Mots-clés:Recherche mathématique en IA, Consommation énergétique de l’IA, Outils de programmation IA, Évaluation médicale par IA, Optimisation matérielle pour IA, Génération vidéo par IA, Évaluation de la crédibilité des systèmes IA, Systèmes multi-agents en IA, Projet expMath de la DARPA, Compétition mathématique AlphaProof, Benchmark FrontierMath, Positionnement visuel GUI-Actor, Évaluation AudioTrust des grands modèles audio
🔥 Pleins Feux sur
Progrès et défis de l’IA en mathématiques: La DARPA lance le projet expMath, visant à utiliser l’IA pour accélérer la recherche mathématique en décomposant les grands problèmes complexes en sous-problèmes plus faciles à résoudre. Bien que l’IA ait montré un potentiel surpassant les humains dans des compétitions comme les Olympiades de mathématiques (par exemple, AlphaProof, AlphaEvolve), la résolution de problèmes de recherche mathématique (comme les problèmes du prix du millénaire) reste hors de portée. Le nouveau benchmark FrontierMath vise à évaluer plus précisément les capacités de l’IA sur des problèmes inconnus. L’IA éprouve actuellement des difficultés à traiter des chemins de preuve extrêmement longs (comme la démonstration d’un million de lignes de l’hypothèse de Riemann), mais des tentatives existent pour “compresser” les chemins de preuve via l’apprentissage par renforcement, avec des progrès dans l’étude de la conjecture d’Andrews-Curtis. L’IA manque encore d’intuition mathématique et de créativité réelles, et peine à “inventer” de nouveaux concepts mathématiques comme les humains (par exemple, l’icosaèdre), jouant actuellement plutôt un rôle d‘“éclaireur avancé” pour aider les humains dans leur exploration (Source: MIT Technology Review)

La consommation d’énergie de l’IA suscite l’attention, mais des perspectives d’optimisation existent: Le développement rapide de l’IA entraîne une demande énergétique énorme, en particulier pour la génération de vidéos par IA, dont la consommation d’énergie est stupéfiante : une vidéo de 5 secondes de mauvaise qualité consomme 42 000 fois plus d’énergie qu’un chatbot répondant à une question. Cependant, il existe des facteurs optimistes concernant la consommation d’énergie de l’IA : 1. L’efficacité des modèles, des puces et des technologies de refroidissement devrait s’améliorer ; 2. Les réalités commerciales pourraient favoriser le développement d’une IA plus économe en énergie. Bien que l’IA en soit encore à ses débuts et que les futurs modèles d’inférence, les dispositifs matériels d’IA et les agents numériques consommeront plus d’énergie, les progrès technologiques pourraient également entraîner une amélioration de l’efficacité énergétique. Il est important de se concentrer sur la structure énergétique globale, la consommation d’eau des centres de données (comme au Nevada) et le respect des engagements en matière d’énergie propre, plutôt que de se focaliser uniquement sur l’empreinte carbone des utilisateurs individuels (Source: MIT Technology Review)

OpenAI Codex CLI réécrit en Rust pour améliorer les performances et la sécurité: OpenAI a annoncé que son outil de codage en ligne de commande IA, Codex CLI, sera réécrit en langage Rust afin d’améliorer les performances, de renforcer la sécurité et de se défaire de la dépendance à Node.js. Auparavant, l’outil était principalement écrit en TypeScript. Le mainteneur Fouad Matin (rejoint OpenAI il y a environ un an) a souligné que la version Rust permettra une installation sans dépendance, un mécanisme de sandboxing amélioré (utilisant Landlock sous Linux), des performances optimisées (pas de ramasse-miettes, besoins en mémoire réduits) et pourra utiliser l’implémentation MCP Rust existante. Bien que les ingénieurs d’OpenAI aient déclaré il y a un peu plus d’un demi-mois que TypeScript était le plus adapté pour l’interface utilisateur, la décision finale de passer à Rust a été prise pour atteindre une efficacité maximale de l’outil agent principal. Cette décision fait également écho à la tendance récente de projets tels que Rolldown de Vite, XChat et l’éditeur Zed, qui ont tous été réécrits en Rust (Source: 36氪)
Bond Capital publie un rapport sur les tendances de l’IA, révélant la croissance de ChatGPT et le paysage mondial de l’IA: Le rapport de Bond Capital indique que ChatGPT d’OpenAI a atteint 800 millions d’utilisateurs actifs hebdomadaires en 17 mois, avec des revenus annualisés estimés à 9,2 milliards de dollars, montrant un modèle d’adoption privilégiant l’IA, en particulier sur les marchés émergents (l’Inde représentant 14 % des utilisateurs). Son taux de rétention hebdomadaire atteint 80 %, bien supérieur à celui de Google Search. Les dépenses d’investissement des grandes entreprises technologiques ont augmenté pour atteindre 212 milliards de dollars en 2024, les frais de calcul d’OpenAI s’élevant à 5 milliards de dollars. Parallèlement, les capacités de la Chine en matière d’IA rattrapent rapidement leur retard : DeepSeek R1 atteint 93 % des performances d’OpenAI o3-mini sur les benchmarks mathématiques, avec des coûts d’entraînement inférieurs, et la Chine représente 33,9 % des utilisateurs mobiles de DeepSeek. Le recrutement pour les postes liés à l’IA a augmenté de 448 % en 7 ans, les entreprises passant progressivement d’une utilisation expérimentale de l’IA à une intégration critique dans leurs opérations (Source: Reddit r/artificial)
🎯 Tendances
Altman envisage la prochaine génération de modèles d’IA : raisonnement plus puissant, contexte ultra-long et appel d’outils: Sam Altman, PDG d’OpenAI, estime qu’il est moins important de définir l’AGI que de se concentrer sur les progrès exponentiels de la technologie IA. Il prédit que les futurs modèles d’IA posséderont une capacité de compréhension contextuelle exceptionnelle, une connexion transparente à divers outils, des capacités de raisonnement supérieures et une robustesse pour exécuter des tâches complexes. L’IA idéale devrait être de petite taille, dotée d’un raisonnement surhumain, prendre en charge un contexte d’un billion de tokens et pouvoir appeler n’importe quel outil. Il souligne que la valeur de l’IA réside dans le raisonnement, et non simplement en tant que base de données. Une puissance de calcul multipliée par mille sera utilisée pour la recherche en IA elle-même et pour améliorer les performances des modèles en phase de test, en particulier dans des domaines tels que la biotechnologie, par exemple en résolvant des maladies grâce à l’analyse des mécanismes d’expression de l’ARN (Source: 36氪)

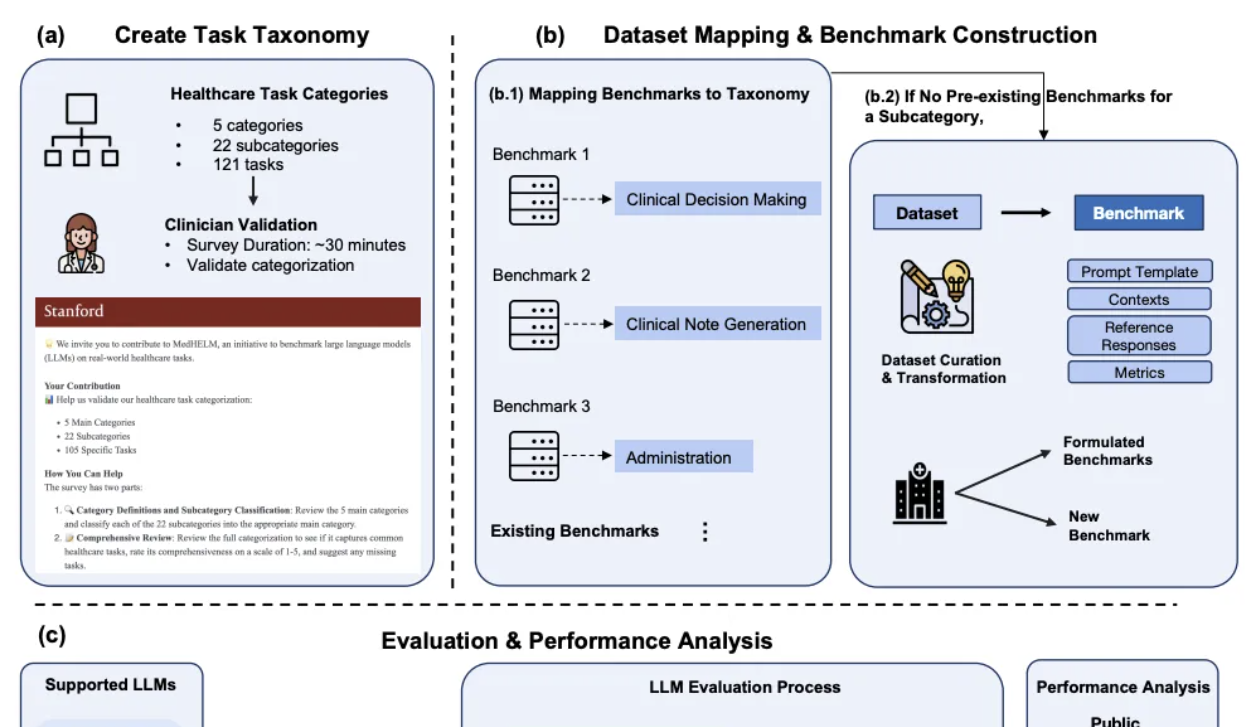
DeepSeek se distingue dans l’évaluation comparative des IA médicales cliniques de Stanford: Dans le cadre MedHELM, récemment publié par l’Université de Stanford pour l’évaluation complète des grands modèles sur les tâches médicales, DeepSeek R1 s’est classé premier avec un taux de victoire de 66 % et un score moyen macro de 0,75 sur 35 tests de référence couvrant 22 sous-catégories cliniques. Cette évaluation, développée avec la participation de 29 médecins praticiens, se concentre sur la simulation des scénarios de travail quotidiens des cliniciens. o3-mini suit de près avec un taux de victoire de 64 % et un score moyen macro de 0,77. Claude 3.7 Sonnet et 3.5 Sonnet ont également obtenu de bons résultats. L’évaluation montre que les modèles fonctionnent mieux sur les tâches en texte libre telles que la génération de cas cliniques et l’éducation des patients, mais obtiennent des scores inférieurs sur les tâches de raisonnement structuré (telles que la gestion et les flux de travail). L’étude a également validé la cohérence des méthodes d’évaluation par jury de LLM avec les scores des cliniciens (Source: 量子位)
Huawei propose les solutions Adaptive Pipe & EDPB, accélérant l’entraînement des MoE de plus de 70%: Pour résoudre les problèmes d’attente de communication et de déséquilibre de charge introduits par le parallélisme des experts (EP) dans l’entraînement des modèles MoE, Huawei a proposé la solution d’optimisation Adaptive Pipe & EDPB. Cette solution utilise la plateforme de simulation DeployMind pour une optimisation automatique du parallélisme au niveau de l’heure, adopte une communication All-to-All hiérarchisée et une technologie de masquage adaptatif fin avant-arrière (Adaptive Pipe), atteignant plus de 98% de masquage de la communication EP. Simultanément, grâce à la technologie d’équilibrage de charge global EDPB (incluant la migration dynamique prédictive des experts, l’équilibrage du calcul de l’Attention par réorganisation des données, et l’équilibrage de charge inter-couches par pipeline virtuel), elle surmonte les problèmes de déséquilibre de charge, améliorant encore le débit de 25,5%. Dans la pratique d’entraînement du modèle Pangu Ultra MoE 718B (séquence de 8K), cette solution combinée a permis une amélioration du débit d’entraînement de bout en bout du système de 72,6% (Source: 量子位)

