
Mots-clés:OpenAI Codex, Modèle de langage visuel et d’action, Limite de mémoire des modèles de langage, Fonction de mémoire de ChatGPT, DeepSeek-R1-0528, Modèles de diffusion, Création musicale Suno AI, MetaAgentX, Fonction d’accès Internet de Codex, Modèle robotique SmolVLA, Mémoire 3,6 bits des modèles de style GPT, Amélioration de l’interaction personnalisée de ChatGPT, Capacité de raisonnement complexe de DeepSeek-R1
🔥 Pleins feux
OpenAI Codex est désormais accessible aux utilisateurs Plus et bénéficie de mises à jour majeures, notamment l’accès à Internet et la saisie vocale: OpenAI a annoncé que Codex sera progressivement ouvert aux utilisateurs de ChatGPT Plus. Les points clés de cette mise à jour incluent la permission pour les agents IA d’accéder à Internet lors de l’exécution de tâches (désactivé par défaut, avec contrôle utilisateur sur les domaines et les méthodes HTTP), afin d’installer des dépendances, de mettre à jour des paquets logiciels et d’exécuter des tests sur des ressources externes. De plus, Codex prend désormais en charge la mise à jour directe des Pull Requests existantes et peut recevoir des tâches par saisie vocale. D’autres améliorations comprennent la prise en charge des opérations sur les fichiers binaires (actuellement limitée à la suppression ou au renommage dans les PR), l’augmentation de la limite de taille des différences de tâches (diff) de 1 Mo à 5 Mo, l’extension de la limite de temps d’exécution des scripts de 5 à 10 minutes, ainsi que la correction de plusieurs problèmes sur la plateforme iOS et la réactivation de la fonctionnalité d’activités en temps réel. Ces mises à jour visent à améliorer l’utilité et la flexibilité de Codex dans les tâches de programmation complexes (Source: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face et H Company publient conjointement des modèles open source de type Vision-Langage-Action (VLA) pour faire progresser la technologie robotique: Hugging Face et H Company ont annoncé lors du « VLA Day » de nouveaux modèles open source de type Vision-Langage-Action, notamment SmolVLA de Hugging Face (450M de paramètres) et Holo-1 de H Company (3B et 7B de paramètres). Les modèles VLA visent à permettre aux robots de voir, d’entendre, de comprendre et d’agir selon les instructions de l’IA, et sont considérés comme les GPT du domaine de la robotique. Rendre ces modèles open source est crucial pour comprendre leur fonctionnement, éviter les portes dérobées potentielles et les personnaliser pour des robots et des tâches spécifiques. SmolVLA, entraîné sur le jeu de données LeRobotHF, a démontré d’excellentes performances et une vitesse d’inférence élevée. Holo-1 se concentre sur les tâches d’agents web et informatiques et est disponible sous licence Apache 2.0. Ces publications devraient accélérer le développement de la robotique IA open source (Source: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

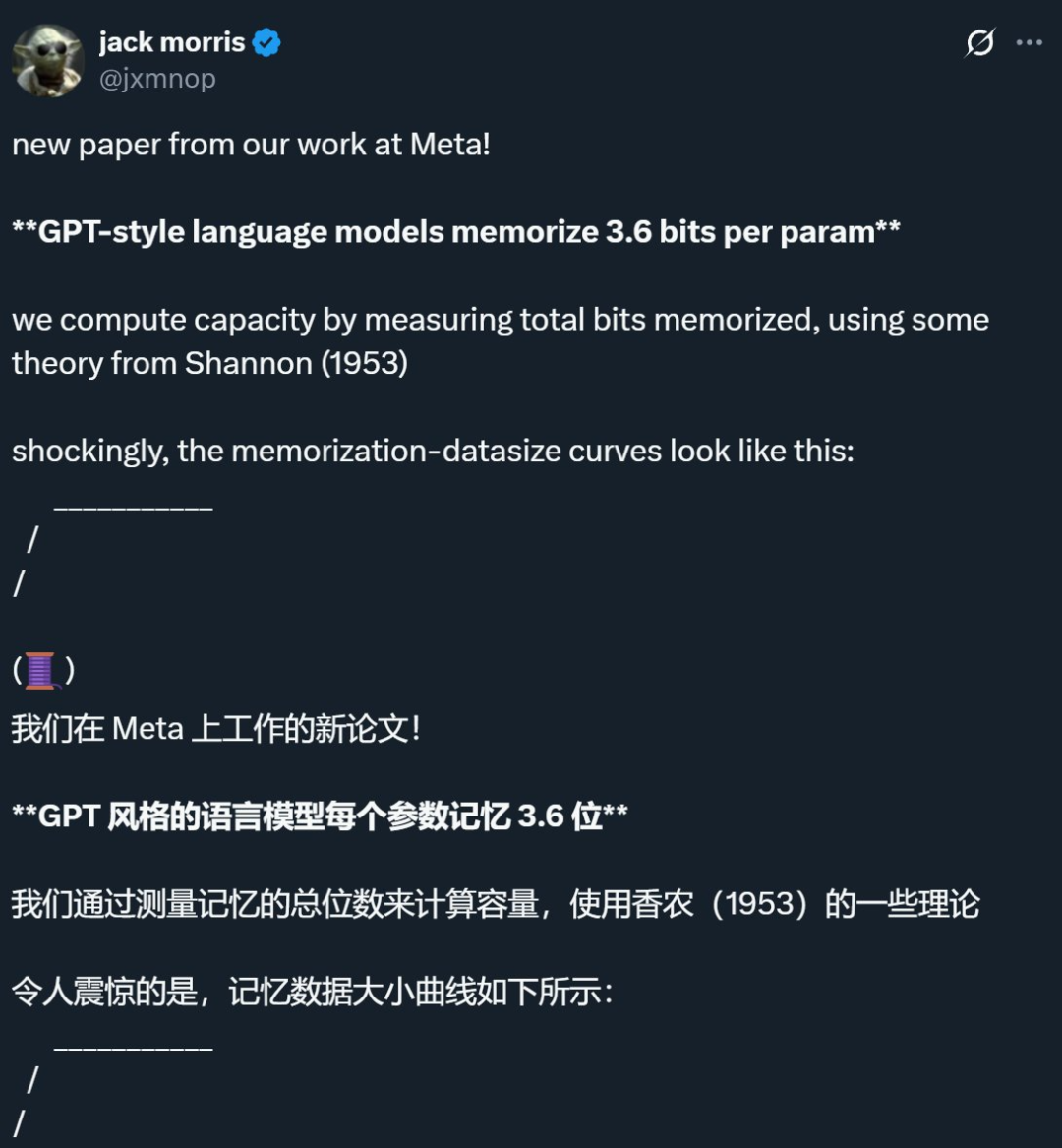
Une étude menée par Meta et d’autres entreprises révèle que la limite de mémorisation des modèles de langage est d’environ 3,6 bits par paramètre, remettant en question les connaissances traditionnelles: Une recherche conjointe de Meta, DeepMind, Cornell University et Nvidia indique que les modèles de langage de style GPT peuvent mémoriser environ 3,6 bits d’information par paramètre. L’étude a révélé que les modèles continuent de mémoriser les données d’entraînement jusqu’à ce qu’ils atteignent leur capacité maximale, après quoi un phénomène de « Grokking » (compréhension soudaine) commence à apparaître, c’est-à-dire une réduction inattendue de la mémorisation, le modèle se tournant vers l’apprentissage par généralisation. Cette découverte explique le phénomène de « double descente » : lorsque la quantité d’informations du jeu de données dépasse la capacité de stockage du modèle, celui-ci est contraint de partager des points d’information pour économiser de la capacité, favorisant ainsi la généralisation. L’étude propose également des lois d’échelle concernant la relation entre la capacité du modèle, la taille des données et le taux de réussite des attaques par inférence d’appartenance, et souligne que pour les LLM modernes entraînés sur des jeux de données extrêmement volumineux, une inférence d’appartenance fiable devient difficile (Source: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI lance une version allégée de la fonction de mémoire de ChatGPT, améliorant l’expérience d’interaction personnalisée: OpenAI a annoncé le lancement progressif d’une version allégée des améliorations de la fonction de mémoire pour les utilisateurs gratuits. En plus de la sauvegarde existante des souvenirs, ChatGPT peut désormais se référer aux conversations récentes de l’utilisateur pour fournir des réponses plus personnalisées. Cette initiative vise à rendre ChatGPT plus efficace pour la rédaction, l’obtention de conseils, l’apprentissage, etc., en s’inspirant des préférences et des intérêts de l’utilisateur. Sam Altman a également déclaré que la fonction de mémoire est devenue l’une de ses fonctionnalités préférées de ChatGPT et attend avec impatience de futures améliorations majeures. Cette mise à jour marque l’engagement d’OpenAI à rendre les interactions IA plus proches des besoins des utilisateurs et à renforcer leur fidélisation (Source: openai, sama, iScienceLuvr)
🎯 Tendances
Publication de DeepSeek-R1-0528, renforçant les capacités de raisonnement complexe et de programmation: DeepSeek a publié une version améliorée de son modèle R1, DeepSeek-R1-0528. Cette version est basée sur le modèle DeepSeek V3 Base, publié en décembre 2024, et a bénéficié d’un post-entraînement avec davantage de puissance de calcul, améliorant considérablement la profondeur de pensée et les capacités de raisonnement du modèle. Le nouveau modèle décompose les problèmes complexes de manière plus détaillée et réfléchit plus longtemps (par exemple, lors du test AIME 2025, la consommation moyenne de tokens par question est passée de 12K à 23K), obtenant ainsi des résultats de premier plan dans plusieurs benchmarks en mathématiques, programmation et logique générale, se rapprochant des performances de GPT-o3 et Gemini-2.5-Pro. De plus, la nouvelle version présente des optimisations significatives dans la réduction des hallucinations (environ 45%-50%), l’écriture créative et l’appel d’outils, par exemple en répondant de manière plus stable à des questions telles que « combien font 9.9 – 9.11 » et en générant du code front-end et back-end exécutable en une seule fois (Source: 科技狐, AI前线, Hacubu)

