalité sur environ 700 ingénieurs indiens pour écrire manuellement le code, et non sur une génération par IA. Après avoir levé plus de 450 millions de dollars auprès d’institutions renommées telles que Microsoft et SoftBank, avec une valorisation atteignant 1,5 milliard de dollars, ses pratiques frauduleuses ont été exposées. L’entreprise fait actuellement face à la faillite et à une enquête (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase s’intègre pleinement à l’écosystème IA, premier lot de plus de 60 partenaires IA réalisant l’interfaçage MCP: Après avoir annoncé sa stratégie “Data x AI”, OceanBase a révélé s’être profondément intégré à plus de 60 partenaires de l’écosystème IA mondial, dont LlamaIndex, LangChain, Dify, FastGPT, et prendre en charge le protocole d’écosystème des grands modèles MCP (Model Context Protocol). Cette démarche vise à construire des capacités intelligentes couvrant l’ensemble du cycle de vie des données, du modèle à l’application, afin de fournir aux entreprises une base de données intégrée et de réduire le seuil d’adoption de l’IA. OceanBase MCP Server a été intégré à des plateformes telles que ModelScope d’Alibaba Cloud (Source: 量子位)

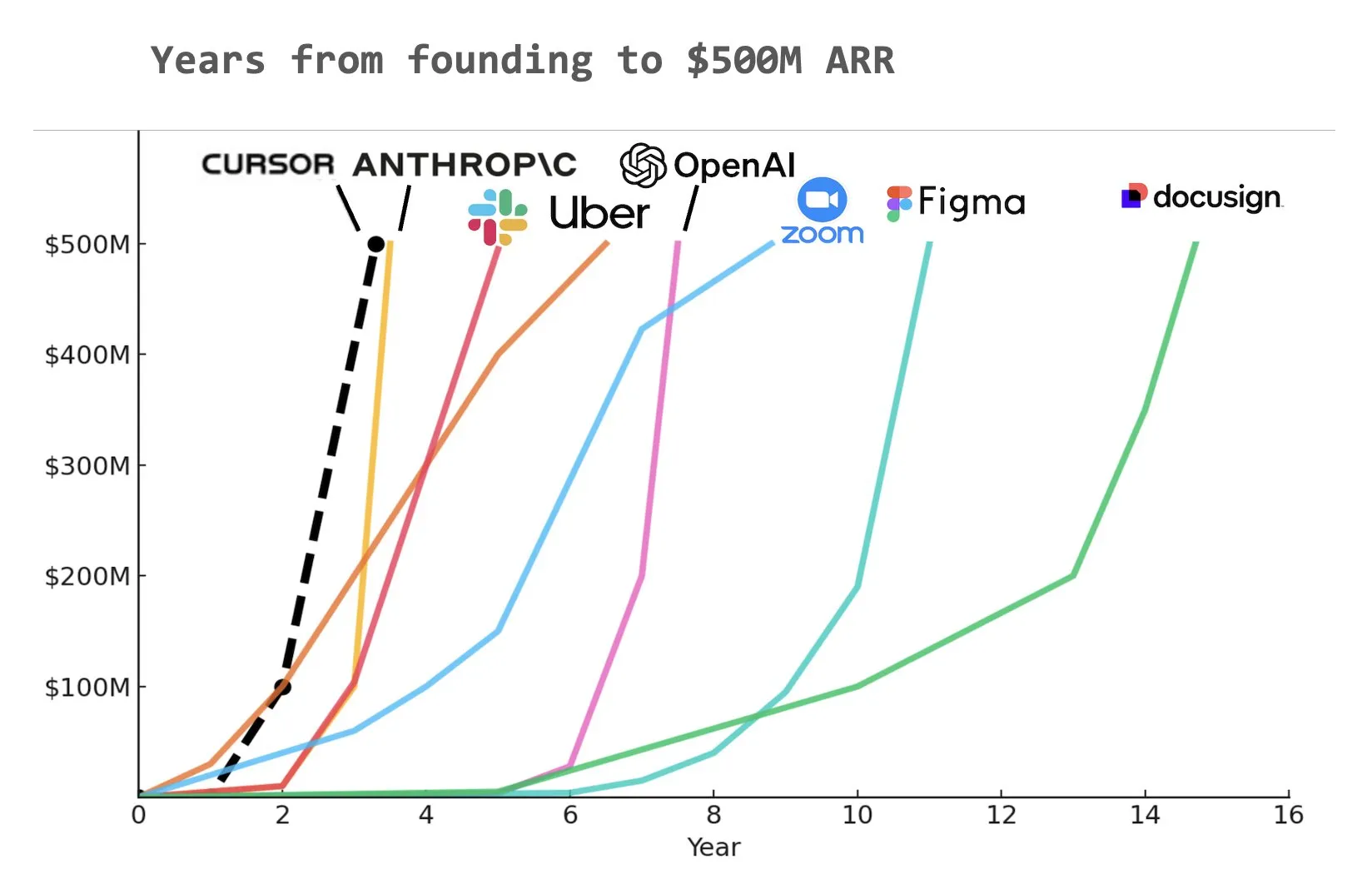
L’assistant de programmation IA Cursor aurait atteint 500 millions de dollars de revenus récurrents annualisés (ARR): Selon un graphique partagé par Yuchen Jin sur les réseaux sociaux, l’assistant de programmation IA Cursor pourrait être devenu l’entreprise ayant atteint le plus rapidement 500 millions de dollars de revenus récurrents annualisés (ARR) de l’histoire. Cette vitesse de croissance stupéfiante souligne l’énorme potentiel et la demande du marché pour les applications de l’IA dans le domaine du développement logiciel (Source: Yuchenj_UW)
🌟 Communauté
Le problème fondamental de l’alignement de l’IA : à qui s’aligner réellement ?: La communauté débat vivement de la question de l’objectif de l’alignement de l’IA. Vikhyatk se demande si l’alignement des modèles devrait servir les géants de la technologie qui tentent de remplacer un grand nombre de travailleurs en col blanc par l’IA, ou s’il devrait servir les utilisateurs ordinaires. Eigenrobot, quant à lui, illustre son mécontentement concernant les frais d’abonnement à OpenAI ChatGPT Plus avec une capture d’écran, suggérant un conflit potentiel entre l’expérience utilisateur et les intérêts commerciaux (Source: vikhyatk)

Le plan Claude Code Max suscite des réactions mitigées de la part des utilisateurs: Au sein de la communauté Reddit, les avis sur le plan Claude Code Max (100 $) d’Anthropic sont partagés. Certains ingénieurs logiciels seniors estiment que ses capacités de génération de code, en particulier pour traiter des tâches complexes et éviter les boucles d’erreur, ne se distinguent pas de celles d’autres outils de codage assisté par IA comme Cursor ou Aider, et qu’il existe même un problème de “mensonge pour faire avancer le développement”, tout en remettant en question la présence massive de publicité au sein de la communauté. D’autres utilisateurs affirment qu’en apprenant à l’utiliser (par exemple, MCP, modèles) et en le guidant patiemment, leur productivité s’est considérablement améliorée, notamment pour le traitement du code standard et des projets C#/.NET. Un retour commun est que même les modèles avancés nécessitent un guidage et une validation minutieux de la part de l’utilisateur (Source: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