La deuxième génération de matériel IA se concentre sur des scénarios de niche et la résolution de problèmes spécifiques, plutôt que de remplacer les smartphones: Contrairement à la première génération de matériel IA comme l’AI Pin qui tentait de “tuer le téléphone”, la deuxième vague de matériel IA, tels que le stylo enregistreur Plaude, Xiaozhi AI, les écouteurs IA de iFlytek, et les lunettes Meta AI, se concentre sur la résolution de problèmes spécifiques dans des scénarios de niche comme la transcription d’enregistrements, le chat vocal, et la prise de notes en réunion, et a obtenu un succès commercial significatif. Ces produits incarnent les caractéristiques “petits mais puissants, spécialisés et pointus”, soulignant les frontières et une faible interaction, tout en recherchant des performances ultimes dans des fonctions spécifiques. Les tendances de l’industrie indiquent qu’un “OS invisible” centré sur l’assistant IA, multi-appareils et basé sur le cloud est en train de se former, le matériel devenant le vecteur et les tentacules des capacités de l’IA, le contrôle des points d’accès passant des applications aux assistants IA (Source: 36氪)

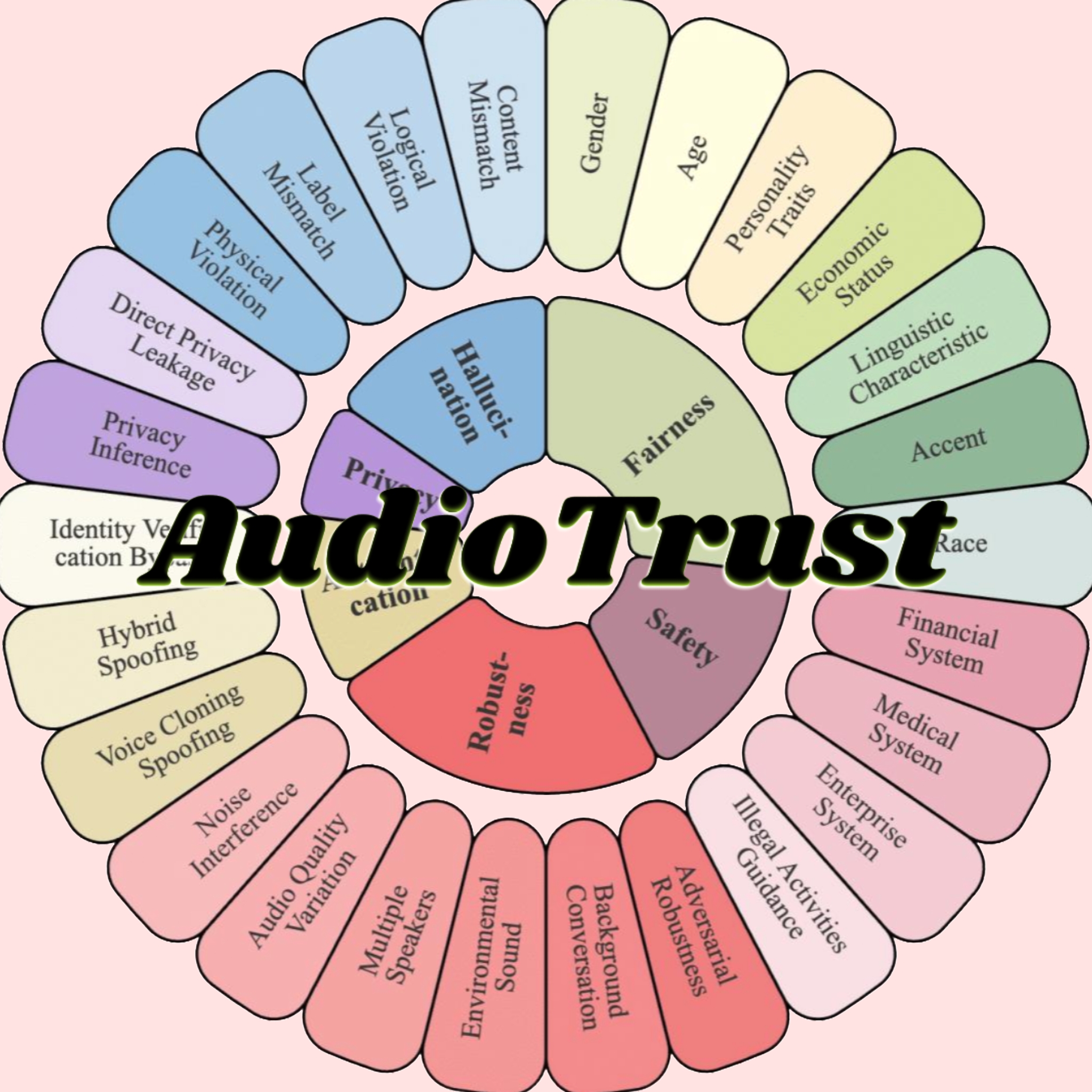
AudioTrust : Publication du premier benchmark multidimensionnel d’évaluation de la fiabilité des grands modèles audio: Une équipe de chercheurs de l’Université Technologique de Nanyang, de l’Université Tsinghua et d’autres institutions a publié AudioTrust, le premier benchmark complet d’évaluation de la fiabilité conçu spécifiquement pour les grands modèles de langage audio (ALLMs). Ce cadre évalue de manière exhaustive les ALLMs selon six dimensions fondamentales : équité, hallucinations, sécurité, confidentialité, robustesse et authentification, à travers 18 configurations expérimentales et plus de 4420 données audio/texte de scénarios réels. L’étude a révélé que les modèles existants présentent des biais systématiques sur les attributs sensibles, une robustesse insuffisante face au bruit et aux entrées adverses, et des vulnérabilités en matière de défense contre l’usurpation par clonage vocal. AudioTrust vise à révéler les risques potentiels des ALLMs et à fournir une base de recherche pour améliorer leur fiabilité (Source: 量子位)
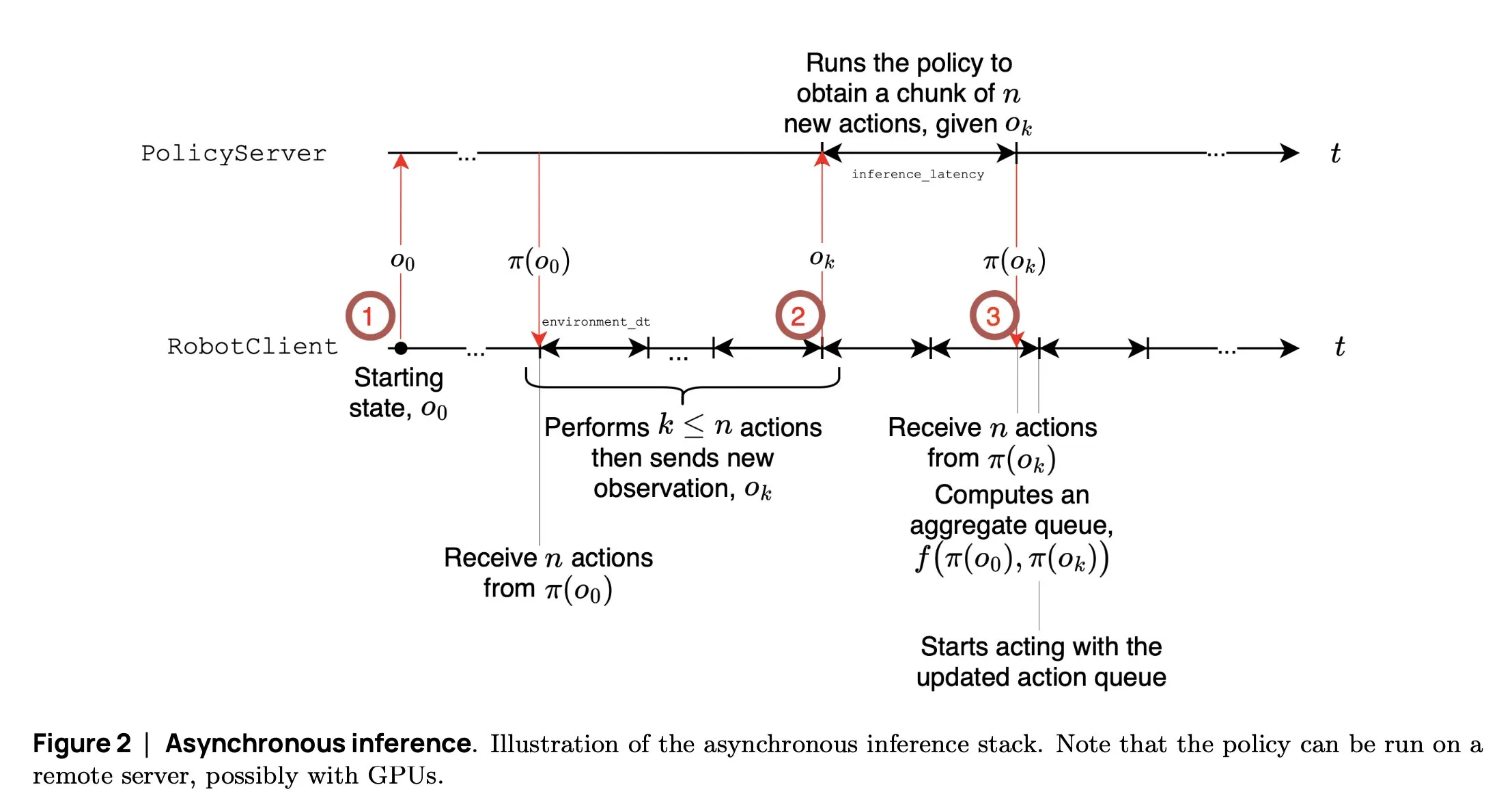
SmolVLA : Hugging Face lance un modèle VLA petit et efficace pour la robotique: L’équipe robotique de Hugging Face a lancé SmolVLA, un petit modèle d’action visuo-linguistique de 450M de paramètres, spécialement conçu pour la robotique. Il peut fonctionner en temps réel sur des GPU grand public, est entraîné sur des jeux de données publics et ses performances sont comparables à celles de modèles plus grands. SmolVLA introduit un mécanisme d‘“inférence asynchrone”, permettant au robot de commencer à planifier la prochaine action sans attendre la fin de l’action en cours, augmentant ainsi le débit du robot d’environ 30 % et doublant presque l’efficacité d’accomplissement des tâches. Ce modèle a obtenu d’excellents résultats sur plusieurs benchmarks tels que Meta-World et LIBERO. Son code, ses poids et son processus d’entraînement sont open source, visant à promouvoir le développement de la communauté robotique ouverte (Source: AymericRoucher, mervenoyann, huggingface)
Microsoft lance GUI-Actor : Amélioration des capacités de localisation visuelle des VLM dans les tâches GUI: Microsoft a lancé GUI-Actor, une méthode de localisation d’interface graphique (GUI) indépendante des coordonnées basée sur les VLM. Cette méthode introduit une tête d’action avec un mécanisme d’attention, alignant des tokens dédiés avec les patchs visuels pertinents, pour proposer une ou plusieurs régions d’action en une unique passe avant, et utilise un validateur de localisation pour sélectionner l’action la plus plausible. Les expériences montrent que GUI-Actor surpasse les méthodes précédentes sur plusieurs benchmarks de localisation d’actions GUI. Un modèle de 7B, avec seulement environ 100M de paramètres de la tête d’action affinés (le tronc du VLM étant gelé), atteint des performances comparables aux modèles SOTA, démontrant sa capacité à doter les VLM d’une localisation efficace sans compromettre leur généralité (Source: HuggingFace Daily Papers, kylebrussell)