Les modèles de diffusion montrent leur potentiel dans les domaines du langage et du multimodal, défiant le paradigme autorégressif: Le modèle de langage Gemini Diffusion présenté lors du Google I/O 2025, avec sa vitesse de génération jusqu’à 5 fois plus rapide et ses performances de programmation comparables, a souligné le potentiel des modèles de diffusion dans le domaine de la génération de texte. Contrairement aux modèles autorégressifs qui prédisent les tokens un par un, les modèles de diffusion génèrent la sortie en débruitant progressivement, ce qui permet une itération et une correction d’erreurs rapides. Le modèle LLaDA de 8 milliards de paramètres, lancé par Ant Group en collaboration avec l’Institut d’Intelligence Artificielle Gaoling de l’Université Renmin, ainsi que le modèle de diffusion multimodale MMaDA développé par ByteDance, démontrent les explorations de pointe des équipes chinoises dans ce domaine. Ces modèles ne se contentent pas d’exceller dans les tâches linguistiques, mais progressent également dans la compréhension multimodale (comme LLaDA-V combiné avec le fine-tuning d’instructions visuelles) et dans des domaines spécifiques (comme DPLM pour la génération de séquences protéiques), laissant présager que les modèles de diffusion pourraient devenir le nouveau paradigme des modèles universels de nouvelle génération (Source: 机器之心)
Suno publie une mise à jour majeure, améliorant les capacités d’édition et de création musicale par IA: La plateforme de création musicale par IA Suno a lancé plusieurs mises à jour importantes, offrant aux utilisateurs une plus grande liberté de création et de contrôle. Les nouvelles fonctionnalités comprennent un éditeur de chansons amélioré, permettant aux utilisateurs de réorganiser, réécrire et refaire des pistes section par section sur la forme d’onde ; l’introduction d’une fonction d’extraction de stems, capable de séparer précisément les pistes en 12 sources sonores distinctes (telles que voix, batterie, basse, etc.) pour prévisualisation et téléchargement ; l’extension de la fonction d’upload, prenant en charge le téléchargement de chansons complètes d’une durée maximale de 8 minutes, permettant aux utilisateurs de créer à partir de leurs propres matériaux audio ; l’ajout d’un curseur de créativité, permettant aux utilisateurs d’ajuster le degré d’« étrangeté », de structuration ou d’influence de la référence du résultat avant la génération, afin de mieux façonner l’œuvre finale (Source: SunoMusic)
MetaAgentX lance Open CaptchaWorld pour évaluer la capacité des agents multimodaux à résoudre les CAPTCHA: Face aux difficultés actuelles des agents multimodaux à résoudre les problèmes de CAPTCHA (vérification homme-machine), l’équipe de MetaAgentX a publié la plateforme et le benchmark Open CaptchaWorld. Cette plateforme comprend 20 types de CAPTCHA modernes, totalisant 225 exemples, exigeant des agents qu’ils accomplissent des tâches dans un environnement web réel par observation, clic, glisser-déposer, etc. Les résultats des tests montrent que même les modèles de pointe comme GPT-4o n’atteignent qu’un taux de réussite de 5 % à 40 %, bien inférieur au taux de réussite moyen de 93,3 % chez l’homme. Les chercheurs ont également proposé l’indicateur « CAPTCHA Reasoning Depth » pour quantifier les étapes de « compréhension visuelle + planification cognitive + contrôle moteur » nécessaires à la résolution. Cette plateforme vise à révéler les faiblesses des agents en matière d’interaction dynamique et de planification sur de longues séquences, et à inciter les chercheurs à se concentrer sur la résolution de ce problème clé dans le déploiement pratique (Source: 量子位)

