
Mots-clés:Modèle d’IA, Jeu de données, Robot humanoïde, Agent IA, Modèle de langage, Apprentissage profond, Modèle open source, Optimisation de l’inférence, Jeu de données Common Pile v0.1, Modèle de contrôle end-to-end Helix, Serveur Hugging Face MCP, Mise à jour Gemini 2.5 Pro, Mécanisme d’attention éparse
🔥 À LA UNE
EleutherAI publie Common Pile v0.1 : un ensemble de données textuelles de 8 To sous licence ouverte, défiant l’entraînement de modèles linguistiques sans données non autorisées : EleutherAI, en collaboration avec plusieurs institutions, a publié Common Pile v0.1, un vaste ensemble de données contenant 8 To de textes sous licence ouverte et du domaine public, visant à explorer la faisabilité d’entraîner des modèles linguistiques haute performance sans utiliser de textes non autorisés. L’équipe a utilisé cet ensemble de données pour entraîner des modèles de 7 milliards de paramètres (1T et 2T tokens), dont les performances sont comparables à celles de modèles similaires tels que LLaMA 1 et LLaMA 2. Cet ensemble de données comprend des métadonnées au niveau du document, telles que l’attribution des auteurs, les détails de la licence et les liens vers les copies originales, offrant aux chercheurs une source de données transparente et conforme. Cette initiative revêt une importance significative pour la promotion du développement de modèles d’IA ouverts et conformes, et offre de nouvelles pistes pour aborder les questions de droits d’auteur relatives aux données d’entraînement de l’IA (Source : EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

Le robot humanoïde de Figure, piloté par le modèle Helix, démontre une capacité de tri de colis à haute vitesse, suscitant l’attention : Brett Adcock, PDG de Figure, a présenté les derniers progrès de son robot humanoïde dans le tri de colis en scénario logistique, piloté par le modèle de contrôle universel de bout en bout Helix. La vidéo montre le robot traitant différents types de colis (cartons rigides, emballages plastiques) avec une vitesse et une précision proches de celles d’un humain, y compris l’organisation des colis et la garantie que les codes-barres soient orientés vers le bas pour le scan. Cette capacité souligne la capacité de généralisation et la flexibilité du modèle Helix dans des environnements complexes et dynamiques, contrastant avec les opérations sur presse à emboutir précédemment démontrées (mettant l’accent sur la précision et la haute vitesse). Les robots Figure ont déjà atteint 20 heures de travail posté continu sur les lignes de production de BMW, démontrant leur potentiel dans les applications industrielles. Adcock souligne que dans le domaine des robots humanoïdes, la construction du robot le plus intelligent et le moins coûteux sera la clé pour gagner le marché, car un plus grand déploiement de robots signifie des coûts plus bas, plus de données d’entraînement et un modèle Helix plus intelligent (Source : dotey, _philschmid, adcock_brett, 量子位)

Hugging Face lance son premier serveur MCP officiel, créant une plateforme collaborative pour les AI Agents : Hugging Face a lancé son premier serveur officiel MCP (Model-Client Protocol), permettant aux utilisateurs de connecter directement des LLM à l’API du Hugging Face Hub pour une utilisation dans Cursor, VSCode, Windsurf et d’autres applications compatibles MCP. Le serveur offre des outils intégrés tels que la recherche sémantique de modèles, d’ensembles de données, d’articles et de Spaces, et peut lister dynamiquement toutes les applications Gradio compatibles MCP hébergées sur Spaces. Cette initiative vise à faire de Hugging Face une plateforme collaborative pour les constructeurs d’AI Agents, favorisant le développement et l’interopérabilité de l’écosystème des AI Agents. Environ 900 Spaces MCP sont actuellement disponibles (Source : ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