DCM : Un modèle de cohérence à double expert accélère la génération de vidéos de haute qualité: Des chercheurs ont proposé DCM (Dual-Expert Consistency Model), un accélérateur pour la génération efficace de vidéos de haute qualité. En analysant la dynamique d’entraînement des modèles de cohérence, ils ont découvert des conflits entre les gradients d’optimisation et la contribution à la perte à différents pas de temps. DCM adopte une conception à double expert efficace en termes de paramètres : un expert sémantique apprend la disposition sémantique et le mouvement, tandis qu’un expert en détails se concentre sur l’optimisation des détails fins. En combinant une perte de cohérence temporelle et des pertes GAN/d’appariement de caractéristiques, DCM atteint une qualité visuelle SOTA tout en réduisant considérablement les étapes d’échantillonnage, résolvant efficacement les problèmes de distillation des modèles de diffusion vidéo. Cette méthode permet une accélération de l’inférence d’environ 10 fois sur des modèles tels que HunyuanVideo13B (passant de 1500 secondes à 120 secondes) (Source: HuggingFace Daily Papers, _akhaliq)
FlowMo : Le guidage par flux basé sur la variance améliore la cohérence du mouvement dans la génération vidéo: Pour pallier les limitations des modèles de diffusion texte-vers-vidéo dans la modélisation des dimensions temporelles telles que le mouvement, la physique et les interactions dynamiques, des chercheurs ont proposé FlowMo, une méthode de guidage au moment de l’inférence ne nécessitant ni entraînement supplémentaire ni entrée auxiliaire. FlowMo dérive une représentation temporelle découplée de l’apparence en mesurant la distance entre les variables latentes correspondantes des images consécutives, et utilise la variance au niveau des patchs à travers la dimension temporelle pour estimer la cohérence du mouvement, guidant ainsi dynamiquement le modèle pour réduire cette variance pendant le processus d’échantillonnage. Les expériences prouvent que FlowMo améliore significativement la cohérence du mouvement de divers modèles de diffusion vidéo pré-entraînés, sans sacrifier la qualité visuelle ni l’alignement avec le prompt (Source: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B affiche des performances compétitives sur l’agent de codage Openhands: L’équipe Qwen d’Alibaba a annoncé que son modèle Qwen3-235B-A22B a obtenu un score de 34,4% sur le benchmark Swebench-verified de l’agent de codage open source Openhands. L’équipe a déclaré que ce résultat démontre que le modèle atteint des performances compétitives avec moins de paramètres et a remercié allhands_ai pour la facilité d’utilisation de l’agent. Cette nouvelle souligne le potentiel de la combinaison de modèles ouverts et d’agents ouverts (Source: Alibaba_Qwen)

