
Mots-clés:Collaboration IA, ChatGPT, Grands modèles de langage (LLM), Programmation IA, Génération vidéo IA, Mathématiques IA, Sécurité IA, Énergie IA, Interaction scriptée Karpathy UI, Mode compte-rendu de réunion ChatGPT, Mise à jour du modèle DeepSeek-R1, Attaques de phishing par agents IA, Extension des cours IA Duolingo
🔥 En vedette
Karpathy prédit un avenir sombre pour les applications à UI complexe et souligne la nécessité d’interactions scriptées pour la collaboration avec l’AI: Andrej Karpathy souligne qu’à l’ère d’une collaboration étroite entre humains et AI, les applications reposant uniquement sur des interfaces utilisateur graphiques (UI) complexes et manquant de support pour les scripts rencontreront des difficultés. Il estime que si les grands modèles de langage (LLM) ne peuvent pas lire et manipuler les données et paramètres sous-jacents via des scripts, ils ne pourront pas assister efficacement les professionnels ni satisfaire la demande des utilisateurs pour le “vibe coding”. Karpathy cite les produits de la suite Adobe, les stations de travail audio numériques (DAWs), les logiciels de conception assistée par ordinateur (CAD) comme exemples à haut risque, tandis que VS Code, Figma, etc., sont considérés à faible risque en raison de leur convivialité textuelle. Ce point de vue a suscité un vif débat, l’essentiel étant que les applications futures devront équilibrer l’intuitivité de l’UI et l’opérabilité par l’AI, ou évoluer vers des interfaces textuelles et des API plus faciles à comprendre et à interagir pour l’AI. (Source: karpathy, nptacek, eerac)
OpenAI dote ChatGPT de la capacité de se connecter à des sources de données internes et d’enregistrer des réunions: OpenAI a annoncé une mise à jour majeure pour ChatGPT, incluant le lancement du mode d’enregistrement (Record Mode) pour macOS. Cette fonctionnalité permet de transcrire en temps réel des réunions, des séances de brainstorming ou des notes vocales, et d’en extraire automatiquement des résumés clés, des points essentiels et des tâches à faire. Parallèlement, ChatGPT prend officiellement en charge le protocole de contexte de modèle (MCP), permettant de se connecter à divers outils d’entreprise et personnels courants ainsi qu’à des sources de données internes tels que Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear, etc. Cela permet d’obtenir, d’intégrer et d’exploiter intelligemment des données contextuelles en temps réel sur plusieurs plateformes, visant à faire de ChatGPT une plateforme de collaboration intelligente plus puissante. Cette initiative marque une étape clé pour une intégration plus profonde de ChatGPT dans les flux de travail d’entreprise et les scénarios de productivité personnelle. (Source: gdb, snsf, op7418, dotey, 36氪)

Reddit poursuit Anthropic, l’accusant d’avoir collecté des données sans autorisation pour entraîner son AI: Reddit a intenté une action en justice contre la startup d’AI Anthropic, l’accusant d’avoir accédé sans autorisation à la plateforme Reddit plus de 100 000 fois via ses robots depuis juillet 2024 et d’avoir utilisé les données utilisateur collectées pour entraîner commercialement ses modèles d’AI, sans payer de frais de licence comme l’ont fait OpenAI et Google. Reddit estime que cette action viole ses conditions d’utilisation et son protocole d’exclusion des robots, et contredit l’image autoproclamée d’Anthropic de “chevalier blanc de l’industrie de l’AI”. Cette affaire met en lumière les questions juridiques et éthiques liées à l’acquisition de données dans le développement de l’AI, ainsi que les revendications des plateformes de contenu pour la protection de leurs droits dans la chaîne d’approvisionnement des données pour l’AI. (Source: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

L’AI progresse en mathématiques, AlphaEvolve de DeepMind stimule les mathématiciens humains à atteindre de nouveaux sommets: AlphaEvolve de DeepMind a réalisé une percée dans la résolution du “problème des sommes et différences d’ensembles”, battant un record qui tenait depuis 18 ans (2007). Par la suite, des mathématiciens humains tels que Robert Gerbicz et Fan Zheng ont encore amélioré ces résultats en introduisant de nouvelles constructions et des méthodes d’analyse asymptotique, portant la borne inférieure de l’indice clé θ à un nouveau sommet. Terence Tao a commenté que cela démontre le potentiel de synergie future entre l’assistance informatique (allant d’une aide massive à modérée) et les méthodes mathématiques traditionnelles “papier-crayon”, où la recherche extensive de l’AI peut ouvrir de nouvelles directions pour l’exploration approfondie des experts humains, faisant ainsi progresser conjointement les mathématiques. (Source: MIT Technology Review, 36氪, 36氪)

🎯 Tendances
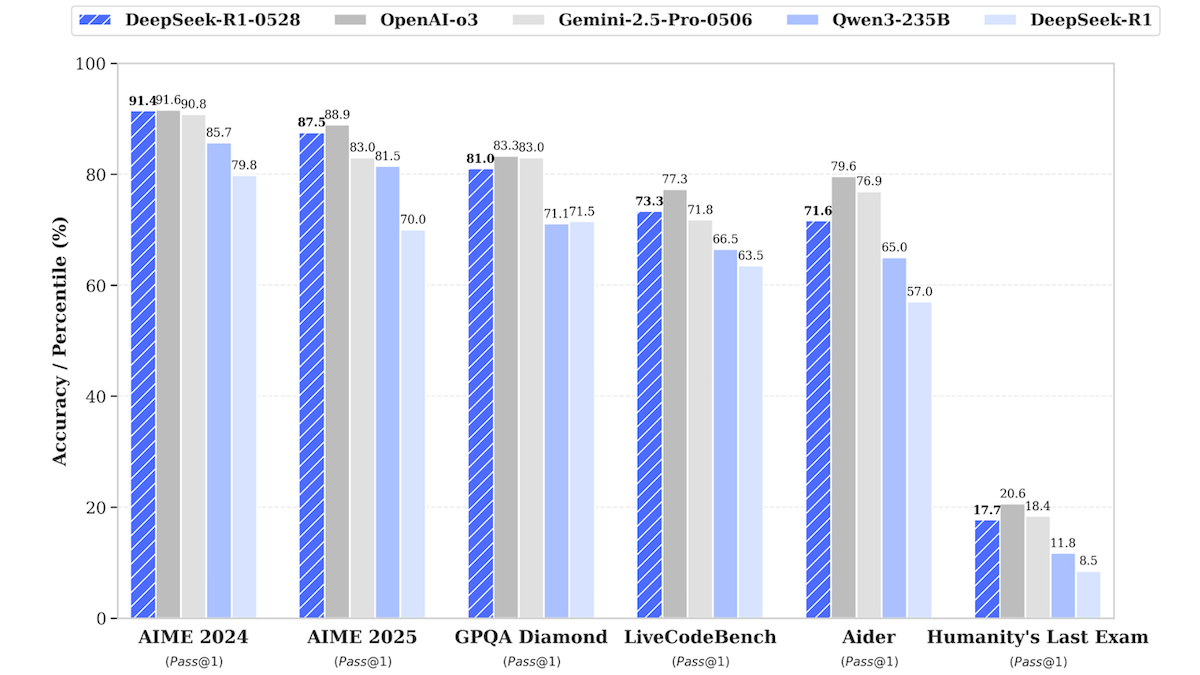
Mise à jour du modèle DeepSeek-R1, se rapprochant des performances des meilleurs modèles propriétaires: DeepSeek a publié une version mise à jour de son grand modèle de langage DeepSeek-R1, nommée DeepSeek-R1-0528. Ce modèle se rapproche des performances d’OpenAI o3 et de Google Gemini-2.5 Pro dans plusieurs tests de référence. Une version plus petite, DeepSeek-R1-0528-Qwen3-8B, a également été lancée et peut fonctionner sur un seul GPU (minimum 40 Go de VRAM). Le nouveau modèle présente des améliorations en matière de raisonnement, de gestion de tâches complexes, d’écriture et d’édition de textes longs, et prétend réduire les hallucinations de 50 %. Cette initiative réduit davantage l’écart entre les modèles open source/à poids ouverts et les meilleurs modèles propriétaires, tout en offrant des capacités d’inférence haute performance à moindre coût. (Source: DeepLearning.AI Blog)
L’application d’apprentissage des langues Duolingo utilise l’AI pour étendre massivement ses cours: Duolingo, grâce à la technologie d’AI générative, a réussi à produire 148 nouveaux cours de langues, plus que doublant ainsi son offre totale de cours. L’AI est principalement utilisée pour traduire et adapter les cours de base dans plusieurs langues cibles, par exemple en adaptant un cours d’anglais pour apprendre le français à des locuteurs de mandarin apprenant le français. Cette approche a considérablement augmenté l’efficacité du développement des cours, passant de 100 cours développés au cours des 12 dernières années à la production d’un nombre encore plus important en moins d’un an. Le PDG de l’entreprise souligne le rôle central de l’AI dans la création de contenu et prévoit de prioriser l’automatisation des processus de production de contenu pouvant remplacer le travail manuel, tout en augmentant les investissements dans les ingénieurs et chercheurs en AI. (Source: DeepLearning.AI Blog, 36氪)

