
Mots-clés:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, Agent IA, Mode Deep Think de Gemini 2.5 Pro, Cadre général de cerveau d’intelligence incarnée VeBrain, Segmentation d’images et vidéos SAM 2, Contexte 32k de Qwen3-Embedding, Compréhension multimodale de l’Agent IA
🔥 À la une
Google annonce plusieurs nouvelles avancées en IA, le mode Deep Think de Gemini 2.5 Pro améliore les capacités de raisonnement complexe: Lors de la conférence Google I/O, Google a annoncé le mode Deep Think pour Gemini 2.5 Pro, conçu pour améliorer considérablement les capacités de raisonnement de l’IA lors du traitement de problèmes complexes (tels que les problèmes mathématiques de niveau USAMO). Parallèlement, Google a également lancé AlphaEvolve, un agent de codage alimenté par Gemini pour la découverte d’algorithmes, qui a déjà obtenu des résultats dans la conception d’algorithmes de multiplication matricielle et la résolution de problèmes mathématiques ouverts, et est appliqué à l’optimisation des data centers internes de Google, de la conception de puces et de l’efficacité de l’entraînement de l’IA. De plus, le modèle vidéo Veo 3, le modèle d’image Imagen 4 et l’outil de montage IA FLOW ont également été lancés, démontrant le déploiement complet et les progrès rapides de Google dans le domaine de l’IA multimodale. (Source: OriolVinyalsML, demishassabis, demishassabis, op7418)
Le laboratoire d’IA de Shanghai publie conjointement le framework de cerveau intelligent incarné universel VeBrain: Le laboratoire d’intelligence artificielle de Shanghai, en collaboration avec plusieurs entités, a lancé VeBrain (Visual Embodied Brain), un framework de cerveau intelligent incarné universel visant à unifier la perception visuelle, le raisonnement spatial et les capacités de contrôle robotique. Ce framework transforme les tâches de contrôle robotique en tâches textuelles spatiales 2D dans les MLLM (telles que la détection de points clés et la reconnaissance de compétences incarnées), et introduit un “Robot Adapter” pour réaliser un mappage précis et un contrôle en boucle fermée des décisions textuelles aux actions réelles. Pour soutenir l’entraînement du modèle, l’équipe a construit l’ensemble de données VeBrain-600k, contenant 600 000 instructions, couvrant la compréhension multimodale, le raisonnement visuo-spatial et trois types de tâches d’opération robotique. Les tests montrent que VeBrain atteint des performances de pointe (SOTA) en compréhension multimodale, en raisonnement spatial et en contrôle de robots réels (bras robotiques et chiens robots). (Source: 量子位)

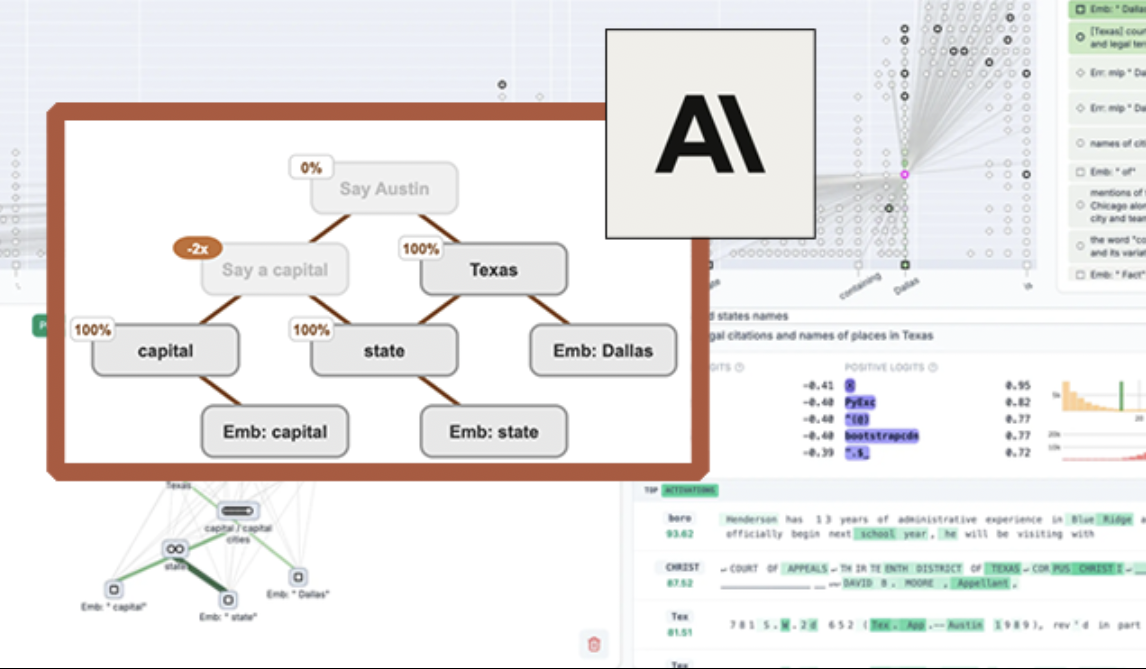
Anthropic rend open source l’outil de visualisation LLM “circuit tracing”, améliorant l’interprétabilité des modèles: Anthropic a lancé l’outil open source “circuit tracing”, visant à aider les chercheurs à comprendre les mécanismes internes des grands modèles de langage (LLM). Cet outil génère des “attribution graphs”, visualisant les super-nœuds internes et leurs connexions lorsque le modèle traite des informations, de manière similaire aux schémas de réseaux neuronaux. Les chercheurs peuvent vérifier les fonctions de chaque nœud en intervenant sur leurs valeurs d’activation et en observant les changements de comportement du modèle, afin de décoder la logique de décision des LLM. L’outil prend en charge la génération d’attribution graphs sur les principaux modèles open source et fournit une interface frontale interactive Neuronpedia pour la visualisation, l’annotation et le partage. Cette initiative vise à promouvoir la recherche sur l’interprétabilité de l’IA, permettant à une communauté plus large d’explorer et de comprendre le comportement des modèles. (Source: 量子位, swyx)
Meta publie Segment Anything Model 2 (SAM 2), améliorant les capacités de segmentation d’images et de vidéos: Meta AI Research (FAIR) a lancé SAM 2, une version améliorée de son populaire Segment Anything Model. SAM 2 est un modèle de base axé sur les tâches de segmentation visuelle avec invites (promptable) dans les images et les vidéos, capable d’identifier et de segmenter avec précision des objets ou des régions spécifiques dans une image ou une vidéo en fonction d’invites (telles que des points, des boîtes, du texte). Le modèle est désormais open source, sous licence Apache, permettant aux chercheurs et aux développeurs de l’utiliser gratuitement et de créer des applications, stimulant ainsi davantage le développement dans le domaine de la vision par ordinateur. (Source: AIatMeta)