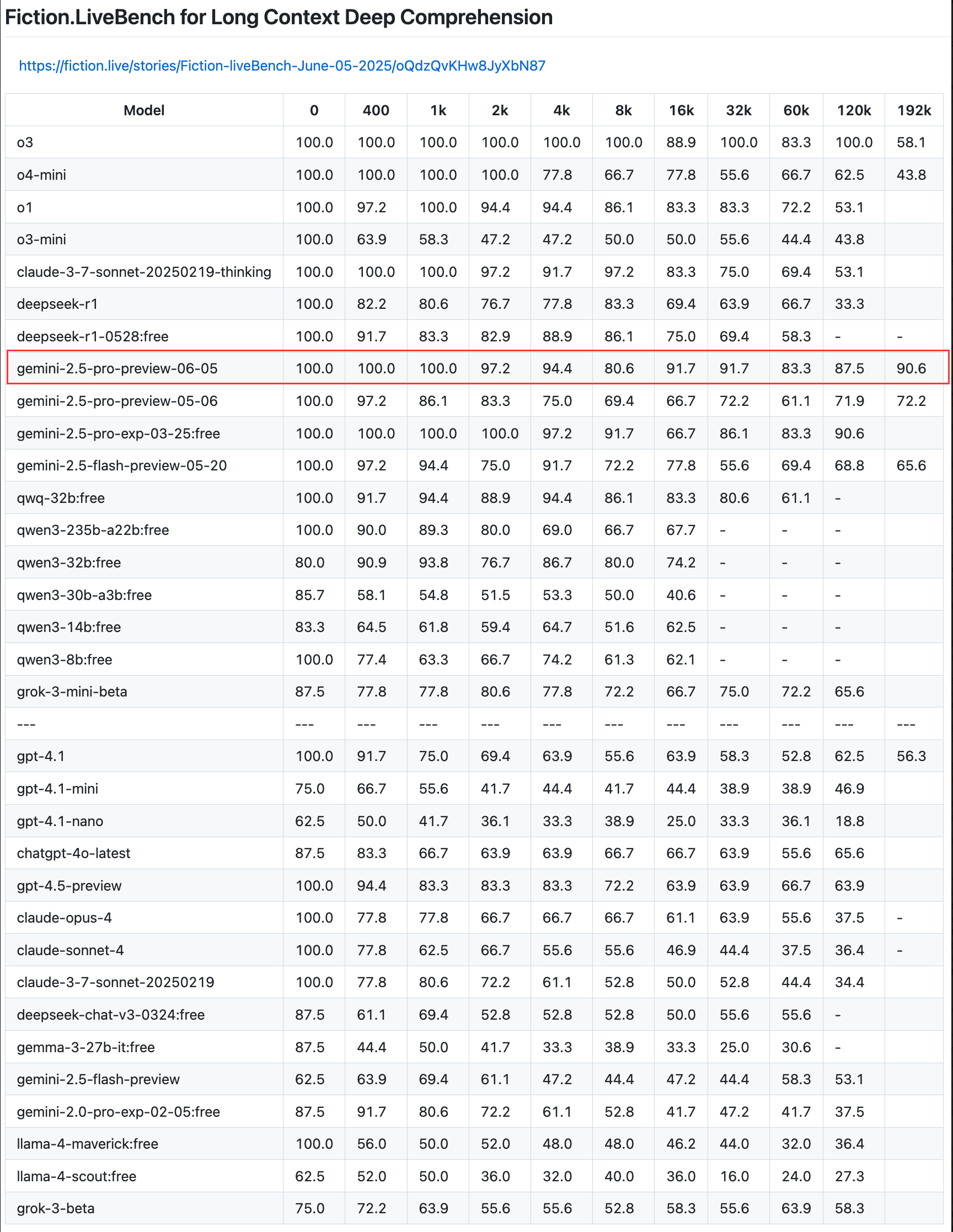
Google met à jour la version préliminaire de Gemini 2.5 Pro, améliorant les capacités de codage, de raisonnement et de création, et introduit un “budget de réflexion” : Google a annoncé une mise à jour de la version préliminaire de son modèle le plus intelligent, Gemini 2.5 Pro, améliorant davantage ses capacités en matière de codage, de raisonnement logique et d’écriture créative. La nouvelle version introduit notamment une fonctionnalité de “budget de réflexion” (thinking budget), permettant aux développeurs de mieux contrôler la consommation de ressources de calcul du modèle. Les retours des utilisateurs indiquent que la nouvelle version (06-05) excelle dans le rappel de textes longs, atteignant notamment un taux de rappel de 90,6 % sur une longueur de 192K, surpassant OpenAI-o3. Le modèle a été intégré à LangChain et LangGraph, facilitant son essai et la création d’applications par les développeurs. Google a également démontré les capacités créatives de Gemini 2.5 Pro en matière de compréhension d’images et de génération de légendes contextualisées et pleines d’esprit (Source : Teknium1, Google, karminski3, hwchase17, )
🎯 TENDANCES
DeepSeek publie une version améliorée de DeepSeek-R1-0528, aux performances comparables aux modèles propriétaires : DeepSeek a lancé une version améliorée de son modèle phare à poids ouverts, DeepSeek-R1-0528. Selon les informations, ce modèle affiche des performances comparables à celles de modèles propriétaires tels que o3 d’OpenAI et Gemini-2.5 Pro de Google dans plusieurs benchmarks. Bien que l’entreprise n’ait pas divulgué les détails de l’entraînement, il est rapporté que le nouveau modèle présente des améliorations significatives en matière de raisonnement, de traitement de la complexité des tâches et de réduction des hallucinations, défiant une fois de plus l’idée reçue selon laquelle une IA de haut niveau nécessite des ressources considérables. Unsloth AI propose déjà un notebook gratuit pour le fine-tuning de DeepSeek-R1-0528-Qwen3 avec GRPO, affirmant que sa nouvelle fonction de récompense peut augmenter le taux de réponse multilingue (ou dans des domaines personnalisés) de plus de 40 %, et rendre le fine-tuning de R1 2 fois plus rapide tout en réduisant la VRAM de 70 % (Source : DeepLearningAI, ImazAngel)
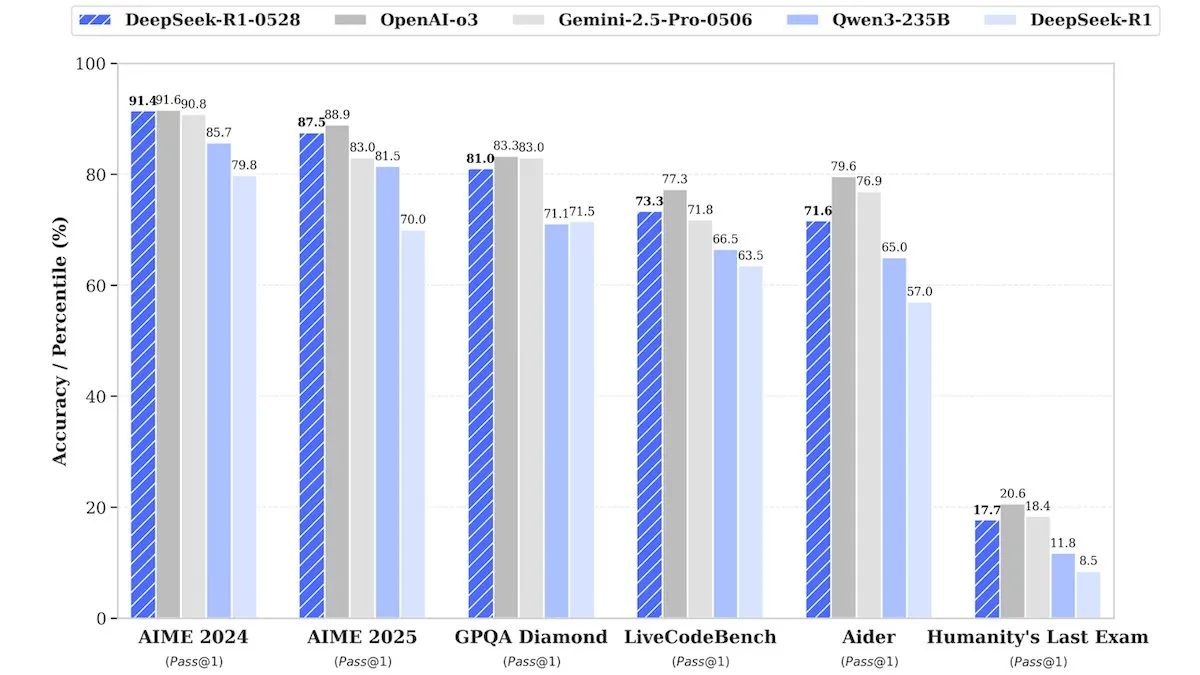
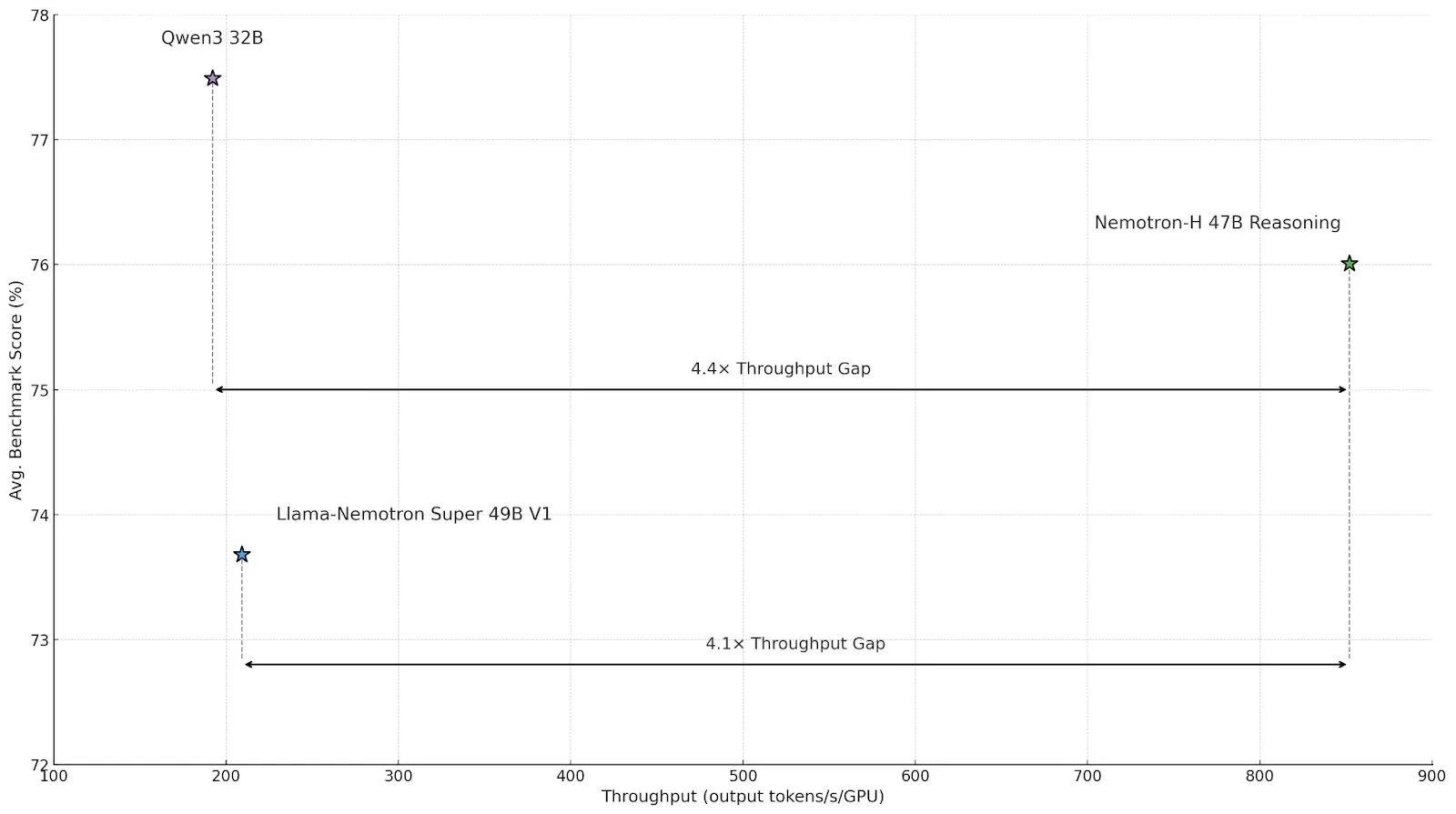
Nvidia lance Nemotron-H, un modèle d’inférence à architecture hybride, pour améliorer le débit et l’efficacité : Nvidia a présenté un nouveau modèle d’inférence, Nemotron-H, disponible en versions 47B et 8B (supportant BF16 et FP8), adoptant une architecture hybride Mamba-Transformer. Ce modèle vise à résoudre les problèmes d’inférence à grande échelle tout en maintenant une vitesse élevée. Son débit serait 4 fois supérieur à celui des modèles Transformer comparables. Nemotron-H-47B-Reasoning-128k présente une précision légèrement supérieure à Llama-Nemotron-Super-49B-1.0 dans tous les benchmarks, mais avec un coût d’inférence jusqu’à 4 fois inférieur. Les poids du modèle ont été publiés sur HuggingFace sous une licence non productive, et un rapport technique sera bientôt disponible (Source : ClementDelangue, ctnzr)
Anthropic lance Claude Gov, conçu spécifiquement pour le gouvernement américain et les agences de renseignement militaire : Anthropic a annoncé un nouveau service d’IA nommé Claude Gov, spécialement conçu pour répondre aux besoins du gouvernement américain, de la défense et des agences de renseignement. Cette initiative marque l’extension officielle par Anthropic de sa technologie d’IA avancée aux applications gouvernementales et militaires, potentiellement utilisée pour l’analyse de données, le traitement du renseignement, l’aide à la décision et divers autres scénarios. Anthropic a également rejoint précédemment un fonds fiduciaire à long terme visant à aider l’entreprise à réaliser sa mission d’intérêt public (Source : MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face s’associe à Google Colab pour simplifier le processus d’essai de modèles et de prototypage : Hugging Face a annoncé un partenariat avec Google Colaboratory, ajoutant la prise en charge de “Ouvrir dans Colab” à toutes les fiches de modèles sur le Hugging Face Hub. Les utilisateurs peuvent désormais lancer directement un notebook Colab à partir de n’importe quelle fiche de modèle, facilitant ainsi l’expérimentation et l’évaluation des modèles. De plus, les utilisateurs peuvent placer un fichier notebook.ipynb personnalisé dans leurs dépôts de modèles, et Hugging Face fournira directement ce notebook, améliorant encore l’accessibilité des modèles d’IA et la capacité de prototypage rapide (Source : huggingface, osanseviero, ClementDelangue, mervenoyann)
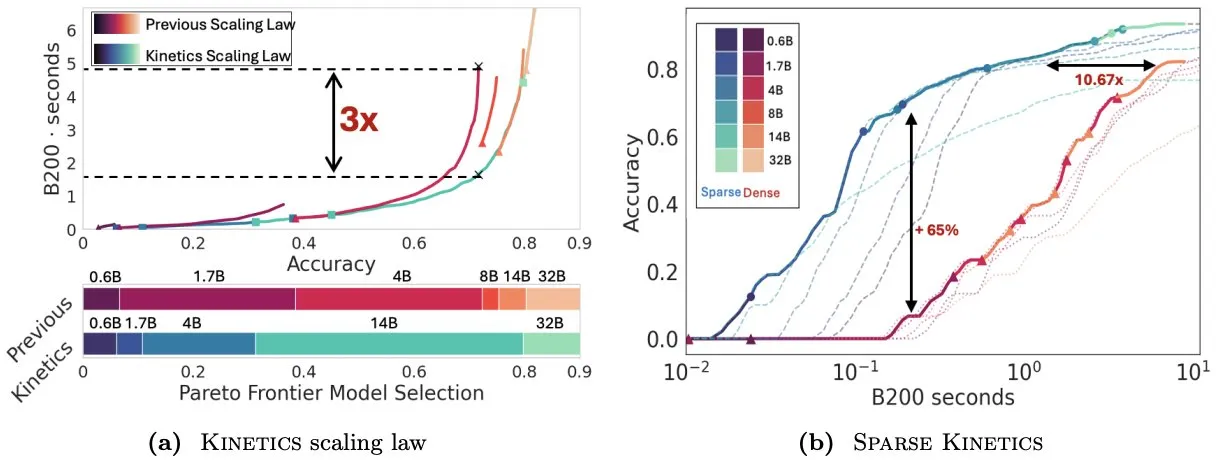
L’article Kinetics repense les lois d’échelle au moment du test, soulignant l’importance de la sparse attention pour l’efficacité de l’inférence : Infini-AI-Lab a publié l’article « Kinetics: Rethinking Test-Time Scaling Laws », soulignant que les lois d’échelle antérieures basées sur l’optimalité computationnelle surestimaient l’efficacité des petits modèles, ignorant les goulots d’étranglement d’accès mémoire induits par les stratégies au moment de l’inférence (telles que Best-of-N, long CoT). L’étude propose de nouvelles lois d’échelle Kinetics, prenant en compte à la fois les coûts de calcul et d’accès mémoire, arguant que les ressources de calcul au moment du test sont utilisées plus efficacement pour les grands modèles que pour les petits, car l’attention, et non le nombre de paramètres, devient le coût dominant. L’article propose ensuite un paradigme d’échelle centré sur la sparse attention, réalisant une génération plus longue et plus d’échantillons parallèles en réduisant le coût par token unitaire. Les expériences montrent que les modèles à sparse attention surpassent les modèles denses dans différentes plages de coûts, ce qui est crucial pour améliorer l’efficacité de l’inférence des modèles à grande échelle (Source : realDanFu, tri_dao, simran_s_arora)
Le marché chinois des AI Agents en plein essor, Manus mène la vague entrepreneuriale : Après la vague des modèles de base de l’année dernière, l’accent de cette année dans le domaine de l’IA en Chine s’est déplacé vers les AI Agents. Les AI Agents se concentrent davantage sur l’accomplissement autonome de tâches pour les utilisateurs, plutôt que sur la simple réponse à des requêtes. Manus, en tant que pionnier des AI Agents universels, a suscité une large attention après sa sortie limitée début mars et a donné naissance à un groupe de start-ups construisant des outils numériques universels capables de traiter des e-mails, de planifier des voyages et même de concevoir des sites web interactifs. Cette tendance indique que l’industrie technologique chinoise explore activement les applications pratiques et les modèles commerciaux des AI Agents (Source : MIT Technology Review)

