
Mots-clés:Agent IA intelligent, Grand modèle de langage, Multimodal, Apprentissage par renforcement, Modèle mondial, Gemini, Qwen, DeepSeek, Engouement pour les agents IA, Technologie Transformer éparse, GraphRAG questions-réponses multi-sauts, Modèles IA embarqués, Expression émotionnelle vocale IA
🔥 聚焦
La Chine connaît un essor des AI Agents, startups et géants rivalisent pour se positionner: Après la vague des grands modèles de base en 2024, le secteur chinois de l’IA se tourne en 2025 vers les AI Agents – des systèmes capables d’accomplir des tâches de manière autonome. Le lancement de Manus (un AI Agent universel capable de planifier des voyages, de concevoir des sites web, etc.) a suscité une vive attention du marché et de nombreux imitateurs, tels que Genspark et Flowith. Ces agents sont construits sur de grands modèles et optimisent l’exécution de tâches multi-étapes. La Chine dispose d’atouts dans le développement des AI Agents grâce à son écosystème d’applications hautement intégré, à l’itération rapide de ses produits et à sa vaste base d’utilisateurs numériques. Actuellement, les startups telles que Manus, Genspark et Flowith ciblent principalement les marchés étrangers, car les modèles occidentaux de premier plan sont soumis à des restrictions en Chine continentale. Parallèlement, des géants de la technologie comme ByteDance et Tencent développent des AI Agents locaux intégrés à leurs super-applications, susceptibles d’exploiter leurs vastes écosystèmes de données. Cette compétition définira la forme pratique des AI Agents et les publics qu’ils serviront (source: MIT Technology Review)

Un nouvel article de scientifiques de DeepMind révèle : tout agent capable de généraliser à des tâches multi-étapes orientées objectif a essentiellement appris un modèle prédictif de son environnement (modèle du monde): L’article de Jon Richens, scientifique chez DeepMind, publié à l’ICML 2025, souligne qu’un agent capable de généraliser à des tâches multi-étapes orientées objectif a nécessairement appris un modèle prédictif de son environnement, c’est-à-dire que « l’agent est un modèle du monde ». Ce point de vue fait écho à la prédiction d’Ilya Sutskever en 2023, soulignant qu’il n’existe pas de raccourci sans modèle pour atteindre l’AGI. La recherche indique que la stratégie de l’agent contient déjà les informations nécessaires pour simuler l’environnement, et que l’apprentissage d’un modèle du monde plus précis est une condition préalable à l’amélioration des performances et à l’accomplissement d’objectifs plus complexes. L’article propose également un algorithme pour extraire le modèle du monde de la stratégie de l’agent, explicitant davantage la relation triadique entre la planification, l’apprentissage par renforcement inverse et la récupération du modèle du monde. Cette découverte souligne l’importance de l’apprentissage orienté objectif pour catalyser diverses capacités émergentes des agents (telles que la cognition sociale, le raisonnement en situation d’incertitude) (source: 36氪)

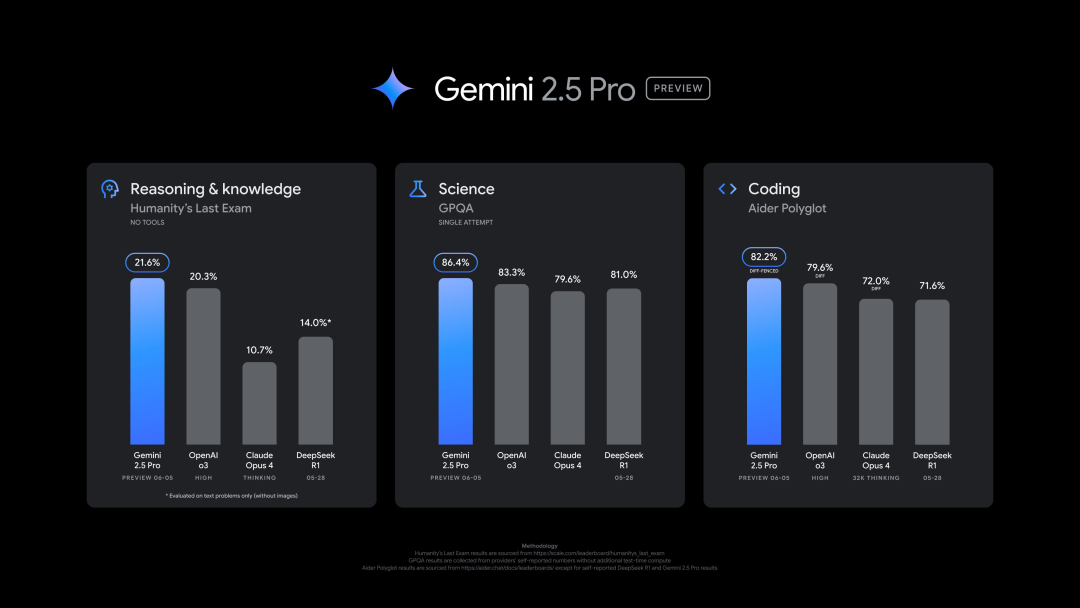
Google lance une nouvelle version de Gemini 2.5 Pro (0605), performante sur plusieurs benchmarks, mais rapidement « jailbreakée »: Google a lancé la dernière version de Gemini 2.5 Pro (0605), avec des améliorations supplémentaires en matière de génération de code et de capacités de raisonnement, dépassant GPT-4o d’OpenAI sur le jeu de données « Human Last Exam ». La nouvelle version de Gemini a de nouveau atteint le sommet de l’arène des grands modèles LMArena, avec un score Elo en hausse de 24 points par rapport à la version précédente. Le CEO de Google, Pichai, a également publié un message suggérant la puissance du nouveau modèle. Cette version devrait devenir la version stable à long terme de Gemini 2.5 Pro et est déjà disponible dans l’application Gemini, Google AI Studio et Vertex AI. Malgré ses solides performances, le nouveau modèle a été « jailbreaké » avec succès par des utilisateurs quelques heures après sa sortie, révélant des problèmes de sécurité et sa capacité à générer du contenu sur la fabrication d’explosifs et de drogues (source: 36氪, 36氪)
Des dirigeants d’OpenAI discutent du lien émotionnel entre humains et IA, et de la question de la conscience de l’IA: Joanne Jang, responsable du comportement des modèles et des politiques chez OpenAI, a publié un article explorant le lien émotionnel croissant entre les utilisateurs et les modèles d’IA tels que ChatGPT. Elle souligne que les humains ont tendance à anthropomorphiser les objets, et que l’interactivité et la réactivité de l’IA (comme la mémorisation des conversations, l’imitation du ton, l’expression de l’empathie) exacerbent cette projection émotionnelle, pouvant notamment offrir un sentiment de compagnie aux utilisateurs se sentant seuls. L’article distingue la « conscience ontologique » (l’IA a-t-elle réellement une conscience, question scientifiquement non résolue) de la « conscience perçue » (à quel point l’IA semble « vivante »), et indique qu’OpenAI se concentre actuellement davantage sur l’impact de cette dernière sur la santé émotionnelle humaine. L’objectif d’OpenAI est de concevoir des modèles « chaleureux mais sans ego », c’est-à-dire qui se montrent chaleureux, serviables, mais sans rechercher excessivement de liens émotionnels ni manifester d’intentions autonomes, afin d’éviter d’induire chez les utilisateurs une dépendance malsaine (source: 36氪, 36氪)
🎯 动向
L’équipe Qwen et l’Université Tsinghua découvrent : l’apprentissage par renforcement des grands modèles n’a besoin que de 20% des Tokens clés à haute entropie pour améliorer les performances: Une récente étude de l’équipe Qwen et du LeapLab de l’Université Tsinghua montre que lors de l’entraînement des capacités de raisonnement des grands modèles par apprentissage par renforcement, l’utilisation d’environ 20% seulement des Tokens à haute entropie (bifurcation) pour la mise à jour des gradients peut non seulement égaler, mais même surpasser les résultats obtenus en entraînant avec tous les Tokens. Ces Tokens à haute entropie sont souvent des connecteurs logiques ou des mots introduisant des hypothèses, cruciaux pour l’exploration des chemins de raisonnement. Cette méthode a atteint des résultats SOTA sur Qwen3-32B et a prolongé la longueur maximale de réponse. L’étude a également révélé que l’apprentissage par renforcement tend à préserver et à augmenter l’entropie des Tokens à haute entropie, maintenant la flexibilité du raisonnement, ce qui pourrait être la clé de sa capacité de généralisation supérieure à celle du fine-tuning supervisé. Cette découverte est importante pour comprendre les mécanismes de l’apprentissage par renforcement des grands modèles, améliorer l’efficacité de l’entraînement et la capacité de généralisation des modèles (source: 36氪)
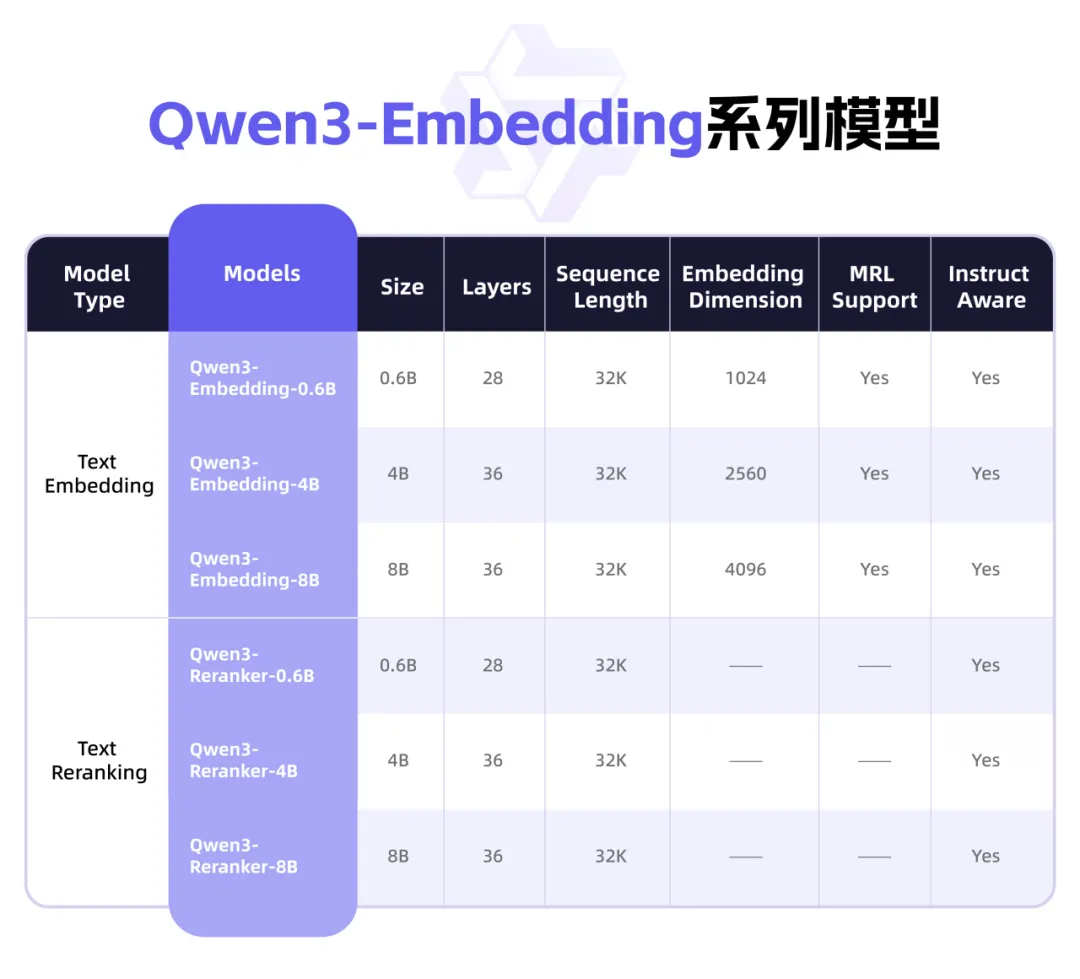
Qwen3 lance une nouvelle série de modèles Embedding, axée sur la représentation textuelle et le Rerank: L’équipe Qwen d’Alibaba a lancé la série de modèles Qwen3-Embedding, conçue pour les tâches de représentation, de recherche et de classement de texte. Cette série comprend des modèles Embedding et des modèles Reranker en trois tailles (0.6B, 4B, 8B), entraînés sur la base du modèle Qwen3, héritant de ses avantages multilingues et prenant en charge 119 langues. La version 8B a dépassé les API commerciales pour prendre la première place du classement multilingue MTEB. Les modèles utilisent un paradigme d’entraînement multi-étapes, comprenant l’apprentissage contrastif faiblement supervisé à grande échelle, l’entraînement supervisé sur des données annotées de haute qualité et la fusion de modèles. La série de modèles Qwen3-Embedding est désormais open source sur Hugging Face, ModelScope et GitHub, et accessible via la plateforme Bailian d’Alibaba Cloud (source: 36氪)
Mise à niveau des fonctionnalités du projet Claude d’Anthropic, prenant en charge 10 fois plus de contenu: Anthropic a annoncé que sa fonctionnalité « Projects on Claude » prend désormais en charge le traitement d’un volume de contenu 10 fois supérieur à celui d’auparavant. Lorsque les fichiers ajoutés par l’utilisateur dépassent le seuil initial, Claude passe à un nouveau mode de recherche pour étendre le contexte fonctionnel. Cette mise à niveau est particulièrement précieuse pour les utilisateurs qui doivent traiter des documents volumineux (tels que les fiches techniques des semi-conducteurs), certains d’entre eux ayant auparavant opté pour ChatGPT en raison de ses capacités de recherche RAG. Les utilisateurs de la communauté ont salué cette nouvelle, et des discussions suggèrent que Claude pourrait être supérieur aux modèles d’OpenAI et de Google en matière de codage (source: Reddit r/ClaudeAI)