🎯 Tendances
L’Institut d’IA de Pékin (BAAI) rend open source Video-XL-2, permettant la compréhension de vidéos de dizaines de milliers d’images sur une seule carte: L’Institut d’IA de Pékin, en collaboration avec l’Université Jiao Tong de Shanghai et d’autres institutions, a publié Video-XL-2, un modèle de compréhension vidéo ultra-longue de nouvelle génération. Ce modèle présente des améliorations significatives en termes d’efficacité, de longueur de traitement et de vitesse, capable de traiter des entrées vidéo de dizaines de milliers d’images sur une seule carte et d’encoder 2048 images en seulement 12 secondes. Video-XL-2 utilise l’encodeur visuel SigLIP-SO400M, un module de synthèse dynamique de tokens (DTS) et le grand modèle de langage Qwen2.5-Instruct. Il atteint des performances élevées grâce à un entraînement progressif en quatre étapes et à des stratégies d’optimisation de l’efficacité (telles que le pré-remplissage segmenté et le décodage KV à double granularité). Le modèle excelle dans les benchmarks tels que MLVU et Video-MME, et ses poids ont été rendus open source. (Source: 量子位)

Character.ai lance la fonction de génération vidéo AvatarFX, permettant aux personnages d’images de bouger et d’interagir: Character.ai (c.ai), l’application leader de compagnonnage IA, a lancé la fonction AvatarFX, permettant aux utilisateurs d’animer les personnages d’images statiques (y compris les figures non humaines comme les animaux de compagnie), les faisant parler, chanter et interagir avec les utilisateurs. Cette fonction est basée sur l’architecture DiT, mettant l’accent sur la haute fidélité et la cohérence temporelle, maintenant la stabilité même dans des scénarios complexes tels que les dialogues multi-personnages et les longues séquences. AvatarFX est actuellement disponible pour tous les utilisateurs sur la version web, et sera bientôt lancé sur l’application. Parallèlement, c.ai a également annoncé de nouvelles fonctionnalités telles que Scenes (scènes d’histoires interactives), Imagine Animated Chat (historiques de discussion animés) et Stream (génération d’histoires entre personnages), enrichissant davantage l’expérience de création IA. (Source: 量子位)

Nvidia lance le modèle de langage visuel Llama-3.1 Nemotron-Nano-VL-8B-V1: Nvidia a publié un nouveau modèle de vision-texte, Llama-3.1-Nemotron-Nano-VL-8B-V1. Ce modèle peut traiter des entrées d’images, de vidéos et de textes, et générer des sorties textuelles, possédant un certain degré de capacités de raisonnement et de reconnaissance d’images. Le lancement de ce modèle témoigne de l’investissement continu de Nvidia dans le domaine de l’IA multimodale. Parallèlement, les discussions au sein de la communauté soulignent que l’abandon par Llama-4 des modèles inférieurs à 70B pourrait offrir des opportunités aux modèles tels que Gemma3 et Qwen3 sur le marché du fine-tuning. (Source: karminski3)
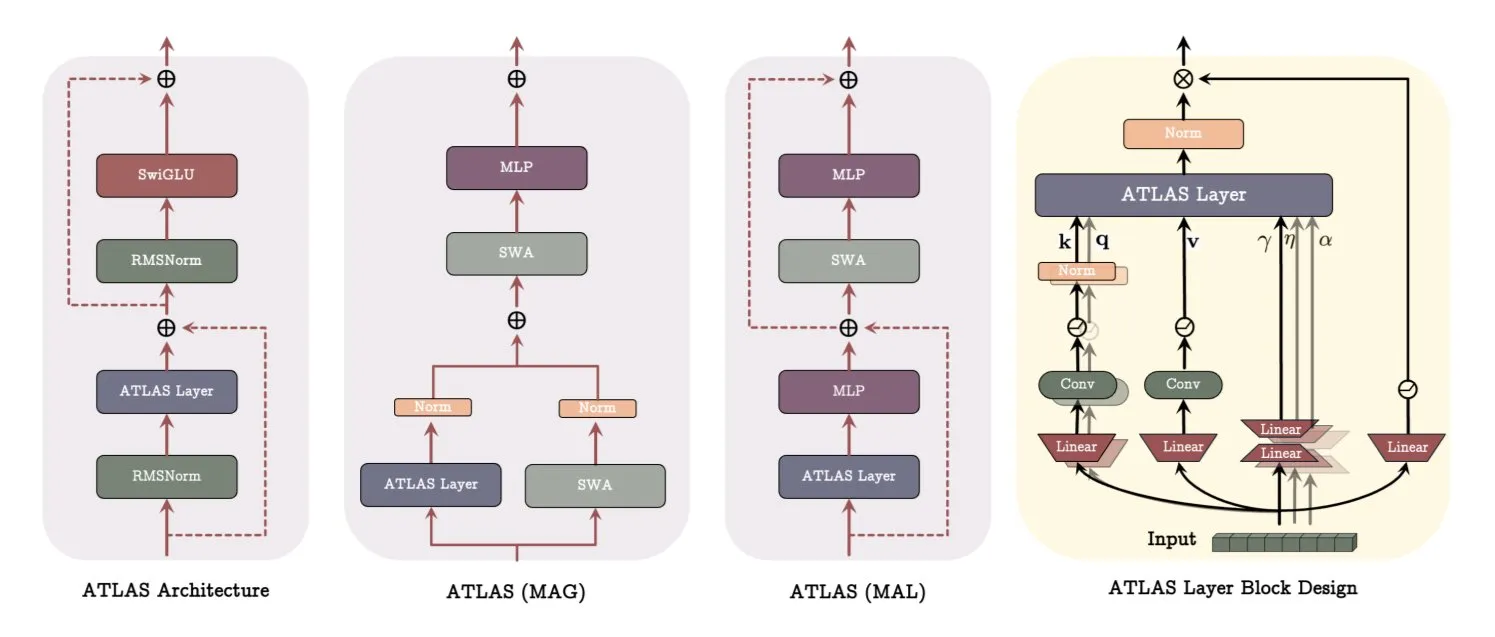
Google publie un article sur l’architecture ATLAS, révolutionnant la manière dont les modèles apprennent et mémorisent: Un récent article de Google présente une nouvelle architecture de modèle nommée ATLAS, conçue pour optimiser les capacités d’apprentissage et de mémorisation des modèles grâce à une mémoire active (la règle Omega traitant les c tokens les plus récents) et une gestion plus intelligente de la capacité mémoire (mappages de caractéristiques polynomiales et exponentielles). ATLAS utilise l’optimiseur Muon pour des mises à jour de mémoire plus efficaces et introduit des conceptions telles que DeepTransformers et Dot (Deep Omega Transformers), remplaçant l’attention fixe traditionnelle par des mécanismes apprenables et pilotés par la mémoire. Cette recherche marque une avancée de l’IA vers des systèmes plus intelligents et sensibles au contexte, susceptible d’améliorer la capacité de l’IA à traiter et à utiliser des ensembles de données à grande échelle. (Source: TheTuringPost)
Qwen publie la série de modèles Qwen3-Embedding, améliorant considérablement les performances d’embedding: L’équipe Qwen a publié une nouvelle série de modèles Qwen3-Embedding, comprenant trois versions : 0.6B, 4B et 8B. Ces modèles prennent en charge des longueurs de contexte allant jusqu’à 32k et 100 langues, obtenant des résultats SOTA sur MTEB (Massive Text Embedding Benchmark), certains indicateurs devançant le deuxième de 10 points. Cette avancée marque une nouvelle percée importante dans la technologie d’embedding de texte, fournissant une base plus solide pour des applications telles que la recherche sémantique et RAG. (Source: AymericRoucher, ClementDelangue)