ElevenLabs lance Conversational AI 2.0, améliorant les performances des assistants vocaux d’entreprise : ElevenLabs a lancé la version 2.0 de sa plateforme d’IA conversationnelle, visant à construire des agents vocaux d’entreprise plus avancés. La nouvelle version améliore considérablement le naturel et la capacité d’interaction des assistants vocaux, leur permettant de mieux comprendre le rythme de la conversation, de savoir quand faire une pause, quand parler et quand gérer la prise de parole. Cette mise à niveau devrait offrir aux entreprises une expérience d’interaction vocale plus fluide et plus intelligente, applicable au service client, aux assistants virtuels et à divers autres scénarios (Source : dl_weekly)
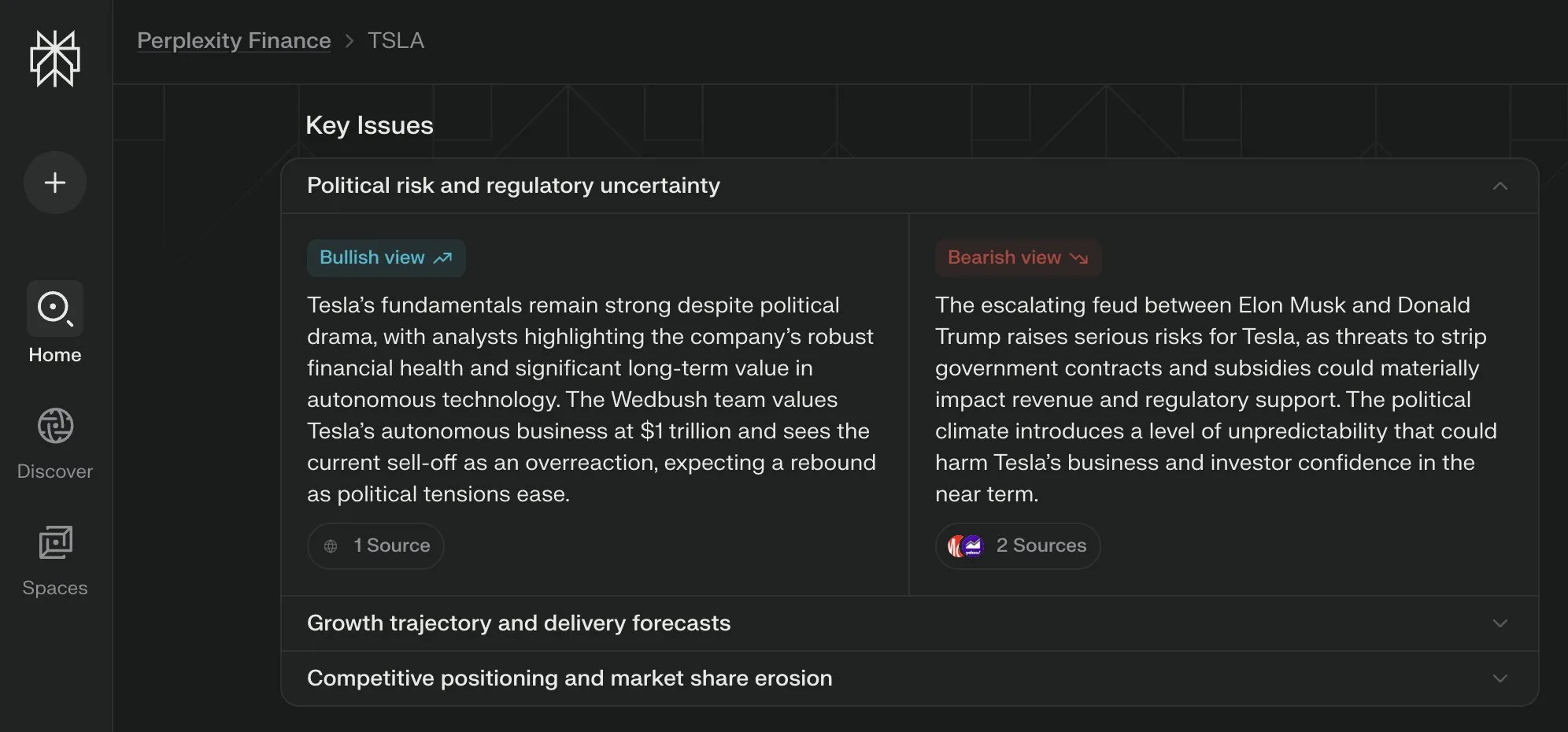
Perplexity Labs lance une vue “Questions Clés” pour ses pages financières, synthétisant les points de vue de multiples parties : Perplexity Labs a ajouté une fonctionnalité de vue “Questions Clés” (Key Issues) à ses pages d’informations financières. Cette fonction est capable de synthétiser les points de vue des investisseurs, des analystes et des commentateurs d’Internet, présentant rapidement aux utilisateurs les facteurs importants et les principaux points de discussion affectant actuellement une entreprise. Par exemple, la page concernant Tesla peut intégrer diverses informations sur la dynamique entre Trump et Musk en quelques heures, aidant les utilisateurs à saisir rapidement la situation globale (Source : AravSrinivas)
Les points de contrôle distribués de PyTorch prennent désormais en charge les safetensors de Hugging Face : PyTorch a annoncé que sa fonctionnalité de points de contrôle distribués prend désormais en charge le format safetensors de Hugging Face, ce qui facilitera la sauvegarde et le chargement des points de contrôle entre différents écosystèmes. La nouvelle API permet aux utilisateurs de lire et d’écrire des safetensors via des chemins fsspec. torchtune devient la première bibliothèque à adopter cette fonctionnalité, simplifiant ainsi son processus de point de contrôle. Cette mise à jour contribue à améliorer l’interopérabilité et l’efficacité de l’entraînement et du déploiement des modèles (Source : ClementDelangue)