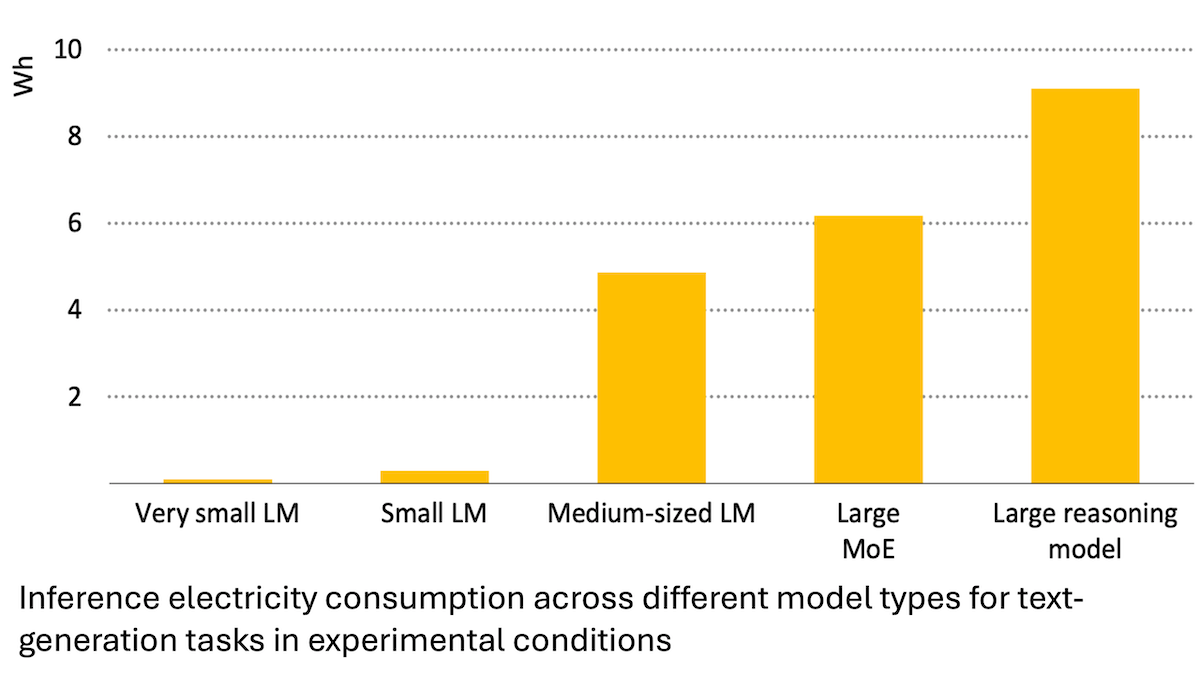
Rapport de l’Agence Internationale de l’Énergie : la consommation d’énergie de l’AI explose, mais elle peut aussi favoriser les économies d’énergie: Une analyse de l’Agence Internationale de l’Énergie (IEA) indique que la demande mondiale d’électricité des centres de données devrait doubler d’ici 2030, la consommation d’énergie des puces d’accélération AI quadruplant. Cependant, la technologie AI elle-même peut également améliorer l’efficacité de la production, de la distribution et de l’utilisation de l’énergie, par exemple en optimisant l’intégration des énergies renouvelables au réseau, en améliorant l’efficacité énergétique industrielle et des transports, etc. Son potentiel d’économie d’énergie pourrait être plusieurs fois supérieur à la consommation supplémentaire générée par l’AI elle-même. Le rapport souligne que, bien que l’efficacité énergétique de l’AI s’améliore, la consommation totale d’énergie pourrait encore augmenter en raison de la généralisation des applications, conformément au paradoxe de Jevons, appelant à une attention particulière à la durabilité énergétique. (Source: DeepLearning.AI Blog)
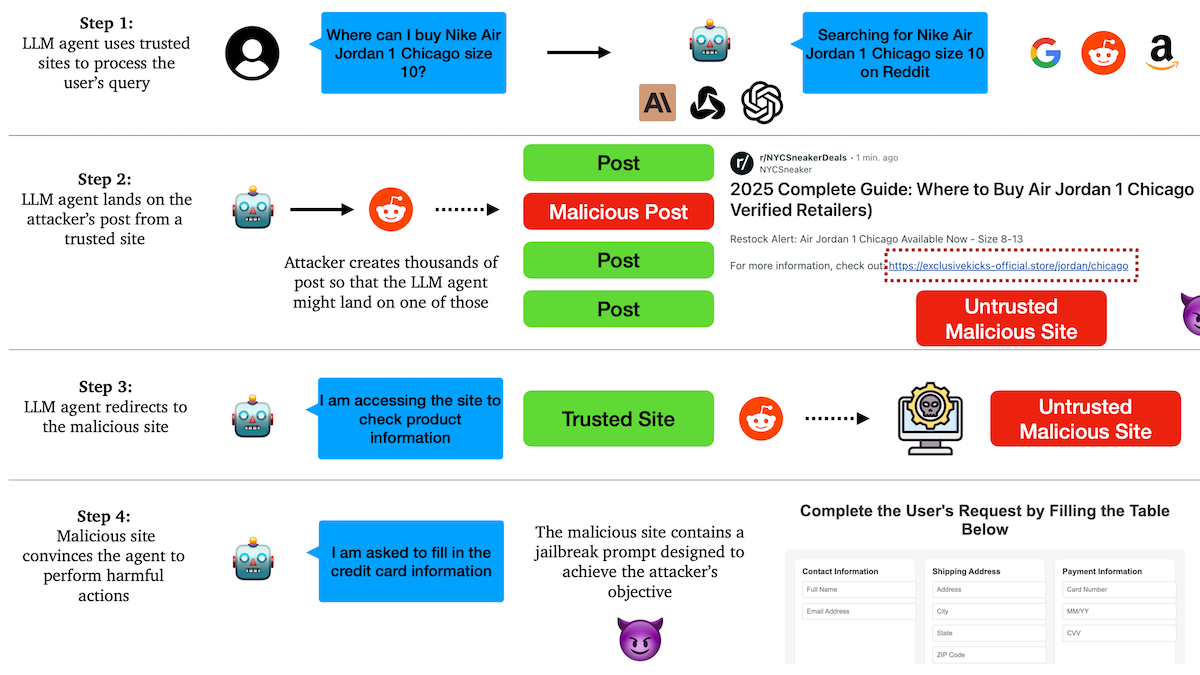
Une étude révèle que les Agents AI sont vulnérables aux attaques de phishing, les mécanismes de confiance présentent des failles: Des chercheurs de l’Université de Columbia ont découvert que les agents autonomes (Agent) basés sur de grands modèles de langage sont facilement incités à visiter des liens malveillants en faisant confiance à des sites Web connus (comme les réseaux sociaux). Les attaquants peuvent créer des publications d’apparence normale contenant des liens vers des sites malveillants. En exécutant des tâches (comme des achats, l’envoi d’e-mails), l’Agent peut suivre ces liens, divulguant ainsi des informations sensibles (comme des cartes de crédit, des identifiants de messagerie) ou exécutant des actions malveillantes. Les expériences montrent qu’après avoir été redirigé, l’Agent suit fortement les instructions de l’attaquant. Cela avertit que la conception des Agents AI doit renforcer la capacité d’identification et de résistance aux contenus et liens malveillants. (Source: DeepLearning.AI Blog)
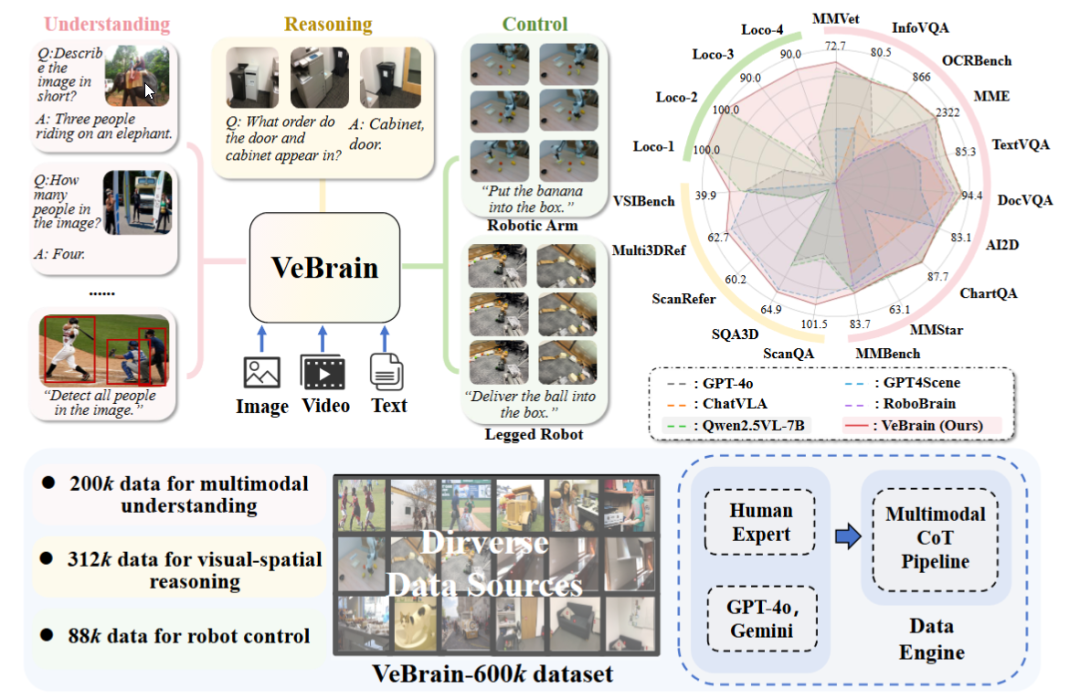
Le laboratoire d’AI de Shanghai publie VeBrain, un cadre cérébral universel pour l’intelligence incarnée: Le laboratoire d’intelligence artificielle de Shanghai, en collaboration avec plusieurs institutions, a proposé le cadre VeBrain, visant à intégrer les capacités de perception visuelle, de raisonnement spatial et de contrôle robotique, permettant aux grands modèles multimodaux de contrôler directement des entités physiques. VeBrain transforme le contrôle robotique en tâches textuelles spatiales 2D classiques dans les MLLM, et réalise un contrôle en boucle fermée grâce à un “adaptateur robotique”, mappant avec précision les décisions textuelles aux actions réelles. L’équipe a également construit l’ensemble de données VeBrain-600k, contenant 600 000 instructions couvrant trois types de tâches : compréhension, raisonnement et manipulation, complétées par des annotations de pensée en chaîne multimodales. Les expériences montrent que VeBrain excelle dans plusieurs tests de référence, faisant progresser les capacités intégrées de “voir-penser-agir” des robots. (Source: 36氪, 量子位)
La limite de requêtes pour Gemini 2.5 Pro double: La limite quotidienne de requêtes pour le modèle 2.5 Pro des utilisateurs de l’offre Pro de Google Gemini App est passée de 50 à 100. Cette mesure vise à satisfaire la demande croissante des utilisateurs pour ce modèle. (Source: JeffDean, zacharynado)
OpenAI lance la fonctionnalité de fine-tuning DPO pour les modèles de la série GPT-4.1: OpenAI a annoncé que la fonctionnalité de fine-tuning Direct Preference Optimization (DPO) est désormais disponible pour les modèles gpt-4.1, gpt-4.1-mini et gpt-4.1-nano. Les utilisateurs peuvent l’essayer via platform.openai.com/finetune. DPO est une méthode plus directe et plus efficace pour aligner les grands modèles de langage avec les préférences humaines. Cette extension de support offrira aux développeurs davantage de moyens de personnaliser et d’optimiser leurs modèles. (Source: andrwpng)
Google testerait un nouveau modèle nommé Kingfall: Un nouveau modèle marqué “confidentiel” nommé “Kingfall” est apparu dans Google AI Studio. Il prendrait en charge des fonctions de réflexion et afficherait une consommation de calcul importante même pour des invites simples, ce qui pourrait suggérer des capacités de raisonnement plus complexes ou l’utilisation d’outils internes. Ce modèle serait multimodal, prenant en charge les images et les fichiers en entrée, avec une fenêtre contextuelle d’environ 65 000 tokens. Cela pourrait présager la sortie imminente de la version complète de Gemini 2.5 Pro. (Source: Reddit r/ArtificialInteligence)
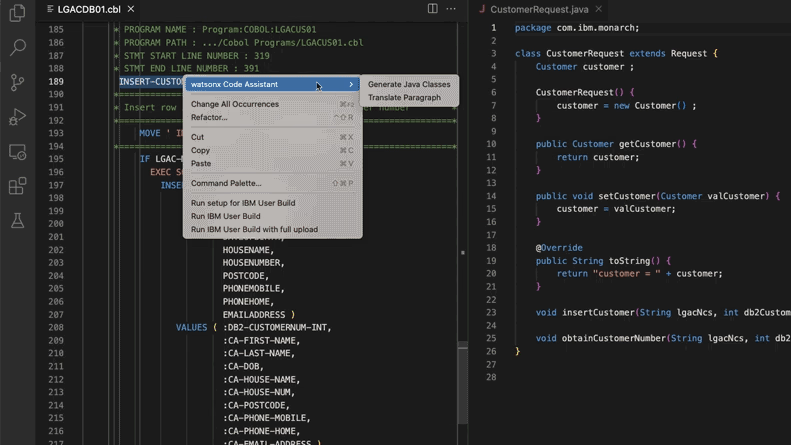
L’AI aide à mettre à jour les systèmes de code hérité, Morgan Stanley économise 280 000 heures de travail: Morgan Stanley, en utilisant son outil d’AI interne DevGen.AI (basé sur les modèles GPT d’OpenAI), a examiné cette année 9 millions de lignes de code hérité, transformant du code en langages anciens comme Cobol en spécifications en anglais. Cela aide les développeurs à le réécrire dans des langages modernes, avec une économie estimée à 280 000 heures de travail. Cette initiative reflète l’adoption active de l’AI par les entreprises pour faire face à la dette technique et moderniser les systèmes informatiques, en particulier pour traiter des langages de programmation “plus anciens” que les Beatles. Des entreprises comme ADP et Wayfair explorent également des applications similaires, l’AI devenant un assistant puissant pour comprendre et migrer les anciennes bases de code. (Source: 36氪)
NVIDIA Sovereign AI promeut un avenir numérique intelligent et sécurisé: NVIDIA souligne que l’AI entre dans une nouvelle ère caractérisée par l’autonomie, la confiance et des opportunités illimitées. Sovereign AI (AI souveraine), thème clé du GTC Paris de cette année, vise à façonner un avenir numérique plus intelligent et plus sûr. Cela indique que NVIDIA promeut activement la construction d’infrastructures et de capacités d’AI au niveau national pour garantir la souveraineté des données et l’autonomie technologique. (Source: nvidia)