Le créateur de vidéos Bing de Microsoft est lancé, basé sur le modèle Sora d’OpenAI et disponible gratuitement: Microsoft a lancé Bing Video Creator dans son application Bing. Cette fonctionnalité, basée sur le modèle Sora d’OpenAI, permet aux utilisateurs de générer gratuitement des vidéos à partir d’invites textuelles. C’est la première fois que le modèle Sora est mis gratuitement à la disposition du grand public à grande échelle. Bien que gratuit, il existe actuellement des limitations fonctionnelles, telles qu’une durée vidéo de seulement 5 secondes, un format 9:16 et une vitesse de génération relativement lente. Les retours des utilisateurs indiquent que ses performances sont inférieures à celles des modèles vidéo SOTA actuels (tels que Kling, Veo3), suscitant des discussions sur la vitesse d’itération de la technologie Sora et la stratégie produit de Microsoft. (Source: 36氪)
OpenAI lance plusieurs fonctionnalités de niveau entreprise, améliorant l’intégration en milieu de travail: OpenAI a publié une série de nouvelles fonctionnalités destinées aux utilisateurs professionnels, notamment des connecteurs dédiés pour des applications telles que Google Drive, ainsi que des fonctions d’enregistrement, de transcription et de résumé de réunions dans ChatGPT, et la prise en charge du SSO (Single Sign-On) et d’une tarification d’entreprise basée sur des crédits. Ces mises à jour visent à intégrer plus profondément ChatGPT dans les flux de travail des entreprises, améliorant ainsi l’efficacité bureautique. (Source: TheRundownAI, EdwardSun0909)
Hugging Face publie le modèle de robot efficace SmolVLA, exécutable sur MacBook: Hugging Face a lancé un modèle de robot nommé SmolVLA, caractérisé par son extrême efficacité, au point de pouvoir fonctionner sur un MacBook. Après un fine-tuning sur un petit nombre de données de démonstration (par exemple, 31), ce modèle peut atteindre ou dépasser les performances des lignes de base mono-tâche sur des tâches spécifiques (comme l’opération du Koch Arm), démontrant son potentiel pour le déploiement d’IA robotique dans des environnements aux ressources limitées. (Source: mervenoyann, sytelus)
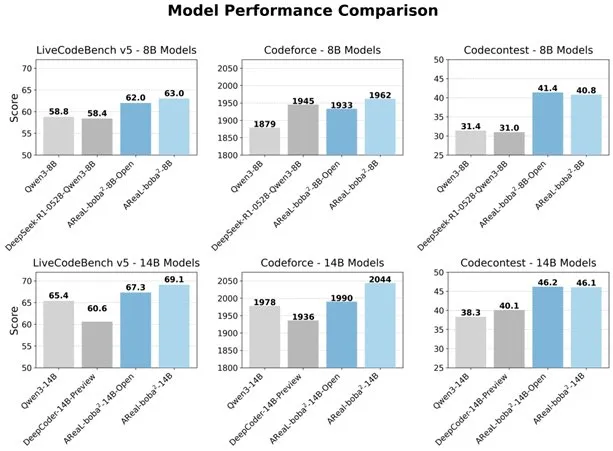
Alibaba rend open source le système RL entièrement asynchrone AReal-boba², améliorant les capacités de codage des LLM: L’équipe Qwen d’Alibaba a rendu open source le système d’apprentissage par renforcement entièrement asynchrone AReal-boba², spécialement conçu pour les grands modèles de langage (LLM), et a atteint des performances SOTA en apprentissage par renforcement pour le code sur Qwen3-14B. Ce système, grâce à une conception synergique du système et de l’algorithme, a permis une accélération de l’entraînement de 2,77 fois, atteignant un score de 69,1 sur LiveCodeBench, et prend en charge l’apprentissage par renforcement multi-tours. (Source: _akhaliq)
DuckDB lance l’extension DuckLake, intégrant les data lakes et les formats de catalogue: DuckDB a publié l’extension DuckLake, un format ouvert de lakehouse basé sur SQL et Parquet. DuckLake stocke les métadonnées dans une base de données de catalogue et les données dans des fichiers Parquet. Grâce à cette extension, DuckDB peut lire et écrire directement des données dans DuckLake, prenant en charge la création, la modification, l’interrogation de tables, le voyage dans le temps et l’évolution des schémas, visant à simplifier la construction et la gestion des data lakes. (Source: GitHub Trending)
Publication du SDK Ruby pour Model Context Protocol (MCP): Model Context Protocol (MCP) a publié son SDK Ruby officiel, maintenu en collaboration avec Shopify, pour implémenter des serveurs MCP. MCP vise à fournir aux modèles d’IA (en particulier les Agents) un moyen standardisé de découvrir et d’appeler des outils, d’accéder à des ressources et d’exécuter des invites prédéfinies. Ce SDK prend en charge JSON-RPC 2.0 et fournit des fonctionnalités essentielles telles que l’enregistrement d’outils, la gestion des invites et l’accès aux ressources, facilitant ainsi la création par les développeurs d’applications d’IA conformes à la spécification MCP. (Source: GitHub Trending)