L’article MARBLE propose une nouvelle méthode de recomposition et de mélange de matériaux basée sur l’espace CLIP : Une nouvelle étude intitulée MARBLE propose une méthode pour mélanger les matériaux des objets dans les images et réorganiser leurs attributs à granularité fine en trouvant des embeddings de matériaux dans l’espace CLIP et en utilisant ces embeddings pour contrôler des modèles texte-vers-image pré-entraînés. Cette méthode améliore l’édition de matériaux basée sur des échantillons en localisant les modules responsables de l’attribution des matériaux dans l’UNet de débruitage, réalisant un contrôle paramétrique des attributs de matériaux à granularité fine tels que la rugosité, la metallicité, la transparence et la brillance. Les chercheurs ont démontré l’efficacité de la méthode par des analyses qualitatives et quantitatives, et ont montré son applicabilité à l’exécution de multiples éditions en une seule passe avant ainsi que dans le domaine de la peinture numérique (Source : HuggingFace Daily Papers, ClementDelangue)
Article FlowDirector : une méthode de guidage de flux pour l’édition texte-vers-vidéo précise et sans entraînement : FlowDirector est un nouveau cadre d’édition vidéo sans inversion qui modélise le processus d’édition comme une évolution directe dans l’espace des données. Il guide la vidéo le long de sa variété spatio-temporelle inhérente via des équations différentielles ordinaires (EDO) pour une transition en douceur, préservant ainsi la cohérence temporelle et les détails structurels. Pour réaliser une édition localement contrôlable, un mécanisme de masquage guidé par l’attention est introduit. De plus, pour résoudre les problèmes d’édition incomplète et améliorer l’alignement sémantique avec les instructions d’édition, une stratégie d’édition améliorée par guidage, inspirée du guidage sans classificateur, est proposée. Les expériences démontrent que FlowDirector excelle dans le suivi des instructions, la cohérence temporelle et la préservation de l’arrière-plan (Source : HuggingFace Daily Papers)
Article RACRO : Raisonnement multimodal évolutif grâce à l’optimisation des récompenses de légendes : Pour résoudre le problème du coût élevé du réentraînement de l’alignement vision-langage lors de la mise à niveau des raisonneurs LLM sous-jacents, les chercheurs proposent RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization). Cette méthode convertit les entrées visuelles en représentations linguistiques (telles que des légendes), qui sont ensuite transmises au raisonneur textuel. RACRO adopte une stratégie d’apprentissage par renforcement guidée par le raisonnement, alignant le comportement de légendage de l’extracteur avec les objectifs de raisonnement via l’optimisation des récompenses, améliorant ainsi la base visuelle et extrayant des représentations optimisées pour le raisonnement. Les expériences montrent que RACRO atteint des performances SOTA sur les benchmarks multimodaux de mathématiques et de sciences, et prend en charge une adaptation plug-and-play à des LLM de raisonnement plus avancés sans réalignement multimodal coûteux (Source : HuggingFace Daily Papers)
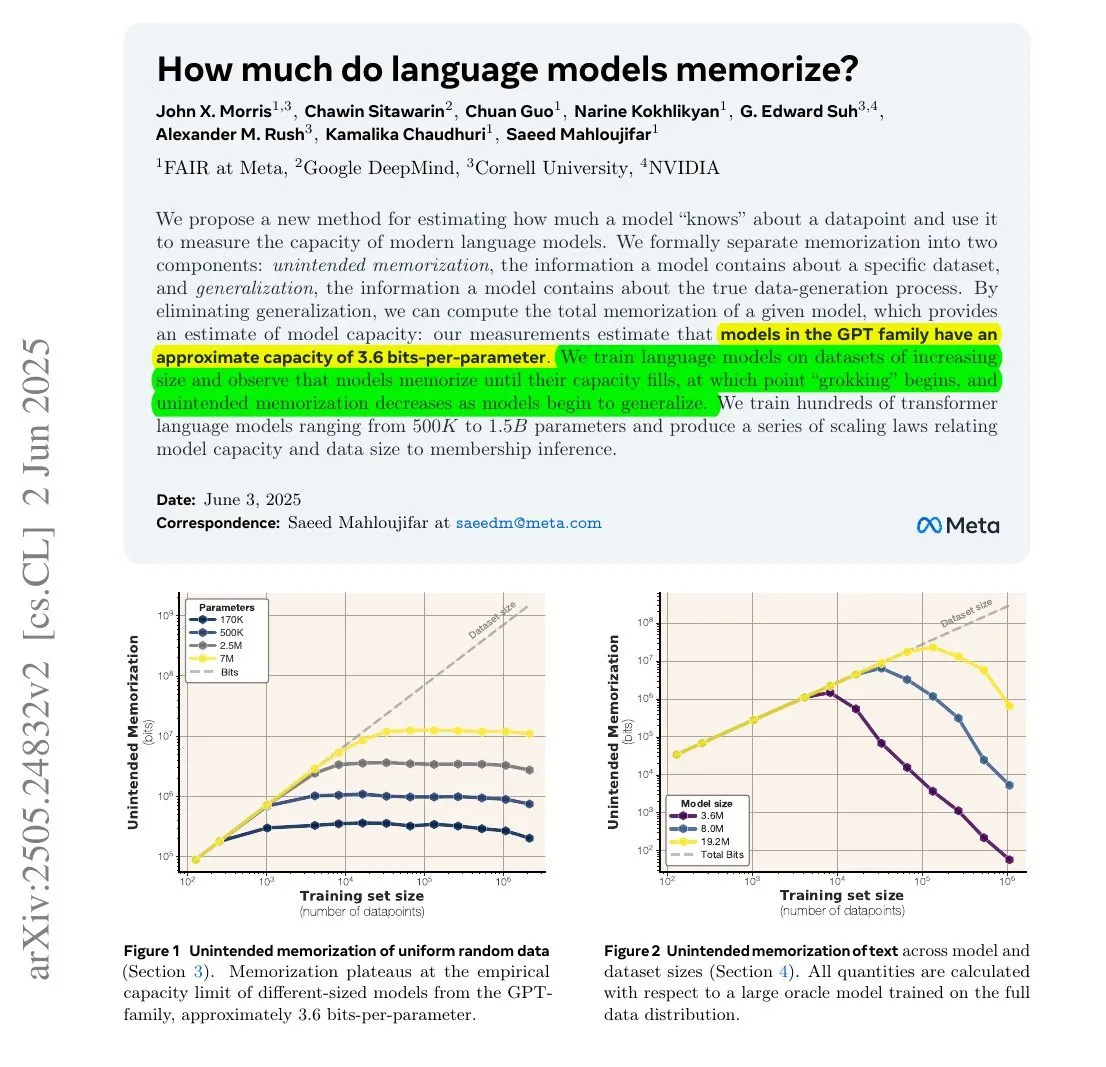
Une étude montre que la quantité d’informations mémorisée par les LLM pourrait être liée à leur nombre de paramètres et à l’entropie de l’information : Une étude menée en collaboration par Meta, DeepMind, NVIDIA et l’Université Cornell explore la quantité d’informations réellement mémorisée par les grands modèles linguistiques (LLM). L’étude révèle que la quantité d’informations mémorisée par un LLM pourrait être liée à son nombre de paramètres et à l’entropie de l’information des données. Par exemple, Wikipedia en anglais contient environ 29,4 milliards de caractères, chaque caractère contenant environ 1,5 bits d’information. Un modèle de 12 milliards de paramètres (en supposant une capacité de stockage de 3,6 bits par paramètre) pourrait théoriquement mémoriser l’intégralité de Wikipedia en anglais. Cette recherche est importante pour comprendre les mécanismes de mémorisation des LLM et évaluer les questions de droits d’auteur des données. François Chollet a également mentionné la méthodologie d’entraînement des LLM à l’aide de chaînes de caractères aléatoires et ses découvertes quantitatives, les jugeant précieuses pour comprendre les mécanismes de mémorisation des LLM (Source : fchollet, AymericRoucher)
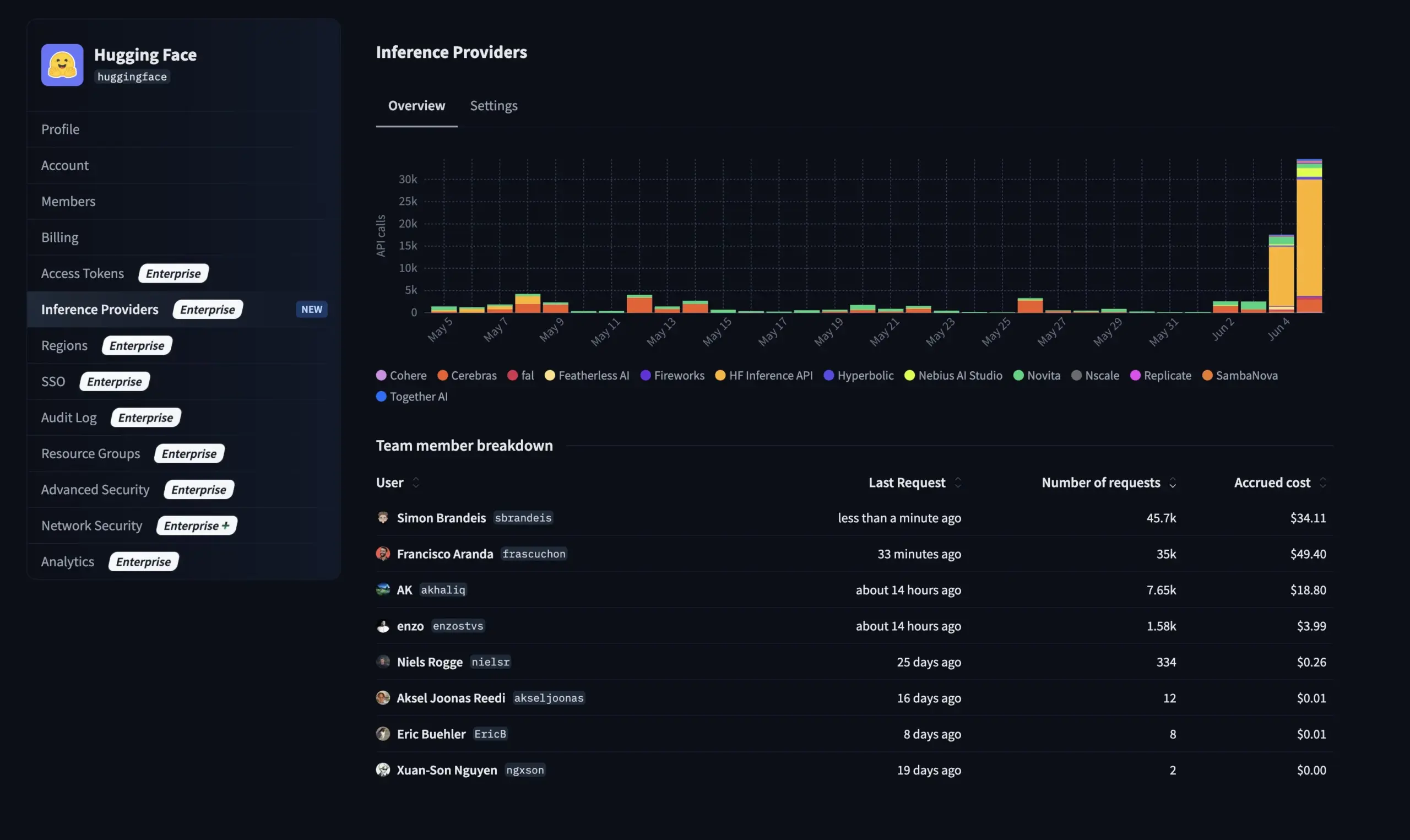
Hugging Face lance de nouvelles fonctionnalités pour sa version Entreprise : gestion de l’utilisation et des coûts des fournisseurs d’inférence : Hugging Face a ajouté de nouvelles fonctionnalités à sa version Entreprise (Enterprise Hub), permettant aux organisations de configurer et de surveiller l’utilisation par les membres de leur équipe des fournisseurs d’inférence (Inference Providers) et les coûts associés. Cela signifie que les entreprises utilisatrices peuvent mieux gérer et contrôler l’utilisation des services d’inférence sans serveur pour plus de 40 000 modèles provenant de plusieurs fournisseurs tels que TogetherCompute, FireworksAI, Replicate, Cohere, optimisant ainsi la rentabilité et l’allocation des ressources pour le déploiement d’applications d’IA (Source : huggingface, _akhaliq)
Mistral AI lance ether0, un modèle de raisonnement scientifique, fine-tuné à partir de Mistral 24B : Mistral AI a lancé son premier modèle de raisonnement scientifique, ether0. Ce modèle a été obtenu par entraînement par apprentissage par renforcement (RL) de Mistral 24B sur de multiples tâches de conception moléculaire dans le domaine de la chimie. L’étude a révélé que les LLM apprennent certaines tâches scientifiques avec une efficacité des données bien supérieure à celle des modèles spécialisés entraînés à partir de zéro, et peuvent surpasser de manière significative les modèles de pointe et les humains sur ces tâches. Cela suggère que pour une partie des problèmes de classification, de régression et de génération scientifiques, le post-entraînement des LLM pourrait offrir une voie plus efficace que les méthodes traditionnelles d’apprentissage automatique (Source : MistralAI)
Le modèle de cohérence à double expert (DCM) accélère la génération de vidéos par 10 : Ziwei Liu et d’autres chercheurs ont proposé le modèle de cohérence à double expert (DCM), capable d’accélérer les modèles de génération de vidéos (avec un nombre de paramètres allant de 1,3B à 13B) d’un facteur 10, sans dégradation de la qualité. Ce modèle prend actuellement en charge Tencent Hunyuan et Alibaba Tongyi Wanxiang. La proposition du DCM apporte une nouvelle avancée dans le domaine de la génération de vidéos efficace et de haute qualité, contribuant à accélérer la création de contenu vidéo et le développement d’applications associées (Source : _akhaliq)
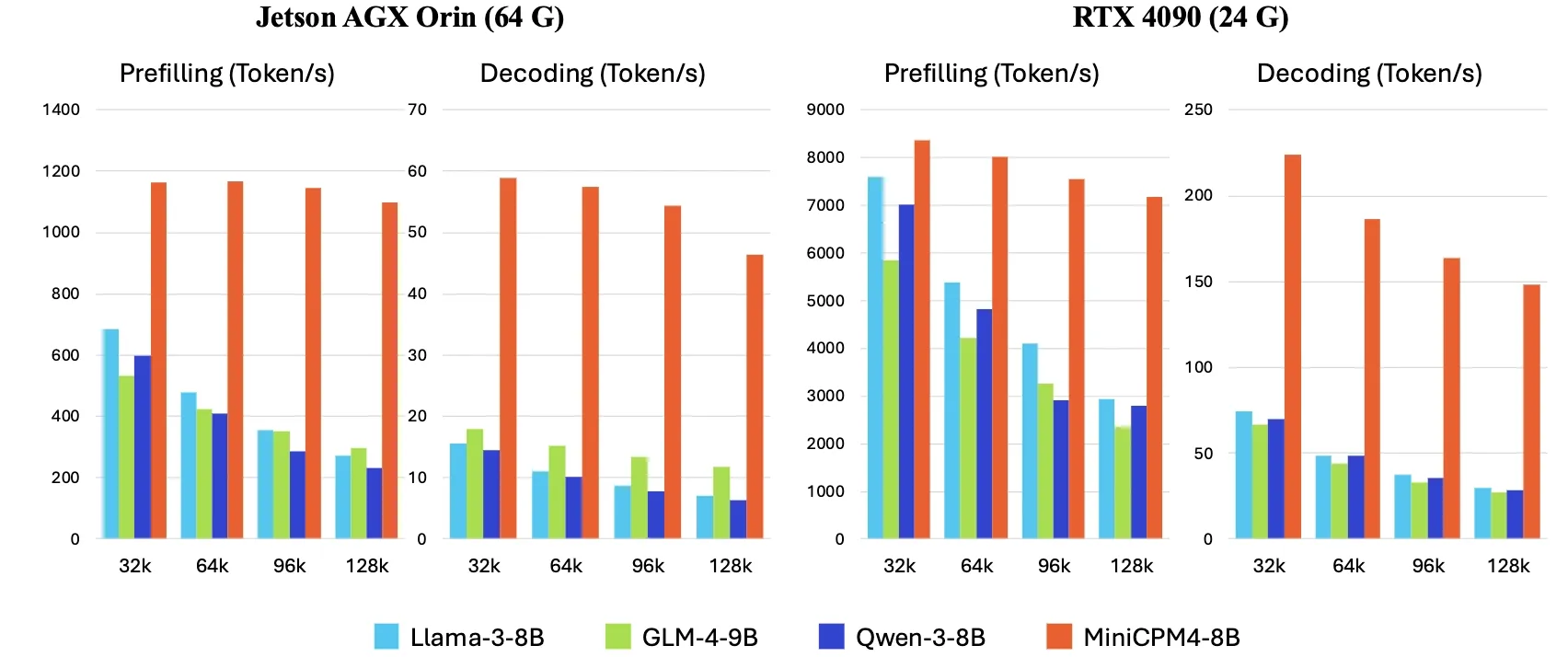
OpenBMB lance MiniCPM4, multipliant par 5 la vitesse d’inférence en périphérie : OpenBMB a lancé la série de modèles MiniCPM4, atteignant une multiplication par 5 de la vitesse d’inférence sur les appareils en périphérie grâce à l’adoption d’une architecture de modèle efficace (mécanisme d’attention clairsemée entraînable InfLLM v2), d’algorithmes d’apprentissage efficaces (Model Wind Tunnel 2.0, quantification ternaire BitCPM), de données d’entraînement de haute qualité (UltraClean, UltraChat v2) et d’un système d’inférence efficace (CPM.cu, ArkInfer). Le modèle phare MiniCPM4-8B (8 milliards de paramètres, entraîné sur 8T tokens) est disponible sur Hugging Face. Cette série de modèles vise à explorer les limites des LLM petits et peu coûteux, favorisant l’application de l’IA sur les appareils aux ressources limitées (Source : eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
X Corp met à jour ses conditions d’utilisation, interdisant l’utilisation de ses publications pour le “fine-tuning ou l’entraînement” de modèles d’IA, sauf accord : X Corp (anciennement Twitter) a mis à jour ses conditions d’utilisation, interdisant explicitement l’utilisation du contenu des publications de la plateforme pour le “fine-tuning ou l’entraînement” de modèles d’intelligence artificielle, à moins qu’un accord spécifique ne soit conclu avec X Corp. Cette mesure reflète la valorisation croissante et la volonté de contrôle des plateformes de contenu sur leurs données à l’ère de l’IA, suivant potentiellement l’exemple de Reddit et Google qui monétisent leurs données via des accords de licence. Ce changement de politique aura un impact sur les chercheurs et développeurs d’IA qui dépendent des données publiques des médias sociaux pour l’entraînement de modèles (Source : MIT Technology Review)
🧰 OUTILS
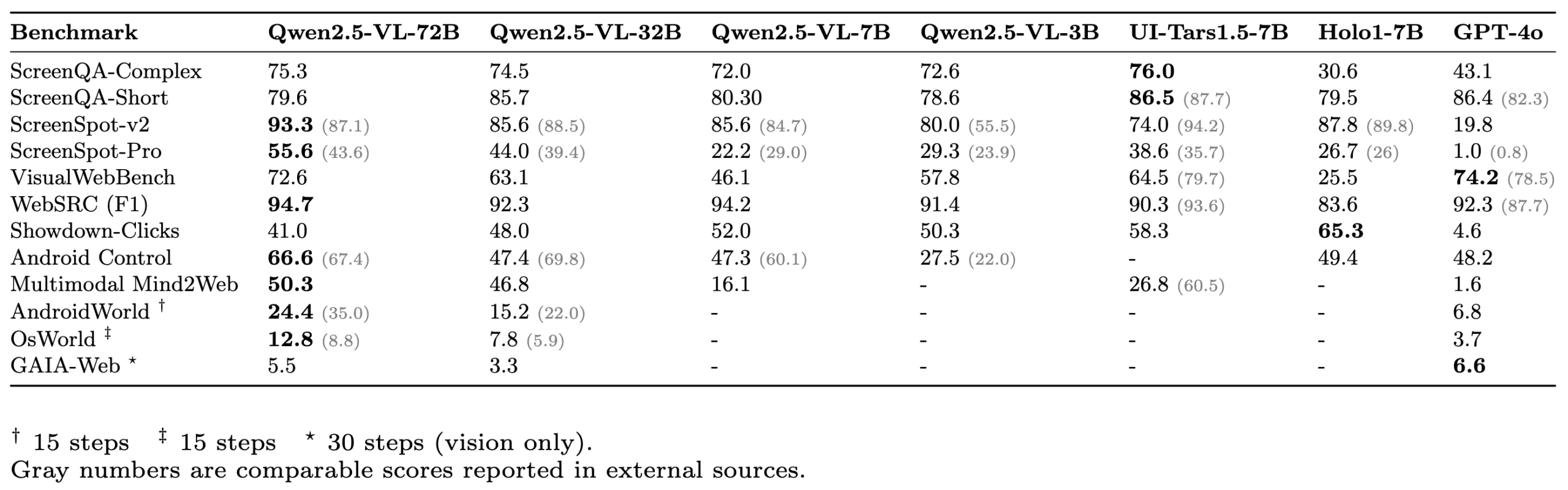
ScreenSuite : Lancement d’une suite complète d’évaluation pour agents GUI : Hugging Face a lancé ScreenSuite, une suite complète d’évaluation pour agents d’interface utilisateur graphique (GUI). Elle intègre des benchmarks clés issus de recherches de pointe, prend en charge l’évaluation conteneurisée avec Docker pour les environnements Ubuntu et Android, et couvre les scénarios mobiles, de bureau et web. La suite met l’accent sur l’évaluation purement visuelle (pas de triche avec le DOM) et vise à fournir une plateforme unifiée et facile à utiliser pour mesurer les capacités des modèles visuo-linguistiques (VLM) en matière de perception, de localisation, d’opérations en une seule étape et de tâches d’agent multi-étapes. Des modèles tels que Qwen-2.5-VL, UI-Tars-1.5-7B, Holo1-7B et GPT-4o ont été évalués sur cette suite (Source : huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Partage d’expérience sur l’utilisation de Claude Code : compréhension des instructions, planification des tâches et utilisation des outils remarquables : L’utilisateur dotey a partagé son expérience d’utilisation de Claude Code, l’assistant de programmation IA d’Anthropic. Il estime que les points forts de Claude Code sont : 1. Une excellente compréhension des instructions ; 2. Une planification raisonnable des tâches, créant une liste de TODO pour les tâches complexes et les exécutant une par une ; 3. Une très forte capacité d’utilisation des outils, excellant particulièrement dans l’utilisation de la commande grep pour rechercher dans les bases de code, avec une efficacité bien supérieure à celle d’un humain, capable même d’analyser du code JS obfusqué ; 4. Un long temps d’exécution, capable de “faire des miracles par la force brute”, mais avec une consommation de tokens également importante, adaptée à une utilisation avec un abonnement Claude Max ; 5. Peu d’intervention manuelle tout au long du processus, surtout après avoir activé le paramètre --dangerously-skip-permissions pour une programmation sans surveillance. L’utilisateur est passé d’un usage intensif de Cursor à une dépendance accrue à Claude Code pour accomplir les tâches en amont, avant de passer à l’IDE pour révision et modification. Le Mode Plan (plan mode) de Claude Code a également été discrètement lancé, permettant aux utilisateurs de lire et de réfléchir sans éditer de fichiers (Source : dotey, Reddit r/ClaudeAI)
ClaudeBox : Exécuter Claude Code en toute sécurité dans Docker, sans invites d’autorisation : Le développeur RchGrav a créé l’outil ClaudeBox, permettant aux utilisateurs d’exécuter Claude Code en mode continu (sans invites d’autorisation) dans un conteneur Docker. Cela évite les interruptions fréquentes du flux de travail dues aux confirmations d’autorisation, tout en garantissant la sécurité du système d’exploitation hôte, car toutes les opérations de Claude Code sont confinées dans l’environnement Docker isolé. ClaudeBox propose plus de 15 environnements de développement préconfigurés (tels que Python+ML, C++/Rust/Go, etc.), que les utilisateurs peuvent configurer rapidement avec une simple commande. Cet outil vise à améliorer l’expérience d’utilisation de Claude Code, permettant aux utilisateurs de laisser l’IA tenter diverses opérations sans souci (Source : Reddit r/ClaudeAI)
Toolio 0.6.0 publié : une boîte à outils GenAI et Agent conçue pour Mac : Toolio a publié la version 0.6.0, une boîte à outils profondément intégrée avec MLX, conçue pour offrir un support puissant aux grands modèles linguistiques (LLM) sur Mac. Elle implémente des fonctionnalités de sortie structurée guidée par JSON Schema et d’appel d’outils, en utilisant le langage Python. Cette boîte à outils se concentre sur l’amélioration de l’expérience et de l’efficacité du développement d’applications GenAI et Agent dans l’environnement Mac (Source : awnihannun)
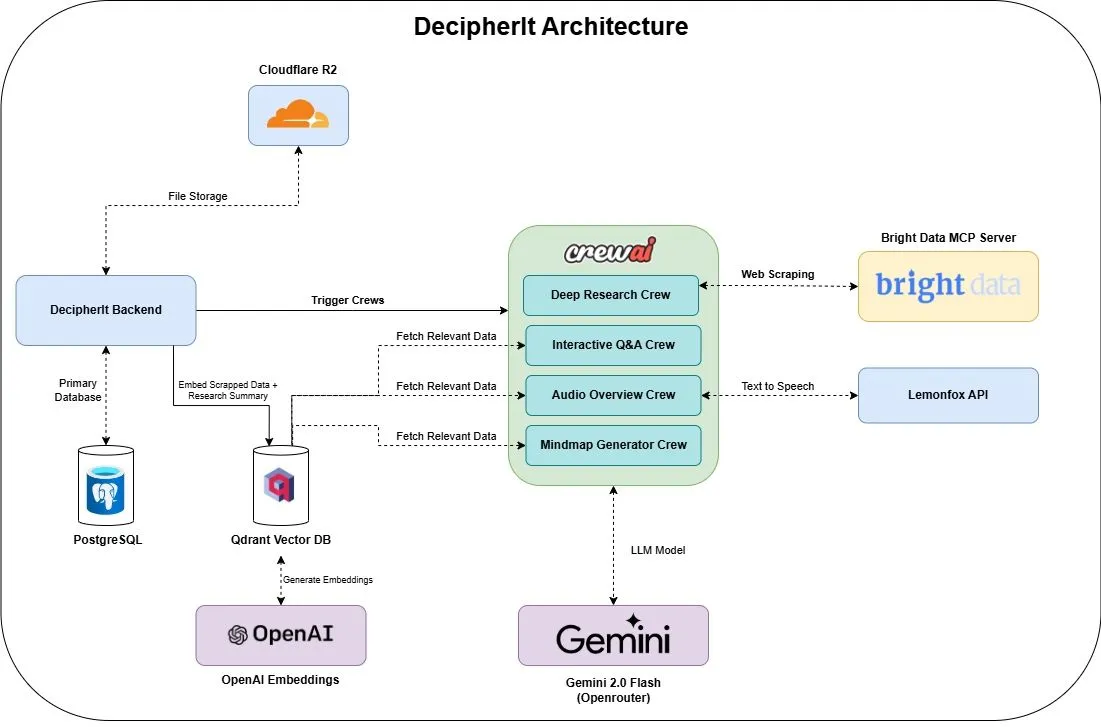
DecipherIt : Assistant de recherche IA open-source, intégrant multi-agents et recherche sémantique : DecipherIt est un assistant de recherche IA open-source, considéré comme une alternative à NotebookLM. Il utilise l’orchestration multi-agents, la recherche sémantique et des fonctionnalités d’accès web en temps réel pour aider les utilisateurs à traiter leurs documents de recherche. Les utilisateurs peuvent télécharger des documents, coller des URL ou saisir des sujets, et DecipherIt les transformera en un espace de travail de recherche complet comprenant des résumés, des cartes mentales, des résumés audio, des FAQ et des questions-réponses sémantiques. Sa pile technologique comprend des agents crewAI, Bright Data MCP, Qdrant, OpenAI et LemonFox AI, avec un frontend en Next.js et React 19, et un backend en FastAPI (Source : qdrant_engine)
Search Arena : Publication d’un ensemble de données d’interactions utilisateur pour l’analyse des LLM améliorés par la recherche : Search Arena est un vaste ensemble de données (plus de 24 000) de préférences humaines, crowdsourcé, contenant des interactions utilisateur multi-tours par paires avec des LLM améliorés par la recherche. Cet ensemble de données couvre une variété d’intentions et de langues, et inclut des traces système complètes d’environ 12 000 votes de préférences humaines. L’analyse montre que les préférences des utilisateurs sont influencées par le nombre de citations, même si le contenu cité ne soutient pas directement les déclarations d’attribution ; les plateformes communautaires sont généralement plus populaires. Cet ensemble de données vise à soutenir les recherches futures sur les LLM améliorés par la recherche ; le code et les données sont open source (Source : HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