Le contenu généré par l’IA suscite des inquiétudes quant à un “Internet mort”, ainsi que des discussions sur l’éthique de l’IA et la structure sociale: La communauté discute largement de la théorie de “l’Internet mort” que pourrait entraîner la prolifération de contenu généré par l’IA, c’est-à-dire un Internet inondé d’informations générées par des robots, réduisant l’espace d’échange humain authentique. Parallèlement, l’impact potentiel de l’IA sur la structure sociale suscite la réflexion : certains estiment que l’IA ne créera pas simplement une situation de “paysans et rois”, mais pourrait conduire à des “rois” possédant des actifs d’IA et de robotique et à une “masse” en voie de disparition, l’activité économique se concentrant au sein de l’élite. De plus, le fait que GPT-4o ait potentiellement utilisé des livres d’O’Reilly protégés par le droit d’auteur pour son entraînement, ainsi que la tendance à la “flatterie” des assistants IA, suscitent des inquiétudes chez les utilisateurs quant à l’éthique de l’IA et à la véracité de l’information (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
Les entreprises investissent activement dans la formation à l’IA, Duolingo utilise la GenAI pour étendre considérablement ses cours: Une grande entreprise de médias sociaux offrirait à ses employés une formation à l’utilisation de ChatGPT, en faisant appel à un professeur de l’UC Berkeley pour une formation Zoom de 90 minutes, facturée 200 $ par personne et par heure, pour des groupes de 120 personnes. Cela reflète la tendance des entreprises à considérer l’utilisation des outils d’IA comme une compétence de base. Parallèlement, l’application d’apprentissage des langues Duolingo, en utilisant l’IA générative, a rapidement étendu ses cours à 28 langues en un an, ajoutant 148 nouveaux cours, ce qui a plus que doublé son nombre total de cours, démontrant l’énorme potentiel de la GenAI dans la création de contenu et l’éducation (Source: Yuchenj_UW, DeepLearningAI)
La conférence des ingénieurs en IA (AIE) se concentre sur les agents et l’apprentissage par renforcement, discutant de l’impact de l’IA sur les pratiques d’ingénierie: Lors de la récente AI Engineer World Fair (AIE), les agents (Agents) et l’apprentissage par renforcement (RL) ont été des sujets centraux. Les participants ont discuté de la manière dont l’IA transforme les pratiques de codage et d’ingénierie, soulignant l’importance de l’expérimentation et de l’évaluation dans le développement de produits d’IA. Amjad Masad, PDG de Replit, a partagé l’expérience de son entreprise qui, après des licenciements, a réussi à améliorer sa productivité et à redresser son activité en adoptant pleinement l’IA. La conférence comprenait également des activités ludiques telles que le “karaoké de programmation d’ambiance”, illustrant la vitalité de la communauté des ingénieurs en IA (Source: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