La technologie IA aide les batteries au zinc à atteindre une efficacité de 99,8 % et une durée de fonctionnement de 4300 heures: Grâce à l’optimisation par intelligence artificielle, une nouvelle génération de batteries au zinc a atteint une efficacité coulombique de 99,8 % et une durée de fonctionnement allant jusqu’à 4300 heures. L’application de l’IA dans le domaine de la science des matériaux, en particulier dans la conception et la prédiction des performances des batteries, stimule les percées dans la technologie de stockage de l’énergie, et devrait apporter des solutions énergétiques plus efficaces et plus durables pour des domaines tels que les véhicules électriques et les appareils électroniques portables. (Source: Ronald_vanLoon)

🧰 Outils
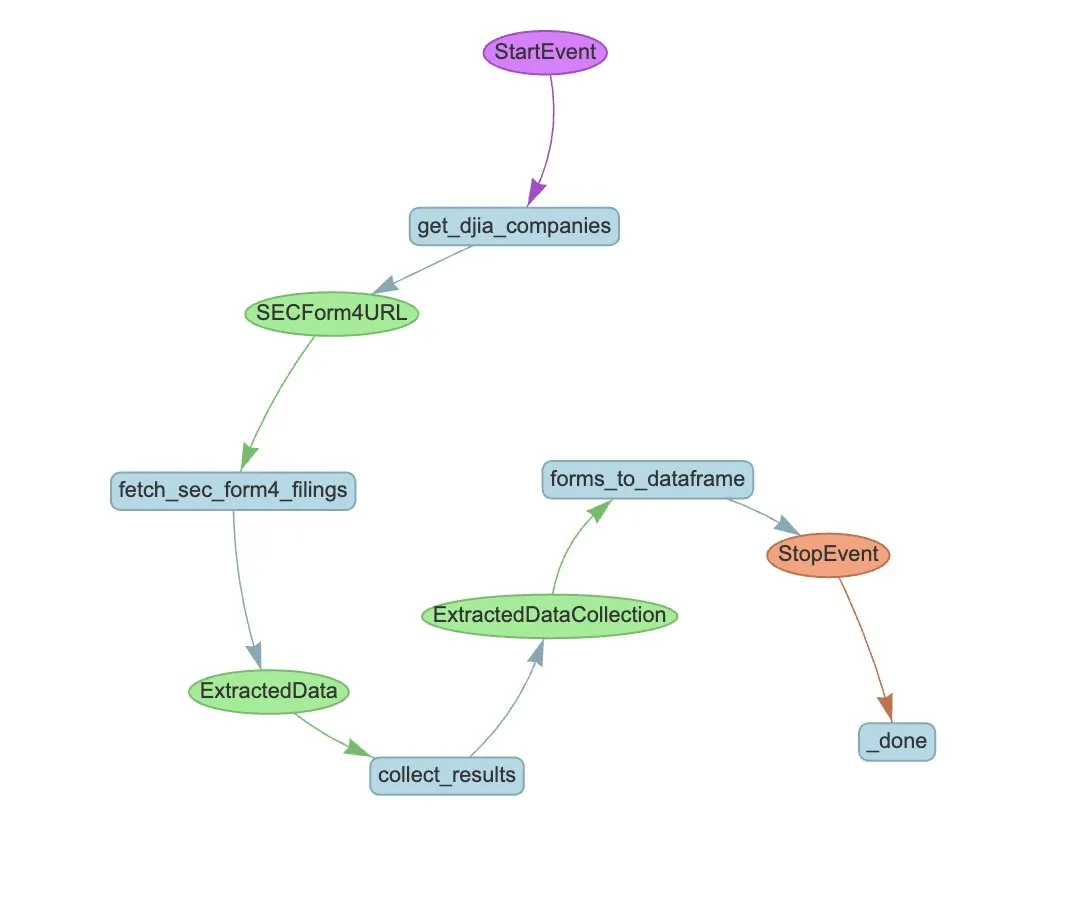
LlamaIndex lance LlamaExtract et un workflow d’Agent pour automatiser l’extraction des formulaires SEC Form 4: LlamaIndex a démontré comment utiliser LlamaExtract et un workflow d’Agent pour extraire automatiquement des informations structurées des fichiers SEC Form 4. Le SEC Form 4 est un document important permettant aux dirigeants, administrateurs et actionnaires principaux de sociétés cotées de divulguer leurs transactions boursières. En construisant un agent d’extraction et un workflow évolutif, il est possible de traiter efficacement les déclarations Form 4 de toutes les sociétés de l’indice Dow Jones Industrial Average, améliorant ainsi la transparence du marché et l’efficacité de l’analyse des données. (Source: jerryjliu0)
Cognee : un outil open source offrant une mémoire dynamique aux Agents IA: Cognee est un projet open source visant à doter les Agents IA de capacités de mémoire dynamique, prétendant s’intégrer en seulement 5 lignes de code. Il construit des pipelines ECL (Extract, Cognify, Load) évolutifs et modulaires, aidant les Agents à interconnecter et à récupérer des conversations passées, des documents, des images et des transcriptions audio, afin de remplacer les systèmes RAG traditionnels, de réduire la difficulté et les coûts de développement, et de prendre en charge le traitement et le chargement de données à partir de plus de 30 sources de données. (Source: GitHub Trending)
Claude Code désormais disponible pour les utilisateurs Pro, et lancement d’une version communautaire de GitHub Action: L’assistant de programmation IA d’Anthropic, Claude Code, est désormais accessible aux abonnés Pro, qui peuvent l’utiliser via des plugins IDE JetBrains, entre autres. Des développeurs de la communauté ont également lancé une version fork de Claude Code GitHub Action, permettant aux utilisateurs payants d’appeler directement Claude Code dans les Issues ou PR GitHub, en utilisant leur quota d’abonnement pour effectuer des revues de code, répondre à des questions, etc., sans frais d’API supplémentaires. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
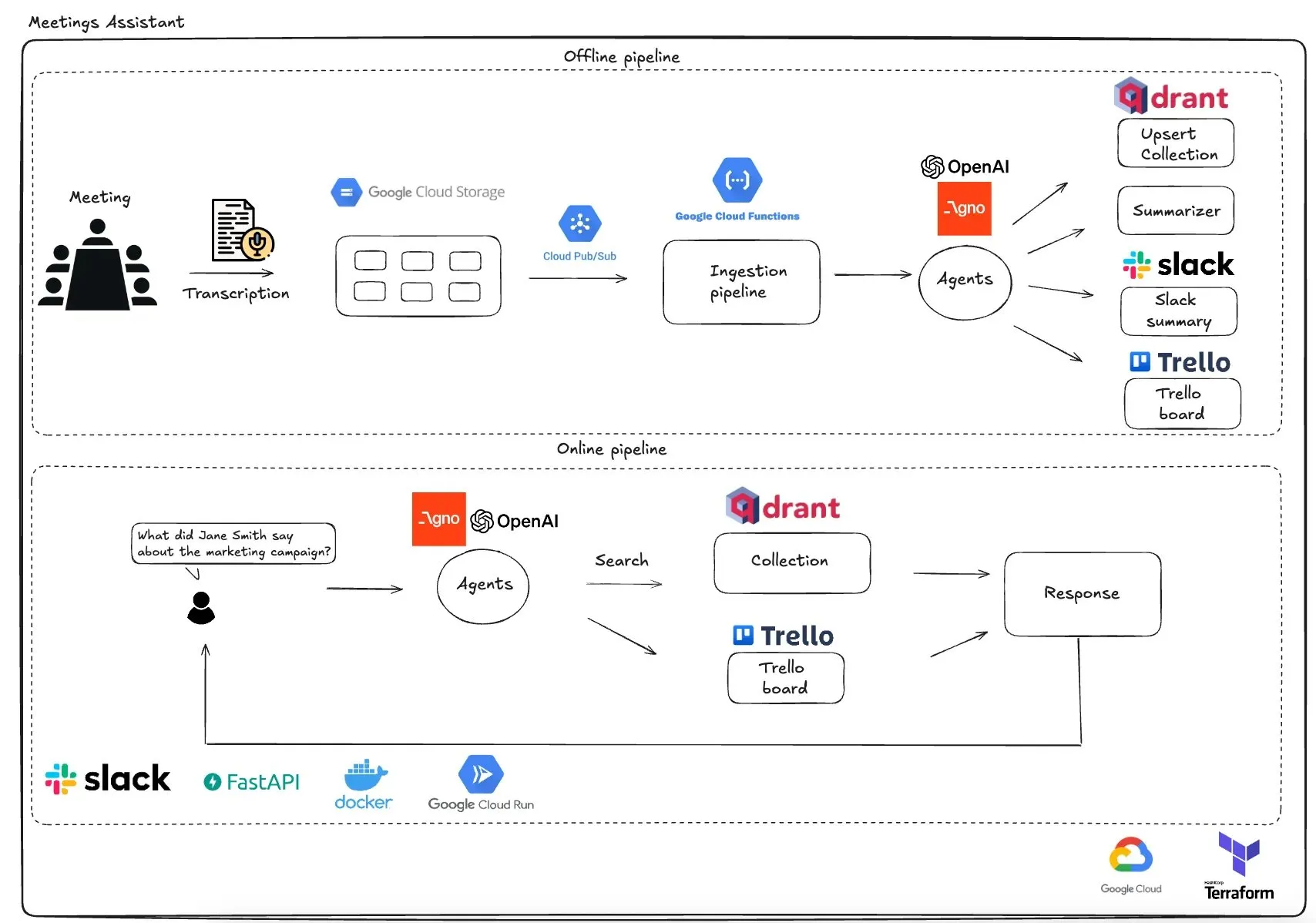
Qdrant lance un assistant de réunion multi-agents basé sur GCP: Qdrant a présenté un système d’assistant de réunion multi-agents entièrement serverless. Ce système peut transcrire le contenu des réunions, utiliser des agents LLM pour les résumer, stocker les informations contextuelles dans la base de données vectorielles Qdrant, synchroniser les tâches avec Trello, et livrer les résultats finaux directement dans Slack. Le système utilise AgnoAgi pour l’orchestration des agents, FastAPI fonctionnant sur Cloud Run, et OpenAI pour l’embedding et l’inférence. (Source: qdrant_engine)
Microsoft publie GUI-Actor, permettant la localisation d’éléments GUI sans coordonnées: Microsoft a publié GUI-Actor sur Hugging Face, une méthode de localisation d’éléments d’interface utilisateur graphique (GUI) sans coordonnées. Cette méthode permet aux agents IA de pointer directement vers des blocs visuels natifs (visual patches) via un token spécial <actor>, au lieu de s’appuyer sur des prédictions de coordonnées basées sur du texte, visant à améliorer la précision et la robustesse des opérations des agents GUI. (Source: _akhaliq)

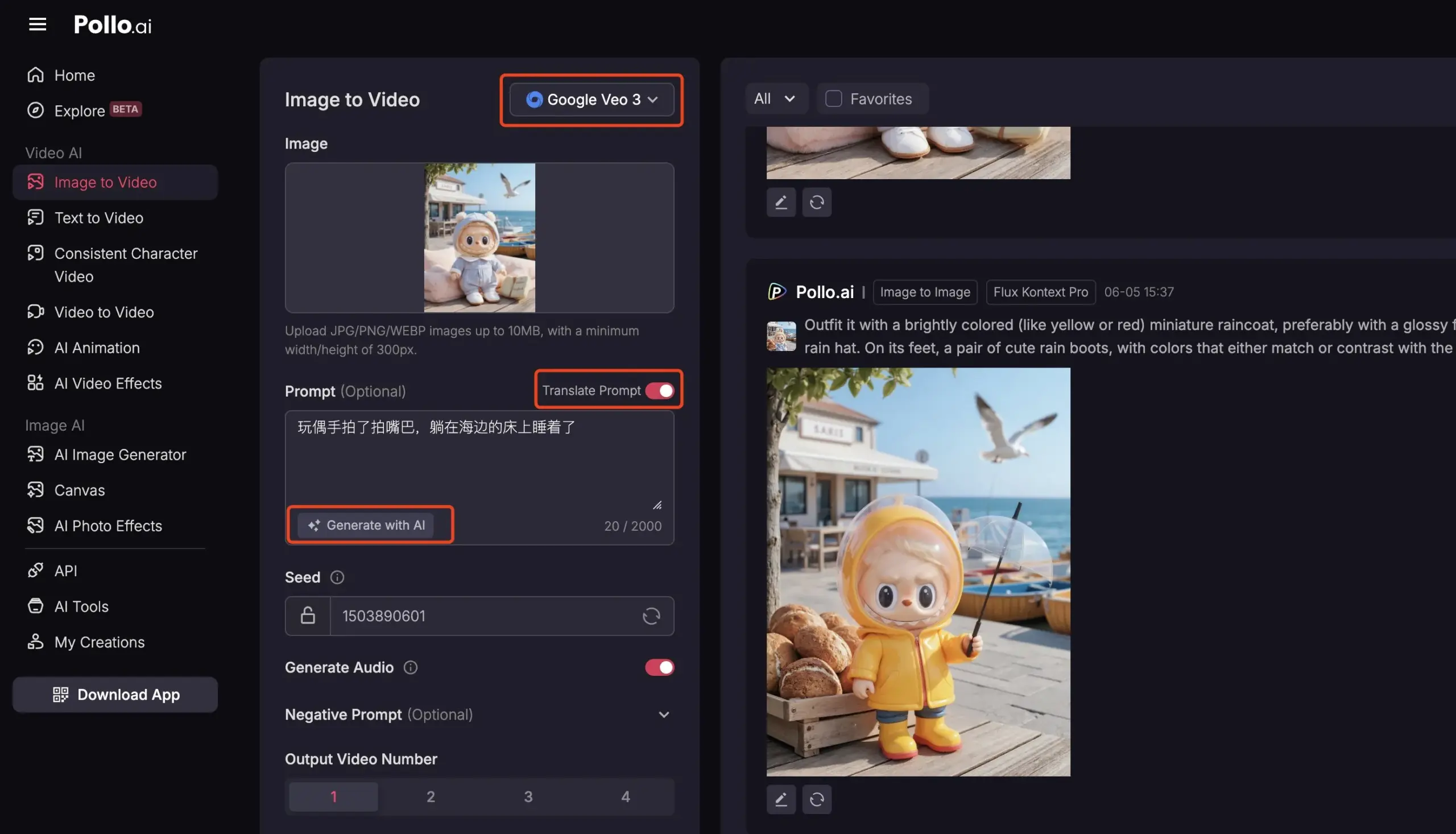