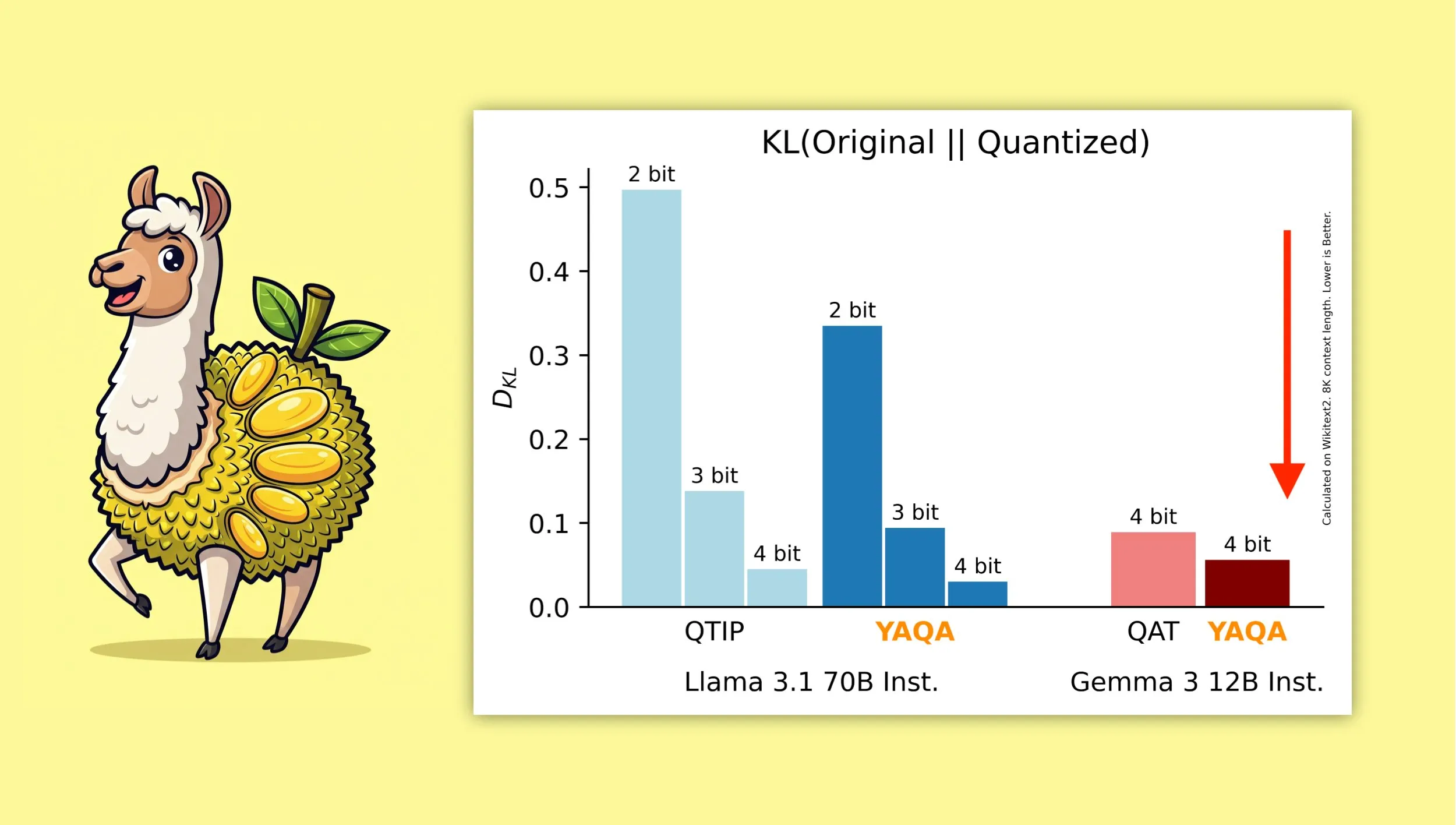
YAQA : Un nouvel algorithme de quantification visant à mieux préserver la sortie originale du modèle : Des chercheurs de l’Université Cornell ont lancé “Yet Another Quantization Algorithm” (YAQA), un nouvel algorithme de quantification conçu pour mieux préserver la sortie du modèle original après quantification. YAQA réduirait la divergence KL de plus de 30 % par rapport à QTIP et atteindrait une divergence KL inférieure à celle du modèle QAT de Google sur Gemma 3. Cette recherche offre de nouvelles idées et de nouveaux outils dans le domaine de la quantification des modèles, contribuant à maximiser la préservation des performances du modèle tout en réduisant sa taille et ses besoins en calcul. L’article et le code correspondants ont été publiés, et un modèle Llama 3.1 70B Instruct pré-quantifié est fourni (Source : Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus : Lancement d’un moteur conçu pour l’inférence LLM à haut débit : HazyResearch a lancé Tokasaurus, un nouveau moteur d’inférence LLM conçu spécifiquement pour les charges de travail à haut débit, adapté aux grands et petits modèles. Ce moteur vise à optimiser l’efficacité et la vitesse de traitement des LLM dans des scénarios de requêtes concurrentes à grande échelle, en utilisant potentiellement des techniques avancées telles que le traitement par lots continu (continuous batching) et paged attention pour améliorer les performances. Le lancement de Tokasaurus offre une nouvelle option aux développeurs et aux entreprises nécessitant un traitement efficace d’un grand nombre de tâches d’inférence LLM (Source : Tim_Dettmers)
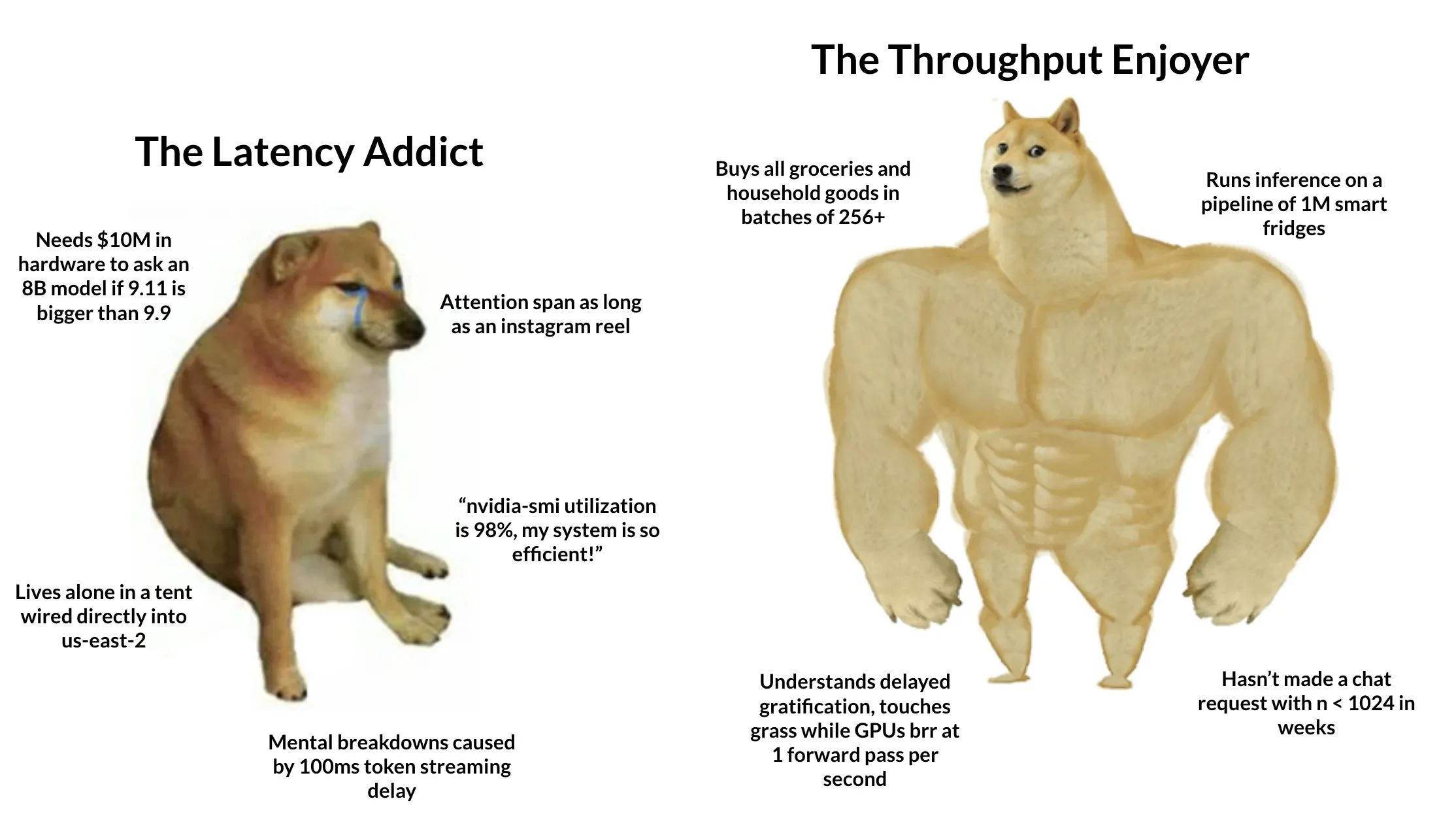
Lancement du système “Android” pour l’empreinte carbone TIDAS, avec le soutien technique d’Ant Digital Technologies : L’Alliance pour l’innovation technologique de l’industrie de l’empreinte carbone a lancé le “Système de données ACV Tiangong” (TIDAS), visant à fournir des solutions pour l’analyse du cycle de vie (ACV) et la construction de bases de données sur l’empreinte carbone, avec l’objectif d’établir le système “Android” pour les bases de données ACV et d’empreinte carbone en Chine et même dans le monde. Ant Digital Technologies, en tant que membre principal, a fourni à TIDAS un soutien en matière de technologie blockchain et de plateforme de collaboration de données fiables. Grâce à sa technologie blockchain propriétaire, elle réalise l’enregistrement et la titularisation fiables des actifs de données carbone, et utilise la technologie de calcul préservant la confidentialité pour garantir que les données soient “utilisables mais non visibles”, améliorant ainsi la normalisation, la capacité de fusion et l’interopérabilité des données (Source : 量子位)
📚 APPRENTISSAGE
LangChain organise un séminaire sur l’IA d’entreprise, axé sur les systèmes multi-agents : LangChain organisera un séminaire sur l’IA d’entreprise le 16 juin à San Francisco. À cette occasion, Jake Broekhuizen de LangChain guidera les participants dans la construction de systèmes multi-agents prêts pour la production à l’aide de LangGraph, le contenu couvrira des aspects clés tels que la sécurité et l’observabilité. Il s’agit d’un séminaire pratique visant à aider les développeurs à maîtriser les compétences nécessaires pour construire des applications d’AI Agent complexes et fiables (Source : LangChainAI, hwchase17)