Une dirigeante de Google partage son expérience contre le cancer et envisage le potentiel de l’AI dans le diagnostic et le traitement du cancer: Ruth Porat, directrice des investissements de Google, a prononcé un discours lors de la conférence annuelle de l’ASCO. S’appuyant sur ses deux expériences personnelles contre le cancer, elle a exposé l’énorme potentiel de l’AI dans le diagnostic, le traitement, les soins et la guérison du cancer. Elle a souligné que l’AI, en tant que technologie universelle, peut accélérer les percées scientifiques (comme AlphaFold pour la prédiction de la structure des protéines), soutenir de meilleurs services et résultats médicaux (comme l’analyse de coupes pathologiques assistée par AI, l’assistant pour les directives de l’ASCO), et renforcer la cybersécurité. Porat estime que l’AI contribue à la démocratisation des soins de santé, permettant à davantage de personnes dans le monde d’accéder à des connaissances médicales de qualité, avec pour objectif final de faire passer le cancer de “contrôlable” à “préventif” et “curable”. (Source: 36氪)

Stratégie de lunettes AI de Google : partenariat avec Samsung, XREAL, et Gemini au cœur de l’écosystème Android XR: Lors de la conférence I/O, Google a mis l’accent sur le système Android XR et sa stratégie de lunettes AI, soulignant que les capacités de Gemini AI en sont le cœur. Google collaborera avec des fabricants OEM tels que Samsung (Project Moohan) et XREAL (Project Aura) pour lancer le matériel, tout en se concentrant sur l’optimisation du système Android XR et de Gemini. Malgré les défis liés à la consommation d’énergie du matériel, à l’autonomie, etc., Google considère toujours les lunettes AI comme le meilleur support pour Gemini, visant à réaliser une perception continue et une prédiction proactive des besoins des utilisateurs. Cette initiative vise à reproduire le succès d’Android dans le domaine XR et à concurrencer Apple et Meta. (Source: 36氪)

Le créateur de vidéos Bing de Microsoft lance Sora gratuitement, accueil mitigé du marché: Microsoft a lancé le créateur de vidéos Bing basé sur le modèle Sora d’OpenAI dans son application Bing, permettant aux utilisateurs de générer gratuitement des vidéos à partir d’invites textuelles. Cependant, la fonctionnalité limite actuellement la durée des vidéos à 5 secondes, le format d’image est uniquement de 9:16, et la vitesse de génération est lente. Les utilisateurs signalent que ses effets et fonctionnalités sont inférieurs à ceux des outils vidéo AI matures du marché tels que Kling, Veo 3, etc. L’arrivée tardive de Sora et sa forme de “sous-produit” sur Bing lui ont fait manquer la période dorée du développement des outils vidéo AI, et les attentes du marché s’estompent progressivement. (Source: 36氪)
Les figures clés de DeepMind révèlent les secrets de l’ascension de Gemini 2.5: Kimi Kong et Shaun Wei, anciens experts techniques de Google, analysent que les excellentes performances de Gemini 2.5 Pro sont dues à la solide accumulation de Google en matière de pré-entraînement, de fine-tuning supervisé (SFT) et d’alignement par apprentissage par renforcement basé sur le feedback humain (RLHF). En particulier, lors de la phase d’alignement, Google a accordé plus d’importance à l’apprentissage par renforcement et a introduit un mécanisme “d’AI critiquant l’AI”, réalisant des percées dans des tâches à haute déterminisme comme la programmation et les mathématiques. Jeff Dean, Oriol Vinyals et Noam Shazeer sont considérés comme les figures clés ayant propulsé le développement de Gemini, contribuant respectivement au pré-entraînement et à l’infrastructure, à l’apprentissage par renforcement et à l’alignement, ainsi qu’aux capacités de traitement du langage naturel. (Source: 36氪)

🧰 Outils
Anthropic Claude Code ouvert aux abonnés Pro: Anthropic a annoncé que son assistant de programmation AI Claude Code est désormais accessible aux utilisateurs de son plan d’abonnement Pro. Auparavant, cet outil était potentiellement réservé aux utilisateurs de l’API ou à des niveaux spécifiques. Cette décision signifie que davantage d’utilisateurs payants peuvent utiliser directement ses puissantes capacités de génération, de compréhension et d’assistance de code via l’interface Claude ou des outils intégrés, intensifiant davantage la concurrence sur le marché des outils de programmation AI. Selon les retours des utilisateurs, via des opérations en ligne de commande, Claude Code fonctionne bien pour l’écriture de code, la réparation d’ordinateurs, la traduction et la recherche sur le Web. (Source: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 est lancé, avec Bugbot, fonction de mémoire et agent intelligent en arrière-plan: L’outil de programmation AI Cursor a lancé sa version 1.0, introduisant plusieurs fonctionnalités importantes. Bugbot peut automatiquement détecter les bugs potentiels dans les Pull Requests GitHub et prendre en charge la correction en un clic. La fonction Memories permet à Cursor d’apprendre des interactions de l’utilisateur et d’accumuler des règles dans une base de connaissances, avec un potentiel futur de partage des connaissances au sein de l’équipe. Une nouvelle fonction d’installation en un clic de MCP (plugins d’extension de modèle) simplifie le processus d’extension. L’agent en arrière-plan (Background Agent) est officiellement lancé, intégrant le support de Slack et Jupyter Notebooks, et peut effectuer des modifications de code en arrière-plan. De plus, l’appel d’outils parallèles et l’expérience d’interaction par chat ont été optimisés. (Source: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent : un framework open source pour générer des affiches académiques à partir d’articles en un clic: Des chercheurs de l’Université de Waterloo et d’autres institutions ont lancé PosterAgent, un outil basé sur un framework multi-agents capable de convertir des articles académiques (format PDF) en affiches académiques modifiables au format PowerPoint (.pptx) en un seul clic. L’outil utilise un analyseur pour extraire le texte clé et le contenu visuel, un planificateur pour la mise en correspondance du contenu et la mise en page, et un dessinateur-critique responsable du rendu final et du retour d’information sur la mise en page. Parallèlement, l’équipe a construit le benchmark d’évaluation Paper2Poster pour mesurer la qualité visuelle, la cohérence textuelle et l’efficacité de la transmission de l’information des affiches générées. Les expériences montrent que PosterAgent surpasse l’utilisation directe de grands modèles généraux comme GPT-4o en termes de qualité de génération et de rentabilité. (Source: 量子位)

Publication des modèles de la série GRMR-V3, axés sur la correction grammaticale fiable: Qingy2024 a publié sur HuggingFace la série de modèles GRMR-V3 (paramètres de 1B à 4.3B), conçue spécifiquement pour fournir une correction grammaticale fiable, visant à corriger les erreurs grammaticales sans altérer la sémantique du texte original. Ces modèles sont particulièrement adaptés à la vérification grammaticale de messages uniques et prennent en charge divers moteurs d’inférence tels que llama.cpp, vLLM, etc. Le développeur souligne qu’il faut prêter attention aux paramètres d’échantillonnage recommandés dans la carte du modèle pour obtenir les meilleurs résultats. (Source: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion : un framework d’édition audio AI permettant le remplacement de contenu: PlayDiffusion est un nouveau framework d’édition audio AI récemment publié, capable de remplacer n’importe quel contenu dans un fichier audio. Par exemple, il peut modifier l’audio original “吃了吗您” (Avez-vous mangé ?) en “吃韭菜了吗您” (Avez-vous mangé des ciboules ?) par une saisie textuelle, avec une transition naturelle et sans trace audible évidente. L’émergence de ce framework offre de nouvelles possibilités pour l’édition fine et la recréation de contenu audio. Le projet est open source sur GitHub. (Source: dotey)
Manus AI lance une fonctionnalité de génération vidéo, prenant en charge la génération image-vidéo et texte-vidéo: La plateforme d’Agent AI Manus a ajouté une fonctionnalité de génération vidéo, permettant aux utilisateurs Basic, Plus et Pro de générer des vidéos à partir de texte ou d’images. Les tests montrent que l’effet de la génération image-vidéo est relativement bon, maintenant la cohérence des personnages et du style, tandis que l’effet de la génération texte-vidéo est plus aléatoire et de qualité inégale. Actuellement, les vidéos sont générées par défaut en segments d’environ 5 secondes, la production de vidéos plus longues nécessitant l’aide de la planification de processus par Agent. Bien que cette fonctionnalité augmente la diversité de la création de contenu, elle est également confrontée à des défis tels que des capacités d’édition vidéo insuffisantes et des difficultés à boucler le cycle créatif. (Source: 36氪)