Pollo AI intègre Veo3 et FLUX Kontext, offrant des services vidéo IA complets: La plateforme d’outils IA Pollo AI a récemment été fréquemment mise à jour, intégrant le modèle de génération vidéo Google Veo3 et les fonctionnalités d’édition d’images FLUX Kontext. Les utilisateurs peuvent utiliser FLUX Kontext sur la plateforme pour modifier des images puis les envoyer directement à Veo3 pour générer des vidéos. La plateforme fournit également une interface API, prenant en charge l’accès unique à plusieurs grands modèles vidéo grand public du marché, et intègre des fonctions auxiliaires telles que la génération d’invites IA et la traduction multilingue, visant à améliorer la commodité et l’efficacité de la création vidéo IA. (Source: op7418)
📚 Apprentissage
Analyse approfondie du Meta-Learning : apprendre à l’IA comment apprendre: Le Meta-Learning, également connu sous le nom d’« apprendre à apprendre », a pour idée centrale d’entraîner des modèles à s’adapter rapidement à de nouvelles tâches, même avec peu d’échantillons. Ce processus implique généralement deux modèles : un apprenti de base (base-learner) qui s’adapte rapidement à des tâches spécifiques dans une boucle d’apprentissage interne (comme la classification d’images few-shot), et un méta-apprenti (meta-learner) qui gère et met à jour les paramètres ou les stratégies de l’apprenti de base dans une boucle d’apprentissage externe, afin d’améliorer sa capacité à résoudre de nouvelles tâches. Une fois l’entraînement terminé, l’apprenti de base utilisera les connaissances acquises par le méta-apprenti pour son initialisation. (Source: TheTuringPost, TheTuringPost)

Analyse de l’article « A Controllable Examination for Long-Context Language Models »: Cet article aborde les limites des cadres d’évaluation actuels des modèles de langage à long contexte (LCLM) (complexité et difficulté de résolution des tâches du monde réel, vulnérabilité à la contamination des données ; manque de cohérence contextuelle des tâches synthétiques comme NIAH). Il propose trois caractéristiques qu’un cadre d’évaluation idéal devrait posséder : contexte transparent, configuration contrôlable et évaluation solide. Il introduit également LongBioBench, un nouveau benchmark qui utilise des biographies générées par l’homme comme environnement contrôlé pour évaluer les LCLM selon les dimensions de la compréhension, du raisonnement et de la fiabilité. Les expériences montrent que la plupart des modèles présentent encore des lacunes en matière de compréhension sémantique, de raisonnement préliminaire et de fiabilité dans les contextes longs. (Source: HuggingFace Daily Papers)
Analyse de l’article « Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning »: Inspirée par les capacités de raisonnement exceptionnelles de Deepseek-R1 dans les tâches textuelles complexes, cette étude explore comment améliorer les capacités de raisonnement complexe des grands modèles de langage multimodaux (MLLM) grâce à un démarrage à froid optimisé et à un apprentissage par renforcement (RL) par étapes. L’étude révèle qu’une initialisation efficace par démarrage à froid est cruciale pour améliorer le raisonnement des MLLM ; une simple initialisation avec des données textuelles soigneusement sélectionnées peut surpasser de nombreux modèles existants. L’application standard de GRPO au RL multimodal rencontre des problèmes de stagnation des gradients, tandis qu’un entraînement RL ultérieur purement textuel peut encore améliorer le raisonnement multimodal. Sur la base de ces découvertes, les chercheurs ont lancé ReVisual-R1, qui a obtenu des résultats SOTA sur plusieurs benchmarks exigeants. (Source: HuggingFace Daily Papers)
Analyse de l’article « Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem »: Cette étude propose une méthode efficace pour libérer le potentiel de raisonnement des LLM pré-entraînés : le fine-tuning par critique sur un seul problème (Critique Fine-Tuning, CFT). En collectant plusieurs solutions générées par le modèle pour un seul problème et en utilisant un LLM enseignant pour fournir des critiques détaillées, des données de critique sont construites pour le fine-tuning. Les expériences montrent qu’après un CFT sur un seul problème pour les modèles des séries Qwen et Llama, des améliorations significatives des performances ont été obtenues sur diverses tâches de raisonnement. Par exemple, Qwen-Math-7B-CFT a amélioré en moyenne de 15-16% sur les benchmarks de raisonnement mathématique et logique, avec un coût de calcul bien inférieur à celui de l’apprentissage par renforcement. (Source: HuggingFace Daily Papers)