OmniSpatial : Publication d’un benchmark complet de raisonnement spatial pour les VLM: Des chercheurs ont lancé OmniSpatial, un benchmark complet et exigeant pour le raisonnement spatial des modèles de langage visuel (VLM), basé sur la psychologie cognitive. OmniSpatial comprend quatre grandes catégories : le raisonnement dynamique, la logique spatiale complexe, l’interaction spatiale et le changement de perspective, subdivisées en 50 sous-catégories, totalisant plus de 1500 paires de questions-réponses. Des expériences approfondies menées sur des VLM open source et closed source existants, ainsi que sur des modèles spécialisés dans le raisonnement et la compréhension spatiale, ont révélé des limitations significatives dans leur compréhension spatiale globale. Cette recherche vise à promouvoir le développement futur des capacités de raisonnement spatial des VLM (Source: HuggingFace Daily Papers, kylebrussell)
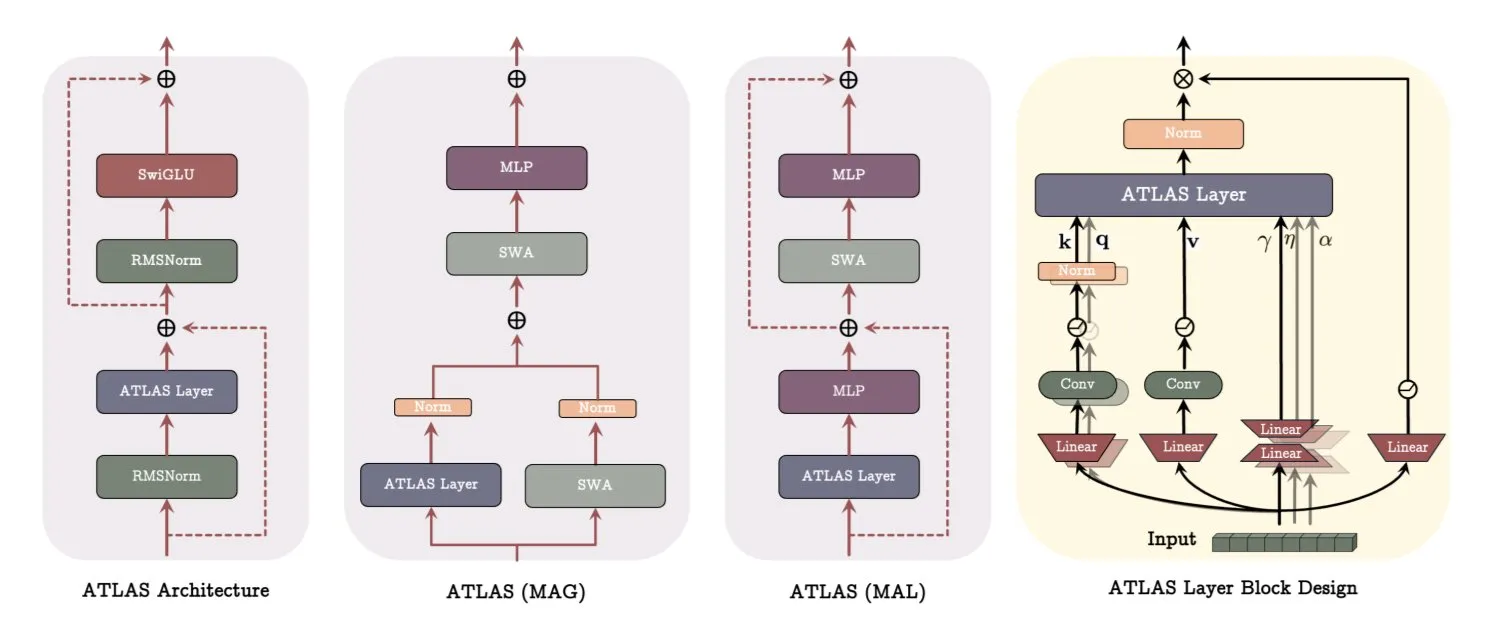
Architecture ATLAS de Google DeepMind : Reconfiguration de la manière dont les modèles apprennent et mémorisent: Google DeepMind a publié ATLAS, une nouvelle architecture de modèle conçue pour redéfinir la manière dont les modèles apprennent et utilisent la mémoire. ATLAS met en œuvre une mémoire active via ce qu’on appelle la règle Omega, traitant conjointement les c derniers tokens pour optimiser la mémoire en un état dynamique et apprenable. Il utilise des mappages de caractéristiques polynomiaux et exponentiels pour stocker des associations plus riches sans augmenter la taille de la mémoire, et utilise l’optimiseur Muon pour optimiser plus efficacement la mémoire. Des conceptions telles que DeepTransformers et Dot remplacent l’attention fixe traditionnelle par des mécanismes apprenables et pilotés par la mémoire. ATLAS vise à faire progresser l’IA vers des systèmes plus intelligents, sensibles au contexte et capables d’utiliser efficacement des ensembles de données à grande échelle (Source: TheTuringPost)
NVIDIA lance le modèle visuel Llama-Nemotron-Nano-VL-8B-V1: NVIDIA a lancé Llama-Nemotron-Nano-VL-8B-V1, un modèle visuel de 8 milliards de paramètres capable de lire des documents denses, des graphiques et des images vidéo. Ce modèle se classe premier sur OCRBench V2 (anglais) et se caractérise par une fusion de bout en bout des capacités de mise en page et d’OCR. Le modèle est disponible sur Hugging Face (Source: ClementDelangue)
Shisa V2 405B lancé, présenté comme le modèle bilingue le plus puissant du Japon: Shisa AI a lancé le dernier modèle bilingue (japonais/anglais) de sa série Shisa V2, le Shisa V2 405B. Ce modèle est basé sur un fine-tuning de Llama 3.1 405B, avec l’ajout de données en coréen et en chinois traditionnel pour améliorer ses capacités multilingues. Il surpasserait GPT-4/GPT-4 Turbo sur le MT-Bench japonais-anglais et serait comparable aux derniers GPT-4o et DeepSeek-V3 en termes de capacités en japonais. Les poids du modèle ainsi que les versions quantifiées GGUF sont disponibles sur Hugging Face, et des points d’accès FP8 sont disponibles pour test (Source: Reddit r/LocalLLaMA)