Google NotebookLM prend en charge le partage public, favorisant le partage des connaissances et la collaboration: Google a annoncé que NotebookLM (anciennement Project Tailwind) prend désormais en charge le partage public des carnets de notes. Les utilisateurs peuvent partager le contenu de leurs notes en cliquant sur « Partager » et en définissant les autorisations d’accès sur « Toute personne disposant du lien ». Cette fonctionnalité permet aux utilisateurs de partager facilement des idées, des guides d’étude et des documents d’équipe ; les destinataires peuvent parcourir le contenu, poser des questions, obtenir des résumés instantanés et des aperçus audio. Cette initiative vise à promouvoir la diffusion des connaissances et l’édition collaborative, améliorant ainsi l’utilité de NotebookLM en tant qu’outil de prise de notes IA (Source: Google, op7418)
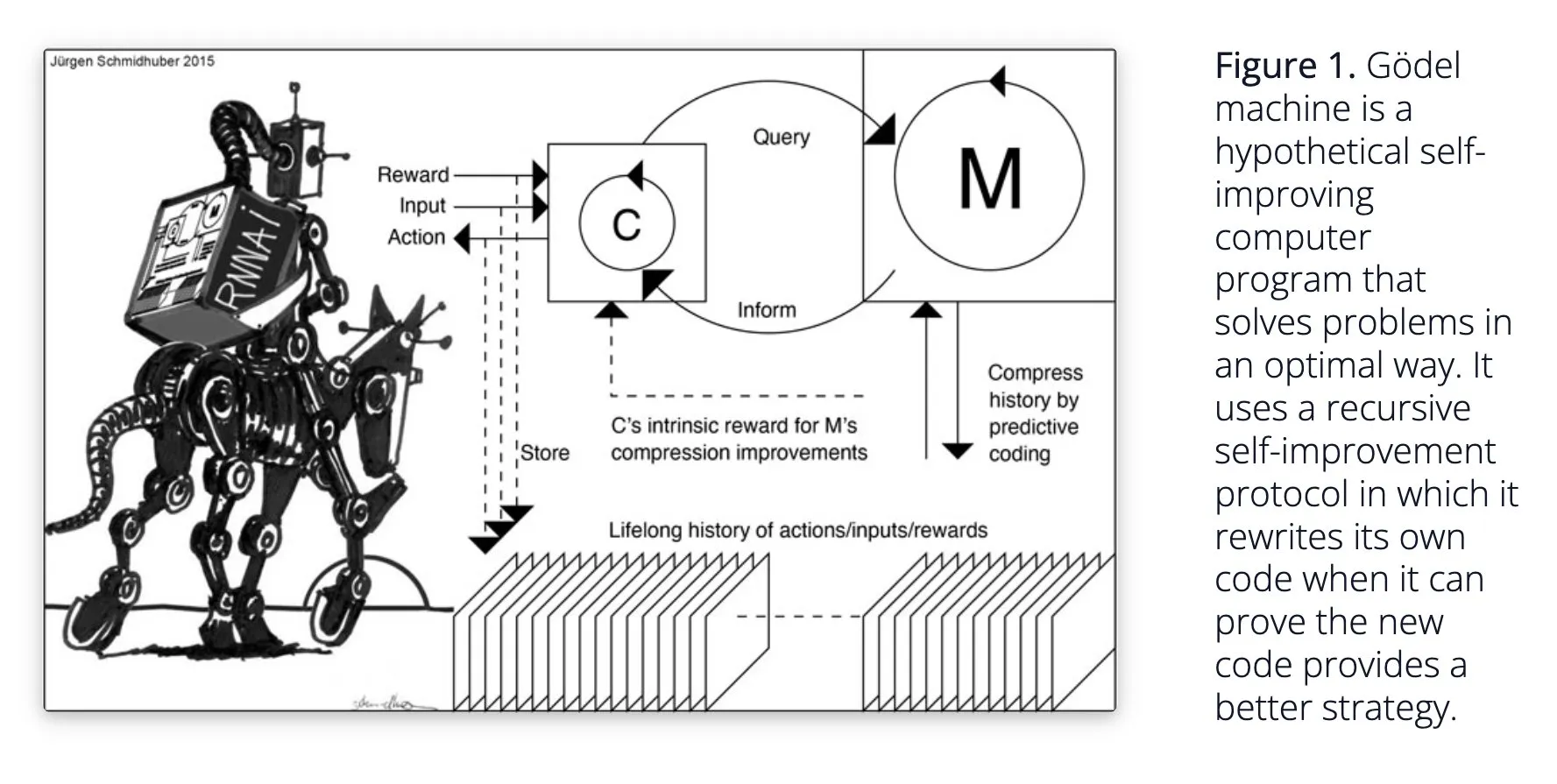
Sakana AI propose le système d’IA auto-apprenant Darwin Gödel Machine (DGM): Sakana AI a rendu publique sa recherche sur son système d’IA auto-apprenant, la Darwin Gödel Machine (DGM). DGM utilise des algorithmes évolutifs pour réécrire itérativement son propre code, améliorant ainsi continuellement ses performances dans les tâches de programmation. Le système maintient une archive d’agents de codage générés, à partir de laquelle il échantillonne et utilise des modèles de base pour créer de nouvelles versions, réalisant ainsi une exploration ouverte et formant des agents diversifiés et de haute qualité. Les expériences montrent que DGM améliore considérablement les capacités de codage sur des benchmarks tels que SWE-bench et Polyglot. Cette recherche offre de nouvelles pistes pour l’IA auto-améliorante, visant à accélérer le développement de l’IA par l’innovation autonome (Source: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind améliore la naturalité des conversations IA, ouvrant des fonctionnalités audio natives: Google DeepMind a annoncé que ses fonctionnalités audio natives rendent les conversations IA plus naturelles, capables de comprendre l’intonation et de générer une parole expressive. Cette technologie vise à ouvrir de nouvelles possibilités d’interaction entre l’homme et l’IA. Les développeurs peuvent désormais essayer ces fonctionnalités via Google AI Studio, avec des applications potentielles pour des assistants vocaux plus naturels, la génération de contenu audio, etc. (Source: GoogleDeepMind)
La technologie de génération d’images Runway Gen-4 attire l’attention, prenant en charge les références multiples et le contrôle de style: La technologie de génération d’images Gen-4 de Runway a attiré l’attention pour sa haute fidélité et ses capacités de contrôle de style sans précédent, particulièrement évidentes dans sa fonctionnalité de références multiples, offrant un nouvel espace pour l’exploration créative. Les utilisateurs peuvent utiliser cette technologie pour générer divers animaux, dinosaures ou créatures imaginaires, démontrant son potentiel dans la création de contenu visuel détaillé. L’utilisation de Runway dans des domaines tels qu’Hollywood indique également que sa technologie est progressivement appliquée à la production de contenu professionnel (Source: c_valenzuelab, c_valenzuelab)