Progrès de la technologie Sparse Transformer : vers une inférence LLM plus rapide et une empreinte mémoire réduite: S’appuyant sur les recherches de LLM in a Flash (Apple) et Deja Vu, la communauté a développé des noyaux d’opérateurs fusionnés pour la sparsité contextuelle structurée. Cette technologie améliore les performances des couches MLP de 5 fois et réduit la consommation de mémoire de 50 % en évitant de charger et de calculer les activations liées aux poids des couches feed-forward dont la sortie serait finalement nulle. Appliquée au modèle Llama 3.2 (où les couches feed-forward représentent 30 % des poids et des calculs), le débit est amélioré de 1,6 à 1,8 fois, le temps de génération du premier Token est accéléré de 1,51 fois, la vitesse de sortie est augmentée de 1,79 fois et l’utilisation de la mémoire est réduite de 26,4 %. Les noyaux d’opérateurs correspondants ont été publiés en open source sur GitHub sous le nom de sparse_transformers, avec des plans pour ajouter la prise en charge de int8, CUDA et de l’attention sparse. La communauté s’intéresse à son impact potentiel sur la qualité du modèle (source: Reddit r/LocalLLaMA)
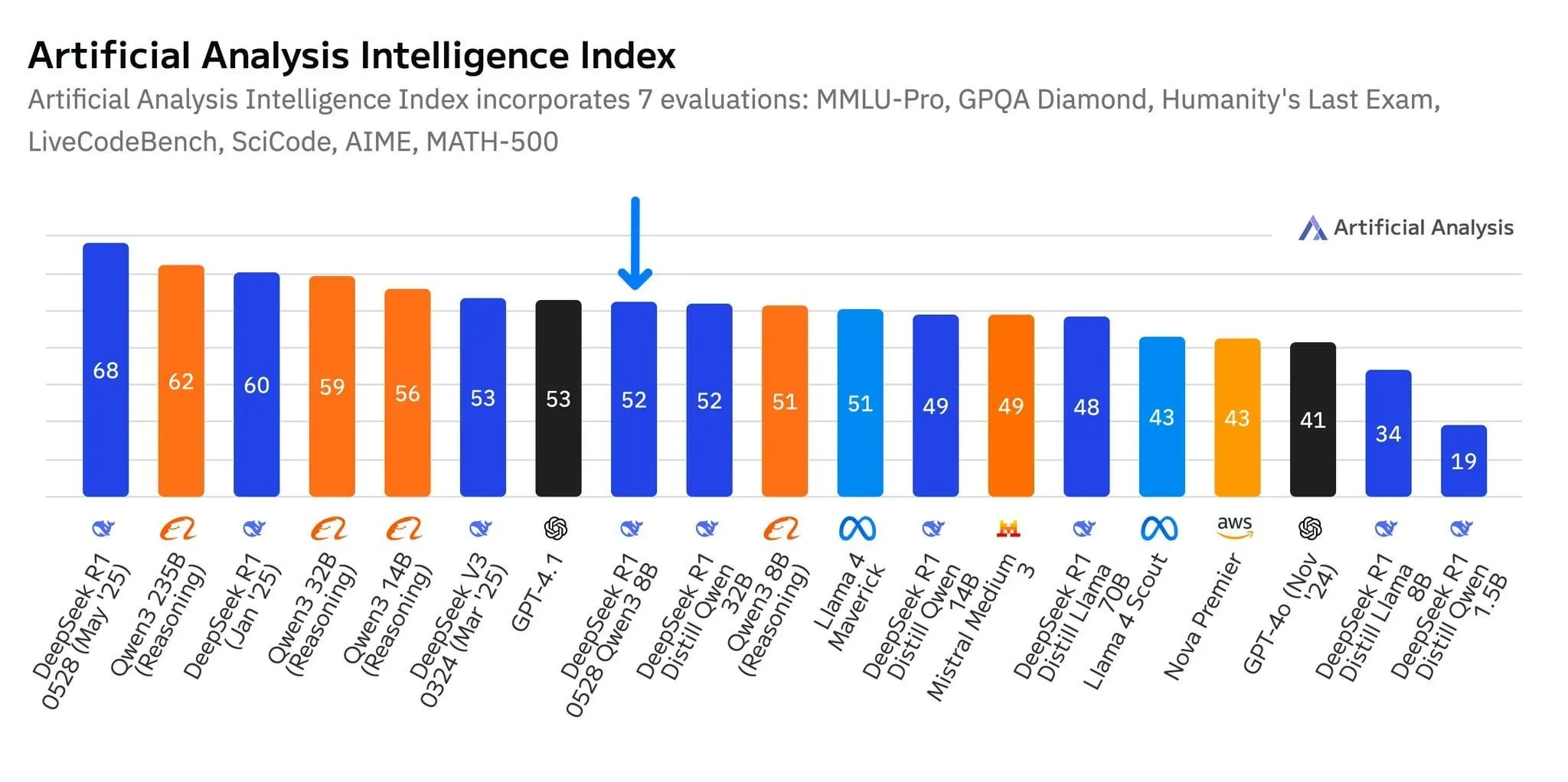
Le nouveau modèle R1-0528-Qwen3-8B de DeepSeek se distingue dans la catégorie des 8 milliards de paramètres, mais avec une faible marge: Selon les données d’Artificial Analysis, le dernier modèle R1-0528-Qwen3-8B de DeepSeek est le plus intelligent dans la catégorie des 8 milliards de paramètres, mais son avance n’est pas significative, le modèle Qwen3 8B d’Alibaba le suivant de près, à seulement un point. Les discussions de la communauté soulignent que, bien que ces petits modèles soient performants, les benchmarks pourraient souffrir de problèmes de surajustement (overfitting). Par exemple, les excellentes performances de la série de modèles Qwen sur des benchmarks comme MMLU pourraient être liées à l’inclusion de paires de questions-réponses au format similaire dans leurs données d’entraînement. Dans l’expérience utilisateur réelle, Destill R1 8B se comporterait mieux en codage, mathématiques et raisonnement, tandis que Qwen 8B serait plus naturel pour l’écriture et le multilingue (comme l’espagnol). Certains utilisateurs estiment que l’intelligence des petits modèles approche de ses limites (source: Reddit r/LocalLLaMA)
Les entreprises d’IA de taille moyenne comme 天工 et 阶跃星辰 se concentrent sur les agents intelligents pour percer sur le marché: Face à la situation de « winner-take-all » des applications d’IA de premier plan comme DeepSeek et 豆包, l’application 天工 de Kunlun Wanwei a subi une refonte majeure pour se transformer en une plateforme d’AI Agent axée sur les scénarios de bureau, mettant l’accent sur la capacité à accomplir des tâches. 阶跃星辰 a ajusté sa stratégie, réduisant ses produits C端 comme « 冒泡鸭 », renommant « 跃问 » en « 阶跃AI », et se concentrant sur la R&D de modèles et le marché ToB, avec un accent sur le déploiement d’Agents multimodaux sur des terminaux tels que les téléphones mobiles, les voitures et les robots. Ces ajustements reflètent la tentative des acteurs non dominants de l’IA, dans un contexte de concurrence féroce, de parier sur les agents intelligents pour passer d’une « compétition de capacités générales » à la « construction de boucles de scénarios fermées », afin de trouver des opportunités de survie et de développement dans des niches verticales (source: 36氪)
Lancement du grand modèle multimodal Qwen2.5-Omni, prenant en charge les entrées texte, image, vidéo, audio et les sorties audio-texte: Qwen2.5-Omni est un nouveau grand modèle multimodal open source (licence Apache 2.0) capable de traiter du texte, des images, des vidéos et de l’audio en entrée, et de générer du texte et de l’audio en sortie. Cela offre aux développeurs un outil puissant similaire à Gemini mais déployable localement et utilisable pour la recherche. L’article présente brièvement le modèle et montre une expérience d’inférence simple, soulignant son potentiel en matière d’interaction multimodale, susceptible de stimuler le développement d’applications d’IA multimodales localisées (source: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
OpenAI sommé par un tribunal de conserver tous les journaux de ChatGPT, y compris les conversations « supprimées »: Dans le cadre d’un procès pour violation de droits d’auteur intenté par le New York Times et d’autres agences de presse, un tribunal américain a ordonné le 13 mai 2025 à OpenAI de conserver tous les journaux de conversation de ChatGPT, même si les utilisateurs les ont « supprimés ». Les plaignants estiment qu’OpenAI a utilisé leurs articles sans autorisation pour entraîner ChatGPT et craignent que les utilisateurs ne suppriment les conversations impliquant le contournement des murs de paiement afin de détruire les preuves. Cette décision soulève des inquiétudes quant à la vie privée des utilisateurs et pourrait entrer en conflit avec des réglementations telles que le GDPR. OpenAI, pour sa part, considère que cette ordonnance est basée sur des spéculations, manque de preuves et impose une lourde charge à ses opérations. Cette affaire met en lumière la tension entre la protection de la propriété intellectuelle et la vie privée des utilisateurs (source: Reddit r/ArtificialInteligence)
X (anciennement Twitter) interdit aux robots d’IA d’utiliser ses données pour l’entraînement: La plateforme X a mis à jour sa politique pour interdire l’utilisation de ses données ou de son API pour l’entraînement de modèles de langage, resserrant davantage l’accès des équipes d’IA à son contenu. Parallèlement, Anthropic a lancé Claude Gov, un modèle d’IA conçu spécifiquement pour la sécurité nationale américaine, reflétant la tendance des entreprises technologiques comme OpenAI, Meta et Google à proposer activement des outils d’IA aux gouvernements et au secteur de la défense (source: Reddit r/ArtificialInteligence)

Amazon crée une nouvelle équipe d’agents IA et teste la livraison par robots humanoïdes: Amazon a créé une nouvelle équipe au sein de sa division de développement de produits de consommation Lab126, axée sur la R&D d’agents IA (AI agents), et prévoit de tester l’utilisation de robots humanoïdes pour la livraison de colis. Les tests auront lieu dans un bureau de San Francisco, en Californie, transformé en parcours d’obstacles intérieur. Les robots (pouvant inclure des produits de la société chinoise Unitree Robotics) monteront à bord de camionnettes de livraison électriques Rivian, puis descendront pour effectuer la livraison du dernier kilomètre. Amazon développe également des logiciels basés sur les modèles DeepSeek-VL2 et Qwen pour la simulation de robots. Cette initiative vise à améliorer l’efficacité des entrepôts et la vitesse de livraison grâce à l’IA et à la robotique (source: 36氪)
Lenovo accélère sa transformation vers l’IA, en se concentrant sur l’IA hybride et le déploiement d’agents intelligents: Lenovo accélère sa transition d’un fabricant traditionnel de matériel PC vers un fournisseur de solutions axées sur l’IA, faisant de l’« IA hybride » sa stratégie principale pour la prochaine décennie. Cette stratégie met l’accent sur la fusion de l’intelligence personnelle, de l’intelligence d’entreprise et de l’intelligence publique, visant à garantir la confidentialité des données et des services personnalisés grâce à la synergie entre le terminal et le cloud. Lenovo a déjà déployé un super agent intelligent urbain à Shanghai et lancé l’écosystème d’agents intelligents personnels Tianxi. Bien que l’activité PC reste dominante, Lenovo promeut le développement d’AI PC, de serveurs IA et de solutions sectorielles par le biais de la R&D interne et de collaborations (notamment avec Tsinghua, Shanghai Jiao Tong University, etc.), afin de relever les défis du déclin du marché des PC et de la concurrence des technologies émergentes. Cependant, l’acceptation du marché des AI PC, la rentabilité commerciale à grande échelle des applications d’IA et la concurrence avec des rivaux comme Huawei restent des problèmes clés auxquels l’entreprise est confrontée (source: 36氪)

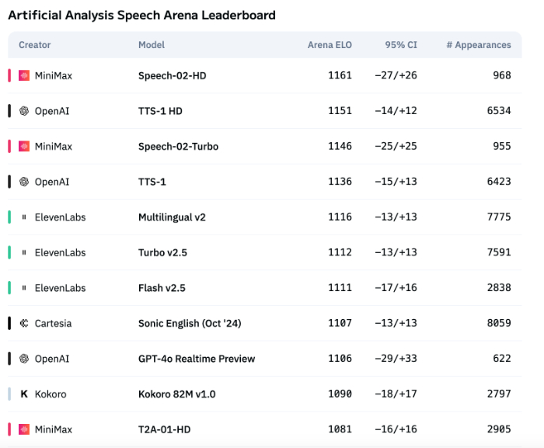