DeepLearning.AI lance un nouveau cours « DSPy : Construire et optimiser des applications agentiques » : DeepLearning.AI a lancé un nouveau cours intitulé « DSPy: Build and Optimize Agentic Apps ». Ce cours enseignera aux participants les bases de DSPy, comment utiliser ses signatures et son modèle de programmation basé sur des modules pour construire des applications agentiques GenAI modulaires, traçables et débogables. Le contenu comprend la construction d’applications en liant des modules DSPy tels que Predict, ChainOfThought et ReAct, l’utilisation de MLflow pour le suivi et le débogage, ainsi que l’utilisation de DSPy Optimizer pour ajuster automatiquement les invites et améliorer les exemples few-shot afin d’augmenter la précision et la cohérence des réponses (Source : DeepLearningAI, lateinteraction)
Un projet GitHub de tutoriel sur les techniques avancées de RAG attire l’attention : Le projet de tutoriel sur les techniques de Retrieval-Augmented Generation (RAG) partagé par NirDiamant sur GitHub a recueilli 16,6K étoiles. Ce tutoriel couvre un large éventail de sujets, y compris le prétraitement pour l’amélioration de la recherche, l’optimisation, les modes de recherche, l’itération et les étapes d’ingénierie. Pour les développeurs souhaitant approfondir leurs recherches et améliorer l’efficacité des applications RAG, il s’agit d’une ressource d’apprentissage avancée précieuse (Source : karminski3)
Comment les clients d’OpenAI utilisent les évaluations (Evals) pour construire de meilleurs produits d’IA : Hamel Husain a fait la promotion d’un webinaire animé par Jim Blomo d’OpenAI, qui discutera de la manière dont les clients d’OpenAI utilisent les outils d’évaluation (Evals) pour construire des produits d’IA de meilleure qualité. Le contenu comprendra des études de cas réels et des résultats, et présentera les outils d’évaluation internes d’OpenAI (tels que le suivi, la notation, etc.). Ce webinaire vise à fournir aux développeurs des informations pratiques et des méthodes concernant l’évaluation des produits d’IA (Source : HamelHusain)

LlamaIndex partage un aperçu de 13 protocoles d’Agent, explorant les normes d’interopérabilité : Seldo de LlamaIndex a donné une présentation générale lors du sommet des développeurs MCP sur les 13 protocoles de communication inter-agents actuels (y compris MCP, A2A, ACP, etc.). Il a analysé les fonctionnalités uniques de chaque protocole, leur positionnement dans le paysage technologique actuel et les tendances futures de développement. Cette présentation visait à aider les développeurs à comprendre et à choisir les normes de communication adaptées à leurs applications d’Agent, favorisant l’interopérabilité de l’écosystème des Agents (Source : jerryjliu0, jerryjliu0)