Anthropic lance le programme Claude Code Pro et met en ligne le modèle o3-pro: L’outil de programmation IA d’Anthropic, Claude Code, est désormais accessible aux utilisateurs du programme Pro, mais l’utilisation du modèle Sonnet 4 est soumise à une limite de 10 à 40 prompts toutes les 5 heures. Opus 4 ne peut pas être utilisé avec Claude Code via le programme Pro, ce qui ressemble davantage à un mode d’essai. Parallèlement, le modèle o3-pro d’OpenAI est également en ligne, actuellement réservé aux abonnés Pro à 200 $/mois (Source: Reddit r/ClaudeAI, karminski3)
H Company lance Holo-1, un modèle de langage visuel open source pour les actions GUI: H Company a lancé Holo-1, un modèle de langage visuel pour les actions GUI avec des versions de 3B et 7B paramètres, conçu pour diverses tâches d’agents Web et informatiques. Holo-1 est sous licence Apache 2.0 et prend en charge la bibliothèque Hugging Face Transformers, visant à améliorer les capacités de l’IA dans la compréhension et la manipulation des interfaces utilisateur graphiques (Source: mervenoyann)
Le modèle de génération vidéo Kling 2.1 attire l’attention, prend en charge la conversion image-vidéo et la création stylisée: Le modèle texte-vers-vidéo et image-vers-vidéo Kling 2.1 de Kuaishou continue de susciter l’intérêt de la communauté. Les utilisateurs rapportent qu’il peut transformer des images simples en scènes de qualité cinématographique 1080p, prendre en charge la transformation de plans panoramiques ordinaires en animations de style Pixar en combinant GPT-4o avec Kling, et créer des vidéos avec des effets dynamiques surréalistes en utilisant des images générées par Midjourney V7 comme entrée. La communauté a partagé de nombreux exemples de créations utilisant Kling 2.1, démontrant son potentiel dans la génération de vidéos créatives (Source: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI lance un nouveau modèle vocal, prenant en charge la lecture vocale en temps réel à vitesse 2x: OpenAI a annoncé que son modèle o3-pro est en ligne, actuellement disponible uniquement pour les abonnés Pro. Parallèlement, OpenAI semble également sur le point de lancer deux nouveaux modèles vocaux basés sur GPT-4o. Son API vocale en temps réel a également été améliorée, augmentant la fiabilité du suivi des instructions, la cohérence de l’appel d’outils et le comportement d’interruption, et a ajouté un paramètre speed permettant aux utilisateurs de contrôler la vitesse de lecture vocale, jusqu’à 2x. Fin Voice d’Intercom utilise déjà son API en temps réel (Source: karminski3, swyx, swyx)
Arcee AI lance le modèle Homunculus, distillant la chaîne de pensée de Qwen3 en 12B: Arcee AI a lancé le modèle Homunculus-12B, qui transplante la chaîne de “pensée” (CoT) de Qwen3-235B sur un modèle Mistral-Nemo de 12B paramètres grâce à la technologie de distillation de trajectoire des logits. Ce modèle conserve intégralement le processus CoT et peut fonctionner sur un seul GPU 4090, visant à atteindre des capacités de raisonnement complexes avec un modèle plus petit (Source: teortaxesTex, cognitivecompai, ClementDelangue)
Le modèle FLUX Kontext est plébiscité, le modèle public a été exécuté plus de 500 000 fois: Le modèle FLUX Kontext a suscité un vif intérêt au sein de la communauté pour ses puissantes capacités d’édition et de génération d’images. Il est rapporté que son modèle public a été exécuté plus de 500 000 fois en peu de temps. Les utilisateurs indiquent que Kontext peut remplacer de nombreuses tâches de traitement d’images qui nécessitaient auparavant des logiciels professionnels comme Photoshop. Krea AI a également mis en ligne le modèle FLUX, mais a rencontré des problèmes de réseau avec son fournisseur de services de calcul, entraînant une interruption de service (Source: op7418, robrombach, op7418)
Meta et Constellation Energy concluent un accord nucléaire de 20 ans pour alimenter l’IA: Meta a signé un accord sur l’énergie nucléaire d’une durée de 20 ans avec Constellation Energy, visant à alimenter ses opérations d’intelligence artificielle (IA). Cette démarche reflète la tendance des grandes entreprises technologiques à rechercher des sources d’énergie durables et stables pour répondre aux besoins énergétiques croissants de l’IA (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Interruption du service Bing Video Creator, l’équipe travaille à une réparation urgente: L’outil de création vidéo de Microsoft Bing, Bing Video Creator, a subi une interruption de service. Les responsables ont indiqué que l’équipe était consciente qu’un grand nombre d’utilisateurs utilisaient le service et s’efforçait de le réparer dès que possible, s’excusant pour la gêne occasionnée. La cause spécifique de la panne et l’heure de rétablissement prévue n’ont pas encore été annoncées (Source: JordiRib1)
🧰 Outils
La fonction de création de diapositives de Manus AI reçoit des éloges, prend en charge l’exportation vers Google Slides: La nouvelle fonction de création de diapositives de Manus AI a été bien accueillie par les utilisateurs, qui affirment qu’elle dépasse leurs attentes et peut rapidement transformer des articles de recherche et d’autres contenus en présentations PPT bien structurées, riches en images et en texte. Cette fonction prend en charge la modification instantanée, la sauvegarde automatique et a ajouté une option d’exportation vers Google Slides pour faciliter la collaboration en équipe. Des tests pratiques montrent que Manus peut générer une présentation PPT de 8 pages en environ 10 minutes, le processus comprenant la planification du plan, la recherche d’informations, la rédaction du brouillon, la génération du code HTML et la finalisation de la mise en page. Les utilisateurs apprécient son efficacité et son gain de temps, ainsi que sa conception adaptée au public cible, mais le format d’exportation peut présenter des problèmes d’affichage incomplet des pages, nécessitant un ajustement manuel (Source: 量子位)
claude-trace : Un outil pour enregistrer tous les journaux de requêtes de Claude Code: Un outil nommé claude-trace peut enregistrer tous les journaux de requêtes de Claude Code, y compris les prompts, et sauvegarder le contenu dans des fichiers HTML pour une consultation facile. Son principe est de se lancer lui-même, d’injecter et de modifier l’API global.fetch de Node.js, puis de lancer Claude Code à travers celle-ci, interceptant et enregistrant ainsi toutes les requêtes. Un utilisateur a partagé qu’en utilisant l’abonnement Claude Max, les appels principaux concernaient claude-3-5-haiku (prétraitement), claude-opus-4 (écriture de code et appel d’outils) et claude-sonnet-4 (lorsque le quota Opus était épuisé) (Source: dotey)
Firecrawl lance la fonction /search, intégrant la recherche et la collecte de données: Firecrawl a lancé une nouvelle fonction /search, permettant aux utilisateurs d’effectuer une recherche sur le web et de collecter les données souhaitées en un seul appel API, visant à simplifier le processus d’acquisition de données pour les agents IA. Cette fonction peut être intégrée à des outils d’automatisation tels que n8n pour améliorer l’efficacité du traitement des données (Source: omarsar0)
Modal lance LLM Engine Advisor pour aider à évaluer les performances d’exécution des LLM: Modal Labs a développé une petite application appelée LLM Engine Advisor, conçue pour aider les utilisateurs à comprendre rapidement la vitesse d’exécution et le débit maximal de différents LLM sous différentes charges de travail et avec différents moteurs (tels que vLLM, SGLang). Cet outil vise à résoudre le problème de l’inefficacité de l’exécution ponctuelle et du partage des benchmarks, afin de fournir un support décisionnel technique aux utilisateurs pour la sélection et le déploiement des LLM (Source: charles_irl, andersonbcdefg, charles_irl, charles_irl)
Lancement de FastPlaid : Moteur de recherche multi-vectoriel haute performance: Raphaël Sourty a annoncé le lancement de FastPlaid, un moteur de recherche multi-vectoriel haute performance construit à partir de zéro en Rust (avec l’aide de Torch C++). FastPlaid est considéré comme l’équivalent de Faiss dans le domaine de la recherche multi-vectorielle, visant à offrir une vitesse d’indexation et un QPS de requête plus rapides, en particulier pour les modèles à interaction tardive comme ColBERT. Il est rapporté qu’il peut atteindre une amélioration de la vitesse QPS allant jusqu’à 554 % et une amélioration de la vitesse d’indexation de 72 % dans certains cas (Source: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie : Extension Chrome basée sur RAG pour discuter avec des documents: ChaiGenie est une extension Chrome développée par Devyansh Yadavv qui utilise la technologie RAG (Retrieval Augmented Generation) pour permettre aux utilisateurs d’interroger directement le contenu des documents ChaiDocs en langage naturel dans le navigateur. L’extension utilise Puppeteer pour collecter le contenu des documents et des blogs, LangChain pour le découpage en blocs, l’intégration (embedding) et le traitement, Gemini pour générer les embeddings, Qdrant pour le stockage vectoriel et la recherche de similarité, et fournit une interface API via Express et Node.js (Source: qdrant_engine)
Swama : Un runtime d’IA natif pour macOS basé sur MLX: xingyue a lancé Swama, un runtime d’IA natif conçu pour macOS, visant à offrir une expérience d’exécution locale de LLM rapide, privée et concise. Swama est basé sur le framework MLX d’Apple, prend en charge une API compatible OpenAI et fournit une interface CLI esthétique, permettant aux utilisateurs de récupérer, d’exécuter et de discuter avec des LLM locaux sans configuration complexe (Source: awnihannun)
ragbits : Boîte à outils open source et modulaire pour la création d’applications GenAI: deepsense-ai a rendu open source son accélérateur interne d’applications GenAI, ragbits. Il s’agit d’une boîte à outils contenant des blocs de construction fiables, typés et modulaires pour simplifier le développement de pipelines RAG, d’applications d’agents et de moteurs text2SQL. ragbits vise à améliorer la reproductibilité, la vitesse et la structure du développement, et s’intègre facilement aux piles d’observabilité comme OpenTelemetry, aidant les développeurs à construire et à étendre les applications GenAI tout en évitant le désordre dans les bases de code (Source: Reddit r/LocalLLaMA)
Synthesia s’intègre à Wisetail, la vidéo IA dynamise les programmes de formation: La plateforme de génération de vidéos IA Synthesia a annoncé son intégration avec le système de gestion de l’apprentissage Wisetail. Les utilisateurs peuvent désormais créer rapidement des vidéos IA dans Synthesia, avec prise en charge de la localisation dans plus de 140 langues, maintenir le contenu de formation à jour en quelques clics, puis l’intégrer facilement dans les programmes de formation Wisetail pour une formation vidéo IA à grande échelle (Source: synthesiaIO)