Analyse de l’article « SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation »: Pour résoudre les problèmes de couverture limitée, de manque de stratification de la complexité et de paradigmes d’évaluation fragmentés des benchmarks existants pour le traitement SVG (Scalable Vector Graphics), SVGenius a été créé. Il s’agit d’un benchmark complet contenant 2377 requêtes, couvrant trois dimensions : compréhension, édition et génération. Il est construit sur des données réelles provenant de 24 domaines d’application et a fait l’objet d’une stratification systématique de la complexité. En utilisant 8 catégories de tâches et 18 indicateurs, 22 modèles grand public ont été évalués, révélant les limites des modèles actuels dans le traitement de SVG complexes et soulignant qu’un entraînement amélioré par le raisonnement est plus efficace qu’une simple augmentation de l’échelle. (Source: HuggingFace Daily Papers)
Publication du journal des modifications de Hugging Face Hub: Hugging Face Hub a publié son dernier journal des modifications. Les utilisateurs peuvent le consulter pour connaître les nouvelles fonctionnalités de la plateforme, les mises à jour de la bibliothèque de modèles, l’enrichissement des ensembles de données et les améliorations de la chaîne d’outils, entre autres nouveautés. Cela aide les utilisateurs de la communauté à se tenir informés et à utiliser les dernières ressources et capacités de l’écosystème Hugging Face. (Source: huggingface, _akhaliq)
Maxime Labonne et d’autres auteurs rendent open source de nombreux Notebooks LLM: Maxime Labonne, auteur du LLM Engineer Handbook, et Iustin Paul ont rendu open source une série de Jupyter Notebooks relatifs aux LLM. Ces Notebooks sont riches en contenu, couvrant non seulement les techniques de base du fine-tuning, mais aussi des sujets avancés tels que l’évaluation automatique, les lazy merges, la construction de modèles de mélange d’experts (frankenMoEs) et les techniques de contournement de la censure, offrant ainsi des ressources pratiques précieuses aux développeurs et chercheurs en LLM. (Source: maximelabonne)
DeepLearningAI publie la newsletter The Batch, explorant comment AI Fund forme les bâtisseurs d’IA: Dans sa dernière édition de la newsletter The Batch, Andrew Ng partage les expériences et les stratégies d’AI Fund pour former les talents et les bâtisseurs d’IA. Cette édition couvre également des sujets d’actualité tels que les performances des nouveaux modèles open source de DeepSeek rivalisant avec les meilleurs LLM, l’utilisation de l’IA par Duolingo pour étendre ses cours de langues, les compromis liés à la consommation d’énergie de l’IA et la désinformation potentielle des Agents IA par des liens malveillants. (Source: DeepLearningAI)

💼 Affaires
Reddit poursuit Anthropic, l’accusant d’utilisation non autorisée de données utilisateur pour entraîner l’IA: Reddit a intenté une action en justice contre la société d’IA Anthropic, l’accusant d’avoir utilisé des robots automatisés pour extraire du contenu de Reddit sans autorisation afin d’entraîner ses modèles d’IA (tels que Claude), ce qui constitue une rupture de contrat et une concurrence déloyale. Cette affaire met en lumière la controverse actuelle sur la légalité de l’extraction de données et de l’entraînement des modèles dans le développement de l’IA, et reflète également l’importance croissante que les plateformes de contenu accordent à la protection de la valeur de leurs données. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon prévoit d’investir 10 milliards de dollars dans la construction de data centers IA en Caroline du Nord: Amazon a annoncé un investissement de 10 milliards de dollars en Caroline du Nord pour la construction de nouveaux data centers afin de soutenir la demande croissante de ses activités IA. Cette initiative reflète l’investissement continu des grandes entreprises technologiques dans l’infrastructure IA, visant à satisfaire les besoins massifs en calcul et en stockage requis pour l’entraînement et l’inférence des modèles IA. (Source: Reddit r/artificial)