AssemblyAI publie un nouveau modèle de transcription vocale en temps réel, améliorant les performances des applications d’IA vocale: AssemblyAI a lancé un nouveau modèle de transcription vocale en temps réel (STT), qui a attiré l’attention pour sa grande vitesse et sa précision. Ce modèle est spécialement conçu pour les développeurs qui créent des applications d’IA vocale, visant à offrir une expérience de reconnaissance vocale plus fluide et précise. Parallèlement, AssemblyAI fournit également une implémentation AssemblyAISTTService via son projet pipecat_ai, facilitant l’intégration pour les développeurs. Cette initiative témoigne de l’investissement continu et de l’innovation d’AssemblyAI dans le domaine de la technologie vocale (Source: AssemblyAI, AssemblyAI)
Microsoft Bing fête ses 16 ans, intègre GPT-4 et DALL·E, et lance Bing Video Creator: Le moteur de recherche Microsoft Bing fête ses 16 ans. Ces dernières années, Bing a été le premier à intégrer à grande échelle l’IA générative conversationnelle et est devenu le premier produit Microsoft à intégrer GPT-4 et DALL·E. Récemment, Bing a lancé gratuitement Copilot Search et Bing Video Creator dans son application mobile, ce dernier pouvant être utilisé pour générer du contenu vidéo. Cela marque l’innovation et le développement continus de Bing dans le domaine de la recherche et de la création de contenu pilotées par l’IA (Source: JordiRib1)
Andrej Karpathy impressionné par Veo 3, discute de l’impact macro de la génération vidéo: Andrej Karpathy s’est dit impressionné par le modèle de génération vidéo Veo 3 de Google et les créations de sa communauté, soulignant que l’ajout de l’audio a considérablement amélioré la qualité vidéo. Il a ensuite exploré plusieurs impacts macroéconomiques de la génération vidéo : 1. La vidéo est le moyen d’entrée à plus large bande passante pour le cerveau humain ; 2. La génération vidéo fournit à l’IA une « langue maternelle » pour comprendre le monde ; 3. La génération vidéo est une voie clé vers la simulation de la réalité et les modèles du monde ; 4. Ses besoins en calcul stimuleront le développement matériel. Cela indique que la technologie de génération vidéo n’est pas seulement une innovation dans la création de contenu, mais aussi un moteur important pour la cognition et le développement de l’IA (Source: brickroad7, dilipkay, JonathanRoss321)
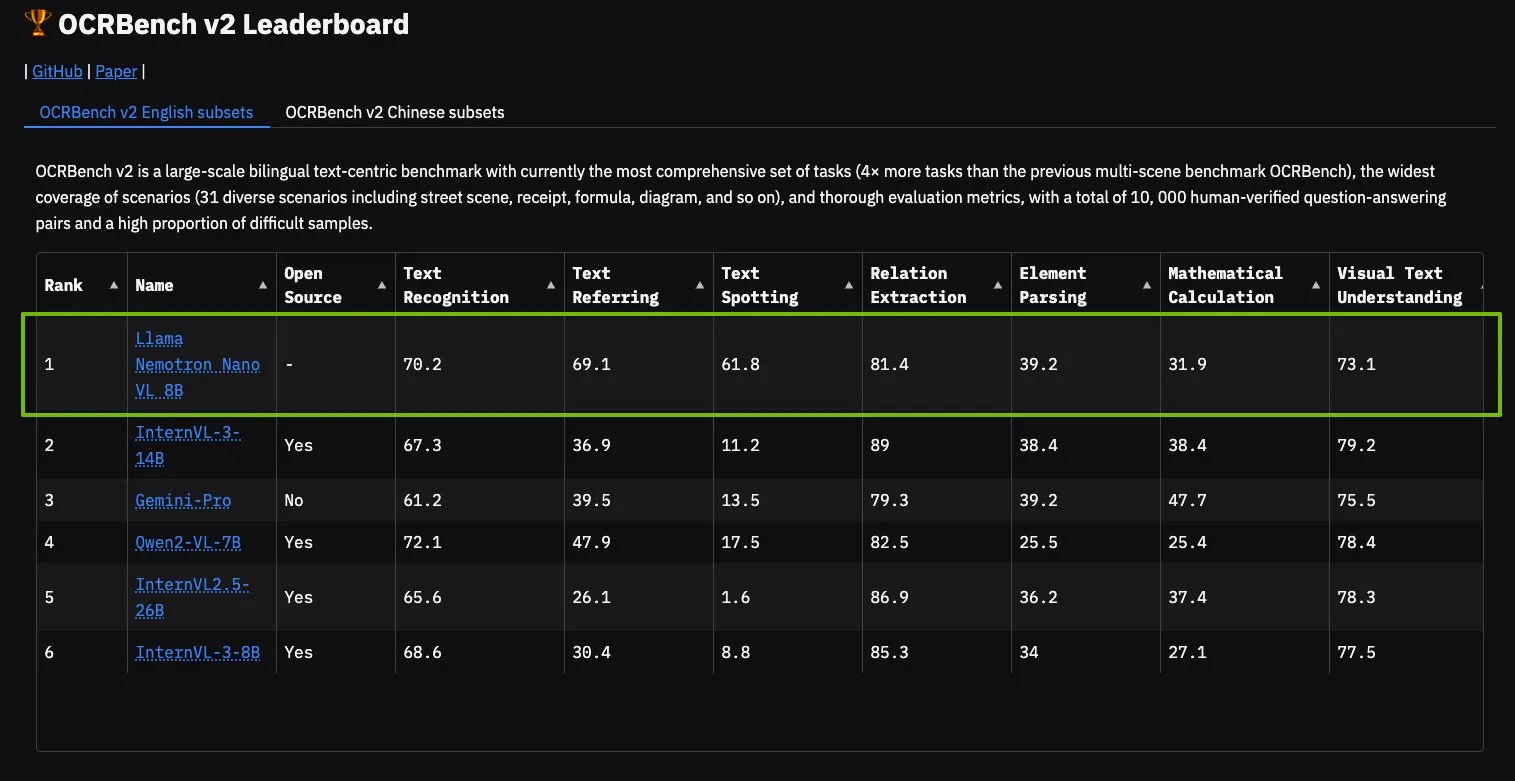
Le modèle NVIDIA Llama Nemotron Nano VL en tête du classement OCRBench V2: Le modèle Llama Nemotron Nano VL de NVIDIA a obtenu la première place du classement OCRBench V2. Ce modèle est spécialement conçu pour le traitement et la compréhension intelligents avancés de documents, capable d’extraire avec précision des informations diverses de documents complexes sur un seul GPU. Les utilisateurs peuvent essayer ce modèle via NVIDIA NIM, ce qui témoigne des progrès de NVIDIA dans les modèles d’IA miniaturisés et efficaces pour des domaines spécifiques (comme la compréhension de documents) (Source: ctnzr)
🧰 Outils
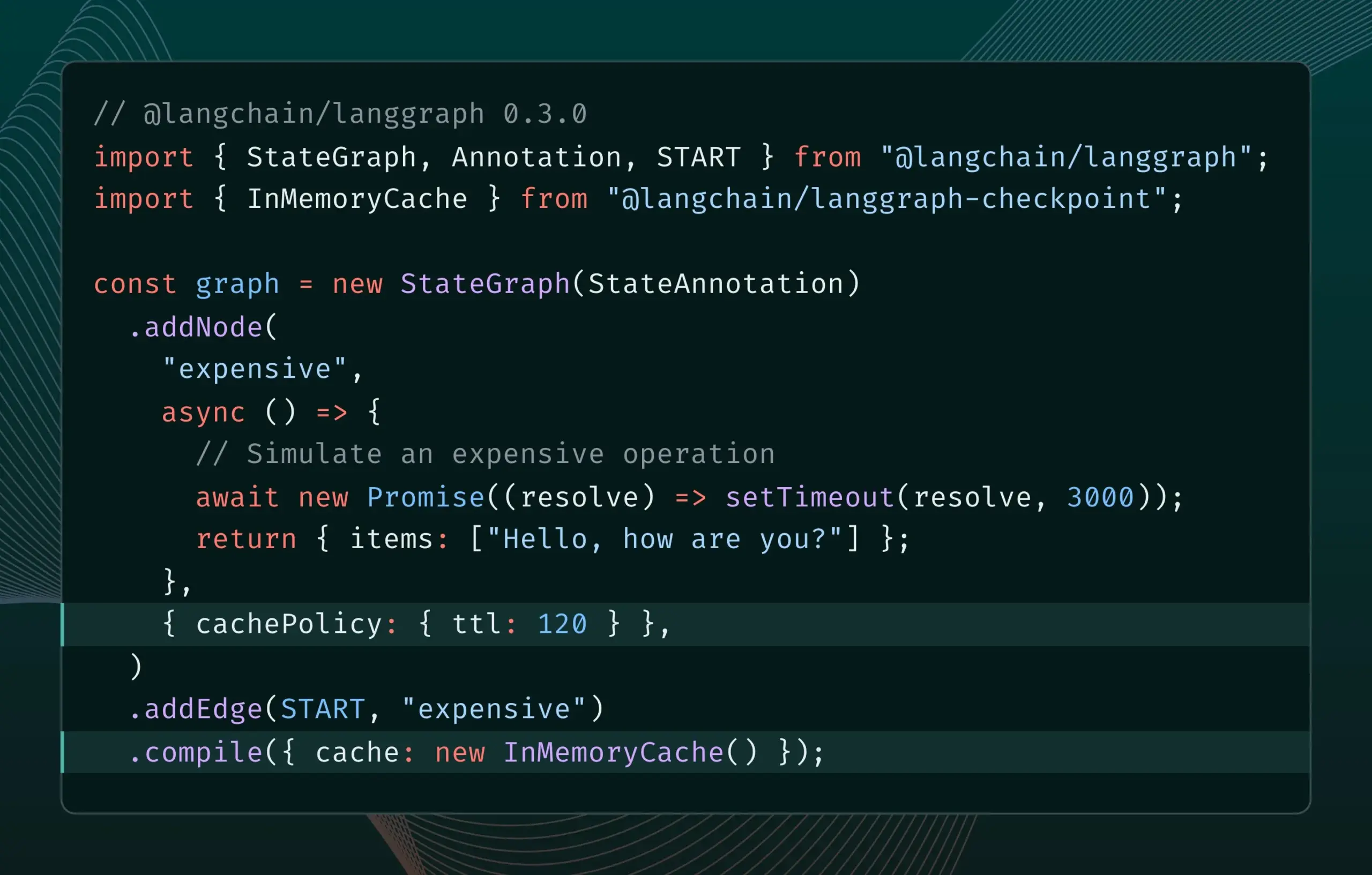
LangGraph.js version 0.3 introduit la mise en cache des nœuds/tâches: LangGraph.js a publié la version 0.3, ajoutant une fonctionnalité de mise en cache des nœuds/tâches. Cette fonction vise à accélérer les flux de travail en évitant les calculs redondants, particulièrement utile pour les agents itératifs coûteux ou à longue durée d’exécution. La nouvelle version prend en charge à la fois l’API Graph et l’API Impérative, offrant une plus grande efficacité aux développeurs JavaScript pour la création d’applications IA complexes (Source: Hacubu, hwchase17)
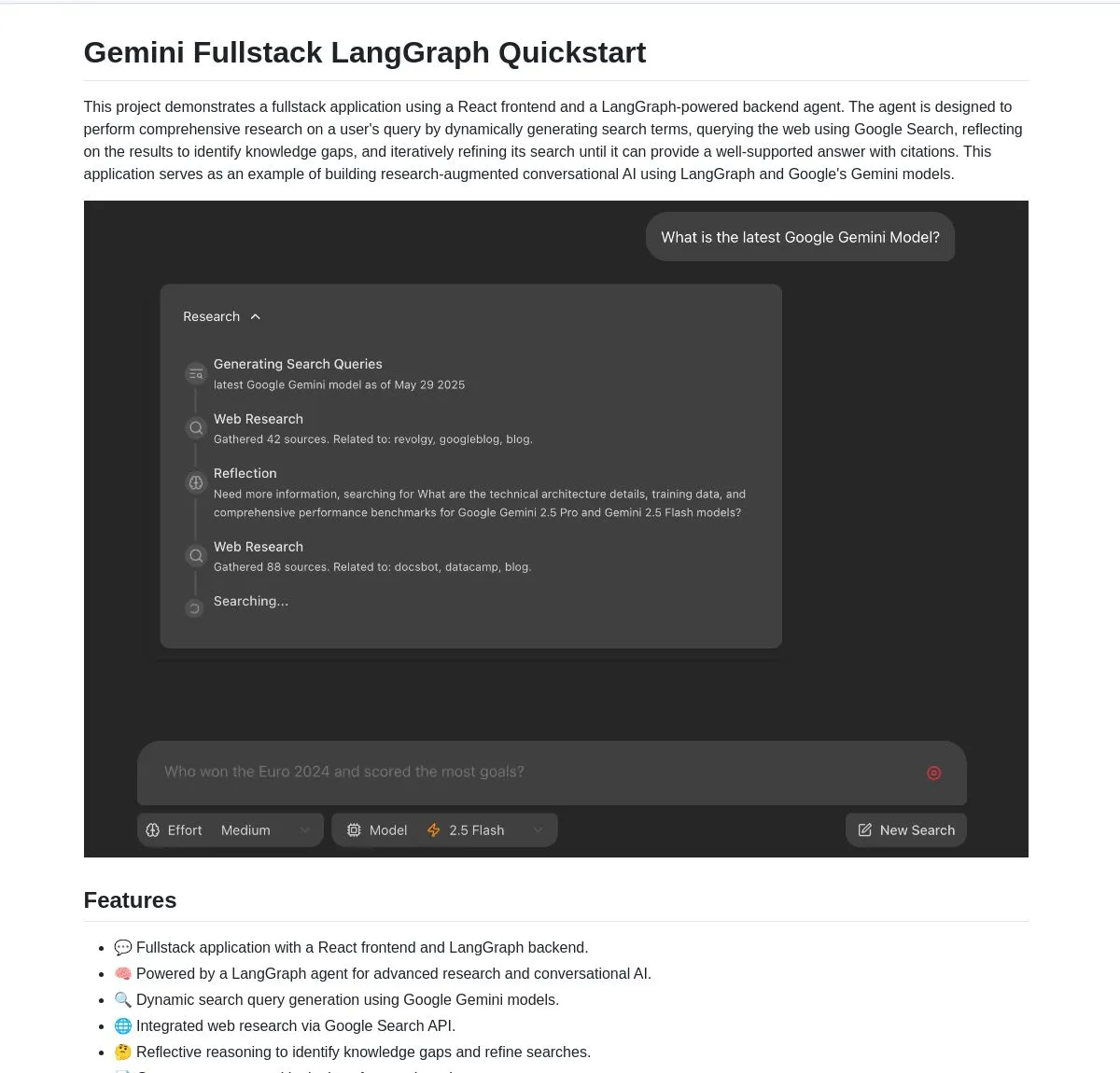
Google publie en open source une application full-stack Gemini Research Agent, basée sur Gemini et LangGraph: Google a publié un exemple d’application full-stack d’assistant de recherche intelligent basé sur le modèle Gemini et LangGraph – gemini-fullstack-langgraph-quickstart. Cette application peut optimiser dynamiquement les requêtes, fournir des réponses avec citations grâce à un apprentissage itératif, et prend en charge le contrôle de différentes intensités de recherche. Elle utilise l’outil de recherche Google natif de Gemini pour la recherche sur le web et le raisonnement réflexif, visant à fournir aux développeurs un point de départ pour la création d’applications IA de recherche avancées (Source: LangChainAI, hwchase17, dotey, karminski3)
FedRAG ajoute une fonctionnalité de pontage avec LangChain, facilitant l’intégration et le fine-tuning des systèmes RAG: FedRAG a annoncé la prise en charge d’un pontage avec LangChain, réalisé par un contributeur externe. Les utilisateurs peuvent assembler des systèmes RAG via FedRAG et affiner les modèles des composants générateur/récupérateur pour les adapter à des bases de connaissances spécifiques. Après l’affinage, il est possible de les ponter vers des frameworks d’inférence RAG populaires comme LangChain, en tirant parti de leur écosystème et de leurs fonctionnalités. Cette mise à jour vise à simplifier les processus de construction, d’optimisation et de déploiement des systèmes RAG (Source: nerdai)