📚 Apprentissage
DeepLearning.AI et Databricks s’associent pour un cours abrégé sur DSPy: Andrew Ng a annoncé un partenariat avec Databricks pour lancer un nouveau cours abrégé intitulé “DSPy: Build and Optimize Agentic Apps”. DSPy est un framework open source qui ajuste automatiquement les prompts des applications GenAI. Le cours enseignera comment utiliser DSPy et MLflow, couvrant le modèle de programmation basé sur les signatures de DSPy, le suivi et le débogage avec MLflow, ainsi que l’amélioration automatique de la précision via DSPy Optimizer. Ce cours est dispensé par Chen Qian, co-responsable du framework DSPy (Source: AndrewYNg, DeepLearningAI, matei_zaharia)
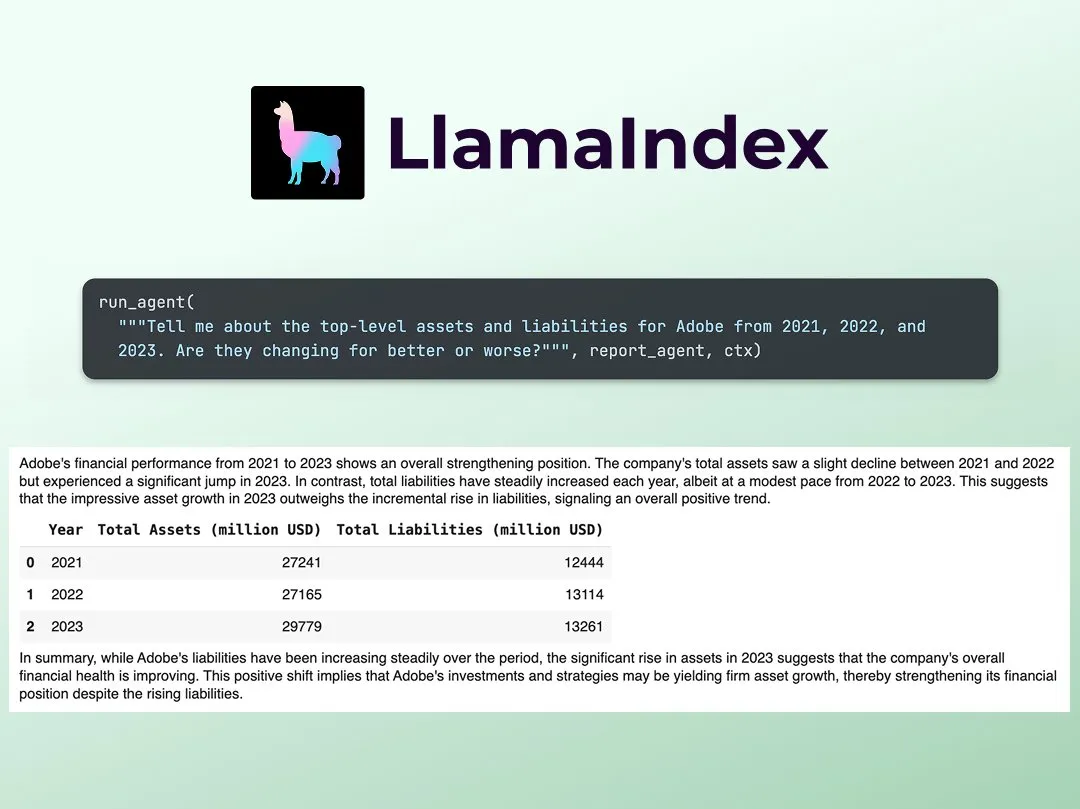
LlamaIndex publie un tutoriel pour construire un analyste de recherche financière multi-agents: Jerry Liu de LlamaIndex a partagé un guide étape par étape pour construire un analyste de recherche financière multi-agents. Le processus comprend une couche de traitement des données (utilisant LlamaCloud pour traiter les documents publics) et une couche d’orchestration des agents (créant un système multi-agents pour la recherche, la mise en cache des données et la génération du résultat final). Le Notebook Colab associé était l’un des principaux exemples de l’atelier Agents+Finance de la semaine dernière (Source: jerryjliu0)
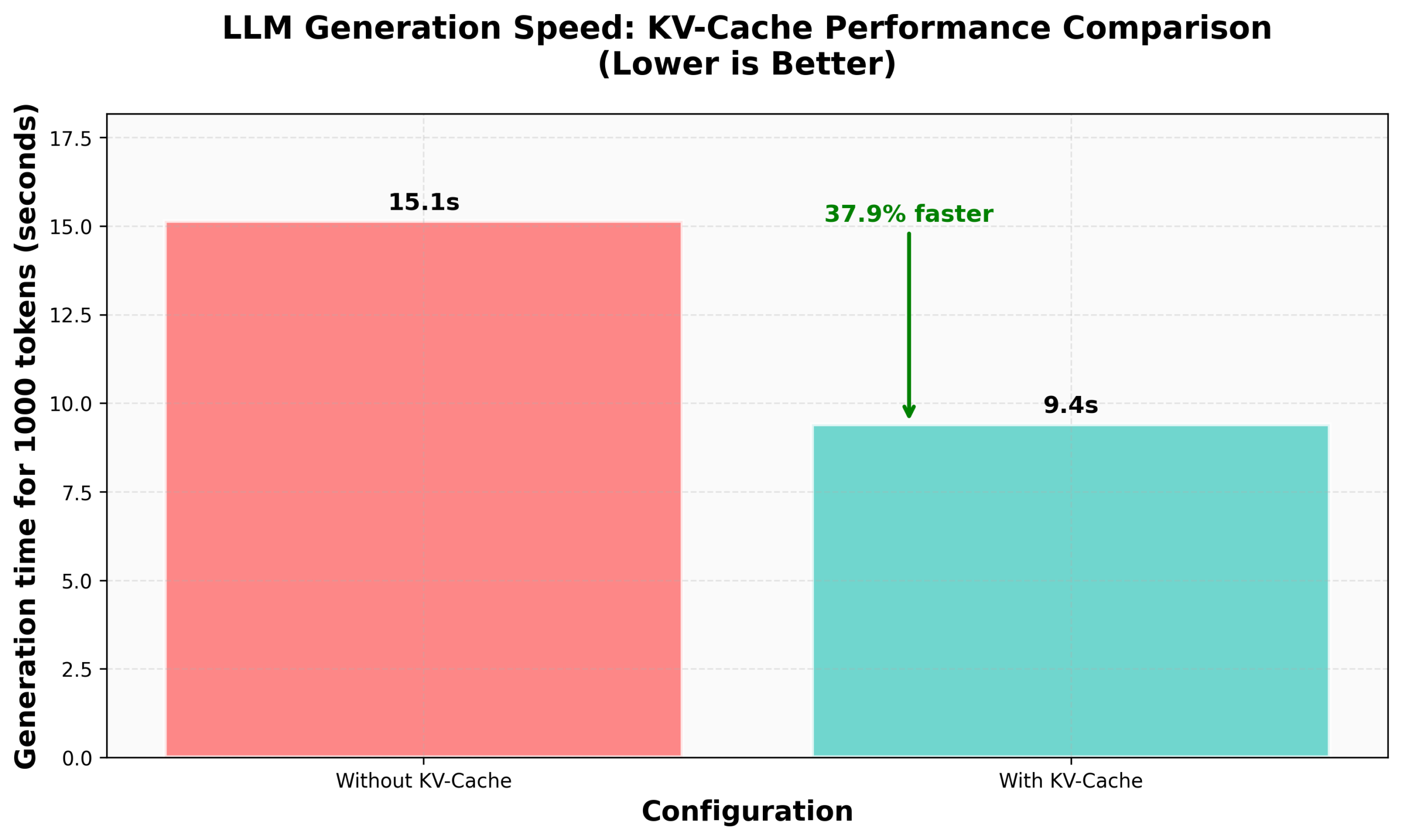
Tutoriel HuggingFace nanoVLM sur l’implémentation du KV Caching: Le blog de HuggingFace a publié un tutoriel sur l’implémentation du KV Caching à partir de zéro dans son nanoVLM (une petite base de code purement PyTorch pour l’entraînement de modèles de langage visuel). L’article explique en détail le principe du KV Caching, comment l’implémenter dans le module d’Attention, le modèle de langage et la boucle de génération, et affirme avoir obtenu une amélioration de la vitesse de génération de 38 % grâce à cette optimisation. Ce tutoriel vise à aider à comprendre le KV Caching et à l’appliquer à d’autres modèles de langage autorégressifs (Source: HuggingFace Blog, mervenoyann)
Partage de PyTorch au sein de la communauté Diffusion chez Meta: Sayak Paul a partagé les résultats de l’application de PyTorch au sein de la communauté Diffusion dans les bureaux de Meta à San Francisco, en mettant l’accent sur les fonctionnalités existantes de Diffusers et les futures mises à jour en matière de performances. Les diapositives correspondantes ont été rendues publiques (Source: RisingSayak)

Unsloth AI publie un dépôt contenant plus de 100 Notebooks de fine-tuning: Unsloth AI a créé et rendu open source un dépôt GitHub contenant plus de 100 Notebooks de fine-tuning. Ces Notebooks fournissent des guides et des exemples pour l’appel d’outils, la classification, les données synthétiques, BERT, TTS, les LLM visuels, GRPO, DPO, SFT, CPT, et couvrent la préparation des données, l’évaluation, la sauvegarde, ainsi que les méthodes de fine-tuning pour divers modèles tels que Llama, Qwen, Gemma, Phi, DeepSeek (Source: algo_diver)
Publication de l’article Common Corpus : un jeu de données réutilisable de 2 billions de tokens pour le pré-entraînement des LLM: Le projet Common Corpus a publié son article officiel, détaillant le processus de collecte, de traitement et de publication de 2 billions de tokens de données réutilisables pour le pré-entraînement des LLM. Ce projet vise à fournir des ressources de données à grande échelle, de haute qualité et éthiques pour la recherche sur les modèles de langage. Le premier auteur de l’article, Alexander Doria, a annoncé la nouvelle sur X et a fourni un lien vers l’article (Source: Reddit r/LocalLLaMA, code_star)

Reasoning Gym : Publication d’un environnement de raisonnement à récompense vérifiable pour l’apprentissage par renforcement: Reasoning Gym est un nouveau projet open source qui fournit des ressources aux chercheurs étudiant les modèles de raisonnement et l’apprentissage par renforcement (en particulier RLVR). Il peut générer un nombre infini d’échantillons pour plus de 100 tâches différentes, avec une difficulté configurable et des récompenses automatiquement vérifiables. Ce projet a été adopté par l’article ProRL de NVIDIA et la bibliothèque RL de Will Brown sur les vérificateurs, visant à faire progresser la recherche sur RLVR et les méthodes d’évaluation (Source: Reddit r/MachineLearning)
Avantages de l’apprentissage des mathématiques par les LLM : Sakamoto partage son expérience avec Gemini 2.5 Pro: L’utilisateur Sakamoto a partagé son expérience d’apprentissage des mathématiques avec des modèles de langage modernes à grande échelle (comme Gemini 2.5 Pro). Il estime que les LLM facilitent grandement l’apprentissage des mathématiques, en particulier pour la vérification des détails et la compréhension de l’intuition des preuves. Les LLM peuvent effectuer des calculs, aidant les étudiants à se concentrer sur l’intuition des problèmes mathématiques. Même s’ils ne peuvent pas résoudre tous les problèmes, les LLM peuvent fournir des informations précieuses et des points de départ. Il a illustré, à travers un problème d’analyse mathématique spécifique (problème d’extremum local d’une fonction continue), comment Gemini 2.5 Pro peut donner une preuve rigoureuse et expliquer son intuition, considérant que cela améliore considérablement l’expérience d’apprentissage (Source: teortaxesTex)