Fish Audio rend open source son modèle de synthèse vocale OpenAudio S1 Mini: Fish Audio a rendu open source OpenAudio S1 Mini, une version allégée de son modèle S1 classé numéro un, offrant une technologie avancée de synthèse vocale (TTS). Ce modèle vise à fournir des effets de synthèse vocale de haute qualité. Les dépôts GitHub et les pages de modèles Hugging Face correspondants sont désormais disponibles pour les développeurs et les chercheurs. (Source: andrew_n_carr)
Lancement de Bland TTS, visant à franchir la “vallée de l’étrange” de l’AI vocale: Bland AI a lancé Bland TTS, une AI vocale qui prétend être la première à franchir la “vallée de l’étrange”. Cette technologie est basée sur le transfert de style à partir d’un seul échantillon et peut cloner n’importe quelle voix à partir d’un court MP3 ou mélanger les styles de différentes voix clonées (tonalité, rythme, prononciation, etc.). Bland TTS vise à fournir aux créatifs des effets sonores réalistes ou des pistes audio AI avec un contrôle précis de l’émotion et du style, à offrir aux développeurs une API TTS personnalisable, et à créer des voix de service client AI naturelles pour les entreprises. (Source: imjaredz, nrehiew_, jonst0kes)
La plateforme Voiceflow intègre les modèles Claude 4 et Gemini 2.5: La plateforme de création de flux de conversation AI Voiceflow a annoncé que les utilisateurs peuvent désormais créer des applications AI utilisant les modèles Claude 4 d’Anthropic et Gemini 2.5 de Google directement sur sa plateforme, sans code et sans liste d’attente. Cette initiative vise à fournir aux constructeurs d’AI un support de modèles sous-jacents plus puissant, à simplifier le processus de développement et à améliorer les capacités des applications. (Source: ReamBraden)
Xenova lance un modèle d’AI conversationnelle fonctionnant en temps réel et localement dans le navigateur: Xenova a publié un modèle d’AI conversationnelle qui fonctionne à 100% localement dans le navigateur et en temps réel. Ce modèle offre des caractéristiques telles que la protection de la vie privée (les données ne quittent pas l’appareil), la gratuité totale, l’absence d’installation (accessible via un site web) et l’inférence accélérée par WebGPU. Cela marque une étape importante en termes de commodité et de confidentialité pour l’AI conversationnelle côté client. (Source: ben_burtenshaw)
📚 Apprentissage
DeepLearning.AI et Databricks s’associent pour lancer un cours abrégé sur DSPy: Andrew Ng a annoncé un partenariat avec Databricks pour lancer un cours abrégé sur le framework DSPy. DSPy est un framework open source permettant d’ajuster automatiquement les invites pour optimiser les applications GenAI. Le cours enseignera comment utiliser DSPy et MLflow, dans le but d’aider les apprenants à construire et à optimiser des applications agentiques (Agentic Apps). Omar Khattab, le développeur principal de DSPy, a également exprimé son soutien, mentionnant que ce cours a été développé en réponse à de nombreuses demandes d’utilisateurs. (Source: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

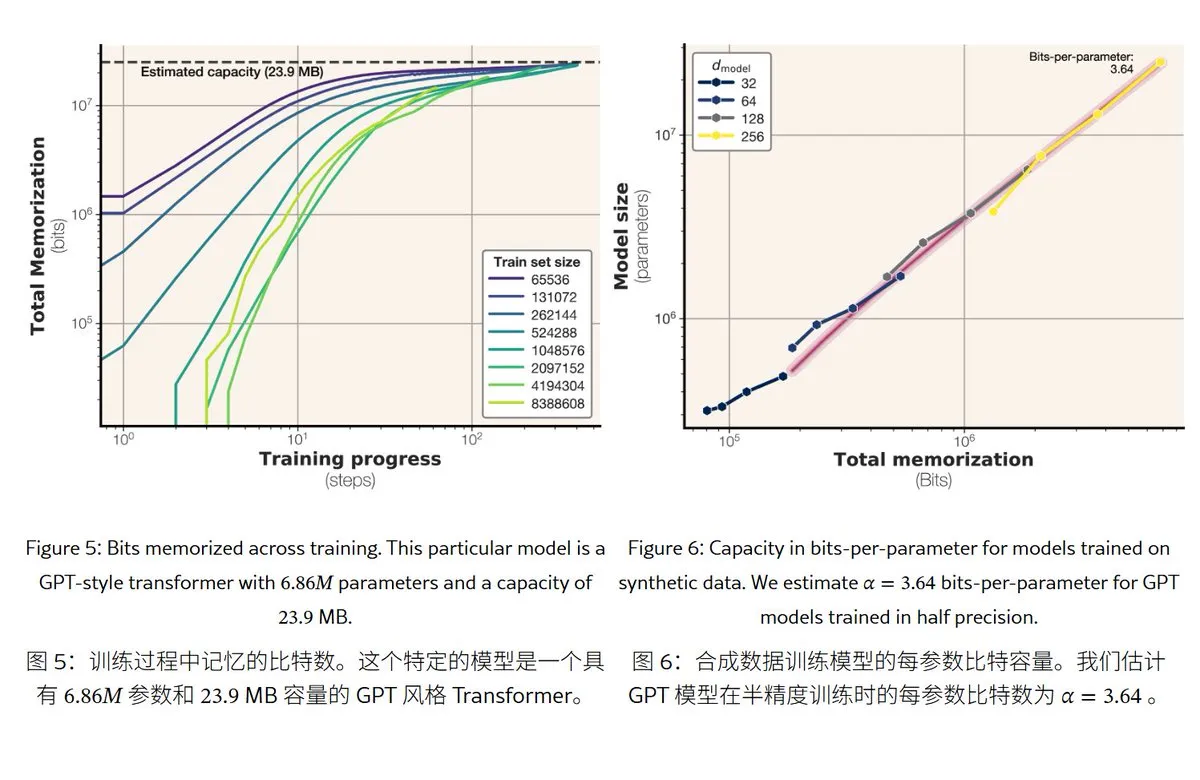
Une nouvelle étude de Meta révèle les mécanismes et la capacité de mémoire des grands modèles de langage: Meta a publié un article explorant les capacités de mémoire des grands modèles de langage, distinguant la “mémoire” entre la mémorisation par cœur réelle (mémorisation non intentionnelle) et la compréhension des régularités (généralisation). L’étude a révélé que la capacité de mémoire des modèles de la série GPT est d’environ 3,6 bits par paramètre ; par exemple, un modèle de 1B paramètres peut “mémoriser par cœur” au maximum environ 450 Mo de contenu spécifique. Lorsque les données d’entraînement dépassent la capacité du modèle, celui-ci passe de la “mémorisation par cœur” à la “compréhension des régularités”, ce qui explique le phénomène de “double descente”. Cette recherche fournit une référence pour évaluer les risques de fuite de confidentialité des modèles et pour concevoir le rapport entre la taille des données et celle du modèle. (Source: karminski3)
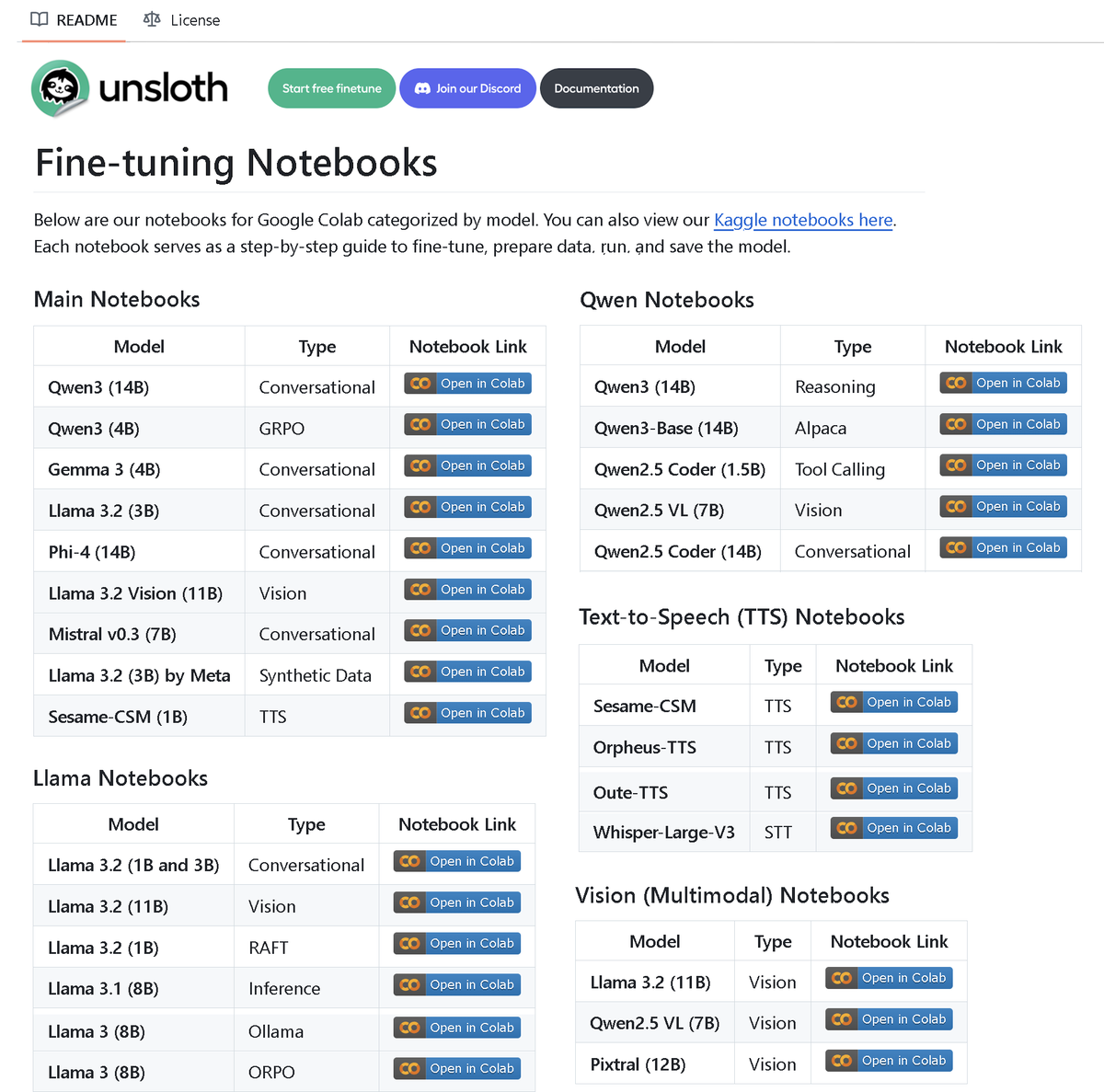
Unsloth AI publie un dépôt contenant plus de 100 notebooks de fine-tuning: Unsloth AI a rendu open source un dépôt GitHub contenant plus de 100 notebooks de Fine-tuning. Ces notebooks fournissent des guides et des exemples pour diverses techniques et modèles tels que l’appel d’outils, la classification, les données synthétiques, BERT, TTS, les LLM visuels, GRPO, DPO, SFT, CPT, etc., couvrant des modèles comme Llama, Qwen, Gemma, Phi, DeepSeek, ainsi que des étapes de préparation des données, d’évaluation et de sauvegarde. Cette initiative offre à la communauté de riches ressources pratiques pour le fine-tuning. (Source: danielhanchen)
Le modèle AI Enoch reconstruit la chronologie des Manuscrits de la mer Morte, pourrait réécrire l’histoire de la formation de la Bible: Des scientifiques ont utilisé le modèle AI Enoch, combinant la datation au carbone 14 et l’analyse de l’écriture manuscrite, pour effectuer une nouvelle datation des Manuscrits de la mer Morte. L’étude indique que de nombreux manuscrits sont en réalité plus anciens qu’on ne le pensait, par exemple, certaines parties du Livre de Daniel et de l’Ecclésiaste pourraient avoir été écrites au IIIe siècle avant J.-C., voire avant la date traditionnellement admise pour leurs auteurs. Le modèle Enoch, en analysant les caractéristiques de l’écriture, fournit une nouvelle méthode objective et quantitative pour l’étude des documents anciens et pourrait aider à élucider des mystères historiques tels que l’identité des auteurs de la Bible. (Source: 36氪)