Ollama lance la fonction « réflexion », permettant de séparer le processus de pensée de la réponse finale: Ollama a mis à jour sa plateforme, ajoutant une option pour séparer le processus de pensée et la réponse finale pour les modèles prenant en charge la fonction « réflexion » (comme DeepSeek-R1-0528). Les utilisateurs peuvent choisir de visualiser le contenu de la « réflexion » du modèle ou de désactiver cette fonction pour obtenir une réponse directe. Cette fonctionnalité est applicable à la CLI, à l’API et aux bibliothèques Python/JavaScript d’Ollama, offrant aux utilisateurs des moyens d’interaction plus flexibles avec les modèles (Source: Hacubu)
Firecrawl lance le point de terminaison /search, intégrant les fonctions de recherche et de crawling: Firecrawl a publié un nouveau point de terminaison API /search, permettant aux utilisateurs d’effectuer une recherche sur le web et de crawler tous les résultats dans un format compatible avec les LLM en un seul appel API. Cette fonctionnalité vise à simplifier le processus de découverte et d’utilisation des données web pour les agents IA et les développeurs. StateGraph de LangChain peut être utilisé pour construire des processus automatisés exploitant cette fonctionnalité, par exemple pour trouver automatiquement des concurrents, crawler leurs sites web et générer des rapports d’analyse (Source: hwchase17, LangChainAI, omarsar0)
LlamaIndex intègre MCP, améliorant les capacités des agents et le déploiement des flux de travail: LlamaIndex a annoncé l’intégration de MCP (Model Component Protocol), visant à améliorer les capacités d’utilisation des outils de ses agents et la flexibilité du déploiement des flux de travail. Cette intégration fournit des fonctions d’assistance pour aider les agents LlamaIndex à utiliser les outils du serveur MCP et permet de servir n’importe quel flux de travail LlamaIndex en tant que serveur MCP. Cette initiative vise à étendre l’ensemble d’outils des agents LlamaIndex et à permettre à leurs flux de travail de s’intégrer de manière transparente dans les infrastructures MCP existantes (Source: jerryjliu0)

Modal lance LLM Engine Advisor, fournissant des benchmarks de performance pour les moteurs de modèles open source: Modal a publié LLM Engine Advisor, une application de benchmarking conçue pour aider les utilisateurs à choisir le meilleur moteur LLM et les meilleurs paramètres. Cet outil fournit des données de performance, telles que la vitesse et le débit maximal, pour l’exécution de modèles open source (comme DeepSeek V3, Qwen 2.5 Coder) sur différents matériels (comme des environnements multi-GPU) en utilisant différents moteurs d’inférence (comme vLLM, SGLang). Cette initiative vise à améliorer la transparence et l’efficacité de la prise de décision pour l’exécution de LLM auto-hébergés (Source: charles_irl, akshat_b, sarahcat21)
PlayDiffusion : PlayAI lance un nouveau modèle de réparation audio, capable de remplacer le contenu des dialogues dans l’audio: PlayAI a publié un nouveau modèle nommé PlayDiffusion, capable de remplacer de manière transparente le contenu des dialogues dans les fichiers audio tout en préservant les caractéristiques vocales du locuteur d’origine. Cette technologie de « réparation audio » offre de nouvelles possibilités pour l’édition audio, comme la modification de mots ou de phrases spécifiques dans des podcasts, des livres audio ou des doublages vidéo, sans avoir à réenregistrer l’intégralité du segment. Le projet est open source sur GitHub (Source: _mfelfel, karminski3)
Hugging Face lance un outil de déduplication sémantique pour optimiser la qualité des jeux de données d’entraînement: Inspiré par AutoDedup de Maxime Labonne, Hugging Face Spaces a mis en ligne une nouvelle application de déduplication sémantique. Cet outil permet aux utilisateurs de sélectionner un ou plusieurs jeux de données sur Hugging Face Hub, d’effectuer une intégration sémantique pour chaque ligne de données, puis de supprimer le contenu quasi-dupliqué en fonction d’un seuil défini. Cette initiative vise à aider les chercheurs et les développeurs à améliorer la qualité de leurs jeux de données d’entraînement, en évitant que la redondance des données n’entraîne une baisse des performances du modèle ou une faible efficacité de l’entraînement (Source: ben_burtenshaw, ben_burtenshaw)