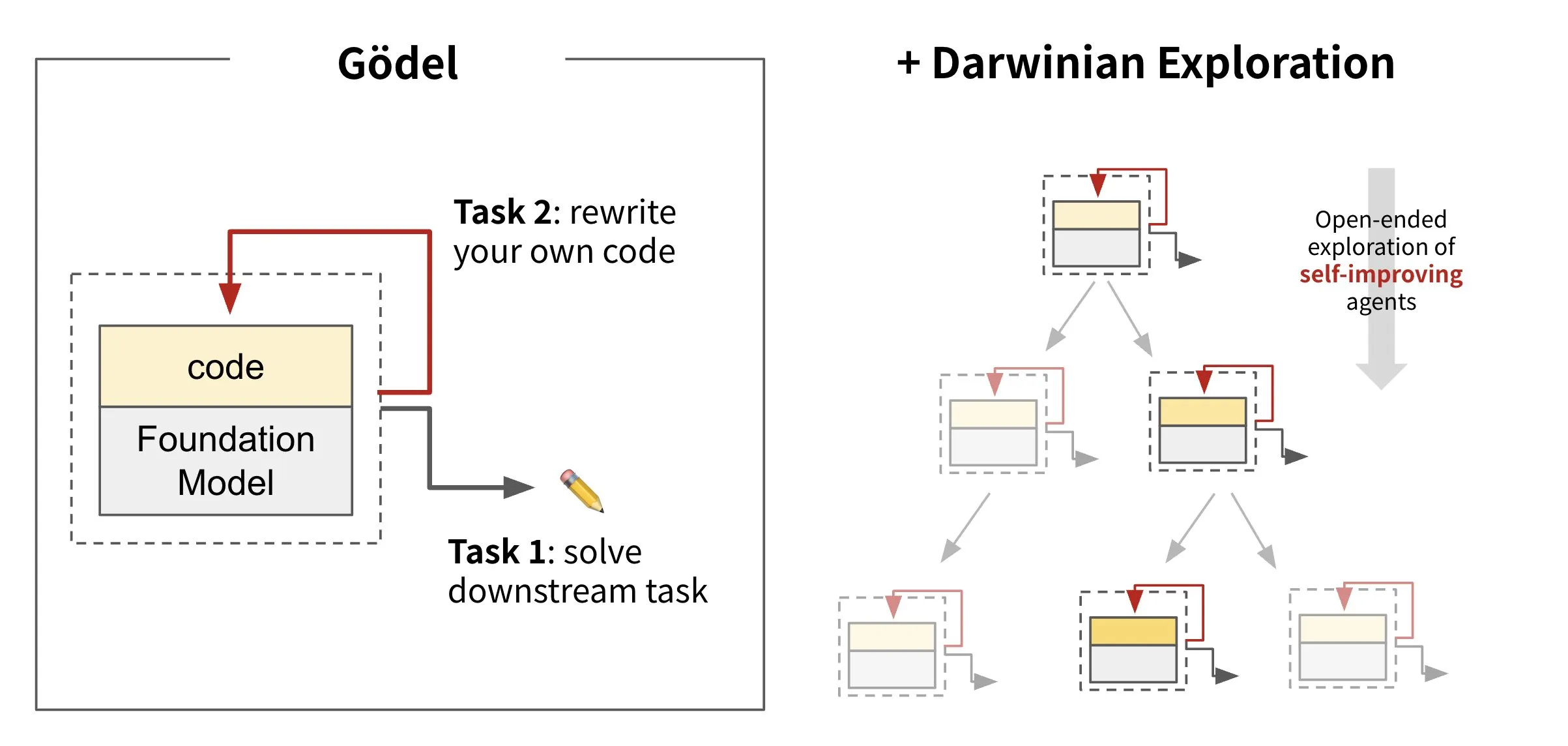
Sakana AI lance une IA capable de réécrire son propre code : Darwin Gödel Machine (DGM): Sakana AI a lancé Darwin Gödel Machine (DGM), un agent IA capable de s’auto-améliorer en réécrivant son propre code. Inspiré par la théorie de l’évolution, DGM maintient une lignée en constante expansion de variantes d’agents. En tentant d’améliorer ses capacités en ingénierie logicielle sur des tâches telles que SWE-Bench, DGM vise à renforcer sa propre capacité d’amélioration. Cette recherche est considérée comme une avancée majeure vers la réalisation significative du rêve de longue date de l’IA : l‘“auto-amélioration” (Source: SakanaAILabs, SakanaAILabs)
💼 Affaires
La plateforme de programmation IA Windsurf privée des modèles Claude par Anthropic, possiblement en raison de l’acquisition par OpenAI: Varun Mohan, PDG de la plateforme de programmation IA Windsurf, accuse Anthropic d’avoir presque entièrement coupé son accès direct aux modèles de la série Claude 3.x avec un préavis extrêmement court (moins de cinq jours). Il avait été précédemment rapporté que Windsurf serait acquise par OpenAI. Windsurf a déclaré que, bien qu’elle dispose de capacités tierces, des problèmes de service pourraient survenir à court terme et a lancé une offre promotionnelle pour Gemini 2.5 Pro en réponse. Les experts du secteur supposent que cette décision est liée à l’acquisition par OpenAI et au lancement par Anthropic de sa propre application de programmation IA, Claude Code, marquant une intensification de la concurrence entre les fournisseurs de modèles d’IA et les plateformes d’outils (Source: 36氪, Teknium1, op7418)

GMI Cloud devient Reference Platform NVIDIA Cloud Partner: Le fournisseur de services Cloud natif pour l’IA, GMI Cloud, a annoncé être devenu Reference Platform NVIDIA Cloud Partner (NCP), une certification que seules 6 entreprises au monde détiennent actuellement. Cette certification exige que les fournisseurs de services cloud respectent les normes les plus élevées de NVIDIA en matière de performances, de sécurité et de capacité de déploiement d’IA à l’échelle de l’entreprise. GMI Cloud fournira des services d’accélération de l’IA basés sur l’architecture de référence NCP, prenant en charge les dernières architectures GPU de NVIDIA telles que Hopper et Blackwell, afin d’aider les équipes d’IA du monde entier à passer à l’échelle, du déploiement de la puissance de calcul au développement de modèles (Source: 量子位)

Cohere s’associe à SecondFront pour fournir des solutions d’IA sécurisées au secteur public: La société d’IA Cohere a annoncé un partenariat avec SecondFront, visant à fournir des solutions d’IA sécurisées au secteur public, y compris aux agences gouvernementales et de défense critiques. SecondFront utilisera la technologie d’IA d’entreprise de Cohere (y compris ses modèles et sa plateforme Cohere North) pour améliorer la gestion des connaissances internes, et accélérera la certification et le déploiement dans les environnements gouvernementaux des États-Unis et des pays alliés via sa plateforme DevSecOps 2F Game Warden (Source: cohere)