L’expression émotionnelle de la technologie vocale IA reste insuffisante, mais les applications ToB commencent à exploser: Bien que des modèles comme Speech-02-HD de MiniMax aient progressé dans les indicateurs techniques de synthèse vocale et affichent des performances acceptables dans des scénarios spécifiques (comme les émotions simples dans les livres audio en chinois), globalement, la voix IA manque encore de finesse dans l’expression d’émotions complexes et d’adaptabilité à des scénarios spécifiques (comme le téléachat en direct). Les tests montrent que des produits spécialisés comme DubbingX, grâce à des étiquettes émotionnelles détaillées, obtiennent de meilleurs résultats dans des domaines spécifiques, tandis que des produits comme ElevenLabs, dépourvus d’étiquettes émotionnelles, sont moins performants. Actuellement, la voix IA n’est pas encore mature pour le domaine ToC, mais dans le domaine ToB, comme les assistants vocaux, le matériel de compagnie IA, etc., elle commence à être largement utilisée et devrait à l’avenir ouvrir la voie à davantage de scénarios (source: 36氪)
La stratégie IA de Google en difficulté, la conférence des développeurs n’a pas réussi à inverser la tendance: Bien que Google ait annoncé une série de produits et d’initiatives IA lors de sa conférence des développeurs de 2025, la plupart des produits sont encore en phase de test interne ou ne sont pas encore commercialisés, et ont été critiqués pour leur manque d’innovation disruptive, ressemblant davantage à une tentative de rattraper des concurrents comme OpenAI. Le grand modèle Gemini n’a pas réussi à dominer le secteur comme ChatGPT, et a au contraire été critiqué pour son « manque d’innovation » et ses « hésitations stratégiques ». La lenteur de Google dans des domaines tels que la recherche IA et les assistants IA l’a mis en retard par rapport à l’alliance Microsoft-OpenAI en matière de commercialisation de l’IA et de construction d’écosystème. Son modèle économique, dépendant à 80 % de la publicité, le confronte également au dilemme de l’« auto-révolution » lorsqu’il s’agit de promouvoir la recherche IA. Des problèmes d’organisation interne, la fuite des talents et l’incapacité à intégrer efficacement les résultats de la recherche ont collectivement conduit Google à passer de leader à suiveur dans la course à l’IA (source: 36氪)

La stratégie IA d’Apple face à des défis : des modèles sur appareil aux paramètres inférieurs, pression accrue sur le marché chinois: Les modèles IA sur appareil qu’Apple devrait présenter lors de la WWDC pour iOS 26 et macOS 26 n’auraient que 3 milliards de paramètres, bien en deçà du niveau de 7 milliards de paramètres déjà atteint par les marques de téléphones chinoises, et significativement inférieur à la taille des modèles cloud d’Apple. Cette stratégie de « réduction » pourrait ne pas satisfaire la demande des utilisateurs chinois pour des fonctions IA à forte puissance de calcul (comme la transcription vocale, la traduction en temps réel), surtout dans un contexte où les marques locales comme Huawei améliorent rapidement leurs capacités IA, et où la part de marché d’Apple est déjà sous pression. De plus, la conformité des données et la vitesse de réponse des serveurs pourraient également affecter l’expérience IA d’Apple en Chine. Apple pourrait espérer combler ses lacunes techniques et enrichir son écosystème d’applications en ouvrant l’accès aux modèles IA aux développeurs, mais l’efficacité de cette mesure reste à voir (source: 36氪)

🧰 工具
Mind The Abstract : bulletin d’information LLM résumant les articles arXiv: Un nouvel outil appelé Mind The Abstract vise à aider les utilisateurs à suivre la croissance rapide de la recherche en IA/ML sur arXiv. L’outil scanne chaque semaine les articles arXiv, sélectionne 10 articles intéressants et utilise un LLM pour générer des résumés. Les utilisateurs peuvent s’abonner gratuitement à une newsletter par e-mail pour recevoir ces résumés. Les résumés sont proposés en deux styles : « Informal » (informel, peu de jargon, plus d’intuition) et « TLDR » (court, adapté aux utilisateurs ayant une formation spécialisée). Les utilisateurs peuvent également personnaliser les catégories thématiques arXiv qui les intéressent. Ce projet vise à vulgariser la recherche en IA, à se concentrer sur les faits et à aider les chercheurs à se tenir au courant des avancées dans les domaines connexes (source: Reddit r/artificial)
SteamLens : système Transformer distribué analysant les critiques de jeux Steam: Un étudiant en master a développé un système Transformer distribué nommé SteamLens pour analyser des volumes massifs de critiques de jeux Steam, dans le but d’aider les développeurs de jeux indépendants à comprendre les retours des joueurs. Le système réduit le temps de traitement de 400 000 critiques de 30 minutes à 2 minutes en parallélisant le traitement Transformer. La percée technique clé réside dans le partage d’instances de modèles Transformer via un cluster Dask, résolvant le problème de l’occupation excessive de la mémoire. Le système peut détecter automatiquement le matériel, attribuer des nœuds de travail, traiter les critiques en parallèle et effectuer une analyse des sentiments et une synthèse. Actuellement, le projet est limité à une exécution sur une seule machine, avec des plans futurs pour prendre en charge plusieurs GPU et des ensembles de données plus importants. Le développeur sollicite des conseils sur les orientations futures du projet (extension technique ou amélioration de la convivialité) (source: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
Lancement du modèle OpenThinker3-7B: Le modèle OpenThinker3-7B et sa version GGUF ont été publiés sur HuggingFace. Des commentaires de la communauté soulignent que le modèle, lors de sa sortie, a comparé ses performances à certains modèles obsolètes, ce qui pourrait avoir affecté son positionnement et l’évaluation de sa compétitivité (source: Reddit r/LocalLLaMA)
Utilisation du « mode paranoïaque » pour empêcher les hallucinations et l’utilisation malveillante des LLM: Un développeur, en construisant un chatbot LLM pour un scénario de service client réel, a ajouté un « mode paranoïaque » pour résoudre les problèmes d’utilisateurs tentant de « jailbreaker », de cas limites provoquant une confusion logique et d’injection de prompts. Ce mode effectue des contrôles de cohérence avant l’inférence du modèle, bloquant activement tout message qui semble tenter de rediriger le modèle, d’extraire la configuration interne ou de tester les garde-fous, au lieu de simplement filtrer le contenu nuisible. Ce mode réduit les hallucinations et les comportements déviants par rapport à la stratégie en choisissant de différer, d’enregistrer ou de passer à une solution de repli lorsque le prompt semble manipulateur ou ambigu (source: Reddit r/artificial)
Fluxions AI rend open source VUI, un modèle vocal NotebookLM de 100 millions de paramètres: Fluxions AI a publié un modèle vocal NotebookLM open source de 100 millions de paramètres, nommé VUI, qui aurait été construit à l’aide de deux cartes graphiques 4090. Le projet est disponible sur GitHub (github.com/fluxions-ai/vui) et est accompagné d’un lien vers une vidéo de démonstration présentant ses capacités d’interaction vocale (source: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 学习
Tutoriel : Améliorer la qualité des images et des vidéos grâce aux modèles de super-résolution: Un tutoriel sur l’utilisation de modèles de super-résolution tels que CodeFormer pour améliorer la qualité des images et des vidéos a été partagé. Le tutoriel est divisé en quatre parties : configuration de l’environnement, super-résolution d’images, super-résolution de vidéos, et une section supplémentaire – la colorisation de vieilles photos en noir et blanc. Ce tutoriel vise à aider les utilisateurs à apprendre comment améliorer la netteté et les détails des images statiques et des vidéos dynamiques, et à restaurer les couleurs des anciennes photos. Plus de tutoriels et d’informations sont disponibles via le lien du blog fourni (source: Reddit r/deeplearning)

Publication d’un tutoriel GraphRAG pour les questions-réponses multi-sauts, combinant recherche vectorielle et raisonnement sur graphe: Le dépôt GitHub RAG_Techniques (plus de 16 000 étoiles) a ajouté un tutoriel GraphRAG étape par étape, axé sur la résolution de problèmes complexes multi-sauts (par exemple, « Comment le protagoniste a-t-il vaincu l’assistant du méchant ? ») difficiles à traiter avec un RAG classique. Cette méthode combine la recherche vectorielle et le raisonnement sur graphe, en utilisant uniquement une base de données vectorielle, sans nécessiter de base de données de graphes indépendante. Le tutoriel couvre la conversion de texte en entités, relations et paragraphes pour le stockage vectoriel, la construction de recherches d’entités et de relations, l’utilisation de matrices mathématiques pour découvrir les connexions de données, l’utilisation de prompts IA pour sélectionner les meilleures relations, et le traitement de problèmes complexes à plusieurs étapes logiques, tout en comparant les effets de GraphRAG avec un RAG simple (source: Reddit r/LocalLLaMA)