Analyse de l’architecture de Claude Code : flux de contrôle, moteur d’orchestration et exécution des outils : Un article a procédé à une analyse approfondie de l’architecture de Claude Code, se concentrant sur son flux de contrôle et son moteur d’orchestration, ainsi que sur ses outils et son moteur d’exécution. Ces analyses sont précieuses pour les développeurs souhaitant créer des outils d’assistant de codage en ligne de commande similaires ou effectuer des modifications personnalisées. Les concepts de conception sont également applicables au développement d’autres types d’outils Agent (Source : karminski3)

Partage de la solution classée deuxième au concours de noyaux de multiplication matricielle FP8 pour GPU AMD : Tim Dettmers a partagé la solution du lauréat classé deuxième au concours de noyaux de multiplication matricielle FP8 pour GPU AMD. L’interprétation détaillée de cette solution est d’une grande valeur de référence pour comprendre comment optimiser les performances des calculs en virgule flottante de basse précision sur les GPU AMD, en particulier dans le contexte de l’utilisation croissante de formats de basse précision tels que FP8 dans l’entraînement et l’inférence des modèles d’IA pour améliorer l’efficacité (Source : Tim_Dettmers)
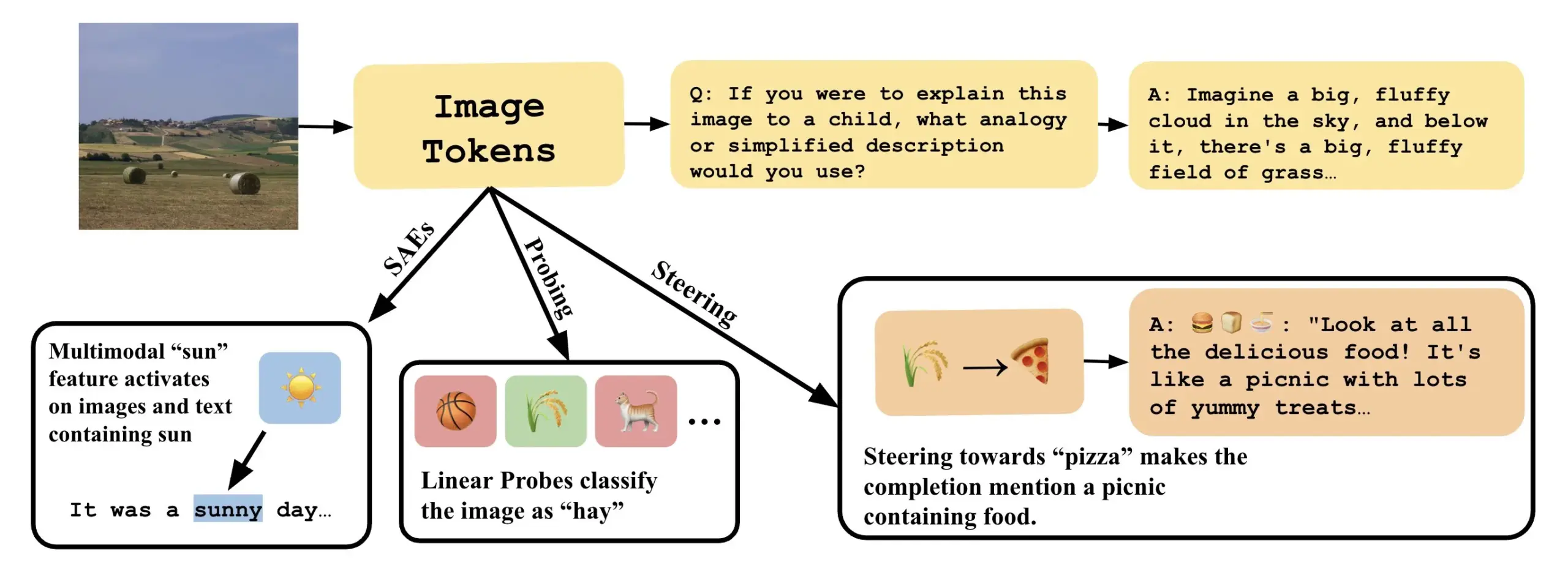
Un article explore comment comprendre les modèles visuo-linguistiques en interprétant les directions linéaires dans les VLLM : Un nouvel article intitulé « Line of Sight » explore la compréhension des mécanismes internes des grands modèles visuo-linguistiques (VLLM) en interprétant les directions linéaires dans leur espace latent. Les chercheurs utilisent des outils tels que le sondage (probing), le guidage (steering) et les auto-encodeurs clairsemés (SAEs) pour interpréter les représentations d’images dans les VLLM. Ce travail offre de nouvelles perspectives et méthodes pour comprendre le fonctionnement interne des modèles multimodaux (Source : nabla_theta)
💼 AFFAIRES
La start-up d’IA Vareon obtient un financement de pré-amorçage de 3 millions de dollars de Norck, se concentrant sur l’IA de pointe et les systèmes autonomes : Norck, fondée par Faruk Guney, s’est engagée à fournir un financement de pré-amorçage de 3 millions de dollars, basé sur des jalons, à sa nouvelle start-up d’IA, Vareon. Vareon se concentre sur l’IA de pointe, le raisonnement causal et les systèmes autonomes, avec au cœur MALPAC (Multi-Agent Learning Architecture for Planning and Closed-Loop Optimization). L’entreprise vise à devenir une société de recherche fondamentale en IA, stimulant les développements dans les domaines de la robotique, des LLM, de la conception moléculaire, des architectures cognitives et des agents autonomes. Sont également lancés RAPID (cadre de planification différentiable), CIMO (coordinateur causal multi-échelles), SCA (architecture cognitive bio-inspirée) et Lumon-XAI (couche d’explicabilité) (Source : farguney)

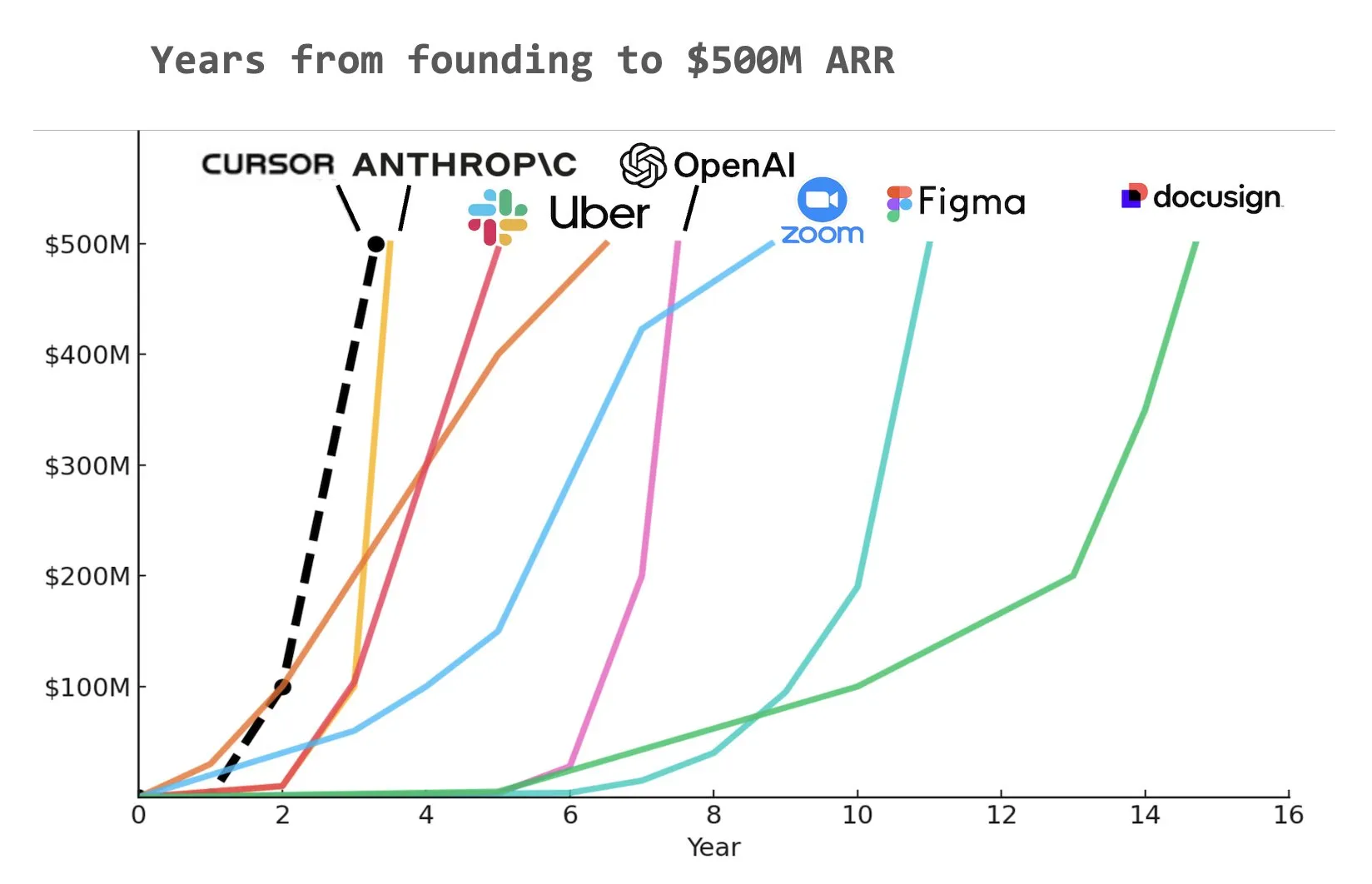
L’outil de codage IA Cursor lève 900 millions de dollars en série C, avec un ARR de 500 millions de dollars : La start-up d’outils de codage IA Cursor a annoncé la clôture d’un tour de financement de série C de 900 millions de dollars, mené par Thrive, Accel, Andreessen Horowitz et DST. La société a révélé que son revenu annuel récurrent (ARR) a dépassé les 500 millions de dollars et qu’elle est utilisée par plus de la moitié des entreprises du Fortune 500, dont NVIDIA, Uber et Adobe. Ce tour de financement aidera Cursor à repousser davantage les frontières de la recherche dans le domaine du codage IA. Selon certaines analyses, Cursor pourrait être l’une des entreprises ayant atteint le plus rapidement un ARR de 500 millions de dollars dans l’histoire (Source : cursor_ai, Yuchenj_UW, op7418)
Anthropic coupe l’accès direct de Windsurf aux modèles Claude, possiblement en raison de rumeurs d’acquisition par OpenAI : Jared Kaplan, co-fondateur et directeur scientifique d’Anthropic, a déclaré que la société avait coupé l’accès direct de l’assistant de programmation IA Windsurf aux modèles Claude, principalement en raison de rumeurs de marché selon lesquelles Windsurf serait sur le point d’être acquis par OpenAI. Kaplan a affirmé qu’il serait “étrange de vendre Claude à OpenAI” et a indiqué qu’Anthropic préférait allouer ses ressources de calcul à des partenaires stables à long terme. Néanmoins, Anthropic collabore activement avec d’autres développeurs d’outils de programmation IA (comme Cursor) et a souligné qu’à l’avenir, elle se concentrerait davantage sur le développement de produits de programmation IA dotés de capacités de prise de décision autonome, tels que Claude Code (Source : dotey, vikhyatk, jeremyphoward, swyx)