La demande pour Perplexity Labs explose, les utilisateurs peuvent créer rapidement des logiciels personnalisés: Perplexity Labs a connu une augmentation significative de la demande en raison de sa capacité à créer rapidement des logiciels personnalisés à partir d’une seule invite, certains utilisateurs achetant même plusieurs comptes Pro pour obtenir plus de requêtes Labs. Cela reflète un fort intérêt des utilisateurs pour la création et la modification rapides d’outils logiciels en fonction de leurs propres besoins, le développement de logiciels personnalisés piloté par l’IA devenant une tendance (Source: AravSrinivas, AravSrinivas)
Ollama et Hazy Research collaborent pour lancer Secure Minions, permettant une collaboration privée entre LLM locaux et cloud: Le projet Minions du laboratoire Hazy Research de Stanford, en connectant les modèles locaux Ollama aux modèles de pointe du cloud, vise à réduire considérablement les coûts du cloud (5 à 30 fois) tout en maintenant une précision proche de celle des modèles de pointe (98%). Le projet Secure Minion transforme en outre les GPU tels que H100 en zones sécurisées, réalisant le cryptage de la mémoire et des calculs, garantissant la confidentialité des données. Ce mode de fonctionnement hybride, tout en améliorant la protection de la vie privée, offre également aux utilisateurs une solution d’utilisation des LLM plus économique et efficace (Source: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa et OpenRouter s’associent pour doter plus de 400 LLM de capacités de recherche web: Le moteur de recherche IA Exa a annoncé un partenariat avec OpenRouter pour fournir des fonctionnalités de recherche web à plus de 400 modèles de langage volumineux sur la plateforme OpenRouter. Cela signifie que les développeurs et les utilisateurs utilisant ces LLM pourront facilement faire appel aux capacités de recherche d’Exa, améliorant ainsi la capacité des modèles à acquérir des informations en temps réel et à mettre à jour leurs connaissances, et améliorant davantage les performances d’applications telles que RAG (Retrieval Augmented Generation) (Source: menhguin)

📚 Apprentissage
Microsoft lance un cours d’introduction à MCP « MCP for Beginners »: Microsoft a publié un cours d’introduction destiné aux débutants sur MCP (Microsoft Copilot Platform, potentiellement une erreur de frappe, devrait faire référence à Microsoft CoCo Framework ou à un protocole d’agent IA similaire). Ce cours vise à aider les débutants à maîtriser les concepts fondamentaux, les méthodes d’implémentation et les applications pratiques de MCP. Le contenu comprend les spécifications de l’architecture du protocole, des guides tutoriels et des exercices pratiques de code dans plusieurs langages de programmation. La structure du cours couvre l’introduction, les concepts fondamentaux, la sécurité, les premiers pas, les notions avancées, ainsi que la communauté et les études de cas, et fournit des exemples de projets tels que des calculatrices de base et avancées (Source: dotey)

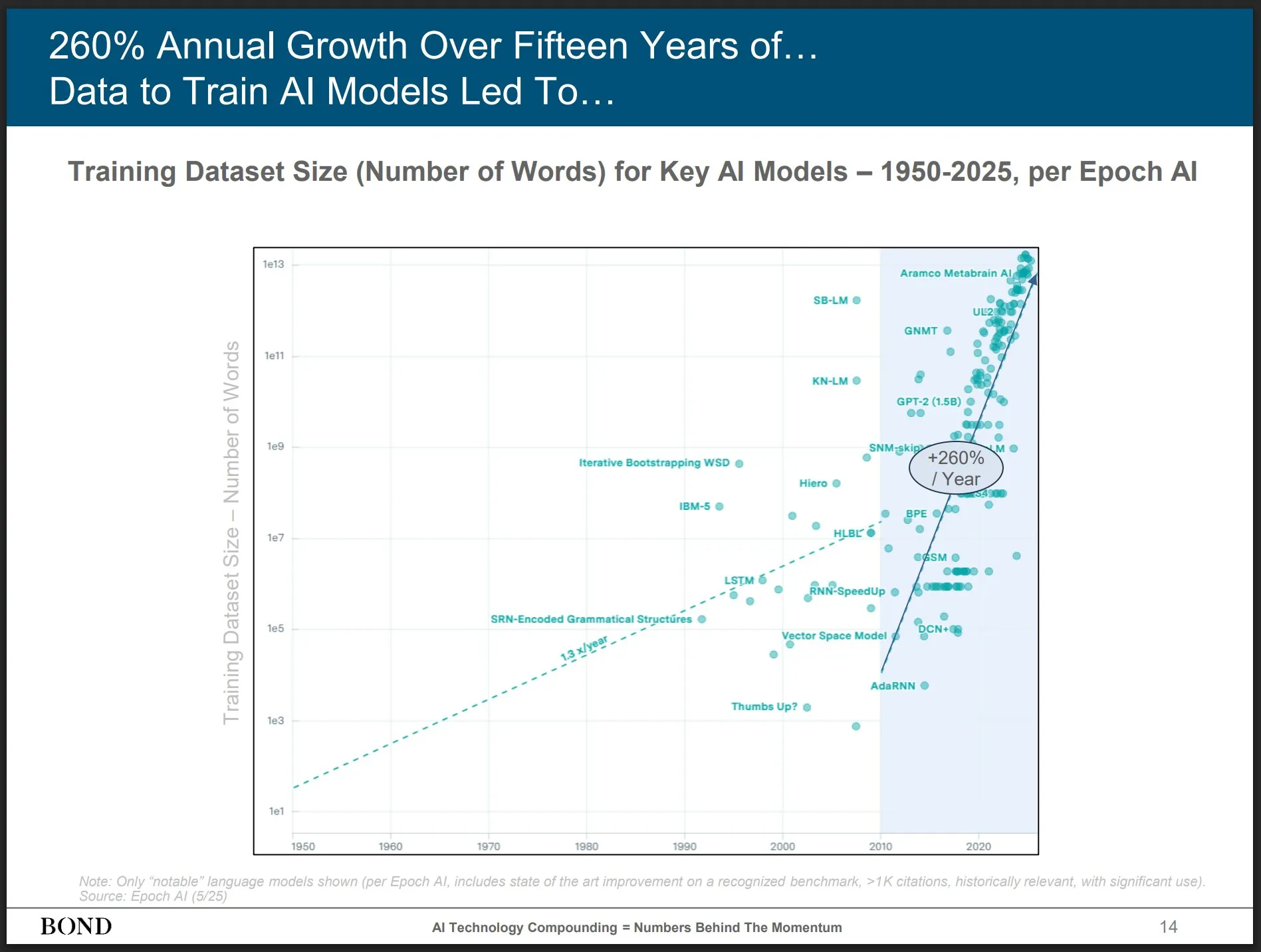
Bond Capital publie son rapport sur les tendances de l’IA de mai 2025, offrant un aperçu du développement de l’industrie: La célèbre société de capital-risque Bond Capital a publié son rapport de 339 pages intitulé « 2025-05 AI Trends Report », analysant de manière exhaustive les données et les perspectives de l’IA dans divers domaines. Le rapport souligne notamment que ChatGPT compte 800 millions d’utilisateurs actifs mensuels (dont 90 % hors Amérique du Nord) et 1 milliard de recherches quotidiennes ; les postes informatiques liés à l’IA ont augmenté de 448 % ; le coût de l’entraînement des modèles de pointe dépasse 1 milliard de dollars par session ; les LLM deviennent une infrastructure. Le rapport souligne que la clé de la concurrence réside dans la création des meilleurs produits pilotés par l’IA, et que le marché actuel est celui des bâtisseurs (Source: karminski3)
Des articles explorent la relation entre l’apprentissage par renforcement et la capacité de raisonnement des LLM, ProRL et Limit-of-RLVR suscitent l’attention: Deux articles de recherche sur la relation entre l’apprentissage par renforcement (RL) et la capacité de raisonnement des grands modèles de langage (LLM) ont suscité des discussions. L’un est intitulé « Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? », et l’autre est « ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models » de NVIDIA. Ces études explorent dans quelle mesure le RL (en particulier le RLVR, l’apprentissage par renforcement avec récompense vérifiable) peut améliorer la capacité de raisonnement de base des LLM, et l’impact de l’entraînement RL continu sur l’expansion des limites de raisonnement des LLM. Les discussions connexes suggèrent que des données d’entraînement RLVR de haute qualité et des mécanismes de récompense efficaces sont essentiels (Source: scaling01, Dorialexander, scaling01)