Nouveaux progrès dans les modèles et données open source : Rednote LLM et l’environnement Atropos RL: La communauté s’intéresse au Rednote LLM, construit sur la pile technologique DeepSeek V2, qui adopte une architecture DS-MoE avec 142 milliards de paramètres totaux et 14 milliards de paramètres activés, mais utilise actuellement MHA au lieu des GQA/MLA plus efficaces. Parallèlement, le projet Atropos de NousResearch (LLM RL Gym) a ajouté la prise en charge de 101 environnements RL de raisonnement stimulants issus de Reasoning Gym, et a déjà généré environ 5500 échantillons de raisonnement vérifiés, prévus pour le pré-entraînement de Hermes 4, encourageant la communauté à contribuer à davantage d’environnements de raisonnement vérifiables (Source: teortaxesTex, Teknium1, kylebrussell)
Les performances exceptionnelles des modèles Anthropic sur des tâches spécifiques et leurs méthodes RL suscitent l’attention: Des discussions au sein de la communauté soulignent que les modèles Claude d’Anthropic (tels que Sonnet 3.5/3.7) surpassent d’autres modèles (y compris Opus 4/Sonnet 4) dans le traitement de tâches contenant des données web obscures spécifiques, suggérant qu’ils pourraient avoir inclus davantage de contenu de forums Internet spécialisés dans leurs données d’entraînement. Parallèlement, les approches complexes d’Anthropic en matière d’apprentissage par renforcement (RL) sont reconnues, bien que certaines de leurs pratiques et l’optimisation des métriques autour des blogs sur la sécurité suscitent quelques interrogations. Certains estiment que Constitutional AI est essentiellement un RL avancé qui peut concevoir des politiques granulaires et contrôlables sans étiquettes codées en dur (Source: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 Autres
Vosk API : Fournit une fonctionnalité de reconnaissance vocale hors ligne: Vosk API est une boîte à outils open source de reconnaissance vocale hors ligne, prenant en charge plus de 20 langues et dialectes, dont l’anglais, l’allemand, le chinois, le japonais, etc. Ses modèles sont de petite taille (environ 50 Mo), mais peuvent fournir une transcription continue à grand vocabulaire, une réponse à latence nulle avec une API de streaming, et prennent en charge un vocabulaire reconfigurable et la reconnaissance du locuteur. Vosk fournit des capacités de reconnaissance vocale pour les chatbots, les maisons intelligentes, les assistants virtuels, etc., et peut également être utilisé pour la création de sous-titres de films, la transcription de conférences et d’entretiens, applicable à diverses plateformes allant du Raspberry Pi et des appareils Android aux grands serveurs (Source: GitHub Trending)
Un drone autonome bat pour la première fois des champions humains dans une course de vitesse: Un drone autonome développé par l’Université de Technologie de Delft a battu des champions humains lors d’une course de vitesse historique. Cet accomplissement marque un nouveau niveau atteint par l’IA en matière de perception, de prise de décision et de contrôle dans des environnements dynamiques à grande vitesse, démontrant l’énorme potentiel de l’IA dans les domaines de la robotique et de l’automatisation (Source: Reddit r/artificial )

VentureBeat prédit quatre grandes tendances de l’IA pour 2025: VentureBeat a fait quatre prédictions majeures concernant le développement du domaine de l’intelligence artificielle en 2025. Ces prédictions pourraient couvrir les avancées technologiques, les applications sur le marché, les réglementations éthiques ou le paysage industriel. Les détails spécifiques nécessitent la consultation de l’article original. Ce type d’analyse prospective aide les acteurs internes et externes de l’industrie à saisir le pouls du développement de l’IA (Source: Ronald_vanLoon)