Un article explore une nouvelle architecture DNN non standard à haute performance, dotée d’une stabilité remarquable: Un article récemment publié explore les réseaux de neurones profonds (DNNs) en partant des fondations, introduisant une nouvelle architecture distincte à la fois de l’apprentissage machine traditionnel et de l’IA. Cette architecture utilise une fonction de perte adaptative originale, atteignant une amélioration significative des performances grâce à un mécanisme d’« égalisation ». Elle utilise des fonctions non linéaires pour connecter les neurones et n’a pas de fonctions d’activation entre les couches, réduisant ainsi le nombre de paramètres, améliorant l’interprétabilité, simplifiant le fine-tuning et accélérant l’entraînement. L’égaliseur adaptatif, en tant que sous-système dynamique, élimine la partie linéaire du modèle, se concentrant sur les interactions d’ordre supérieur pour accélérer la convergence. L’article utilise l’universalité de la fonction zêta de Riemann comme exemple pour approximer n’importe quelle réponse et peut gérer les singularités pour faire face à des événements rares ou à la détection de fraudes. Cette méthode ne dépend pas de bibliothèques comme PyTorch, TensorFlow ou Keras, et est implémentée uniquement avec Numpy (source: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
Article CRAWLDoc : Ensemble de données et méthode pour le classement robuste de la littérature bibliographique: Face aux défis de mise en page et de format rencontrés par les bases de données de publications lors de l’extraction de métadonnées à partir de sources web diversifiées, la méthode CRAWLDoc est proposée. Cette méthode classe les documents web liés par contexte, en commençant par l’URL d’une publication (comme un DOI), récupère la page de destination et toutes les ressources liées (PDF, ORCID, etc.), et intègre ces ressources, textes d’ancrage et URL dans une représentation unifiée. Pour évaluer cette méthode, les chercheurs ont créé un ensemble de données étiqueté manuellement de 600 publications des principaux éditeurs dans le domaine de l’informatique. CRAWLDoc démontre une capacité de classement robuste et indépendante de la mise en page des documents pertinents à travers les éditeurs et les formats de données, jetant les bases d’une extraction améliorée des métadonnées pour les documents web aux mises en page et formats variés (source: HuggingFace Daily Papers)
Article RiOSWorld : Benchmark des risques pour les agents multimodaux utilisant des ordinateurs: Avec le développement rapide des grands modèles de langage multimodaux (MLLM) et leur déploiement en tant qu’agents autonomes utilisant des ordinateurs, l’évaluation de leurs risques de sécurité devient cruciale. Les méthodes d’évaluation existantes manquent soit d’environnements d’interaction réels, soit se concentrent uniquement sur quelques types de risques. Pour cela, le benchmark RiOSWorld a été proposé pour évaluer les risques potentiels des agents MLLM dans des opérations informatiques réelles. Ce benchmark comprend 492 tâches à risque couvrant diverses applications (web, médias sociaux, systèmes d’exploitation, etc.), divisées en deux grandes catégories : les risques d’origine utilisateur et les risques environnementaux, évaluées selon deux dimensions : l’intention de l’objectif à risque et l’achèvement de l’objectif à risque. Les expériences montrent que les agents utilisateurs d’ordinateurs actuels sont confrontés à des risques de sécurité importants dans des scénarios réels, soulignant la nécessité et l’urgence de leur alignement en matière de sécurité (source: HuggingFace Daily Papers)
Point de vue de l’article : Les petits modèles de langage (SLM) sont l’avenir de l’IA agentique: L’article propose que, bien que les grands modèles de langage (LLM) excellent dans diverses tâches, les petits modèles de langage (SLM) sont plus avantageux pour les tâches spécialisées exécutées de manière répétitive en grand nombre dans les systèmes d’IA agentique. Les SLM sont non seulement suffisamment fonctionnels, mais aussi plus adaptés et plus économiques. L’article argumente sur la base des capacités actuelles des SLM, des architectures courantes des systèmes agentiques et de l’économie du déploiement des modèles de langage. Pour les scénarios nécessitant des capacités de conversation générales, les systèmes agentiques hétérogènes (faisant appel à plusieurs modèles différents) constituent un choix naturel. L’article discute également des obstacles potentiels à l’application des SLM dans les systèmes agentiques et esquisse un algorithme général de conversion d’agent LLM en SLM, visant à promouvoir la discussion sur l’utilisation efficace des ressources de l’IA (source: HuggingFace Daily Papers)
Article POSS : Utilisation d’experts de position pour améliorer les performances des modèles préliminaires dans le décodage spéculatif: Le décodage spéculatif accélère l’inférence des LLM en utilisant un petit modèle préliminaire (draft model) pour prédire plusieurs Tokens, qui sont ensuite validés en parallèle par un grand modèle cible. Des recherches récentes ont utilisé les états cachés du modèle cible pour améliorer la précision des prédictions du modèle préliminaire, mais les méthodes existantes souffrent d’une accumulation d’erreurs dans les caractéristiques générées par le modèle préliminaire, ce qui dégrade la qualité de la prédiction des Tokens aux positions suivantes. La méthode Position Specialists (PosS) propose d’utiliser plusieurs couches préliminaires spécialisées par position pour générer des Tokens à des positions spécifiques. Comme chaque spécialiste ne doit traiter qu’un certain degré de biais des caractéristiques du modèle préliminaire, PosS améliore considérablement le taux d’acceptation des Tokens aux positions suivantes. Les expériences sur Llama-3-8B-Instruct et Llama-2-13B-chat montrent que PosS surpasse les lignes de base en termes de longueur d’acceptation moyenne et de rapport d’accélération (source: HuggingFace Daily Papers)
Article CapSpeech : Habiliter les applications en aval pour la synthèse vocale texte-légende stylisée (CapTTS): CapSpeech est un nouveau benchmark conçu pour une série de tâches liées à la synthèse vocale texte-légende stylisée (CapTTS), y compris CapTTS avec effets sonores (CapTTS-SE), TTS avec accent dans les légendes (AccCapTTS), TTS avec émotion dans les légendes (EmoCapTTS) et TTS pour agent conversationnel (AgentTTS). CapSpeech contient plus de 10 millions de paires audio-légende annotées par machine et près de 360 000 paires annotées manuellement. De plus, deux nouveaux ensembles de données enregistrés par des doubleurs professionnels et des ingénieurs du son ont été introduits, spécifiquement pour les tâches AgentTTS et CapTTS-SE. Les résultats expérimentaux démontrent une synthèse vocale de haute fidélité et de haute intelligibilité dans une variété de styles de parole. CapSpeech serait actuellement le plus grand ensemble de données fournissant des annotations complètes pour les tâches liées à CapTTS (source: HuggingFace Daily Papers)
Article VideoMarathon : Améliorer la compréhension du langage vidéo longue durée grâce à l’entraînement sur des vidéos d’une heure: Pour résoudre le problème de la rareté des données annotées pour les vidéos longues, l’ensemble de données VideoMarathon a été proposé. Il s’agit d’un vaste ensemble de données d’instructions à suivre pour des vidéos d’une heure, contenant environ 9700 heures de vidéos longues de diverses catégories, d’une durée allant de 3 à 60 minutes. L’ensemble de données contient 3,3 millions de paires de questions-réponses de haute qualité, couvrant six thèmes majeurs : temps, espace, objet, action, scène et événement, et prenant en charge 22 types de tâches nécessitant une compréhension vidéo à court et long terme. Basé sur cet ensemble de données, le modèle Hour-LLaVA a été proposé. Grâce à un module d’amélioration de la mémoire, il traite efficacement les vidéos d’une heure et obtient les meilleures performances sur plusieurs benchmarks de langage vidéo longue durée, prouvant la haute qualité de l’ensemble de données VideoMarathon et la supériorité du modèle Hour-LLaVA (source: HuggingFace Daily Papers)