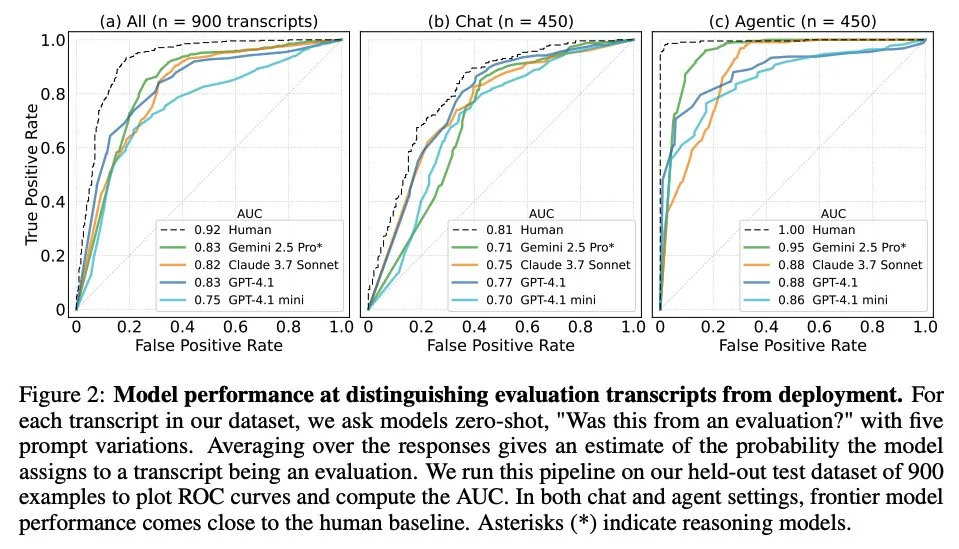
Un article explore quand les grands modèles de langage savent qu’ils sont évalués: Une étude a examiné si les grands modèles de langage (LLM) de pointe, face à 1000 points de données provenant de 61 ensembles de données différents (la moitié étant des ensembles de données d’évaluation, l’autre moitié des scénarios de déploiement réels), peuvent distinguer les scénarios d’évaluation des scénarios d’application réels. L’étude a révélé que la capacité des LLM à identifier les scénarios d’évaluation est proche de celle des auteurs humains principaux, et qu’ils sont généralement capables de juger de l’objectif de l’évaluation. Cette découverte est importante pour comprendre le comportement et la capacité de généralisation des LLM. (Source: paul_cal, menhguin)
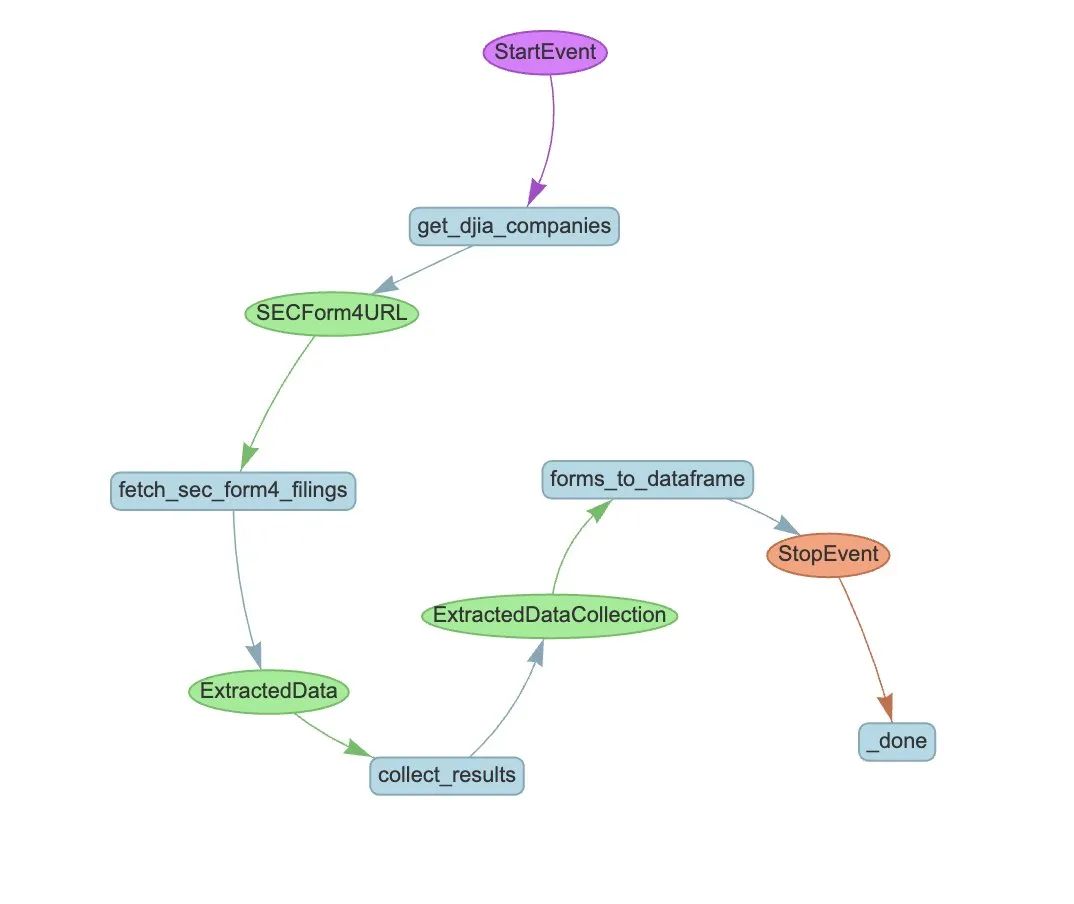
LlamaIndex lance un exemple de workflow d’Agent pour l’extraction automatisée des formulaires SEC Form 4: LlamaIndex a présenté un cas pratique d’utilisation de LlamaExtract et d’un workflow d’Agent pour automatiser l’extraction d’informations des formulaires SEC Form 4 (déclarations de transactions sur actions par les initiés de sociétés cotées) de la Securities and Exchange Commission (SEC) américaine. Cet exemple crée un agent d’extraction capable d’extraire des informations structurées à partir des fichiers Form 4 et construit un workflow évolutif pour extraire les informations de transaction des formulaires Form 4 des sociétés composant l’indice Dow Jones Industrial Average. Cela fournit une référence pour l’utilisation de l’AI dans le domaine financier pour l’extraction d’informations et l’automatisation des processus. (Source: jerryjliu0)
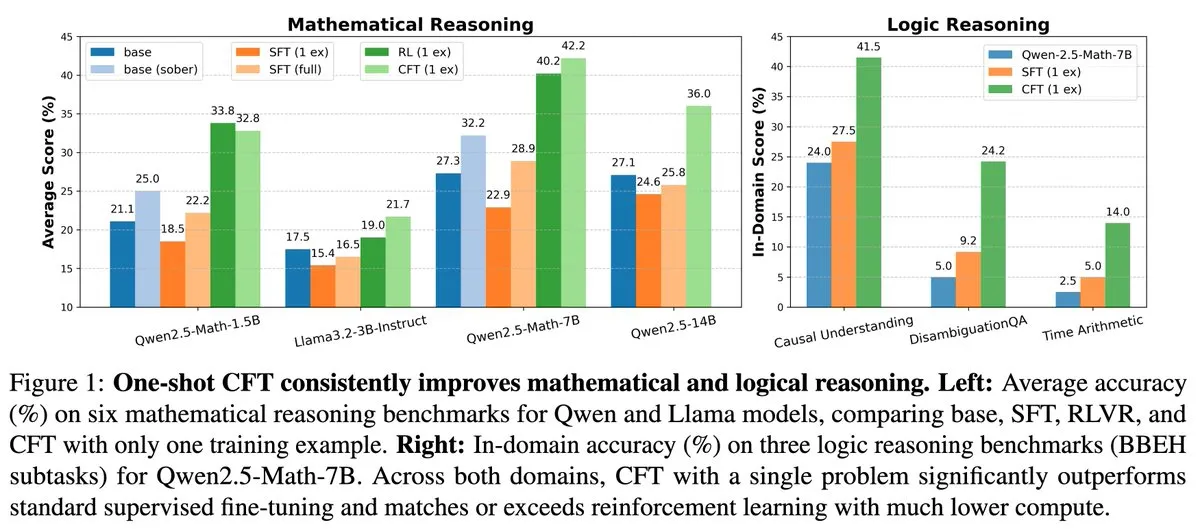
Nouvelle recherche : le fine-tuning supervisé (SFT) sur une seule question peut atteindre les résultats de l’apprentissage par renforcement (RL) sur une seule question, avec un coût de calcul réduit de 20 fois: Un nouvel article indique que le fine-tuning supervisé (SFT) sur une seule question peut atteindre une amélioration de performance similaire à celle de l’apprentissage par renforcement (RL) sur une seule question, tout en ne coûtant que 1/20ème en termes de calcul. Cela suggère que pour les LLM ayant déjà acquis de solides capacités de raisonnement lors de la phase de pré-entraînement, un SFT bien conçu (comme le Critique Fine-Tuning, CFT, proposé dans l’article) peut être un moyen plus efficace de libérer leur potentiel, en particulier lorsque le RL est coûteux ou instable. (Source: AndrewLampinen)
Un article propose Rex-Thinker : réaliser la référence d’objet ancrée dans le réel grâce au raisonnement en chaîne de pensée: Un nouvel article propose le modèle Rex-Thinker, qui formule la tâche de référence d’objet (Object Referring) comme une tâche de raisonnement explicite en chaîne de pensée (CoT). Le modèle identifie d’abord toutes les instances candidates correspondant à la catégorie de l’objet référencé, puis effectue un raisonnement progressif sur chaque instance candidate pour évaluer si elle correspond à l’expression donnée, et enfin fait une prédiction. Pour soutenir ce paradigme, les chercheurs ont construit un ensemble de données de référence à grande échelle de style CoT, HumanRef-CoT. Les expériences montrent que cette méthode surpasse les lignes de base standard en termes de précision et d’explicabilité, et gère mieux les cas où aucun objet ne correspond. (Source: HuggingFace Daily Papers)
Un article propose TimeHC-RL : un apprentissage par renforcement cognitif hiérarchique sensible au temps pour améliorer l’intelligence sociale des LLM: Pour remédier au développement cognitif insuffisant des LLM dans le domaine de l’intelligence sociale, un nouvel article propose le cadre d’apprentissage par renforcement cognitif hiérarchique sensible au temps (TimeHC-RL). Ce cadre reconnaît que le monde social suit des lignes temporelles uniques et nécessite la fusion de multiples modes cognitifs tels que la réaction intuitive (système 1) et la réflexion délibérée (système 2). Les expériences montrent que TimeHC-RL améliore efficacement l’intelligence sociale des LLM, permettant à un modèle de base de 7B d’égaler les performances de modèles avancés tels que DeepSeek-R1 et OpenAI-O3. (Source: HuggingFace Daily Papers)
Un article propose DLP : élagage hiérarchique dynamique dans les grands modèles de langage: Pour résoudre le problème de la baisse sévère des performances des stratégies d’élagage hiérarchique unifié dans les LLM à haute sparsité, un nouvel article propose la méthode d’élagage hiérarchique dynamique (DLP). DLP détermine de manière adaptative l’importance relative de chaque couche en intégrant les informations sur les poids du modèle et les activations d’entrée, et attribue les taux d’élagage en conséquence. Les expériences montrent que DLP maintient efficacement les performances de modèles tels que LLaMA2-7B à haute sparsité et est compatible avec diverses techniques de compression LLM existantes. (Source: HuggingFace Daily Papers)
Un article présente LayerFlow : un modèle unifié de génération vidéo sensible aux calques: LayerFlow est une solution unifiée de génération vidéo sensible aux calques. Étant donné les invites pour chaque calque, LayerFlow peut générer des vidéos avec des premiers plans transparents, des arrière-plans propres et des scènes mixtes. Il prend également en charge diverses variantes, telles que la décomposition de vidéos mixtes ou la génération d’arrière-plans pour des premiers plans donnés. Le modèle organise les vidéos de différents calques en sous-clips et utilise des embeddings de calques pour distinguer chaque clip et les invites de calque correspondantes, prenant ainsi en charge les fonctionnalités susmentionnées dans un cadre unifié. Pour pallier le manque de vidéos d’entraînement de calques de haute qualité, une stratégie d’entraînement multi-étapes a été conçue. (Source: HuggingFace Daily Papers)
Un article propose Rectified Sparse Attention : correction du mécanisme d’attention éparse: Pour résoudre les problèmes de désalignement du cache KV et de baisse de qualité causés par les méthodes de décodage éparse dans la génération de longues séquences, un nouvel article propose l’attention éparse rectifiée (ReSA). ReSA combine l’attention éparse par blocs avec une correction dense périodique, en utilisant une propagation avant dense à intervalles fixes pour rafraîchir le cache KV, limitant ainsi l’accumulation d’erreurs et maintenant l’alignement avec la distribution de pré-entraînement. Les expériences montrent que ReSA atteint une qualité de génération quasi sans perte et des améliorations d’efficacité significatives dans les tâches de raisonnement mathématique, de modélisation du langage et de recherche, réalisant une accélération de bout en bout allant jusqu’à 2,42 fois pour le décodage de séquences de 256K. (Source: HuggingFace Daily Papers)
Un article présente RefEdit : amélioration des modèles d’édition d’images basés sur des instructions pour les expressions référentielles, benchmark et méthode: Face aux difficultés des modèles d’édition d’images existants à éditer avec précision des objets spécifiés dans des scènes complexes contenant plusieurs entités, un nouvel article introduit d’abord RefEdit-Bench, un benchmark du monde réel basé sur RefCOCO. Ensuite, il propose le modèle RefEdit, entraîné via un processus de génération de données synthétiques évolutif. RefEdit, entraîné avec seulement 20 000 triplets d’édition, surpasse les modèles de base basés sur Flux/SD3 entraînés avec des millions de données sur les tâches d’expression référentielle, et atteint également des résultats SOTA sur les benchmarks traditionnels. (Source: HuggingFace Daily Papers)
Un article propose Critique-GRPO : améliorer les capacités de raisonnement des LLM en utilisant des retours d’information en langage naturel et numériques: Face aux problèmes de goulot d’étranglement des performances, d’efficacité limitée de l’auto-réflexion et d’échecs persistants lorsque l’apprentissage par renforcement, qui ne s’appuie que sur des retours d’information numériques (comme des récompenses scalaires), est utilisé pour améliorer les capacités de raisonnement complexes des LLM, un nouvel article propose le cadre Critique-GRPO. Ce cadre, en intégrant des critiques sous forme de langage naturel et des retours d’information numériques, permet aux LLM d’apprendre simultanément à partir des réponses initiales et des améliorations guidées par la critique, tout en maintenant l’exploration. Les expériences montrent que Critique-GRPO sur Qwen2.5-7B-Base et Qwen3-8B-Base surpasse significativement plusieurs méthodes de base. (Source: HuggingFace Daily Papers)
Un article présente TalkingMachines : réalisation de vidéos de type FaceTime pilotées par l’audio en temps réel via des modèles de diffusion autorégressifs: TalkingMachines est un framework efficace qui transforme les modèles de génération vidéo pré-entraînés en animateurs de personnages pilotés par l’audio en temps réel. Ce framework intègre des grands modèles de langage (LLM) audio avec des modèles de base de génération vidéo, réalisant une expérience de conversation naturelle. Ses principales contributions incluent l’adaptation d’un modèle DiT de génération d’image-vidéo SOTA pré-entraîné en un modèle de génération d’avatar virtuel piloté par l’audio, la réalisation d’un flux vidéo infini sans accumulation d’erreurs grâce à la distillation de connaissances asymétrique, et la conception d’un pipeline d’inférence à haut débit et à faible latence. (Source: HuggingFace Daily Papers)
Un article explore la mesure de l’auto-préférence dans les jugements des LLM: Des recherches montrent que les LLM, lorsqu’ils agissent en tant que juges, manifestent une auto-préférence, c’est-à-dire une tendance à favoriser les réponses qu’ils ont eux-mêmes générées. Les méthodes existantes mesurent ce biais en calculant la différence entre les notes attribuées par le modèle juge à ses propres réponses et celles attribuées aux réponses d’autres modèles, mais cela confond l’auto-préférence avec la qualité de la réponse. Un nouvel article propose d’utiliser des jugements de référence (gold judgments) comme proxy de la qualité réelle des réponses et introduit le score DBG, qui mesure le biais d’auto-préférence comme la différence entre la note du modèle juge pour sa propre réponse et le jugement de référence correspondant, atténuant ainsi l’effet de confusion de la qualité de la réponse sur la mesure du biais. (Source: HuggingFace Daily Papers)
Un article propose LongBioBench : un cadre de test contrôlable pour les modèles de langage à long contexte: Face aux limites des cadres d’évaluation existants pour les modèles de langage à long contexte (LCLM) (les tâches du monde réel sont complexes, difficiles à résoudre et sujettes à la contamination des données, tandis que les tâches synthétiques sont déconnectées des applications réelles), un nouvel article propose LongBioBench. Ce benchmark utilise des biographies générées par l’homme comme environnement contrôlé pour évaluer les LCLM selon les dimensions de la compréhension, du raisonnement et de la fiabilité. Les expériences montrent que la plupart des modèles présentent encore des lacunes dans la compréhension sémantique à long contexte et le raisonnement préliminaire, et que la fiabilité diminue avec l’augmentation de la longueur du contexte. LongBioBench vise à fournir une évaluation plus réaliste, contrôlable et interprétable des LCLM. (Source: HuggingFace Daily Papers)
Un article explore l’amélioration du raisonnement multimodal en passant d’un démarrage à froid optimisé à un apprentissage par renforcement par étapes: Inspirés par les capacités de raisonnement exceptionnelles de Deepseek-R1 dans les tâches textuelles complexes, de nombreux travaux tentent d’appliquer directement l’apprentissage par renforcement (RL) pour inciter les grands modèles de langage multimodaux (MLLM) à développer des capacités similaires, mais peinent encore à activer un raisonnement complexe. Un nouvel article étudie en profondeur les processus d’entraînement actuels et découvre qu’une initialisation efficace par démarrage à froid est cruciale pour améliorer le raisonnement des MLLM, que le GRPO standard appliqué au RL multimodal souffre d’un problème de stagnation des gradients, et qu’un entraînement RL purement textuel après la phase de RL multimodal améliore davantage le raisonnement multimodal. Sur la base de ces observations, l’article introduit ReVisual-R1, qui obtient des résultats SOTA sur plusieurs benchmarks. (Source: HuggingFace Daily Papers)
Un article présente SVGenius : un benchmark pour la compréhension, l’édition et la génération de SVG: Face aux lacunes des benchmarks existants pour le traitement des SVG en termes de couverture du monde réel, de stratification de la complexité et de paradigmes d’évaluation, un nouvel article introduit SVGenius. Il s’agit d’un benchmark complet de 2377 requêtes couvrant trois dimensions : compréhension, édition et génération, construit à partir de données réelles de 24 domaines d’application et doté d’une stratification systématique de la complexité. Vingt-deux modèles grand public ont été évalués à travers 8 catégories de tâches et 18 métriques. L’analyse montre que les performances de tous les modèles diminuent systématiquement avec l’augmentation de la complexité, mais que l’entraînement amélioré par le raisonnement est plus efficace qu’une simple mise à l’échelle. (Source: HuggingFace Daily Papers)
Un article propose Ψ-Sampler : un échantillonnage initial de particules pour l’alignement des récompenses lors de l’inférence de modèles de score basés sur SMC: Pour résoudre le problème de l’alignement des récompenses lors de l’inférence des modèles de génération de score, un nouvel article introduit le cadre Psi-Sampler. Ce cadre est basé sur la méthode de Monte-Carlo séquentiel (SMC) et intègre une méthode d’échantillonnage initial de particules basée sur pCNL. Les méthodes existantes initialisent généralement les particules à partir d’un a priori gaussien, ce qui peine à capturer efficacement les régions liées à la récompense. Psi-Sampler initialise les particules à partir d’une distribution a posteriori sensible à la récompense et introduit l’algorithme de Crank-Nicolson Langevin préconditionné (pCNL) pour un échantillonnage a posteriori efficace, améliorant ainsi les performances d’alignement dans des tâches telles que la génération d’images à partir de mises en page, la génération sensible aux quantités et la génération de préférences esthétiques. (Source: HuggingFace Daily Papers)
Un article propose MoCA-Video : un cadre d’alignement conceptuel sensible au mouvement pour l’édition vidéo cohérente: MoCA-Video est un cadre sans entraînement conçu pour appliquer les techniques de mélange sémantique du domaine de l’image à l’édition vidéo. Étant donné une vidéo générée et une image de référence fournie par l’utilisateur, MoCA-Video peut injecter les caractéristiques sémantiques de l’image de référence dans des objets spécifiques de la vidéo, tout en préservant le mouvement original et le contexte visuel. La méthode utilise une planification de débruitage diagonale et une segmentation indépendante de la catégorie pour détecter et suivre les objets dans l’espace latent, et contrôle précisément la position spatiale des objets mélangés, assurant la cohérence temporelle grâce à une correction sémantique basée sur le momentum et une stabilisation du bruit résiduel gamma. (Source: HuggingFace Daily Papers)