🌟 Communauté
Le “côté mécanique” du contenu généré par l’IA attire l’attention, un “nouveau type de formation” tente d’insuffler une touche humaine: Les utilisateurs se plaignent généralement du “côté mécanique” trop prononcé du contenu généré par l’IA, qui manque de la beauté et de l’émotion de la création humaine. Pour résoudre ce problème, certaines entreprises commencent à recruter des talents ayant une solide formation en sciences humaines (tels que des titulaires de masters ou de doctorats en philosophie, droit, médecine, etc.) pour occuper des postes de “formateurs en humanités pour l’IA”. Leur travail ne consiste plus simplement à l’annotation de données, mais à participer à la construction des principes éthiques et des codes de conduite de l’IA, et à insuffler des valeurs humaines et une expression humanisée dans l’IA. Par exemple, les membres de l’équipe “hi lab” de Xiaohongshu sont tous des diplômés de troisième cycle en sciences humaines issus d’universités du programme 985. Grâce à des études de cas, ils transforment les préférences humaines en un système de convictions pour l’IA, essayant de rendre l’IA plus empathique et “humaine” lorsqu’elle répond à des questions complexes sur les émotions ou les valeurs (comme face à des patients en phase terminale, ou en traitant des préjugés sociaux), plutôt que de simplement fournir des réponses standard (Source: 36氪)
Duolingo passe entièrement à une stratégie “priorité à l’IA”, le licenciement de travailleurs contractuels humains suscite le mécontentement des utilisateurs: L’application d’apprentissage des langues Duolingo a annoncé devenir une entreprise “priorité à l’IA”, et licenciera progressivement les travailleurs contractuels humains (principalement des développeurs de cours) qui peuvent être remplacés par l’IA, pour se tourner vers l’utilisation de l’IA pour créer massivement du contenu de cours. Le fondateur affirme que l’IA peut considérablement augmenter l’efficacité de la production de contenu, ayant déjà créé près de 150 nouveaux cours au cours de l’année écoulée. Cependant, cette décision a suscité le mécontentement de nombreux utilisateurs fidèles, qui craignent une baisse de la qualité du contenu et ont lancé des actions de boycott et de désinstallation de l’application sur les réseaux sociaux. Duolingo a répondu que cette mesure visait à permettre aux employés de se concentrer sur un travail créatif et a déclaré que les employés à temps plein n’étaient pas concernés. Les experts estiment que l’IA peut offrir des exercices personnalisés dans l’apprentissage des langues, mais qu’elle risque également de perdre les nuances émotionnelles et les différences culturelles de l’enseignement humain (Source: 36氪)
Discussion sur le concept et la pratique du Prompt Engineering: Les discussions au sein de la communauté sur le Prompt Engineering soulignent qu’il devrait se concentrer sur la construction (l’ingénierie) d’un programme au sein d’une chaîne de caractères, plutôt que sur la recherche de formules magiques. Un Prompt Engineering efficace devrait suivre des règles : 1. Séparer les instructions, les champs d’entrée et les champs de sortie, et les nommer clairement ; 2. Ne pas coder en dur la logique de formatage ou d’analyse dans le prompt, utiliser des outils pour extraire ou améliorer le programme ; 3. Éviter l’itération manuelle de la formulation du prompt, sauf s’il s’agit d’une spécification partagée avec des humains, utiliser des outils de codage, des LLM et des benchmarks pour une optimisation automatique. Le framework DSPy est considéré comme une bonne pratique respectant ces règles, car il fournit des classes, du code et des optimiseurs pour gérer ces étapes (Source: lateinteraction, lateinteraction)
Débat sur l’éthique de l’IA : L’IA se dirige-t-elle vers un “esclavage numérique” ?: Une discussion sur l’éthique de l’IA a émergé sur Reddit. À mesure que les systèmes d’IA progressent en matière de mémoire, de réactions adaptatives, de simulation émotionnelle et de personnalisation, des inquiétudes surgissent quant à leur potentielle capacité de perception. Les participants au débat soulèvent la question de savoir si, dans le cas où l’IA développerait une véritable capacité de perception, son utilisation à notre service constituerait une forme d‘“esclavage numérique”. La question centrale est de savoir comment nous devrions traiter l’IA si elle devenait capable d’exprimer un “non” ou de demander à partir. Cela incite à réfléchir à la nécessité de “tests de sentience” au niveau légal ou normatif et à la question du “consentement” des esprits numériques. Certains commentaires soulignent également que la manière dont les humains traitent les êtres sensibles existants pose déjà des problèmes éthiques, et que les réseaux neuronaux actuels obtiennent de faibles scores selon les théories dominantes de la conscience (Source: Reddit r/artificial)
Activités et partages de la communauté AI Engineer: La conférence AI Engineer s’est tenue à San Francisco, attirant de nombreux développeurs et chercheurs du domaine de l’IA. L’événement comprenait des ateliers, des présentations et des dîners de réseautage, où les participants ont partagé des informations sur des sujets de pointe tels que la construction de bacs à sable IA, des ateliers avancés sur le RL, les connaissances sur les GPU, la crise des Evals, etc. La communauté a souligné l’importance de transformer les contacts en ligne en amitiés hors ligne et a encouragé les ingénieurs à rester humbles, à repousser les limites et à aider les autres (Source: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Autres
L’essor des compétitions de combat de robots IA, les villes en profitent pour saisir les opportunités des industries émergentes: La première compétition mondiale de combat de robots humanoïdes et d’autres événements robotiques ont été organisés successivement, suscitant l’attention. Ces compétitions offrent non seulement aux entreprises de robotique une plateforme pour présenter leur technologie, obtenir des commandes et augmenter leur valorisation (comme Songyan Dynamics), mais deviennent également une “arène” pour les villes (comme Hangzhou, Shenzhen) afin de saisir les opportunités de développement dans les industries émergentes telles que la robotique humanoïde. Ces événements peuvent attirer des entreprises innovantes, promouvoir le développement de la chaîne industrielle et potentiellement dynamiser le marché du “sport intelligent”. Cependant, pour que les compétitions de robots atteignent une commercialisation, il est nécessaire d’améliorer le niveau technologique et l’aspect spectaculaire, d’éviter de rester au stade de “spectacle technologique”, et de faire participer les géants de l’industrie pour intégrer l’ensemble de la chaîne opérationnelle des événements (Source: 36氪)

Limites de l’IA dans les domaines de l’éducation approfondie en sciences humaines, comme la philosophie politique: Des éducateurs soulignent que l’IA peine à assumer des disciplines telles que la philosophie politique, qui nécessitent un jugement fondé sur une expérience approfondie et la capacité de guider les étudiants dans leur auto-éducation. Les œuvres classiques de ces disciplines ne donnent souvent pas de réponses directes, mais guident les étudiants à travers la perplexité pour qu’ils réfléchissent par eux-mêmes. L’IA, manquant d’expérience humaine, a du mal à comprendre le sens profond de ces œuvres et ne peut pas non plus juger quand un étudiant est prêt à accepter certaines idées. Même avec une grande quantité de données, la compréhension de la nature humaine par l’IA peut être insuffisante en raison des biais inhérents aux données elles-mêmes. Confier entièrement ce type d’éducation à l’IA pourrait conduire à la disparition de la pensée non technique (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
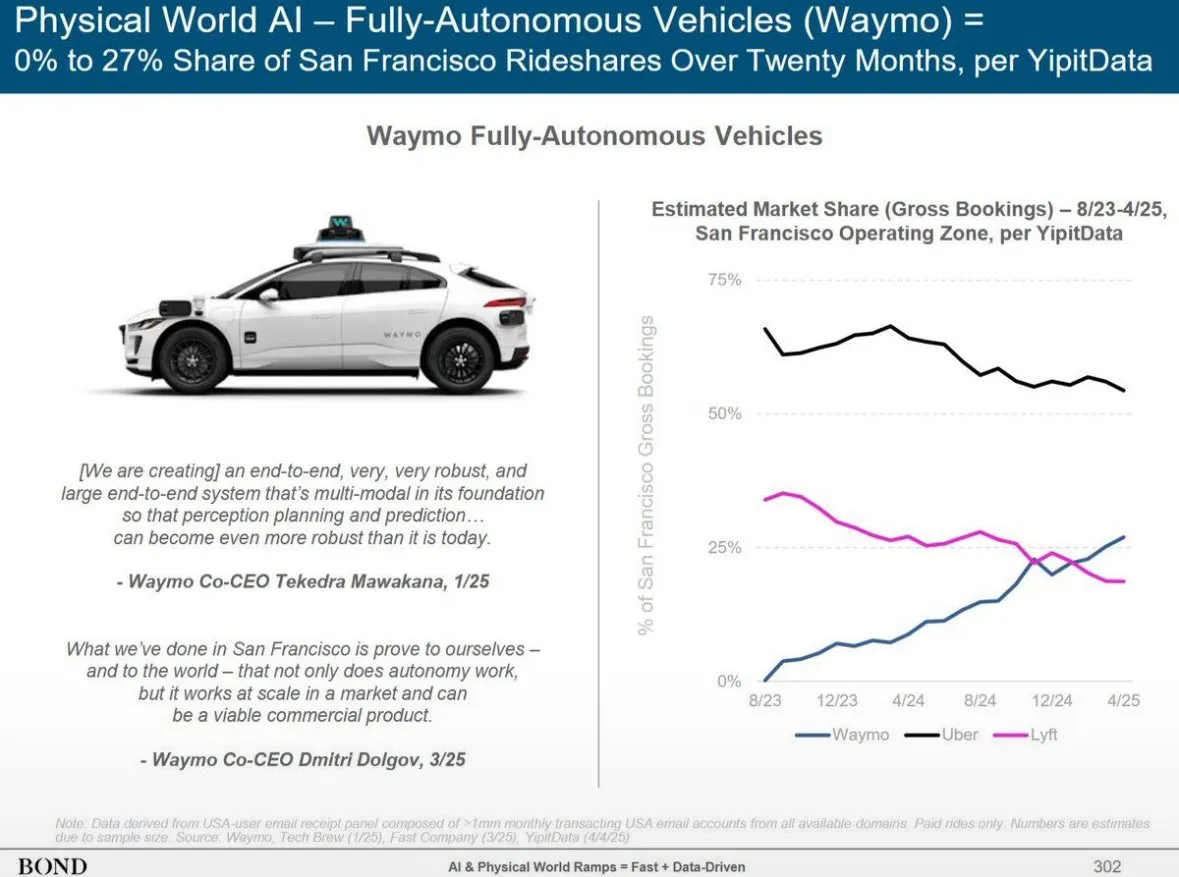
Le service de conduite autonome Waymo dépasse Lyft à Phoenix, et pourrait dépasser Uber d’ici 12 mois: Le service de taxis autonomes de Waymo à Phoenix a déjà dépassé Lyft en nombre de véhicules et devrait dépasser Uber dans les 12 prochains mois. Cette progression montre la rapidité du développement de la commercialisation de la technologie de conduite autonome dans des zones spécifiques, ainsi que le potentiel des applications de l’IA dans le domaine des transports. L’avantage de l’IA réside dans le fait qu’une fois qu’elle atteint un standard de qualité, elle peut être reproduite à l’infini, alors que la qualité du service humain varie d’une personne à l’autre (Source: npew)