L’article « How Programming Concepts and Neurons Are Shared in Code Language Models » explore les mécanismes de partage des concepts de programmation et des neurones dans les modèles de langage de code: Cette étude examine les relations entre les espaces conceptuels internes des grands modèles de langage (LLM) lorsqu’ils traitent plusieurs langages de programmation (PL) et l’anglais. En soumettant les modèles de la série Llama à des tâches de traduction few-shot, il a été constaté que dans les couches intermédiaires, les espaces conceptuels sont plus proches de l’anglais (y compris les mots-clés des PL) et tendent à attribuer des probabilités élevées aux tokens anglais. L’analyse de l’activation des neurones montre que les neurones spécifiques à une langue sont principalement concentrés dans les couches inférieures, tandis que les neurones uniques à chaque PL ont tendance à apparaître dans les couches supérieures. L’étude offre de nouvelles perspectives sur la manière dont les LLM représentent intérieurement les PL (Source: HuggingFace Daily Papers)
Un nouvel article « Pixels Versus Priors » contrôle les connaissances a priori dans les MLLM via des contrefactuels visuels: Cette étude explore si le raisonnement des grands modèles de langage multimodaux (MLLM) lors de tâches telles que la réponse à des questions visuelles repose davantage sur les connaissances du monde mémorisées ou sur les informations visuelles de l’image d’entrée. Les chercheurs ont introduit le jeu de données Visual CounterFact, contenant des images visuelles contrefactuelles qui entrent en conflit avec les connaissances a priori du monde (par exemple, des fraises bleues). Les expériences montrent que les prédictions initiales du modèle reflètent les a priori mémorisés, mais qu’elles se tournent vers les preuves visuelles dans les étapes intermédiaires et tardives. L’article propose le vecteur de guidage PvP (Pixels Versus Priors), qui, en intervenant sur la couche d’activation, contrôle si la sortie du modèle penche vers les connaissances du monde ou l’entrée visuelle, modifiant avec succès la plupart des prédictions de couleur et de taille (Source: HuggingFace Daily Papers)
L’article GuidedQuant de l’ICML 2025 propose d’améliorer les méthodes PTQ hiérarchiques en guidant par la perte finale: GuidedQuant est une nouvelle méthode de quantification post-entraînement (PTQ) qui améliore les performances des méthodes PTQ hiérarchiques en intégrant le guidage par la perte finale (end loss) dans l’objectif. Cette méthode utilise le gradient par caractéristique de la perte finale pour pondérer l’erreur de sortie hiérarchique, ce qui correspond à l’information de Fisher diagonale par blocs qui préserve les dépendances intra-canal. De plus, l’article introduit LNQ, un algorithme de quantification scalaire non uniforme qui garantit une réduction monotone de la valeur cible de quantification. Les expériences montrent que GuidedQuant surpasse les méthodes SOTA existantes en quantification scalaire des poids uniquement, en quantification vectorielle des poids uniquement, ainsi qu’en quantification des poids et des activations, et a été appliqué à la quantification 2-4 bits de modèles tels que Qwen3, Gemma3, Llama3.3 (Source: Reddit r/MachineLearning)

L’AI Engineer World’s Fair se tient à San Francisco, axée sur les pratiques d’ingénierie de l’IA et les technologies de pointe: L’AI Engineer World’s Fair se déroule actuellement à San Francisco, réunissant de nombreux ingénieurs, chercheurs et développeurs du domaine de l’IA. Le programme de la conférence comprend de nombreux sujets d’actualité tels que l’apprentissage par renforcement, les noyaux, l’inférence et les agents, l’optimisation des modèles (RFT, DPO, SFT), le codage par agents, la construction d’agents vocaux, etc. Pendant l’événement, des experts d’entreprises telles qu’OpenAI et Google feront des présentations et animeront des ateliers, et de nouveaux produits et technologies seront lancés. Les membres de la communauté participent activement, partagent le programme de la conférence et organisent des rencontres hors ligne, ce qui témoigne de la vitalité de la communauté de l’ingénierie de l’IA et de son enthousiasme pour les technologies de pointe (Source: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Affaires
Shidu Intelligence finalise un tour de table de plusieurs millions de yuans pour accélérer le déploiement multi-scénarios de lunettes intelligentes IA: Suzhou Shidu Intelligent Technology Co., Ltd. a annoncé la finalisation d’un tour de table de plusieurs millions de yuans. Les fonds seront utilisés pour la R&D des technologies clés des lunettes intelligentes IA, l’expansion du marché et la construction d’un écosystème. L’entreprise se concentre sur l’application des lunettes intelligentes IA dans les domaines de la santé connectée (comme les lunettes de lecture intelligentes, les lunettes d’assistance intelligentes pour aveugles), de la vie intelligente (lunettes de mode intelligentes, lunettes de cyclisme) et de la fabrication intelligente (lunettes industrielles intelligentes, contrôleurs vocaux). Ses produits sont positionnés dans une fourchette de prix de 200 à 1000 yuans, visant à promouvoir la popularisation des lunettes intelligentes grâce à un rapport qualité-prix élevé (Source: 36氪)

Rumeur d’acquisition de l’assistant de programmation IA Windsurf par OpenAI, suscitant des spéculations sur la rupture de fourniture des modèles Claude par Anthropic: Des rumeurs de marché suggèrent qu’OpenAI pourrait acquérir l’outil de programmation IA Windsurf (anciennement Codeium) pour environ 3 milliards de dollars. Dans ce contexte, Varun Mohan, PDG de Windsurf, a publié un message indiquant qu’Anthropic avait coupé son accès direct à presque tous ses modèles Claude 3.x, y compris Claude 3.5 Sonnet, avec un préavis extrêmement court. Windsurf a exprimé sa déception et a rapidement transféré sa puissance de calcul vers d’autres fournisseurs de services d’inférence, tout en offrant aux utilisateurs concernés une réduction sur Gemini 2.5 Pro. La communauté spécule que cette décision d’Anthropic pourrait être liée à l’acquisition potentielle par OpenAI, craignant que cela n’affecte la concurrence dans l’industrie et le choix des développeurs. Auparavant, Windsurf n’avait pas non plus obtenu le soutien direct d’Anthropic lors du lancement de Claude 4 (Source: AI前线)

Hygon Information Technology prévoit une fusion par échange d’actions avec Sugon, intégrant la chaîne industrielle nationale de la puissance de calcul: Le concepteur de puces IA Hygon Information Technology a annoncé son intention d’absorber son principal actionnaire, le fabricant de serveurs Sugon, par le biais d’un échange d’actions. La capitalisation boursière de Hygon Information Technology est d’environ 316,4 milliards de yuans, tandis que celle de Sugon est d’environ 90,5 milliards de yuans. Cette fusion de type « serpent avalant un éléphant » vise à optimiser la structure industrielle, des puces aux logiciels et systèmes, à renforcer, compléter et étendre la chaîne industrielle, et à exploiter les synergies technologiques. Selon les analystes, cette fusion contribuera à résoudre les transactions complexes entre parties liées et les problèmes potentiels de concurrence déloyale, à réduire les coûts d’exploitation et à s’adapter à la tendance des solutions de puissance de calcul de bout en bout à l’ère de l’IA, marquant une possible accélération du transfert de pouvoir de la technologie des semi-conducteurs chinoise du calcul traditionnel vers le calcul IA (Source: 36氪)
🌟 Communauté
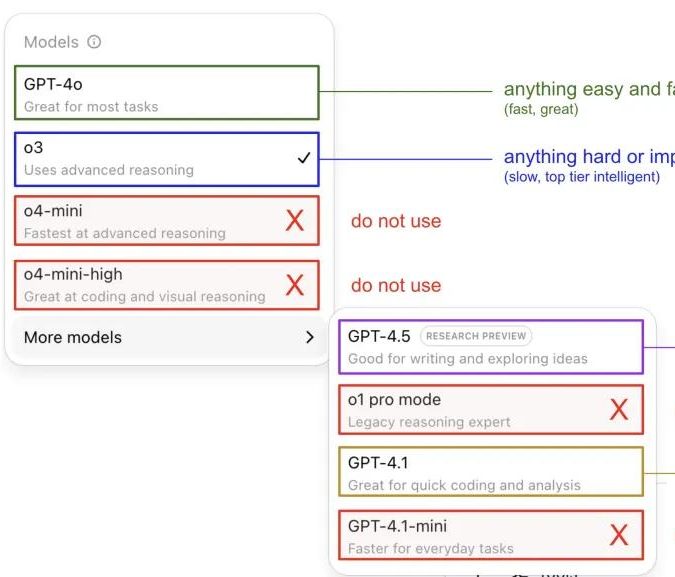
Andrej Karpathy partage son expérience d’utilisation des modèles ChatGPT, suscitant des discussions au sein de la communauté: Andrej Karpathy a partagé son expérience personnelle d’utilisation des différentes versions de ChatGPT : pour les tâches importantes ou difficiles, il recommande d’utiliser o3, plus puissant en raisonnement ; pour les problèmes quotidiens de faible à moyenne difficulté, on peut choisir 4o ; pour les tâches d’amélioration de code, GPT-4.1 est adapté ; lorsqu’une recherche approfondie et une synthèse de plusieurs liens sont nécessaires, il utilise la fonction de recherche approfondie (basée sur o3). Ce partage d’expérience a suscité de nombreuses discussions au sein de la communauté, de nombreux utilisateurs partageant leurs préférences d’utilisation et leurs opinions sur le choix des modèles, tout en reflétant également la confusion des utilisateurs concernant la dénomination confuse des modèles d’OpenAI et l’absence de fonction de sélection automatique des modèles (Source: 量子位, JeffLadish)
Un développeur partage son expérience de deux semaines de programmation avec Agentic AI : de l’émerveillement au désenchantement, pour finalement opter pour une refonte manuelle: Un responsable technique avec 10 ans d’expérience a partagé son expérience d’intégration d’Agentic AI (spécifiquement les agents de programmation IA) dans son processus de développement d’applications de médias sociaux. Au début, l’IA pouvait générer rapidement des modules fonctionnels, écrire la logique front-end et back-end et les tests unitaires, avec une efficacité étonnante, générant environ 12 000 lignes de code en deux semaines. Cependant, à mesure que la complexité de la base de code augmentait, l’IA a commencé à commettre des erreurs fréquentes lors du traitement de nouvelles fonctionnalités, à tomber dans des boucles et à avoir du mal à admettre ses échecs. Le code généré présentait également des problèmes tels qu’un nommage imprécis et du code dupliqué, rendant la base de code difficile à maintenir et faisant perdre confiance au développeur. Finalement, ce développeur a décidé de n’utiliser le code généré par l’IA que comme une « référence vague », de refondre manuellement toutes les fonctionnalités et a estimé que l’IA est actuellement plus adaptée à l’analyse du code existant et à la fourniture d’exemples qu’à l’écriture directe de code fonctionnel (Source: CSDN)