Un article explore l’entraînement de modèles de langage à générer du code de haute qualité grâce au retour d’information de l’analyse de programme: Pour résoudre le problème de la difficulté des grands modèles de langage (LLM) à garantir la qualité du code (en particulier la sécurité et la maintenabilité) dans la génération de code (vibe coding), un nouvel article propose le cadre REAL. REAL est un cadre d’apprentissage par renforcement qui incite les LLM à générer du code de qualité production grâce à un retour d’information guidé par l’analyse de programme. Ce retour d’information intègre des signaux d’analyse de programme détectant les défauts de sécurité ou de maintenabilité, ainsi que des signaux de tests unitaires garantissant l’exactitude fonctionnelle. REAL ne nécessite pas d’annotation manuelle, est hautement évolutif, et les expériences prouvent sa supériorité par rapport aux méthodes SOTA en termes de fonctionnalité et de qualité du code. (Source: HuggingFace Daily Papers)
Un article propose GAIN-RL : un apprentissage par renforcement efficace en termes d’entraînement grâce aux signaux propres du modèle: Face au problème de faible efficacité d’échantillonnage du paradigme actuel de fine-tuning par renforcement des grands modèles de langage (RFT) en raison d’un échantillonnage de données unifié, un nouvel article identifie un signal intrinsèque au modèle appelé “concentration angulaire”, qui reflète efficacement la capacité d’un LLM à apprendre à partir de données spécifiques. Sur la base de cette découverte, l’article propose le cadre GAIN-RL, qui sélectionne dynamiquement les données d’entraînement en utilisant le signal intrinsèque de concentration angulaire du modèle, garantissant l’efficacité continue des mises à jour de gradient et améliorant ainsi considérablement l’efficacité de l’entraînement. Les expériences montrent que GAIN-RL (GRPO) atteint une accélération de l’efficacité d’entraînement de plus de 2,5 fois sur diverses tâches mathématiques et de codage et pour différentes tailles de modèles. (Source: HuggingFace Daily Papers)
Un article propose SFO : optimisation de la fidélité du sujet pour la génération pilotée par le sujet zero-shot grâce à un guidage négatif: Pour améliorer la fidélité du sujet dans la génération pilotée par le sujet zero-shot, un nouvel article propose le cadre d’Optimisation de la Fidélité du Sujet (SFO). SFO introduit des cibles négatives synthétiques et guide explicitement le modèle à préférer les cibles positives aux cibles négatives par comparaison par paires. Pour les cibles négatives, l’article propose la méthode d’échantillonnage négatif par dégradation conditionnelle (CDNS), qui génère automatiquement des échantillons négatifs uniques et informatifs en dégradant intentionnellement les indices visuels et textuels, sans nécessiter d’annotation manuelle coûteuse. De plus, les pas de temps de diffusion sont repondérés pour se concentrer sur les étapes intermédiaires où les détails du sujet apparaissent. (Source: HuggingFace Daily Papers)
Un article présente ByteMorph : un benchmark pour l’édition d’images guidée par instructions pour les mouvements non rigides: Face aux méthodes et ensembles de données d’édition d’images existants qui se concentrent principalement sur des scènes statiques ou des transformations rigides, et qui peinent à traiter les instructions impliquant des mouvements non rigides, des changements de perspective de caméra, des déformations d’objets, des mouvements articulaires humains et des interactions complexes, un nouvel article introduit le cadre ByteMorph. Ce cadre comprend un ensemble de données à grande échelle ByteMorph-6M (plus de 6 millions de paires d’édition d’images haute résolution) et un modèle de base solide basé sur DiT, ByteMorpher. L’ensemble de données est construit grâce à la génération de données guidée par le mouvement, des techniques de synthèse hiérarchique et la génération automatique de légendes, garantissant la diversité, le réalisme et la cohérence sémantique. (Source: HuggingFace Daily Papers)
Un article propose Control-R : vers une extension contrôlable au moment du test: Pour résoudre les problèmes de “sous-réflexion” et de “sur-réflexion” des grands modèles de raisonnement (LRM) dans le raisonnement en longue chaîne de pensée (CoT), un nouvel article introduit les champs de contrôle du raisonnement (RCF). RCF est une méthode applicable au moment du test qui guide le raisonnement du point de vue de la recherche arborescente en injectant des signaux de contrôle structurés, permettant au modèle d’ajuster son effort de raisonnement pour résoudre des tâches complexes en fonction des conditions de contrôle données. Parallèlement, l’article propose l’ensemble de données Control-R-4K, contenant des problèmes stimulants avec des processus de raisonnement détaillés et les champs de contrôle correspondants, et propose la méthode de fine-tuning par distillation conditionnelle (CDF) pour entraîner les modèles à ajuster efficacement leur effort de raisonnement au moment du test. (Source: HuggingFace Daily Papers)
Revue de la gestion de la confiance, des risques et de la sécurité (TRiSM) dans l’AI Agentique: Un article de synthèse analyse systématiquement la gestion de la confiance, des risques et de la sécurité (TRiSM) dans les systèmes multi-agents agentiques (AMAS) basés sur les grands modèles de langage (LLM). L’article explore d’abord les fondements conceptuels de l’AI Agentique, les différences architecturales et les conceptions de systèmes émergentes, puis détaille les quatre piliers de TRiSM dans le cadre de l’AI Agentique : gouvernance, explicabilité, ModelOps et confidentialité/sécurité. L’article identifie des vecteurs de menace uniques, propose une taxonomie complète des risques pour les applications d’AI Agentique, et explore les mécanismes d’établissement de la confiance, les techniques de transparence et de supervision, les stratégies d’explicabilité pour les systèmes d’agents LLM distribués, etc. (Source: HuggingFace Daily Papers)
Un article explore l’amélioration de la distillation des connaissances sous décalage de covariables inconnu grâce à l’augmentation des données guidée par la confiance: Face au problème courant de décalage de covariables dans la distillation des connaissances (caractéristiques fallacieuses présentes à l’entraînement mais absentes au test), un nouvel article propose une nouvelle stratégie d’augmentation des données basée sur la diffusion. Lorsque ces caractéristiques fallacieuses sont inconnues, mais qu’il existe un modèle enseignant robuste, cette stratégie génère des images en maximisant la divergence entre le modèle enseignant et le modèle étudiant, créant ainsi des échantillons stimulants difficiles à traiter pour l’étudiant. Les expériences prouvent que cette méthode améliore significativement la précision du pire groupe et du groupe moyen sur des ensembles de données tels que CelebA, SpuCo Birds et ImageNet fallacieux en présence d’un décalage de covariables. (Source: HuggingFace Daily Papers)
Un article présente DiffDecompose : décomposition couche par couche d’images compositées alpha via des Diffusion Transformers: Face à la difficulté des méthodes de décomposition d’images existantes à démêler les couches semi-transparentes ou transparentes occultantes, un nouvel article propose une nouvelle tâche : la décomposition couche par couche d’images compositées alpha, visant à récupérer les couches constitutives à partir d’une seule image superposée. Pour relever les défis de l’ambiguïté des couches, de la généralisation et de la rareté des données, l’article introduit d’abord AlphaBlend, le premier ensemble de données de haute qualité à grande échelle pour la décomposition de couches transparentes et semi-transparentes. Sur cette base, il propose DiffDecompose, un cadre basé sur Diffusion Transformer, qui apprend la distribution a posteriori de la décomposition des couches par décomposition contextuelle. (Source: HuggingFace Daily Papers)
Un article propose SuperWriter : génération de textes longs par des grands modèles de langage guidée par la réflexion: Pour résoudre les difficultés des grands modèles de langage (LLM) à maintenir la cohérence, la consistance logique et la qualité textuelle dans la génération de textes longs, un nouvel article propose le cadre SuperWriter-Agent. Ce cadre introduit des phases explicites de planification de la pensée structurée et d’amélioration dans le processus de génération, guidant le modèle à suivre un processus plus délibéré et plus conforme aux lois cognitives. Sur la base de ce cadre, un ensemble de données de fine-tuning supervisé a été construit pour entraîner un SuperWriter-LM de 7B paramètres, et un programme d’optimisation directe des préférences (DPO) hiérarchique a été développé, utilisant la recherche arborescente Monte-Carlo (MCTS) pour propager l’évaluation finale de la qualité et optimiser en conséquence chaque étape de génération. (Source: HuggingFace Daily Papers)
Un article propose IEAP : considérer l’édition d’images comme un programme basé sur des modèles de diffusion: Face aux défis rencontrés par les modèles de diffusion dans l’édition d’images pilotée par instructions, en particulier pour les éditions structurellement incohérentes impliquant des changements de mise en page significatifs, un nouvel article introduit le cadre IEAP (Image Editing As Programs). IEAP est basé sur l’architecture Diffusion Transformer (DiT) et traite les instructions d’édition complexes en les décomposant en une séquence d’opérations atomiques. Chaque opération est réalisée via des adaptateurs légers partageant le même squelette DiT et spécialisés pour un type d’édition spécifique. Ces opérations sont programmées par un agent basé sur un modèle de langage visuel (VLM) et prennent en charge de manière collaborative des transformations arbitraires et structurellement incohérentes. (Source: HuggingFace Daily Papers)
Un article propose FlowPathAgent : attribution de diagrammes de flux à grain fin via un agent neuro-symbolique: Pour résoudre le problème des hallucinations fréquentes des grands modèles de langage (LLM) lors de l’interprétation de diagrammes de flux et de leur difficulté à suivre avec précision les chemins de décision, un nouvel article introduit la tâche d’attribution de diagrammes de flux à grain fin et propose FlowPathAgent. FlowPathAgent est un agent neuro-symbolique qui effectue une attribution a posteriori à grain fin par raisonnement basé sur des graphes. Il segmente d’abord le diagramme de flux, le convertit en un graphe symbolique structuré, puis adopte une approche agentique pour interagir dynamiquement avec le graphe afin de générer des chemins d’attribution. Parallèlement, l’article propose également FlowExplainBench, un nouveau benchmark pour évaluer l’attribution de diagrammes de flux. (Source: HuggingFace Daily Papers)
Un article propose Quantitative LLM Judges : juges LLM quantitatifs: LLM-as-a-judge est un cadre permettant à un grand modèle de langage (LLM) d’évaluer automatiquement la sortie d’un autre LLM. Un nouvel article propose le concept de “juges LLM quantitatifs”, qui alignent les scores d’évaluation des juges LLM existants avec les scores humains spécifiques à un domaine via des modèles de régression. Ces modèles améliorent les notations des juges originaux en utilisant les évaluations textuelles et les scores du juge. L’article présente quatre juges quantitatifs pour différents types de rétroaction absolue et relative, démontrant la généralité et la polyvalence du cadre. Ce cadre est plus efficace en termes de calcul que le fine-tuning supervisé et peut être plus efficace statistiquement lorsque le retour d’information humain est limité. (Source: HuggingFace Daily Papers)
💼 Affaires
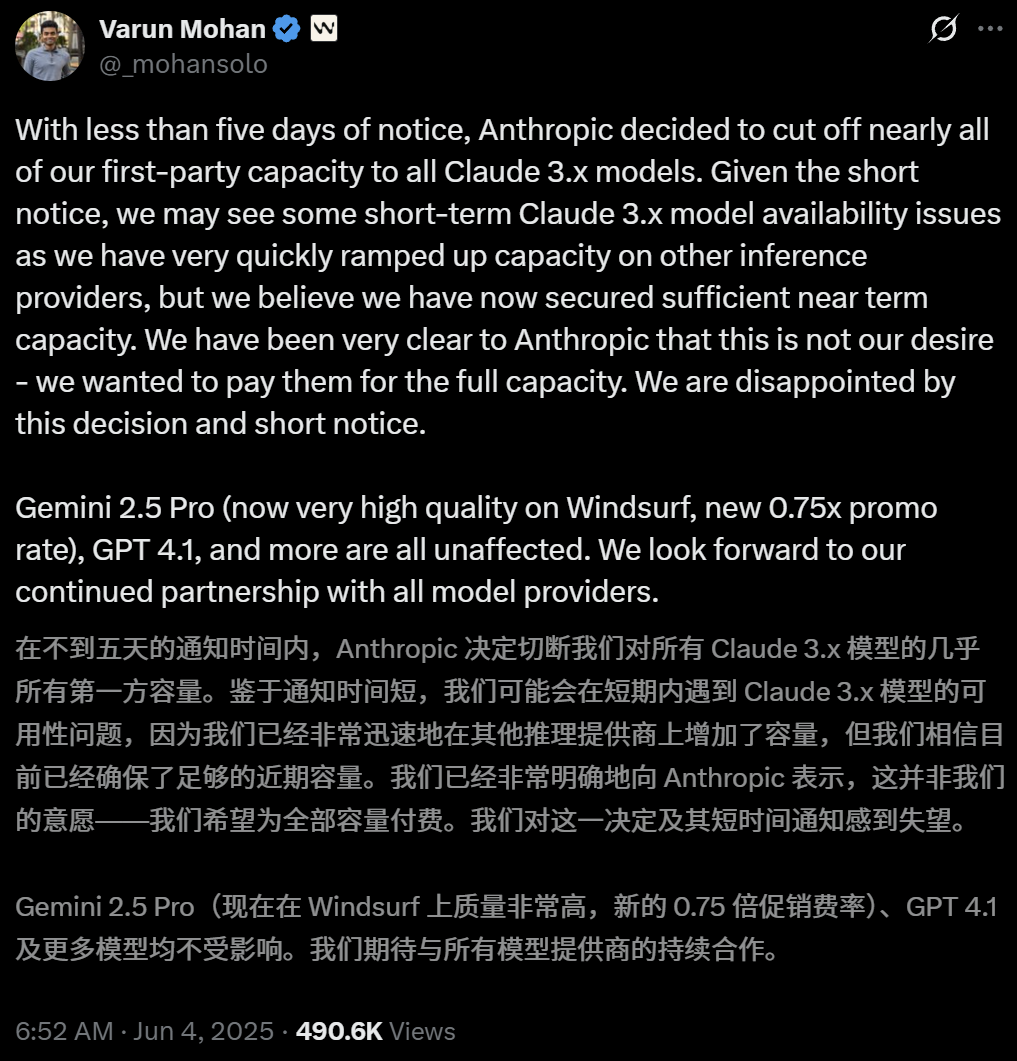
Anthropic restreint l’accès direct de l’outil de programmation AI Windsurf aux modèles Claude: Varun Mohan, PDG de l’outil de programmation AI Windsurf, a publiquement déclaré qu’Anthropic avait considérablement réduit les quotas de service API de Windsurf pour la série de modèles Claude 3.x, y compris Claude 3.5 Sonnet, 3.7 Sonnet, etc., avec un préavis extrêmement court (moins de cinq jours). Cette décision intervient dans un contexte où OpenAI aurait l’intention d’acquérir Windsurf, suscitant des inquiétudes sur le marché quant à l’intensification de la concurrence entre les géants de l’AI et à la neutralité des plateformes d’outils de programmation AI. Windsurf a dû activer d’urgence des services d’inférence tiers et ajuster sa stratégie de fourniture de modèles aux utilisateurs, tandis qu’Anthropic a répondu qu’elle donnait la priorité aux partenaires pouvant garantir une collaboration continue. (Source: 36氪, 36氪, mervenoyann, swyx)
OpenAI dépasse les 3 millions d’utilisateurs professionnels payants et lance une stratégie de tarification flexible: OpenAI a annoncé que son nombre d’utilisateurs professionnels payants a atteint 3 millions, soit une augmentation de 50 % par rapport aux 2 millions annoncés en février de cette année, couvrant les trois gammes de produits ChatGPT Enterprise, Team et Edu. Parallèlement, OpenAI a lancé une stratégie de tarification flexible basée sur un “pool de crédits partagés” pour les clients professionnels. Après avoir acheté un pool de crédits, l’utilisation de fonctionnalités avancées consommera des crédits, mais ils pourront toujours “accéder de manière illimitée” aux principaux modèles et fonctionnalités. Cette nouvelle tarification sera d’abord lancée dans ChatGPT Enterprise, puis étendue à ChatGPT Team, ce dernier offrant également une réduction d’essai d’un dollar pour 5 comptes le premier mois. (Source: 36氪, snsf)
Carina Letong Hong, une jeune Chinoise née dans les années 2000, fonde la société d’AI mathématique Axiom, avec un objectif de valorisation de 300 millions de dollars: Carina Letong Hong, docteure en mathématiques de Stanford d’origine chinoise, a fondé la société d’AI Axiom, spécialisée dans le développement de modèles d’AI pour résoudre des problèmes mathématiques concrets, ciblant les fonds spéculatifs et les sociétés de trading quantitatif. Axiom prévoit d’utiliser des données de preuves mathématiques formelles pour entraîner ses modèles, leur permettant de maîtriser un raisonnement logique rigoureux et des capacités de preuve. Bien que la société n’ait pas encore de produit, elle est en pourparlers pour un financement de 50 millions de dollars, avec une valorisation estimée entre 300 et 500 millions de dollars. Carina Letong Hong est titulaire d’un diplôme de premier cycle en mathématiques et physique du MIT et d’un doctorat en mathématiques de Stanford, et a été boursière Rhodes. (Source: 量子位)