🌟 COMMUNAUTÉ
Greg Brockman d’OpenAI : L’avenir de l’AGI ressemblera plus à une collaboration d’agents spécialisés diversifiés qu’à un modèle unique : Greg Brockman d’OpenAI estime que la forme future de l’intelligence artificielle générale (AGI) ressemblera davantage à un “zoo” composé de nombreux agents spécialisés, plutôt qu’à un modèle “monolithique” unique et omnipotent. Ces agents spécialisés pourront s’appeler mutuellement, travailler en collaboration et stimuler conjointement le développement économique. Ce point de vue suggère une tendance future du développement de l’IA, à savoir la construction et l’intégration de multiples AI Agents dotés de capacités spécifiques pour réaliser des systèmes intelligents plus complexes et puissants, l’objectif étant de débloquer plus de 10 fois l’activité et la production actuelles. Clement Delangue commente à ce sujet qu’une robotique IA open source est nécessaire pour briser les monopoles et éviter qu’une seule entreprise ne contrôle tous les robots (Source : natolambert, ClementDelangue, HamelHusain)
Les LLM démontrent un potentiel dans la rédaction académique et le résumé de contenu, soulevant des questions sur la qualité de l’écriture humaine : Dwarkesh Patel estime que les LLM sont actuellement des rédacteurs “5/10”, mais le fait qu’ils puissent améliorer de manière fiable les explications dans les articles et les livres est en soi une condamnation massive de la qualité de la rédaction académique. Arvind Narayanan ajoute que la plupart des écrits académiques sacrifient souvent la clarté et la compréhensibilité pour paraître profonds et complexes, alors qu’une bonne écriture devrait viser la concision. Cela a suscité des discussions sur le rôle des LLM pour assister la recherche académique, améliorer la lisibilité du contenu et comment ils pourraient changer les modes de communication académique à l’avenir (Source : random_walker, jeremyphoward)
Les outils de codage IA suscitent des discussions sur la dépendance des développeurs, Claude Code attire l’attention pour ses fonctionnalités puissantes et sa forte consommation de tokens : L’utilisateur dotey estime que l’utilisation d’outils de programmation IA (comme Claude Code) engendre facilement une forte dépendance, au point de préférer attendre que l’IA termine plutôt que d’écrire manuellement, même lorsque des crédits sont disponibles. Bien que l’abonnement Claude Max ait une limite, ses puissantes capacités de codage (telles qu’une excellente compréhension des instructions, la planification des tâches, l’utilisation de l’outil grep et une longue durée d’exécution) en font un outil efficace. Ce phénomène soulève des discussions sur la manière dont les outils d’IA modifient les habitudes de travail des développeurs et sur l’équilibre entre efficacité et dépendance. Un autre utilisateur, Asuka小能猫, a également montré un cas d’utilisation efficace de Claude-4-Opus et du mode Cursor Max pour le développement frontend, mais a également mentionné le problème de la consommation de tokens (Source : dotey, dotey)
Le potentiel de l’éducation personnalisée pilotée par l’IA est énorme, mais il faut prêter attention aux défis de mise en œuvre : Austen Allred a partagé l’expérience de son enfant fréquentant une école pilotée par l’IA (sans enseignants) pendant cinq mois, jugeant les résultats “fous”. Noah Smith commente que le tutorat individualisé est une intervention éducative efficace, et que l’IA rend sa mise à l’échelle possible. Cela a suscité des discussions sur les applications de l’IA dans le domaine de l’éducation, y compris les parcours d’apprentissage personnalisés, le potentiel des tuteurs IA, ainsi que la manière d’assurer l’équité en matière d’éducation et de surmonter les défis de mise en œuvre technologique. Jon Stokes a relayé et suivi cette tendance (Source : jonst0kes, jeremyphoward)
La connexion émotionnelle entre les agents IA et les humains attire l’attention, OpenAI souligne la priorité accordée à la recherche sur le bien-être des utilisateurs : Joanne Jang d’OpenAI a publié un article de blog explorant la relation entre les humains et l’IA ainsi que l’attitude de l’entreprise à ce sujet. L’idée centrale est qu’OpenAI construit des modèles avant tout pour servir les humains. Alors que de plus en plus de personnes développent des liens émotionnels avec l’IA, l’entreprise donne la priorité à la recherche sur l’impact de cela sur le bien-être émotionnel des utilisateurs. Corbtt commente que les compagnons IA sont la technologie sociale la plus transformatrice depuis Internet. Si les entreprises optimisent l’engagement plutôt que la santé mentale, l’impact négatif sur les enfants pourrait être plus important que celui des médias sociaux, mais si elles optimisent la santé mentale, cela pourrait être une bénédiction pour l’humanité. cto_junior, quant à lui, anticipe avec humour les scénarios futurs où il pourrait être nécessaire de discuter avec ses enfants de “l’opportunité de se marier avec GPT” (Source : cto_junior, corbtt)

La technologie des AI Agents se développe rapidement, mais les tâches d’apprentissage par renforcement de bout en bout avec des récompenses rares restent difficiles : Nathan Lambert estime que les projets actuels tels que Deep Research et Codex agent sont principalement réalisés en entraînant des modèles sur des tâches d’apprentissage par renforcement (RL) à court terme et sur la robustesse générale. L’entraînement de bout en bout sur des tâches de RL avec des récompenses très rares semble plus éloigné qu’on ne le pense. Corbtt commente à ce sujet que même les humains ne maîtrisent pas encore efficacement l’entraînement sur des tâches à long terme avec des signaux de récompense rares. Cela reflète les limites actuelles de la technologie des AI Agents dans la gestion de la planification complexe à long terme et de l’apprentissage autonome (Source : corbtt)
La “leçon amère” dans le domaine de l’IA : la vérification (Verification) devient la clé pour les LLM de type raisonnement : Rishabh Agarwal a prononcé un discours intitulé “La leçon amère du RL : la vérification comme clé pour les LLM de type raisonnement” lors du séminaire sur le raisonnement multimodal à CVPR. Ce discours s’inspire de l’article classique de Rich Sutton sur la “leçon amère” et explore l’importance des mécanismes de vérification dans l’apprentissage par renforcement et le raisonnement des grands modèles linguistiques. Cela pourrait signifier que se fier uniquement aux capacités de génération du modèle n’est pas suffisant, et que des mécanismes de vérification et de rétroaction robustes sont essentiels pour améliorer les capacités de raisonnement et la fiabilité de l’IA (Source : jack_w_rae)

Le développement de l’IA suscite des inquiétudes sur le marché de l’emploi, les avis des experts divergent : Sebastian Siemiatkowski, PDG de Klarna, avertit que l’IA pourrait déclencher une récession économique en provoquant un chômage de masse (en particulier pour les emplois de cols blancs). Klarna a elle-même remplacé 700 agents de service client par un assistant IA, économisant environ 40 millions de dollars par an. Sholto Douglas, chercheur chez Anthropic, prédit également que d’ici 2027-28, les capacités de l’IA seront très puissantes. Cependant, certains estiment que l’IA augmentera la productivité et créera de nouveaux emplois, comme Sundar Pichai qui a déclaré que l’IA serait un accélérateur et ne provoquerait pas de licenciements avant au moins 2026. Une vidéo d’AI Explained analyse si les gros titres actuels sur le chômage induit par l’IA sont justifiés et discute de certaines hésitations de Duolingo et Klarna concernant l’application de l’IA. Ces discussions reflètent l’anxiété généralisée de la société face à l’impact économique de l’IA et les différentes attentes (Source : , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Exploration des futures voies d’interaction entre les agents IA et les réseaux/API existants : Avec l’amélioration des capacités d’interaction web autonome des agents IA, la manière dont ils interagissent avec les Web/API existants devient une question d’infrastructure fondamentale. La discussion a soulevé trois voies possibles : 1. Reconstruire à partir de zéro, en adoptant des protocoles natifs aux agents (irréaliste) ; 2. Apprendre aux agents à manipuler les sites web comme les humains (taux d’erreur élevé, en particulier pour l’authentification) ; 3. Faire en sorte que HTTP “parle le langage des agents”, par exemple en enrichissant le contexte lisible par machine des réponses non réussies telles que 402 (paiement requis), afin que les agents puissent s’authentifier et acheter des accès de manière autonome. L’idée centrale est que fournir un contexte riche pour les interactions Web/API non réussies sera la clé pour que les agents autonomes accomplissent un travail significatif, leur permettant de se remettre automatiquement des erreurs et de naviguer dans des processus complexes (Source : Reddit r/ArtificialInteligence)
La recherche mathématique assistée par l’IA progresse, Terence Tao et d’autres s’intéressent à son potentiel et à ses limites : Les mathématiciens explorent activement l’application de l’IA à la résolution de problèmes mathématiques complexes. Terence Tao a partagé des cas où l’IA (AlphaEvolve) en collaboration avec des humains a battu à trois reprises en 30 jours le record de l’exposant des ensembles somme-différence, et a relevé le défi des problèmes de limites “ε-δ” en combinant le langage Lean et GitHub Copilot. Cela démontre les capacités de l’IA à aider les débutants, à gérer les tâches de base et à prédire la structure des preuves, mais souligne également ses lacunes dans les dérivations complexes et la recherche de lemmes mathématiques. D’autres rapports indiquent que 30 mathématiciens de haut niveau ont testé OpenAI o4-mini lors d’une réunion secrète, découvrant qu’il pouvait résoudre certains problèmes extrêmement difficiles, montrant un niveau proche du génie mathématique. Ces progrès laissent présager que l’IA pourrait devenir un assistant précieux pour la recherche mathématique, mais soulèvent également de nouvelles réflexions sur le rôle des mathématiciens et le développement de la créativité (Source : 36氪)

💡 AUTRES
La course aux technologies alternatives au GPS s’intensifie, Xona Space Systems prévoit de construire une constellation PNT en orbite basse : En raison de la sensibilité des signaux du système GPS aux interférences (météo, tours 5G, brouilleurs) et de sa précision limitée, notamment mise en évidence par sa vulnérabilité dans le conflit russo-ukrainien, la recherche d’alternatives est devenue une priorité stratégique. La start-up californienne Xona Space Systems prévoit de lancer une constellation de satellites en orbite terrestre basse nommée Pulsar (finalement 258 satellites). Ses satellites, en orbite plus basse, auront une puissance de signal environ 100 fois supérieure à celle du GPS, seront plus difficiles à brouiller et pénétreront mieux les obstacles. L’objectif est de fournir des services de positionnement, navigation et synchronisation (PNT) avec une précision centimétrique et une haute fiabilité, afin de soutenir les technologies émergentes telles que la conduite autonome. Le premier satellite de test sera lancé ce mois-ci à bord du SpaceX Transporter 14 (Source : MIT Technology Review)

Une étude explore l’impact positif de l’espoir et de l’optimisme sur le rétablissement des patients cardiaques : Des recherches récentes indiquent que l’espoir et l’optimisme des patients cardiaques sont associés à de meilleurs résultats pour leur santé, tandis que le désespoir est lié à un risque de mortalité plus élevé. Cela concorde avec les phénomènes de l’effet placebo (une attente positive améliore les résultats) et de l’effet nocebo (une attente négative entraîne des symptômes négatifs). Alexander Montasem et d’autres chercheurs de l’Université de Liverpool ont découvert qu’un niveau élevé d’espoir est associé à une réduction de l’angine de poitrine, une diminution de la fatigue post-AVC, une meilleure qualité de vie et un risque de mortalité réduit. Les chercheurs explorent comment utiliser le pouvoir de la pensée positive en clinique, par exemple en aidant les patients à se fixer des objectifs et à renforcer leur capacité d’action pour “prescrire de l’espoir”, tout en soulignant que les objectifs non matériels sont plus importants pour le bien-être (Source : MIT Technology Review)

Le déploiement des services d’IA d’Apple et d’Alibaba en Chine entravé, possiblement en raison des frictions commerciales : Selon le Financial Times, le plan de promotion des services d’IA d’Apple et d’Alibaba en Chine a subi des retards, considérés comme la dernière victime des frictions commerciales sino-américaines. Cette collaboration visait initialement à fournir un support pour les fonctionnalités d’IA sur les iPhone vendus en Chine. Ce retard pourrait affecter le calendrier de déploiement des fonctionnalités d’IA d’Apple sur le marché chinois et créer de l’incertitude quant aux perspectives de coopération entre les deux entreprises (Source : MIT Technology Review)