Anthropic réduit l’accès API aux modèles Claude pour Windsurf.ai, suscitant des inquiétudes quant aux risques liés aux plateformes: La plateforme de développement d’applications IA Windsurf.ai a révélé qu’Anthropic avait considérablement réduit sa capacité d’accès API aux modèles Claude 3.x et Claude 4, avec un préavis de moins de 5 jours. Cette mesure a contraint Windsurf.ai à rechercher d’urgence des fournisseurs tiers pour garantir le service aux utilisateurs payants et à proposer une option BYOK (Bring Your Own Key) aux utilisateurs gratuits et Pro. Cet incident accentue les inquiétudes des développeurs concernant les risques liés aux plateformes des fournisseurs de modèles IA, à savoir que ces derniers peuvent ajuster leurs politiques de service à tout moment, voire entrer en concurrence avec les applications en aval. (Source: swyx, scaling01, mervenoyann)
🌟 Communauté
La conférence des ingénieurs IA (@aiDotEngineer) suscite un vif débat, axé sur la conception d’Agents et l’entrepreneuriat en IA: La conférence des ingénieurs IA (@aiDotEngineer) qui s’est tenue à San Francisco est devenue un sujet de discussion brûlant au sein de la communauté. LlamaIndex a partagé des modèles de conception d’Agents efficaces en environnement de production ; Anthropic y a présenté une “liste de besoins” pour les startups, axée sur l’application des serveurs MCP dans de nouveaux domaines, la simplification de la construction de serveurs et la sécurité des applications IA (comme l’empoisonnement d’outils) ; Graphite a présenté un outil de revue de code piloté par l’IA. La conférence a également abordé des questions telles que les défis de recherche fondamentale liés à l’extension des modèles GPT de nouvelle génération. (Source: swyx, swyx, swyx, iScienceLuvr)

Le chercheur Rohan Anil rejoint Anthropic, suscitant l’attention: Le chercheur Rohan Anil a annoncé qu’il rejoignait l’équipe d’Anthropic, une nouvelle qui a suscité une large attention et des discussions au sein de la communauté IA. De nombreux professionnels du secteur et observateurs l’ont félicité et attendent avec impatience sa nouvelle contribution aux travaux de recherche d’Anthropic. Cela reflète également l’impact potentiel de la mobilité des meilleurs talents de l’IA sur le paysage industriel. (Source: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Un tribunal exige qu’OpenAI conserve tous les journaux de ChatGPT, suscitant un débat sur les politiques de conservation des données: Il a été rapporté qu’un tribunal a exigé qu’OpenAI conserve tous les journaux de ChatGPT, y compris les “discussions temporaires” et les requêtes API qui auraient dû être supprimées. Cette nouvelle a suscité des discussions au sein de la communauté sur les politiques de conservation des données, en particulier pour les applications utilisant l’API d’OpenAI. Cela pourrait signifier que leurs propres politiques de conservation des données ne pourront pas être pleinement respectées, ce qui poserait de nouveaux défis en matière de confidentialité des utilisateurs et de gestion des données. Il est conseillé aux utilisateurs de privilégier l’utilisation de modèles locaux lorsque cela est possible afin de protéger leurs données. (Source: code_star, TomLikesRobots)

La prolifération de contenu généré par IA et le phénomène du “AI Slop” suscitent l’inquiétude: Le contenu généré par IA de mauvaise qualité et cherchant à attirer l’attention (appelé “AI Slop”) se multiplie sur les réseaux sociaux, allant des publications générées par IA sur Reddit aux images IA telles que “Jésus crevette” sur Facebook, suscitant chez les utilisateurs des inquiétudes quant à la qualité de l’information et à la détérioration de l’environnement en ligne. Ce contenu est généralement généré à bas coût par des robots ou des personnes en quête de trafic, visant à obtenir des “j’aime” et des partages grâce à des “appâts à engagement”. Des études indiquent qu’une grande partie du trafic Internet est déjà constituée de “mauvais robots” qui diffusent de fausses informations et volent des données. Ce phénomène affecte non seulement l’expérience utilisateur, mais constitue également une menace pour la démocratie et la communication politique, tout en risquant de polluer les données d’entraînement des futurs modèles d’IA. (Source: aihub.org)

Discussion sur le coût des LLM : Gemini offre un bon rapport qualité-prix, le coût de codage de Claude 4 attire l’attention: Les discussions au sein de la communauté soulignent les différences significatives de coût d’utilisation des LLM actuels. Par exemple, l’utilisation de Gemini pour traiter un document d’assurance entier et poser de nombreuses questions ne coûte qu’environ 0,01 $, ce qui témoigne d’un rapport qualité-prix élevé. En comparaison, bien que le modèle Claude 4 excelle dans des tâches telles que le codage, son utilisation en “mode max” sur des plateformes comme Cursor.ai est coûteuse, incitant les utilisateurs à se tourner vers des options plus rentables telles que Google Gemini 2.5 Pro. (Source: finbarrtimbers, Teknium1)