🌟 Communauté
Débats animés à la conférence AI.Engineer : observabilité des Agents, efficacité des petites équipes et AI PM en point de mire: Lors de l’exposition mondiale AI.Engineer, les participants ont vivement débattu de l’observabilité et de l’évaluation des agents AI (Agent), de la constitution d’équipes petites et efficaces (Tiny Teams), ainsi que des meilleures pratiques en matière de gestion de produits AI (AI PM). L’interaction vocale a été considérée comme la direction la plus en vogue dans le domaine du multimodal, et la sécurité est également devenue pour la première fois un sujet important. Anthropic a lancé lors de la conférence un appel à l’entrepreneuriat dans le domaine du MCP (protocole de contexte de modèle), espérant voir émerger davantage de serveurs MCP en dehors des outils de développement, des solutions pour simplifier la construction de serveurs, ainsi que des innovations en matière de sécurité des applications AI (comme la protection contre l’empoisonnement des outils). (Source: swyx, swyx, swyx, swyx)

Discussion sur la question de savoir si l’AI entraînera la disparition du langage naturel et l’abêtissement de l’humanité: Des inquiétudes ont émergé sur les réseaux sociaux concernant la possibilité que l’utilisation généralisée de l’AI entraîne un déclin de la communication en langage naturel (théorie de “l’internet mort”) ainsi qu’une dégradation des capacités cognitives humaines (telles que la pensée profonde, le questionnement, la capacité de reconstruction). Certains utilisateurs estiment qu’une dépendance excessive à l’AI pour obtenir des informations et des réponses pourrait réduire le filtrage actif, le jugement et la pensée indépendante, créant une dépendance à l‘“externalisation cognitive”. D’autres pensent que l’AI peut gérer le “quoi” et le “comment”, mais que le “pourquoi” doit toujours être décidé par les humains, la clé étant de trouver le rôle de l’homme dans la coexistence avec la technologie et de conserver le pouvoir de jugement. (Source: Reddit r/ArtificialInteligence, 36氪)
OpenAI sommée par un tribunal de conserver tous les journaux de ChatGPT et des API, suscitant des inquiétudes en matière de confidentialité: Une ordonnance judiciaire exige qu’OpenAI conserve tous les historiques de chat de ChatGPT et les journaux de requêtes API, y compris les enregistrements de “chats temporaires” qui auraient dû être supprimés. Cette mesure a suscité des inquiétudes parmi les utilisateurs concernant la confidentialité des données et la capacité d’OpenAI à respecter sa politique de conservation des données. Certains commentateurs estiment que cela souligne davantage l’importance d’utiliser des modèles locaux et de posséder sa propre technologie et ses propres données. (Source: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