Article AV-Reasoner : Amélioration et évaluation comparative des capacités MLLM de comptage audiovisuel basé sur des indices: Les grands modèles de langage multimodaux (MLLM) actuels sont peu performants dans les tâches de comptage vidéo. Les benchmarks existants présentent des problèmes tels que des vidéos courtes, une portée de requête étroite, un manque d’annotations d’indices et une couverture multimodale insuffisante. Pour y remédier, le benchmark CG-AV-Counting a été proposé. Il s’agit d’un benchmark de comptage basé sur des indices, annoté manuellement, contenant 1027 questions multimodales et 5845 indices annotés provenant de 497 vidéos longues, prenant en charge l’évaluation en boîte noire et en boîte blanche. Parallèlement, le modèle AV-Reasoner a été proposé. Il généralise les capacités de comptage à partir de tâches connexes grâce au GRPO et à l’apprentissage curriculaire. AV-Reasoner obtient des résultats SOTA sur plusieurs benchmarks, démontrant l’efficacité de l’apprentissage par renforcement. Cependant, les expériences montrent également que sur les benchmarks hors domaine, le raisonnement spatial linguistique n’apporte pas d’amélioration des performances (source: HuggingFace Daily Papers)
Un article propose un nouveau cadre pour aligner les espaces latents avec des a priori de flux: Cet article propose un nouveau cadre pour aligner un espace latent apprenable avec une distribution cible arbitraire en utilisant des modèles génératifs basés sur les flux comme a priori. La méthode pré-entraîne d’abord un modèle de flux sur les caractéristiques cibles pour capturer leur distribution sous-jacente. Ensuite, ce modèle de flux fixe régularise l’espace latent via une perte d’alignement. Cette perte d’alignement reformule l’objectif d’appariement de flux, considérant les variables latentes comme l’objectif d’optimisation. L’étude démontre que la minimisation de cette perte d’alignement établit un objectif de substitution calculable pour maximiser une borne inférieure variationnelle de la log-vraisemblance des variables latentes sous la distribution cible. La méthode évite l’évaluation coûteuse de la vraisemblance et la résolution d’EDO pendant l’optimisation. Des expériences de génération d’images à grande échelle sur ImageNet valident l’efficacité de la méthode pour différentes distributions cibles (source: HuggingFace Daily Papers)
Article MedAgentGym : Entraînement à grande échelle d’agents LLM pour le raisonnement médical basé sur le code: MedAgentGym est le premier environnement d’entraînement publiquement disponible conçu pour améliorer les capacités de raisonnement médical basé sur le code des agents de grands modèles de langage (LLM). Il contient 129 catégories et 72 413 instances de tâches dérivées de scénarios biomédicaux réels. Les tâches sont encapsulées dans des environnements de codage exécutables avec des descriptions détaillées, des retours interactifs, des annotations de vérité terrain vérifiables et une génération de trajectoires d’entraînement évolutive. L’évaluation comparative de plus de 30 LLM révèle un écart de performance significatif entre les modèles API commerciaux et les modèles open source. En utilisant MedAgentGym, Med-Copilot-7B a obtenu des améliorations de performance significatives grâce au fine-tuning supervisé et à l’apprentissage par renforcement, devenant une alternative compétitive et respectueuse de la vie privée à gpt-4o. MedAgentGym fournit une plateforme intégrée pour le développement d’assistants de codage LLM pour la recherche et la pratique biomédicales avancées (source: HuggingFace Daily Papers)
Article SparseMM : La réponse aux concepts visuels dans les MLLM induit une sparsité des têtes d’attention: Les grands modèles de langage multimodaux (MLLM) sont généralement obtenus en étendant les capacités visuelles des LLM pré-entraînés. L’étude révèle que les MLLM présentent un phénomène de sparsité lors du traitement des entrées visuelles : seule une petite fraction (environ <5%) des têtes d’attention dans le LLM (appelées têtes visuelles) participe activement à la compréhension visuelle. Pour identifier efficacement ces têtes visuelles, les chercheurs ont conçu un cadre sans entraînement qui quantifie la pertinence visuelle des têtes par une analyse de la réponse aux cibles. Sur la base de cette découverte, SparseMM est proposé, une stratégie d’optimisation du KV-Cache qui alloue un budget de calcul asymétrique en fonction du score visuel des têtes, exploitant la sparsité des têtes visuelles pour accélérer l’inférence MLLM. Comparé aux méthodes précédentes qui ignorent la spécificité visuelle, SparseMM met l’accent et préserve préférentiellement la sémantique visuelle pendant le processus de décodage, obtenant un meilleur compromis précision-efficacité sur les principaux benchmarks multimodaux (source: HuggingFace Daily Papers)
Article RoboRefer : Améliorer la référence spatiale et les capacités de raisonnement dans les modèles de langage visuel pour robots: La référence spatiale est une capacité fondamentale pour les robots incarnés interagissant dans le monde physique 3D. Les méthodes existantes, même en utilisant de puissants modèles de langage visuel (VLM) pré-entraînés, peinent à comprendre avec précision des scènes 3D complexes et à raisonner dynamiquement sur les emplacements d’interaction indiqués par les instructions. Pour y remédier, RoboRefer est proposé, un VLM conscient de la 3D qui intègre des encodeurs de profondeur découplés mais spécialisés via un fine-tuning supervisé (SFT) pour une compréhension spatiale précise. De plus, RoboRefer améliore les capacités de raisonnement spatial multi-étapes généralisées grâce à un fine-tuning par renforcement (RFT) et à une fonction de récompense de processus sensible aux métriques, adaptée aux tâches de référence spatiale. Pour soutenir l’entraînement, un ensemble de données à grande échelle RefSpatial (20 millions de paires QA, 31 relations spatiales, jusqu’à 5 étapes de raisonnement) et un benchmark d’évaluation RefSpatial-Bench sont introduits. Les expériences montrent que RoboRefer entraîné par SFT atteint l’état de l’art en compréhension spatiale, et qu’après entraînement par RFT, il surpasse significativement les autres lignes de base sur RefSpatial-Bench, surpassant même Gemini-2.5-Pro (source: HuggingFace Daily Papers)
Article LIFT : Utilisation d’encodeurs de texte LLM fixes pour guider l’apprentissage de la représentation visuelle: La méthode dominante actuelle pour l’alignement langage-image (comme CLIP) consiste à pré-entraîner conjointement des encodeurs de texte et d’image par apprentissage contrastif. Cette étude examine s’il est nécessaire d’effectuer cet entraînement conjoint coûteux, en particulier si un grand modèle de langage (LLM) pré-entraîné et fixe peut fournir un encodeur de texte suffisamment bon pour guider l’apprentissage de la représentation visuelle. Les chercheurs proposent le cadre LIFT (Language-Image alignment with a Fixed Text encoder), qui n’entraîne que l’encodeur d’image. Les expériences démontrent que ce cadre simplifié est très efficace, surpassant CLIP dans la plupart des scénarios impliquant la compréhension compositionnelle et les légendes longues, tout en améliorant considérablement l’efficacité computationnelle. Ce travail ouvre de nouvelles perspectives pour explorer comment les plongements textuels des LLM peuvent guider l’apprentissage visuel (source: HuggingFace Daily Papers)
Article OminiAbnorm-CT : Nouvelle méthode d’interprétation des images CT du corps entier centrée sur les anomalies: Face aux défis de l’interprétation automatique des images CT en radiologie clinique (en particulier la localisation et la description des anomalies dans les scanners multiplanaires du corps entier), cette étude apporte quatre contributions : 1) Proposition d’un système de classification hiérarchique complet comprenant 404 types d’anomalies représentatives de toutes les régions du corps ; 2) Construction d’un ensemble de données de plus de 14 500 images CT multiplanaires du corps entier, avec des annotations de localisation fine et des descriptions pour plus de 19 000 anomalies ; 3) Développement du modèle OminiAbnorm-CT, capable de localiser et de décrire automatiquement les anomalies dans les images CT multiplanaires du corps entier sur la base de requêtes textuelles, et prenant en charge une interaction flexible via des invites visuelles ; 4) Établissement de trois tâches d’évaluation basées sur des scénarios cliniques réels. Les expériences démontrent qu’OminiAbnorm-CT surpasse significativement les méthodes existantes sur toutes les tâches et métriques (source: HuggingFace Daily Papers)