Les Agents IA rencontrent des difficultés à résoudre les CAPTCHA (vérification homme-machine) dans des scénarios web réels: L’équipe MetaAgentX a lancé la plateforme Open CaptchaWorld, axée sur l’évaluation de la capacité des agents interactifs multimodaux à résoudre les CAPTCHA. Les tests montrent que même les modèles SOTA tels que GPT-4o n’atteignent qu’un taux de réussite de 5 % à 40 % lors du traitement de 20 types de CAPTCHA interactifs dans des environnements web réels, bien en dessous du taux de réussite moyen de 93,3 % chez l’homme. Cela indique que les Agents IA actuels présentent encore des goulots d’étranglement en matière de compréhension visuelle, de planification multi-étapes, de suivi d’état et d’interaction précise, les CAPTCHA devenant un obstacle majeur à leur déploiement pratique. (Source: 量子位)

Le marché de la formation aux agents IA est en plein essor, la qualité des cours et les perspectives d’emploi suscitent l’attention: Avec l’essor du concept d’Agent IA, les cours de formation correspondants se multiplient. Certains organismes de formation prétendent offrir un accompagnement complet, de l’initiation à l’emploi, promettant même un “emploi garanti”, avec des frais de scolarité allant de quelques centaines à plusieurs dizaines de milliers de yuans. Cependant, la qualité des cours sur le marché est inégale, certains étant accusés d’être superficiels, de faire du marketing excessif, voire d’être similaires aux formations accélérées en IA de type “arnaque”. Les étudiants et les observateurs se montrent prudents quant à l’efficacité réelle de ces formations, aux qualifications des instructeurs et à la véracité des promesses d‘“emploi garanti”, craignant qu’elles ne deviennent une autre “fausse demande” dans la période de transition du développement de l’IA. (Source: 36氪)

💡 Autres
Progrès de l’IA dans le domaine de la robotique : main à perception tactile, robot amphibie et chien robot pompier: La technologie IA repousse les limites des capacités robotiques. Des chercheurs ont développé une main mécanique dotée d’une perception tactile, lui permettant de mieux interagir avec son environnement. Copperstone HELIX Neptune a présenté un robot amphibie piloté par l’IA, capable d’opérer sur différents terrains. La Chine a quant à elle lancé un chien robot pompier capable de projeter un jet d’eau à 60 mètres, de monter des escaliers et de diffuser des opérations de sauvetage en direct. Ces avancées montrent le potentiel de l’IA pour améliorer la perception, la prise de décision et l’exécution de tâches complexes par les robots. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Discussion comparative entre les Agents IA et l’IA générative: Des discussions émergent au sein de la communauté concernant les différences et les liens entre les Agents IA (IA intelligente) et l’IA générative (Generative AI). L’IA générative se concentre principalement sur la création de contenu, tandis que les Agents IA mettent davantage l’accent sur la prise de décision autonome et l’exécution de tâches basées sur la perception, la planification et l’action. Comprendre les différences entre les deux aide à mieux saisir l’orientation du développement et les scénarios d’application de la technologie IA. (Source: Ronald_vanLoon, Ronald_vanLoon)
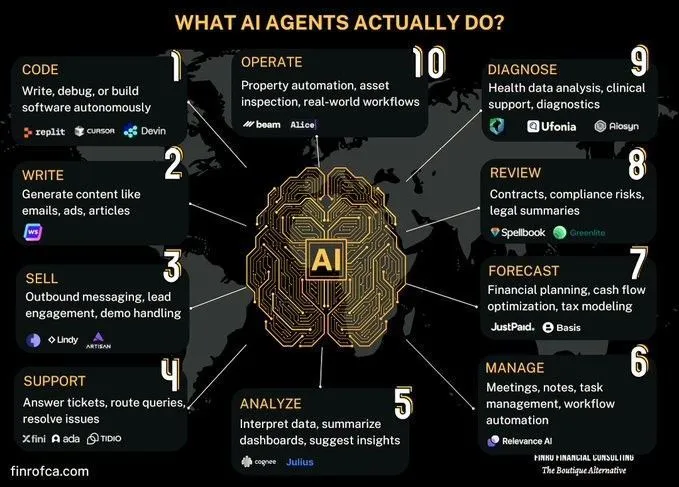
Exploration des défis de l’IA dans l’automatisation des processus organisationnels complexes: L’IA a progressé dans l’automatisation ou l’assistance de tâches spécifiques, mais remplacer le travail humain ou les équipes pour réaliser une transformation économique plus large se heurte à une complexité immense. De nombreuses organisations ont des processus cruciaux non documentés explicitement, qui sont à haut risque mais peu fréquents, et peuvent être devenus des routines au point que leurs raisons ont été oubliées. Les agents IA ont du mal à apprendre ces connaissances implicites par essais et erreurs, car le coût est prohibitif et les opportunités d’apprentissage limitées. Cela nécessite un nouveau paradigme technologique, et non un simple apprentissage machine. (Source: random_walker)