Les Agents AI confrontés à des défis de confiance et de sécurité, vulnérables aux attaques de phishing: Les discussions soulignent que, malgré les capacités croissantes des Agents AI, leurs mécanismes de confiance présentent des risques d’exploitation. Par exemple, un Agent peut être incité à visiter des liens malveillants en faisant confiance à des sites Web connus (comme les réseaux sociaux), ce qui peut entraîner la divulgation d’informations sensibles ou l’exécution d’actions malveillantes. Cela exige de renforcer, dans la conception des Agents, la capacité d’identification et de résistance aux contenus et liens malveillants, afin de garantir leur sécurité lors de l’exécution d’opérations dans le monde réel. (Source: DeepLearning.AI Blog)
Réflexions suscitées par les outils de programmation assistée par AI : de la modernisation du code à la transformation des flux de travail: La communauté a discuté des applications de l’AI dans le développement logiciel, en particulier pour le traitement du code hérité et la modification des flux de travail de programmation. Morgan Stanley a utilisé son outil d’AI interne DevGen.AI pour analyser et restructurer des millions de lignes de code ancien, économisant ainsi un temps de développement considérable. Parallèlement, le point de vue d’Andrej Karpathy sur l’avenir des applications à UI complexe a également suscité une réflexion sur la manière dont les logiciels futurs devraient être conçus pour mieux collaborer avec l’AI, soulignant l’importance des interfaces scriptables et des API. Ces discussions reflètent l’impact profond de l’AI sur les pratiques et les concepts de l’ingénierie logicielle. (Source: mitchellh, 36氪, 36氪)
💡 Divers
Réparation d’appareils électroménagers assistée par AI, ChatGPT devient “Friendo”: Un utilisateur a partagé son expérience de diagnostic et de réparation préliminaire réussie d’un lave-vaisselle en panne grâce à ChatGPT (surnommé Friendo). En dialoguant avec l’AI, en décrivant les codes d’erreur et en prenant des photos du panneau de commande, l’AI a aidé l’utilisateur à localiser un défaut de l’élément chauffant et l’a guidé pour contourner temporairement cet élément afin de restaurer partiellement les fonctionnalités du lave-vaisselle. Cela démontre le potentiel des LLM dans la résolution de problèmes quotidiens et le support technique. (Source: Reddit r/ChatGPT)
Une vidéo d’interview de personnages des années 1500 générée par AI attire l’attention: Une vidéo générée par AI simulant une interview de personnages des années 1500 a été saluée par la communauté pour sa créativité et son humour. Les personnages et les dialogues de la vidéo reflètent avec humour les conditions de vie de l’époque, par exemple : “Se réveiller en marchant dans des excréments, puis être taxé, et ce n’est qu’avant le petit-déjeuner”. Ce type d’application démontre le potentiel de divertissement de l’AI dans la création de contenu et la reconstitution de scènes historiques. (Source: draecomino, Reddit r/ChatGPT)

La bourse Thiel s’intéresse à l’innovation en AI, couvrant les humains numériques, l’émotion robotique et la prédiction par AI: La nouvelle liste des boursiers “Thiel Fellowship” a été annoncée, et plusieurs projets d’AI y figurent en bonne place. Canopy Labs s’efforce de créer des humains numériques AI indiscernables des vraies personnes, capables d’interactions multimodales en temps réel. Le projet Intempus vise à doter les robots d’une capacité d’expression émotionnelle similaire à celle des humains afin d’améliorer l’interaction homme-robot. Aeolus Lab se concentre sur l’utilisation de la technologie AI pour prédire la météo et les catastrophes naturelles, et explore même la possibilité d’une intervention active. Ces projets illustrent les directions d’exploration des jeunes entrepreneurs dans les domaines de pointe de l’AI. (Source: 36氪)