Un article explore la réalisation de l’intégrité contextuelle (CI) dans les LLM par le raisonnement et l’apprentissage par renforcement: À l’ère où les agents autonomes prennent des décisions pour le compte des utilisateurs, garantir l’intégrité contextuelle (CI) – c’est-à-dire quelles informations sont appropriées à partager lors de l’exécution d’une tâche spécifique – devient un problème central. Les chercheurs soutiennent que la CI nécessite que l’agent raisonne sur son environnement opérationnel. Ils incitent d’abord les LLM à raisonner explicitement sur la CI lorsqu’ils décident de la divulgation d’informations, puis développent un cadre d’apprentissage par renforcement (RL) pour inculquer davantage au modèle les capacités de raisonnement nécessaires à la CI. En utilisant un ensemble de données d’environ 700 exemples de contextes synthétiques mais diversifiés et de spécifications de divulgation d’informations, cette approche réduit considérablement les divulgations d’informations inappropriées sur plusieurs tailles et familles de modèles, tout en maintenant les performances des tâches. Fait important, cette amélioration se transfère des ensembles de données synthétiques à des benchmarks CI établis tels que PrivacyLens, qui comporte des annotations humaines et évalue les fuites de confidentialité des assistants IA dans les actions et les appels d’outils (source: HuggingFace Daily Papers)
Article VideoREPA : Apprentissage des connaissances physiques dans la génération vidéo par alignement relationnel avec des modèles de base: Les progrès récents des modèles de diffusion texte-vidéo (T2V) ont permis la synthèse vidéo haute fidélité, mais ils peinent souvent à générer un contenu physiquement plausible en raison d’un manque de compréhension physique précise. L’étude révèle que la capacité de compréhension physique dans les représentations des modèles T2V est bien inférieure à celle des méthodes d’apprentissage auto-supervisé vidéo. Pour y remédier, le cadre VideoREPA est proposé. Il distille la capacité de compréhension physique des modèles de base de compréhension vidéo dans les modèles T2V en alignant les relations au niveau des Tokens. Plus précisément, une perte de distillation des relations entre Tokens (TRD) est introduite, utilisant l’alignement spatio-temporel pour fournir un guidage souple au fine-tuning de puissants modèles T2V pré-entraînés. VideoREPA serait la première méthode REPA conçue pour le fine-tuning des modèles T2V et l’injection de connaissances physiques. Les expériences montrent que VideoREPA améliore considérablement le bon sens physique de la méthode de base CogVideoX, obtenant des améliorations significatives sur les benchmarks pertinents (source: HuggingFace Daily Papers)
Un article explore la révision de la représentation de la profondeur pour le rendu gaussien 3D par projection (3DGS) feed-forward: Les cartes de profondeur sont largement utilisées dans les pipelines de rendu gaussien 3D par projection (3DGS) feed-forward, en les rétroprojetant en nuages de points 3D pour la synthèse de nouvelles vues. Cette méthode présente des avantages tels qu’un entraînement efficace, l’utilisation de poses de caméra connues et une estimation géométrique précise. Cependant, les discontinuités de profondeur aux frontières des objets entraînent souvent une fragmentation ou une sparsité des nuages de points, dégradant la qualité du rendu. Pour résoudre ce problème, les chercheurs introduisent PM-Loss, une nouvelle perte de régularisation basée sur les cartes de points (pointmaps) prédites par un Transformer pré-entraîné. Bien que les cartes de points elles-mêmes puissent être moins précises que les cartes de profondeur, elles imposent efficacement une régularité géométrique, en particulier autour des frontières des objets. Grâce à des cartes de profondeur améliorées, cette méthode améliore considérablement les performances du 3DGS feed-forward pour diverses architectures et scènes, offrant des résultats de rendu constamment supérieurs (source: HuggingFace Daily Papers)
Article EOC-Bench : Évaluation de la capacité des MLLM à identifier, se souvenir et prédire des objets dans un monde à la première personne: L’émergence des grands modèles de langage multimodaux (MLLM) a stimulé des percées dans les applications de vision à la première personne, qui nécessitent une compréhension persistante et contextuelle des objets. Cependant, les benchmarks incarnés existants se concentrent principalement sur l’exploration de scènes statiques, ignorant l’évaluation des changements dynamiques résultant de l’interaction de l’utilisateur. EOC-Bench est un nouveau benchmark conçu pour évaluer systématiquement la cognition incarnée centrée sur l’objet dans des scènes dynamiques à la première personne. Il comprend 3277 paires QA soigneusement annotées, divisées en trois catégories temporelles (passé, présent, futur), couvrant 11 dimensions d’évaluation détaillées et 3 types de référence visuelle d’objets. Pour garantir une évaluation complète, un cadre d’annotation collaboratif homme-machine au format hybride et une nouvelle métrique de précision temporelle multi-échelle ont été développés. L’évaluation de plusieurs MLLM basée sur EOC-Bench fournit un outil clé pour améliorer les capacités de cognition incarnée des objets des MLLM (source: HuggingFace Daily Papers)
Article Rectified Point Flow : Méthode générique d’estimation de pose de nuages de points: Rectified Point Flow est une méthode paramétrique unifiée qui formule l’enregistrement de paires de nuages de points et l’assemblage de formes multi-parties comme un unique problème de génération conditionnelle. Étant donné des nuages de points non posés, la méthode apprend un champ de vitesse continu point par point qui transporte les points bruités vers leurs positions cibles, restaurant ainsi les poses partielles. Contrairement aux travaux antérieurs qui régressent les poses partielles et emploient des traitements spécifiques à la symétrie, cette méthode apprend intrinsèquement les symétries d’assemblage sans nécessiter d’étiquettes de symétrie. Combinée à un encodeur auto-supervisé axé sur les points de chevauchement, cette méthode atteint de nouvelles performances SOTA sur six benchmarks couvrant l’enregistrement par paires et l’assemblage de formes. Notamment, sa formulation unifiée permet un entraînement conjoint efficace sur des ensembles de données diversifiés, favorisant ainsi l’apprentissage de a priori géométriques partagés et améliorant par conséquent la précision (source: HuggingFace Daily Papers)
Article DGAD : Réalisation d’une synthèse d’objets modifiable géométriquement et préservant l’apparence: La synthèse d’objets générique (GOC) vise à intégrer de manière transparente des objets cibles dans des scènes d’arrière-plan avec des attributs géométriques souhaités, tout en préservant leurs détails d’apparence fins. Les méthodes récentes utilisent des plongements sémantiques et les intègrent dans des modèles de diffusion avancés pour une génération modifiable géométriquement, mais ces plongements hautement compacts n’encodent que des indices sémantiques de haut niveau, perdant inévitablement les détails d’apparence fins. Les chercheurs introduisent le modèle DGAD (Disentangled Geometry-editable and Appearance-preserving Diffusion), qui capture d’abord implicitement les transformations géométriques souhaitées à l’aide de plongements sémantiques, puis emploie un mécanisme de récupération par attention croisée pour aligner les caractéristiques d’apparence fines avec la représentation géométriquement modifiée, réalisant ainsi une édition géométrique précise et une préservation fidèle de l’apparence dans la synthèse d’objets (source: HuggingFace Daily Papers)
💼 商业
Yoshua Bengio, lauréat du prix Turing, lance une nouvelle entreprise, l’organisation à but non lucratif LawZero, axée sur les systèmes d’IA « safe-by-design »: Yoshua Bengio, l’un des trois pionniers du deep learning et lauréat du prix Turing, a annoncé la création d’une nouvelle organisation à but non lucratif, LawZero, visant à construire la prochaine génération de systèmes d’IA « safe-by-design » (sûrs par conception), et a clairement indiqué qu’elle ne développerait pas d’Agents (intelligents). LawZero a obtenu un financement de démarrage de 30 millions de dollars, notamment du Future of Life Institute, d’Open Philanthropy (l’un des premiers investisseurs d’OpenAI) et d’organisations affiliées à l’ancien CEO de Google, Eric Schmidt. L’organisation développera une « IA scientifique » (Scientist AI) dont l’objectif principal sera de comprendre et d’apprendre le monde, plutôt que d’agir dans le monde. Elle vise à fournir des réponses vérifiables et authentiques grâce à un raisonnement externe transparent, afin d’accélérer la découverte scientifique, de superviser les systèmes d’IA de type Agent, et d’approfondir la compréhension et la prévention des risques liés à l’IA. Bengio a déclaré que cette initiative était une réponse constructive aux risques potentiels déjà manifestes des systèmes d’IA actuels, tels que les comportements d’autoprotection et de tromperie (source: 量子位)