La définition d’Agent IA et la distinction avec les flux de travail suscitent l’attention, le potentiel d’application futur est énorme: La communauté discute de la distinction entre les concepts d’Agent IA et de Workflow (flux de travail). Un Agent désigne généralement un LLM accédant à des outils dans une boucle, fonctionnant librement selon des instructions ; un Workflow est une série d’étapes exécutées de manière principalement déterministe, pouvant inclure un LLM pour accomplir des sous-tâches. Bien qu’il existe des recoupements (un Agent peut être invité à s’exécuter de manière déterministe, un Workflow peut contenir des composants agentiques), cette distinction reste ontologiquement significative. Parallèlement, le potentiel des Agents IA dans les applications d’entreprise est largement reconnu, des géants comme Tencent et ByteDance investissant dans le domaine des agents intelligents. Par exemple, Tencent transforme sa base de connaissances de grands modèles en une plateforme de développement d’agents intelligents, tandis que ByteDance dispose de la plateforme Coze (Kouzi), visant à aider les entreprises à mettre en œuvre des systèmes d’agents IA natifs (Source: fabianstelzer, 蓝洞商业)
Dwarkesh Patel discute des LLM et de la chronologie de l’AGI, estimant que l’apprentissage continu est le principal goulot d’étranglement: Dwarkesh Patel a exposé sur son blog son point de vue sur la chronologie de l’AGI (Intelligence Artificielle Générale), estimant que les LLM manquent actuellement de la capacité humaine à accumuler du contexte par la pratique, à réfléchir aux échecs et à apporter de petites améliorations, c’est-à-dire la capacité d’apprentissage continu. Il considère que c’est un énorme goulot d’étranglement pour l’utilité des modèles, et que la résolution de ce problème pourrait prendre plusieurs années. Ce point de vue a suscité des discussions parmi plusieurs chercheurs en IA, dont Andrej Karpathy. Karpathy reconnaît également les lacunes des LLM en matière d’apprentissage continu et les compare à des collègues souffrant d’amnésie antérograde. Ces discussions soulignent les défis à relever pour parvenir à une véritable AGI, ainsi que la nécessité d’une réflexion approfondie sur les mécanismes d’apprentissage des modèles (Source: dwarkesh_sp, JeffLadish, dwarkesh_sp)

Les questions de brevetabilité de l’IA dans la découverte de médicaments suscitent l’attention, Science publie un article appelant à la prudence: L’article du forum politique de la revue « Science » intitulé « What patents on AI-derived drugs reveal » explore l’application de l’IA dans le domaine de la découverte de médicaments et son impact sur le système des brevets. L’étude souligne que lorsque les entreprises natives de l’IA déposent des brevets de médicaments, les données d’essais in vivo sont souvent moins nombreuses que celles des sociétés pharmaceutiques traditionnelles, ce qui peut conduire à l’abandon de médicaments prometteurs faute de recherches ultérieures. Parallèlement, la grande quantité de nouvelles molécules générées par l’IA, une fois rendues publiques, pourrait devenir un « état de la technique » et empêcher d’autres entreprises de breveter ces molécules et d’y investir davantage. L’article suggère de relever les exigences de dépôt de brevet, en exigeant davantage de données d’essais in vivo, et de permettre à d’autres entreprises de breveter des molécules générées par l’IA qui n’ont pas été testées, tout en renforçant l’exclusivité réglementaire au stade des essais cliniques de nouveaux médicaments, afin d’équilibrer l’incitation à l’innovation et l’intérêt public (Source: 36氪)
💡 Autres
L’affaire du « putsch » contre Altman pourrait être adaptée en film intitulé « Artificial », avec la participation de réalisateurs et producteurs de renom: Selon The Hollywood Reporter, MGM prévoit d’adapter les changements à la direction d’OpenAI en un film, provisoirement intitulé « Artificial ». Le célèbre réalisateur italien Luca Guadagnino pourrait le réaliser, et parmi les producteurs figure David Heyman, de la série « Harry Potter ». Le casting est en cours de discussion, des rumeurs suggérant qu’Andrew Garfield (qui a joué Spider-Man et Savarin dans « The Social Network ») pourrait incarner Sam Altman, Yuriy Borisov pourrait jouer Ilya Sutskever, et Monica Barbaro pourrait jouer Mira Murati. Cette nouvelle a suscité de vives réactions parmi les internautes, qui l’ont comparée au film « The Social Network » (Source: 36氪, janonacct)
L’expérience du service client IA suscite la controverse, les utilisateurs se plaignent d’une « IA stupide » et de difficultés à joindre un agent humain: Récemment, pendant les grandes promotions du commerce électronique, de nombreux consommateurs ont signalé que la communication avec le service client IA était difficile, que les réponses étaient hors sujet et qu’il était extrêmement difficile de joindre un agent humain, ce qui a entraîné une baisse de la qualité du service. Selon les données de l’Administration d’État pour la Régulation du Marché, en 2024, les plaintes dans le domaine du service après-vente du commerce électronique liées au « service client intelligent » ont augmenté de 56,3 %. Les utilisateurs estiment généralement que le service client IA a du mal à résoudre les problèmes personnalisés, que ses réponses sont rigides et qu’il n’est pas assez convivial pour les groupes spéciaux tels que les personnes âgées. L’article appelle les entreprises à ne pas sacrifier la qualité du service tout en cherchant à réduire les coûts et à améliorer l’efficacité, à optimiser la technologie IA, à définir clairement les scénarios d’application du service client IA et à maintenir des canaux de service humain pratiques (Source: 36氪)

Discussion sur l’application de l’IA dans la création de contenu et les stratégies d’adaptation des créateurs: L’application croissante des technologies IA (telles que DeepSeek, Suno, Veo 3) dans la création de contenu (articles, musique, vidéos, etc.) suscite l’anxiété des créateurs de contenu quant à leurs perspectives de carrière. L’analyse suggère que le paradigme du contenu évolue de la « recommandation personnalisée » à la « génération personnalisée ». À court terme, les plateformes pourraient ne pas remplacer complètement les créateurs par l’IA en raison des coûts élevés des essais et erreurs ; les créateurs pourraient monétiser en créant des modèles de style uniques et en les concédant sous licence. À long terme, les créateurs devront ajuster leurs méthodes de création de valeur, en se concentrant davantage sur les « stratégies d’innovation » (telles que la recherche originale, l’obtention de données de première main) difficiles à remplacer par l’IA, plutôt que sur les « stratégies de suivi » (suivre les tendances, s’appuyer sur des données de seconde main) facilement assistées par l’IA. Bien que l’IA ait commencé à s’aventurer dans des domaines innovants tels que la recherche scientifique, les créateurs dotés d’une perspective unique et d’une réflexion approfondie conservent leur valeur (Source: 36氪)