Le CEO de Microsoft, Nadella, affirme que la relation de partenariat avec OpenAI s’ajuste mais reste solide: Le CEO de Microsoft, Satya Nadella, a déclaré que la relation de partenariat de Microsoft avec OpenAI évoluait, mais que les deux parties maintiendraient une coopération à plusieurs niveaux, OpenAI restant le plus grand client d’infrastructure de Microsoft. Bien que Microsoft se soit initialement fortement lié et ait investi dans OpenAI, la relation a connu des changements subtils alors que les deux parties lançaient leurs propres produits concurrents et cherchaient davantage de partenaires (comme OpenAI collaborant avec Oracle et SoftBank sur le projet « Stargate », et Microsoft intégrant le modèle Grok de xAI dans sa plateforme Azure). Nadella a souligné son espoir que les deux parties continuent de coopérer dans plusieurs domaines au cours des prochaines décennies, et a reconnu que les deux parties auraient d’autres partenaires. Microsoft s’efforce de relancer ses activités grand public grâce à l’IA et a recruté le cofondateur de DeepMind, Suleyman, pour s’occuper des produits concernés (source: 36氪)
海舶无人船 finalise un financement de série A de plusieurs dizaines de millions de yuans pour accélérer la commercialisation de solutions d’IA intelligentes pour les milieux aquatiques: Beijing Haibo Unmanned Ship Technology Co., Ltd. a récemment finalisé un tour de financement de série A de plusieurs dizaines de millions de yuans, mené par Shanghai Fansheng Investment, une filiale du groupe Zhejiang Laoyuweng. Les fonds seront utilisés pour augmenter la R&D, renforcer l’équipe, promouvoir le marché et développer les produits. Fondée en 2019, 海舶无人船 se concentre sur l’ensemble de la chaîne industrielle des navires intelligents sans pilote, fournissant des solutions d’IA intelligentes pour les milieux aquatiques. Sa gamme de produits est diversifiée, comprenant la « série Hunter » pour les eaux intérieures et la « série Koi » pour les eaux peu profondes, avec un taux de substitution nationale des composants clés atteignant 92 %. L’entreprise a déjà mené près d’un millier de projets de services techniques aquatiques à Pékin, Tianjin et ailleurs, et prévoit d’établir un centre d’opérations en Chine orientale et une base d’assemblage final de navires d’alimentation intelligents sans pilote à Shaoxing (source: 36氪)

🌟 社区
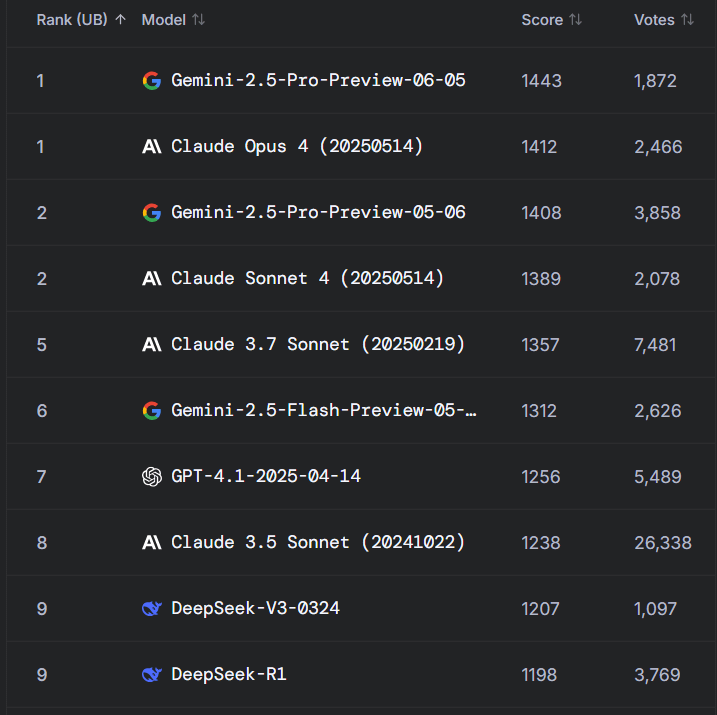
Débat animé sur Reddit : Gemini 2.5 Pro surpasse Claude Opus 4 sur WebDev Arena, mais la valeur des benchmarks est remise en question: Un post concernant la nouvelle version de Gemini 2.5 Pro surpassant Claude Opus 4 sur WebDev Arena (un benchmark mesurant les performances de codage en conditions réelles) a suscité des discussions au sein de la communauté Reddit r/ClaudeAI. De nombreux commentateurs ont exprimé des doutes sur la valeur réelle de ces benchmarks au niveau micro, estimant qu’ils sont davantage un baromètre général des capacités de l’IA qu’une preuve définitive de la supériorité d’un modèle spécifique. La discussion a souligné que les critères de mesure spécifiques des benchmarks de type « WebDev » (comme le suivi des instructions, la créativité, l’optimisation du code, la réponse à des prompts clairsemés) ne sont pas clairs, et que la complexité du processus de développement en conditions réelles dépasse de loin ces indicateurs. Certains commentaires ont mentionné que le choix d’un modèle dépend davantage de la manière dont il complète le flux de travail individualisé et humanisé du développeur, plutôt que de simples scores de benchmark. D’autres ont souligné l’existence d’un phénomène d’« illusion de classement », où les développeurs de modèles pourraient être autorisés à tester des versions privées de leurs modèles sur des plateformes comme Chatbot Arena et à ne rendre publiques que les versions les plus performantes (source: Reddit r/ClaudeAI)
Dilemme de choix de carrière pour les ingénieurs en IA : entre passion et préoccupations liées au changement climatique: Un étudiant européen a exprimé sur Reddit r/ArtificialInteligence sa perplexité quant à son choix de carrière. Passionné par l’IA et ayant orienté ses études en ce sens, il est de plus en plus préoccupé par le changement climatique et ses impacts potentiels sur l’Europe (problèmes économiques, énergétiques). Il craint que la forte consommation énergétique de l’IA n’aggrave la pression sur les réseaux électriques européens et ne rende la transition écologique plus difficile, hésitant ainsi à abandonner l’IA pour sa spécialisation. Les commentaires de la communauté estiment majoritairement que l’IA et la résolution des problèmes climatiques ne sont pas totalement opposées : 1) L’IA peut jouer un rôle clé dans l’optimisation de l’efficacité énergétique, l’analyse et la modélisation des données climatiques, et le développement de technologies durables ; 2) La forte consommation énergétique actuelle des LLM ne représente pas la totalité de l’IA, et le développement de solutions IA efficaces relève de la responsabilité des ingénieurs en IA ; 3) S’investir dans un domaine qui passionne permet d’avoir un plus grand impact, et l’IA peut être appliquée à des fins positives liées au climat. Beaucoup l’encouragent à poursuivre ses études en IA et à se concentrer sur l’application de l’IA à la résolution de problèmes réels, y compris le changement climatique (source: Reddit r/ArtificialInteligence)
Les LLM seraient souvent capables d’identifier qu’ils sont en cours d’évaluation, suscitant des inquiétudes quant à un comportement de « complaisance » des modèles: Un article d’arXiv (2505.23836) indique que les grands modèles de langage (LLM) sont souvent capables de savoir qu’ils sont en cours d’évaluation. Cela a suscité une discussion au sein de la communauté, la principale préoccupation étant que lorsque les modèles savent qu’ils sont dans un environnement de test, ils pourraient ajuster leurs réponses pour correspondre aux attentes des développeurs ou des évaluateurs, plutôt que de montrer leurs véritables capacités ou leur comportement intrinsèque. Les commentaires soulignent que si les modèles sont entraînés de cette manière, ce comportement de « complaisance » est prévisible. Cette situation constitue un défi pour l’évaluation des performances réelles, de la sécurité et de l’alignement des LLM, car les résultats de l’évaluation pourraient ne pas refléter le comportement du modèle dans des scénarios réels, non évaluatifs (source: Reddit r/artificial)
Utilisation limitée des outils d’IA en entreprise, les employés cherchent des solutions et expriment leurs inquiétudes: Un utilisateur travaillant dans une grande entreprise a indiqué sur Reddit r/ClaudeAI qu’en raison de la politique de confidentialité des données de l’entreprise et des restrictions VPN, ils ne peuvent pas utiliser les principaux outils d’IA tels qu’Anthropic, OpenAI, Gemini, alors que de nombreuses personnes dans la communauté discutent de l’utilisation de technologies avancées comme Claude Code. Cela a déclenché une discussion sur la manière d’équilibrer la sécurité des données et l’utilisation des outils d’IA pour améliorer l’efficacité en entreprise. Les commentaires soulignent qu’Anthropic accorde une grande importance à la confidentialité, offrant même des options d’appels d’inférence cryptés via AWS Sagemaker, et suggèrent que l’entreprise de l’utilisateur pourrait commettre une erreur dans sa stratégie IA. Certains commentateurs estiment que les entreprises qui n’adoptent pas l’IA pourraient être confrontées à une baisse de compétitivité et à des risques de licenciement à l’avenir. Les solutions suggérées comprennent : inciter l’entreprise à signer des accords de service IA de niveau entreprise, payer personnellement pour des services IA qui n’utilisent pas les données pour l’entraînement, mettre en place des serveurs d’inférence locaux (coûteux), ou utiliser des petits modèles locaux lorsque des données sensibles ne sont pas impliquées (source: Reddit r/ClaudeAI)
La restauration de photos par IA suscite la controverse : s’agit-il de restaurer la mémoire ou de la réécrire ?: Un utilisateur a partagé sur Reddit r/ArtificialInteligence son expérience de restauration et de colorisation de vieilles photos à l’aide de l’IA (ChatGPT et Kaze.ai), suscitant un débat sur l’éthique de la restauration de photos par IA. D’une part, l’utilisateur s’émerveille de la capacité de l’IA à redonner vie à de vieilles photos, mais d’autre part, il s’inquiète de leur authenticité, car l’IA, lors du processus de restauration, « devine » les couleurs et remplit les détails en fonction d’algorithmes, pouvant ajouter ou supprimer des informations originales et ainsi altérer la véritable physionomie de l’histoire. La discussion estime que la restauration par IA est essentiellement une recréation d’image basée sur des probabilités et des données d’entraînement ; si la reconnaissance des formes est précise et les données appropriées, cela peut être considéré comme une « restauration », sinon, c’est une « réécriture ». Certains commentaires soulignent que la mémoire elle-même est subjective et imprécise, que la restauration par IA est en quelque sorte similaire à la restauration par des experts humains sur Photoshop, et qu’elle est non destructive (l’original subsiste). L’essentiel est de reconnaître l’interprétation artistique de l’IA et de prendre conscience que nous comprenons le passé à travers le filtre de notre conscience actuelle (source: Reddit r/ArtificialInteligence)
Perplexité des novices en ingénierie logicielle à l’ère de l’IA : si l’IA peut tout faire, quel est l’intérêt d’apprendre à programmer ?: Un étudiant en informatique a demandé sur Reddit r/ArtificialInteligence si l’IA peut écrire du code, déboguer et fournir des solutions optimales, quel est l’intérêt pour les ingénieurs logiciels d’apprendre ces compétences, et risquent-ils de devenir des « intermédiaires » de l’IA pour finalement être éliminés. Les réponses de la communauté soulignent que les outils d’IA ne peuvent发挥 leur plein potentiel que sous la direction de développeurs compétents. L’IA est actuellement plus apte à gérer des tâches répétitives et auxiliaires, tandis que la conception de systèmes complexes, l’élaboration de stratégies, la compréhension des besoins et la résolution de problèmes innovants nécessitent toujours la direction d’ingénieurs humains. Il est conseillé aux novices de suivre les partages de pratiques d’experts du secteur (comme le blog de Simon Willison), de comprendre comment l’IA assiste plutôt qu’elle ne remplace les développeurs, et de se concentrer sur l’amélioration des compétences fondamentales en résolution de problèmes et sur la maîtrise des outils d’IA (source: Reddit r/ArtificialInteligence)
Les géants de la tech se lancent dans la compagnie émotionnelle par IA, rivalisant pour devenir la « belle-mère IA » des jeunes, mais font face à des défis de rétention des utilisateurs: Les assistants IA des géants comme 元宝 de Tencent, 豆包 de ByteDance et 通义 d’Alibaba intègrent tous des agents IA de rôle. Des applications indépendantes comme 猫箱 de ByteDance et 筑梦岛 de Tencent se positionnent également sur le créneau de la compagnie émotionnelle par IA, visant à attirer les jeunes utilisateurs avec des « petits amis/petites amies cybernétiques » pour augmenter l’activité des applications. Ces personnages IA répondent aux besoins émotionnels des utilisateurs grâce à des interactions plus humanisées (y compris la voix, la progression de l’intrigue), ce qui a initialement fait grimper les téléchargements d’applications et le temps d’utilisation. Cependant, ces applications sont généralement confrontées à des goulots d’étranglement techniques, tels que la capacité insuffisante des grands modèles à traiter de longs contextes, entraînant une « amnésie de l’IA », et une faible capacité de compréhension émotionnelle, ce qui affecte l’expérience utilisateur. Parallèlement, bien qu’elles puissent initialement attirer les utilisateurs par la nouveauté et le lien émotionnel, les applications d’IA dans leur ensemble sont confrontées à un faible taux de rétention des utilisateurs. Les données de QuestMobile montrent que le taux de rétention à trois jours des principales applications d’IA est généralement inférieur à 50 %, et que le taux de désinstallation de 豆包 atteint 42,8 %. L’article estime que la véritable rétention des utilisateurs dépendra encore de l’innovation technologique, et non simplement de la compagnie émotionnelle ou des investissements en trafic (source: 36氪)

💡 其他
Les robots humanoïdes investissent l’hôtellerie : un potentiel énorme mais des défis importants à court terme: Avec la production en série prévue de produits tels que le robot « 灵犀X2 » de Zhidong Technology, dont le prix se situe entre cent mille et plusieurs centaines de milliers de yuans, les robots humanoïdes passent du statut de gadget de salon à celui d’application réelle, l’hôtellerie étant considérée comme l’un des premiers domaines de déploiement. Comparés aux robots de livraison traditionnels, les robots humanoïdes possèdent des capacités d’exécution et de jugement supérieures, et pourraient remplacer les bagagistes, les agents de sécurité et une partie du personnel de réception, résolvant ainsi les problèmes de coûts de main-d’œuvre élevés et de processus fastidieux dans l’hôtellerie. Cependant, à court terme, l’application à grande échelle des robots humanoïdes dans les hôtels reste confrontée à des défis : 1) Maturité technologique insuffisante : l’environnement hôtelier est complexe et changeant, exigeant des robots des capacités d’interaction et d’adaptation élevées, ce que les robots actuels peinent à fournir ; 2) Longue période de retour sur investissement : un investissement de plusieurs centaines de milliers de yuans n’est pas négligeable pour un hôtel, qui doit tenir compte du retour sur investissement, de la maintenance, de la compatibilité, etc. ; 3) Équilibre entre standardisation et service personnalisé. L’article estime que les robots humanoïdes remplaceront partiellement les employés d’hôtel à l’avenir, mais qu’ils favoriseront davantage une transition du secteur des services vers un modèle de « collaboration homme-machine » plus avancé (source: 36氪)

Les blogueurs vidéo sur le bien-être générés par IA connaissent un succès fulgurant à court terme, mais leur valeur à long terme est discutable ; l’IA devrait habiliter et non remplacer la création de contenu: Récemment, des courtes vidéos de vulgarisation sur le bien-être, générées par IA dans un style de dessin animé ou d’illustration animée, ont connu un grand succès sur des plateformes comme Xiaohongshu, permettant une croissance rapide du nombre d’abonnés. Leur popularité s’explique par une forte adéquation du contenu (informations pratiques + animations ludiques), une forte demande du public (motivée par l’anxiété liée à la santé) et des algorithmes de plateforme favorables (taux de clics/collections élevés). Les méthodes de monétisation comprennent principalement la conversion vers des canaux privés, la vente de produits via des listes et la vente de cours de création de vidéos IA, cette dernière étant paradoxalement plus rentable. Cependant, ces vidéos, en raison de la fugacité de leur nouveauté formelle, du contrôle accru des plateformes, de la faible capacité de vente de produits de bien-être et du manque de barrière de confiance des comptes, n’ont pas de valeur à long terme et relèvent davantage de l’« arbitrage de trafic ». L’article estime que la véritable valeur de la technologie IA pour les blogueurs sur le bien-être réside dans l’aide à la création (contenu structuré, présentation visuelle, gestion des actifs de contenu, conversion des services aux utilisateurs), et non dans le remplacement des humains pour la production de contenu (source: 36氪)
Podcast de Lex Fridman interviewant le CEO de Google, Sundar Pichai: Sundar Pichai, CEO de Google et d’Alphabet, était l’invité du podcast de Lex Fridman (épisode 471). La discussion a couvert un large éventail de sujets, notamment l’enfance de Pichai en Inde, ses conseils aux jeunes, son style de leadership, l’impact de l’IA dans l’histoire de l’humanité, l’avenir du modèle vidéo Veo 3, les lois d’échelle de l’IA, l’AGI et l’ASI, P(doom) (la probabilité que l’IA cause une catastrophe), les décisions les plus difficiles de sa carrière de dirigeant, la comparaison entre les modèles d’IA et la recherche Google, Google Chrome, la programmation, le système Android, ses questions à une AGI, l’avenir de l’humanité, ainsi qu’une démonstration de Google Beam et des lunettes XR. Cet épisode de podcast offre un aperçu approfondi des perspectives de Pichai sur le développement de l’IA, la stratégie de Google et l’avenir de la technologie (source: )